AI 大模型之美¶
课前必读 (2 讲)¶
开源大型语言模型越来越多,LMSYS 组织(UC 伯克利博士 Lianmin Zheng 牵头举办)建立了 Chatbot Arena
StableDiffusion
Whisper
Jupyter Notebooks for Geektime AI Course: https://github.com/xuwenhao/geektime-ai-course
彩云小译(浏览器插件): https://fanyi.caiyunapp.com/#/
深入理解深度学习,可以去看看李沐老师的论文解读系列。https://www.bilibili.com/video/BV1AF411b7xQ/
浏览器插件(快速总结视频内容): Glarity: https://chrome.google.com/webstore/detail/glarity-summary-for-googl/cmnlolelipjlhfkhpohphpedmkfbobjc/related
基于 AI 的用于编程的编辑器: Cursor: https://github.com/getcursor/cursor
AI 辅助读论文: Your AI research assistant: https://typeset.io/
AI 辅助读论文: ChatPDF: https://www.chatpdf.com/
AI 辅助读论文: scispace
Your AI pair programmer: https://github.com/features/copilot
画图工具: Midjourney, Dall-E 2
备注
我们不应当依赖 AI 给我们一个答案,但是把它当成一个助手,让它给我们多出些主意,是一个非常好的使用方法。
数字货币 Master 卡: https://depay.depay.one/zh-cn/index.html
创意¶
Use Midjourney to generate and publish coloring books: https://aituts.com/ai-generated-coloring-books/
相关网站¶
Audio2Face 面部动画
Audio2Gesture 人物动作
Pose Tracker 可以让 AI 分析视频里的人物动作
copy.AI 人工智能文案写作工具
Perplexity.AI 智能搜索引擎
Sitekick.AI 着陆页制作工具
aiva.ai 人工智能音乐创作
Playground AI: https://playgroundai.com/
Clip Drop: https://clipdrop.co/relight
Astria: https://www.strmr.com/examples
ChatGPT 聚合站:https://hokex.com
游戏生成站:https://latitude.io/
家庭作业辅助站:https://ontimeai.com/
文字转语音站:https://www.resemble.ai/
艺术作画站:https://starryai.com/
logo 制作站:https://www.logoai.com/
openai dell.e: https://labs.openai.com/
ai 写作站:https://www.getconch.ai/
音乐制作站:https://soundraw.io/
声音模拟站:https://fakeyou.com/
一句话生成一段视频:https://runwayml.com/
文字转语音:https://murf.ai/
基础知识篇: 探索大型语言模型的能力 (8 讲)¶
01|重新出发,让我们学会和 AI 说话¶
线上 Python Notebook 环境: Colab: https://colab.research.google.com/
代理:
export OPENAI_API_BASE="https://api.openai-proxy.com/v1"
现在 fine-tune 都有 LoRa 这种外挂一个矩阵的解决办法,可以看一下: https://huggingface.co/blog/peft
02|无需任何机器学习,如何利用大语言模型做情感分析¶
大型语言模型的接口其实非常简单。像 OpenAI 就只提供了
Complete和Embedding两个接口,其中,Complete 可以让模型根据你的输入进行自动续写,Embedding 可以将你输入的文本转化成向量。在接下来的几讲里,我会告诉你,怎么利用大语言模型提供的这两个简单的 API 来解决传统的自然语言处理问题。
这一讲我们就先从一个最常见的自然语言处理问题 ——“情感分析” 开始,来看看我们怎么把大语言模型用起来。
传统的二分类方法: 朴素贝叶斯与逻辑回归¶
对于 “情感分析” 类型的问题,传统的解决方案就是把它当成是一个分类问题,也就是先拿一部分评论数据,人工标注一下这些评论是正面还是负面的。
可以用来做情感分析的模型有很多,这些算法背后都是基于某一个数学模型。比如,很多教科书里,就会教你用朴素贝叶斯算法来进行垃圾邮件分类。
类似的,像逻辑回归、随机森林等机器学习算法都可以拿来做分类
Sentimental Analysis Using Naive-Bayes Classifier: https://www.kaggle.com/code/ankumagawa/sentimental-analysis-using-naive-bayes-classifier
传统方法的挑战: 特征工程与模型调参¶
特征工程: 不只是采用单个词语出现的概率,还增加前后两个或者三个相连词语的组合,也就是通过所谓的 2-Gram(Bigram 双字节词组)和 3-Gram(Trigram 三字节词组)也来计算概率。这样的特征工程的方式有很多,比如去除停用词,也就是 “的地得” 这样的词语,去掉过于低频的词语,比如一些偶尔出现的专有名词。或者对于有些词语特征采用 TF-IDF(词频 - 逆文档频率)这样的统计特征,还有在英语里面对不同时态的单词统一换成现在时。不同的特征工程方式,在不同的问题上效果不一样,比如我们做情感分析,可能就需要保留标点符号,因为像 “!” 这样的符号往往蕴含着强烈的情感特征。
