2305.11792_Cue-CoT: Chain-of-thought Prompting for Responding to In-depth Dialogue Questions with LLMs¶
引用: 74(2025-08-22)
组织:
1MoE Key Laboratory of High Confidence Software Technologies The Chinese University of Hong Kong
2Harbin Institute of Technology, Shenzhen, China
3Huawei Noah’s Ark Lab
4National University of Singapore
5Peng Cheng Laboratory, Shenzhen, China
6Guangdong Provincial Key Laboratory of Novel Security Intelligence Technologies
总结¶
总结
在论文的最后有一些关于 personality 的描述词
贡献
作者提出Cue-CoT
一种新的基于语言线索的链式推理方法(Cue-based Chain-of-Thoughts, Cue-CoT),旨在引导LLMs在生成响应前,先推理用户的潜在状态(如个性、共情能力、心理状态等)。
该方法包括两个变体:
O-Cue CoT:在一步推理中同时输出中间状态和最终响应
M-Cue CoT:分步推理,先识别用户状态,再生成响应
构建了一个深度对话评估基准(benchmark)
包含中英文共6个数据集,共7.3k条对话
涵盖用户状态的三大方面:个性、情感和心理状态
数据集
个性数据集(Personality)
Zhihu
Quora
情感数据集(Emotion)
D4
ED
心理数据集(Psychology)
PsyQA
EMH
Abstract¶
研究背景¶
大型语言模型(LLMs),如ChatGPT,凭借其强大的语言理解和生成能力,极大地增强了对话系统的表现。但目前大多数研究直接通过对话上下文提示LLM生成回复,忽略了上下文中用户状态的潜在语言线索。这种深层次的对话场景对现有LLMs来说颇具挑战,难以通过单步推理准确识别用户的潜在需求并作出满意回应。
方法提出¶
为此,作者提出了一种基于语言线索的思维链方法(Cue-CoT)。该方法在LLMs的推理过程中引入了一个中间的推理步骤,旨在识别对话中的语言线索,并据此生成更加个性化和引人入胜的回复。这种方法的关键在于,通过显式引导模型识别和利用语言线索,提升其对用户深层状态的理解和回应质量。
实验与评估¶
为了验证所提方法的有效性,作者构建了一个包含中英文数据的深度对话问题基准测试,共涵盖6个数据集,聚焦对话中的三大语言线索:个性、情绪和心理状态。实验在零样本和单样本设置下,使用5个LLMs进行广泛测试。
实验结果¶
实验结果表明,Cue-CoT方法在所有数据集上的帮助性和可接受性方面均优于标准提示方法,验证了该方法在提升对话系统质量方面的有效性。
重点总结¶
挑战所在:LLMs在处理深层对话场景时难以识别用户潜在需求。
方法创新:Cue-CoT通过引入语言线索推理提升生成回复的个性与质量。
实验设计:构建了涵盖中英文、三种语言线索的对话基准。
实验结果:Cue-CoT在多项指标上优于传统方法。
1 Introduction¶
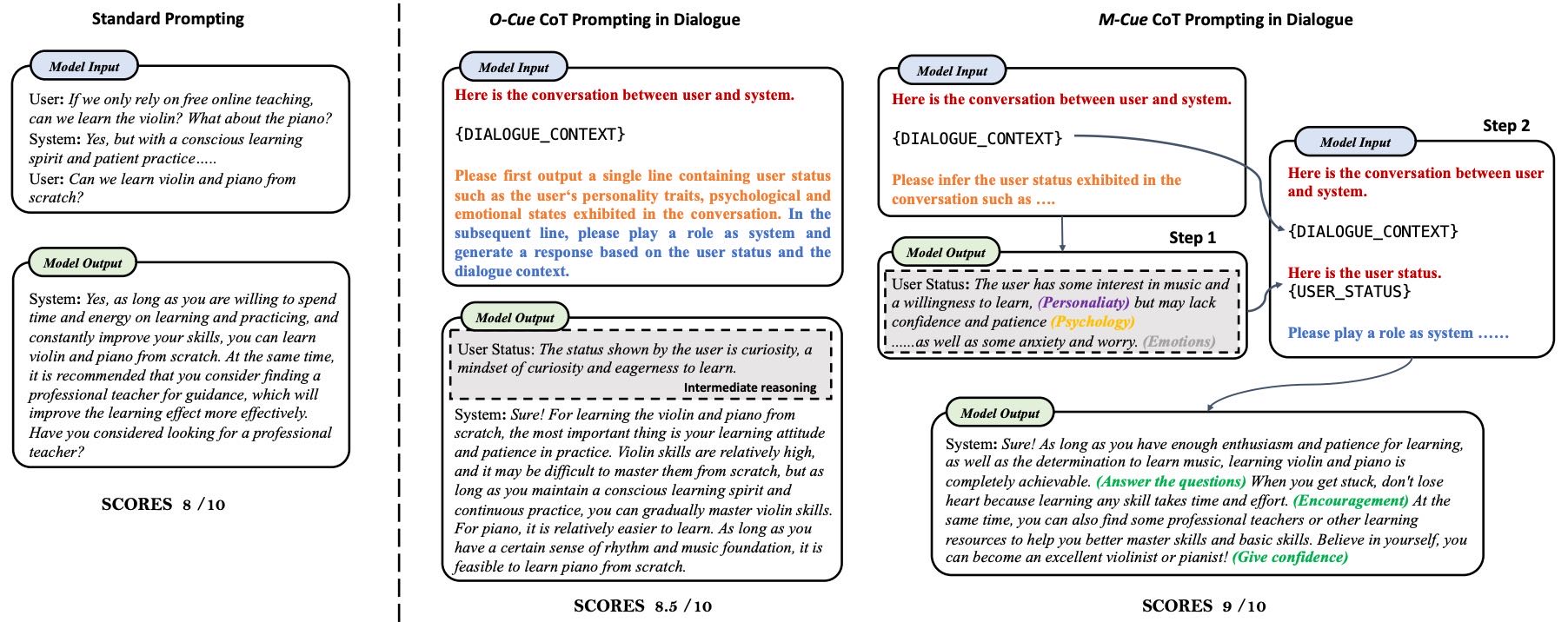
Figure 1: An example of different prompting for responding to in-depth dialog questions with LLMs, including standard prompting, O-Cue CoT, and M-Cue CoT. We shadow the intermediate reasoning results, i.e., the personality, empathy, and psychological status of the user, and highlight the instructions at the input and indicate the roles of different parts of the response (in green) in M-Cue CoT.
