容器实战高手课¶
目录
学习总结:
一个态度
不要浅尝辄止,要刨根问底
两个步骤
1 化繁为简,重现问题
2 想办法把黑盒系统变成白盒系统
容器化的好处是:
1. 对于应用,它容器化之后,发布和部署更加方便,特别是在扩容的时候更快了。
2. 对于平台,我们用一套平台 kubernetes 来管理所有的应用,对于硬件资源的利用率得以提高。
Namespace¶
备注
Namespace 是 Linux 中实现容器的两大技术之一,它最重要的作用是保证资源的隔离。
Namespace:
其实就是一种隔离机制,
主要目的是隔离运行在同一个宿主机上的容器,让这些容器之间不能访问彼此的资源。
这种隔离有两个作用:
1. 可以充分地利用系统的资源,也就是说在同一台宿主机上可以运行多个用户的容器
2. 保证了安全性,因为不同用户之间不能访问对方的资源
Namespace种类:
1. PID Namespace
2. Network Namespace
3. Mount Namespace
4. cgroup Namespace
5. ipc Namespace
6. time Namespace
7. user Namespace
8. uts Namespace
这些 Namespace 尽管类型不同,其实都是为了隔离容器资源:
1. PID Namespace 负责隔离不同容器的进程
2. Network Namespace 又负责管理网络环境的隔离
3. Mount Namespace 管理文件系统的隔离
4. ...
Cgroups¶
备注
