AI 绘画核心技术与实战¶
南柯 某头部大厂图像团队技术 leader,高级算法专家
目前在某头部大厂工作,带领团队推动多模态大模型领域的能力建设。长期活跃于 AI 绘画技术领域,对 AIGC 内容生成、数字人技术(AI 捏脸、数字人驱动)、传统图像、深度学习相关的图像技术(目标检测、分割、分类、人脸识别等),都有深入的理解和丰富的项目经验。有 100 余项算法创新专利,在视觉领域顶会发表过多篇论文。
热身篇: 开启 AI 绘画旅程,带你熟悉各种 AI 绘画工具与模型,带你安装和部署 WebUI,体验 Midjourney 和 LoRA 的玩法,探索 AI 绘画的无限潜能。
基础篇: 深入剖析 AI 绘画背后的“黑魔法”,让你真正了解 AI 算法从业者需要掌握的理论技术基础,理解图像生成如何从 GAN 过渡到扩散模型的全过程,并掌握扩散模型各个模块的算法原理。这个模块的最后,还会带你自己动手训练一个扩散模型,为后续进阶学习做好准备。
进阶篇: 了解主流模型技术方案,包括 DALL-E 2、Imagen、Stable Diffusion、DeepFloyd、Midjourney 等业界最新最火的模型。掌握了这类技术的学习方法,未来你遇到新的 AI 绘画论文、代码、模型,也能举一反三。这部分还会带你训练一个扩散模型,为后续实战演练打牢基础。
综合演练篇: 结合前面所学,带你动手尝试各类 AI 绘画项目,包括训练 DreamBooth、LoRA 模型,使用 ControlNet 精细化控制内容的生成,做出类似于 LensaAI 这样的相册类效果,借助 Stable Diffusion 给你的照片渲染出各色风格等等。最后,还会分享 AI 视觉相关的前沿应用,帮你开阔视野。
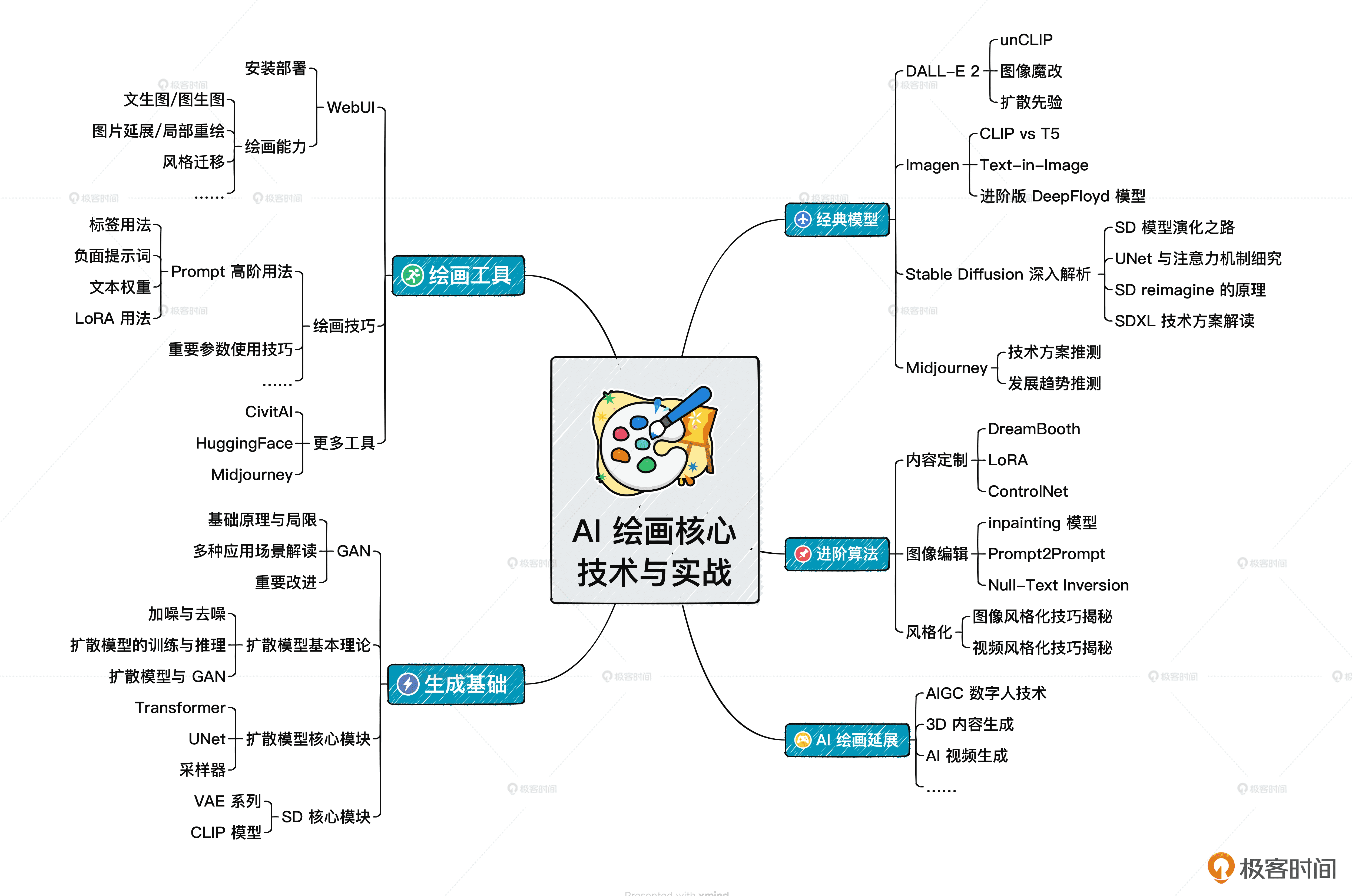
开篇词 (2讲)¶
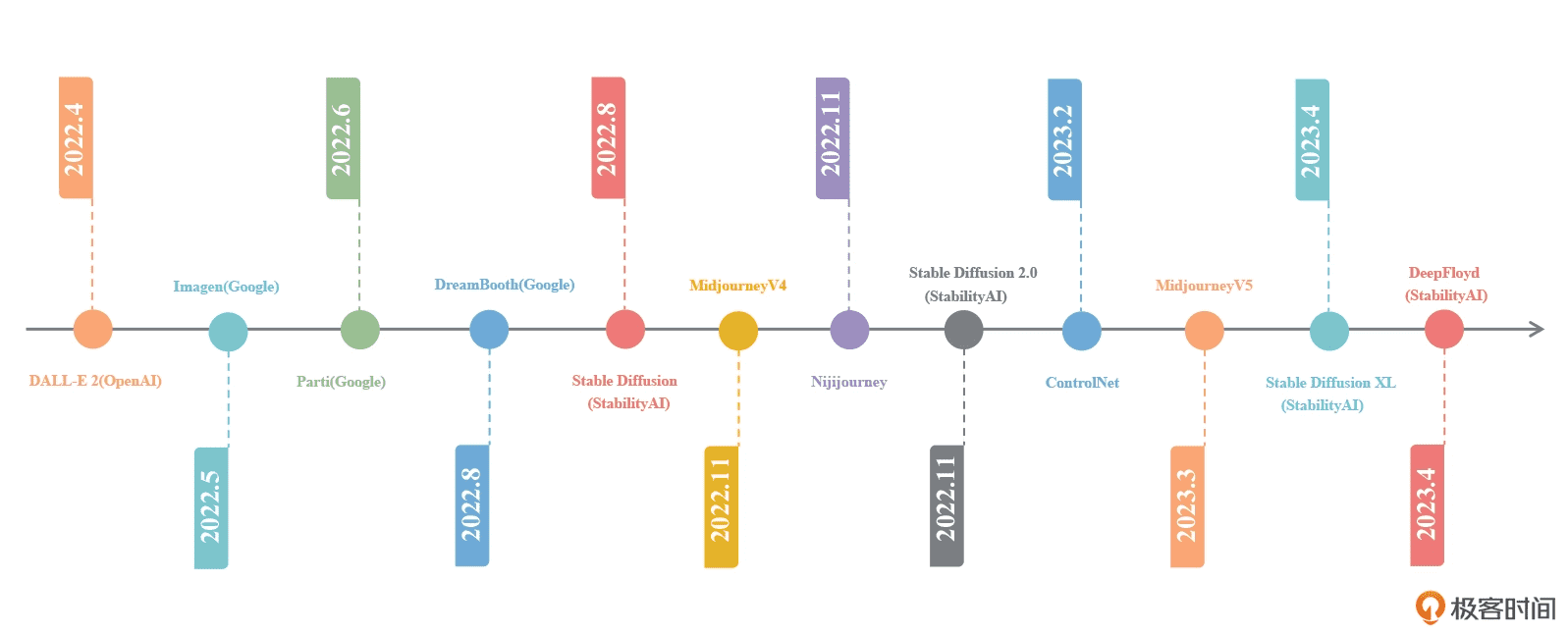
从 DALL-E 2 推出以来,AI 绘画领域一些有影响力的模型和算法¶
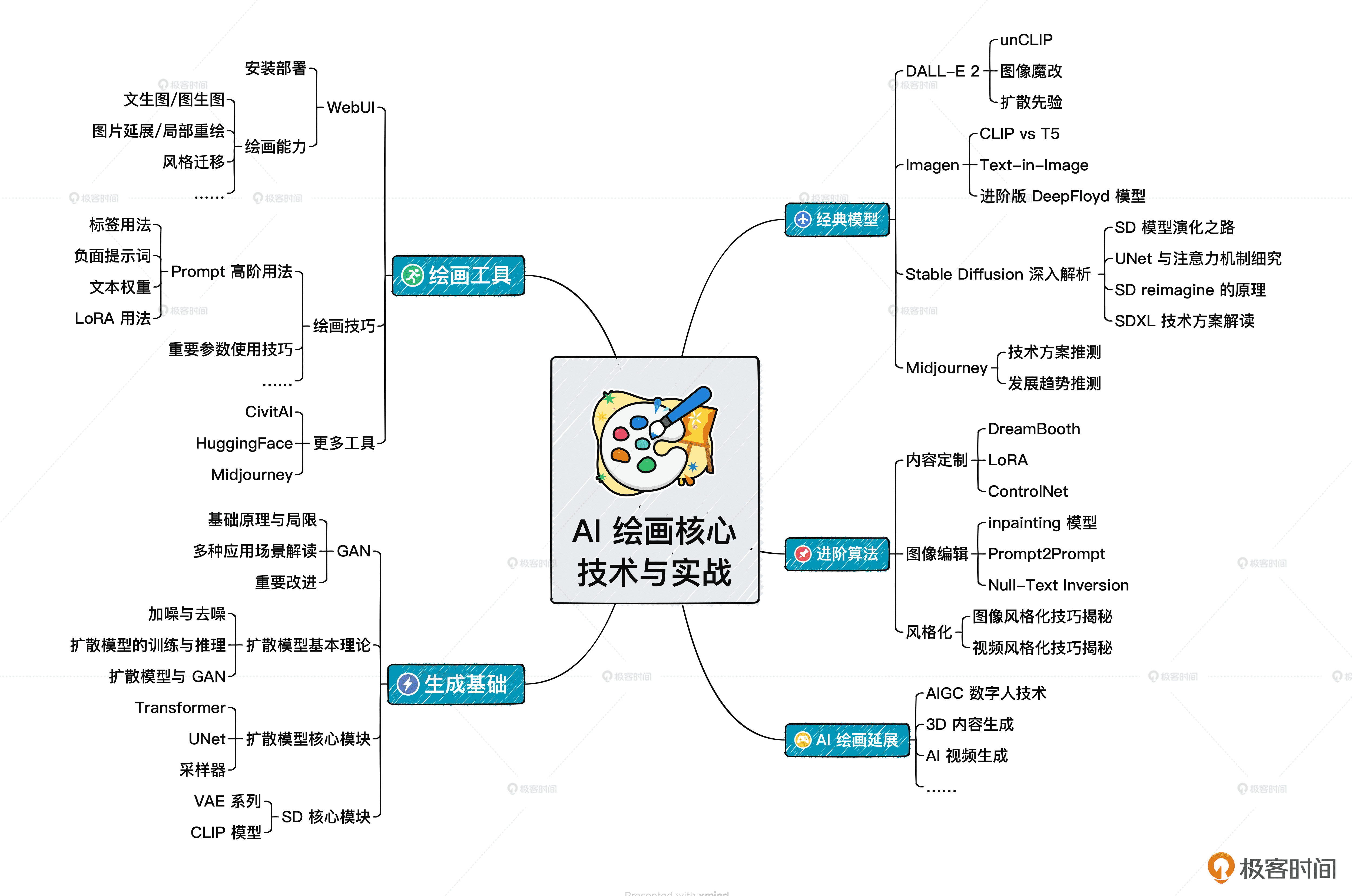
思维导图¶
视频生成¶
Meta 提出的 Make-a-video 技术: https://makeavideo.studio/
runway 提出的 Gen-2 技术: https://research.runwayml.com/gen2
英伟达的 Video LDM 技术: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
定义¶
Realistic Vision(现实视觉):在计算机图形学和计算机视觉领域,”Realistic Vision”通常指的是产生逼真、仿真度高的图像或视频的技术。这包括使用光照模型、材质模型、阴影生成、纹理映射等技术来模拟真实世界中的光影效果、物体外观和场景。
Stable Diffusion(稳定扩散):在物理学和化学领域,”Stable Diffusion”通常指的是扩散过程中的稳定性。扩散是指物质在空间中由高浓度区域向低浓度区域的自然传播。稳定扩散表示在扩散过程中,物质的浓度分布保持稳定,不会出现剧烈的波动或不稳定现象。
生成对抗网络(GANs):由 Ian Goodfellow 和他的同事于2014年提出的。它由两个主要部分组成:生成器(Generator)和判别器(Discriminator)。这两个部分通过博弈的方式相互竞争,使得生成器能够生成逼真的数据样本。以下是 GANs 的关键概念和工作原理:
生成器(Generator):生成器是一个神经网络,它接受一个随机噪声向量作为输入,并尝试生成与训练数据相似的图像或数据样本。 生成器的目标是欺骗判别器,使其无法区分生成的样本和真实数据。 判别器(Discriminator):判别器也是一个神经网络,它的任务是评估给定的数据样本是真实数据还是生成器生成的假数据。 判别器的目标是尽可能准确地区分真假样本。 对抗训练(Adversarial Training):GANs 的训练过程涉及到生成器和判别器之间的对抗训练。 生成器试图生成更逼真的数据来愚弄判别器,而判别器则努力提高其区分真伪的能力。 这个过程持续进行,直到生成器生成的样本足够逼真为止。变分自动编码器(VAEs):一种生成模型,旨在通过学习潜在变量的分布来生成数据。它于2013年由 Kingma 和 Welling 提出。VAEs 的关键概念包括以下要点:
编码器(Encoder):编码器是一个神经网络,它将输入数据映射到潜在空间中的潜在变量(通常是高维度的向量)。 这个潜在变量表示了输入数据的特征。 解码器(Decoder):解码器是另一个神经网络,它接受潜在变量作为输入,并尝试从中生成与原始数据相似的数据样本。 变分推断(Variational Inference):VAEs 使用变分推断来训练模型。 这意味着模型试图学习数据的潜在分布,并通过最大化似然性来近似这个分布。 同时,模型还受到正则化项的约束,以确保生成的潜在表示在潜在空间中均匀分布。
常见的基础模型:
生成对抗网络 (GANs):
GANs 被广泛用于生成逼真的图像和艺术作品。通过训练生成器和判别器网络,GANs 能够生成高质量的图像,这些图像在视觉上难以与真实世界中的图像区分开。例如,DeepDream 和 DCGAN(Deep Convolutional GAN)都是使用 GANs 的变种来生成艺术作品。
风格迁移网络 (Style Transfer Networks):
风格迁移网络允许将一个图像的艺术风格应用于另一个图像。这些模型可以将一幅图像的绘画风格(如梵高的星空、毕加索的立体主义等)应用于输入图像,从而创建出具有不同艺术风格的图像。
变分自动编码器 (VAEs):
VAEs 可以用于生成具有潜在连续变化的图像。它们通过学习数据的潜在分布来生成图像,因此可以生成具有多样性和连续性的艺术作品。
循环神经网络 (RNNs) 和卷积神经网络 (CNNs):
RNNs 和 CNNs 被用于生成手写字体、文本艺术、字符生成等任务。这些模型可以生成具有时间序列性质的图像,如手写字体的生成或基于文本描述的图像生成。
自动绘图算法:
一些基于规则或算法的方法可以用于生成特定类型的艺术作品,例如分形艺术、自动绘制算法、以及根据数学公式生成的艺术作品。
图像转换网络 (Image-to-Image Translation Networks):
这些网络用于将一种图像转换为另一种图像,例如将素描转换为彩色图像、将黑白照片转换为彩色照片等。
热身篇:AI 绘画初体验 (4讲)¶
01|WebUI¶
🌟Stable Diffusion AI绘画模型分享平台: https://civitai.com/
Realistic Vision V5.1模型下载地址: https://civitai.com/models/4201?modelVersionId=6987
人工智能和机器学习的博客网站: https://www.happyaccidents.ai/
AI绘画功能:
txt2img:文生图
img2img:图生图
Outpainting:延展图像
Inpainting:局部重绘
02|Prompt使用技巧¶
ControlNet 模型。它能够更精确地控制生成的图像,让我们能够更好地实现自己的创作愿景。
LoRA 模型可以看作是原始模型的新特效,你可以这样理解:LoRA 相当于给原有模型穿上了“新服饰”一样,能让图像呈现出不同的表现。
在 prompt 中添加 () ,默认情况下会让对应的单词产生 1.1 倍的强度。双括号 (()) ,则表示 1.1 x 1.1 倍的加强。当然,我们也可以直接将数字写上去,例如 (dog:1.2) 。通常情况下,我不建议该权重超过 1.3,否则对画面的影响很大,甚至不能产生正常的图像。
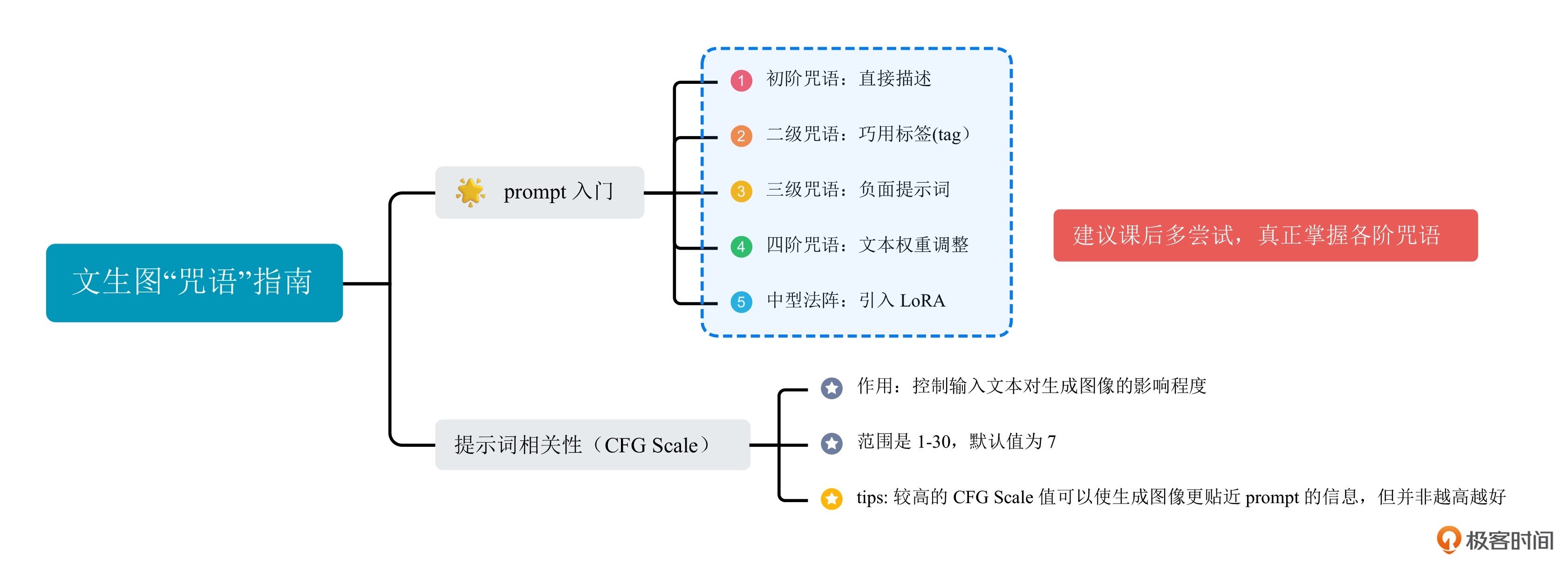
WebUI 咒语指南:
1. 初阶咒语:直接描述
2. 二阶咒语:巧用标签
3. 三阶咒语:负面提示词
4. 四阶咒语:文本权重调整
5. 中型法阵:引入 LoRA
重要参数:
CFG Scale(Guidance Scale),“提示词相关性”
03|进阶应用¶
图生图可以做哪些事情:
1. 输入一张真实拍摄的照片,保持图像构图输出一张风格化的绘画结果
2. 输入一张低分辨率的照片,输出一张高分辨率的清晰照片
3. 输入一件衣服,输出一个模特穿着这件衣服
4. 输入一张局部涂抹的照片,输出一张 AI 算法补全后的照片
5. 输入一张图片,输出这种图片向外延展之后的效果等等
04|实战项目1¶
两个要点。
第一,选择不同功能的 LoRA 模型。根据创作需求,可以选择风格化的 LoRA 或人物化的 LoRA。风格化的 LoRA 可用于生成具有特定风格的图像,而人物化的 LoRA 则更适用于创建独特的人物形象。
第二,选择合适的 LoRA 权重。权重越高,生成的图像越接近 LoRA 模型的效果。但在 AI 绘画中,并不是权值越高越好。权重的选择需要根据设计师的意图和具体应用场景来权衡。
基础篇:AI 绘画原理揭秘 (9讲)¶
05| 旧画师GAN¶
2022 年以前,GAN 才是业界公认的 AI 绘画技术首选。在老一辈的 AI 画图中,GAN(生成对抗网络)可以说是唯一的选择。在各种社交软件上见到过各种变小孩、变老、性别变换的视觉特效,这类效果通常就是靠 GAN 完成的。
2022 年 DALL-E 2、Stable Diffusion 的推出,扩散模型技术逐渐成为了 AI 绘画的主流技术。
2014 年说起。Ian Goodfellow 等人提出了生成对抗网络——也就是 GAN 这个全新的概念。GAN 模型由两个模块构成,也就是常说的生成器(Generator)和判别器(Discriminator)。可以这样类比,生成器是一位名画伪造家,目标是创作出逼真的艺术品,判别器是一位艺术鉴赏家,目标是从细节中找出伪造破绽。生成器与判别器在模型训练的过程中持续更新与对抗,最终达到平衡。它的精髓在于对抗训练思想。GAN 通过生成器和判别器的竞争和学习,使得生成的图像逐渐趋近于真实图像。在现实世界中,GAN 的应用场景广泛,包括图像合成、图像修复、图像风格转换等。
2015 年由 Radford 等人提出的深度卷积 GAN(DCGAN)给 GAN 带来了进化可能。主要创新就是引入卷积神经网络(CNN)结构,通过卷积层和反卷积层替代全连接层,使得生成器和判别器能够感知和利用图像的局部关系,更好地处理图像数据,从而生成更逼真的图像。
条件 GAN,简称 cGAN,允许我们在生成图像的过程中引入额外的条件信息。这样一来,我们可以控制生成图像的特征,比如生成特定类别的图像。
Wasserstein GAN,简称 wGAN,是另一个重要的改进,它通过使用 Wasserstein 距离(瓦瑟斯坦距离,也被称为地面距离)来衡量生成图像和真实图像之间的差异,这样就能提升训练的稳定性和生成图像的质量。
