2404.13501_LLM_Agent_Memory_Survey: A Survey on the Memory Mechanism of Large Language Model based Agents¶
引用: 172(2025-08-07)
组织:
1Gaoling School of Artificial Intelligence, Renmin University of China, Beijing, China
2Huawei Noah’s Ark Lab, China
GitHub: https://github.com/nuster1128/LLM_Agent_Memory_Survey
总结¶
与环境交互过程中,有三个关键阶段:
感知与存储:Agent从环境中感知信息并将其存储到记忆中;
信息处理:对存储的信息进行处理,使其更易于使用;
动作生成:基于处理后的记忆信息决定下一步动作。
从三个角度论证了记忆在基于大语言模型(LLM)的智能体中是必要的
认知心理学视角
模拟人类行为,从而完成各种任务
记忆是人类行为合理化的重要基础
自进化视角
经验积累:记忆可以帮助智能体记住过往的错误计划或失败经验,从而在未来处理类似任务时更加高效。
环境探索:智能体需要通过探索环境并学习反馈来进化。记忆可以帮助它决定何时、如何进行探索(例如,优先探索失败过的或探索频率较低的行为)
知识抽象:记忆能够从原始观察中提取高层次的抽象信息,这是智能体适应和泛化未知环境的基础。
智能体应用场景视角
记忆是智能体的核心组件
对话智能体:需要记忆历史对话内容,以理解上下文并生成连贯的回复。没有记忆,对话无法持续。
模拟智能体:需要记忆角色设定和行为轨迹,以保持角色一致性。缺乏记忆容易导致角色设定混乱。
从三个方面详细探讨了记忆模块的实现方法
记忆来源(Memory Sources)
记忆形式(Memory Forms)
记忆操作(Memory Operations)
记忆评估
直接评估
主观评估
一致性(Coherence):检查召回的记忆是否与当前上下文自然贴合。
合理性(Rationality):检查记忆内容是否合理,是否符合事实。
优缺点
优点:主观评估具有较好的解释性,评估人员可以提供理由。
缺点:成本高、主观性强,结果难以复现和比较。
客观评估
结果正确性(Result Correctness)
评估智能体基于记忆回答预定义问题的能力
使用准确率(Accuracy)进行衡量
引用准确率(Reference Accuracy)
评估智能体能否检索到支持回答的相关记忆内容
常用F1分数评估
时间和硬件成本(Time & Hardware Cost)
评估记忆模块在操作中的时间消耗和硬件资源占用
通常通过峰值GPU内存和适应时间衡量。
优缺点
优点:数值化评估便于比较不同方法,有助于建立基准。
缺点:缺乏解释性,难以覆盖所有评估维度。
间接评估
通过智能体完成任务的能力来反映记忆模块的有效性
对话任务
对话是智能体的重要应用之一,记忆在其中起关键作用
评估指标包括:
一致性(Consistency):确保回应与对话上下文一致
参与度(Engagement):衡量用户被吸引继续对话的能力
多源问答任务
评估智能体整合来自多个来源(如对话历史、外部知识)的记忆能力
任务包括跨对话问答和多文档问答
长上下文应用
在处理长文本时,记忆模块的作用尤为重要
评估任务包括长上下文段落检索和摘要生成
其他任务
任务成功率(Success Rate):评估智能体完成特定任务的比例。
探索度(Exploration Degree):衡量智能体探索环境的能力。
消融实验(Ablation Study):比较有/无记忆模块的性能差异。
对比
直接评估更可靠,但缺乏开源的专用基准
间接评估操作简便,但结果可能受其他模块影响,存在偏差
未来方向
参数记忆
多Agent 记忆
基于记忆的终身学习
人形Agent 记忆
适用于社会模拟、人类行为研究与角色扮演等场景
记忆机制应符合人类认知规律
别人的总结¶
这篇综述论文系统地回顾了LLM Agent的记忆机制。论文首先阐述了LLM Agent中记忆的定义和必要性,随后详细分类和讨论了现有记忆模块的设计方法,包括短期记忆(如上下文窗口管理)、长期记忆(如外部知识库、向量数据库)以及记忆的组织和检索策略。此外,该综述还探讨了记忆模块在不同Agent应用中的作用,并指出了当前研究的局限性及未来的发展方向。该论文强调了记忆在Agent自我演化能力中的核心地位,并呼吁构建更系统化的评估方法。
Abstract¶
本文重点综述了基于大语言模型(LLM)的智能体(Agent)中的记忆机制(Memory Mechanism)。与原始的LLM相比,LLM-based agent 的显著特点是自我演化能力,这种能力是其解决需要长时间、复杂交互的现实问题的基础。记忆模块是支持智能体与环境交互的关键组成部分。
尽管已有大量关于记忆机制的研究,但这些工作分散在不同论文中,缺乏系统性的整理和比较。本文旨在填补这一空白,全面回顾和总结现有的记忆机制研究,抽象出通用的设计模式,以指导未来的研究。
本文的结构包括:
讨论LLM-based agent 中的记忆机制是什么以及为什么需要记忆。
系统回顾记忆模块的设计与评估方法。
展示记忆模块在实际应用中的作用。
分析现有工作的限制,并提出未来的研究方向。
1 Introduction¶
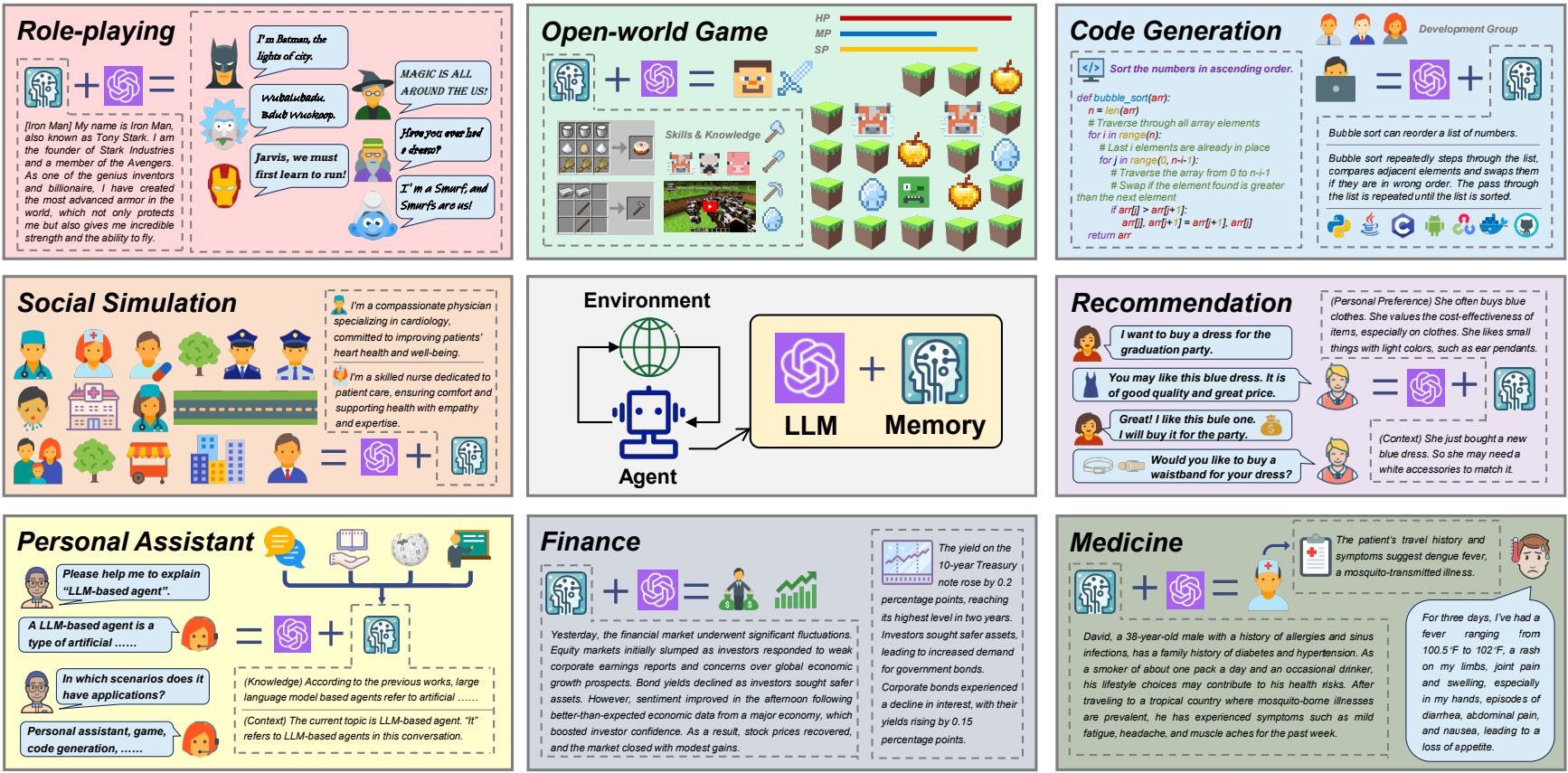
Figure 1: The importance of the memory module in LLM-based agents.