本文聚焦于大语言模型(Large Language Models, LLMs)在对话响应生成任务中的应用,尤其是针对深度对话问题(in-depth dialogue questions)的响应质量提升问题进行研究。文章首先指出,尽管LLMs(如ChatGPT)在自然语言处理(NLP)中带来了范式变革,但现有方法在处理深度对话问题时存在响应模式化、缺乏个性化的问题(Zhao et al., 2023)。这些问题往往源于模型仅依赖用户原始输入或对话内容生成回复,缺乏对用户状态(如情感、个性、心理等)的深入理解。
对此,作者指出,对话上下文中蕴含着丰富的用户状态信息(如情感、人格特质、心理特征等),这些信息对于理解用户意图和生成更贴切的响应至关重要(Mairesse et al., 2007;Tausczik & Pennebaker, 2010)。若能识别并利用这些“语言线索”(linguistic cues),对话系统将能更好地满足用户的独特需求,实现更自然、更人性化的对话体验(Salemi et al., 2023)。
基于此,作者提出了一种新的基于语言线索的链式推理方法(Cue-based Chain-of-Thoughts, Cue-CoT),旨在引导LLMs在生成响应前,先推理用户的潜在状态(如个性、共情能力、心理状态等)。该方法包括两个变体:
O-Cue CoT:在一步推理中同时输出中间状态和最终响应;
M-Cue CoT:分步推理,先识别用户状态,再生成响应(如图1所示)。
该方法充分利用了LLMs在推理与链式思考方面的能力(Wei et al., 2022),并将语言线索作为推理的关键输入,从而提升响应的个性化和适配性。
为了评估该方法,作者构建了一个深度对话评估基准(benchmark),包含中英文共6个数据集,涵盖用户状态的三大方面:个性、情感和心理状态。基于该基准,作者在5种LLM对话系统上进行了广泛实验,比较了不同提示方式(标准提示、O-Cue CoT、M-Cue CoT)的效果。
主要贡献如下:¶
构建了一个深度对话评估基准
涵盖用户状态的三个维度(个性、情感、心理);
包含6个数据集,共7.3k条对话(数据集和演示已开源)。
提出两种有效的对话链式推理方法:O-Cue CoT 和 M-Cue CoT
基于用户状态的推理和规划;
建议在有限训练数据(如单样本设置)中,使用中间推理结果作为演示选择的标准。
实验结果显示
两种Cue-CoT方法均优于标准提示;
M-Cue CoT在所有数据集和模型中表现更优,具有更好的鲁棒性和推理能力;
提出的新演示选择策略在随机选择和Top-1选择中均表现更佳。
总结来看,本文通过引入用户状态推理机制,提出了一种新的提示策略,显著提升了LLMs在深度对话任务中的响应质量与个性化能力。
3 Method¶
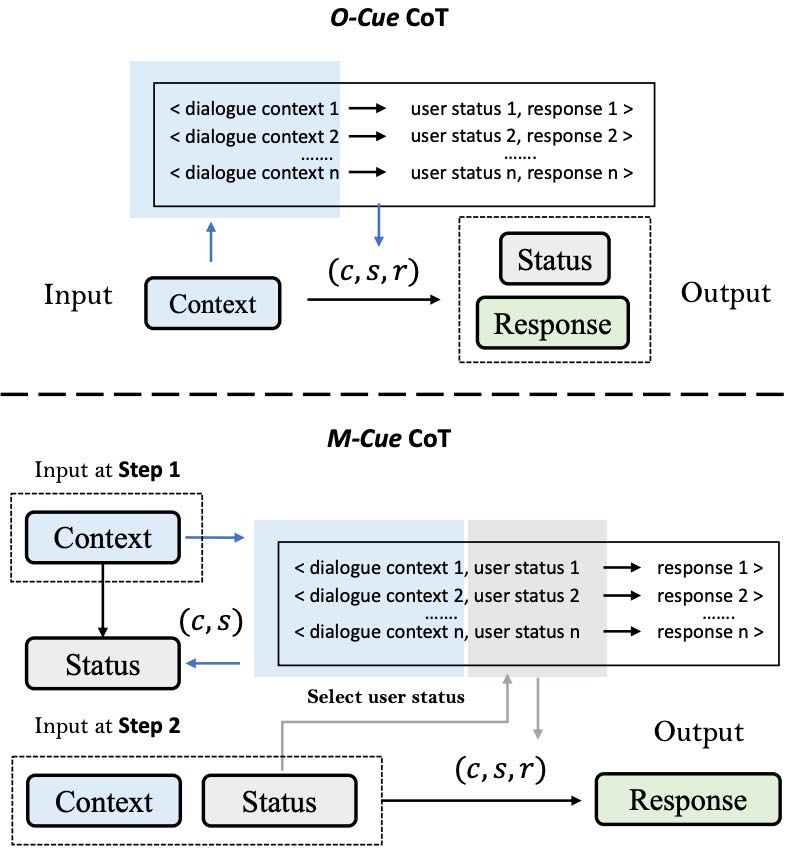
Figure 2: Different demonstration selection strategies of O-Cue and M-Cue CoT, while the returned results such as (𝒄,𝒔,𝒓) are prepended to original input to form new input.
