深入浅出计算机组成原理¶
目录
备注
操作系统也是一个 “软件”,开发操作系统,只需要关注到 “组成原理” 或者 “体系结构” 就好了,不需要真的了解硬件。操作系统,其实是在 “组成原理” 所讲的 “指令集” 上做一层封装。体系结构、操作系统、编译原理以及计算机网络,都可以认为是组成原理的后继课程。体系结构不是一个系统软件,它更多地是讲,如何量化地设计和研究体系结构和指令集。操作系统、编译原理和计算机网络都是基于体系结构之上的系统软件。
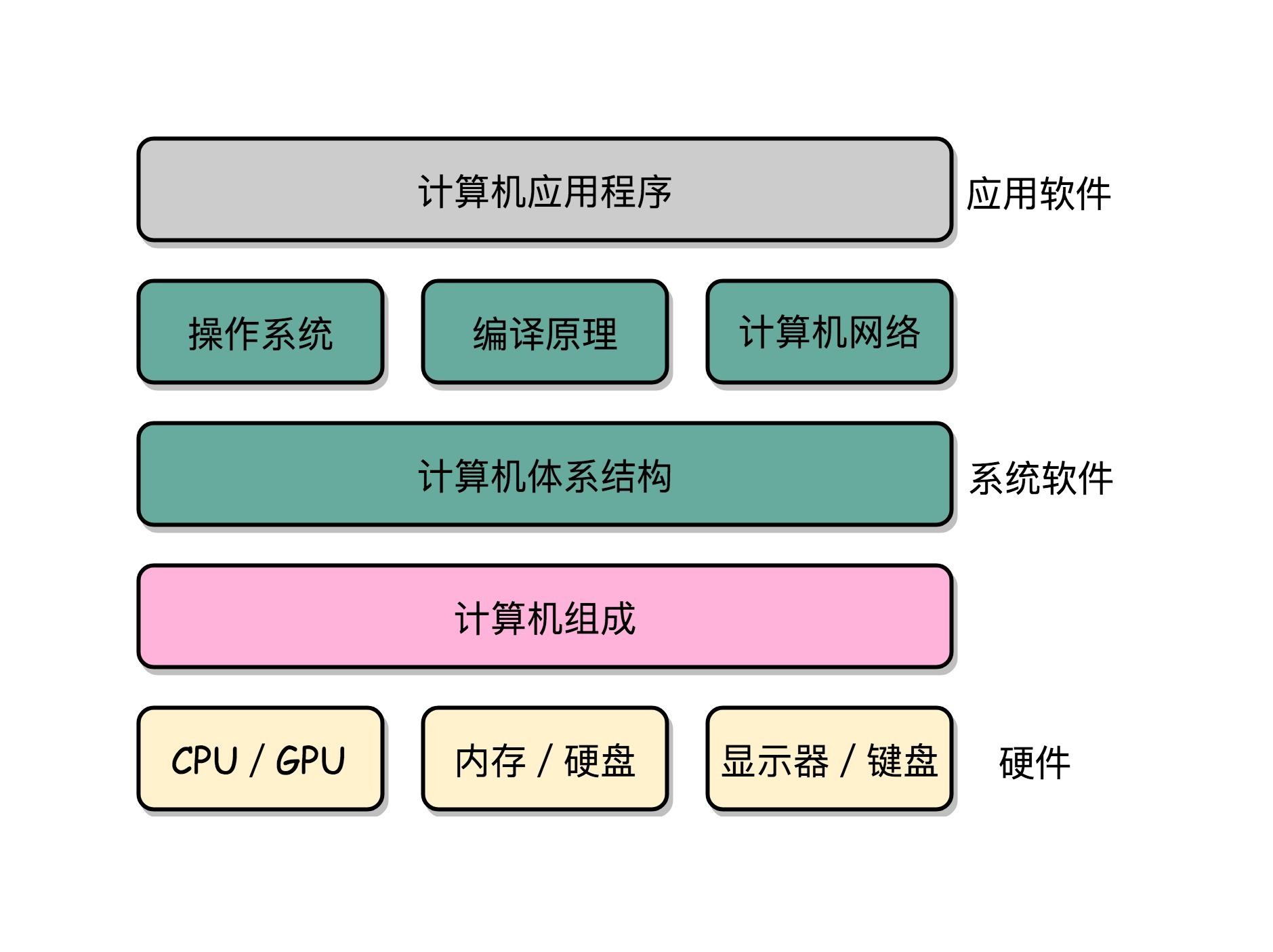
在硬件和软件之间需要一座桥梁,而 “计算机组成原理” 就扮演了这样一个角色,它既隔离了软件和硬件,也提供了让软件无需关心硬件,就能直接操作硬件的接口。¶
计算机组成原理: Computer Organization
南桥(SouthBridge)
北桥

著名的 Engima Machine 就用到了 Plugboard 来进行 “编程”¶
一台计算机应该有哪些部分组成:
1. 一个处理器单元(Processing Unit)
包含算术逻辑单元(Arithmetic Logic Unit,ALU)和处理器寄存器(Processor Register)
用来完成各种算术和逻辑运算。
因为它能够完成各种数据的处理或者计算工作,因此也有人把这个叫作数据通路(Datapath)或者运算器
2. 一个控制器单元(Control Unit/CU)
包含指令寄存器(Instruction Register)和程序计数器(Program Counter)
用来控制程序的流程,通常就是不同条件下的分支和跳转。
在现在的计算机里,上面的算术逻辑单元和这里的控制器单元,共同组成了我们说的 CPU
3. 用来存储数据(Data)和指令(Instruction)的内存,以及更大容量的外部存储
外部存储在过去,可能是磁带、磁鼓这样的设备,现在通常就是硬盘
4. 各种输入和输出设备,以及对应的输入和输出机制
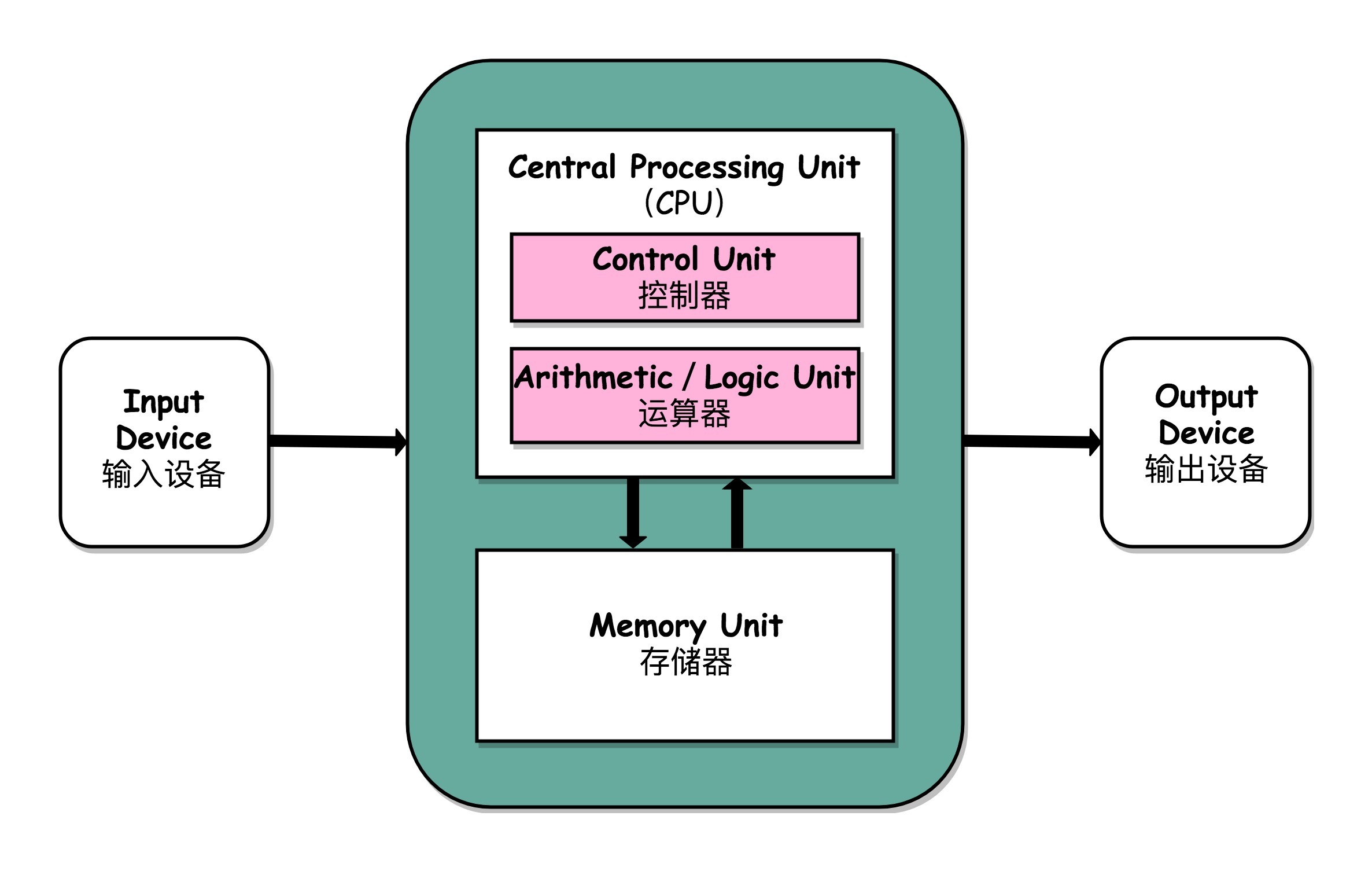
冯・诺依曼体系结构示意图¶
备注
具体来说,学习组成原理,其实就是 1. 学习控制器、运算器的工作原理,也就是 CPU 是怎么工作的,以及为何这样设计;2. 学习内存的工作原理,从最基本的电路,到上层抽象给到 CPU 乃至应用程序的接口是怎样的;3. 学习 CPU 是怎么和输入设备、输出设备打交道的。
论文: First Draft of a Report on the EDVAC
计算机行业的两大祖师爷,冯・诺依曼机、图灵(Alan Mathison Turing)
图灵机是一种思想模型(计算机的基本理论基础),是一种有穷的、构造性的问题的问题求解思路,图灵认为凡是能用算法解决的问题也一定能用图灵机解决;
冯诺依曼提出了 “存储程序” 的计算机设计思想,并 “参照” 图灵模型设计了历史上第一台电子计算机,即冯诺依曼机
图灵机是一个抽象的” 思维实验 “,而冯诺依曼机就是对应着这个” 思维实验 “的” 物理实现 “。相互之间颇有理论物理学家和实验物理学家的合作关系的意思,可谓是一个问题的一体两面。
哈弗结构算是冯诺依曼结构的一个特殊形式吧,把指令和数据分开存储,不过现在很少见有人提了。
计算机的性能衡量标准中主要有两个指标:
1. 响应时间(Response time)或者叫执行时间(Execution time)
2. 吞吐率(Throughput)或者带宽(Bandwidth)
time 命令。它会返回三个值,第一个是 real time,也就是我们说的 Wall Clock Time,也就是运行程序整个过程中流逝掉的时间;第二个是 user time,也就是 CPU 在运行你的程序,在用户态运行指令的时间;第三个是 sys time,是 CPU 在运行你的程序,在操作系统内核里运行指令的时间。而程序实际花费的 CPU 执行时间(CPU Time),就是 user time 加上 sys time:
$ time seq 1000000 | wc -l
1000000
real 0m0.101s
user 0m0.031s
sys 0m0.016s
程序的 CPU 执行时间 = CPU 时钟周期数 × 时钟周期时间
CPU 时钟周期数 = 指令数 × 每条指令的平均时钟周期数(CPI)
=>
程序的 CPU 执行时间 = 指令数 ×CPI×Clock Cycle Time
1. 时钟周期时间,就是计算机主频,这个取决于计算机硬件
2. 每条指令的平均时钟周期数 CPI,就是一条指令到底需要多少 CPU Cycle
现代的 CPU 通过流水线技术(Pipeline),让一条指令需要的 CPU Cycle 尽可能地少
对于 CPI 的优化,也是计算机组成和体系结构中的重要一环
3. 指令数,代表执行我们的程序到底需要多少条指令、用哪些指令
编译器做优化
从 1978 年 Intel 发布的 8086 CPU 开始,计算机的主频从 5MHz 开始,不断提升。1980 年代中期的 80386 能够跑到 40MHz,1989 年的 486 能够跑到 100MHz,直到 2000 年的奔腾 4 处理器,主频已经到达了 1.4GHz,2019 年的最高配置 Intel i9 CPU,主频也只不过是 5GHz 而已。相较于 1978 年到 2000 年,这 20 年里 300 倍的主频提升,从 2000 年到2019年的这 19 年,CPU 的主频大概提高了 3 倍。
在 “摩尔定律” 和 “并行计算” 之外,在整个计算机组成层面,还有这样几个原则性的性能提升方法:
1. 加速大概率事件
2. 通过流水线提高性能
3. 通过预测提高性能
指令和运算¶
纸带编程¶

上世纪 60 年代晚期或 70 年代初期,Arnold Reinold 拍摄的 FORTRAN 计算程序的穿孔卡照片¶
一台 IBM 的 Plugboard Computer“插线板计算机”。在一个布满了各种插口和插座的板子上,工程师们用不同的电线来连接不同的插口和插座,从而来完成各种计算任务。¶
把对应的汇编代码和机器码都打印出来:
$ gcc -g -c test.c
$ objdump -d -M intel -S test.o

CPU 指令可以分成五大类:
1. 第一类是算术类指令。我们的加减乘除,在 CPU 层面,都会变成一条条算术类指令。
2. 第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。
3. 第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。
4. 第四类是条件分支类指令。日常我们写的 “if/else”,其实都是条件分支类指令。
5. 最后一类是无条件跳转指令。
MIPS 的指令是一个 32 位的整数,高 6 位叫操作码(Opcode),也就是代表这条指令具体是一条什么样的指令,剩下的 26 位有三种格式,分别是 R、I 和 J:
1. R 指令是一般用来做算术和逻辑操作,里面有读取和写入数据的寄存器的地址。
2. I 指令,则通常是用在数据传输、条件分支,以及在运算的时候使用的并非变量还是常数的时候。
3. J 指令就是一个跳转指令,高 6 位之外的 26 位都是一个跳转后的地址。
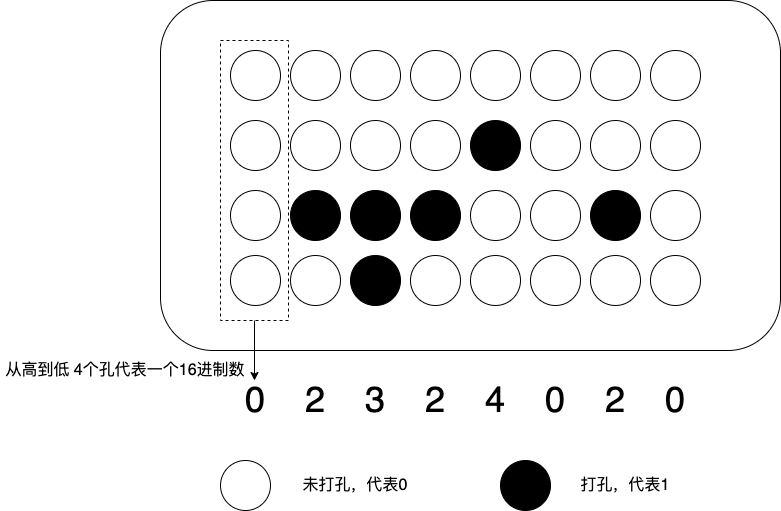
用打孔代表 1,没有打孔代表 0,用 4 行 8 列代表一条指令来打一个穿孔纸带,那么这条命令大概就长这样¶
寄存器¶
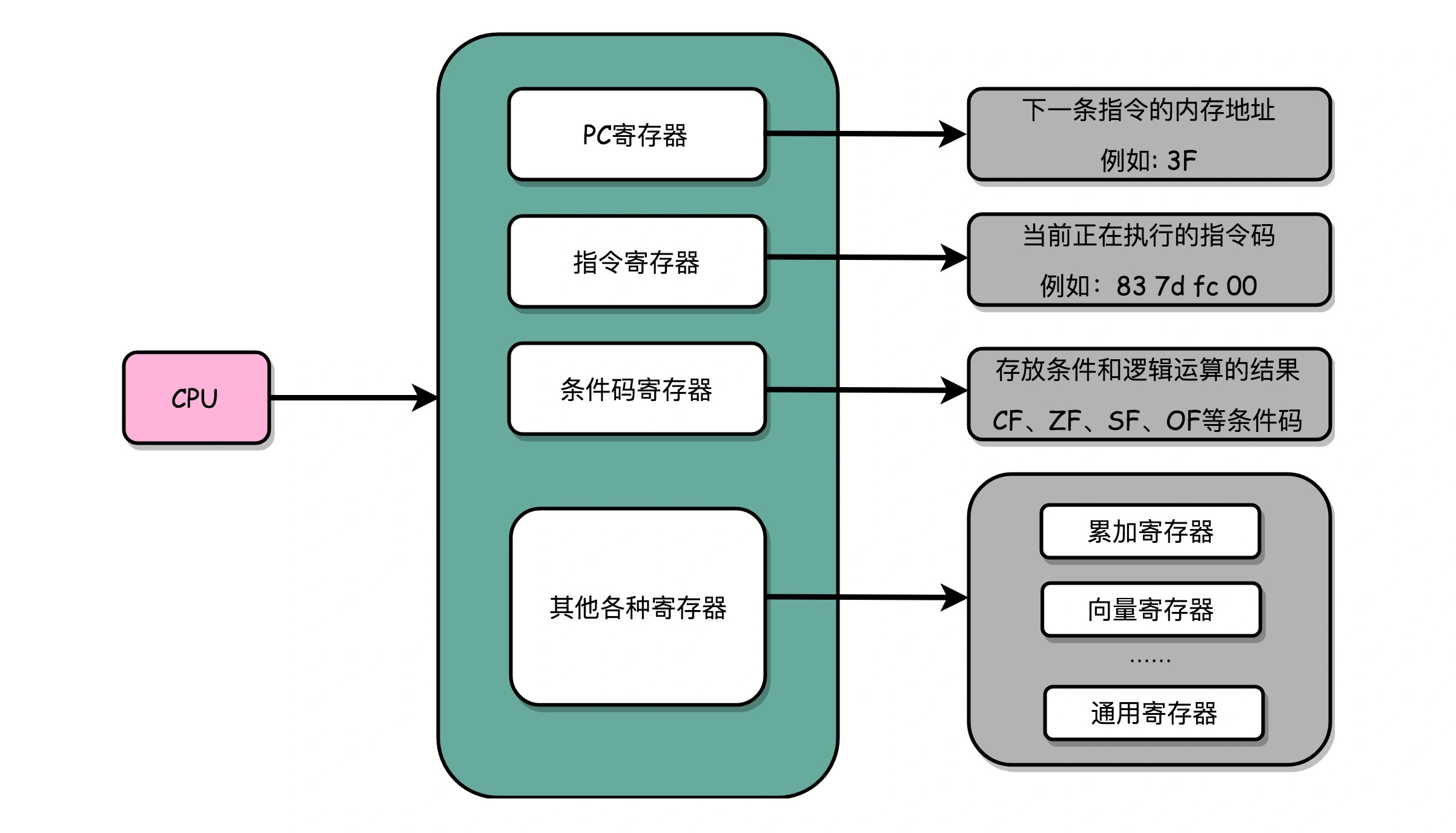
N 个触发器或者锁存器,就可以组成一个 N 位(Bit)的寄存器,能够保存 N 位的数据。比方说,我们用的 64 位 Intel 服务器,寄存器就是 64 位的。¶
一个 CPU 里面会有很多种不同功能的寄存器。我这里给你介绍三种比较特殊的:
1. PC 寄存器(Program Counter Register),也叫指令地址寄存器(Instruction Address Register)
顾名思义,它就是用来存放下一条需要执行的计算机指令的内存地址。
PC 寄存器还有一个名字,就叫作程序计数器
顾名思义,就是随着时间变化,不断去数数。数的数字变大了,就去执行一条新指令。
2. 指令寄存器(Instruction Register),用来存放当前正在执行的指令。
3. 条件码寄存器(Status Register),用里面的一个一个标记位(Flag),
存放 CPU 进行算术或者逻辑计算的结果。
还有更多用来存储数据和内存地址的寄存器。这样的寄存器通常一类里面不止一个:
我们通常根据存放的数据内容来给它们取名字,比如:
1. 整数寄存器
2. 浮点数寄存器
3. 向量寄存器
