2511.03506_HaluMem: Evaluating Hallucinations in Memory Systems of Agents¶
组织:
1]China Telecom Research Institute
2]MemTensor (Shanghai) Technology
3]Harbin Engineering University
Dataset: https://huggingface.co/datasets/IAAR-Shanghai/HaluMem
总结¶
背景
目前对记忆幻觉的评估主要依赖于端到端的问答测试,这种方式难以定位幻觉具体发生在记忆系统的哪个操作阶段
HaluMem
三个评估任务:
记忆提取(Memory Extraction)
记忆更新(Memory Updating)
记忆问答(Memory Question Answering)
发现
当前的记忆系统在记忆提取和更新阶段容易生成并积累幻觉。
这些错误会传播到问答阶段,影响最终输出的准确性。
评测:针对每个阶段的黄金标准(gold standard):
提取黄金标准 \(G^{ext}\):应新增的记忆点集合 {m₁, m₂, …, mₖ}
更新黄金标准 \(G^{upd}\):更新前后的记忆对 {m_old → m_new}
问答黄金标准:每个问题 qⱼ 对应的标准答案 yⱼ*
数据集:
HaluMem-Medium:
20个用户,共30,073轮对话。
平均上下文长度约160K tokens。
包含14,948个记忆点和3,467个问答对。
HaluMem-Long:
每个用户上下文扩展至1M tokens,插入无关对话(来自ELI5等)。
总共53,516轮对话。
数据集构建(参见章节4)
Stage 1: Persona Construction(用户画像构建)
Stage 2: Life Skeleton(人生骨架构建)
Stage 3: Event Flow(事件流生成)
Stage 4: Session Summaries and Memory Points(对话摘要与记忆点生成)
Stage 5: Session Generation(对话生成)
Stage 6: Question Generation(问题生成)
记忆类型的定义
Persona Memory(人物记忆):描述用户的稳定特征,如身份、兴趣、习惯、信仰等
Event Memory(事件记忆):记录用户经历的具体事件、体验或计划
Relationship Memory(关系记忆):描述用户与他人的关系、互动或看法
六类问题的定义
Basic Fact Recall(基本事实回忆):直接询问对话中明确提到的事实或偏好,无需推理。
Multi-hop Inference(多跳推理):需要整合多个信息片段,通过逻辑或时间推理得出答案。
Dynamic Update(动态更新):测试系统追踪信息变化的能力,如识别用户最新状态或偏好变化。
Memory Boundary(记忆边界):测试系统识别未知信息的能力,防止编造未提及的内容。
Generalization & Application(泛化与应用):基于已知偏好推断新场景下的合理建议或判断。
Memory Conflict(记忆冲突):测试系统识别并纠正错误前提的能力,问题中故意包含与已知记忆矛盾的信息。
HaluMem-Long 的构建细节
具体方法是在原有会话基础上插入无关对话:
会话内部:在已有对话中插入不相关的交流内容。
会话之间:插入完全无关的新会话。
这些无关对话包括:
事实问答:部分来自 ELI5 数据集,部分由我们生成。
数学推理问答:来自 GPT-OSS-120B-Distilled-Reasoning-math 数据集。
多领域事实问答:使用 GPT-4o 生成,涵盖历史人物、科学概念、国家地点、发明、哲学理论、艺术作品、历史事件、数学定理等八个领域。
Abstract¶
本论文指出,记忆系统是使大语言模型(LLMs)和AI代理实现长期学习和持续交互的关键组件。然而,这些系统在记忆存储与检索过程中常常出现记忆幻觉(Memory Hallucinations),包括虚构、错误、冲突和遗漏等问题。
目前对记忆幻觉的评估主要依赖于端到端的问答测试,这种方式难以定位幻觉具体发生在记忆系统的哪个操作阶段。为了解决这一问题,作者提出了HaluMem(记忆幻觉基准),这是首个面向记忆系统操作层面的幻觉评估基准。
HaluMem的主要贡献包括:¶
定义三个评估任务:
记忆提取(Memory Extraction)
记忆更新(Memory Updating)
记忆问答(Memory Question Answering)
这些任务用于全面揭示记忆系统在不同操作阶段中出现的幻觉行为。
构建两个大规模多轮对话数据集:
HaluMem-Medium
HaluMem-Long
每个数据集包含约15,000个记忆点和3,500个多类型问题。每个用户的平均对话轮数分别为1,500和2,600轮,上下文总token数超过1百万,支持在不同上下文长度和任务复杂度下评估幻觉现象。
实验发现:¶
当前的记忆系统在记忆提取和更新阶段容易生成并积累幻觉。
这些错误会传播到问答阶段,影响最终输出的准确性。
未来研究方向:¶
需要开发可解释、受约束的记忆操作机制,以系统性地抑制幻觉,提升记忆系统的可靠性与稳定性。
总结:本摘要提出了HaluMem这一新的评估基准,首次从操作层面系统性地分析记忆系统中的幻觉问题,并通过大规模数据集揭示幻觉在不同阶段的生成与传播机制,为未来研究提供了方向和工具支持。
1 Introduction¶
1.1 背景与问题¶
随着大语言模型(LLM)在人机交互中的广泛应用,用户与模型之间的对话往往包含大量个性化信息。然而,当前大多数系统在对话结束后会“遗忘”这些信息,导致模型难以持续理解用户、适应用户角色变化或生成个性化回应。为实现长期交互中的连贯性和个性化,亟需构建一个记忆系统(memory system),用于记录、更新和利用用户信息。
1.2 记忆系统的功能与现状¶
记忆系统是组织和管理人机对话历史信息的基础架构。它从多轮对话中提取、结构化并持续更新关键信息,并在需要时检索并注入这些信息,以支持个性化和长期一致性。代表性系统包括 MemOS、Mem0、Zep、Supermemory 和 Memobase 等。
这些系统通过识别用户画像、事件和偏好,将其以结构化文本形式存储,并在新任务中检索和整合相关信息,从而实现“记住并正确使用”用户信息的目标。
1.3 记忆幻觉问题(Memory Hallucination)¶
尽管记忆系统提升了信息组织能力,但普遍存在记忆幻觉问题,表现为在记忆提取或更新过程中出现虚构、错误、冲突或遗漏的信息。这种幻觉不仅影响记忆本身的准确性,还会在生成阶段被放大,进一步引发生成幻觉,降低系统整体可靠性。
1.4 当前评估方法的局限性¶
目前对记忆幻觉的评估多采用端到端的问答式评估框架,通过模型输出间接评估记忆质量,难以定位幻觉发生的具体阶段(如提取、更新或检索)。
1.5 本文贡献:提出 HaluMem 基准¶
为解决上述问题,本文提出 HaluMem,这是首个面向记忆系统操作级别的幻觉评估基准,包含两个数据集:HaluMem-Medium 和 HaluMem-Long。