后来的 PGGAN、BigGAN、StyleGAN 等,将生成图像的分辨率提高了 1024x1024 分辨率之上。
Pix2Pix 系列工作延续了 cGAN 的思想,将 cGAN 的条件换成了与原图尺寸大小相同的图片,可以实现类似轮廓图转真实图片、黑白图转彩色图等效果(GAN 时代的 ControlNet)。Pix2Pix 最大的缺点就是训练需要大量目标图像与输入图像的图像对,优点是模型可以做到很轻很快,甚至能在很低端的手机上也能达到实时效果。从 18 年至今,我们在短视频平台上看到的各种实时变脸特效,比如年龄转换、性别编辑等特效,都是基于这个技术。
2017 年 Jun-Yan Zhu 等人提出了 CycleGAN,也就是循环一致性生成对抗网络(解决获取大师困难且耗时的成对的图数据)。CycleGAN 的核心要点就是让两个不同领域的图像可以互相转换。它有两个生成器,分别是 G(A→B)和 G(B→A),它们的任务是把 A 领域的图像变成 B 领域的,反之亦然。同时,还有两个判别器,D_A 和 D_B,负责分辨 A 和 B 领域里的真实图像和生成的图像。CycleGAN 的关键点在于循环一致性损失。这个方法把原图像转换到目标领域,然后再转换回原来的领域,就可以确保生成的图像跟原图像差别不大。CycleGAN 的优势是不需要成对的训练数据便可以实现图像转换,在很多图像转换任务上都表现得非常出色,比如风景、动物、风格等转换。
英伟达在 2018 年提出的生成对抗网络模型 StyleGAN,彻底改变了 GAN 在图像合成和风格迁移方面的应用前景。与传统的 GAN 模型相比,StyleGAN 在图像生成的质量、多样性和可控性方面取得了显著的突破。StyleGAN 的核心思想是用风格向量来控制生成图像的各种属性特点,并通过自适应实例归一化(AdaIN)把风格向量和生成器的特征图结合在一起。另外,用渐进式的生成器结构逐渐提高分辨率,这样可以提高训练的稳定性和生成图像的质量。
超分辨率生成对抗网络(SRGAN)的模型,它的目标是将低分辨率图像转换成高分辨率的图像。
有兴趣的话你可以了解下 BigGAN、StarGAN、Progressive GAN 等模型。
GAN 的局限性主要表现在训练不稳定性、生成图像模糊、难以评估和控制生成质量等问题。此外,在图像风格化、图像编辑等任务中,通常是每个任务一个 GAN。训练成本、数据需求量、使用场景局限性都是实际工作中的痛点。
2015 年就有人提出了图像扩散模型的概念。扩散模型在很大程度上解决了 GAN 的痛点。
2021 年之前 GAN 一直在图像生成领域处于制霸地位,直到 2021 年 10 月,一篇名为“扩散模型在图像生成领域击败了 GAN” 的文章横空出世,扩散模型在图像生成领域的潜力才广为人知。
2023 年 3 月,Adobe 的学者提出了 GigaGAN, 一个新的 GAN 架构。热衷于 GAN 的研究人员并没有放弃。
DragGAN 是一种交互式图像操作方法,为各种 GAN 开发提供了一种神奇的功能,我们用鼠标简单拉伸图像,就能够生成全新的图像。
06 | 颠覆者扩散模型¶
扩散模型的灵感源自热力学。我们可以想象一下这样的过程,朝着一杯清水中滴入一滴有色碘伏,然后观察这杯水。
基于扩散模型实现 AI 绘画包括两个过程——加噪过程和去噪过程。即把一张图片加噪到纯噪声(即全是噪点的图片),还是把纯噪声做去噪处理,生成一张干净的图片
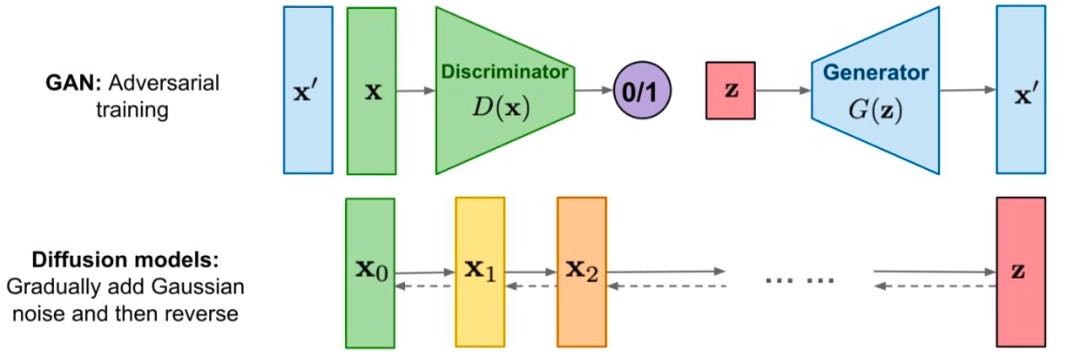
扩散模型和 GAN 的原理:GAN 是通过生成器、判别器对抗训练的方式来实现图像生成能力的,本质上是神经网络的左右互搏。而扩散模型,则是通过学习一个去除噪声的过程来实现图像生成的。¶
加噪过程的是通过参数化马尔可夫链将干净的图片逐步变为纯噪声;去噪的过程就是从噪声出发,逐步预测噪声并去除噪声。神经网络 UNet 被用于预测噪声,各式各样的采样器则用于去除噪声。
07|AIGC的核心魔法:搞懂Transformer¶
Stable Diffusion 模型在原始的 UNet 模型中加入了 Transformer 结构,这么做可谓一举两得,因为 Transformer 结构不但能提升噪声去除效果,还是实现 prompt 控制图像内容的关键技术。
在深度学习中,有很多需要处理时序数据的任务,比如语音识别、文本理解、机器翻译、音乐生成等。不过,经典的卷积神经网络,也就是 CNN 结构,主要擅长处理空间相关的任务,比如图像分类、目标检测等。因此,RNN(循环神经网络)、LSTM(长短时记忆网络)以及 Transformers 这些解决时序任务的方案便应运而生。
RNN 的主要特点是在处理序列数据时,对前面的信息会产生某种“记忆”,通过这种记忆效果,RNN 可以捕捉序列中的时间依赖关系。这种“记忆”在 RNN 中被称为隐藏状态(hidden state)。
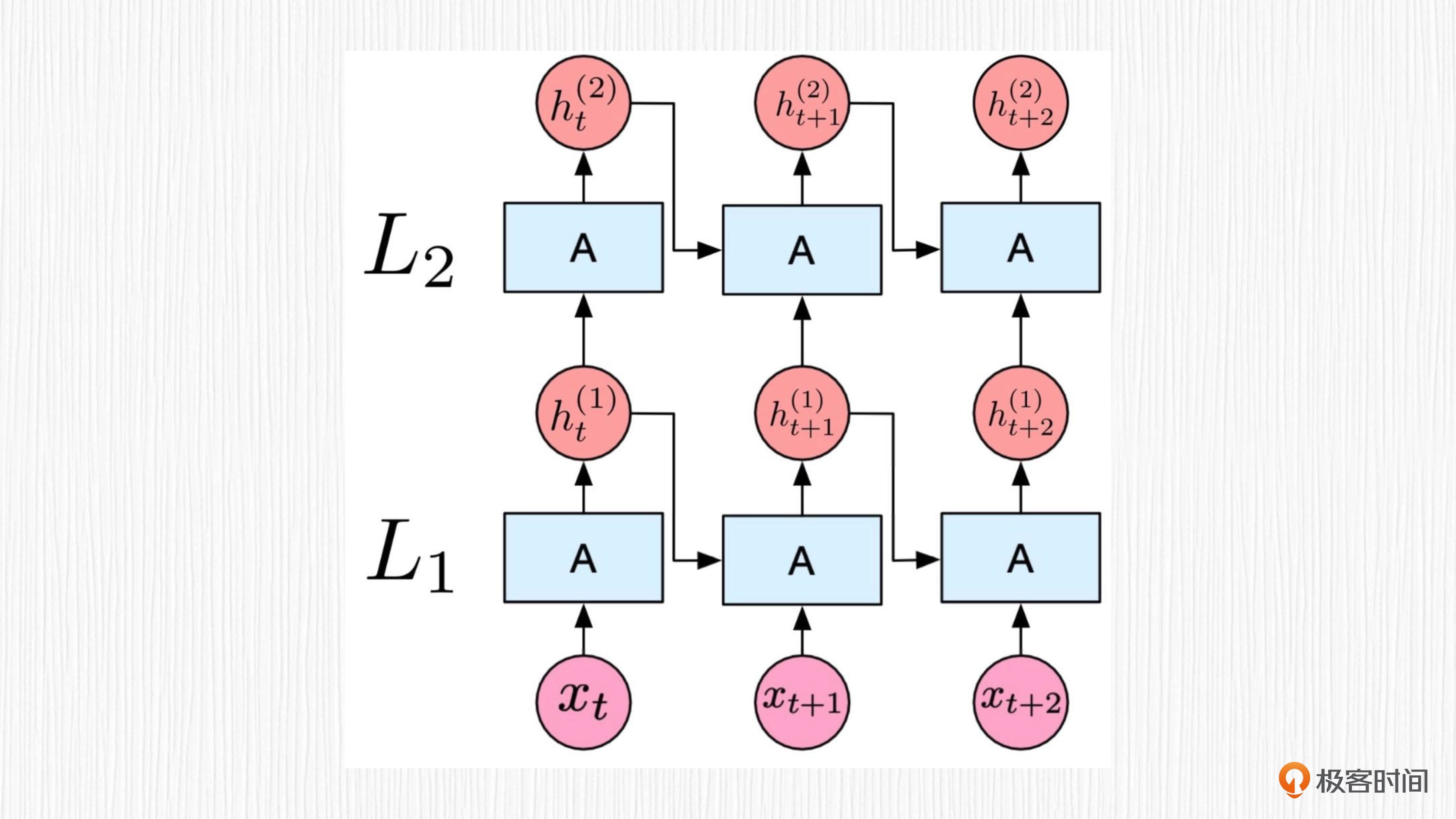
传统的 RNN 存在一个关键的问题,即“长时依赖问题”——当序列很长时,RNN 在处理过程中会出现梯度消失(梯度趋近于 0)或梯度爆炸(梯度趋近于无穷大)现象。这种情况下,RNN 可能无法有效地捕捉长距离的时间依赖信息。
为了解决这个问题, LSTM 这种特殊的 RNN 结构就派上用场了。LSTM 通过加入遗忘门、记忆门和输出门来处理长时依赖问题。这些门有助于 LSTM 更有效地保留和更新序列中的长距离信息。
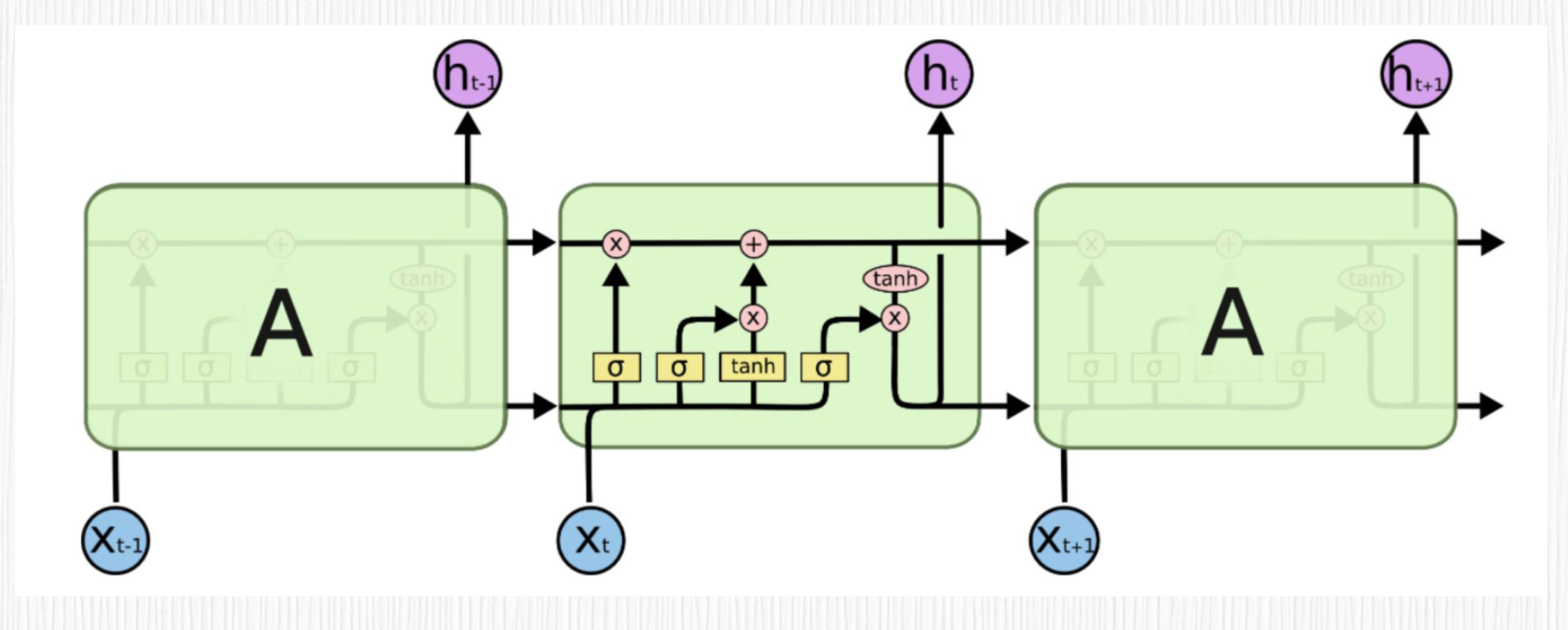
以 LSTM 为代表的 RNN 类方案虽然在许多时序任务中取得了良好的效果,但是也有它的局限,主要是三个方面。
第一,并行计算问题。由于 LSTM 需要递归地处理序列数据,所以在计算过程中无法充分利用并行计算资源,处理长序列数据时效率较低。
第二,长时依赖问题。虽然 LSTM 有效地改善了传统 RNN 中的长时依赖问题,但在处理特别长的序列时,仍然可能出现依赖关系捕捉不足的问题。
第三,复杂性高。LSTM 相比简单的 RNN 结构更复杂,增加了网络参数和计算量,这在一定程度上影响了训练速度和模型性能。
Transformer 的整体方案¶
在 2017 年由 Google 提出的 Transformer,是一种基于自注意力机制(self-attention)的模型,它有效解决了 RNN 类方法的并行计算和长时依赖两大痛点。
Transformer 结构包括编码器(Encoder)和解码器(Decoder)两个部分,通过这两个部分完成对输入序列的表示学习和输出序列的生成。
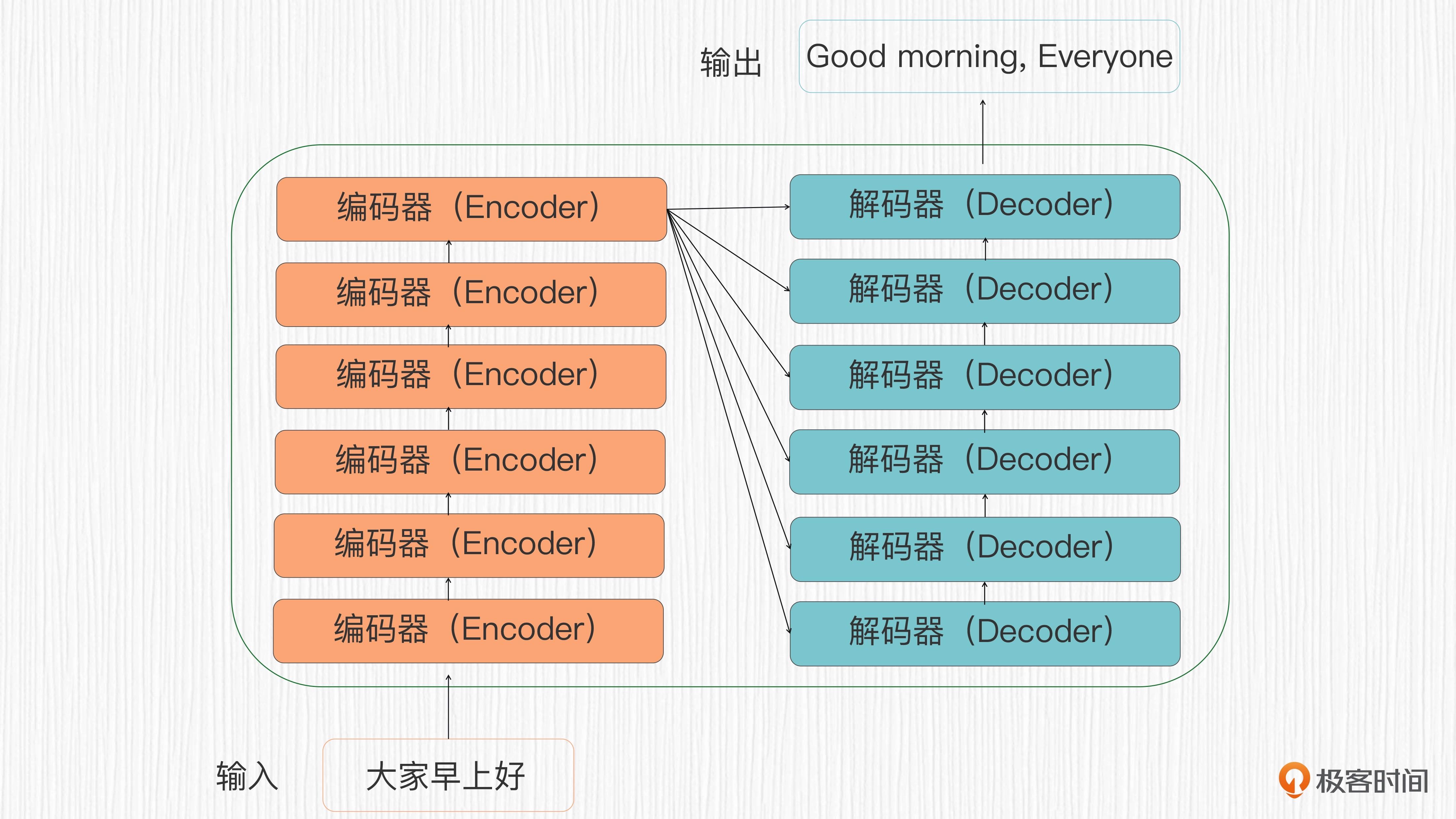
编码器和解码器分别由 6 层相同的结构堆叠而成¶
编码器负责处理输入序列。它会根据全局上下文,提取输入数据中的有用信息,并学习输入序列的有效表示。解码器则会根据编码器输出的表示,生成目标输出序列。它会关注并利用输入序列的表示以及当前位置的上下文信息,生成输出序列中每个元素的预测。
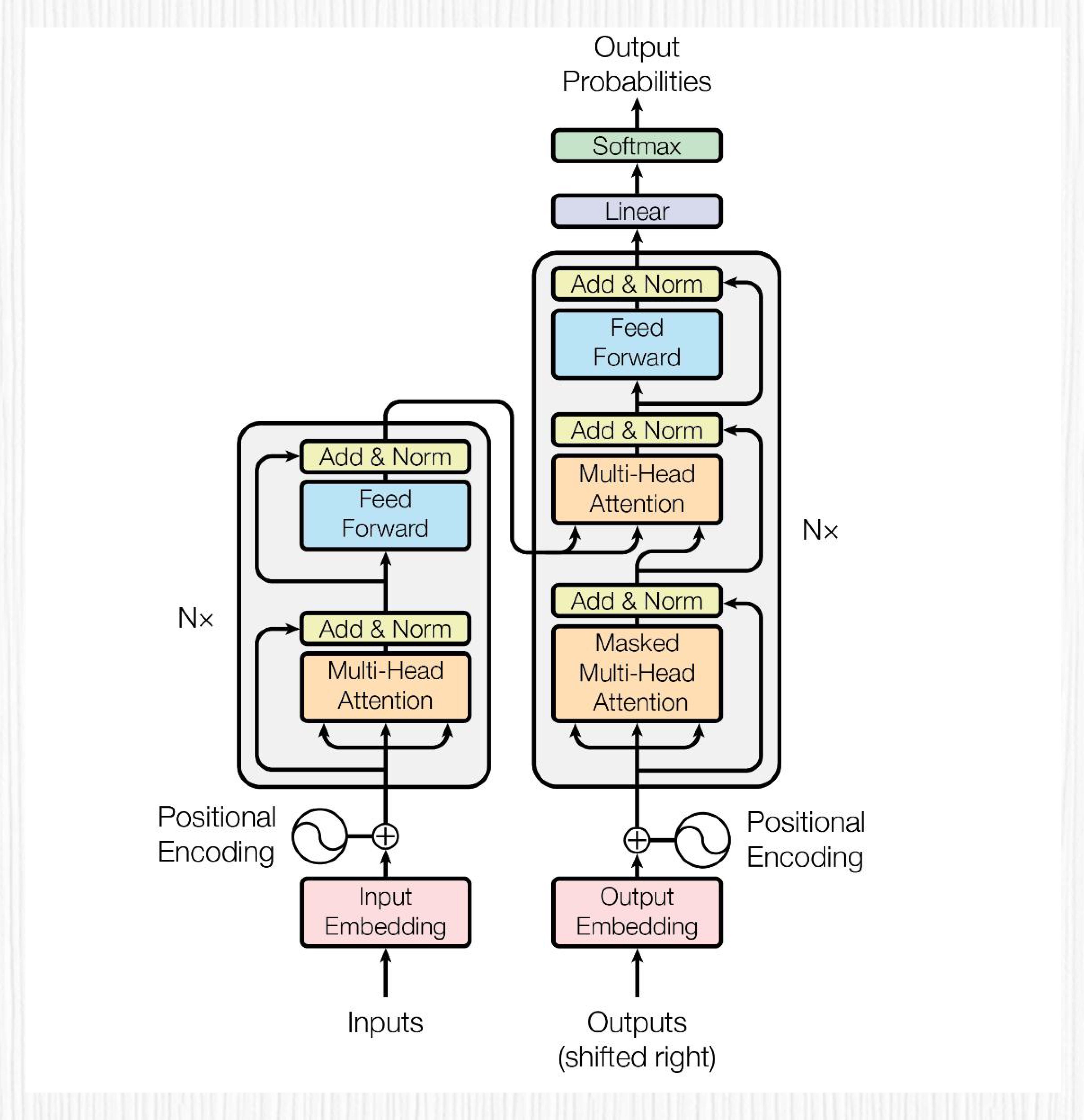
编码器负责对输入序列进行抽象表示,解码器根据这些表示构建合适的输出序列。¶
4 个关键的概念¶
首先是源序列。源序列是输入的文本序列。例如在机器翻译任务中,源序列就是待翻译的文本。
其次是目标序列。目标序列是输出的文本序列,例如在机器翻译任务中,目标序列代表翻译后的文本,通常为目标语言。
之后是 Token(词符)。Token 是文本序列中的最小单位,可以是单词、字符等形式。文本可以拆分为一系列 tokens。
最后是词嵌入(Word Embedding)。词嵌入的目标是把每个 token 转换为固定长度的向量表示,这些向量可以根据 token ID 在预训练好的词嵌入库(例如 Word2Vec 等)中拿到。在 Transformer 中,编码器和解码器的输入的都是序列经过 token 化之后得到的词嵌入。
Self-Attention 模块¶
各种不同类型的注意力机制:
1. 自注意力 (Self-Attention)
2. 交叉注意力 (Cross Attention)
3. 单向注意力 (Unidirectional Attention)
4. 双向注意力 (Bidirectional Attention)
5. 因果注意力 (Causal Attention)
6. 多头注意力(Multi-Head Attention)
7. 编码器 - 解码器注意力(Encoder-Decoder Attention)
备注
注意力模块通常作为一个子结构嵌入到更大的模型中,作用是提供全局上下文信息的感知能力。
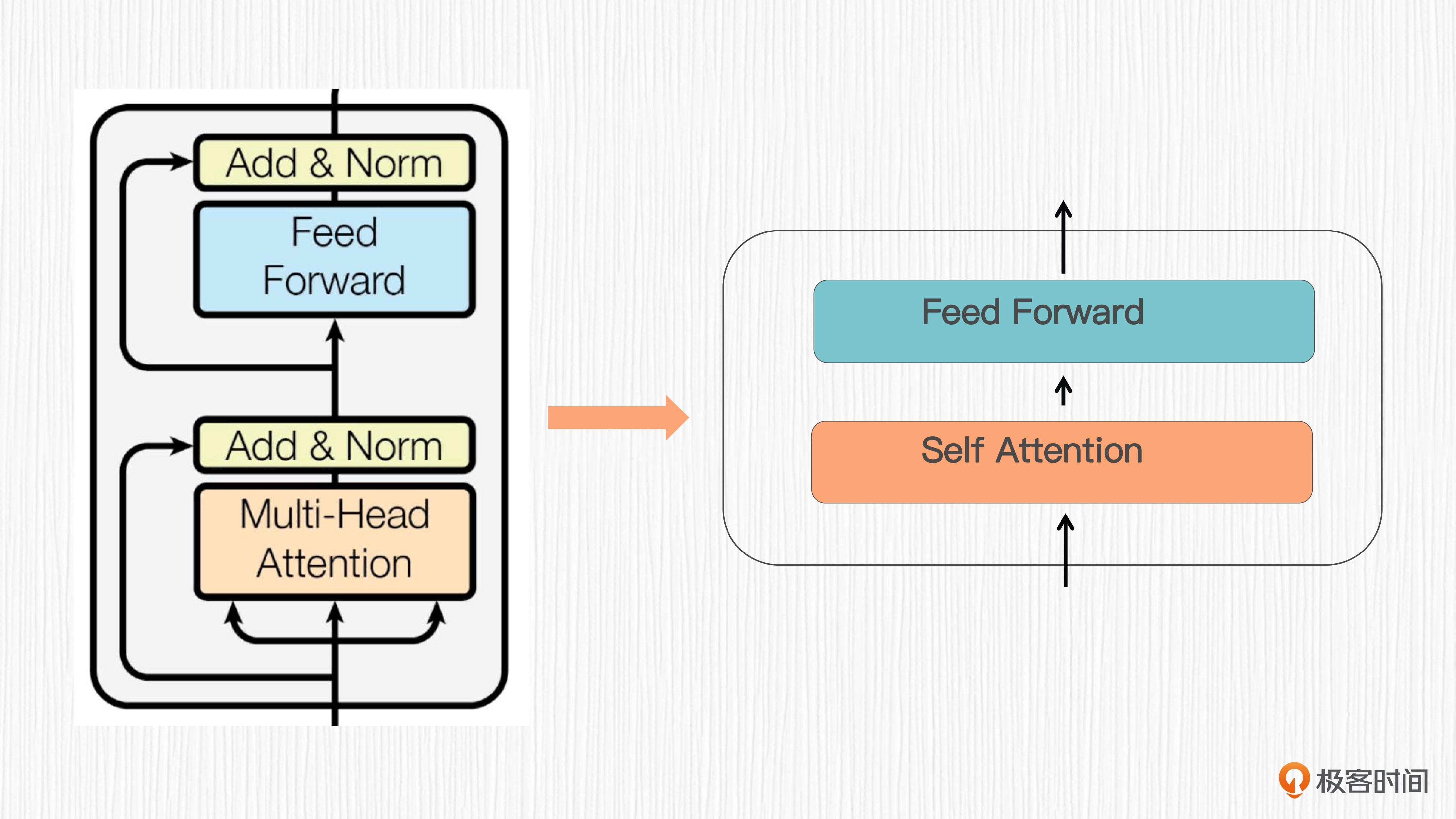
自注意力模块¶
交叉注意力模块¶
备注
最基础的自注意力模块,计算方法你可以看下面这张图。自注意力模块会计算输入序列中所有元素之间的相似性得分,再通过归一化处理得到注意力权重。这些权重可以视为输入元素与其他元素之间的联系强度。注意力模块通过对权重与输入元素做加权求和来生成输出,输出的向量维度与输入相同。
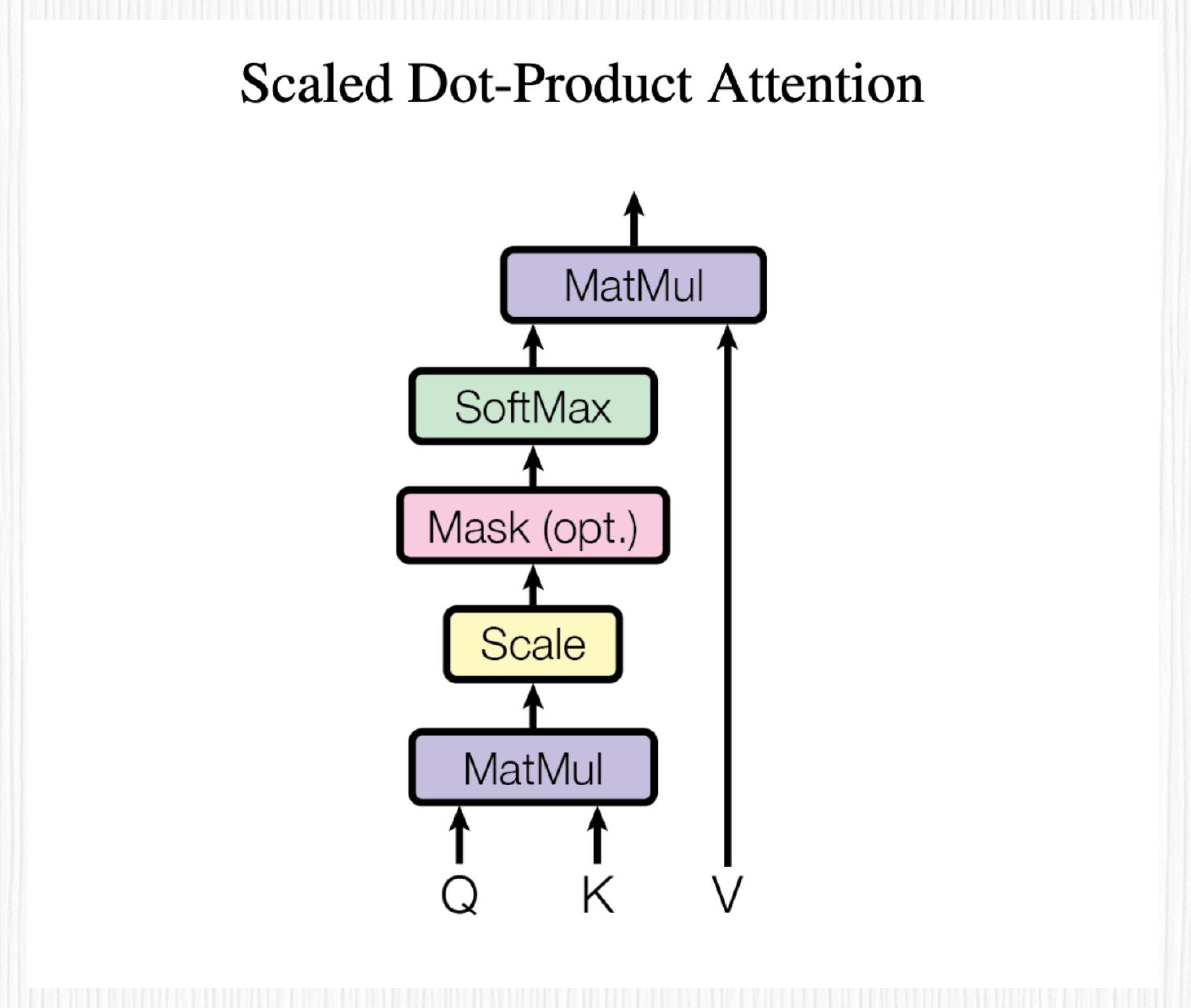
首先通过三个可学习的权重矩阵 W_Q, W_K, W_V 分别将模块输入序列投影成 Q、K、V 三个向量。Q 代表 Query,K 代表 Key,V 代表 Value。然后通过计算 Q、K 之间的关系,获得注意力权重,最后将这些权重与 V 向量相结合,得到输出向量。(图片来源:https://arxiv.org/abs/1706.03762)¶
整个计算过程伪代码:
# 从同一个输入序列产生Q、K和V向量。
Q = X * W_Q
K = X * W_K
V = X * W_V
# 计算Q和K向量之间的点积,得到注意力分数。
Scaled_Dot_Product = (Q * K^T) / sqrt(d_k)
# 应用Softmax函数对注意力分数进行归一化处理,获得注意力权重。
Attention_Weights = Softmax(Scaled_Dot_Product)
# 将注意力权重与V向量相乘,得到输出向量。
Output = Attention_Weights * V
三个小细节
Q 和 K 的向量维度是相同的,比如都是 d_k,V 和 Q、K 的向量维度可以不同,称之为 d_v。
缩放因子 Scale 的计算方式是对 d_k 开根号之后的结果,在 Transformer 论文中,d_k 的取值为 64,因此 Scale 的取值为 8。
图中被标记为可选(Opt)的 Mask 模块的作用是屏蔽部分注意力权重,限制模型关注特定范围内的元素。你可别小看这个 Mask 模块,它便是自注意力升级为单向注意力、双向注意力、因果注意力的精髓所在!