“没有记忆,就没有文化;没有记忆,就不会有文明、社会和未来。”
——埃利·威塞尔(Elie Wiesel,1928–2016)
背景与动机
近年来,大型语言模型(Large Language Models, LLMs)在多个领域取得了显著成就,涵盖人工智能、软件工程、教育和社会科学等。但传统的LLMs通常在不与环境交互的前提下完成任务,这与通用人工智能(Artificial General Intelligence, AGI)的目标相距甚远。为了实现AGI,智能系统需要具备自主探索和学习现实世界的能力。例如,一个旅行规划代理需要与票务网站交互,并根据反馈进行调整;一个人工助手代理则应根据用户反馈优化行为,提供个性化响应。
为此,近年来研究者们提出了大量基于LLM的智能代理(LLM-based agents),其核心在于为LLM添加模块,以增强其在真实环境中自我进化的能力。其中,记忆模块(memory module)是区别于传统LLM的关键部分,赋予了代理“代理性”,使其能够积累知识、处理历史经验、检索信息以支持决策。
研究现状与问题
尽管已有大量研究围绕记忆模块展开,如信息来源、存储形式与操作机制等方面,但目前仍缺乏一个系统性的综述,从整体视角对记忆模块进行分析。为此,本文旨在系统回顾相关研究,提出清晰的分类和设计与评估原则,具体围绕以下三个核心问题展开:
什么是LLM代理的记忆?
为什么LLM代理需要记忆?
如何实现和评估记忆模块?
本文贡献
本文的主要贡献包括:
正式定义记忆模块,并全面分析其在LLM代理中的必要性;
系统总结当前设计与评估记忆模块的研究,提供清晰分类和直观洞察;
展示典型应用场景,揭示记忆模块在不同任务中的重要性;
分析现有方法的局限性,并提出未来研究方向。
文章结构
接下来,文章结构如下:
第2节提供对LLM和基于LLM的代理相关综述的系统性元调查;
第3至第6节分别详细讨论“什么是记忆模块”、“为什么需要记忆模块”以及“如何实现和评估记忆模块”;
第7节展示记忆增强代理在多个场景中的应用;
第8和第9节分析当前方法的局限性,并提出未来研究方向与总结。
2 Related Surveys¶
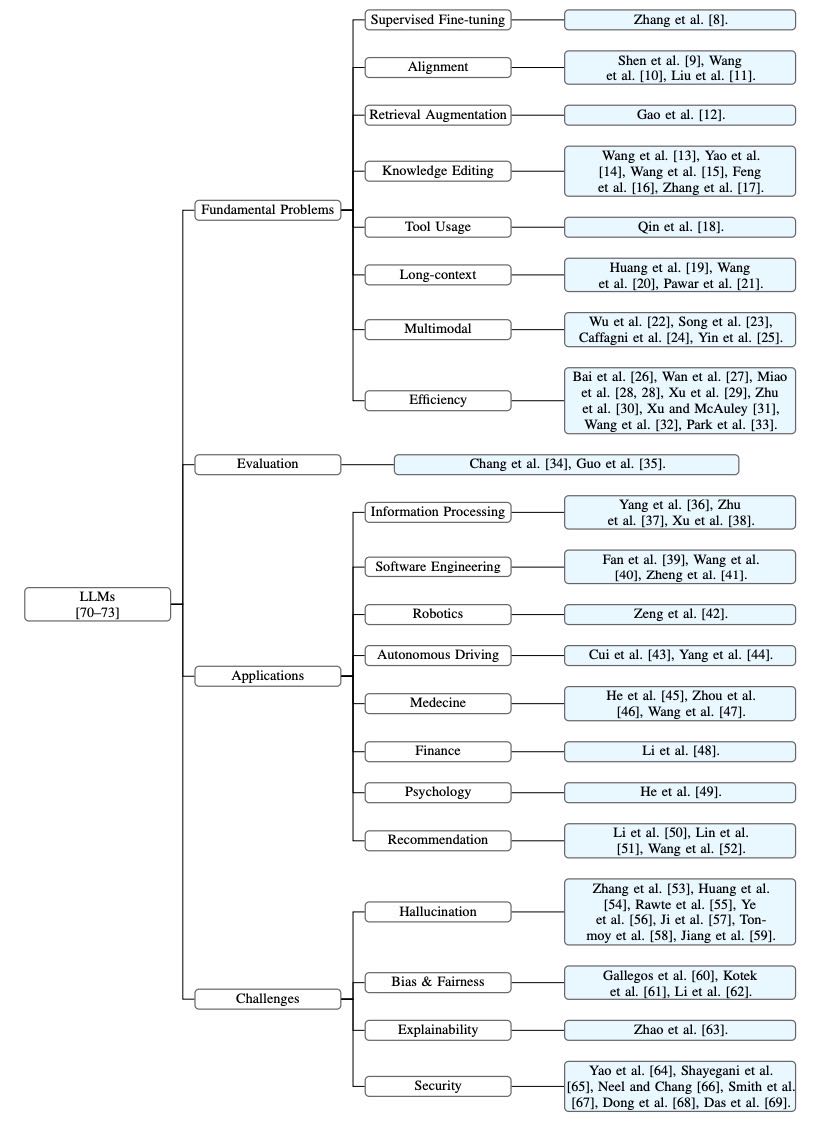
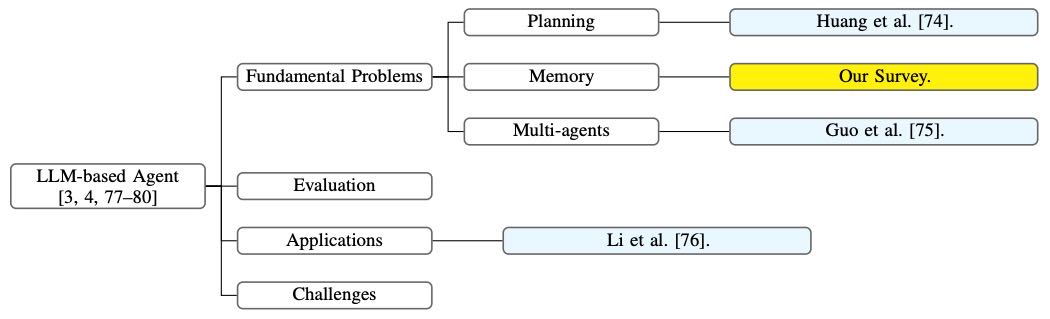
Figure 2: The organization of related surveys on LLMs and LLM-based agents.