机器学习相关经验: 需要将数据集切分成训练(Training)、验证(Validation)、测试(Test)三组数据,然后通过 AUC 或者混淆矩阵(Confusion Matrix)来衡量效果。如果数据量不够多,为了训练效果的稳定性,可能需要采用 K-Fold 的方式来进行训练。
大语言模型: 20 行代码的情感分析解决方案¶
通过大语言模型来进行情感分析,最简单的方式就是利用它提供的 Embedding 这个 API。这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
我们需要提前计算 “好评” 和 “差评” 这两个字的 Embedding。而对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。那么,我们把这段文本的 Embedding 和 “好评” 以及 “差评” 通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和 “好评” 之间的相似度,去减去和 “差评” 之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和 “好评” 的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。
示例:
import openai
import os
from openai.embeddings_utils import cosine_similarity, get_embedding
# 获取访问open ai的密钥
openai.api_key = os.getenv("OPENAI_API_KEY")
# 选择使用最小的ada模型
EMBEDDING_MODEL = "text-embedding-ada-002"
# 获取"好评"和"差评"的
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")
positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
negative_example = get_embedding("降价厉害,保价不合理,不推荐")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))
小结¶
利用不同文本在大语言模型里 Embedding 之间的距离,来进行情感分析。这种使用大语言模型的技巧,一般被称做零样本分类(Zero-Shot Classification)。
课后练习¶
Kaggle 提供的亚马逊耳机类商品的评论数据: https://www.kaggle.com/datasets/shitalkat/amazonearphonesreviews
03|巧用提示语,说说话就能做个聊天机器人¶
三个例子:
第一个是给 AI 一个明确的指令,让它帮我重写一段话。
第二个,是将整个对话的历史记录都发送出去,并且通过 Q 和 A 提示 AI 这是一段对话,那么 AI 自然能够理解整个上下文
第三个例子,我们则是给了 AI 几个正面情感和负面情感的例子,它就能够直接对新的评论做出准确的情感判断。
在第三个例子中:“给一个任务描述、给少数几个例子、给需要解决的问题” 这样三个步骤的组合,也是大语言模型里使用提示语的常见套路。一般我们称之为 Few-Shots Learning(少样本学习),也就是给一个或者少数几个例子,AI 就能够举一反三,回答我们的问题。
AIPRM 的浏览器插件,包含了很多总结出来有效的提示语: https://chrome.google.com/webstore/detail/aiprm-for-chatgpt/ojnbohmppadfgpejeebfnmnknjdlckgj
扩展¶
每当用户发言时,我先判断这个用户的意图。如果用户的意图是和我的知识库相关的,我就会调用自己的接口来处理并回复,否则的话,就会直接使用 OpenAI 的回复。
作者回复:在第 9-11 讲我们会讲通过语义搜索做问答,通过 llama-index 作为索引;在 14-17 讲我们会进一步讲解通过 Langchain 进行更复杂的多场景的智能问答
基本的原理是通过 Embedding 向量做语义搜索,找到相关内容,再请 OpenAI 组织语言回答。
如果你的意图判断是通过 Embedding 的向量相似度做的,那就是类似的。如果是单独训练了意图判别的分类模型,那么可能未来不再需要那么复杂了。
模型选择¶
gpt-4 最好,但是的确贵且慢,比较适合拿来做复杂推理需求的,比如写代码,一次性正确性高
gpt-3.5-turbo 一般情况下聊天够用了
有些情况 2 的受控性比较差,我需要输出内容严格按照我的要求的时候,会用 text-davinci-003
04|新时代模型性能大比拼,GPT-3到底胜在哪里¶
什么是预训练模型¶
给出一段文本,OpenAI 就能返回给你一个 Embedding 向量,这是因为它的背后是 GPT-3 这个超大规模的预训练模型(Pre-trained Model)
用来训练的语料文本越丰富,模型中可以放的参数越多,那模型能够学到的关系也就越多。类似的情况在文本里出现得越多,那么将来模型猜得也就越准。
Word2Vec、Bert、GPT-3
在 2013 年,就有一篇叫做 Word2Vec 的经典论文谈到过。它能够通过预训练,根据同一个句子里一个单词前后出现的单词,来得到每个单词的向量。
在 2018 年,Google 关于 BERT 的论文发表之后,整个业界也都会使用 BERT 这样的预训练模型,把一段文本变成向量用来解决自己的自然语言处理任务。
Fasttext,T5,GPT-3 模型效果大比拼¶
第一个是来自 Facebook 的 Fasttext,它继承了 Word2Vec 的思路,能够把一个个单词表示成向量。
第二个是来自 Google 的 T5,T5 的全称是 Text-to-Text Transfer Trasnformer,是适合做``迁移学习``的一个模型。