备注
自注意力和交叉注意力的区别你只需要记住一句话:自注意力的 Q、K、V 都源自同一个输入序列,而交叉注意力的 K、V 源自源序列,Q 源自目标序列,其余计算过程完全相同。对于 Transformer 这类编码器 - 解码器结构来说,源序列从编码器输出,目标序列从解码器输出。
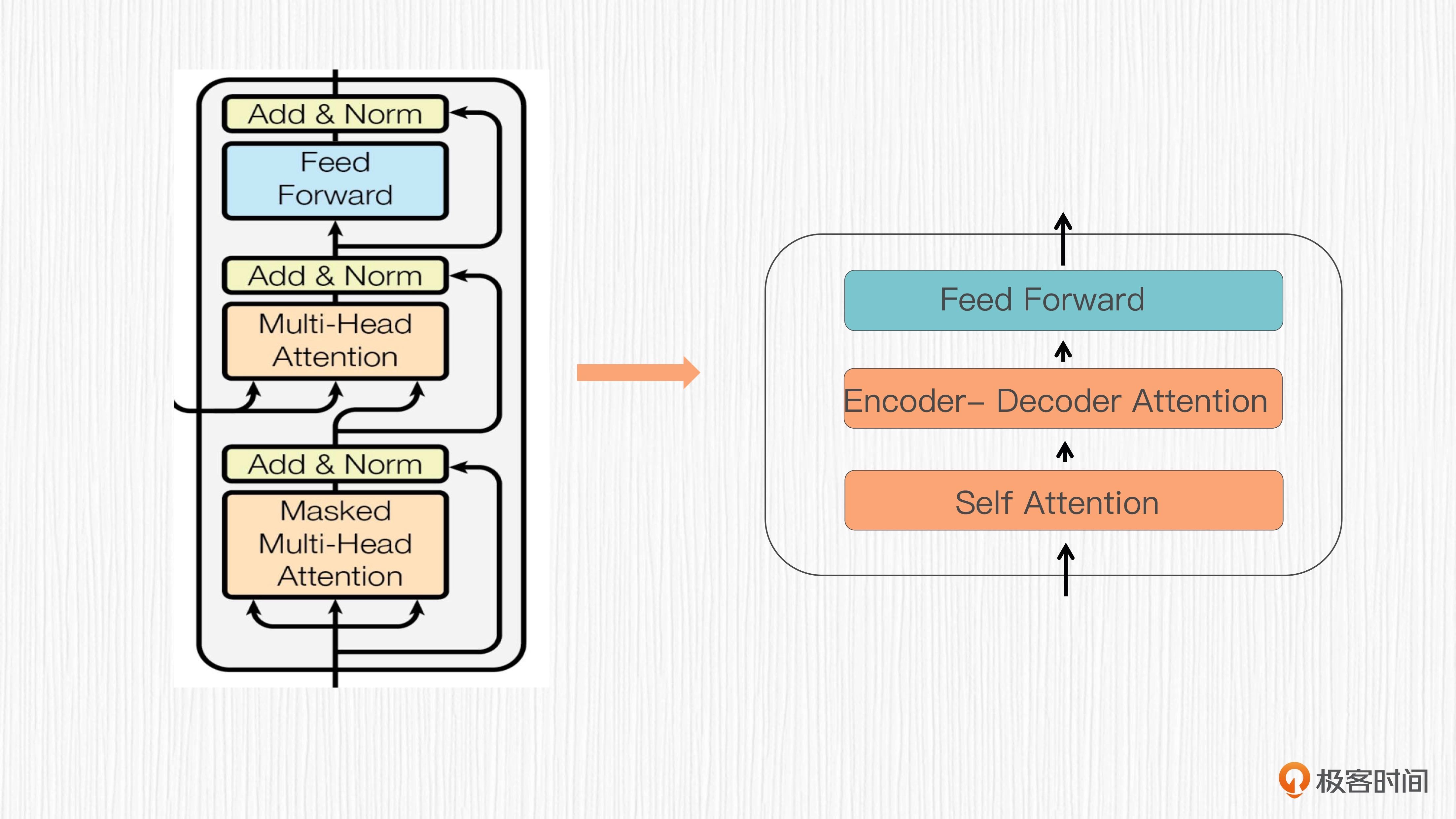
Encoder-Decoder Attention 模块¶
编码器 - 解码器注意力(Encoder-Decoder Attention)模块是解码器中的一个关键子模块,实际上它是一个交叉注意力模块
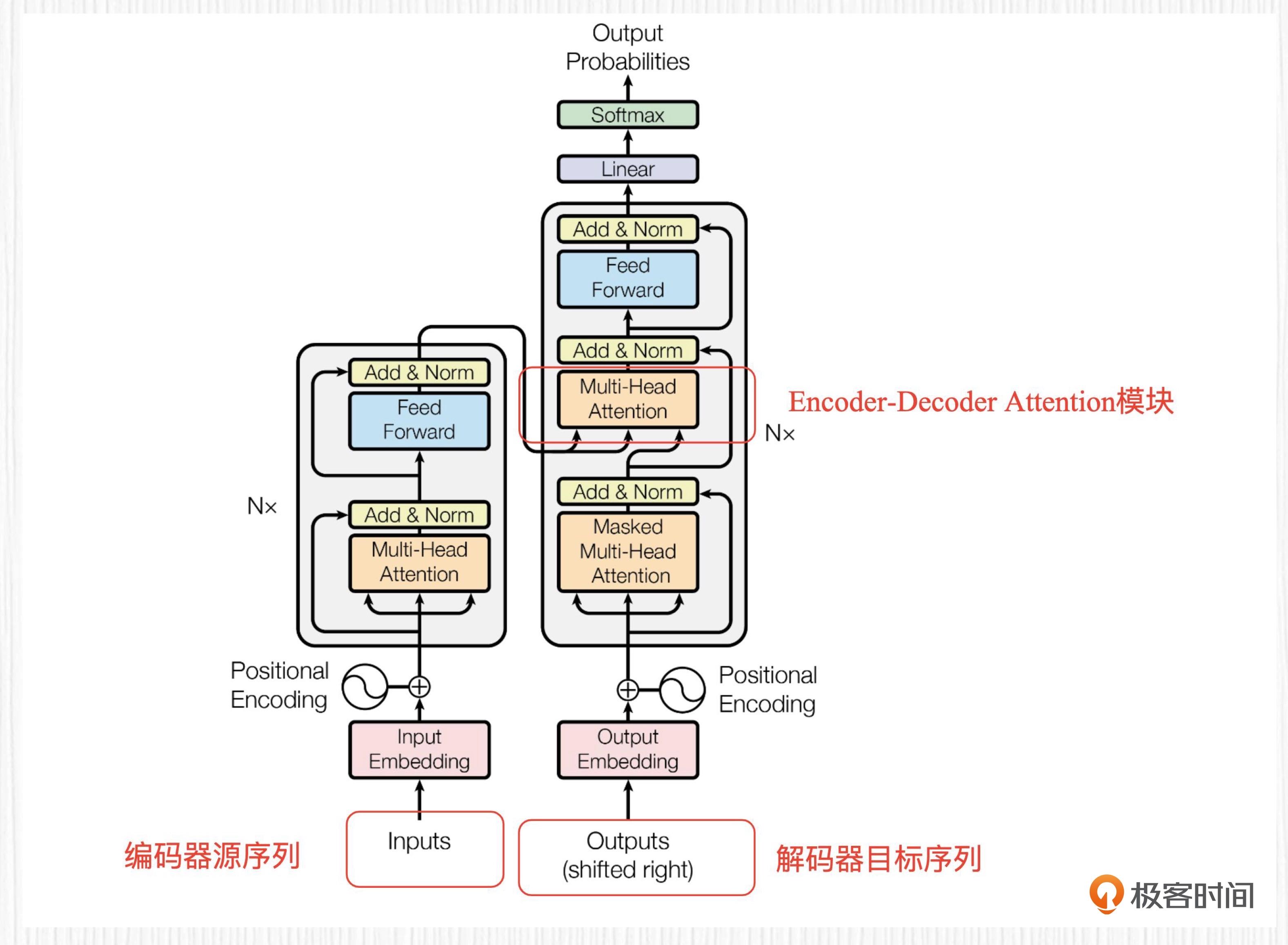
如图:这个模块的 Q、K、V 源自不同序列。编码器 - 解码器注意力模块的目标是统合源序列和目标序列之间的关系,以便生成更准确的输出序列。¶
多头注意力机制的设计和优势¶
多头注意力(Multi-head Attention)是 Transformer 的工作里首次提出和使用的,它强化了编码器解码器的能力,你可以把它看作注意力模块的升级版。
Transformer vs LSTM¶
尽管 Transformer 在很多任务中表现出优越性能,但它的训练通常需要大量的数据,对内存和计算资源的需求通常较高。另外,LSTM 和 Transformer 在特定任务上可能具有各自的优势,我们仍然需要根据具体问题和数据情况来选择最合适的模型。
08|巧用神经网络:如何用UNet预测噪声¶
UNet 出现之前,图像分割采用的主要方法是 2015 年提出的 FCN(全卷积网络)。与传统的 CNN(卷积神经网络)不同,FCN 去掉了最后的全连接层,而是使用转置卷积层实现上采样的过程。通过这样的操作,FCN 可以获得与输入图像相同尺寸的输出。
FCN 为图像分割任务带来了显著的改进,但仍然有一定的局限性。比如,FCN 结构无法最大限度地利用不同层级的特征,这会导致分割结果中存在边缘细节丢失等问题。
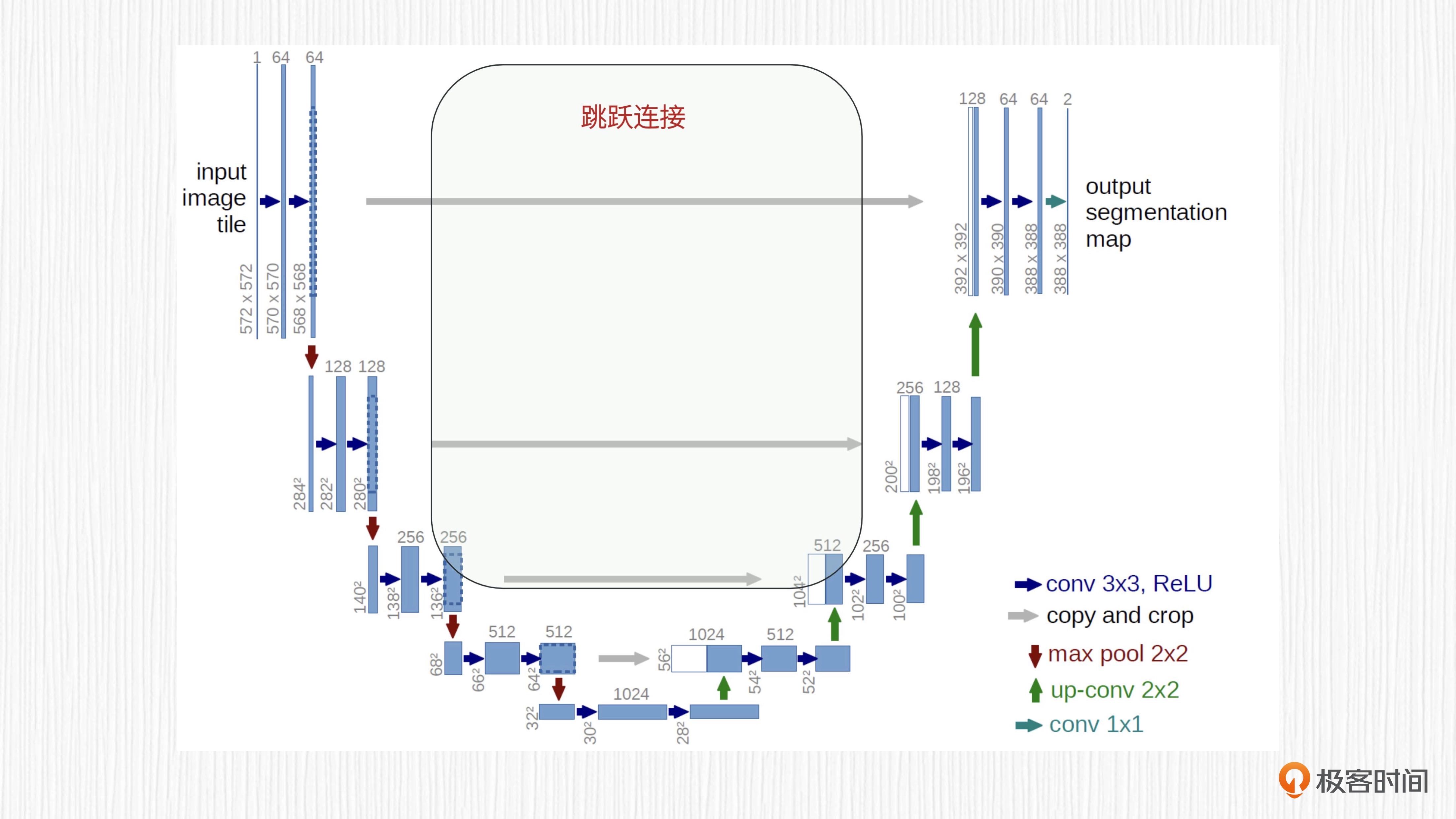
同样出现在 2015 年的UNet是一种 U 型的全卷积神经网络,存在一个明显的编码、解码过程,并且编码器和解码器中间存在特征融合。UNet 一经提出,便成为处理图像分割任务的经典模型。
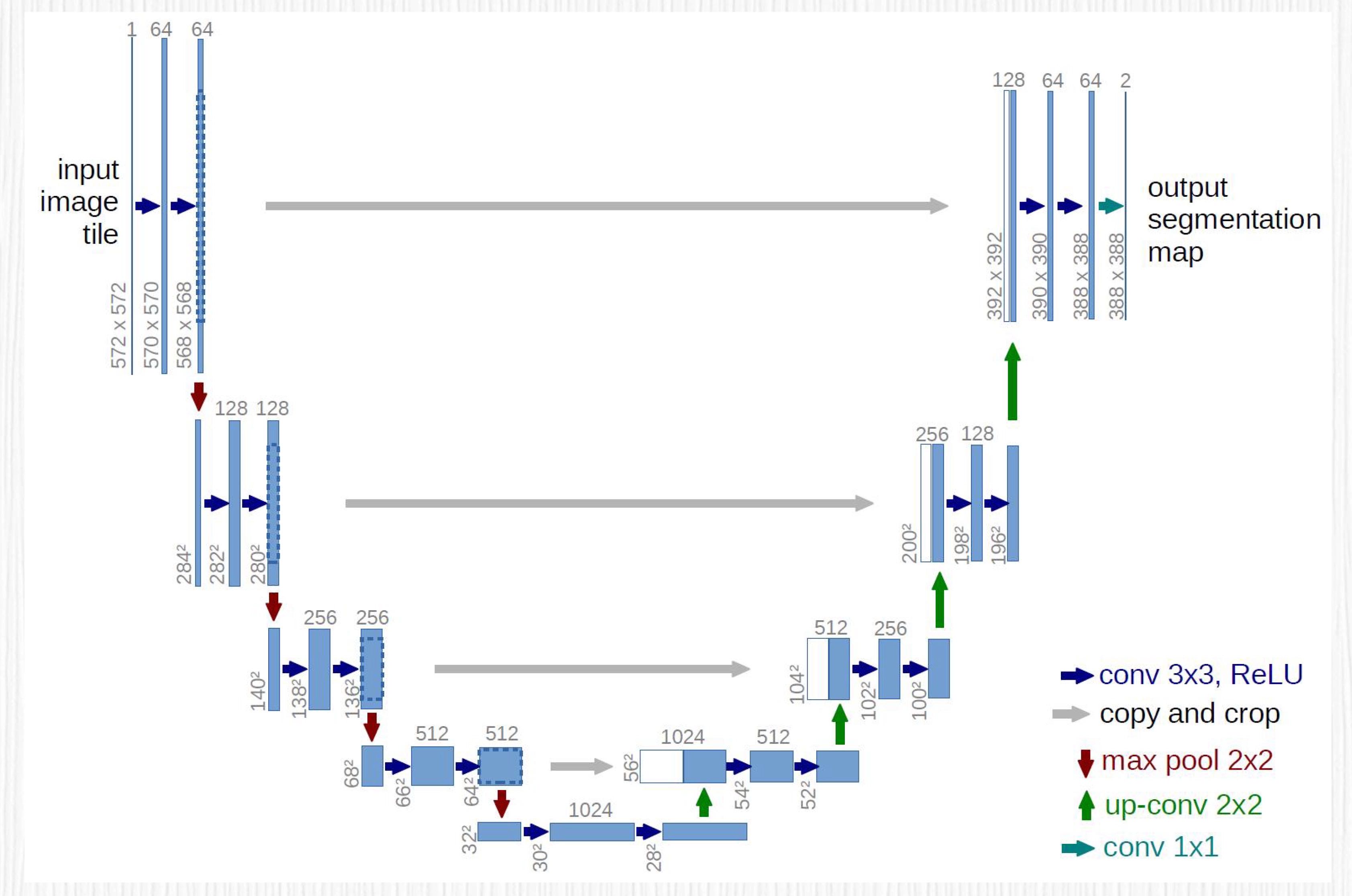
UNet 的 U 型结构:左侧是编码器,右侧是解码器。¶
基本结构¶
UNet 的基本结构:
第一是它独特的 U 形结构
第二是其基于编码器 - 解码器设计思想
第三是编码器和解码器之间的跳跃连接
对于图像分割任务,编码器的输入是原始图像,解码器的输出是分割结果。
UNet 的编码器由连续的卷积层和池化层交替组成,每个卷积层用于提取更深层次的图像特征,通常在卷积之后使用非线性激活函数(如 ReLU)以引入非线性。随后,池化层(如最大池化)用于进行降采样,以减小每一层的空间尺寸。经过编码器阶段后,高分辨率的输入图像就转化成了具备较低空间尺寸的特征图。
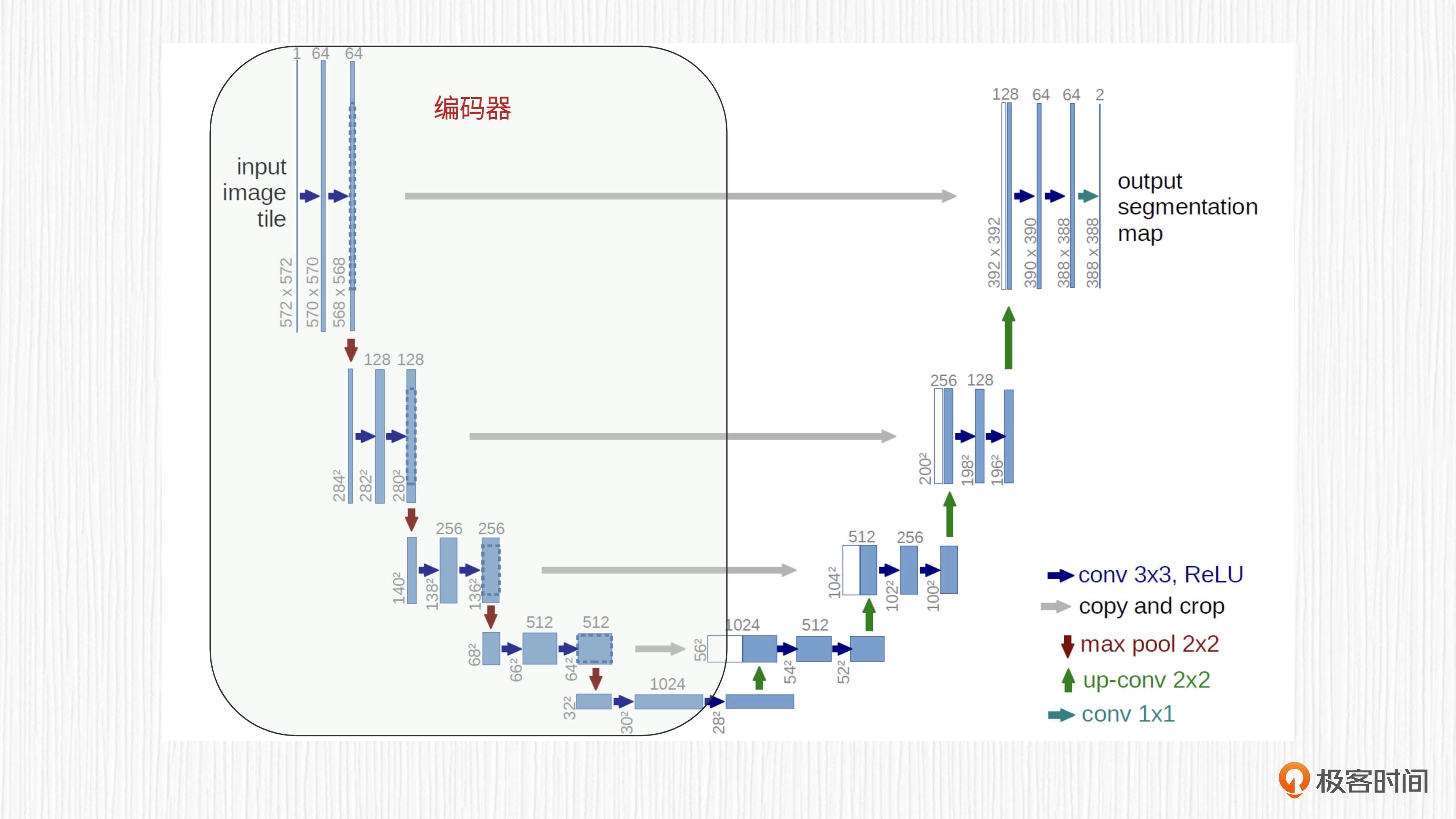
UNet 的解码器与编码器相反,它通过连续的反卷积或转置卷积层进行上采样,逐步将低维特征图恢复到原始图像的分辨率。每个反卷积或转置卷积操作后,得到的特征同样会执行非线性激活函数,以增加模型的非线性。解码器的目的是利用编码器生成的深层特征,生成与输入图像空间维度相同的结果(可能需要插值后处理),以便进行像素级预测。
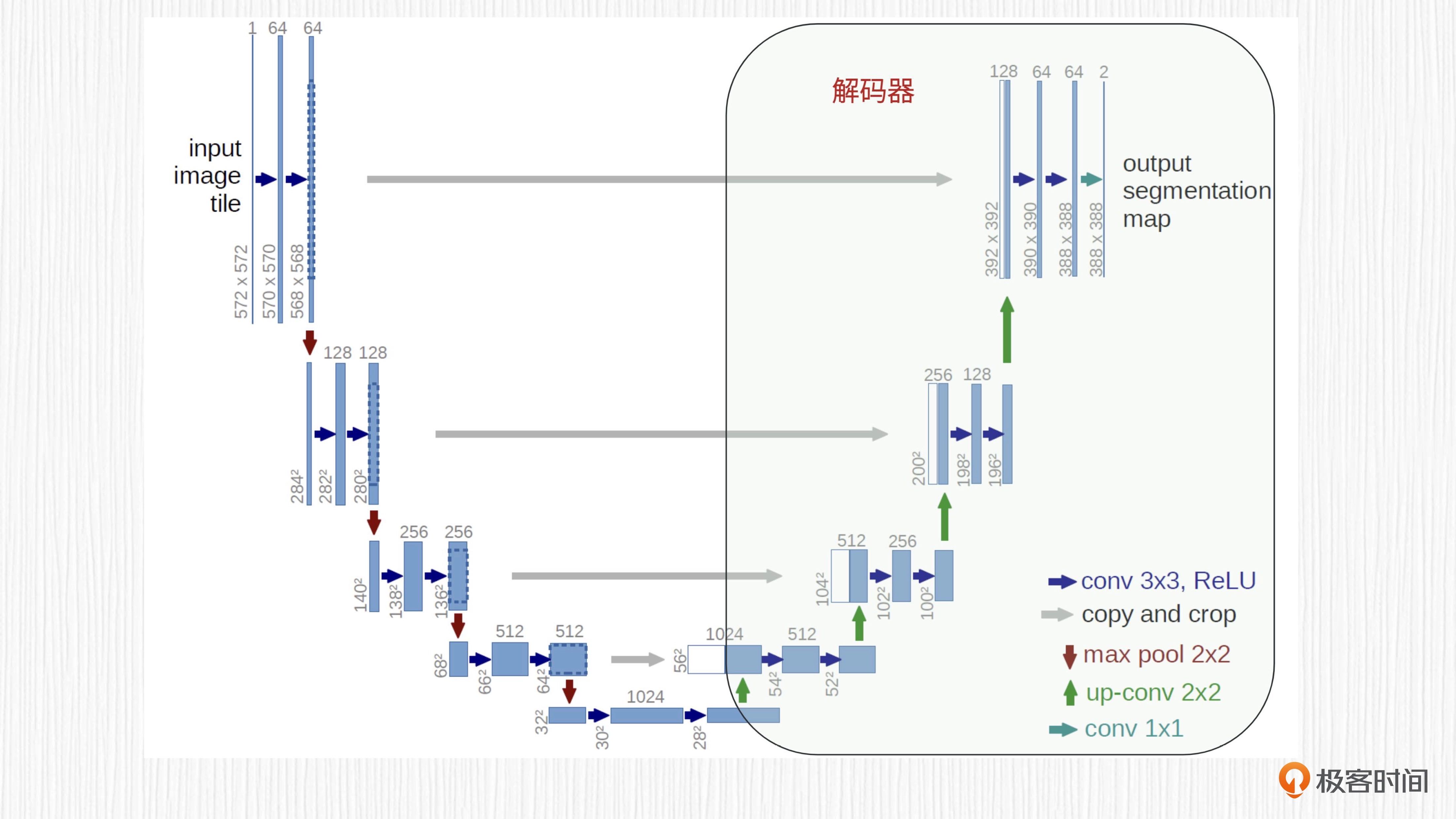
最后我们来看跳跃连接。编码器和解码器之间的特征融合是通过跳跃连接实现的。跳跃连接将编码器中相应层级的特征图与解码器中的特征图连接在一起,这样解码器才能捕捉更丰富的细节信息,进一步提高网络性能。
损失函数¶
对于图像分割任务,交叉熵损失函数(Cross Entropy Loss)是一种常用的损失函数。
交叉熵损失函数广泛用于分类任务,它能度量模型的预测概率分布与真实标签分布之间的差异。
对于图像分割任务,每个像素都需要进行分类,也就是判断这个像素属于哪一个类别。因此,我们需要对图像中每一个像素都计算交叉熵损失,用平均或者求和的方式将这些损失合并,得到最终的损失值。
图像分类任务和图像分割任务中交叉熵损失函数的代码实现:
import numpy as np
def cross_entropy_classification(y_true, y_pred):
"""
y_true: 真实标签。这是任务的真实答案,通常由人类标注或事先知道。
对于分类任务(如猫狗分类),y_true可以是类别的索引或 one-hot 编码表示。
y_pred: 预测标签。这是模型预测的结果。
对于分类任务,y_pred是一个概率分布向量,表示每个类别的预测概率。
"""
y_pred = np.clip(y_pred, 1e-9, 1 - 1e-9) # 数值稳定性处理,将预测值限制在[1e-9, 1-1e-9]范围内
return -np.sum(y_true * np.log(y_pred))
def cross_entropy_segmentation(y_true, y_pred):
"""
y_true: 真实标签。这是任务的真实答案,通常由人类标注或事先知道。
对于分割任务(如语义分割),y_true是一个二维或多维数组,
表示每个像素对应的类别索引或 one-hot 编码表示。
y_pred: 预测标签。这是模型预测的结果。
对于分割任务,y_pred是一个三维数组,存储每个类别在每个像素位置的预测概率。
"""
y_pred = np.clip(y_pred, 1e-9, 1 - 1e-9) # 数值稳定性处理,将预测值限制在[1e-9, 1-1e-9]范围内
num_classes, height, width = y_true.shape
total_loss = 0
for c in range(num_classes):
for i in range(height):
for j in range(width):
total_loss += y_true[c, i, j] * np.log(y_pred[c, i, j])
return -total_loss
# 示例代码(假设类别是经过 one-hot 编码的)
y_true_class = np.array([0, 1, 0])
y_pred_class = np.array([0.1, 0.8, 0.1])
y_true_segment = np.random.randint(0, 2, (3, 32, 32))
y_pred_segment = np.random.rand(3, 32, 32)
# 计算分类任务损失
classification_loss = cross_entropy_classification(y_true_class, y_pred_class)
# 计算分割任务损失
segmentation_loss = cross_entropy_segmentation(y_true_segment, y_pred_segment)
print("分类任务损失:", classification_loss)
print("分割任务损失:", segmentation_loss)
UNet 的应用¶
医学图像分割领域。UNet 可以用于细胞分割,识别生物显微镜下的细胞边界,用于计数、分型等任务。UNet 也可以用于器官分割,识别 MRI 或 CT 等影像中的目标结构,比如识别脑部病变、肝脏肿瘤或肺结节等。UNet 应用于血管分割,可以识别眼底图像中的血管结构,有助于眼科疾病的诊断。
自然图像分割。对于街景分割任务,可用于识别道路、行人、车辆等元素,辅助无人驾驶、智慧交通等领域。对于航拍图像分割,UNet 可以从高分辨率的航空图像中提取建筑、湖泊、森林等地物信息,帮助城市规划和资源调查。此外,UNet 还能用于人像分割,可以识别人像照片的背景,实现背景替换、虚化等目的。
用于 AI 绘画,具体的用法就是把 UNet 用于扩散模型的噪声预测
与扩散模型结合¶
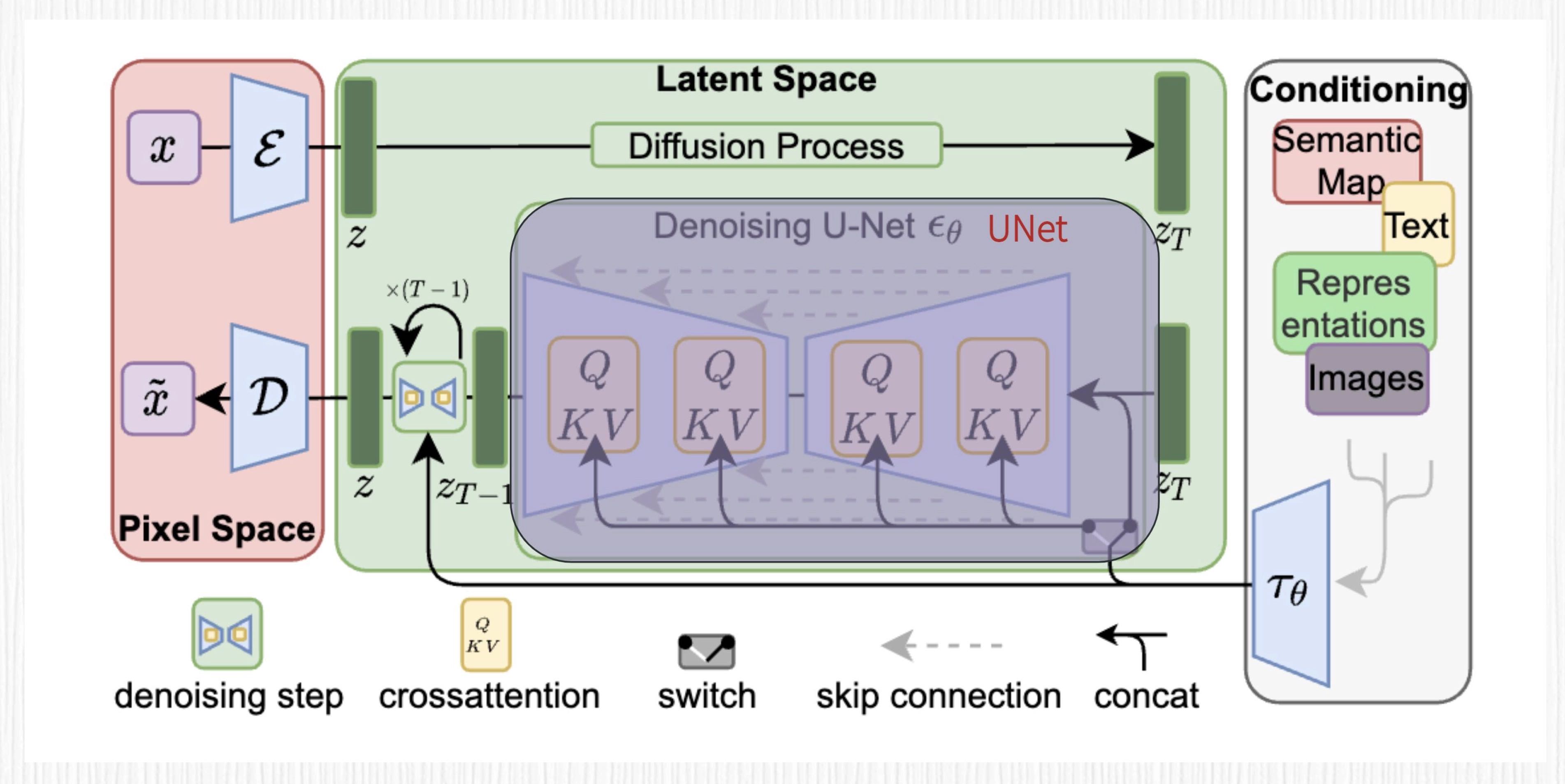
交叉注意力机制(Cross Attention):交叉注意力机制从源序列产生 K 和 V 向量,从目标序列产生 Q 向量。在 Stable Diffusion 中,我们将 Z_T 视为目标序列,得到 Q;将 prompt 描述经过 CLIP 模型得到的特征向量作为源序列,得到 K 和 V。¶
