18xx_GPT1: Improving Language Understanding by Generative Pre-Training¶
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
组织:OpenAI
作者:Alec Radford、Karthik Narasimhan、Tim Salimans、Ilya Sutskever
自然语言理解包括多种多样的任务,例如文本蕴涵、问答、语义相似性评估和文档分类。尽管大量未标记的文本语料库非常丰富,但用于学习这些特定任务的标记数据却很少,这使得经过判别性训练的模型难以充分发挥作用。我们证明,通过在多样化的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行判别性微调,可以在这些任务上实现巨大收益。与以前的方法相比,我们在微调过程中利用任务感知输入转换来实现有效迁移,同时只需对模型架构进行最小的更改。我们在广泛的自然语言理解基准上证明了我们的方法的有效性。我们的通用任务无关模型优于使用专门为每个任务设计的架构的经过判别性训练的模型,在所研究的 12 个任务中的 9 个任务中显著提高了最新水平。例如,我们在常识推理(Stories Cloze Test)方面取得了 8.9% 的绝对改进,在问答(RACE)方面取得了 5.7% 的绝对改进,在文本蕴涵(MultiNLI)方面取得了 1.5% 的绝对改进。
Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
Abstract¶
本文介绍了一种自然语言理解的方法,通过对大量未标记的文本进行生成式预训练,再进行有标记数据的判别式微调,可以在多种任务上取得显著的提升。该方法还使用了任务感知的输入转换,以实现有效的迁移学习,同时最小化对模型架构的改动。实验结果表明,该方法在自然语言理解的多个基准测试中均取得了优异的表现,超过了针对每个任务特定设计的判别式模型。
1. Introduction¶
本文探讨了一种半监督的语言理解任务方法,使用无监督预训练和有监督微调相结合的方式,旨在学习一个通用的表示,可以在多个任务中进行迁移。使用Transformer模型进行训练,通过任务特定的输入适应来进行微调,实验结果表明,该方法在自然语言推理、问答、语义相似度和文本分类等任务中表现优异,超过了特定任务架构的有监督模型。同时,预训练模型在零样本情况下也表现出了有用的语言知识。
3. Framework¶
训练过程分为两个阶段:
第一阶段是在大量文本语料库上学习高容量语言模型
第二阶段是通过有标签数据将模型调整为判别性任务
3.1 Unsupervised pre-training¶
介绍了如何使用一个神经网络模型来进行语言建模,以最大化给定语料库中的单词序列的概率。
模型使用了Transformer解码器,并通过多头自注意力机制和位置编码来生成目标单词的概率分布。
模型参数通过随机梯度下降进行训练。
3.2 Supervised fine-tuning¶
介绍了一种基于预训练的方法来解决自然语言处理任务的方法。
首先使用大规模无标签数据进行预训练,然后在有标签数据上进行微调。
微调时,除了需要添加一个线性输出层和分隔符嵌入层外,不需要额外的参数。
同时还发现在微调时加入语言模型作为辅助目标可以提高模型的泛化性能和加速收敛。
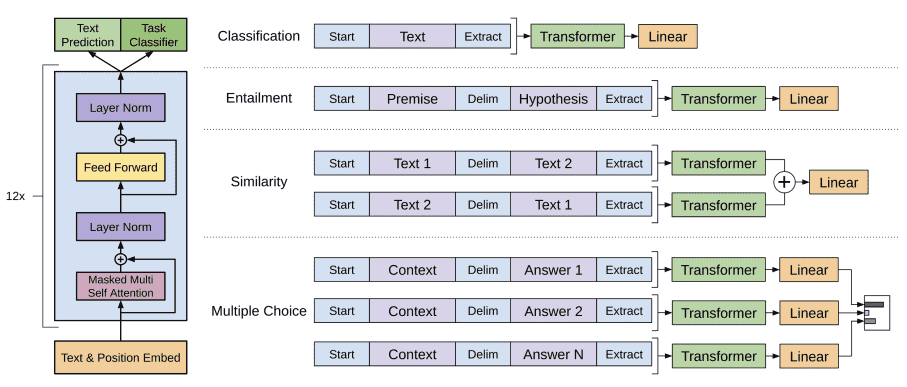
Figure 1: (left) Transformer architecture and training objectives used in this work. (right) Input transformations for fine-tuning on different tasks. We convert all structured inputs into token sequences to be processed by our pre-trained model, followed by a linear+softmax layer¶