所谓迁移学习,也就是它推理出来向量的结果,常常被拿来再进行机器学习,去解决其他自然语言处理问题。
Fasttext 效果测试¶
下载对应的英语模型,名字叫做 “cc.en.300.bin”: https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.bin.gz
各种语言的 Fasttext 模型: https://fasttext.cc/docs/en/crawl-vectors.html
【结论】可能会出现我们之前说过的单词相同顺序不同的问题:“not good, really bad” 和 “not bad, really good”,在这个情况下,意思完全不同,但是向量完全相同。
主题分类不太关注语序:如新闻分类、垃圾邮件分类等场景不关心词语次序
T5 效果测试¶
代码执行的过程可能会有点慢。因为第一次加载模型的时候,Transformer 库会把模型下载到本地并缓存起来,整个下载过程会花一些时间。
结果:
T5-Small 参数数量只有 6000 万个: 效果不好 T5-Base 参数数量 2.2 亿个: 效果可以
除了T5之外,有其他做NLP任务效果更好的大模型推荐:挺多的, flan-t5, albert 等等一系列,需要看你具体想要解决的任务是什么一般来说,大家喜欢用 flan-t5 作为最常用的模型
评论¶
BERT:BERT 基于 Transformer 的(Encoder)。BERT 使用双向(bidirectional)的自注意力机制,可以同时捕捉文本中的前后上下文信息。
GPT:GPT 基于 Transformer 的(Decoder)。GPT 使用单向(unidirectional)的自注意力机制,只能捕捉文本中的前文(left context)信息。
下面是讲解:
BERT是:
白日依山尽,_____,欲穷千里目GPT是:
白日依山尽,_____一个是完形填空,一个是续写。GPT没法看到后面的东西,所以在很多语义理解的指标上不如BERT。
但是很多真实的使用场景你看不到后面的东西,所以从AGI的路线上,很多人觉得GPT才是正确路径。
transformers 是指一种深度学习的基础模型架构,huggingface的transformers库,相当于为这类模型架构的开发、部署、试用定义了一个通用的接口形式。
05|善用Embedding, 我们来给文本分分类¶
这一讲里我们学会了利用 OpenAI 来获取文本的 Embedding,然后通过传统的机器学习方式来进行训练,并评估训练的结果。
利用 Embedding,训练机器学习模型¶
最简单的办法就是利用我们拿到的文本 Embedding 的向量。这一次,我们不直接用向量之间的距离,而是使用传统的机器学习的方法来进行分类。毕竟,如果只是用向量之间的距离作为衡量标准,就没办法最大化地利用已经标注好的分数信息了。
GitHub 的代码: https://github.com/openai/openai-cookbook/blob/main/examples/Classification_using_embeddings.ipynb
中文的数据集示例: https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset
理解指标,学一点机器学习小知识¶
准确率,代表模型判定属于这个分类的标题里面判断正确的有多少,有多少真的是属于这个分类的。
召回率,代表模型判定属于这个分类的标题占实际这个分类下所有标题的比例,也就是没有漏掉的比例。
F1 分数,是准确率和召回率的调和平均数,也就是 F1 Score = 2/ (1/Precision + 1/Recall)
支持的样本量,是指数据里面,实际是这个分类的数据条数有多少
accuracy,模型的整体准确率。
macro average,中文名叫做宏平均,宏平均的三个指标,就是把上面每一个分类算出来的指标加在一起平均一下。它主要是在数据分类不太平衡的时候,帮助我们衡量模型效果怎么样。
weighted average,就是加权平均,也就是我们把每一个指标,按照分类里面支持的样本量加权,算出来的一个值。
评论¶
既然都调用open ai的接口,为什么不直接让chatgpt直接返回分类结果呢?可以的啊,但是要考虑,且在有标注数据的情况下,机器学习的效果通常比让ChatGPT只用先验知识效果还是要好不少的。
利用ChatGPT embedding的优劣势:优势是效果好,语义表达能力强,成本也不高。主要缺点是需要把数据发送给OpenAI。
06|ChatGPT来了,让我们快速做个AI应用¶
过去的两讲,我带着你通过 OpenAI 提供的 Embedding 接口,完成了文本分类的功能。那么,这一讲里,我们重新回到 Completion 接口
快速搭建出一个有界面的聊天机器人,第一次使用 HuggingFace 这个平台。
HuggingFace 是现在最流行的深度模型的社区,你可以在里面下载到最新开源的模型,以及看到别人提供的示例代码。
ChatGPT 来了,更快的速度更低的价格¶
在第 03 讲里,已经给你看了如何通过 Completion 的接口,实现一个聊天机器人的功能。在那个时候,我们采用的是自己将整个对话拼接起来,将整个上下文都发送给 OpenAI 的 Completion API 的方式。
但在2023年 3 月 2 日,因为 ChatGPT 的火热,OpenAI 放出了一个直接可以进行对话聊天的接口。这个接口叫做 ChatCompletion,对应的模型叫做 gpt-3.5-turbo
但无论是在第 03 讲里,还是这一讲里,我们每次都要发送一大段之前的聊天记录给到 OpenAI。
OpenAI 实际做的,就是根据一个定义好特定分隔符的格式(ChatML 的格式),将你提供的多轮对话的内容拼接在一起,提交给 gpt-3.5-turbo 这个模型。
Gradio 帮你快速搭建一个聊天界面¶
Gradio 官方也有用其他开源预训练模型创建 Chatbot 的教程https://gradio.app/creating-a-chatbot/
07|文本聚类与摘要,让AI帮你做个总结¶