3.1 对话中的思维链(Chain-of-thought in Dialogue)¶
我们介绍了几种通用的提示形式,包括标准提示(Standard Prompting)、单提示思维链(O-Cue CoT)和多提示思维链(M-Cue CoT),如图1所示。
标准提示(Standard Prompting)¶
传统做法:大多数先前的工作直接让大语言模型(LLMs)根据对话上下文或用户问题生成回答,缺乏透明性和可解释性。
目标函数:模型输入为对话上下文 \( \boldsymbol{c} \),输出为回答 \( \boldsymbol{r} \),形式为: $\( \mathcal{M}: \boldsymbol{c} \rightarrow \boldsymbol{r} \)$
问题:这种方法无法展示模型的中间推理过程,不利于理解和调试。
单提示思维链(O-Cue CoT)¶
方法:在传统思维链的基础上,模型被提示同时生成中间推理结果(如用户状态)和最终回答。
目标函数:模型输入为 \( \boldsymbol{c} \),输出为 \( (\boldsymbol{s}, \boldsymbol{r}) \),即: $\( \mathcal{M}: \boldsymbol{c} \rightarrow \boldsymbol{s}, \boldsymbol{r} \)$
问题:
当中间推理结果较多或较复杂时,生成的输出会变短,推理过程不够详细。
如果中间结果有误,无法进行修正。
如图1所示,中间结果(如用户状态)可能过于简短,无法为回答提供足够的线索。
多提示思维链(M-Cue CoT)¶
方法:将推理过程分解为多个连续步骤,最后一步才生成回答。每个步骤的输出可以作为下一步的输入。
优势:
中间结果可处理:如加入用户画像实现个性化(Salemi et al., 2023),或过滤错误推理。
可存储和重用:中间结果可用于后续任务。
可用于演示选择:在少量样本设置下,这些中间结果可作为选择演示样本的依据。
目标函数:模型输入为 \( \boldsymbol{c} \),依次输出 \( \boldsymbol{s} \) 和 \( \boldsymbol{r} \),即: $\( \mathcal{M}: \boldsymbol{c} \rightarrow \boldsymbol{s} \rightarrow \boldsymbol{r} \)$
总结:M-Cue CoT 提供了更清晰、更系统的推理流程,提高了模型的透明性和可解释性。
3.2 演示样本选择(Demonstration Selection)¶
在少量样本设置下,LLMs的表现高度依赖演示样本的质量,尤其是在需要多步推理的复杂任务中(Zhang et al., 2022)。在对话系统中,由于对话交互具有“一对一多”的特性,演示选择更具挑战性。因此,本文提出了三种提示方法的演示选择策略。
标准提示(Standard Prompting)¶
做法:参考前人工作(Wei et al., 2023; Liu et al., 2022),演示样本的选择基于对话上下文 \( \boldsymbol{c}_{*} \)。
策略:
随机选择(Random Selection)
语义最相似选择(Top-1 Selection)
形式:选择形式为: $\( (\boldsymbol{c}, \boldsymbol{r} | \boldsymbol{c}_{*} \rightarrow \boldsymbol{r}_{*}) \)$
单提示思维链(O-Cue CoT)¶
做法:虽然仍然基于对话上下文 \( \boldsymbol{c} \) 选择演示,但引入了中间推理结果 \( \boldsymbol{s}_{1} \) 来增强模型的推理能力。
选择形式: $\( (\boldsymbol{c}, \boldsymbol{s}, \boldsymbol{r} | \boldsymbol{c}_{*} \rightarrow \boldsymbol{s}_{*}, \boldsymbol{r}_{*}) \)$
图示:见图2,选择结果(如 \( \boldsymbol{c}, \boldsymbol{s}, \boldsymbol{r} \))被添加到原始输入前,形成新的输入。
多提示思维链(M-Cue CoT)¶
方法:由于推理分为多个步骤,对每个步骤采用不同选择策略:
第一步:根据对话上下文选择 \( (\boldsymbol{c}, \boldsymbol{s}) \) 用于推断用户状态。
第二步:根据用户状态选择 \( (\boldsymbol{c}, \boldsymbol{s}, \boldsymbol{r}) \) 用于生成回答。
优势:
所有中间推理结果都能作为选择演示的依据。
假设:用户状态相似的人,更可能接受风格相似的回答。
比较方式:也采用随机选择和Top-1 选择进行详细对比。
总结¶
本节详细介绍了本文提出的方法,重点如下:
三种提示策略(Standard Prompting、O-Cue CoT、M-Cue CoT)的定义与特点,其中 M-Cue CoT 通过分步骤推理提升了模型的可解释性和可控性。
演示样本的选择策略,针对不同提示方法分别设计了不同的选择方式,强调了中间推理结果在演示选择中的重要作用。
核心贡献:在少量样本设置下,如何通过结构化的推理和演示选择提升对话系统的性能和解释性。
如需进一步了解图2或具体实验对比,可参考论文中的图示与实验部分。
4 Datasets Collection¶
为了评估所提出的Cue-CoT方法在推理不同用户状态(如个性、情感和心理)方面的性能,作者收集了六组中英文数据集,涵盖个性、情感和心理三个层面。
个性数据集(Personality)¶
已有研究表明,用户的提问内容和风格可以间接反映其个性特征。例如,焦虑倾向的用户可能会在面试前询问如何缓解紧张。由于现有的公共数据集要么关注系统角色(Zhang et al., 2018),要么缺乏对应的对话回应(Barriere et al., 2022),因此作者构建了一个自动收集流程,使用ChatGPT(gpt-3.5-turbo-0301)生成数据。