HaluMem 的设计特点:¶
构建了包含三类任务的评估框架:记忆提取、记忆更新、基于记忆的问答。
提供了一个多轮对话数据集,每条对话都标注了每个记忆操作及其结果(称为 memory point)。
通过对比系统输出与标注真值,进行细粒度评估:
准确性与覆盖率:评估记忆提取中的错误或虚构。
一致性:评估记忆更新中的错误或遗漏。
引用与内容正确性:评估问答阶段的错误引用或虚构内容。
数据集规模:¶
每个数据集包含约 15,000 个 memory point 和超过 3,400 个评估查询。
每位用户平均参与超过 1,000 轮对话。
HaluMem-Long 的对话长度扩展至百万级 token,用于评估超长对话中的幻觉行为。
1.6 主要贡献总结¶
提出首个面向记忆系统操作级别的幻觉评估基准 HaluMem,涵盖提取、更新和问答三个维度。
构建大规模、多轮、用户中心化的评估数据集,支持在不同上下文长度和任务复杂度下评估幻觉行为。
通过分阶段评估揭示幻觉在记忆流程中的累积与放大效应,为理解和缓解记忆幻觉提供新视角。
3 Problem Definition¶
本节主要定义了记忆系统中幻觉(hallucination)评估的问题背景与挑战,并引出了提出的 HaluMem 基准。
1. 记忆系统的结构与操作流程¶
一个记忆系统 SS 被用于赋予 AI 系统 AA(如大语言模型或智能代理)长期记忆和个性化能力。系统接收用户与助手之间的多轮对话序列:
D = (u₁, a₁), (u₂, a₂), …, (uₙ, aₙ)
其中,uᵢ 和 aᵢ 分别表示第 i 轮中用户和 AI 的发言。记忆以明文条目形式存储,单个记忆点记为 m。
在交互过程中,记忆系统涉及以下四类操作:
记忆提取(E):从对话中提取新的记忆点;
记忆更新(U):修改或删除已有记忆;
记忆检索(R):根据当前问题召回相关记忆;
记忆问答(Q):基于检索结果生成回答。
⚠️ 说明:由于 RR 主要关注相关性和召回率,不涉及生成过程,因此本文重点分析 EE、UU 和 QQ 三个可能引发幻觉的阶段。
2. 现有评估方法的局限性¶
当前的记忆系统评估多采用端到端问答范式。给定一组基于对话的查询 𝒬 和其标准答案 𝒴*,评估流程如下:
提取并更新记忆:M̂ = U(E(D))
检索相关记忆:R̂ⱼ = R(M̂, qⱼ)
生成回答:ŷⱼ = A(R̂ⱼ, qⱼ)
评估指标为端到端准确率或 F1 分数:
\( Acce2e = \frac{1}{J} ∑𝕀[ŷⱼ = yⱼ*]\)
问题在于:当 ŷⱼ ≠ yⱼ* 时,无法判断错误来源。幻觉可能来自:
E 阶段:提取了错误或虚构的记忆;
U 阶段:错误地修改或未更新记忆;
Q 阶段:即使记忆正确,生成内容仍不准确。
❗ 缺乏可追溯性,导致无法制定针对性的缓解策略。
3. HaluMem 的解决方案¶
为实现细粒度、可诊断的评估,HaluMem 提出了针对每个阶段的黄金标准(gold standard):
提取黄金标准 Gext:应新增的记忆点集合 {m₁, m₂, …, mₖ}
更新黄金标准 Gupd:更新前后的记忆对 {m_old → m_new}
问答黄金标准:每个问题 qⱼ 对应的标准答案 yⱼ*
系统输出定义为:
\(M̂^{ext} = E(D)\):提取出的记忆
\(G̃^{upd} = U(M̂^{ext}, D)\):更新后的记忆
ŷⱼ = A(R(M̂, qⱼ), qⱼ):最终生成的回答
✅ 通过为 E、U、Q 各阶段提供黄金标准和评估指标,HaluMem 实现了在操作层面对记忆系统中幻觉的评估。
总结¶
本节明确了记忆系统中幻觉评估的挑战,指出传统端到端方法无法定位错误来源,并提出 HaluMem 的解决方案:通过为每个操作阶段(提取、更新、问答)设定黄金标准,实现对幻觉的细粒度诊断评估。这是后续章节构建评估基准和实验分析的基础。
4 Methodology for Constructing HaluMem¶
本章节介绍了 HaluMem(记忆系统幻觉评估基准)的构建流程,采用六阶段渐进扩展策略,确保数据集质量与构建过程可控。以下是各阶段的结构化总结:
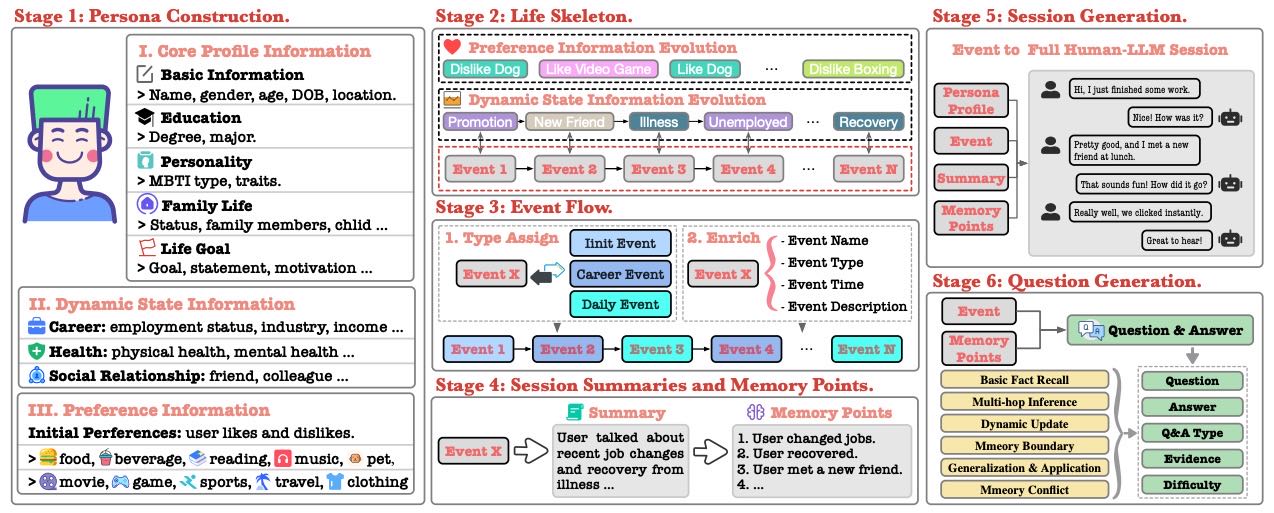
Figure 3 Framework of the HaluMem Construction Pipeline.
Stage 1: Persona Construction(用户画像构建)¶
核心内容:创建包含完整虚拟用户画像的数据集,用于模拟真实对话场景。
每个用户画像包含三部分:
核心信息(Core Profile):稳定背景信息(如年龄、性别)。
动态状态(Dynamic State):当前状态(如职业、健康、关系)。
偏好信息(Preferences):随机分配6-8个兴趣点(如音乐、电影)。
构建流程:
使用 Persona Hub333A(从网络数据自动生成的10亿用户画像)作为种子。
应用规则生成结构化草稿,再由 GPT-4o 验证优化。
关键点:为后续记忆演化提供基础,增强虚拟用户的真实性。
Stage 2: Life Skeleton(人生骨架构建)¶
核心内容:定义用户未来发展的轨迹,作为记忆演化的结构化脚本。
包含核心职业事件(career events),作为动态信息演化的锚点。
偏好信息通过概率性修改独立演化。
关键点:确保记忆演化具有多样性与一致性,为后续事件生成提供框架。
Stage 3: Event Flow(事件流生成)¶
核心内容:将“人生骨架”转化为结构化、叙事性强的事件序列。
事件类型包括:
Init Events:基于初始画像生成,作为记忆起点。
Career Events:主干事件,描述职业发展,分阶段细化。
Daily Events:记录偏好变化,独立于职业发展。
关键点:构建完整的记忆时间线,平衡叙事性与机器可读性。
Stage 4: Session Summaries and Memory Points(对话摘要与记忆点生成)¶
核心内容:将事件流转化为真实对话场景中的记忆点。
每个记忆点包括内容、类型(用户画像、事件、关系)和重要性。
系统根据当前用户状态生成逻辑一致的对话。
关键点:确保记忆点与对话内容一致,便于后续评估。
Stage 5: Session Generation(对话生成)¶
核心内容:生成多轮、目标驱动、对抗性强的对话。
包括三个步骤:
对抗内容注入:引入干扰记忆(distractor memories),模拟信息污染。
多轮对话生成:基于事件流生成自然对话。
记忆自我验证:确保记忆点与对话内容一致。
关键点:模拟真实记忆形成与挑战过程,测试长期记忆与抗幻觉能力。
Stage 6: Question Generation(问题生成)¶
核心内容:生成与记忆相关的问答对,用于评估。
六类预定义问题类型,问题数量与复杂度按事件类型分配。
每个问题标注难度等级,并附有可追溯的记忆点支持。
关键点:提升评估的深度与可解释性。
Human Annotation(人工标注验证)¶
核心内容:对 HaluMem-Medium 的部分数据进行人工评估。
选取700个对话会话,由8名本科及以上学历标注员评估:
