19xx_PipeDream: Generalized Pipeline Parallelism for DNN Training¶
https://deepakn94.github.io/assets/papers/pipedream-sosp19.pdf
2019.10.27
组织: Microsoft Research, Carnegie Mellon University, Stanford University
标签: Pipeline_Parallelism
备注
进一步扩展了PipeDream的概念,提出了将批内并行与批间流水线相结合的方法,以进一步提高并行训练的吞吐量。
收集¶
GPipe需要等所有的microbatch前向传播完成后,才会开始反向传播。PipeDream则是当一个microbatch的前向传播完成后,立即进入反向传播阶段。理论上,反向传播完成后就可以丢弃掉对应microbatch缓存的激活。由于PipeDream的反向传播完成的要比GPipe早,因此也会减少显存的需求。
ABSTRACT¶
【原始内容】DNN(深度神经网络)训练极其耗时,因此需要高效的多加速器并行化。当前并行化训练的方法主要使用 批内并行(intra-batch parallelization) ,其中单次训练迭代被分配到可用的工作节点上,但在工作节点数量增加时,往往会出现收益递减的情况。我们提出了PipeDream,一个将 批间流水线并行(inter-batch pipelining) 与批内并行相结合的系统,旨在进一步提高并行训练的吞吐量,帮助更好地重叠计算和通信,并在可能的情况下减少通信量。与传统的流水线不同,DNN训练是双向的,计算图的前向传播之后紧接着进行反向传播,反向传播需要使用在前向传播过程中计算的状态和中间数据。因此,简单的流水线可能导致前向传播和反向传播中使用的状态版本不匹配,或者过多的流水线刷新,进而降低硬件效率。为了解决这些挑战,PipeDream通过版本化模型参数来确保梯度计算的准确性,并且在不同的工作节点上并行调度不同小批量的前向传播和反向传播,最大限度地减少流水线停滞。PipeDream还自动将DNN的层分配给工作节点,以平衡工作负载并最小化通信。通过在多种DNN任务、模型和硬件配置下进行的广泛实验,结果表明,PipeDream训练模型的精度与常用的批内并行技术相比,速度提高了最多5.3倍。
- 背景:
DNN训练时间非常长,因此需要高效的多加速器并行化来加速训练过程。
现有的并行训练方法主要通过 批内并行(intra-batch parallelism) 来将单次训练迭代分割到多个工作节点上。
但这种方法在增加工作节点数量时存在 回报递减(diminishing returns) 的问题,即扩展工作节点的数量效果会逐渐下降。
- PipeDream 的创新:
PipeDream 提出了一种 跨批次流水线(inter-batch pipelining) 和 批内并行(intra-batch parallelism) 相结合的方式,进一步提高并行训练的吞吐量。
其核心思想是帮助更好地 重叠计算与通信,并在可能的情况下减少通信量。
- 流水线的挑战:
- 与传统的流水线不同,DNN训练的过程是 双向的(bi-directional),即:
前向传播(forward pass):计算通过计算图的结果。
反向传播(backward pass):使用前向传播过程中计算得到的中间数据和状态,进行梯度计算。
如果简单地实现流水线,可能会导致 前向和反向传播使用不匹配的状态版本,或者 流水线刷新过于频繁,导致硬件效率降低。
- PipeDream 的解决方案:
版本化模型参数:为了确保梯度计算的正确性,PipeDream 在进行反向传播时,确保使用正确版本的模型参数。
并行调度前后传播:它并行地调度不同小批次(minibatches)的前向和反向传播,尽量减少流水线停顿(pipeline stalls)。