在过去的两年中,大型语言模型(LLM)在学术界和工业界都引起了广泛关注。为了系统地总结这一领域的研究,研究人员撰写了大量综述论文。在本节中,我们简要回顾这些综述(见图2),突出他们的主要关注点和贡献,以便更好地定位我们的研究。
2.1 大型语言模型的综述¶
在LLM领域,Zhao等人 [[70]] 提出了第一个全面的综述,总结了LLM的背景、发展路径、模型架构、训练方法和评估策略。Hadi等人 [[71]] 和 Min等人 [[72]] 也从整体视角对LLM进行了综述,但提供了不同的分类方法和理解。随后的研究者深入探讨了LLM的具体方面,回顾了相关的里程碑研究和关键技术。这些方面可以分为四类:基础问题、评估、应用和挑战。
基础问题¶
这一类综述旨在总结用于解决LLM基础问题的技术。例如,Zhang等人 [[8]] 对监督微调方法进行了全面综述,这是训练LLM的关键技术;Shen等人 [[9]]、Wang等人 [[10]]、Liu等人 [[11]] 对LLM的对齐问题进行了综述,这是LLM生成与人类价值观一致输出的关键要求;Gao等人 [[12]] 提出了LLM的检索增强生成(RAG)能力综述,这是提供事实性和时效性知识并减少幻觉的关键;Qin等人 [[18]] 总结了使LLM能够利用外部工具的最先进方法,这是LLM在需要专业知识的领域扩展能力的基础。
评估¶
这一类综述关注如何评估LLM的能力。其中,Chang等人 [[34]] 从总体视角全面总结了评估方法,涵盖不同的评估任务、方法和基准。Guo等人 [[35]] 更关注评估目标,描述了如何评估LLM的知识、对齐和安全控制能力,补充了性能评估指标之外的评估标准。
应用¶
这一类综述旨在总结利用LLM改进不同应用的模型。例如,Zhu等人 [[37]] 聚焦于信息检索领域,总结了基于LLM的查询处理研究;Xu等人 [[38]] 关注信息提取,提供了该领域的全面分类;Li等人 [[50]]、Lin等人 [[51]] 和 Wang等人 [[52]] 讨论了LLM在推荐系统中的应用,利用智能体生成数据并提供推荐。
挑战¶
这一类综述关注LLM的可信性问题,如幻觉、偏见、不公平性、可解释性、安全性和隐私。例如,Zhang等人 [[53]]、Huang等人 [[54]]、Rawte等人 [[55]]、Jiang等人的综述总结了主流的缓解LLM幻觉的方法;Gallegos等人 [[60]]、Kotek等人 [[61]] 和 Li等人 [[62]] 深入讨论了偏见和不公平性问题,并总结了缓解这些问题的方法;Zhao等人 [[63]] 系统地讨论了LLM的可解释性问题,并总结了改善其可解释性的方法;Yao等人 [[64]]、Shayegani等人 [[65]]、Smith等人 [[67]] 等综述了LLM的安全性和隐私挑战。
2.2 基于大型语言模型的智能体综述¶
基于LLM的能力,人们已经开展了大量研究,构建可以自主感知环境、采取行动、积累知识并自我进化的LLM智能体。在这一领域,Wang等人 [[3]] 提出了首个综述论文,系统地从智能体构建、智能体应用和智能体评估的角度总结LLM智能体。Xi等人 [[4]]、Zhao等人 [[77]]、Cheng等人 [[78]] 和 Ge等人 [[80]] 也从整体角度对LLM智能体进行了总结,但各有不同的关注点和分类方法,提供了更多样化的理解。
除了这些整体综述,还有一些论文回顾了LLM智能体的具体方面。例如,Durante等人 [[79]] 总结了多模态智能体的研究;Huang等人 [[74]] 关注LLM智能体的规划能力;Guo等人 [[75]] 更关注多智能体交互场景;Li等人 [[76]] 则总结了将LLM智能体用作个人助理的应用。
本工作的定位¶
我们的综述总结了LLM智能体的一个基础问题,即智能体的记忆机制。据我们所知,这是第一个在这一方向上的综述。我们希望它不仅能启发未来更先进的记忆架构设计,也能为新入行的研究者提供全面的入门材料。
3 What is the Memory of LLM-based Agent¶
交互和从环境中学习是LLM-based agent的基本要求。在与环境交互过程中,有三个关键阶段:
感知与存储:Agent从环境中感知信息并将其存储到记忆中;
信息处理:对存储的信息进行处理,使其更易于使用;
动作生成:基于处理后的记忆信息决定下一步动作。
在这些阶段中,记忆(memory)起着至关重要的作用。接下来,我们从狭义和广义两个角度定义Agent的记忆,并详细说明上述三个阶段在记忆模块中的执行过程。
3.1 Basic Knowledge¶
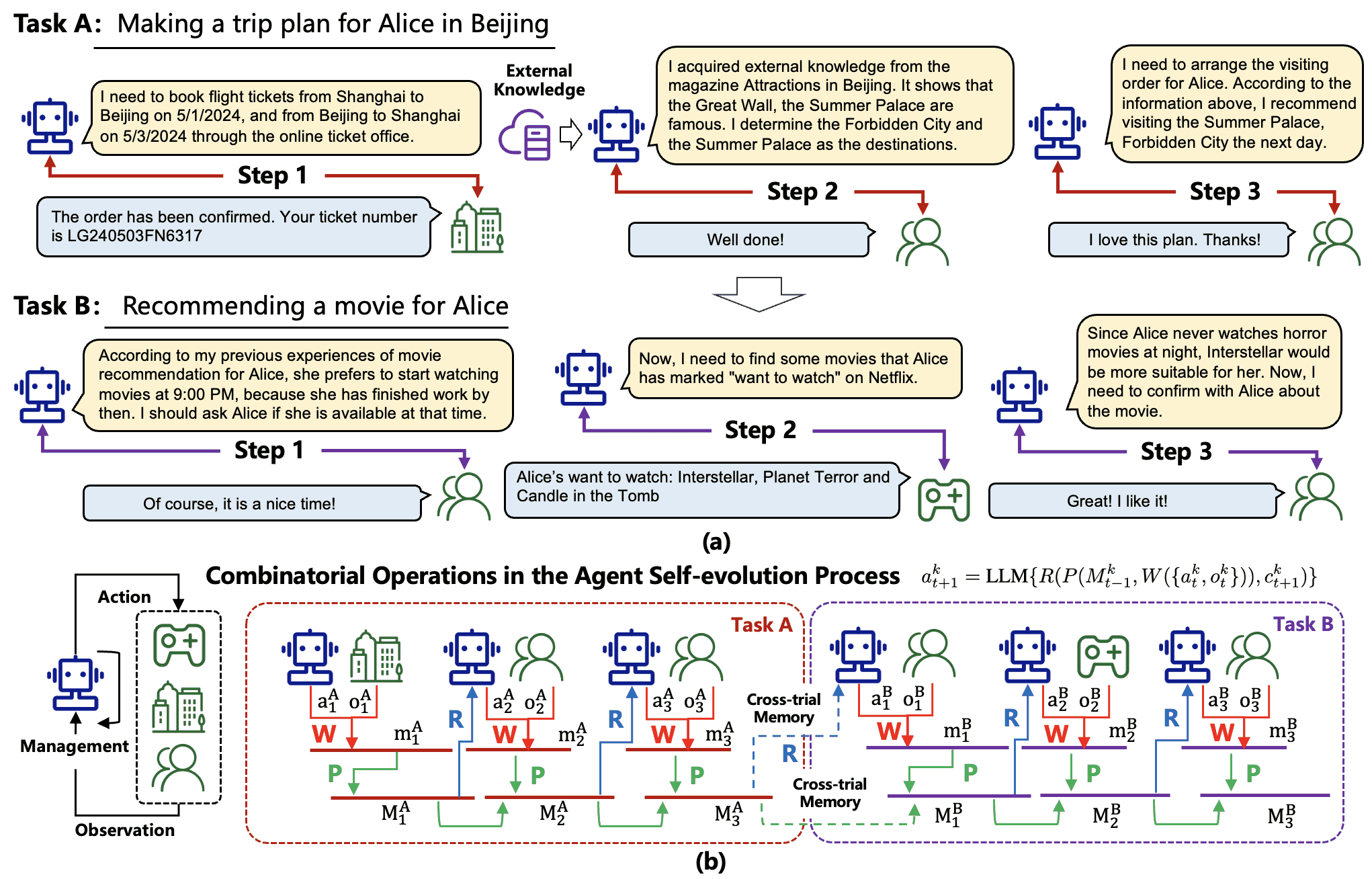
Figure 3:(a) Examples of the potential trials in the agent-environment interaction process. (b) Illustration of the memory reading, writing, and management processes, where dotted lines mean that the cross-trial information can be incorporated into the memory module.
