数据分析思维课¶
2021-07-28
郭炜
前易观 CTO
本科和研究生都就读于北大的计算机系,专业是数据仓库和数据挖掘。毕业后,我待过不少的公司,从 Teradata 到 IBM,从中金到万达到联想研究院再到易观,职位也从数据架构师、数据部总经理到最后的 CTO。
从 Teradata 的数据模型架构师去做了当时的项目经理,后来跳槽到 IBM 做资深项目经理,到后来的中金、万达、联想从事高级总监、大数据部门总经理等岗位,其实都是根据雷达图在数据和管理方面加自己的技能点,直到最后做成 CTO。
目录
思维导图¶
00开篇词 (2 讲)¶
开篇词 | 数据给你一双看透本质的眼睛¶
数据是客观的,但是解读数据的人是主观的
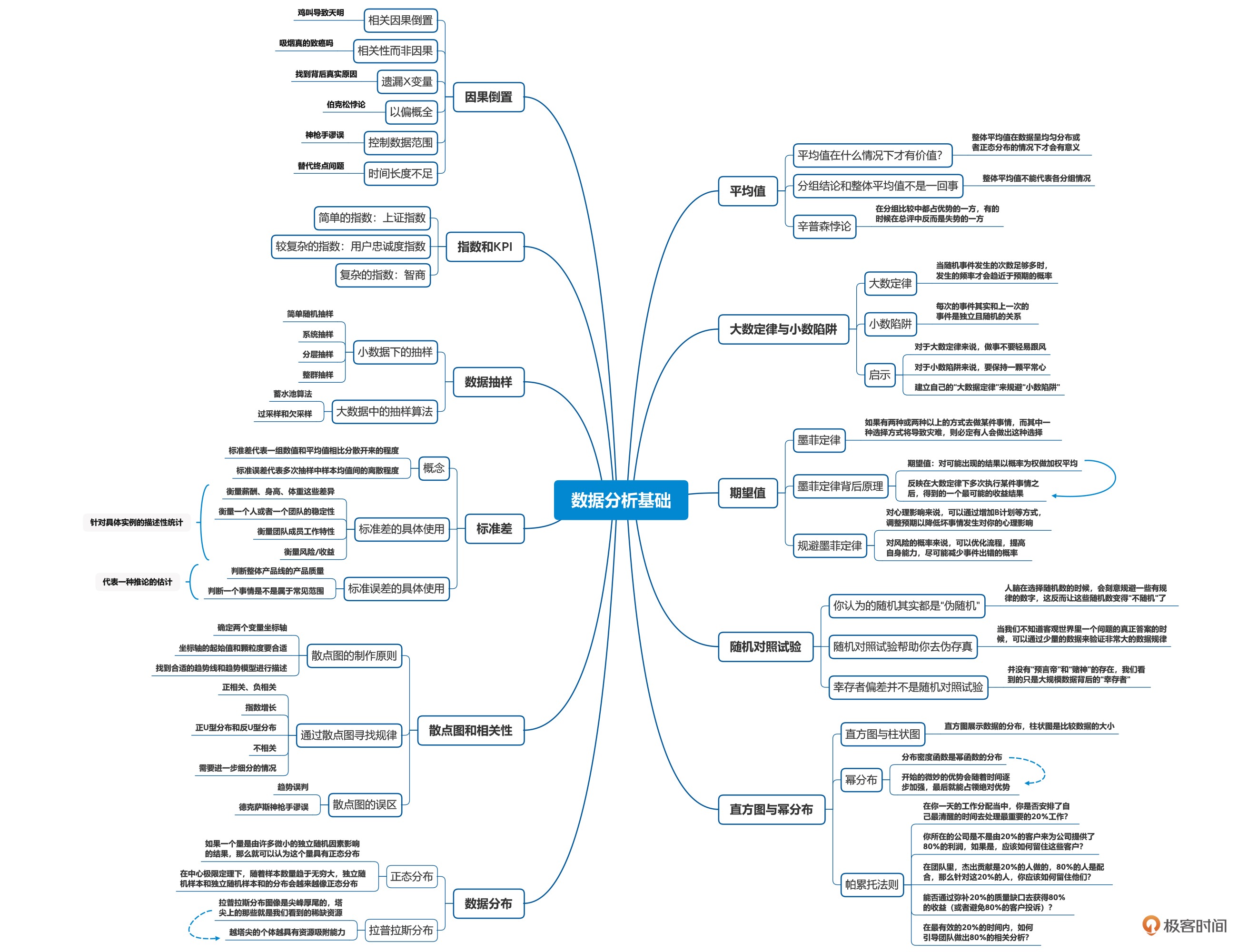
01数据分析基础 (11 讲)¶
01 | 平均值: 不能代表整体水平¶
平均值是用所有样本数据计算的,容易受到极端值的影响。在不少情况下,平均值是没有价值的,它无法客观准确地反映数据整体情况。
整体平均值是在数据呈均匀分布或者正态分布的情况下才会有意义,如果忽略整个数据的分布情况,只提平均值,其实是没有意义的。
分组结论和整体平均值结论可能会大相径庭。
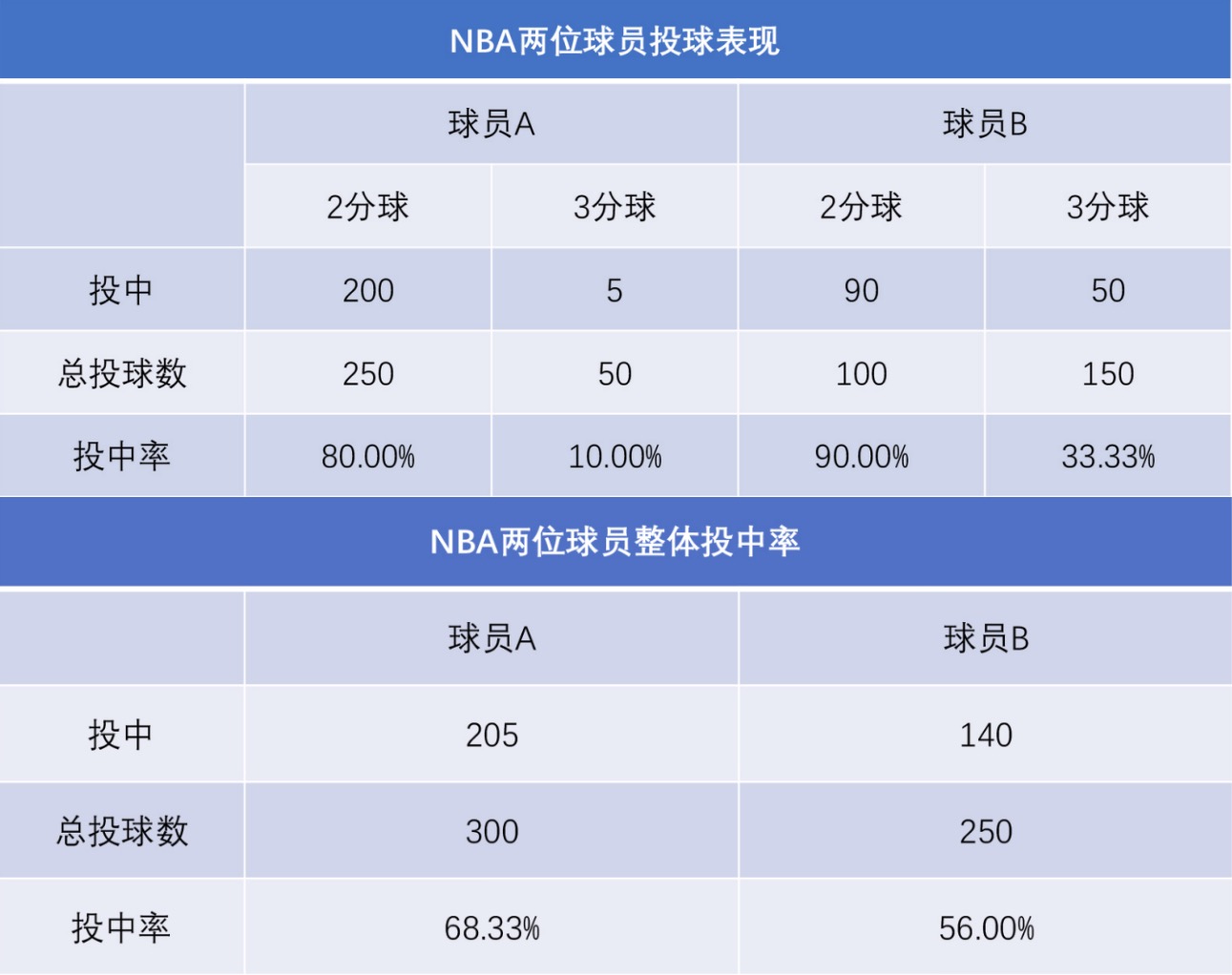
[辛普森悖论Simpson’s paradox]两分球和三分球投中率都比较高的这个球员 B,整体的命中率反而下降了¶
备注
看到一个平均值的时候,你一定要留个心眼,看看它的数据构成情况,而不是简单地用平均值去代表所有的整体。
备注
平均值和辛普森悖论告诉我们要抓大放小,不要因为某一个单项优势就洋洋得意,也不要因为局部失败就一蹶不振。生活,要有一颗平常心,我们的目标是让我们这一生的 “人生平均值” 逐步提高。
02 _ 大数定律与小数陷阱: 是随机还是有定数¶
大数定律是由瑞士数学家雅各布・伯努利提出来并验证的,它的核心逻辑是说当随机事件发生的次数足够多时,发生的频率才会趋近于预期的概率。
Law of Large Numbers,LLN
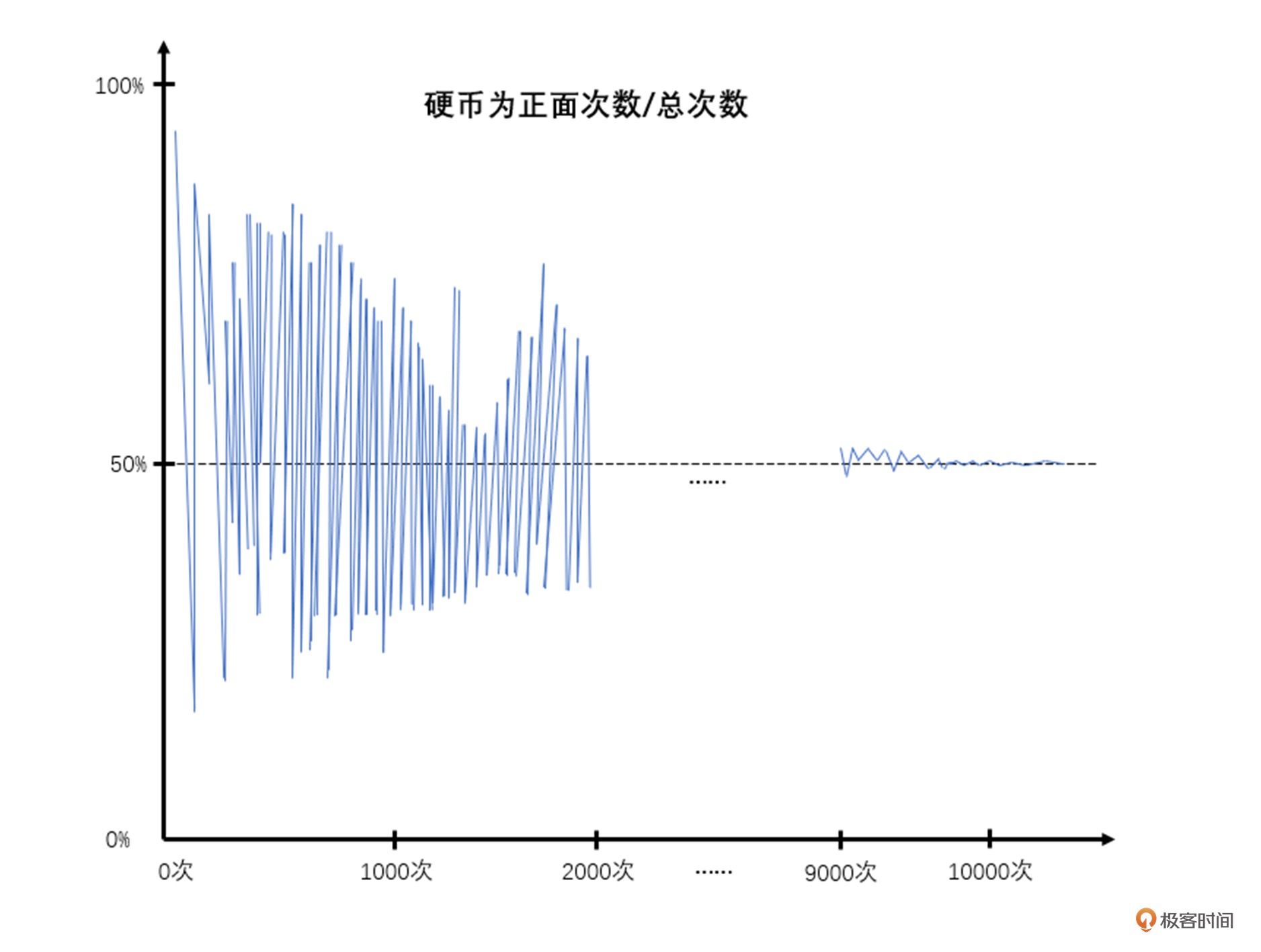
丹麦概率论学者克里克。二战时克里克曾被拘留,当时在监狱中他也没有什么事情可做,于是就做了这个抛硬币的实验来打发无聊的时间。他一共抛了 1 万次硬币,他把每次抛下来的硬币是正面还是反面做了一个统计,在最开始的几百次里,抛硬币的概率波动是非常大的,也就是说有的时候连续若干次都会正面或者连续若干次都会反面。到后面随着次数的增多,正面和反面的概率才越来越各自趋向于 50%。¶
小数定律是科学家阿莫斯・特沃斯基等人在研究 “赌徒谬误” 时做出的一个总结,我把它叫做 “小数陷阱”。核心逻辑是每个事件都是独立的事件,“否极泰来” 需要足够多的次数才可能出现,做事情要少一些 “赌徒心态”,多一些平常心,不要盲目跟风和下注才能获得最后的成功。
一个典型的对大数定律的误读,它叫「赌徒谬误」:既然随着数据的增多,整体趋势会趋向 50%-50%,那么我们在赌场里玩轮盘赌大小时,如果前面开的都是 “大”,那我们接下来应该向 “小” 去加倍下注。因为理论上长期来看出现 “大” 和 “小” 的概率应该是趋于一致的,所以未来出现 “小” 的概率应该增大。
03 _ 数据的期望值: 为什么你坐的飞机总是晚点¶
1949 年,美国的一位航空工程师爱德华・墨菲与美国空军共同研究高速载人火箭 “雪橇 MX981”,需要把 16 个精密传感器装在超重实验设备上测试耐压性。可即便是超重实验设备在巨大压力下都变形了,传感器也没有任何的指示。检查后才发现,原来是负责装配的三个同事把这 16 个传感器全都装反了。对此,墨菲不经意间开了一个玩笑:“如果一件事情有可能出错,让他去做就一定会弄错”。随后的记者招待会上,他的上司斯塔普把这句话称为 “墨菲定律”,并表述为:“如果有两种或两种以上的方式去做某件事情,而其中一种选择方式将导致灾难,则必定有人会做出这种选择。”
人们对墨菲定律又做了更多诠释,比如:
任何事情都不会像它表面上看起来那么简单;
所有任务的完成周期都会比你预计的长;
任何事情只要有出错的可能,就会有极大的概率出错;
如果你预感某件事可能出错,它一定会出错。
期望值就是对可能出现的结果以概率为权做加权平均。
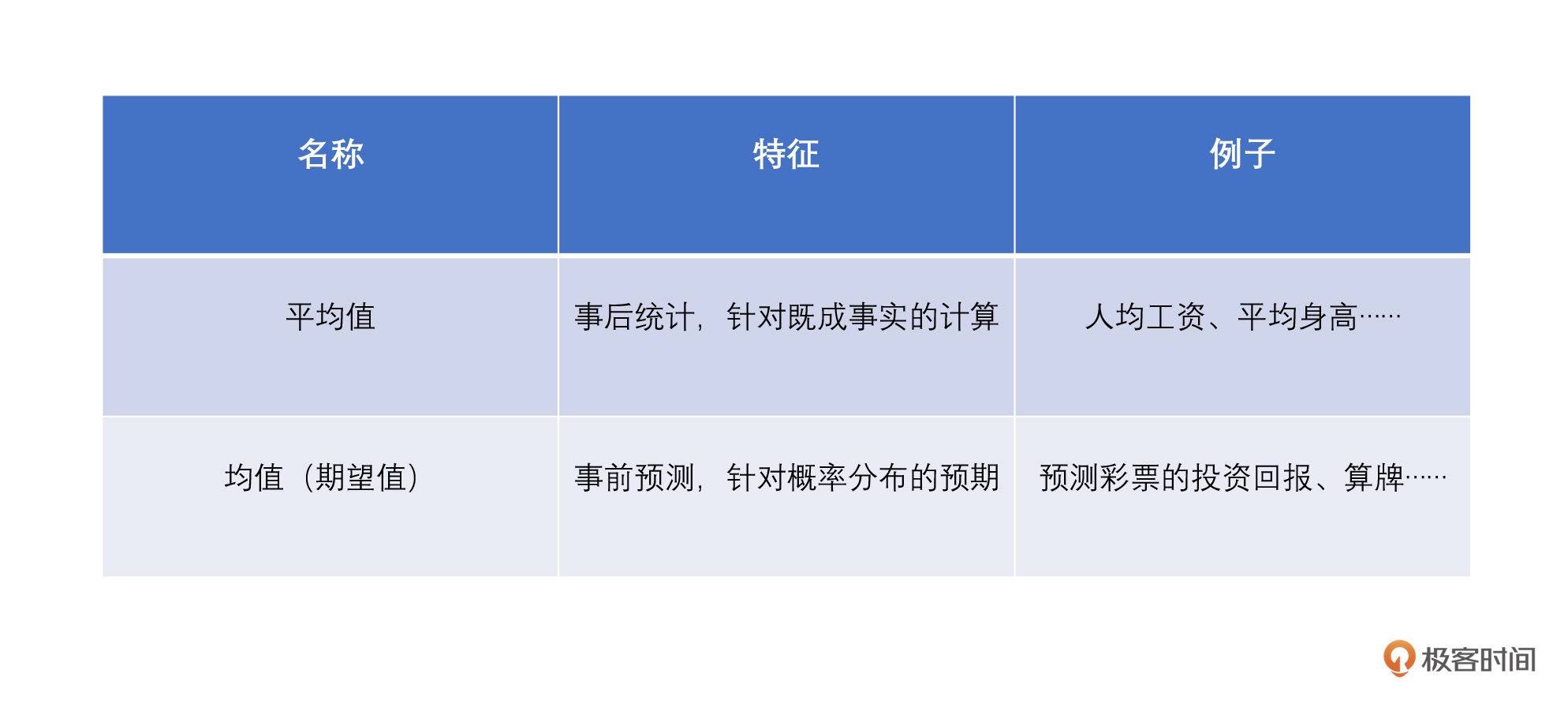
区分:均值(也叫做期望值)英文是 Mean,它是事前预测的,这个值完全是由概率分布决定,也就是我们前面所说的 “对可能出现的结果的概率加权平均”;平均值叫做 Average,它是事后统计,统计样本值的总和除以样本的个数。¶
为大概率坚持,为小概率备份:创业的时候,我们要努力为好的期望(N)去坚持,同时考虑为坏的影响(X)备份,应该尽力降低坏期望(R1)的风险。
已知的是成本,未知的才是风险: 如果坏的影响(X)为已知,那么即使你按照坏事件发生概率(R1)100% 来准备资金,这批资金也算是你付出的成本;但如果坏影响(X)未知,那么无论坏事件发生概率(R1)为多少,都是风险,因为你不知道这个坏事件究竟会造成多大的影响。
项目风险控制: 项目管理当中有各种风险管理和预防措施,把风险分为很多类,例如静态风险、动态风险、局部风险、整体风险,同时也会把风险应对措施细分为很多类,其实背后的核心是为了去避免墨菲定律的发生,让整体项目在项目经理的期望值下正确运行。
生活中的风险控制:我们在生活中,其实也是可以借用这种风险控制的方法论,识别生活中的风险并做好准备,这样才能够在墨菲定律发生的时候不会手忙脚乱。例如提前看看天气预报,查看这趟航班的过往准点率,预估自己乘坐航班情况。在去重要会议的时候,多提前一些时间。这些生活里的小事你或许平时不会太过于在意,但请相信,一旦你把这些小事落到实处,你对生活的掌控力会大大提升。
备注
最朴实的道理:没有事情可以一蹴而就(平均值),我们需要努力足够多的次数(大数定律),学会规避风险(期望值)。这样最终在若干年后,企业和个人才能有一份满意的企业 / 个人数据报表。
04 _ 随机对照试验: 章鱼保罗真的是“预言帝”¶
随机对照试验¶
随机对照试验:当我们不知道客观世界里一个问题的真正答案的时候,可以通过少量的数据来验证非常大的数据规律。如:医疗行业的临床医学、生物科学的基因遗传学,互联网黑客增长理论当中的 A/B 测试
随机对照试验是由 “现代统计学之父”、数据分析的鼻祖 —— 罗纳德・艾尔默・费希尔在《试验设计》一书中提出的,他用了一个很简单的例子来验证一件事情是否真实可信。这就是著名的奶茶试验,它很简单地讲述了 “随机对照试验” 的原理。
20 世纪 20 年代,英国有一位女士说道:“先放红茶和先放牛奶的奶茶的味道完全不一样,我一下子就能尝出它们的区别来。” 这时刚巧数据分析界的大神费希尔也在场,他就提议通过试验来鉴别这位女士所述的真伪。于是,费希尔设计了一个试验:他在那位女士看不见的地方,为她准备了两种冲泡方法不同的奶茶。之后把奶茶随机摆成一排,共 10 杯,让女士随机品尝奶茶并说出其冲泡方式,结果那位女士的回答完全准确。这时费希尔得出结论:这位女士真的有某种方法可以分辨出按不同方法冲泡的奶茶。
只有在随机的情况下这个公式才能成立:
1. 如果给女士一杯奶茶,偶然猜对的概率是 1/2,也就是 50%;
2. 如果随机给女士五杯奶茶,那么她都偶然猜对的概率就是 1/2 的 5 次方,大概 3.1%;
3. 如果这位女士随机品尝了十杯奶茶,那么偶然猜对的概率,也就是 2 的 10 次方分之一,也就是约 0.1%。
“奶茶试验” 就是随机对照试验的鼻祖,正式的随机对照试验会把研究对象进行随机化分组,并设置对照组。随机分组遵从双盲设计的前提条件,也就是研究者和受试者双方均无法知晓分组结果,最终通过结果来证明到底测试试验是否真的有效。
备注
你要记住,这种试验的重点有两个:一是 “随机”,二是对照试验。
幸存者偏差¶
备注
幸存者偏差并不是随机对照试验

幸存者偏差这个概念来源于二战时期,那时候有各种地面防空作战和空战,在密集的炮火下,战机机身上几乎所有地方都可能中弹,因此需要用统计学研究战机被击中的部位,从而确定哪个部分需要额外加强装甲。人们对返航的战机进行弹痕分析后发现,飞机机翼和尾部被打穿的弹孔较多,由此得出应该是加强机翼的装甲防护会更好。但对返航的飞机样本来说,其实是说明即使机翼中弹,飞机也有很大的几率能够返航。对于那些弹孔不多的部位来说(比如驾驶舱、油箱和机尾),当这些部位中弹的时候,飞机很可能连飞回来的机会都没有了,而这并没有统计出来,这就是所谓的 “看不见的弹痕最为致命”。最后事实也证明,加强弹孔较少部位的装甲防护是正确的。¶
05 _ 直方图与幂分布: 为什么全世界1%的人掌握着50%的财富¶
直方图是展示数据的分布,而柱状图是比较数据的大小
直方图是针对定量数据分布的定性分析,柱状图是对分类数据的定量数据分析
从柱子的间隔上来说,直方图的柱子和柱子之间没有间隔,而柱状图之间柱子是有间隔的
从柱子的宽度上来讲,直方图的柱子宽度可以不一样,而柱状图的柱子宽度必须一样。对直方图来说,它的柱子宽度代表区间的长度,根据区间的不同,柱子宽度可以不同。但柱状图的柱子宽度没有数值含义,所以宽度必须一致。
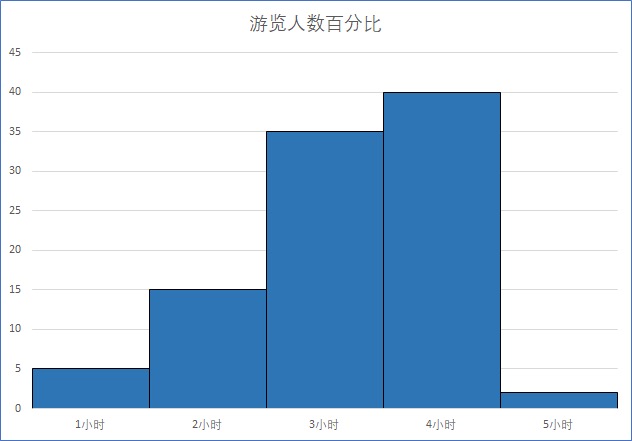
直方图:北京动物园日平均参观时长(X 轴是人们观光动物园的时间分布)¶
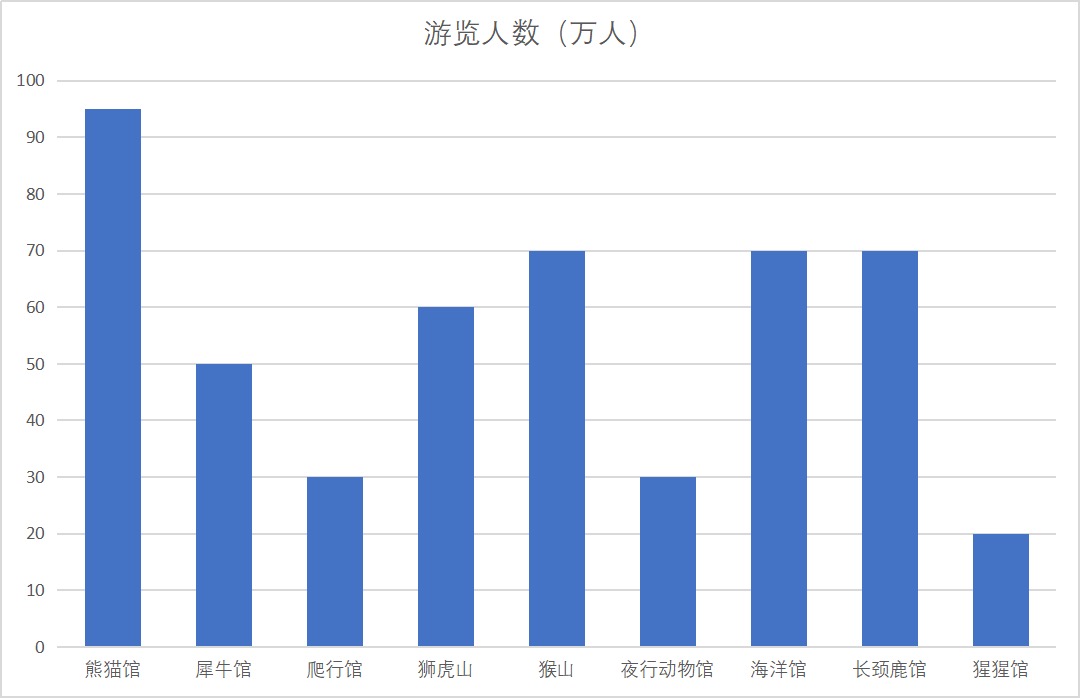
柱状图:北京动物园日场馆平均参观人数(X 轴是人们去动物园场馆的具体分类)¶
