通用¶
评测标准¶
准确率,代表模型判定属于这个分类的标题里面判断正确的有多少,有多少真的是属于这个分类的。
召回率,代表模型判定属于这个分类的标题占实际这个分类下所有标题的比例,也就是没有漏掉的比例。
F1 Score,是准确率和召回率的调和平均数,也就是 F1 Score = 2/ (1/Precision + 1/Recall)
总结来说,准确率是一个全局的指标,它考虑了所有类别的分类结果;而精确率和召回率则更侧重于正样本的分类效果。精确率关注预测为正样本的实例中有多少是真正的正样本,而召回率则关注所有正样本中有多少被模型预测出来。在实际应用中,我们通常会根据具体的任务需求来选择合适的评估指标。
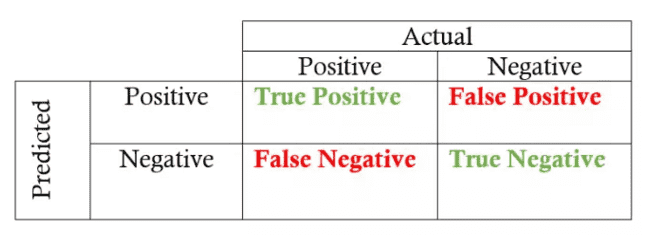
基础定义:
真正例(TP):模型预测为正,实际也为正
假正例(FP):模型预测为正,但实际为负
真反例(TN):模型预测为负,实际也为负
假反例(FN):模型预测为负,但实际为正
准确率(Accuracy)¶
准确率是分类模型正确分类的样本数占总样本数的比例。
计算公式为::
准确率 = (TP + TN) / (TP + FP + TN + FN)
= 真正例 + 真反例 / 总样本数
准确率是一个简单直观的指标,但它可能在一些特定场景下并不那么有用,比如当正负样本数量极度不平衡时。
例如
在一个信用卡欺诈检测系统中,正常交易(负样本)的数量可能远大于欺诈交易(正样本)的数量。在这种情况下,即使模型将所有的交易都预测为正常,准确率也会非常高,但这显然不是一个好的欺诈检测模型。
美国全年平均有 8 亿人次的乘客,并且在 2000-2017 年间共发现了 19 名恐怖分子,这个模型达到了接近完美的准确率——99.9999999%。尽管这个模型拥有接近完美的准确率,但是在这个问题中准确率显然不是一个合适的度量指标。
精确率(Precision, 精准率)¶
精确率表示模型预测为正样本的实例中,真正为正样本的比例。
计算公式为:
精确率 = TP / (TP + FP)
= 真正例 / (真正例 + 假正例)
精确率关注的是预测为正样本的实例中,有多少是真正的正样本。
示例:
在上面的信用卡欺诈检测例子中,我们希望模型预测的欺诈交易中有尽可能多的真实欺诈交易,即精确率要高。
精确率衡量的是所有被分类为欺诈的交易中,真正是欺诈的比例。
在信用卡欺诈检测中,如果精确率很高,
则分类为欺诈的交易中,绝大多数确实是欺诈,这可以降低误报率,减少对客户的不必要困扰和调查。
在所有判为恐怖分子中,真正的恐怖分子的比例。
召回率(Recall)¶
召回率表示所有实际为正样本的实例中,被模型预测为正样本的比例。
计算公式为::
召回率 = TP / (TP + FN)
= 真正例 / (真正例 + 假反例)
召回率关注的是所有正样本中,有多少被模型正确地预测出来。
示例:
在信用卡欺诈检测中,我们希望尽可能多地找出所有的欺诈交易,即使这意味着可能会误判一些正常交易,即召回率要高。
召回率衡量的是所有实际欺诈交易中,被正确分类为欺诈的比例。
在信用卡欺诈检测中,高召回率意味着检测到了更多的欺诈交易,减少了漏报率,有助于防止欺诈行为。
F1 Score¶
F1 Score 是一种用于评估二分类问题的性能指标。它结合了精确度和召回率,以计算出模型的总体性能。
它的计算公式是:
F1 = 2 * (precision * recall) / (precision + recall)
可视化精度和召回率¶
混淆矩阵(confusion matrix)¶
受试者特征曲线(ROC 曲线,Receiver Operating Characteristic curve)¶
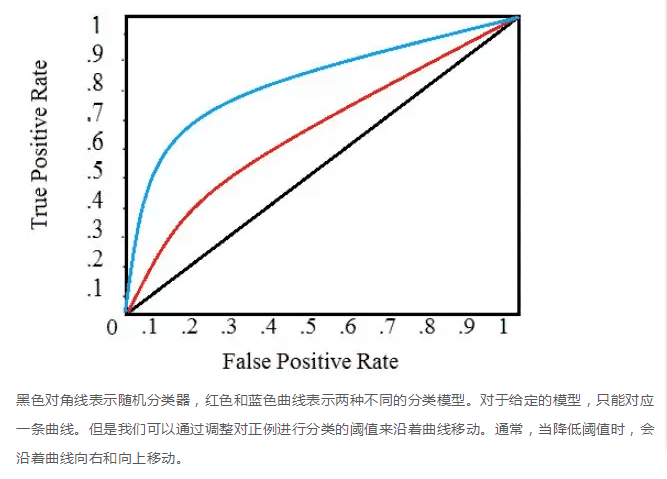
ROC 曲线展示了当改变在模型中识别为正例的阈值时,召回率和精度的关系会如何变化。
为了将某个病人标记为患有某种疾病(一个正例标签),我们为每种疾病在这个范围内设置一个阈值,通过改变这个阈值,我们可以尝试实现合适的精度和召回率之间的平衡。如果我们有一个用来识别疾病的模型,我们的模型可能会为每一种疾病输出介于 0 到 1 之间的一个分数,为了将某个病人标记为患有某种疾病(一个正例标签),我们为每种疾病在这个范围内设置一个阈值,通过改变这个阈值,我们可以尝试实现合适的精度和召回率之间的平衡。
ROC 曲线在 Y 轴上画出了真正例率(TPR),在 X 轴上画出了假正例率 (FPR)。TPR 是召回率,FPR 是反例被报告为正例的概率。这两者都可以通过混淆矩阵计算得到。