支撑容器的第二个技术 Cgroups (Control Groups)了。Cgroups 可以对指定的进程做各种计算机资源的限制,比如限制 CPU 的使用率,内存使用量,IO 设备的流量等等。
几种比较常用的 Cgroups 子系统:
1. CPU 子系统,用来限制一个控制组(一组进程,可、理解为一个容器里所有的进程)可使用的最大 CPU
2. memory 子系统,用来限制一个控制组最大的内存使用量
3. pids 子系统,用来限制一个控制组里最多可以运行多少个进程
4. cpuset 子系统,这个子系统来限制一个控制组里的进程可以在哪几个物理 CPU 上运行
Linux Kernel¶
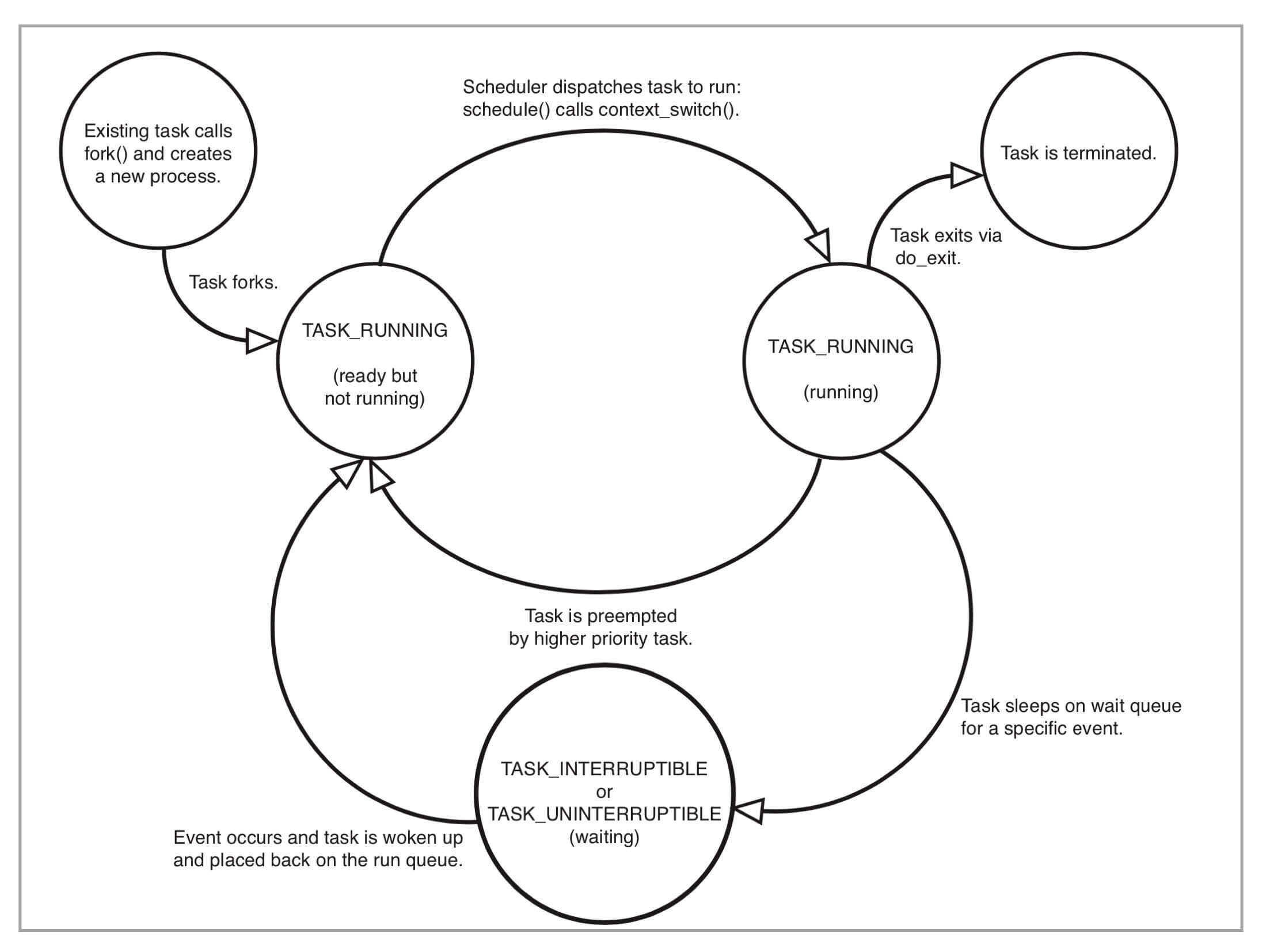
在进程 “活着” 的时候就只有两个状态:运行态(TASK_RUNNING)和睡眠态(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE)¶
睡眠态具体还包括两个子状态:
1. 可以被打断的(TASK_INTERRUPTIBLE),用 ps 查看到的进程,显示为 S stat。
2. 不可被打断的(TASK_UNINTERRUPTIBLE),用 ps 查看进程,就显示为 D stat。
进程在调用 do_exit () 退出的时候,还有两个状态:
1. EXIT_DEAD,也就是进程在真正结束退出的那一瞬间的状态
2. EXIT_ZOMBIE 状态,这是进程在 EXIT_DEAD 前的一个状态
备注
