Microsoft Learn: Introduction to NLP with PyTorch¶
from: https://learn.microsoft.com/en-us/training/modules/intro-natural-language-processing-pytorch/
GitHub: https://github.com/MicrosoftDocs/pytorchfundamentals
备注
具体详情参见demo_python项目的pytorch的microsoft-learn
简介¶
We will learn about different NLP techniques such as using bag-of-words (BoW), word embeddings and recurrent neural networks for classifying text from news headlines to one of the 4 categories (World, Sports, Business and Sci-Tech).
Learning objectives:
1. Understand how text is processed for natural language processing tasks
2. Get introduced to using Recurrent Neural Networks (RNNs) and Generative Neural Networks (GNNs)
3. Learn how to build text classification models
Natural Language Tasks:
1. Text Classification
2. Intent Classification
one specific case of text classification,
when we want to map input utterance in the conversational AI system into one of the intents
that represent the actual meaning of the phrase, or intent of the user.
当想将对话式 AI 系统中的输入话语映射到表示短语的实际含义或用户意图的意图之一时。
3. Sentiment Analysis
4. Named Entity Recognition (NER)
5. Keyword extraction
can be used to find the most meaningful words inside a text, which can then be used as tags.
6. Text Summarization
7. Question/Answer
备注
对于本模块的范围,我们将主要关注文本分类任务。
2. Representing text as Tensors¶
Representing text¶
If we want to solve Natural Language Processing (NLP) tasks with neural networks, we need some way to represent text as tensors. Computers already represent textual characters as numbers that map to fonts on your screen using encodings such as ASCII or UTF-8.
We understand what each letter represents, and how all characters come together to form the words of a sentence. However, computers by themselves do not have such an understanding, and neural network has to learn the meaning during training.
Therefore, we can use different approaches when representing text: * Character-level representation, when we represent text by treating each character as a number. Given that we have $C$ different characters in our text corpus, the word Hello would be represented by $5times C$ tensor. Each letter would correspond to a tensor column in one-hot encoding. * Word-level representation, in which we create a vocabulary of all words in our text, and then represent words using one-hot encoding. This approach is somehow better, because each letter by itself does not have much meaning, and thus by using higher-level semantic concepts - words - we simplify the task for the neural network. However, given large dictionary size, we need to deal with high-dimensional sparse tensors.
To unify those approaches, we typically call an atomic piece of text a token. In some cases tokens can be letters, in other cases - words, or parts of words.
>>> For example, we can choose to tokenize indivisible as in-divis-ible, where the # sign represents that the token is a continuation of the previous word. This would allow the root divis to always be represented by one token, corresponding to one core meaning.
The process of converting text into a sequence of tokens is called tokenization. Next, we need to assign each token to a number, which we can feed into a neural network. This is called vectorization, and is normally done by building a token vocabulary.
BiGrams, TriGrams and N-Grams¶
One limitation of word tokenization is that some words are part of multi word expressions, for example, the word ‘hot dog’ has a completely different meaning than the words ‘hot’ and ‘dog’ in other contexts. If we represent words ‘hot` and ‘dog’ always by the same vectors, it can confuse the model.
To address this, N-gram representations are sometimes used in document classification, where the frequency of each word, bi-word or tri-word is a useful feature for training classifiers.
In bigram representation, for example, we will add all word pairs to the vocabulary, in addition to original words. To get n-gram representation, we can use ngrams_iterator function that will convert the sequence of tokens to the sequence of n-grams. In the code below, we will build bigram vocabulary from our news dataset:
The main drawback of N-gram approach is that vocabulary size starts to grow extremely fast. Here we specify min_freq flag to Vocab constructor in order to avoid those tokens that appear in the text only once. We can also increase min_freq even further, because infrequent words/phrases usually have little effect on the accuracy of classification.
In practice, n-gram vocabulary size is still too high to represent words as one-hot vectors, and thus we need to combine this representation with some dimensionality reduction techniques, such as embeddings.
3. Bag-of-Words and TF-IDF representations¶
In the previous unit, we have learnt to represent text by numbers. In this unit, we’ll explore some of the approaches to feeding variable-length text into a neural network to collapse the input sequence into a fixed-length vector, which can then be used in the classifier.
Bag of Words text representation¶
Because words represent meaning, sometimes we can figure out the meaning of a text by just looking at the individual words, regardless of their order in the sentence. For example, when classifying news, words like weather, snow are likely to indicate weather forecast, while words like stocks, dollar would count towards financial news.
Bag of Words (BoW) vector representation is the most commonly used traditional vector representation. Each word is linked to a vector index, vector element contains the number of occurrences of a word in a given document.
> Note: You can also think of BoW as a sum of all one-hot-encoded vectors for individual words in the text.
Training BoW classifier¶
Now that we have learned how to build a Bag-of-Words representation of our text, let’s train a classifier on top of it. First, we need to convert our dataset for training in such a way, that all positional vector representations are converted to bag-of-words representation. This can be achieved by passing bowify function as collate_fn parameter to standard torch DataLoader. The collate_fn gives you the ability to apply your own function to the dataset as it’s loaded by the Dataloader:
Term Frequency Inverse Document Frequency TF-IDF¶
In BoW representation, word occurrences are evenly weighted, regardless of the word itself. However, it is clear that frequent words, such as a, in, etc. are much less important for the classification, than specialized terms. In fact, in most NLP tasks some words are more relevant than others.
TF-IDF stands for term frequency–inverse document frequency. It is a variation of bag of words, where instead of a binary 0/1 value indicating the appearance of a word in a document, a floating-point value is used, which is related to the frequency of word occurrence in the corpus.
