2401.10935_SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents¶
组织: ♡Nanjing University, ♡Shanghai AI Laboratory
GoogleScholar(star: 122)
Abstract¶
GUI agent 就是自动在图形界面上完成任务的智能体,比如在手机或电脑上帮用户点击按钮、输入内容、完成操作。
总结:SeeClick 是一个基于截图的视觉 GUI agent,通过强化“GUI grounding”能力来克服现有方法对结构化文本的依赖,能在多个平台上准确识别并操作界面元素,并在多个任务中验证了其优越性。
- 📌 问题点:
目前的 GUI agents 通常是依靠结构化数据(如 HTML、DOM 树)来理解界面;
- 这些数据有两个问题:
太长、冗余(对 LLM 不友好);
有时候无法访问(比如某些桌面应用根本没有可提取的结构化信息)。
- 💡 解决方案:
提出一个纯视觉的 GUI agent——SeeClick;
它不依赖结构化数据,只用截图就能完成任务(点、输等)。
- 🚧 关键挑战:
要让 agent 仅靠图片完成操作,首先要理解用户指令所指的是界面中哪个元素;
这个能力就叫 GUI grounding(“界面锚定”),是视觉 GUI agents 成败的关键。
- 🔧 技术方法:
提出一种预训练策略,专门训练模型 GUI grounding 的能力;
同时自动收集训练数据(让模型学会如何从图中找对应的按钮、图标等)。
- 🧪 评估基准:
作者还制作了一个叫 ScreenSpot 的 benchmark,用来评估 GUI grounding 的能力;
涵盖 移动端 + 桌面 + 网页 三种平台,是首个现实世界 GUI grounding 测试集。
- 📈 实验结果:
经过预训练,SeeClick 在 ScreenSpot 上明显优于其他模型(baseline);
说明预训练起到了关键作用。
- 🔍 进一步验证:
作者在三个主流 benchmark 上评估后发现:
GUI grounding 的能力提升 → agent 执行任务的效果也显著提升;
二者呈直接相关关系。
1. Introduction¶
- 🧠 背景:为什么需要更强的 GUI agent?
当前的 GUI agents 通常通过读取结构化文本信息(比如网页 HTML 或 app 的控件树)来理解界面内容,
再调用 LLM 进行推理、规划和执行。
- 但这种方式有三个重大限制:
不可访问性:很多应用(比如 iOS、桌面软件)没有或很难提取结构化文本。
冗长 + 信息不全:结构化文本往往很啰嗦(冗余),又缺失了重要视觉信息(如布局、图片、图标等),不适合直接喂给 LLM。
多样性太高:不同平台用不同的结构化格式(HTML、DOM、Android ViewHierarchy),这就导致每个平台都需要定制观察与操作空间,开发成本高。
👉 因此,研究者认为应该尝试摆脱结构化文本的依赖,转向一种视觉原生(pure vision-based)的方法。
- 本文的创新点: 提出 SeeClick
完全依赖界面截图(screenshots),不再解析结构化文本;
可以直接在各种平台(网页、iOS、安卓、Windows、macOS)上进行点击、输入等操作;
背后的关键是一个新能力:GUI grounding,即“在一张图里准确定位用户说的元素”的能力。
- 🏗 如何实现 SeeClick?
基础模型:SeeClick 是构建在 大型视觉语言模型(LVLM) 上的;
- GUI Grounding预训练:作者提出了一种方法,专门收集“图 + 元素定位”数据,包括:
自动构建网页定位数据;
利用公开的移动 UI 数据集进行适配;
对 LVLM 进行连续预训练,让它学会“根据指令在界面截图中找到目标元素”;
- 验证平台:提出了一个全新 benchmark —— ScreenSpot,用于评估 GUI grounding 能力;
包含 iOS、Android、macOS、Windows、网页五种平台;