僵尸进程的产生原因是:父进程在创建完子进程之后就不管了。需要父进程调用 wait () 或者 waitpid () 系统调用来避免僵尸进程产生。三个主要的知识点:1. 每一个 Linux 进程在退出的时候都会进入一个僵尸状态(EXIT_ZOMBIE);2. 僵尸进程如果不清理,就会消耗系统中的进程数资源,最坏的情况是导致新的进程无法启动;3. 僵尸进程一定需要父进程调用 wait () 或者 waitpid () 系统调用来清理,这也是容器中 init 进程必须具备的一个功能。
进程退出时,为什么先进入僵尸状态而不是直接消失:
这是留给父进程一次机会,
查看子进程的 PID、终止状态(退出码、终止原因,比如是信号终止还是正常退出等)、资源使用信息。
如果子进程直接消失,那么父进程没有机会掌握子进程的具体终止情况。
一般情况下,程序逻辑可能会依据子进程的终止情况做出进一步处理:
比如 Nginx Master 进程获知 Worker 进程异常退出,则重新拉起来一个 Worker 进程。
信号在接收处理的三个选择:
1. 忽略
2. 捕获
3. 缺省行为
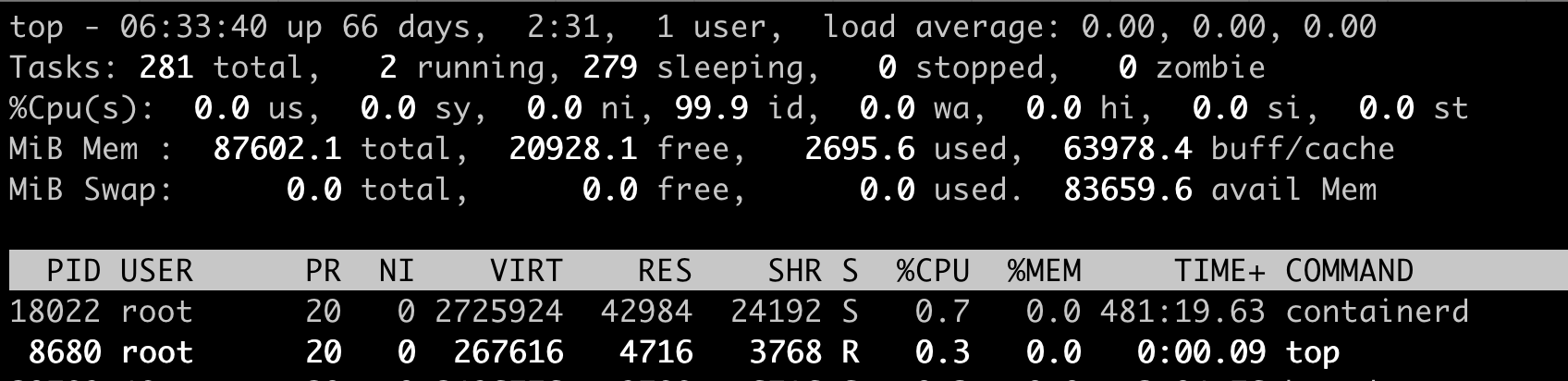
Top 运行界面: “0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st”,那么这里的每一项值的含义。¶
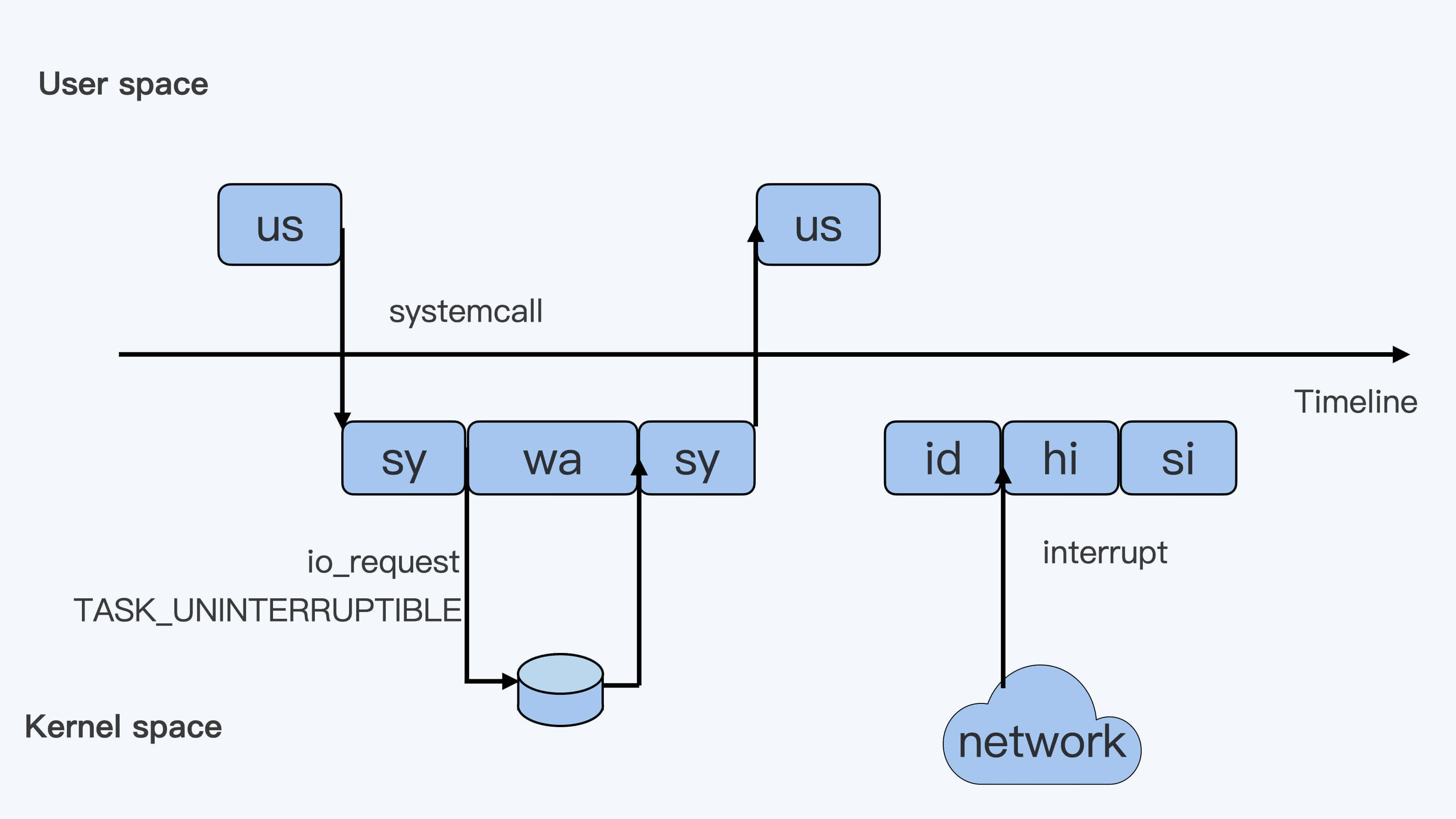
假设只有一个 CPU:最长的带箭头横轴,我们可以把它看成一个时间轴。同时,它的上半部分代表 Linux 用户态(User space),下半部分代表内核态(Kernel space)。¶
每一项值的含义:
1. "us" 是 "user" 的缩写,代表 Linux 的用户态 CPU Usage