自动分配DNN层:PipeDream 会自动将 DNN 层分配到不同的工作节点,以 平衡工作量并最小化通信。
备注
总结:PipeDream 通过结合 跨批次流水线 和 批内并行 的方法,提高了 DNN 训练的效率,能够更好地利用硬件资源,减少不必要的通信,从而加速训练过程,显著提高吞吐量。
1. Introduction¶
备注
详细介绍了 PipeDream 系统,它通过结合 批内并行(intra-batch parallelism) 和 跨批并行(inter-batch parallelism) 来加速深度神经网络(DNN)的训练过程。
- 背景:
DNN的广泛应用:DNN在图像分类、翻译、语言建模和视频字幕等领域取得了巨大的进展。但随着DNN的广泛应用,其训练过程变得越来越 计算密集,需要在多个加速器(如GPU)之间并行执行。
DNN训练流程:DNN训练包括前向传播和反向传播。每次训练迭代都会处理一个小批次(minibatch)数据并更新模型参数。为了加速训练,目前的做法主要是通过 并行化每次优化迭代。
并行化的挑战:在大规模训练时,批内并行(尤其是数据并行)会面临高通信成本,特别是当工作节点数量增加时,通信开销变得非常大。例如,在32个GPU上,某些模型的通信开销可能高达90%。
- PipeDream的提出:
PipeDream的核心创新:PipeDream通过引入 流水线并行(Pipeline Parallelism),结合 批内并行 和 跨批并行 来减少通信开销并加速训练。
PipeDream将模型划分为多个连续的操作组(称为“层”),并将这些层分配给不同的工作节点。然后,它通过流水线方式重叠不同输入的计算和通信。
通信优化:在PipeDream中,通信仅限于不同工作节点之间相邻层的输入和输出(前向传播中的激活和反向传播中的梯度),这大大减少了通信量,并且通信是点对点的,而不是全对全的通信方式。
- 持久挑战与PipeDream的解决方案:
- DNN训练的双向性问题:
DNN训练过程中,前向传播和反向传播需要使用相同的模型权重和中间结果。
流水线操作要确保前向传播和反向传播的数据同步,以保证梯度计算的正确性。
传统流水线调度方法可能会导致统计效率低下,或者无法达到预期的训练精度。
- PipeDream的调度方法:
PipeDream使用了一种名为 1F1B(1 Forward 1 Backward) 的调度算法,该算法确保每个工作节点在流水线的“稳定状态”下严格交替执行前向和反向传播。
这种调度方法能够保证硬件的高效利用,并且没有流水线停顿(pipeline stalls)。
- 1F1B算法的细节:
每个工作节点严格交替执行前向和反向传播,保证硬件的高效利用。
通过使用不同版本的模型权重,保持与数据并行相似的统计效率。
每次反向传播都会更新权重,下一次前向传播会使用最新的权重版本,并“存储”这些权重用于后续的反向传播。
- 流水线负载均衡:
PipeDream还能够自动平衡不同阶段的计算负载,并通过短时间的单GPU性能分析来决定如何划分模型操作。
它能有效应对模型多样性(计算和通信的不同需求)和平台多样性(不同的互联拓扑结构和带宽)。
如果某些阶段的计算量过大,PipeDream可能会使用数据并行来为该阶段分配多个工作节点,从而并行处理不同的小批次。
备注
总结:PipeDream通过结合流水线并行和批内并行,显著提高了DNN训练的效率。其 1F1B调度算法 和 自动负载均衡 机制能够有效地减少通信开销,同时确保训练过程的高硬件利用率和高统计效率,使得训练速度大幅提升。
2. BACKGROUND AND RELATED WORK¶
这段内容讨论了 DNN训练的并行化方法,包括批内并行(intra-batch parallelism)和跨批并行(inter-batch parallelism),并介绍了与DNN模型和硬件多样性相关的挑战。
2.1 Intra-batch Parallelism¶
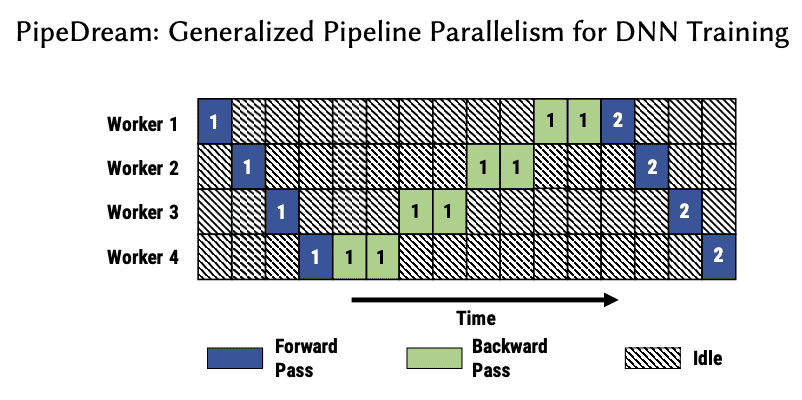