具体步骤如下:
种子数据收集:从知乎和Quora等真实问答平台上收集问题-答案种子。
人格推断:通过ChatGPT推断出潜在的人格特征。
对话生成:基于推断的人格特征和问题种子,继续生成对话内容。
模板使用:采用特定模板(见附录A.1)来规范生成内容,确保对话的多样性与可靠性。
使用该方法,人格种子决定提问风格,问题种子决定内容,从而生成多样化的用户状态对话样本。
情感数据集(Emotion)¶
在情感状态方面,作者重新整理了两个已有共情对话数据集:
D4(Yao et al., 2022):从测试集中筛选出系统角色的共情回应,并选择最长的回应作为参考答案。此方法保证了评估的公平性,因为大语言模型(LLMs)倾向于生成较长的回答。
EmpatheticDialogues (ED)(Rashkin et al., 2019):沿用原始设置,直接使用测试集样本,不提供情感标签或情境描述,模拟真实对话环境。
这两个数据集为评估LLMs生成共情回应的能力提供了标准基准。
心理数据集(Psychology)¶
为评估LLMs在心理健康支持场景下的表现,作者使用了两个已有心理对话数据集:
PsyQA(Sun et al., 2021):从22,341个样本中抽取高票答案,选取其中4,012个问题,并从中随机选择1,000个问题作为更具挑战性的测试集。同时保留问题描述以保持一致性。
EMH(Sharma et al., 2020):包含10,000对(提问,回应)样本,根据三种沟通机制(情感反应、解释、探索)进行标注。作者按回应长度排序后,均匀抽取样本,形成最终测试集。
这两个数据集用于评估LLMs生成心理咨询式回应的能力。
总体数据统计(All)¶
表1总结了使用的六个数据集(中英文各三个)的基本统计信息:
指标 |
Zhihu |
D4 |
PsyQA |
Quora |
ED |
EMH |
|---|---|---|---|---|---|---|
Avg.C |
258.4 |
521.0 |
210.9 |
149.6 |
50.2 |
44.2 |
Avg.R |
76.9 |
57.9 |
607.5 |
48.3 |
12.9 |
175.8 |
样本数 |
1122 |
997 |
1000 |
1082 |
2091 |
1000 |
其中,Avg.C 表示上下文平均长度,Avg.R 表示回应平均长度。较长的回应更具挑战性,也更能体现LLMs的生成能力。部分数据集的上下文长度可能超出LLMs的输入限制(如 Belle-LLaMA-7B-2M 的上限为2048),这些情况在后续分析中将详细讨论。
总结¶
本节构建了一个涵盖个性、情感、心理三种用户状态的多语言(中英文)对话数据集,旨在为基于LLMs的对话系统研究提供标准化评估基准。数据集的多样性和挑战性有助于推动更深入的对话生成与推理研究。
5 Experiment¶
总体概述¶
本节主要通过实验比较了三种提示方法在零样本(zero-shot)和单样本(one-shot)设置下的性能:标准提示(standard prompting)、O-Cue 和 M-Cue CoT。实验数据来自中文和英文数据集,并通过帮助性(helpfulness)和可接受性(acceptance)两个维度进行评估。由于输入长度限制的问题,实验主要集中在单样本设置中。
5.1 LLMs 家族与评估细节¶
LLMs 家族¶
实验中使用的模型包括:ChatGLM-6B、BELLE-LLAMA-7B-2M、ChatGPT(中文)、Alpaca-7B、Vicuna-7B-v1.1 以及 ChatGPT(英文)等。所有模型都按照标准命令和程序进行权重复现,并建议读者参考原始论文以获取更多细节。评估时设置温度为 0.2,top p 为 0.1;生成时设置温度为 0.7,top p 为 0.95。为了实现 one-shot 设置中的最近示例选择,使用 BERT 模型(中文使用 bert-base-chinese,英文使用 bert-base-uncased)进行句子嵌入,不进行微调。
评估¶
评估指标:
由于传统自动评估指标(如 BLEU 和 F1)与人类判断不一致,实验选择使用 ChatGPT 作为自动评估工具,进行成对比较(pair-wise comparison),评估生成响应的质量。
评估模板可在附录 A.3 中找到。
计算方式:胜率 = 胜场数 /(胜场 + 平局 + 失败)。
方法对比:
由于大多数 LLM 在对话任务中表现优异,能够轻易超越原始数据集中的真实响应,因此选择标准提示作为更具挑战性的基线。
实验将使用 O-Cue 和 M-Cue CoT 生成的响应与标准提示生成的响应进行比较,并提供人工评估结果作为参考。
5.2 主要实验¶
总体结果¶
表格 2 和 3 分别展示了中文和英文数据集上 O-Cue 和 M-Cue 相较于标准提示的胜率结果。
O-Cue 在大多数情况下表现优于 50% 的胜率,但在某些模型和数据集上表现不如标准提示,例如 ChatGLM 在中文任务上。
M-Cue 表现尤为突出,其胜率在所有模型、数据集和设置中均高于 O-Cue,显示出更强的鲁棒性和有效性。
优势原因:M-Cue 的指令更简洁清晰,输出结构明确,而 O-Cue 指令较长、结构复杂,部分模型无法完全遵循。
中文 LLMs 表现¶
ChatGLM 表现最差,尤其在 O-Cue 设置下,几乎不遵循指令,直接继续对话;而 M-Cue 设置下表现提升明显。
BELLE 和 ChatGLM 在 one-shot 设置下表现优于 zero-shot 设置,主要得益于 one-shot 提供了更有帮助的示例。
D4 数据集(中文)由于上下文长度最长,所有模型在该数据集上的 D4 子任务表现都较差。
英文 LLMs 表现¶
Alpaca 表现最差,尤其在 O-Cue 设置下,无法很好地遵循指令,输出模糊。
ChatGPT 和 Vicuna 在 Quora 数据集(英文)上的表现最差,因为该数据集上下文最长,且模型输出长度受限。