4. 地址寄存器
有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器。
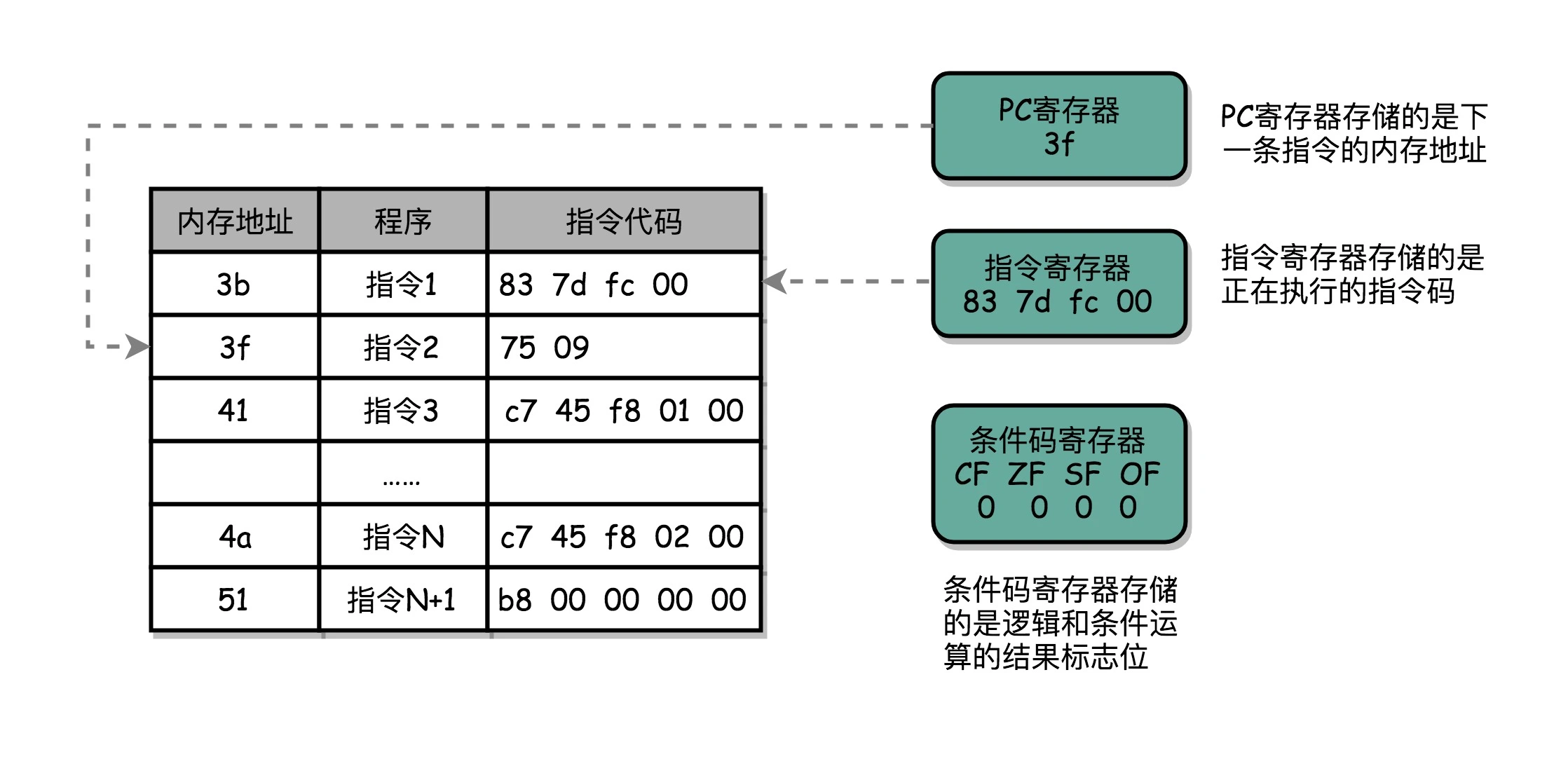
一个程序执行的时候,CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。有些特殊指令,比如上一讲我们讲到 J 类指令,也就是跳转指令,会修改 PC 寄存器里面的地址值。这样,下一条要执行的指令就不是从内存里面顺序加载的了。¶
备注
核心在于理解几个寄存器的作用,从而理解 cpu 运行程序的过程:cpu 从 PC 寄存器中取地址,找到地址对应的内存位子,取出其中指令送入指令寄存器执行,然后指令自增,重复操作。所以只要程序在内存中是连续存储的,就会顺序执行这也是冯诺依曼体系的理念吧。而实际上跳转指令就是当前指令修改了当前 PC 寄存器中所保存的下一条指令的地址,从而实现了跳转。当然各个寄存器实际上是由数电中的一个一个门电路组合出来的,而各个门电路的具体电路形式也是属于模电的东西
汇编¶
C源码:
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
}
执行命令:
$ gcc -g -c test.c
$ objdump -d -M intel -S test.o
生成汇编:
if (r == 0)
3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
3f: 75 09 jne 4a <main+0x4a>
{
a = 1;
41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
48: eb 07 jmp 51 <main+0x51>
}
else
{
a = 2;
4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
51: b8 00 00 00 00 mov eax,0x0
}
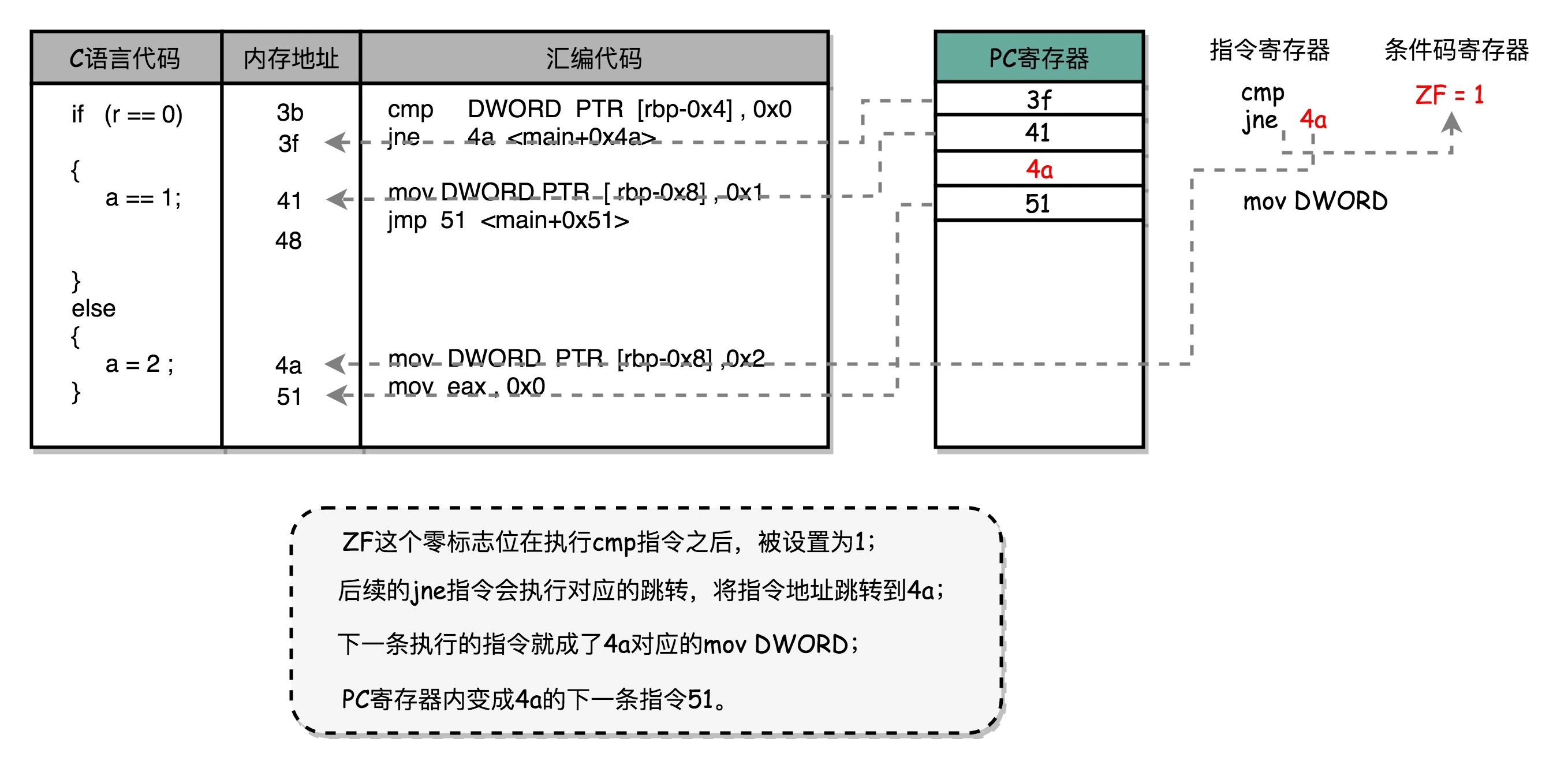
可以看到,这里对于 r == 0 的条件判断,被编译成了 cmp 和 jne 这两条指令。 cmp 指令比较了前后两个操作数的值,这里的 DWORD PTR 代表操作的数据类型是 32 位的整数,而 [rbp-0x4] 则是变量 r 的内存地址。所以,第一个操作数就是从内存里拿到的变量 r 的值。第二个操作数 0x0 就是我们设定的常量 0 的 16 进制表示。cmp 指令的比较结果,会存入到条件码寄存器当中去。 在这里,如果比较的结果是 True,也就是 r == 0,就把零标志条件码(对应的条件码是 ZF,Zero Flag)设置为 1。除了零标志之外,Intel 的 CPU 下还有进位标志(CF,Carry Flag)、符号标志(SF,Sign Flag)以及溢出标志(OF,Overflow Flag),用在不同的判断条件下。 cmp 指令执行完成之后,PC 寄存器会自动自增,开始执行下一条 jne 的指令。 跟着的 jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。如果为 0,会跳转到后面跟着的操作数 4a 的位置。这个 4a,对应这里汇编代码的行号,也就是上面设置的 else 条件里的第一条指令。当跳转发生的时候,PC 寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的 4a 这个地址。这个时候,CPU 再把 4a 地址里的指令加载到指令寄存器中来执行。 跳转到执行地址为 4a 的指令,实际是一条 mov 指令,第一个操作数和前面的 cmp 指令一样,是另一个 32 位整型的内存地址,以及 2 的对应的 16 进制值 0x2。mov 指令把 2 设置到对应的内存里去,相当于一个赋值操作。然后,PC 寄存器里的值继续自增,执行下一条 mov 指令。 这条 mov 指令的第一个操作数 eax,代表累加寄存器,第二个操作数 0x0 则是 16 进制的 0 的表示。这条指令其实没有实际的作用,它的作用是一个占位符。我们回过头去看前面的 if 条件,如果满足的话,在赋值的 mov 指令执行完成之后,有一个 jmp 的无条件跳转指令。跳转的地址就是这一行的地址 51。我们的 main 函数没有设定返回值,而 mov eax, 0x0 其实就是给 main 函数生成了一个默认的为 0 的返回值到累加器里面。if 条件里面的内容执行完成之后也会跳转到这里,和 else 里的内容结束之后的位置是一样的。
stack¶
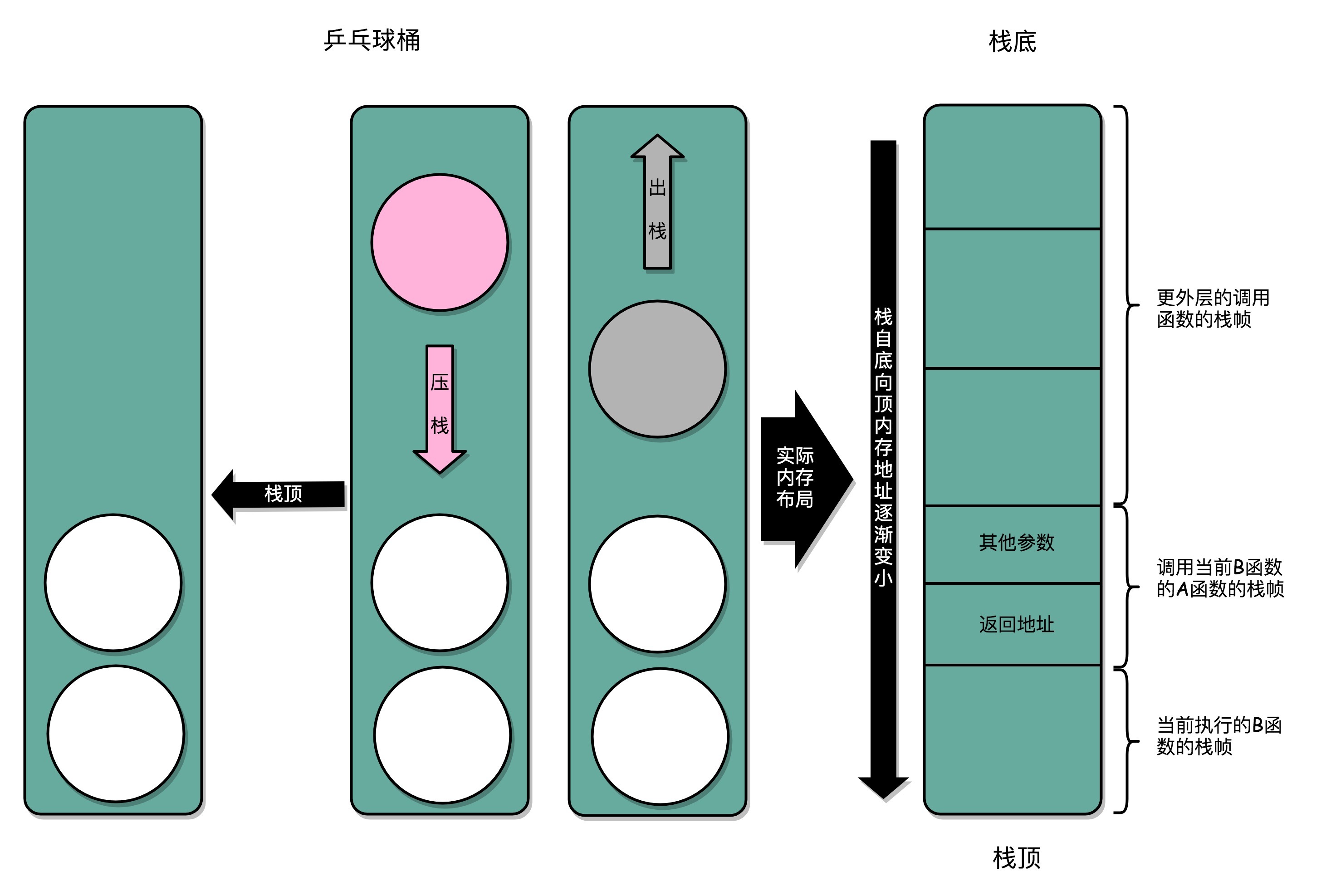
实际的程序栈布局,底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大。¶
https://blog.holbertonschool.com/hack-virtual-memory-stack-registers-assembly-code/
汇编指令操作栈的步骤一步步画: https://manybutfinite.com/post/journey-to-the-stack/
How Stacks are Handled in Go: https://blog.cloudflare.com/how-stacks-are-handled-in-go/
How Stacks are Handled in Go: https://studygolang.com/topics/491
ELF 与静态链接¶
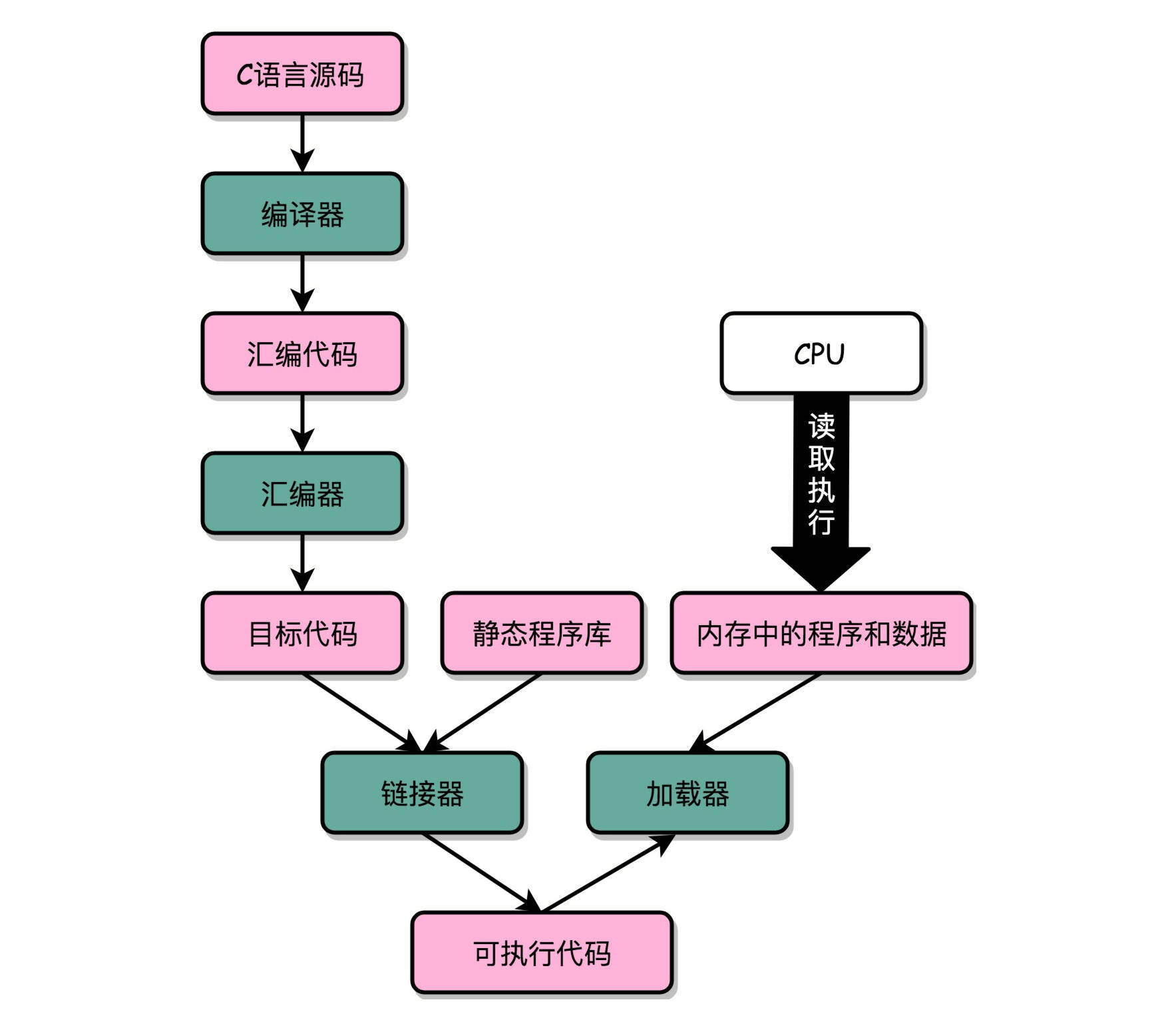
“C 语言代码 - 汇编代码 - 机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。¶
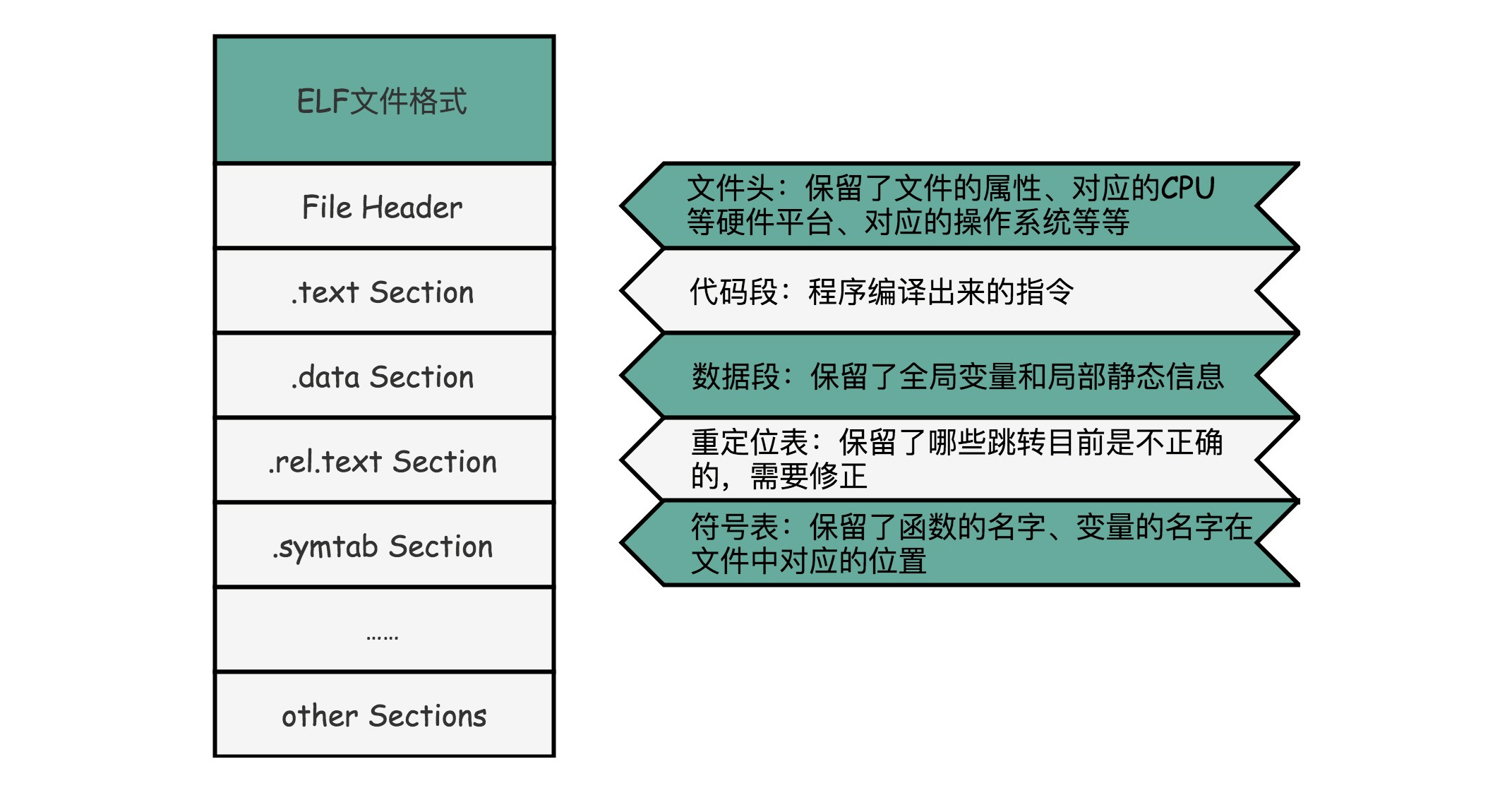
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来。ELF 有一个基本的文件头(File Header),用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等¶
除了这些基本属性之外,大部分程序还有这么一些 Section:
1. 首先是.text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;
2. 接着是.data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;
3. 然后就是.rel.text Secion,叫作重定位表(Relocation Table)。
重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。
在链接发生之前,我们并不知道该跳转到哪里,这些信息就会存储在重定位表里;
4. 最后是.symtab Section,叫作符号表(Symbol Table)。符号表保留了我们所说的当前文件里面定义的函数名称和对应地址的地址簿。
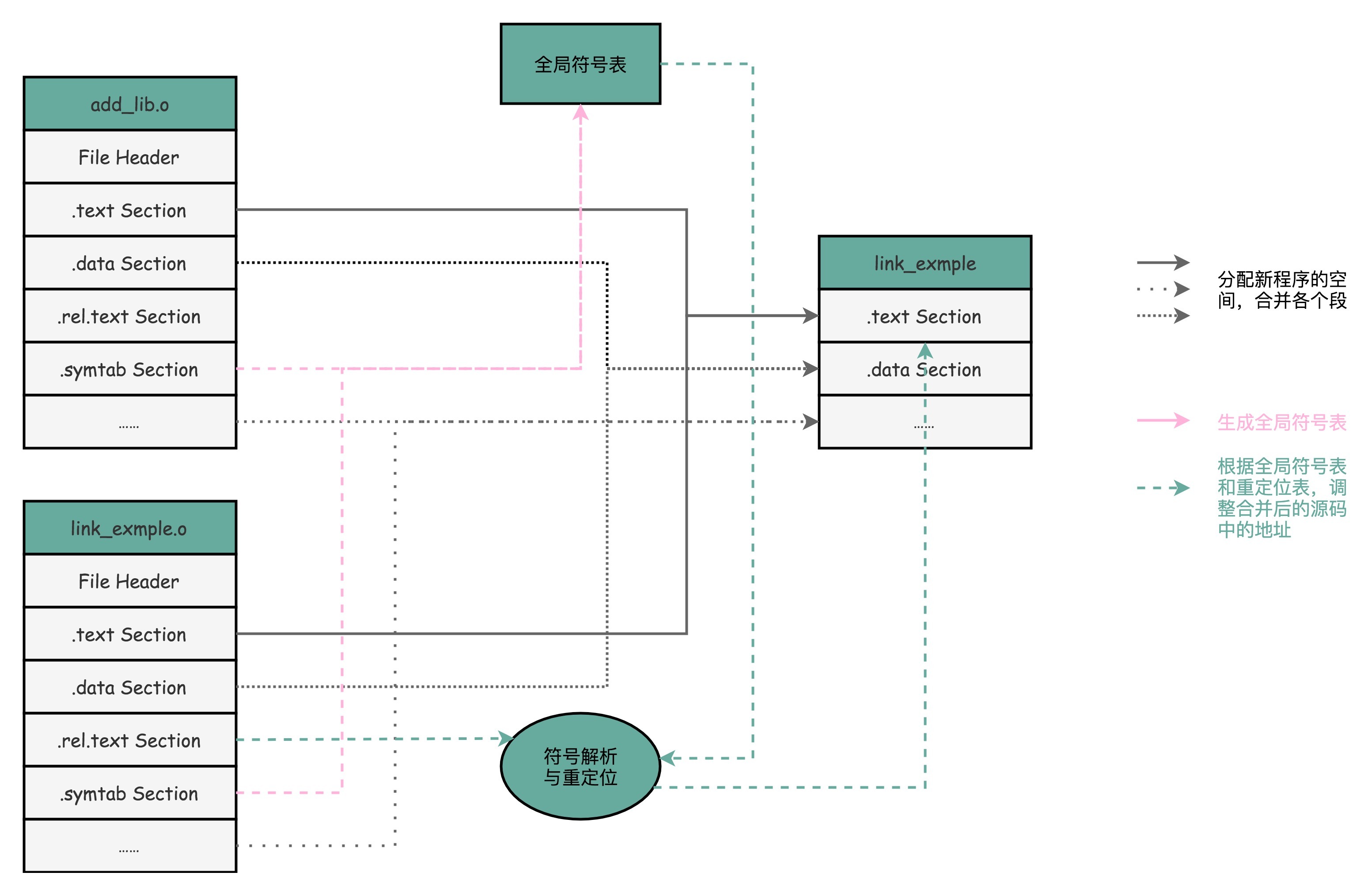
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。这也是为什么,可执行文件里面的函数调用的地址都是正确的。¶
ELF
PE
Wine
WSL
命令:
$ readelf -s link_example.o //查看符号表
$ objdump -r link_example.o //查看重定位表
装载器¶
装载器需要满足两个要求:
第一,可执行程序加载后占用的内存空间应该是连续的
第二,我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置
虚拟内存地址(Virtual Memory Address)
物理内存地址(Physical Memory Address)
内存碎片(Memory Fragmentation)
内存交换(Memory Swapping)
内存分页(Paging)
全局符号表是虚拟内存内的内存寻址和跳转。
页表是虚拟内存和物理内存之间的映射关系。
内存分段: 找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。¶
备注
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。
Linux 系统设置的页的大小:
$ getconf PAGE_SIZE
备注
