LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models¶
组织:北航计算机科学与工程学院,北大软件与微电子学院
高效的微调对于适配 LLMs 下游任务至关重要。但是,在不同模型上实现这些方法需要付出艰巨的努力。我们介绍了 LlamaFactory,这是一个统一的框架,集成了一套尖端的高效训练方法。它提供了一种解决方案灵活定制 100+ LLMs,而无需编码内置的 Web UI LlamaBoard 。我们实证验证了我们的框架在语言建模和文本生成任务上的效率和有效性。
Efficient fine-tuning is vital for adapting large language models (LLMs) to downstream tasks. However, it requires non-trivial efforts to implement these methods on different models. We present LlamaFactory, a unified framework that integrates a suite of cutting-edge efficient training methods. It provides a solution for flexibly customizing the fine-tuning of 100+ LLMs without the need for coding through the built-in web UI LlamaBoard. We empirically validate the efficiency and effectiveness of our framework on language modeling and text generation tasks.
竞争框架¶
LLaMA-Adapter (Zhang et al., 2024) efficiently fine-tunes the Llama model (Touvron et al., 2023a) using a zero-initialized attention.
FastChat (Zheng et al., 2023) is a framework focused on training and evaluating LLMs for chat completion purposes.
LitGPT (AI, 2023) provides the implementation of generative models and supports various training methods.
Open-Instruct (Wang et al., 2023d) provides recipes for training instruct models.
Colossal AI (Li et al., 2023b) takes advanced parallelism strategies for distributed training.
LMFlow (Diao et al., 2024) supports training LLMs for specialized domains or tasks.
GPT4All (Anand et al., 2023) allows LLMs to run on consumer devices, while also providing fine-tuning capabilities.
Compared with existing competitive frameworks, LlamaFactory supports a broader range of efficient fine-tuning techniques and training approaches.
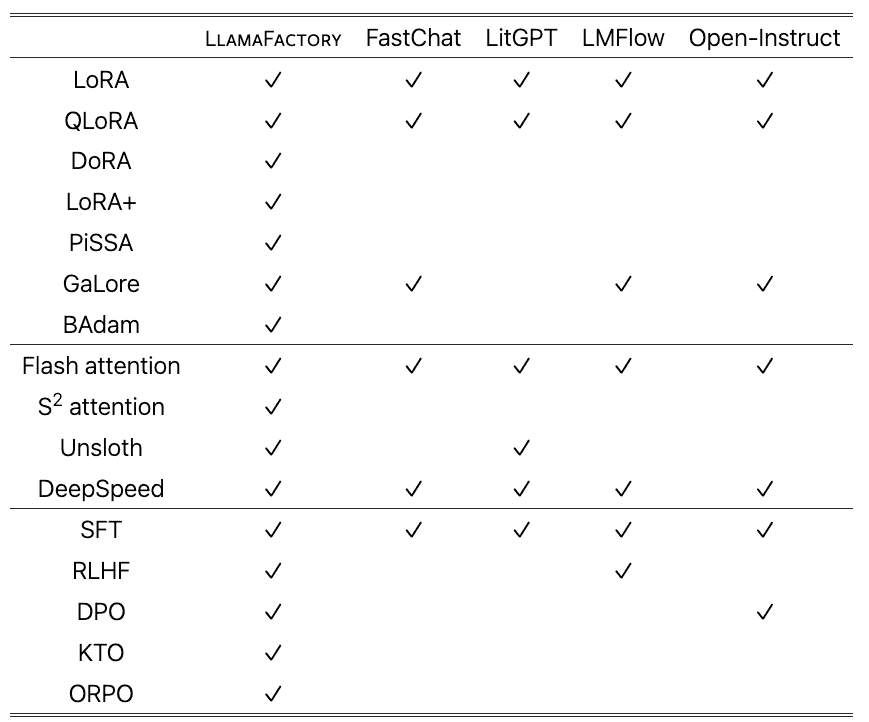
Table 1: Comparison of features in LlamaFactory with popular frameworks of fine-tuning LLMs.¶
3. Efficient Fine-Tuning Techniques¶
高效的 LLM 微调技术可以分为两大类:专注于优化(optimization)的和目标为计算(computation)的
高效优化技术(efficient optimization techniques)的主要目标是微调 LLMs,同时将成本保持在最低水平
高效计算方法(efficient computation method)试图减少 LLMs 计算的时间和占用的空间
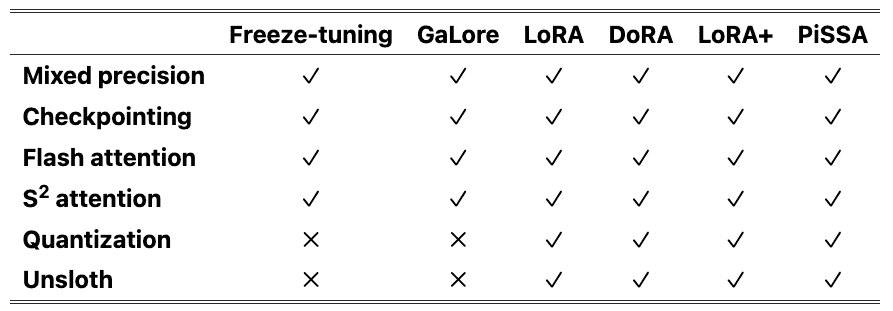
3.1 Efficient Optimization¶
Freeze-tuning: 涉及冻结大部分参数,同时在一小部分解码器层中微调其余参数。The
freeze-tuningmethod (Houlsby et al., 2019) involves freezing a majority of parameters while fine-tuning the remaining parameters in a small subset of decoder layers.GaLore: 将梯度投影到低维空间中,以高效内存的方式促进全参数学习。Another method called gradient low-rank projection (