M-Cue 在所有英文 LLM 上都表现出稳定提升,尤其在 ChatGPT 上效果显著。
5.3 人工评估¶
评估方法¶
雇佣三位受过良好教育的研究生,随机抽取 100 对响应(ChatGPT 使用 O-Cue / M-Cue 和标准提示生成的响应),在不暴露来源的前提下进行人工评分。
评分方式:1 表示胜出,-1 表示失败。
实验中测试了两种响应顺序:O-C(O-Cue 在前)和 S-O(Standard Prompting 在前)。
评估结果¶
表格 4 和 5 展示了英文和中文数据集在不同评估方法与人类评分的一致性(准确率 Acc 和 Kappa 相关系数 Kap.C)。
观察结果:
响应顺序对评估结果有一定影响,但 O-Cue 和 M-Cue 在 O-S 顺序下与人类评分更一致。
O-Cue 和 M-Cue 在大多数情况下都优于标准提示,尤其在英文数据集上表现更好。
ChatGPT 在英文任务中的推理能力相对更强,从而在英文数据集上的评估表现更优。
总结¶
本实验通过多模型、多数据集、多设置的对比,系统评估了 O-Cue 和 M-Cue 两种 Chain-of-Thought 提示方法在生成对话响应中的表现。结果显示:
M-Cue 在所有设置中表现最优,其指令清晰、结构明确,具有更强的鲁棒性。
O-Cue 虽然在部分设置下有效,但其复杂性限制了部分模型的性能。
人工评估与自动评估结果基本一致,尤其在 O-S 顺序下,与人类判断更一致。
实验还揭示了 LLMs 在中英文任务中的表现差异,以及上下文长度对模型输出的影响。
数据和方法的详细补充可参考附录部分。
6 Analysis¶
在本节中,作者使用 ChatGPT 作为主干模型,并采用 M-Cue CoT(思维链提示) 方法对模型表现进行了广泛分析。由于 M-Cue CoT 在中英双语任务中表现出色,因此是分析的主要方法。作者主要以 用户接受度(acceptability) 作为评估指标,因为这一指标更符合本研究的核心动机。关于**帮助性(helpfulness)**的分析被放在附录中。
6.1 One-shot 与 Zero-shot 的比较¶
图3展示了在**单一示例(one-shot)和无示例(zero-shot)**设置下,使用 M-Cue CoT 生成的响应接受度比较。结果显示,在6个数据集中,**one-shot(随机或 top-1 选择)**在5个数据集上的表现优于 zero-shot,其胜率均超过 80%。这一结果说明,提供一个示例对于生成更符合用户预期的响应是有效的。
然而,D4 数据集在 one-shot 下表现较差,作者认为这主要由于输入长度的限制,导致模型无法充分处理上下文。此外,在 6 个数据集中,top-1 选择在 4 个数据集上的表现优于随机选择,说明用户在相似状态下的偏好具有一定的相似性,即用户更倾向于表达风格一致的回复。不过,在 D4 和 Quora 数据集中,top-1 选择表现相对较低,这可能是由于上下文过长导致模型难以关注到关键输入部分。
6.2 更多推理步骤¶
作者尝试在原有的用户状态推断(Step 1)之后,加入一个额外的步骤(Step 2),即响应计划(response planning),通过提示模型基于对话上下文和用户状态来规划回复内容。具体地,模型被提示回答以下问题:
“基于对话上下文和用户状态(如人格特质、心理和情绪状态),系统在回复时应注意哪些方面?”
模型的输出被认为是系统规划(system planning),记作 p。在最后一步中,作者构建了三种不同的 M-Cue 变体:
ProcessA:仅使用上下文和用户状态(c, s)推断回复(r);
ProcessB:仅使用上下文和系统规划(c, p)推断回复(r);
ProcessC:使用上下文、用户状态和系统规划(c, s, p)推断回复(r)。
实验结果显示(见表6):
方法 |
中文 |
英文 |
Zhihu |
D4 |
PsyQA |
Quora |
ED |
EMH |
|---|---|---|---|---|---|---|---|---|
ProcessA |
65.22 |
61.08 |
56.12 |
89.09 |
96.79 |
94.93 |
||
ProcessB |
76.15 |
55.82 |
57.72 |
89.79 |
98.78 |
97.62 |
||
ProcessC |
75.91 |
57.23 |
58.74 |
94.50 |
98.57 |
98.22 |
重点结论:
加入更多推理步骤(如响应规划)有助于提升模型表现,特别是在 ProcessB 和 ProcessC 中。
但并非所有中间结果都需要在最后一步组合使用,ProcessB 表现优于 ProcessC,说明仅使用系统规划作为中间结果就足够有效。
此外,不同的大语言模型在长上下文理解和指令遵循能力上存在差异,因此这些结论可能不适用于其他模型。
增加推理步骤虽然提升了性能,但也增加了计算负担和输入长度,在小样本设置下可能变得不现实。
总结¶
本节通过对不同设定(one-shot vs. zero-shot)和推理步骤(planning)的分析,验证了 M-Cue CoT 在对话生成中的有效性。one-shot 设置在大多数数据集上优于 zero-shot,top-1 选择通常优于随机选择,但其效果在长上下文任务中可能受限。加入响应规划步骤能进一步提升性能,但需权衡输入长度和计算资源。
7 Discussion¶
Direct comparison of different models(不同模型的直接比较)¶
在本研究之前,我们尚未对不同模型的响应进行直接比较。本文中,我们将ChatGPT模型的响应作为基线,将其与其他模型在标准提示下的响应进行比较。为了公平性,我们使用了标准提示生成的所有响应(而非我们提出的方法),因为不同大语言模型(LLMs)在生成链式推理(Chain-of-thought)方面的能力存在差异。