由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
备注
通过虚拟内存、内存交换和内存分页这三个技术的组合,我们最终得到了一个让程序不需要考虑实际的物理内存地址、大小和当前分配空间的解决方案。这些技术和方法,对于我们程序的编写、编译和链接过程都是透明的。这也是我们在计算机的软硬件开发中常用的一种方法,就是加入一个间接层。
备注
通过引入虚拟内存、页映射和内存交换,我们的程序本身,就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
动态链接¶
动态链接(Dynamic Link)
静态链接(Static Link)
共享库(Shared Libraries)
地址无关码(Position-Independent Code)
相对地址(Relative Address)
PLT: Procedure Link Table(程序链接表)
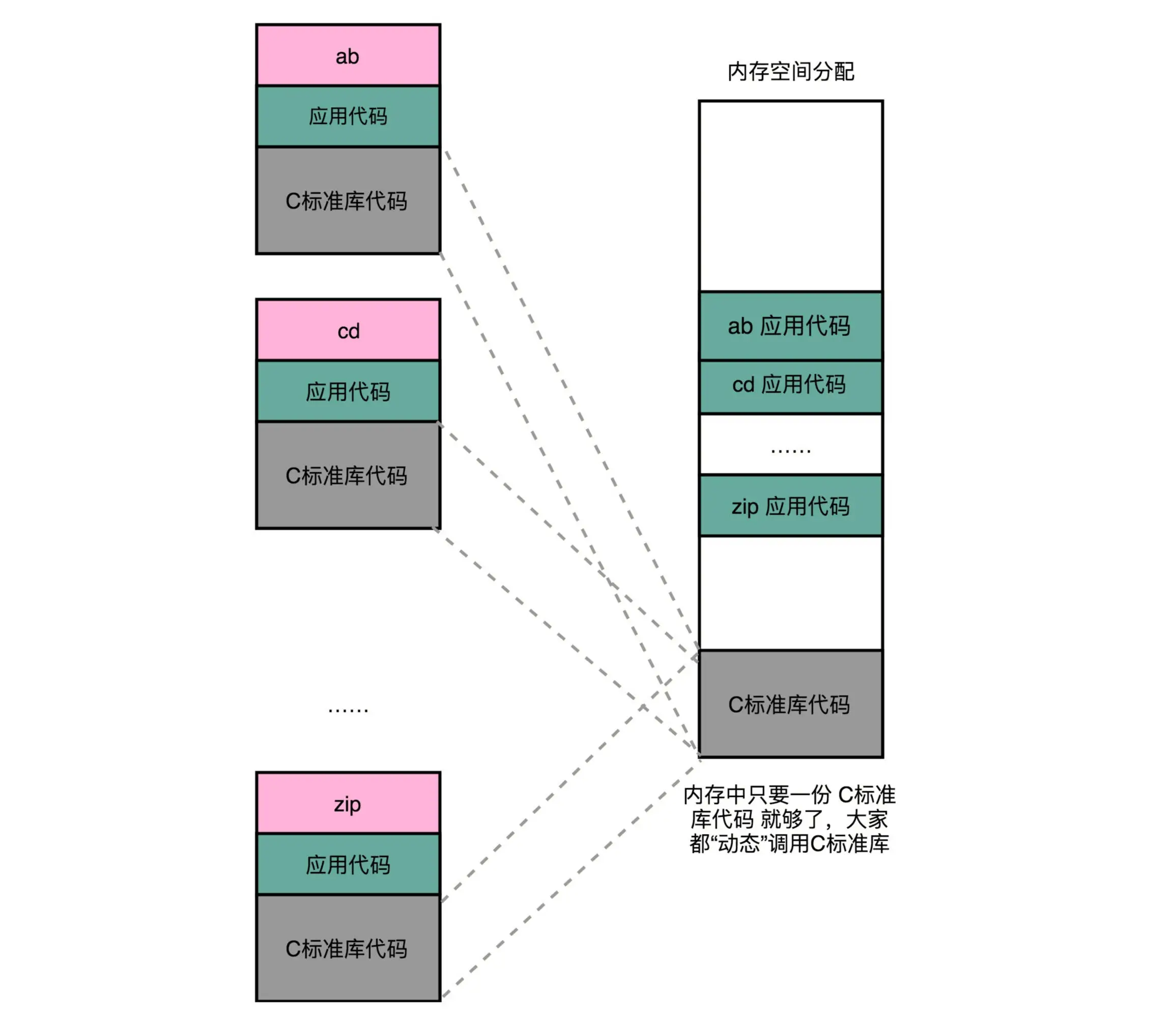
两方面的含义:一个是 “动态链接” ,另一个是 “共享”¶
$ gcc lib.c -fPIC -shared -o lib.so
$ gcc -o show_me_poor show_me_poor.c ./lib.so
说明:
-fPIC: 编译成一个地址无关代码
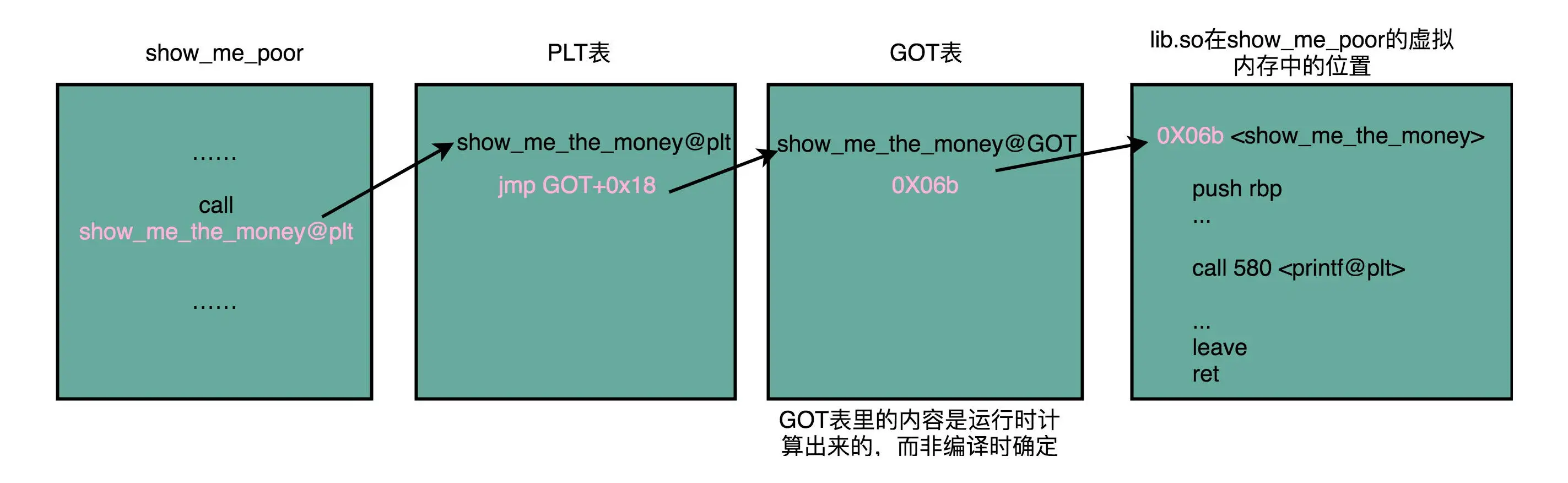
虽然不同的程序调用的同样的动态库,各自的内存地址是独立的,调用的又都是同一个动态库,但是不需要去修改动态库里面的代码所使用的地址,而是各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了。使用动态链接的话,每个程序都维护一张GOT表。¶
备注
为什么要采用 PLT 和 GOT 两级跳转,直接用 GOT 有问题吗?PLT 是为了做延迟绑定,如果函数没有实际被调用到,就不需要更新 GOT 里面的数值。因为很多动态装载的函数库都是不会被实际调用到的。
二进制编码¶
字符集(Charset)和字符编码(Character Encoding)
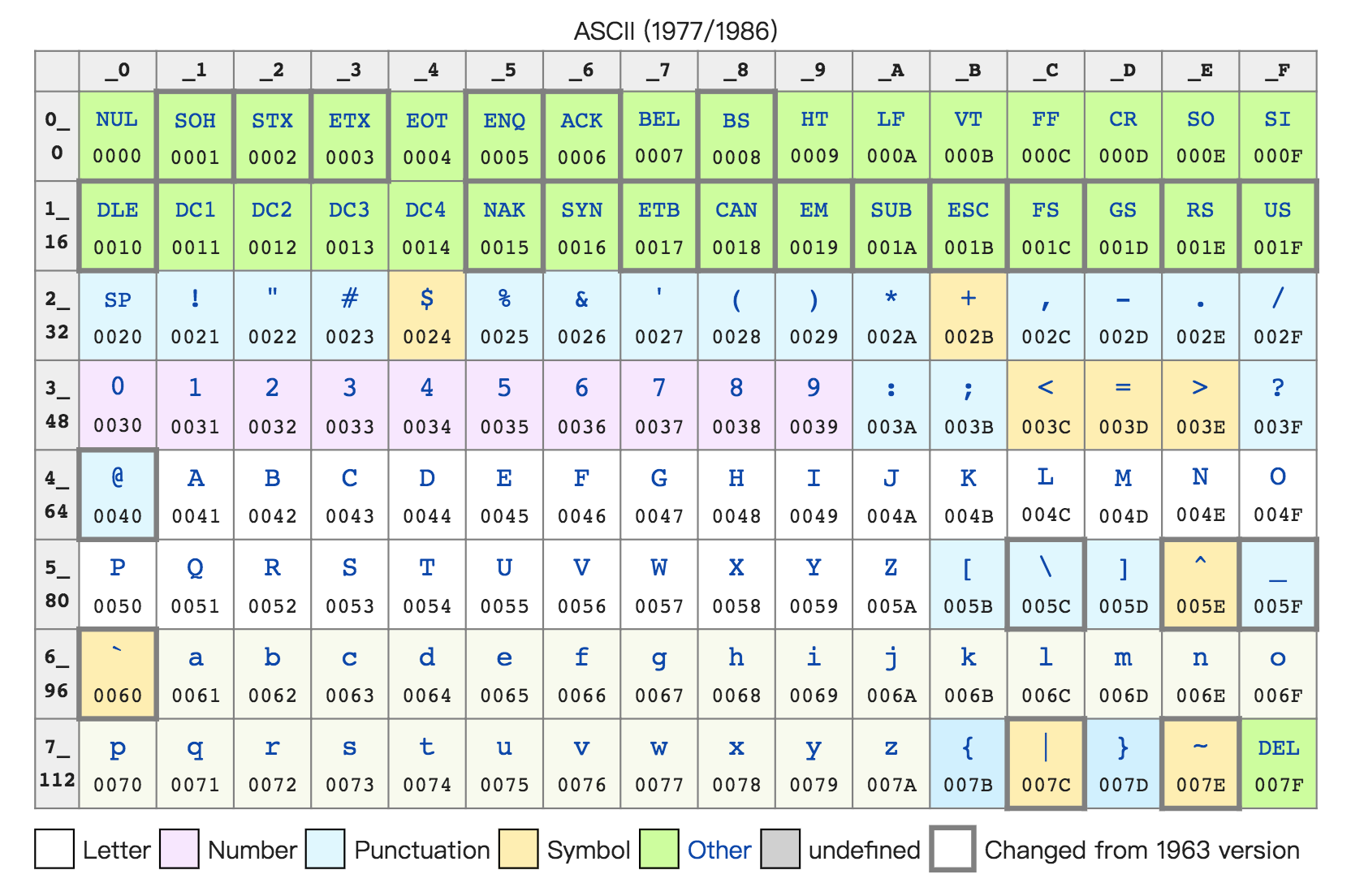
ASCII 码: 最大的 32 位整数,就是 2147483647。如果用整数表示法,只需要 32 位就能表示了。但是如果用字符串来表示,一共有 10 个字符,每个字符用 8 位的话,需要整整 80 位。比起整数表示法,要多占很多空间。不管是整数也好,浮点数也好,采用二进制序列化会比存储文本省下不少空间。¶
Unicode 是一个字符集,包含了 150 种语言的 14 万个不同的字符。
字符编码则是对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。如: Unicode,就可以用 UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。

在中文世界里,最典型的就是“手持两把锟斤拷,口中疾呼烫烫烫”的典故。“锟斤拷”和“烫烫烫”的来龙去脉:1. “锟斤拷”的来源是这样的。如果我们想要用 Unicode 编码记录一些文本,特别是一些遗留的老字符集内的文本,但是这些字符在 Unicode 中可能并不存在。于是,Unicode 会统一把这些字符记录为 U+FFFD 这个编码。如果用 UTF-8 的格式存储下来,就是xefxbfxbd。如果连续两个这样的字符放在一起,xefxbfxbdxefxbfxbd,这个时候,如果程序把这个字符,用 GB2312 的方式进行 decode,就会变成“锟斤拷”。 2. “烫烫烫”,则是因为如果你用了 Visual Studio 的调试器,默认使用 MBCS 字符集。“烫”在里面是由 0xCCCC 来表示的,而 0xCC 又恰好是未初始化的内存的赋值。于是,在读到没有赋值的内存地址或者变量的时候,电脑就开始大叫“烫烫烫”了。参考: https://stackoverflow.com/questions/6276681/what-characters-are-not-present-in-unicode¶
电路¶
继电器(Relay)
反向器(Inverter)
电报传输的信号有两种:
1. 一种是短促的点信号(dot 信号)
2. 一种是长一点的划信号(dash 信号)
把“点”当成“1”,把“划”当成“0”
例:
电影里最常见的电报信号是“SOS”,这个信号表示出来就是 “点点点划划划点点点”

一个摩尔斯电码的电报机¶
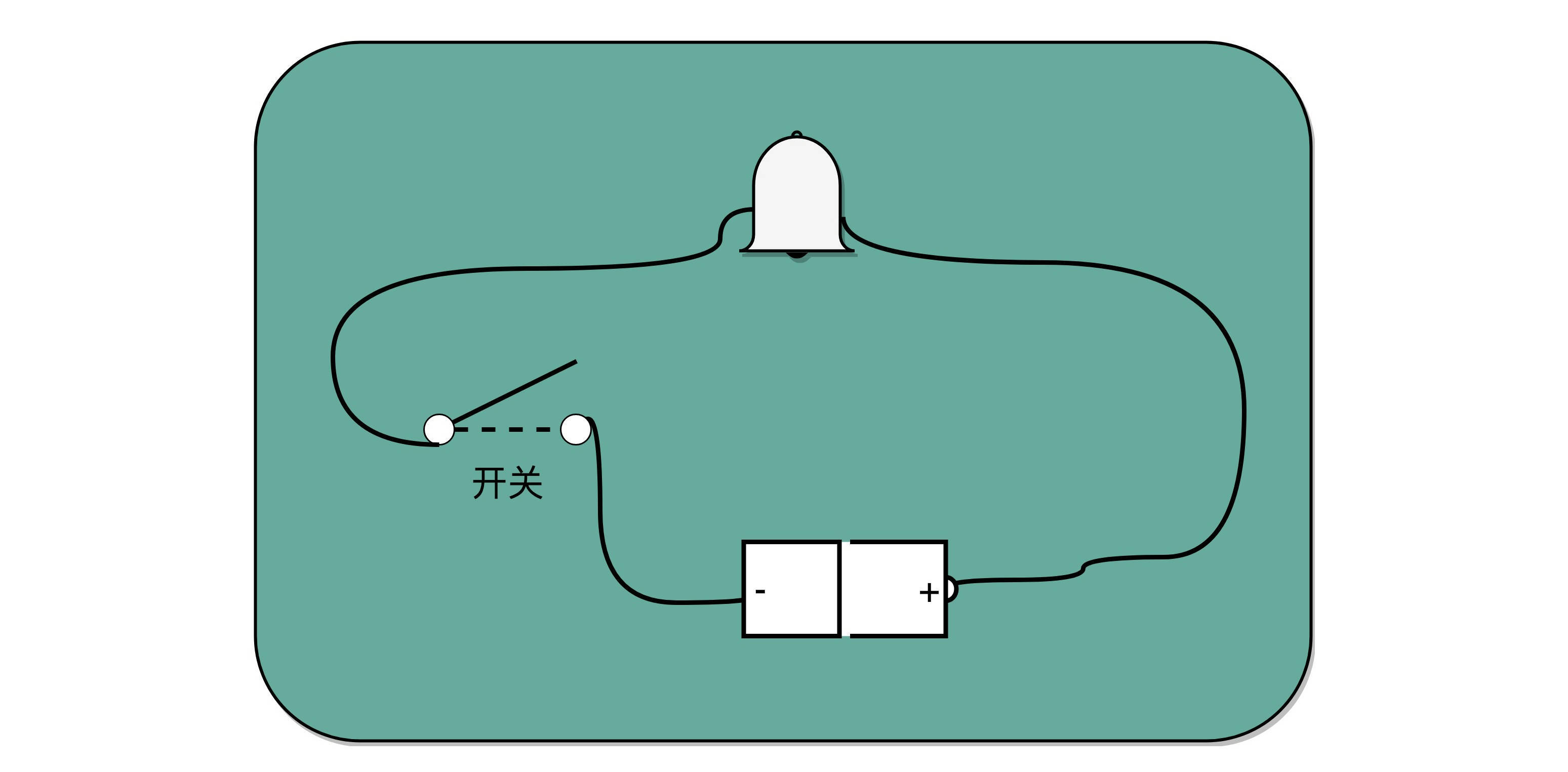
有了电池开关和铃铛,你就有了最简单的摩尔斯电码发报机。制造一台电报机也非常容易。电报机本质上就是一个“蜂鸣器 + 长长的电线 + 按钮开关”。蜂鸣器装在接收方手里,开关留在发送方手里。双方用长长的电线连在一起。¶
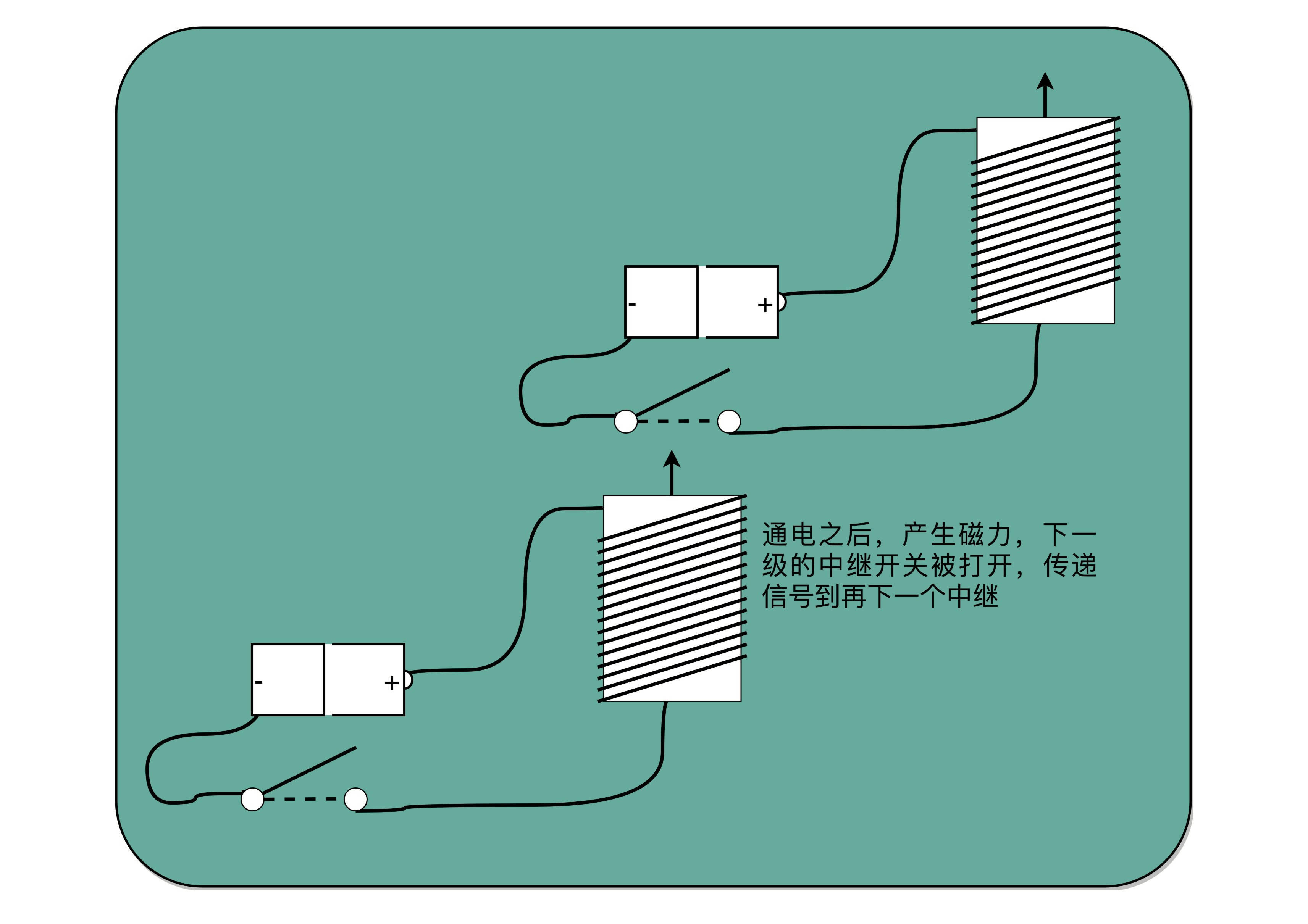
为了能够实现接力传输信号,在电路里面,工程师们造了一个叫作继电器(Relay)的设备。中继,其实就是不断地通过新的电源重新放大已经开始衰减的原有信号¶
加法器¶
半加器(Half Adder)
全加器(Full Adder)
组合电路套件(淘宝上买)
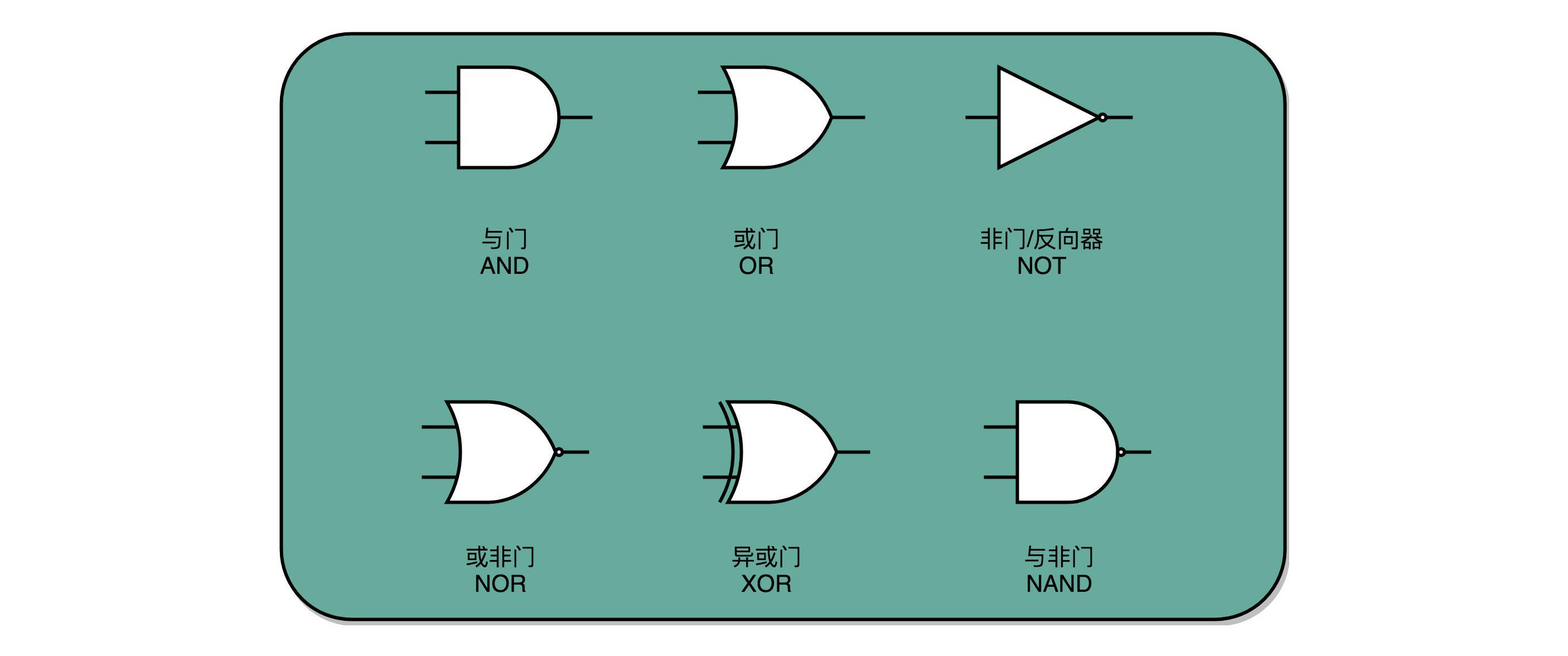
在计算机硬件层面设计最基本的单元,门电路¶
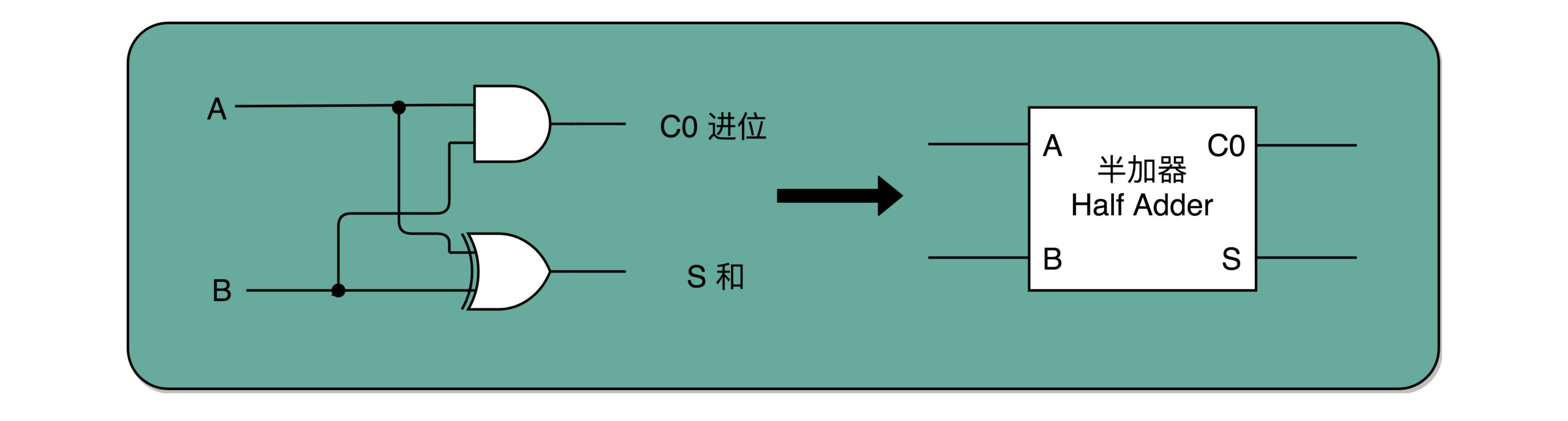
通过一个异或门计算出个位,通过一个与门计算出是否进位,我们就通过电路算出了一个一位数的加法。于是,我们把两个门电路打包,给它取一个名字,就叫作半加器(Half Adder)。¶
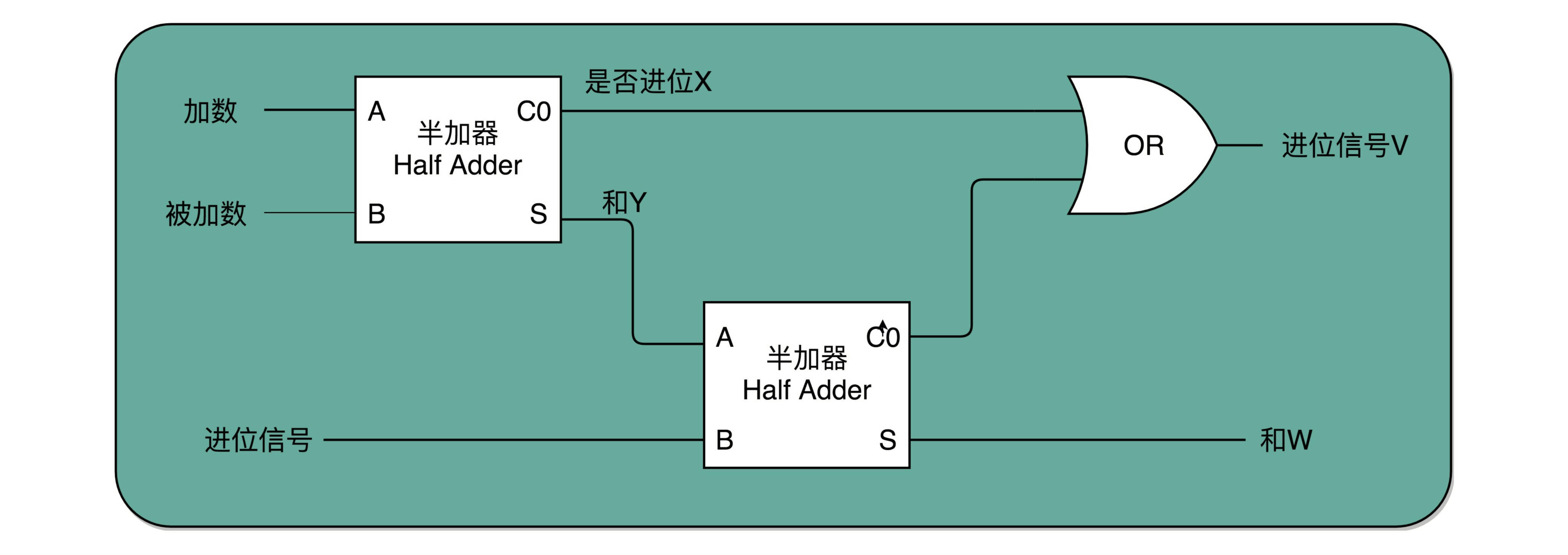
全加器就是两个半加器加上一个或门¶
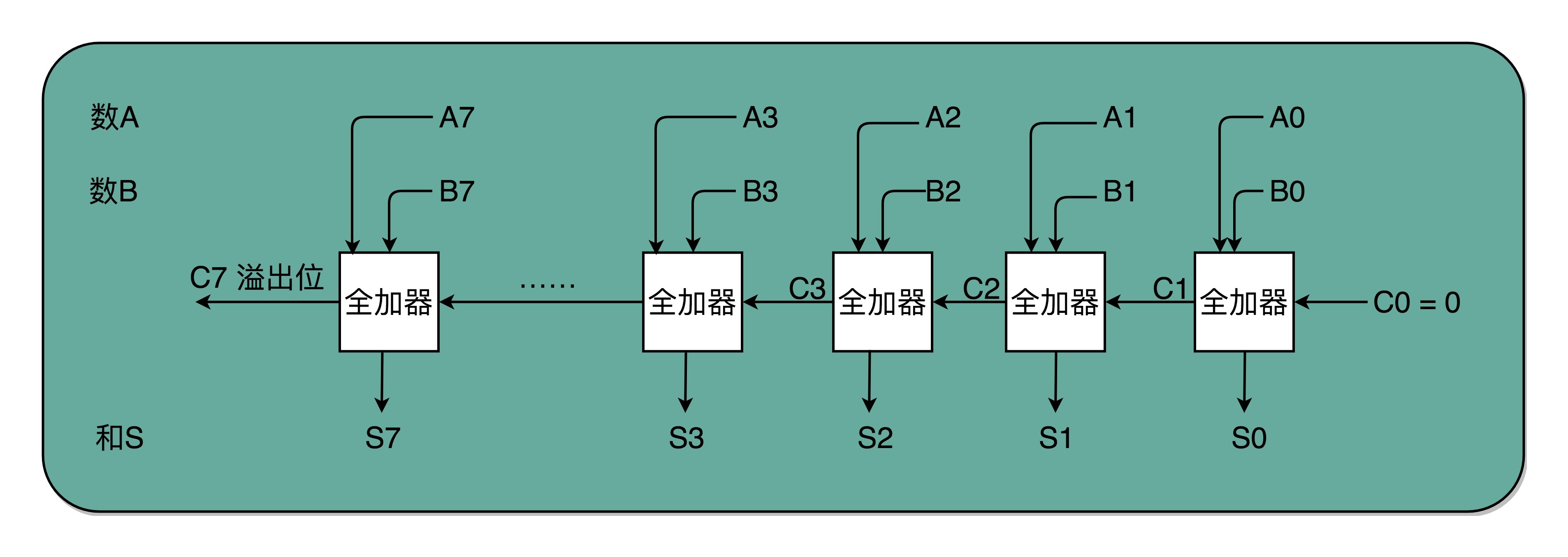
8 位加法器可以由 8 个全加器串联而成¶
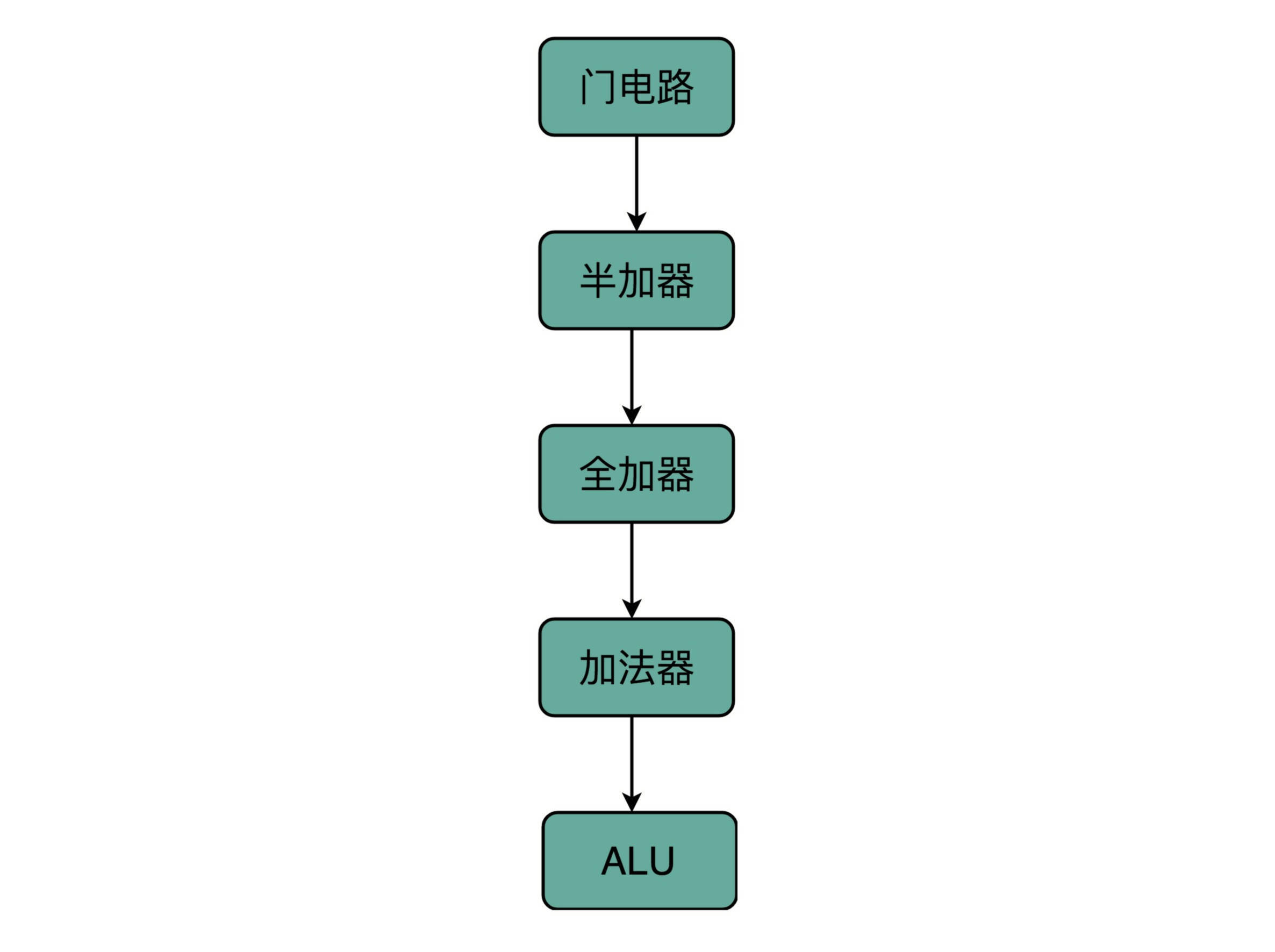
计算机中,无论软件还是硬件中一个很重要的设计思想,分层。从简单到复杂,我们一层层搭出了拥有更强能力的功能组件。在上面的一层,我们只需要考虑怎么用下一层的组件搭建出自己的功能,而不需要下沉到更低层的其他组件。¶
备注
出于性能考虑,实际 CPU 里面使用的加法器,比起我们今天讲解的电路还有些差别,会更复杂一些。真实的加法器,使用的是一种叫作超前进位加法器的东西。实际的加法器,并不是由全加器串联组成的,实际高位的计算结果直接来自低位的组合电路里面的输入。封装意味着我们提供了更多的“简单电路”或者说“简单指令”来操作。但这也意味着同样复杂的操作需要更多条指令。可以像人一样,逐位计算,但线性带来时间复杂度高。从而可以考虑通过增加线路 / 硬件复杂度,从空间换时间的思路,加快乘法速度。但 CPU 毕竟也是很珍贵的资源,晶体管也不宜太多,这中间需要相互平衡。这个也是为什么在计算机体系结构里面会有 RISC 和 CISC 这样的复杂/精简 指令之争最朴素的由来。
乘法器¶
门延迟(Gate Delay)
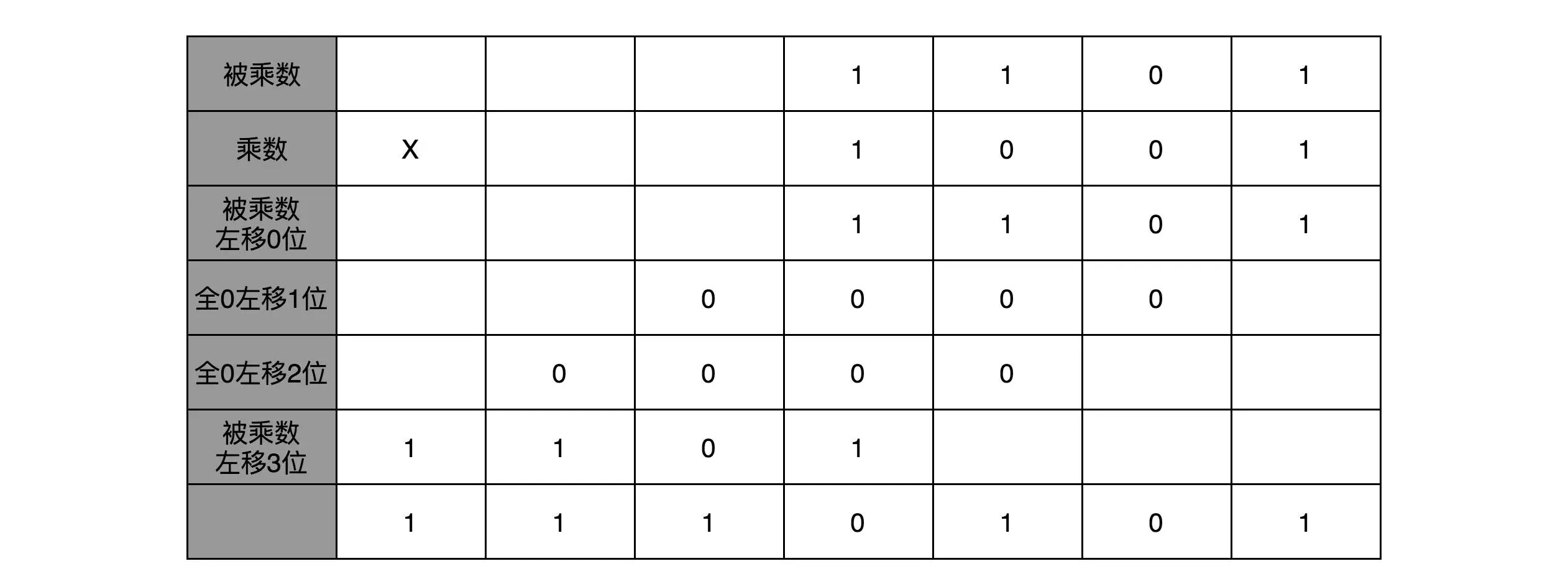
在 13×9 这个例子里面,被乘数 13 表示成二进制是 1101,乘数 9 在二进制里面是 1001。最右边的个位是 1,所以个位乘以被乘数,就是把被乘数 1101 复制下来。因为二位和四位都是 0,所以乘以被乘数都是 0,那么保留下来的都是 0000。乘数的八位是 1,我们仍然需要把被乘数 1101 复制下来。不过这里和个位位置的单纯复制有一点小小的差别,那就是要把复制好的结果向左侧移三位,然后把四位单独进行乘法加位移的结果,再加起来,我们就得到了最终的计算结果。¶
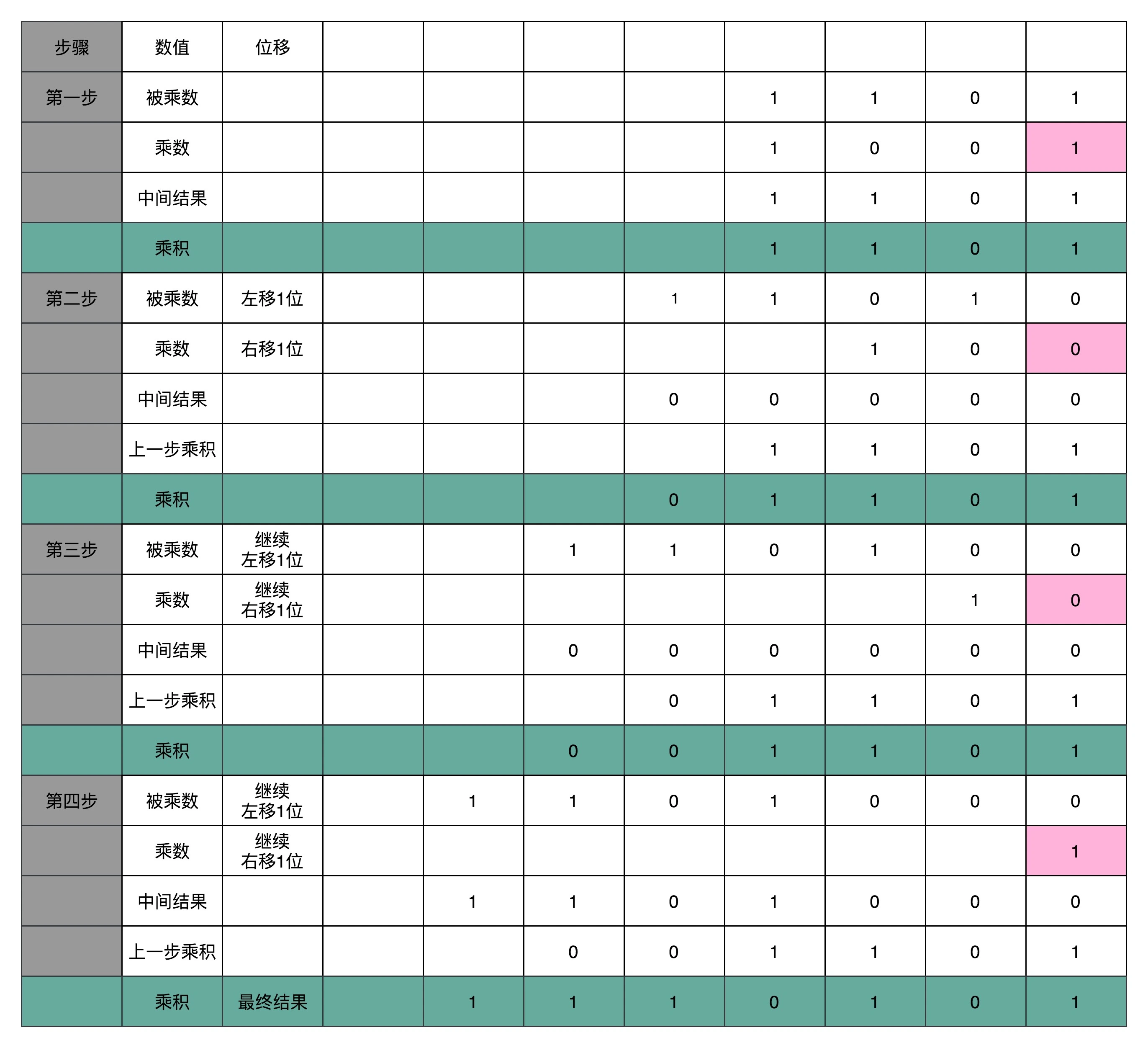
顺序乘法有一个很大的缺点,那就是慢。在这个乘法器的实现过程里,我们其实就是把乘法展开,变成了 “加法 + 位移” 来实现。因为下一组的加法要依赖上一组的加法后的计算结果,下一组的位移也要依赖上一组的位移的结果。这样,整个算法是 “顺序” 的,每一组加法或者位移的运算都需要一定的时间。¶
1.顺序乘法:实现就像是单败淘汰赛¶
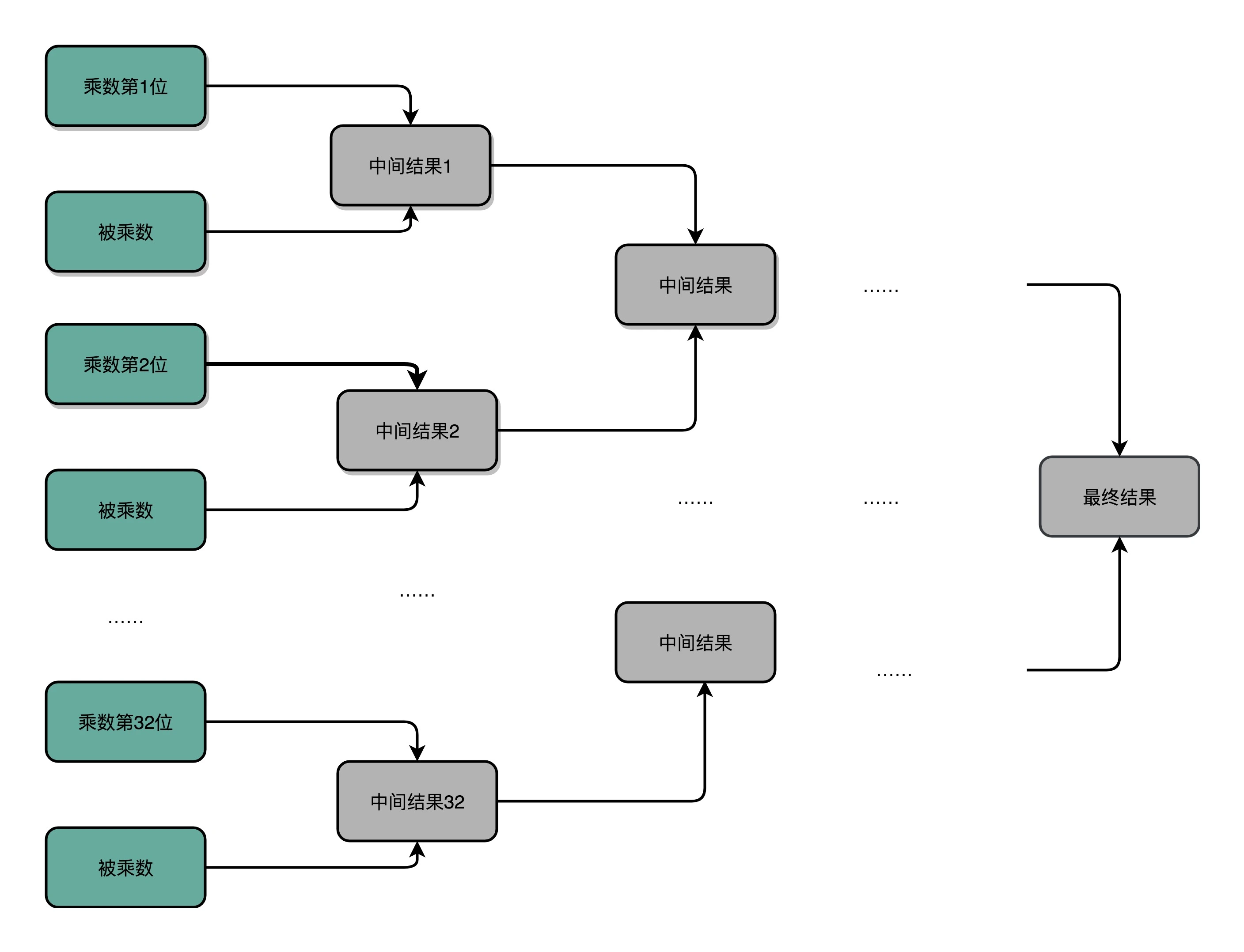
2.通过并联更多的 ALU,加上更多的寄存器,我们也能加速乘法。这种的复杂度是 O(log2N)¶
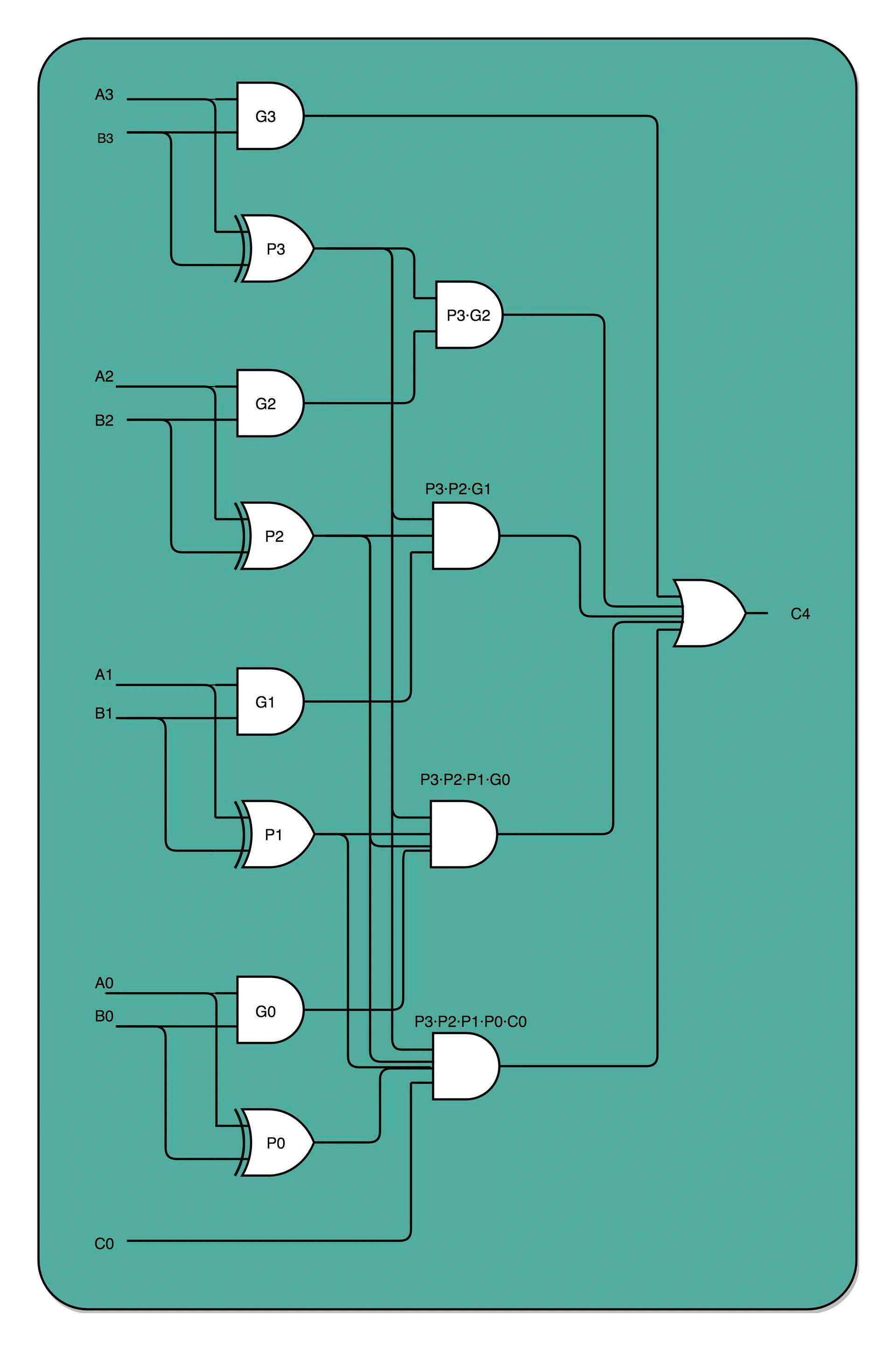
3.电路并行方案:C4 是前 4 位的计算结果是否进位的门电路表示。这个优化,本质上是利用了电路天然的并行性。电路只要接通,输入的信号自动传播到了所有接通的线路里面,这其实也是硬件和软件最大的不同。¶