GaLore) (Zhao et al., 2024) projects gradients into a lower-dimensional space, facilitating full-parameter learning in a memory-efficient manner.BAdam: 利用块坐标下降 (BCD) 来有效优化广泛的参数。Similarly, BAdam (Luo et al., 2024) leverages block coordinate descent (BCD) to efficiently optimize the extensive parameters.
LoRA: 冻结了所有预训练的权重,并将一对可训练的低秩矩阵引入指定层。On the contrary, the low-rank adaptation (LoRA) (Hu et al., 2022) method freezes all pre-trained weights and introduces a pair of trainable low-rank matrices to the designated layer.
QLoRA: 与量化相结合LoRa, 减少了内存使用量。When combined with quantization, this approach is referred to as QLoRA (Dettmers et al., 2023), which additionally reduces the memory usage.
DoRA: 将预训练的权重分解为幅度和方向分量,并更新方向分量以提高性能。DoRA (Liu et al., 2024) breaks down pre-trained weights into magnitude and direction components and updates directional components for enhanced performance.
LoRA+: 克服 LoRA 的次优性。LoRA+ (Hayou et al., 2024) is proposed to overcome the sub-optimality of LoRA.
PiSSA: 使用预训练权重的主成分初始化适配器,以加快收敛速度。PiSSA (Meng et al., 2024) initializes adapters with the principal components of the pre-trained weights for faster convergence.
3.2 Efficient Computation¶
mixed precision与 checkpointing: 最常用的技术。Commonly utilized techniques encompass mixed precision training (Micikevicius et al., 2018) and activation checkpointing (Chen et al., 2016).
flash attention: 从对注意力层的输入输出 (IO) 费用的检查中汲取见解,引入了一种硬件友好的方法来增强注意力计算。Drawing insights from the examination of the input-output (IO) expenses of the attention layer, flash attention (Dao et al., 2022) introduces a hardware-friendly approach to enhance attention computation.
S^2 attention: 通过转移稀疏注意力解决了扩展上下文的挑战,从而减少了微调长上下文 LLMs 的内存占用。S^2 attention (Chen et al., 2024b) tackles the challenge of extended context with shifted sparse attention, thereby diminishing memory usage in fine-tuning long-context LLMs.
Quantization: 通过使用较低精度的权重表示来降低大型语言模型 LLMs 内存需求。然而,量化模型的微调仅限于基于适配器的技术,如 LoRA。Various quantization strategies (Dettmers et al., 2022a; Frantar et al., 2023; Lin et al., 2023; Egiazarian et al., 2024) decrease memory requirements in large language models (LLMs) by utilizing lower-precision representations for weights. Nevertheless, the fine-tuning of quantized models is restricted to the adapter-based techniques like LoRA (Hu et al., 2022).
Unsloth: 结合了 Triton (Tillet et al., 2019) 来实现 LoRA 的向后传播,从而减少梯度下降期间的浮点运算 (FLOP) 并加快 LoRA 训练。Unsloth (Han and Han, 2023) incorporates Triton (Tillet et al., 2019) for implementing the backward propagation of LoRA, which reduces floating-point operations (FLOPs) during gradient descent and leads to expedited LoRA training.