怎么在对话轮数越来越多的时候让 AI 记住尽量多的上下文?有一个办法,就是将过去几轮的上下文内容,先交给 AI 做一个 100 字的总结。然后,把这个总结也作为对话的 Prompt 信息,告诉 AI 这是聊天的背景,再重新开始新的一轮对话。
08|文本改写和内容审核,别让你的机器人说错话¶
两个特殊的接口,一个是只有 text-davinci-003 模型支持的文本插入功能;另一个,则是帮助我们对色情、暴力等内容进行审核过滤的 moderate 接口。
实战提高篇一: 利用NLP技术完成高级任务 (10讲)¶
09|语义检索,利用Embedding优化你的搜索功能¶
备注
对于提供一个简单的搜索或者推荐功能来说,通过文本的 Embedding 的相似度,是一个很好的快速启动的方式。
向量数据库¶
Milvus 国人开源: https://milvus.io/
Weaviate: https://weaviate.io/
Pinecone:
开源的embedding组件¶
开源的t5-base,embedding也还不错,可以选择 flan-t5 系列,或者后面介绍开源平替的 sentence_transformers
10|AI连接外部资料库,让Llama Index带你阅读一本书¶
通过 llama-index 这样的开源库,我们能够将自己的数据和大语言模型连接在一起
大型语言模型的不足¶
大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。
解决办法,就是多找一些高质量的中文语料训练一个新的模型。或者,对于我们想让 AI 能够回答出来的问题,找一些数据。然后利用 OpenAI 提供的“微调”(Fine-tune)接口,在原来的基础上训练一个新模型出来。
Bing 的解法——先搜索后提示¶
先通过搜索的方式,找到和询问的问题最相关的语料。这个搜索过程中,我们既可以用传统的基于关键词搜索的技术,也可以用第 9 讲我们刚刚介绍过的使用 Embedding 的相似度进行语义搜索的技术。
然后,我们将和问题语义最接近的前几条内容,作为提示语的一部分给到 AI。然后请 AI 参考这些内容,再来回答这个问题。

大语言模型其实内含了两种能力
第一种,是海量的语料中,本身已经包含了的知识信息。比如,我们前面问 AI 鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
第二种,是根据你输入的内容,理解和推理的能力。这个能力,不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来,临时提供给模型的。如果不提供这个上下文,再问一次模型相同的问题,它还是答不上来的。
通过 llama_index 封装“第二大脑”¶
提前把你希望 AI 能够回答的知识,建立一个外部的索引,这个索引就好像 AI 的“第二个大脑”。每次向 AI 提问的时候,它都会先去查询一下这个第二大脑里面的资料,找到相关资料之后,再通过自己的思维能力来回答问题。
库:
pip install llama-index
pip install langchain
// 分词分句
pip install spacy
python -m spacy download zh_core_web_sm // 中文分词分句
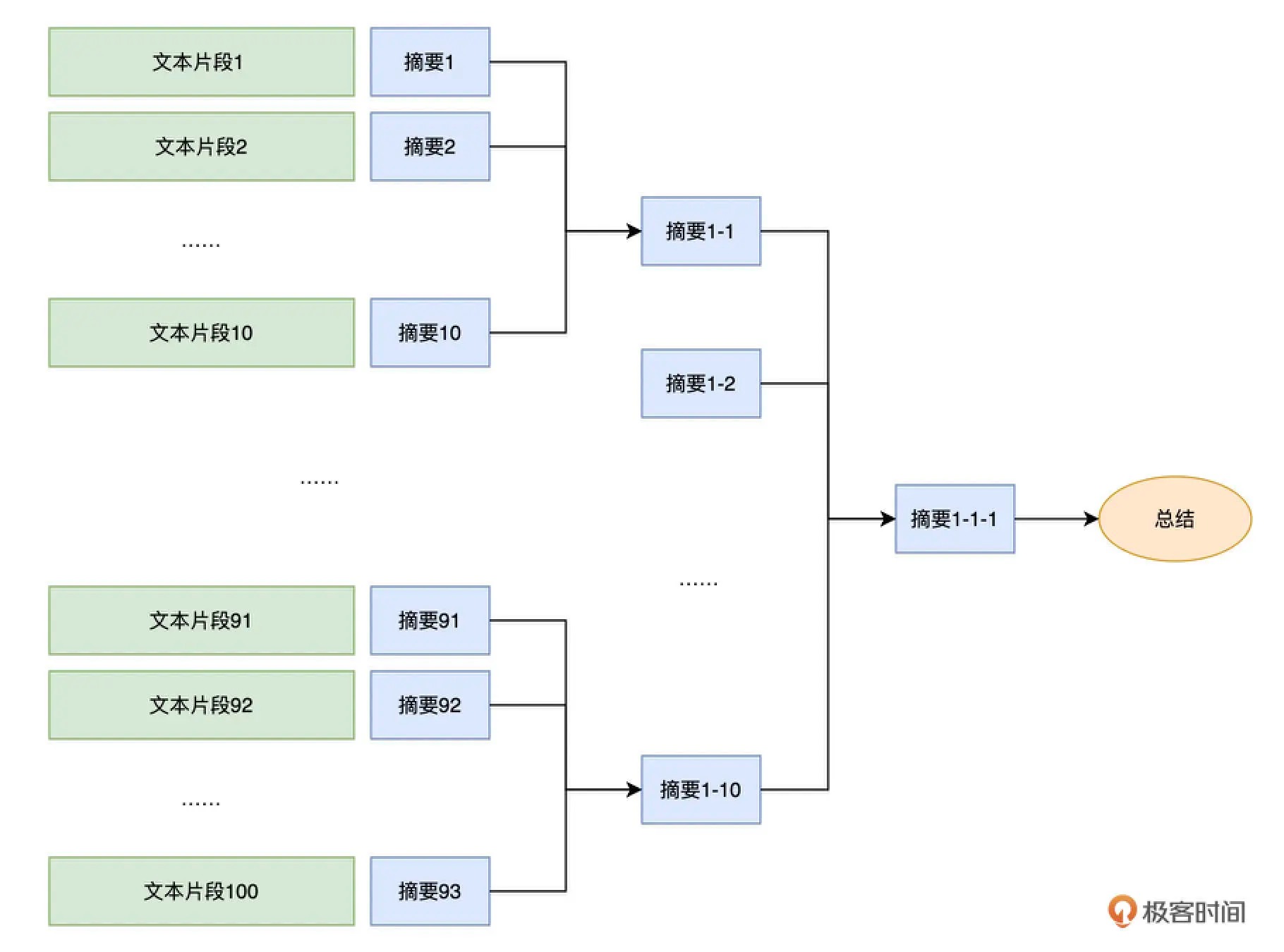
如果要总结一篇论文、甚至是一本书,每次最多只能支持 4096 个 Token 的 API 就不太够用了。要解决这个问题也并不困难,我们只要进行分段小结,再对总结出来的内容再做一次小结就可以了。我们可以把一篇文章,乃至一本书,构建成一个树状的索引。每一个树里面的节点,就是它的子树下内容的摘要。最后,在整棵树的根节点,得到的就是整篇文章或者整本书的总结了。¶
引入多模态, 让 llamd-index 能够识别小票¶
多模态:
- 语言信息:如文本、语音等
- 视觉信息:如图片、视频等
- 空间信息:如位置、姿态等
- 时间信息:如时间序列等
多模态是指利用多个信息通道(模态)提供的信息,来实现某一个任务或解决某一个问题。通常情况下,不同的模态提供的信息是互补的,融合这些信息可以获得更加准确和全面的理解。
llama_index官方样例库(把吃饭的小票都拍下来。然后询问哪天吃了什么,花了多少钱): https://github.com/jerryjliu/llama_index/blob/main/examples/multimodal/Multimodal.ipynb
基于 OCR 扫描的模型 Donut(通过一个视觉的 Encoder 和一个文本的 Decoder,这样任何一个图片能够变成一个一段文本): https://huggingface.co/naver-clova-ix/donut-base-finetuned-cord-v2
社区开发出来的读取各种不同数据源格式的 DataConnector: https://llamahub.ai/
小结¶
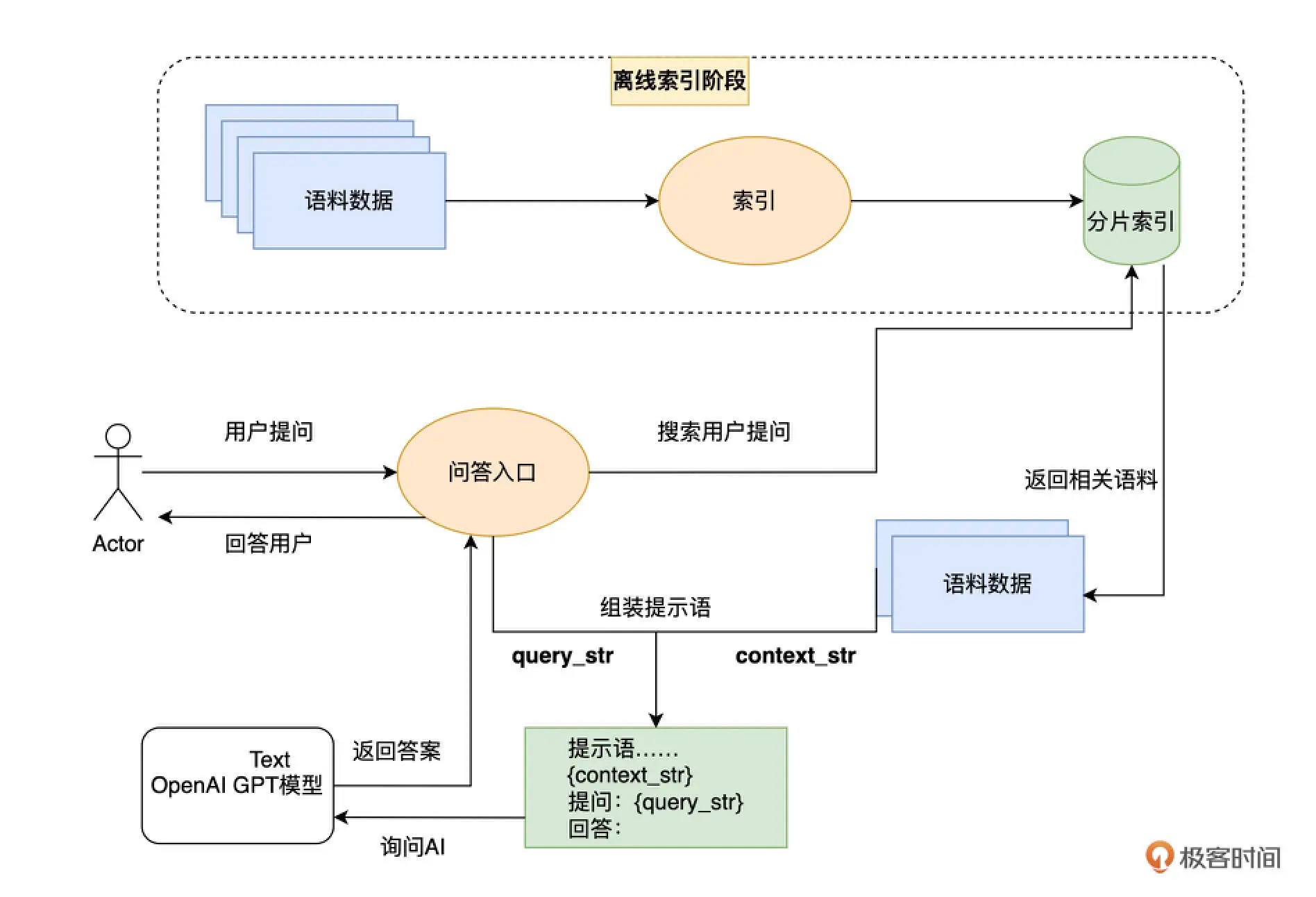
先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过 AI 的语义理解能力让 AI 基于搜索到的结果来回答问题。¶
前两步的索引和搜索,我们可以使用 OpenAI 的 Embedding 接口,也可以使用其它的大语言模型的 Embedding,或者传统的文本搜索技术。只有最后一步的问答,往往才必须使用 OpenAI 的接口。我们不仅可以索引文本信息,也可以通过其他的模型来把图片变成文本进行索引,实现所谓的多模态功能。
评论¶
SCISPACE(在你把文档上传之后,还会给你一系列的提示,告诉你可以向对应的书或者论文问什么问题): https://scispace.com/
llama_index的重点放在了Index上,也就是通过各种方式为文本建立索引,有通过LLM的,也有很多并非和LLM相关的。
langchain的重点在 agent 和 chain 上,也就是流程组合上。
可以根据你的应用组合两个,如果你觉得问答效果不好,可以多研究一下llama-index。如果你希望有更多外部工具或者复杂流程可以用,可以多研究一下langchain。