09|采样器¶
采样器存在的价值就是从噪声出发,逐步去噪,得到一张清晰的图像。
UNet 负责预测噪声,采样器负责“减去”噪声。这个过程反复迭代,我们就能从噪声图 x_t 得到 x_t−1 ,然后得到 x_t−2 ,最终得到 x_0 ,也就是清晰可辨的图像。
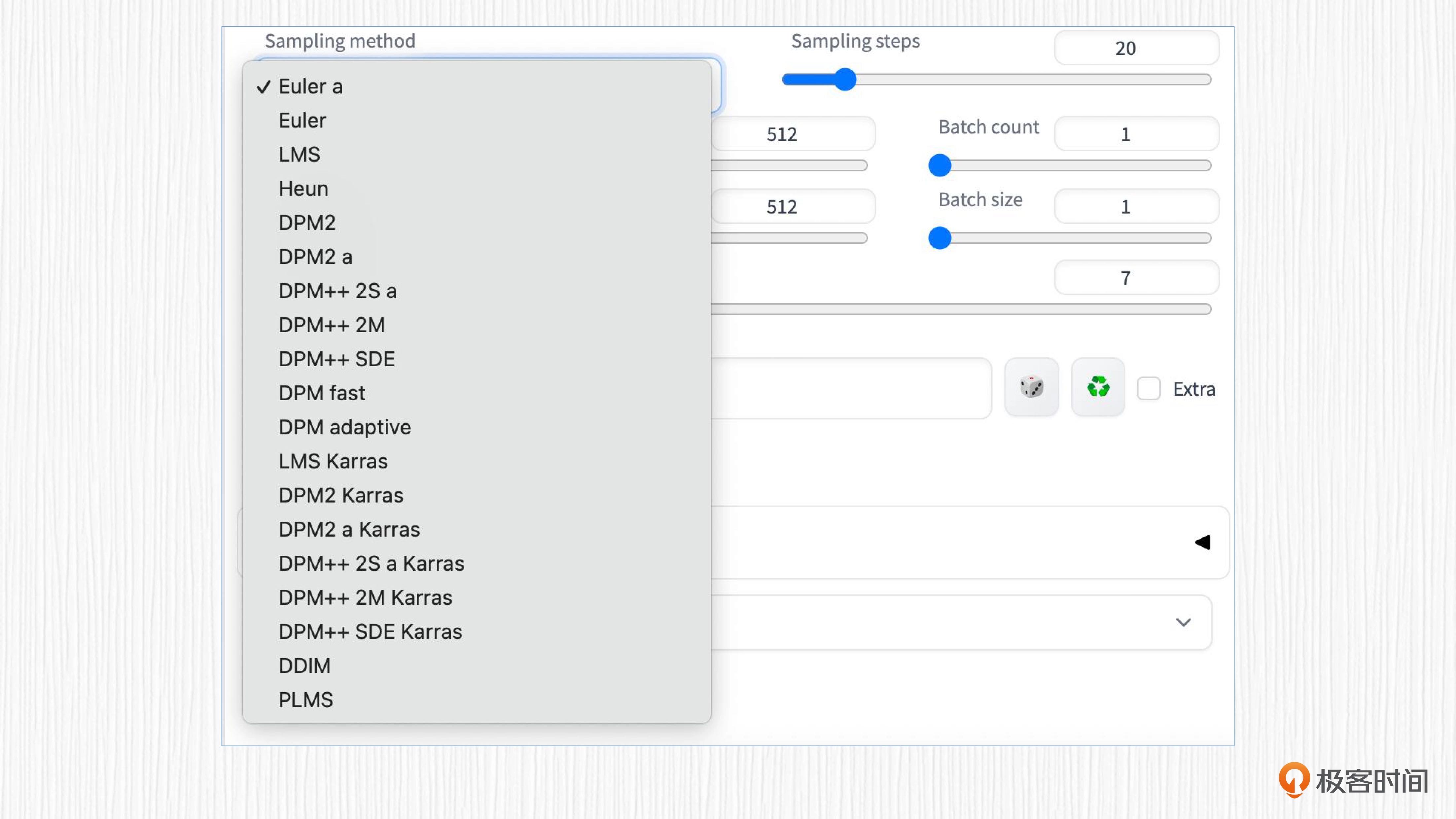
三个老派采样器¶
Euler,可以看作是最简单的求解器。
Heun,比欧拉法更准确但速度较慢。
LMS (Linear multi-step method),与欧拉法速度差不多,但(据说)更准确。
祖先采样器(ancestral samplers)¶
采样器的名称中有一个字母 a
如Euler a、DPM2 a、DPM++ 2S a、DPM++ 2S a Karras
祖先采样器会在每个采样步骤中向图像添加噪声。因为采样结果有一定的随机性,所以它们是随机采样器。
采用Karras 文章中推荐的噪声策略¶
采样器的名称中带有 “Karras” 标签
在接近去噪过程结束时,将噪声步长变小。研究人员发现这可以提高图像的质量。
过时采集器¶
最初发布的 SD 模型 v1 中附带的采样器。
DDIM(去噪扩散隐式模型)和 PLMS(伪线性多步方法)
DPM¶
2022 年发布的专为扩散模型设计的新采样器。
DPM(扩散概率模型求解器)和 DPM++ 采样器
使用效果¶

选择采样器的建议。
如果你想使用快速、新颖且质量不错的算法,最好的选择是 DPM++ 2M Karras,设置 20~30 步。
如果你想要高质量的图像,那么可以考虑使用 DPM++ SDE Karras,设置 10~15 步,但要注意这是一个计算较慢的采样器。或者使用 DDIM 求解器,设置 10~15 步。
如果你喜欢稳定、可重现的图像,请避免使用任何原始采样器(SDE 类采样器)。
如果你喜欢简单算法,Euler 和 Heun 是不错的选择。
10|CLIP¶
OpenAI 在 2021 年提出的 CLIP 算法。
在 AI 绘画的过程中,CLIP 的作用是理解我们给到模型的 prompt 指令,将 prompt 指令编码为模型能理解的“语言”。
最早提出 CLIP 模型并不是帮助 AI 绘画模型理解 prompt 指令,而是用于连接图像和文本这两种模态。如今,随着 AIGC 技术的大爆发,CLIP 模型又在 AI 绘画、多模态大模型等方向发挥了巨大价值。
模态(Modality)的概念:在深度学习领域,模态可以用于描述输入数据的不同形式,比如图像、文本、音频等。不同的模态可以提供不同的特征,使模型能够从更多的角度理解和处理数据。在实践中,通过整合多种模态的信息,通常能够帮助模型获得更好的性能。
CLIP 的提出背景¶
在 NLP 领域,早在 2020 年,OpenAI 便已经发布了 GPT-3 这个技术,证明了使用海量互联网数据得到的预训练模型可以用于各种文本类任务,比如文本分类、机器翻译、文本情感分析、文本问答等,GPT-3 的工作直接衍生出后来大火的 ChatGPT。
在 CV 领域里,最常见的模式还是使用各种各样既定任务的数据集,通过标注员的标注获得训练样本,针对特定任务来训练。CV 任务千千万,便催生了各式各样的数据集,比如图像分类、目标检测、图像分割、图像生成等。不过,在每个训练集上得到的模型通常只能完成特定的任务,无法在其他任务上推广。
CLIP 被提出之前主要有这样两个痛点:
第一,CV 数据集标注是个劳动密集型任务,标注成本高昂。
第二,每个 CV 模型通常只能胜任一个任务,无法轻易迁移到新的任务。
CLIP 解决方案¶
CLIP 工作的初衷:将 GPT-3 的经验迁移到图像领域,使用海量互联网数据做一个大一统的模型,同时能够很好地支持各种图像任务,比如图像分类、文字识别、视频理解等等
要达成这个目的,有两个关键点,一是怎么利用海量的互联网数据,二是如何训练这样一个模型。
数据来源¶
首先,为了解决数据的问题,OpenAI 选定了 50 万条不同的查询请求,从互联网上获取到 4 亿图像 - 文本对,来源包括 Google 这类通用搜索引擎和 Twitter 这类垂直领域社区。
互联网上天然就存在已经标注好的 CV 数据集,而且每天还在飞速新增。此外,使用互联网数据的另一个优势是它的数据非常多样,包含各种各样的图像内容,因此训练得到的模型自然就可以迁移到各种各样的场景。
监督信号¶
CLIP 通过巧妙的设计利用了图像模态和文本模态的对应关系。CLIP 分别构造了一个图像编码器和一个文本编码器,将图像及其文本描述映射到一个特征空间,比如我们可以映射到 512 维度的特征空间。简言之,一张图或者一个文本描述,经过映射都是 512 个浮点数。
利用图文成对的关系,通过对比学习,驱动两个编码器模型学习到有效的特征提取能力。
具体思路是这样的。我们可以计算图像特征向量和文本特征向量之间的余弦距离,余弦距离的范围是 -1 到 1,越大表示距离越接近。CLIP 的训练目标是让对应的图像、文本得到的特征向量靠近,也就是余弦距离越大越好,让不对应的图像、文本得到的特征向量远离,也就是余弦距离尽可能小。
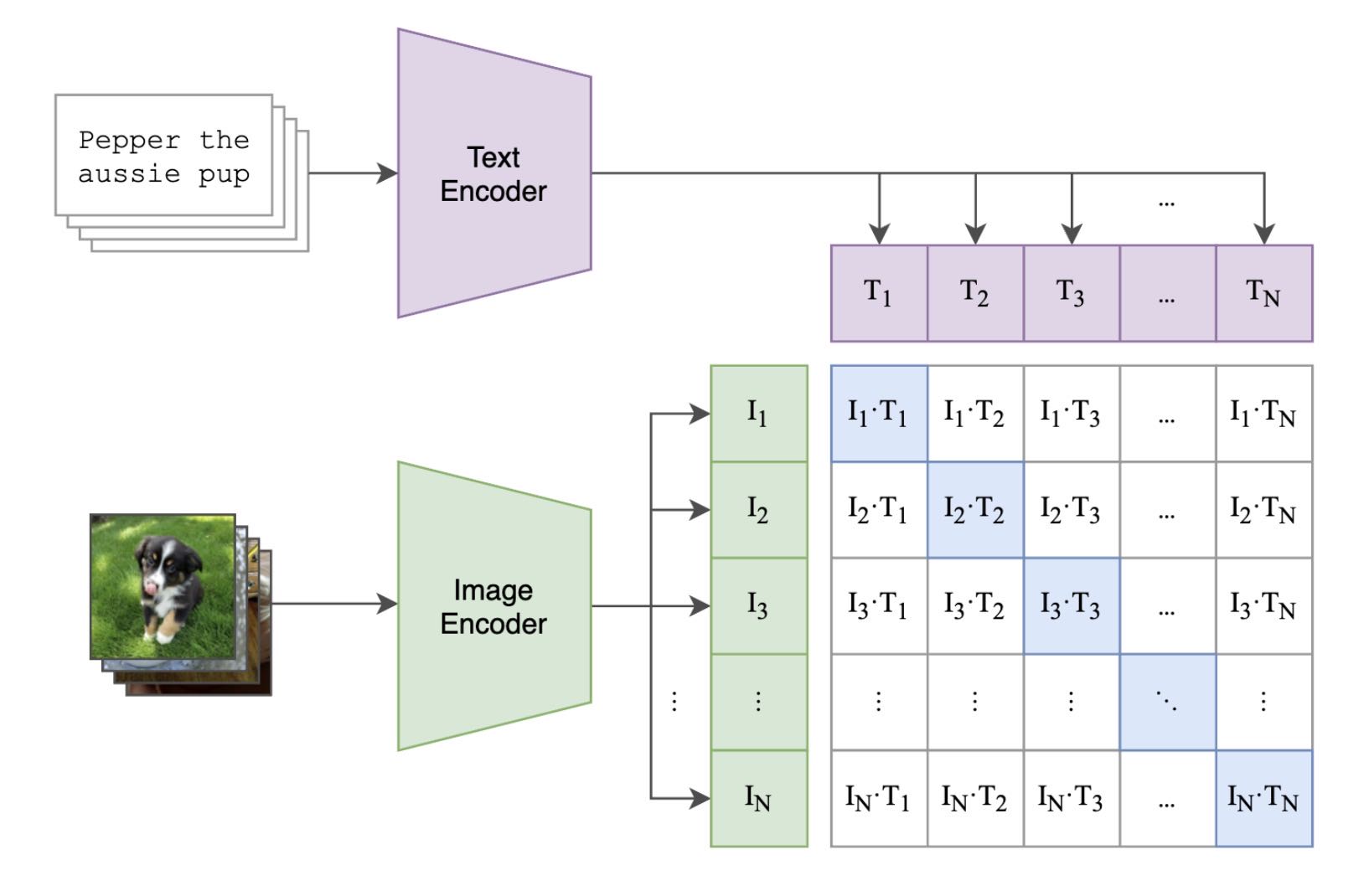
CLIP 通过 4 亿图文对数据进行对比学习,得到一个图像编码器和一个文本编码器。在使用 CLIP 时,成对的图像文本经过对应模态的编码器后,得到的特征会更接近。(图片来源:https://openai.com/research/clip)¶
这个过程的伪代码:
# image_encoder - 图像编码器可以使用ResNet或者Vision Transformer结构
# text_encoder - 文本编码器可以使用CBOW或者Text Transformer结构
# I[n, h, w, c] - 一个训练批次的图像
# T[n, l] - 一个训练批次的对应文本图像
# W_i[d_i, d_e] - 可学习的图像特征投影层权重
# W_t[d_t, d_e] - 可学习的文本特征投影层权重
# t - 一个可学习的温度系数
# 1. 提取图像和文本模态的表征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 2. 图像表征和文本表征分别映射到共同的多模态空间 [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 3. 计算余弦相似度 [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 4. 计算损失值
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
训练过程分为四步:提取表征、映射和归一化、计算距离和更新模型权重。
首先,使用图像编码器提取图像表征 I_f,使用文本编码器提取文本表征 T_f。
然后,分别引入一个线性投影(Linear Projection),将图像表征和文本表征分别映射到共同的多模态空间。这里线性投影的参数对应伪代码中的 W_i 和 W_t,然后将投影后的特征向量分别进行归一化,归一化后的表征平方和等于 1。
之后,我们要计算这批图文归一化表征两两之间的距离,距离范围是 -1 到 1,然后再乘以一个温度系数相关的数值项(伪代码第 18 行),这里的温度系数是一个可学习的参数。
最后,通过交叉熵损失函数进行模型监督,匹配的图文对距离拉近、不匹配的图文对距离拉远。

CLIP 进阶探索¶
CLIP 应用¶
经典的图像分类任务通常需要使用人工标注的标签数据来训练,训练完成后只能区分训练时限定的类别。
而CLIP使用的可以称为跨模态检索:由于 CLIP 见过 4 亿图文,拥有海量的知识,我们便可以直接通过跨模态检索的方式直接进行分类。以 ImageNet 的 1000 类别为例,得到 1000 个不同的 prompt。这 1000 个 prompt 经过预训练得到的文本编码器之后,便得到 1000 个文本表征;对于输入图像,我们经过预训练的图像编码器可以得到 1 个图像表征。将图像表征和 1000 个文本表征线性投影、归一化之后计算余弦距离,余弦距离最大的 prompt 对应的类别便是 CLIP 模型预测的类别。
检索方案的扩展性要强于分类方案,比如上面这个任务的候选类别,你可以随意设计。