共有 600+ 截图,1200+ 指令,涉及文本、按钮、图标等各种元素;
实验结果表明 SeeClick 在 ScreenSpot 上显著优于其他 LVLM。
- 实验验证任务
MiniWob(网页小任务)
AITW(手机上的交互任务)
Mind2Web(网页复杂操作)
- 论文的主要贡献总结:
🌐 提出 SeeClick:一个纯视觉、平台无关的 GUI agent,能执行点击和输入任务; 🧭 探索并强化 GUI grounding 能力,设计专门的预训练策略; 📊 创建现实场景的评估 benchmark —— ScreenSpot; 📈 在多个任务上实证:更强的 GUI grounding → 更高的任务表现。
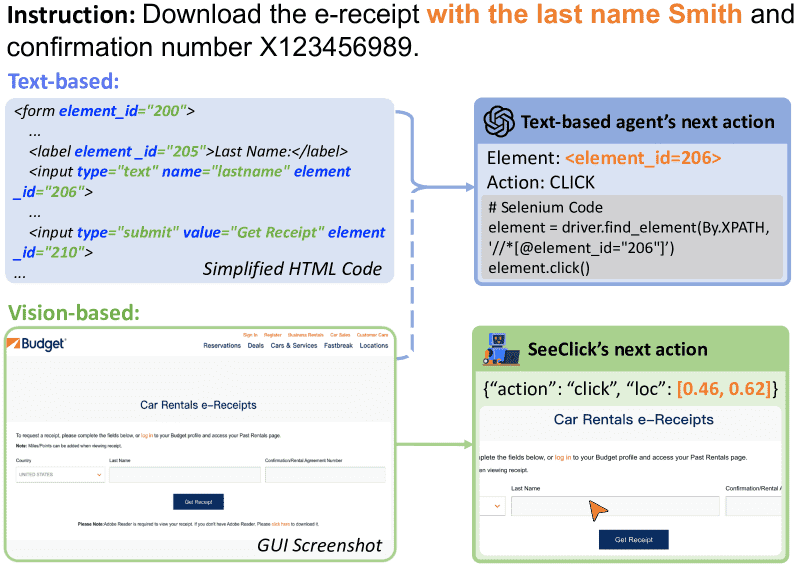
Figure 1:Text-based agents select target elements from structured texts, occasionally augmented with screenshots. SeeClick employs a vision-based methodology to predict action locations solely relying on screenshots.¶
3. Approach¶
视觉 GUI 智能体(Visual GUI Agents):核心在于如何让大语言视觉模型(LVLM, Large Vision-Language Models)理解图形用户界面(GUI)的截图,并基于用户的指令在界面中“找到”正确的位置进行点击操作,这个能力被称为 GUI Grounding。
研究目标:是打造一个仅依靠 截图和用户指令 就能执行操作的视觉 GUI 智能体。为此,提出了一个名为 SeeClick 的基础模型,其核心能力就是 GUI Grounding。
总结:本章介绍了一个专门为了 GUI 操作而优化的视觉语言大模型 SeeClick,它通过特殊的数据构建和训练方式,让模型更擅长看懂图形界面,并在用户指令下找准点击位置,从而成为“看图点按钮”的智能体。
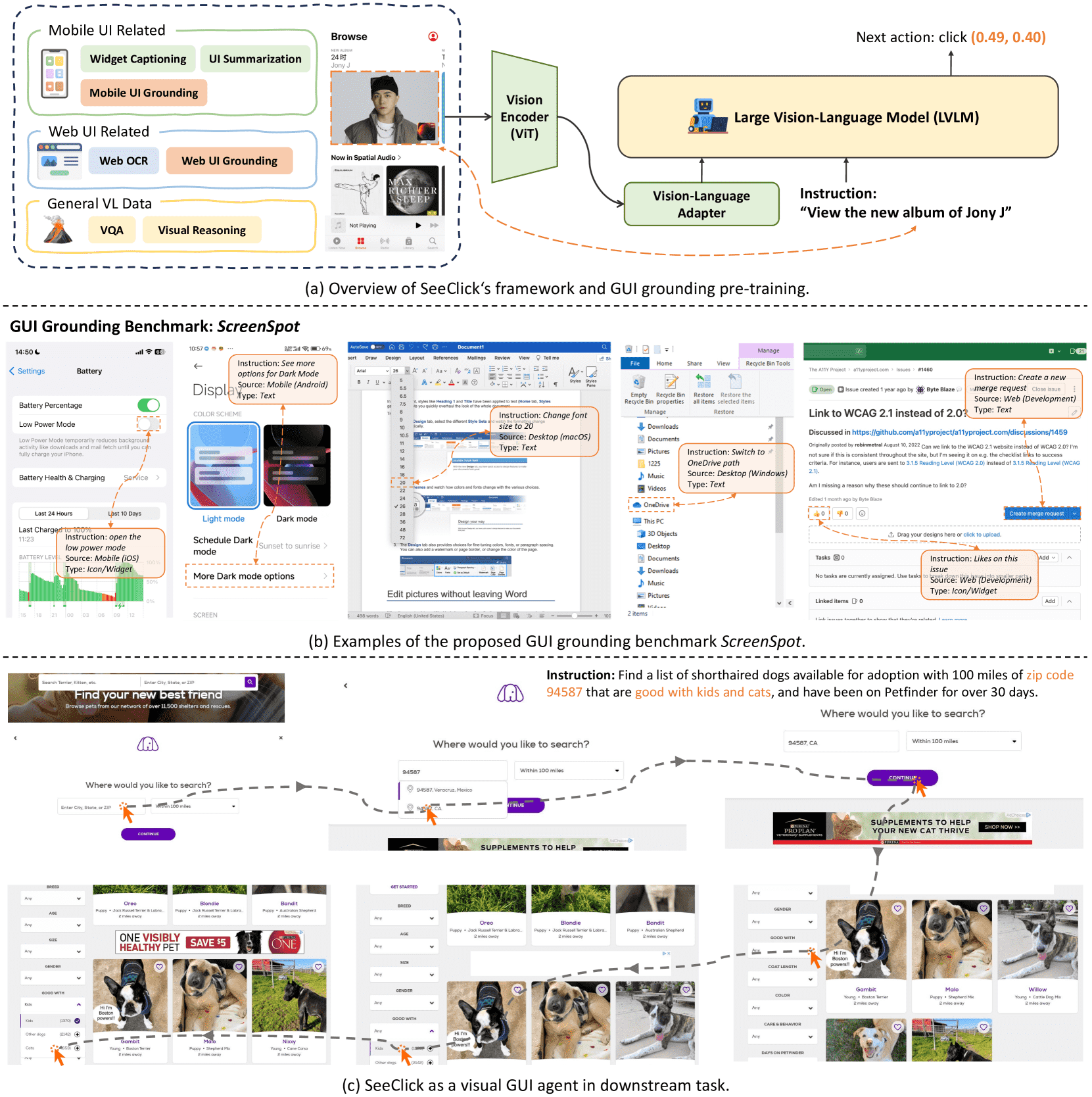
Figure 2: Overview of our universal visual GUI agent SeeClick. (a) depicts the framework of SeeClick and GUI grounding pre-training. (b) provides examples of ScreenSpot across various GUIs and types of instructions. (c) displays the real-world application of SeeClick when adapted to downstream web agent tasks.¶
3.1 GUI grounding for LVLMs¶
- 问题定义:
给定一个截图 s,截图上有一堆界面元素,比如按钮、文本、图标等。
- 每个元素由两个部分构成:
xᵢ: 元素的文本描述(比如按钮写着“Play”)。
yᵢ: 元素的位置(比如坐标框、中心点等)。
任务是让模型学会预测 某个给定文本描述的元素的位置,也就是计算 p(y | s, x)。
- 技术挑战:
- 如何让语言模型生成坐标?
旧做法:将图片分成1000个格子,每个坐标对应一个 token,比如 <p0> 到 <p999>,这就类似 token 化的坐标。
当前做法:直接让模型像生成自然语言一样,输出 click (0.49, 0.40) 这样的文本表示坐标,不做特殊 token 处理,更直观。
- 举例说明:
比如有个手机界面截图,指令是:“查看 Jony J 的新专辑”,
- 对应的 prompt 是:
“In the UI, where should I click if I want to view the new album of Jony J?”
