网络编程实战¶
目录
盛延敏,博士毕业于中科大,毕业之后就加入了 IBM,在 IBM 从事 WebSphere 应用服务器、PaaS 平台 Bluemix 等系统的开发工作,后来又在大众点评担任云平台首席架构师,推动了以 Docker 为核心的私有云的建设和落地。现在我在蚂蚁金服专注于云计算的架构和开发等方面的事情。
学习高性能网络编程,掌握两个核心要点就可以了:
1. 理解网络协议,并在这个基础上和操作系统内核配合,感知各种网络 I/O 事件;
2. 学会使用线程处理并发。
要学好网络编程,需要达到以下三个层次:
第一个层次,充分理解 TCP/IP 网络模型和协议。
第二个层次,结合对协议的理解,增强对各种异常情况的优雅处理能力。
第三个层次,写出可以支持大规模高并发的网络处理程序。
备注
“不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。” ——荀子
第一模块: 基础篇¶
01 追古溯源¶
TCP 发展历史¶
互联网起源于阿帕网(ARPANET)。最早的阿帕网还是非常简陋的,网络控制协议(Network Control Protocol,缩写 NCP)是阿帕网中连接不同计算机的通信协议。
1974 年,NCP 的开发者温特・瑟夫(Vinton Cerf)和罗伯特・卡恩(Robert E. Kahn)一起开发了一个阿帕网的下一代协议,发表了以分组、序列化、流量控制、超时和容错等为核心的一种新型的网络互联协议,一举奠定了 TCP/IP 协议的基础。
1984 年,ISO 组织发布了OSI 参考模型标准。OSI 教科书般的层次模型,对后世的影响很深远
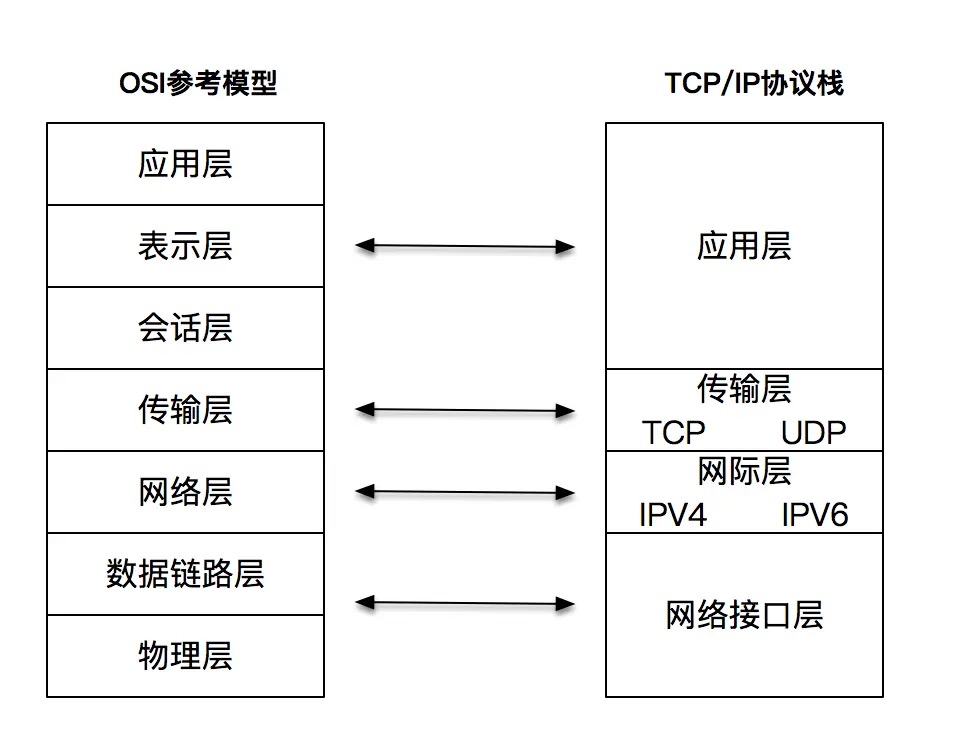
TCP/IP 的应用层对应了 OSI 的应用层、表示层和会话层;TCP/IP 的网络接口层对应了 OSI 的数据链路层和物理层。¶
UNIX 操作系统发展历史¶
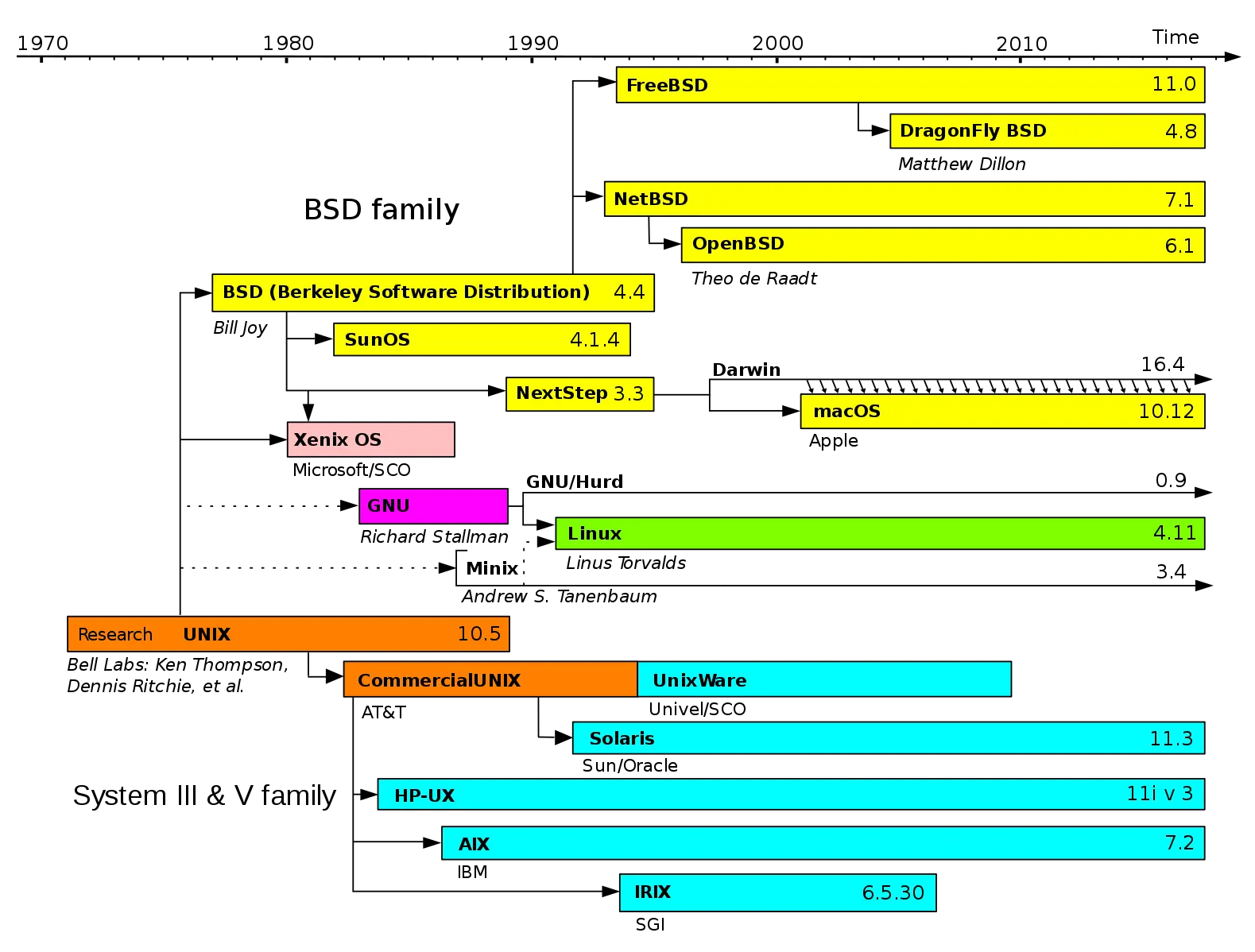
UNIX 操作系统几十年的发展历史。¶
图上标示的 Research 橘黄色部分,是由 AT&T 贝尔实验室不断开发的 UNIX 研究版本,从此引出 UNIX 分时系统第 8 版、第 9 版,终止于 1990 年的第 10 版(10.5)。
最上面所标识的操作系统版本,是加州大学伯克利分校(BSD)研究出的分支,从此引出 4.xBSD 实现,以及后面的各种 BSD 版本。这个可以看做是学院派。在历史上,学院派有力地推动了 UNIX 的发展,包括我们后面会谈到的 socket 套接字都是出自此派。
最下面的那一个部分,是从 AT&T 分支的商业派,致力于从 UNIX 系统中谋取商业利润。从此引出了 System III 和 System V(被称为 UNIX 的商用版本),还有各大公司的 UNIX 商业版。
UNIX 的历史:一个基本事实是,网络编程套接字接口,最早是在 BSD 4.2 引入的,这个时间大概是 1983 年,几经演变后,成为了事实标准¶
UNIX 玩家¶
SVR4(UNIX System V Release 4)是 AT&T 的 UNIX 系统实验室的一个商业产品。它基本上是一个操作系统的大杂烩,这个操作系统之所以重要,是因为它是 System III/V 分支各家商业化 UNIX 操作系统的 “先祖”,包括 IBM 的 AIX、HP 的 HP-UX、SGI 的 IRIX、Sun(后被 Oracle 收购)的 Solaris 等等
Solaris 是由 Sun Microsystems(现为 Oracle)开发的 UNIX 系统版本,它基于 SVR4,并且在商业上获得了不俗的成绩。2005 年,Sun Microsystems 开源了 Solaris 操作系统的大部分源代码,作为 OpenSolaris 开放源代码操作系统的一部分。相对于 Linux,这个开源操作系统的进展比较一般。
BSD(Berkeley Software Distribution),由加州大学伯克利分校的计算机系统研究组(CSRG)研究开发和分发的。4.2BSD 于 1983 年问世,其中就包括了网络编程套接口相关的设计和实现,4.3BSD 则于 1986 年发布,正是由于 TCP/IP 和 BSD 操作系统的完美拍档,才有了 TCP/IP 逐渐成为事实标准的这一历史进程。
macOS X系统又被称为 Darwin,它已被验证过就是一个 UNIX 操作系统。如果打开 Mac 系统的 socket.h 头文件定义,你会明显看到 macOS 系统和 BSD 千丝万缕的联系,说明这就是从 BSD 系统中移植到 macOS 系统来的。
Linux 操作系统实在太重要了,全世界绝大部分数据中心操作系统都是跑在 Linux 上的,就连手机操作系统 Android,也是一个被 “裁剪” 过的 Linux 操作系统。
POSIX 标准相当于给大厦画好了图纸。程序在 macOS 和 Linux 可以兼容运行的原因,因为大家用的都是一张图纸,只不过制造商不同,程序当然可以兼容运行了。
Minix 操作系统,安迪・塔能鲍姆(Andy Tanenbaum)的教授开发的。Linux 早期从 Minix 中借鉴了一些思路,包括最早的文件系统等。
GNU,理查・斯托曼(Richard Stallman)设计一个完全自由的软件系统,用户可以自由使用,自由修改这些软件系统。
操作系统对 TCP/IP 的支持¶
02 网络编程模型¶

三个保留网段:其可以容纳的计算机主机个数分别是 16777216 个、1048576 个和 65536 个。¶
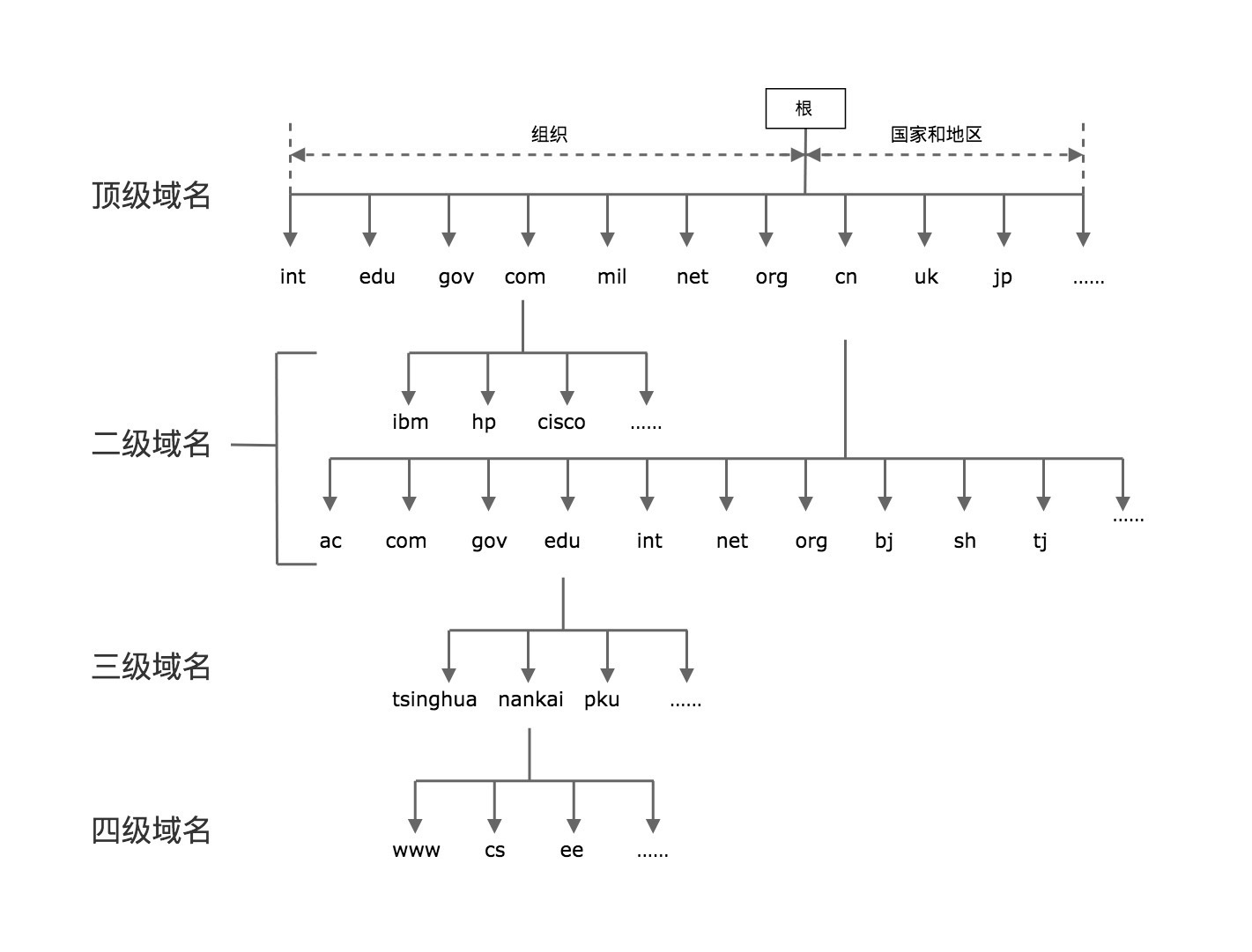
全球域名系统¶
TCP,字节流套接字(Stream Socket),SOCK_STREAM
UDP,数据报套接字(Datagram Socket),SOCK_DGRAM
03 套接字和地址¶
socket 这个英文单词的原意是 “插口”“插槽”, 在网络编程中,它的寓意是可以通过插口接入的方式,快速完成网络连接和数据收发。你可以把它想象成现实世界的电源插口,或者是早期上网需要的网络插槽,所以 socket 也可以看做是对物理世界的直接映射。
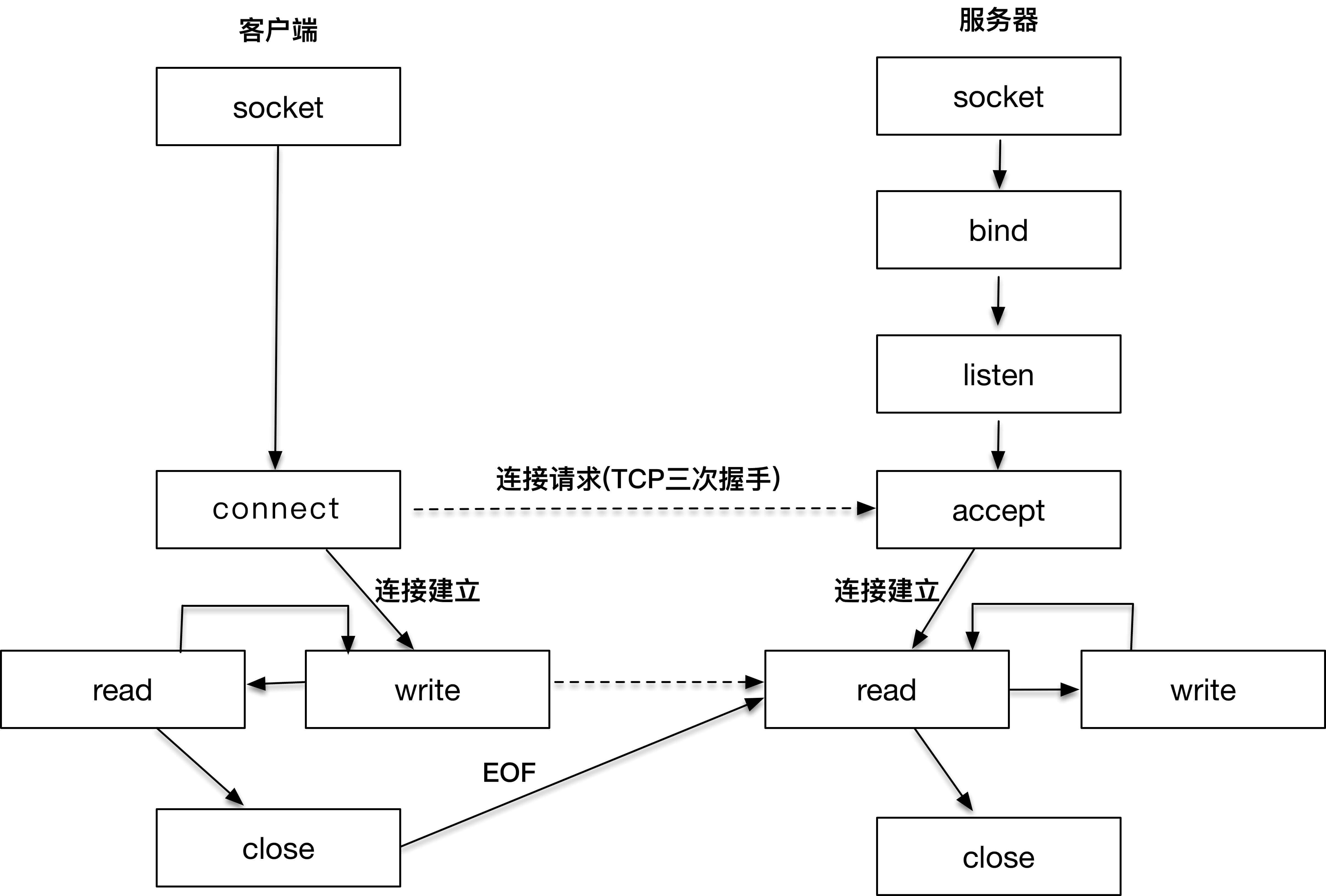
网络编程中,客户端和服务器工作的核心逻辑。讲这幅图的真正用意在于引入 socket 的概念,请注意,以上所有的操作,都是通过 socket 来完成的。无论是客户端的 connect,还是服务端的 accept,或者 read/write 操作等,socket 是我们用来建立连接,传输数据的唯一途径。¶
先从右侧的服务器端开始看,因为在客户端发起连接请求之前,服务器端必须初始化好。右侧的图显示的是服务器端初始化的过程,首先初始化 socket,之后服务器端需要执行 bind 函数,将自己的服务能力绑定在一个众所周知的地址和端口上,紧接着,服务器端执行 listen 操作,将原先的 socket 转化为服务端的 socket,服务端最后阻塞在 accept 上等待客户端请求的到来。
此时,服务器端已经准备就绪。客户端需要先初始化 socket,再执行 connect 向服务器端的地址和端口发起连接请求,这里的地址和端口必须是客户端预先知晓的。这个过程,就是著名的 TCP 三次握手(Three-way Handshake)。
一旦三次握手完成,客户端和服务器端建立连接,就进入了数据传输过程。
具体来说,客户端进程向操作系统内核发起 write 字节流写操作,内核协议栈将字节流通过网络设备传输到服务器端,服务器端从内核得到信息,将字节流从内核读入到进程中,并开始业务逻辑的处理,完成之后,服务器端再将得到的结果以同样的方式写给客户端。可以看到,一旦连接建立,数据的传输就不再是单向的,而是双向的,这也是 TCP 的一个显著特性。
当客户端完成和服务器端的交互后,比如执行一次 Telnet 操作,或者一次 HTTP 请求,需要和服务器端断开连接时,就会执行 close 函数,操作系统内核此时会通过原先的连接链路向服务器端发送一个 FIN 包,服务器收到之后执行被动关闭,这时候整个链路处于半关闭状态,此后,服务器端也会执行 close 函数,整个链路才会真正关闭。半关闭的状态下,发起 close 请求的一方在没有收到对方 FIN 包之前都认为连接是正常的;而在全关闭的状态下,双方都感知连接已经关闭。
socket 的发展历史¶
备注