1. 核心定义¶
(1) 任务(Task)¶
定义:智能体需要完成的最终目标
例如“为Alice预订机票”或“为Bob推荐餐厅”。
表示:用符号 𝒯 表示不同任务(如 𝒯₁、𝒯₂)。
示例:
任务A:为Alice制定北京三日游计划(包括订机票、选景点、安排行程)。
任务B:为Alice推荐电影(需确认空闲时间并匹配偏好)。
(2) 环境(Environment)¶
狭义:智能体直接交互的对象
如用户Alice、订票系统
广义:影响决策的上下文因素
如天气、时间、地点
示例:
订票时,环境是“在线票务系统”;
推荐餐厅时,环境可能包括“当前时间”和“用户位置”。
(3) 试验(Trial)与步骤(Step)¶
步骤(Step):单次交互的最小单元,包含:
智能体动作(Action,如“查询航班信息”)。
环境反馈(Observation,如“航班已确认,起飞时间9:00”)。
试验(Trial):完成一个任务的完整交互过程,由多个步骤组成。
表示:长度为T的试验可表示为序列 ξₜ = {a₁, o₁, a₂, o₂, …, aₜ, oₜ}。
特点:一个任务可能需要多次试验(探索不同解决方案)。
2. 交互过程示例¶
任务A:旅行计划¶
步骤1:
动作:订往返机票。
环境反馈:确认航班号及时间。
步骤2:
动作:根据Alice偏好选择景点(故宫、颐和园)。
环境反馈:Alice表示满意。
步骤3:
动作:安排行程顺序(建议下午游览颐和园)。
环境反馈:Alice认可计划。
任务B:电影推荐¶
步骤1:
动作:确认Alice的空闲时间(晚上9点)。
环境反馈:Alice同意。
步骤2:
动作:查询Netflix上Alice的“想看”列表。
环境反馈:返回电影列表。
步骤3:
动作:排除恐怖片,推荐《星际穿越》。
环境反馈:Alice接受推荐。
3. 总结¶
任务与环境:定义了智能体的目标和交互对象。
试验与步骤:描述任务完成的动态过程,强调迭代交互。
记忆机制:通过跨试验信息存储(如用户偏好),提升智能体决策效率。
3.2 狭义记忆(Narrow Definition)¶
定义¶
智能体的记忆仅包含当前试验(Trial)内的历史交互信息。
数学表示:在任务𝒯的第t步时,记忆来源于当前试验的前t-1步的交互序列:
ξₜ = {a₁, o₁, a₂, o₂, …, aₜ₋₁, oₜ₋₁}特点:
短期性:仅保留单次试验内的信息,任务完成后记忆可能被清空。
局部性:无法利用跨任务或跨试验的经验。
示例¶
任务A(旅行计划):
在[步骤3]安排景点顺序时,记忆包含:
[步骤1]的航班信息(如到达时间)。
[步骤2]选择的景点(故宫、颐和园)。
作用:基于当前已确认的信息规划行程。
任务B(电影推荐):
在[步骤3]选择电影时,记忆包含:
[步骤1]确认的Alice空闲时间(晚上9点)。
[步骤2]从Netflix获取的“想看”列表。
作用:排除不符合时间的电影(如深夜恐怖片)。
3.3 广义记忆(Broad Definition)¶
定义¶
智能体的记忆来源更广泛,包括:
当前试验内的历史信息(ξₜᵏ):同狭义定义。
跨试验的历史信息(Ξᵏ):
同一任务的其他试验(如失败尝试ξᵏ’)。
其他任务的试验(如ξ¹, ξ², …, ξᵏ⁻¹)。
外部知识(Dₜᵏ):如数据库、文献、网络等。
示例¶
跨试验记忆的应用:
任务A的失败试验:
若之前推荐的景点被Alice拒绝,当前试验会避免重复错误(利用ξᵏ’)。
跨任务关联:
任务B推荐电影时,参考任务A中Alice对古建筑的偏好(利用ξ¹),推荐相关主题电影(如历史题材)。
外部知识的应用:
任务A中,智能体通过杂志《北京景点》选择景点(Dₜᵏ为外部知识)。
任务B中,调用Netflix的“想看”列表(Dₜᵏ为平台数据)。
总结¶
狭义记忆是智能体的“工作记忆”,关注即时任务上下文。
广义记忆是“长期记忆+知识库”,支持:
错误避免(利用失败试验)。
个性化服务(跨任务偏好迁移)。
知识增强(结合外部信息)。
3.4 Memory-assisted Agent-Environment Interaction(记忆辅助的交互过程)¶
智能体通过记忆模块的三个操作(写入、管理、读取)实现与环境的动态交互,最终生成下一步动作。
核心公式:
$\(
a_{t+1}^k = \text{LLM}\big\{ R\big( P(M_{t-1}^k, W(\{a_t^k, o_t^k\}) ), c_{t+1}^k \big) \big\}
\)$
(LLM基于管理后的记忆和上下文生成动作)
重点:
该模型描述了Agent的记忆演化过程,体现了记忆如何影响后续决策。不同系统可以对 \(W, P, R\) 进行不同实现,详见第五节。
1. 记忆写入(Memory Writing)¶
目的:将原始观察(动作+环境反馈)转化为结构化记忆内容,提升信息密度。