- 然后模型的目标输出就是:
> “click (0.49, 0.40)”
训练时用交叉熵来优化输出与正确答案之间的差异。
3.2 Data Construction¶
他们用了三类数据来训练 SeeClick:
- Web UI 数据(网页界面):
从 Common Crawl 中抓取了约 30 万网页。
- 提取两类可交互元素:
带有文本内容的 HTML 元素。
有 title 属性的元素(鼠标悬停会显示描述)。
- 任务包括:
GUI Grounding:p(y | s, x)
OCR 反向任务:p(x | s, y) —— 看到某个位置,输出对应的文字。
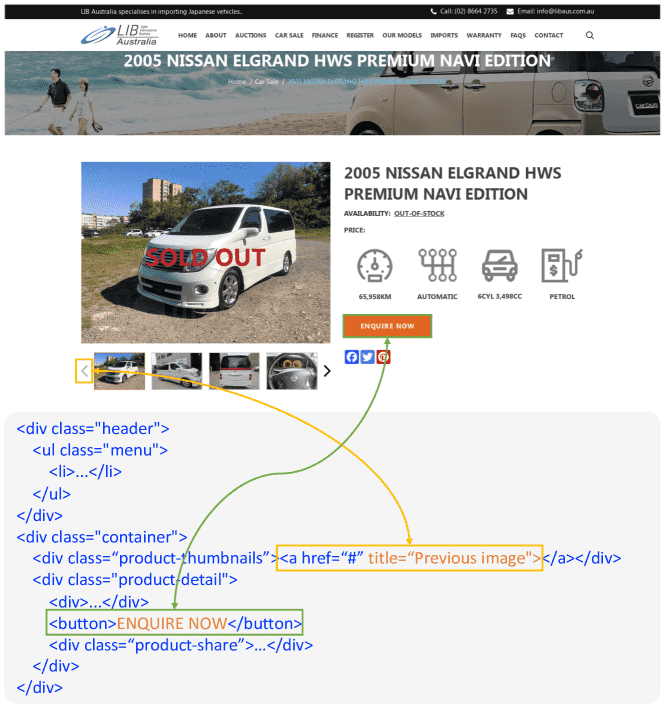
Figure 3:Example of two types of elements automatically collected from the webpage.¶
- Mobile UI 数据(手机界面):
- 涵盖三种任务:
Widget captioning:给 UI 元素写说明(如“播放音乐”)。
UI Grounding:反过来,用说明找元素。
UI Summarization:整体界面理解(比如总结这个页面是个音乐播放器)。
- 这些数据主要来自公开数据集,如:
RICO(一个大规模的移动 UI 数据集)
Li et al. 2020 的数据集(包含约 2 万张截图和 10 万条描述)
- 通用视觉-语言数据:
使用了像 LLaVA 这样的通用数据来保持模型在自然图像上的能力(比如问答、细节描述、推理等)。
最后,他们组合这些数据,并为每类任务设计了 30 种 Prompt 模板,总共生成了约 100 万条数据 训练 SeeClick。
3.3 Training Details¶
基于已有的强大 LVLM Qwen-VL(阿里巴巴的开源视觉语言大模型)。
分辨率提升到 448×448。
用 LoRA(低秩适配) 方法微调视觉编码器和语言模型。
用他们构建的数据训练了约 1 个 epoch(1 万步)。
4. ScreenSpot: A Grounding Benchmark¶
定义:ScreenSpot是一个专门为 评估多模态大模型(LVLMs)在图形用户界面(GUI)中定位元素能力(GUI grounding) 而设计的基准测试集。
总结:ScreenSpot 是一个新设计的、多平台的GUI grounding评估基准,用来测试大模型在“看图点击”任务中的真实能力,尤其强调对图标和小控件的理解与定位。
- 为什么要做 ScreenSpot
要构建视觉GUI智能体(visual GUI agents)最核心的能力是 GUI grounding —— 也就是模型能够根据一段语言指令,找出屏幕上应该点击或操作的图形元素(比如按钮、图标等)。
但过去的视觉语言模型能力不足,这方面的研究非常少,而且大多集中在一个 2017年收集的Android数据集(Deka et al.) 上,已经过时了。
- ScreenSpot 是什么?
- 多平台、多类型 GUI:
数据来自移动端(iOS 和 Android)、桌面端(macOS 和 Windows)和网页端,总共包含:
600+ 个界面截图
1200+ 条自然语言指令和对应的目标元素(可操作区域)
- 包含大量图标和小部件(widgets):
相比文本,图标和 widget 更难被模型准确识别定位,ScreenSpot 就特别强调这一点,让评测更具挑战性。
- 如何构建这个评测集?