再举个人脸识别的例子,如果我们把人脸识别当做是分类任务,那么每次系统中录入一个新人,都需要将分类类别数加一,然后重新训练模型;如果我们将人脸识别建模为检索任务,我们只需要像 CLIP 这样,对每个人脸提一个特征,然后通过检索的方式进行身份定位即可。这样就不需要重新训练模型了。
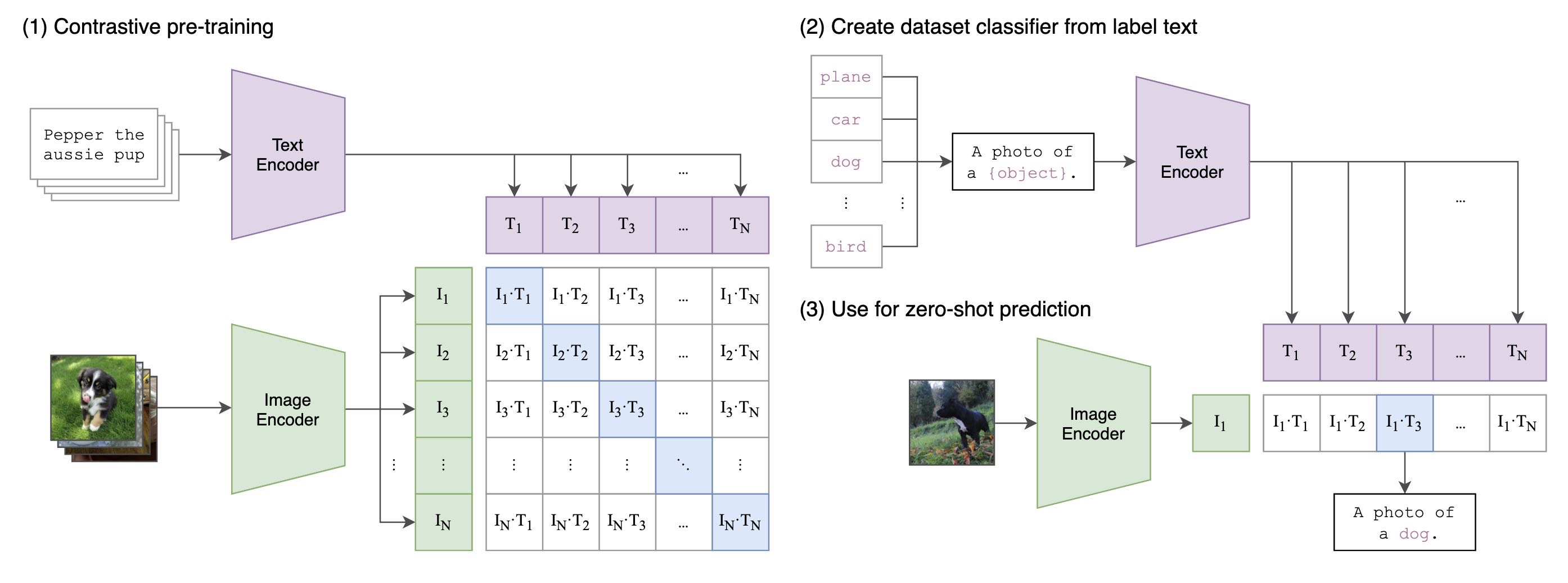
CLIP 通过检索为图像分类的整体过程¶
对于我们 AI 绘画这门课,CLIP 模型便是让 AI 绘画模型听我们话的关键!在 CLIP 的训练过程中,图像表征和文本表征被线性投影到共同的多模态空间,在文本生图的过程中,prompt 信息便可以通过 CLIP 抽取特征,然后指导模型作画。
DALL-E 2 模型,在 CLIP 的基础上进一步扩展,提出 unCLIP 结构,不仅能够用文本指导图像生成,还能输入图像生成多个相似变体。
CLIP 增强版¶
OpenAI 只是开源了 CLIP 模型的权重,并没有开源对应的 4 亿图文对。后来的学者便开始复现 OpenAI 的工作。比较有代表性的工作包括 OpenCLIP、ChineseCLIP 和 EVA-CLIP。
OpenCLIP 基于 LAION 公司收集的 4 亿开源图文数据 训练而成,相当于是对 OpenAI 的 CLIP 模型的复现。公开的 LAION 5B 数据集和开源的 OpenCLIP 代码库,打破了此前 OpenAI 的“数据垄断”。你可以点开`这个链接 <https://github.com/mlfoundations/open_clip>`_了解更多细节。
ChineseCLIP 的目标是用中文的图文数据完成 CLIP 训练,强化文本编码器的中文理解能力。比如说,ChineseCLIP 模型可以帮助 AI 绘画模型更好地理解中文。ChineseCLIP 使用大约 2 亿中文图文对数据进行训练,你可以点开`这个链接 <https://github.com/OFA-Sys/Chinese-CLIP>`_了解更多细节。
EVA-CLIP 是 2023 年 3 月由北京智源研究院提出的模型,通过提高训练效率和优化模型设计,取得了比传统 CLIP 更好的性能。感兴趣的同学可以点开`这个链接 <https://arxiv.org/abs/2303.15389>`_了解更多细节。
如何使用 CLIP¶
示例: Colab 链接
小结¶
CLIP 模型的两种常用用法
基于检索的方式为图像分类
实现 AI 绘画模型的 prompt 信息提取
原始论文(Learning Transferable Visual Models From Natural Language Supervision): https://readpaper.com/pdf-annotate/note?pdfId=4557522938392223745¬eId=1772676889632149504
11|VAE系列¶
【概念】潜在空间:通过神经网络,在保留原始数据的关键信息的条件下,将输入的原始数据压缩到一个更低维度的空间,得到一个低维的向量表示,并且这个低维的向量表示可以通过解码恢复出原始的数据。这里的低维空间就是潜在空间(latent space,也称为隐空间),低维的向量也叫潜在表示(latent representation)。你可以这样理解,潜在空间是较低维度的空间,用于表示原始数据的结构和特征。潜在表示便是原始数据在潜在空间中对应的特征向量。
VAE简介¶
VAE 的全称是变分自动编码器(Variational Autoencoder),在 2013 年被提出,是自动编码器(AE,Autoencoder)的一种扩展。你可能听过很多不同的名词,比如 AE、VAE、DAE、MAE、VQVAE 等。其实这些带 “AE” 的名字,你都可以理解成是一个编码器和一个解码器。
尽管术语一样,但是 VAE 和 Transformer 中的编码器、解码器解决的是不同类型的问题,并具有不同的结构和原理。
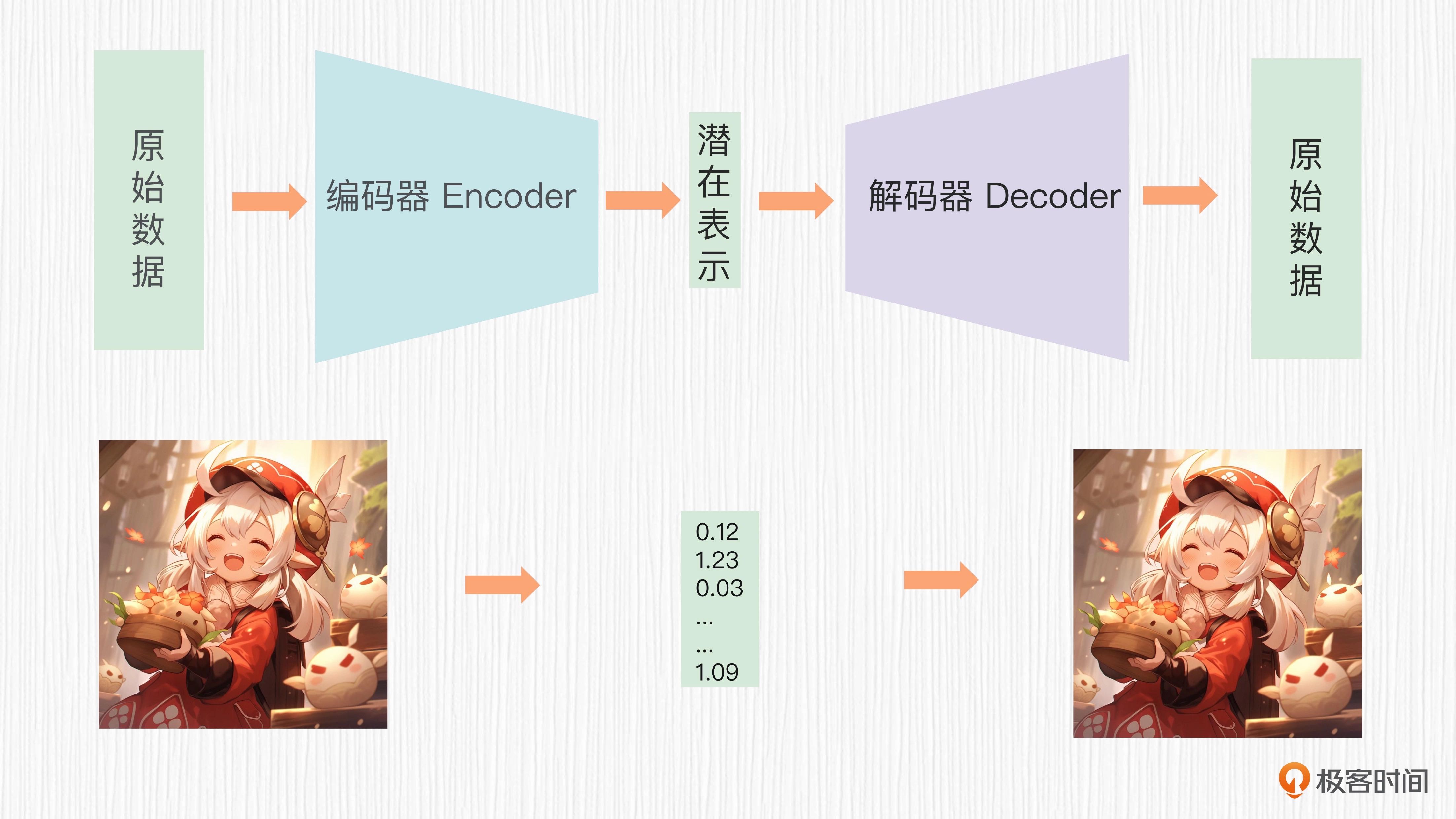
以 VAE 为代表的 “AE” 系列工作,都是希望编码器将原始数据编码成低维的潜在表示,并且这个潜在表示可以通过解码器近乎无损地恢复出原始数据。这里的原始数据,可以是图像、文本等多种模态。¶
VAE 细节探究¶
AE 的长处和短板¶
优点
首先是 AE 结构(自编码器)。AE 结构使用无监督的方式进行训练,以图像任务为例,使用大量的图像数据,依次经过编码器和解码器得到重建图像,训练目标是最小化原始数据与重构数据之间的差异。实际操作中,损失函数可以是 L1 损失或者 L2 损失。
AE 结构是无监督学习,是因为损失函数的计算只依赖于输入数据本身,而不涉及任何标签或类别信息。
缺点
第一,潜在表示缺乏直接的约束,在潜在空间中一个个孤立的点。如果对于输入图像的潜在表示稍加扰动,比如加上一个标准高斯噪声,解码器便会得到无意义的输出。
第二,潜在表示难以解释和编辑。我举个例子来说明,比如我们想得到“半月图像”的潜在表示,但手里又只有满月和新月图片。
改进
针对第一个缺点,DAE(去噪自编码器)的改进方式就是故意在输入数据中加入噪声,这样得到的潜在表示更加鲁棒。(DAE 只是改善了 AE 的表现,并没有真正补全 AE 的短板。)
VAE 的工作原理¶
真正解决 AE 两大痛点的工作就是 VAE。在 VAE 中,编码器的输出不再是潜在表示,而是某种已知概率分布的均值 μ 和方差 σ,比如最常用的高斯分布。根据均值、方差和一个随机噪声 ϵ,我们便可以根据下面的公式计算出最终的潜在表示,给到解码器。
VAE 中计算潜在表示的过程便是大名鼎鼎的重参数化技巧,解决了梯度不能直接通过随机采样操作进行传播的问题。
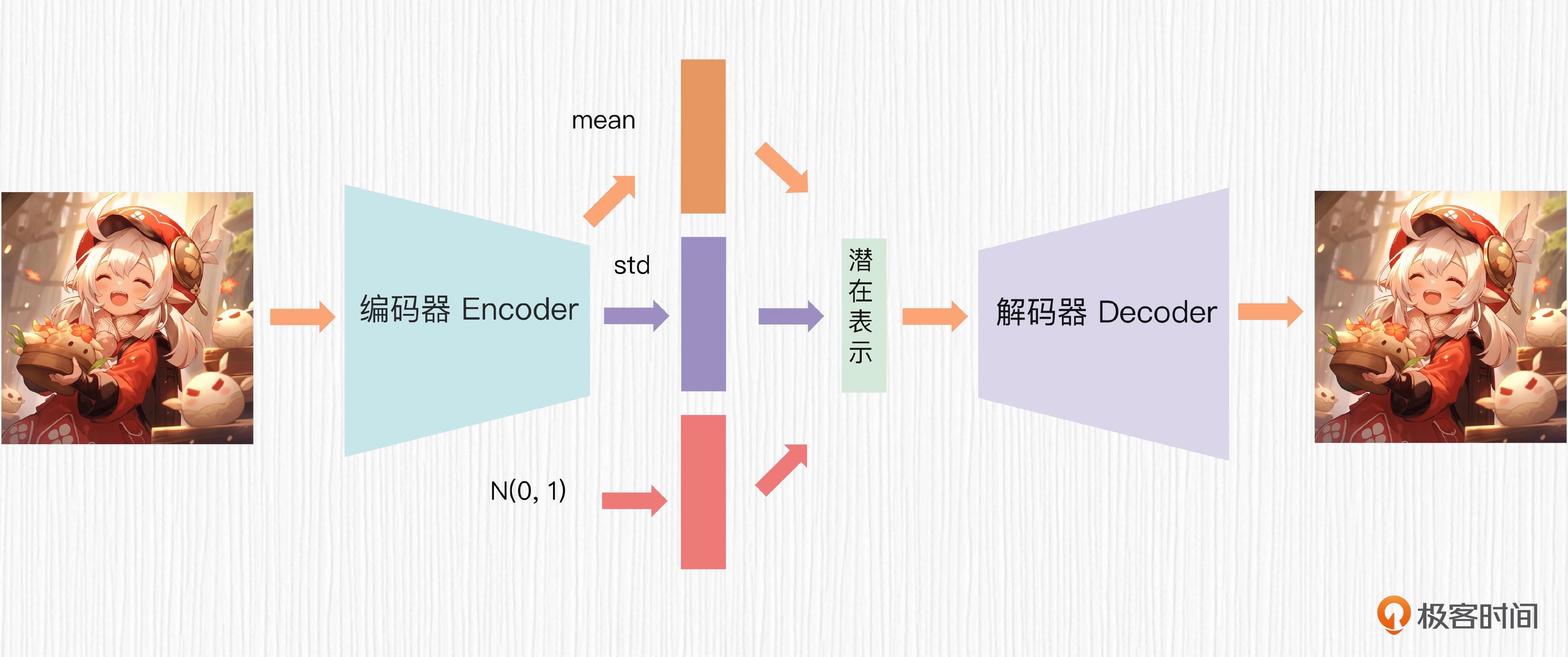
VAE 的整体过程¶
用 VAE 做图像插值¶
讲了这么多原理,也是在为 VAE 的应用做铺垫。VAE 不仅可以有效地压缩和重构图像,它得到的潜在表示还可以进行插值编辑。
使用 Stable Diffusion 中使用的 VAE 权重进行重建,从我们视觉来看,几乎是 100% 复原

左边是原始图像,右边是 VAE 重建图像¶
VAE 的应用¶
VAE 与经典任务¶
VAE 可以用于图像生成,比如人脸、动漫等角色的创建。以动漫角色生成为例,VAE 可以用来创建具有独特外观和特征的全新动漫角色。为此,我们首先需要使用现有的动漫角色数据集训练 VAE 的编码器和解码器。完成后,我们在潜在空间中采样,便可以得到新的角色图像。
VAE 可以用于自然语言处理,比如用于带情感的评论生成等任务。假设我们有一个餐馆评论数据集(包含正、负评论),我们可以使用第 7 讲提到的时序模型设计 VAE 的编码器,比如 RNN、LSTM、Transformer 等,得到潜在表示,然后再把潜在表示与特定情感信息(如正面或负面)一起传递至解码器进行训练。训练完成后,我们便得到了一个能够控制情感倾向的餐馆评论生成模型。
VAE 还可以用于聚类分析和异常检测。比如,在数据的潜在空间中把具有相似结构和内容的数据聚集在一起,为后续的聚类分析提供便利,或者用于识别潜在空间中明显异常的数据。
VAE 与扩散模型¶
原始的扩散模型需要在原图上进行加噪和去噪操作,过程非常耗时。Stable Diffusion 在 VAE 的潜在空间上进行加噪和去噪
VAE 模型是按照我们前面讲的 VAE 训练过程预先获得的。我们使用 LoRA 等技术训练自己的 AI 绘画模型时,并不会改变 VAE 模型的权重。但这并不意味着 VAE 对图像质量没有影响。其实在某种程度上,VAE 代表了 AI 绘画生成质量的上限。
虽然我们上面新月满月的例子证明了 VAE 的图像重建能力几乎无损,但如果是更困难复杂的场景,VAE 重建的图像会存在明显的模糊。
重新训练 VAE: https://github.com/cccntu/fine-tune-models/#fine-tuning-vae-decoder-of-stable-diffusion
总结¶
结构:VAE通常是简单的全连接网络或卷积神经网络;Transformer基于多头注意力机制,结构更复杂。
原理:VAE关注于在潜在空间中建立数据的概率分布;Transformer通过自注意力机制捕获长距离的依赖关系。
功能:VAE主要是为了生成数据和降维;而Transformer则是为了处理序列到序列的任务,捕获序列中的依赖关系。
Pytorch的VAE实现可以看这个代码:https://github.com/AntixK/PyTorch-VAE/blob/master/models/vanilla_vae.py