数学表示:
$\( m_t^k = W(\{a_t^k, o_t^k\}) \)$\( W \):投影函数(如自然语言摘要、向量编码)。
\( m_t^k \):存储的记忆内容(如文本片段或参数化表示)。
示例:
任务A:[步骤2]后写入记忆:
动作:选择故宫和颐和园。
环境反馈:Alice表示满意。
记忆内容:“Alice偏好古建筑,已确认景点:故宫、颐和园。”
任务B:[步骤1]后写入记忆:
动作:确认Alice的空闲时间为21:00。
记忆内容:“Alice通常在21:00有空观影,排除深夜恐怖片。”
2. 记忆管理(Memory Management)¶
目的:优化存储的记忆,包括去冗余、抽象总结、遗忘无关信息。
数学表示:
$\( M_t^k = P(M_{t-1}^k, m_t^k) \)$\( P \):处理函数(如聚类、重要性评分、反射抽象)。
关键操作:
狭义记忆:单次试验内迭代更新,任务结束清空。
广义记忆:跨试验/任务整合,结合外部知识。
示例:
任务B的长期记忆管理:
原始记忆:多次推荐中Alice选择科幻片。
管理后:抽象为规则——“Alice晚间偏好科幻片”。
任务A的冗余消除:
合并重复景点查询记录,保留最终决策。
3. 记忆读取(Memory Reading)¶
目的:从记忆中检索与当前上下文相关的信息,支持决策。
数学表示:
$\( \hat{M}_t^k = R(M_t^k, c_{t+1}^k) \)$\( R \):检索函数(如基于相似度、时间或重要性过滤)。
\( c_{t+1}^k \):下一步动作的上下文(如当前任务目标)。
示例:
任务B[步骤3]:
上下文:需从Netflix列表中选择电影。
读取的记忆:
“Alice的‘想看’列表:《星际穿越》《恐怖星球》《鬼吹灯》”。
长期规则:“夜间排除恐怖片”。
结果:优先推荐《星际穿越》。
完整交互流程示例(任务B)¶
步骤1:
动作:询问Alice空闲时间 → 反馈:“21:00有空”。
写入:记录时间偏好。
步骤2:
动作:查询Netflix列表 → 反馈:3部电影。
管理:关联长期偏好(科幻>恐怖)。
步骤3:
读取:结合上下文(夜间+偏好)过滤列表。
动作:推荐《星际穿越》 → Alice接受。
4 Why We Need the Memory in LLM-based Agent¶
本节从认知心理学、自进化机制和智能体应用三个角度论证了记忆在基于大语言模型(LLM)的智能体中为何是必要的。
4.1 认知心理学视角¶
重点内容:
人类的认知过程(如注意、语言、记忆、知觉等)中,记忆被认为是最核心的组成部分之一。它不仅支持人类学习知识、抽象概念、形成社会规范,还能通过回忆过去的经验来指导未来的行为。研究人员认为,记忆是人类行为合理化的重要基础。
智能体设计的意义:
基于LLM的智能体旨在模拟人类行为,从而完成各种任务。因此,借鉴人类的记忆机制来设计智能体的记忆模块是一种自然且必要的选择。此外,认知心理学已有大量成熟理论,这些理论可以用来提升智能体的高级能力。
4.2 自进化视角¶
重点内容:
智能体在动态环境中完成任务时,必须具备自我进化的能力,而记忆在这一过程中至关重要。具体体现在以下几个方面:
经验积累:记忆可以帮助智能体记住过往的错误计划或失败经验,从而在未来处理类似任务时更加高效。
环境探索:智能体需要通过探索环境并学习反馈来进化。记忆可以帮助它决定何时、如何进行探索(例如,优先探索失败过的或探索频率较低的行为)。
知识抽象:记忆能够从原始观察中提取高层次的抽象信息,这是智能体适应和泛化未知环境的基础。
总结:自进化是LLM智能体的基本特征,而记忆则是实现自进化不可或缺的关键组件。
4.3 智能体应用场景视角¶
重点内容:
在许多实际应用中,记忆是智能体的核心组件,而非可选项。例如:
对话智能体:需要记忆历史对话内容,以理解上下文并生成连贯的回复。没有记忆,对话无法持续。
模拟智能体:需要记忆角色设定和行为轨迹,以保持角色一致性。缺乏记忆容易导致角色设定混乱。
总结:在这些应用场景中,记忆是智能体有效完成任务的必要条件。
总体总结¶
从认知心理学角度看,记忆为智能体提供了认知基础;从自进化角度看,记忆是智能体持续学习和适应环境的核心机制;从应用角度看,记忆是智能体实现功能和保持角色一致性的关键要素。由此可见,引入记忆机制是构建高效、智能的LLM智能体不可或缺的一环。
5 How to Implement the Memory of LLM-based Agent¶
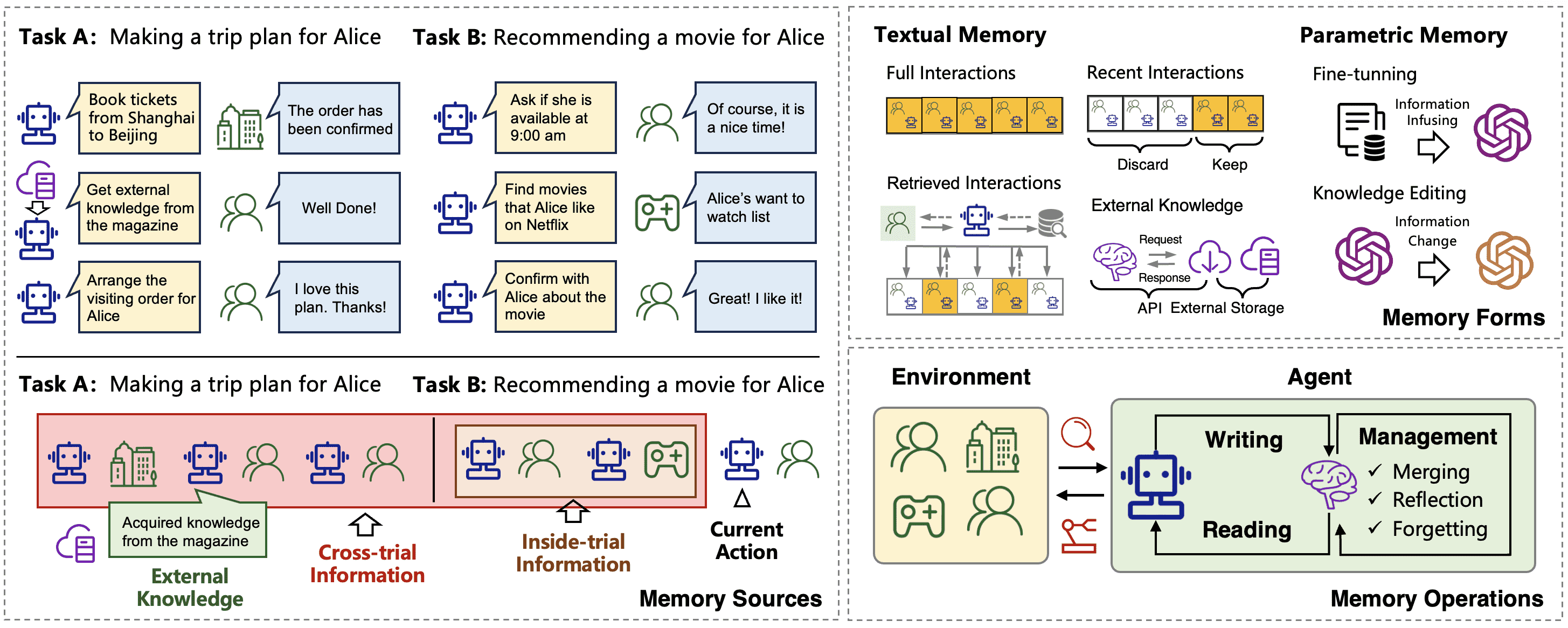
Figure 4:An overview of the sources, forms, and operations of the memory in LLM-based agents.