定点数&浮点数¶
浮点数公式:
说明:
s: 符号位, 用来表示是正数还是负数
f: 有效数位, 23 个比特
e: 指数位, 8 个比特
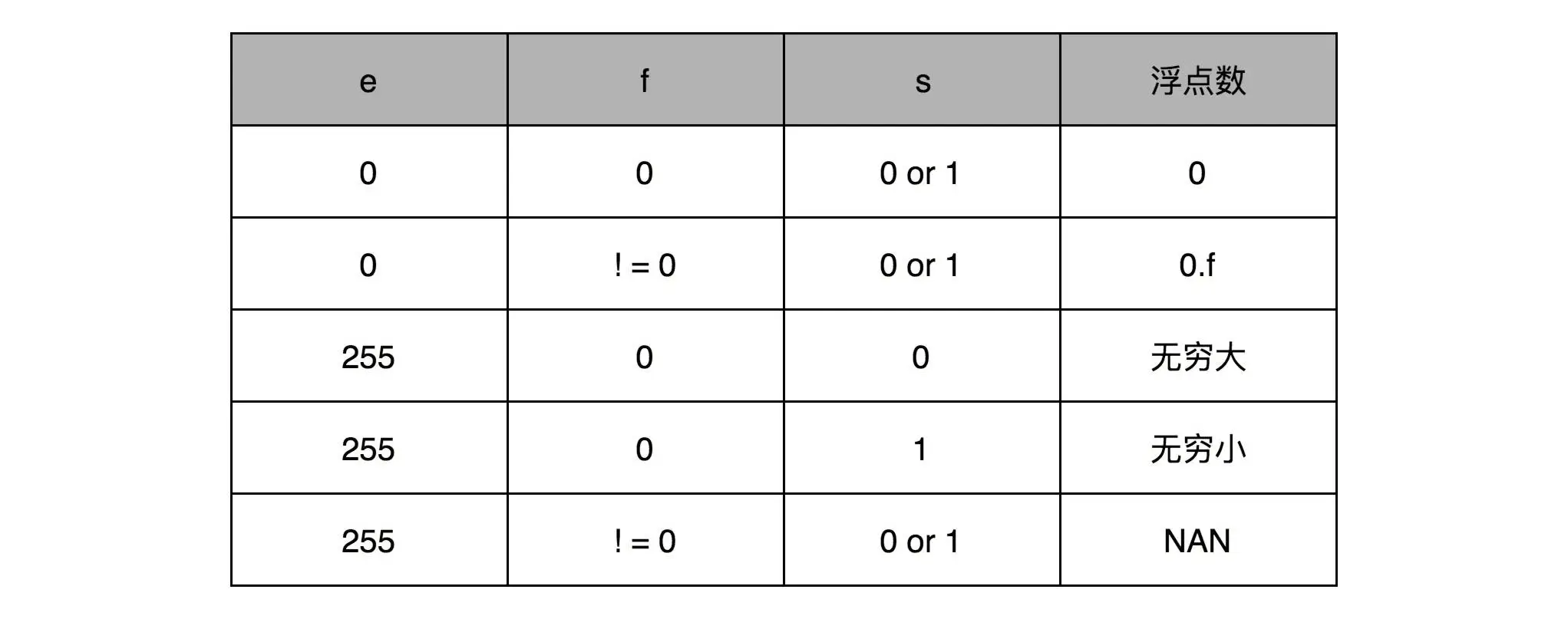
可以表示出无穷大、无穷小、NAN 以及一个特殊的不规范数¶

以 0.5 为例子。0.5 的符号为 s 应该是 0,f 应该是 0,而 e 应该是 -1,也就是0.5=(−1)^0 × 1.0 × 2^−1 = 0.5,对应的浮点数表示,就是 32 个比特。s=0,e=-1: 需要注意,e 表示从 -126 到 127 个,-1 是其中的第 126 个数,这里的 e 如果用整数表示,就是 2^6 +2^5 +2^4 +2^3 +2^2 +2^1=126,1.f=1.0。在这样的浮点数表示下,不考虑符号的话,浮点数能够表示的最小的数和最大的数,差不多是 1.17×10^−38 和 3.40×10^38¶
例:
表示成二进制就是 1.11111... ^(2^127)
差不多就是 1.9999999 ^(2^127)
差不多正好是 3.4028235 x (10 ^ 38)
最小的数就是 1.000..... ^ (2^-126)
差不多就是 1.0000 ^ (2^-126)
差不多正好就是 1.17549435 x (10^-38)
和整数的二进制表示采用 “除以 2,然后看余数” 的方式相比,小数部分转换成二进制是用一个相似的反方向操作,就是乘以 2,然后看看是否超过 1。如果超过 1,我们就记下 1,并把结果减去 1,进一步循环操作。¶
备注
32 位浮点数的有效位长度一共只有 23 位,如果两个数的指数位差出 23 位,较小的数右移 24 位之后,所有的有效位就都丢失了。例:用一个循环相加 2000 万个 1.0f,最终的结果会是 1600 万左右,而不是 2000 万。这是因为,加到 1600 万之后的加法因为精度丢失都没有了。用 Kahan Summation 的算法来解决这个问题。
备注
Kahan Summation 算法 原理其实并不复杂,就是在每次的计算过程中,都用一次减法,把当前加法计算中损失的精度记录下来,然后在后面的循环中,把这个精度损失放在要加的小数上,再做一次运算。
处理器¶
数据通路¶
指令周期(Instruction Cycle)
组合逻辑元件(Combinational Element)
状态元件(State Element)
锁存器(Latch)
组合逻辑电路(Combinational Logic Circuit)
时序逻辑电路(Sequential Logic Circuit)
反馈电路(Feedback Circuit)
反相器(Inverter)
触发器(Flip-Flop)
D 触发器(Data/Delay Flip-flop)
复位置位触发器(Reset-Set Flip Flop)
计算机每执行一条指令的过程,可以分解成这样几个步骤:
1. Fetch(取得指令)
也就是从 PC 寄存器里找到对应的指令地址,
根据指令地址从内存里把具体的指令,加载到指令寄存器中
然后把 PC 寄存器自增,好在未来执行下一条指令。
2. Decode(指令译码)
就是根据指令寄存器里面的指令,解析成要进行什么样的操作,
是 R、I、J 中的哪一种指令,具体要操作哪些寄存器、数据或者内存地址。
3. Execute(执行指令)
也就是实际运行对应的 R、I、J 这些特定的指令,
进行算术逻辑操作、数据传输或者直接的地址跳转。
4. 重复进行 1~3 的步骤。
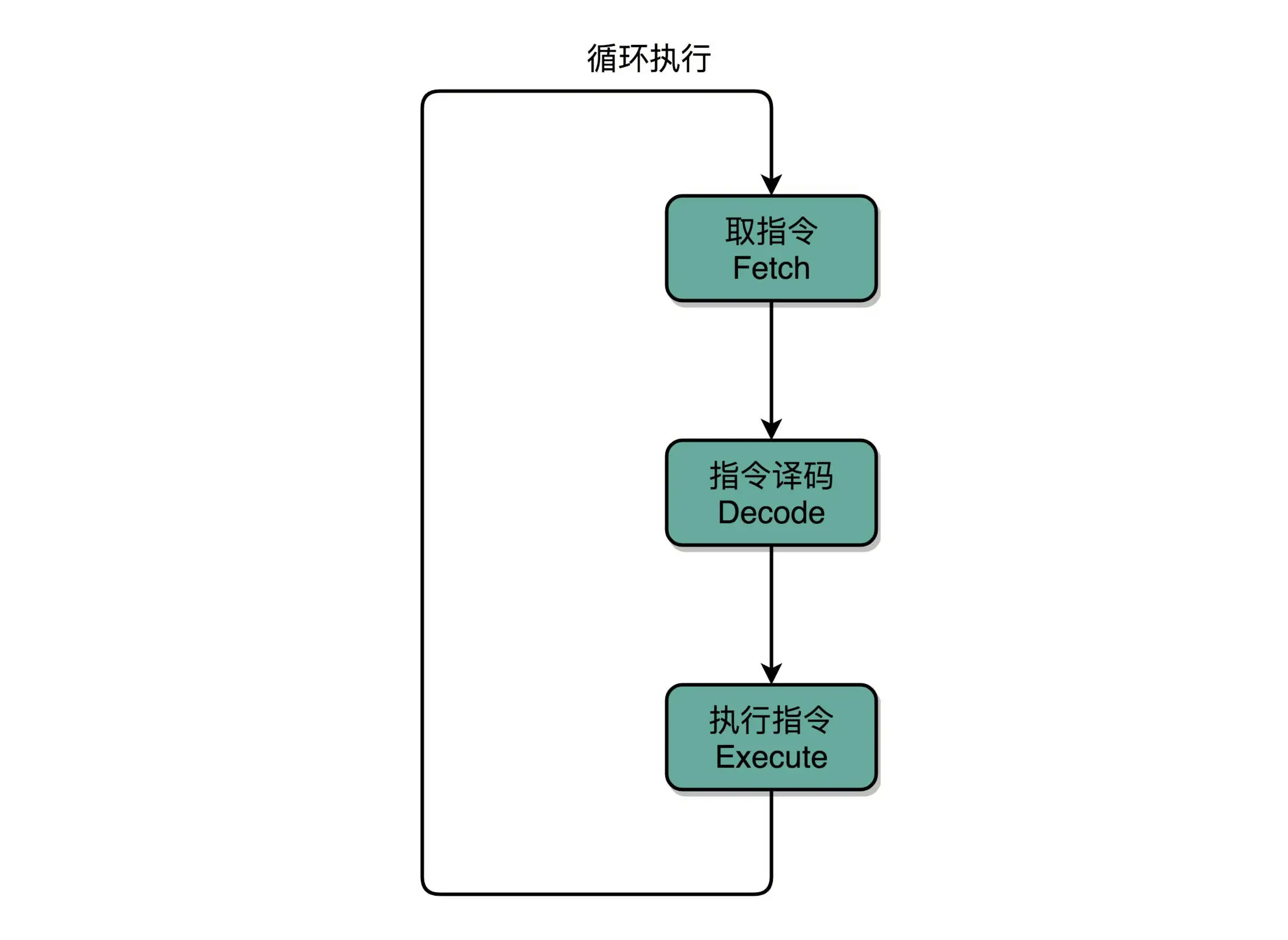
指令周期(Instruction Cycle): 执行命令的过程其实就是一个永不停歇的 “Fetch - Decode - Execute” 的循环,我们把这个循环称之为指令周期(Instruction Cycle)¶
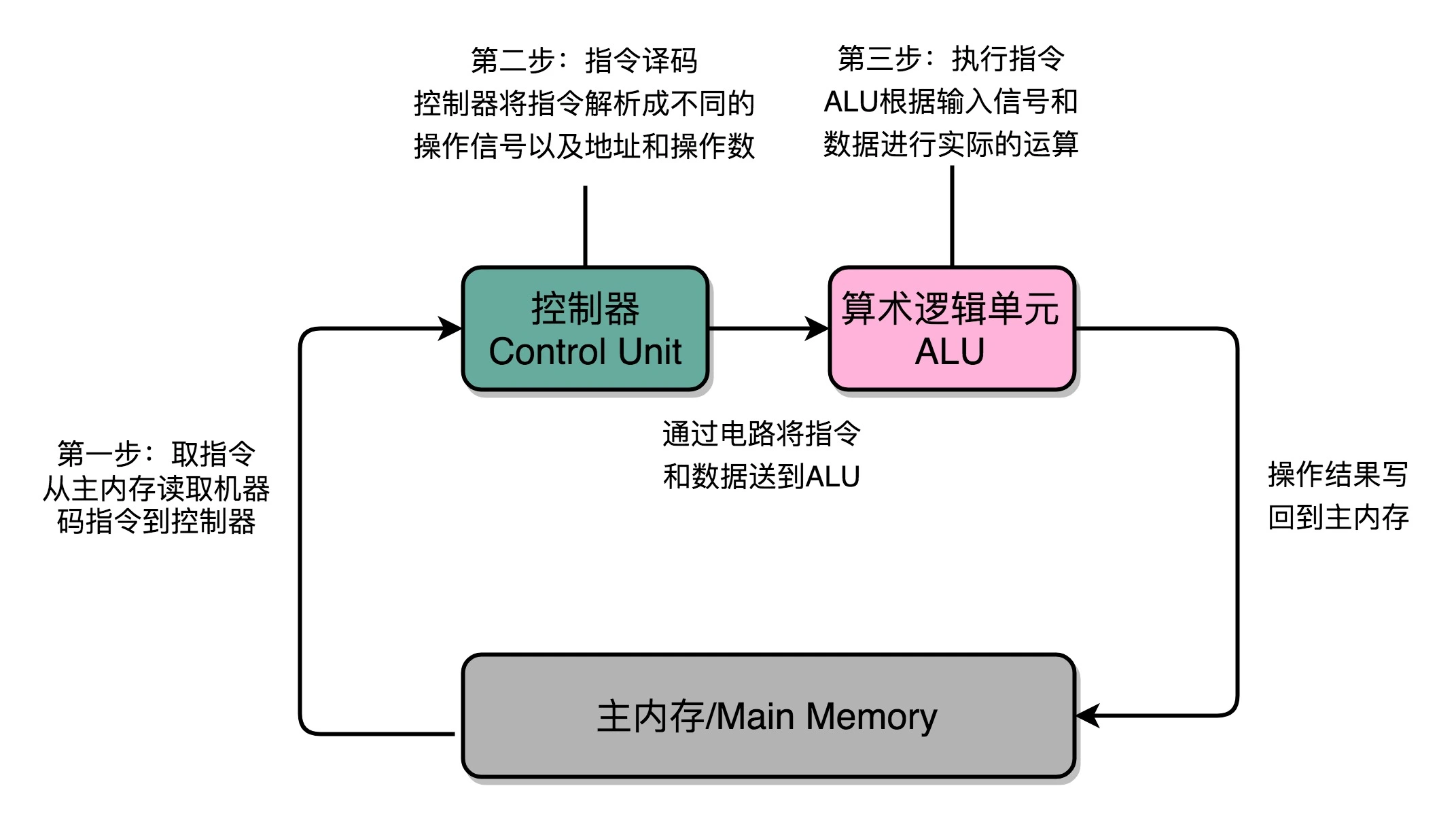
不同步骤在不同组件之内完成:在取指令的阶段,我们的指令是放在存储器里的,实际上,通过 PC 寄存器和指令寄存器取出指令的过程,是由控制器(Control Unit)操作的。指令的解码过程,也是由控制器进行的。一旦到了执行指令阶段,无论是进行算术操作、逻辑操作的 R 型指令,还是进行数据传输、条件分支的 I 型指令,都是由算术逻辑单元(ALU)操作的,也就是由运算器处理的。不过,如果是一个简单的无条件地址跳转,那么我们可以直接在控制器里面完成,不需要用到运算器。¶
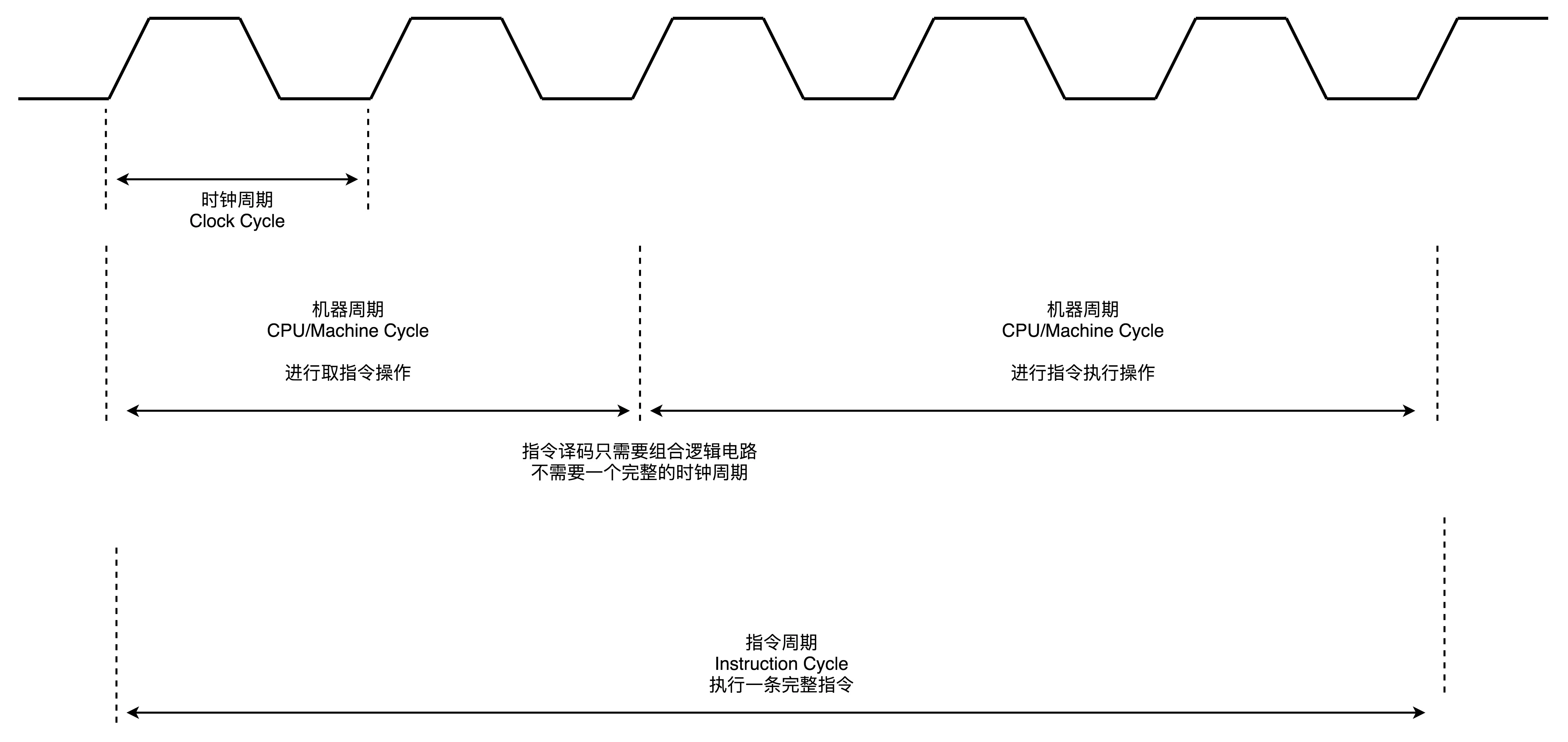
1.Clock Cycle(时钟周期),我们机器的主频。 2.Machine Cycle(机器周期或 CPU 周期)。CPU 内部的操作速度很快,但是访问内存的速度却要慢很多。每一条指令都需要从内存里面加载而来,所以我们一般把从内存里面读取一条指令的最短时间,称为 CPU 周期。 3.Instruction Cycle(指令周期)对于一个指令周期来说,我们取出一条指令,然后执行它,至少需要两个 CPU 周期。取出指令至少需要一个 CPU 周期,执行至少也需要一个 CPU 周期,复杂的指令则需要更多的 CPU 周期。¶
数据通路就是我们的处理器单元。它通常由两类原件组成:
1. 操作元件,也叫组合逻辑元件(Combinational Element),其实就是我们的 ALU
2. 存储元件,也叫状态元件(State Element)。
如我们在计算过程中需要用到的寄存器,无论是通用寄存器还是状态寄存器,其实都是存储元件
3. 通过数据总线的方式,把它们连接起来,就可以完成数据的存储、处理和传输了,这就是所谓的建立数据通路
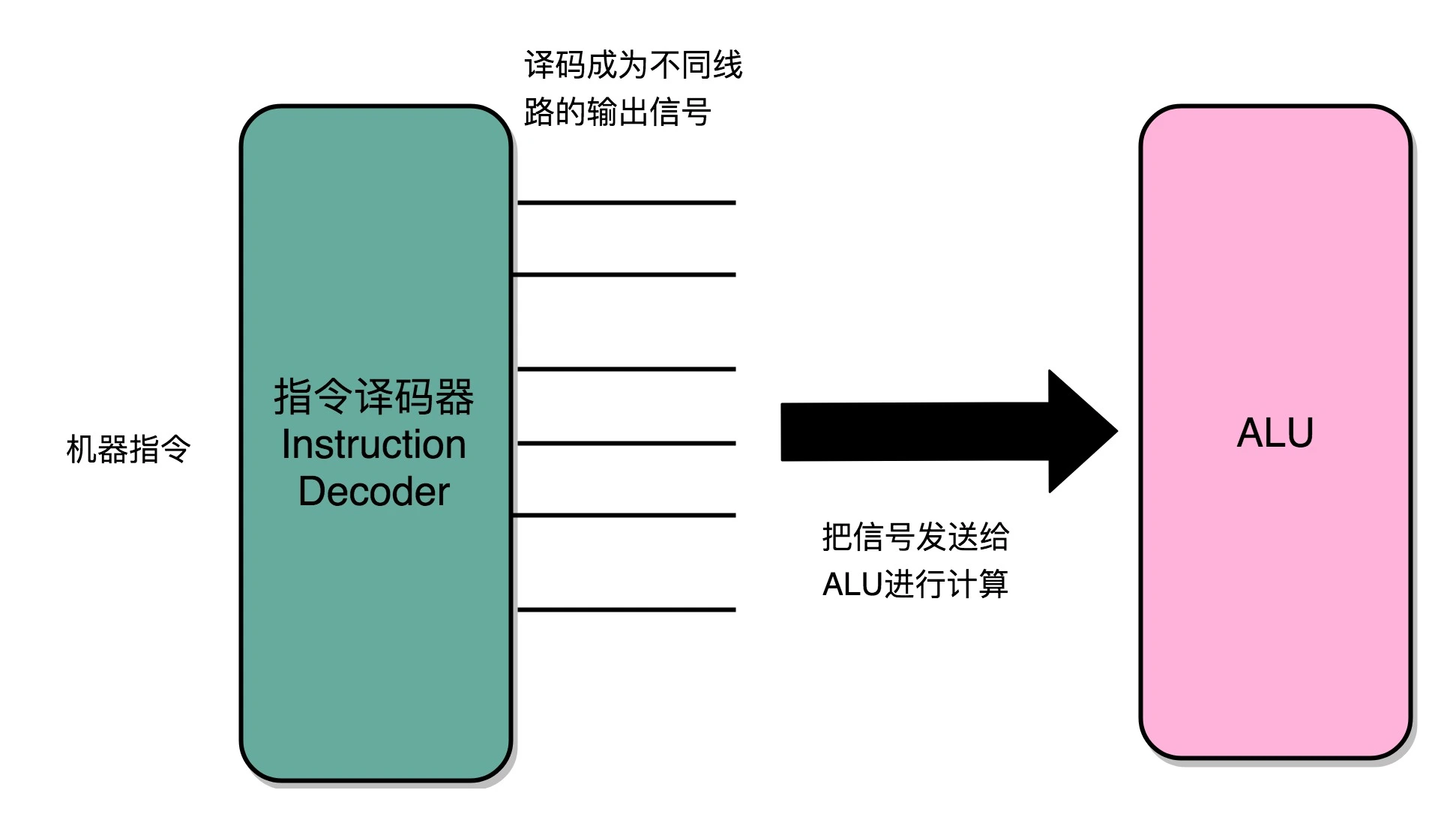
指令译码器将输入的机器码,解析成不同的操作码和操作数,然后传输给 ALU 进行计算¶
要想搭建出来整个 CPU,需要 4 种基本电路:
1. ALU 这样的组合逻辑电路
2. 用来存储数据的锁存器和 D 触发器电路
3. 用来实现 PC 寄存器的计数器电路
4. 用来解码和寻址的译码器电路
组合逻辑电路: 只需要给定输入,就能得到固定的输出
时序逻辑电路解决这样几个问题:
1. 自动运行的问题。时序电路接通之后可以不停地开启和关闭开关,进入一个自动运行的状态。这个使得我们上一讲说的,控制器不停地让 PC 寄存器自增读取下一条指令成为可能 2. 存储的问题。通过时序电路实现的触发器,能把计算结果存储在特定的电路里面,而不是像组合逻辑电路那样,一旦输入有任何改变,对应的输出也会改变。 3. 本质上解决了各个功能按照时序协调的问题。无论是程序实现的软件指令,还是到硬件层面,各种指令的操作都有先后的顺序要求。时序电路使得不同的事件按照时间顺序发生。
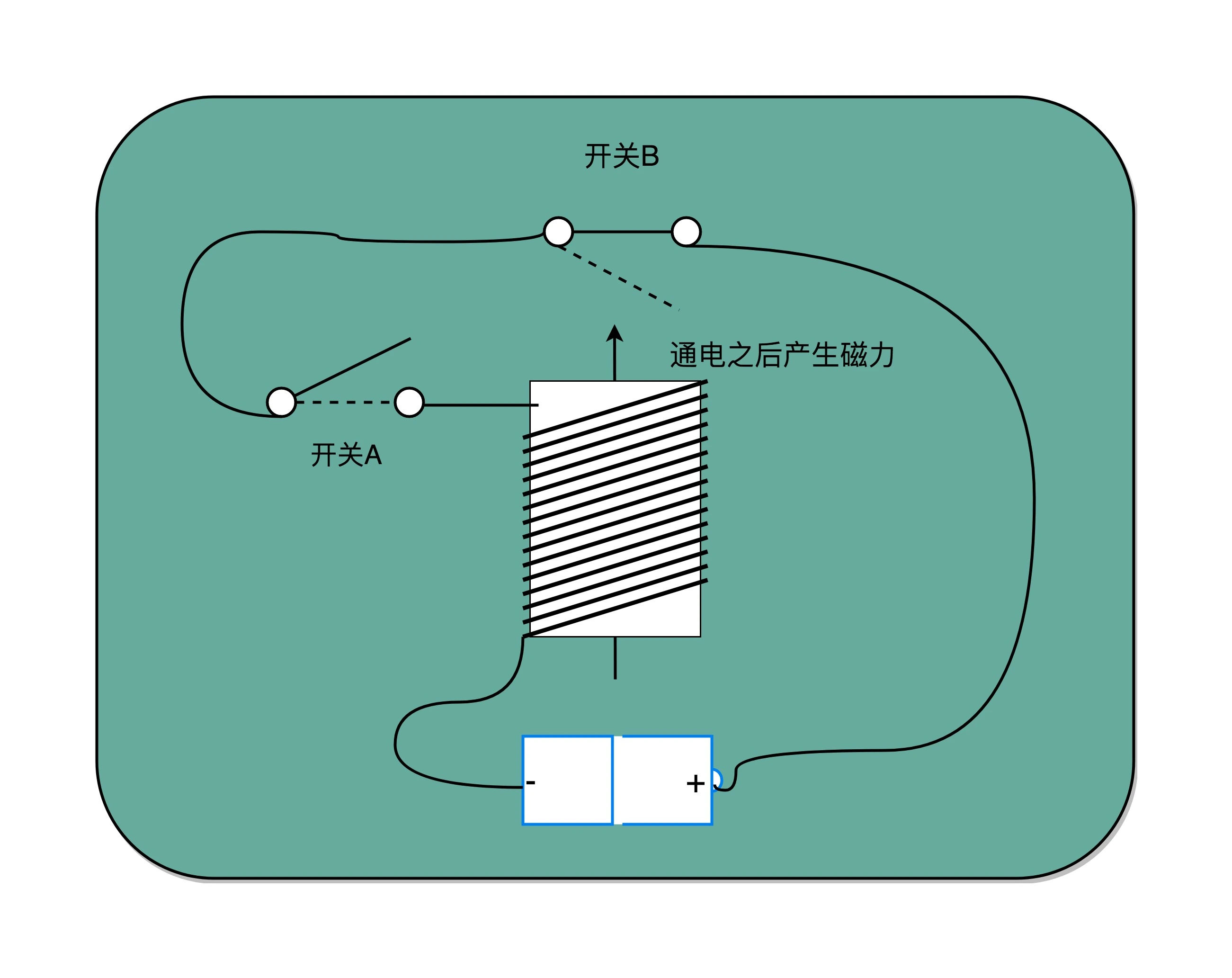
开关 A 闭合(也就是相当于接通电路之后),开关 B 就会不停地在开和关之间切换,生成对应的时钟信号。这个不断切换的过程,对于下游电路来说,就是不断地产生新的 0 和 1 这样的信号。这个按照固定的周期不断在 0 和 1 之间切换的信号,就是我们的时钟信号(Clock Signal)。¶
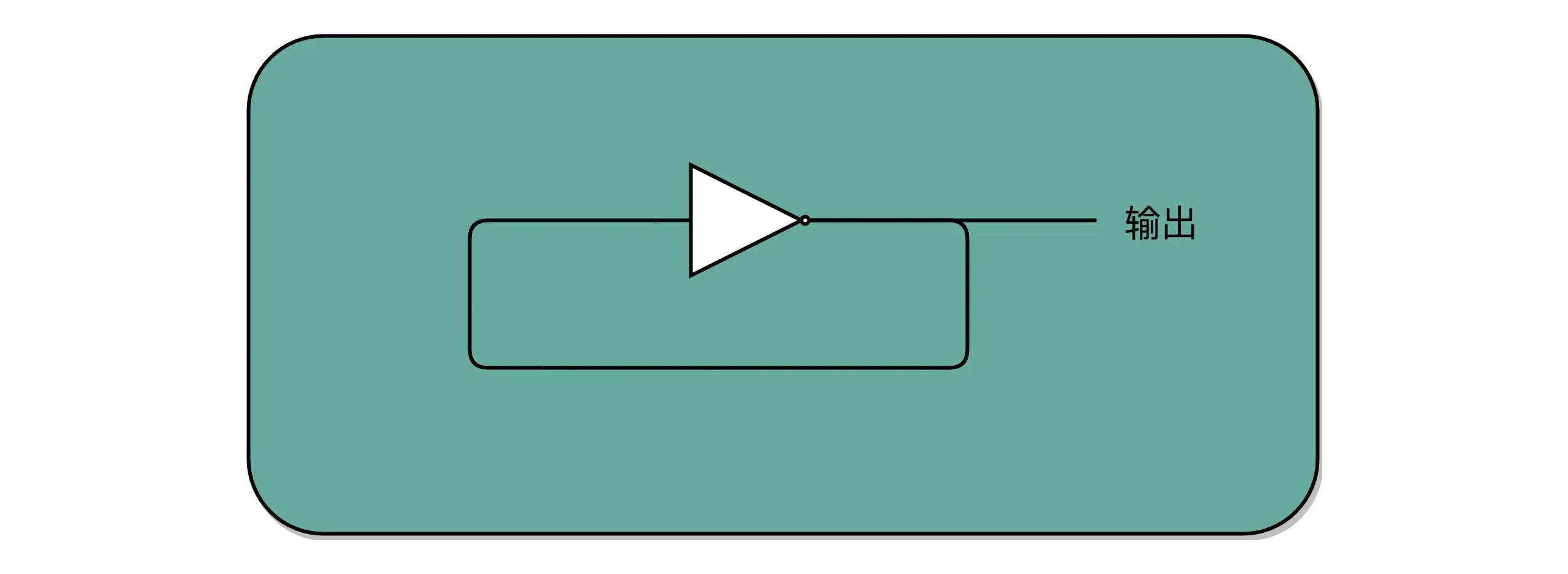
把电路的输出信号作为输入信号,再回到当前电路。这样的电路构造方式呢,我们叫作反馈电路(Feedback Circuit)。如:通过一个反相器实现时钟信号¶
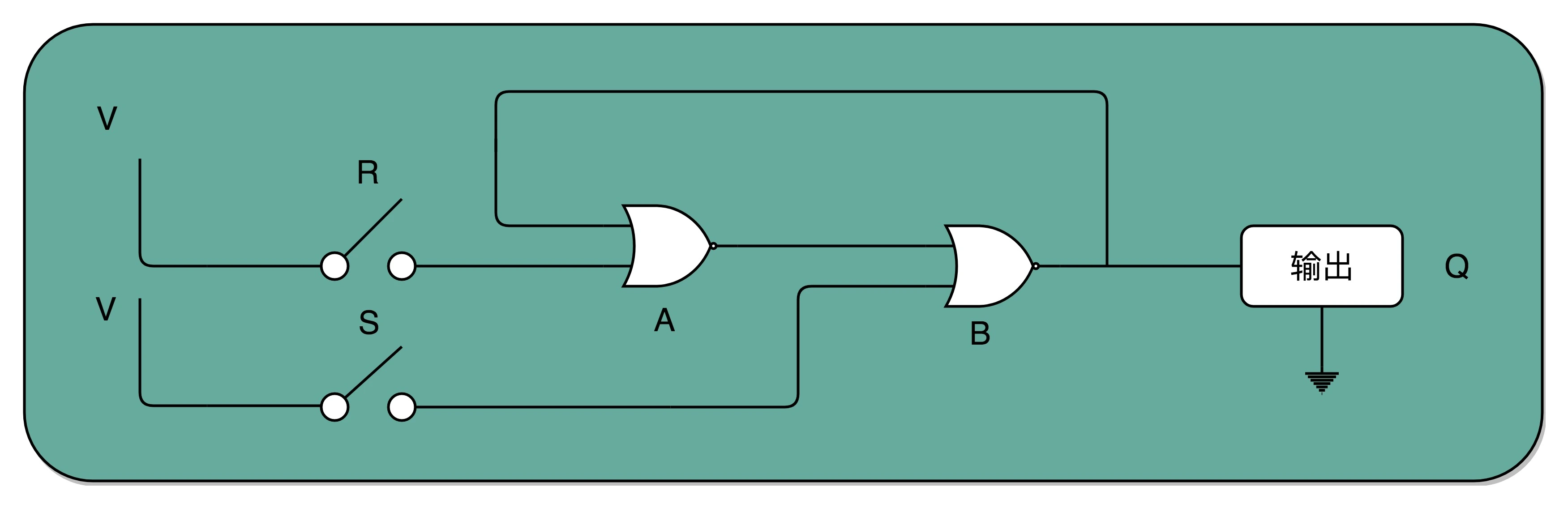
RS 触发器电路:最简单的 RS 触发器,也就是所谓的复位置位触发器(Reset-Set Flip Flop) 。接通开关 R,输出变为 1,即使断开开关,输出还是 1 不变。接通开关 S,输出变为 0,即使断开开关,输出也还是 0。也就是,当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。¶
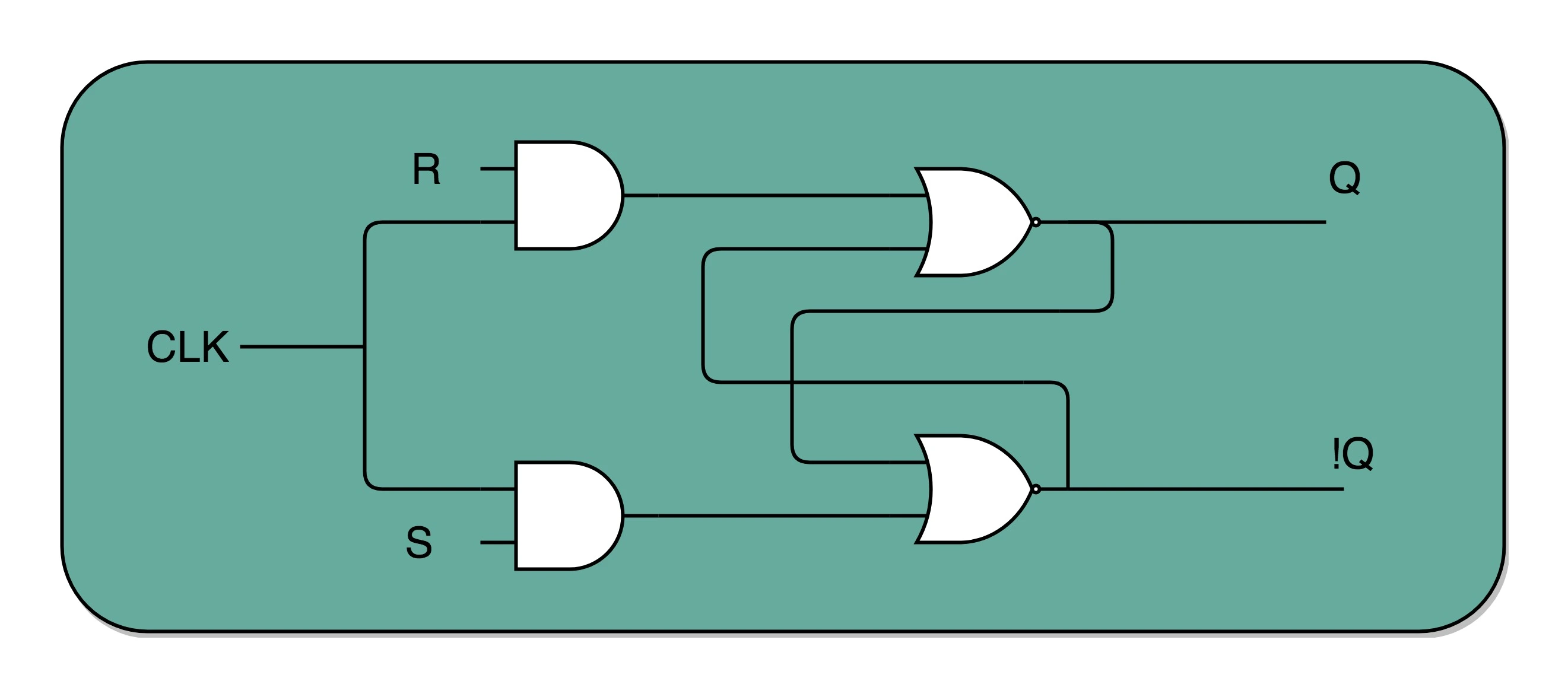
通过一个时钟信号,我们可以在特定的时间对输出的 Q 进行写入操作¶
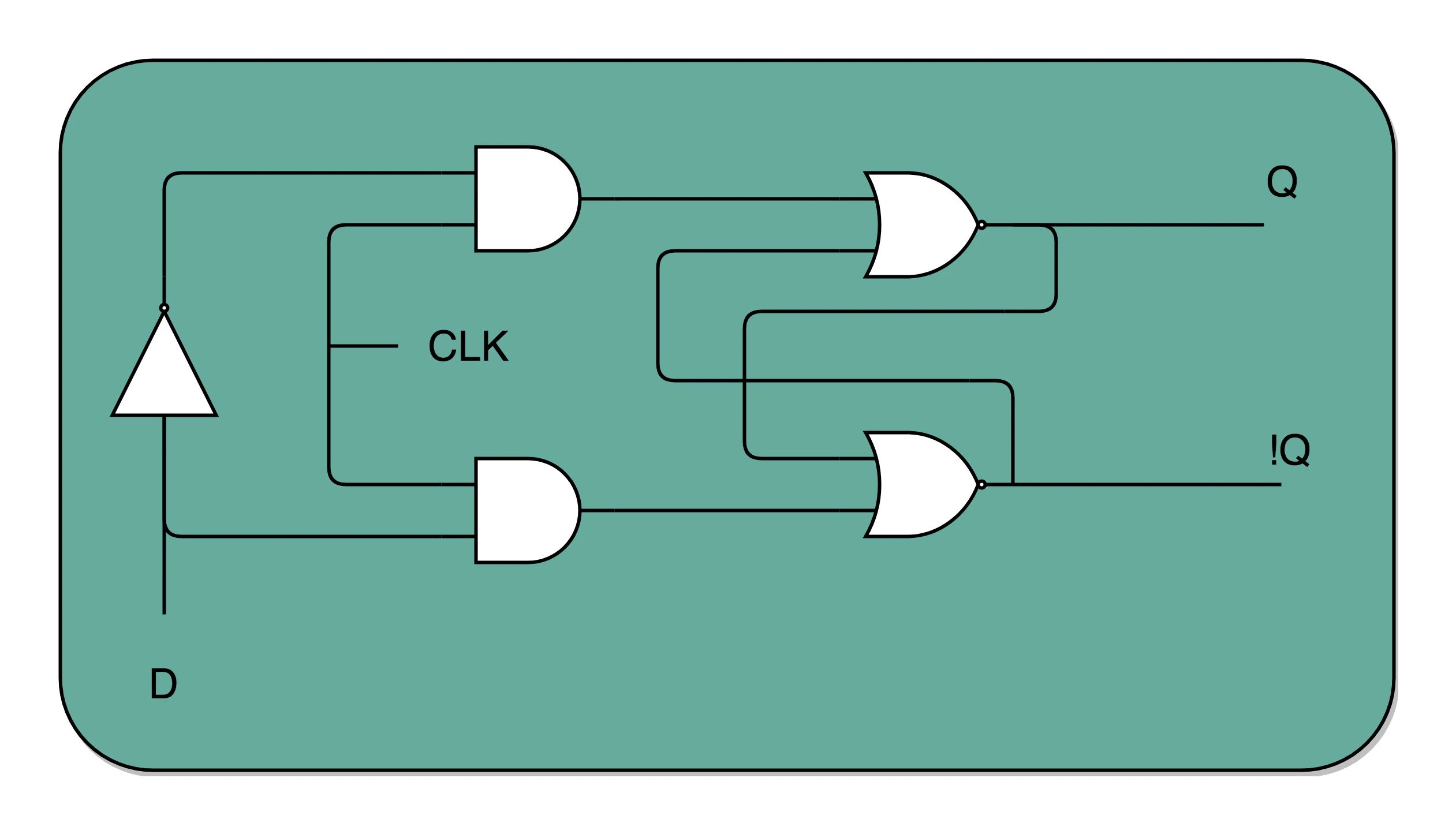
把 R 和 S 两个信号通过一个反相器合并,我们可以通过一个数据信号 D 进行 Q 的写入操作。一个 D 型触发器,只能控制 1 个比特的读写,但是如果我们同时拿出多个 D 型触发器并列在一起,并且把用同一个 CLK 信号控制作为所有 D 型触发器的开关,这就变成了一个 N 位的 D 型触发器,也就可以同时控制 N 位的读写。¶