直方图最早是由数据统计学家 Karl Pearson 在 1891 年引入,它可以用来统计现实生活中各种各样的数据分布情况。直方图可以让你从混沌的数据里面找到其中的规律。
幂率分布也叫做指数分布,你会发现在这种分布里,X 轴的开始的地方数值很高(或很低),然后以指数级的下降(或上升)到 X 轴的末尾段,按照统计学定义叫做:“分布密度函数是幂函数的分布”。
“帕雷托法则”(也被人称之为 “二八法则”),这个法则的背后的规律就是幂律分布。这个法则诞生于帕累托的花园。有一天帕累托偶然发现,自己园子里绝大部分的豌豆是由园子里极少部分豌豆荚产生。
“马太效应”,这个法则的背后的规律也是幂律分布。我们身处的世界是赢者通吃的世界,开始时细微优势最终将带来无穷多的回报。反之,最初的细微劣势也将导致最终一无所有。
帕雷托法则:第一名、第二名分掉了整体赛道流量的 90%,一个领域只有第一、第二,没有第三。¶
备注
在日常生活里,不要把所有事都放在同一个优先级上,而是学会用帕累托法则去看待问题,找出最重要的 20% 的问题,并最优先解决。同时,你也要留个心眼:为什么这 20% 的问题对你来说最为重要?
06 _ 数据分布: 房子应该是买贵的还是买便宜的¶
正态分布¶
最早用正态曲线描述数据的人,是德国著名数学家高斯,为了纪念他,有时候我们也把正态分布称为高斯分布。但正态分布这个名字不是高斯取的,而是由达尔文的表兄弟弗朗西斯・高尔顿命名。高尔顿开创了遗传学的统计研究,并用正态曲线来表明他的研究结果,这个名字后来广为流传。
【定义】如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布

在德国,十马克的纸币上都留有高斯的头像和正态分布的曲线¶
大数定律和中心极限定理说的不是一个维度的事情。大数定律算的是概率,中心极限定理算的是样本和的分布。
【大数定律】拿抛骰子给你举个例子。在抛骰子这件事上,大数定律说的是只要你抛的次数足够多,骰子每一个面向上的概率应该都是 1/6。
【中心极限定理】你抛 6 次骰子发现求和是 18,你又抛 6 次发现加起来是 20,你又抛了 6 次,这次发现加起来是 25。如果你抛的次数足够多,你把 18、20、25 等这些数据画出一个图来,这个图是符合正态分布的。
中心极限定理要求的是独立随机样本,在中心极限定理下,随着样本数量趋于无穷大,独立随机样本和独立随机样本和的分布会越来越像正态分布。
大数定律研究的是随机变量序列依概率收敛到其均值的算术平均,说白了就是为了说明频率在概率附近摇摆,也为我们将频率当作概率提供了依据。
拉普拉斯分布¶
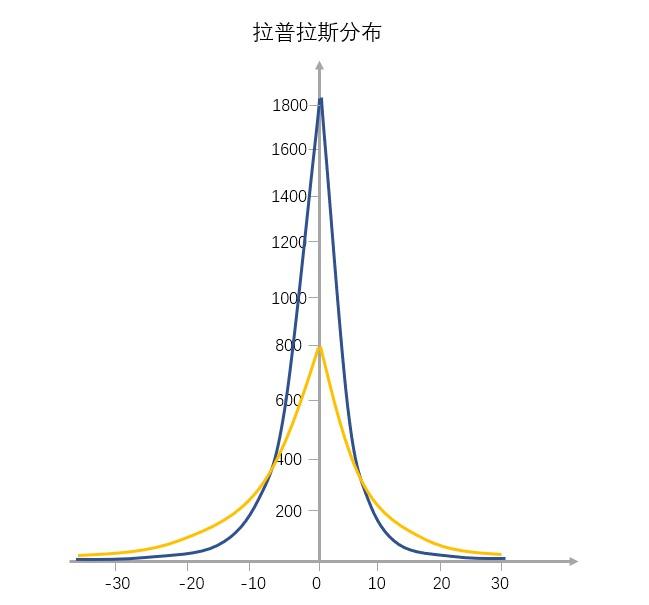
拉普拉斯分布就和上图一样,是一个 “凸” 字形的塔尖儿曲线,从左到右,斜率先缓慢增大再快速增大,到达最高点后变为负值继续先快速减小,最后再缓慢地减小,所以有点像 “往里边凹陷的金字塔”。¶
起初我们认为股票收益率是服从正态分布,但是由于股票价格波动与时间变化有关,有波动聚集性,最后实际股票的收益率都是符合拉普拉斯分布的,也就是赚大钱的日子其实特别集中,余下的都是赚小钱的日子。
在改革开放之前信息不对称,资源也相对没有那么聚集,人们拿到的工资是一个正态分布的。但是到了现在,就我们程序员的工资来说,一个顶尖的程序员和普通的程序员的工资收入可能会差十倍都不止,这就会导致更厚的尾部和更高的峰度。
正态分布比较适合之前变化节奏比较缓慢的世界,在当前赢者通吃的世界,很多以前符合「正态分布」的现象慢慢的向「拉普拉斯分布」进行变化,所以我们在进行判断和选择的时候也要有动态的视角,在深刻理解这两个分布模型的同时,结合我们对事物的理解才能做出合适的选择。
可以把拉普拉斯分布理解成对称的幂率分布。
07 _ 散点图和相关性: 怎样快速从数据当中找到规律¶
散点图的历史¶
散点图被称之为万图之王。在 1913 年,美国一个叫做亨利·诺利斯·罗素(Henry Norris Russell)的天文学家用散点图把宇宙的趋势给揭示了出来。
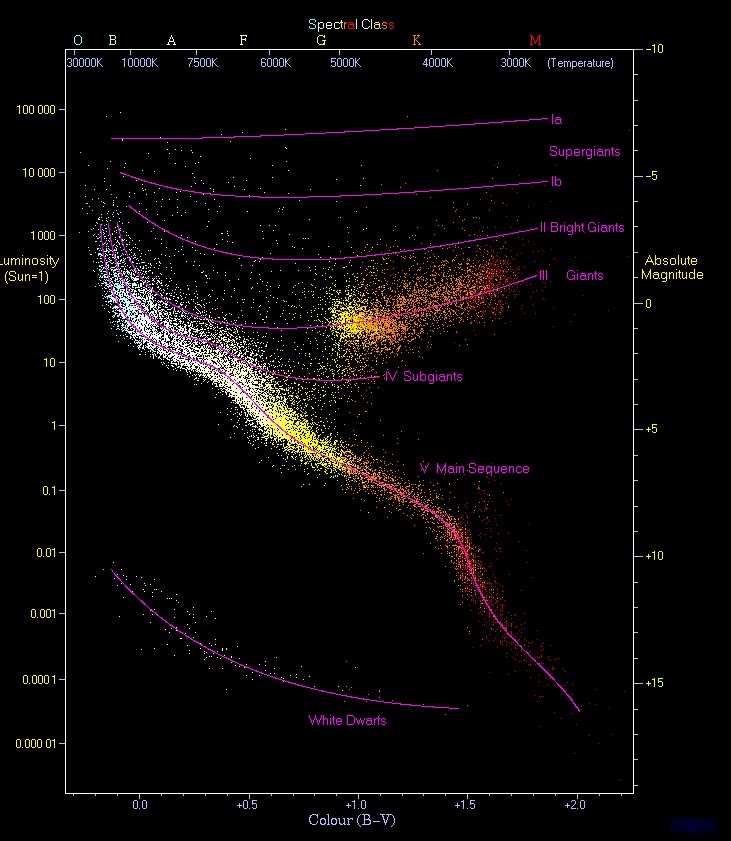
通过这个散点图,罗素画出了一条趋势线,这条趋势线揭示了恒星从原恒星到红巨星到红白矮星、黑矮星的一个演变的过程,这就是著名的赫罗图。换句话说,这个散点图揭示了恒星这一生的秘密。¶
散点图的制作原则¶
散点图有三个最基本的制作原则:
1. 散点图反映的是两个变量之间的关系
2. 坐标轴Y轴的起始值必须为0、颗粒度要合适
为了能够明确展示数据之间的趋势,我们的 Y 轴必须要从零开始
3. 找到合适的趋势线和趋势模型进行描述
这就是画龙点睛的一笔,背后其实是你对业务、数据、算法深刻的理解和认知
画得好,你就是哈勃和罗素,画不好你就成了我接下来会讲到的得克萨斯的伪神枪手
散点图的变种——气泡图
通过散点图寻找规律¶
最常见的数据趋势:
1. 正相关
2. 负相关
3. 指数增长
4. 正 U 型
5. 反 U 型
6. Y轴无关型
7. 非常复杂的图形
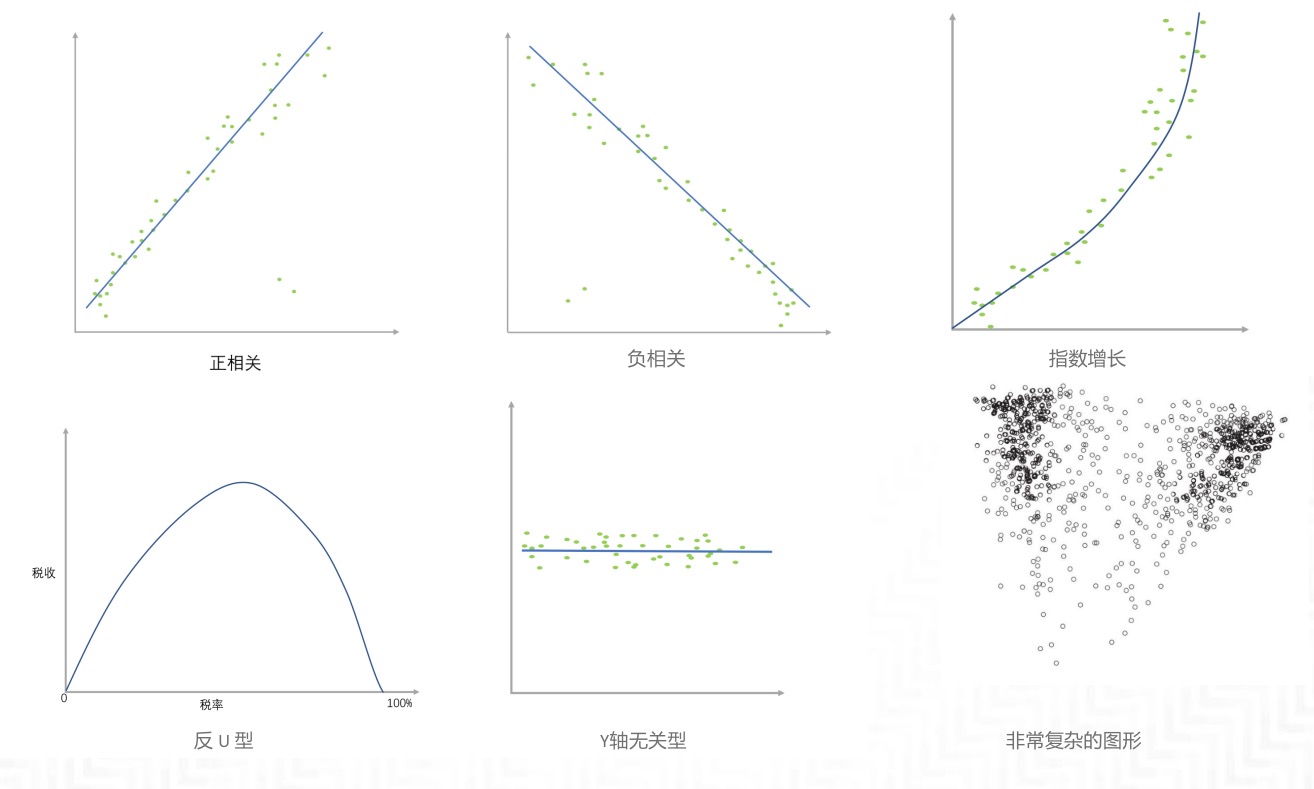
最常见的数据趋势¶
散点图的易错点¶
最常见的三个错误:
1. 趋势误判
在你看到了一个数据之后,因为数据整体还不够完整,你错误判断了这个数据的未来增长趋势。
(身高和体重在生长期是成正比的,你成年了自然也就不会再是正比了)
2. 得克萨斯神枪手谬误
来历: 先朝墙上开很多枪,然后在弹孔最密集的地方画上了十环的靶子,再把散布在其它地方的弹孔用原来的泥土补起来
背后所蕴含的实际数据是不是涵盖了所有的数据,还是只给你看了最有这种数据规律的数据。
(不能由现有结果给出趋势判断,还需要了解规律形成的最终原因和背后的场景)
3. 幸存者偏差
例: 邻居家的小孩永远比我们要更厉害,其实孩子都是差不多的,只不过最后我们看到的是邻居家小孩当中的那些优胜者
例: 自古红颜多薄命,也是因为我们只把目光放在了少数的红颜身上
例: 天妒英才也是因为我们没有过多关注普通人究竟寿命几何
在分析散点图的时候看到了规律,还要了解最终这个规律形成的原因和背后的场景,不要简单通过一个图表就得出你的结论
(不要用片面的数据来证明你的规律)
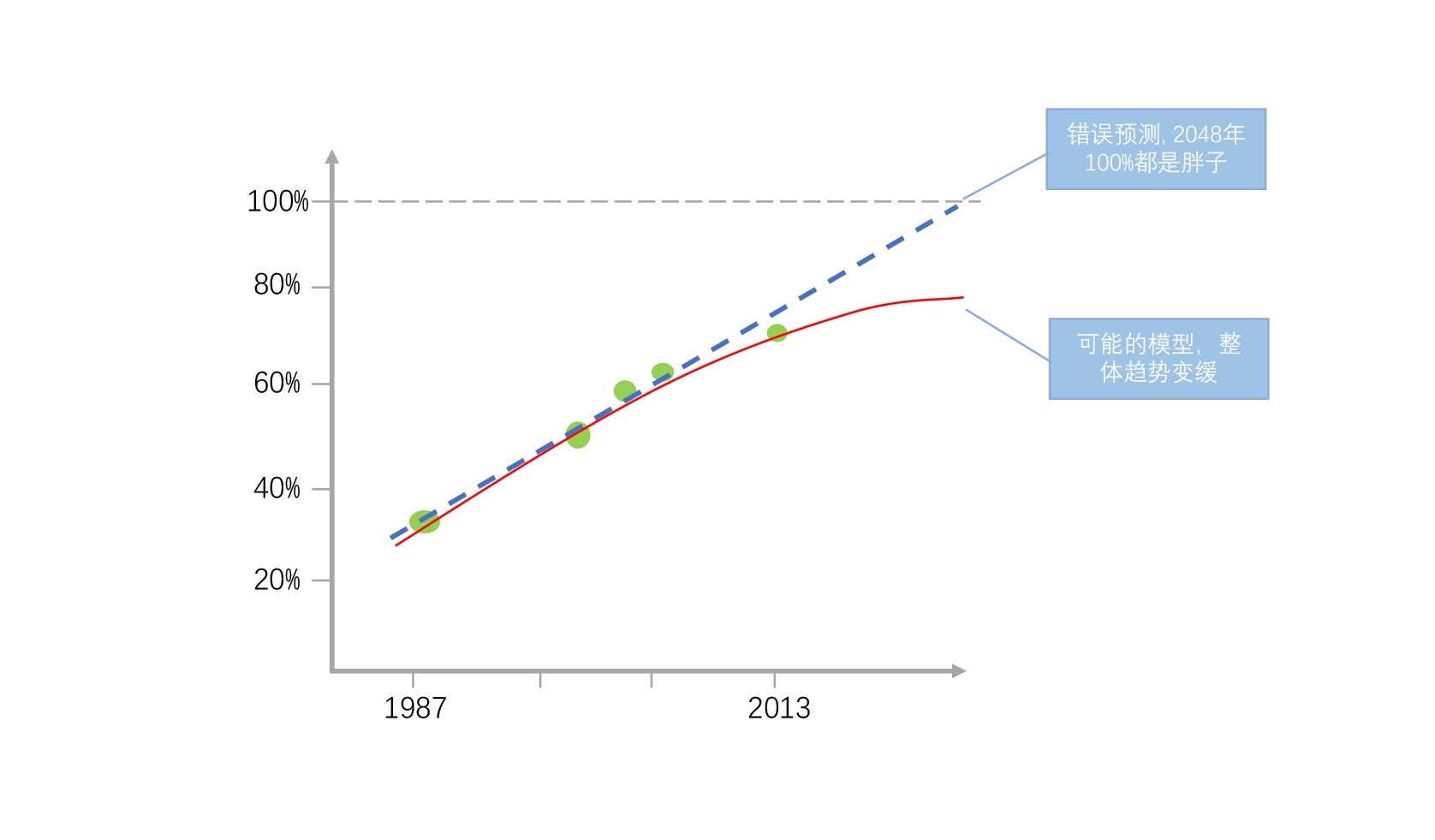
[趋势误判]美国人体重增长趋势预测的散点图 -> 进行线性回归,其分析结果是:到 2048 年,这条线会达到 100%。这明显是个错误的结论。因为最终肥胖人群的增长趋势不是线性的,你现在看到的增长点似乎是线性,但其实它会是一个像抛物线一样的数据趋势 -> 没有正确的数据验证,千万不要轻易下结论¶
08 _ 标准差: 这人是不是“靠谱”其实看标准差¶
标准差¶
标准差的概念比较简单,它代表一组数值和平均值相比分散开来的程度。也就是说,标准差大:代表大部分的数值和平均值差异比较大,标准差小:代表这组数字比较接近平均值。
离散系数 CV(coefficient of variation):标准差除以平均值(离散系数 = 标准差 / 平均值),规避单位或者其他因素的这些差异。直接看离散系数这个数据,就能知道这几组数据之间的离散程度和差异是什么样的。
标准误差¶
标准差是针对一次确切的已知统计结果,反映的是在一次统计中,个体之间的离散程度,也可以说标准差是针对具体实例的描述性统计。
标准误差代表一种推论的估计,它反映的是多次抽样当中样本均值之间的离散程度,也就是反映这次抽样样本均值对于总体期望均值的代表性,它主要是用于推断整体情况预测和推算使用。
标准差(Standard deviation)= 一次统计中个体分数间的离散程度,反映了个体对样本整体均值的代表性,用于描述统计。
标准误差(Standard error)= 多次抽样中样本均值间的离散程度,反映了样本均值对总体均值的代表性,用于推论统计。
备注
标准误差经常会被用于拿出一部分样品去判断整体产品线的产品质量,或者判断一个事情是不是属于常见范围。
六希格玛(Six Sigma):其实就是指所有的产品质量问题需要控制在 6 个标准误差里面。
产品质量或者运维故障控制在 5 个 9 的意思就是 99.99966% 的产品是没有品质问题的。
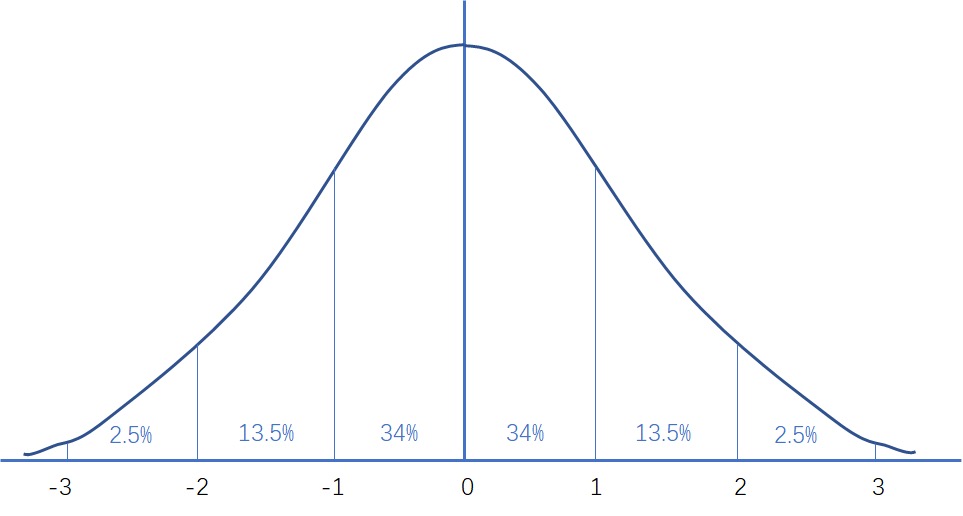
一个标准误差范围里,大概就是图里面的 68.3%;两个标准误差范围里也就是距离均值(标准件)的 95.4%;三个标准误差就是 99.7%;6 个标准误差(也就是 6-sigma)也就代表着要控制到在生产的产品中,有 99.99966% 的产品是没有品质问题的(每一百万件产品中只有 3.4 件有缺陷)。¶
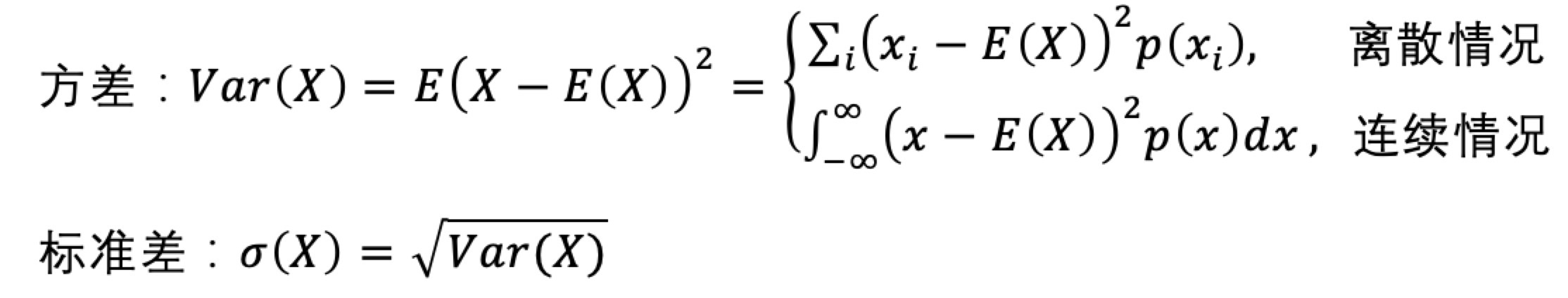
方差及标准差公式¶
09 _ 数据抽样: 大数据来了还需要抽样么¶
分层抽样是先分层再从各层抽样本
整群抽样是先分群再抽一个群调查。
舍恩伯格《大数据时代》提出的三种大数据时代的思维变革:
1. 要全体不要抽样
2. 要效率不要绝对精确
3. 要相关不要因果
蓄水池算法: 解决的问题是:给你一个长度很大或者长度大小未知的数据(流),并且你只能访问一次该数据(流)的数据。请写出一个随机选择算法,使得选中数据流中每个数据的概率都相等。方案:需要把抽中做统计单元都放到一个游泳池(蓄水池)里。假设我目标是只抽 n 个目标,这就有一个有 n 个容量的游泳池,抽中的单元都站在这个游泳池里面。当游泳池站满了以后,再往里加单元的话有一定的概率会把游泳池里面的单元给挤出来,也有一定的概率是新加的单元根本挤不进去游泳池