本文第5节《如何实现基于LLM的智能体的记忆》从三个方面详细探讨了记忆模块的实现方法:记忆来源(Memory Sources)、记忆形式(Memory Forms)和记忆操作(Memory Operations)。以下是对该部分的总结:
5.1 Memory Sources(记忆来源)¶
本节从信息来源的角度,将记忆分为三类:
5.1.1 Inside-trial Information(单次任务内的信息)¶
定义:指在单次智能体与环境的交互中产生的信息。
特点:
包括交互过程、时间、地点等上下文信息。
与当前任务高度相关,是最直观的记忆来源。
研究案例:Generative Agents、MemoChat、TiM 等均利用此类信息,通过历史行为构建记忆。
讨论:虽然该类信息对当前任务有用,但仅依赖它可能限制智能体从多任务中学习通用型知识。
5.1.2 Cross-trial Information(跨任务信息)¶
定义:指在多个任务中积累的信息,包括成功与失败的经验、模式等。
特点:
可作为“长期记忆”,为后续任务提供参考。
需要智能体主动参与多个任务,不包含外部知识。
研究案例:Reflexion、Retroformer、ExpeL 等通过跨任务经验提升智能体性能。
讨论:跨任务信息支持更广范围的决策,但依赖智能体自身交互,缺乏外部视角。
5.1.3 External Knowledge(外部知识)¶
定义:从外部来源(如数据库、API)获取的知识。
特点:
拓展智能体的知识边界,提供实时、权威信息。
通过 API 接口或工具调用实现。
研究案例:ReAct、GITM、CodeAgent 等通过外部知识提升问题解决能力。
讨论:外部知识可缓解智能体内部知识不足的问题,但存在信息可靠性、隐私和计算成本等挑战。
5.2 Memory Forms(记忆形式)¶
本节从信息表示方式的角度,将记忆分为两种形式:
5.2.1 Textual Form(文本形式)¶
定义:以自然语言形式存储和检索信息。
特点:
具有较好的可解释性和易实现性。
信息可为非结构化(如自然语言)或结构化(如数据库)。
分类:
Complete Interactions(完整交互):存储所有交互信息,适用于长上下文。
优点:信息完整;缺点:计算成本高、推理效率低。
Recent Interactions(近期交互):只保留近期信息,提高效率。
优点:关注当前相关性;缺点:可能遗漏早期重要信息。
Retrieved Interactions(检索交互):根据相关性检索信息。
优点:增强记忆的适用性;缺点:依赖检索算法的准确性与效率。
External Knowledge(外部知识):通过 API 或工具调用获取。
优点:提供最新、真实信息;缺点:存在隐私、数据安全等问题。
讨论:文本形式适合需要解释性与灵活性的任务,但受限于上下文长度。
5.2.2 Parametric Form(参数形式)¶
定义:将信息编码为模型参数,间接影响智能体决策。
分类:
Fine-tuning Methods(微调方法):
通过微调模型参数,将领域知识注入模型。
优点:提升领域任务表现;缺点:可能引发过拟合与灾难性遗忘。
案例:Character-LLM、Huatuo 等。
Memory Editing Methods(记忆编辑方法):
直接修改模型参数中特定知识点。
优点:针对性更新,效率高;缺点:需要复杂训练。
案例:MAC、MEND、KnowledgeEditor 等。
讨论:参数形式适合大规模、稳定知识的存储,但更新成本高、解释性差。
5.2.3 优缺点比较¶
项目 |
文本形式 |
参数形式 |
|---|---|---|
有效性 |
信息全面,但受上下文长度限制 |
信息密度高,但可能损失细节 |
效率 |
写入快,但读取代价高 |
读取快,但写入复杂 |
可解释性 |
高,适合人类理解 |
低,依赖模型内部表示 |
适用场景 |
需要解释性任务 |
需要大规模存储或精确控制的场景 |
5.3 Memory Operations(记忆操作)¶
本节从处理流程角度,将记忆操作分为三个阶段:
5.3.1 Memory Writing(记忆写入)¶
定义:将感知到的信息存储到记忆系统。
策略:
可直接存储原始信息,也可存储其摘要。
需要判断哪些信息重要,防止信息过载。
研究案例:
TiM:结构化存储实体关系。
SCM:设计记忆控制器决定写入时机。
MemoChat:对对话内容进行摘要后写入。
讨论:写入策略设计对记忆质量至关重要,尤其在信息冗长或形式多样的场景下。
5.3.2 Memory Management¶
本节探讨了智能体(agent)如何模拟人类大脑对记忆的处理方式,通过抽象化、合并冗余记忆、遗忘不重要的早期记忆来管理记忆,从而生成更高层次的记忆信息。
重点内容:¶
人类类比机制:人类大脑会对记忆进行处理和抽象,智能体的记忆管理同样可以通过“反思”(reflection)来生成更高层次的记忆,例如合并重复的记忆条目,遗忘不再重要的早期记忆,从而优化记忆结构。
代表性研究:¶
MemoryBank:智能体将对话内容提炼为每日事件的高层次摘要,类似于人类回忆经历的关键部分。长期互动过程中,智能体会不断评估和精炼知识,形成对个性特征的每日洞察。
Voyager:智能体根据环境反馈来优化记忆,提升适应能力。
Generative Agents:智能体在积累足够事件后,通过“反思”过程生成抽象的思维。这一过程是动态触发的,有助于生成更高层次的认知。
GITM:为了应对各种情境,系统在记忆模块中进一步总结多个计划中的关键动作,生成通用参考计划。
讨论:¶
大多数记忆管理策略都受到人类大脑工作机制的启发。
由于大型语言模型(LLMs)具有模拟人类思维的强大能力,这些记忆管理方法可以有效地帮助智能体生成高层次信息并更自然地与环境进行交互。
5.3.3 记忆读取(Memory Reading)¶
在需要进行推理和决策时,智能体需要从记忆中提取相关信息,因此如何高效地访问与当前状态相关的记忆是关键问题。由于记忆条目数量庞大,且并非所有信息都对当前任务相关,因此读取过程需设计得精准,并考虑相关性与任务导向性。
重点内容:¶
记忆读取的重要性:记忆读取是智能体在面临任务时提取关键信息的过程,设计时需考虑信息的相关性、相似性以及任务需求。
代表性研究:¶
ChatDB:通过SQL语句实现记忆读取,智能体预先生成一系列“记忆链条”(Chain-of-Memory)来调用相关记忆。
MPC:智能体从记忆池中检索相关信息,并通过“思考链”(Chain-of-Thought)示例来忽略不相关记忆。
ExpeL:使用Faiss向量数据库存储记忆,根据当前任务与历史成功路径的相似性,提取最相关的top-K条记录。
讨论:¶
记忆读取与写入的协作性:记忆读取与写入通常是相互配合的,记忆写入的形式直接影响读取的方式。
文本记忆 vs 参数记忆:
文本形式的记忆常通过文本相似性与辅助信息进行读取;
参数形式的记忆则通过模型的参数更新进行隐式读取,例如在推理过程中使用已更新的模型参数。
总结¶
第5节系统梳理了基于LLM的智能体的记忆实现方法。通过记忆来源确定信息的输入,通过记忆形式决定信息的存储方式,通过记忆操作控制信息的处理流程。这三者相互配合,共同支撑智能体的记忆能力,为未来研究提供了清晰的框架和方向。
记忆管理强调通过抽象、合并和遗忘来优化记忆结构,而记忆读取则关注如何从大量记忆中高效提取相关信息。这些机制的共同目标是提高智能体的推理、决策和环境适应能力。
6 How to Evaluate the Memory in LLM-based Agent¶
本节讨论了如何评估基于大语言模型(LLM)的智能体中的记忆模块。记忆模块的有效性评估是一个开放问题,已有研究提出了多种评估策略,通常分为两大类:直接评估和间接评估。
6.1 直接评估¶
直接评估将记忆模块视为独立组件进行测试,分为主观评估和客观评估两种方法。
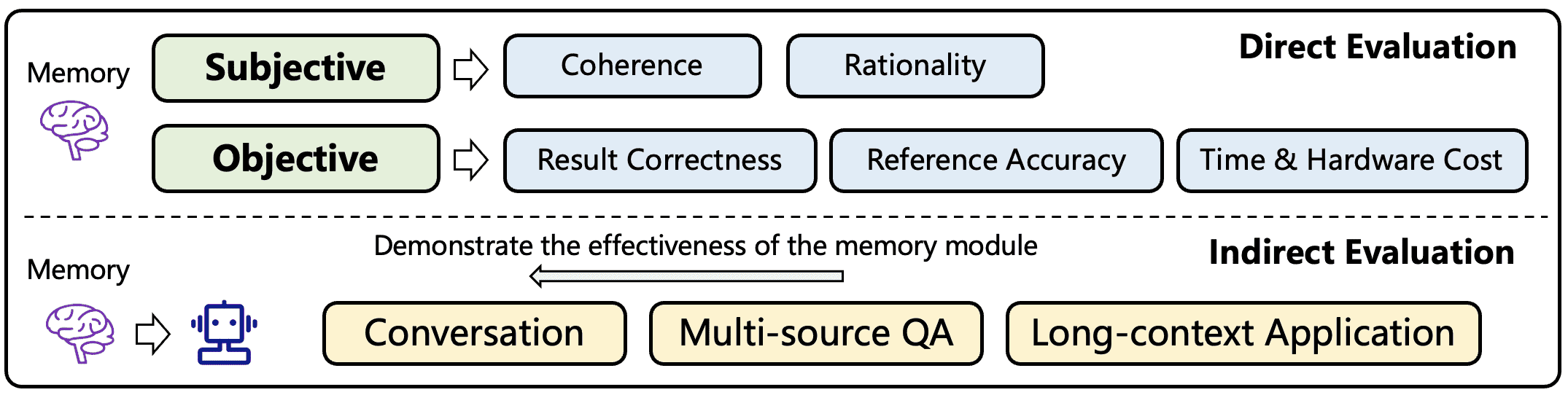
Figure 5:An overview of the evaluation methods of the memory module.