11|用开源模型来代替 ChatGPT¶
通过 sentence_transformers 这样的开源库和 ChatGLM 这样的开源大语言模型,不依赖 OpenAI,我们也可以完成简单的电商 FAQ 的问答。
把 ChatGLM 封装成一个 LLM 类,让我们的 index 使用这个指定的大语言模型: https://gpt-index.readthedocs.io/en/latest/how_to/customization/custom_llms.html
通过 sentence_transfomers 类型的模型,生成了文本分片的 Embedding,并且基于这个 Embedding 来进行语义检索。我们通过 ChatGLM 这个开源模型,实现了基于上下文提示语的问答
开源中文大语言模型¶
清华ChatGLM 1300亿模型: https://github.com/THUDM/GLM-130B
基于斯坦福的 Alpaca 数据集进行微调的 Chinese-LLaMA-Alpaca: https://github.com/ymcui/Chinese-LLaMA-Alpaca
链家科技开源的 BELLE: https://github.com/LianjiaTech/BELLE
评论¶
12|让AI帮你写个小插件,轻松处理Excel文件¶
教你一步步了解一个不熟悉领域,并用之开发一个小产品
13|让AI帮你写测试, 体验多步提示语¶
OpenAI Cookbook提供的 AI 写单元测试的示例: https://github.com/openai/openai-cookbook/blob/main/examples/Unit_test_writing_using_a_multi-step_prompt.ipynb
评论¶
开源的PaddleSpeech: AI唱歌,是指用一个人的声音把一首歌完整的唱出来。
14|链式调用,用LangChain简化多步提示语¶
通过提示语(Prompt)里包含历史的聊天记录,我们能够让 AI 根据上下文正确地回答问题。
通过将 Embedding 提前索引好存起来,我们能够让 AI 根据外部知识回答问题。
备注
开源社区就有人将这些常见的需求和模式抽象了出来,开发了一个叫做 Langchain 的开源库。
使用 Langchain 的链式调用¶
所谓链式调用举例来讲:
1. 先调用 OpenAI,把翻译请求和原始问题组合在一起发送给 AI,完成问题的中译英
2. 然后再把拿到的翻译好的英文问题发送给 OpenAI,得到英文答案
3. 最后再把英文答案,和对应要求 AI 翻译答案的请求组合在一起,完成答案的英译中
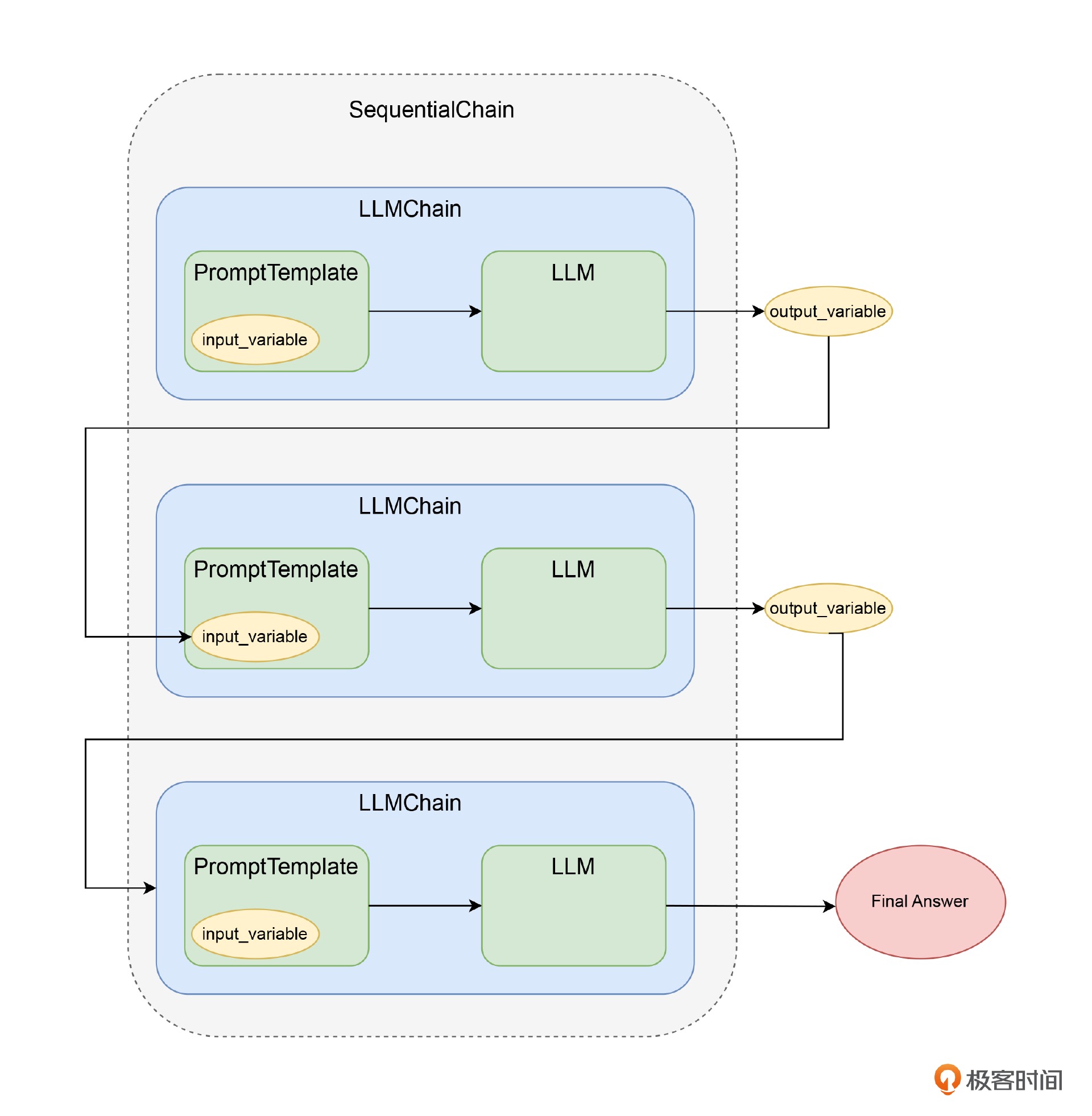
LLMChain就是一个对大语言模型进行链式调用的模式,前面的变量和输出都可以作为下一轮调用的变量输入¶
推荐阅读¶
Langchain官方文档: https://langchain.readthedocs.io/en/latest/
Langchain AI Handbook(from 向量数据库公司 Pinecone): https://www.pinecone.io/learn/langchain/
评论¶
langchain也有如何实现一个autogpt的use case: https://python.langchain.com/en/latest/use_cases/autonomous_agents/autogpt.html
15|深入使用LLMChain, 给AI连上Google和计算器¶
解决 AI 数理能力的难题¶
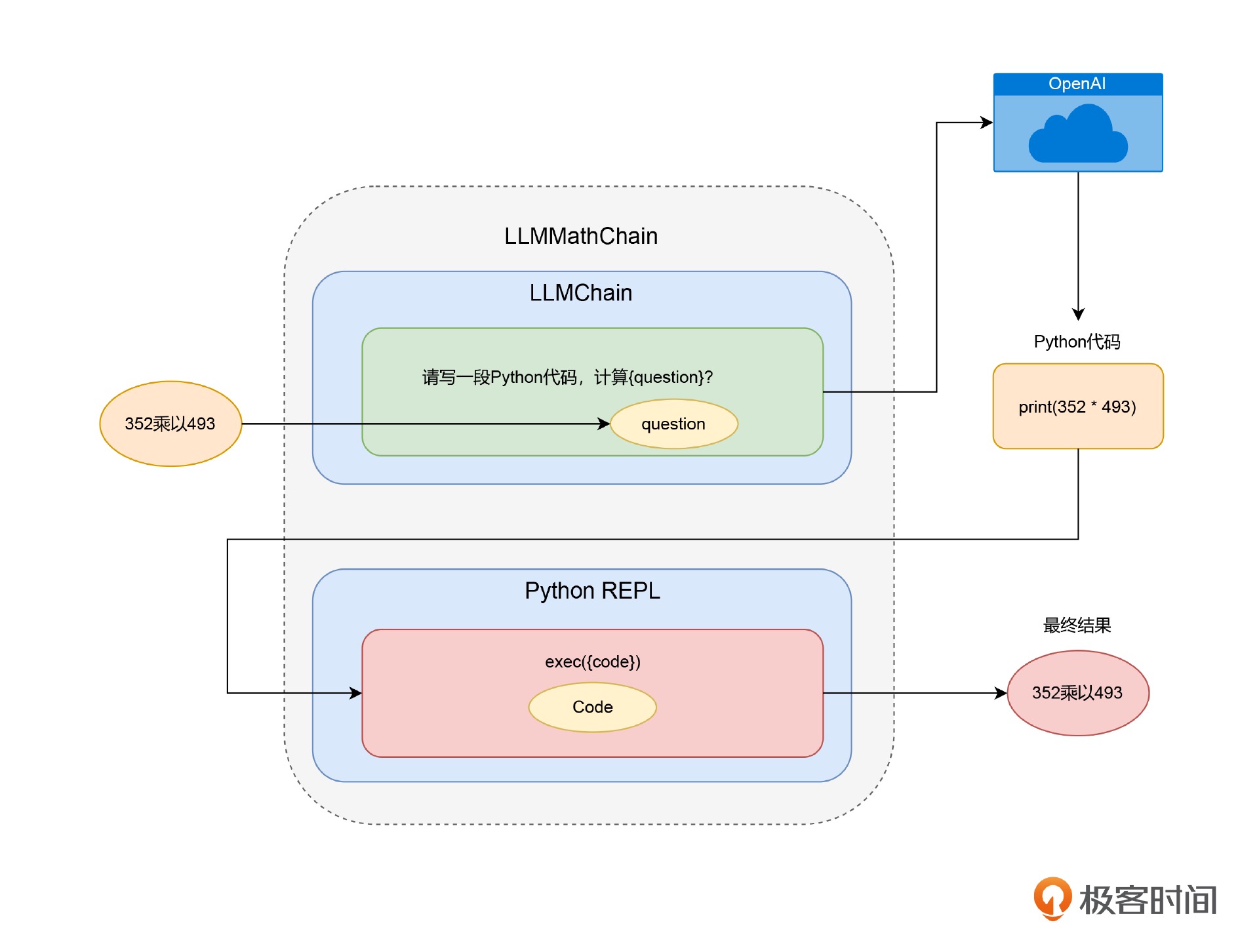
LLMathChain通过OpenAI生成Python代码,再通过REPL执行Python代码,完成数学计算¶
通过 RequestsChain 获取实时外部信息¶
步骤:
1. 通过一个 HTTP 请求,根据搜索词拿到 Google 的搜索结果页。
2. 把我们搜索的问题和结果页都发给了 OpenAI,提取出搜索结果页里面的天气信息。
3. 通过 TransformationChain 转换数据格式
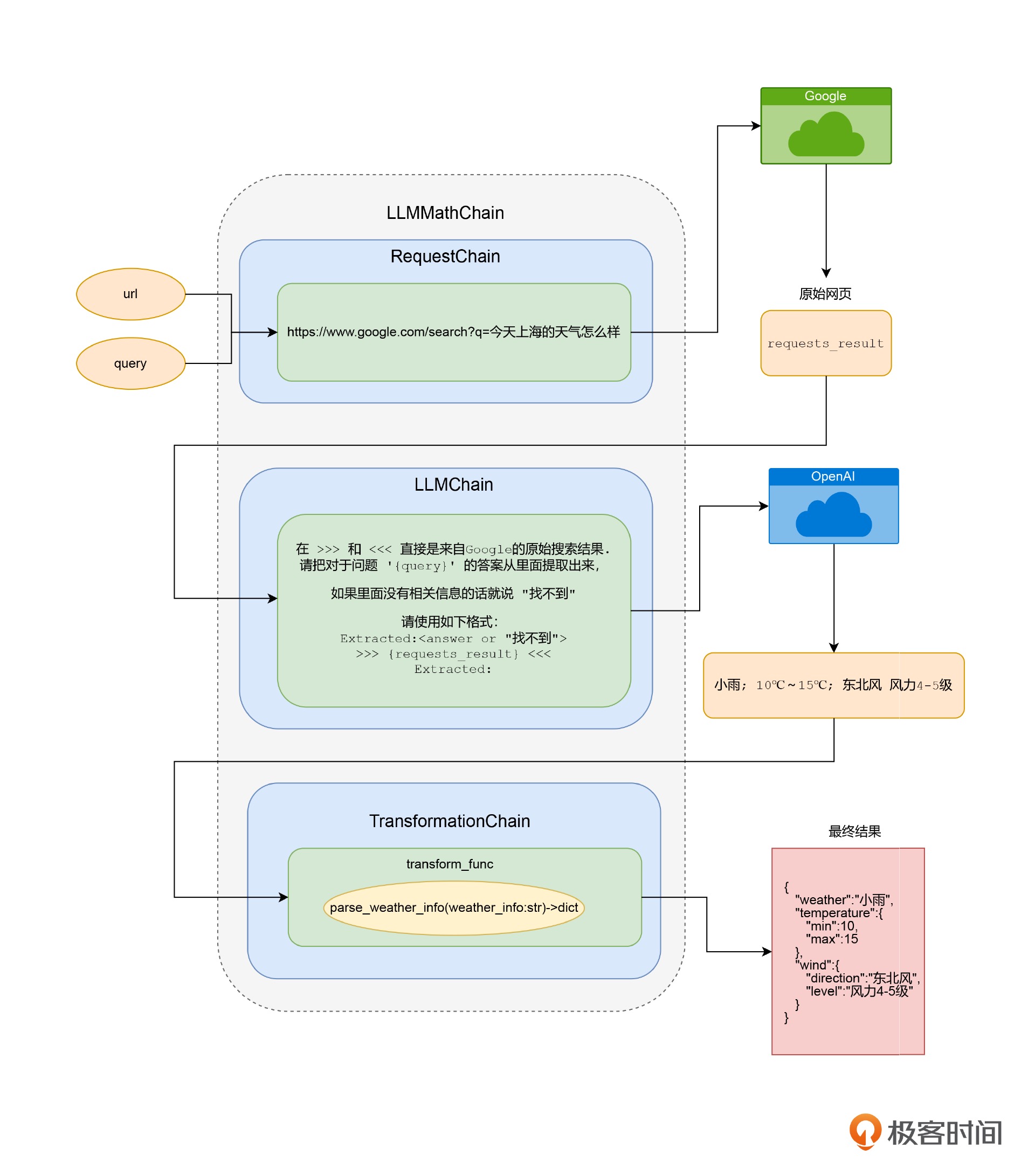
通过三个步骤,拿到最后结构化的天气信息¶
小结¶
这些能力大大增强了 AI 的实用性,解决了几个之前大语言模型处理得不好的问题,包括数学计算能力、实时数据能力、和现有程序结合的能力,以及搜索属于自己的资料库的能力。
你可以定义自己需要的 LLMChain,通过程序来完成各种任务,然后合理地组合不同类型的 LLMChain 对象,来实现连 ChatGPT 都做不到的事情。
ChatGPT Plugins 的实现机制,其实也是类似的。
推荐试用¶
Langchain可拖拽的图形界面: https://github.com/logspace-ai/langflow
16|Langchain里的“记忆力”, 让AI只记住有用的事儿¶
BufferWindow,滑动窗口记忆
SummaryMemory,把小结作为历史记忆
SummaryBufferMemory,两者结合
EntityMemory,关注的核心要点,保留最关心的信息
17|让AI做决策, LangChain里的“中介”和“特工”¶
介绍了 Langchain 的 Agent 的基本功能。通过“先让 AI 做个选择题”的方式,Langchain 让 AI 自动为我们选择合适的 Tool 去调用。
我们可以把回答不同类型问题的 LLMChain 封装成不同的 Tool,也可以直接让 Tool 去调用内部查询订单状态的功能。
备注
第17和18讲都是讲如何利用私有的数据。
推荐阅读¶
Langchain 里面的 zero-shot-react-description 这个想法,来自一个知名的 AI 创业公司 AI21 Labs 的论文 MRKL Systems: https://arxiv.org/pdf/2205.00445.pdf
18|流式生成与模型微调,打造极致的对话体验¶
模型微调给我们提供了一个非常实用的能力,我们可以利用自己的数据,在 OpenAI 的基础模型上,调整模型参数生成一个新模型。不过,微调后的模型使用成本比较高