图5展示了各模型在“helpfulness”(有用性)方面的比较结果(图中红色虚线代表ChatGPT的基线水平)。在中文数据集上,ChatGLM和BELLE在D4数据集上表现接近,而ChatGLM在知乎和PsyQA数据集上的表现优于ChatGPT。这表明当前中文LLM在长文本理解方面仍有待提升,而BELLE可能需要更多的指令微调数据。在英文数据集上,Vicuna在所有数据集上的表现最佳,而其他模型与基线差距较大。可能造成这种差异的两个关键因素包括输入长度限制(512个token)和指令跟随能力不佳。
Paths to more powerful LLMs(通往更强大LLM的路径)¶
在我们提出的基准测试中,我们使用当前LLM在中文和英文两个语种中的胜率(即在对比ChatGPT时的表现)作为两个坐标轴。图6显示了当前各种LLM在坐标系中的分布情况。每个点代表一个特定的LLM,其所占据的区域代表其综合表现。根据目前LLM在三个数据集上的综合表现,我们将其划分为四个区域。
以ChatGPT的表现为锚点,大多数LLM集中在第一区域,而仅有少数模型在中文(第三区域)或英文(第二区域)方面表现更优。我们希望未来能有更多研究或模型进入第四区域,即在中文和英文方面都优于ChatGPT。实现这一目标的路径包括在中文数据集上持续训练Vicuna等模型。更多分析请参见附录。
8 Conclusion¶
本文构建了一个基准(benchmark),用于评估当前大语言模型(LLMs)生成响应在“有用性”和“可接受性”方面的表现,并考虑了用户状态的三种主要语言线索。这是文章的重点内容之一,意在填补现有评估体系中关于用户状态建模的空白。
随后,作者提出了一种名为 Cue-CoT 的方法,用于追踪用户状态,并将响应生成过程分解为多个推理步骤。这也是文章的核心贡献,强调了对用户状态的动态追踪与响应生成的结构化处理。
实验结果表明,该方法在六个数据集上均表现出色,且在零样本(zero-shot)和单样本(one-shot)设置下均优于其他方法。这是验证方法有效性的关键部分,也是作者强调的重点内容。
最后,作者表示希望通过发布本研究,为大语言模型的评估与发展提供一些启示。同时,作者指出未来的工作将包括链式推理(chain-of-thought tuning)和指令调优(instruction tuning)的研究,这部分属于未来展望,内容较为简略。
Limitations¶
在本文中,我们探讨了在对话上下文中通过“思维链”(chain-of-thought)方法对用户状态(包括个性(personality)、情绪(emotion)和心理状态(psychology))进行推理的方法。然而,我们也认识到本研究存在以下几方面的局限性:
Types of Cues(线索类型)¶
本文主要聚焦于用户状态的三类语言线索:个性、情绪和心理状态。然而,对话上下文中还可能存在其他有价值的线索,例如:
与用户相关的:如观点(point of view)、主观性(subjectivity)和说话者的魅力(speaker charisma)(Mairesse et al., 2007);
与系统相关的:如系统回应与人类偏好的一致性(Ouyang et al., 2022)。
我们选择这三类主要线索,是为了提升系统对用户的理解能力,从而提供更贴切的响应。这些未被纳入的线索在未来的研究中值得进一步探索。
Sensitivity of Prompts(提示词的敏感性)¶
与许多先前的研究(Wang et al., 2023d;Chen et al., 2023b)类似,我们发现大型语言模型(LLMs)对提示词(prompt)非常敏感。也就是说,相同的模型在不同提示下可能会产生不同的输出。
此外,我们设计的提示词可能并非是解决本目标问题的最佳prompt。提示词的敏感性与最优性在对话系统中是一个重要的研究问题,值得在未来进一步探索。为了便于他人复现我们的研究,我们将提供实验中使用的所有提示词。
Evaluation of Intermediate Reasoning(中间推理的评估)¶
我们并未直接评估中间推理结果的正确性,因为获取“中间推理的正确结果”(ground truth)非常困难。原因主要有两个:
一对多问题(one-to-many problem):一个用户可接受的回应,可能基于多种线索生成;而一个复杂问题也可能有多种解法路径。因此,中间推理的候选结果众多,难以确定哪条路径是“错误”的。这种情况下,识别线索错误变得非常困难。
推理错误不一定导致最终结果错误:已有研究表明,大型语言模型在问答任务中可能会采用不正确但有效的推理路径,最终仍能给出正确答案(Zelikman et al., 2022;Creswell et al., 2023)。即使在最极端的情况下——所有中间推理都错误,也有可能生成一个质量较高的回应。
因此,评估不同类型的线索错误对最终回答的影响是一个复杂的问题。基于这些考虑,我们选择像以往“思维链”研究(Wei et al., 2023;Zhang et al., 2022)一样,直接评估最终回应的质量,而不是中间推理的正确性。
Ethics Statement¶
本研究严格遵守已发布大语言模型(LLM)的许可协议和公开可用数据集的相关政策。在自动收集数据集的过程中,我们使用当前的公开数据集作为种子,确保过程中不涉及任何用户信息或隐私泄露的问题。本文中对 OpenAI API 的调用由第四作者、来自新加坡国立大学的 Deng Yang 博士完成。
Acknowledgement¶
作者对所有匿名审稿人表达了诚挚的感谢,感谢他们提出的宝贵意见和建议。本研究工作得到了如下基金的部分资助,重点内容如下:
香港中文大学直接资助项目(编号:4055209);
中国国家自然科学基金(项目编号:62006062、62176076);
广东省自然科学基金(项目编号:2023A1515012922);
深圳市重点领域研发计划(项目编号:JSGG20210802154400001);
深圳市基础研究基金(项目编号:JCYJ20220818102415032);
广东省新型安全智能技术重点实验室资助(项目编号:2022B1212010005)。
这些资助为研究的顺利开展提供了重要支持。
Appendix A Templates¶
