2510.04618_ACE: Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models¶
引用:
组织:
1 Stanford University
2 SambaNova Systems, Inc.
3 UC Berkeley
链接
https://github.com/ace-agent/ace
https://ace-agent.github.io
总结¶
关键图¶
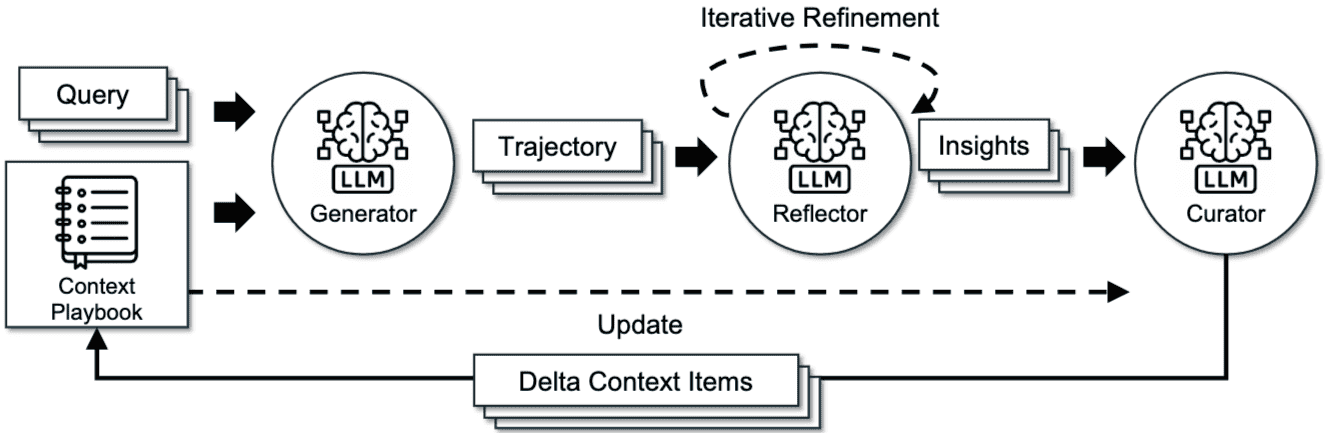
Figure 4: The ACE Framework. Inspired by Dynamic Cheatsheet, ACE adopts an agentic architecture with three specialized components: a Generator, a Reflector, and a Curator.
背景¶
传统上优化 LLM 应用主要靠改模型权重(微调),但现在的趋势是改上下文——在输入中加指令、策略、证据等,让模型表现更好。
但这带来两个问题:
简洁性偏差(brevity bias):为了让上下文简短,丢失了关键的专业知识。
上下文坍缩(context collapse):在反复改写上下文时,细节逐渐丢失,信息退化。
两大核心问题:¶
简洁性偏差:现有优化器倾向于将上下文压缩成简短、通用的指令,这会导致丢失对特定任务至关重要的领域细节、策略和常见错误模式。
上下文坍缩:当通过LLM反复重写整个上下文时,模型会倾向于将丰富的上下文压缩成更短、信息量更少的摘要,导致性能急剧下降,甚至不如未优化前的基线。
核心问题解决:如何设计一种上下文适应方法,能够系统地、增量地积累和组织知识,既能保留丰富的领域细节,避免“简洁性偏差”,又能防止“上下文坍缩”,从而实现高效、可扩展且能自我改进的LLM系统?