指令设计¶
指令周期
机器周期(或者 CPU 周期)
时钟周期
指令流水线(Instruction Pipeline)
流水线阶段或者流水线级(Pipeline Stage)
流水线寄存器(Pipeline Register)
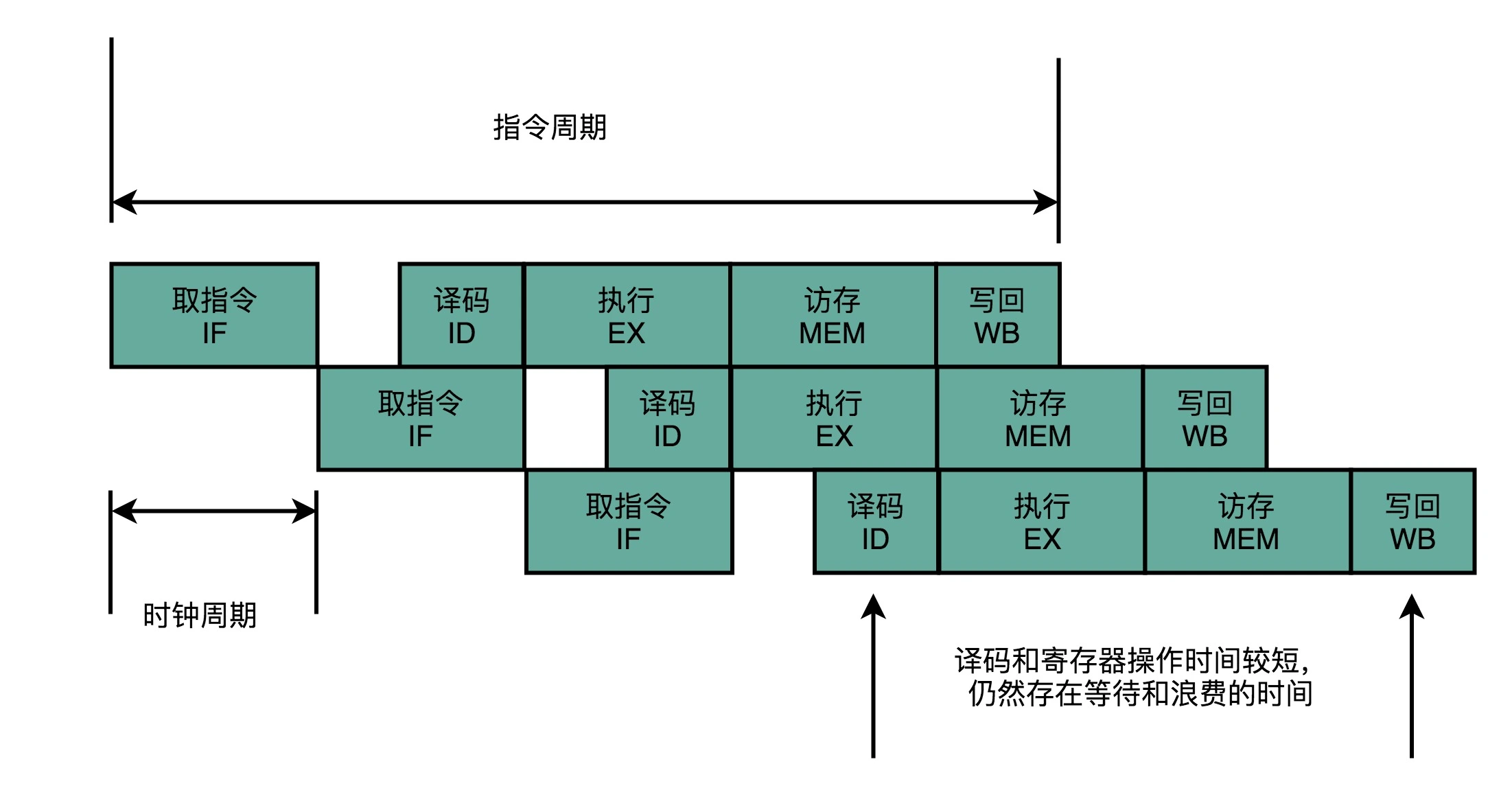
流水线执行示意图:不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。如果我们把一个指令拆分成 “取指令 - 指令译码 - 执行指令” 这样三个部分,那这就是一个三级的流水线。如果我们进一步把 “执行指令” 拆分成 “ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线。¶
备注
我们不需要确保最复杂的那条指令在时钟周期里面执行完成,而只要保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了。
备注
虽然我们不能通过流水线,来减少单条指令执行的 “延时” 这个性能指标,但是,通过同时在执行多条指令的不同阶段,我们提升了 CPU 的 “吞吐率”。在外部看来,我们的 CPU 好像是 “一心多用”,在同一时间,同时执行 5 条不同指令的不同阶段。在 CPU 内部,其实它就像生产线一样,不同分工的组件不断处理上游传递下来的内容,而不需要等待单件商品生产完成之后,再启动下一件商品的生产过程。
冒险和预测¶
流水线设计需要解决的三大冒险,分别是:
1. 结构冒险(Structural Hazard)
2. 数据冒险(Data Hazard)
3. 控制冒险(Control Hazard)
结构冒险¶
备注
解决方案是增加资源,通过添加指令缓存和数据缓存,让我们对于指令和数据的访问可以同时进行。这个办法帮助 CPU 解决了取指令和访问数据之间的资源冲突。
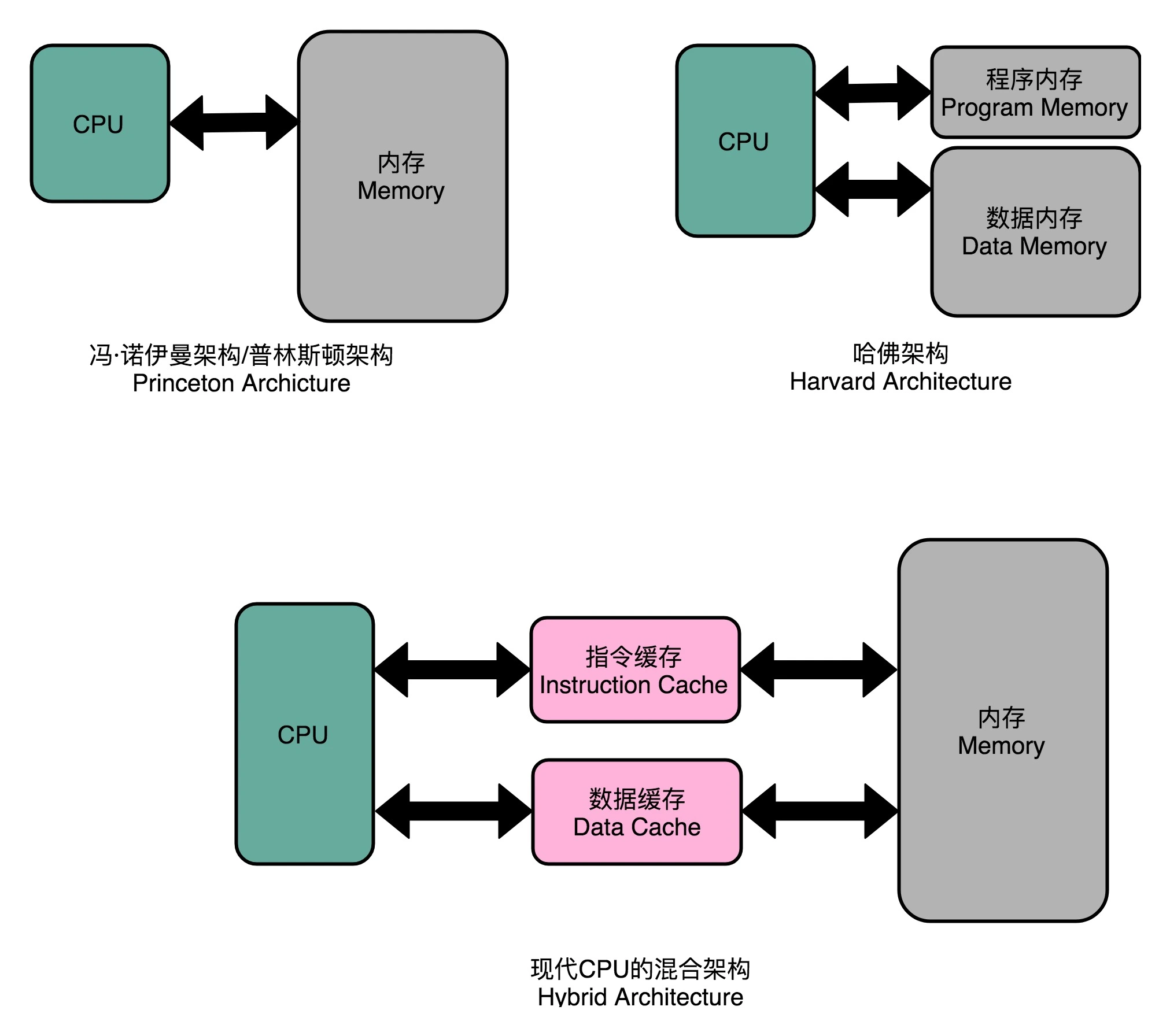
把内存拆成两部分的解决方案,在计算机体系结构里叫作哈佛架构(Harvard Architecture),来自哈佛大学设计Mark I 型计算机时候的设计。对应的冯·诺依曼体系结构,又叫作普林斯顿架构(Princeton Architecture)。今天使用的 CPU,仍然是冯·诺依曼体系结构的,并没有把内存拆成程序内存和数据内存这两部分。因为如果那样拆的话,对程序指令和数据需要的内存空间,我们就没有办法根据实际的应用去动态分配了。虽然解决了资源冲突的问题,但是也失去了灵活性。不过,借鉴了哈佛结构的思路,现代的 CPU 虽然没有在内存层面进行对应的拆分,却在 CPU 内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存(Instruction Cache)和数据缓存(Data Cache)两部分。内存的访问速度远比 CPU 的速度要慢,所以现代的 CPU 并不会直接读取主内存。它会从主内存把指令和数据加载到高速缓存中,这样后续的访问都是访问高速缓存。而指令缓存和数据缓存的拆分,使得我们的 CPU 在进行数据访问和取指令的时候,不会再发生资源冲突的问题了。¶
数据冒险¶
三种不同的依赖关系:
1. 先写后读(Read After Write,RAW)
数据依赖,也就是 Data Dependency
2. 先读后写(Write After Read,WAR)
反依赖,也就是 Anti-Dependency
3. 写后再写(Write After Write,WAW)
输出依赖,也就是 Output Dependency
备注
解决方案是直接进行等待:再等等:通过流水线停顿解决数据冒险。通过插入 NOP 这样的无效指令,等待之前的指令完成。这样我们就能解决不同指令之间的数据依赖问题。
流水线停顿(Pipeline Stall),或者叫流水线冒泡(Pipeline Bubbling)
操作数前推(Operand Forwarding),或者操作数旁路(Operand Bypassing)
乱序执行(Out-of-Order Execution,OoOE)
控制冒险¶
备注
用于解决if…else 这样的条件分支,或者 for/while 循环
分支预测(Branch Prediction)技术
一级分支预测(One Level Branch Prediction)或 1 比特饱和计数(1-bit saturating counter)
2 比特饱和计数,或 双模态预测器(Bimodal Predictor)
分支预测:
1. 假装分支不发生
2. 静态预测
3. 动态分支预测
SIMD¶
超线程(Hyper-Threading)技术 or 同时多线程(Simultaneous Multi-Threading,简称 SMT)技术
指令级并行(Instruction-level parallelism,简称 IPL)的技术方案
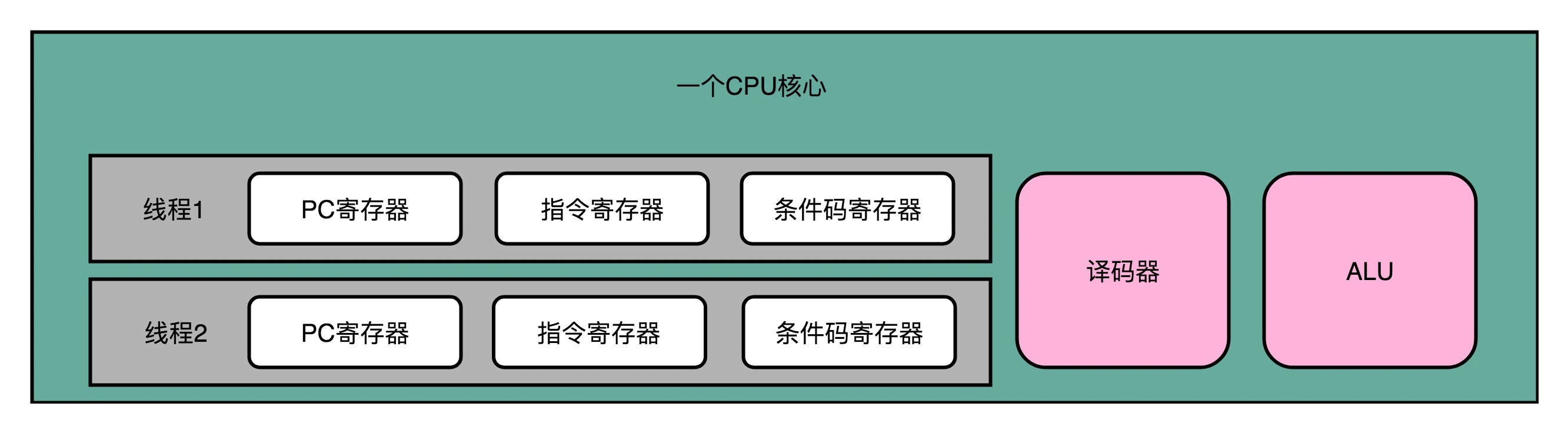
超线程的 CPU,其实是把一个物理层面 CPU 核心,“伪装” 成两个逻辑层面的 CPU 核心。这个 CPU,会在硬件层面增加很多电路,使得我们可以在一个 CPU 核心内部,维护两个不同线程的指令的状态信息。¶
备注
超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。CPU 通过很小的代价,就能实现 “同时” 运行多个线程的效果。通常我们只要在 CPU 核心的添加 10% 左右的逻辑功能,增加可以忽略不计的晶体管数量,就能做到这一点。
SISD,单指令单数据(Single Instruction Single Data)
MIMD,多指令多数据(Multiple Instruction Multiple Dataa)
SIMD,单指令多数据流(Single Instruction Multiple Data)
备注
使用循环来一步一步计算的算法一般被称为 SISD;而使用向量方式计算的算法则是SIMD。SIMD 指令能快那么多的原因是:SIMD 在获取数据和执行指令的时候,都做到了并行。一方面,在从内存里面读取数据的时候,SIMD 是一次性读取多个数据。
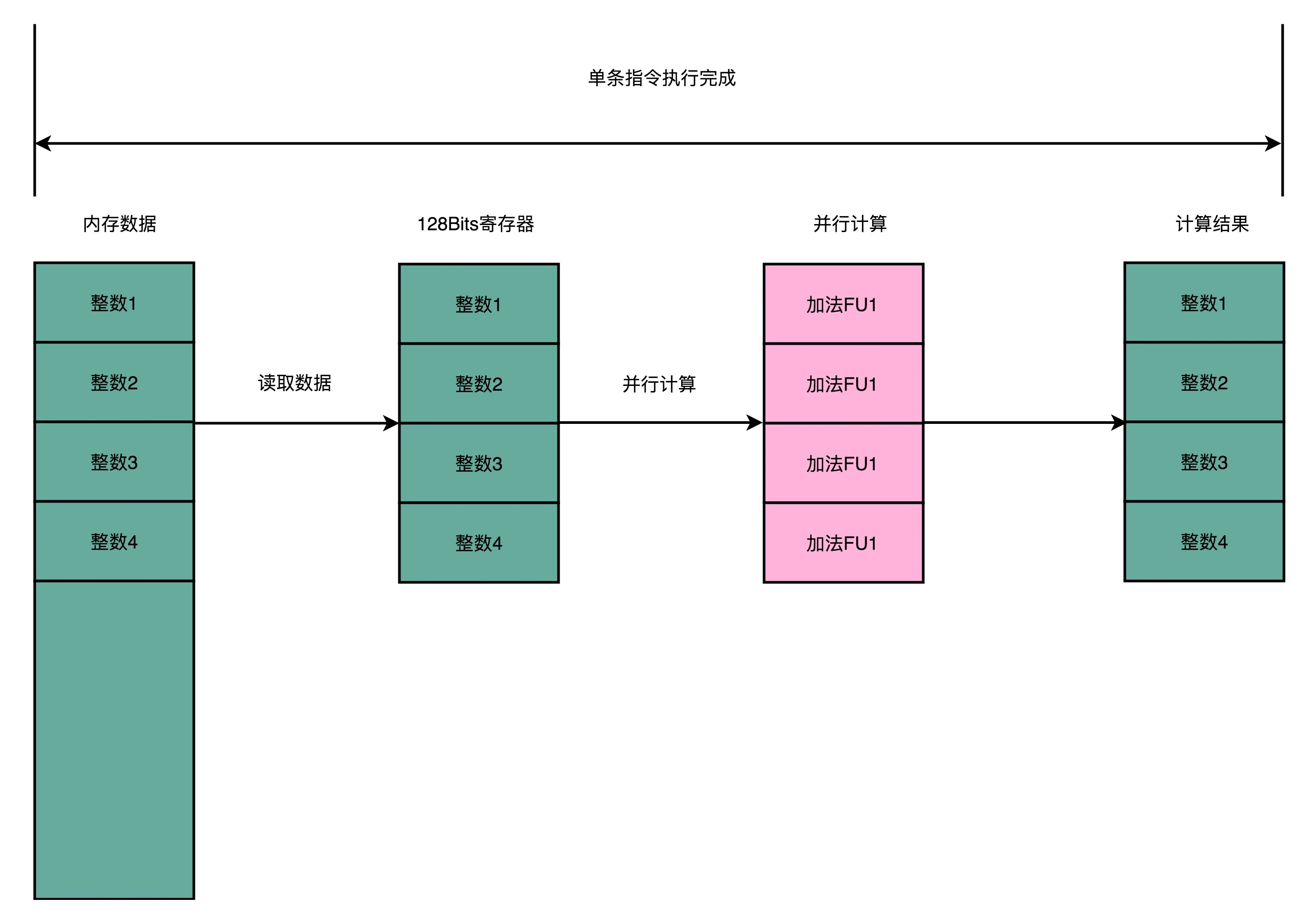
Intel 在引入 SSE 指令集的时候,在 CPU 里面添上了 8 个 128 Bits 的寄存器。128 Bits 也就是 16 Bytes ,也就是说,一个寄存器一次性可以加载 4 个整数。比起循环分别读取 4 次对应的数据,时间就省下来了。¶
异常&中断¶
异常的分类:
1. 中断(Interrupt): I/O 设备的输入
2. 陷阱(Trap): 程序主动触发的状态切换
3. 故障(Fault): 异常情况下的程序出错
4. 中止(Abort): 出错之后无可挽回的退出程序
备注
故障和陷阱、中断的一个重要区别是,故障在异常程序处理完成之后,仍然回来处理当前的指令,而不是去执行程序中的下一条指令。因为当前的指令因为故障的原因并没有成功执行完成。
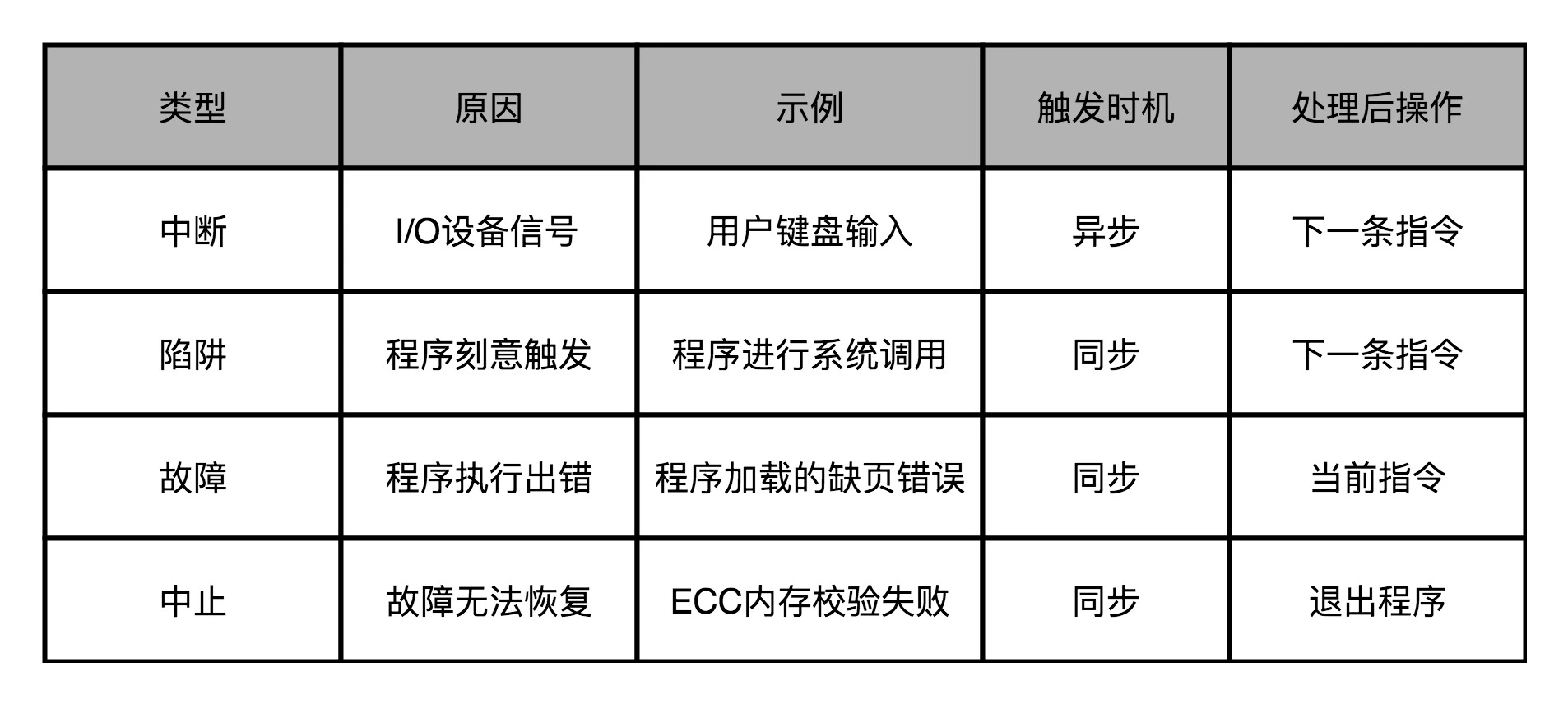
在这四种异常里,中断异常的信号来自系统外部,而不是在程序自己执行的过程中,所以我们称之为 “异步” 类型的异常。而陷阱、故障以及中止类型的异常,是在程序执行的过程中发生的,所以我们称之为 “同步 “类型的异常。¶
上下文切换(Context Switch)
指令集: CISC&RISC¶
备注
UC Berkeley 的大卫・帕特森(David Patterson)教授发现,实际在 CPU 运行的程序里,80% 的时间都是在使用 20% 的简单指令。于是,他就提出了 RISC 的理念。自此之后,RISC 类型的 CPU 开始快速蓬勃发展。
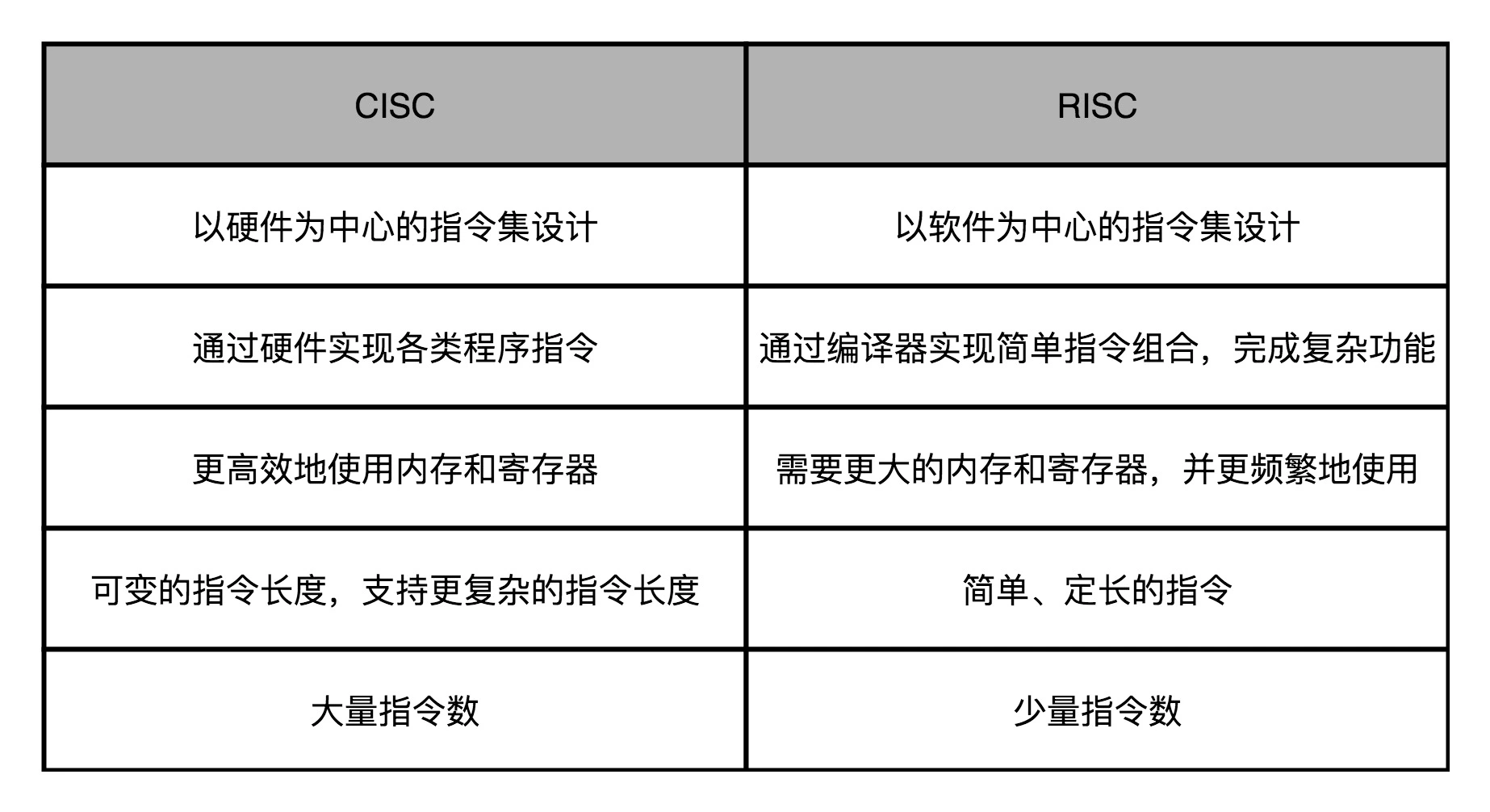
CISC&RISC: RISC 的通过减少 CPI 来提升性能,而 CISC 通过减少需要的指令数来提升性能。¶
备注
“开源硬件” 也慢慢发展起来了。一方面,MIPS 在 2019 年宣布开源;另一方面,从 UC Berkeley 发起的 RISC-V 项目也越来越受到大家的关注。而 RISC 概念的发明人,图灵奖的得主大卫・帕特森教授从伯克利退休之后,成了 RISC-V 国际开源实验室的负责人,开始推动 RISC-V 这个 “CPU 届的 Linux” 的开发。
GPU¶
图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤:
1. 顶点处理(Vertex Processing)
2. 图元处理(Primitive Processing)