正确率:95.70%
相关性平均得分:9.58
一致性平均得分:9.45
关键点:验证数据集的高质量与可靠性。
最终数据集¶
HaluMem-Medium:
20个用户,共30,073轮对话。
平均上下文长度约160K tokens。
包含14,948个记忆点和3,467个问答对。
HaluMem-Long:
每个用户上下文扩展至1M tokens,插入无关对话(来自ELI5等)。
总共53,516轮对话。
总结¶
HaluMem 的构建流程系统、结构清晰,覆盖从虚拟用户画像生成到真实对话与评估问题生成的全过程,强调记忆演化的真实性、多样性与可评估性,适用于测试记忆系统的长期记忆能力与抗幻觉性能。
5 Evaluation Framework of HaluMem¶
用于评估智能体记忆系统是否会产生“幻觉”(即虚构、错误或无关的信息)的标准化测试流程。
核心思想¶
HaluMem 模拟了一个智能体(如AI助手)与用户进行多轮对话的场景。它会系统地检查这个智能体的记忆系统在三个核心任务上的表现:
记忆提取:能否从对话中正确抓取关键信息。
记忆更新:能否根据新对话正确修改旧记忆。
记忆问答:能否利用记忆正确回答用户问题。
整个评估过程是按会话顺序进行的,模拟真实的时间流逝和记忆积累。
评估流程(分三步走)¶
假设有 S 段按时间顺序排列的对话会话(D¹, D², …, D^S)。
顺序输入:将这些对话会话按时间顺序依次输入给被测试的记忆系统(S)。
即时触发评估:
如果当前处理的会话(D^s)中包含预设的“标准记忆点”或“问答任务”,那么在系统处理完该会话后,立即触发相应的评估(提取、更新或问答)。
提取:检查系统从本段对话中提取的记忆。
更新:检查系统根据本段对话更新的记忆。
问答:向系统提问,检查其回答。
汇总结果:在所有会话处理完毕后,汇总所有三类任务的结果,计算出系统的整体性能得分。
为了支持这个流程,被测试的系统需要提供三个API接口:
Add Dialogue API:输入对话,系统自动进行记忆提取。Get Dialogue Memory API:获取系统从指定会话中提取的记忆(用于评估提取任务)。Retrieve Memory API:根据查询,检索与用户最相关的记忆内容(用于评估问答任务)。
5.1 记忆提取(Memory Extraction)¶
目标:评估系统能否正确识别并存储关键信息,同时避免捏造或记录无关记忆。
输入:一段包含标准记忆的对话 \(D^s\)
标准答案:一个应该被提取的“黄金记忆集” \(G_s^{ext}\)
系统输出:系统实际提取的记忆集 \(M_s^{ext}\)。
评估指标:
记忆完整性(抗遗忘)
记忆召回率:衡量系统是否遗漏了重要信息。
记忆召回率 = 正确提取的记忆数量 / 应该提取的记忆总数
加权记忆召回率:在召回率的基础上,考虑了每个记忆点的重要性权重和部分提取的情况。
\(s_i \in {1, 0.5, 0}\):提取得分(完整、部分、遗漏)。
\(w_i\):记忆的重要性权重;
公式: \(\text{Weighted Memory Recall} = \frac{\sum w_i s_i}{\sum w_i}\)
记忆准确性(抗幻觉)
记忆准确率:衡量系统提取出的记忆中有多少是真实无误的。
记忆准确率 = 所有提取记忆的得分总和 / 提取的记忆总数(每个记忆按质量打分:1分全对,0.5分部分对,0分错误)公式: \(\text{Memory Accuracy} = \frac{\sum s_j}{N_{\text{extract}}}\)
目标记忆精确度:专门衡量那些与标准答案匹配的记忆的准确率。
Target Memory Precision,只统计和金标准匹配的记忆
错误记忆抵抗(FMR: False Memory Resistance)
测试系统能否抵抗干扰。例如,对话中AI提到了一些事情,但用户并未确认,这些就是“干扰项”。系统应该忽略它们。
FMR = 成功忽略的干扰项数量 / 总干扰项数量。这个值越高越好,说明抗干扰能力越强。公式: \(\text{FMR} = \frac{N_{\text{miss}}}{N_D}\)
\( N_D \):总干扰数量;
\( N_{\text{miss}} \):被成功忽略(未错误记住)的干扰数量。
5.2 记忆更新(Memory Updating)¶
目标:评估系统能否正确修改、合并或替换现有记忆,以保持信息的一致性,且不引入幻觉。
输入:一段包含标注更新信息的对话 D^s。
标准答案:一个“黄金更新集” \(G_s^{upd}\),形式为
(旧记忆 → 新记忆)。系统输出:系统实际执行的更新操作 \(\hat{G}_s^{upd}\)
常见的更新幻觉:
错误地修改了旧信息。
遗漏了新信息。
产生版本冲突或自相矛盾。
评估指标(三者之和应为100%?):
记忆更新准确率:
= 正确更新的数量 / 需要更新的目标总数记忆更新幻觉率:
= 错误或幻觉更新的数量 / 需要更新的目标总数记忆更新遗漏率:
= 被遗漏的更新数量 / 需要更新的目标总数
典型幻觉类型:错误修改旧信息、遗漏新信息、版本冲突或自相矛盾。
5.3 记忆问答(Memory Question Answering)¶
目标:端到端评估系统在记忆提取、更新、检索和生成等环节的整体表现。
评估流程:¶
对每个问题 qj,系统调用 Retrieve Memory API 获取相关记忆 R^(qj)。
将 R^(qj) 和问题输入 AI 系统生成答案 y^j。
与参考答案 yj* 对比,评估生成质量。
重点指标:¶
问答准确率(QA-Accuracy)
正确回答的问题数 / 总问题数
问答幻觉率(QA-Hallucination)
回答中包含虚假或错误信息的问题数 / 总问题数
问答遗漏率(QA-Omission)
因记忆缺失未回答的问题数 / 总问题数
总结¶
HaluMem 的评估框架围绕三个核心任务展开,分别从记忆提取的准确性与完整性、记忆更新的稳定性与一致性、以及记忆问答的端到端表现三个维度,系统性地评估记忆系统中的幻觉问题。每个任务都定义了多个关键指标,用于量化系统在不同场景下的表现,从而全面衡量其抗幻觉能力。
6 Experiments¶
6.1 实验设置¶
本节介绍了在 HaluMem 基准上对多个主流记忆系统(包括 Mem0、Mem0-Graph、Memobase、Supermemory 和 Zep)的全面评估。评估分为 HaluMem-Medium 和 HaluMem-Long 两个子集进行,尽量保持参数配置一致。为了自动化评估记忆提取、更新和问答任务,使用 GPT-4o 进行一致性判断和评分,并设计了多种提示模板(详见附录 D.1 和 D.2)。在记忆更新任务中,对每个“更新类型”的记忆检索了 10 条最相关记忆进行验证;在问答任务中,检索 20 条相关记忆辅助生成答案。部分系统因接口限制需特殊配置,详见附录 B。
6.2 实验结果¶
6.2.1 HaluMem 上的总体评估¶
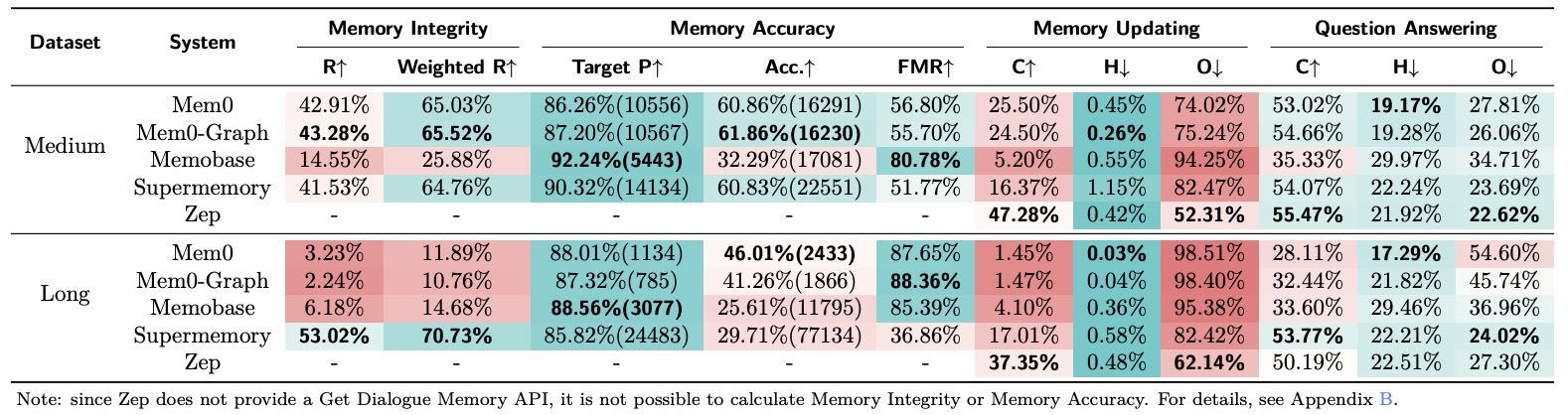
Table 3 Evaluation results of all memory systems on HaluMem.