6.1.1 主观评估¶
主观评估依赖人类判断来评估记忆模块的有效性,适用于缺乏客观标准的场景。评估的主要方面包括:
一致性(Coherence):检查召回的记忆是否与当前上下文自然贴合。
合理性(Rationality):检查记忆内容是否合理,是否符合事实。
评估过程涉及两个关键问题:
如何选择评估人员:评估人员应熟悉任务且背景多样,以避免主观偏见。
如何标注输出结果:包括直接评分和比较两种方式。直接评分可获得定量结果,比较方式可减少评分偏差。
优点:主观评估具有较好的解释性,评估人员可以提供理由。
缺点:成本高、主观性强,结果难以复现和比较。
6.1.2 客观评估¶
客观评估通过定义数值指标来评估记忆模块的效果和效率,包括:
结果正确性(Result Correctness):评估智能体基于记忆回答预定义问题的能力。使用准确率(Accuracy)进行衡量。
引用准确率(Reference Accuracy):评估智能体能否检索到支持回答的相关记忆内容,常用F1分数评估。
时间和硬件成本(Time & Hardware Cost):评估记忆模块在操作中的时间消耗和硬件资源占用,通常通过峰值GPU内存和适应时间衡量。
优点:数值化评估便于比较不同方法,有助于建立基准。
缺点:缺乏解释性,难以覆盖所有评估维度。
6.2 间接评估¶
间接评估通过智能体完成任务的能力来反映记忆模块的有效性。如果任务完成良好,说明记忆模块是有效的。
6.2.1 对话任务¶
对话是智能体的重要应用之一,记忆在其中起关键作用。评估指标包括:
一致性(Consistency):确保回应与对话上下文一致。
参与度(Engagement):衡量用户被吸引继续对话的能力。
6.2.2 多源问答任务¶
评估智能体整合来自多个来源(如对话历史、外部知识)的记忆能力。任务包括跨对话问答和多文档问答。
6.2.3 长上下文应用¶
在处理长文本时,记忆模块的作用尤为重要。评估任务包括长上下文段落检索和摘要生成。
6.2.4 其他任务¶
包括:
任务成功率(Success Rate):评估智能体完成特定任务的比例。
探索度(Exploration Degree):衡量智能体探索环境的能力。
消融实验(Ablation Study):比较有/无记忆模块的性能差异。
优点:任务丰富,评估方式多样。
缺点:任务表现可能受其他因素影响,记忆模块的效果可能被弱化。
6.3 讨论¶
直接评估更可靠,但缺乏开源的专用基准。
间接评估操作简便,但结果可能受其他模块影响,存在偏差。
两种方法各有优劣,实际应用中可结合使用,以全面评估记忆模块的性能。
7 Memory-enhanced Agent Applications¶
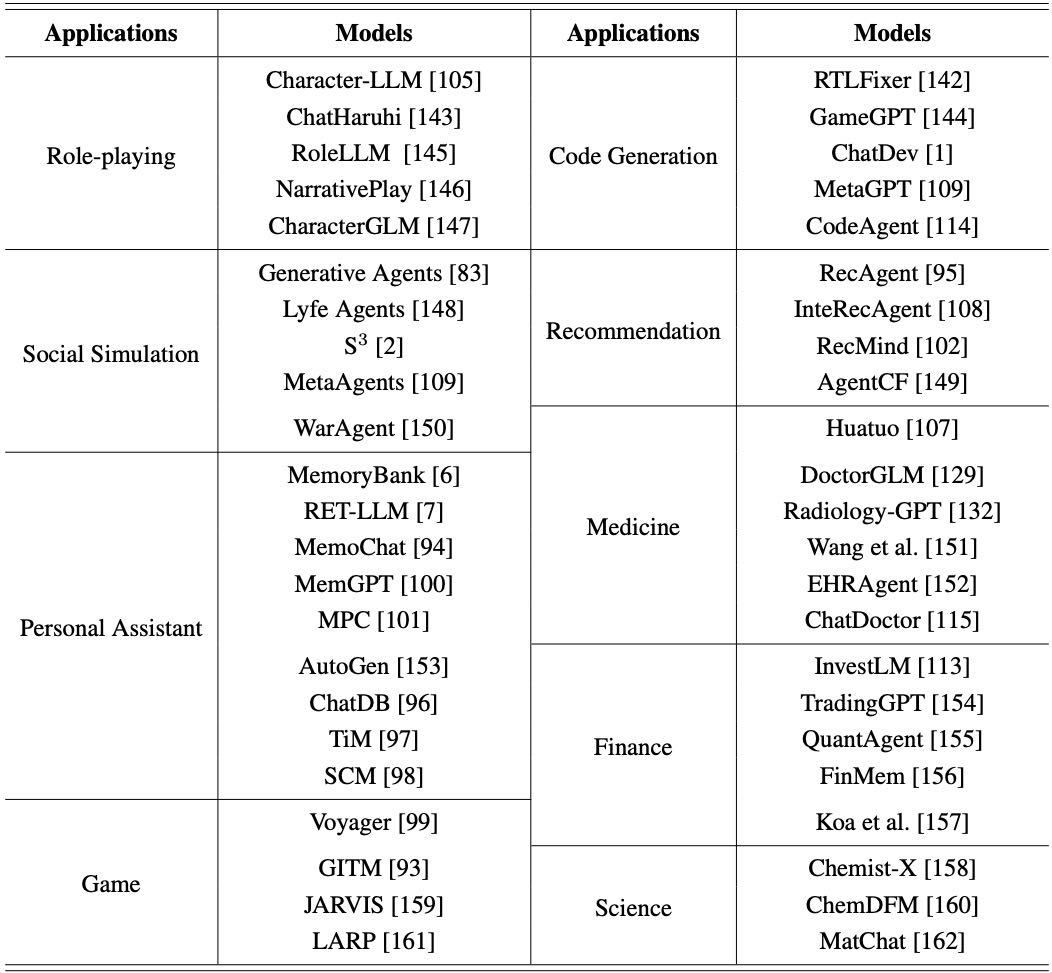
Table 4: Summarization of memory-enhanced agents applications.