12|实战项目2: 动手训练一个你自己的扩散模型¶
关键知识串联¶
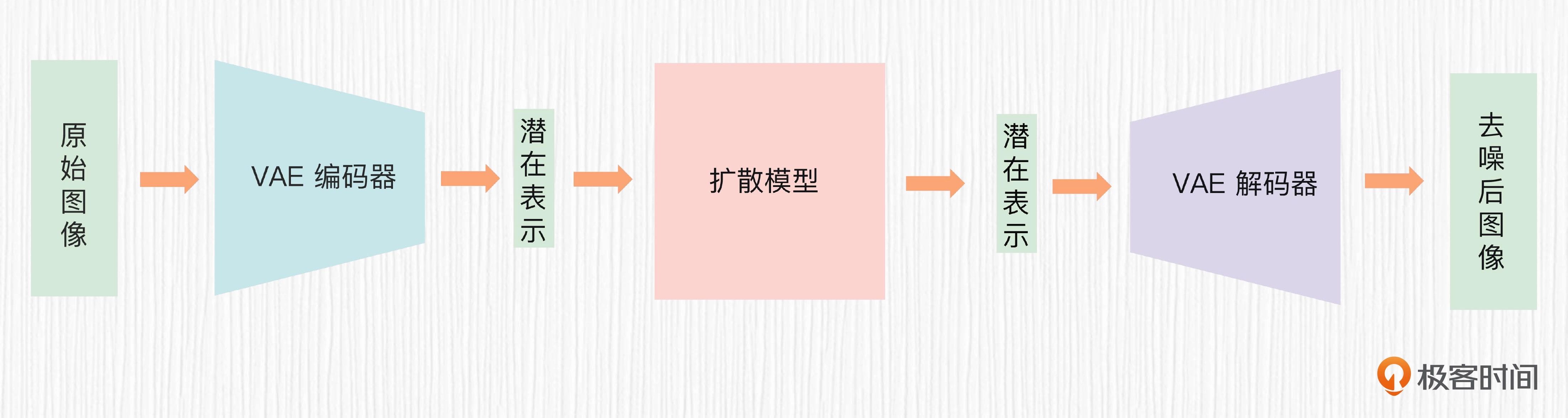
标准扩散模型的训练过程包含 6 个步骤,分别是随机选取训练图像、随机选择时间步 t、随机生成高斯噪声、一步计算第 t 步加噪图、使用 UNet 预测噪声值和计算噪声数值误差。
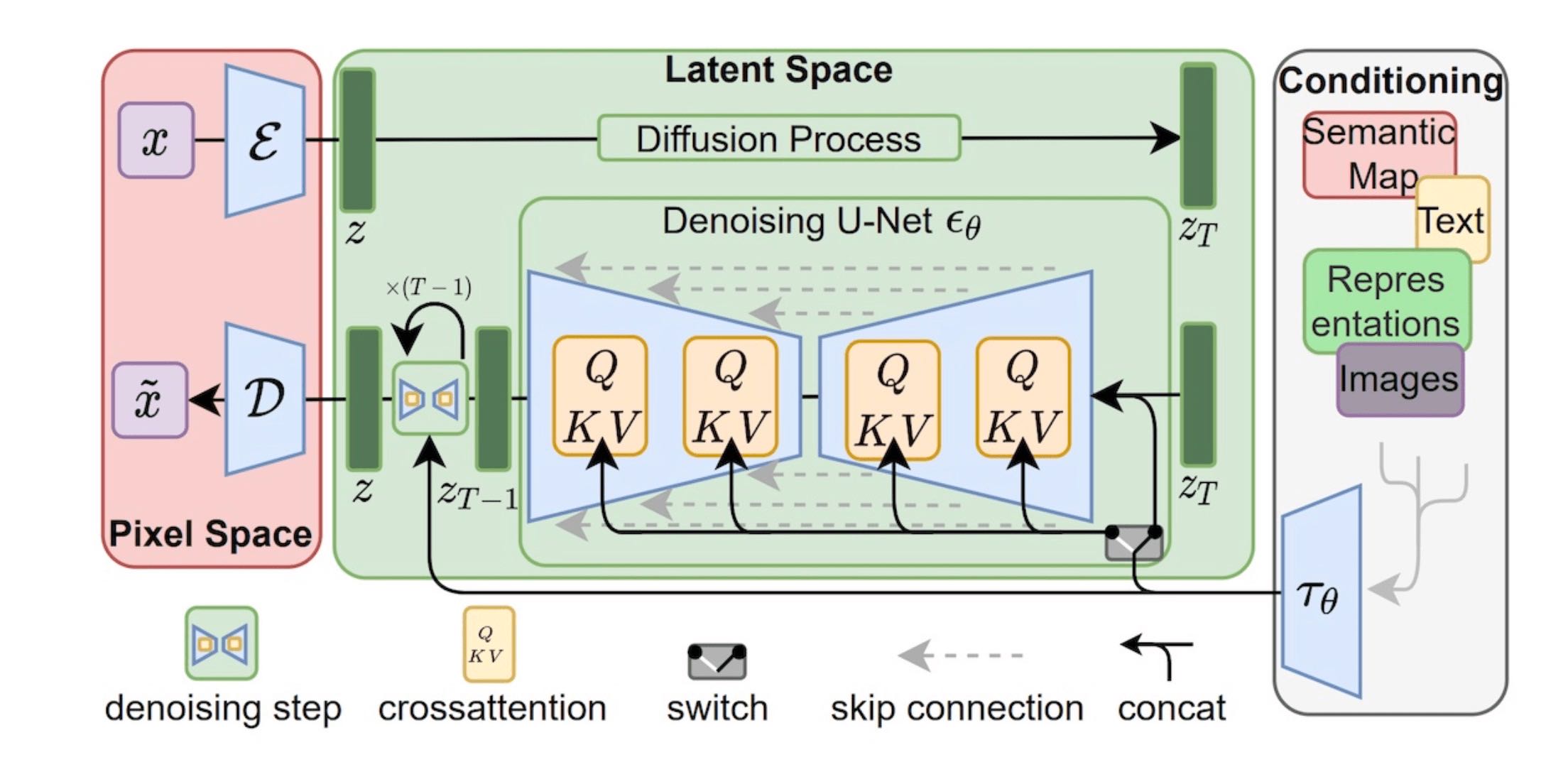
Stable Diffusion 在此基础上,增加了 VAE 模块和 CLIP 模块。VAE 模块的作用是降低输入图像的维度,从而加快模型训练、给 GPU 腾腾地方;CLIP 模块的作用则是将文本描述通过交叉注意力机制注入到 UNet 模块,让 AI 绘画模型做到言出法随。
在 Stable Diffusion 中,还有很多其他黑魔法,比如无条件引导控制(Classifier-Free Guidance)、引导强度(Guidance Scale)等
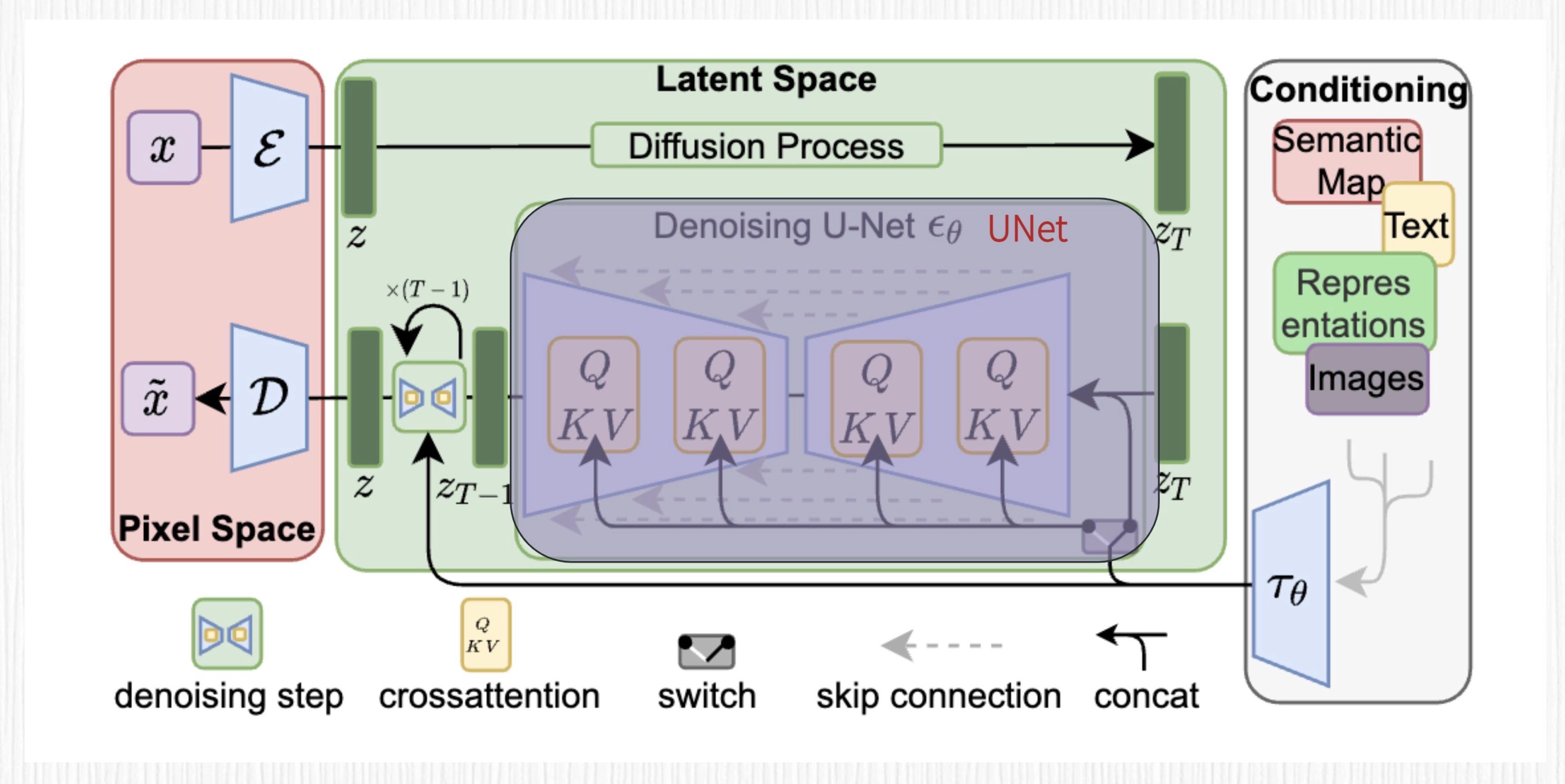
图中最左侧粉色区域便是 VAE 模块,最右侧的条件控制模块便可以是 CLIP(也可以是其他控制条件),而中间 UNet 部分展示的 QKV 模块,便是 prompt 通过交叉注意力机制引导图像生成。¶
训练扩散模型¶
通过两种方式来训练扩散模型。
第一种是使用 denoising_diffusion_pytorch 这个高度集成的工具包
第二种则是基于 diffusers 这种更多开发者使用的工具包。
进阶到 diffusers 训练¶
微调 Stable Diffusion¶
diffusers 官方提供的训练代码: https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py
比于上面提到的标准扩散模型训练,核心也只是多了 VAE 和 CLIP 的部分。
要进一步确认文本描述如何通过交叉注意力机制起作用: 推荐你去看看 UNet2DConditionModel 这个模块的代码
如何调用各种 SD 模型¶
总结¶
评论¶
换脸换衣服这类任务选择生成能力较强的真人模型,比如墨幽人造人、Realistic这类
关掉NSFW检测,可以参考这个链接: https://stackoverflow.com/questions/73828107/how-to-fix-nsfw-error-for-stable-diffusion
进阶篇:从 DALL-E 2 到 Stable Diffusion (5讲)¶
13|前浪DALL-E 2¶
初识 DALL-E 2¶
DALL-E 2 是 2022 年 4 月由 OpenAI 发布的 AI 绘画模型,它的绘画效果相比过去的工作有了质的飞跃,而且它提出的 unCLIP 结构、图像变体能力也被后来的方法所效仿。
DALL-E 这个名字源自西班牙艺术家 Salvador Dali 和皮克斯动画机器人 Wall-E 的组合。
功能:
1. 基于文本描述生成高清图像
2. 生成图像变体(对经典画作进行“魔改”)
3. 图像的融合
4. 局部编辑

生成图像变体(对经典画作进行“魔改”)¶

图像的融合。比如输入两张图片,DALL-E 2 可以对两张图片进行插值,生成融合后的新图片。这里的融合既可以是图像风格上的融合,也可以是图像内容上的融合,或者是图像内容和图像风格二者的融合。¶

局部编辑。输入一张图片,DALL-E 2 可以根据我们的指令局部编辑图像,让我们仿佛拥有了指令级 PS 的能力。¶
工作原理¶
DALL-E 2 就是个“缝合怪”。我们把 CLIP 和扩散模型,或者 CLIP 和自回归模型组合到一起,引入大量图像文本数据进行模型训练后,便得到了 DALL-E 2。
标记 1。它是原始的 CLIP 结构,这部分在 DALL-E 2 的链路中是固定住的,无需训练。
标记 2。它代表 CLIP 的文本编码器提取的文本表征。文本表征是指根据输入的文本,用 CLIP 文本编码器提取得到的数值特征。图中三处标记为 2 的表征是完全相同的。
标记 3 和标记 4 是两种可以互相替代的方案。标记 3 代表需要训练的自回归先验模型,也称为 Prior 模型。先验模型的作用,就是将 CLIP 提取的文本表征转换为 CLIP 图像表征。
标记 4 表示需要训练的扩散先验模型。DALL-E 2 经过实验验证,使用扩散先验模型和自回归先验模型在生成效果上差不太多,扩散先验模型在计算效率上更有优势。
标记 5 是先验模块输出的图像表征,该表征类似于 CLIP 图像编码器提取的特征。
标记 6 则是扩散模型,作用是将上一步得到的图像表征转换为图像。
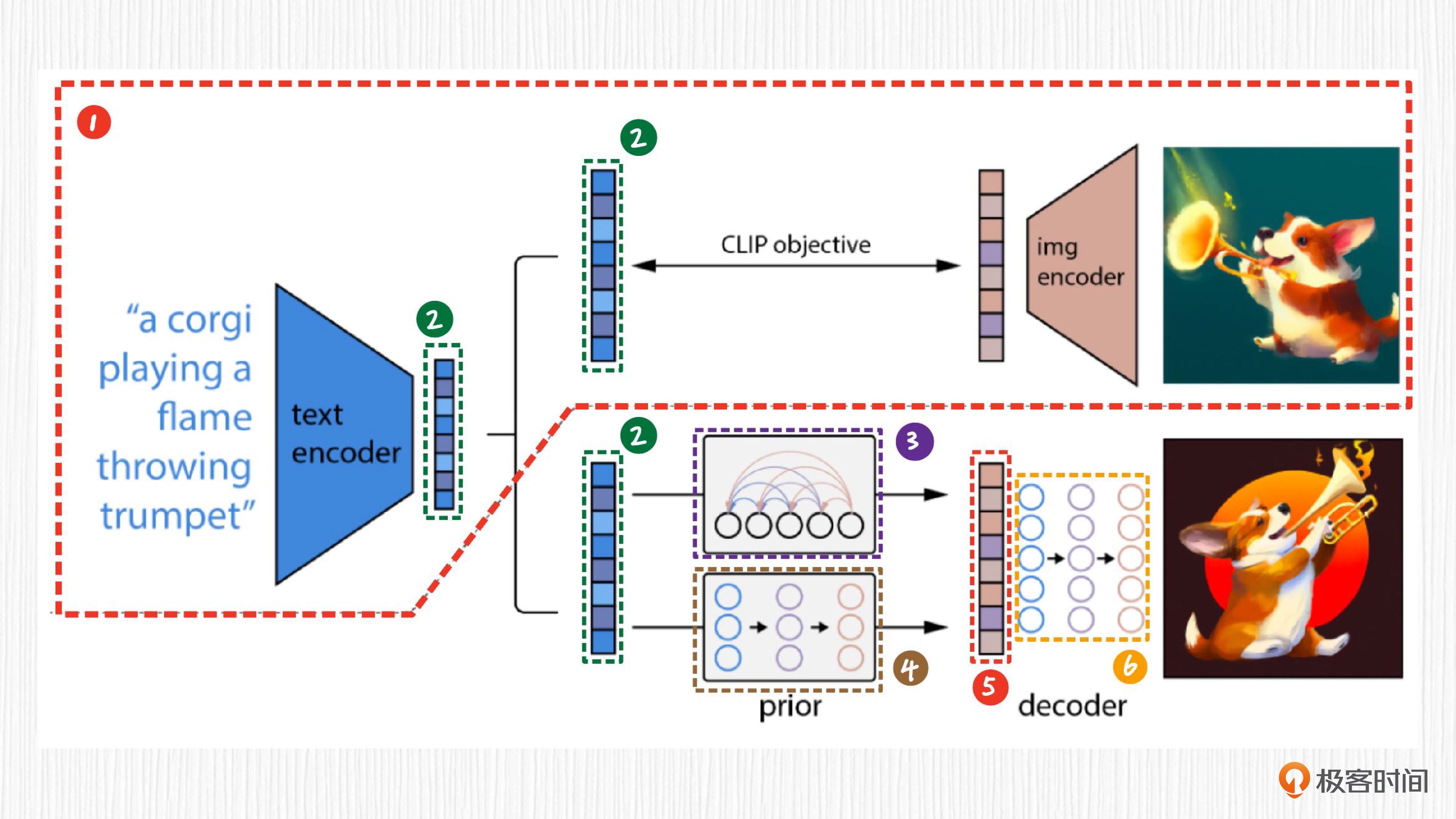
DALL-E 2 标记后的整体方案说明¶
DALL-E 2 的结构可以归纳为后面这三个步骤
首先,使用一个预训练好的 CLIP 文本编码器将文本描述映射为文本表征。
然后,训练一个扩散先验模型,将文本表征映射为对应的图像表征。
最后,训练一个基于扩散模型的图像解码器,该解码器可以基于图像表征生成图像。
这三步便是 DALL-E 2 实现 AI 绘画能力的全部过程。
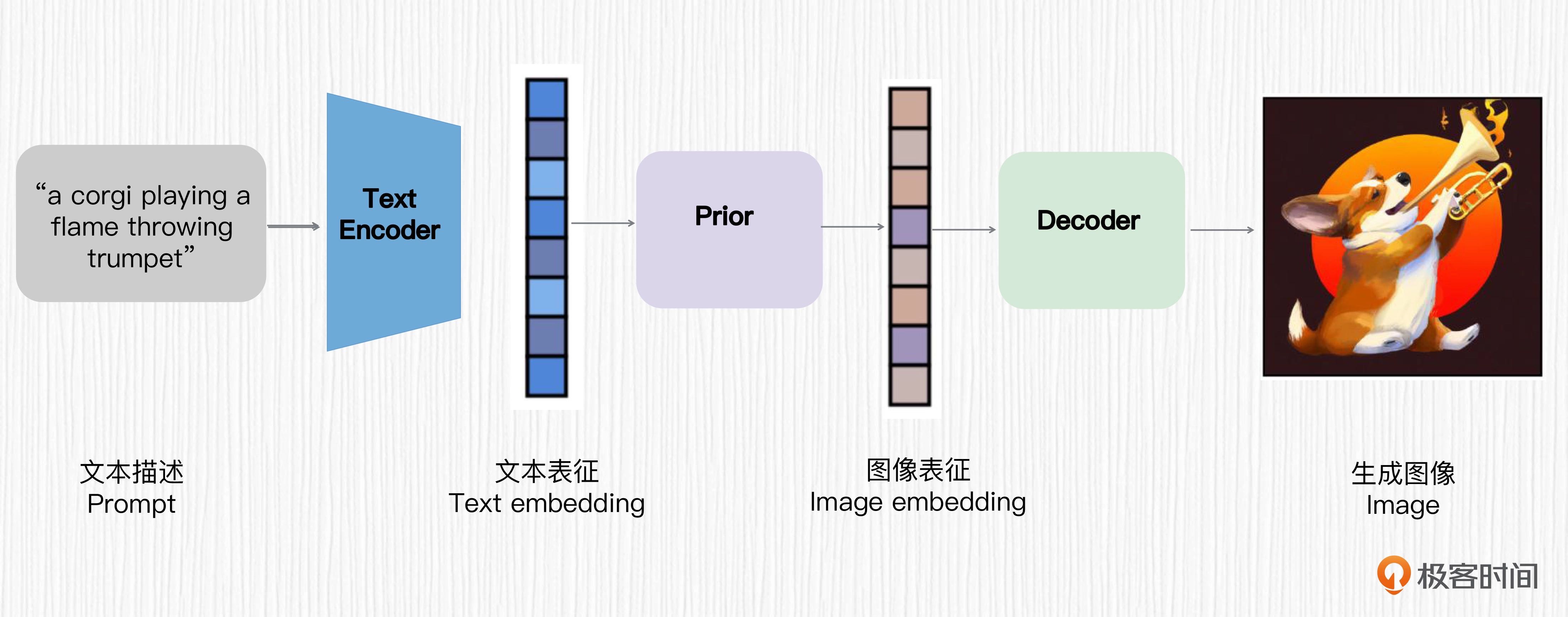
用一句话总结就是,DALL-E 2 设计的核心思路是,用 CLIP 提取文本表征,通过一个扩散模型将文本表征转换为图像表征,然后通过另一个扩散模型指导图像的生成。¶
扩散先验模型该如何训练¶
扩散先验模型的目标是将 CLIP 文本表征转换为 CLIP 图像表征。DALL-E 2 的扩散先验模型并没有使用 UNet 结构,而是直接使用一个 Transformer 解码器。
UNet 结构擅长解决图像分割问题,因为 UNet 的输入和输出都是类似于图像的特征图;而 Transformer 的输入输出是序列化的特征,更适合完成 CLIP 文本表征到图像表征的转换。基于 Transformer 的扩散先验并不是预测每一步的噪声值,而是直接预测每一步去噪后的图像表征。
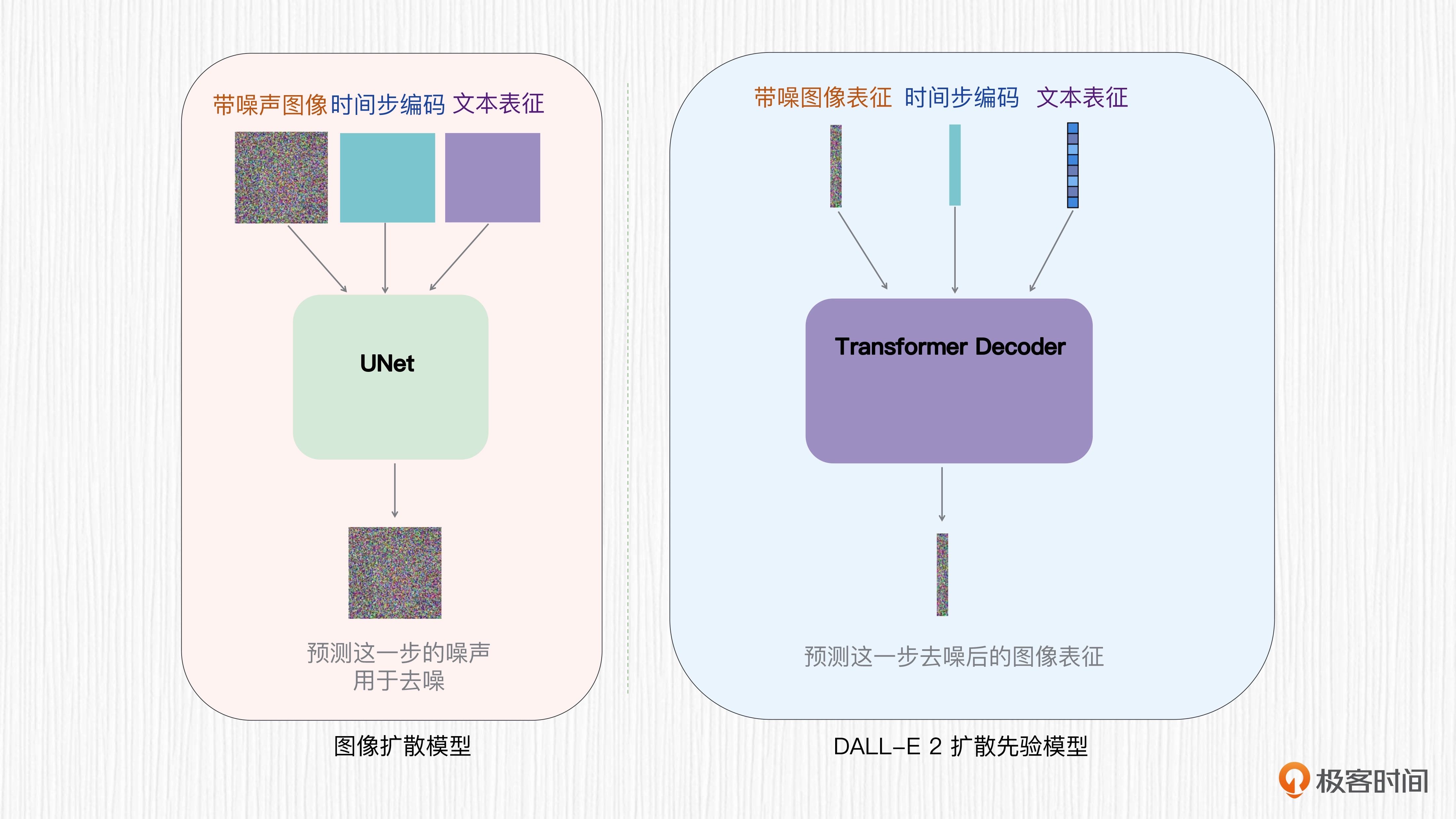
基于 Transformer 的扩散先验模型和普通扩散模型的区别¶
基于图像 - 文本成对训练数据,扩散先验模型的训练可以分为以下几个步骤
首先,使用预训练好的 CLIP 文本编码器提取文本描述的文本表征
然后,使用预训练好的 CLIP 图像编码器提取对应的图像表征
之后,随机采样一个时间步 t,以时间步 t、CLIP 提取的文本表征、加噪之后的图像表征作为条件,基于 Transformer 去预测下一步去噪后的图像表征
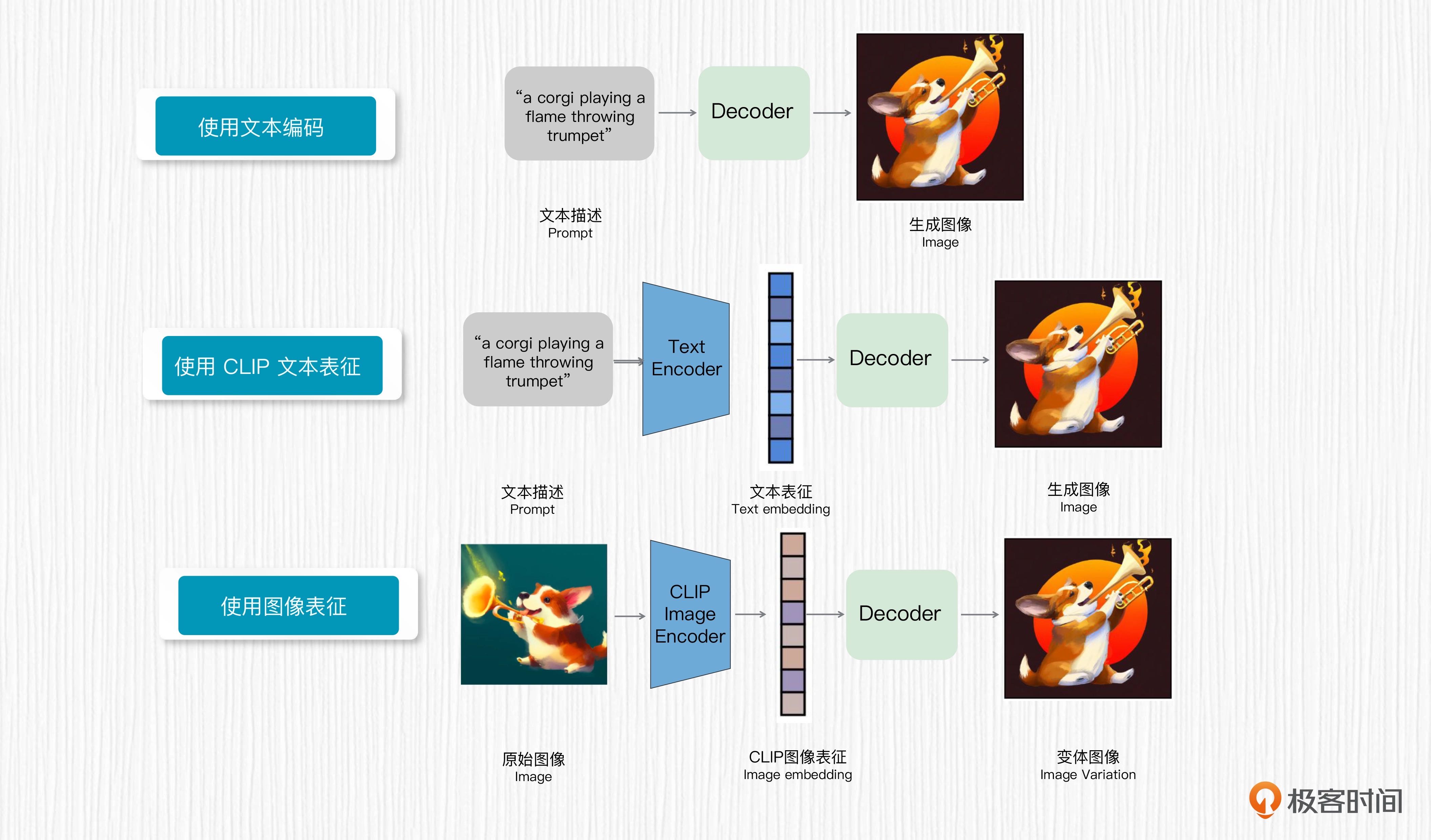
图像变体¶
虽然在生图效果、生图速度等方面,标准的 Stable Diffusion 毫不逊色于 DALL-E 2,但图像变体功能仍是 DALL-E 2 的亮点功能之一。
我们常常把 DALL-E 2 的文生图方案称为 unCLIP,这种方案和 Stable Diffusion 的技术链路是不同的。unCLIP 模型有一些独特的优势,比如用户输入一张图像,unCLIP 模型可以保留原始图像的关键信息,生成一系列图像变体。
预训练好的 CLIP 图像编码器可以提取到图像表征,文本编码器可以提取到文本表征。DALL-E 2 从图像表征直接生成图像,正好和 CLIP 从图像提取图像表征是一个相反的过程,这个过程被称为 unCLIP。
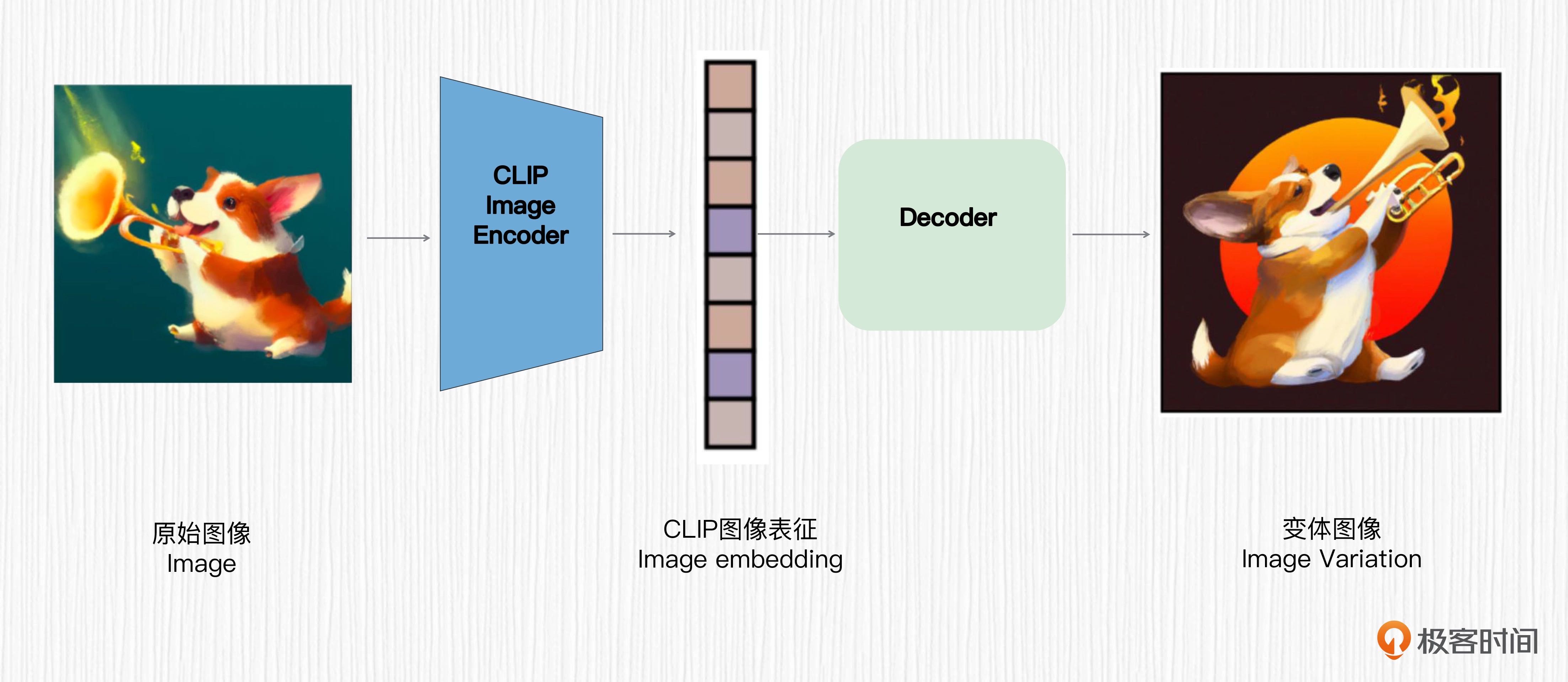
生成图像变体的过程:用户输入一张图像,使用 CLIP 的图像编码器提取图像表征作为图像解码器的输入,这样就实现了生成图像变体的能力。前面我们提到扩散先验模型的作用是得到类似于 CLIP 图像编码器提取的图像表征,而图像变体功能使用 CLIP 图像编码器提取图像表征,二者是类似的。unCLIP 的精妙之处就在这里¶
虽然 CLIP 的图像编码器是固定的,从给定原始图像得到的图像表征是一个确定性的过程。但扩散解码器每次从随机噪声出发,结合 CLIP 图像表征会生成变体图像,这个生成图像的过程是有随机性的,所以 DALL-E 2 才会轻易得到很多变体图像。
Imagen 模型并没有使用扩散先验,而是直接从文本表征生成图像,效果优于 DALL-E 2。从后来主流模型如 Stable Diffusion 的做法来看,扩散先验并不是必须的,代价是失去了生成图像变体的能力。
局限性¶