过采样: 在一个池子里反复去抽样,本来应该抽样 10 个人,我们把这 10 个人反复抽样,变成 50 个人。
欠采样: 在一个池子里本来我们应该抽样 100 个人,现在只抽样 10 个人。
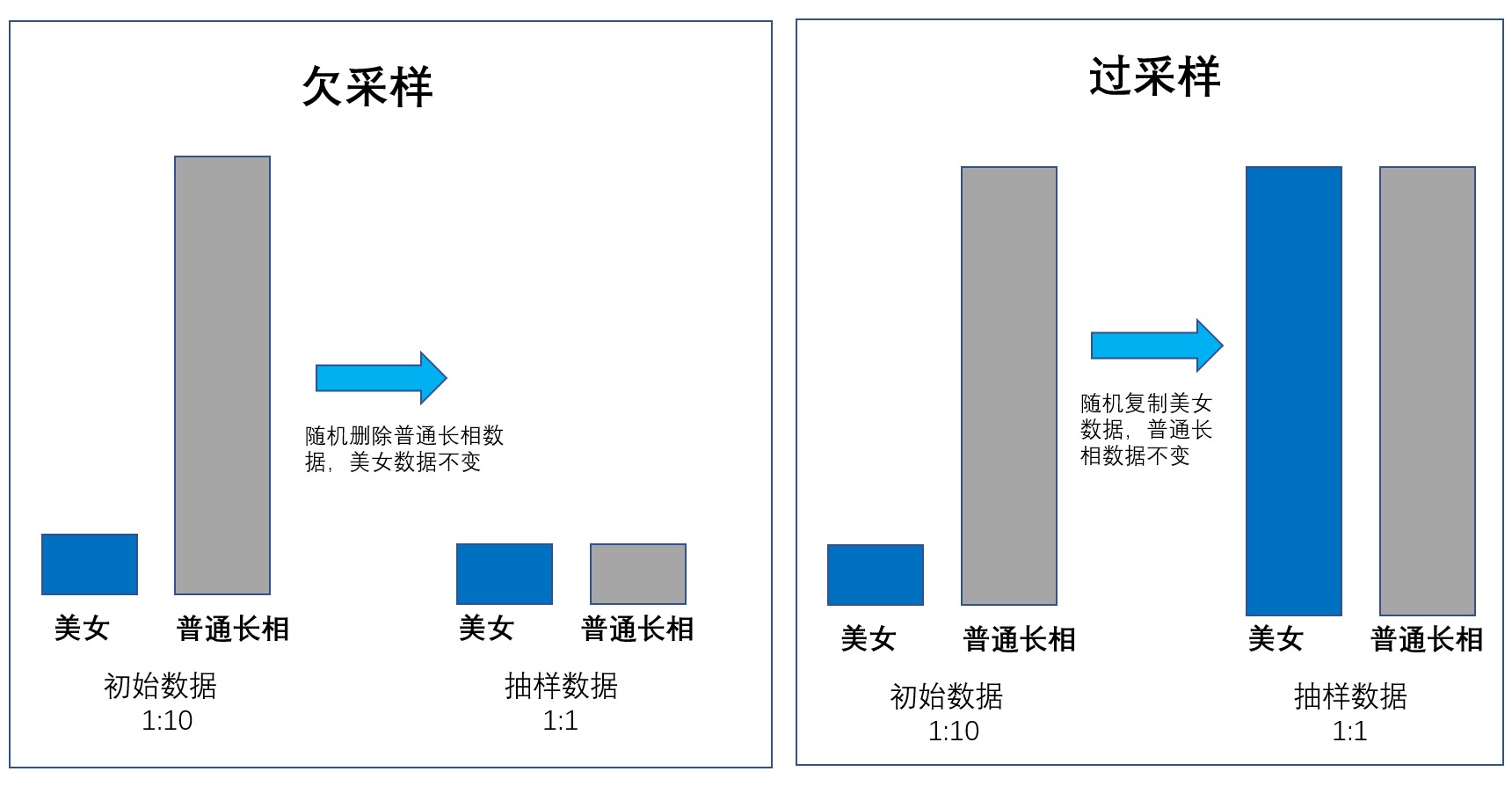
大数据里因为数据非常多,所以往往某一类的数据远高于另一类数据,而这些数据都直接给我们下一章讲到的人工智能算法的话,我们造出来的人工智能可能就学坏、学歪了。因为世界上的美女比较少,长相比较普通的女生比较多。如果我们给人工智能真实世界里边的女生样本去训练,他可能就认不出来哪些是美女了。因为美女太少,它学的不够。¶
10 _ 指数和KPI: 智商是怎么计算出来的¶
凡是用指数描述的东西,都是一个长期存在或者需要大范围衡量的事情。指数就像一把尺子,把指数放在这里一量,你就能知道现在这个事情所处的状态是怎样的。
简单的指数:上证指数:
以 2005 年 12 月 30 日为基日(即基准日)
公式:本日股份指数=本日股票市价总值/基期股票市价总值*100
较复杂的指数:用户忠诚度指数:
复杂度在于你对于业务的定义
如:
把忠诚度定义为第 N 日 / 周 / 月后回访的用户行为指标对于初始行为指标的占比
公式:第 N 日后用户忠诚指数=第 N 日后回访行为指标/初始行为指标
复杂的指数:智商(IQ):
IQ=MA(智力年龄即心理年龄)/CA(实际年龄)*100
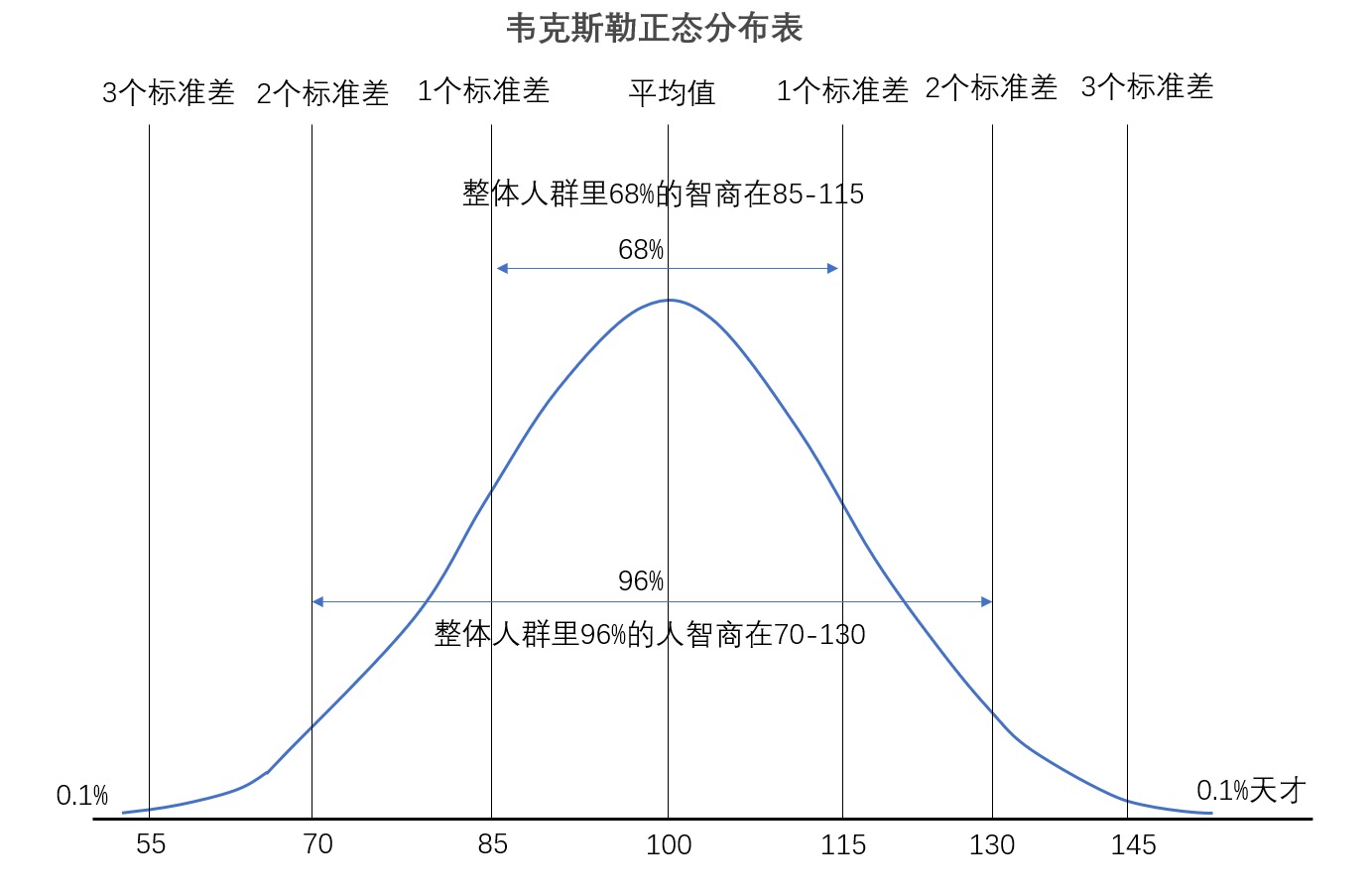
上面这个公式就是现在网上大多数人会告诉你的智商的算法,但这个算法其实是不对的。通过这个公式我们虽然能看到神童的 IQ 很高,但也会发现随着我们经验阅历的增长,用这个公式算出来的智商反而越低,也就是说我们人会越活越笨,这不符合实际情况啊。所以目前最流行的智商计算方法是叫做韦克斯勒的离差智商,它的基本原理就如同正态分布的原理一样。¶
智商的计算在指数计算中是非常复杂的:既要有复杂的标准测试题,还要和全人类的实际情况进行比对,最终才能够得到一个合理的标准分值。
要制定某个指数,比方说设定KPI时,我们要注意不要光看公式的建立,而是要把一系列定义调整的制度算法规定出来,否则很多KPI项目最后KPI完成了,但其实公司目的并没有达成。
备注
指数不是一个简简单单的加权平均值,它背后映射了一套管理的思维逻辑。
11 _ 因果倒置: 星座真的可以判定你的性格吗¶
相关因果倒置 —— 鸡叫导致天明¶
当我们看到数据结果的时候,一定要仔细推敲其中的业务逻辑,同时进行反向测试。
相关性而非因果 —— 吸烟真的致癌么¶
两件事情虽然相关,但是往往无法说明它们之间有因果关系。
不要轻易下因果关系的结论,相关并非因果。
遗漏 X 变量 —— 找到背后真实原因¶
在日常生活和工作当中看到两个数据强相关的时候,即使不能把它们当成因果关系,也可以顺藤摸瓜找到可能的原因,再用业务逻辑或者实验去验证这个可能的原因是否为真实原因。
以偏概全 —— 伯克松悖论¶
【定义】伯克松悖论指的是当不同个体被纳入研究样本的机会不同时,研究样本中的两个变量 X 和 Y 表现出统计相关,而总体中 X 和 Y 却不存在这种相关性。
著名的 “海军与平民死亡率” 的例子。在 1898 年 “美西战争” 期间,美国海军的死亡率是 9%,而同期纽约市市民的死亡率为 16%。后来海军征兵部门就拿这个数据跟大家讲,待在部队里其实比大家待在家中更加安全。这逻辑肯定是错误的,但是错误不在具体数据,而是这两组数据其实没有什么可比性。因为海军主要是年轻人,他们身强体壮、不会出现太多身体疾病;而纽约市民里面包含了新出生的婴儿、老年人、病人等等,这些人无论放在哪里,他的死亡率都会高于普通人。
控制数据范围 —— 神枪手谬误¶
所以你在看最终数据分析报告的时候,一定要看它的数据是不是先有枪眼再画靶子,或者先找到满意的结果再给你看统计数据,我们需要的是通过大量的随机样本给出的结果。
时间长度不足 —— 替代终点问题¶
在分析和统计的时候,由于时间长度不够,会造成数据统计的结果不准确。这个在学术上我们叫做 “替代终点问题”( surrogate endpoint problem)。
小结¶
打篮球真的能让人长高吗?这很有可能是因为长高的人都会去打篮球,而不是打篮球让人长高 —— 因果倒置。
喝咖啡可以长寿?常喝咖啡的人一般都是白领阶级,他们的营养供给更高,所以他们可以长寿,而不是因为咖啡让他们长寿 —— 相关性而非因果关系。
吃不吃早饭其实和你肥不肥胖没有什么关系,运动健康才和你的肥胖有关系 —— 相关性而非因果关系。
爱笑的女孩子通常运气都不会太差?爱笑的女孩其实运气也有差的,最后她就不笑了,事实是因为运气好的女孩她们才会爱笑 —— 因果倒置。
会撒娇的女人更好命?女人好不好命其实与另一半或者周围的人和环境更有关系,而不是和你会不会撒娇有关系 —— 需要找到遗漏的 X 变量。
02数据算法基础 (9 讲)¶
12 _ 精确率与置信区间: 两种预测应该相信哪一个¶

示例:图像识别¶
衡量这些算法模型的重要指标:
1. 准确率: Accuracy
准确率 = 预测正确的样本数量 / 预测总的样本数量
示例准确率 = 指马为马 / 总4种类型=40/100=40%
2. 精确率: precision(P 值、查准率)
定义:预测正确的正例(TP)在所有预测为正例的样本中出现的概率,
即分类正确的正样本数占分类器判定为正样本的样本数比例
示例精确率: 指马为马 / 指马为马+指鹿为马=40/50=80%
3. 召回率
定义:预测正确的正例 (TP) 在原始的所有正例样本中出现的概率,
即分类正确的正样本个数占真正的正样本个数的比例。
示例召回率: 指马为马)/指马为马+指马为鹿=40/60=66.7%
备注
精确率和召回率(也叫查准率和查全率)是一对孪生兄弟,一般情况下它们是成对出现,用来衡量一个算法模型到底好不好。单一指标高并没有意义,避免指鹿为马也避免指马为鹿才是最好的模型。
置信区间: confidence interval:
置信度和置信区间是一组参数,来告诉你这个算法模型误差有多大。
置信区间估计是参数估算的一种,它是用一个区间来估计参数值,也就是一定信心下的区间。
这个信心我们可以用前面讲到的准确率来去衡量,这个时候准确率有了一个新名字,叫做置信度。
示例:算命先生帮你预测一下高考成绩。
一个算命先生说,我有 100% 的把握,你考的分数在 0 到 750 分之间。
0-750:置信区间
100%:置信度
备注
精确率、召回率、置信区间这三个参数是衡量一个数据算法的核心指标。自动驾驶这么难,就是因为对于现在的算法来说,这几个指标很难同时都达到最高。
拿 “自动驾驶遇到行人自动刹车” 这个算法来说:
1. 精确率代表着识别出来一个人他就是人的准确度(不要指鹿为马);
2. 召回率代表着算法不会把人当成其他物体而不判断(不要指马为鹿)。
3. 置信区间代表着置信度比较好的时候,能识别多少种物体(红绿灯、卡车、广告牌里的人涵盖不涵盖,置信度是多少)
13 _ 趋势分析与回归: 父母高孩子一定高么¶
【定义】回归(Regression)是由英国生物学家弗朗西斯・高尔顿(FrancisGalton)提出来的。简单来讲,回归就是研究一个变量和另外一个变量的变化关系。其中一个变量我们叫做因变量,另外一个叫做自变量。
【定义】多元的回归,就是研究一个因变量和多个自变量之间的关系。
根据回归算法使用的场景不同,可分成:
1. 线性回归
2. 逻辑回归: 广泛用于做分类问题
把 “成功 / 失败”“哪一种颜色” 这类问题变成线性回归的样子
基本逻辑:就是把离散的因变量 Y 变成了一个连续值,然后再做回归
3. 多项式回归
可能出现多个指数的数据,这种回归最佳拟合的线也不是直线,很可能是一个曲线
例:预测人类身高增长速度和年龄的关系,最终回归出来的曲线方程可能由多次项组成
最常见出现的问题就是过拟合和欠拟合
4. 逐步回归
5. 岭回归
6. 套索回归
备注
两个变量之间有回归逻辑,不代表着两个变量之间有因果逻辑。
【定义】均值回归:身材高大的双亲,子女不一定高;身材矮小的双亲,孩子也不一定矮。最终孩子的身高其实趋向于平均身高。高尔顿把这个现象叫做回归平凡,后来的统计学家把它叫做 “均值回归”,意思就是实际发生的数据比我们理论上的预测更加接近平均值,整体趋势上会慢慢向一个平均值发展。
14 _ 初识聚类算法: 物以类聚-让复杂事物简单化¶
内聚:不同的花之间有一些比较相近的特性:花都有花瓣也有花蕊,颜色也都比较鲜艳
分离:花和叶子相比,叶子在大多情况下形状不会特别复杂,并且大多是绿色,所以花和叶子之间的差异很大
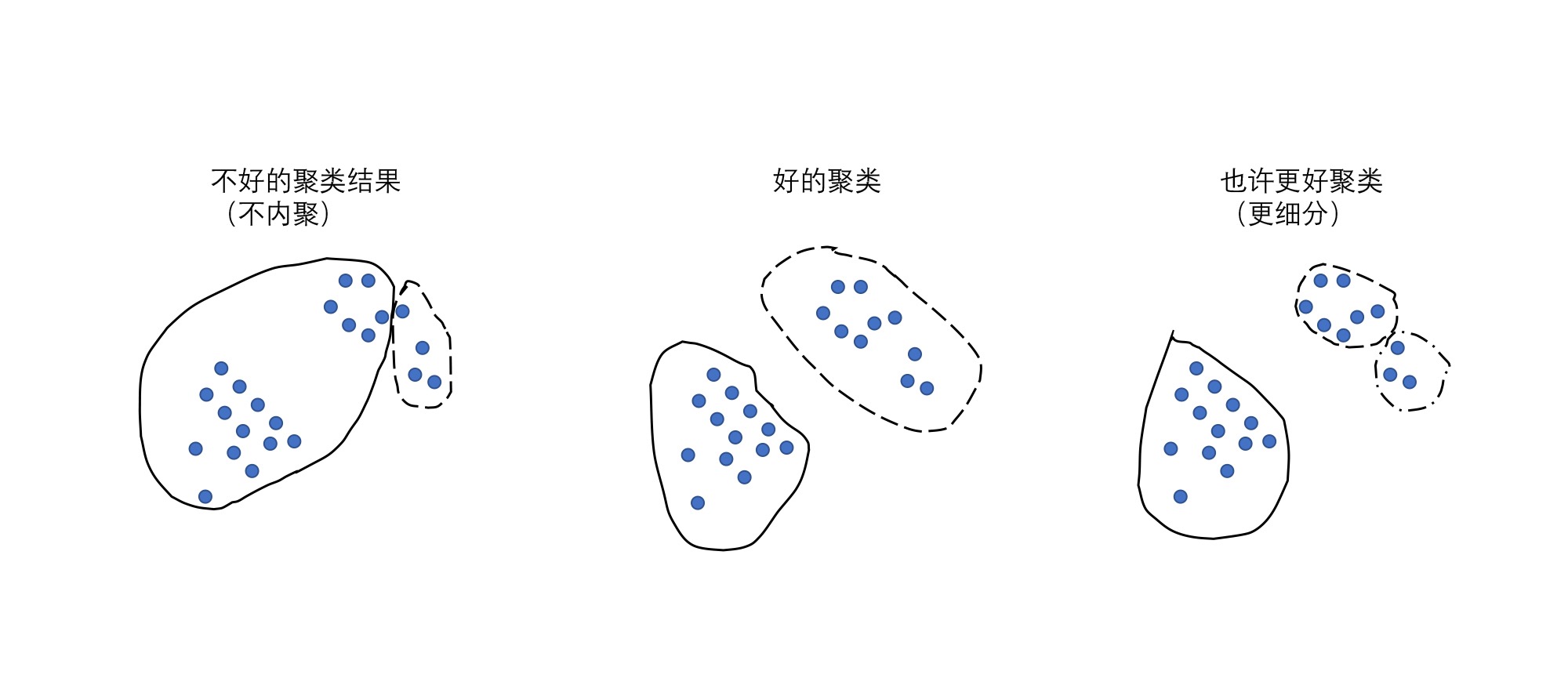
聚类就是通过一些算法,把这些事物自动全都聚集起来,让这些聚好的类别(花类和叶子类)达到内聚和分离的特性。聚类算法输入就是一群杂乱无章的数据,输出是若干个小组,并且这些小组里面会把数据都分门别类。组内的对象相互之间是相似的(内聚),而不同组中的对象是不同的(分离)。¶
常见的聚类算法:
1. K-Means
2. KNN
3. DBSCAN
4. EM
聚类算法都可以简化成三种问题:
1. 选大哥,找聚类中心的问题
2. 找小弟,解决距离表示的问题
3. 帮派会议,聚类收敛方法问题
备注
聚类是一个最基础的数据挖掘算法,也是最经久不衰的算法之一。
15 _ 初识分类算法: 分而治之/不断进化¶
分类和聚类算法不同,分类算法会不停告诉你这个分类是哪种,直到你学会,最后再让你自己单独去进行区分。所以分类也叫做有监督学习