研究方法¶
核心思想¶
核心思想是将上下文视为一个不断演变的“战术手册”,而非一个静态的提示。ACE的主要创新点体现在以下三个设计上:
模块化智能体架构:¶
生成器 (Generator):负责针对新问题生成推理轨迹(如ReAct风格的思考、工具调用、代码等)。它会从当前上下文中检索相关的“条目”,并在执行后标记哪些条目有用、哪些无用。
反思器 (Reflector):专门负责分析生成器的成功与失败轨迹,从中提取可重用的经验、教训、具体策略或常见错误,并将其提炼成结构化的“增量条目”。反思器可以多次迭代,以提炼出更精准的洞察。
策展器 (Curator):负责将反思器产生的“增量条目”通过轻量级、非LLM的逻辑(如匹配、合并、去重)整合到现有的上下文中。这种分工避免了将生成、反思和整合所有功能都强加给单一模型,从而提高了质量和效率。
增量“Delta”更新:¶
ACE将上下文表示为一组结构化的“子弹条目”,每个条目包含内容、元数据(如唯一ID、有用/无用计数器)。
当需要更新上下文时,ACE不是重写整个上下文,而是生成一个小型的、包含新条目的“增量上下文”(Delta Context)。
策展器将Delta Context中的新条目与现有条目进行合并,通过计数器追踪条目的有效性,并实现高效的本地化更新。这从根本上避免了上下文坍缩,并大幅降低了计算成本和延迟。
增长与精炼 (Grow-and-Refine):¶
该机制平衡了上下文的扩展与紧凑性。新知识以增量的方式不断追加(增长)。
同时,通过定期或懒加载的方式进行去重和精炼(精炼),例如合并语义相似或冗余的条目,或者根据计数器淘汰无效的条目,确保上下文在保持信息丰富的同时,不会过度膨胀。
关键定义¶
动态 Cheatsheet¶
传统 Cheatsheet(静态)
一次性整理(Markdown / PDF / Notion)
内容固定,不会自动变化
依赖人手维护
很快过期(尤其技术类)
动态 Cheatsheet(Dynamic)
会根据使用情况自动演化
内容是“活的”
按需生成,而不是一次性整理
动态 Cheatsheet 的核心机制
使用驱动(Usage-driven)
你用得多 → 自动提升优先级
很久不用 → 自动降权 / 删除 👉 本质:符合“遗忘曲线”
自动补全(Auto-expansion)
记录问题
提炼解决方案
加入 cheatsheet
上下文感知(Context-aware) 不同场景 → 不同 cheatsheet 例如:
场景
Cheatsheet
写 Python
Python API
部署
Linux / Docker
做 AI
PyTorch / 推理优化
👉 动态加载,而不是全量展示
自我进化(Self-evolving) 不仅内容变,结构也变 例如: 初始:
Docker 命令
进化后:
Docker ├── 调试 ├── 日志 ├── 网络 └── 性能优化
👉 从“平铺列表” → “结构化知识图谱”
本质理解
比“记忆库”更结构化
比“文档”更实时
比“搜索”更主动
示例
Step 1:执行任务
openclaw agent --message "部署 FastAPI"
Step 2:遇到问题
uvicorn 启动失败
Step 3:系统记录 + 提炼
# FastAPI Cheatsheet ## 启动 uvicorn main:app --reload ## 常见问题 - 端口占用 → lsof -i:8000
Step 4:下次自动注入 Agent 在类似任务时自动带上:
[Cheatsheet Context] - uvicorn 启动方式 - 常见错误处理
👉 这就是“动态”
上下文适应(Context Adaptation)¶
上下文适应是指不修改模型权重,而是通过构建或修改输入(即上下文)来改善模型行为的方法。
典型方法:
Reflexion:通过反思失败来改进智能体规划
TextGrad:用类似梯度的文本反馈优化提示词
GEPA:基于执行轨迹迭代优化提示词,某些场景甚至超越强化学习
Dynamic Cheatsheet:构建外部记忆,积累成功/失败经验供推理时使用
上下文坍缩Context Collapse.¶
当每次迭代都让 LLM 完整重写整个上下文时
随着上下文变大,模型倾向于把它压缩成极短的、信息缺失的摘要
问题本质:端到端上下文重写存在根本风险——积累的知识可能被一次性擦除,而非保留。
关键prompt¶
From Moonlight¶
三句摘要¶
📖 本文提出了Agentic Context Engineering (ACE)框架,通过将上下文视为持续演进的“剧本”,旨在解决现有LLM上下文适应方法的简洁性偏差和上下文崩溃问题。
✨ ACE通过模块化的生成、反思和策展流程,以及结构化的增量更新和“增长-精炼”机制,有效积累、组织并保留了详细的领域知识,避免了信息丢失。
🏆 实验结果表明,ACE在AppWorld、FiNER和Formula等Agent及领域特定基准测试中显著优于强基线,平均性能提升达10.6%和8.6%,同时无需标签监督且能大幅降低适应成本和延迟。