3. 栅格化(Rasterization)
4. 片段处理(Fragment Processing)
5. 像素操作(Pixel Operations)
图形流水线(Graphic Pipeline)
可编程管线(Programable Function Pipeline)
统一着色器架构(Unified Shader Architecture)
现代 GPU 的三个核心创意:
1. 芯片瘦身
2. 多核并行和 SIMT
3. GPU 里的“超线程”
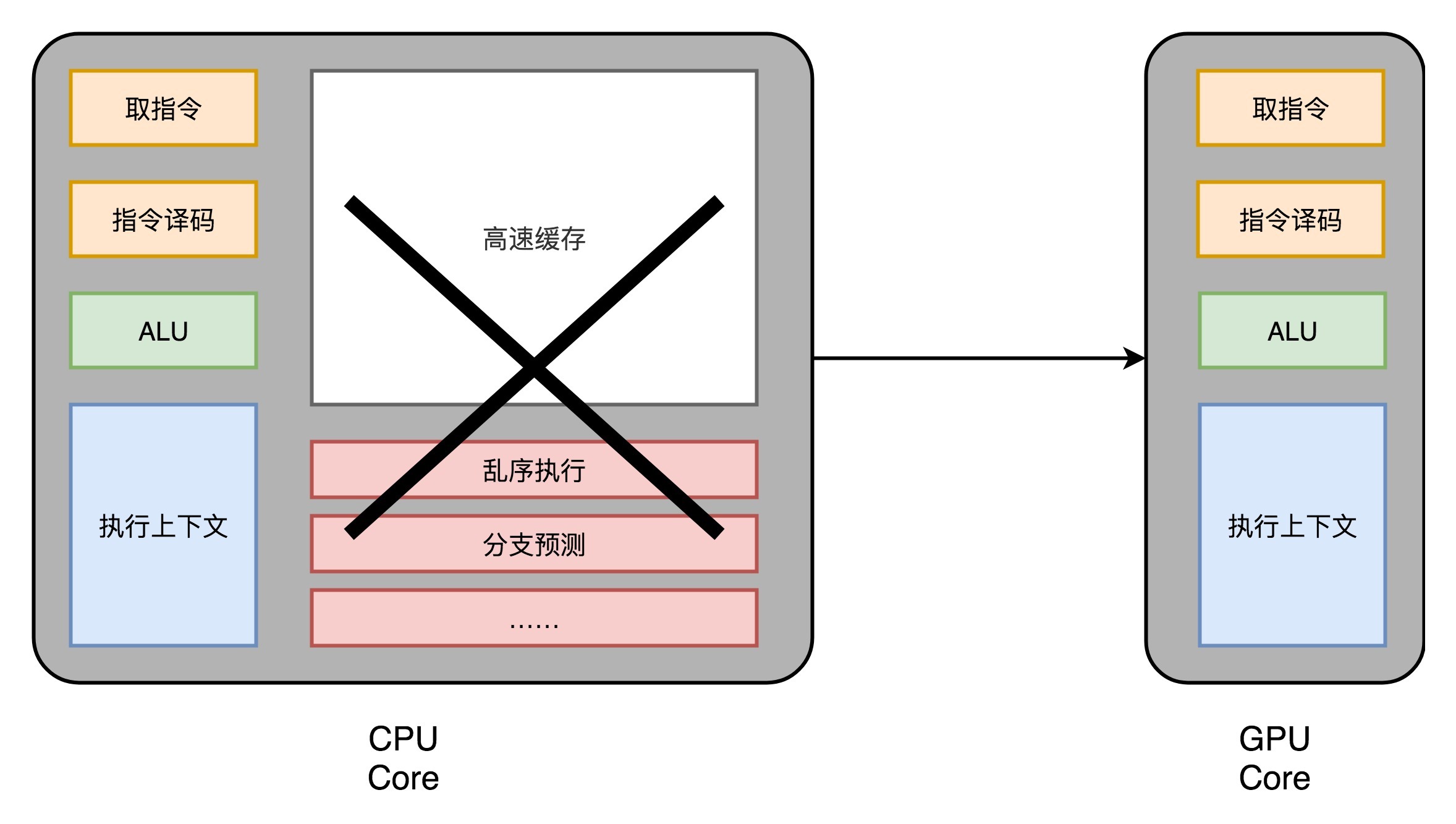
1.芯片瘦身: 现代 CPU 里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及我们之后要在存储器讲的高速缓存部分。而在 GPU 里,这些电路就显得有点多余了,GPU 的整个处理过程是一个流式处理(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,我们可以把 GPU 里这些对应的电路都可以去掉,做一次小小的瘦身,只留下取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存就好了。¶
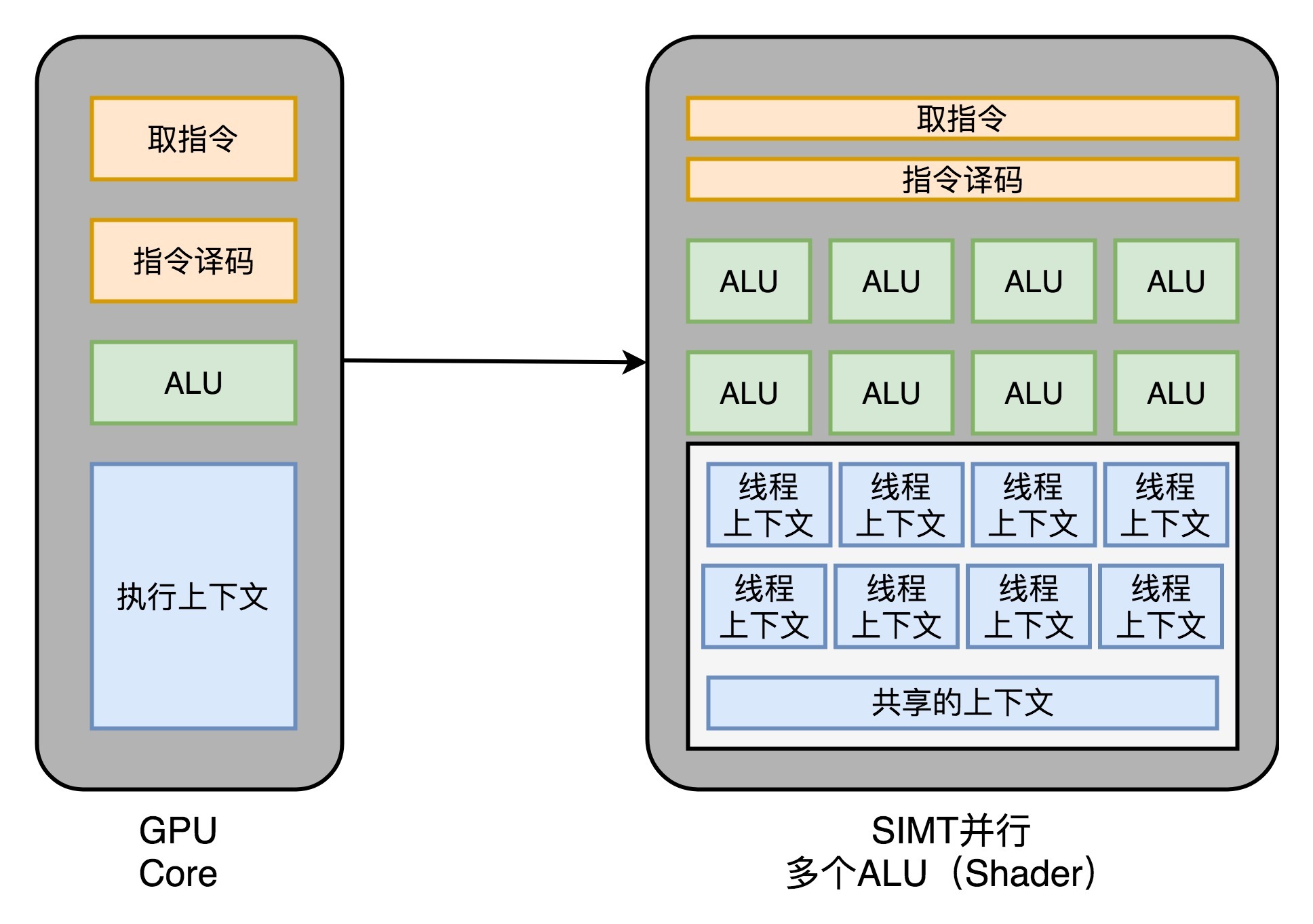
2.多核并行和 SIMT: GPU 设计可以进一步进化,也就是在取指令和指令译码的阶段,取出的指令可以给到后面多个不同的 ALU 并行进行运算。这样,我们的一个 GPU 的核里,就可以放下更多的 ALU,同时进行更多的并行运算了。¶
3.GPU 里的“超线程”: 既然已经是一个“通用计算”的架构了,GPU 里面也避免不了会有 if…else 这样的条件分支。但是,在 GPU 里我们可没有 CPU 这样的分支预测的电路。这些电路在上面“芯片瘦身”的时候,就已经被我们砍掉了。遇到和 CPU 类似的“流水线停顿”问题时,可以考虑使用 CPU 里面讲过超线程技术。和超线程一样,既然要调度一个不同的任务过来,我们就需要针对这个任务,提供更多的执行上下文。所以,一个 Core 里面的执行上下文的数量,需要比 ALU 多。¶
FPGA 和 ASIC¶
FPGA,也就是现场可编程门阵列(Field-Programmable Gate Array)
ASIC(Application-Specific Integrated Circuit),也就是专用集成电路
备注
一块 FPGA 这样的板子,可以在“现场”多次进行编程。它不像 PAL(Programmable Array Logic,可编程阵列逻辑)这样更古老的硬件设备,只能“编程”一次,把预先写好的程序一次性烧录到硬件里面,之后就不能再修改了。
FPGA 的解决方案:
1. 用存储换功能实现组合逻辑
2. 对于需要实现的时序逻辑电路,我们可以在 FPGA 里面直接放上 D 触发器,作为寄存器
3. FPGA 是通过可编程逻辑布线,来连接各个不同的 CLB,最终实现我们想要实现的芯片功能
备注
FPGA 本质上是一个可以通过编程,来控制硬件电路的芯片。我们通过用 LUT 这样的存储设备,来代替需要的硬连线的电路,有了可编程的逻辑门,然后把很多 LUT 和寄存器放在一起,变成一个更复杂的逻辑电路,也就是 CLB,然后通过控制可编程布线中的很多开关,最终设计出属于我们自己的芯片功能。FPGA,常常被我们用来进行芯片的设计和验证工作,也可以直接拿来当成专用的芯片,替换掉 CPU 或者 GPU,以节约成本。
“FPGA 的历史、现状和未来”: https://www.infoq.cn/article/wmijrofwZCEHRk0OySjP
TPU¶
模型的训练和推断有什么不同:
1. 深度学习的推断工作更简单,对灵活性的要求也就更低
2. 深度学习的推断的性能,首先要保障响应时间的指标
3. 深度学习的推断工作,希望在功耗上尽可能少一些
备注
第一代 TPU 的设计目标。那就是,在保障响应时间的情况下,能够尽可能地提高能效比这个指标
TPU 的论文 In-Datacenter Performance Analysis of a Tensor Processing Unit: https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
Google 官方专门讲解 TPU 构造的博客文章 An in-depth look at Google’s first Tensor Processing Unit(TPU): https://cloud.google.com/blog/products/gcp/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
虚拟机¶
解释型虚拟机¶
备注
这种解释执行方式的最大的优势就是,模拟的系统可以跨硬件。比如,Android 手机用的 CPU 是 ARM 的,而我们的开发机用的是 Intel X86 的,两边的 CPU 指令集都不一样,但是一样可以正常运行。
两个明显的缺陷:
1. 第一个是,做不到精确的 “模拟”。
很多的老旧的硬件的程序运行,要依赖特定的电路乃至电路特有的时钟频率,
想要通过软件达到 100% 模拟是很难做到的。
2. 第二个缺陷就更麻烦了,那就是这种解释执行的方式,性能实在太差了。
因为我们并不是直接把指令交给 CPU 去执行的,而是要经过各种解释和翻译工作。
Type-1 和 Type-2¶
虚拟化技术,能够克服上面的模拟器方式的两个缺陷。同时,需要放弃掉模拟器方式能做到的跨硬件平台的这个能力。解决方案就是加入一个中间层:在虚拟机技术里面,这个中间层就叫作虚拟机监视器,英文叫 VMM(Virtual Machine Manager)或者 Hypervisor。
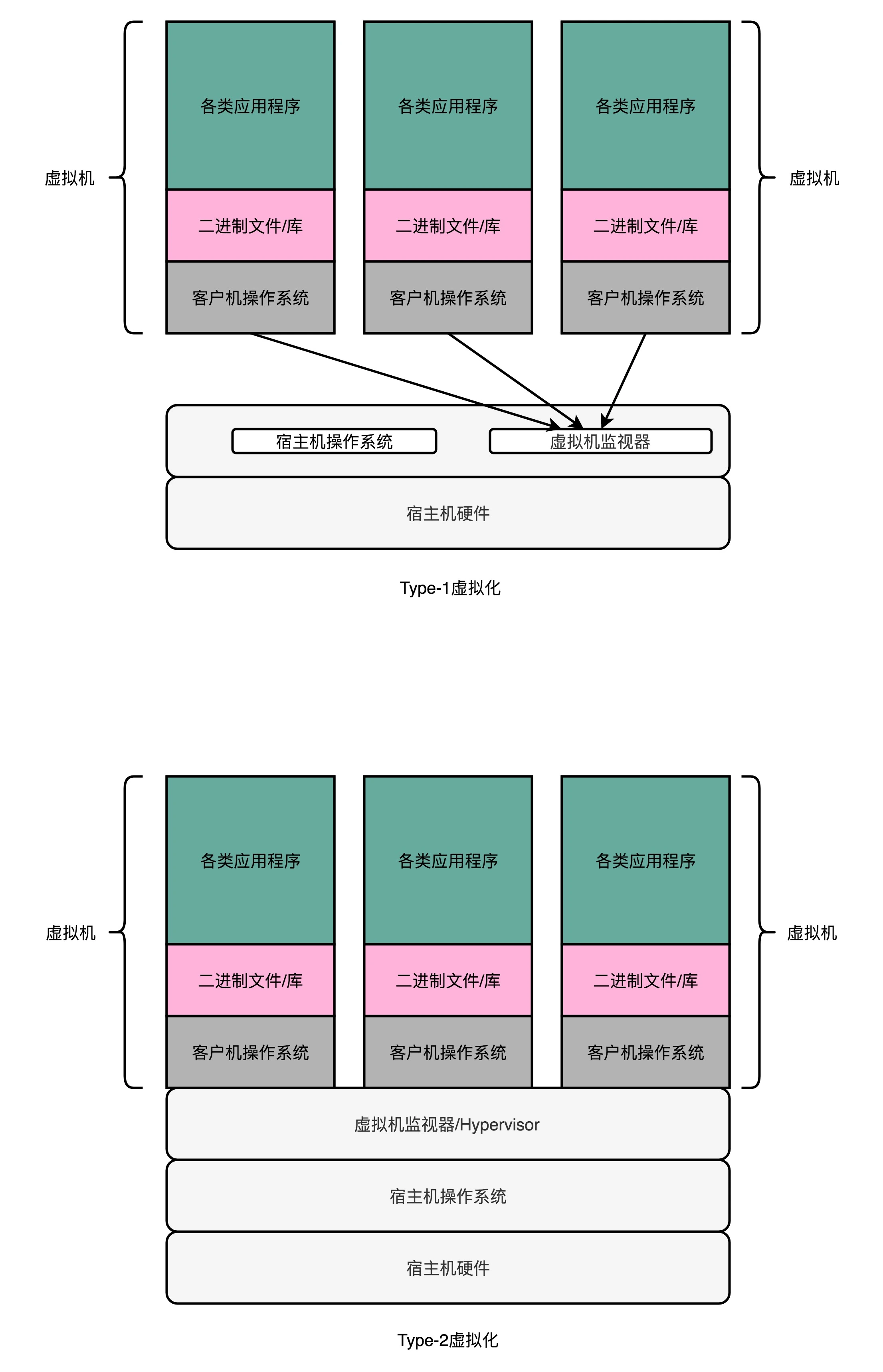
Type-2 型的虚拟机,更多是用在我们日常的个人电脑里,而不是用在数据中心里。而无论是 KVM、XEN 还是微软自家的 Hyper-V,其实都是系统级 Type-1 型的虚拟机。因为虚拟机监视器需要直接和硬件打交道,所以它也需要包含能够直接操作硬件的驱动程序。所以 Type-1 的虚拟机监视器更大一些,同时兼容性也不能像 Type-2 型那么好。不过,因为它一般都是部署在我们的数据中心里面,硬件完全是统一可控的,这倒不是一个问题了。¶
Docker¶
对Type-1 型的虚拟机来说,在我们实际的物理机上,我们可能同时运行了多个的虚拟机,而这每一个虚拟机,都运行了一个属于自己的单独的操作系统。而对 Docker 这种隔离资源的方式,也有人称之为 “操作系统级虚拟机”,好和上面的全虚拟化虚拟机对应起来。不过严格来说,Docker 并不能算是一种虚拟机技术,而只能算是一种资源隔离的技术而已。¶
存储¶
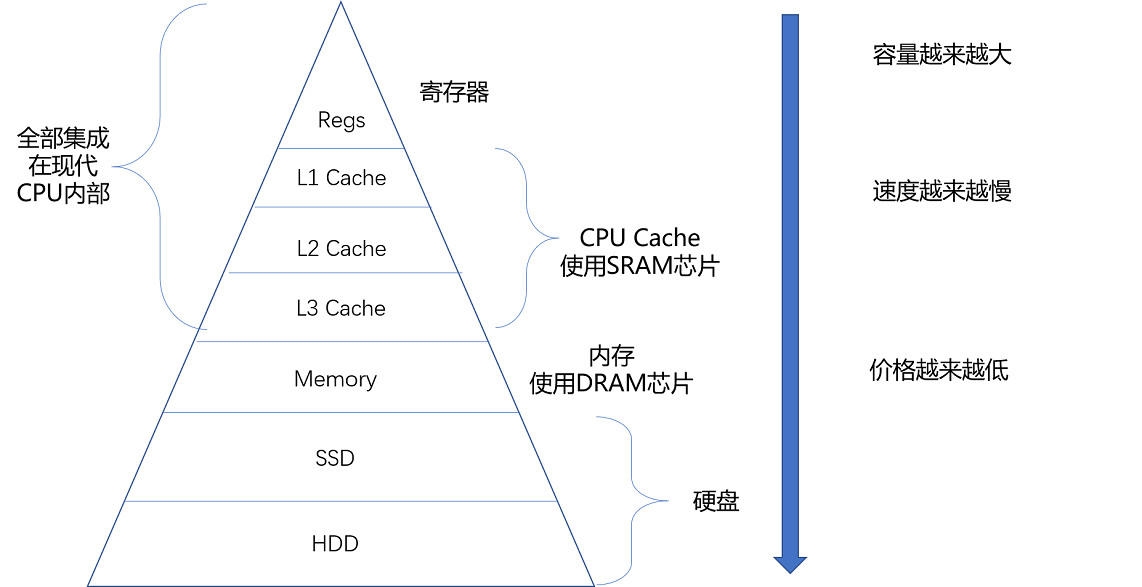
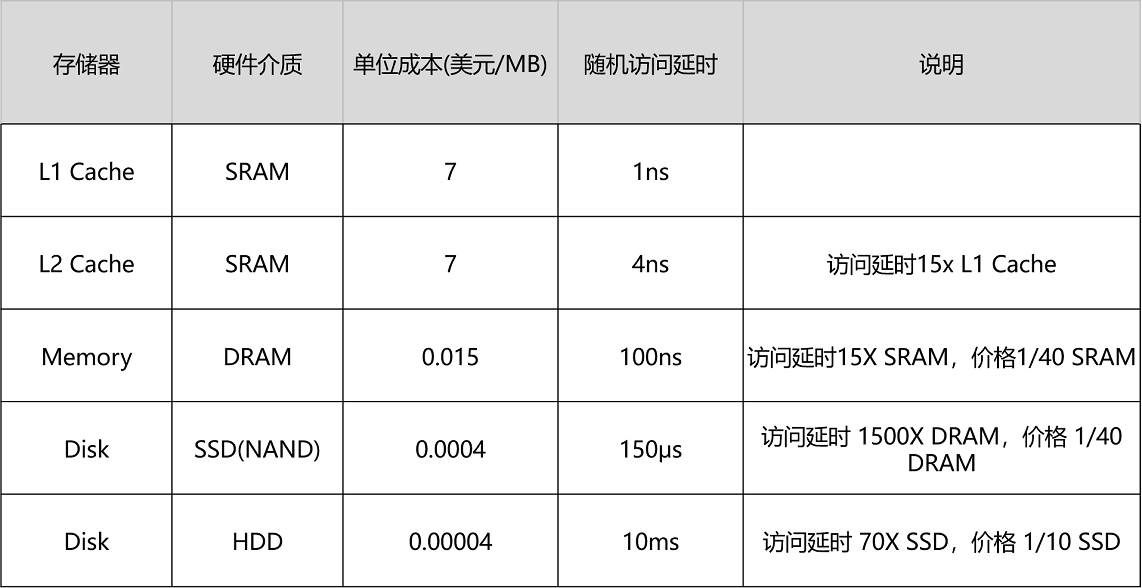
各种存储器成本的对比¶
备注
NVME 是一个接口规范,现在存储用的也还是 SSD,只是这个接口带宽比 PCI-E 要高,顺序读写的吞吐率能做得更高。
🔥局部性原理¶
局部性原理(Principle of Locality):
1. 时间局部性(temporal locality)
这个策略是说,如果一个数据被访问了,那么它在短时间内还会被再次访问
2. 空间局部性(spatial locality)
如果一个数据被访问了,那么和它相邻的数据也很快会被访问
把访问次数多的数据,放在贵但是快一点的存储器里
把访问次数少的数据,放在慢但是大一点的存储器里
高速缓存¶
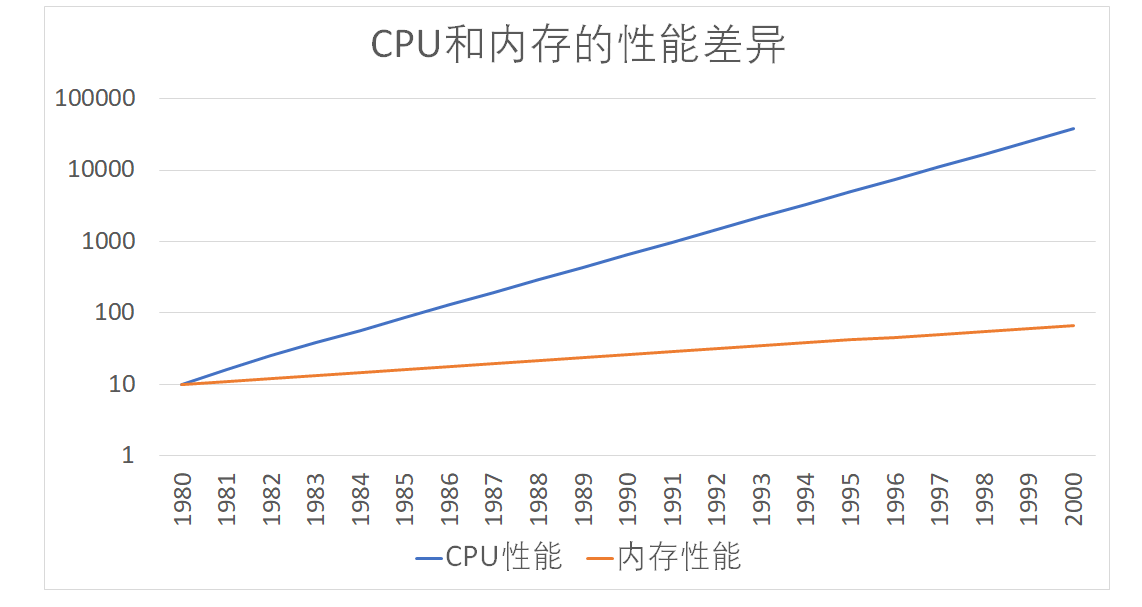
按照摩尔定律,CPU 的访问速度每 18 个月便会翻一番,相当于每年增长 60%。内存的访问速度虽然也在不断增长,却远没有这么快,每年只增长 7% 左右。而这两个增长速度的差异,使得 CPU 性能和内存访问性能的差距不断拉大。到今天来看,一次内存的访问,大约需要 120 个 CPU Cycle,这也意味着,在今天,CPU 和内存的访问速度已经有了 120 倍的差距。¶
备注
为了弥补两者之间的性能差异,我们能真实地把 CPU 的性能提升用起来,而不是让它在那儿空转,我们在现代 CPU 中引入了高速缓存。在各类基准测试(Benchmark)和实际应用场景中,CPU Cache 的命中率通常能达到 95% 以上。
常见的缓存放置策略:
1. 直接映射 Cache(Direct Mapped Cache)
2. 全相连 Cache(Fully Associative Cache)
3. 组相连 Cache(Set Associative Cache)