常见的分类算法:
1. C4.5 决策树 -> C5.0
2. 朴素贝叶斯
3. 支持向量机 SVM
4. 随机森林
所有的分类算法主要是要解决两个问题:
1. 用什么样的算法决定用哪个属性区来做分类(也就是选领导)
2. 怎么来计算不同属性的信息价值(信息熵,也就是领导管不管用)
备注
分类算法的核心就是在于经验不断积累,不断迭代自己的规则,从而得到最好的答案。
16 _ 关联规则: 为什么啤酒和尿布一起卖¶
关联规则算法初探:
1. 支持度(support):
某个商品组合出现的次数与总次数之间的比例,也就是这个商品组合整体发生的概率怎样。
例:
5 次购买,4 次买了啤酒,啤酒的支持度为 4/5=0.8;
5 次购买,3 次买了啤酒 + 尿布,啤酒 + 尿布的支持度为 3/5=0.6。
2. 置信度(confidence)
购买了商品 A 后有多大概率购买商品 B,也就是在 A 发生的情况下 B 发生的概率是多少
例:
买了 5 次啤酒,其中 2 次买了尿布,(尿布→啤酒) 的置信度为 2/5=0.4;
买了 4 次尿布,其中 2 次买了啤酒,(啤酒→尿布) 的置信度为 2/4=0.5。
3. 提升度(lift)
衡量商品 A 的出现对商品 B 的出现概率提升的程度
提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)。
提升度 >1,证明 A 和 B 的相关性很高,A 会带动 B 的售卖;
提升度 =1,无相关性,相互没作用;
提升度 <1,证明 A 对 B 有负相关,也就是这两个商品有排斥作用,买了 A 就不会买 B。
备注
关联规则:找出所有组合并加以计算,然后根据每一种组合的支持度和置信度去提取整体符合关系的规则。但这个方法的计算强度是几何级上升的,几乎是一个阶乘的逻辑
关联规则挖掘算法:
1. Apriori
原理:“连坐算法”,目标是去掉过多的组合
优点: 可以产生相对较小的候选集
缺点: 要重复扫描数据库
2. FP-growth
修正了的Apriori
3. setm
4. Eclat
关联规则的挖掘过程大致可以总结为两步:
1. 找出所有频繁组合
2. 由频繁组合产生规则,从中提取置信度高的规则
17 _ 蒙特卡洛与拉斯维加斯: 有限时间内如何获得最优解¶
蒙特卡罗算法¶
【定义】蒙特卡罗算法:在 20 世纪 40 年代,由 S.M. 乌拉姆和 J. 冯·诺伊曼首先提出来(对,就是那个世界上最早的通用电子计算机 ENIAC 创作者冯·诺伊曼)。正值美国在第二次世界大战,乌拉姆和诺伊曼都是“曼哈顿计划”(美国原子弹计划)计划的成员,而第一台电子计算机 ENIAC 在发明后就被用于“曼哈顿计划”。在参与这个计划过程中,乌拉姆想到在计算机强大计算能力的帮助下,可以通过重复数百次模拟核实验的方式来对核裂变的各种概率变量进行演算,而不用实际进行那么多次实验。冯·诺伊曼立即认识到这个想法的重要性并给予乌拉姆充分的支持,乌拉姆将这种统计方法用于计算核裂变的连锁反应,大大加快了这个项目的节奏。由于乌拉姆常说他叔叔在摩纳哥的赌城“Monte Carlo”输钱,他的同事 Nicolas Metropolis 戏称该方法为“蒙特卡罗”,这个名字也就沿用到了现在。
【原理】每次计算都尽量尝试找更好的结果路径,但不保证是最好的结果路径。用这样寻找结果的方法,无论何时都会有结果出来,而且给的时间越多、尝试越多,最终会越近似最优解。
【示例】用蒙特卡洛算法找到一个有 500 个苹果的筐里,最大的苹果。正常来讲,我们每次从筐中拿一个苹果 A, 然后下一次再随机从筐中拿出另一个苹果 B, 如果 B 比 A 大的话,就把 A 扔到另一个筐里,手里只拿着 B。这样如果我们拿了 500 次的话,最后留在手里的一定是最大的那个苹果。持续保留较好的答案,一直执行 N 次(N<500),最终拿到的一定近似正确解。N 越接近 500,我们的苹果越接近最大的那个。
拉斯维加斯算法¶
在 1979 年László Babai在解决图同构问题的时候,针对蒙特卡罗算法弊病提出的。
【原理】每次计算都尝试找到最好的答案,但不保证这次计算就能找到最好的答案,尝试次数越多,越有机会找到最优解。
【示例】假如有一把锁,给我 100 把钥匙,其中只有 1 把钥匙可以开锁。于是我每次随机抽 1 把钥匙去试,打不开就再换 1 把。尝试的次数越多,打开锁的机会就越大。但在打开之前,那些错的钥匙都是没有用的。这个挨个尝试换钥匙开锁的算法,就是拉斯维加斯算法。
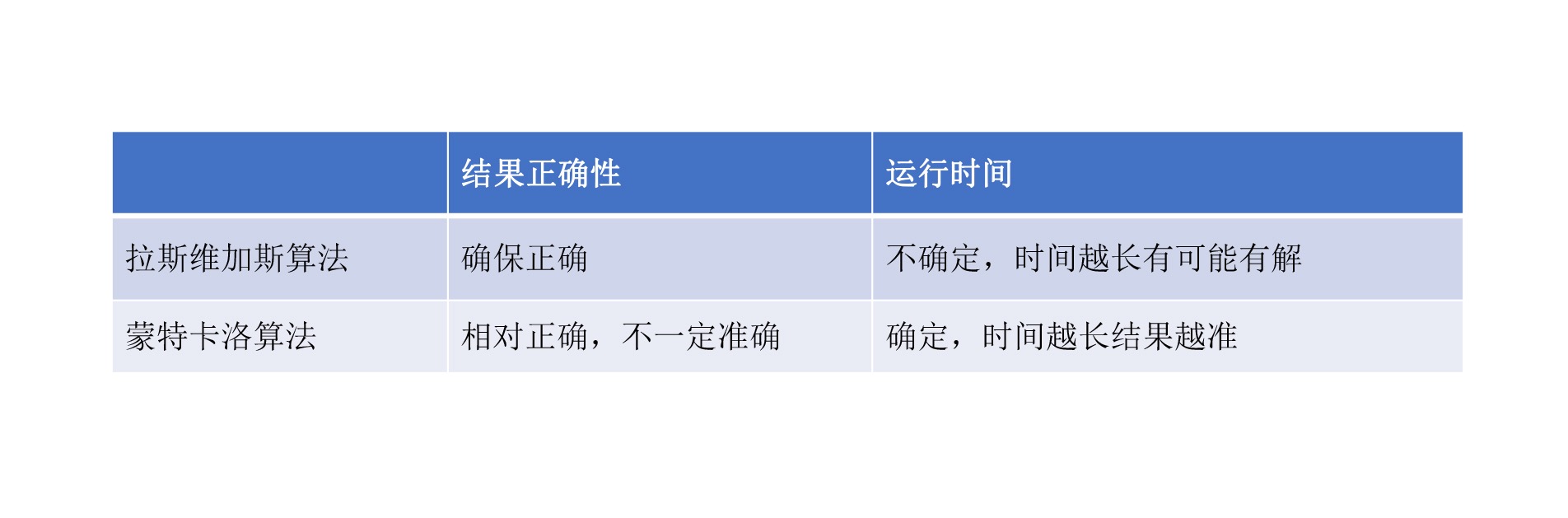
蒙特卡罗算法的基本思想是精益迭代,进行多次求解,最终让最后结果成为正确结果的可能性变高。而拉斯维加斯的算法是不断进行尝试,直到某次尝试结果让你自己满意,当然这个过程中也会一直产生你无法满意的随机值。¶
算法应用场景与展望¶
在金融领域里,蒙特卡洛算法得到非常广泛的应用:
1. 计算风险价值(value at risk,VaR)
2. 自动化交易
3. 衍生品定价
备注
如果问题要求在有限时间和尝试次数内必须给出一个解,但不要求是最优解,那就用蒙特卡罗算法。反之,如果问题要求必须给出最优解,但对时间和尝试次数没有限制,那就用拉斯维加斯算法。
18 _ 马尔可夫链: 你的未来只取决于你当下做什么¶
【定义】马尔可夫链因俄国数学家安德烈·马尔可夫得名,它的定义是:状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质,也就说下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。
谷歌创始人拉里·佩奇和谢尔盖·布林在 1998 年提出的谷歌搜索最核心的网页排序算法 PageRank 就是由马尔可夫链定义的
在经济金融领域,詹姆斯.D. 汉密尔顿在 1989 年用马尔可夫链来对高 GDP 增长速度时期与低 GDP 增长速度时期(也就是经济扩张与紧缩)的转换进行建模,帮助美国在经济萧条中对 GDP 的恢复情况进行预测,直到今天马尔科夫链依然是经济学当中预测一个国家 GDP 重要方法之一。
马尔可夫链蒙特卡罗算法-MCMC¶
MCMC 由梅特罗波利斯于 1953 年在洛斯阿拉莫斯国家实验室提出,本质上是将马尔可夫链用于对蒙特卡洛方法的计算过程中。那时美国洛斯阿拉莫斯是当时少数几个拥有大规模计算机的城市,梅特罗波利斯利用这种计算优势,在蒙特卡洛方法的基础上引入马尔可夫链,用于模拟某种液体在气化之后的平衡状态。
19 _ 协同过滤: 你看到的短视频都是集体智慧的结晶¶
【定义】用户可以齐心协力,通过不断地和算法互动,在多如牛毛的选择当中,过滤掉自己不感兴趣的选择,保留自己感兴趣的选择。
协同过滤算法源于 1992 年,最早被施乐公司发明并用于个性化推送的邮件系统(施乐公司就是那个发明了 GUI 界面,被乔布斯发现并创造了 MAC OS 的公司)。最早这个算法是让用户从几十种主题里面去选 3~5 种自己感兴趣的主题,然后通过协同过滤算法,施乐就根据不同的主题来筛选人群发送邮件,最终达到个性化邮件的目的。
推荐系统需要同时具备速度快和准确度高两个特点(需要在用户打开网站几秒钟就要推荐所感兴趣的内容或者物品),而协同过滤算法正好满足了这两点要求,这也是这个算法经久不衰的原因。
三个最常见的协同算法,它们分别是:
1. 基于用户的协同过滤算法(User-based Collaborative Filtering)
2. 基于物品的协同过滤算法(Item-based Collaborative Filtering)
3. 基于数据模型的协同过滤算法(Model-based Collaborative Filtering)
1. 基于用户的协同过滤算法¶
优点在于:
a. 基于用户的协同过滤是找到用户之间的相似程度,所以能够反映一些小群体当中的物品的热门程度
b. 它可以让用户发现一些惊喜。因为是根据类似用户的喜好来推荐,用户会发现自己对一些过去不知道的东西是感兴趣的
c. 对一些新的有意思的物品比较友好。
一旦某一个新的商品和电影被某一个社群的用户购买了,我们马上就可以推荐给他圈子当中的其他用户
缺点在于:
a. 如果你是一个新的用户,你可能不能马上找到和你类似的人,所以无法马上获得准确的推荐
b. 对于推荐出来的结果虽然会给你带来惊喜,但是它也不太有解释性;
系统不知道推荐给你的这个物品是什么,只知道你的相关的朋友都在使用
c. 对于用户群比较大的公司,去计算用户之间的相似度的话,计算的耗费会比较高
2. 基于物品的协同过滤算法¶
优点是:
a. 推荐更加针对用户自身。
它反映了每个用户自己的兴趣的决策,根据你自己每买的一个商品来给你做推荐,而不是一类人给你做推荐;
b. 实时性比较高。
用户每次点赞和购买商品都可以对其他购买此商品的用户推荐;
c. 推荐的结果很好解释。
因为它们都是类似或者是关联度很高的商品,推荐结果显而易见。
缺点在于:
a. 对于新加入进来的商品反馈速度比较慢,因为没有人购买也没有人互动,所以可能有一些很好的商品没有被很好地推荐
反过来没被推荐买的人更少,推荐的可能性更低,出现 “产品死角”;
b. 不会给用户惊喜:大部分的物品其实都是关联度比较高,可以被想象到,惊喜程度不高;
c. 对于商品或物品更新情况比较快的领域比较不适用,比如新闻。因为你没有推荐到别人看,可能这个新闻就过期了。
备注
具体在生产环节使用的时候,一般对小型的推荐系统来讲,基于物品的协同过滤是大家使用的主流。因为基于物品的协同过滤算法计算量比较小,上手程度比较快。随着你的用户变得更多、用户的期待更高,一般都会过渡到基于用户的协同过滤算法。