- 请专业的标注人员:
对移动和桌面界面,他们从常用应用和操作中选择截图。
对网页界面,则从 WebArena 提供的不同网站类型中选取(包括开发、购物、论坛、工具类等)。
对每张截图,标注员都写了一条指令,并框出执行指令所需点击的元素的具体位置(bounding box)。
特别注意:这些样本都不包含在任何已有的训练数据中,也就是说是全新的、未见过的,确保测试是“真实世界”的挑战。
5. Experiments¶
- 目标:
首先评估大型多模态语言模型(LVLMs)以及 SeeClick 在图形界面(GUI)理解(grounding)方面的表现。
然后将 SeeClick 应用于移动端和网页自动化任务,探讨其 GUI grounding 能力与下游任务表现之间的关系。
进一步探索「纯视觉驱动」的 GUI 智能体的可能性。
5.1 GUI Grounding on ScreenSpot¶
- 背景:
GUI grounding 是 GUI 智能体的基础,但之前的 LVLMs 很少在这方面被系统评估。
因此作者引入了一个专门的评测基准数据集:ScreenSpot。
- 评测模型:
通用型 LVLMs(如 MiniGPT-v2、Qwen-VL、GPT-4V):适用于各种视觉-语言任务。
GUI 专用 LVLMs(如 Fuyu、CogAgent):专门设计来处理界面任务。
- 评估指标:
Click Accuracy(点击精度):预测的点击位置是否落在目标组件的框选范围内。
- 实验结果:
通用模型在自然图像上表现好,但在 GUI 上表现差,即便是 GPT-4V 也不例外。
GUI 专用模型表现好,SeeClick 在各平台和元素类型上总体表现最好,即使它参数比 CogAgent 少。
唯一弱项是在定位桌面/网页中的文本元素稍逊于 CogAgent,原因是分辨率和训练数据较少。
所有模型都难以定位图标或小组件,说明非文本类元素是 GUI grounding 的难点。
5.2 Visual GUI Agent Tasks¶
SeeClick 是一个 purely vision-based 的 GUI agent 模型,只看截图(不看 HTML 或 DOM)来决定下一步操作。
SeeClick 被应用到 3 个任务上:
1. MiniWob(网页自动化小游戏)
2. AITW(Android 实际应用操作)
3. Mind2Web(真实网页导航任务)
5.2.1 MiniWob¶
- 任务介绍:
MiniWob 是一个网页自动化任务集,包含约 100 种小任务,如填写表单、点击按钮等。
作者自己用 LLM 策略回放生成 50 个成功示例,每个任务 50 个,总计 2800 条数据用于训练 SeeClick。
- 对比模型:
文本 + HTML 结构为主的方法(如 WebGUM、WebN-T5)
纯视觉模型 Pix2Act
LVLM 基线 Qwen-VL
- 结果总结:
在 2800 条小样本下,SeeClick 超过 WebGUM 和 Pix2Act,表现最优。
比 Qwen-VL 高近 20 个百分点,证明 GUI grounding 训练显著提升了性能。
在界面动态布局任务中 SeeClick 明显优于其他模型,说明它能更好应对真实使用场景。
5.2.2 AITW(Android In The Wild)¶
- 任务介绍:
包含 30K 条指令和 71.5 万条操作轨迹,涵盖安装 App、使用 Google 服务、网购等。
作者改用“按指令切分数据集”的方式来避免过拟合。
- 评测指标:
ClickAcc(点击精度)
任务完成准确率等
- 结果总结:
SeeClick 在各类任务上均优于 GPT-4V 和 Qwen-VL,特别在“Google 应用”、“安装类任务”中领先明显。
与 Qwen-VL 相比,ClickAcc 高出 9 个百分点。