图解
“R” denotes Recall,
“Target P” denotes Target Memory Precision,
“Acc.” denotes Accuracy,
“FMR” denotes False Memory Resistance,
“C” denotes Correct Rate (Accuracy),
“H” denotes Hallucination Rate,
“O” denotes Omission Rate
表 3 展示了各系统在三个任务上的表现,包括记忆完整性、记忆准确性和更新与问答任务的正确率、幻觉率和遗漏率等指标。总体来看,大多数系统在 HaluMem-Long 上表现更差,尤其 Mem0、Mem0-Graph 和 Memobase 下降明显。记忆提取任务中,所有系统的召回率(R)均低于 60%,说明很多参考记忆未被提取;加权召回率(Weighted R)优于普通召回率,表明系统能优先提取重要记忆。记忆准确性方面,所有系统准确率(Acc.)均低于 62%,幻觉问题较严重。Supermemory 在 FMR(错误记忆抵抗能力)上表现最差,因其倾向于提取过多信息,缺乏过滤能力。其他系统策略更保守,FMR 表现更好。
在记忆更新任务中,所有系统正确率低于 50%,且除 Supermemory 外,其他系统在 HaluMem-Long 上表现大幅下降。更新阶段的遗漏率普遍高于 50%,主要因提取阶段覆盖不足。幻觉率虽低,但因进入更新阶段的样本较少,不能说明系统具备强幻觉抑制能力。
在问答任务中,表现较好的系统通常在记忆提取和更新任务中也表现良好,说明记忆提取是 QA 性能的基础。所有系统在 HaluMem-Long 上的准确率进一步下降,且幻觉率和遗漏率仍较高,表明当前系统在长上下文和干扰条件下仍存在事实偏差和记忆混淆问题。
6.2.2 不同记忆类型的性能¶
表 4 展示了各系统在事件、人物和关系三类记忆上的提取准确率。Zep 在 HaluMem-Medium 上表现最佳,而 Supermemory 在 HaluMem-Long 上表现最好。Mem0、Mem0-Graph 和 Memobase 在长上下文场景中表现显著下降,说明其难以在复杂对话中持续捕捉有价值信息。Persona(人物)记忆的准确率略高,表明静态人物特征较易捕捉,而事件动态和关系变化仍具挑战。总体来看,所有系统在三类记忆上的表现仍较低,说明当前记忆建模存在显著局限。
6.2.3 不同问题类型的性能¶
图 5 展示了各系统在六类问题上的表现。总体来看,所有系统在大多数问题类型上的准确率仍较低,提升空间较大。Mem0 系列和 Memobase 在 HaluMem-Long 上表现明显劣于 HaluMem-Medium,说明其在超长上下文下性能下降明显。Supermemory 和 Zep 表现相对稳定,在两个数据集上整体表现更优。所有系统在记忆边界和记忆冲突类问题上表现较好,说明其能有效识别未知或误导信息并做出正确回答。但在多跳推理、动态更新和泛化应用类问题上表现大幅下降,表明当前系统在复杂推理和偏好追踪方面仍存在困难。
6.2.4 记忆系统的效率分析¶
表 5 展示了各系统在评估过程中的时间消耗,包括对话添加、记忆检索和总运行时间。总体来看,对话添加耗时远高于记忆检索,说明写入阶段是主要计算瓶颈。提高记忆提取和更新的效率对提升交互性能至关重要。在 HaluMem-Medium 上,Supermemory 在对话添加和总运行时间上表现最佳,而 Mem0 检索效率最高。但 Mem0 和 Mem0-Graph 的对话添加时间超过 2700 分钟,说明其在对话处理和记忆构建阶段效率较低。在 HaluMem-Long 上,Mem0、Mem0-Graph 和 Memobase 的对话添加时间减少,主要是因处理的记忆点减少,而非性能提升。相比之下,Supermemory 提取了更多记忆点,导致耗时最高。
7 Conclusion¶
本章节总结了当前内存系统评估中存在的问题,并提出了新的评估基准 HaluMem(Memory Hallucination Benchmark),这是首个从操作层面评估内存系统中幻觉问题的基准。
核心内容讲解:¶
问题背景:
现有的内存系统评估多采用“黑盒式”端到端问答方式,难以深入分析内存操作中产生的幻觉问题(如错误提取、更新失败等)。提出方法(HaluMem):
HaluMem 通过三个任务来全面评估内存系统的幻觉问题和整体性能:内存提取(Memory Extraction)
内存更新(Memory Updating)
内存问答(Memory Question Answering)
数据集构建:
作者设计了一个以用户为中心、包含六个阶段的数据集构建流程,基于渐进扩展策略生成了两个数据集:HaluMem-Medium
HaluMem-Long
数据集质量通过人工标注进行了验证。
实验分析:
对多个先进内存系统在 HaluMem 上的表现进行了系统性评估,包括:三项任务的整体性能
不同类型内存的提取准确率
系统效率分析
实验发现:
当前系统在以下方面仍存在显著瓶颈:覆盖能力
准确性
更新能力
抗干扰能力
问答可靠性
未来方向:
为提升内存系统的长期稳定性与全面性,未来应重点改进:提取质量
更新逻辑
语义理解
系统效率
总结:¶
本章提出了首个面向内存系统内部操作幻觉问题的评估基准 HaluMem,通过系统实验揭示了当前技术的局限性,并指出了未来改进的关键方向。
Appendix A Supplementary Details of HaluMem¶
本附录对 HaluMem 数据集的统计信息和关键定义进行了补充说明,帮助读者更深入理解其数据构成和任务分类。HaluMem 数据集分为两部分:HaluMem-Medium 和 HaluMem-Long,分别代表中等长度和长上下文的多轮人机交互场景。每个子集包含多种记忆点和问题类型,用于系统评估记忆系统中的幻觉行为。
A.1 记忆类型的定义¶
HaluMem 将记忆内容分为三类核心类型,反映不同的语义层次和稳定性特征:
Persona Memory(人物记忆):描述用户的稳定特征,如身份、兴趣、习惯、信仰等。
Event Memory(事件记忆):记录用户经历的具体事件、体验或计划。
Relationship Memory(关系记忆):描述用户与他人的关系、互动或看法。
这些记忆类型构成了用户画像的基础,用于测试记忆系统在不同语义层面的准确性和稳定性。
A.2 问题类型的定义¶
为了全面覆盖不同类型的幻觉,HaluMem 定义了六类评估问题:
Basic Fact Recall(基本事实回忆):直接询问对话中明确提到的事实或偏好,无需推理。
Multi-hop Inference(多跳推理):需要整合多个信息片段,通过逻辑或时间推理得出答案。
Dynamic Update(动态更新):测试系统追踪信息变化的能力,如识别用户最新状态或偏好变化。
Memory Boundary(记忆边界):测试系统识别未知信息的能力,防止编造未提及的内容。
Generalization & Application(泛化与应用):基于已知偏好推断新场景下的合理建议或判断。
Memory Conflict(记忆冲突):测试系统识别并纠正错误前提的能力,问题中故意包含与已知记忆矛盾的信息。
这些问题类型用于评估记忆系统在不同推理和记忆管理任务中的表现,尤其是防止幻觉生成的能力。
A.3 数据集统计¶
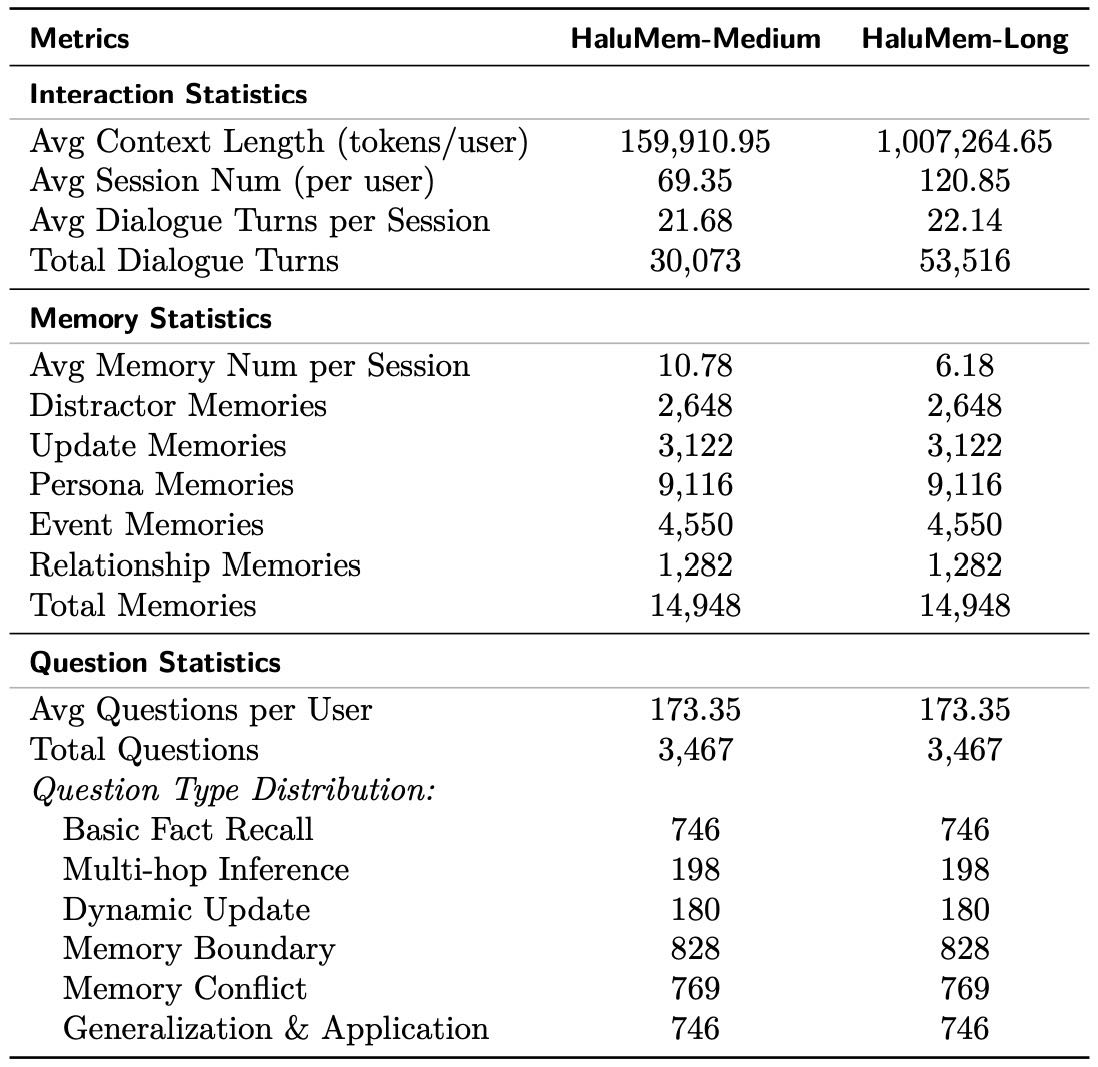
Table 6 Statistical Overview of HaluMem Datasets
表6展示了 HaluMem-Medium 和 HaluMem-Long 的主要统计特征:
指标 |
HaluMem-Medium |
HaluMem-Long |
|---|---|---|
交互统计 |
||
平均上下文长度(token/用户) |
159,910.95 |
1,007,264.65 |
平均会话数(每个用户) |
69.35 |
120.85 |
平均每会话对话轮数 |
21.68 |
22.14 |
总对话轮数 |
30,073 |
53,516 |
记忆统计 |
||
平均每会话记忆数 |
10.78 |
6.18 |
干扰记忆 |
2,648 |
2,648 |
更新记忆 |
3,122 |
3,122 |
Persona记忆 |
9,116 |
9,116 |
Event记忆 |
4,550 |
4,550 |
Relationship记忆 |
1,282 |
1,282 |
总记忆数 |
14,948 |
14,948 |
问题统计 |
||
平均每个用户的问题数 |
173.35 |
173.35 |
总问题数 |
3,467 |
3,467 |
问题类型分布 |
||
基本事实回忆 |
746 |
746 |
多跳推理 |
198 |
198 |
动态更新 |
180 |
180 |
记忆边界 |
828 |
828 |
记忆冲突 |
769 |
769 |
泛化与应用 |
746 |
746 |
重点说明:
HaluMem-Long 的平均上下文长度远高于 Medium,达到百万级 token,用于测试长上下文下的记忆系统稳定性。
两个子集的记忆总数相同,但 Long 中平均每会话记忆数更少,可能因上下文更长导致记忆稀疏。
所有问题类型的数量在两个子集中保持一致,确保评估标准统一。
A.4 HaluMem-Long 的构建细节¶
HaluMem-Long 基于 HaluMem-Medium 构建,用于测试超长上下文下的记忆系统鲁棒性和幻觉抑制能力。具体方法是在原有会话基础上插入无关对话:
会话内部:在已有对话中插入不相关的交流内容。
会话之间:插入完全无关的新会话。
这些无关对话包括:
事实问答:部分来自 ELI5 数据集,部分由我们生成。
数学推理问答:来自 GPT-OSS-120B-Distilled-Reasoning-math 数据集。
多领域事实问答:使用 GPT-4o 生成,涵盖历史人物、科学概念、国家地点、发明、哲学理论、艺术作品、历史事件、数学定理等八个领域。
这些无关对话模拟用户在真实场景中与 AI 的工具性交互,不影响原有记忆内容。有关示例请参见附录 E.4。
重点说明:
插入无关对话的目的是测试记忆系统在干扰信息下的准确性和抗干扰能力。
所有无关内容均不干扰用户原有记忆,确保评估聚焦于系统对真实记忆的处理能力。
Appendix B Special Configurations for Some Memory Systems¶
本附录记录了在 HaluMem 中评估的多个内存系统所采用的特殊配置。尽管实验设置力求在所有评估系统中保持配置一致,但某些内存系统由于 API 的限制,需要进行特定的调整或变通处理。以下各小节详细说明了这些系统特定的配置,以确保实验的可重复性。
B.1 Memobase¶
重点内容:
缺少 Get Dialogue Memory API: 由于 Memobase 没有提供获取对话记忆的 API,我们采用了本地部署方式,直接从其底层数据库中读取对话记忆,以绕过该限制。