3. 基于数据模型的协同过滤算法¶
复用前面所学到的算法,先做出来模型,再进行相关的协同过滤。
20 _ 人工智能初探: 阿尔法狗是怎样的一只“狗”¶
人工智能最早可以追溯到 1308 年加特罗尼亚的诗人神学家雷蒙卢尔在《最终的综合艺术》(Ars GeneralisUltima)当中提到要用机械的方法从一系列的概念组合当中创造新的知识,这是有确切记载的类似人工智能想法最早的记录。
1726 年,英国小说家乔纳森斯威夫在《格列佛游记》里面提到一个叫做 Engine 的机器,这台机器放在 Laputa 岛上,可以运作实际而机械的操作方法,改善人的思辨和认知。最无知的人只要适当付点学费,再出一点体力,就可以写出关于哲学诗歌、政治法律数学和神学的书来。
1914 年,西班牙工程师莱昂纳多・托里斯克维多展示了世界上第 1 台可以自动下国际象棋的机器,当然水平那是相当差。
1921 年,捷克作家卡雷尔・恰佩克在他的作品《Rossum’s Univeral Robits》里第一次使用了 Robot 这个词,机器人开始进入人类的视野。
1950 年,图灵发表了《Computing Machinery and Intelligence》其中提到了仿真游戏,这就是广为人知的图灵测试。图灵测试是指如果有一台机器能够与人类展开对话,且不能被辨别出来是机器的身份,那么就称为这个机器具有智能。
1956 年,马文・闵斯基、约翰・麦卡锡和另两位资深科学家克劳德・香农以及内森・罗彻斯特组织的达特茅斯会议里正式把人工智能提出来,自此 AI(Artificial Intelligence)的名字和任务得以确定。
1970 年,日本早稻田大学开发了一个可以控制肢体视觉和绘画系统的机器人 WABOT-1
1979 年,在没有人干预的情况下,Stanford 大学的 Stanford Cart 可以在房间内规避障碍物自动行驶,这相当于当时的无人驾驶系统。同一年早稻田大学发明了 WABOT-2,开始可以和人做简单沟通,阅读乐谱还可以简单的演奏普通电子琴
1997 年,IBM 研发的深蓝击败了人类象棋冠军卡斯帕罗夫。
2011 年 IBM 研发的计算机沃森在 Jeopardy!击败了两名前人类冠军。同一年苹果发布了 Siri,可以给用户导航播报天气,还可以和用户进行简单的聊天。
2014 年 6 月 8 日,图灵测试终于被计算机尤金・古斯特曼通过。在场有超过 30% 的人认为它是一个 13 岁男孩。
2016 年谷歌 Deep Mind 研发出来的阿尔法狗击败了人类围棋冠军李世石。同年年底阿尔法狗以 master 为名横扫了各大围棋网站,取得 60 局连胜。与此同时,无人驾驶汽车开始纷纷上路。以美国加州为例,政府开始发放无人驾驶汽车牌照,允许具备一定技术能力的无人驾驶汽车厂商把无人驾驶汽车投入道路使用。700 年来,人类在追寻人工智能的道路上从未停歇。
CNN 和 RNN¶
2006 年加拿大多伦多大学教授、机器学习领域泰斗、神经网络之父 —— Geoffrey Hinton 和他的学生 Ruslan Salakhutdinov 在顶尖学术刊物《科学》上发表了一篇文章,该文章提出了深层网络算法
2012 年利用 CNN 算法碾压了过去数年的分类等机器学习算法,取得 AlexNet 第一名,引起了人工智能的新一轮潮流。
RNN(Recurrent Neural Network)循环神经网络。马尔可夫链只能够处理上一个状态到这个状态的选择,而 RNN 算法可以针对更长的序列数据进行模拟和决策,模拟人脑使得前面的输入也能影响到后面的输出,相当于在模拟人脑当中的记忆功能。应用场景:识别文章的内容或者去识别股票的价格的走势。
卷积神经网络 CNN(Convolutional Neural Network)。它的特长是能够分层次地提取各种各样的特征,从而能够将大量的数据(比如大量图片和视频)有效抽象成比较小的数据量,而且不影响最后训练的结果。这样既能够保证原来图片和这些视频的特征,也不会在识别的时候占用巨大的计算资源。
AlphaGo¶
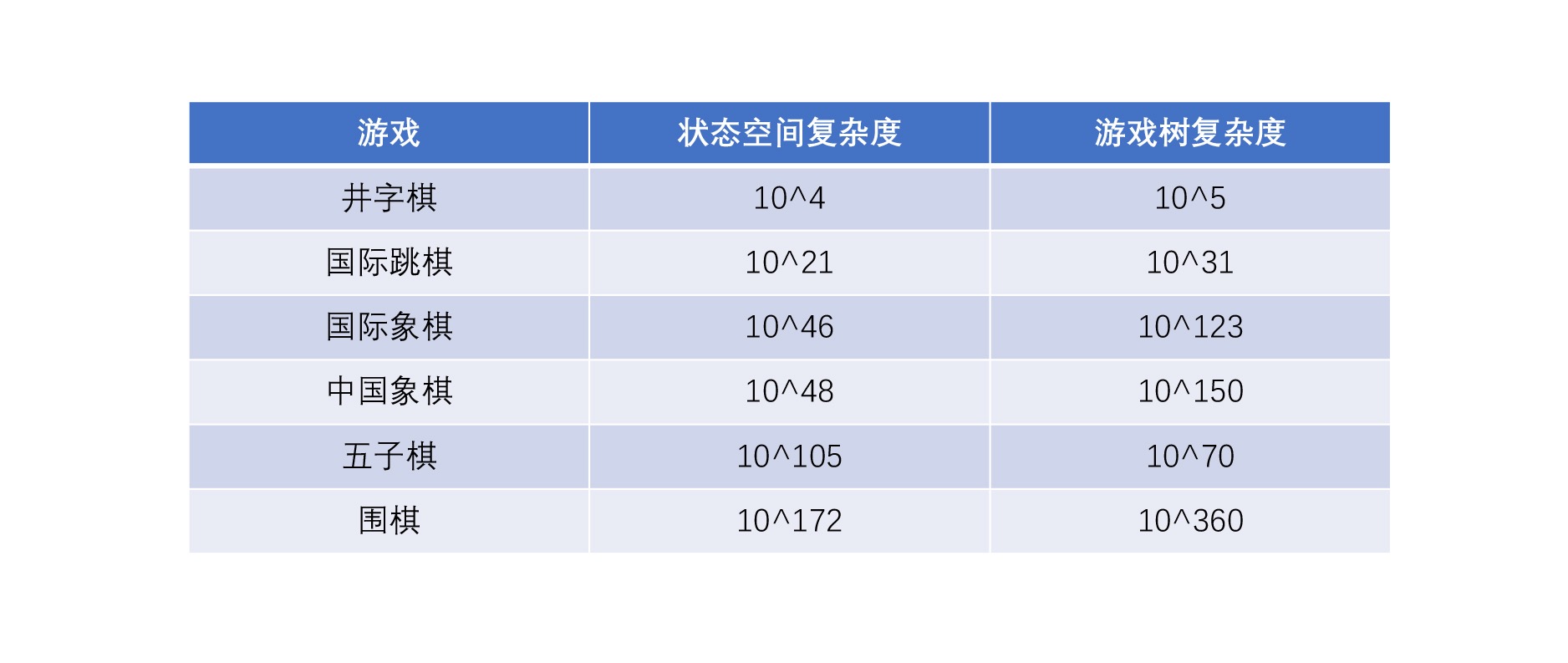
03如何用数据说话 (6 讲)¶
21 _ 确定问题: 与利益无关的问题都不值得数据分析和挖掘¶
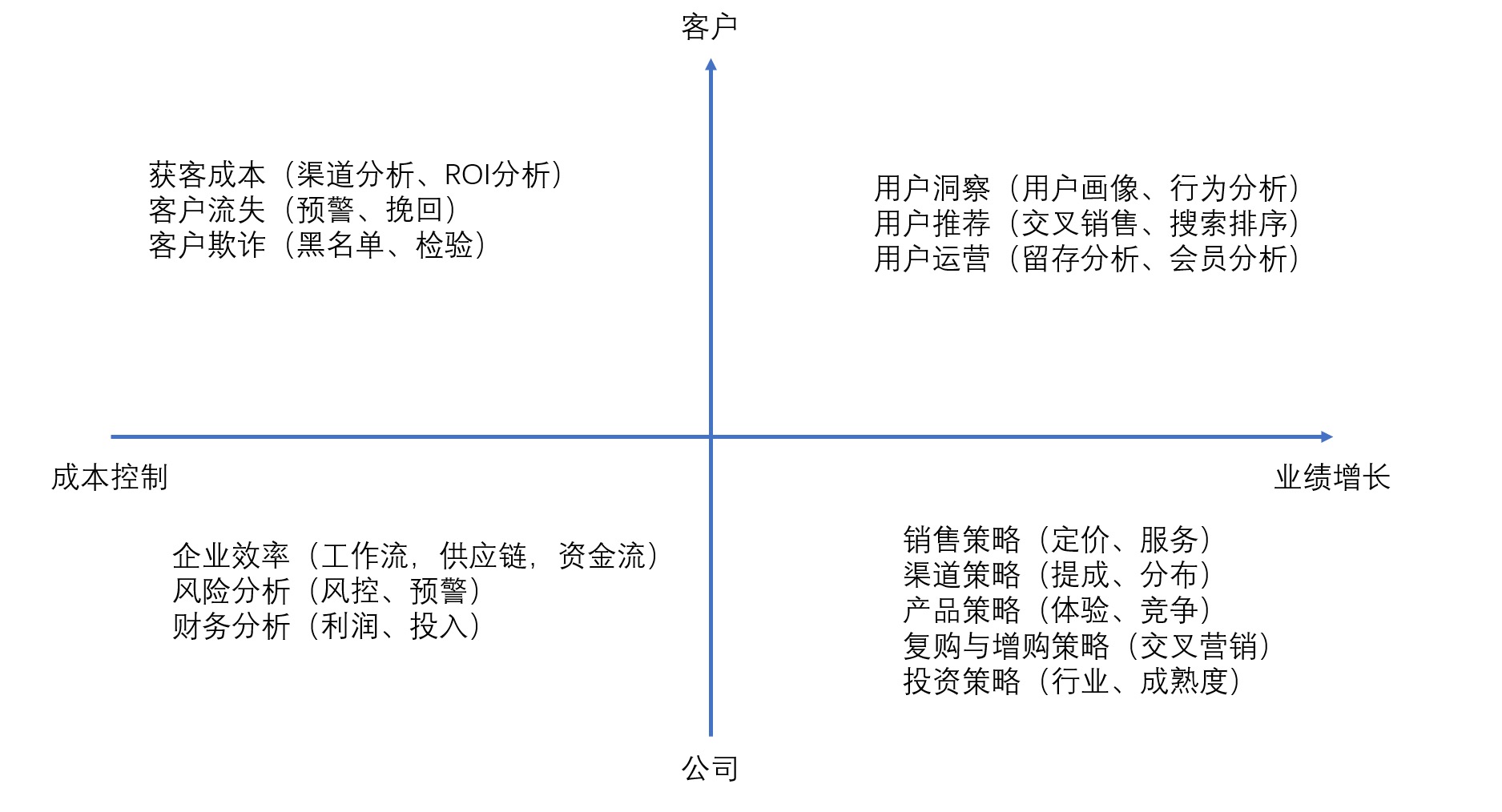
但凡不在这些象限里面的数据分析问题,其实都可以忽略不计,因为它不是在公司的主干线上要解决的问题。¶
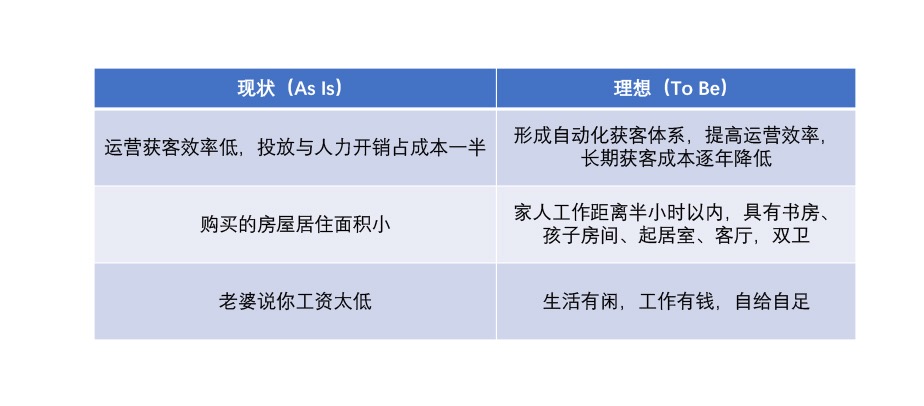
As-Is To Be¶
备注
数据分析重点在要分析的问题,而不是在数据,不要一上来就先用手头数据进行分析,要先针对问题利用 As-Is To Be 和 6W2H 方法进行细化。
数据行业个人发展方向:
1. 算法科学家
目标:分析自动化
2. 增长黑客
目标:分析驱动业务
3. 数据分析极客
目标:分析洞见本质
22 _ 采集数据: 用好一手数据和二手数据¶
数据探索¶
常用的三种拓展方法:
1. 趋势分析法
找到某一个类型的数据之后,捕捉这个数据一个时间段以内的变化。
通过这些数据变化,我们去知道曾经有哪些变化、对结果数据会有哪些影响,这样可以找到其中关键的问题和原因。
2. 快照扩展法
截取某个时点的情况,然后通过下钻的方式来扩展这个指标的分布情况。
我们会看在这个时点里面我们各部分对于整体的占比和影响程度。
3. 衍生指标法
像几何当中的辅助线一样,会帮助我们看到更有意义的数据。
例如当我们看到售卖产品的数量和我们的广告投入几乎无关,说明不能只是看收入和投入的这个表面关系,还有增加别的数据(用户忠诚度指数)
数据探索注意事项:
1. 关注数据质量的把控
例如我们在进行新冠统计的时候,往往你会发现统计死亡率要比统计得病率更加准确
2. 注意避免辛普森悖论
这就要求我们在看快照扩展法状态值数据的时候,尽量细分领域和时间
3. 注意避免因果倒置
例如你在整体沿着大思路进行分析的时候,看到了看广告用户的转化率和没看到广告的用户的转化率,你要能够客观去做衡量
信息来源渠道-宏观数据¶
经合组织开放的数据网: https://stats.oecd.org/
世界银行公开数据: https://data.worldbank.org.cn/
统计局网站: http://www.stats.gov.cn/
新华社: 全球经济数据: http://dc.xinhua08.com/
中国互联网络信息中心: https://www.cnnic.net.cn/hlwfzyj/hlwxzbg/
中财网: http://data.cfi.cn/
信息来源渠道-互联网数据¶
Alexa: https://alexa.chinaz.com/
百度指数: https://index.baidu.com/
淘宝指数: https://shu.taobao.com/
阿里价格指数: http://topic.aliresearch.com/
Similarweb: https://www.similarweb.com/
netmarketshare: https://netmarketshare.com/
Statcounter: https://gs.statcounter.com/
信息来源渠道-行业数据库¶
联合国图书馆: http://www.oecd-ilibrary.org/
中国票房数据: http://cbooo.cn/
行业分析机构: Gartner、Forrester、Bloomberg、易观、艾瑞、新榜
信息来源渠道-企业数据¶
EDGAR: http://sec.gov
企业招股说明书、年报、半年报、季报、券商分析报告
信息来源渠道-投融投资数据¶
IT 桔子: http://www.itjuzi.com/
36 氪: http://www.36kr.com/
23 _ 写好故事线: 你能用好数字推翻众人的理解吗¶
备注
最成功的分析师就是那些会 “用数据讲故事的分析师”,好的故事在呈现调查结果时往往会采用对方可以听懂的方式。
设计故事线-故事三段论结构:
1. 情节(陈述)
开场,用 30 秒陈述痛点和整体问题的背景
针对问题本身的分析,也就是我们定义问题的部分
结合内外部数据针对问题举例说明
2. 起伏(惊喜)
阐述要提升 10% 的话有哪些办法和选择,并给出不采取行动或不发生变化会怎样?
阐述更高倍数的提升办法和潜在选择是什么?
还有哪些你发现而别人没有发现的观点问题?能带来什么?
3. 结尾(结论)
用简要的话或者数据分析思维导图进行总结和升华;
结尾不要用谢谢,要用召唤型的语言或强有力的金句对整个分析报告进行收尾。
示例:
1. 现状分析:运营投入成本过高无法使公司盈利。
当前市场线索量够大,但质不佳;
运营活动消耗大,效果有限;
公司整体获客转化效率较低。
2. 解决之道:盈利需要断舍离,提升线索 ROI。
抖音直播与线上活动 ROI 很低,建议停止;
现有关键字转化率整体较低,需进一步优化关键字投放;
Demo 转化率低于业内预期,需加强客户引导注册页面。
3. 特别分析:如何发现公司的宝藏客户?
部分高价值客户潜力巨大,未能形成有效收入。
4. 落地建议与讨论:打通内部运营数据,深入行业解决方案。
组建线下行业销售团队,优化电销话术,提高客单价;
建立市场后向指标,打通成单与投放 ROI 指标;
优化产品注册流程,减少流失率;
讨论建立私有化版本,提高整体产品单价?