只要不是调用系统调用(System Call),这些代码的指令消耗的 CPU 就都属于 "us"
例: 当程序代码中调用了系统调用,如 read() 读取文件,用户进程就会从用户态切换到内核态
2. "sy" 是 "system" 的缩写,代表内核态 CPU 使用
例: 内核态 read() 系统调用在读到真正 disk 上的文件前,就会进行一些文件系统层的操作
那么这些代码指令的消耗就属于 "sy"
3. "wa" 是 "iowait" 的缩写,代表等待 I/O 的时间,这里的 I/O 是指 Disk I/O
例: 这个 read() 系统调用会向 Linux 的 Block Layer 发出一个 I/O Request,
触发一个真正的磁盘读取操作
这个进程一般会被置为 TASK_UNINTERRUPTIBLE。而 Linux 会把这段时间标示成 "wa"
4. "id" 是 "idle" 的缩写,代表系统处于空闲状态
例: 用户进程在读取数据之后,没事可做就休眠了。
这时在这个 CPU 上也没有其他需要运行的进程了,那么系统就会进入 "id"
5. "hi" 是 "hardware irq" 的缩写,代表 CPU 处理硬中断的开销
由于我们的中断服务处理需要关闭中断,所以这个硬中断的时间不能太长。
例: 这时这台机器在网络收到一个网络数据包,网卡就会发出一个中断(interrupt)
相应地,CPU 会响应中断,然后进入中断服务程序
6. si" 是 "softirq" 的缩写,代表 CPU 处理软中断的开销
发生中断后的工作是必须要完成的,如果这些工作比较耗时那怎么办呢?