如果内存中的数据已经在 CPU Cache 里了,那一个内存地址的访问,就会经历这样 4 个步骤:
1. 根据内存地址的低位,计算在 Cache 中的索引;
2. 判断有效位,确认 Cache 中的数据是有效的;
3. 对比内存访问地址的高位和 Cache 中的组标记,
确认 Cache 中的数据就是我们要访问的内存数据,
从 Cache Line 中读取到对应的数据块(Data Block);
4. 根据内存地址的 Offset 位,从 Data Block 中,读取希望读取到的字。
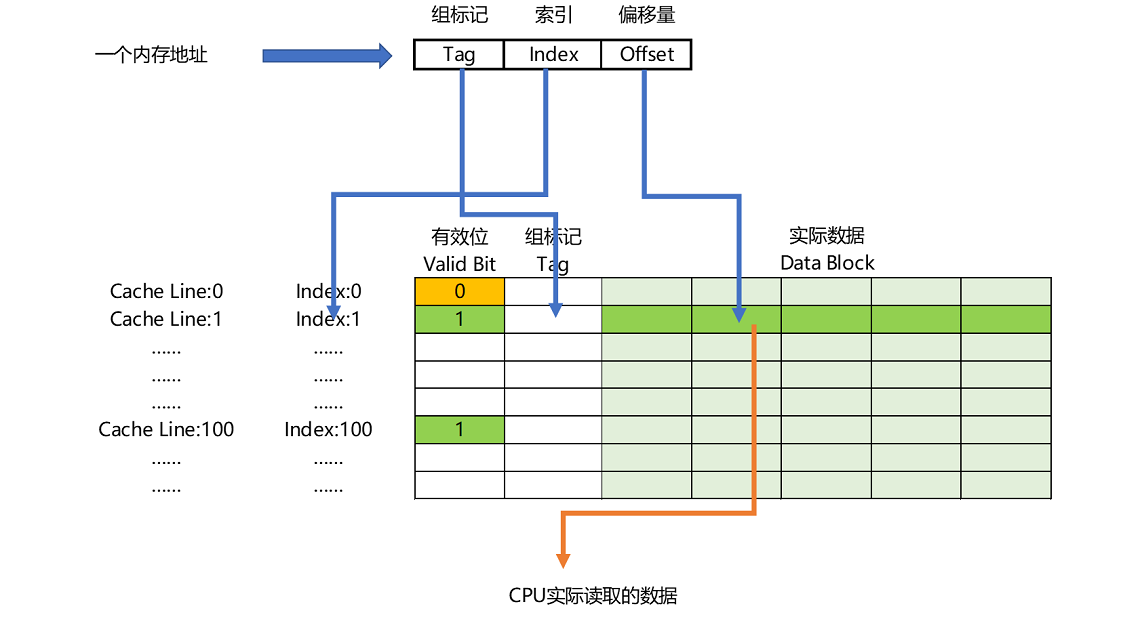
内存地址到 Cache Line 的关系¶
两种写入策略:
1. 写直达(Write-Through)
在这个策略里,每一次数据都要写入到主内存里面:
先去判断数据是否已经在 Cache 里面了。
如果数据已经在 Cache 里面了,我们先把数据写入更新到 Cache 里面,再写入到主内存里面
如果数据不在 Cache 里,我们就只更新主内存
2. 写回(Write-Back)
这个策略里,我们不再是每次都把数据写入到主内存,而是只写到 CPU Cache 里。
只有当 CPU Cache 里面的数据要被 “替换” 的时候,我们才把数据写入到主内存里面去。
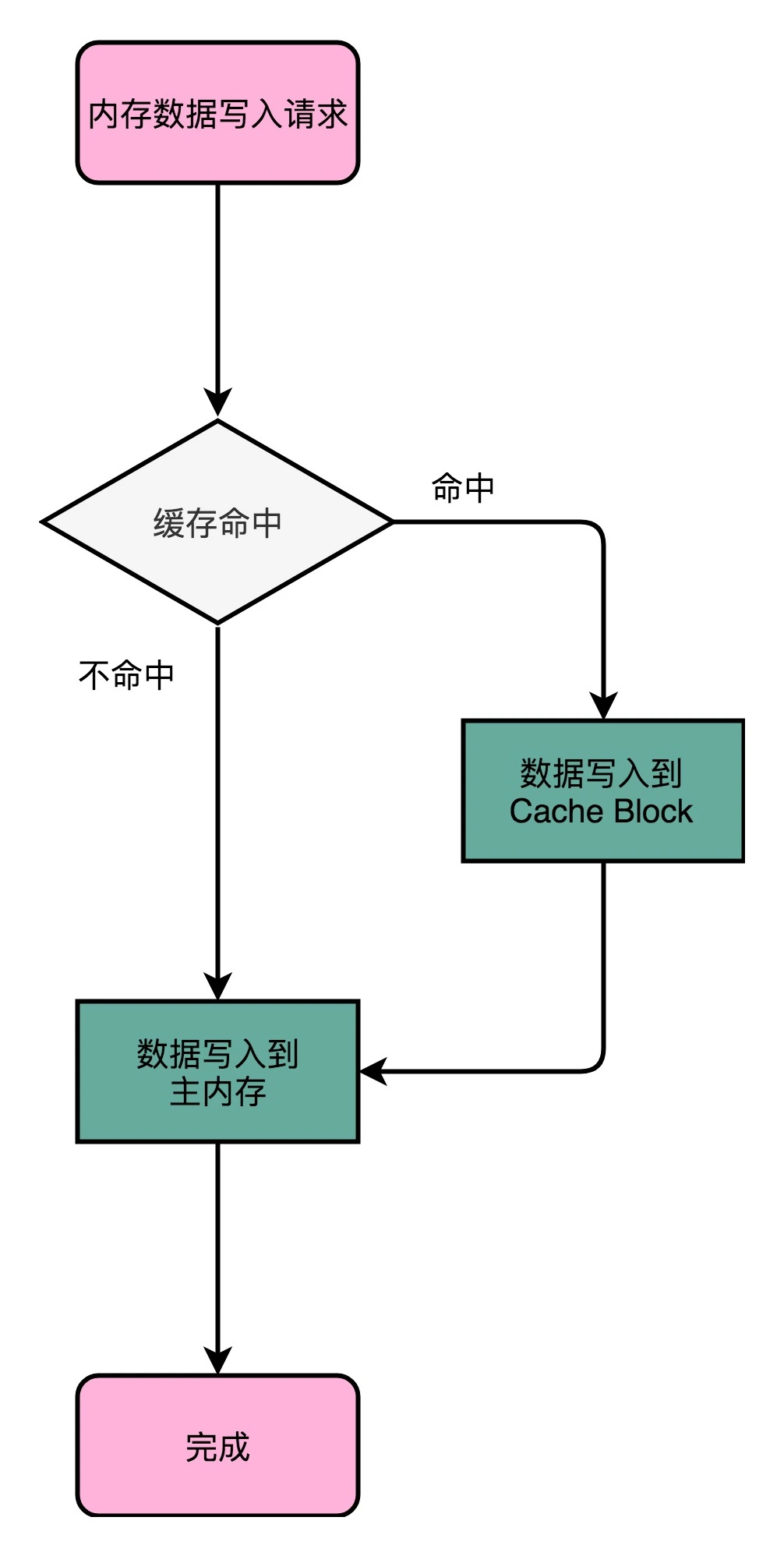
写直达(Write-Through)¶
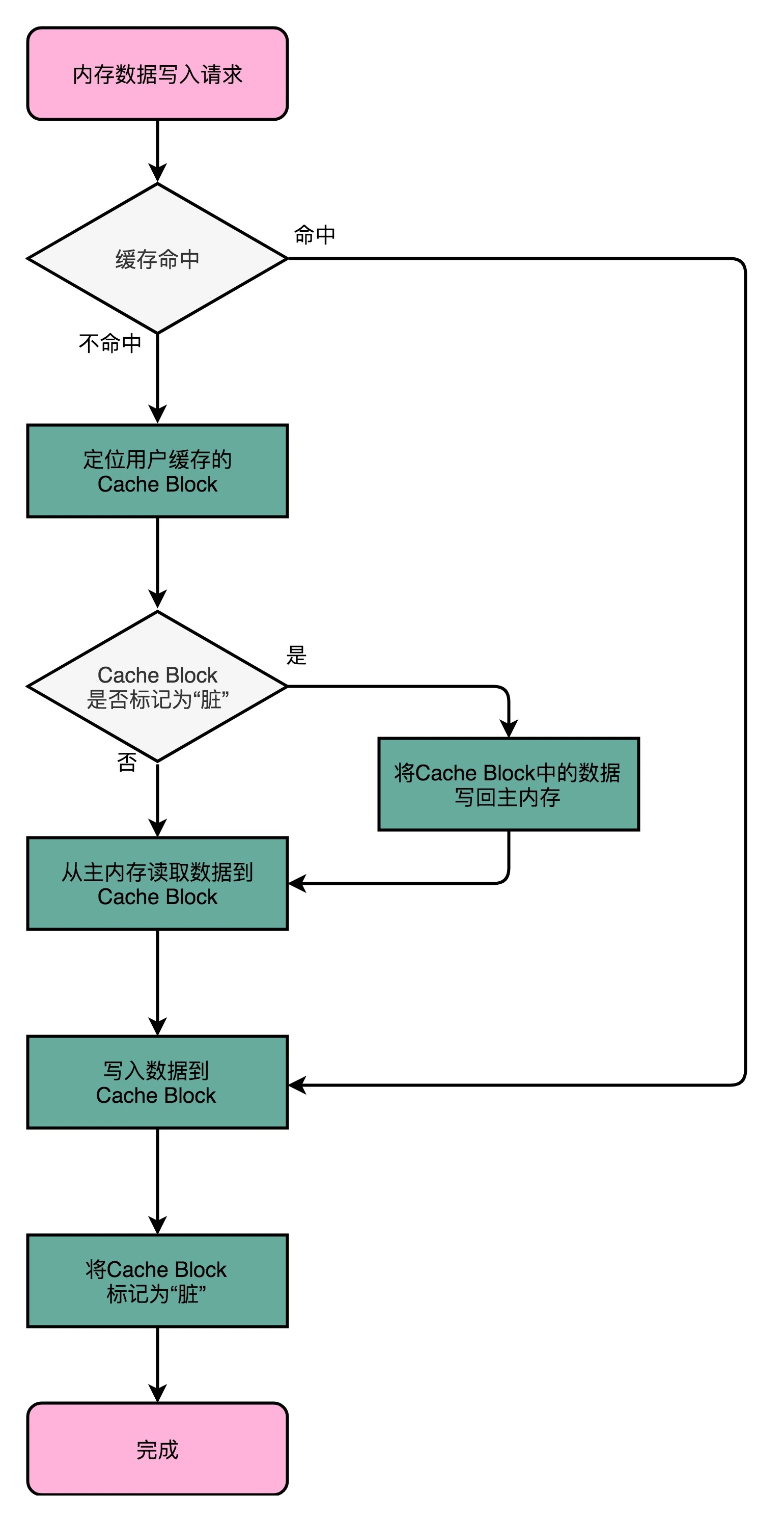
写回(Write-Back):1. 如果发现我们要写入的数据,就在 CPU Cache 里面,那么我们就只是更新 CPU Cache 里面的数据。同时,我们会标记 CPU Cache 里的这个 Block 是脏(Dirty)的。所谓脏的,就是指这个时候,我们的 CPU Cache 里面的这个 Block 的数据,和主内存是不一致的。2. 如果我们发现,我们要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,那么我们就要看一看,那个 Cache Block 里面的数据有没有被标记成脏的。如果是脏的话,我们要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。如果 Block 里面的数据没有被标记成脏的,那么我们直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。3. 在用了写回这个策略之后,我们在加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,我们也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。¶
备注
无论是写回还是写直达,其实都还没有解决这个问题:就是多个线程,或者是多个 CPU 核的缓存一致性的问题。这也就是我们在写入修改缓存后,需要解决的第二个问题。
MESI¶
多核缓存如何解决缓存不一致的问题:
1. 写传播(Write Propagation)
在一个 CPU 核心里,我们的 Cache 数据更新,
必须能够传播到其他的对应节点的 Cache Line 里
2. 事务的串行化(Transaction Serialization)
在一个 CPU 核心里面的读取和写入,在其他的节点看起来,顺序是一样的
备注
CPU Cache 里做到事务串行化,需要做到两点,第一点是一个 CPU 核心对于数据的操作,需要同步通信给到其他 CPU 核心。第二点是,如果两个 CPU 核心里有同一个数据的 Cache,那么对于这个 Cache 数据的更新,需要有一个 “锁” 的概念。只有拿到了对应 Cache Block 的 “锁” 之后,才能进行对应的数据更新。MESI 协议正是实现了这2点。
备注
总线嗅探(Bus Snooping):本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去 “嗅探” 这些请求,再根据本地的情况进行响应。基于总线嗅探机制,其实还可以分成很多种不同的缓存一致性协议。不过其中最常用的,就是 MESI 协议。和很多现代的 CPU 技术一样,MESI 协议也是在 Pentium 时代,被引入到 Intel CPU 中的。
总线嗅探有两种实现方式:
写失效(Write Invalidate)的协议(MESI 协议使用这种)
写广播(Write Broadcast)的协议
备注
写失效: 只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个 “失效” 请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个 “失效” 版本的 Cache Block,然后把这个也标记成失效的就好了。
备注
写广播: 一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。
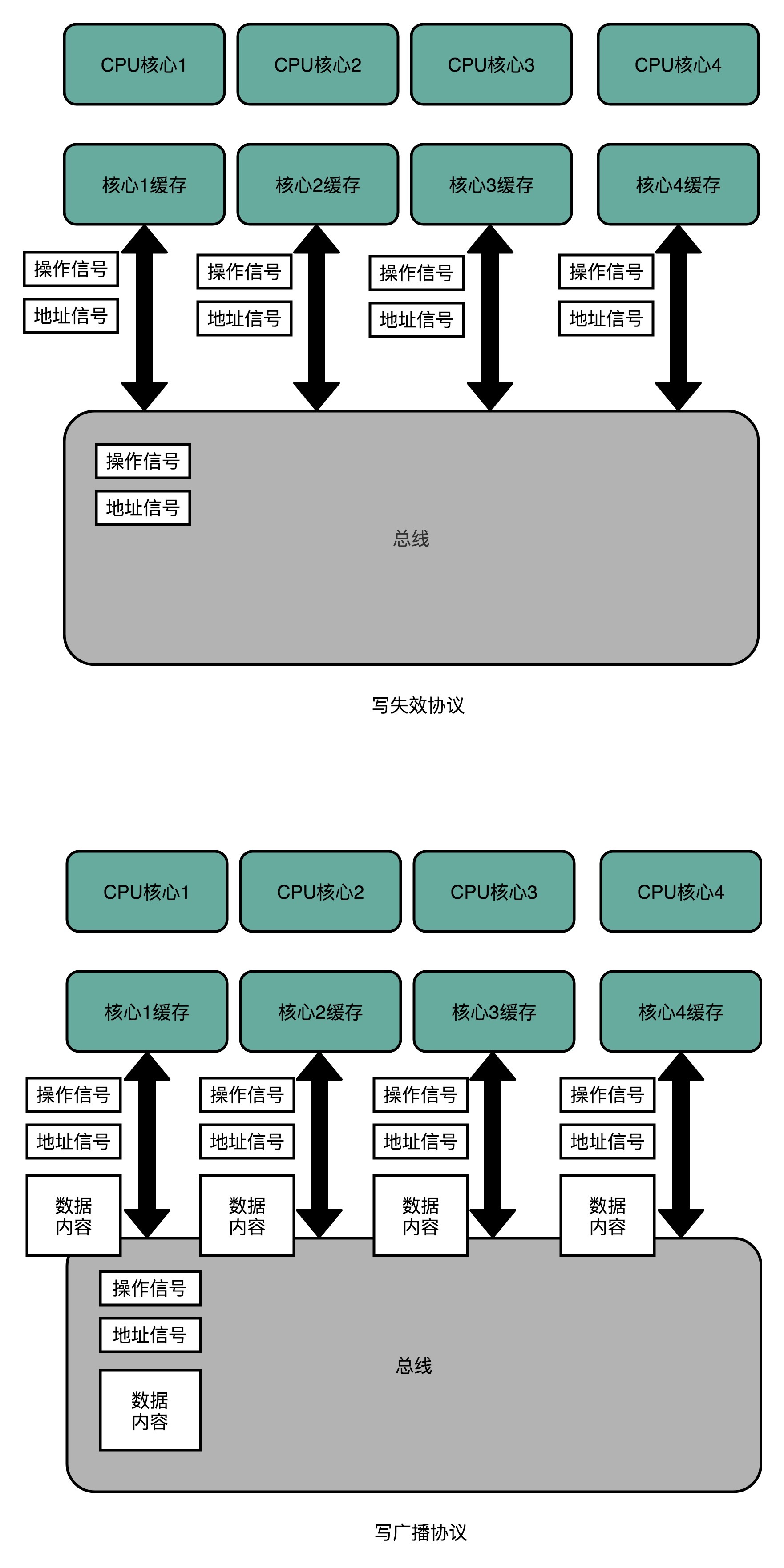
[对比]写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽。写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。¶
对 Cache Line 的四个不同的标记,分别是:
注: MESI 协议,是已修改、独占、共享以及已失效这四个缩写的合称
M: 代表已修改(Modified)
表示“脏” 的 Cache Block
E: 代表独占(Exclusive)
表示“干净” 的 Cache Block
在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里
要向独占的 Cache Block 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核
在独占状态下的数据,如果收到了一个来自于总线的读取对应缓存的请求,它就会变成共享状态
S: 代表共享(Shared)
表示“干净” 的 Cache Block
在共享状态下,因为同样的数据在多个 CPU 核心的 Cache 里都有
所以,当我们想要更新 Cache 里面的数据的时候,不能直接修改,
而是要先向所有的其他 CPU 核心广播一个请求,
要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,
然后再更新当前 Cache 里面的数据
这个广播操作,一般叫作 RFO(Request For Ownership),
也就是获取当前对应 Cache Block 数据的所有权
I: 代表已失效(Invalidated)
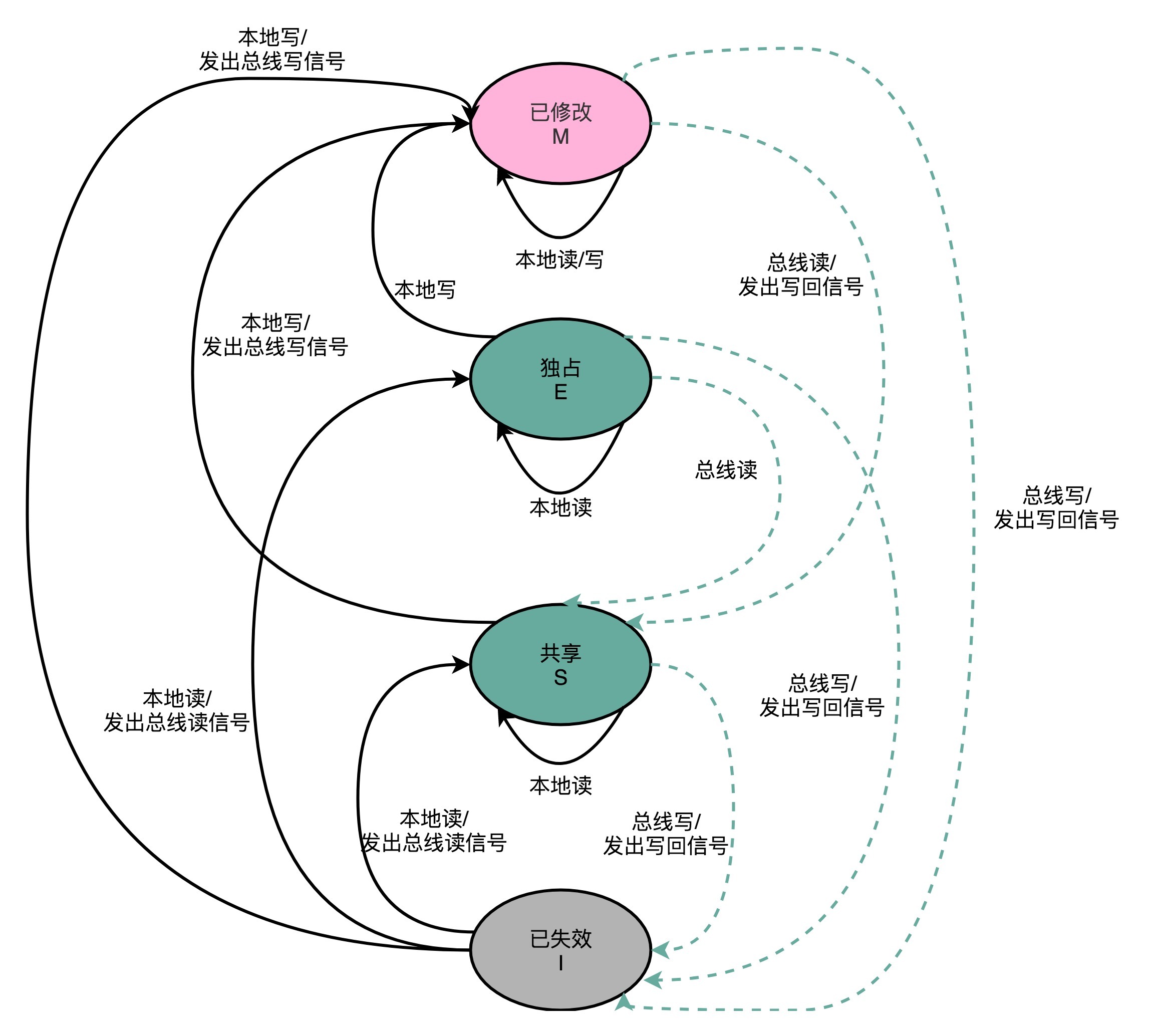
状态机流转图¶
内存¶
页(Page)
虚拟内存地址(Virtual Address)
物理内存地址(Physical Address)
地址转换(Address Translation)
页表(Page Table)
页号(Directory)
偏移量(Offset)
页表树(Page Table Tree):因为多级页表就像一个多叉树的数据结构
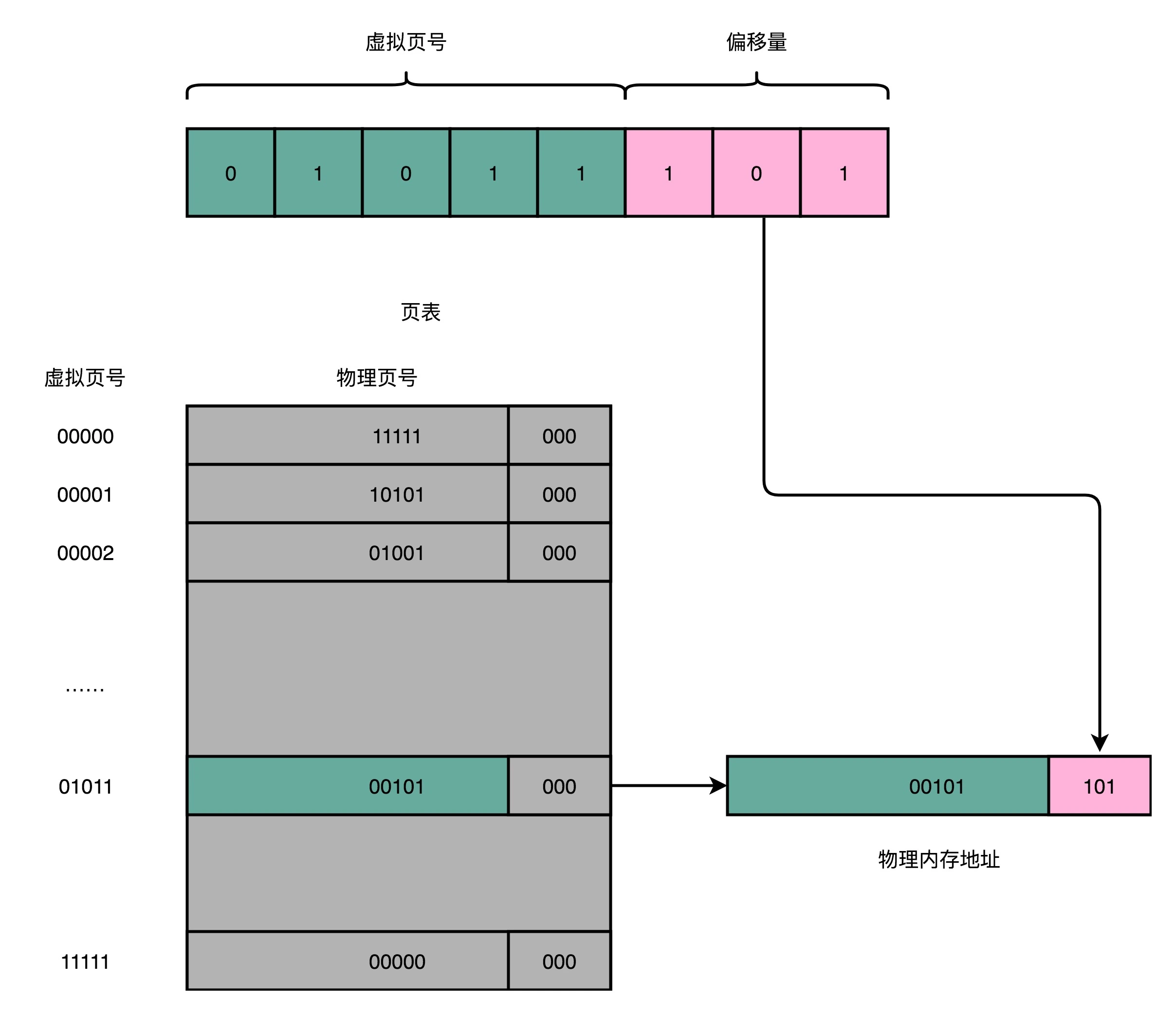
对于一个内存地址转换,其实就是这样三个步骤:1. 把虚拟内存地址,切分成页号和偏移量的组合;2. 从页表里面,查询出虚拟页号,对应的物理页号;3. 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。¶
备注
【问题-简单页表】32 位的内存地址空间,页表一共需要记录 2^20 个到物理页号的映射关系。一个页号是完整的 32 位的 4 字节(Byte),这样一个页表就需要 4MB 的空间。但是:这个空间可不是只占用一份哦。我们每一个进程,都有属于自己独立的虚拟内存地址空间。这也就意味着,每一个进程都需要这样一个页表。
备注
在程序运行的时候,内存地址从顶部往下,不断分配占用的栈的空间。而堆的空间,内存地址则是从底部往上,是不断分配占用的。在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间(堆和栈)。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
备注
为啥用多级页表而不是哈希表:哈希表是数组 + 链表组成的,充分的结合了数组和链表的优势,互补!但是哈希表存在哈希冲突,并且是无序的!不符合局部性原理!