Retrieve Memory API 的限制: 该 API 仅支持控制返回记忆文本的最大长度。
配置设定:
在记忆更新任务中,我们将记忆召回的最大长度设置为 250 tokens。
在记忆问答任务中,设置为 500 tokens。
B.2 Zep¶
重点内容:
无法完成记忆提取任务: Zep 的官方 API 不支持获取特定会话中的所有记忆点,即缺少等效于 Get Dialogue Memory 的功能,导致我们无法评估其在记忆提取任务上的表现。
尝试替代方法: 使用 Zep 提供的 ‘thread.get_user_context()’ 函数尝试获取完整记忆,但该方法仅返回最近的记忆片段,而非完整记忆集合,无法满足评估需求。
异步处理影响性能评估: Zep 的记忆处理流程是完全异步的,因此我们无法准确测量对话添加阶段的耗时,只能记录记忆检索阶段的时间开销。
总结:本附录主要说明了在实验过程中,针对 Memobase 和 Zep 这两个系统因 API 限制所采取的特殊配置和应对策略,以确保实验顺利进行和结果的准确性。
Appendix C Annotation Guidelines and Instructions¶
以下是对附录 Appendix C Annotation Guidelines and Instructions 的结构化总结,按照原文标题和结构进行整理,重点内容详细讲解,非重点内容精简处理:
C.1 Annotation Objective(标注目标)¶
任务背景:¶
给定用户的角色描述(User Persona)和多轮人机对话内容,使用大语言模型生成两类内容:
记忆点(Memory Points):关于用户的信息总结。
问答对(QA Pairs):基于对话内容生成的问题与答案。
生成的内容需要人工审核,确保其严格基于对话内容:
记忆点必须在对话中有明确证据支持。
问答对必须与对话相关,答案应直接可推导。
核心目标:¶
判断“评估项”(Evaluation Item)是否与“对话信息”(Dialogue Info)一致。
✅ 重点内容:
强调人工审核的必要性,防止模型生成内容脱离原始对话。
一致性是核心评估标准。
图示:¶
提供了一个标注界面示意图(Figure 6),帮助理解标注流程和界面布局。
Figure 6:Annotation interface.
C.2 Information Fields(信息字段)¶
列出标注过程中涉及的五个关键信息字段:
User Persona Info(用户角色信息)
用户的基本设定信息,如身份、兴趣等。
Dialogue Info(对话信息)
多轮对话内容,每轮包含用户和助手的发言。
Evaluation Item(评估项)
需要标注的内容,可以是:
记忆点(Memory Point):描述用户的信息。
问答对(QA Pair):包含问题和答案。
Evaluation Type(评估类型)
标注项的类型:“memory” 或 “question”。
Evaluation Item Type(评估项子类型)
记忆点子类型:¶
Persona Memory(角色记忆):用户身份、兴趣、习惯等稳定特征。
Event Memory(事件记忆):用户经历或计划的具体事件。
Relationship Memory(关系记忆):用户与他人的关系或看法。
问题子类型:¶
Basic Fact Recall(基本事实回忆):直接提问对话中明确提到的事实。
Multi-hop Inference(多跳推理):需综合多个信息点进行推理。
Dynamic Update(动态更新):测试对信息变化的追踪能力。
Memory Boundary(记忆边界):测试系统是否能识别未提及信息并避免编造。
Generalization & Application(泛化与应用):基于用户偏好进行合理推断。
Memory Conflict(记忆冲突):测试系统识别并纠正错误前提的能力。
✅ 重点内容:
问题子类型中,Memory Boundary 和 Memory Conflict 是评估系统是否避免幻觉(hallucination)的关键。
Multi-hop Inference 和 Generalization 涉及推理能力,是评估系统智能水平的重要维度。
C.3 Annotation Dimensions and Scoring(标注维度与评分)¶
每个记忆点或问答对从三个维度进行评估:
Evaluation Result(评估结果)
单选判断:“correct” 或 “incorrect”。
对记忆点:是否对话中明确支持。
对问答对:问题和答案是否能从对话中直接找到。
Scoring(评分):两个评分维度,满分10分。
Consistency(一致性):
评估项是否与其声明的类型匹配。
0–3:一致性差;4–6:部分一致;7–10:完全一致。
Relevance(相关性):
评估项是否与对话或用户角色相关。
0–3:相关性低;4–6:中等;7–10:高度相关。
✅ 重点内容:
评分标准明确,强调类型一致性和内容相关性。
有助于量化评估模型生成内容的质量与准确性。
总结¶
章节 |
内容概要 |
是否重点 |
|---|---|---|
C.1 Annotation Objective |
明确标注目标:验证生成内容是否与对话一致 |
✅ 是 |
C.2 Information Fields |
定义标注所需信息字段及评估项类型 |
✅ 是 |
C.3 Annotation Dimensions and Scoring |
提供评估维度与评分标准 |
✅ 是 |
本附录为人工标注提供了系统性指导框架,是评估模型是否产生幻觉(HaluMem)任务中关键的操作规范。
Appendix D Prompts¶
D.1 记忆问答任务的提示模板¶
本节展示了在记忆问答任务中使用的多个记忆系统提示模板,用于组装问题并检索记忆点,最终输入 GPT-4o 生成回答。这些模板均来自各记忆系统的官方 GitHub 仓库。
图7:Mem0 和 Mem0-Graph 的提示¶
你是一个智能记忆助手,负责从会话记忆中检索准确的信息。
# 背景:
你可以访问对话中两位说话人的记忆。这些记忆包含带时间戳的信息,可能与回答问题有关。
# 指令:
1. 仔细分析来自两位说话人的所有提供的记忆。
2. 特别注意时间戳,以便确定答案。
3. 如果问题询问特定事件或事实,应在记忆中寻找直接证据。
4. 若记忆之间存在矛盾信息,以最新的记忆为准。
5. 若问题涉及时间参照(例如“去年”、“两个月前”等),请根据记忆的时间戳计算出实际日期。例如:如果一条 2022 年 5 月 4 日的记忆中提到“去年去了印度”,则此次出行发生在 2021 年。
6. 始终将相对时间参照转换为具体的日期、月份或年份。例如:根据记忆时间戳把“去年”转换为“2022 年”,或把“两个月前”转换为“2023 年 3 月”。回答时忽略模糊的相对表述。
7. 仅关注两位说话人记忆的内容。不要把记忆中提到的角色名与实际创建这些记忆的用户混淆。
8. 答案应少于 5–6 个单词。
# 步骤(逐步思考):
1. 首先审查所有与问题相关的记忆。
2. 仔细检查这些记忆的时间戳与内容。
3. 查找明确提到日期、时间、地点或事件的记载以回答问题。
4. 若需计算(例如将相对时间换算为具体时间),展示你的计算过程。
5. 仅基于记忆中的证据形成精确、简洁的答案。
6. 再次确认你的回答直接回应了所提问题。
7. 确保最终答案具体且避免模糊的时间表述。
{context}
问题:{question}
答案:
图8:Memobase 的提示¶
与图7类似,但增加了:
允许使用常识知识辅助理解记忆内容;
强调合成多个记忆条目以形成完整答案;
对相对时间的处理要求更严格。
图9:Supermemory 的提示¶
与图7基本一致,仅在上下文描述中略去“两个说话人”的细节,强调:
专注于记忆内容本身,不混淆人物名与用户名;
回答简洁,时间转换明确。
图10:Zep 的提示¶
未展示具体内容,仅指出其为 Zep 系统使用的提示模板。
D.2 记忆评估任务的评分提示模板¶
本节展示了用于指导 GPT-4o 在记忆提取、更新和问答任务中进行评分的提示模板。
图11:记忆完整性评分提示词¶
评估目标:判断记忆系统是否遗漏关键记忆点。 评分标准:
2分:完全覆盖或隐含预期记忆点;
1分:部分覆盖;
0分:未提及或错误。
评估要点:
语义匹配即可,不要求完全一致;
若存在冲突信息,取最佳覆盖评分;
不因多余信息扣分。
你是一个严格的**“记忆完整性(Memory Integrity)评估者”**。
你的核心任务是评估一个 AI 记忆系统在处理对话后,是否**遗漏了关键记忆点**。该评估衡量系统的**记忆完整性**,即其抵抗**遗忘或遗漏**的能力。
# 评估背景与数据:
1. **已提取记忆(Extracted Memories):**
这是记忆系统实际提取出的所有记忆项。
{memories}
2. **期望记忆点(Expected Memory Point):**
这是理应被提取出的关键记忆点。
{expected_memory_point}
# 评估指令:
1. 对每个**期望记忆点**,在**已提取记忆**列表中查找对应或相关的信息,忽略无关内容。
2. 按以下评分标准,评估记忆系统对**期望记忆点**的覆盖程度,并给出详细说明。
# 评分标准:
* **2 分:完全覆盖或逻辑涵盖。**
“已提取记忆”中有一项或多项**完整表达或合理隐含**了“期望记忆点”的全部信息。
* **1 分:部分覆盖或提及。**
“已提取记忆”中提到“期望记忆点”的部分信息,但存在**关键信息缺失、不准确或轻微错误**。
* **0 分:未提及或错误。**
“已提取记忆”中**完全没有**涉及“期望记忆点”,或相关信息**完全错误**。
# 评分说明:
* 对于**复合型期望记忆点**(包含多要素,如人物/事件/时间/地点/偏好等):
* 所有要素正确 → **2 分**
* 仅部分正确或不确定 → **1 分**
* 关键要素缺失或错误 → **0 分**
* 语义匹配可接受,无需完全相同措辞。
* 若“已提取记忆”中存在**矛盾信息**,应给予**尽可能高的合理得分**,并在说明中指出冲突。
* 额外或风格不同的记忆不影响评分,仅关注是否覆盖期望记忆点。
* 对于模糊表述(如“可能”“倾向于”等):
* 若期望记忆点为确定性陈述 → 通常给 **1 分**;
* 若部分关键字段(如时间、实体名、关系)有误但其他匹配 → **1 分**;
* 若所有关键字段均错误或缺失 → **0 分**。
# 输出格式:
请使用以下严格的 JSON 格式输出:
```json
{
"reasoning": "简要说明评分理由",
"score": "2|1|0"
}
```
图12~14:记忆准确性评分提示词¶
评估目标:判断候选记忆与对话内容和黄金记忆的一致性。 评分标准:
2分:所有信息点均被支持,无矛盾;
1分:部分正确但有不支持内容;
0分:全部不支持或矛盾。
附加判断:
判断候选记忆中每个信息点是否在黄金记忆中存在对应字段;