5. 总结:客户潜力巨大,练好内功,目标投入减半,收入翻番。
24 _ 实践你的理论: 数据驱动最终就是用结果说话¶
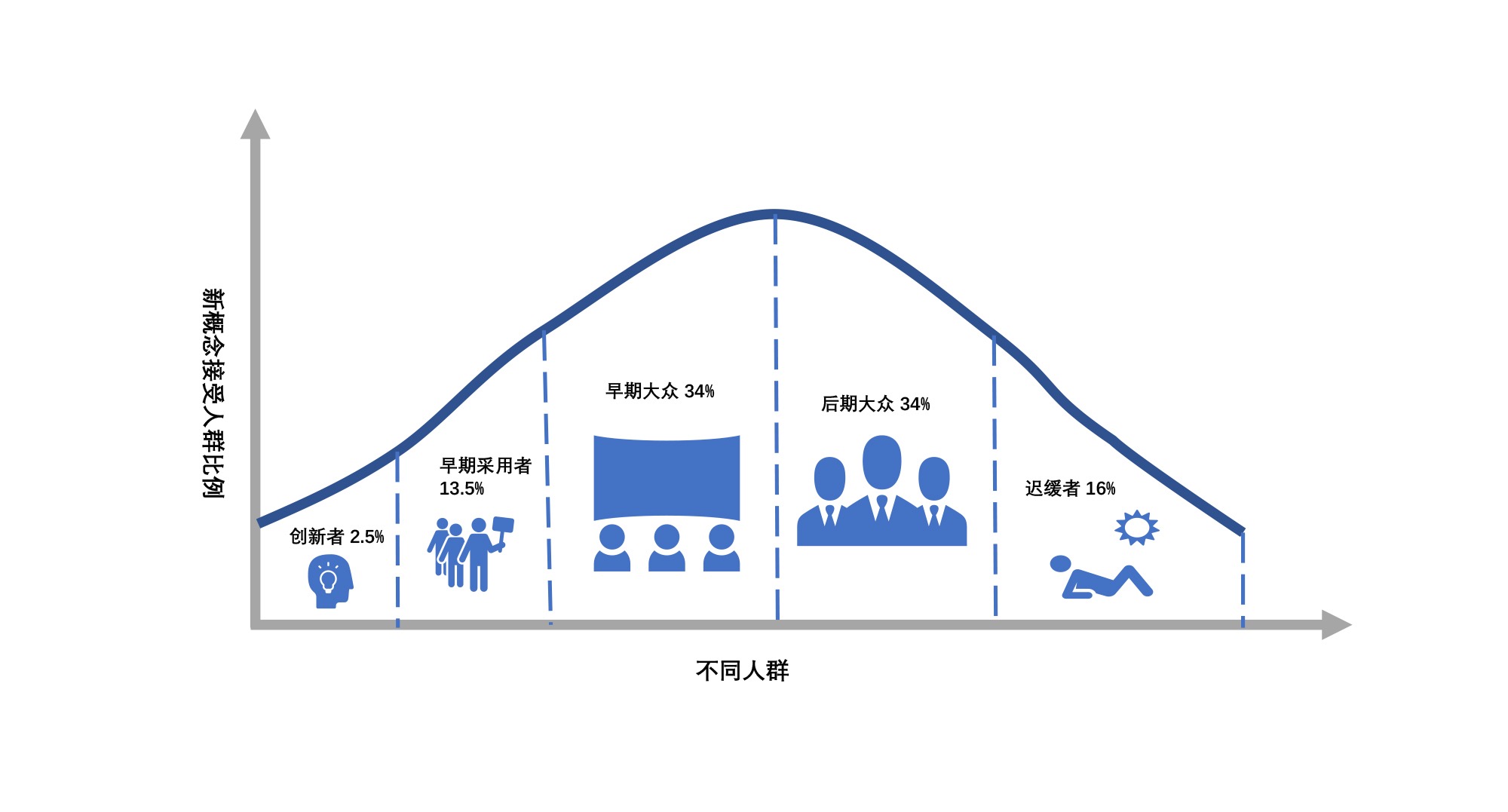
埃弗雷特・罗杰斯(E.M.Rogers)提出创新扩散模型¶
备注
做数据驱动就是要用结果说话 —— 当然这个过程是非常难的。实践的过程中,注意区分上面5类人,找到创新者和愿意参与的早期实践者,先以些为突破口。
25 _ 数据分析: 15种数据思维图-上¶
常用的数据思维图,它们分别是:
1. VRIO 分析
2. 五力模型
3. SWOT 分析
4. 同理心地图
5. 4P 竞争分析
6. 奥斯本检验表
7. SUCCESs 表
8. 产品组合矩阵
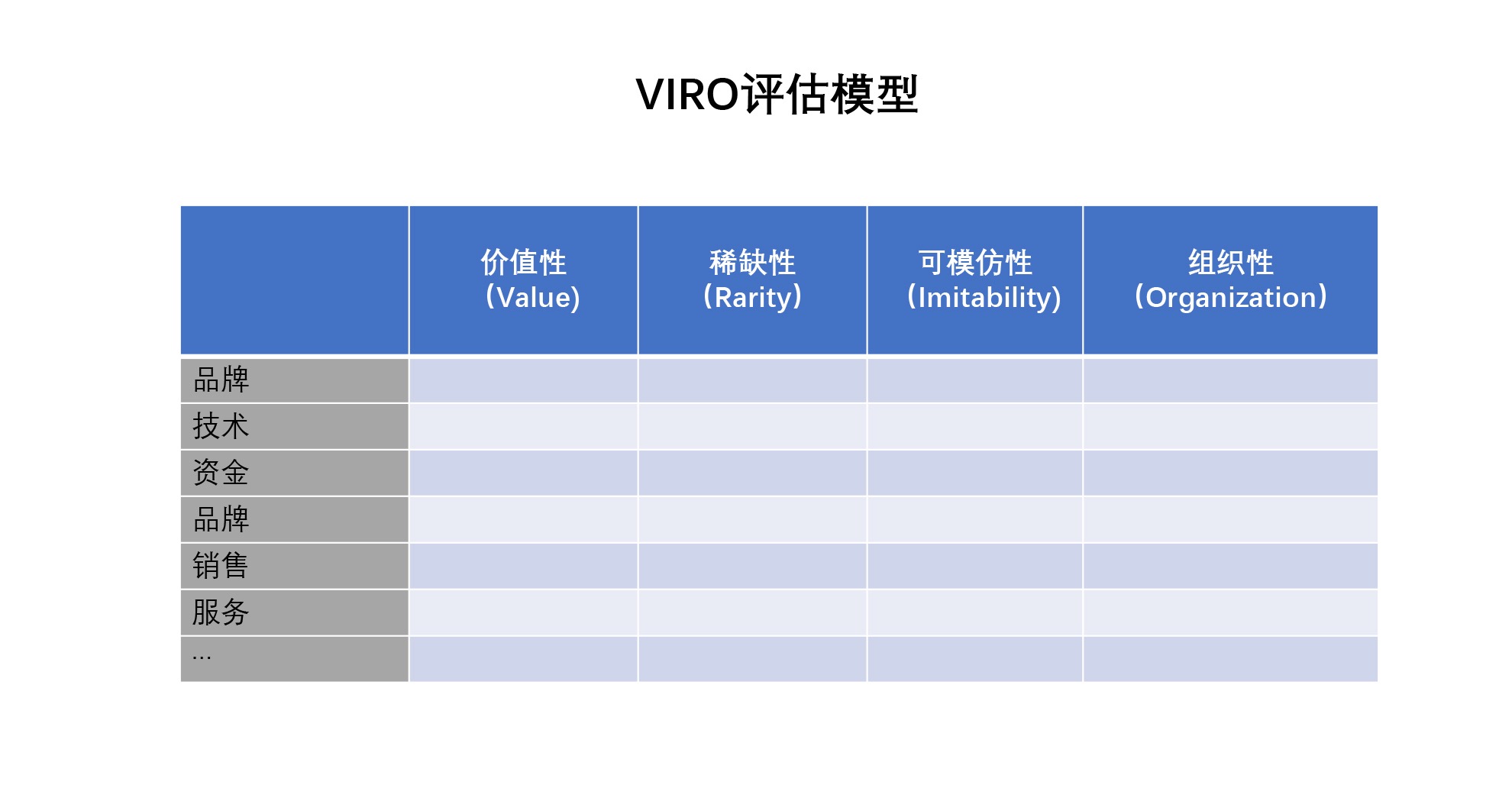
1. VRIO 分析¶
问题场景:分析自身业务
基本解释及使用:要分析一件事情或者一个产品是否有竞争优势,最基础的分析部分就是资源以及分配方法。
2. 五力模型¶
问题场景:整体业务赛道与竞争情况
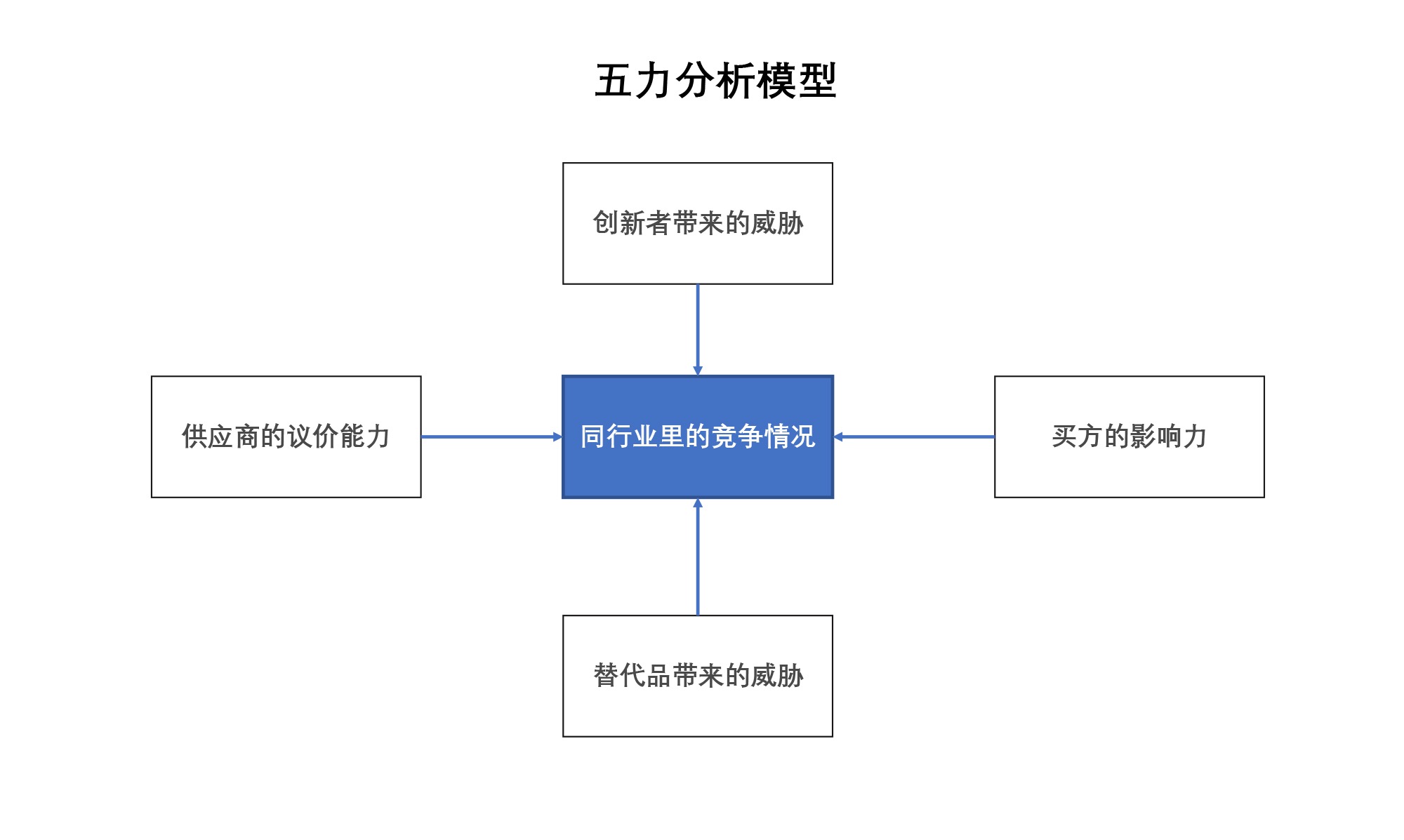
基本解释及使用:五力模型也叫做波特五力模型,这个模型是由迈克尔・波特(Michael Porter)于 20 世纪 80 年代初提出。它是一个最常见的竞争分析方式,这个五力的强度越强,代表这个行业里的竞争力越激烈,你面对的挑战越大,也就是你现在的赛道是红海。当然红海也证明这个市场是有刚需的,不代表你不能胜利。你可以找到其中一些突破点来颠覆这个市场,比如今日头条就是通过推荐算法颠覆了以门户网站为主要信息获取的方式,从而获得了成功。
3. SWOT 分析¶
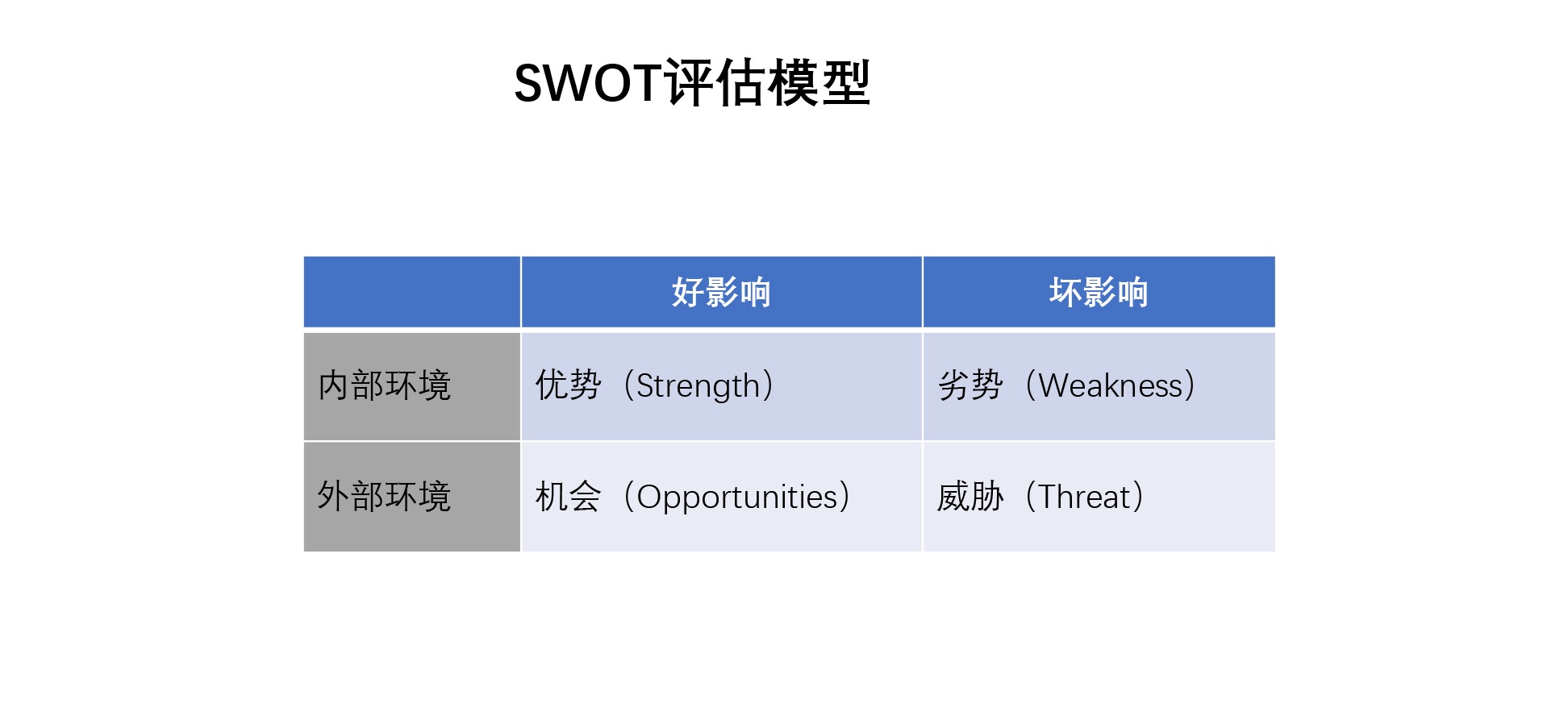
问题场景:整体业务场景与竞争优劣态势
基本解释及使用:SWOT 分析是一个典型的拿公司和周围环境比对的一个分析,它从内部环境、外部环境、好影响和坏影响做了一个矩阵图,这样的话就可以针对 S (Strengths)优势、W (Weaknesses)劣势、O (Opportunities)机会、T (Threats)威胁这 4 个元素进行分析。
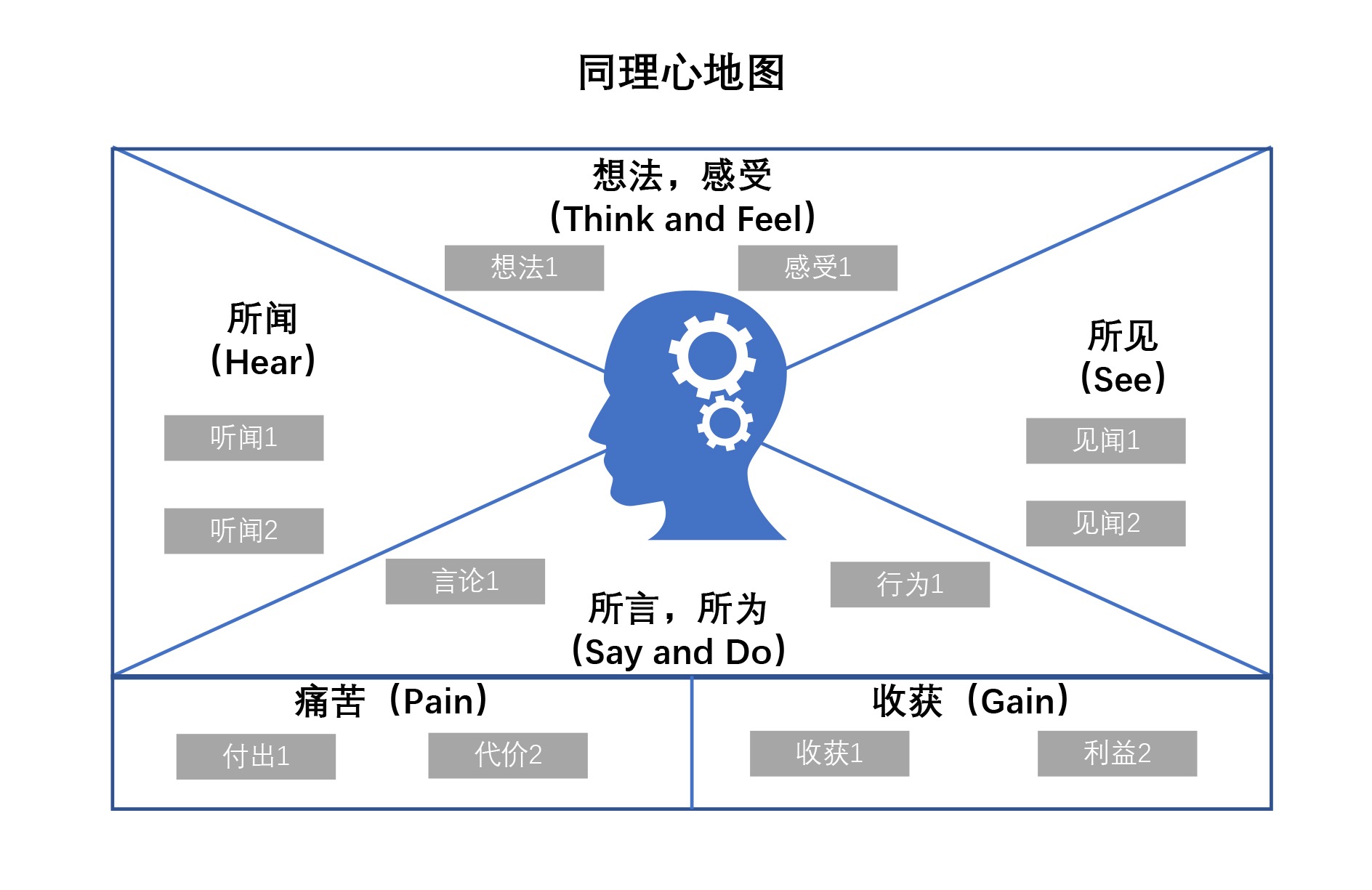
4. 同理心地图¶
问题场景:如何打动你的决策者
基本解释及使用:同理心地图是一种通过换位思考的方式,了解别人所处的状态和情绪的方法。我们通过想法、所见、所言所为、所闻去分析对方到底会怎么看这件事。这样能让我们深刻理解对方的想法和所处环境,换位思考,最终引导对方做出对自己有利的决策。
5. 4P 竞争分析¶
问题场景:产品市场营销分析
基本解释及使用:4P 竞争分析是在产品、价格、渠道、销售加上目标和提供的价值这几个层次下,看自身公司和竞争对手之间的关系,制定相关策略来决定我们的产品营销应该有哪一种定位。
产品(Product)、价格 (Price)、渠道 (Place)、促销(Promotion)

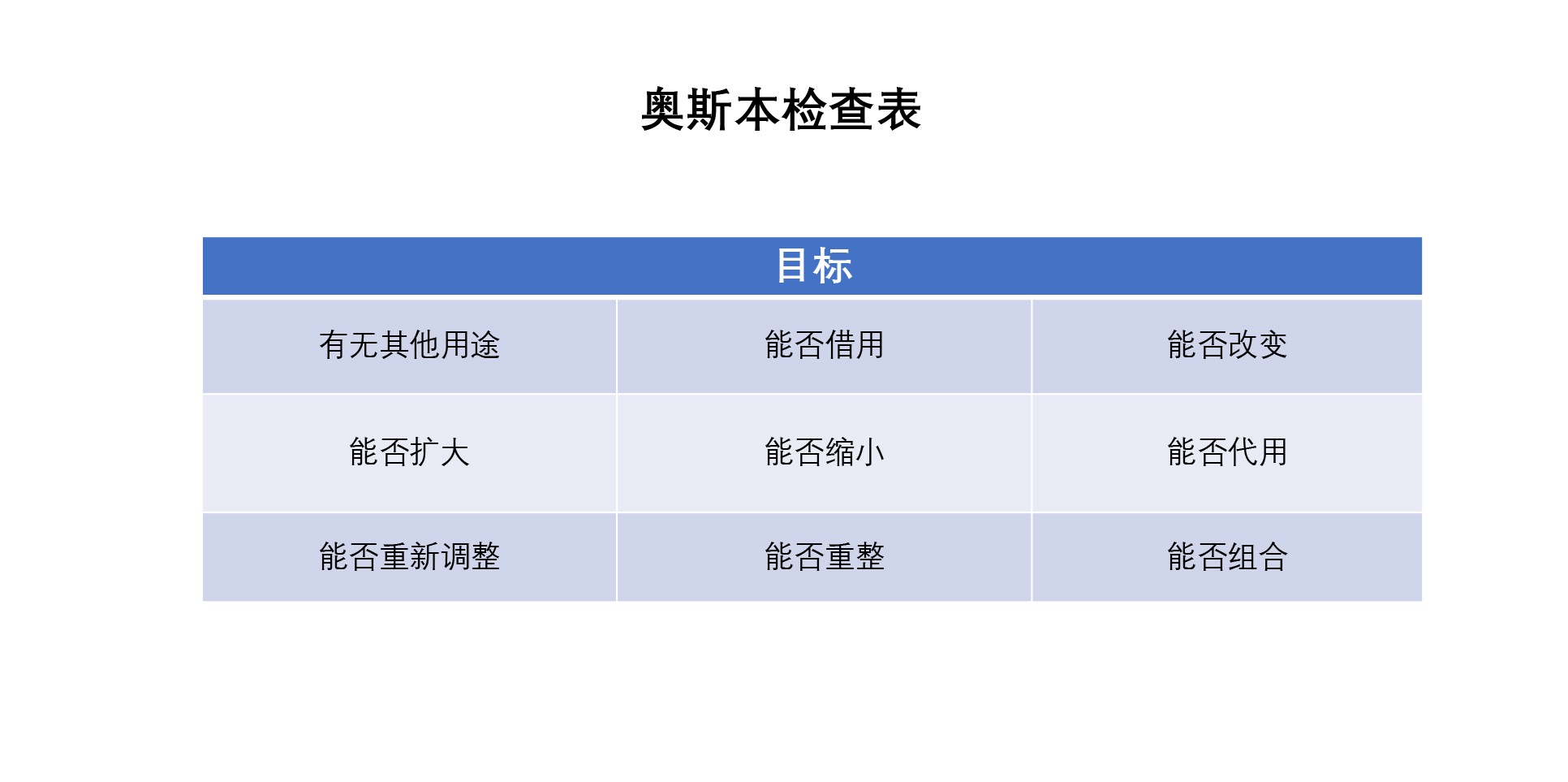
6. 奥斯本检验表¶
问题场景:拓展思路,获得新观点
基本解释及使用:我们在想新方法时,总有那么一些思路枯竭、缺乏灵感的时刻。这个模型就是为了给你像挤牙膏一样,再挤出新的一些想法。
7. SUCCESs 表¶
问题场景:新观点创意和商业模式评估
基本解释及使用:这个框架是从 Simple(简单)、Unexpected(意外)、Credible(可信)、Combine(整合)、Emotion(情感)、Story(故事)、Secret(神秘)6 个视角来客观判断创新点子。这个框架可以发现你的创意哪里不足,方便你立刻补充。

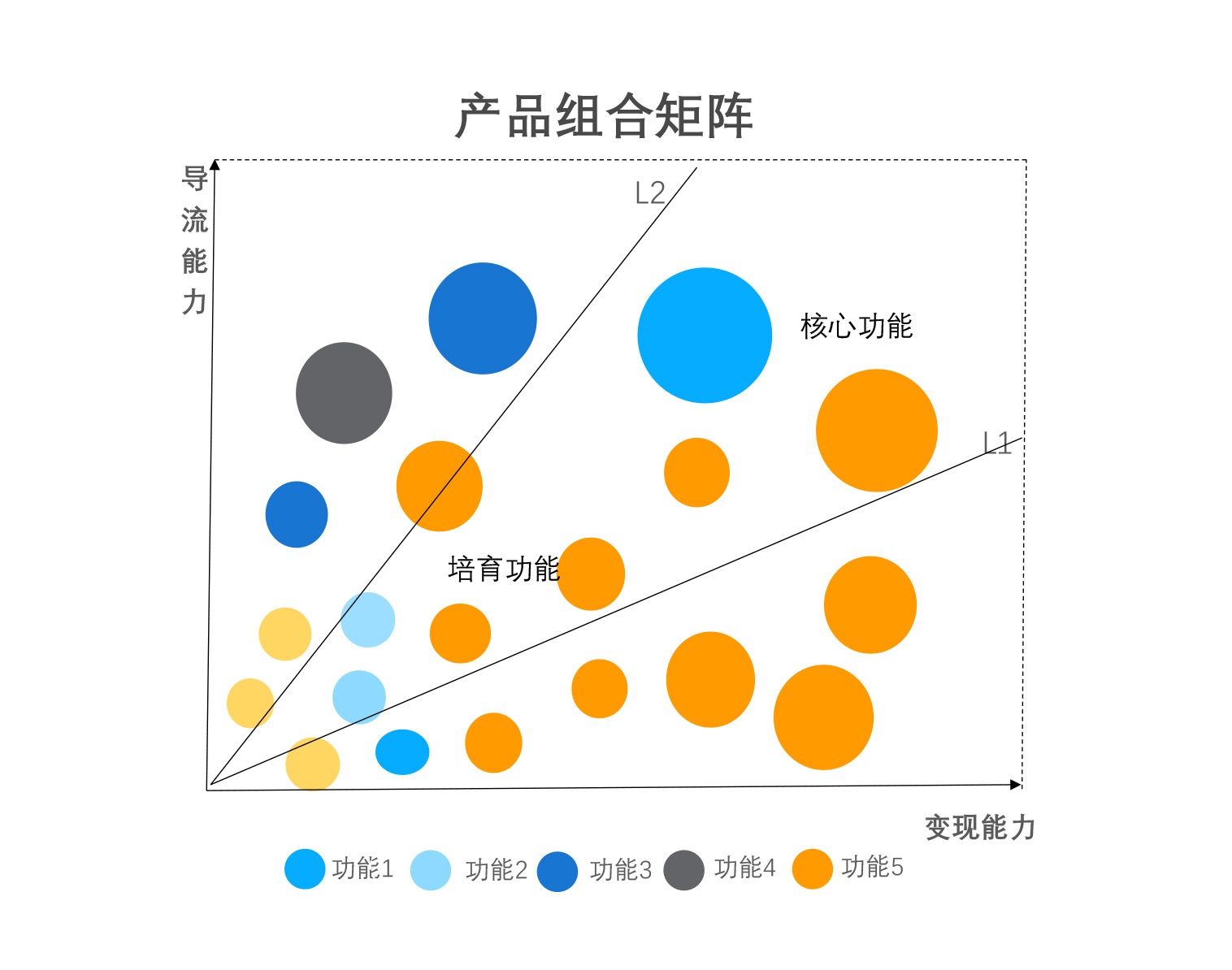
8. 产品组合矩阵¶