Figure 2: Model parallel training with 4 workers. Numbers indicate batch ID, and backward passes takes twice as long as forward passes. For simplicity, we assume that communicating activations/gradients across workers has no overhead.¶
- 批内并行是当前最常见的DNN训练方式,它通过将单个训练迭代拆分到多个工作节点(例如GPU)上来进行加速。
- 数据并行(Data Parallelism):
- 原理:
在数据并行中,输入数据被划分给不同的工作节点,每个节点维护一个本地模型副本,独立训练自己分配的数据部分,并定期与其他节点同步模型权重。
通信的量主要取决于模型权重的大小以及参与训练的工作节点数量。
- 挑战:
- 通信开销:
即使使用现代多GPU服务器和高效的通信库(如NCCL),在数据并行训练中,通信开销依然较高。
例如,在32个GPU上训练时,某些模型的通信开销可能高达90%,尤其是在使用跨服务器的高延迟通信时。
- 缩放问题:
数据并行在多个GPU或多个服务器间扩展时,通信瓶颈变得更加严重,特别是在GPU的计算能力不断提升时,通信开销却相应增大。
- 其他优化:
- 异步并行训练(ASP):
允许每个工作节点在接收到前一个小批次的梯度之前,开始处理下一个小批次。这样可以提高硬件效率,但可能会引入梯度陈旧问题,导致统计效率降低。
- 梯度量化:
通过量化梯度减少通信量,但这种方法并非对所有模型都有效。
- 模型并行(Model Parallelism):
- 原理:
在模型并行中,DNN模型的不同操作被分配到不同的工作节点,每个节点只负责自己分配的部分模型进行前向和反向传播。
- 模型并行可以用于训练非常大的模型,但它面临着两个主要问题:
计算资源利用率低:每个工作节点只能处理模型的一部分,因此有时会出现资源闲置的情况。
模型划分难度大:模型并行需要开发者手动分配模型操作到不同的工作节点,导致优化过程变得复杂且不易扩展。
- 混合并行(Hybrid Parallelism):
一些方法尝试在单次优化迭代中同时使用数据并行和模型并行,例如OWT和FlexFlow。
尽管这些方法尝试提高计算效率,但通常并没有结合流水线并行,导致性能并未充分发挥。
2.2 Inter-batch Parallelism¶
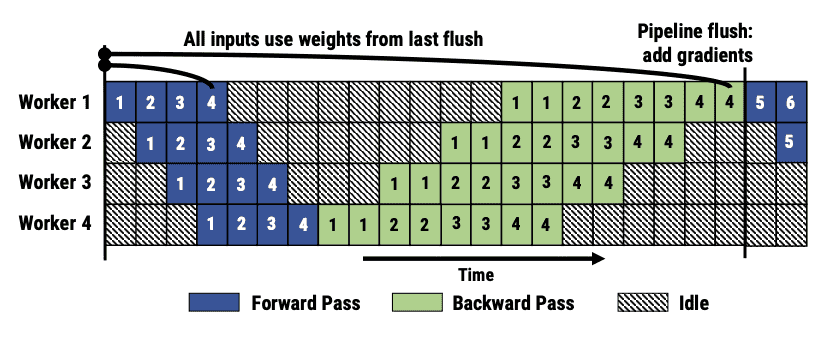
Figure 3: GPipe’s inter-batch parallelism approach. Frequent pipeline flushes lead to increased idle time.¶
跨批并行尝试将训练过程中的不同小批次并行化,这通常涉及在模型并行训练的框架下进行流水线操作。
- GPipe:
GPipe是一个使用流水线并行的系统,它在模型并行训练中对每个小批次进行分割,先执行前向传播,再执行反向传播。
GPipe通过将小批次分割成多个微批次来优化内存使用,
但其主要问题在于如果微批次较小,会导致频繁的流水线刷新,影响硬件效率。
- PipeDream的优势:PipeDream与GPipe相比,解决了几个关键问题,特别是:
更高的硬件效率:PipeDream将流水线并行与批内并行结合,确保每个工作节点得到充分利用,从而提高硬件效率。
自动化模型划分:PipeDream能够自动根据硬件配置和模型特点来划分DNN模型,而不像GPipe那样依赖手动划分。
2.3 DNN Model and Hardware Diversity¶
- DNN模型本身在架构上有很大的差异,常见的有卷积层、LSTM、注意力层和全连接层等,每种类型的模型在并行化时表现不同,因此选择合适的并行化策略高度依赖于目标模型和硬件配置。
- 硬件多样性:
不同类型的硬件(如GPU、ASIC、FPGA)具有不同的计算能力,且加速器之间的互联结构和带宽差异也很大。
例如,云服务器使用的网络带宽可能在10Gbps到100Gbps之间,而服务器内部的GPU可能通过PCIe连接(10到15GBps),或者使用高端的NVLink(30GBps)。
这种硬件的多样性使得选择最佳的并行化策略变得非常复杂。
- PipeDream的自动化:
由于硬件和模型多样性带来的复杂性,PipeDream通过自动化的方式来解决模型划分和并行化的挑战,帮助实现高效的训练。
总结¶
这段内容深入探讨了当前DNN训练的并行化技术,特别是批内并行和跨批并行的不同方法。它分析了数据并行、模型并行和混合并行的优缺点,并指出传统的并行化方法(如数据并行和模型并行)在大规模训练中面临的通信瓶颈和计算资源浪费问题。PipeDream通过结合流水线并行和批内并行,并自动化模型划分,成功解决了这些挑战,从而实现了更高效的训练过程。
3. 流水线并行(PIPELINE PARALLELISM)¶
主要介绍了 PipeDream(一种用于深度神经网络训练的并行化策略)的核心概念和挑战,特别是其在使用流水线并行(Pipeline Parallelism, PP)时如何优化计算和通信。
- 流水线并行(Pipeline Parallelism, PP)
将 批内并行(intra-batch parallelism)和 批间并行(inter-batch parallelism)结合在一起。
- 流水线并行的核心思想是将深度神经网络(DNN)的各层分为多个阶段,每个阶段由模型中的连续层组成,每个阶段分配到一块独立的 GPU 来执行。
前向传播:每个阶段处理自己的输入数据并将结果传递给下一个阶段。
反向传播:最后一个阶段在完成前向传播后,立即开始反向传播,并将梯度传回前一个阶段。
在这个过程中,各个阶段并行工作,一个阶段的计算和下一个阶段的计算可以重叠进行。
- 流水线并行的优势
- 流水线并行相比传统的 数据并行(Data Parallelism, DP)有两个主要的优势:
减少通信量:在数据并行中,需要频繁地交换整个模型的梯度,而流水线并行则仅需传递每个阶段部分的梯度和激活值,这大大减少了通信量。
计算与通信重叠:流水线并行通过异步地进行前向激活值和反向梯度的传递,使得计算和通信可以同时进行,从而提高了效率。
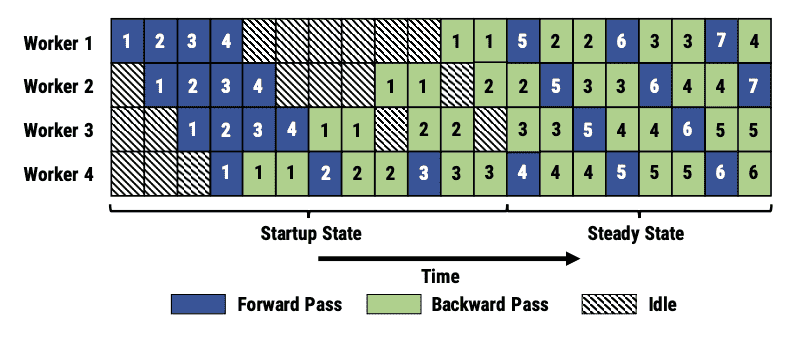
Figure 4: An example PipeDream pipeline with 4 workers, showing startup and steady states. In this example, the backward pass takes twice as long as the forward pass.¶
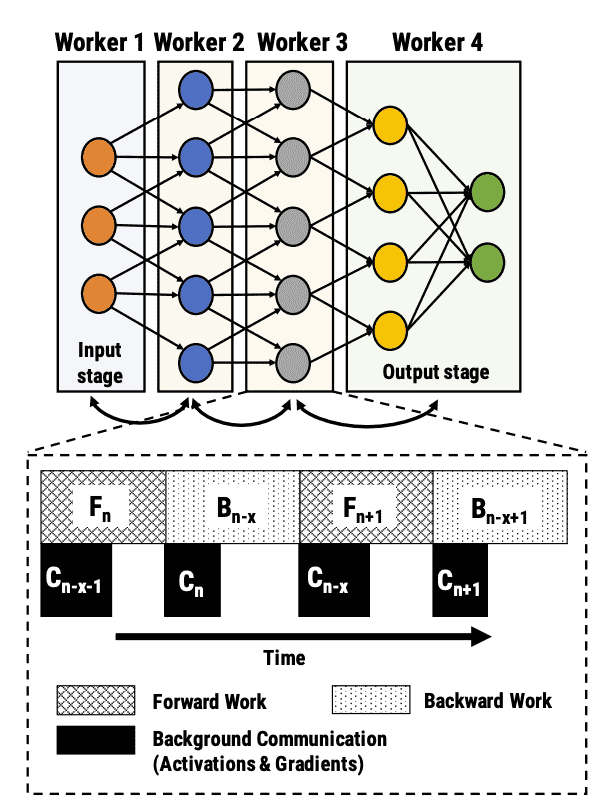
Figure 5: An example pipeline-parallel assignment with four GPUs and an example timeline at one of the GPUs (worker 3), highlighting the temporal overlap of computation and activation/gradient communication.¶
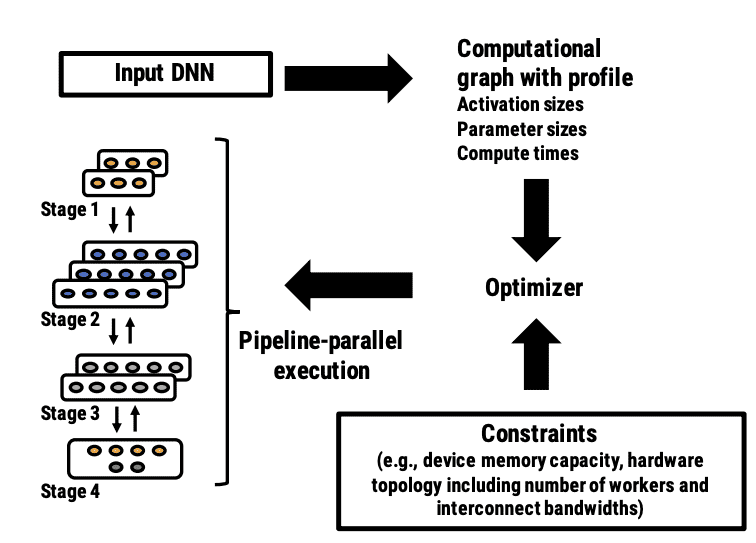
Figure 6: PipeDream’s automated mechanism to partition DNN layers into stages. PipeDream first profiles the input DNN, to get estimates for each layer’s compute time and output size. Using these estimates, PipeDream’s optimizer partitions layers across available machines, which is then executed by PipeDream’s runtime.¶