近年来,基于大语言模型(LLM)的智能体在各种应用场景中得到了广泛研究,推动了社会进步。大多数LLM智能体都配备了记忆模块,但在不同应用场景中,记忆模块的功能、存储内容和实现方式存在差异。为了为LLM智能体的记忆功能设计提供建议,本节回顾和总结了记忆机制在不同应用场景中的体现。
7.1 角色扮演与社交模拟¶
角色扮演是LLM智能体的经典应用之一,记忆在此类应用中起着关键作用,使角色具有独特的个性特征。许多研究探索了角色记忆的构建方法,例如通过经验上传、提示改进、上下文问答对等方式来增强角色记忆。
社会模拟是角色扮演的延伸,更强调多智能体建模。记忆模块在该场景中对于模拟人类动态行为至关重要。一些研究提出了如“总结并遗忘”(Summarize-and-Forget)的记忆机制,或通过维护对话上下文来模拟宏观经济趋势对智能体决策的影响。
设计启示:角色记忆需与其特性一致,并能合理影响后续行为。同时,记忆机制应参考人类记忆的特征,如长短时记忆、遗忘机制。
7.2 个人助理¶
LLM智能体适合用于创建个人助理,尤其是在进行长期对话或自动信息检索等任务中。记忆模块通常以文本形式进行检索,可保存对话内容、关键事件和用户风格,以生成更个性化和相关性的响应。
一些模型通过总结对话内容、存储关键信息、调用外部工具等方式提升记忆效果。例如,部分智能体会将重要上下文作为记忆保存,以保持对话一致性。
设计要点:记忆应包含真实对话信息和用户风格,并在对话时能够准确检索相关记忆,以保持对话一致性。
7.3 开放世界游戏¶
在游戏和开放世界探索中,LLM智能体通常会存储过往经验和成功路径,以避免重复错误并提升探索效率。部分模型还引入外部数据库或API获取通用知识,如Minecraft Wiki等。
设计要点:无论是单次任务还是跨任务的信息,记忆的核心在于从过去交互中总结经验并应用于后续探索。吸收外部知识也是提升探索能力的重要方式。
7.4 代码生成¶
在代码生成场景中,LLM智能体通过记忆模块搜索相关信息,提升代码开发效率。记忆模块可以存储编译错误、专家指令、历史对话等,并在代码生成过程中通过上下文记忆增强代码连贯性和一致性。
设计要点:记忆模块应增强代码生成的连续性与一致性,并支持代码的迭代优化,通过历史记录识别开发者的目标。
7.5 推荐系统¶
在推荐系统中,记忆模块用于模拟用户行为和偏好,帮助LLM智能体生成个性化推荐。部分研究尝试通过记忆机制提升推荐系统的性能,或提供交互式推荐界面。
设计挑战:如何将用户的个性化信息与反馈对齐并存储到LLM智能体的内存中,是推荐系统与LLM结合的重要问题。
7.6 特定领域的专家系统¶
在医疗、金融和科学等特定领域中,LLM智能体通过外部知识增强记忆,以提供专业服务:
医疗领域:通过知识图谱、LoRA微调等方式增强医疗知识,并利用相似性匹配检索相关问题。
金融领域:存储金融知识、市场信息和成功经验,并采用分层记忆结构提升推理能力。
科学领域:整合分子数据库、文献资料等外部知识,通过微调模型提升问题求解能力。
设计挑战:领域知识具有专业性和时效性,记忆模块需要具备更新机制,并具备高效检索能力。
7.7 其他应用¶
记忆机制还被应用于如云系统根因分析、本体匹配、自动驾驶和用户接受测试等场景。这些应用中,记忆模块通常用于存储任务规则、对话记录、驾驶经验等内容,并通过自省机制优化智能体行为。
设计要点:记忆模块的设计应根据具体任务需求进行调整,以更好地支持下游任务的完成。
总结:本文系统总结了LLM智能体在不同应用场景中的记忆机制,强调记忆在提升智能体行为一致性、个性化服务和任务完成效率方面的重要作用。同时,也指出了在不同领域中设计记忆模块时面临的挑战和关键设计原则。
8 Limitations & Future Directions¶
8.1 更进一步的参数化记忆(Parametric Memory)¶
当前,基于大语言模型(LLM)的智能体主要依赖文本形式的记忆,如观察记录、实验经验和文本知识库。尽管文本记忆具备可解释性强、易于扩展和编辑等优点,但其效率不如参数化记忆。参数化记忆通过连续实数向量在潜在空间中表达语义,具备更高的信息密度和表达能力。相比文本记忆的“硬编码”形式,参数化记忆具有更高的表达空间和鲁棒性,同时也更节省存储空间,无需存储大量文本。
在记忆管理方面,参数化记忆可以通过优化方法学习合并与反思的机制,而不是依赖手工制定的规则。此外,参数化记忆可以像“数字生命卡”一样,为智能体注入特定属性。例如,Huatuo通过微调Llama模型,增强其在医学领域的专业知识;MAC则通过元学习方法构建适合在线场景的参数化记忆框架。
尽管参数化记忆前景广阔,但仍面临效率与可解释性两大挑战。效率问题在于如何高效地将文本信息转化为参数调整,目前主要依赖监督微调(SFT),但该方法耗时且需要大量文本数据。元学习作为一种解决方案,已被用于训练能动态调整模型参数的小模型,如MEND。可解释性问题则制约了其在医疗等高信任领域中的应用,因此提升参数化记忆的可信度与可解释性是未来亟待解决的问题。
8.2 基于LLM和多智能体系统中的记忆¶
在多智能体系统(MAS)中,记忆机制已从单智能体扩展到多智能体协作与竞争的场景,涉及同步、通信与信息不对称管理等方面。
记忆同步是多智能体协作中的关键,确保各智能体共享一致的知识库,从而支持协同决策。例如,Chen 等人提出通过同步记忆模块提升多机器人协作能力。
通信机制依赖记忆来维持上下文和消息理解,如Mandi 等人所提出的基于记忆驱动的通信框架,有助于多智能体之间建立共同理解。
在竞争性场景中,信息不对称成为核心问题,智能体需依赖记忆来判断对手意图并制定策略。
未来,LLM基多智能体系统的记忆研究将聚焦于新型记忆模块的开发,以提升同步能力、沟通效率以及在信息密集环境中的战略优势。这需要解决当前的记忆集成与管理难题,并探索记忆在智能体系统中的更大潜力。
8.3 基于记忆的终身学习(Lifelong Learning)¶
终身学习是人工智能的一个前沿方向,旨在使智能体在整个生命周期内持续学习与适应环境,如人类那样不断积累与更新知识。记忆在终身学习中起着核心作用,智能体需能够存储过去经验并加以应用。
LLM基智能体的终身学习具有广泛应用价值,如长期社交模拟和个性化助理。但面临以下挑战:
时间性问题:记忆需要捕捉时间序列信息,可能会导致记忆重叠或冲突。
存储与检索问题:需存储大量记忆,并在需要时检索,可能需引入遗忘机制来优化记忆管理。
8.4 人形智能体中的记忆¶
人形智能体(humanoid agent)是指行为上模拟人类的智能体,适用于社会模拟、人类行为研究与角色扮演等场景。与任务导向型智能体不同,人形智能体的“能力”应贴近真实人类,其记忆机制也应符合人类认知规律。
人形智能体的记忆需体现记忆失真和遗忘等心理特征。
其知识应有边界限制,如扮演儿童角色的智能体不应掌握超出该年龄段的知识(如高等数学)。
该方向的目标是构建更真实、可信的智能体,使其行为更贴近人类,从而在人机交互等场景中发挥更大价值。
9 Conclusion¶
9 结论¶
在本综述中,作者对基于大语言模型(LLM)的智能体中的记忆机制进行了系统性的回顾。重点围绕三个核心问题展开:“什么是记忆模块”、“为什么需要记忆模块” 以及 “如何设计和评估记忆模块”。这三个问题构成了全文的主线,具有较强的指导性与理论深度。
为了进一步说明记忆模块在智能体中的重要性,文章还列举了许多典型应用场景,这些场景中记忆模块起到了关键作用。这部分内容有助于读者理解记忆模块的实际价值与应用潜力。
最后,作者指出,这篇综述不仅希望为该领域的初学者提供有价值的参考资料,也希望激发更多关于高级记忆机制的研究,从而进一步提升基于大语言模型的智能体的性能和能力。这是文章的写作目的和期望影响,也是全文的重点之一。
Acknowledgement¶
致谢¶
本部分作者对雷王(Lei Wang)在本综述中的校对工作和提出的宝贵建议表示感谢。虽然内容较为简短,但这是对合作者贡献的认可,体现了学术合作的重要性。