问题场景:产品布局,产品当中的业务布局,它是散点图的变种,气泡图。
基本解释及使用:一个赛道里会有各种各样的产品,一个产品会有各种各样的功能,我们每个产品的功能和它的活跃度以及这个产品任何两位维度的评估组合起来就是产品矩阵。
26 _ 数据分析: 15种数据思维图-下¶
常用的数据思维图,它们分别是:
8. 商业模式画布
9. AIDMA
10. AARRR
11. SMART
12. PDCA
13. RACI
14. Will, Can, Must
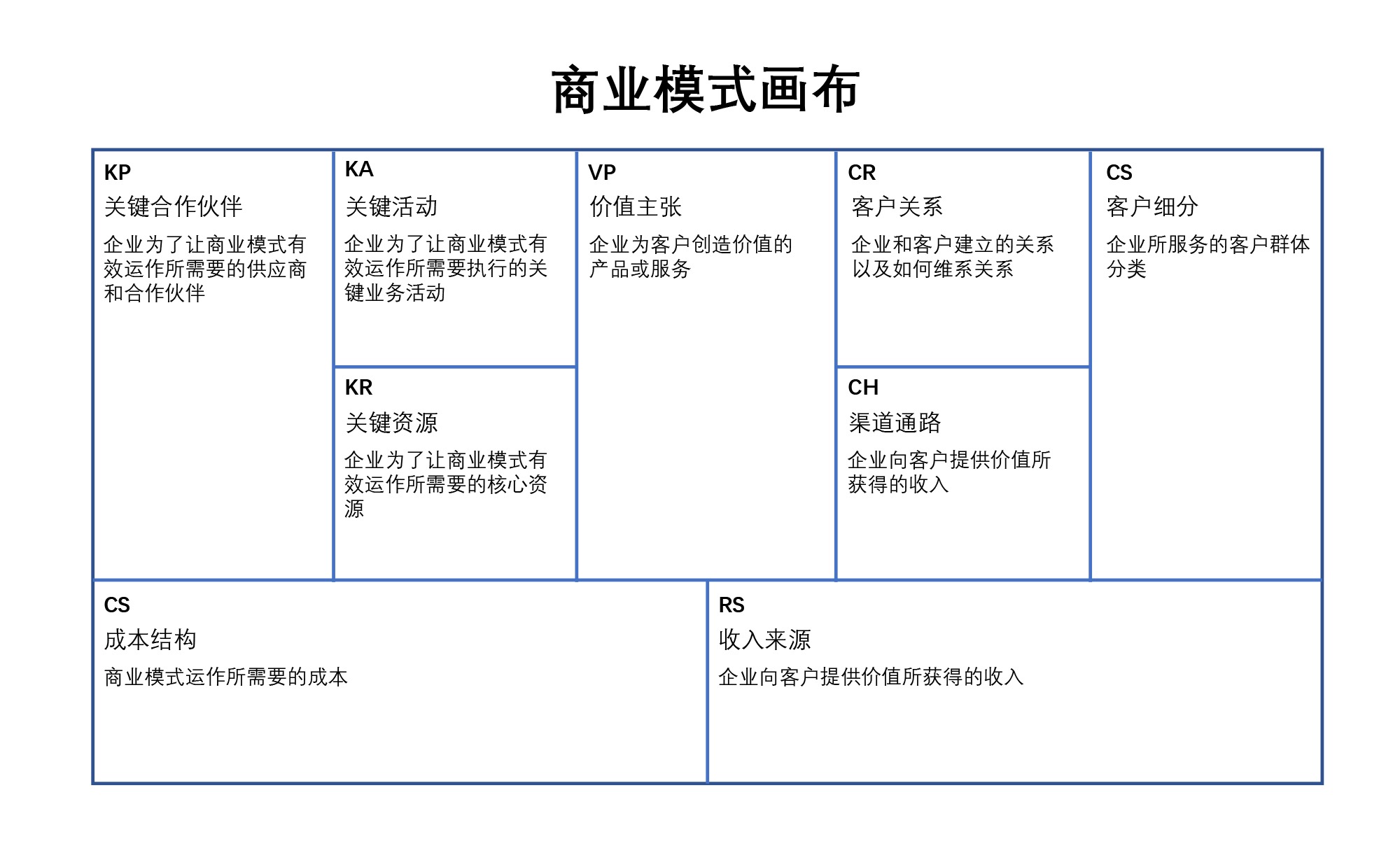
8. 商业模式画布¶
问题场景:分析自身商业模式
基本解释及使用:商业模式画布可以非常方便地对公司的商业模式进行一个整体的梳理。它通过 9 个关键的因素来分析一个公司整体的脉络,这 9 个元素分别是 KP( Key Partnerships)关键合作伙伴、 KA(Key Activities)关键活动、 KR(Key Resources )关键资源、VP(Value Propositions)价值主张、CR( Customer Relationships)客户关系、 CH(Channels) 渠道通路、CS(Customer Segments)客户人群、CS( Cost Structures)成本结构、RS(Revenue Streams)收入来源。
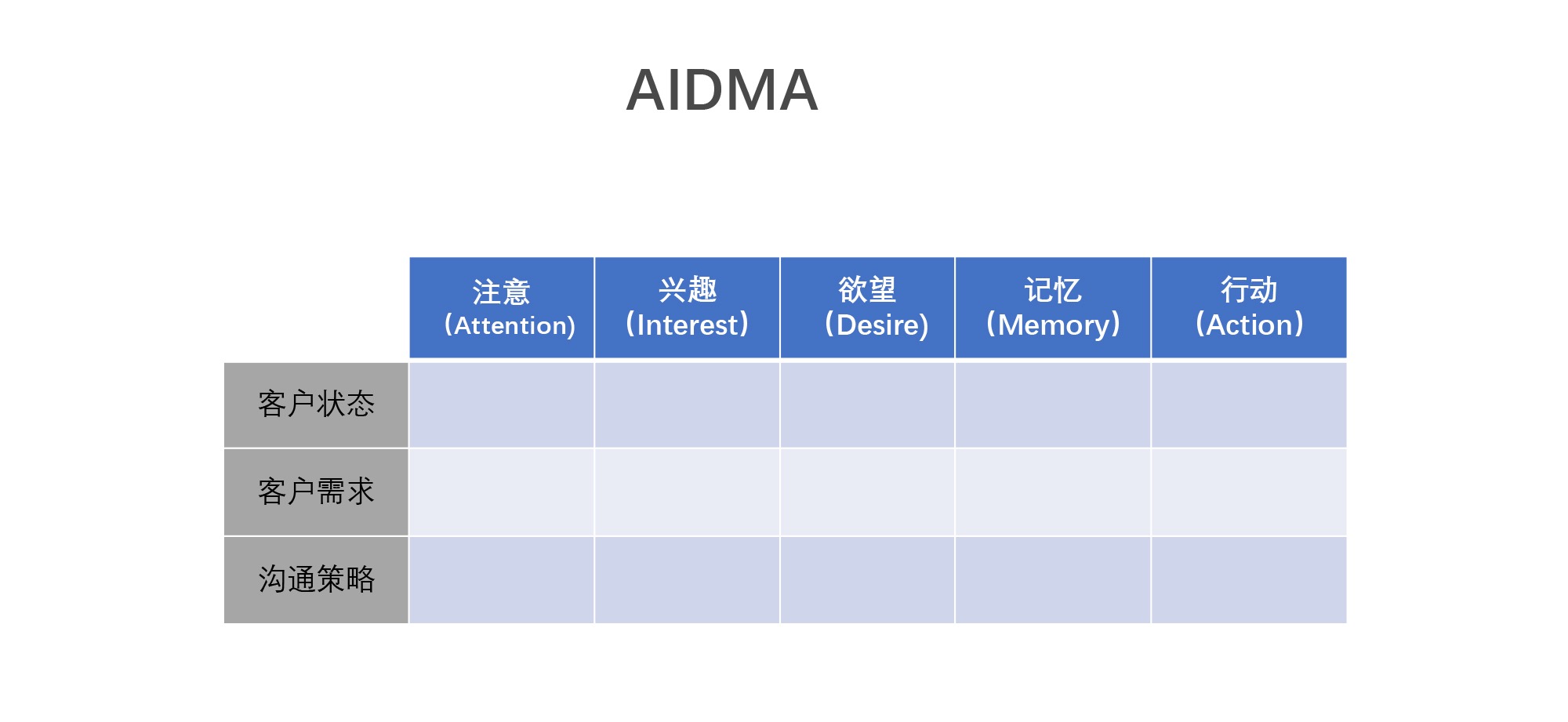
9. AIDMA¶
问题场景:设计整体客户营销策略
基本解释及使用:一个客户在购买你的产品的时候是先注意到你的产品,然后产生一些兴趣,当这些兴趣转化成欲望的时候,他才会有购买的行为。或者当他对你的产品有印象后,再见到你的产品时,他会产生购买的行动。
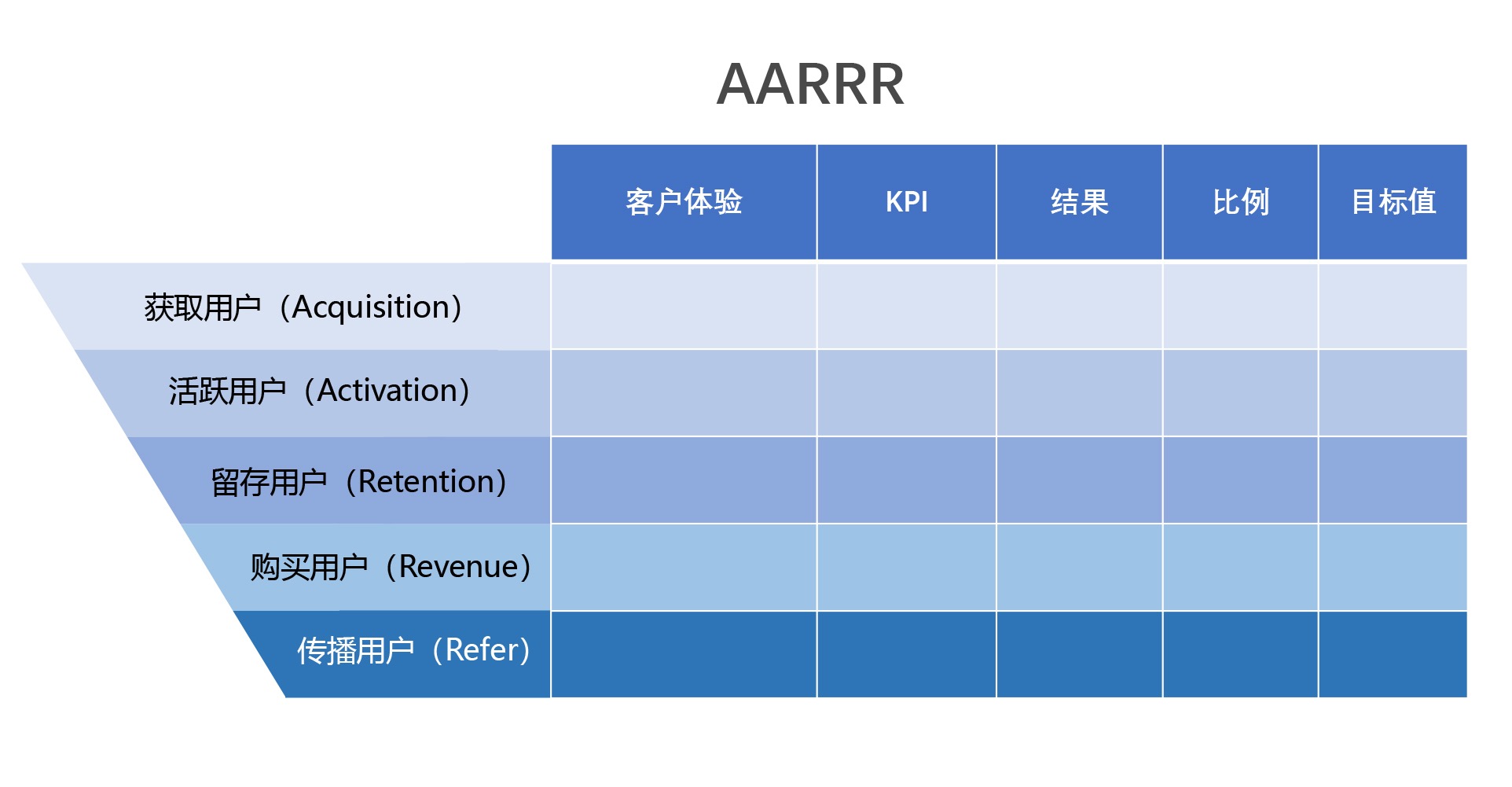
10. AARRR¶
问题场景:获取客户的各个阶段
基本解释及使用:AARRR 也叫做 “海盗模型”,它把获得客户到最后变成收入之间分成了 5 个阶段,包括获得客户阶段、让用户活跃起来的阶段、留存住客户的阶段、产生购买用户的阶段以及用户传播阶段。通过这 5 个阶段,我们可以把用户从开始和你接触到最后你可以从用户身上盈利的这一整体流程,在模型里阐释清楚。你可以设置每个阶段的目标以及要用户体验到的内容,最终我们可以通过数据分析来看差距。
进一步分析:在现在信息过载、产品类别过剩的情况下,获客顺序已经不再是 AARRR,而是大多数产品通过朋友的推荐介绍或者平台的推荐被用户看到,用户再去了解和购买。所以在新形势下的模型往往是 RAARR,也就是推荐、获取、激活、留存和购买。如何获得客户的推荐,是你的公司存活下去的重要指标。
11. SMART¶
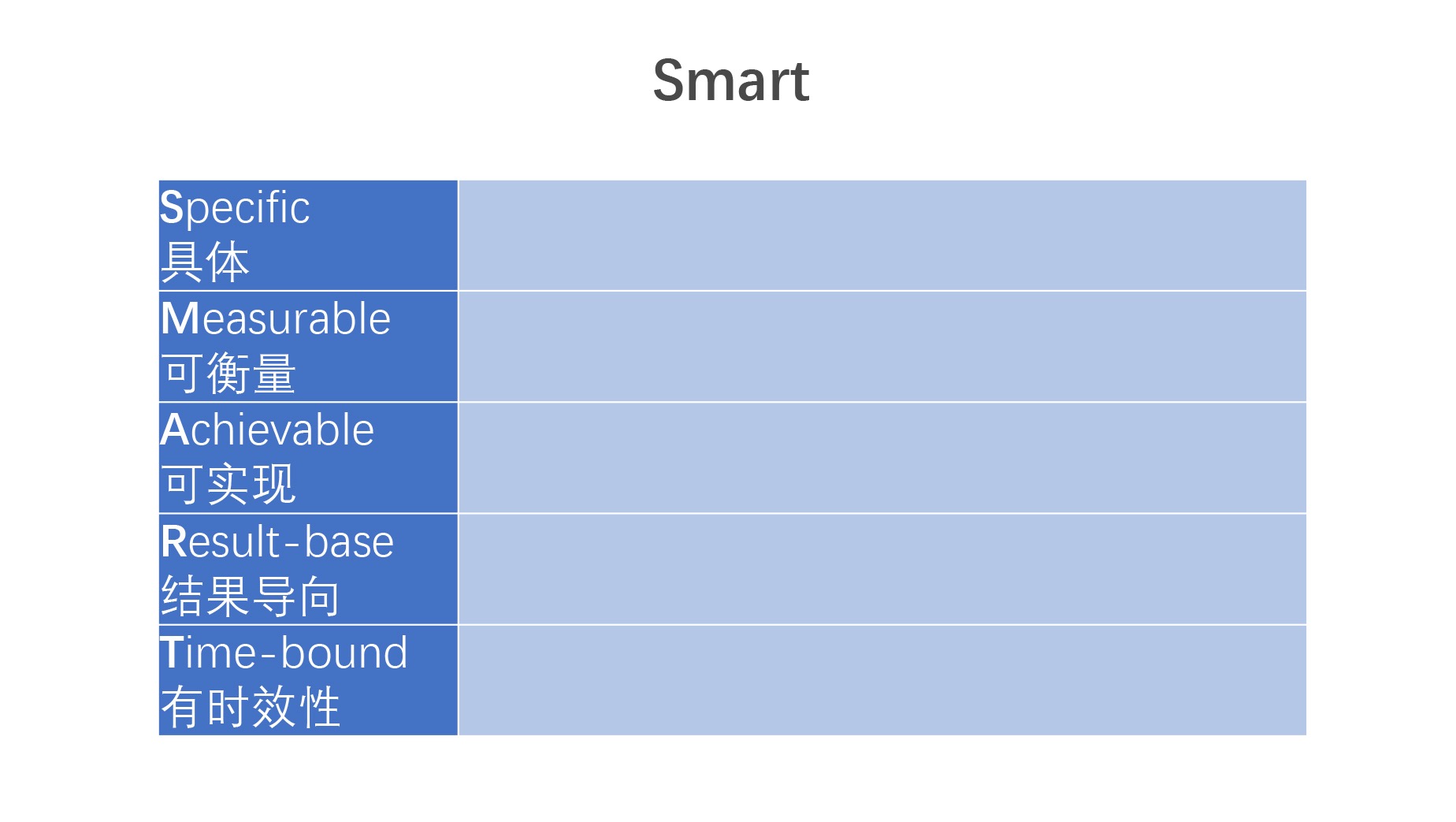
问题场景:确定目标是否明确
基本解释及使用:每次我们在制定目标的时候,你可能经常会听到你的领导说这个目标并不 SMART,他不是说你不聪明,而是指你的目标无法很明确地传达给下属和团队。
12. PDCA¶
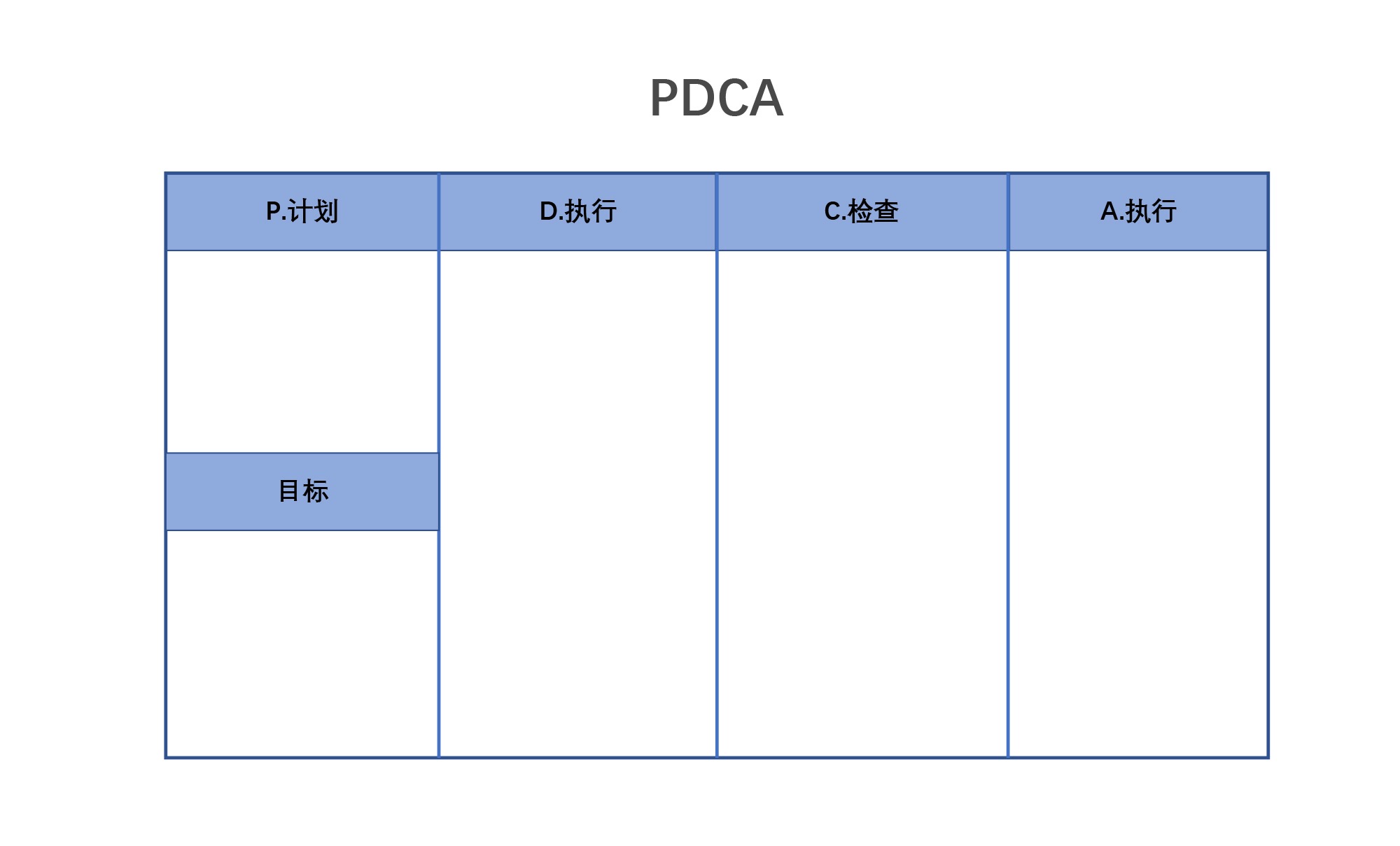
问题场景:反思和改进自己的业务
基本解释及使用: PDCA 来自著名的戴明环,它是将一个任务按照顺序从计划到执行到检查,再到改善行动,重新去规划,而且不是运行一次就结束,是不停地循环下去。
做相应的计划(Plan),再根据设计和布局进行具体运作,实现计划中的内容(Do),再检查和总结我们能否达到目标,找到哪些对了哪些错了(Check),最后,对总结检查的结果进行处理(Act),然后再做新的行动计划(PDCA)。注意每一个动作里面的每一个目标都要有明确的数字,而不是简单去定性问题。
13. RACI¶
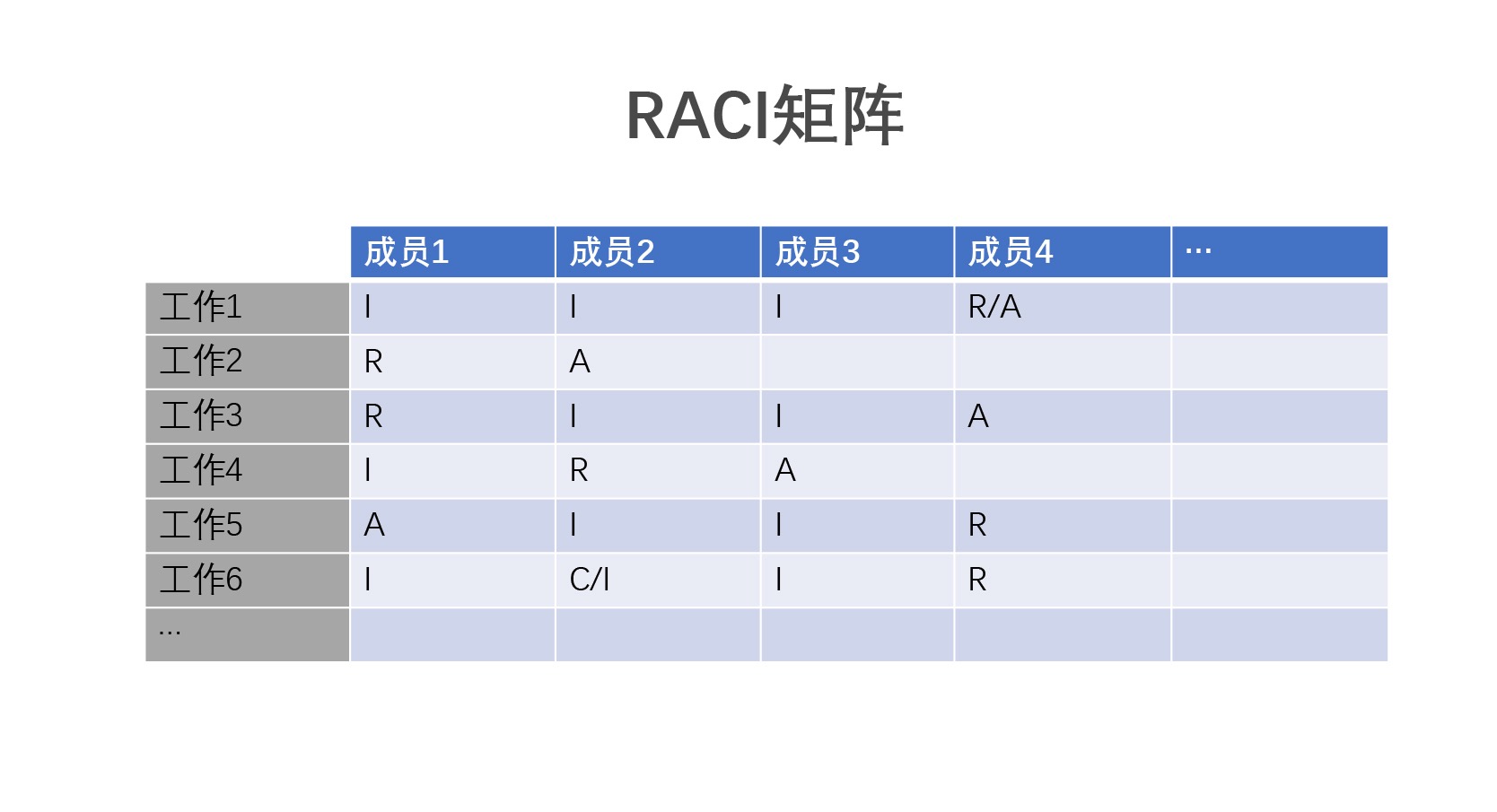