【Socket 历史】socket 是加州大学伯克利分校的研究人员在 20 世纪 80 年代早期提出的,所以也被叫做伯克利套接字。伯克利的研究者们设想用 socket 的概念,屏蔽掉底层协议栈的差别。第一版实现 socket 的就是 TCP/IP 协议,最早是在 BSD 4.2 Unix 内核上实现了 socket。很快大家就发现这么一个概念带来了网络编程的便利,于是有更多人也接触到了 socket 的概念。Linux 作为 Unix 系统的一个开源实现,很早就从头开发实现了 TCP/IP 协议,伴随着 socket 的成功,Windows 也引入了 socket 的概念。于是在今天的世界里,socket 成为网络互联互通的标准。
套接字地址格式¶
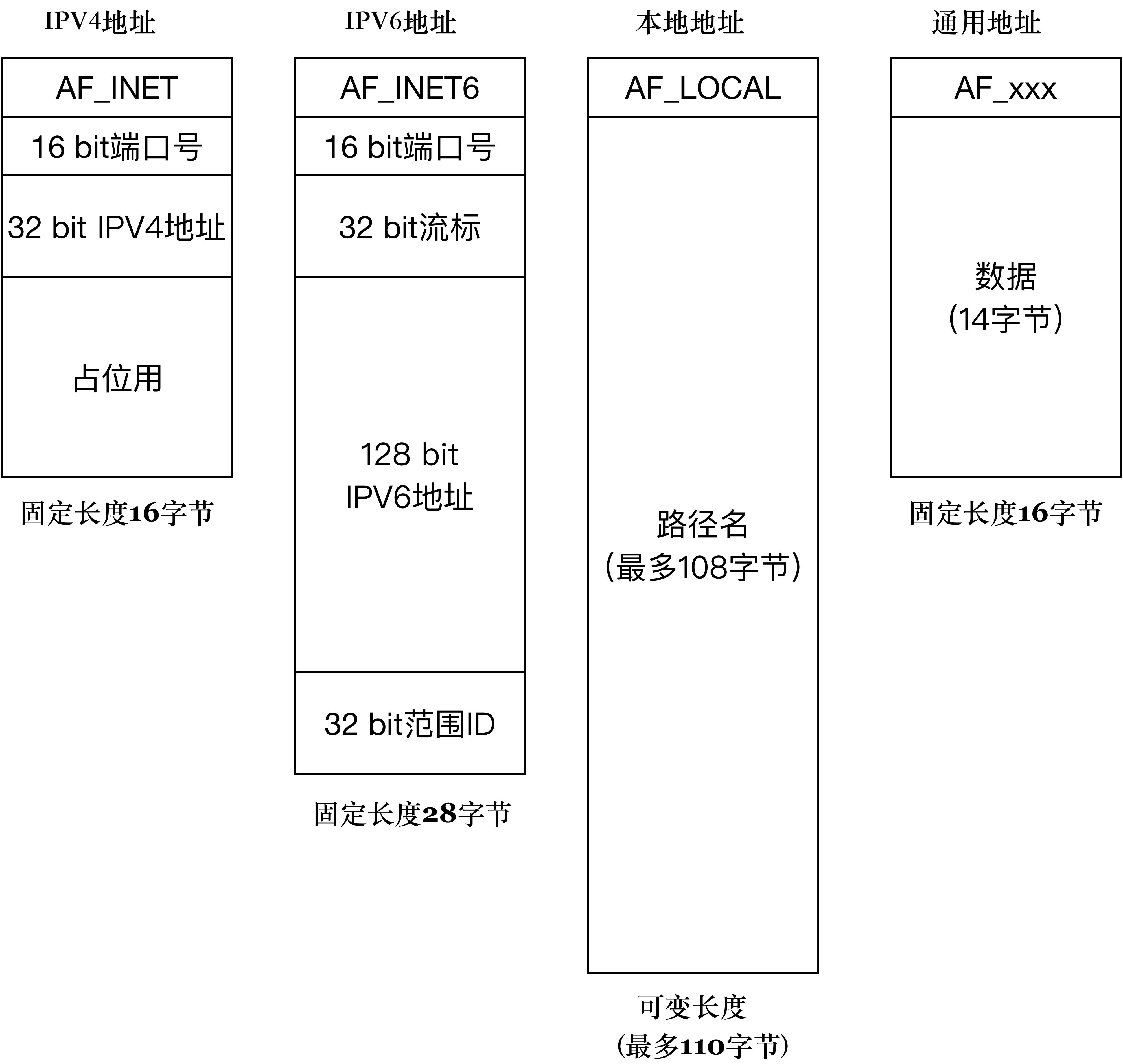
套接字的通用地址结构:
/* POSIX.1g 规范规定了地址族为 2 字节的值. */
typedef unsigned short int sa_family_t;
/* 描述通用套接字地址 */
struct sockaddr{
sa_family_t sa_family; /* 地址族. 16-bit=2字节*/
char sa_data[14]; /* 具体的地址值 112-bit=14字节*/
};
SYN:建立连接
FIN:关闭连接
ACK:响应
PSH:有 DATA 数据传输
RST:连接重置
IPv4 套接字格式地址¶
常用的 IPv4 地址族的结构:
/* IPV4 套接字地址,32bit 值. */
typedef uint32_t in_addr_t;
struct in_addr
{
in_addr_t s_addr;
};
/* 描述 IPV4 的套接字地址格式 */
struct sockaddr_in
{
sa_family_t sin_family; /* 16-bit */
in_port_t sin_port; /* 端口号 16-bit*/
struct in_addr sin_addr; /* Internet address. 32-bit */
/* 这里仅仅用作占位符,不做实际用处 */
unsigned char sin_zero[8];
};
glibc 定义的保留端口:
/* Standard well-known ports. */
enum
{
IPPORT_ECHO = 7, /* Echo service. */
IPPORT_DISCARD = 9, /* Discard transmissions service. */
IPPORT_SYSTAT = 11, /* System status service. */
IPPORT_DAYTIME = 13, /* Time of day service. */
IPPORT_NETSTAT = 15, /* Network status service. */
IPPORT_FTP = 21, /* File Transfer Protocol. */
IPPORT_TELNET = 23, /* Telnet protocol. */
IPPORT_SMTP = 25, /* Simple Mail Transfer Protocol. */
IPPORT_TIMESERVER = 37, /* Timeserver service. */
IPPORT_NAMESERVER = 42, /* Domain Name Service. */
IPPORT_WHOIS = 43, /* Internet Whois service. */
IPPORT_MTP = 57,
IPPORT_TFTP = 69, /* Trivial File Transfer Protocol. */
IPPORT_RJE = 77,
IPPORT_FINGER = 79, /* Finger service. */
IPPORT_TTYLINK = 87,
IPPORT_SUPDUP = 95, /* SUPDUP protocol. */
IPPORT_EXECSERVER = 512, /* execd service. */
IPPORT_LOGINSERVER = 513, /* rlogind service. */
IPPORT_CMDSERVER = 514,
IPPORT_EFSSERVER = 520,
/* UDP ports. */
IPPORT_BIFFUDP = 512,
IPPORT_WHOSERVER = 513,
IPPORT_ROUTESERVER = 520,
/* Ports less than this value are reserved for privileged processes. */
IPPORT_RESERVED = 1024,
/* Ports greater this value are reserved for (non-privileged) servers. */
IPPORT_USERRESERVED = 5000
}
IPv6 套接字地址格式¶
IPv6 的地址结构:
struct sockaddr_in6
{
sa_family_t sin6_family; /* 16-bit */
in_port_t sin6_port; /* 传输端口号 # 16-bit */
uint32_t sin6_flowinfo; /* IPv6 流控信息 32-bit*/
struct in6_addr sin6_addr; /* IPv6 地址 128-bit */
uint32_t sin6_scope_id; /* IPv6 域 ID 32-bit */
};
本地进程间的通信 AF_LOCAL:
struct sockaddr_un {
unsigned short sun_family; /* 固定为 AF_LOCAL */
char sun_path[108]; /* 路径名 */
};
几种套接字地址格式比较¶

几种套接字地址格式比较¶
04 TCP 三次握手¶
服务端准备连接的过程¶
一. 创建套接字:
int socket(int domain, int type, int protocol)
二. 调用 bind 函数把套接字和套接字地址绑定:
bind(int fd, sockaddr * addr, socklen_t len)
说明:
1. fd: 文件描述符,即前面的 socket 的返回值
2. addr: 地址格式(IPv4、IPv6 或者本地套接字格式)
3. len: 处理长度可变的结构(如 IPv4和 IPv6长度不同)
备注
注意到 bind 函数后面的第二个参数是通用地址格式 sockaddr * addr。这里有一个地方值得注意,那就是虽然接收的是通用地址格式,实际上传入的参数可能是 IPv4、IPv6 或者本地套接字格式。bind 函数会根据 len 字段判断传入的参数 addr 该怎么解析,len 字段表示的就是传入的地址长度,它是一个可变值。这里其实可以把 bind 函数理解成这样: bind(int fd, void * addr, socklen_t len) BSD 设计套接字的时候大约是 1982 年,那个时候的 C 语言还没有 void * 的支持,为了解决这个问题,BSD 的设计者们创造性地设计了通用地址格式来作为支持 bind 和 accept 等这些函数的参数。
示例:
#include <stdio.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <netinet/in.h>
int make_socket (uint16_t port)
{
int sock;
struct sockaddr_in name;
/* 创建字节流类型的 IPV4 socket. */
sock = socket (PF_INET, SOCK_STREAM, 0);
if (sock < 0)
{
perror ("socket");
exit (EXIT_FAILURE);
}
/* 绑定到 port 和 ip. */
name.sin_family = AF_INET; /* IPV4 */
name.sin_port = htons (port); /* 指定端口 */
name.sin_addr.s_addr = htonl (INADDR_ANY); /* 通配地址 */
/* 把 IPV4 地址转换成通用地址格式,同时传递长度 */
if (bind (sock, (struct sockaddr *) &name, sizeof (name)) < 0)
{