Linux 中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作
例: 从网卡收到数据包的大部分工作,都是通过软中断来处理的
注意: 无论是 "hi" 还是 "si",它们的 CPU 时间都不会计入进程的 CPU 时间。
这是因为本身它们在处理的时候就不属于任何一个进程
7. "ni",是 "nice" 的缩写,这里表示如果进程的 nice 值是正值(1-19)
代表优先级比较低的进程运行时所占用的 CPU
8. "st" 是 "steal" 的缩写,是在虚拟机里用的一个 CPU 使用类型
表示有多少时间是被同一个宿主机上的其他虚拟机抢走的

Load Average¶
1. Load Average 是 Linux 进程调度器中可运行队列里的一段时间的平均进程数目
不论计算机 CPU 是空闲还是满负载
可运行队列: Running Queue
2. 计算机上的 CPU 还有空闲的情况下,CPU Usage 可以直接反映到 "load average" 上
什么是 CPU 还有空闲呢?
具体来说就是可运行队列中的进程数目小于 CPU 个数
这种情况下,单位时间进程 CPU Usage 相加的平均值应该就是 "load average" 的值
3. 计算机上的 CPU 满负载的情况下,同时还有更多的进程在排队需要 CPU 资源。
这时 "load average" 就不能和 CPU Usage 等同了
比如:
对于单个 CPU 的系统,CPU Usage 最大只是有 100%,也就 1 个 CPU;
而 "load average" 的值可以远远大于 1,
因为 "load average" 看的是操作系统中可运行队列中进程的个数。
4. 对于 Linux 的 Load Average 来说,除了可运行队列中的进程数目,
等待队列中的 UNINTERRUPTIBLE 进程数目也会增加 Load Average
即: D 状态的进程数量
(注:Unix 环境下不会计算)
备注
TASK_UNINTERRUPTIBLE 是 Linux 进程状态的一种,是进程为等待某个系统资源而进入了睡眠的状态,并且这种睡眠的状态是不能被信号打断的。对于处于 I/O 资源等待的进程都是处于 TASK_UNINTERRUPTIBLE 状态的,其他比如等待信号量的进程也会进入到这个状态。
Memory Cgroup¶
总结:
1. Memory Cgroup 中每一个控制组可以为一组进程限制内存使用量
一旦所有进程使用内存的总量达到限制值,缺省情况下,就会触发 OOM Killer。
这样一来,控制组里的 “某个进程” 就会被杀死。
2. 这里杀死 “某个进程” 的选择标准是:
控制组中总的可用页面乘以进程的 oom_score_adj,