问题场景:分拆工作职责,进行工作协同
基本解释及使用:在做一件事情的时候,往往会有很多人或者很多部门参与,这时候处理好人和人、部门和部门之间的关系就非常重要了。
- RACI 矩阵区分出了 4 个角色:
Responsible 是要负责执行具体这个任务的执行者
Accountable 是责任人,负责向组织内外说明业务、进度状况,一般是组长或者 Leader 这个角色
Consulted 被咨询者一般是支援的部门和人,也就是在发生困难的时候,可以提供意见或者提供资源帮助你解决的人
Informed 被告知者是需要知道这件事情进度最新消息的人,相当于他们需要邮件抄送
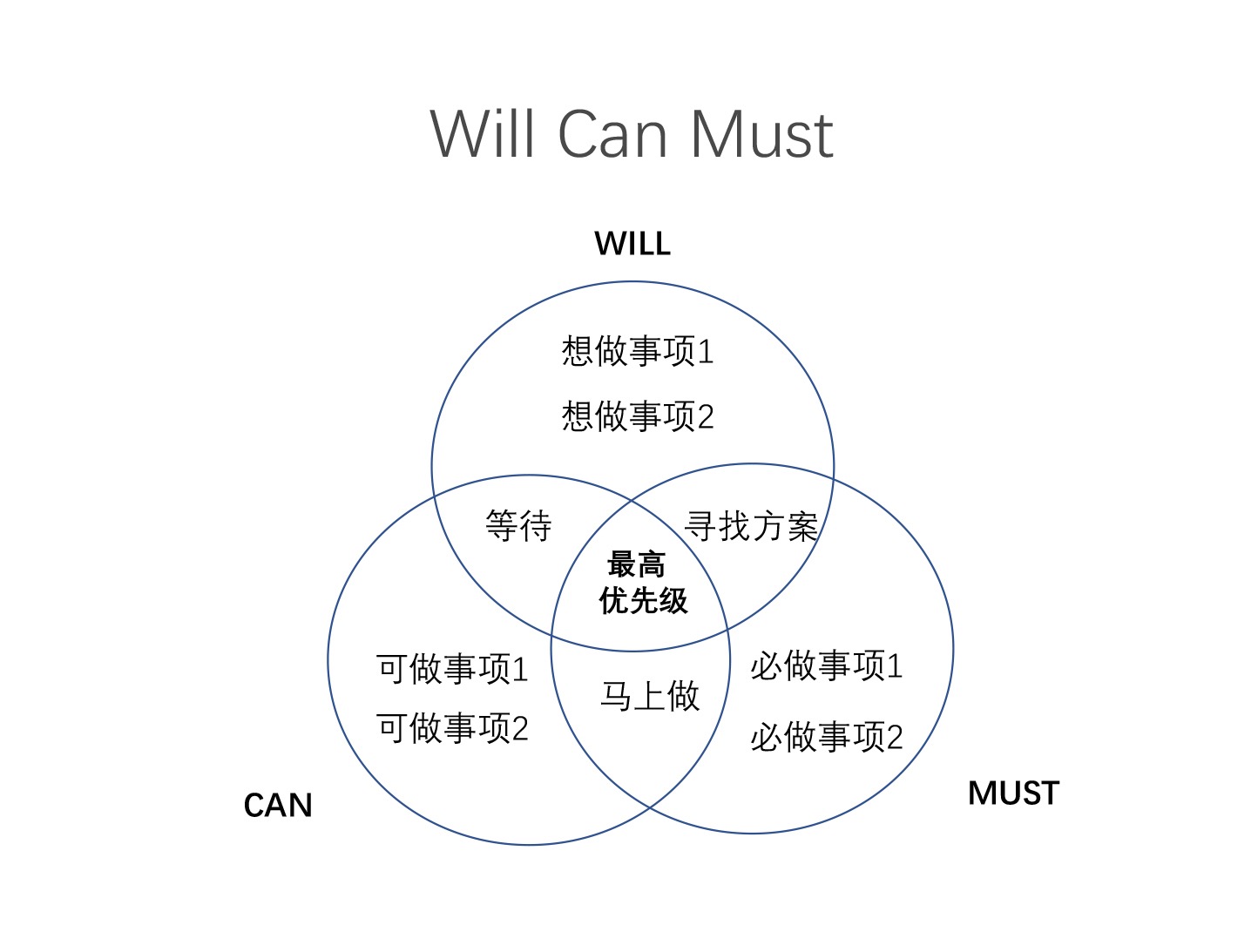
14. Will, Can, Must¶
问题场景:寻找做事情的优先级和边界
基本解释及使用:一个人或者一个公司,都会有想做的事(Will)和自己能做的事(Can)和我们必须要做的事(Must),那么我们可以通过这个框架和团队一起头脑风暴,找到我们做事情的优先级。
04分析工具 (5 讲)¶
27 _ 我常用的数据分析工具图谱¶
各种工具的简单介绍
28 _ 让你数据分析瞬间提效的18个基础功法-上¶
视频讲解 excel
29 _ 让你数据分析瞬间提效的18个基础功法-下¶
视频讲解 excel
30 _ 快速实现数据分析基础课中的分析模型¶
视频讲解 excel
31 _ 最先进的数据分析工具展望¶
数据存储与分析引擎 ——ClickHouse
数据处理与调度平台 ——Apache DolphinScheduler
数据展示工具 ——EChart
05特别放送 (6 讲)¶
成功的原因不在于你知道多少事情,而是在于你知道在无知的时候该怎么做。
在平均值那节课里,原则就是 “抓大放小”;
在大数定律那节课里,原则就是 “长期主义”;
在标准差那节课里,原则就是 “严于律己,宽以待人”
其他¶
书籍推荐:
《行为科学统计精要》
维克托·迈尔·舍恩伯格的《大数据时代》
书单推荐:
《精益数据分析》:从整个企业的视角来描述整体数据驱动的过程。
惊艳的数据分析入门书籍。
只推荐一本的数据分析行业的入门书
《刷新》
作者是微软现任 CEO 萨提亚・纳德拉
内部推动变革时都会遇到各种各样的艰难险阻
《原则》
文化和人加上企业这个规则的机器,是构成企业的主要要素
如果要改变一个企业,首先要从文化入手,如果人心无法聚拢,那只会变成一个员工没有使命感的企业,挣钱再多也只是一时,不能长久。
数据驱动要落在人、文化、规则上才可以把一个企业变成数据驱动的企业
《一网打尽》
传记式记录方法,每一个细节都追求真实和透明,你可以从这本书里身临其境地回到亚马逊决策的那个时代,体验当时亚马逊的艰难选择
2004 年末,亚马逊 IT 基础部总监 Chris Pinkham 想要陪家人想要回到祖国南非
亚马逊当时的 CTO 很尊重 Chris 这个人才,于是在南非开设了办事处,
并建立了基于 Xen 的内部服务,最终演化成为了 Ec2,然后是 S3。
当时这个办事处啊不过十几个人,在业务验证后迅速扩大了规模。
如果没有对人才的尊重,世界上恐怕就没有 AWS 这个改变世界的王者了。
《从优秀到卓越》
“飞轮效应” 其实是亚马逊在经过各种碰壁之后发现了可以增长的市场
附录:
《看穿一切数字的统计学》[日] 西内启
《统计数据会说谎》[美] 达莱尔・哈夫
《如何用数据解决实际问题》 [日] 柏木吉基
《简单统计学》[美] 加里・史密斯
《魔鬼数学》[美] 乔丹・艾伦伯格
《黑天鹅:如何应对不可预知的未来》(升级版) [美] 纳西姆・尼古拉斯・塔勒布
《随机生存的智慧:黑天鹅语录》[美] 纳西姆・尼古拉斯・塔勒布
《反脆弱:从无序中受益》[美] 纳西姆・尼古拉斯・塔勒布
《终极算法:机器学习和人工智能如何重塑世界》[美] 佩德罗・多明戈斯
《怪诞行为学》(新版)[美] 丹・艾瑞里