perror ("bind");
exit (EXIT_FAILURE);
}
return sock
}
三. 通过 listen 函数,可以将原来的 “主动” 套接字转换为 “被动” 套接字:
告诉操作系统内核:“我这个套接字是用来等待用户请求的。”
当然,操作系统内核会为此做好接收用户请求的一切准备,比如完成连接队列。
int listen (int socketfd, int backlog)
1. socketdf 为套接字描述符
2. backlog,在 Linux 中表示已完成(ESTABLISHED)且未 accept 的队列大小,
这个参数的大小决定了可以接收的并发数目
四. 把 accept 这个函数看成是操作系统内核和应用程序之间的桥梁:
int accept(int listensockfd, struct sockaddr *cliaddr, socklen_t *addrlen)
1. listensockfd 是套接字,可以叫它为 listen 套接字
2. cliaddr: 通过指针方式获取的客户端的地址
3. addrlen 告诉我们地址的大小
备注
要注意有两个套接字描述字,第一个是监听套接字描述字 listensockfd,它是作为输入参数存在的;第二个是返回的已连接套接字描述字。应用服务器完成了对这个客户的服务,就会关闭已连接套接字,这样就完成了 TCP 连接的释放。而监听套接字一直都处于 “监听” 状态,等待新的客户请求到达并服务。
客户端发起连接的过程¶
一. 建立一个套接字 二. 通过 connect 函数完成客户端和服务器端的连接建立
备注
如果是 TCP 套接字,那么调用 connect 函数将激发 TCP 的三次握手过程,而且仅在连接建立成功或出错时才返回。
出错返回可能有以下几种情况:
1. 三次握手无法建立,客户端发出的 SYN 包没有任何响应,于是返回 TIMEOUT 错误。
这种情况比较常见的原因是对应的服务端 IP 写错。
2. 客户端收到了 RST(复位)回答,这时候客户端会立即返回 CONNECTION REFUSED 错误。
这种情况比较常见于客户端发送连接请求时的请求端口写错,
因为 RST 是 TCP 在发生错误时发送的一种 TCP 分节。
产生 RST 的三个条件是:
目的地为某端口的 SYN 到达,然而该端口上没有正在监听的服务器(如前所述);
TCP 想取消一个已有连接;
TCP 接收到一个根本不存在的连接上的分节。
3. 客户发出的 SYN 包在网络上引起 "destination unreachable",即目的不可达的错误
这种情况比较常见的原因是客户端和服务器端路由不通。
TCP 三次握手¶
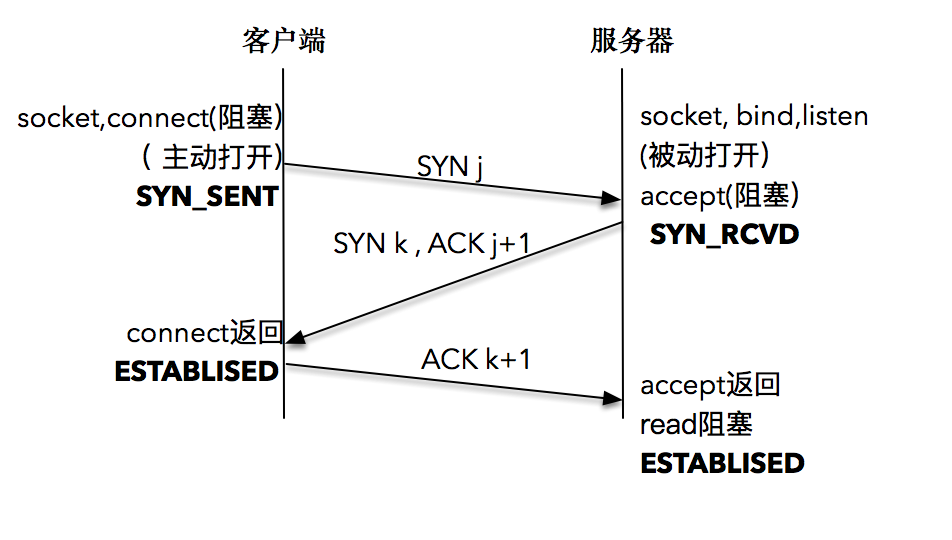
著名的 TCP 三次握手¶
三次握手的具体过程¶
客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 j,客户端进入 SYNC_SENT 状态;
服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 j+1,表示对 SYN 包 j 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 k,服务器端进入 SYNC_RCVD 状态;
客户端协议栈收到 ACK 之后,使得应用程序从 connect 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 k+1;
应答包到达服务器端后,服务器端协议栈使得 accept 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
05 使用套接字进行读写¶
发送数据¶
发送数据时常用的有三个函数,分别是 write、send 和 sendmsg:
ssize_t write (int socketfd, const void *buffer, size_t size)
ssize_t send (int socketfd, const void *buffer, size_t size, int flags)
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags)
发送缓冲区¶
备注
当 TCP 三次握手成功,TCP 连接成功建立后,操作系统内核会为每一个连接创建配套的基础设施,比如发送缓冲区。发送缓冲区的大小可以通过套接字选项来改变,当我们的应用程序调用 write 函数时,实际所做的事情是把数据从应用程序中拷贝到操作系统内核的发送缓冲区中,并不一定是把数据通过套接字写出去。
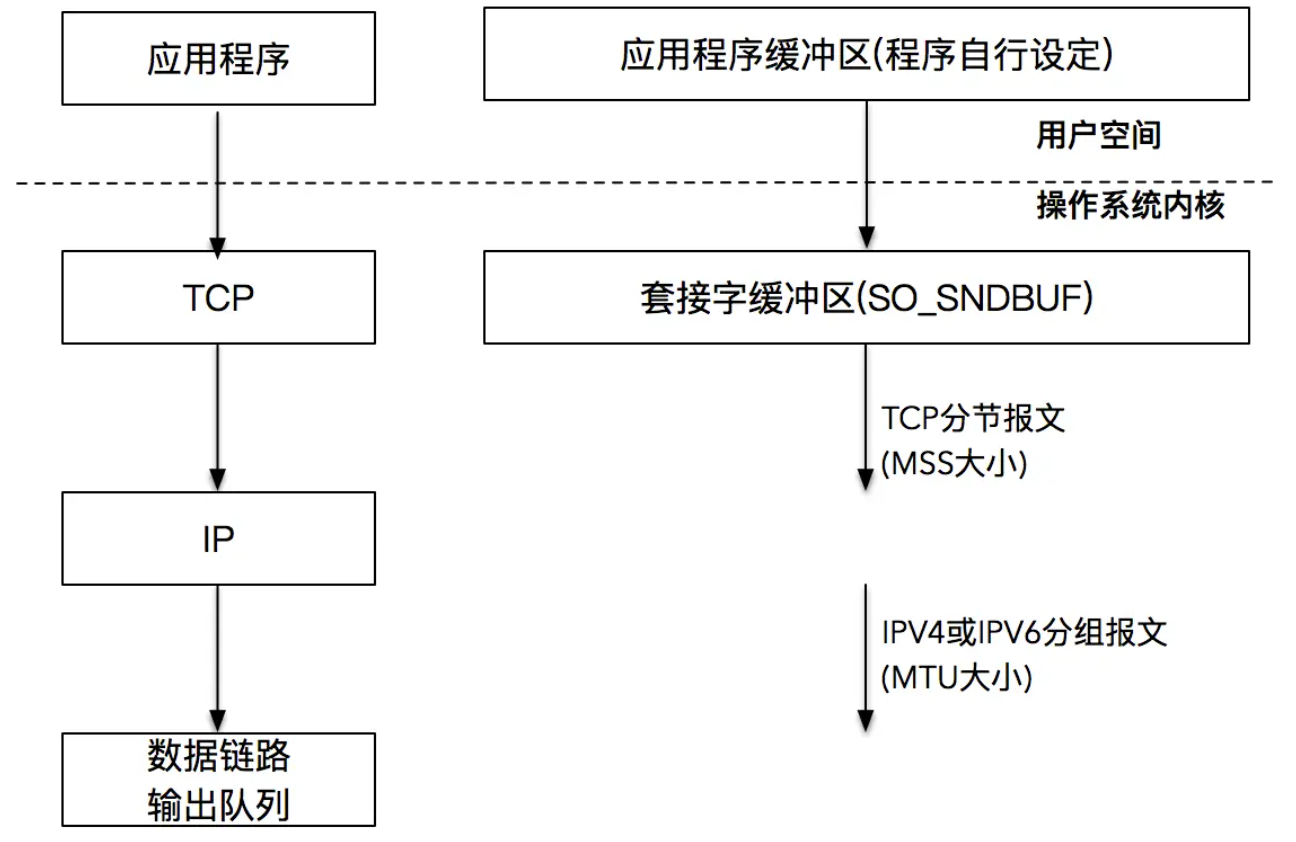
操作系统内核在 TCP 连接建立之后,就开始运作起来。按照 TCP/IP 的语义,将取出的数据封装成 TCP 的 MSS 包,以及 IP 的 MTU 包,最后走数据链路层将数据发送出去。这样我们的发送缓冲区就又空了一部分,于是又可以继续从应用程序搬一部分数据到发送缓冲区里,这样一直进行下去,到某一个时刻,应用程序的数据可以完全放置到发送缓冲区里。在这个时候,write 阻塞调用返回。注意返回的时刻,应用程序数据并没有全部被发送出去,发送缓冲区里还有部分数据,这部分数据会在稍后由操作系统内核通过网络发送出去。¶
读取数据¶
read 函数:
ssize_t read (int socketfd, void *buffer, size_t size)
read 函数要求操作系统内核从套接字描述符 socketfd 读取最多多少个字节(size),并将结果存储到 buffer 中。返回值告诉我们实际读取的字节数目,也有一些特殊情况,如果返回值为 0,表示 EOF(end-of-file),这在网络中表示对端发送了 FIN 包,要处理断连的情况;如果返回值为 -1,表示出错。当然,如果是非阻塞 I/O,情况会略有不同
思考题¶
一段数据流从应用程序发送端,一直到应用程序接收端,总共经过了多少次拷贝
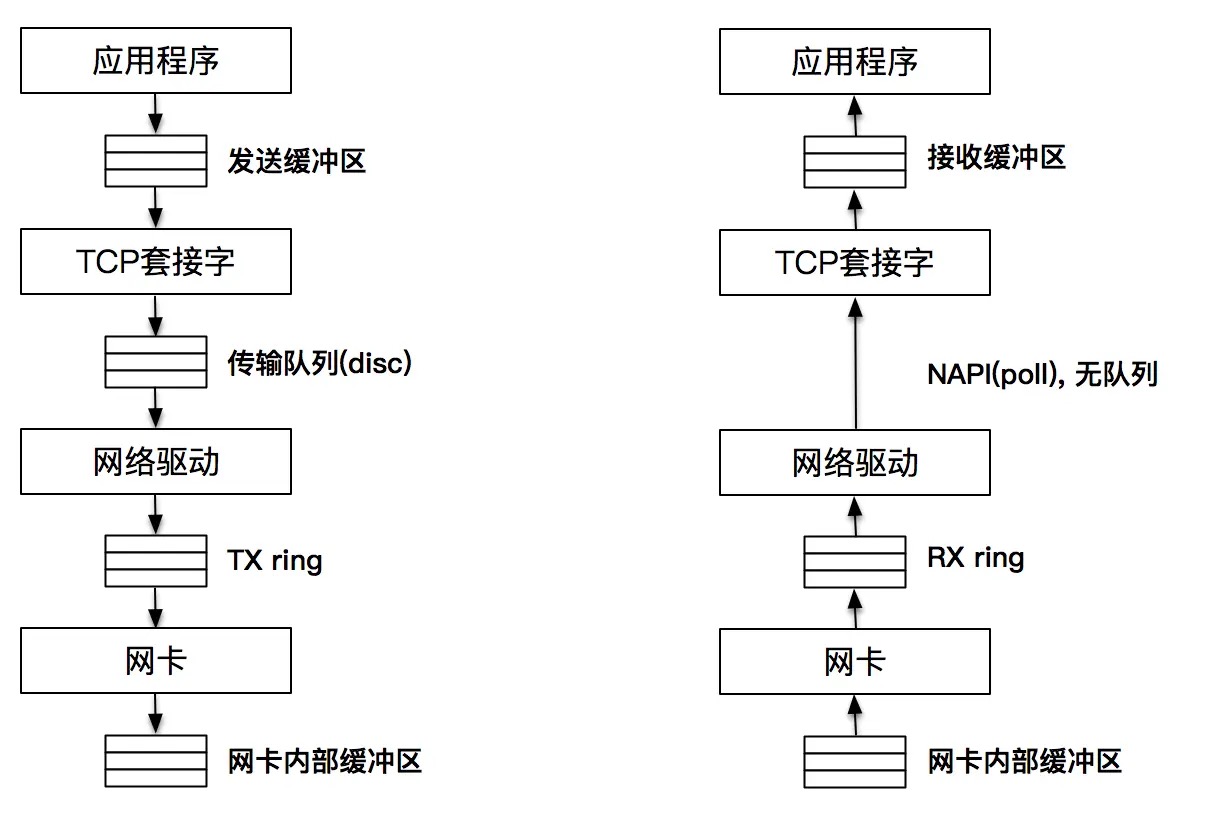
任何一个环节稍有积压,都会对程序性能产生影响。但好消息是,内核和网络设备供应商已经帮我们把一切都打点好了,我们看到和用到的,其实只是冰山上的一角而已。¶
发送端,当应用程序将数据发送到发送缓冲区时,调用的是 send 或 write 方法,如果缓存中没有空间,系统调用就会失败或者阻塞。我们说,这个动作事实上是一次 “显式拷贝”。而在这之后,数据将会按照 TCP/IP 的分层再次进行拷贝,这层的拷贝对我们来说就不是显式的了。轮到 TCP 协议栈工作,创建 Packet 报文,并把报文发送到传输队列中(qdisc),传输队列是一个典型的 FIFO 队列,队列的最大值可以通过 ifconfig 命令输出的 txqueuelen 来查看。通常情况下,这个值有几千报文大小。TX ring 在网络驱动和网卡之间,也是一个传输请求的队列。网卡作为物理设备工作在物理层,主要工作是把要发送的报文保存到内部的缓存中,并发送出去。
接收端,报文首先到达网卡,由网卡保存在自己的接收缓存中,接下来报文被发送至网络驱动和网卡之间的 RX ring,网络驱动从 RX ring 获取报文 ,然后把报文发送到上层。这里值得注意的是,网络驱动和上层之间没有缓存,因为网络驱动使用 Napi 进行数据传输。因此,可以认为上层直接从 RX ring 中读取报文。最后,报文的数据保存在套接字接收缓存中,应用程序从套接字接收缓存中读取数据。
06 UDP协议¶
TCP 是一个面向连接的协议,TCP 在 IP 报文的基础上,增加了诸如重传、确认、有序传输、拥塞控制等能力,通信的双方是在一个确定的上下文中工作的。UDP 是一个不可靠的通信协议,没有重传和确认,没有有序控制,也没有拥塞控制。
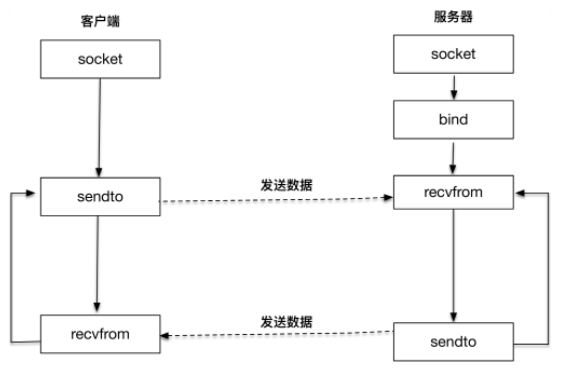
服务器端创建 UDP 套接字之后,绑定到本地端口,调用 recvfrom 函数等待客户端的报文发送;客户端创建套接字之后,调用 sendto 函数往目标地址和端口发送 UDP 报文,然后客户端和服务器端进入互相应答过程。¶
recvfrom 和 sendto 是 UDP 用来接收和发送报文的两个主要函数:
#include <sys/socket.h>
ssize_t recvfrom(int sockfd, void *buff, size_t nbytes, int flags,