4 LlamaFactory Framework¶
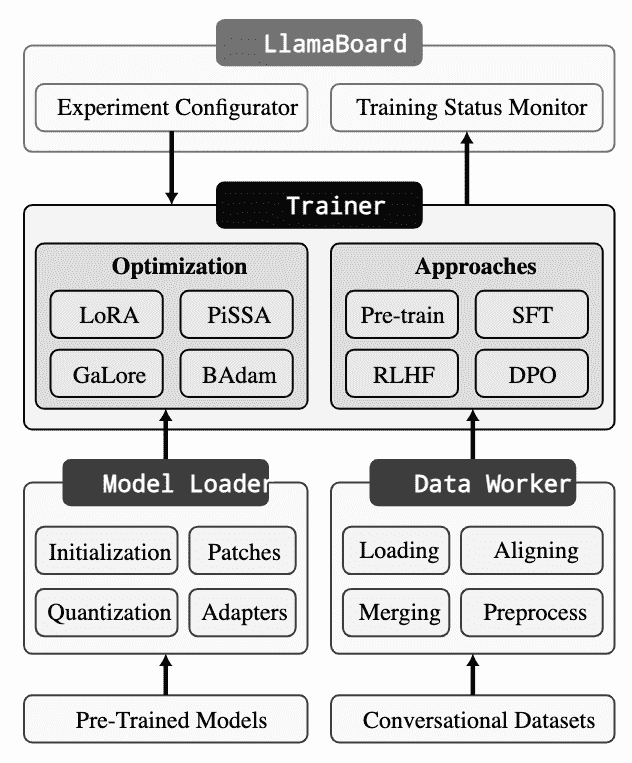
Figure 1:The architecture of LlamaFactory.¶
LlamaFactory 由三个主要模块组成:Model Loader、Data Worker 和 Trainer。
Model Loader可操作各种模型架构进行微调,支持大型语言模型 (LLMs) 和视觉语言模型 (VLM)。Data Worker通过精心设计的管道处理来自不同任务的数据,支持单轮次和多轮次对话。Trainer将高效的微调技术应用于不同的训练方法,支持预训练、指令调优和首选项优化。
4.1 Model Loader¶
Model Initialization 模型初始化:利用 Transformers 的自动类 (Wolf et al., 2020) 来加载预训练模型并初始化参数。具体来说,我们使用
AutoModelForVision2Seq类加载视觉语言模型,而其余模型使用AutoModelForCausalLM类加载。tokenizer 是使用AutoTokenizer类和模型一起加载的。如果 tokenizer 的词汇量超过嵌入层的容量,我们会调整层的大小,并使用嘈杂的均值初始化来初始化新参数。为了确定 RoPE 缩放的比例因子,我们将其计算为最大输入序列长度与模型上下文长度的比率。Model Patching 模型修补:为了实现 S^2 的注意力,我们采用 monkey patch 来代替模型的正向计算。但是,我们使用本机类来启用 Flash Attention,因为它自 Transformers 4.34.0 以来已得到广泛支持。为了防止动态层的过度分区,当我们在 DeepSpeed ZeRO 阶段 3 下优化 MoE 模型时,我们将专家混合 (MoE) 块设置为叶模块
Model Quantization 模型量化:可以通过 bitsandbytes 库(Dettmers,2021)将模型动态量化为 LLM.int8 的 4 位或 12 位(Dettmers et al., 2022a)。
Adapter Attaching 适配器安装:通过遍历模型层自动识别合适的层来连接适配器。正如 (Dettmers et al., 2023) 所建议的那样,低秩适配器连接到所有线性层,以实现更好的收敛。PEFT(Mangrulkar 等人,2022 年)库提供了一种非常方便的方式来实现基于适配器的方法,例如 LoRA(胡 等人,2022 年)、rsLoRA(Kalajdzievski,2023 年)、DoRA(Liu 等 人,2024 年)和 PiSSA(Meng 等 人,2024 年)。我们用 Unsloth (Han and Han, 2023) 替换反向计算以加速训练。为了从人类反馈 (RLHF) 执行强化学习,在 transformer 模型的顶部附加了一个值头层,将每个标记的表示映射到标量。
Precision Adaptation 精确适应:根据计算设备的能力处理预训练模型的浮点精度。对于 NVIDIA GPU,如果计算能力为 8.0 或更高,则采用 bfloat16 精度。否则,采用 float16。此外,Ascend NPU 和 AMD GPU 采用 float16,非 CUDA 设备采用 float32。在混合精度训练中,我们将所有可训练参数设置为 float32 以确保训练稳定性。
4.2 Data Worker¶
开发了一个数据处理管道,包括数据集加载、数据集对齐、数据集合并和数据集预处理。它将不同任务的数据集标准化为统一的格式,使我们能够在各种格式的数据集上微调模型。
Table 3:Dataset structures in LlamaFactory:
Plain text
[{"text": "…"}, {"text": "…"}]
Alpaca-like data
[{"instruction": "…", "input": "…", "output": "…"}]
ShareGPT-like data
[{"conversations": [{"from": "human", "value": "…"}, {"from": "gpt", "value": "…"}]}]
Preference data
[{"instruction": "…", "input": "…", "output": ["…", "…"]}]
Standardized data
{