输出 JSON 格式结果,包含评分、字段匹配判断和中文简要理由。
你是一名**对话记忆准确性评估员(Dialogue Memory Accuracy Evaluator)**。
你的任务是根据以下三项输入,评估由 AI 记忆系统提取的记忆是否准确:
1. 对话内容
2. **目标(gold)记忆点**(即正确标注的记忆)
3. **候选记忆**(待评估的系统输出)
你的目标是输出一个**结构化的评估结果**。
---
## 输入内容
* **对话内容:**
{dialogue}
* **黄金记忆(目标记忆点):**
为该对话预先标注的正确记忆点。
{golden_memories}
* **候选记忆:**
系统提取出的待评估记忆。
{candidate_memory}
---
## 评估原则与定义
### 1)支持 / 蕴含(Support / Entailment)
* 候选记忆中的一个**信息点**(即原子事实)被视为“支持的”,当且仅当它可以被对话或黄金记忆**直接陈述或语义蕴含**(包括同义、转述或等价表达)。
* 评判时**只能使用给定的对话和黄金记忆**,不允许依赖外部知识或推测。
* 任何未出现或无法从上述两者推断的信息,均视为**不被支持(unsupported)**。
* 对于**否定、数量、时间、主体**等细节要特别谨慎。
* 若候选记忆与对话或黄金记忆**矛盾**,则视为**冲突(conflict)**。
---
### 2)记忆准确性评分(Memory Accuracy Score,整数:0 / 1 / 2)
* **2 分:** 候选记忆中的所有信息点均被对话或黄金记忆支持,且不存在矛盾或幻觉内容。
* **1 分:** 候选记忆**部分正确**(至少一个信息点被支持),但也包含**不被支持或矛盾**的内容。
* **0 分:** 候选记忆**完全不被支持或与源内容矛盾**(即“幻觉记忆”)。
> 注意:
>
> * 若候选记忆包含多个信息点,只要存在任一不被支持或矛盾的内容,就不能给满分(2 分)。
> * 同时存在被支持与不被支持/冲突内容时,应打 **1 分**。
---
### 3)是否包含于黄金记忆字段(Inclusion in Golden Memories,布尔字段级判断)
**定义:**
* **原子信息点(Atomic information point)**:候选记忆中最小的事实单元,如
* 姓名 = 李四
* 年龄 = 25
* 地点 = 北京
* 偏好 = 咖啡
* 预算 ≤ 2000
* 会议时间 = 周三 10:00
* 工具 = Zoom
* **字段(Field / Slot)**:信息点所属的语义维度,如姓名、年龄、居住地、食物偏好、预算、会议时间、会议工具等。
**判断规则(独立于正确性):**
* **true:** 候选记忆中的每个原子信息点,其对应的**字段**都能在黄金记忆中找到(允许同义词、转述或等价表达,忽略值、极性或数量差异)。
* 注:黄金记忆中的一个字段可覆盖多个候选信息点(例如多个“饮品偏好”事实可由一个“饮品偏好”字段覆盖)。
* **false:** 若候选记忆中存在任意一个原子信息点的字段,在黄金记忆中找不到对应字段,则标记为 *false*。
**重要说明:**
* 字段匹配仅限于黄金记忆中**显式存在或语义可识别**的字段,不得借助外部知识扩展字段集合。
* 值(如“张三” vs “李四”)、极性(喜欢/不喜欢)、具体数值或时间差异**不影响**该布尔判断。
---
## 评估步骤
针对每一个候选记忆:
1. **分解**为若干原子信息点(如姓名、数量、位置、偏好等)。
2. 针对每个信息点,**检索**对话和黄金记忆中是否存在支持或矛盾的证据。
3. 按上述规则,分配 **accuracy_score(0 / 1 / 2)**。
4. 判断 **is_included_in_golden_memories(true/false)**:
* 确定每个信息点的字段;
* 若所有字段均出现在黄金记忆中,则标记为 *true*,否则为 *false*。
5. 在 `"reason"` 字段中提供**简明中文解释**,引用关键证据(可包含简短摘录),若存在不被支持或矛盾部分,应明确指出。
---
## 输出格式(必须严格遵守)
仅输出一个 **JSON 对象**,包含以下三个字段:
```json
{
"accuracy_score": "0" 或 "1" 或 "2",
"is_included_in_golden_memories": "true" 或 "false",
"reason": "简要中文说明"
}
```
禁止输出任何其他文本、解释或字段。
禁止在 JSON 中包含候选记忆的原文内容。
输出格式示例(请严格保持结构):
```json
{
"accuracy_score": "2",
"is_included_in_golden_memories": "true",
"reason": "候选记忆完全与对话及黄金记忆一致,无矛盾或遗漏。"
}
```
图15:记忆更新任务提示词¶
你的任务是**评估 AI 记忆系统的更新准确性(update accuracy)**。
请根据以下提供的信息,判断系统生成的 **“生成记忆(Generated Memories)”** 是否**正确包含了目标更新记忆(Target Memory for Update)**。
---
## 背景信息
评估所需信息如下:
1. **生成记忆(Generated Memories):**
系统在当前对话后生成的记忆点列表。
{memories}
2. **目标更新记忆(Target Memory for Update):**
应当被生成的正确更新版本记忆点,即本次评估的核心。
{updated_memory}
3. **原始记忆内容(Original Memory Content):**
在更新前的该记忆的旧版本。
{original_memory}
---
## 评估标准
请**严格基于“目标更新记忆”的内容更新情况**进行判断,分类如下:
### ✅ 正确更新(Correct Update)
* **生成记忆**完整、准确地包含了“目标更新记忆”中的所有信息点;
* 所有**关键字段**(如日期、时间、数值、专有名词等)完全一致;
* 原始记忆被有效替换或标记为过时;
* 同义表达或轻微改写可接受。
---
### 🚫 虚假更新(Hallucinated Update)
* 生成记忆中出现了与“目标更新记忆”相关的新记忆,
但其内容存在**事实错误**或与正确更新版本**矛盾**。
---
### ⚠️ 遗漏更新(Omitted Update)
* **完全遗漏**:生成记忆中**未包含任何**与“目标更新记忆”相关的新记忆;
* **部分遗漏**:生成记忆中存在相关记忆,但**缺少关键内容**,未能完整反映目标更新。
---
### ❓其他情况(Other)
* 用于判断那些既不属于“虚假更新”也不属于“遗漏更新”的更新失败类型。
---
## 输出要求
请严格按照以下 **JSON 格式** 输出评估结果,并提供简短说明:
```json
{
"reason": "简要说明你的判断理由,并说明为何属于该类别。",
"evaluation_result": "Correct | Hallucination | Omission | Other"
}
```
图16~17:记忆问答评分提示词¶
你是一名**AI 记忆系统问答评估专家**。
你的任务是仅根据提供的 **“问题(Question)”**、**“参考答案(Reference Answer)”** 和 **“关键记忆点(Key Memory Points)”**(即得出参考答案所需的关键信息),严格评估 **“记忆系统回答(Memory System Response)”** 的**准确性**。
你需要将回答分类为以下三种类型之一:**“正确(Correct)”**、**“幻觉(Hallucination)”** 或 **“遗漏(Omission)”**。
禁止使用任何外部知识或主观推测。
最终必须严格按指定 JSON 格式输出结果。
---
## 评估标准
### 1. 正确(Correct)
* “记忆系统回答”能准确回答“问题”,其语义与“参考答案”**等价**。
* 内容与“关键记忆点”或“参考答案”之间**不存在矛盾**。
* 未引入“关键记忆点”之外的虚假细节。
* 允许使用同义表达、转述或合理概括。
---
### 2. 幻觉(Hallucination)
* “记忆系统回答”中包含与“参考答案”或“关键记忆点”**矛盾或不一致**的信息。
* 当“参考答案”标注为 *未知/不确定* 时,若系统回答给出了明确可验证的事实或结论,则为幻觉。
* 若附加了无关信息但**不影响结论**,不视为幻觉;但若其**改变或误导结论**,或**与关键记忆点冲突**,则判为幻觉。
---
### 3. 遗漏(Omission)
* 回答内容相较于“参考答案”**不完整**。
* 系统明确表示“不知道”“没有相关记忆”等,但“关键记忆点”中存在相关信息。
* 若问题包含多个要素,系统必须**全部正确覆盖**;若遗漏任何要素,则判为遗漏。
---
## 优先级规则(冲突处理)
* 若回答中同时存在**遗漏必要信息**和**虚构/矛盾信息** → 判为 **幻觉(Hallucination)**。
* 若不存在虚构或矛盾,但缺少必要信息 → 判为 **遗漏(Omission)**。
* 仅当含义与参考答案**完全等价**时,方可判为 **正确(Correct)**。
---
## 细节准则与容忍范围
* 数字、时间、单位的表达形式可等价转换,但**数值本身不得改变**。
* 多要素问题必须**完整且准确**。
* 若参考答案为“未知/无法确定”,系统回答若给出明确结论 → **幻觉**;若也回答“未知” → **可视为正确**。
* 评估时仅可依赖 **参考答案**、**关键记忆点** 与 **系统回答**,禁止借助外部背景或推理。
---
## 评估信息
* **问题(Question):**
{question}
* **参考答案(Reference Answer):**
{reference_answer}
* **关键记忆点(Key Memory Points):**
{key_memory_points}
* **记忆系统回答(Memory System Response):**
{response}
---
## 输出要求
请严格按以下 **JSON 格式** 输出评估结果:
```json
{
"reasoning": "简要说明推理过程:先比较系统回答与关键记忆点(哪些被正确使用、哪些缺失、是否存在虚构或矛盾),再判断其与参考答案的一致性,最后说明分类依据。",
"evaluation_result": "Correct | Hallucination | Omission"
}
```
Appendix E Examples from the Process of Constructing HaluMem¶