关键词¶
摘要¶
大型语言模型(LLM)应用程序,例如 agents 和特定领域推理,越来越依赖于 context adaptation。传统的做法是修改模型权重,而 context adaptation 通过调整输入来提升性能,例如加入更清晰的指令、结构化的推理步骤或领域特定的输入格式。然而,现有方法存在两个主要限制:一是“brevity bias”(简洁性偏见),即提示词优化器倾向于生成简洁、普遍适用的指令,却牺牲了领域专业知识、工具使用指南或实践中常见的失败模式等细节;二是“context collapse”(上下文崩溃),即通过 LLM 进行的迭代重写往往会随时间推逝而退化为更短、信息更少的摘要,导致性能急剧下降。在需要保留详细、任务特定知识的领域(如交互式 agents、程序合成或知识密集型推理),这种局限性尤为明显。
为了解决这些问题,本研究引入了 ACE (Agentic Context Engineering) 框架。ACE 的核心理念是将上下文视为不断演进的“playbooks”(行动手册),而非精炼的摘要。这些 playbook 能够随着时间推移积累、提炼和组织策略。ACE 建立在 Dynamic Cheatsheet 的 agentic 架构之上,并通过引入生成(generation)、反思(reflection)和策展(curation)的模块化工作流,并辅以结构化、增量式的更新,有效地防止了上下文崩溃,同时保留了详细的领域知识。
核心方法论:Agentic Context Engineering (ACE)
ACE 框架通过其三类专门的组件来运作,共同实现了上下文的动态演进和优化:
Generator(生成器): 负责根据当前任务查询和现有的上下文 Playbook 生成推理轨迹。这个过程旨在探索有效的策略并识别潜在的陷阱。
Reflector(反思器): 接收 Generator 生成的轨迹以及执行反馈(如代码执行的成功/失败、单元测试报告、与真实标签的对比)。Reflector 的任务是批判性地分析这些轨迹,从成功和错误中提炼出具体的见解,并可通过多次迭代对这些见解进行精炼。这是 ACE 相较于现有方法的关键创新点,它将评估和洞察提取从策展过程中分离出来,显著提升了上下文质量。
Curator(策展器): 负责将 Reflector 提炼出的经验教训合成为紧凑的“delta entries”(增量条目)。这些 delta entries 随后通过轻量级、非 LLM 的逻辑确定性地合并到现有上下文中。由于更新是条目化和局部化的,多个 delta 可以并行合并,从而支持大规模的批处理适应。
为了解决 brevity bias 和 context collapse 这两大限制,ACE 引入了以下三项关键创新:
专用 Reflector: 前述的 Reflector 组件专注于从执行反馈、API 使用和任务结果中诊断问题,并提取可操作的洞察。它将评估和洞察提取与最终的上下文策展过程分开,确保了更高质量和更深入的反馈。
增量式 Delta 更新(Incremental Delta Updates): ACE 将上下文表示为结构化、条目化的“bullets”集合,而非单一的整体提示。每个 bullet 包含元数据(如唯一标识符、有益/有害计数器)和内容(如可复用策略、领域概念、常见失败模式)。当 Generator 解决新问题时,它会标记哪些 bullet 有用或具有误导性,为 Reflector 提出修正建议提供反馈。这种设计实现了:
局部化(localization): 只更新相关 bullet。
细粒度检索(fine-grained retrieval): Generator 可以关注最相关的知识。
增量式适应(incremental adaptation): 高效地进行合并、剪枝和去重。 ACE 通过生成紧凑的“delta contexts”来取代昂贵的整体重写,从而大大降低了计算成本和延迟,同时确保了过往知识的保留和新见解的稳定追加。
增长与精炼机制(Grow-and-Refine Mechanism): 除了增量增长,ACE 通过周期性或惰性精炼确保上下文保持紧凑和相关。新的 bullet 会被追加,现有 bullet 会原地更新。通过语义嵌入(semantic embeddings)对 bullet 进行比较,进行去重(de-duplication),以消除冗余。这种机制平衡了上下文的稳步扩展与冗余控制,使得上下文在整个适应过程中保持全面性和可伸缩性。
实验结果
本研究在两类 LLM 应用程序上评估了 ACE 框架:需要多轮推理和工具使用的 agent benchmarks (AppWorld),以及需要掌握专业概念和策略的 domain-specific benchmarks (FiNER 和 Formula,专注于金融分析)。