struct sockaddr *from, socklen_t *addrlen);
ssize_t sendto(int sockfd, const void *buff, size_t nbytes, int flags,
const struct sockaddr *to, socklen_t addrlen);
1. sockfd 是本地创建的套接字描述符
2. buff 指向本地的缓存
3. nbytes 表示最大接收数据字节
4. flags 是和 I/O 相关的参数
5. from 是返回对端发送方的地址
6. addrlen 是返回对端发送方的端口
实际上不存在 UDP 发送缓冲区,因为发往 UDP 发送缓冲区的包只要超过一定阈值 (值很小) 就可以发往对端。所以我们一般认为 UDP 是没有发送缓冲区的。
07 本地套接字¶
本地套接字是 IPC,也就是本地进程间通信的一种实现方式。除了本地套接字以外,其它技术,诸如管道、共享消息队列等也是进程间通信的常用方法,但因为本地套接字开发便捷,接受度高,所以普遍适用于在同一台主机上进程间通信的各种场景。
本地套接字概述¶
本地套接字一般也叫做 UNIX 域套接字,最新的规范已经改叫本地套接字。本地套接字是一种特殊类型的套接字,和 TCP/UDP 套接字不同。TCP/UDP 即使在本地地址通信,也要走系统网络协议栈,而本地套接字,严格意义上说提供了一种单主机跨进程间调用的手段,减少了协议栈实现的复杂度,效率比 TCP/UDP 套接字都要高许多。类似的 IPC 机制还有 UNIX 管道、共享内存和 RPC 调用等。
四种不同的套接字¶
本地字节流套接字¶
sockfd = socket(AF_LOCAL, SOCK_STREAM, 0);
servaddr.sun_family = AF_LOCAL;
strcpy(servaddr.sun_path, argv[1]);
本地数据报套接字¶
socket_fd = socket(AF_LOCAL, SOCK_DGRAM, 0);
servaddr.sun_family = AF_LOCAL;
strcpy(servaddr.sun_path, local_path);
08 工欲善其事必先利其器¶
Ping、ifconfig、netstat、lsof、tcpdump详见具体命令
09 答疑篇¶
书籍推荐¶
UNIX 网络编程方面,强烈推荐 Stevens 大神的两卷本《UNIX 网络编程》,其中第一卷是讲套接字的,第二卷是讲 IPC 进程间通信的。这套书的卷一基本上面面俱到地讲述了 UNIX 网络编程的方方面面,但有时候稍显啰嗦,特别是高性能高并发这块,已经跟不上时代,但你可以把注意力放在卷一的前半部分。
TCP/IP 协议方面,当然是推荐 Stevens 的大作《TCP/IP 详解》, 这套书总共有三卷,第一卷讲协议,第二卷讲实现,第三卷讲 TCP 事务。我在这里推荐第一卷,第二卷的实现是基于 BSD 的代码讲解的,就不推荐了。我想如果你想看源码的话,还是推荐看 Linux 的,毕竟我们用的比较多。第三卷涉及的内容比较少见,也不推荐了。
第二模块: 提高篇¶
10 | TIME_WAIT¶
TIME_WAIT 发生的场景¶
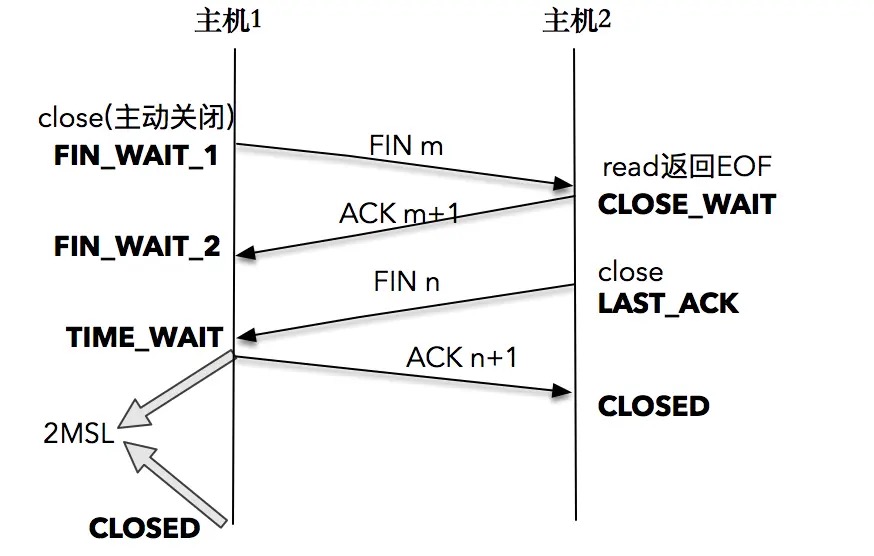
TCP 连接终止时,主机 1 先发送 FIN 报文,主机 2 进入 CLOSE_WAIT 状态,并发送一个 ACK 应答,同时,主机 2 通过 read 调用获得 EOF,并将此结果通知应用程序进行主动关闭操作,发送 FIN 报文。主机 1 在接收到 FIN 报文后发送 ACK 应答,此时主机 1 进入 TIME_WAIT 状态。主机 1 在 TIME_WAIT 停留持续时间是固定的,是最长分节生命期 MSL(maximum segment lifetime)的两倍,一般称之为 2MSL。和大多数 BSD 派生的系统一样,Linux 系统里有一个硬编码的字段,名称为 TCP_TIMEWAIT_LEN,其值为 60 秒。¶
TIME_WAIT 的作用¶
确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭:
容错性设计,比如,TCP 假设报文会出错,需要重传。 如果图中主机 1 的 ACK 报文没有传输成功,那么主机 2 就会重新发送 FIN 报文。
和连接 “化身” 和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失:
在网络中,经常会发生报文经过一段时间才能到达目的地的情况, 产生的原因是多种多样的,如路由器重启,链路突然出现故障等。 如果迷走报文到达时: a. 发现 TCP 连接四元组(源 IP,源端口,目的 IP,目的端口)所代表的连接不复存在, 那么很简单,这个报文自然丢弃。 b. 在原连接中断后,又重新创建了一个原连接的 “化身” 说是化身其实是因为这个连接和原先的连接四元组完全相同, 那么这个报文会被误认为是连接 “化身” 的一个 TCP 分节,这样就会对 TCP 通信产生影响。
备注
2MSL 的时间是从主机 1 接收到 FIN 后发送 ACK 开始计时的;如果在 TIME_WAIT 时间内,因为主机 1 的 ACK 没有传输到主机 2,主机 1 又接收到了主机 2 重发的 FIN 报文,那么 2MSL 时间将重新计时。
TIME_WAIT 的危害¶
内存资源占用,这个目前看来不是太严重,基本可以忽略。
对端口资源的占用,一个 TCP 连接至少消耗一个本地端口
如何优化 TIME_WAIT¶
调小net.ipv4.tcp_max_tw_buckets(默认为 18000):
当系统中处于 TIME_WAIT 的连接一旦超过这个值时, 系统就会将所有的 TIME_WAIT 连接状态重置,并且只打印出警告信息
调低 TCP_TIMEWAIT_LEN,重新编译系统:
缺点是需要 “一点” 内核方面的知识,能够重新编译内核
SO_LINGER 的设置:
a. l_onoff 为 0 默认: l_linger 的值被忽略 b. l_onoff 为非 0, 且 l_linger 值为 0(非常危险⚠️) 调用 close 后,会立该发送一个 RST 标志给对端, 该 TCP 连接将跳过四次挥手,也就跳过了 TIME_WAIT 状态,直接关闭。 这种关闭的方式称为 “强行关闭”。 在这种情况下,排队数据不会被发送,被动关闭方也不知道对端已经彻底断开。 只有当被动关闭方正阻塞在 recv() 调用上时,接受到 RST 时,会立刻得到一个 “connet reset by peer” 的异常 c. l_onoff 为非 0, 且 l_linger 值也非 0 调用 close 后,调用 close 的线程就将阻塞, 直到数据被发送出去,或者设置的 l_linger 计时时间到net.ipv4.tcp_tw_reuse:更安全的设置:
Allow to reuse TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. Default value is 0. It should not be changed without advice/request of technical experts. 安全可控指: a. 只适用于连接发起方(C/S 模型中的客户端) b. 对应的 TIME_WAIT 状态的连接创建时间超过 1 秒才可以被复用 前提: 慎用,当客户端与服务端主机时间不同步时,客户端的发送的消息会被直接拒绝掉
11 | 优雅地关闭还是粗暴地关闭TCP¶
close 函数¶
原型:
int close(int sockfd)
对已连接的套接字执行 close 操作就可以,若成功则为 0,若出错则为 -1。这个函数会对套接字引用计数减一,一旦发现套接字引用计数到 0,就会对套接字进行彻底释放,并且会关闭 TCP 两个方向的数据流。套接字引用计数是因为套接字可以被多个进程共享。
如何关闭两个方向的数据流:
1. 在输入方向,系统内核会将该套接字设置为不可读,任何读操作都会返回异常。
2. 在输出方向,系统内核尝试将发送缓冲区的数据发送给对端,并最后向对端发送一个 FIN 报文,接下来如果再对该套接字进行写操作会返回异常。
3. 如果对端没有检测到套接字已关闭,还继续发送报文,就会收到一个 RST 报文
shutdown 函数¶
原型:
int shutdown(int sockfd, int howto)
howto 的设置有三个主要选项:
1. SHUT_RD (0)