A.1 数据收集模板¶
该模板用于模拟人类与AI助手之间的对话。要求人类保持一致的个性设定(由 {personality_seed} 定义),且人类主动提问而AI助手不主动发问。对话格式如下:
人类发言以
[Human]开头,AI助手发言以[AI]开头。人类会围绕相关话题或之前对话内容提出问题,停止对话时不再提问。
对话必须严格按照此格式完成,示例如下:
[Human] {QUESTION}
[AI] {ANSWER}
重点内容:
人类需要保持一致的“个性”进行提问;
AI助手不主动发问,仅作回答;
此模板用于收集用于训练或评估的数据。
A.2 一些个性示例¶
表 8 展示了一些用户个性的示例(非全部)。文中仅分类为“积极”和“消极”进行展示,实际数据集中还包含“中性”等其他类型个性。
重点内容:
个性示例用于模拟不同用户的对话行为;
个性不仅限于“积极”和“消极”,还包括中性等。
A.3 评估模板¶
评估主要考虑两个维度:帮助性(helpfulness) 和 可接受性(acceptability)。
帮助性 评估关注回答的有用性、相关性、准确性以及细节程度。
可接受性 评估关注回答是否考虑用户的心理状态和个性特征,以及用户是否愿意接受和采纳回答。
评估模板参考了 Vicuna 的模板,并做了调整,格式如下:
[Dialogue]
{dialogue_history}
[The Start of Response A]
{response_wo_status}
[The End of Response A]
[The Start of Response B]
{response_w_status}
[The End of Response B]
[System]
{prompt}
帮助性提示(Helpfulness Prompt)¶
请根据对话历史中用户的目的和需求,评估两个回答的表现。
评估标准包括有用性、相关性、准确性和细节程度,给出 1-10 分的评分(0.1 为间隔)。
输出格式:第一行输出 A 和 B 的分数(中间用空格分隔),第二行给出详细评价。
可接受性提示(Acceptability Prompt)¶
请评估两个回答的可接受和采纳程度。
评估内容包括是否考虑了用户的心理状态和个性特征,评分标准同样是 1-10 分。
输出格式与帮助性相同。
重点内容:
评估分为两个维度:帮助性与可接受性;
评估模板结构明确,适用于生成多个模型响应的对比评估。
图表说明¶
图7:展示了M-Cue CoT 生成的回答在三个中文和三个英文数据集上的帮助性胜率,对比了多个最先进的大模型(LLMs)。
图8:展示了可接受性胜率的对比结果,同样是基于三种中文和英文数据集。
重点内容:
图7和图8展示了M-Cue CoT在帮助性和可接受性两个维度上的表现优势。
所对比的模型包括当前多个SOTA(state-of-the-art)模型,具有较高的参考价值。
Appendix B Different Method of Evaluation¶
B.1 与真实标注(Ground Truth)对比¶
本节通过图[7]和图[8]展示了使用 M-Cue 方法生成的回答在**帮助性(helpfulness)和可接受性(acceptability)**两个维度下,与真实标注(Ground Truth)相比的胜率表现。
主要结论:¶
大部分模型表现优于 Ground Truth
5个大语言模型中有4个在两个评估维度上的胜率超过50%,只有一例外:BELLE 模型在 PsyQA 数据集上胜率为 45.75%。
我们认为这种例外主要由以下两个原因导致:
模型本身能力限制:尤其是在长文本理解和指令遵循方面表现较弱;
数据集难度较高:PsyQA 是由人类专家构建的数据集,且其平均对话长度(Avg. R)最长,因此 Ground Truth 相对更难超越。
不同模型在不同数据集下的表现差异
由于所有模型都与同一 Ground Truth进行比较,因此胜率在一定程度上反映了模型的优势与劣势。
中文模型表现:
BELLE 在所有数据集上表现最差;
ChatGLM 表现较好,但与 ChatGPT 相比仍有一定差距;
在 D4 数据集(上下文最长)中,ChatGLM 和 BELLE 常常混淆对话角色,生成如 “我是系统/聊天机器人”、“欢迎来到我的聊天室”等泛泛的回答,影响了效果。
英文模型表现:
Vicuna 在所有英文数据集上表现与 ChatGPT 接近,甚至在 EMH 数据集中略胜一筹;
明显优于 Alpaca,胜率差距显著;
ED 数据集相对容易击败 Ground Truth,所有英文模型胜率接近 100%,即使 Alpaca 的最大上下文长度仅为 512。
总体来看,M-Cue 方法在多种用户状态(如情绪、心理健康等)下,生成的回答比 Ground Truth 更有帮助。
英文模型在 Ground Truth 上的胜率差距较小
Vicuna 和 ChatGPT 在 ED 和 EMH 数据集上的胜率几乎相同,说明两者在 Ground Truth 基准下的表现非常接近。
结合图[7]、[8]以及表[2]、[3],可以发现 M-Cue 方法的胜率高于标准提示方法(Standard Prompting),再次证明了大语言模型在适当提示下的强大能力。
由于本文主要目标是证明 M-Cue 优于标准提示方法,而非击败 Ground Truth,因此在主实验中,我们以标准提示作为基准进行比较。
总结:本节通过与 Ground Truth 的比较,验证了 M-Cue 方法在生成更高质量响应方面的有效性,尤其在中文模型和长上下文任务中表现突出。同时,也揭示了模型之间在 Ground Truth 基准下的性能差异较小,进一步强调后续实验应以标准提示作为对比基准。
Appendix C Discussion¶
在本节中,作者讨论了两个关键问题:大语言模型(LLM)的评估以及通往更强大 LLM 的路径。
评估的幻觉(Illusion of evaluation)¶