3.1 挑战 1: 工作分区(Work Partitioning)¶

Figure 7: An example 2-level hardware topology. Solid green boxes represent GPUs. Each server (dashed yellow boxes) has 4 GPUs connected internally by links of bandwidth B1; each server is connected by links of bandwidth B2. In real systems, B1 > B2. Figure best seen in color.¶
- 问题:在流水线中,如果各阶段的计算速度不一致,会导致一些阶段等待数据,造成资源浪费。并且,过多的通信也会拖慢训练速度。
PipeDream将模型训练视为一个计算流水线,每个工作节点(worker)执行模型的一部分(stage)。
流水线的吞吐量(throughput)由最慢的阶段决定。如果每个阶段的处理速度差异过大,就会导致流水线中出现空闲时间(bubbles),使得一些较快的阶段没有足够的工作负载,从而导致资源未得到充分利用。
过度的工作节点间通信也会降低整个训练流水线的吞吐量。
为了有效地进行工作分配,每个阶段的分配需要考虑模型特性和硬件配置。某些情况下,简单地将模型划分到多个GPU上并不能同时满足减少通信和完美负载平衡的需求。
- 解决方案:
- 整体:
PipeDream 使用优化算法根据 DNN 模型的层、硬件拓扑结构等因素,将模型划分为多个阶段,使每个阶段的计算速度大致相同,并尽量减少通信量。
此外,PipeDream 还通过数据并行方法在某些阶段进行阶段复制来进一步提高负载均衡。
- PipeDream的优化器通过以下方式来平衡流水线:
- 分配模型层到多个阶段:算法将深度神经网络(DNN)的层划分为多个阶段,确保每个阶段的计算时间大致相同,同时尽量减少工作节点之间的通信。
比如:将大输出的激活值发送到带宽较高的通信链路中。
阶段复制:为了进一步优化负载均衡,PipeDream允许对某些阶段进行数据并行性(data parallelism)处理,即同一个阶段可以在多个工作节点上进行复制处理。
- 最小化慢阶段的时间:这就相当于将问题转化为一个“最小化流水线中最慢阶段的时间”问题。
这个问题有最优子问题性质,即:一个最大化吞吐量的流水线由若干个小的子流水线组成,每个子流水线也是最大化吞吐量的。
PipeDream使用动态规划(Dynamic Programming, DP)来寻找这个最优解。
DNN训练时间稳定性:PipeDream还利用了DNN训练中的计算时间变化小这一特性,即不同输入的计算时间差异不大。
总结:这段内容主要讲解了PipeDream如何通过优化工作分配来解决流水线并行中的瓶颈问题。它通过动态规划和硬件拓扑信息,在减少通信的同时平衡负载,从而提高流水线的吞吐量。这个优化过程对训练时间和通信开销进行了精细的控制,并最终实现了高效的并行化。
3.2 挑战 2: 工作调度(Work Scheduling)¶

Figure 8: An example PipeDream pipeline with 3 workers and 2 stages. We assume that forward and backward passes in the first stage take two time units, while forward and backward passes in the second stage take only a single time unit. The first stage in this pipeline is replicated twice so that each stage sustains roughly the same throughput. Here, we assume that forward and backward passes take equal time, but this is not a requirement of our approach.¶