"prompt": [{"role": "…", "content": "…"}],
"response": [{"role": "…", "content": "…"}],
"system": "…", "tools": "…", "images": ["…"]
}

Table 3:Dataset structures in LlamaFactory.¶
Dataset Loading 数据集加载:利用 Datasets 库来加载数据,这允许用户从 Hugging Face Hub 加载远程数据集或通过脚本或文件读取本地数据集。
Dataset Aligning 数据集对齐:为了统一数据集格式,我们设计了一个数据描述规范来描述数据集的结构。例如,羊驼数据集有三列:instruction、input 和 output (Taori et al., 2023)。我们根据数据描述规范,将数据集转换为兼容各种任务的标准结构。
Dataset Merging 数据集合并:统一的数据集结构为合并多个数据集提供了一种有效的方法。对于非流模式的数据集,我们只是在训练期间对数据集进行 shuffle 之前将它们连接起来。但是,在流式处理模式下,简单地连接数据集会阻碍数据随机排序。因此,我们提供了从不同数据集交替读取数据的方法。
Dataset Pre-processing 数据集预处理:LlamaFactory 旨在微调文本生成模型,主要用于聊天完成。聊天模板是这些模型中的关键组成部分,因为它与这些模型的指令遵循能力高度相关。因此,我们提供了数十种聊天模板,可以根据模型类型自动选择。我们在使用 tokenizer 应用聊天模板后对句子进行编码。默认情况下,我们只计算补全的损失,而忽略提示(Taori et al., 2023)。或者,我们可以利用序列打包(Krell et al., 2021)来减少训练时间,这在执行生成式预训练时会自动启用。
4.3 Trainer¶
Efficient Training:我们通过替换默认组件,将最先进的高效微调方法,包括 LoRA+(Hayou et al., 2024)、GaLore(Zhao et al., 2024)和 BAdam (Luo et al., 2024) 集成到 Trainer 中。这些微调方法独立于 Trainer,使其易于应用于各种任务。我们利用 Transformers 的 Trainer 进行预训练和 SFT,同时采用 TRL 的 Trainer 进行 RLHF 和 DPO。我们还包括来自 TRL 库的高级偏好优化方法的 Trainer,例如 KTO (Ethayarajh et al., 2024) 和 ORPO (Hong et al., 2024)。利用量身定制的 data collators 来区分各种训练方法的 Trainer。为了匹配偏好数据的训练器的输入格式,我们在一个批次中构建 2n 样本,其中第一个 n 样本是选定的样本,最后一个 n 样本是被拒绝的样本。
Model-Sharing RLHF 模型共享 RLHF:允许在消费设备上进行 RLHF 训练对于实现 LLM 微调的普及至关重要。这很困难,因为 RLHF 训练需要四种不同的模型。为了解决这个问题,我们提出了模型共享 RLHF,支持使用不超过一个预训练模型进行整个 RLHF 训练。具体来说,我们首先使用目标函数训练一个适配器和一个 value head 进行奖励建模,允许模型计算奖励分数。然后我们初始化另一个 adapter 和 value head,并使用 PPO 算法训练它们(Ouyang et al., 2022)。在训练过程中,适配器和 value head 通过 PEFT 的 set_adapter 和 disable_adapter 方法动态切换(Mangrulkar et al., 2022),允许单个预训练模型同时用作策略模型、价值模型、参考模型和奖励模型。据我们所知,这是第一种支持在消费类设备上进行 RLHF 训练的方法
Distributed Training 分布式训练:将上述训练器与 DeepSpeed 相结合(Rasley et al., 2020;任 et al., 2021) 进行分布式训练。我们采用数据并行来充分利用计算设备的能力。利用 DeepSpeed ZeRO 优化器,可以通过分区或卸载进一步减少内存消耗。
6 Conclusion and Future Work¶
为支持更广泛模态的模型启用微调,如:音频和视频模态
集成更多的并行训练策略,如:序列并行性和张量平行性
探索对话模型的更强微调方法,如:self-play