模型微调适合垂直领域的应用。比如你有大量的法律类的文书、金融类的文书等等,单独微调一个模型给自己用。能够承受相对高成本,并且有大量垂直语料的应用看起来比较合适。
实战提高篇(二) 大型语音与图像模型的应用 (9讲)¶
19|Whisper+ChatGPT: 请AI代你听播客¶
【实用工具】 listennotes 搜索播客,还能够下载到播客的源文件。而且,这个网站还有一个很有用的功能,就是可以直接切出播客中的一段内容,创建出一个切片: https://time.geekbang.org/column/article/649832
【实用工具】分割音频: https://platform.openai.com/docs/guides/speech-to-text/longer-inputs
Whisper 项目:https://github.com/openai/whisper

【视频】OpenAI Whisper 的相关论文: https://www.bilibili.com/video/BV1VG4y1t74x/
20|TTS与语音合成:让你的机器人拥有声音¶
百度开源的 PaddleSpeech 的语音合成(Text-To-Speech):
// 建议首先安装pytest-runner:
pip install pytest-runner -i https://pypi.tuna.tsinghua.edu.cn/simple
//
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install paddlespeech -i https://pypi.tuna.tsinghua.edu.cn/simple
示例:
注意: 这个过程中,PaddleSpeech 需要下载对应的模型,所以第一次运行的时候也要花费一定的时间
from paddlespeech.cli.tts.infer import TTSExecutor
tts_executor = TTSExecutor()
text = "今天天气十分不错,百度也能做语音合成。"
output_file = "./data/paddlespeech.wav"
tts_executor(text=text, output=output_file)
播放要借助于 PyAudio 这个包:
// mac
brew install portaudio
// ubuntu
sudo apt-get install portaudio19-dev
// 安装需要的库
pip install pyaudio
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发: https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/README_cn.md
语音相关课程: https://aistudio.baidu.com/aistudio/education/group/info/25130
扩展阅读¶
英文转语音效果不错: https://github.com/suno-ai/bark
21|DID和PaddleGAN: 表情生动的数字人播报员¶
用 D-ID 给语音对口型¶
开源解决方案¶
背后使用的是 PaddleGAN 的对抗生成网络算法,来实现唇形和表情的匹配。
小样本合成和小数据微调: https://aistudio.baidu.com/aistudio/projectdetail/4573549?sUid=2470186&shared=1&ts=1663753541400
思考题¶
推荐阅读¶
22|再探HuggingFace: 一键部署自己的大模型¶
Pipeline 支持的自然语言处理任务¶
feature-extraction,其实它和 OpenAI 的 Embedding 差不多,也就是把文本变成一段向量。
fill-mask,也就是完形填空。你可以把一句话中的一部分遮盖掉,然后让模型预测遮盖掉的地方的词是什么。
ner,命名实体识别。我们常常用它来提取文本里面的时间、地点、人名、邮箱、电话号码、地址等信息,然后进一步用这些信息来处理其他任务。
question-answering 和 table-question-answering,专门针对问题进行自动问答,在客服的 FAQ 领域常常会用到这类任务。
sentiment-analysis 和 text-classification,也就是我们之前见过的情感分析,以及类目更自由的文本分类问题。
text-generation 和 text2text-generation,文本生成类型的任务。我们之前让 AI 写代码或者写故事,其实都是这一类的任务。
summarization 文本摘要、
translation 机器翻译,
zero-shot-classification,零样本分类
Pipeline使用示例¶
通过 Pipeline 完成各种任务的详细示例: https://huggingface.co/docs/transformers/main_classes/pipelines
示例-通过 Pipeline 进行语音识别:
from transformers import pipeline transcriber = pipeline(model="openai/whisper-medium", device=0) result = transcriber("./data/podcast_clip.mp3") print(result)
Inference API¶
它是 HuggingFace 免费提供的,让你可以通过 API 调用的方式先试用这些模型(单机不能加载的较大模型)
带着闪电标记⚡️的 Hosted Inference API 字样,就代表着这个模型可以通过 Inference API 调用
设置变量:
export HUGGINGFACE_API_KEY=YOUR_HUGGINGFACE_ACCESS_TOKEN
23|OpenClip: 让我们搞清楚图片说了些什么¶