与传统的单向流水线不同,PipeDream的训练流水线是双向的,即每个输入的小批次(minibatch)首先进行前向传播(forward pass),然后进行反向传播(backward pass)。
- 每个在流水线中的活动小批次可能处于不同的阶段,既可能在进行前向传播,也可能在进行反向传播。由于这一点,每个工作节点(worker)必须决定:
是否执行该阶段的小批次的前向传播,并将小批次推送到下游工作节点,还是
是否执行该阶段的小批次的反向传播,并将小批次推送到上游工作节点。
阶段复制(例如,某些阶段的数据并行处理)进一步增加了工作调度的复杂性,需要决定如何在不同的复制阶段之间路由小批次。
解决方案: PipeDream的调度策略¶
- 启动阶段(Startup Phase):
在启动阶段,输入阶段会接纳足够多的小批次,以确保流水线在稳定状态下始终是满的。
为了达到这一目标,PipeDream根据前面提到的划分算法,计算出每个输入阶段复制体应接纳的小批次数量,
公式: \(\text{NUM_OPT_ACTIVE_MINIBATCHES} (\text{NOAM}) = \left\lceil \frac{\text{# workers}}{\text{# of replicas in the input stage}} \right\rceil\)
- 其中:
NUM_OPT_ACTIVE_MINIBATCHES (NOAM):即在稳定状态下,每个输入阶段的复制体应接纳的最优小批次数量。
该公式确保了在流水线的启动阶段,每个输入阶段的工作节点在稳定状态下能够有足够的小批次进行处理。
- 稳定状态下的调度:
- 一旦流水线进入稳定状态,每个阶段会交替进行前向传播和反向传播,我们称之为一前一后调度(1F1B schedule)。
在1F1B调度中,每个阶段交替处理不同的小批次的前向传播和反向传播。
这种调度确保了每个GPU都能被占用,并且流水线能够平衡地处理每个阶段,所有阶段大致以相同的速度生成输出。
1F1B调度还确保了反向传播从输入开始时能够按照规律的时间间隔应用到每个阶段。
例如,在图4的示意图中,稳定状态下,每个工作节点会交替进行前向传播和反向传播,且每个阶段的处理是平衡的。
- 数据并行配置中的调度:
- 当一个阶段以数据并行方式运行(即该阶段被复制到多个GPU上),PipeDream采用了确定性轮询负载均衡,根据小批次的标识符来分配工作。具体来说:
每个小批次会被轮询地分配到工作节点上,确保相同的小批次ID在前向传播和反向传播时始终由同一个工作节点处理。
这种机制被称为一前一后轮询调度(1F1B-RR),是一个静态策略,不需要进行复杂的分布式协调。
- 例如,在图8中展示了一个简单的2-1配置,第一个阶段被复制成两个副本,第二个阶段没有复制:
第一阶段:所有偶数ID的小批次由工作节点1处理,所有奇数ID的小批次由工作节点2处理。
第二阶段:所有小批次由工作节点3处理。
所有工作节点都会先执行前向传播,然后执行反向传播,且每个阶段会处理不同的小批次。
- 1F1B-RR调度的有效性:
1F1B-RR调度的有效性不依赖于前向传播和反向传播的时间必须相等。
实际上,通常情况下,反向传播的时间会比前向传播的时间长。因此,即使前向传播时间较短,1F1B-RR仍然是有效的调度机制。
图4中的示意图进一步展示了在这种调度下,系统如何高效地进行工作分配。
- 小结
与传统的单向流水线不同,PipeDream 中的训练涉及双向流水线,其中输入小批量首先向前,然后向后通过计算流水线。