加上进程已经使用的物理内存页面,所得值最大的进程,就会被系统选中杀死。

Linux 系统内存类型:
1. 内核的内存
Linux 的各个模块都需要内存,比如:
内核需要分配内存给页表,内核栈,还有 slab,也就是内核各种数据结构的 Cache Pool
2. RSS(用户态)
进程真正申请到物理页面的内存大小
对应 「top 命令」的 RES
其中: 「top 命令」虚拟地址空间(VIRT)是进程申请的空间
RSS 内存包含:
进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的。
刚才我们通过 malloc/memset 得到的内存,就是属于堆内存
3. Page Cache
把磁盘上读写到的页面存放在内存中,这部分的内存就是 Page Cache
主要作用是: 提高磁盘文件的读写性能
Linux 的内存管理有一种内存页面回收机制(page frame reclaim)
会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收
swappiness:
1. swappiness 的取值范围在 0 到 100,值为 100 的时系统平等回收匿名内存和 Page Cache 内存;
2. 一般缺省值为 60,就是优先回收 Page Cache;
3. 即使 swappiness 为 0,也不能完全禁止 Swap 分区的使用,就是说在内存紧张的时候,也会使用 Swap 来回收匿名内存。

存储¶
文件系统:
1. XFS
2. ext4
3. OverlayFS
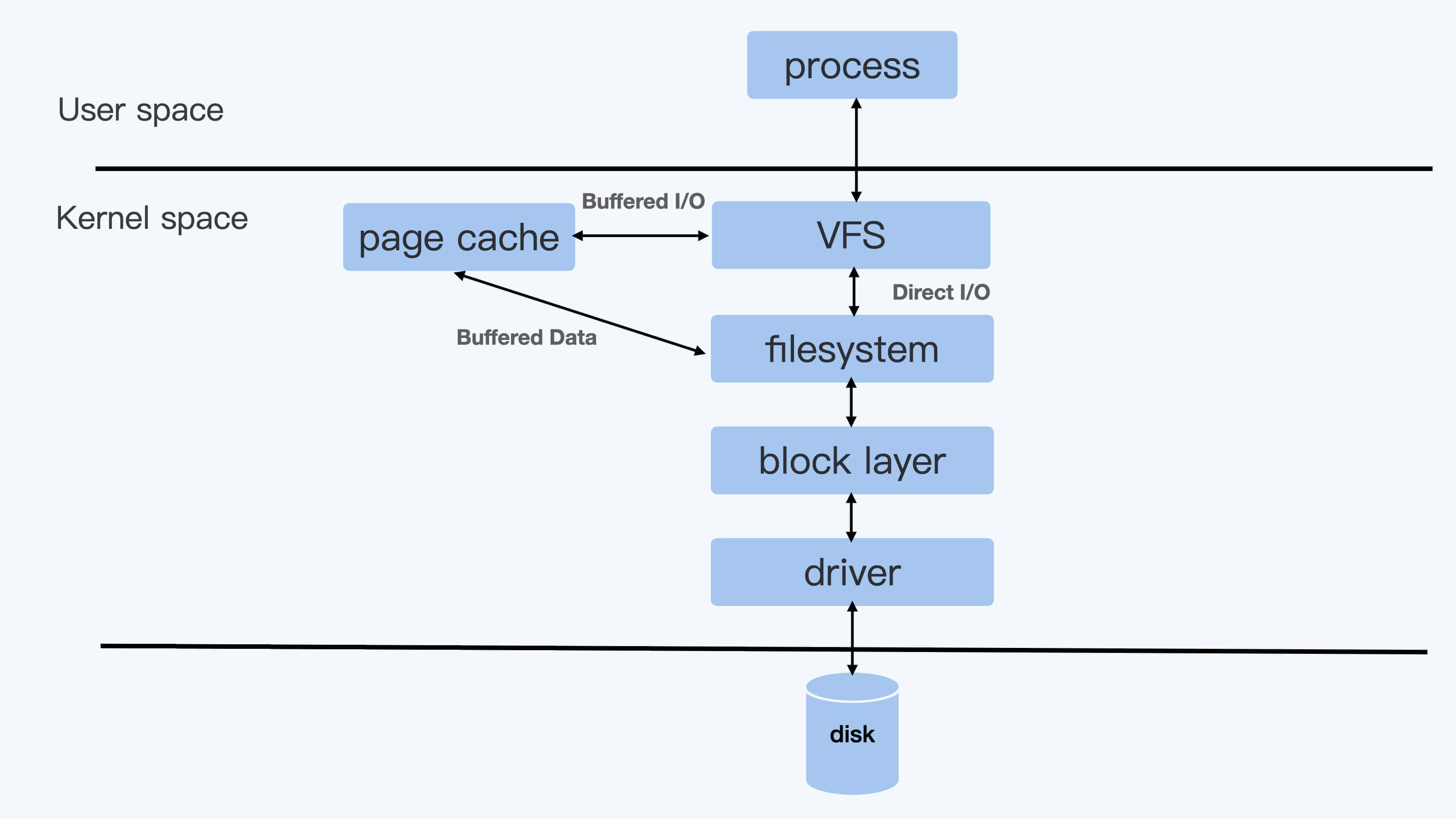
Linux 的两种文件 I/O 模式:
1. Direct I/O
用户进程如果要写磁盘文件,就会通过
-> Linux 内核的文件系统层 (filesystem)
-> 块设备层 (block layer)
-> 磁盘驱动
-> 磁盘硬件
2. Buffered I/O
用户进程只是把文件数据写到内存中(Page Cache)就返回了
而 Linux 内核自己有线程会把内存中的数据再写入到磁盘中
Network¶
通过 Network Namespace 隔离的最主要的几部分资源:
1. 网络设备,这里指的是 lo,eth0 等网络设备。你可以通过 ip link命令看到它们
2. IPv4 和 IPv6 协议栈。IP 层以及上面的 TCP 和 UDP 协议栈也是每个 Namespace 独立工作的
3. IP 路由表,可在不同的 Network Namespace 运行 ip route 命令,就能看到不同的路由表
4. 防火墙规则,即 iptables 规则,每个 Namespace 里都可以独立配置 iptables 规则