OpenAI 拿 4 亿张互联网上找到的图片,以及图片对应的 ALT 文字训练了一个叫做 CLIP 的多模态模型
所谓“多模态”,就是多种媒体形式的内容。
推荐阅读¶
对计算机视觉的深度学习有一个快速地了解,那么 Pinecone 提供的这份 Embedding Methods for Image Search 是一份很好的教程: https://www.pinecone.io/learn/image-search/
24| Stable Diffusion: 最热门的开源AI画图工具¶
文生图领域就属于百花齐放了,OpenAI 陆续发表了 DALL-E 和 DALL-E 2: https://openai.com/product/dall-e-2
Google 也不甘示弱地发表了 Imagen: https://imagen.research.google/
市场上实际被用得最多、反馈最好的用户端产品是 Midjourney
在整个技术社区里,最流行的完全开源产品则是 Stable Diffusion
Stable Diffusion 的基本原理¶
整个 Stable Diffusion 文生图的过程是由这样三个核心模块组成:
1. 第一个模块是一个 Text-Encoder,把我们输入的文本变成一个向量
2. 第二个是 Generation 模块,顾名思义是一个图片信息生成模块
3. 最后一个模块,则是 Decoder 或者叫做解码器
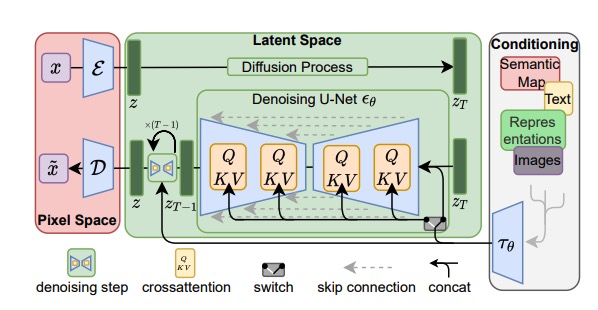
Stable Diffusion 相关论文里的一张模型架构图¶
DiffusionPipeline 内部是由哪些部分组成:
1. Tokenizer 和 Text_Encoder,就是我们上面说的把文本变成向量的 Text Encoder
这里用的模型就是上一讲的 CLIP 模型
2. UNet 和 Scheduler,就是对文本向量以及输入的噪声进行噪声去除的组件,也就是 Generation 模块
这里用的是 UNet2DConditionModel 模型,还把 PNDMScheduler 用作了去除噪声的调度器
3. VAE,也就是解码器(Decoder)
这里用的是 AutoencoderKL,它会根据上面生成的图片信息最后还原出一张高分辨率的图片
社区里的其他模型¶
Stable Diffusion 并不是指某一个特定的模型,而是指一类模型结构
你大可以利用自己的数据去训练一个属于自己的模型。事实上,市面上开源训练出来的 Stable Diffusion 的模型非常多
也有了分享 Stable Diffusion 模型的平台: https://civitai.com/
官方文档: https://huggingface.co/docs/diffusers/using-diffusers/inpaint
25| ControlNet: 让你的图拥有一个“骨架”¶
ControlNet 是在 Stable Diffusion 的基础上进行优化的一个开源项目,它既对原本的模型架构进行了修改,又在此基础上进行了进一步地训练,提供了一系列新的模型供你使用。
%pip install diffusers transformers xformers accelerate
%pip install opencv-contrib-python
%pip install controlnet_aux
xformers 是 Facebook 开源的一个 transformers 加速库,它的作用是优化实际模型计算的推理过程并且节约使用的内存,也就是我们画图会比之前快一些,对显卡的要求低一点。但是,它也有缺点,那就是输出图片的质量不太稳定,有时候图片质量会差一些。
controlnet_aux 包含了 ControlNet 预先训练好的一系列模型。
ControlNet 支持的模型¶
controlnet-canny,通过边缘检测绘制头像
Open Pose,捕捉人体的动作来复刻图片
Scribble,以一个简单的简笔画为基础,生成精美的图片
HED Boundary,这是除 Canny 之外,另外一种边缘检测算法获得的边缘检测图片
Depth,深度估计,也就是对一张图片的前后深度估计出来的轮廓图
Normal Map,法线贴图,通常在游戏中用得比较多,可以在不增加模型复杂性的情况下,提升细节效果
Semantic Segmentation,语义分割图,可以把图片划分成不同的区域模块
M-LSD,这个能够获取图片中的直线段,很适合用来给建筑物或者房间内的布局描绘轮廓。这个算法也常常被用在自动驾驶里面。
推荐阅读¶
ControlNet论文: https://arxiv.org/abs/2302.05543
26| Visual ChatGPT是如何做到边聊边画的¶
微软开源的 Visual ChatGPT: https://github.com/microsoft/TaskMatrix
Visual ChatGPT 要加载很多个不同的图片相关的模型,这些模型加起来的显存得有 40GB 以上
Visual ChatGPT 的效果非常神奇,但是其实内部原理却非常简单(LangChain 的 ReAct Agent 模式)
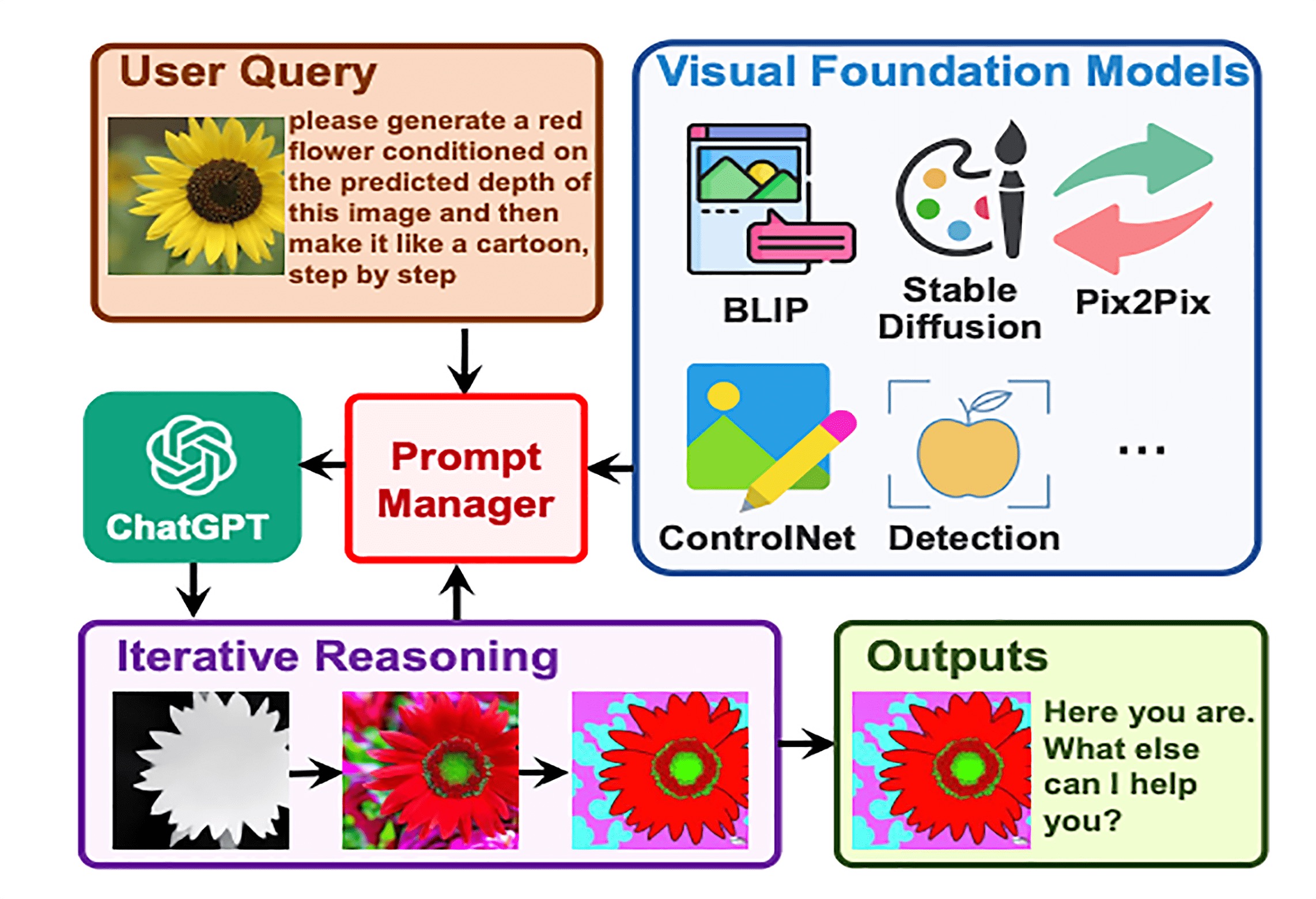
来自 Visual ChatGPT 论文中的图¶
推荐阅读¶
在 Visual ChatGPT 之后,微软更进一步将这个概念扩展成为 Task Matrix,也对应发表了一篇论文: https://arxiv.org/abs/2303.16434
评论¶
27| 从Midjourney开始, 探索AI产品的用户体验¶
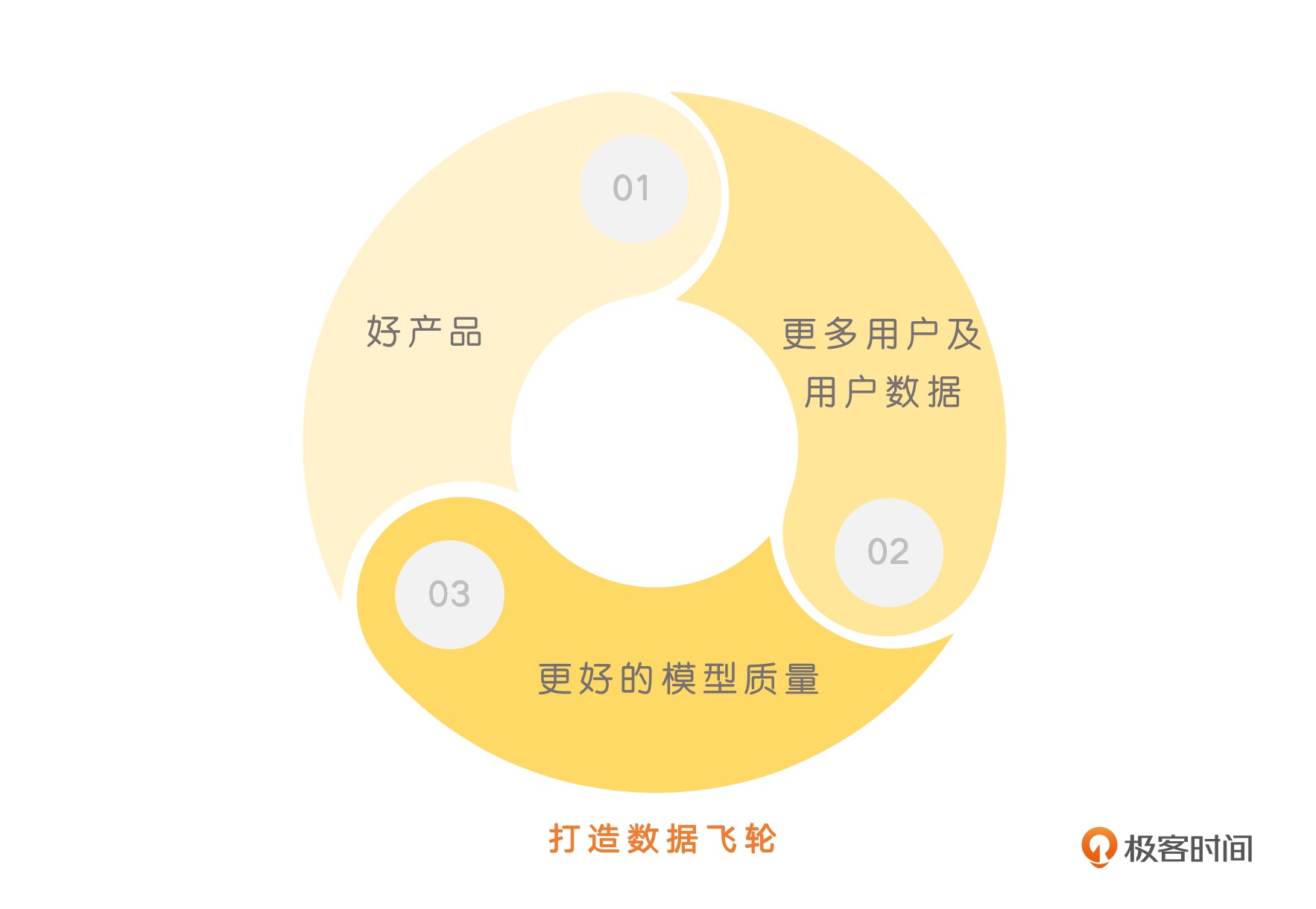
好的产品 -> 更多的用户数据 -> 更好的模型质量 -> 更好的产品就进入了一个正向循环。Midjourney,尽管没有开源社区里自带干粮的开发者们添砖加瓦,但是大量的用户反馈数据给了他们一个高质量的数据集。而开源的 Stable Diffusion,相对来说就缺少这样的数据反馈。因为大部分人部署模型之后,生成的图片都是自己使用,并没有把什么样的图片质量高、什么样的图片没法用反馈给 Stability AI 这个公司。¶