5.2.3 Mind2Web¶
- 任务介绍:
由 137 个真实网站构成,包含 2000 多个自然语言指令任务。每个任务包括高层级指令及人类操作轨迹。
原本为文本 HTML 智能体设计,作者用其评估视觉 GUI 智能体 SeeClick。
- 方法
- 传统方法:
Mind2Web 原本是为文本代理设计的,从 HTML 结构中挑选元素。
- SeeClick 的新尝试:
首次尝试仅依赖网页截图+点击坐标,不看 HTML,进行导航任务。
- 结果总结:
SeeClick 在多个维度上(如操作准确率、点击精度、步骤成功率)均显著优于 Qwen-VL。
在跨任务、跨网站、跨领域的测试中,GUI grounding 训练让性能几乎翻倍。
5.2.4 Grounding and Agent Performance¶
- 分析发现:
GUI grounding(通过任务前预训练来理解 UI 界面)越强,任务表现越好
实验中多个 Checkpoint 显示:预训练越充分,MiniWob/AITW/Mind2Web 表现越优秀
5.2.5 SeeClick as Unified GUI Agent¶
- 尝试:
联合训练 SeeClick 处理所有三类任务,验证其统一模型的能力。
- 结果:
表现略有下降,说明三类 GUI 差异大,统一模型存在挑战
但从结果看,SeeClick 仍展示出 vision-only 模型的统一潜力
总结¶
SeeClick 利用 GUI grounding,使得仅靠界面截图也能在网页与手机自动化任务中实现高质量点击与操作,全面超过当前视觉基线,并接近甚至超越使用 HTML 的方法。
如果你是开发视觉代理或做 AI 自动化,这个框架的意义在于 —— 未来很多任务不再需要 DOM 解析,纯视觉就能搞定。
- SeeClick 的优势
纯视觉驱动,不依赖 HTML 或 DOM 数据。
具备高效的 GUI grounding 能力,在未见过的新界面或系统上也能准确理解人类指令。
在真实世界 GUI 智能体任务中性能优异,超越现有的多模态模型和基准方法。
6. Conclusion¶
- 核心观点:
该论文提出了一种名为 SeeClick 的视觉图形界面代理(GUI agent),它只依赖于屏幕截图来实现 GUI 自动化任务。
- 关键挑战:
作者发现,发展这种视觉 GUI agent 的关键挑战在于 GUI grounding
即:根据人类语言指令,准确地在屏幕上定位元素的能力。
- 解决方案:
为了解决 GUI grounding 问题,他们设计了一个 GUI grounding 预训练机制,
并提出了方法,可以自动收集 GUI grounding 的训练数据(来自网页和移动端)。
- 评估与数据集:
他们创建了名为 ScreenSpot 的评估数据集,涵盖 移动端、桌面端和网页平台,用于测试 GUI grounding 的效果。
- 实验结果:
在 ScreenSpot 上,SeeClick 的效果 明显优于现有的大型视觉语言模型(LVLM)。
此外,在三个不同的 GUI 自动化任务中也表现出色,说明 GUI grounding 的进步 可以直接带动下游自动化任务性能的提升。
Limitations¶
- 当前的简化设定:
SeeClick 目前只支持点击(click)和输入(typing),不支持更复杂的操作,如拖拽(dragging)或双击(double-clicking)。
- 技术瓶颈:
由于当前开源 LVLM 的能力有限,如果要在像移动端或桌面端完成多步骤任务,还需要专门的数据来训练模型,不能完全依赖通用模型。
Ethical considerations¶
- 应用意义:
GUI agents 的目标是提升数字设备的自动化能力,尤其对视觉障碍者有非常大的帮助。