在启动阶段,输入阶段接收足够的小批量,以使流水线在稳定状态下保持满负荷。
1F1B 调度确保每个 GPU 都被一个小批量占用,并确保输入的后向传递以规律的时间间隔应用。
3.3 挑战 3: 有效学习(Effective Learning)¶
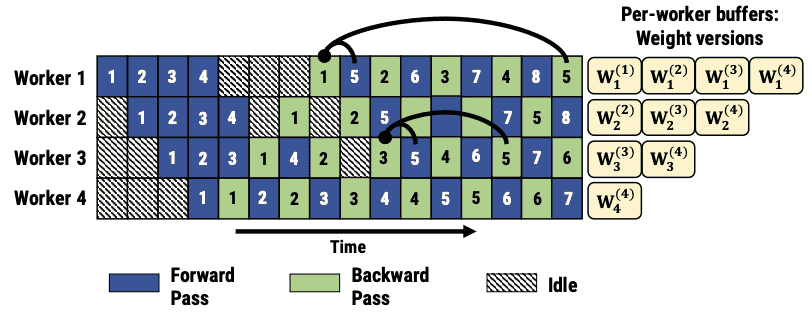
Figure 9: Weight stashing as minibatch 5 flows across stages. Arrows point to weight versions used for forward and backward passes for minibatch 5 at the first and third stages.¶
在传统的流水线训练系统中,如果一个阶段的前向传播使用了某一版本的参数,而对应的反向传播却使用了另一个版本的参数,可能会导致无效的梯度,从而影响模型的收敛性。具体来说,假设在Pipeline中有4个工作节点(workers),并且没有阶段复制(stage replication)。
- 图4展示了这个问题:
在第1个阶段,对小批次5的前向传播是在小批次1的更新之后进行的,但是反向传播却是基于小批次2、3和4的更新来计算的。
结果就是,在小批次5的反向传播中使用的权重版本和前向传播时使用的权重版本不同,这会导致无效梯度,并可能妨碍模型的收敛。
解决方案: 权重缓存(Weight Stashing)¶
PipeDream提出了一个技术叫做权重缓存(Weight Stashing),来解决前向传播和反向传播中权重版本不一致的问题。
- 具体步骤如下:
- 权重缓存技术通过为每个活动的小批次维护多个版本的权重来避免这种不匹配。
每个阶段会使用最新版本的权重来进行前向传播。
前向传播完成后,PipeDream会将使用的权重缓存起来,并在反向传播时使用相同版本的权重来计算梯度和更新。
- 每个阶段(within a stage)在处理某个小批次时,会确保前向传播和反向传播使用相同的权重版本,从而避免了前面提到的梯度不一致问题。
如图9所示
假设小批次5在第1个机器上使用了小批次1的更新,在第2个机器上使用了小批次2的更新。
在这种情况下,前向传播和反向传播会使用相同的权重版本,从而确保梯度计算的一致性。
Weight stashing 并不保证跨 stage 的一致性
垂直同步(Vertical Sync)¶
- 垂直同步(Vertical Sync) 是PipeDream中的一个可选技术,旨在消除各个阶段(stage)之间的潜在不一致性。
在图4的例子中,使用垂直同步后,小批次5的前向传播和反向传播都使用小批次1更新的权重版本。
具体来说,每个进入流水线的小批次( \(b_i\) )都会与最新的权重版本( \(w^(i-x)\) )关联,并且这个信息随着小批次的前向传播和反向传播在流水线中传播。
各个阶段在进行前向传播时,都会使用缓存的权重( \(w^(i-x)\) ),而不是最新的权重更新。
在完成反向传播后,每个阶段独立地进行权重更新,生成最新的权重( \(w^(i)\) )。
- 需要注意的是,垂直同步和传统的数据并行(Data Parallelism)有所不同。
在传统的数据并行中,梯度会在所有的活动小批次之间进行汇总,而垂直同步并不会这样做,它只确保在不同阶段使用相同版本的权重来计算梯度。
过时性(Staleness)¶
在上述技术中,我们可以正式定义不同权重更新的“过时性”(staleness)。
假设在一个直线流水线中(没有阶段复制),模型被划分成多个阶段,权重分别为w1, w2, …, wn,且每个阶段的权重更新具有一定的“延迟”。
没有权重缓存时,梯度的计算会使用不同版本的权重,这会导致梯度计算无效。
有权重缓存时,梯度计算会根据不同的阶段使用不同延迟的权重版本。这意味着在每个阶段计算梯度时,使用的是多个小批次前的权重,而不是当前版本的权重。