首先,DALL-E 2 并不擅长处理逻辑关系。如下图,我们要求其生成“蓝色方块上面放一个红色的方块”,对比 GLIDE 这个论文,DALL-E 2 得到的效果并不准确。

其次,DALL-E 2 并不擅长在生成的图像中写出要求的文字。比如我们要求 DALL-E 2 生成一幅图,“写着 Deep Learning 的标志板”,结果并不理想。

此外,DALL-E 2 不擅长生成复杂的场景,细节不足。比如我们要求其生成“一张高质量的时代广场的照片”,得到的结果很粗糙。
除了上面这些,DALL-E 2 生成的内容还存在一些种族偏见,比如一些特定的职业会生成特定的有色人种;DALL-E 2 也会生成一些色情暴力的内容,这是由于训练的数据中包括这类内容。
14|挑战者Imagen¶
OpenAI 推出的 DALL-E 2 后仅仅过去一个月,在 2022 年 5 月,Google 便发布了自己的 AI 绘画模型 Imagen。Imagen 在效果上显著优于 DALL-E 2,并且通过实验证明,只要文本模型足够大,就不再需要扩散先验模型。
2023 年的 4 月 28 日,后来者 StabilityAI,也就是搞出来 Stable Diffusion 这个模型的公司,发布了 DeepFloyd 模型。这个模型完美地解决了 DALL-E 2 不能在生成图像中指定文字内容的问题,是当下公认的效果最好的 AI 绘画模型之一。而DeepFloyd 模型的技术方案,恰恰就是我们今天要讲的主角 Imagen。
初识 Imagen¶
在 Imagen 的论文中,作者认为 Imagen 的两个核心优势是:图像真实感(photorealism)和更强的语言理解能力(language understanding)。

DALL-E 2 和 Imagen 在“Text-in-Image”能力的效果对比¶

DALL-E 2 和 Imagen 在“处理逻辑关系”能力的效果对比¶
工作原理¶
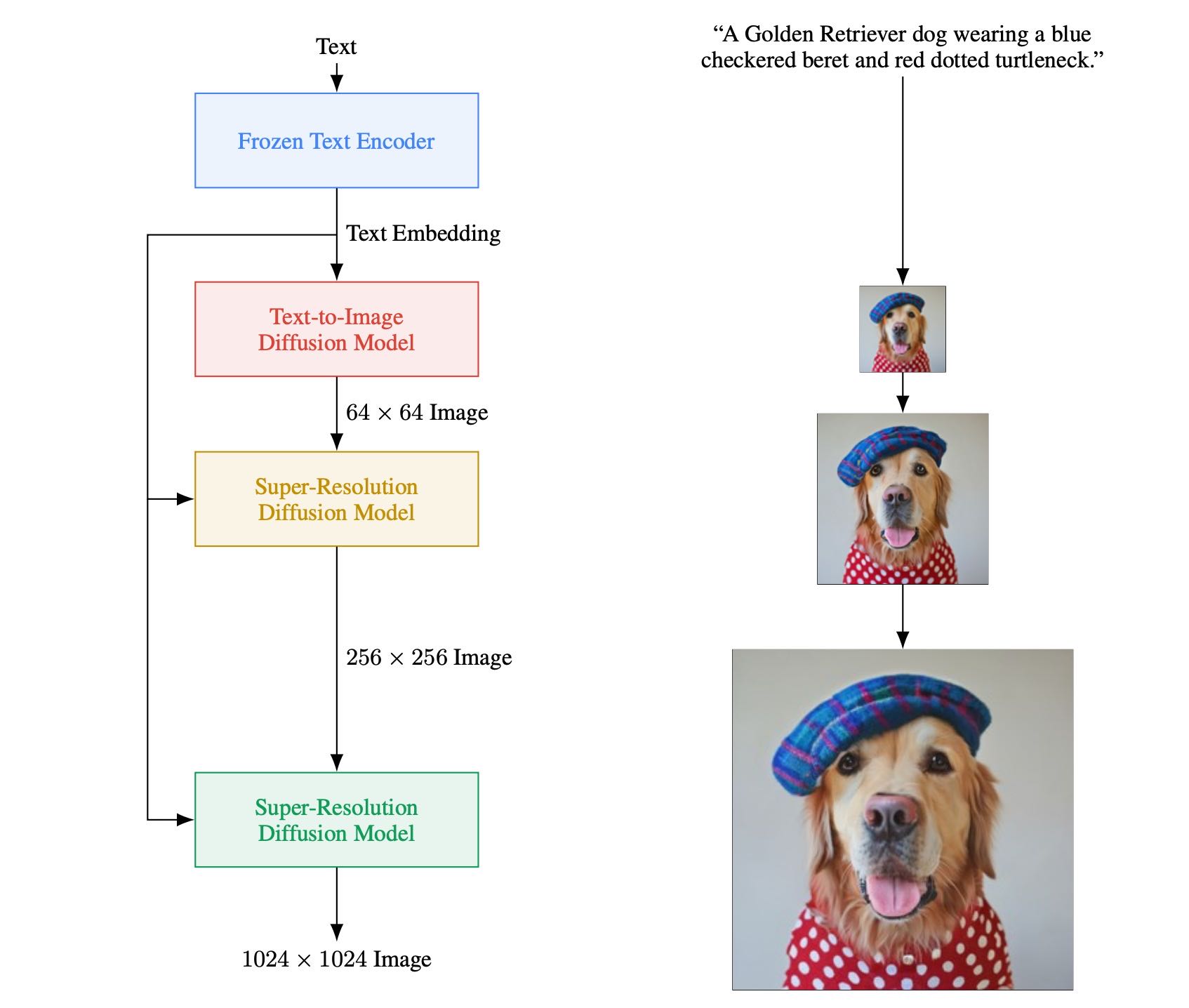
Imagen整体方案流程:首先要将文本表征、初始噪声作为扩散模型的输入,去噪后的图像作为目标输出,就得到了低分辨率扩散模型;然后将低分辨率图像、文本表征作为输入,去噪后的图像作为目标输出,得到更高分辨率的扩散模型。¶
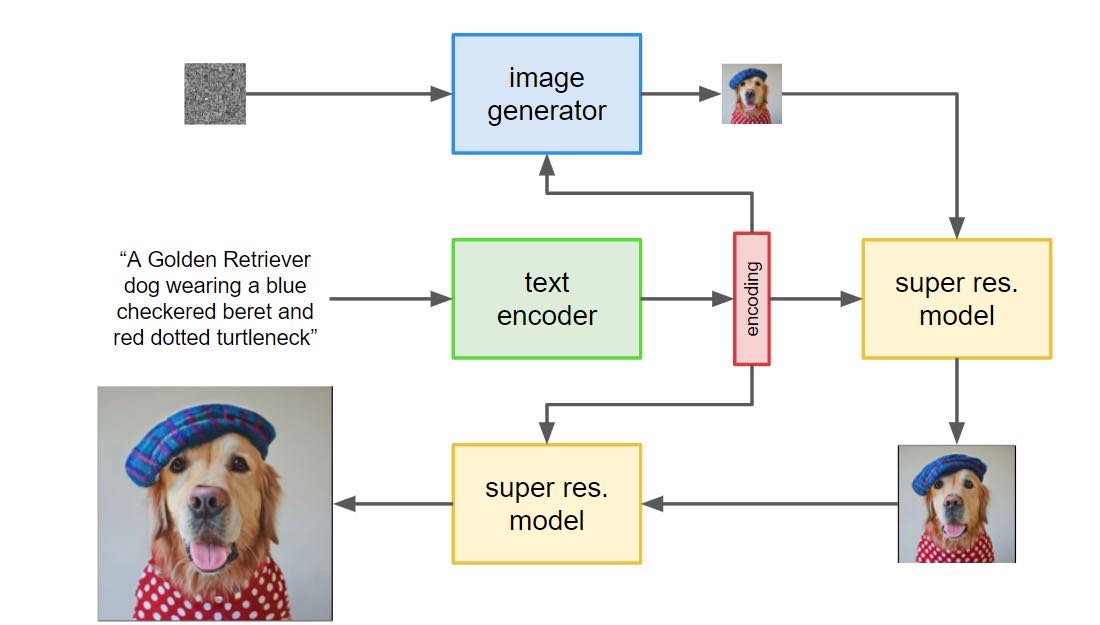
Imagen 相比于 DALL- E 2 在方法上主要有三点不同。
第一,Imagen 没有使用 CLIP 的文本编码器和图像编码器,而是直接使用纯文本大模型 T5 来完成文本编码任务。Imagen 用到的 T5 模型(T5-XXL)参数量共计 110 亿,CLIP 的文本编码器参数量约为 6300 万。这意味着 Imagen 拥有更强大的文本描述理解能力。
第二,Imagen 没有使用 unCLIP 结构,而是直接把文本表征输入给图像解码器,生成目标图像。
第三,Imagen 对扩散模型预测的噪声使用了动态阈值的策略,提升了 AI 绘画效果的稳定性。这一点我们稍后解释。
从文本表征到图像¶
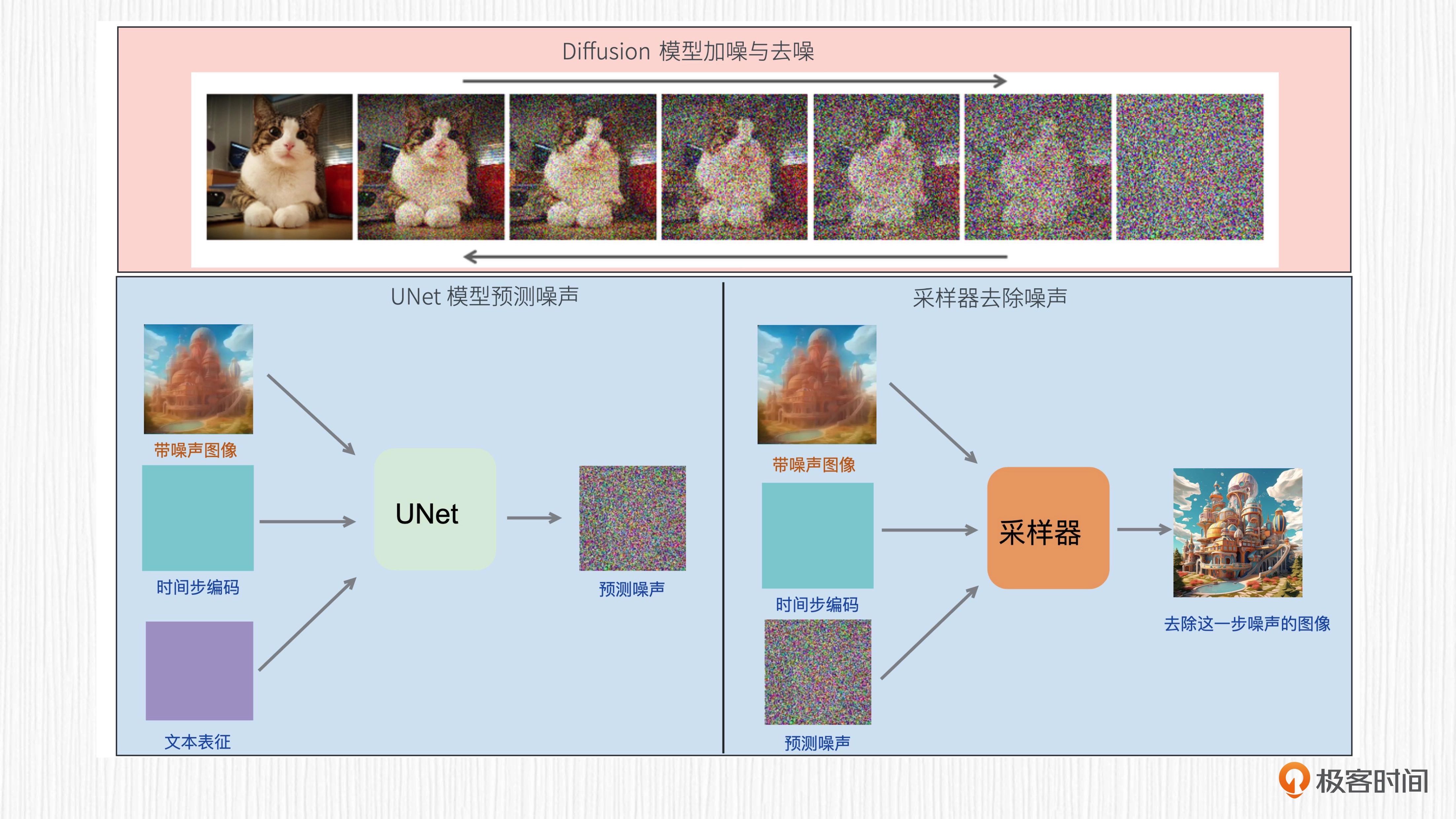
扩散模型的过程图解:扩散模型的主要功能是从噪声通过多步去噪的过程,得到一张清晰的图像。=>扩散模型生成图片的过程需要多个采样步,每一步都使用权重共享的 UNet 结构。对于文生图任务来说,UNet 的输入信息包括当前带噪声的图像、时间步编码、文本表征编码。¶
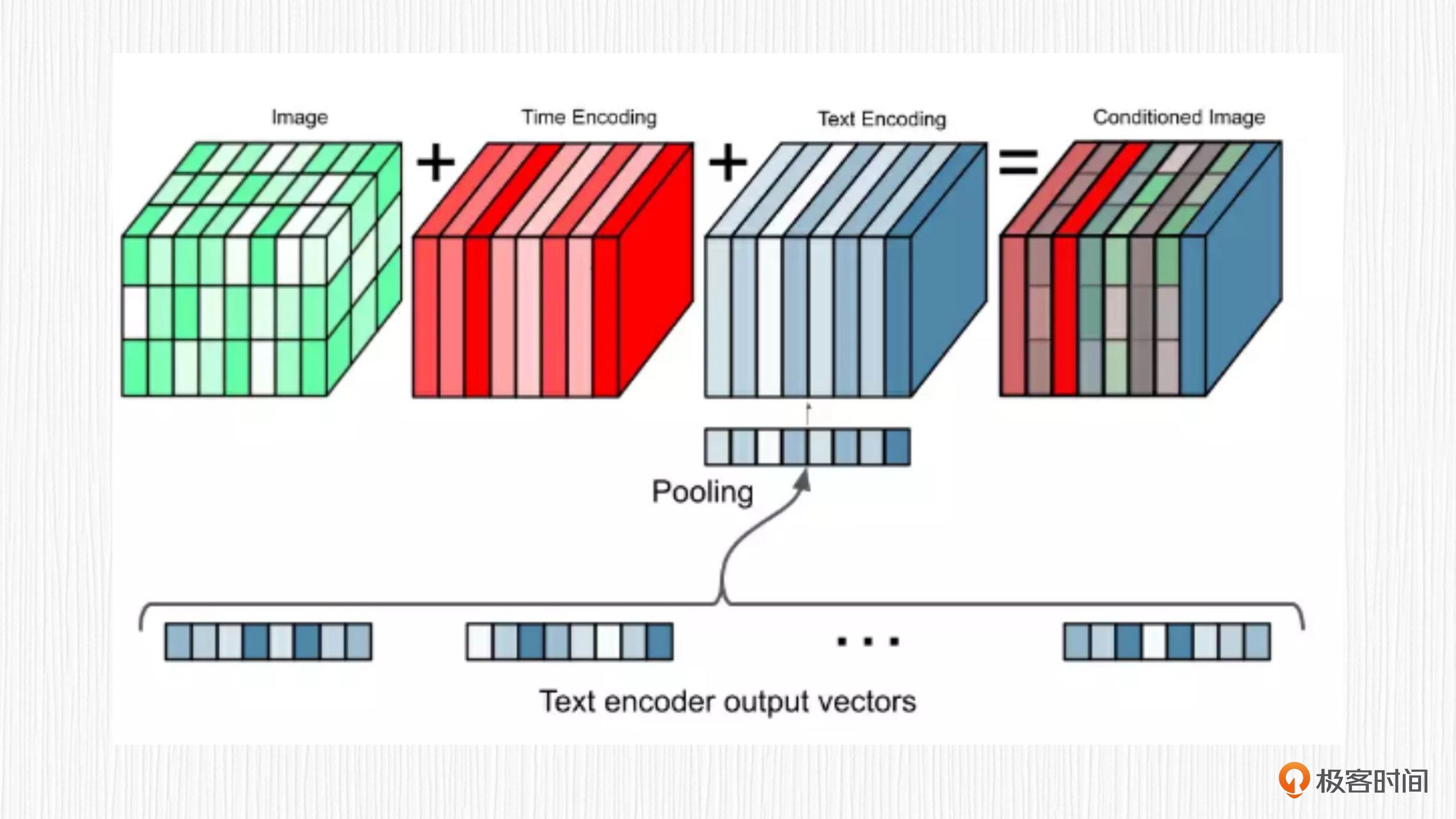
在 Imagen 项目中,图像解码器使用的同样是扩散模型。扩散过程需要多步来完成,逐渐从噪声得到清晰图像。对于每一步去噪,Imagen 都会将当前带噪声图像、时间步编码、文本表征编码进行求和,作为 UNet 模型的输入信息。通过这种方式,T5 模型提取的文本表征就能直接用来指导图像的生成了。这个过程既没有用到 CLIP,也没有文本表征到图像表征的显式转换,自然就不是 unCLIP 的方案了。¶
巧用动态阈值策略¶
动态阈值(Dynamic Threshold)策略为什么能生成更真实的图像。
在扩散模型生成图像的过程中,每一步都会预测一个噪声值,然后基于采样器去除这个噪声。Imagen 的作者发现,预测的噪声如果在数值上不做约束(比如限制到 -1 到 1 的范围),最终可能会生成纯黑图像。
静态阈值策略可以用于缓解这个问题。它的做法是把 UNet 预测的噪声超过 1 的部分全部设置为 1,小于 -1 的部分全部设置为 -1。静态阈值是一种常见的噪声图数值处理方法。作者实验发现使用静态阈值虽然有效果,但还是会产生图像过度饱和的问题。
在已有静态阈值的基础上,作者又提出了动态阈值的策略,解决了 AI 绘画过程中的黑图、过饱和等问题。具体就是先确定一个百分比,比如 90%。对于每一步去噪,都可以计算出一个数值 s,噪声图中 90% 的元素都位于 -s 到 s 的范围内。小于 -s 的部分全部设置为 -s,大于 s 的部分全部设置为 s。然后对于所有元素都除以 s,将最终噪声图标归一化到 -1 到 1 的范围。
这种策略可以有效地动态约束每一步去噪过程的数值范围,提升文生图过程的稳定性。
DeepFloyd IF¶
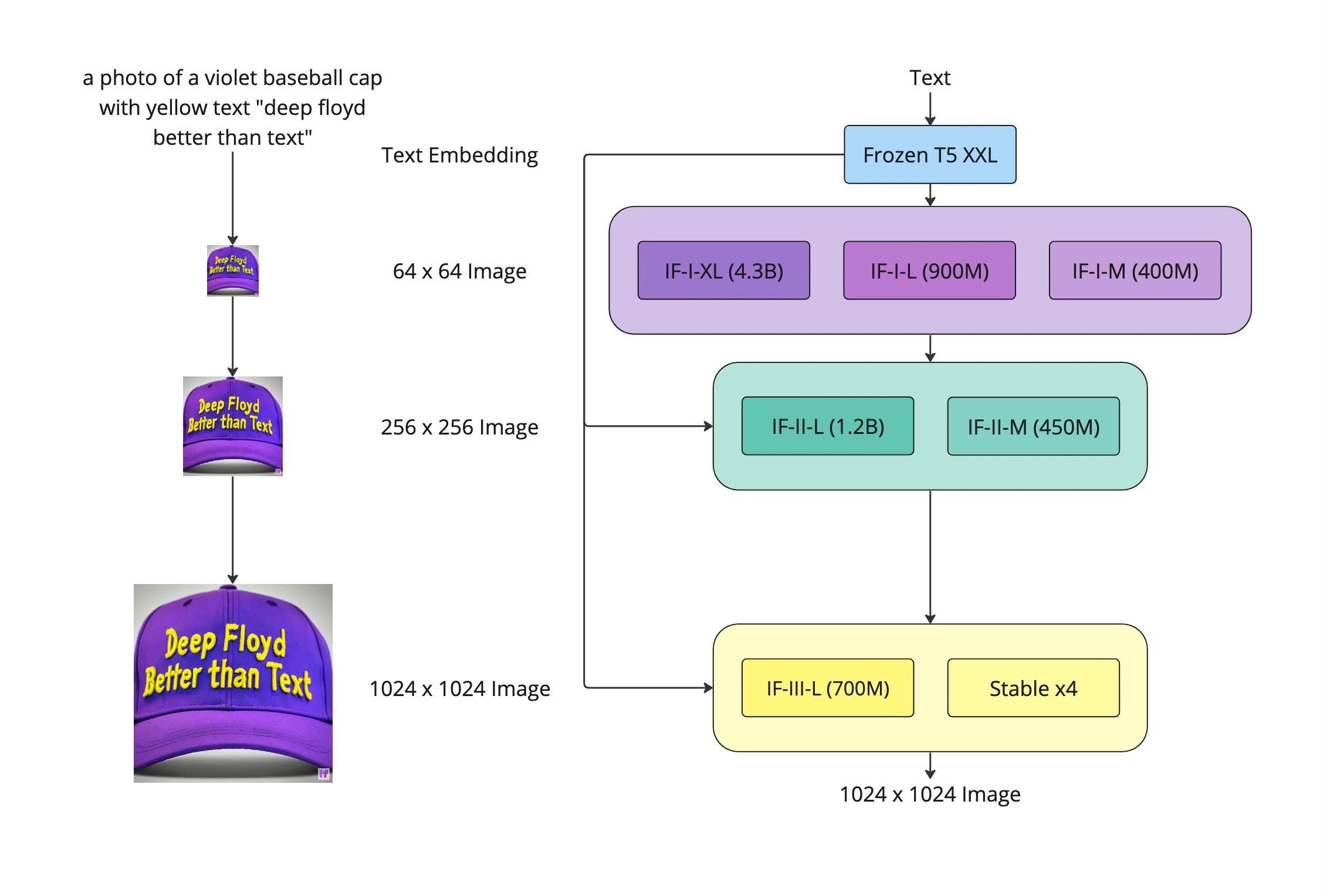
DeepFloyd IF 模型的整体结构¶
它和 Imagen 的结构一模一样。然而,DeepFloyd IF 这个模型,在生成图像的效果上显著优于原始的 Imagen。
DeepFloyd IF 模型能有这样的生成能力,主要源于这两个原因。
扩散模型解码器 IF-I-XL 的参数量达到 43 亿,大力出奇迹。
DeepFloyd 使用的是和 Imagen 一样的 T5 模型,但对 T5 得到的文本表征设计了一个叫最优注意力池化的模块。
评论¶
DeepFloyd IF是Imagen的延续;SD模型和Imagen都是基于扩散模型的AI绘画方案,SD模型中使用了VAE和CLIP,而Imagen用到的则是T5大语言模型做文本编码。生成效果而言,DeepFloyd IF和SDXL应该可以一比,几乎算是同时期的工作,效果优于Imagen和SD1.x。如果算力有限推荐使用SDXL。
Google的research团队最新Text-in-Image模型: https://ideogram.ai/
15|显微镜下的Stable Diffusion1¶
SD 模型的演化之路¶
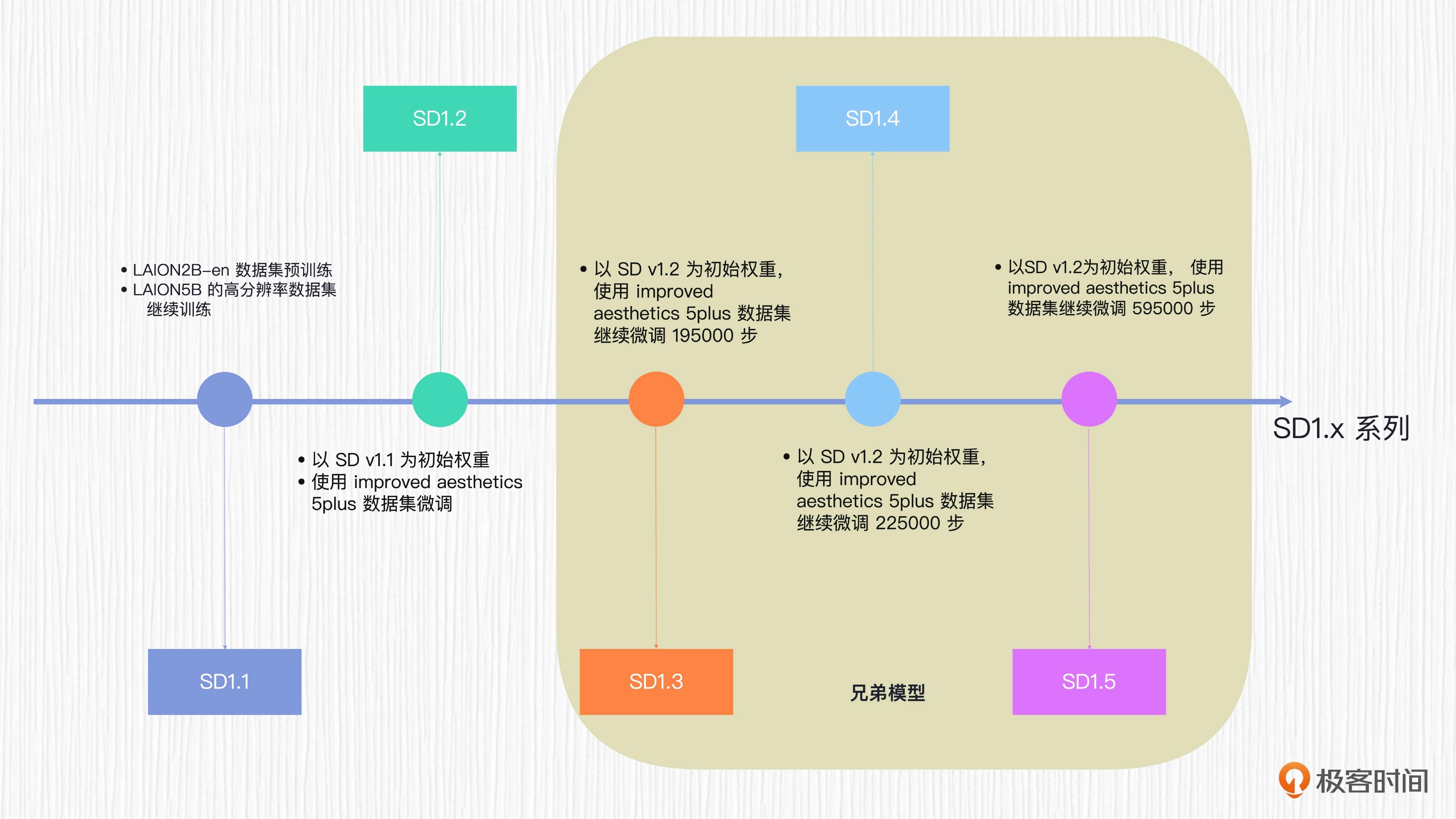
SD1.x系列¶
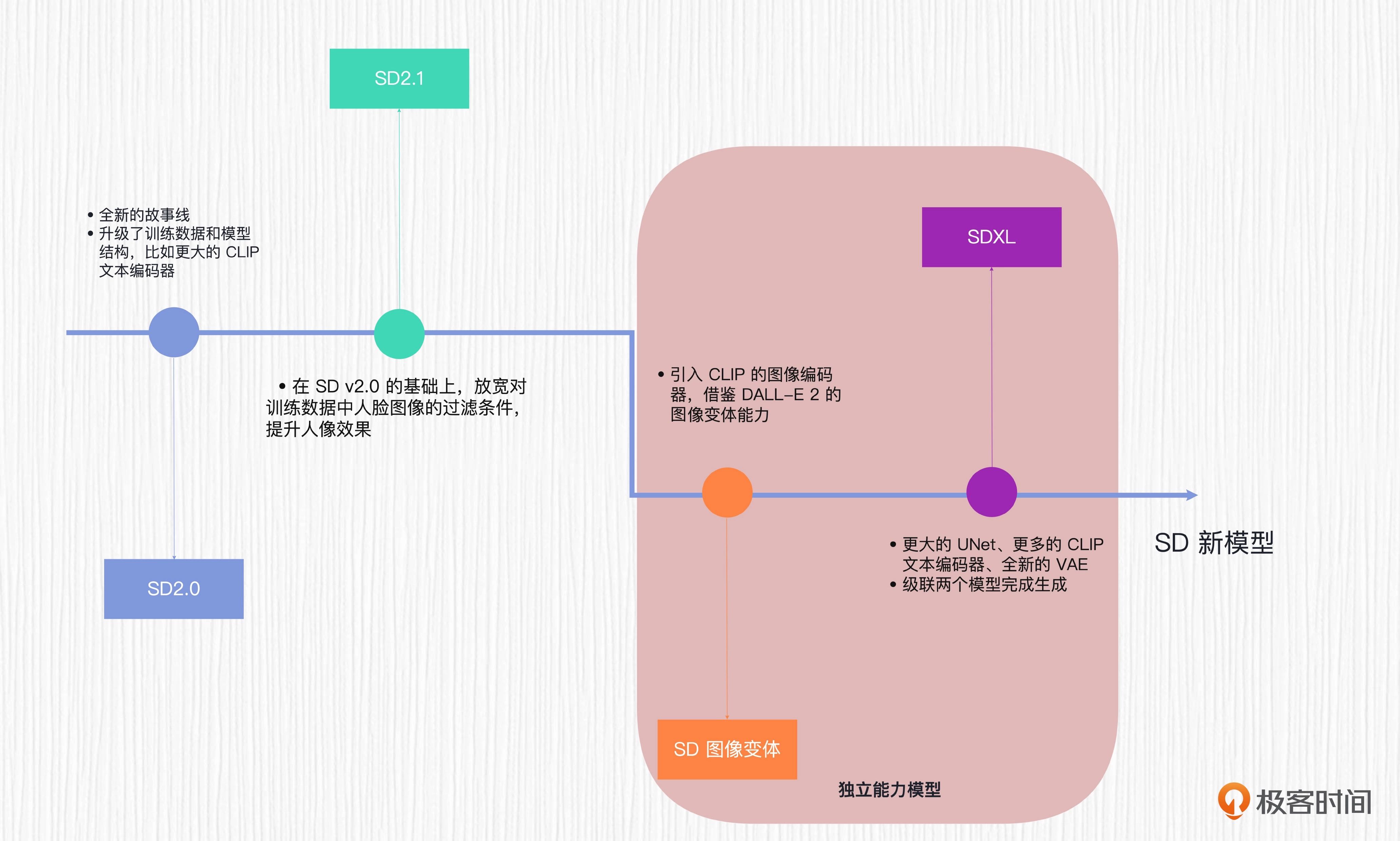
SD新模型¶
SD 模型简单串联¶
SD 的技术思路来自一篇名为潜在扩散模型的论文(2021 年底发表)。
原始扩散模型有两个短板。第一是不能通过 prompt 指令来完成 AI 绘画,而是从纯噪声出发,绘画过程有点类似于开盲盒。第二是加噪和去噪的过程都是在图像空间完成,使用高分辨率训练扩散模型,会占用较多的显存。
潜在扩散模型的前身便是扩散模型,它一方面将扩散过程从图像空间转移到了潜在空间,通过使用 VAE 变分自编码器来压缩和恢复图像,大大提高了速度和效率;另一方面利用 CLIP 等模型的文本编码器,将文本信息转化为文本表征,并通过交叉注意力机制将这些文本信息融入到图像信息空间中,最终实现文本生图。
文本引导原理探秘¶
有分类器引导¶
原始的扩散模型从随机噪声出发,并不能用文本控制内容。于是,OpenAI 在论文中便提出了有分类器引导。
具体做法是训练一个图像分类器,这个分类器需要在加噪之后的数据上进行训练。在文生图的过程中,每一步去噪都需要使用这个分类器计算梯度,用该梯度修正预测的噪声(对应 DDIM 采样),或者用来修正去噪后的图像(DDPM 采样)。
有分类器引导的方案需要训练额外的分类器,并且文本对于图像生成的控制能力不强,因此,它逐渐被无分类器引导的方法取代。我们熟悉的 DALL-E 2、Imagen 以及 SD 模型使用的方案都是无分类器引导。
无分类器引导¶
无分类器引导技术巧妙地引入了一个 Guidance Scale 参数,无需训练额外的分类器,就能实现文本对图像生成的控制。
具体来说,在每次扩散模型预测噪声的过程中,我们需要使用 UNet 预测两次。两次预测有着不同的目的:一次完成有条件的预测,一次完成无条件的预测。我们通过控制有条件预测和无条件预测的插值,便能更好地平衡生成图像的随机性、多样性和图文一致性。
缺点:相比有分类器引导,无分类器引导的计算成本几乎是翻倍的!