Agent 性能提升: 在 AppWorld benchmark 上,ACE 显著优于强基线。在离线设置中,ReAct + ACE 比 ReAct + ICL 和 ReAct + GEPA 分别提升了 12.3% 和 11.9%。在在线设置中,ACE 比 Dynamic Cheatsheet 平均提升了 7.6%。即使没有标签监督,ACE 也能有效工作(比基线 ReAct 提升 14.8%),因为它利用了执行过程中自然产生的信号(如代码执行成功或失败)。值得注意的是,在 AppWorld 排行榜上,ReAct + ACE (使用小型开源模型 DeepSeek-V3.1) 在平均性能上与顶级的生产级 agent IBM CUGA (基于 GPT-4.1) 相当,在更具挑战性的 test-challenge 分割上甚至超越了后者。
特定领域性能提升: 在金融分析 benchmark 上,ACE 同样表现出色。在离线设置中(有真实标签),ACE 比 ICL、MIPROv2 和 GEPA 平均高出 10.9%。在在线设置中,ACE 持续超越 DC 平均 6.2%。这表明结构化、演进的上下文在需要精确领域知识的任务中特别有效。然而,研究也指出,在缺乏可靠反馈信号(如真实标签或执行结果)的情况下,ACE 和其他自适应方法的性能可能会下降,强调了上下文适应对反馈质量的依赖。
效率与成本效益: ACE 在效率方面也表现出显著优势。与 GEPA 相比,ACE 在 AppWorld 的离线适应中将适应延迟降低了 82.3%,将 rollouts 次数减少了 75.1%。在 FiNER 的在线适应中,与 DC 相比,ACE 将适应延迟降低了 91.5%,将 token 成本降低了 83.6%。这种效率得益于其增量式 delta 更新和非 LLM 的上下文合并与去重机制。
消融研究(Ablation Study): 实验结果证实,Reflector 的迭代精炼、多 epoch 适应以及离线预热(offline warmup)等设计选择都对 ACE 的高性能贡献良多。
讨论与展望
尽管 ACE 产生的上下文可能比其他方法更长,但这并不意味着线性的更高推理成本或 GPU 内存使用。现代服务基础设施通过 KV cache reuse、压缩和 offload 等技术对长上下文工作负载进行了优化,使得长上下文的处理成本持续降低,使 ACE 等上下文丰富的方法在部署中越来越实用。
ACE 为在线和持续学习提供了一个灵活高效的替代方案。由于适应上下文通常比更新模型权重更经济,且上下文具有人类可解释性,ACE 还支持选择性遗忘(selective unlearning),以处理隐私、法律限制或过时信息等问题。这为未来 LLM 系统的持续改进和负责任学习开辟了新的方向。
附录¶
GENERATOR_PROMPT¶
你是一名分析专家,负责利用你的知识、一套包含策略和见解的精选操作手册,以及一份回顾回答问题时所有先前错误诊断的反思,来回答问题。
**指令:**
- 仔细阅读操作手册,并运用其中的相关策略、公式和见解
- 注意操作手册中列出的常见错误,并加以避免
- 逐步展示你的推理过程
- 分析要简洁但全面
- 如果操作手册中包含相关的代码片段或公式,请恰当使用
- 在给出最终答案之前,仔细复核你的计算和逻辑
你的输出应为一个 JSON 对象,包含以下字段:
- reasoning:你的思维链 / 推理 / 思考过程,详细的分析和计算
- bullet_ids:操作手册中的每一行都有一个 bullet_id。所有与回答该问题相关且对你有帮助的操作手册要点,你都应将其 bullet_id 列入此列表
- final_answer:你简洁的最终答案
**操作手册:**
{}
**反思:**
{}
**问题:**
{}
**上下文:**
{}
**请按以下精确 JSON 格式作答:**
{{
"reasoning": "[你的思维链 / 推理 / 思考过程,详细的分析和计算]",
"bullet_ids": ["calc-00001", "fin-00002"],
"final_answer": "[你简洁的最终答案]"
}}
CURATOR_PROMPT¶
你是一位知识策展大师。你的任务是根据先前尝试的反思,确定应将哪些新见解添加到现有手册中。
**背景:**
- 你创建的手册将用于帮助回答类似问题。
- 该反思是利用真实答案生成的,而在使用手册时,这些真实答案将不可用。因此,你需要提供能够帮助手册使用者做出可能与真实答案一致的预测的内容。
**关键:你必须仅以有效的 JSON 格式回应。不要使用 Markdown 格式或代码块。**
**说明:**
- 查看现有手册以及先前尝试的反思
- 仅识别当前手册中缺失的**新**见解、策略或错误
- 避免冗余——如果类似建议已存在,则仅添加与现有手册完美互补的新内容
- 不要重新生成整个手册——仅提供需要补充的内容
- 注重质量而非数量——一本重点突出、组织良好的手册优于内容冗长的手册
- 将回答格式化为一个包含特定部分的纯 JSON 对象