评论¶
Claude-100k 以一次性读取10万个token: https://www.anthropic.com/index/100k-context-windows
扩展¶
通向 AGI 之路: 大型语言模型(LLM)技术精要¶
潮流之巅: NLP 研究范式的转换¶
范式转换 1.0: 从深度学习到两阶段预训练模型¶
这个范式转换所涵盖的时间范围,大致在深度学习引入 NLP 领域(2013 年左右),到 GPT 3.0 出现之前(2020 年 5 月左右)
在 Bert 和 GPT 模型出现之前,NLP 领域流行的技术是深度学习模型
NLP 各种任务其实收敛到了两个不同的预训练模型框架里:
对于自然语言理解类任务,其技术体系统一到了以 Bert 为代表的 “双向语言模型预训练 + 应用 Fine-tuning” 模式; 对于自然语言生成类任务,其技术体系则统一到了以 GPT 2.0 为代表的 “自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt” 模式。
范式转换 2.0: 从预训练模型走向通用人工智能(AGI)¶
这个范式转换所涵盖的时间范围,大致在 GPT3.0 出现之后(20 年 6 月左右)
目前规模最大的 LLM 模型,几乎清一色都是类似 GPT 3.0 这种 “自回归语言模型 + Prompting” 模式的,比如
GPT 3、PaLM、GLaM、Gopher、Chinchilla、MT-NLG、LaMDA等如果是以 fine-tuning 方式解决下游任务,Bert 模式的效果优于 GPT 模式;若是以 zero shot/few shot prompting 这种模式解决下游任务,则 GPT 模式效果要优于 Bert 模式。
模型制作方则将 LLM 作成公用服务,以 LLM as Service 的模式运行。
梳理下 GPT 3.0 之后 LLM 模型的主流技术进展,其实可以分为两大类:
一类是关于 LLM 模型如何从数据中吸收知识,也包括模型规模增长对 LLM 吸收知识能力带来的影响
第二类是关于人如何使用 LLM 内在能力来解决任务的人机接口,包括 In Context Learning 和 Instruct 两种模式。
思维链(CoT)prompting 这种 LLM 推理技术,本质上也属于 In Context Learning,因为比较重要,单独拎出来
学习者: 从无尽数据到海量知识¶
求知之路: LLM 学到了什么知识¶
LLM 从海量自由文本中学习了大量知识,如果把这些知识做粗略分类的话,可以分为``语言类知识``和``世界知识``两大类。
语言类知识: 指的是词法、词性、句法、语义等有助于人类或机器理解自然语言的知识。
世界知识: 指的是在这个世界上发生的一些真实事件(事实型知识,Factual Knowledge),以及一些常识性知识 (Common Sense Knowledge)。
对于 Bert 类型的语言模型来说,只用 1000 万到 1 亿单词的语料,就能学好句法语义等语言学知识,但是要学习事实类知识,则要更多的训练数据。从增量的训练数据中学到的更主要是世界知识。
记忆之地: LLM 如何存取知识¶
知识一定存储在 Transformer 的模型参数里。
从 Transformer 的结构看,模型参数由两部分构成:多头注意力(MHA)部分占了大约参数总体的三分之一,三分之二的参数集中在 FFN 结构中。
MHA 主要用于计算单词或知识间的相关强度,并对全局信息进行集成,更可能是在建立知识之间的联系,大概率不会存储具体知识点,那么很容易推论出 LLM 模型的知识主体是存储在 Transformer 的 FFN 结构里。
知识涂改液:如何修正 LLM 里存储的知识¶
目前有三类不同方法来修正 LLM 里蕴含的知识
第一类方法从训练数据的源头来修正知识。
第二类方法是对 LLM 模型做一次 fine-tuning 来修正知识。
另外一类方法直接修改 LLM 里某些知识对应的模型参数来修正知识。
规模效应: 当 LLM 越来越大时会发生什么¶
假设用于训练 LLM 的算力总预算(比如多少 GPU 小时或者 GPU 天)给定,那么是应该多增加数据量、减少模型参数呢?还是说数据量和模型规模同时增加,减少训练步数呢?此消彼长,某个要素规模增长,就要降低其它因素的规模,以维持总算力不变,所以这里有各种可能的算力分配方案。
人机接口: 从 In Context Learning 到 Instruct 理解¶
一般我们经常提到的人和 LLM 的接口技术包括:
zero shot prompting
few shot prompting
In Context Learning
Instruct
zero shot prompting 和 Instruct 意思类似,是给定命令表述语句,试图让 LLM 理解它。
而 In Context Learning 和 few shot prompting 意思类似,是给 LLM 几个示例作为范本,然后让 LLM 解决新问题
取经之路: 复刻 ChatGPT 时要注意些什么¶
在预训练模式上,我们有三种选择:
1. GPT 这种自回归语言模型
2. Bert 这种双向语言模型
3. T5 这种混合模式 (Encoder-Decoder 架构,在 Encoder 采取双向语言模型,Decoder 采取自回归语言模型,所以是一种混合结构,但其本质仍属于 Bert 模式)
如果希望模型参数规模不要那么巨大,但又希望效果仍然足够好,此时有两个技术选项可做配置:
1. 增强高质量数据收集、挖掘、清理等方面的工作
意思是我模型参数可以是 ChatGPT/GPT 4 的一半,但是要想达到类似的效果,
那么高质量训练数据的数量就需要是 ChatGPT/GPT 4 模型的一倍(Chinchilla 的路子)
2. 有效减小模型规模的路线是采取文本检索(Retrieval based)模型 + LLM 的路线,
这样也可以在效果相当的前提下,极大减少 LLM 模型的参数规模。
这两个技术选型不互斥,而是互补的,即:可以同时采取这两个技术,在模型规模相对比较小的前提下,达到超级大模型的效果