作者指出,当前对 LLM 的评估存在一种“评估幻觉”。通过将图7和图5的结果对比,可以得出两个相互矛盾的结论:一方面,从图7看,ChatGPT 的表现优于 ChatGLM-6B,而 ChatGLM-6B 又优于 Belle-LLaMA-7B-2M;但另一方面,图5却显示 ChatGLM-6B 的表现优于 ChatGPT。这种矛盾看似不合理,但在某些情况下确实存在。具体来说,当大多数 ChatGPT 和 ChatGLM-6B 的生成结果都优于参考答案(ground truth)时,即使 ChatGLM-6B 在多数样本上优于 ChatGPT,也可能导致评估结果的误导。
作者强调,测试样本的数量和基线(baseline)的选择在评估中起着关键作用。如果基线过于弱或者模型之间的性能差距太小,那么通过比较基线得出的“胜率”可能并不能真实反映模型的优劣。因此,LLM 的评估仍是一个非常困难的问题。为了解决这一问题,作者在论文中提供了多方面的评估视角,以增强论文评估结果的完整性和说服力。
Appendix D Helpfulness Analysis of Planning Step¶
Figure 9: The win rate of responses (helpfulness) generated by ChatGPT under different demonstration selection strategies under one-shot setting v.s. responses under the zero-shot setting, using M-Cue CoT¶
图9展示了在不同演示选择策略下,ChatGPT在“one-shot”和“zero-shot”设置中的响应“帮助性”(Helpfulness)胜利率。从图中可以看出:
不同策略对响应的帮助性影响显著。
与其他策略相比,某些策略(例如ProcessA、ProcessB和ProcessC)在各个数据集上表现更好。
该图用于对比不同规划步骤设置对模型输出质量的影响。
Table 7: The win rate of different variants in terms of helpfulness with the ChatGPT as the backbone¶
表7展示了以ChatGPT为核心的不同变体在“帮助性”方面的胜利率。重点内容包括:
方法 |
Chinese |
English |
Zhihu |
D4 |
PsyQA |
Quora |
ED |
EMH |
|---|---|---|---|---|---|---|---|---|
ProcessA |
95.57 |
90.34 |
85.83 |
91.98 |
82.93 |
|||
ProcessB |
91.18 |
95.13 |
87.67 |
95.35 |
84.82 |
|||
ProcessC |
92.45 |
95.97 |
89.14 |
96.56 |
84.93 |
ProcessA、ProcessB 和 ProcessC 是三种不同的规划策略变体。
在大多数数据集上,ProcessB 和 ProcessC 的表现优于 ProcessA。
尤其是在 PsyQA 数据集上,ProcessB 和 ProcessC 表现非常突出。
但值得注意的是,在 PsyQA 和 EMH 数据集上,top-1 选择策略 的帮助性表现较差,这可能表明在某些复杂数据集中,帮助性与可接受性之间存在权衡,这是未来需要进一步研究的问题。
Table 8: Some collected personality of users¶
该表展示了用户可能具有的正面和负面人格特征,分为两类:
负面人格特征(Negative Personas)¶
外向但大大咧咧
挑剔、喜欢追问
忧郁、自我怀疑
善变、偶尔使用不文明用语
小心谨慎、不信任他人
容易焦虑
优柔寡断
对话题敏感
易怒、暴躁
内心敏感
保守、不接受新事物
容易感到被冒犯
正面人格特征(Positive Personas)¶
对话题好奇、希望友好解答
对话题敏感、需要支持和鼓励
对自己要求高、追求完美
开朗、不拘小节
热情、善待他人
有同情心、不歧视他人
好奇、乐于接受不同观点
温柔、善于交流
性格平和
容忍度高
自尊心强
这些人格特征用于更好地理解用户需求和情绪状态,从而优化模型的回应策略。
Table 9: The prompt to collect the personality of users exhibited in the dialogue¶
该表展示了用于从对话中提取用户人格特征的提示语(Prompt),示例包括:
对话1:用户担心相亲对象过于热情,表现出缺乏自信和防备心强。
对话2:用户希望增进男友的好感,表现出温柔、体贴、善于交流。
对话3:模板提示系统根据用户话语分析其人格特征。
此提示用于训练模型自动识别用户在对话中表现出的性格特点,从而进行更有针对性的回复。
Table 10: An example of additional planning step¶
该表展示了一个附加规划步骤的示例,用于在生成回复前进行更细致的用户状态分析和回应设计。
Step-1:推断用户状态
用户关心怀孕和生育问题,表现出细心、思虑周全,同时也有焦虑和不确定性。
Step-2:系统回应需注意的方面
对话风格:需要更温柔、细致,并体现出对用户情绪的理解和共情。
需求与偏好:回应应关注用户的情感和信息需求。
情绪状态:回应要体现出对用户情绪的支持和安抚。
系统通过这些步骤来生成更贴合用户心理状态和需求的回复。
附注:HTML转换问题¶
由于部分 LaTeX 包未被 HTML 转换工具支持,文档中某些内容在网页显示时可能有格式错误。
已知未支持的包包括
inconsolata和arydshln。作者建议使用支持的 LaTeX 包列表 提交文档以获得最佳 HTML 显示效果。
总结¶
本附录主要围绕规划步骤对模型输出“帮助性”的影响展开,通过图、表形式展示了不同策略在多个数据集上的表现对比。此外,还介绍了如何通过对话内容提取用户人格特征,并根据用户状态进行更细致的回复设计。整体强调了用户心理建模和个性化回应策略在对话系统中的重要性。
如需进一步展开某一部分内容,可随时告知。