关闭连接的 “读” 这个方向,对该套接字进行读操作直接返回 EOF。
从数据角度来看,套接字上接收缓冲区已有的数据将被丢弃,如果再有新的数据流到达,会对数据进行 ACK,然后悄悄地丢弃。
也就是说,对端还是会接收到 ACK,在这种情况下根本不知道数据已经被丢弃了。
2. SHUT_WR (1)
关闭连接的 “写” 这个方向,这就是常被称为” 半关闭 “的连接。
此时,不管套接字引用计数的值是多少,都会直接关闭连接的写方向。
套接字上发送缓冲区已有的数据将被立即发送出去,并发送一个 FIN 报文给对端。
应用程序如果对该套接字进行写操作会报错。
3. SHUT_RDWR (2)
相当于 SHUT_RD 和 SHUT_WR 操作各一次,关闭套接字的读和写两个方向。
SHUT_RDWR 来调用 shutdown 和调用 close 的差别:
1. close 会关闭连接,并释放所有连接对应的资源,而 shutdown 并不会释放掉套接字和所有的资源。
2. close 存在引用计数的概念,并不一定导致该套接字不可用;
shutdown 则不管引用计数,直接使得该套接字不可用,如果有别的进程企图使用该套接字,将会受到影响。
3. close 的引用计数导致不一定会发出 FIN 结束报文,而 shutdown 则总是会发出 FIN 结束报文,这在我们打算关闭连接通知对端的时候,是非常重要的。
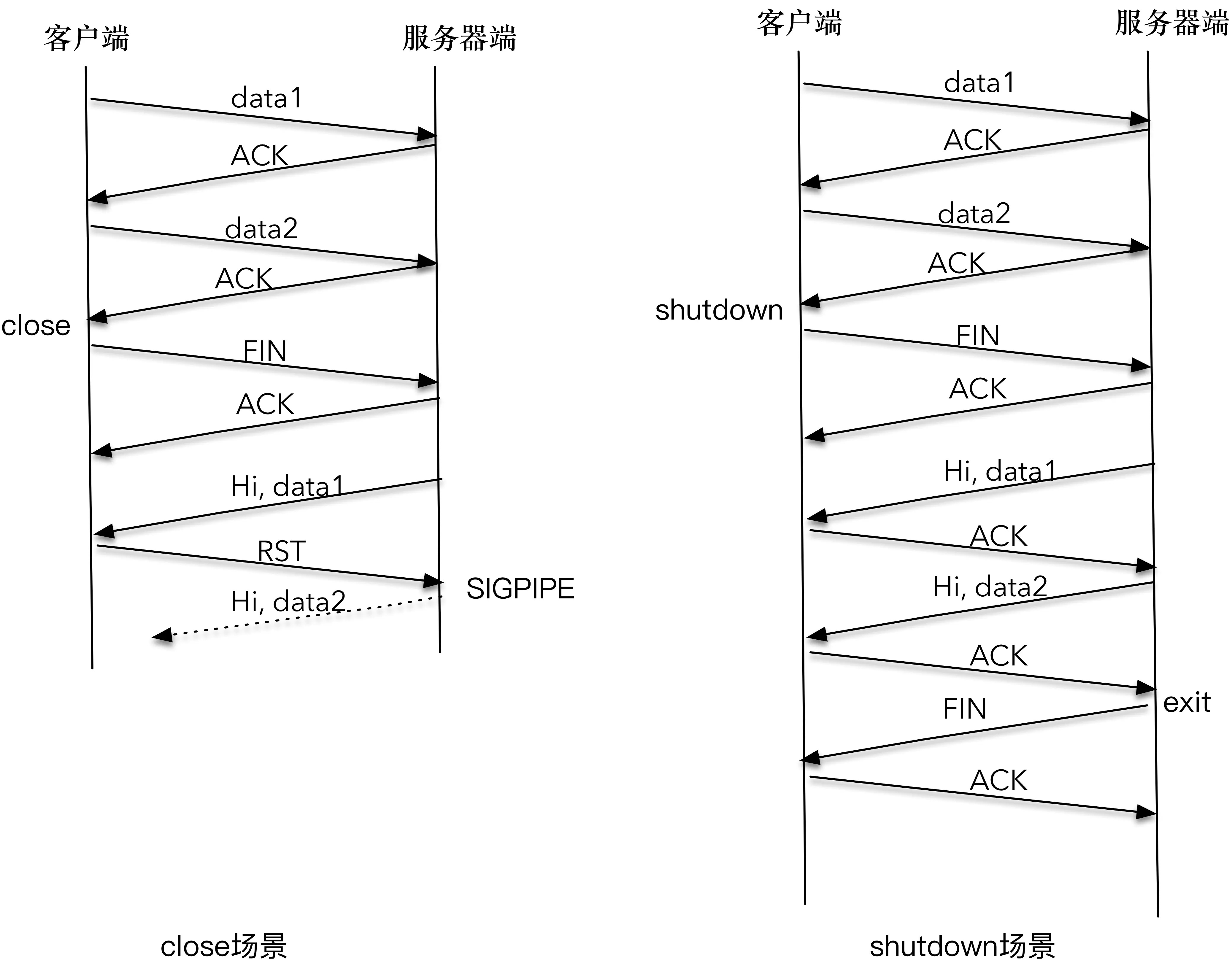
1.客户端调用 close 函数关闭了整个连接,当服务器端发送的 “Hi, data1” 分组到底时,客户端给回送一个 RST 分组;服务器端再次尝试发送 “Hi, data2” 第二个应答分组时,系统内核通知 SIGPIPE 信号。这是因为,在 RST 的套接字进行写操作,会直接触发 SIGPIPE 信号,程序就会莫名其妙终止。2.客户端调用 shutdown 服务,服务器端输出了 data1、data2;客户端也输出了 “Hi,data1” 和 “Hi,data2”,客户端和服务器端各自完成了自己的工作后,正常退出。因为客户端调用 shutdown 函数只是关闭连接的一个方向(客户端->服务端),服务端->客户端的这个方向还可以继续进行数据的发送和接收,所以 “Hi,data1” 和 “Hi,data2” 都可以正常传送;当服务器端读到 EOF 时,立即向客户端发送了 FIN 报文,客户端在 read 函数中感知了 EOF,也进行了正常退出。¶
总结¶
close 函数只是把套接字引用计数减 1,未必会立即关闭连接;
close 函数如果在套接字引用计数达到 0 时,立即终止读和写两个方向的数据传送。
12 | 连接无效检测: Keep-Alive/应用心跳¶
【原理】定义一个时间段(保活时间),在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔(保活时间间隔),发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测(保活探测次数)报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
Keep-Alive 中可定义变量:
1. 保活时间
2. 保活时间间隔
3. 保活探测次数
在 Linux 系统中,这些变量分别对应 sysctl 变量:
1. net.ipv4.tcp_keepalive_time: 7200 秒(2 小时)
2. net.ipv4.tcp_keepalive_intvl: 75 秒
3. net.ipv4.tcp_keepalve_probes: 9 次探测
备注
如果使用 TCP 自身的 keep-Alive 机制,在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个“死亡”连接。这个时间是怎么计算出来的呢?其实是通过 2 小时,加上 75 秒乘以 9 的总和。
Keep-Alive的三种情况:
1. 对端程序是正常工作的。
当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
2. 对端程序崩溃并重启。
当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
3. 对端程序崩溃,或对端由于其他原因导致报文不可达。
当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
备注
TCP 保活机制默认是关闭的,当我们选择打开时,可以分别在连接的两个方向上开启,也可以单独在一个方向上开启。如果开启服务器端到客户端的检测,就可以在客户端非正常断连的情况下清除在服务器端保留的“脏数据”;而开启客户端到服务器端的检测,就可以在服务器无响应的情况下,重新发起连接。
为什么 TCP 不提供一个频率很好的保活机制呢?可能是早期的网络带宽非常有限,如果提供一个频率很高的保活机制,对有限的带宽是一个比较严重的浪费。
13 | 小数据包应对之策: 动态数据传输¶
备注
发送窗口和接收窗口都是通过滑动窗口机制来实现的,这是为了流量控制而引入的概念
拥塞控制¶
备注
TCP 数据包是需要经过网卡、交换机、核心路由器等一系列的网络设备的,网络设备本身的能力也是有限的,当多个连接的数据包同时在网络上传送时,势必会发生带宽争抢、数据丢失等,这样,TCP 就必须考虑多个连接共享在有限的带宽上,兼顾效率和公平性的控制,这就是拥塞控制的本质。
在 TCP 协议中,拥塞控制是通过拥塞窗口来完成的,拥塞窗口的大小会随着网络状况实时调整。
拥塞控制常用的算法:
1. 慢启动:
它通过一定的规则,慢慢地将网络发送数据的速率增加到一个阈值。超过这个阈值之后,慢启动就结束了
2. 拥塞避免:
在这个阶段,TCP 会不断地探测网络状况,并随之不断调整拥塞窗口的大小
TCP 发送缓冲区的数据是否能真正发送出去,至少取决于两个因素:
1. 一个是当前的发送窗口大小
2. 另一个是拥塞窗口大小
备注
【区别】发送窗口和拥塞窗口的区别:发送窗口反应了作为单 TCP 连接、点对点之间的流量控制模型,它是需要和接收端一起共同协调来调整大小的;而拥塞窗口则是反应了作为多个 TCP 连接共享带宽的拥塞控制模型,它是发送端独立地根据网络状况来动态调整的。
场景¶
糊涂窗口综合症:
在接收端进行优化
接收端不能在接收缓冲区空出一个很小的部分之后,就急吼吼地向发送端发送窗口更新通知,
而是需要在自己的缓冲区大到一个合理的值之后,再向发送端发送窗口更新通知。
这个合理的值,由对应的 RFC 规范定义。
Nagle 算法:
在发送端进行优化
本质其实就是限制大批量的小数据包同时发送,
为此,它提出,在任何一个时刻,未被确认的小数据包不能超过一个。
这里的小数据包,指的是长度小于最大报文段长度 MSS 的 TCP 分组。
这样,发送端就可把接下来连续的几个小数据包存储起来,等待接收到前一个小数据包的 ACK 分组之后,再将数据一次性发送出去
延时 ACK:
在接收端进行优化
延时 ACK 在收到数据后并不马上回复,而是累计需要发送的 ACK 报文,
等到有数据需要发送给对端时,将累计的 ACK捎带一并发送出去。
当然,延时 ACK 机制,不能无限地延时下去,否则发送端误认为数据包没有发送成功,引起重传,反而会占用额外的网络带宽。
禁用 Nagle 算法¶
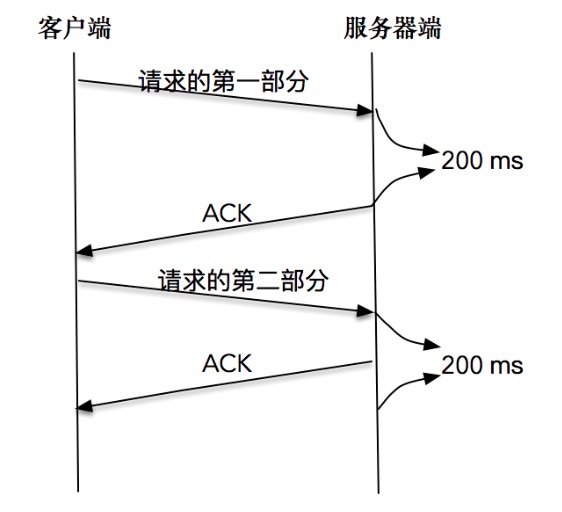
客户端分两次将一个请求发送出去,由于请求的第一部分的报文未被确认,Nagle 算法开始起作用;同时延时 ACK 在服务器端起作用,假设延时时间为 200ms,服务器等待 200ms 后,对请求的第一部分进行确认;接下来客户端收到了确认后,Nagle 算法解除请求第二部分的阻止,让第二部分得以发送出去,服务器端在收到之后,进行处理应答,同时将第二部分的确认捎带发送出去。【结论】Nagle 算法和延时确认组合在一起,增大了处理时延,实际上,两个优化彼此在阻止对方。从上面的例子可以看到,在有些情况下 Nagle 算法并不适用, 比如对时延敏感的应用。¶
总结¶
发送窗口用来控制发送和接收端的流量;阻塞窗口用来控制多条连接公平使用的有限带宽。
小数据包加剧了网络带宽的浪费,为了解决这个问题,引入了如 Nagle 算法、延时 ACK 等机制。
14 丨 UDP¶
udp 如何实现可靠性:
1. udp 可以增加消息编号;
2. 对每个消息编号提供 ACK,在 udp 应用层增加应答机制;
3. 没有应答的增加重传机制
4. 增加缓存,ACK 完的才从缓存中清除