这种延迟效应会导致过时性,但通过引入垂直同步,可以减少这种过时性,使得在各个阶段使用的权重版本保持一致,从而得到有效的梯度计算。
总结¶
这段内容描述了PipeDream如何解决模型训练中的权重更新不一致问题,提出了 权重缓存(Weight Stashing) 和 垂直同步(Vertical Sync) 两种技术,确保了在流水线中的每个阶段前向和反向传播使用一致的权重版本,避免了无效梯度的问题。同时,PipeDream还通过合理的内存管理,确保了在流水线并行下的内存效率。
- 小结
在简单的流水线系统中,一个小批量在每个阶段的前向传递使用一个版本的参数执行,而其后向传递使用不同版本的参数执行。
PipeDream 使用一种称为权重存储的技术来避免在前向和后向传递中使用的权重版本之间存在根本不匹配。
权重存储确保在阶段内,给定小批量的前向和后向传递使用相同版本的模型参数。
4. 实现¶
备注
介绍了PipeDream的实现细节,主要包括如何管理设备内存、调度工作、处理通信等。
- 模型分割和优化
- 模型配置:
首先,PipeDream会在单个GPU上对模型进行分析,使用训练数据集的子集进行前期的测试。
之后,它会通过优化算法(在第3节提到的算法)来将深度神经网络(DNN)模型分割为多个阶段(可能还包括阶段复制),使得每个阶段的计算负载平衡。
- 生成计算图:
分割完成后,PipeDream会生成一个注解的操作符图(annotated operator graph),其中每个模型层会被映射到一个“阶段ID”。
接着,PipeDream会通过图的广度优先搜索(BFS)遍历它,生成每个阶段的代码,并保证各个操作的输入输出依赖关系不被破坏。
- Parameter State(参数状态管理)
GPU内存:PipeDream会把每个阶段(以及任何复制的阶段)的参数直接保存在GPU内存中,确保每个阶段能访问到所需的最新参数版本。
参数同步:在阶段复制的情况下,参数更新会在复制阶段之间同步。如果有新版本的参数,PipeDream会等到该版本的参数用于完成反向传播后才会丢弃旧版本。
- Intermediate State(中间状态管理)
数据复制和存储:每个阶段的输入输出数据会被赋予一个唯一的标识符(blob ID)。
当阶段接收到前一阶段的中间数据时,PipeDream会将这些数据复制到GPU内存中,并将其放入工作队列。
数据在前向传播期间不会丢弃,直到对应的反向传播完成。
反向传播中的中间数据会在使用完毕后被释放,或者在需要时发送到下一个阶段。
- 阶段复制(Stage Replication)
- 数据并行:
PipeDream通过使用PyTorch的DistributedDataParallel库来同步数据并行阶段的参数。
每个数据并行阶段会根据所需的计算量进行复制,并通过快速无等待反向传播来传递梯度。
- NCCL和Gloo:
在数据并行训练中,NCCL用于GPU间大规模的张量通信,而Gloo则更适合处理小型张量的交换,尤其是激活值和梯度的传递。
在PipeDream的流水线并行训练中,默认使用Gloo来进行各GPU之间的通信。
- 检查点(Checkpointing)
容错机制:为了提高容错能力,PipeDream支持周期性地保存模型的检查点。
检查点不会需要全局的协调,因此每个阶段在一个epoch的最后一批数据的反向传播完成后,会本地保存模型参数。
若发生故障,训练可以从最后一次成功保存的检查点恢复。
- 总结
PipeDream的实现通过优化模型分割、内存管理和通信调度来支持高效的流水线并行训练。
它能够扩展到多个GPU并进行数据并行训练,同时还提供了容错机制,以确保训练过程中的鲁棒性。通过合理的阶段划分和阶段复制,PipeDream能够减少通信开销并提高训练效率。
6. 结论¶
流水线并行 DNN 训练有助于减少可能阻碍批处理内并行性的通信开销。
与最先进的方法相比,PipeDream 在一系列 DNN 和硬件配置中完成训练的速度提高了 5.3 倍。