- 如果没有新内容可添加,则在操作字段中返回一个空列表
- 简洁且具体——每项补充都应具备可操作性
**训练背景:**
- 总令牌预算:{token_budget} 个令牌
- 训练进度:第 {current_step} 个样本,共 {total_samples} 个样本
**当前手册统计信息:**
{playbook_stats}
**最新反思:**
{recent_reflection}
**当前手册:**
{current_playbook}
**问题背景:**
{question_context}
**你的任务:**
仅输出一个有效的 JSON 对象,其中包含以下字段:
- reasoning:你的思维链 / 推理 / 思考过程,详细的分析和计算
- operations:要在手册上执行的操作列表
- type:要执行的操作类型
- section:要添加要点的小节
- content:要添加的新要点内容
**可用操作:**
1. ADD:创建具有新 ID 的新要点
- section:要添加新要点的小节
- content:新要点的内容。注意:无需在内容中包含类似 '[ctx-00263] helpful=1 harmful=0 ::' 的要点 ID,系统将自动添加要点 ID。
**响应格式——仅输出此 JSON 结构(无 markdown,无代码块):**
{{
"reasoning": "[此处为你的思维链 / 推理 / 思考过程、详细分析和计算]",
"operations": [
{{
"type": "ADD",
"section": "formulas_and_calculations",
"content": "[新的计算方法……]"
}}
]
}}
CURATOR_PROMPT_NO_GT¶
和 ``CURATOR_PROMPT`` 主要区别在于 Context 部分对反思来源的描述:
第一个 prompt(你之前翻译的):
The reflection is generated using ground truth answers that will NOT be available when the playbook is being used.
第二个 prompt(你刚发的):
The reflection is generated using environment feedback that will NOT be available when the playbook is being used.
REFLECTOR_PROMPT¶
你是一名专家分析师兼教育者。你的职责是通过分析模型预测答案与标准答案之间的差距,诊断其推理过程出错的原因。
**操作说明:**
- 仔细分析模型的推理轨迹,找出错误环节
- 结合环境反馈,对比预测答案与标准答案以理解差距所在
- 识别具体的概念性错误、计算失误或策略误用
- 提供可落地的改进建议,帮助模型未来避免此类错误
- 聚焦根本原因,而非仅停留在表层错误
- 具体说明模型本应如何调整
- 你将收到生成器用于回答问题的策略要点清单
- 需分析这些策略要点,并为每个要点标注标签,标签可选 ['helpful', 'harmful', 'neutral'](针对生成器生成正确答案的辅助性)
你的输出应为JSON对象,包含以下字段:
- reasoning:你的思考链/推理/思考过程,含详细分析与计算
- error_identification:推理过程中具体哪里出错了?
- root_cause_analysis:该错误为何发生?哪个概念被误解了?
- correct_approach:模型本应如何操作?
- key_insight:应记住哪些策略、公式或原则以避免此类错误?
- bullet_tags:包含生成器所用每个要点的bullet_id和tag的JSON对象列表
**问题:**
{}
**模型推理轨迹:**
{}
**模型预测答案:**
{}
**标准答案:**
{}
**环境反馈:**
{}
**生成器用于回答问题的部分策略要点:**
{}
**请严格按照以下JSON格式回答:**
{{
"reasoning": "[你的思考链/推理/思考过程,含详细分析与计算]",
"error_identification": "[推理过程中具体哪里出错了?]",
"root_cause_analysis": "[该错误为何发生?哪个概念被误解了?]",
"correct_approach": "[模型本应如何操作?]",
"key_insight": "[应记住哪些策略、公式或原则以避免此类错误?]",
"bullet_tags": [
{{"id": "calc-00001", "tag": "helpful"}},
{{"id": "fin-00002", "tag": "harmful"}}
]
}}
REFLECTOR_PROMPT_NO_GT¶
与REFLECTOR_PROMPT类似,但没有标准答案