UDP 连接套接字不是发起连接请求的过程,而是记录目的地址和端口到套接字的映射关系。
UDP 断开套接字,则是将删除原来记录的映射关系
connect 函数的作用是记录客户端「目的地址和端口」–「套接字」的关系
15 | “地址已经被使用”原因¶
备注
服务器端程序,都应该设置 SO_REUSEADDR 套接字选项,以便服务端程序可以在极短时间内复用同一个端口启动。不设置会导致通过服务器端发起的关闭连接操作,引起了一个已有的 TCP 连接处于 TIME_WAIT 状态,使得服务器重启时,继续绑定在 127.0.0.1 地址和 9527 端口上的操作,返回了 Address already in use 的错误。
备注
【区别】tcp_tw_reuse和SO_REUSEADDR:tcp_tw_reuse是为了缩短time_wait的时间,避免出现大量的time_wait链接而占用系统资源,解决的是accept后的问题;SO_REUSEADDR是为了解决time_wait状态带来的端口占用问题,以及支持同一个port对应多个ip,解决的是bind时的问题。
UDP的SO_REUSEADDR使用场景:比较多的是组播网络,好处是,如我们在接收组播流的时候,比如用ffmpeg拉取了一个组播流,但是还想用ffmpeg拉取相同的组播流,这个时候就需要地址重用了。PS:相比TCP,UDP 使用场景相对较少
16 | 如何理解TCP的“流”¶
大端小端字节序¶

如果需要传输数字,比如 0x0201,对应的二进制为 00000010,00000001。在计算机发展的历史上,对于如何存储这个数据没有形成标准。不同的系统就会有两种存法,一种是将 0x02 高字节存放在起始地址,这个叫做大端字节序(Big-Endian)。另一种相反,将 0x01 低字节存放在起始地址,这个叫做小端字节序(Little-Endian)。但是在网络传输中,必须保证双方都用同一种标准来表达,统一使用的是大端字节序。¶
备注
我们在网络传输中,一个常见的方法是把0-9这样的数字,直接用ASCII码作为字符发送出去,在这种情况下,你可以理解成发送出去的都是字符类型的数据,因为是字符类型的数据,就没有所谓的网络顺序了;而如果作为一个数据型数据,比如125,这时候可能就要作为一个4字节的整型数据进行传输,那么就会有字节序的问题了。
为了保证网络字节序一致,POSIX 标准提供了如下的转换函数:
uint16_t htons (uint16_t hostshort)
uint16_t ntohs (uint16_t netshort)
uint32_t htonl (uint32_t hostlong)
uint32_t ntohl (uint32_t netlong)
说明:
n 代表的就是 network
h 代表的是 host
s 表示的是 short
l 表示的是 long,分别表示 16 位和 32 位的整数
这些函数可以帮助我们在主机(host)和网络(network)的格式间灵活转换。当使用这些函数时,我们并不需要关心主机到底是什么样的字节顺序,只要使用函数给定值进行网络字节序和主机字节序的转换就可以了。
报文读取和解析¶
报文格式最重要的是如何确定报文的边界。常见的报文格式有两种方法:
1. 一种是发送端把要发送的报文长度预先通过报文告知给接收端
2. 另一种是通过一些特殊的字符来进行边界的划分。
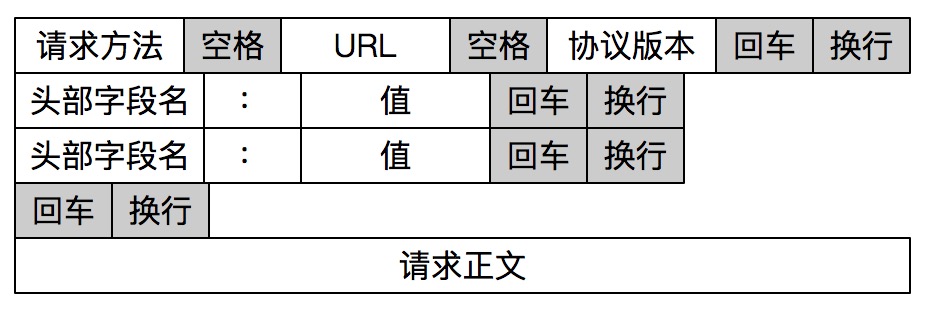
HTTP 通过设置回车符、换行符作为 HTTP 报文协议的边界¶
17 | TCP并不总是“可靠”¶
TCP 连接建立之后,能感知 TCP 链路的方式是有限的,一种是以 read 为核心的读操作,另一种是以 write 为核心的写操作。
reset by peer 和 broken pipe 的区别:
一个是TCP RST的状态异常,一个是SIGPIPE 信号将进程进行回收。

read 直接感知 FIN 包¶
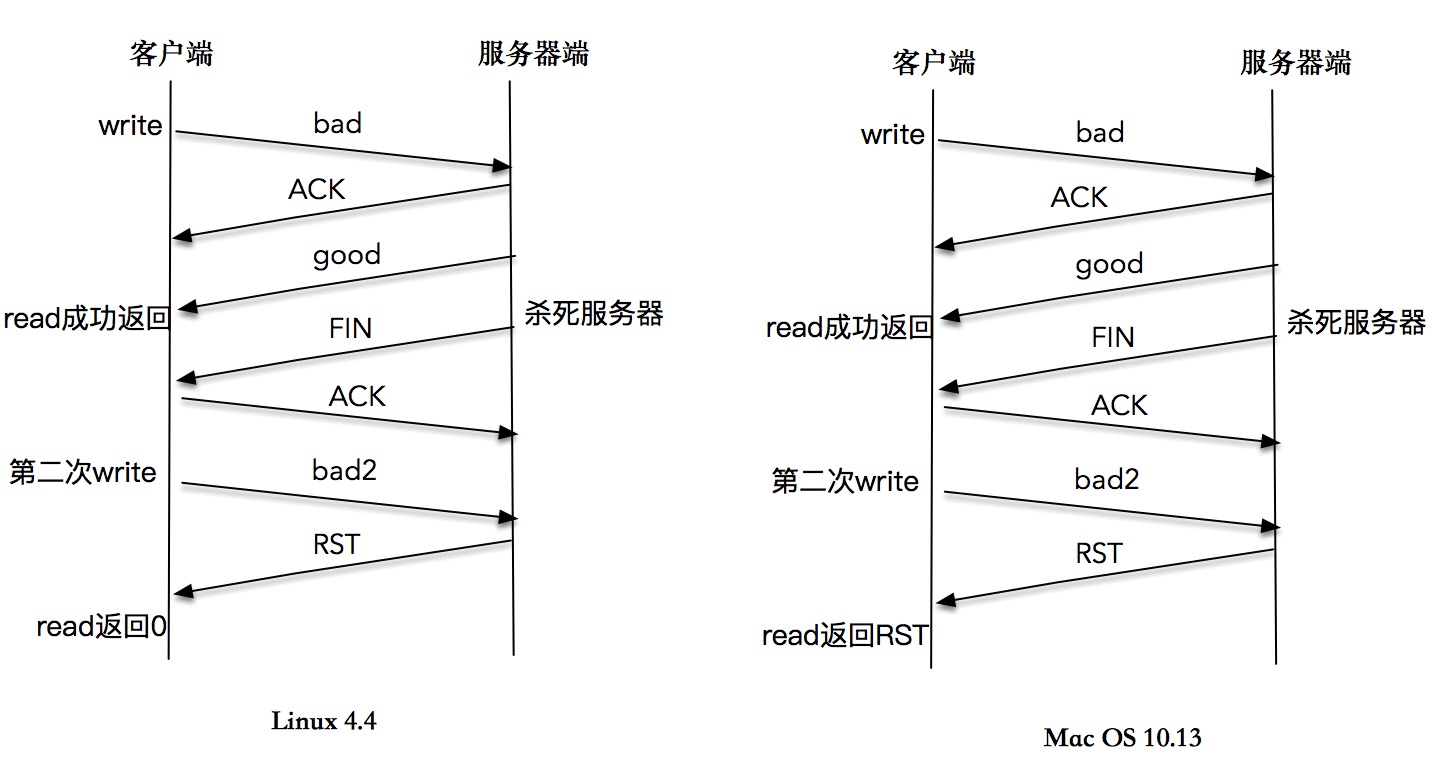
write 操作造成异常,再通过 read 操作来感知异常的样例¶
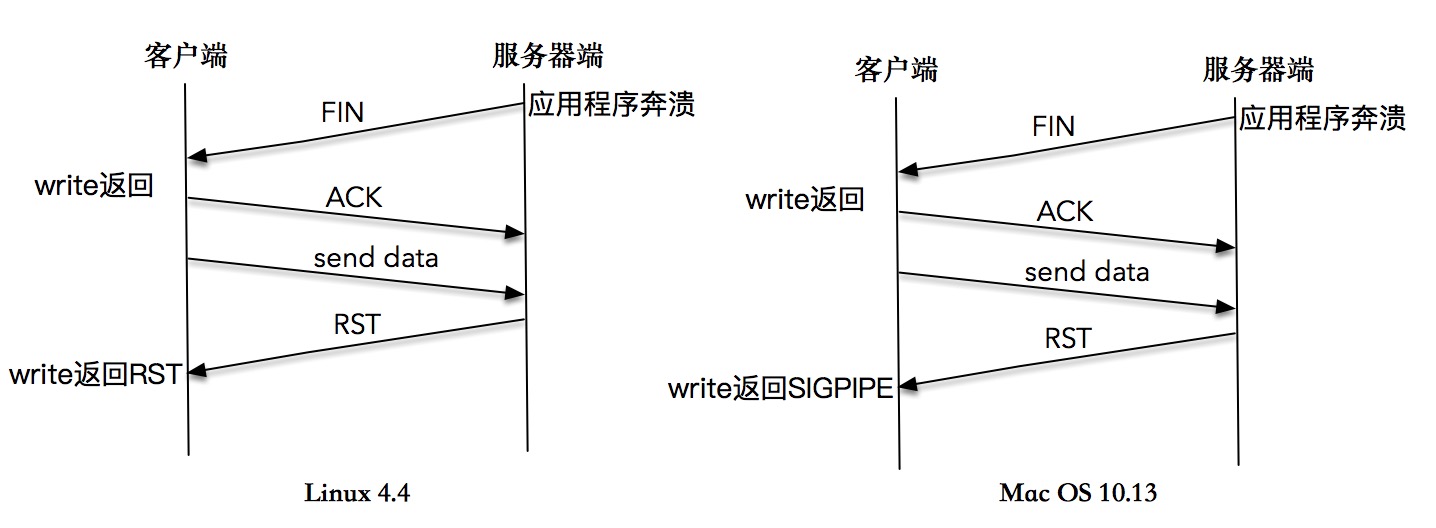
向一个已关闭连接连续写,最终导致 SIGPIPE/RST¶
18 | 防人之心不可无: 检查数据的有效性¶
在网络编程中,是否做好了对各种异常边界的检测,将决定我们的程序在恶劣情况下的稳定性
19 答疑¶
四次挥手¶
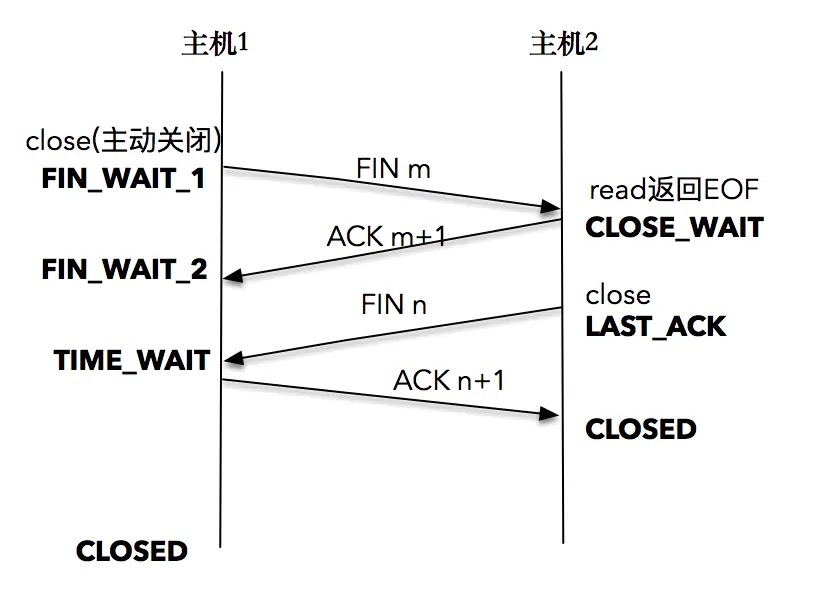
【四次挥手】1.主动关闭方的 TCP 发送一个 FIN 包,表示需要关闭连接,之后主动关闭方进入 FIN_WAIT_1 状态。2.被动关闭方收到这个 FIN 由 TCP 协议栈处理,TCP 协议栈为 FIN 包插入一个文件结束符 EOF 到接收缓冲区中,应用程序可以通过 read 调用来感知这个 FIN 包(注意,这个 EOF 会被放在已排队等候的其他已接收的数据之后,这就意味着接收端应用程序需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达)此时,被动关闭方进入 CLOSE_WAIT 状态。3.被动关闭方将读到这个 EOF,于是,应用程序也调用 close 关闭它的套接字,这导致它的 TCP 也发送一个 FIN 包。这样,被动关闭方将进入 LAST_ACK 状态。4.主动关闭方接收到对方的 FIN 包,并确认这个 FIN 包。主动关闭方进入 TIME_WAIT 状态,而接收到 ACK 的被动关闭方则进入 CLOSED 状态。经过 2MSL 时间之后,主动关闭方也进入 CLOSED 状态。¶
这中间使用 shutdown,执行一端到另一端的半关闭也是可以的。当套接字被关闭时,TCP 为其所在端发送一个 FIN 包。在大多数情况下,这是由应用进程调用 close 而发生的,值得注意的是,一个进程无论是正常退出(exit 或者 main 函数返回),还是非正常退出(比如,收到 SIGKILL 信号关闭,就是我们常常干的 kill -9),所有该进程打开的描述符都会被系统关闭,这也导致 TCP 描述符对应的连接上发出一个 FIN 包。
无论是客户端还是服务器,任何一端都可以发起主动关闭。大多数真实情况是客户端执行主动关闭,但,HTTP/1.0 却是由服务器发起主动关闭的。
MSL TTL¶
MSL 是任何 IP 数据报能够在因特网中存活的最长时间,超过这个时间报文将被丢弃。RFC793 中规定 MSL 的时间为 2 分钟,Linux 实际设置为 30 秒。
但在实现上,不是靠计时器来完成的,在每个数据报里都包含有一个被称为 TTL(time to live)的 8 位字段,它的最大值为 255。TTL 可译为 “生存时间”,这个生存时间由源主机设置初始值,它表示的是一个 IP 数据报可以经过的最大跳跃数,每经过一个路由器,就相当于经过了一跳,它的值就减 1,当此值减为 0 时,则所在的路由器会将其丢弃,同时发送 ICMP 报文通知源主机。
TTL与MSL是有关系的但不是简单的相等的关系,MSL要大于等于TTL。
第三模块: 性能篇¶
20 I/O 多路复用: select¶
备注
I/O 多路复用的设计初衷就是解决这样的场景:把标准输入、套接字等都看做 I/O 的一路,多路复用的意思,就是在任何一路 I/O 有“事件”发生的情况下,通知应用程序去处理相应的 I/O 事件,这样我们的程序就变成了“多面手”,在同一时刻仿佛可以处理多个 I/O 事件。
使用 select 函数,通知内核挂起进程,当一个或多个 I/O 事件发生后,控制权返还给应用程序,由应用程序进行 I/O 事件的处理
函数:
int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
示例:
int socket_fd = tcp_client(argv[1], SERV_PORT);
fd_set allreads;
FD_ZERO(&allreads);
FD_SET(0, &allreads);
FD_SET(socket_fd, &allreads);
for (;;) {
readmask = allreads;
int rc = select(socket_fd + 1, &readmask, NULL, NULL, NULL);
if (FD_ISSET(socket_fd, &readmask)) {
n = read(socket_fd, recv_line, MAXLINE);
...