第一次预测是用 prompt 文本表征预测噪声结果,我们称之为条件预测。第二次则是使用空字符串的文本表征预测噪声结果,我们称之为无条件预测。
CFG: Classifier Free Guidance¶
当训练完成后,文生图的采样过程会用到有条件预测和无条件预测。然后通过引导权重 w(即 Guidance Scale)进行插值。在 WebUI 中,这个参数被称为 CFG Scale,就是 Classifier Free Guidance 的缩写。
引导权重越大,生成的图像与给定的文本越相关。一般来说,引导权重取 3-15 这个范围。继续加大权重,生成的图像容易出现各种不稳定的问题,如图像过饱和(颜色过于鲜艳以至于失真)。当引导权重设置为 0 时,相当于输入的文本信息对于 AI 绘画结果不产生任何作用,产生的图像内容是完全随机的。
注意力机制是如何起作用的¶
SD 的扩散模型是一个 0.86B 的 UNet
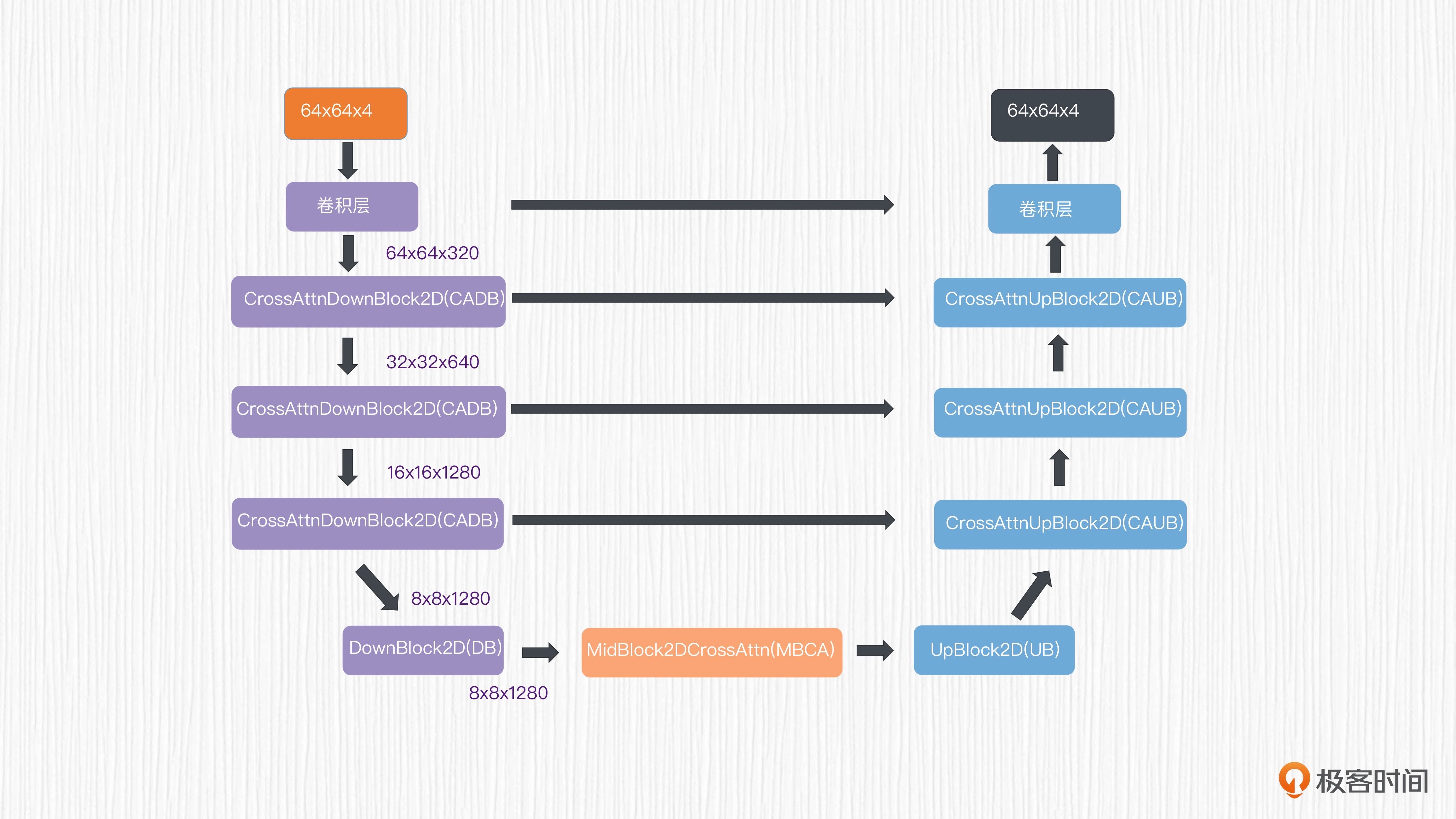
经过 VAE 模块之后,我们可以得到 64x64x4 维度的潜在表示。使用这个潜在表示作为 UNet 的输入,可以得到同样维度的输出,预测的是需要去除的噪声值。 UNet 结构如本图所示。¶
对于 UNet 的编码器部分,潜在表示分别经过 3 个连续的 CADB(CrossAttnDownBlock2D)模块,分辨率从 64x64x4 降采样到 8x8x1280,得到了对应的特征。
接着,这些特征被送入一个不带注意力机制的 DB(DownBLlock2D)模块和一个 MBCA(MidBlock2DCrossAttn)注意力模块。这样,就完成了 UNet 的特征编码。
UNet 的解码器部分与编码器部分完全对应,只不过用上采样计算替代了编码器部分的降采样计算。编码器和解码器之间存在跳跃连接,这是为了进一步强化 UNet 模型的表达能力。
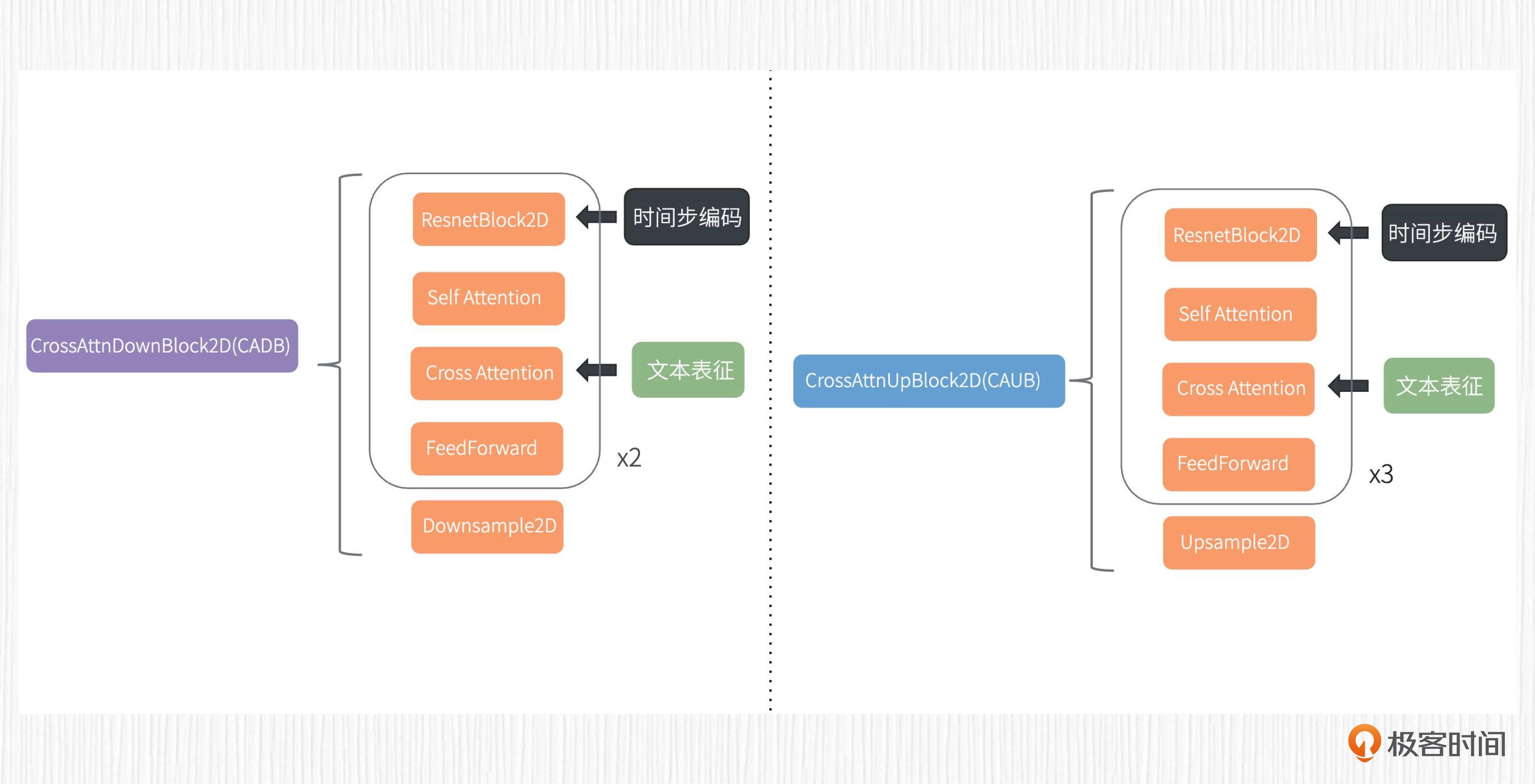
CADB 模块的内部结构¶
对照图解可以看到,CADB 模块包括自注意力模块和交叉注意力模块。我们可以把每个 CADB 中从 ResNetBlock2D 到 FeedForward 的部分,理解成是一层 Transformer,那么图中的 x2 就表示有两层 Transformer 结构。
在实际操作中,prompt 的文本表征通过交叉注意力模块完成信息注入,用于计算得到对应的 K、V 向量。而 Q 向量源自 CADB 模块中自注意力模块输出的结果。
重新探讨图生图¶
对于 SD 模型而言,图生图的过程只需要在文生图的基础上做一点改变。在文生图中,我们选择一个随机噪声作为初始潜在表示。在图生图中,我们对原始图像进行加噪,通过重绘强度这个参数控制加噪的步数,然后以加噪的结果作为图像生成的初始潜在表示。
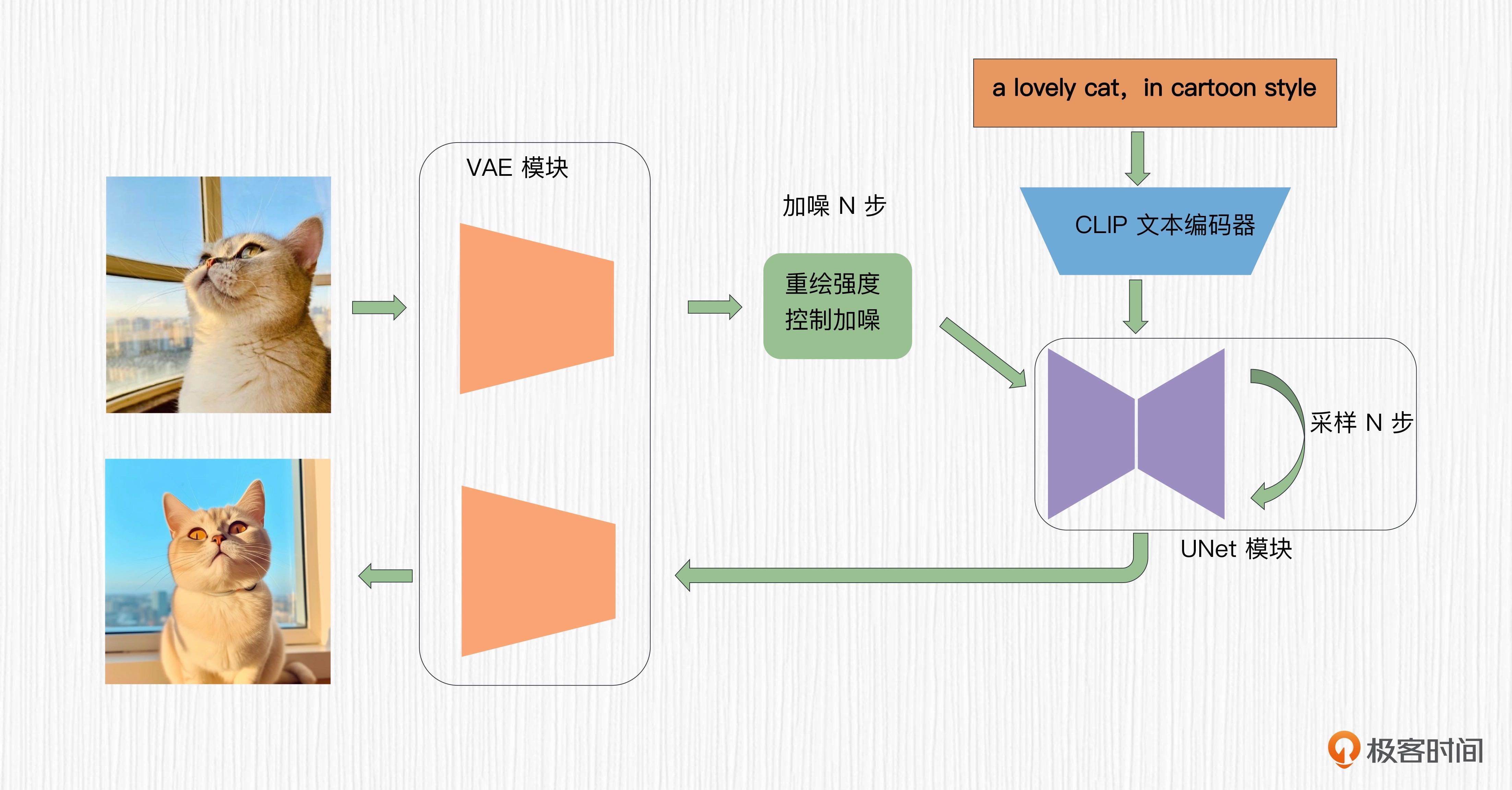
注意:去噪过程的步数要与加噪过程步数一致。换句话说,你在原始图像上加了多少步噪声,就要去除多少步噪声。如果去噪步数过少,有可能会得到“不干净”的图片;如果去噪步数过多,得到的结果和原图之间的相似度会有折损。¶
Negative Prompt 和 CLIP Skip¶
进行 AI 绘画的时候,还有一些关键魔法参数,比如反向描述词(Negative Prompt)、CLIP Skip 两个操作。
首先是反向描述词。其实当我们理解了无分类器引导,反向描述词的作用就非常好理解了。我们知道,正常的无条件预测使用的是空字符串作为 UNet 的输入。我们只需要把无条件预测中的空字符串替换成反向描述词,就能告诉模型不要去生成什么。
另一个常见魔法操作是“CLIP Skip = 2”这个设置。CLIP 文本编码器是一个深度学习模型,拥有多层神经网络结构。研究表明,使用文本编码器倒数第二层获得的特征要比使用最后一层输出的特征效果更好。
小结¶
16|显微镜下的Stable Diffusion2¶
SD 图像变体(Stable Diffusion Reimagine)
“神雕侠侣”(SDXL)
SD 图像变体¶
在 SD 模型中,图生图能力通过重绘强度这个超参数向原始图像添加噪声,并根据 prompt 文本描述重新去噪得到新图像。这种方式生成的新图像在轮廓上会和原始图像非常接近,而内容和风格上则会更接近文本引导。
而图像变体,生成的图像与输入图像在色调、构图和人物形象方面具有相似性。
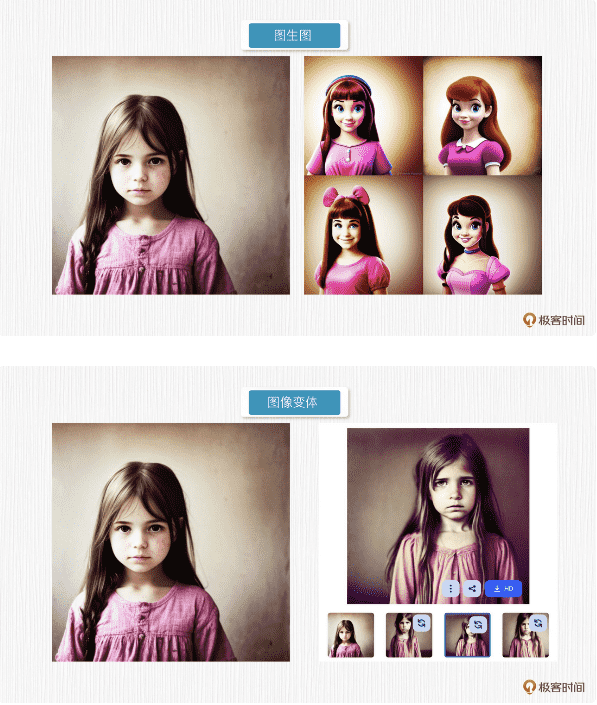
图像变体与图生图的效果图¶
图生图和图像变体,它们都是以图像为主进行变化。图生图本质是依赖于 prompt 来引导相似轮廓下的内容变化;图像变体则以输入图像为基础,生成具有相似内容但不同样式的图像,过程不需要描述语句的引导。
SD 图像变体的使用¶
Stable unCLIP 2.1: https://huggingface.co/stabilityai/stable-diffusion-2-1-unclip
不需要复杂的 prompt,SD 图像变体功能从图像中提取需要使用的信息,帮助用户生成输入图片的多种变化。
SD 图像变体实际上是一个全新的 SD 模型,其官方名称为 Stable unCLIP 2.1,与 DALL-E 2 一样,也属于 unCLIP 模型
SD 图像变体模型是基于 SD2.1 模型微调而来的,能生成 768x768 分辨率的图像。
SDXL(神雕侠侣)¶
标准 SD 模型和 SD 图像变体模型,都是 StabilityAI 这家公司推出的开源 AI 绘画模型,在 Hugging Face、Civitai 这些论坛备受追捧。但遗憾的是,Midjourney 在 AI 绘画生成效果上始终一骑绝尘。为了证明 SD 模型同样拥有无限的 AI 绘画潜力,StabilityAI 决定大力出奇迹,开发一款能与 Midjourney 效果相匹配的模型。于是,SDXL 便应运而生。
初识 SDXL¶
2023 年 6 月,Stable Diffusion XL 0.9 正式发布

SDXL 和 DeepFloyd IF、Midjourney v5.2、DALL-E 2 等方案生成效果图对比¶
SDXL 采用级联模型的方式完成图像生成。所谓级联模型,就是将多个模型按照顺序串联,目的是完成更复杂的任务。
SDXL 的使用¶
官方平台 clipdrop: https://clipdrop.co/stable-diffusion
dreamstudio: https://beta.dreamstudio.ai/generate
代码中我们加载了 Base 和 Refiner 两个扩散模型,AI 绘画的过程也是使用这两个模型通过“接力”的方式生成的。
17|巅峰画师Midjourney¶
回顾 Midjourney 的发展¶
2019 年的时候,David Holz 卖掉了手中的 Leap Motion 公司,创建了 Midjourney。David 上一家公司做的是手部跟踪器,与我们今天要聊的 AI 绘画没有直接关系。但他的技术背景和创业精神为 Midjourney 的发展奠定了基础。
2022 年 2 月,Midjourney v1 模型正式推出。紧接着 4 月,v2 版本正式推出;7 月,v3 版本正式推出;11 月,我们熟悉的 v4 版本正式推出;2023 年 3 月,v5 版本正式推出;6 月,v5.2 版本正式推出。我们惊奇地发现,从 v1 到 v5,其实只用了一年时间。
2022 年 11 月 MJ v4 推出后不久,MJ 公司引入大量二次元数据微调 v4 模型,于是得到了 Nijijourney 这个专注于动漫垂类生成的模型。
All Midjourney Versions [V1-V5.2] Compared: The Evolution of Midjourney: https://aituts.com/midjourney-versions/
Midjourney 的长处与不足¶
缺点
不能很好的处理“Text-in-Image”的任务
无法正确地处理帽子颜色和手套颜色
综合演练篇:AI 绘画高手养成计划 (8讲)¶
18|DreamBooth和LoRA:低成本实现IP专属的AI绘画模型¶
3种经典的定制化算法方案,分别是:
Textual Inversion
DreamBooth
LoRA
海外非常流行的 LensaAI 和国内风靡一时的“妙鸭相机”
Textual Inversion¶
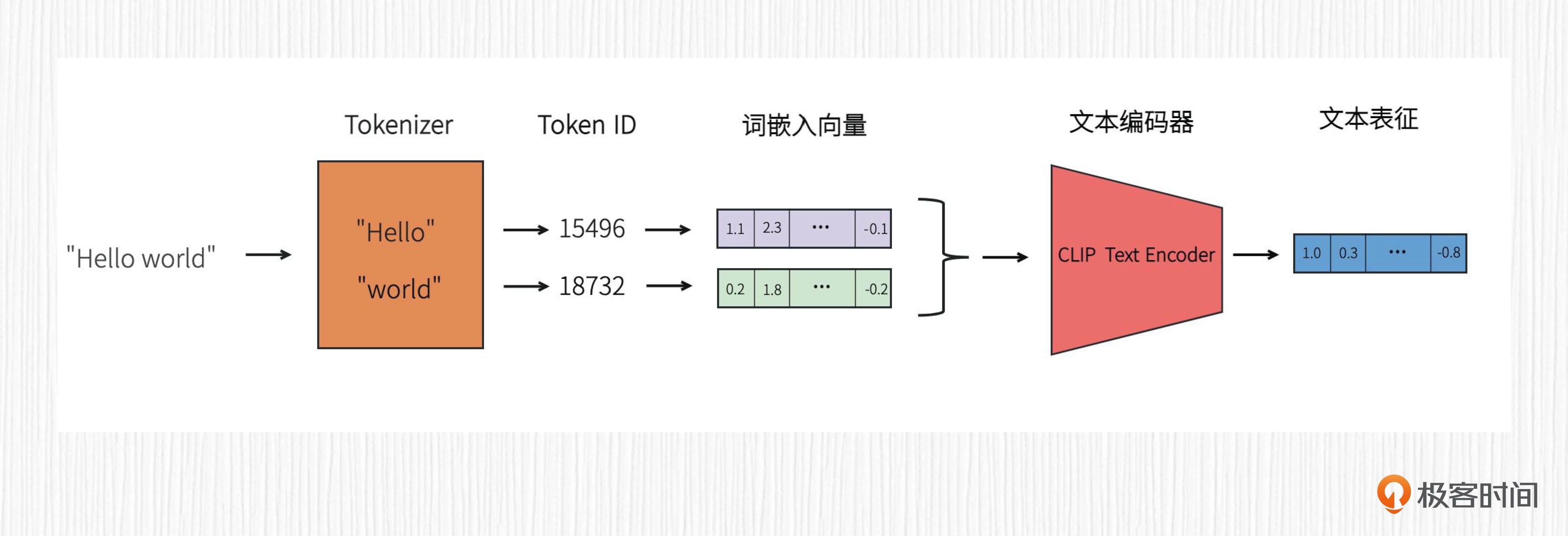
SD 词嵌入向量的使用方式:输入的 prompt 首先会经过 tokenizer 完成分词,得到每个分词的 token_id。之后在预训练的词嵌入库中根据 token_id 拿到词嵌入向量,并将这些词嵌入向量拼接在一起,输入到 CLIP 的文本编码器。接着,经过 CLIP 文本编码器提取到的文本表征,便可以通过交叉注意力机制控制图像生成。¶
备注
Textual Inversion 算法的本质是学习一个全新的词嵌入向量,用于指代定制化的内容。其核心思想便是,对于一个给定的物体或者风格,去学习一个全新的词嵌入向量,并绑定一个符号比如 S*,为其分配一个新的 token_id。这样,每次文生图的时候只需要带上 S*,就能生成我们想要定制化的物体或者风格。


对于一个物体或者风格,我们只需要使用 3~5 张图训练,便可以得到新的关键词 S*,从而完成定制化图像生成的任务。¶
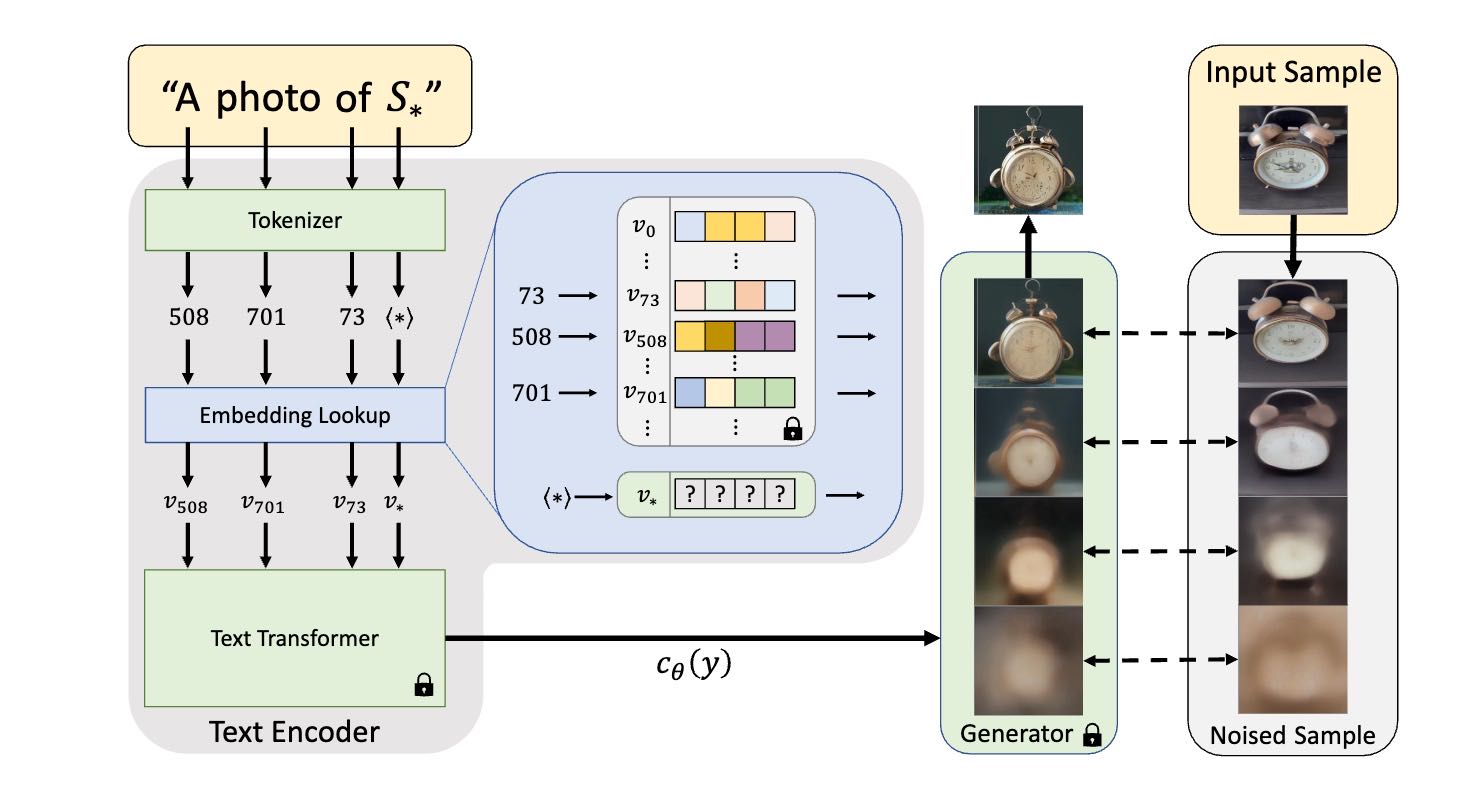
算法原理图¶
Textual Inversion 的训练过程一共分两步。
第一,我们需要为你提供的关键词(比如 S*),绑定一个新的 token_id,并初始化这个 token_id 对应的词嵌入向量。举例来说,比如原始词嵌入库中包括 20000 个关键词,token_id 对应的数值就是 1~20000,那么我们新增关键词 S* 的 token_id 便应该是 20001。
第二,准备好前人已经训练好的 AI 绘画模型,比如 Stable Diffusion 模型或者 DALL-E 2 模型。训练过程中 CLIP 文本编码器、UNet 等模型的权重需要全部固定住。按照对应 AI 绘画模型的标准训练方法,在你提供的 3-5 张图片上进行训练。