备注
【问题-多级页表】多级页表虽然节约了我们的存储空间,却带来了时间上的开销,所以它其实是一个 “以时间换空间” 的策略。原本我们进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是,用了 4 级页表,我们就需要访问 4 次内存,才能找到物理页号了。
内存保护(Memory Protection):
1. 可执行空间保护(Executable Space Protection)
2. 地址空间布局随机化(Address Space Layout Randomization)
备注
【安全】通过让数据空间里面的内容不能执行,可以避免了类似于 “注入攻击” 的攻击方式。通过随机化内存空间的分配,可以避免让一个进程的内存里面的代码,被推测出来,从而不容易被攻击。
总线¶
总线(Bus)
双独立总线(Dual Independent Bus,缩写为 DIB)
总线裁决(Bus Arbitraction)
备注
总线的设计思路,核心是为了减少多个模块之间交互的复杂性和耦合度。
1. 快速的本地总线(Local Bus)
后端总线(Back-side Bus)
现代的 CPU 里,通常有专门的高速缓存芯片。这里的高速本地总线,就是用来和高速缓存通信的
2. 速度相对较慢的前端总线(Front-side Bus)
而前端总线主要是用于CPU、内存、IO 设备间的通信
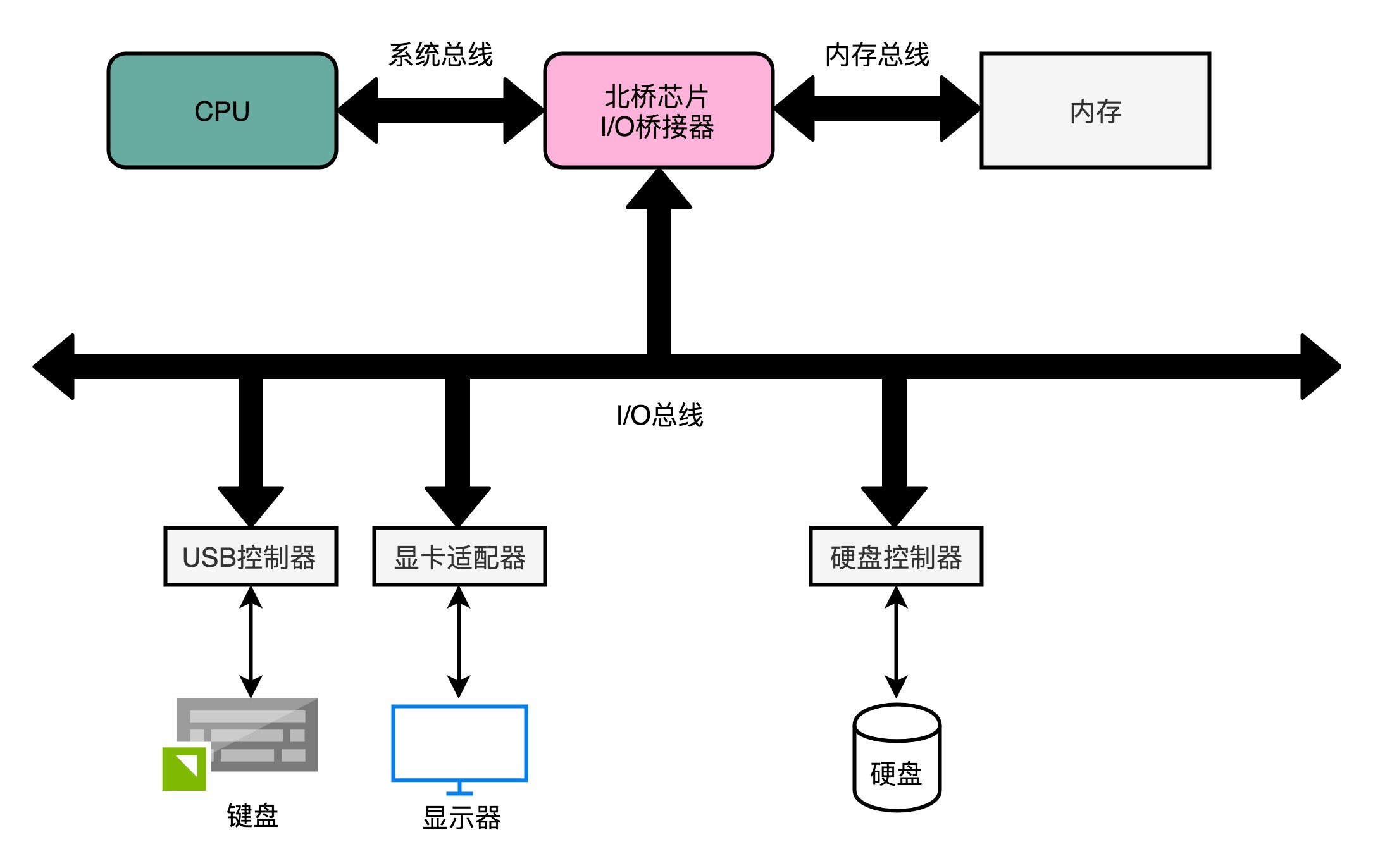
前端总线有很多其他名字,比如处理器总线(Processor Bus)、内存总线(Memory Bus)、系统总线(System Bus)。通过一个 I/O 桥接器,拆分成两个总线,分别来和 I/O 设备以及内存通信。自然,这样拆开的两个总线,就叫作 I/O 总线和内存总线。事实上,真实的计算机里,这个总线层面拆分得更细。根据不同的设备,还会分成独立的 PCI 总线、ISA 总线等等。¶
根据总线本身的电路功能,通常有三类线路:
1. 数据线(Data Bus)
用来传输实际的数据信息
2. 地址线(Address Bus)
用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。
3. 控制线(Control Bus)
用来控制对于总线的访问
输入输出¶
平时说的,设备里面有三类寄存器,其实都在这个设备的接口电路上,而不在实际的设备上:
1. 状态寄存器(Status Register)
2. 命令寄存器(Command Register)
3. 数据寄存器(Data Register)
对于输入输出设备不同角度的描述:
1. Devices: 看重的是实际的 I/O 设备本身
2. Controllers: 看重的是输入输出设备接口里面的控制电路
3. Adaptors: 看重接口作为一个适配器后面可以插上不同的实际设备
磁盘¶
IO_WAIT¶
硬盘性能报告的两个指标:
1. 一个是响应时间(Response Time)
2. 一个是数据传输率(Data Transfer Rate)
数据传输率指标:
SATA 3.0 的接口: 带宽是 6Gb/s(768MB)
PCI Express 的接口:
在读取的时候就能做到 2GB/s 左右,差不多是 HDD 硬盘的 10 倍
在写入的时候也能有 1.2GB/s
随机读取磁盘上某一个 4KB 大小的数据:
在随机读写的时候,数据传输率也只能到 40MB/s 左右,是顺序读写情况下的几十分之一
IOPS 也就是在 2 万左右
HDD 硬盘:
数据传输率,差不多在 200MB/s
IOPS 通常在 100 左右
响应时间指标:
SSD 硬盘: 几十微秒
HDD 硬盘: 几毫秒到十几毫秒
机械硬盘¶
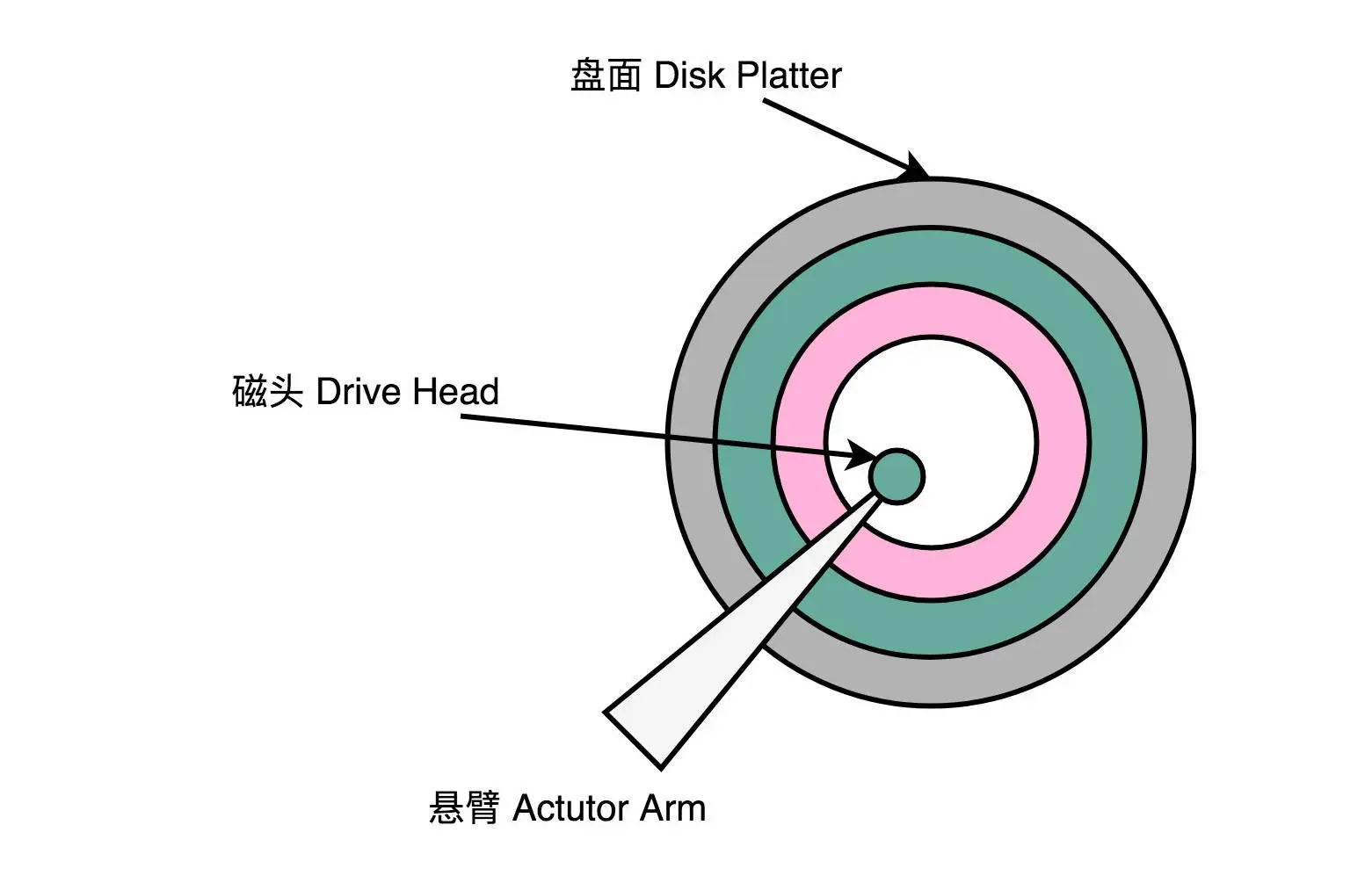
一块机械硬盘是由盘面、磁头和悬臂三个部件组成的。下面我们一一来看每一个部件¶
进行一次硬盘上的随机访问,需要的时间由两个部分组成:
1. 平均延时(Average Latency)
随机情况下,平均找到一个几何扇区,我们需要旋转半圈盘面
在7200 转的硬盘,那么一秒里面,就可以旋转 240 个半圈
平均延时:
1s / 240 = 4.17ms
2. 平均寻道时间(Average Seek Time)
现在用的 HDD 硬盘的平均寻道时间一般在 4-10ms
结论:
如果随机在整个硬盘上找一个数据,需要 8-14 ms
则:一秒钟随机的 IO 访问次数,也就是
1s / 8 ms = 125 IOPS 或者 1s / 14ms = 70 IOPS
备注
【黑科技】Partial Stroking 或者 Short Stroking:根据场景提升性能,可以使用缩短寻道时间来提升硬盘的 IOPS 的解决方案。如果我们只用其中 1/4 的磁道,那么,它的 IOPS 就变成了 1s / (4.17ms + 9ms/4) = 155.8 IOPS 。方案就是:只需要简单地把 C 盘分成整个硬盘 1/4 的容量,剩下的容量弃而不用就
SSD¶
SSD 硬盘的存储和读写原理:CPU Cache 用的 SRAM 是用一个电容来存放一个比特的数据。对于 SSD 硬盘,如图,可以简单地认为,它是由一个电容加上一个电压计组合在一起,记录了一个或者多个比特。¶
在控制电路里,有一个很重要的模块,叫作 FTL(Flash-Translation Layer),也就是闪存转换层,是 SSD 硬盘的一个核心模块,SSD 硬盘性能的好坏,很大程度上也取决于 FTL 的算法好不好。对于 SSD 硬盘来说,数据的写入叫作 Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先去擦除(Erase),然后再写入。SSD 的读取和写入的基本单位,不是一个比特(bit)或者一个字节(byte),而是一个页(Page)。SSD 的擦除单位就更夸张了,我们不仅不能按照比特或者字节来擦除,连按照页来擦除都不行,我们必须按照块来擦除。¶
1. SLC(Single-Level Cell)
2. MLC(Multi-Level Cell)
3. TLC(Triple-Level Cell)
4. QLC(Quad-Level Cell)
备注
SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而 TLC 和 QLC 就只在几千次了。
备注
【问】为什么 ssd 断电后不会丢数据?现在大家用的 SSD 的存储硬件都是 NAND Flash。实现原理和通过改变电压,让电子进入绝缘层的浮栅 (Floating Gate) 内。断电之后,电子仍然在 FG 里面。但是如果长时间不通电,比如几年,仍然可能会丢数据。所以换句话说,SSD 的确也不适合作为冷数据备份。
磨损均衡(Wear-Leveling)
FTL(Flash-Translation Layer),也就是闪存转换层
在 FTL 里面,存放了逻辑块地址(Logical Block Address,简称 LBA)到物理块地址(Physical Block Address,简称 PBA)的映射
DMA¶
傲腾(Optane)
DMA 技术,也就是直接内存访问(Direct Memory Access)
DMA 控制器(DMA Controller,简称 DMAC)。在主板上放一块独立的芯片,这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)
零拷贝(Zero-Copy)
总线上的设备呢,其实有两种类型:
一种我们称之为主设备(Master)
另外一种,我们称之为从设备(Slave)
想要主动发起数据传输,必须要是一个主设备才可以:
CPU 就是主设备
硬盘 就是从设备
DMAC 既是一个主设备,又是一个从设备:
对于 CPU 来说,它是一个从设备
对于硬盘这样的 IO 设备来说呢,它又变成了一个主设备
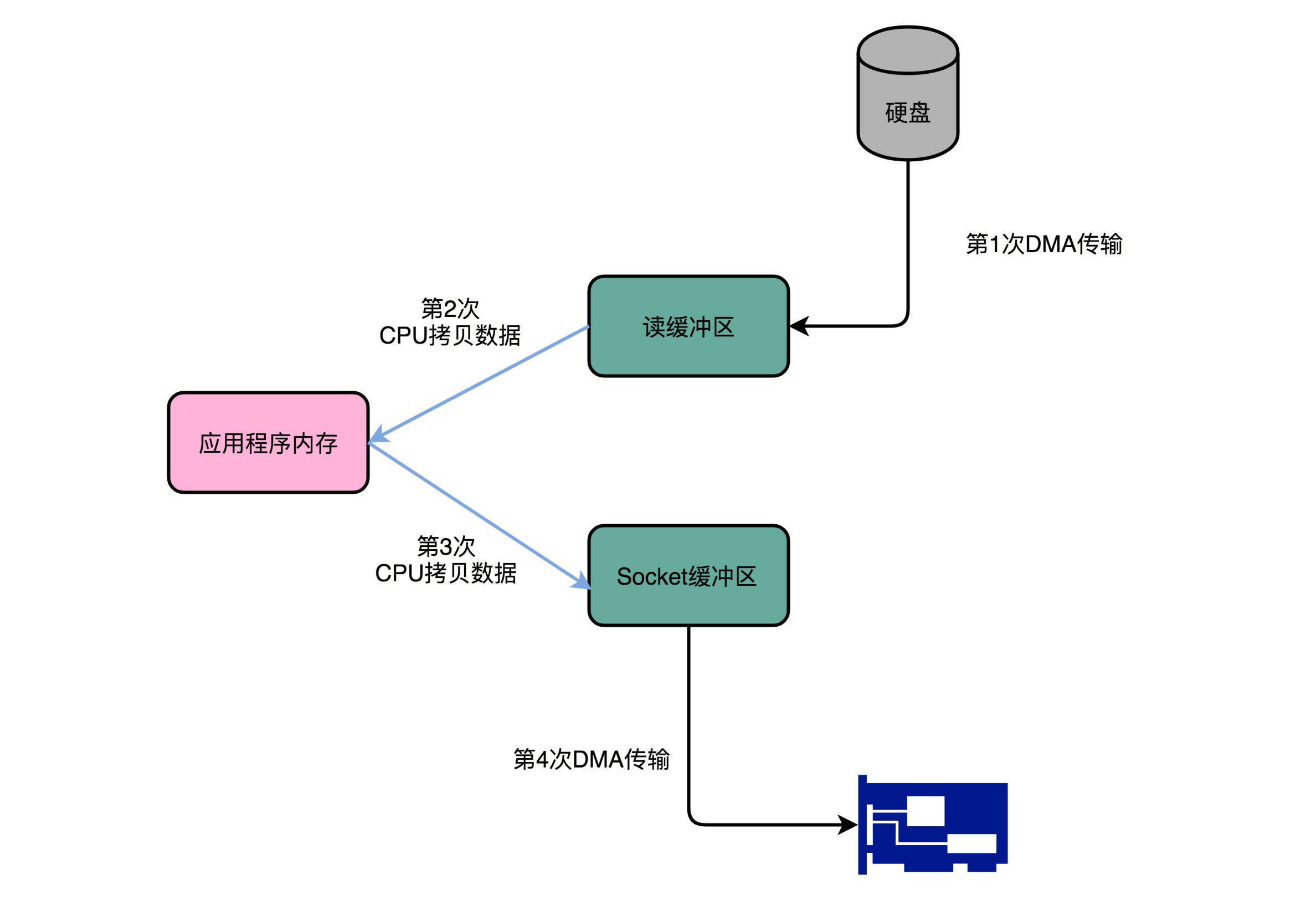
从本地磁盘上读取出文件内容来,然后通过网络发送出去。如图所示,在这个过程中,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。第一次传输,是从硬盘上,读到操作系统内核的缓冲区里。这个传输是通过 DMA 搬运的。第二次传输,需要从内核缓冲区里面的数据,复制到我们应用分配的内存里面。这个传输是通过 CPU 搬运的。第三次传输,要从我们应用的内存里面,再写到操作系统的 Socket 的缓冲区里面去。这个传输,还是由 CPU 搬运的。最后一次传输,需要再从 Socket 的缓冲区里面,写到网卡的缓冲区里面去。这个传输又是通过 DMA 搬运的。¶
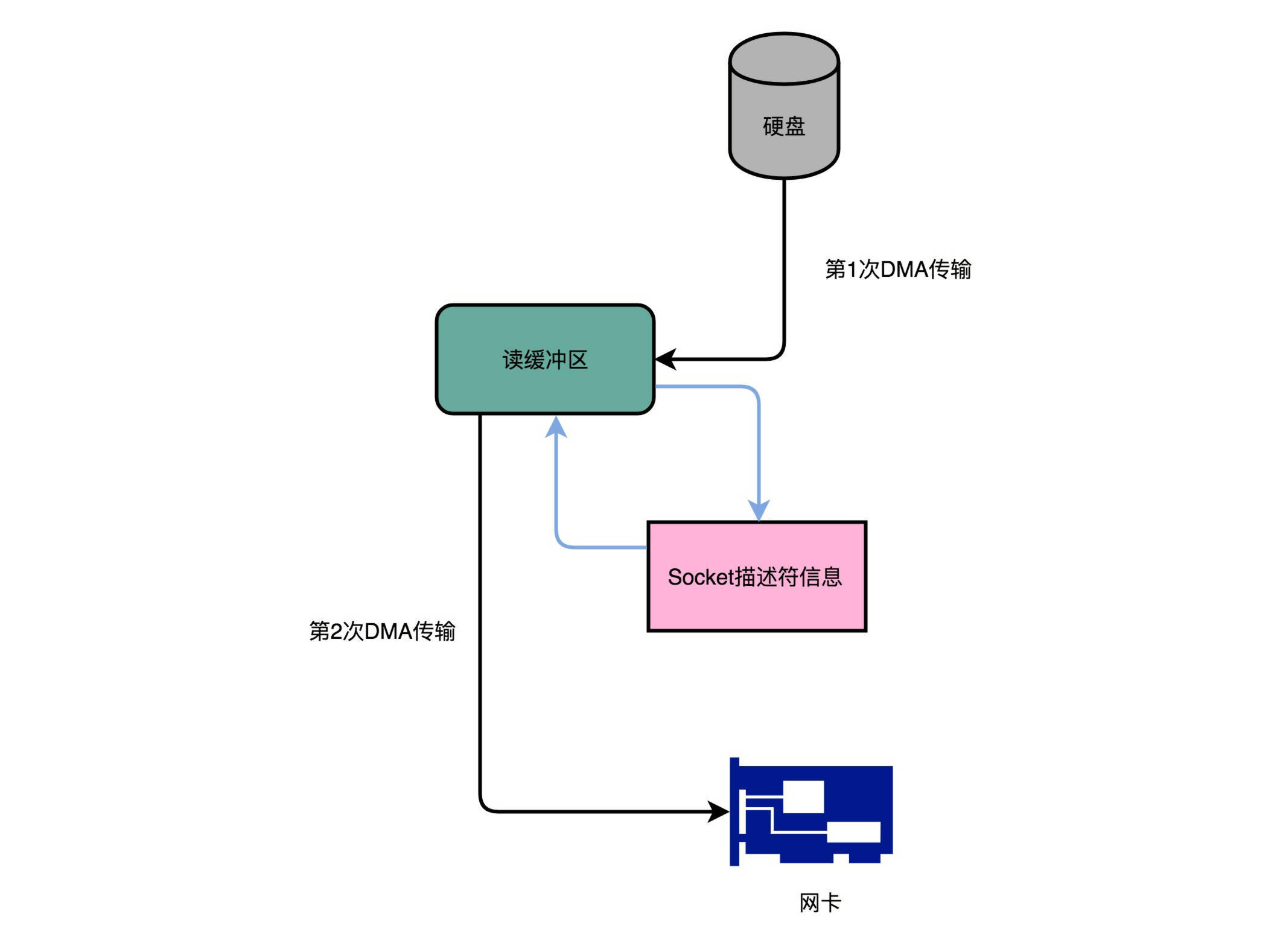
Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。我们的数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,我们只进行了两次数据传输。第一次,是通过 DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据 Socket 的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。在这个方法里面,我们没有在内存层面去 “复制(Copy)” 数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。¶
论文: Kakfa:a Distrubted Messaging System for Log Processing
数据完整性¶
纠错码(Error Correcting Code)
纠删码(Erasure Code)
海明码(Hamming Code)
备注
海明码的纠错能力是有限的,在 7-4 海明码里面,我们只能纠正某 1 位的错误。如果我们的数据位有 K 位,校验位有 N 位。那么我们需要满足下面这个不等式,才能确保我们能够对单比特翻转的数据纠错。这个不等式就是: K + N + 1 <= 2^N
海明码、hamming code: https://blog.csdn.net/Yonggie/article/details/83186280a
分布式计算¶
三个核心问题:
第一个核心问题,叫作垂直扩展和水平扩展的选择问题
第二问题叫作如何保持高可用性(High Availability)
第三个问题叫作一致性问题(Consistency)
1. 低响应时间(Low Response Time)
2. 高可用性(High Availability)
3. 高并发(High Concurrency)
4. 海量数据(Big Data)
5. 付得起对应的成本(Affordable Cost)
投递简历到 hr@bothub.ai 或者 recruit@abukito.com
书籍¶
网站¶
传世之文《Teach Yourself Programming in Ten Years》: http://norvig.com/21-days.html
中文版: https://blog.csdn.net/sinat_33487968/article/details/84504352
Build Software Systems at Google and Lessons Learned: http://www.valleytalk.org/wp-content/uploads/2011/08/101110-slides.pdf
[访谈]David Patterson 老爷爷的 <计算机体系结构新黄金时代:历史、挑战和机遇> 这个访谈: https://www.bilibili.com/video/av46710093/
北大的计算机组成原理公开课
入门书籍¶
《计算机是怎样跑起来的》
《程序是怎样跑起来的》
Coursera 上的北京大学免费公开课《Computer Organization》:
硬件层面的基础实现,比如寄存器、ALU 这些电路
深入学习书籍¶
《计算机组成与设计:硬件 / 软件接口》
经典的CSAPP《深入理解计算机系统》
视频课程: Bilibili 版和 Youtube 版
辅助的参考书: 操作系统大神塔能鲍姆(Andrew S. Tanenbaum)的《计算机组成:结构化方法》
课外阅读¶
Redhat 的 What Every Programmer Should Know About Memory 是写出高性能程序不可不读的经典材料
LMAX 开源的 Disruptor,则是通过实际应用程序,来理解计算机组成原理中各个知识点的最好范例
理解计算机硬件和操作系统层面代码执行的优秀阅读材料: * 《编码:隐匿在计算机软硬件背后的语言》 * 《程序员的自我修养:链接、装载和库》是
CSAPP-深入理解计算机系统¶
可以仔细读一下《深入理解计算机系统(第三版)》的 3.7 小节《过程》,进一步了解函数调用是怎么回事
编码:隐匿在计算机软硬件背后的语言¶
关于二进制和编码,我推荐你读一读这本书。从电报机到计算机,这本书讲述了很多计算设备的历史故事,当然,也包含了二进制及其背后对应的电路原理。
第 6~11 章: 是一个很好的入门材料,可以帮助你深入理解数字电路
想要深入了解计算机里面的各种功能组件,是怎么通过电路来实现的,推荐你去阅读《编码:隐匿在计算机软硬件背后的语言》这本书的第 14 章和 16 章
《编码:隐匿在计算机软硬件背后的语言》的第 17 章,用更多细节的流程来讲解了 CPU 的数据通路。
程序员的自我修养:链接、装载和库¶
想要更深入了解程序的链接过程和 ELF 格式,我推荐你阅读《程序员的自我修养——链接、装载和库》的 1~4 章。这是一本难得的讲解程序的链接、装载和运行的好书
想要更深入地了解代码装载的详细过程,推荐你阅读《程序员的自我修养 —— 链接、装载和库》的第 1 章和第 6 章。
想要更加深入地了解动态链接,我推荐你可以读一读《程序员的自我修养:链接、装载和库》的第 7 章,里面深入地讲解了,动态链接里程序内的数据布局和对应数据的加载关系。
计算机组成与设计:硬件 / 软件接口¶
想要对我们日常使用的 Intel CPU 的指令集有所了解,可以参看《计算机组成与设计:软 / 硬件接口》第 5 版的 2.17 小节
《计算机组成与设计:软 / 硬件接口》(第 5 版)的 1.7 和 1.10 节,也简单介绍了功耗墙和阿姆达尔定律,你可以拿来细细阅读
3.3 节:乘法器更多相关内容
想要更深入地了解浮点数的乘法乃至除法,可以参看《计算机组成与设计 硬件 / 软件接口》的 3.5.2 和 3.5.3 小节。
想要了解数据通路,可以参看《计算机组成与设计 硬件软件接口》的第 5 版的 4.1 到 4.4 节。专栏里的内容是从更高一层的抽象逻辑来解释这些问题,而教科书里包含了更多电路的技术细节。
《计算机组成与设计 硬件 / 软件接口》的 4.1 到 4.4 小节,从另外一个层面和角度讲解了 CPU 的数据通路的建立
想要了解 CPU 的流水线设计,可以参看《计算机组成与设计 硬件 / 软件接口》的 4.5 章节。
深入理解计算机系统¶
第 3 章,详细讲解了 C 语言和 Intel CPU 的汇编语言以及指令的对应关系,以及 Intel CPU 的各种寄存器和指令集
如果你想对阿姆达尔定律有个更细致的了解,《深入理解计算机系统》(第 3 版)的 1.9 节
想要了解 CPU 的流水线设计,可以参看《深入理解计算机系统》的 4.4 章节
数字逻辑应用与设计¶
对于数字电路和数字逻辑特别感兴趣,想要彻底弄清楚数字电路、时序逻辑电路,也可以看一看计算机学科的一本专业的教科书《数字逻辑应用与设计》