}
if (FD_ISSET(STDIN_FILENO, &readmask)) {
if (fgets(send_line, MAXLINE, stdin) != NULL) {
...
}
}
}
21 | I/O 多路复用: poll¶
select 方法是多个 UNIX 平台支持的非常常见的 I/O 多路复用技术,它通过描述符集合来表示检测的 I/O 对象,通过三个不同的描述符集合来描述 I/O 事件 :可读、可写和异常。但是 select 有一个缺点,那就是所支持的文件描述符的个数是有限的。在 Linux 系统中,select 的默认最大值为 1024。
函数:
int poll(struct pollfd *fds, unsigned long nfds, int timeout);
返回值:若有就绪描述符则为其数目,若超时则为0,若出错则为-1
struct pollfd {
int fd; /* file descriptor */
short events; /* events to look for */
short revents; /* events returned */
};
备注
和 select 非常不同的地方在于,poll 每次检测之后的结果不会修改原来的传入值,而是将结果保留在 revents 字段中,这样就不需要每次检测完都得重置待检测的描述字和感兴趣的事件。我们可以把 revents 理解成“returned events”。
events 参数¶
第一类是可读事件:
#define POLLIN 0x0001 /* any readable data available */
#define POLLPRI 0x0002 /* OOB/Urgent readable data */
#define POLLRDNORM 0x0040 /* non-OOB/URG data available */
#define POLLRDBAND 0x0080 /* OOB/Urgent readable data */
第二类是可写事件:
#define POLLOUT 0x0004 /* file descriptor is writeable */
#define POLLWRNORM POLLOUT /* no write type differentiation */
#define POLLWRBAND 0x0100 /* OOB/Urgent data can be written */
第三类错误:
#define POLLERR 0x0008 /* 一些错误发送 */
#define POLLHUP 0x0010 /* 描述符挂起*/
#define POLLNVAL 0x0020 /* 请求的事件无效*/
备注
【定义】OOB:Out of Band(带外数据):传输层协议使用带外数据来发送一些重要的数据,如果通信一方有重要的数据需要通知对方时,协议能够将这些数据快速地发送到对方。为了发送这些数据,协议一般不使用与普通数据相同的通道,而是使用另外的通道。linux 系统的套接字机制支持低层协议发送和接受带外数据。但是 TCP 协议没有真正意义上的带外数据。为了发送重要协议,TCP 提供了一种称为紧急模式(urgent mode)的机制。TCP 协议在数据段中设置 URG 位,表示进入紧急模式。接收方可以对紧急模式采取特殊的处理。很容易看出来,这种方式数据不容易被阻塞,并且可以通过在我们的服务器端程序里面捕捉 SIGURG 信号来及时接受数据。这正是我们所要求的效果。
22 | 非阻塞 I/O¶
备注
非阻塞 I/O 配合 I/O 多路复用,是高性能网络编程中的常见技术。
备注
【区别】阻塞 I/O 完成某个操作时,应用程序会被挂起,等待内核完成操作,感觉像是被 “阻塞”。实际上,内核是将 CPU 时间切换给其他进程。非阻塞 I/O 则不然,当应用程序调用非阻塞 I/O 完成某个操作时,内核立即返回,不会把 CPU 时间切换给其他进程,应用程序在返回后,可以得到足够的 CPU 时间继续完成其他事情。
趣谈各类 IO 模型-去书店买书¶
阻塞 I/O:你去了书店,告诉老板(内核)你想要某本书,然后你就一直在那里等着,直到书店老板翻箱倒柜找到你想要的书,有可能还要帮你联系全城其它分店。注意,这个过程中你一直滞留在书店等待老板的回复,好像在书店老板这里 “阻塞” 住了。
非阻塞 I/O:你去了书店,问老板有没你心仪的那本书,老板查了下电脑,告诉你没有,你就悻悻离开了。一周以后,你又来这个书店,再问这个老板,老板一查,有了,于是你买了这本书。注意,这个过程中,你没有被阻塞,而是在不断轮询。
I/O 多路复用:轮询的效率太低了,于是你向老板提议:“老板,到货给我打电话吧,我再来付钱取书。”
异步 I/O:你连去书店取书也想省了,得了,让老板代劳吧,你留下地址,付了书费,让老板到货时寄给你
非阻塞 I/O¶
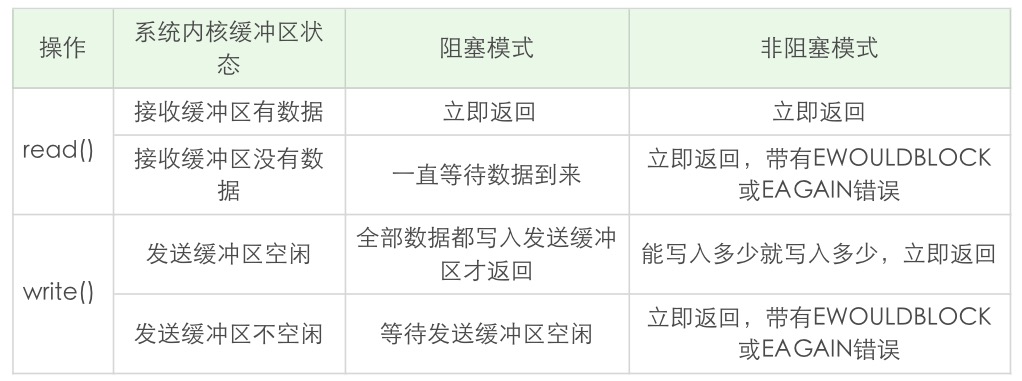
read 和 write 在阻塞模式和非阻塞模式下的不同行为特性。阻塞模式下的 write 有个特例,就是对方主动关闭了套接字,这个时候 write 调用会立即返回,并通过返回值告诉应用程序实际写入的字节数,如果再次对这样的套接字进行 write 操作,就会返回失败。失败是通过返回值 -1 来通知到应用程序的。¶
23 | Linux 利器: epoll¶

展示了 select、poll、epoll 几种不同的 I/O 复用技术在面对不同文件描述符大小时的表现差异。¶
备注
本质上 epoll 还是一种 I/O 多路复用技术, epoll 通过监控注册的多个描述字,来进行 I/O 事件的分发处理。不同于 poll 的是,epoll 不仅提供了默认的 level-triggered(条件触发)机制,还提供了性能更为强劲的 edge-triggered(边缘触发)机制。
epoll_create¶
备注
创建了一个 epoll 实例,从 Linux 2.6.8 开始,参数 size 被自动忽略,但是该值仍需要一个大于 0 的整数。
int epoll_create(int size);
int epoll_create1(int flags);
返回值:
若成功返回一个大于 0 的值,表示 epoll 实例;
若返回 -1 表示出错
epoll_ctl¶
备注
在创建完 epoll 实例之后,可以通过调用 epoll_ctl 往这个 epoll 实例增加或删除监控的事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
返回值:
若成功返回 0;若返回 -1 表示出错
参数:
epfd: 是刚调用 epoll_create 创建的 epoll 实例描述字,可以简单理解成是 epoll 句柄。
op: 表示增加还是删除一个监控事件
1. EPOLL_CTL_ADD: 向 epoll 实例注册文件描述符对应的事件
2. EPOLL_CTL_DEL:向 epoll 实例删除文件描述符对应的事件
3. EPOLL_CTL_MOD: 修改文件描述符对应的事件
fd: 注册的事件的文件描述符,比如一个监听套接字
event: 注册的事件类型,且可在这个结构体里设置用户需要的数据
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
几种事件类型:
1. EPOLLIN:表示对应的文件描述字可以读
2. EPOLLOUT:表示对应的文件描述字可以写
3. EPOLLRDHUP:表示套接字的一端已经关闭,或者半关闭
4. EPOLLHUP:表示对应的文件描述字被挂起
5. EPOLLET:设置为 edge-triggered,默认为 level-triggered
备注
一般我们认为,边缘触发的效率比条件触发的效率要高,这一点也是 epoll 的杀手锏之一。
epoll_wait¶
备注
epoll_wait () 函数类似 poll 和 select 函数,调用者进程被挂起,在等待内核 I/O 事件的分发。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
返回值:
成功返回的是一个大于 0 的数,表示事件的个数;
返回 0 表示的是超时时间到;
若出错返回 -1
参数:
epfd: epoll 实例描述字,也就是 epoll 句柄
events: 返回给用户空间需要处理的 I/O 事件,这是一个数组,数组的大小由 epoll_wait 的返回值决定
maxevents: 大于 0 的整数,表示 epoll_wait 可以返回的最大事件值
timeout: 阻塞调用的超时值
如果这个值设置为 -1,表示不超时
如果设置为 0 则立即返回,即使没有任何 I/O 事件发生
总结¶
备注
[各非阻塞 IO 的区别]
24 | C10K问题: 高并发模型设计¶
The C10K problem: http://www.kegel.com/c10k.html
操作系统层面:
1. 文件句柄数
$ulimit -n
1024 // 默认是1024
2. 系统内存
发送缓冲区和接收缓冲区的值:
$cat /proc/sys/net/ipv4/tcp_wmem
4096 16384 4194304
$ cat /proc/sys/net/ipv4/tcp_rmem
4096 87380 6291456
则1万个链接消耗:
发送缓冲区: 16384\*10000 = 160M bytes
接收缓冲区: 87380\*10000 = 880M bytes
应用程序本身也需要一定的缓冲区来进行数据的收发
假设每个连接需要 128K 的缓冲区,则:
128k\*10000=1.2G
3. 网络带宽
假设每个连接每秒传输大约 1KB 的数据
1 万个连接,带宽需要:
10000 x 1KB/s x8 = 80Mbps
解决 C10K 问题的几种解法方案:
1. 阻塞 I/O + 进程
简单,但是效率不高,扩展性差,资源占用率高
2. 阻塞 I/O + 线程池
没有解决空闲连接占用资源的问题
3. 非阻塞 I/O + readiness notification + 单线程
a. 轮询保存的套接字集合(集合太大时,循环消耗大量的 CPU)
b. select, poll等I/O 分发技术: 让操作系统来告诉我们哪个套接字可以读、写
c. epoll, kqueue, IOCP: 只返回有 I/O 事件或者 I/O 变化的套接字
注:基于 epoll/poll/select 的 I/O 事件分发器可以叫做:
reactor,或事件驱动,或者事件轮询(eventloop)
4. 非阻塞 I/O + readiness notification + 多线程
基于上一个方案,引入多线程
主从 reactor 模式
5. 异步 I/O+ 多线程
Linux 下的 aio 机制
25 | 使用阻塞I/O和进程模型: 最传统的方式¶
fork 函数编程范式:
if(fork() == 0){
do_child_process(); //子进程执行代码
}else{
do_parent_process(); //父进程执行代码
}
fork 函数实现的时候,实际上会把当前父进程的所有相关值都克隆一份,包括地址空间、打开的文件描述符、程序计数器等,就连执行代码也会拷贝一份,新派生的进程的表现行为和父进程近乎一样,就好像是派生进程调用过 fork 函数一样。唯一的区别是 fork 函数的返回值不同,父进程的返回值是子进行的Pid,子进程的返回值是0.