More formally, the weight $w_{ij}$ of a word $i$ in the document $j$ is defined as: $$ w_{ij} = tf_{ij}timeslog({Nover df_i}) $$ where * $tf_{ij}$ is the number of occurrences of $i$ in $j$, i.e. the BoW value we have seen before * $N$ is the number of documents in the collection * $df_i$ is the number of documents containing the word $i$ in the whole collection
TF-IDF value $w_{ij}$ increases proportionally to the number of times a word appears in a document and is offset by the number of documents in the corpus that contains the word, which helps to adjust for the fact that some words appear more frequently than others. For example, if the word appears in every document in the collection, $df_i=N$, and $w_{ij}=0$, and those terms would be completely disregarded.
However even though TF-IDF representations provide frequency weight to different words they are unable to represent meaning or order. As the famous linguist J. R. Firth said in 1935, “The complete meaning of a word is always contextual, and no study of meaning apart from context can be taken seriously.”. We will learn in the later units how to capture contextual information from text using language modeling.
4. Embeddings¶
In our previous example, we operated on high-dimensional bag-of-words vectors with the length of vocab_size, and we were explicitly converting from low-dimensional positional representation vectors into sparse one-hot representations.
The goal of using word embeddings and reducing the dimensionality are: - Finding the meaning of words based on their word approximation to other words. This is done by taken two word vectors and analyzing how often the words in the vectors are used together. The higher the frequency, the more you can find a correlation and relationship between the words. - This process of training the word embedding to find word approximations between words in a given dimension is how we reduce the word representation to low-dimensions. - Embedding vectors serve as numeric representations of words and are used as input to other machine learning network layers. - The embedding vector becomes the stored lookup table for words in the vocabulary
What is embedding¶
The idea of embedding is the process of mapping words into vectors, which reflects the _semantic meaning of a word_. The length of its vectors are the embedding dimensions size. We will later discuss how to build meaningful word embeddings, but for now let’s just think of embeddings as a way to lower dimensionality of a word vector.
So, embedding layer would take a word as an input, and produce an output vector of specified embedding_size. In a sense, it is very similar to Linear layer, but instead of taking one-hot encoded vector, it will be able to take a word number as an input.
By using embedding layer as a first layer in our network, we can switch from bag-or-words to embedding bag model, where we first convert each word in our text into corresponding embedding, and then compute some aggregate function over all those embeddings, such as sum, average or max.
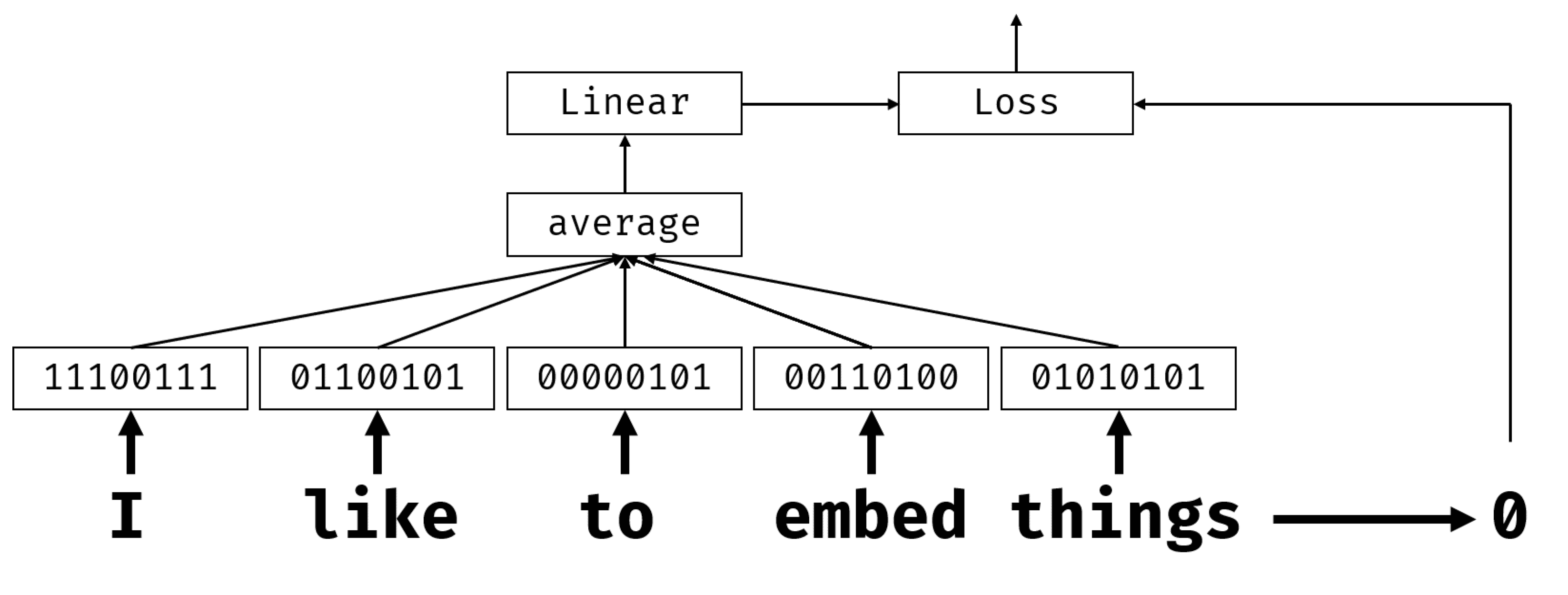
Our classifier neural network will start with embedding layer, then aggregation layer, and linear classifier on top of it:¶