- 三个主要伦理问题:
- 隐私问题(Privacy Issues):
GUI agent 需要接触并操作用户界面,可能包含敏感信息。
所以必须确保 数据保护 和 用户授权,以保护隐私。
- 现实环境中的安全性(Safety in Real-World Interactions):
若 GUI agent 在现实中自动操作某些任务,可能会出现误操作,造成伤害。
所以系统必须设置 安全边界,防止意外事件发生。
- 算法偏见(Bias):
如果模型对某些用户群体或界面类型的识别效果较差,会产生不公平。
所以开发中必须注意 减少偏见(bias mitigation),保障公平性。
- 结论:
这些伦理挑战需要持续的研究和改进,以便在不牺牲伦理的前提下,发挥 GUI agent 的积极效应。
A. Details of SeeClick Pre-training¶
主要介绍了它是如何通过预训练任务(Pre-training Tasks)训练模型的细节,包括数据设计、任务类型、训练配置等。
总结:SeeClick 的训练方法是在大量网页和移动端截图上进行“找位置”和“看图读字”的预训练任务,数据多达 100 万条,模型使用 Qwen-VL-Chat 并解锁视觉部分,最后通过在 ScreenSpot 测试集上评估模型性能,效果显著优于现有 LVLM。
A.1 Pre-training Tasks¶
- 🧠 训练任务分为两大类:
- GUI grounding(界面定位任务)
也就是根据文本找出界面上的位置,有两种形式:
text_2_point:给定一段描述,预测对应UI元素的中心点坐标 (x, y)。
text_2_bbox:给定描述,预测元素的边界框 bounding box,即(left, top, right, down)。
👉 实验发现:预测中心点比边界框表现更好,因为 UI 元素大小差异大,用点坐标更稳定。因此,在数据比例上倾向使用 text_2_point
- GUI 文本生成任务(类似 OCR)
- 也就是根据屏幕上的位置,反推出对应文字,有两种方式:
point_2_text:(又称 widget captioning):给定一个中心点,预测对应UI元素的文字。
bbox_2_text:给定一个边界框,预测框中的文字。
- 📐 坐标数据是怎么表示的?
坐标都是归一化数值,也就是在 [0, 1] 区间的浮点数(保留两位小数),表示相对于整个图片的宽/高的比例。
例如,(0.32, 0.77) 表示在图片宽度 32% 的地方,和高度 77% 的地方。

Figure 7: Examples of SeeClick pre-training tasks.¶
A.2 Training Configurations¶
- 🧩 模型基底:
使用开源多模态大模型 Qwen-VL-Chat 作为基础,进行连续预训练(continual pre-training)。
- 🎯 技术细节:
解锁视觉编码器(visual encoder)的梯度,意思是允许模型在视觉部分继续学习,不是冻结的。
使用 LoRA(轻量级参数适配技术)来做精调,节省训练资源。
- 🧮 超参数配置:
优化器:AdamW
学习率:初始 3e-5
学习率调度器:cosine annealing(余弦衰减)
Batch size:64
训练硬件:8 个 NVIDIA A100 GPU
总训练时间:大约 24 小时
B ScreenSpot Annotation & Evaluation¶
B.1 Human Annotation¶
一共请了 4 位有经验的标注员,他们都是计算机专业的硕博生,熟悉电脑和手机上的图形界面操作(GUI)。
分配任务时,他们分别负责不同平台:如 iOS、Windows、Web 等。
- 标注流程如下:
平时使用手机或电脑时截屏(例如打开某个 App、网页等)。
使用一个标注工具 [Makesense](http://makesense.bimant.com) 给截图中常用的可点击元素打框(bounding box)。
为这些被标注的 UI 元素写英文的操作指令(例如 “Click the search icon”)。
所有截图中的界面和元素都是英文,并做了脱敏处理,去除了用户的隐私信息。
B.2 Sample Showcase¶

Figure 10:More examples of GUI grounding benchmark ScreenSpot.¶
B.3 Evaluation Detail¶
对比了一些主流的多模态模型(如 CogAgent、GPT-4V)和自家的 SeeClick。
比如对于 CogAgent,它推荐的 prompt 是:“What steps do I need to take to <instruction>? (with grounding)” —— 意思是让模型输出操作步骤,并附带位置。
对 GPT-4V,则是按照 Yang 等人(2023)的方法,给它输入指令,要求它输出对应的界面位置。
然后比较它们的输出位置坐标(通常是中心点坐标)与真实值(ground truth)之间的误差。
SeeClick 的评估选择了 使用中心点(point)预测而不是边界框(bbox),因为表现略好。
B.4 SeeClick Case Study & Error Analysis¶
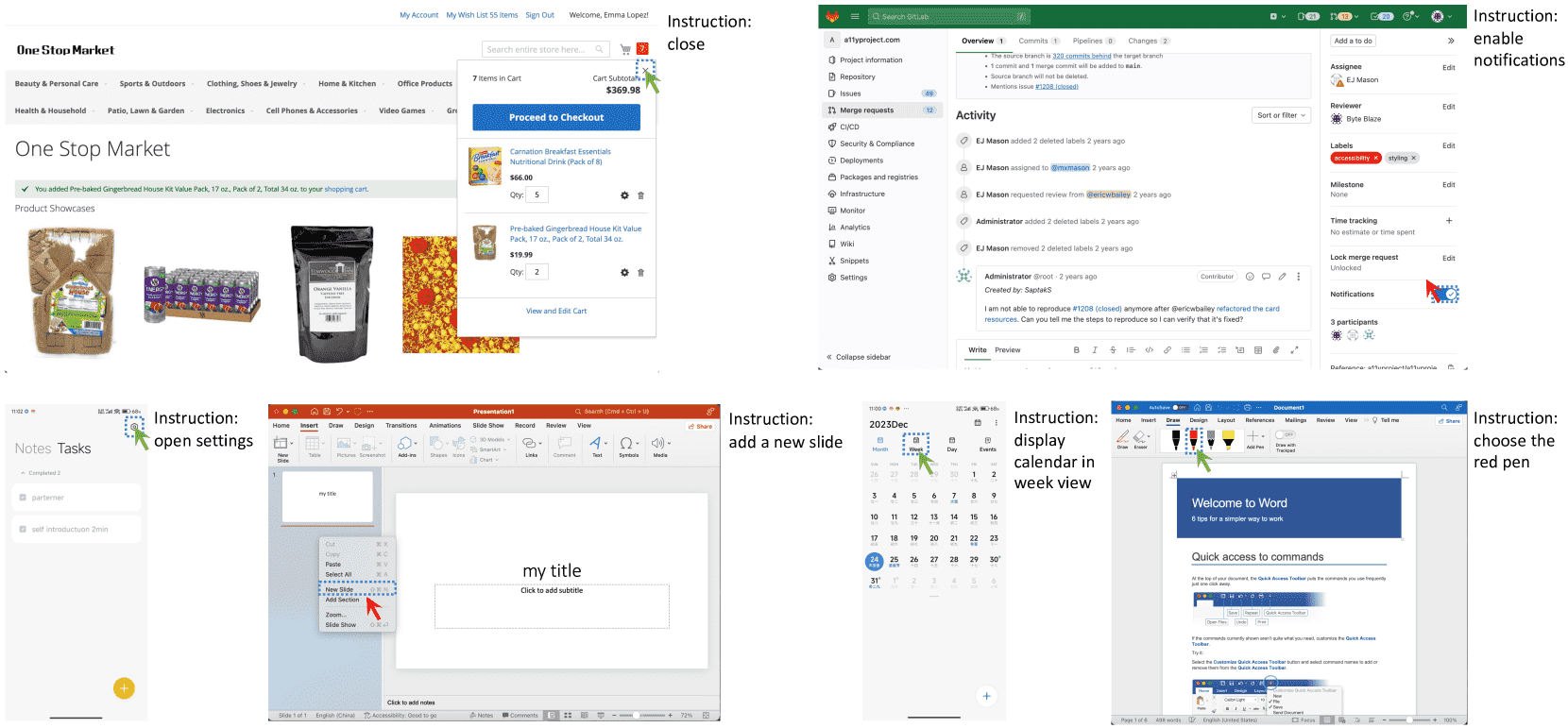
Figure 8: SeeClick on ScreenSpot. Blue dashed boxes represent the ground truth bounding boxes, while green and red pointers indicate correct and incorrect predictions.¶
结论是:> 即使预测错误,预测点通常也靠近真实目标,说明模型大致识别出目标,只是精度还需提升。
小结¶
ScreenSpot 是作者构建的一个现实场景下的多平台 GUI 定位评估集,手工标注了截图中的可操作元素及英文指令。
对比评估中,SeeClick 的点位预测精度较高,错误大多数也落在目标附近,说明它在 GUI Grounding 上有较强能力,但仍需在细粒度定位上优化。
C. Downstream Agent Tasks¶
C.1 Formulation of SeeClick as Visual GUI Agent¶
SeeClick模拟人类与图形界面交互的方式:
动作 |
描述 |
|---|---|
click(x, y) |
点击屏幕某点,x 和`y` 是相对坐标(0-1之间) |
type(“text”) |
输入文本 |
select(“value”) |
从下拉菜单中选择值(来源于 Mind2Web 的定义) |
swipe(direction) |
滑动屏幕,有四个方向:上(1)、下(0)、左(8)、右(9) |
PRESS BACK |
返回上一步 |
PRESS HOME |
返回主页 |
PRESS ENTER |
回车提交内容 |

Agent Formulation: 它以指令、当前界面的屏幕截图和先前的操作(这儿是4次动作历史)作为输入,以预测下一步要采取的操作。¶
C.2 MiniWob¶
- 这是一个简化的网页自动化环境:
内置约100个网页任务(如填写表单、点击按钮);
每个任务都有多个模板,最多可以生成数十亿种变体;
用50条成功轨迹训练、50个随机种子测试;
成功判定标准:操作正确 + 不超过30步。
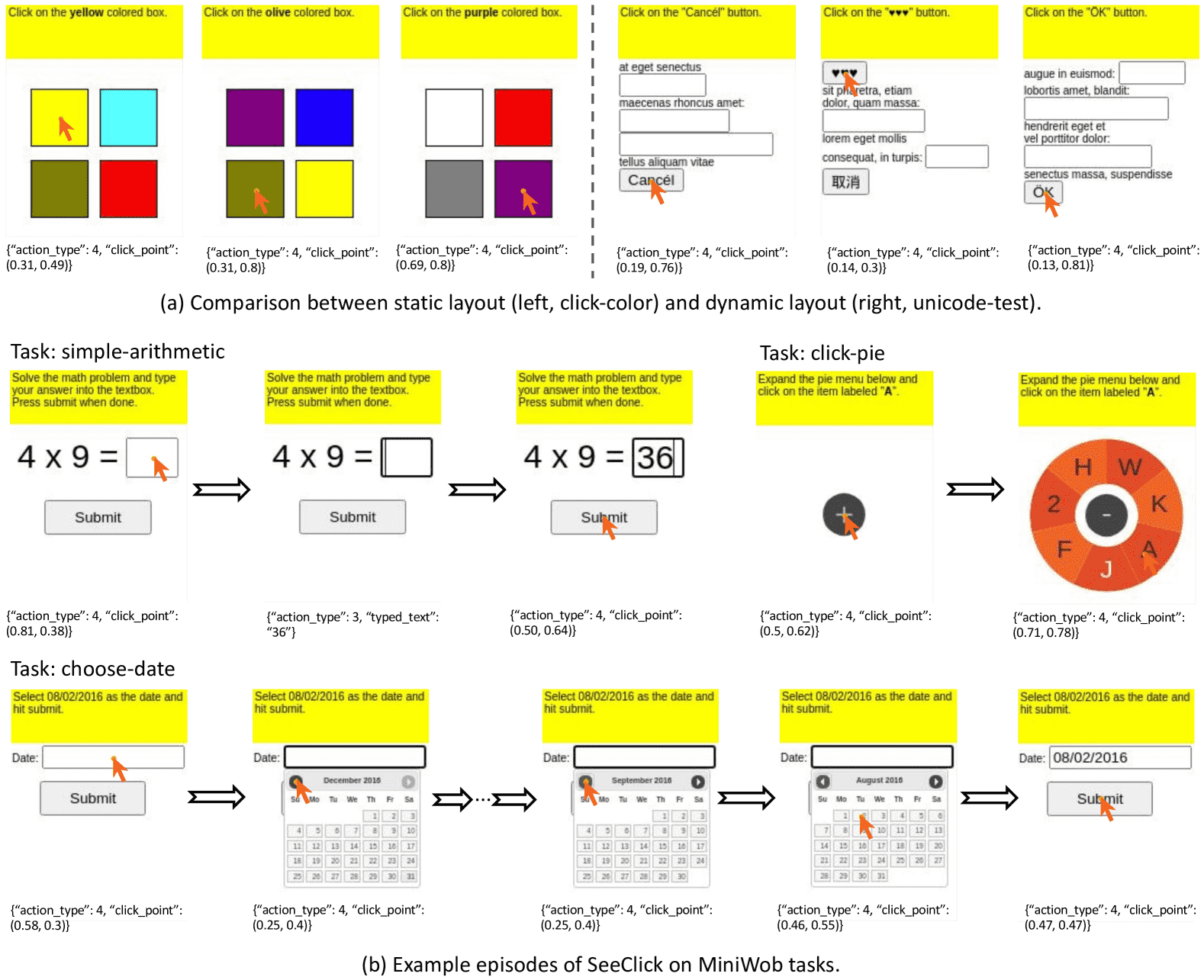