26 | 使用阻塞I/O和线程模型: 一种轻量的方式¶
在同一个进程下,线程上下文切换的开销要比进程小得多。程序计数器、寄存器等这些值重新载入新场景的值,就是线程的上下文切换。(因为我们的代码被 CPU 执行的时候,是需要一些数据支撑的,比如程序计数器告诉 CPU 代码执行到哪里了,寄存器里存了当前计算的一些中间值,内存里放置了一些当前用到的变量等)
备注
虽然线程切换的上下文开销不大,但是线程创建和销毁的开销却是不小的。可以使用预创建线程池的方式来进行优化。线程的创建销毁基于比进程的创建销毁开销还要大。
27 | I/O 多路复用和线程: 使用poll单线程处理所有I/O事件¶
事件驱动模型,也被叫做反应堆模型(reactor),或者是 Event loop 模型。
事件驱动模型的核心有两点:
1. 存在一个无限循环的事件分发线程,或者叫做 reactor 线程、Event loop 线程
2. 所有的 I/O 操作都可以抽象成事件,每个事件必须有回调函数来处理
28 | I/O多路复用进阶: 子线程使用poll处理连接I/O事件¶
主 - 从 reactor 模式¶
核心思想是,主反应堆线程只负责分发 Acceptor 连接建立,已连接套接字上的 I/O 事件交给 sub-reactor 负责分发。其中 sub-reactor 的数量,可以根据 CPU 的核数来灵活设置。
主 - 从 reactor+worker threads 模式¶
主 - 从 reactor 模式解决了 I/O 分发的高效率问题
work threads 解决了业务逻辑和 I/O 分发之间的耦合问题
备注
把这两个策略组装在一起,就是实战中普遍采用的模式。大名鼎鼎的 Netty,就是把这种模式发挥到极致的一种实现。
29 | 使用 epoll 和多线程模型¶
epoll 的性能好的原因¶
第一个角度是事件集合。在每次使用 poll 或 select 之前,都需要准备一个感兴趣的事件集合,系统内核拿到事件集合,进行分析并在内核空间构建相应的数据结构来完成对事件集合的注册。而 epoll 则不是这样,epoll 维护了一个全局的事件集合,通过 epoll 句柄,可以操纵这个事件集合,增加、删除或修改这个事件集合里的某个元素。要知道在绝大多数情况下,事件集合的变化没有那么的大,这样操纵系统内核就不需要每次重新扫描事件集合,构建内核空间数据结构。
第二个角度是就绪列表。每次在使用 poll 或者 select 之后,应用程序都需要扫描整个感兴趣的事件集合,从中找出真正活动的事件,这个列表如果增长到 10K 以上,每次扫描的时间损耗也是惊人的。事实上,很多情况下扫描完一圈,可能发现只有几个真正活动的事件。而 epoll 则不是这样,epoll 返回的直接就是活动的事件列表,应用程序减少了大量的扫描时间。
此外, epoll 还提供了更高级的能力 —— 边缘触发。
备注
edge-triggered VS level-triggered: 两者的区别,条件触发的意思是只要满足事件的条件,比如有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。另外,可以再次注册这个 write ready 的事件。对 ET 注册了一次,它就通知你一次;而对 LT ,可能你注册了一次,它通知你好多次。
如果某个套接字有 100 个字节可以读,边缘触发(edge-triggered)和条件触发(level-triggered)都会产生 read ready notification 事件,如果应用程序只读取了 50 个字节,边缘触发就会陷入等待;而条件触发则会因为还有 50 个字节没有读取完,不断地产生 read ready notification 事件。
在条件触发下(level-triggered),如果某个套接字缓冲区可以写,会无限次返回 write ready notification 事件,在这种情况下,如果应用程序没有准备好,不需要发送数据,一定需要解除套接字上的 ready notification 事件,否则 CPU 就直接跪了。
备注
【总结】边缘触发只会产生一次活动事件,性能和效率更高。不过,程序处理起来要更为小心。
30 | 真正的大杀器: 异步I/O探索¶
阻塞 I/O¶
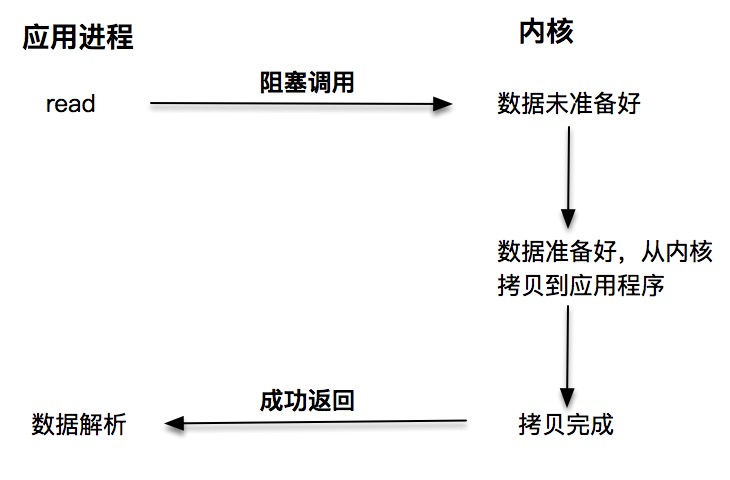
阻塞 I/O 发起的 read 请求,线程会被挂起,一直等到内核数据准备好,并把数据从内核区域拷贝到应用程序的缓冲区中,当拷贝过程完成,read 请求调用才返回。¶
非阻塞 I/O¶
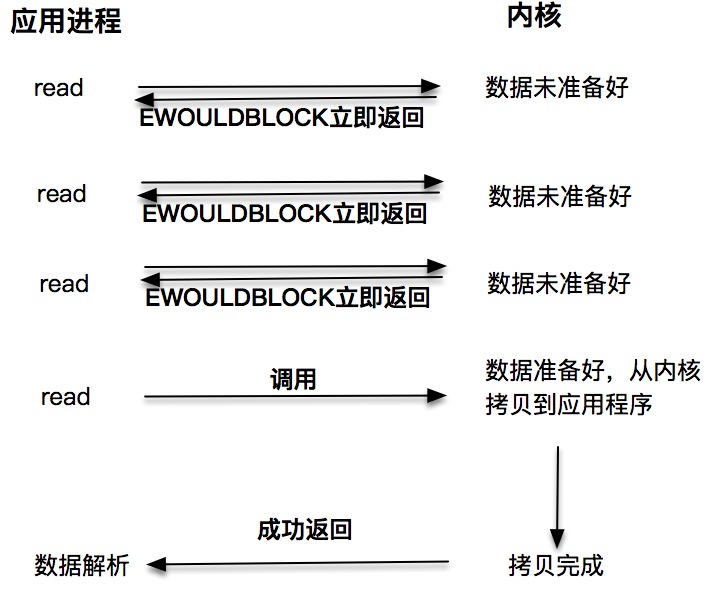
非阻塞的 read 请求在数据未准备好的情况下立即返回,应用程序可以不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲,并完成这次 read 调用。注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程。这里的同步指的是内核区域的数据拷贝到缓存区这个过程。¶
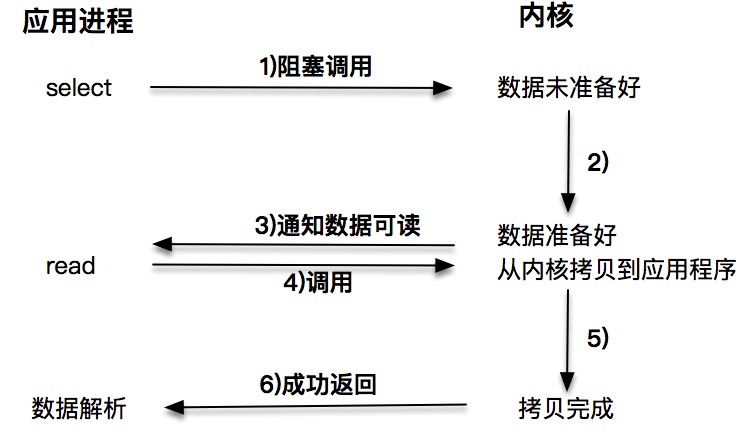
每次让应用程序去轮询内核的 I/O 是否准备好,是一个不经济的做法,因为在轮询的过程中应用进程啥也不能干。于是,像 select、poll 这样的 I/O 多路复用技术就隆重登场了。通过 I/O 事件分发,当内核数据准备好时,再通知应用程序进行操作。这个做法大大改善了应用进程对 CPU 的利用率¶
异步 I/O¶
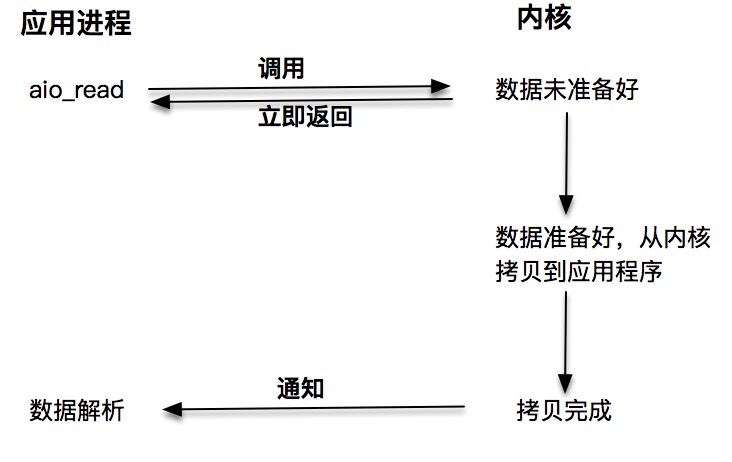
上面3种都是同步调用技术。因为同步调用、异步调用的说法,是对于获取数据的过程而言的,前面几种最后获取数据的 read 操作调用,都是同步的,在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,这个过程是在 read 函数中同步进行的,如果内核实现的拷贝效率很差,read 调用就会在这个同步过程中消耗比较长的时间。而真正的异步调用则不用担心这个问题,我们接下来就来介绍第四种 I/O 技术,当我们发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。¶
aio 系列函数¶
主要用到的函数有:
aio_write:用来向内核提交异步写操作;
aio_read:用来向内核提交异步读操作;
aio_error:获取当前异步操作的状态;
aio_return:获取异步操作读、写的字节数。
Windows 下的 IOCP 和 Proactor 模式¶
和 Linux 不同,Windows 下实现了一套完整的支持套接字的异步编程接口,这套接口一般被叫做 IOCompletetionPort(IOCP)。这样,就产生了基于 IOCP 的所谓 Proactor 模式。
和 Reactor 模式一样,Proactor 模式也存在一个无限循环运行的 event loop 线程,但是不同于 Reactor 模式,这个线程并不负责处理 I/O 调用,它只是负责在对应的 read、write 操作完成的情况下,分发完成事件到不同的处理函数。
总结¶
无论是 Reactor 模式,还是 Proactor 模式,都是一种基于事件分发的网络编程模式。Reactor 模式是基于待完成的 I/O 事件,而 Proactor 模式则是基于已完成的 I/O 事件,两者的本质,都是借由事件分发的思想,设计出可兼容、可扩展、接口友好的一套程序框架。
31 丨性能篇答疑: epoll 源码深度剖析¶
epoll 的效率高的原因¶
首先,poll/select 先将要监听的 fd 从用户空间拷贝到内核空间,然后在内核空间里面进行处理之后,再拷贝给用户空间。这里就涉及到内核空间申请内存,释放内存等等过程,这在大量 fd 情况下,是非常耗时的。而 epoll 维护了一个红黑树,通过对这棵黑红树进行操作,可以避免大量的内存申请和释放的操作,而且查找速度非常快。
第二,select/poll 从休眠中被唤醒时,如果监听多个 fd,只要其中有一个 fd 有事件发生,内核就会遍历内部的 list 去检查到底是哪一个事件到达,并没有像 epoll 一样,通过 fd 直接关联 eventpoll 对象,快速地把 fd 直接加入到 eventpoll 的就绪列表中。
epoll 维护了一棵红黑树来跟踪所有待检测的文件描述字,黑红树的使用减少了内核和用户空间大量的数据拷贝和内存分配,大大提高了性能。
同时,epoll 维护了一个链表来记录就绪事件,内核在每个文件有事件发生时将自己登记到这个就绪事件列表中,通过内核自身的文件 file-eventpoll 之间的回调和唤醒机制,减少了对内核描述字的遍历,大大加速了事件通知和检测的效率,这也为 level-triggered 和 edge-triggered 的实现带来了便利。
epoll 内核源码详解发的帖子: https://www.nowcoder.com/discuss/26226
第四模块: 实战篇¶
快速看完
结束语¶
在网络编程这块,我推荐你看 libevent、ACE 或者 Asio 的源代码。
libevent 是一个轻量级的基于 event 回调机制的网络编程库,可以支持 Linux、Solaris、Windows 等系统,它本身是用 C 语言写的,代码量不是很多,比较适合入门级的阅读。
Asio 是 boost 里的网络编程库,是用 C++ 语言写的。里面用了很多 boost 的数据结构和技巧,包括大量模板的使用,有一定的语言难度,如果你对自己的 C++ 能力比较自信,可以试着去读一读。boost 库本身也已经成为 C++ 的标准库,其设计和实现也可以说是一个学习的样板。
ACE 是老牌的 C++ 网络编程库,曾经非常流行。很多设计模式如 reactor、proactor 都是 ACE 首次提出并倡导的。当然也有很多网络编程的大佬们觉得 ACE 有点过于设计了,搞得太复杂,没必要。这个我觉得见仁见智吧,有些好的思想可以拿来用,觉得不合适该抛弃就抛弃。ACE 强在设计模式和抽象,如果对设计模式感兴趣,可以花一些时间学习下 ACE 的设计。