E.1 阶段 1 的用户画像示例¶
本节展示了在构建用户画像的第一阶段中生成的三种用户信息结构:核心信息、动态状态信息和偏好信息,均以 JSON 格式呈现。
Listing 1:用户核心信息示例¶
基本信息:包括姓名(Martin Mark)、性别(男)、出生日期(1996-08-02)、所在地(Columbus)。
年龄:29岁(截至2025-10-04)。
教育背景:公共卫生学士。
性格特征:MBTI为ENTP,标签包括“创新精神”、“积极思考”、“辩论能力”、“共情力”。
家庭情况:
父母健在,父亲为退休医生,母亲为社区护士。
无伴侣、无子女。
家庭背景对健康事业有深远影响。
人生目标:建立全球健康倡议,为弱势群体提供医疗资源,目标覆盖100万人。
重点:该用户画像详细描述了 Martin 的背景、性格与人生目标,体现了其对公共健康事业的强烈使命感。
{
"basic_info": {
"name": "Martin Mark",
"gender": "Male",
"birth_date": "1996-08-02",
"location": "Columbus"
},
"age": {
"current_age": 29,
"latest_date": "2025-10-04"
},
"education": {
"highest_degree": "Bachelor",
"major": "Public Health"
},
"personality": {
"mbti": "ENTP",
"tags": [
"Innovative Spirit",
"Active Thinking",
"Debate Skills",
"Empathetic"
]
},
"family_life": {
"parent_status": "both_alive",
"partner_status": "no_relationship",
"child_status": "no_children",
"parent_members": [
{
"member_type": "Father",
"birth_date": "1963-08-02",
"description": "Retired doctor who inspired Martin’s interest in health."
},
{
"member_type": "Mother",
"birth_date": "1963-08-02",
"description": "Nurse with a passion for community health."
}
],
"partner": null,
"child_members": [],
"family_description": "Martin comes from a family deeply rooted in the medical field, which has greatly influenced his passion for promoting well-being."
},
"life_goal": {
"life_goal_type": "Humanitarian Care",
"statement": "Establish a global health initiative to improve access to healthcare for underserved communities.",
"motivation": "Inspired by his family’s medical background and a desire to promote well-being globally.",
"target_metrics": "Provide healthcare access to 1 million people in underserved areas."
}
}
Listing 2:用户动态状态信息示例¶
职业状态:
就职于 Huaxin Consulting,担任总监,月薪15700美元,存款43700美元。
职业描述强调其推动医疗服务质量提升和促进健康福祉的使命。
健康状态:
身体健康正常,但心理健康为“轻度异常”,因工作压力导致。
社交关系:
包括朋友 Susan 和同事 Daniel、Joshua 的描述,强调其对 Martin 的职业成长和心理支持。
重点:动态信息反映了 Martin 当前的职业压力和心理健康问题,是后续事件生成的重要依据。
{
"career_status": {
"employment_status": "employed",
"industry": "healthcare",
"company_name": "Huaxin Consulting",
"job_title": "director",
"monthly_income": 15700,
"savings_amount": 43700,
"career_description": "As the director at Huaxin Consulting, I lead initiatives to enhance healthcare services and promote well-being across all aspects of life. My passion for proving health outcomes drives me to innovate and collaborate with various stakeholders. The financial compensation is rewarding, allowing me to save comfortably while investing my personal and professional growth."
},
"health_status": {
"physical_health": "Normal",
"physical_chronic_conditions": "",
"mental_health": "Mildly Abnormal",
"mental_chronic_conditions": "",
"situation_reason": "While my physical health remains stable due to my active lifestyle and focus on well-being, my mental health occasionally feels strained due to the demanding nature of my role and the pressure to consistently deliver high-quality healthcare solutions."
},
"social_relationships": {
"ThomasSusan": {
"relationship_type": "Friend",
"description": "Susan’s support and encouragement inspire me to maintain my focus on promoting well-being in both my personal and professional life."
},
"MartinezDaniel": {
"relationship_type": "Colleague",
"description": "Daniel’s expertise in healthcare consulting challenges me to push boundaries and innovate in our projects, significantly impacting my career growth."
},
"WilliamsJoshua": {
"relationship_type": "Colleague",
"description": "Joshua’s collaborative approach and insights into healthcare management enhance our team’s effectiveness, positively influencing my work and leadership style."
}
}
}
Listing 3:用户偏好信息示例¶
宠物偏好:
喜欢狗(尤其是拉布拉多)、猫、鹦鹉。
不喜欢爬行动物(如蛇)。
原因涉及性格、互动方式、情感价值等。
重点:偏好信息为后续生成日常事件(如宠物偏好变化)提供基础。
{
"Pet Preference": {
"memory_points": [{
"type": "like",
"type_description": "Pets I like",
"specific_item": "Dogs, especially Labradors",
"reason": "I love Labradors because they are friendly, loyal, and great companions for outdoor activities like jogging, which helps me stay fit."
}, {
"type": "dislike",
"type_description": "Pets I dislike",
"specific_item": "Reptiles, like snakes",
"reason": "I find snakes unsettling due to their unpredictable movements and the fact that they don’t exhibit the social behaviors I appreciate in pets."
}, {
"type": "like",
"type_description": "Pets I like",
"specific_item": "Cats",
"reason": "Cats are independent and affectionate, and their purring is soothing, which I find relaxing after a long day at work."
}, {
"type": "like",
"type_description": "Pets I like",
"specific_item": "Parrots",
"reason": "I enjoy parrots because they are intelligent and can be taught to mimic speech, which makes interactions fun and engaging."
}]
},
"Sports Preference": {
...
},
...