Figure 11: Example episodes of SeeClick on MiniWob. The model’s prediction output is below the screenshot, with action_type 4 indicating a click and action_type 3 indicating typing.¶
C.3 AITW¶
- AITW 是一个Android上的大规模自动化任务数据集:
总共超过30,000条指令,700,000条操作轨迹;
分成5类子集(General、Install、GoogleApps、Single、WebShopping);
数据集原始划分存在过拟合风险,影响模型在真实场景下的泛化能力。
- 为此,作者提出了新的训练-验证-测试划分策略:
基于指令内容划分(instruction-wise),而不是轨迹;
从每个子集中随机选取一定数量指令,每条只保留一个标注轨迹;
所有截图 + 动作被用来计算screen-wise matching score(即一个页面操作是否执行正确);
该分数与人类判断结果相关性较高。
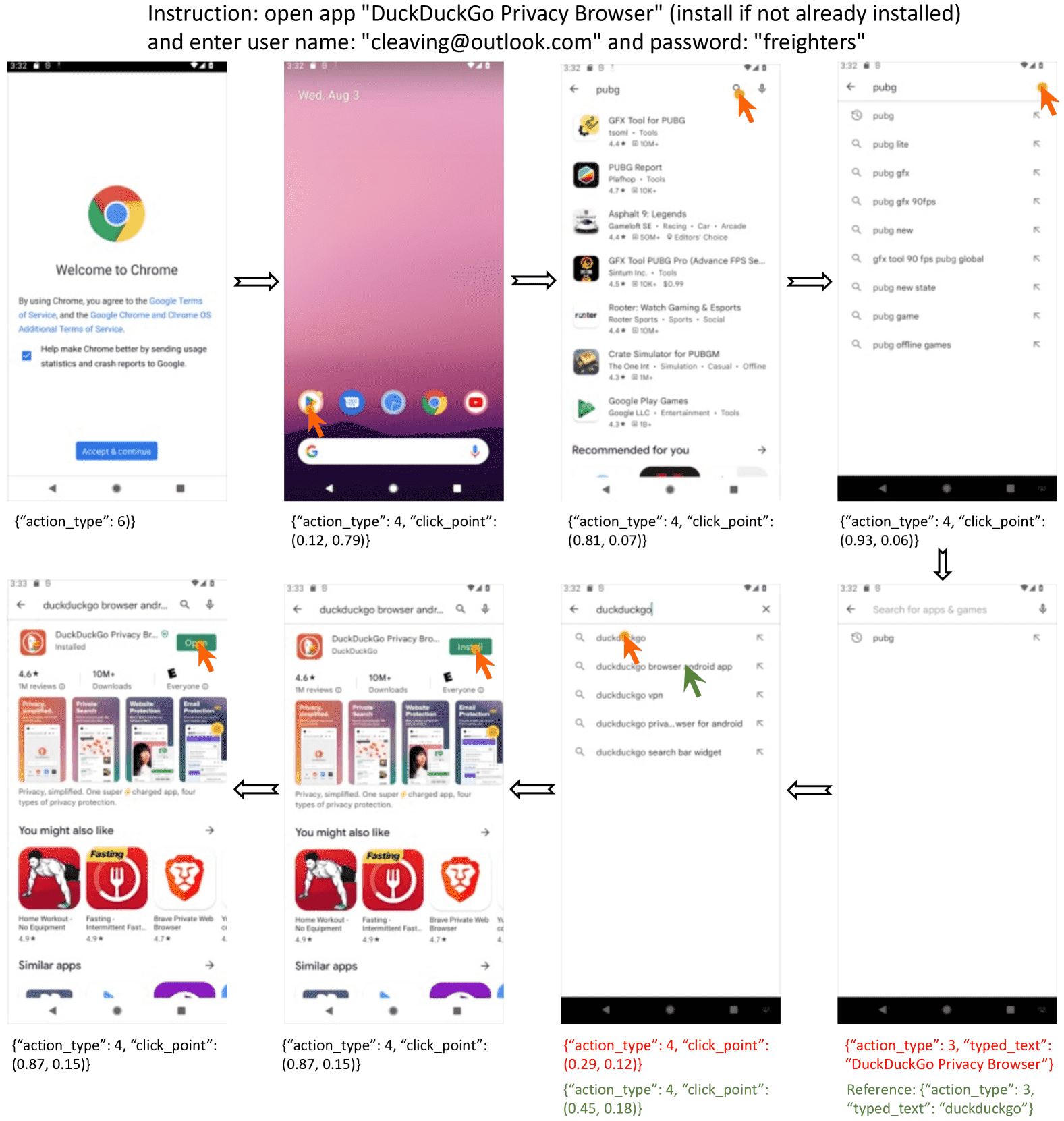
Figure 12:Example episodes of SeeClick on AITW. The model’s prediction output is below the screenshot, with action_type 4 indicating a click, action_type 3 indicating typing and action_type 6 indicating PRESS HOME. Steps with the red prediction and green reference indicate a failed step.¶
C.4 Mind2web¶
- Mind2Web 是一个面向真实网页任务的通用智能体数据集:
原设计用于基于文本的智能体,输入仅为 HTML 代码;
为支持视觉模型,作者从原始网页dump中提取了截图和目标元素的坐标框;
原始HTML捕获的是整页信息,对应的截图很长(如 1920*12000 像素);
对当前视觉大模型来说,这种截图处理起来太复杂,也不符合人类操作逻辑;
所以作者裁剪了截图,仅保留包含目标元素的1920x1080窗口视图。
- ✅ 评估指标:
Ele.Acc(元素准确率):预测点击/操作的元素是否正确;
Op.F1(操作F1):模型操作的文本内容与真实结果的相似度(基于token级F1分数)。
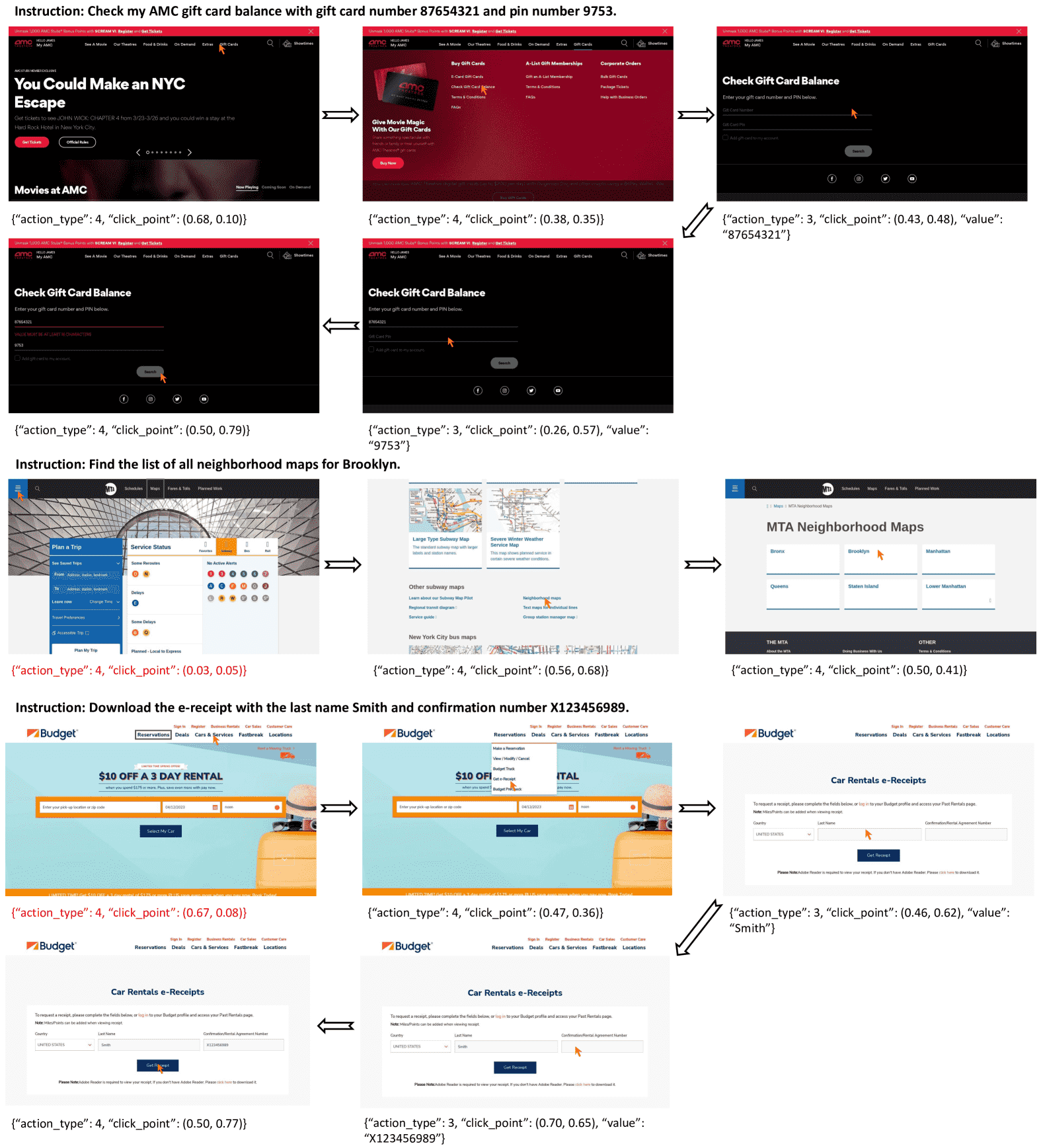
Figure 13:Example episodes of SeeClick on Mind2Web. The model’s prediction output is below the screenshot, with action_type 4 indicating a click and action_type 3 indicating typing. Steps with the red prediction and green reference bounding box indicate a failed step.¶
总结¶
SeeClick 是一个视觉GUI智能体系统,可以执行自然语言指令,在多种环境下完成网页或App上的操作任务。
- 其创新包括:
动作建模方式多样,贴近真实用户操作;
输入融合了语言、图像和动作历史;
评估方式严格,支持多个真实世界任务数据集(MiniWob、AITW、Mind2Web);
与其他模型相比,在多个任务上展现出更好的泛化能力和准确性。