5. 网络的状态信息,可以从 /proc/net 和 /sys/class/net 里得到
这里的状态基本上包括了前面 4 种资源的的状态信息
容器从自己的 Network Namespace 连接到 Host Network Namespace 的方法,只有两类设备接口:
1. 一类是 veth
2. 一类是 macvlan/ipvlan
容器安全¶
Linux capabilities: https://man7.org/linux/man-pages/man7/capabilities.7.html
本质是把 Linux root 用户原来所有的特权做了细化,可以更加细粒度地给进程赋予不同权限 例: $ sudo setcap cap_net_admin+ep ./iptables $ getcap ./iptables
查看容器 init 进程 status 里的 Cap 参数,看一下容器中缺省的 capabilities:
# docker run --name iptables -it registry/iptables:v1 bash
[root@e54694652a42 /]# cat /proc/1/status |grep Cap
CapInh: 00000000a80425fb
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
CapBnd: 00000000a80425fb
CapAmb: 0000000000000000
给容器多加一个 NET_ADMIN 参数:
# docker run --name iptables --cap-add NET_ADMIN -it registry/iptables:v1 bash
[root@cfedf124dcf1 /]# iptables -L
增加 tcpdump 抓包权限,可添加 net_raw、net_admin caps:
sudo setcap cap_net_raw,cap_net_admin+ep $(which tcpdump)
删除全部 capabilites:
$ sudo setcap -r /usr/bin/ping
k8s¶
高层级运行时(High-levelRuntime):
dockershim
containerd
cri-o
低层级运行时(Low-levelRuntime):
runC
kata-runtime
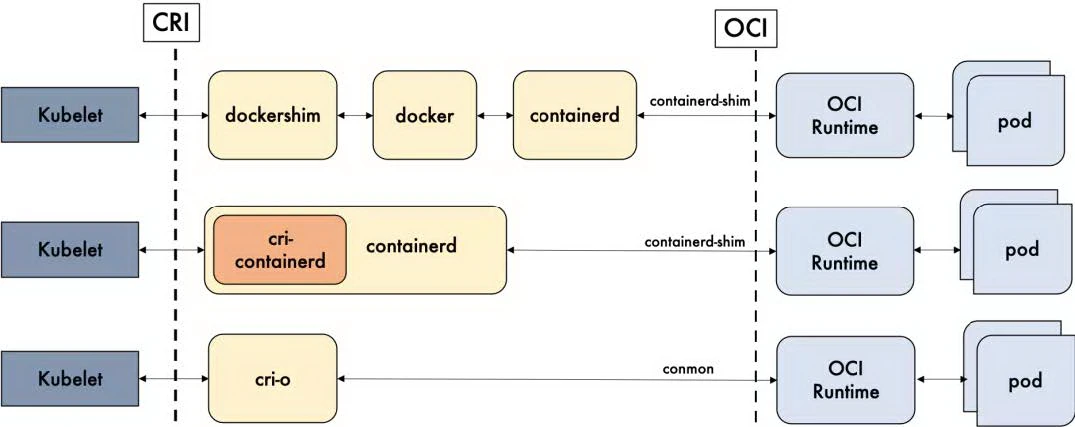
容器运行时调用层级¶
思考¶
备注
突破舒适区的本质就是突破思考的惰性。只有不断思考,才能推着自己不断往前走,才能让我们更从容地解决工作上的问题。