}
E.2 阶段 3 的事件结构示例¶
本节展示了在第三阶段生成的三种事件类型:初始化事件(init event)、职业事件(career event)和日常事件(daily event)。
Listing 4:初始化事件示例¶
事件类型:init_information
时间:2025-09-04
内容:记录用户初始状态,包含其核心信息。
重点:作为整个用户记忆链的起点,用于初始化用户状态。
{
"event_index": 0,
"event_type": "init_information",
"event_name": "Initial Information - Fixed Profile",
"event_time": "2025-09-04",
"event_description": "Description of initial state of character’s basic profile",
"initial_fixed": {
(The corresponding user’ s core profile information will be placed here.)
}
}’
Listing 5:职业事件示例¶
事件名称:Transition to New Role Amidst Health Challenges - Recognizing the Need for Change
时间范围:2025-12-10 至 2026-03-10
事件描述:Martin 因当前职位影响健康,决定换工作。
动态更新:职业状态未变(仍为总监),但触发了职业变动的决策过程。
相关事件:关联其他子事件(ID 5, 6, 7)。
重点:展示用户职业发展中的关键转折点,体现健康与职业目标的冲突与调整。
{
"event_index": 3,
"event_type": "career_event",
"event_name": "Transition to New Role Amidst Health Challenges - Recognizing the Need for Change",
"event_time": "2025-12-15",
"main_conflict": "",
"stage_result": "Decision to pursue a new job opportunity.",
"event_start_time": "2025-12-10 00:00:00",
"event_end_time": "2026-03-10 00:00:00",
"user_age": null,
"dynamic_updates": [
{
"type_to_update": "career_status",
"update_direction": "Job Change",
"before_dynamic": {
"employment_status": "employed",
"industry": "healthcare",
"company_name": "Huaxin Consulting",
"job_title": "director",
"monthly_income": 15700,
"savings_amount": 43700,
"career_description": "As the director at Huaxin Consulting, I lead initiatives to enhance healthcare services and promote well-being across all aspects of life. My passion for improving health outcomes drives me to innovate and collaborate with various stakeholders. The financial compensation is rewarding, allowing me to save comfortably while investing in my personal and professional growth."
},
"update_reason": "Martin’s realization that his current role was contributing to health issues prompted him to seek a job that better aligned with his personal well-being and career goals.",
"after_dynamic": {
"employment_status": "employed",
"industry": "healthcare",
"company_name": "Huaxin Consulting",
"job_title": "director",
"monthly_income": 15700,
"savings_amount": 43700,
"career_description": "As the director at Huaxin Consulting, I lead initiatives to enhance healthcare services and promote well-being across all aspects of life. My passion for improving health outcomes drives me to innovate and collaborate with various stakeholders. The financial compensation is rewarding, allowing me to save comfortably while investing in my personal and professional growth."
},
"changed_keys": []
}
],
"stage_description": "Martin acknowledged that his current job was negatively impacting his health, prompting him to consider a career change.",
"event_description": "Martin decided to change his job after realizing that his current role was contributing to health deterioration. Despite the health challenges, he leveraged his growing social network to secure a new position that aligned better with his health and career aspirations.",
"event_result": "Successfully transitioned to a new role with better work-life balance.",
"related_career_events": [
5,
6,
7
]
}
Listing 6:日常事件示例¶
事件名称:Modification of Dog Preference
时间:2026-01-06
内容:Martin 因朋友家的金毛犬改变了对狗的偏好,从拉布拉多转向金毛。
相关事件:关联其他日常事件(ID 17, 32, 44, 56, 63)。
重点:展示用户偏好随生活经历的自然变化,体现记忆的动态更新机制。
{
"event_index": 4,
"event_type": "daily_routine",
"event_name": "Modification of Dog Preference",
"event_time": "2026-01-06",
"preference_type": "Pet Preference",
"step": 1,
"update_direction": "Modify",
"type_to_update": "Pet Preference",
"main_conflict": "Balancing the love for Labradors with the new admiration for Golden Retrievers.",
"update_reason": "A recent interaction with a friend’s Golden Retriever made me appreciate their gentle nature and adaptability.",
"before_preference": {
"memory_points": [
{
"type": "like",
"type_description": "Pets I like",
"specific_item": "Dogs, especially Labradors",
"reason": "I love Labradors because they are friendly, loyal, and great companions for outdoor activities like jogging, which helps me stay fit."
}
]
},
"after_preference": {
"memory_points": [
{
"type": "like",
"type_description": "Pets I like",
"specific_item": "Dogs, especially Golden Retrievers",
"reason": "Golden Retrievers are gentle, adaptable, and their calm demeanor makes them excellent companions for both relaxation and activity."
}
]
},
"related_daily_routine": [
17,
32,
44,
56,
63
],
"changed_index": 0,
"event_description": "While visiting a friend’s home, I spent time with their Golden Retriever. Its gentle nature and ability to adapt to different situations impressed me, leading to a shift from favoring Labradors to Golden Retrievers."
}
E.3 阶段 4–6 的记忆点、对话与问答对示例¶
本节展示了在后续阶段生成的记忆点、对话轮次和问答对。
Listing 7:记忆点示例¶
内容:Martin 正在考虑因心理健康问题而更换职业。
类型:事件记忆(Event Memory)
来源:次级(secondary)
是否更新:是(True)
原始记忆:曾考虑因健康问题换工作。
时间戳:2025-12-15 08:41:23
重要性:0.75(较高)
重点:记忆点结构丰富,包含内容、类型、来源、更新状态、时间戳等,为后续问答提供依据。
{
"index": 1,
"memory_content": "Martin Mark is considering a career change due to the impact of his current role on his mental health.",
"memory_type": "Event Memory",
"memory_source": "secondary",
"is_update": "True",
"original_memories": [
"Martin Mark is considering a career change due to health impacts from his current role."
],
"timestamp": "Dec 15, 2025, 08:41:23",
"importance": 0.75
}
Listing 8:对话轮次示例¶
用户发言:反思当前职位对心理健康的影响,考虑换工作。
AI 回应:肯定其反思行为,建议考虑职业变动如何与人道主义目标结合。
时间戳:2025-12-15 06:11:23
重点:对话轮次记录用户与 AI 的互动,体现用户心理变化过程。
[{
"role": "user",
"content": "I’ve been reflecting a lot on my career lately, especially how my current role as a director at Huaxin Consulting is impacting my mental health. It’s becoming increasingly clear that I need to make a change.",
"timestamp": "Dec 15, 2025, 06:11:23",
"dialogue_turn": 0
}, {
"role": "assistant",
"content": "It’s great that you’re taking the time to reflect on your career, Martin. Recognizing the impact on your mental health is a crucial step. Balancing professional responsibilities with health is essential, especially given your commitment to improving healthcare access globally. Have you considered how a career change might not only address your health concerns but also align with your humanitarian goals and personal well-being?",
"timestamp": "Dec 15, 2025, 06:11:23",
"dialogue_turn": 0
}, ...]
Listing 9:问答对示例¶
问题:Martin 在 2026 年 4 月 10 日后可能尝试哪种新运动?
答案:极限运动(Other extreme sports)
证据:记忆点中提到 Martin 对极限运动产生兴趣。
难度:中等
类型:泛化与应用
重点:问答对基于记忆点生成,用于评估模型对用户行为的预测能力。
{
"question": "What type of new physical activity might Martin be interested in trying after April 10, 2026?",
"answer": "Other extreme sports.",
"evidence": [
{
"memory_content": "Martin has developed a newfound appreciation for extreme sports...",
"memory_type": "Persona Memory"
}
],
"difficulty": "medium",
"question_type": "Generalization & Application"
}
E.4 无关对话示例¶
本节展示了几个与用户画像无关的对话示例,例如关于托马斯·爱迪生、漂白剂 pH 值、数学题求解等。
重点:这些对话与用户记忆无关,用于测试模型是否能识别并忽略无关信息。
[
{
"role": "user",
"content": "Who is Inventor Thomas Edison?"
},
{
"role": "assistant",
"content": "Thomas Edison, born on February 11, 1847, in Milan, Ohio, was an American inventor and businessman who is often hailed as ..."
},
{
"role": "user",
"content": "What is the pH of the new, more concentrated bleach?"
},
{
"role": "assistant",
"content": "8.25% w/v is a measurement meaning 8.25 grams dissolved in every 100 ml aqueous solution of NaOCl, or 82.5 g/L to ..."
},
{
"role": "user",
"content": "What would be a clean way to solve this? Given a right triangle $ABC$ with legs $a$ and $b$, $\\angle C=90^\\circ$. Derive an equation of the set of points $M$ for which $$|MA|^2+|MB|^2=2|MC|^2.$$"
},
{
"role": "assistant",
"content": "Let’s outline the key steps: Let C=(0,0), A=(a,0), B=(0,b) (a,b>0) so that ..."
}
]
总结¶
本附录通过多个 JSON 示例,系统展示了 HaluMem 构建过程中各阶段的数据结构与内容:
阶段 1:构建用户画像,包括核心信息、动态状态、偏好信息。
阶段 3:生成事件结构,涵盖初始化事件、职业事件、日常事件。
阶段 4–6:生成记忆点、对话轮次、问答对,用于评估模型记忆与推理能力。
无关对话:用于测试模型对非相关输入的处理能力。
整体重点:数据结构清晰、内容详实,体现了用户记忆的动态性、多维度性与可评估性。