3.3 Task-specific input transformations¶
讨论了在应用预训练模型进行文本分类等任务时,对于结构化输入(如问题回答、文本蕴含等)需要进行一些修改。
之前的方法是在预训练模型之上构建任务特定的架构,但这样会引入大量任务特定的定制化,并没有充分利用迁移学习。
相反,作者采用了一种遍历式的方法,将结构化输入转换为预训练模型可以处理的有序序列。这些输入转换允许我们避免在不同任务之间进行大量的架构更改。具体的输入转换方法包括对文本蕴含任务的输入进行连接,对相似度任务的输入进行修改以包含两种可能的句子顺序,并对问答和常识推理任务的输入进行连接。
4 Experiments¶
4.1 Setup¶
介绍了一种基于无监督预训练的语言模型,使用BooksCorpus数据集进行训练,模型采用12层decoder-only transformer,使用Adam优化算法,BPE词汇表,GELU激活函数等。
在细节方面,使用了ftfy库清理原始文本,使用了spaCy分词器。
在微调方面,使用了与无监督预训练相同的超参数设置,加入了分类器dropout,使用线性学习率衰减和warmup。
模型在多个任务上表现良好。
4.2 Supervised fine-tuning¶
介绍了一种基于Transformer的模型,用于处理自然语言理解任务,包括自然语言推理、问答、语义相似度和文本分类等。
在多个数据集上进行了实验,结果表明该模型在大多数任务上都取得了最新的最佳结果。
该模型能够有效地处理长距离上下文,并具有更好的推理能力和语言歧义处理能力。
5 Analysis¶
研究了使用transformer进行预训练的语言模型在目标任务上的迁移效果。
实验结果表明,预训练模型的每一层都包含有用的功能,可以提高目标任务的性能。此外,使用transformer进行预训练的模型在零样本任务上表现更好,这表明transformer的归纳偏差有助于迁移学习。
在消融实验中,辅助语言模型目标对于大型数据集有益,但对于小型数据集则没有帮助。
使用transformer进行预训练的模型在目标任务上表现优于直接在目标任务上训练的模型。
6 Conclusion¶
介绍了一种通过生成式预训练和判别式微调实现强大自然语言理解的框架。通过在多样化的语料库上进行预训练,模型获得了丰富的世界知识和处理长距离依赖的能力,成功地应用于解决问题回答、语义相似度评估、蕴含关系确定和文本分类等判别式任务,提高了9个数据集的性能。这项工作表明,通过无监督(预)训练来提高判别式任务的性能是可能的,并提供了哪些模型(Transformers)和数据集(具有长距离依赖的文本)最适合这种方法的提示。希望这将有助于促进无监督学习的新研究,不仅限于自然语言理解,还包括其他领域,进一步提高我们对无监督学习的理解。
引文口碑¶
优势:
1. 该文提出的预训练语言模型方法在多个NLP任务上取得了显著的性能提升。 展开引文186条
2. 该文中的预训练模型能够学习到丰富的语言表示,对于下游任务具有很强的泛化能力。 展开引文1265条
3. 该文中的预训练模型采用了Transformer架构,能够捕捉长距离的上下文信息,提高了语言理解的能力。 展开引文603条
4. 该文中的预训练模型通过引入不同的预训练目标,如语言建模、掩码语言建模等,进一步提升了模型的性能。 展开引文707条
局限:
1. 该文中的预训练模型需要大量的计算资源和数据来进行训练,对于资源有限的环境可能不太适用。 展开引文663条
2. 该文中的预训练模型在某些任务上可能存在过拟合的问题,需要更多的调优和细节处理来提高性能。 展开引文93条
3. 该文中的预训练模型在某些任务上可能存在泛化能力不足的问题,需要更多的研究来解决这个问题。 展开引文184条
要点解读¶
背景:
本文研究背景:本文旨在通过生成式预训练来提高语言理解能力。
研究工作简述及评价:本文对语言模型的预训练进行了改进,与以往的方法相比,本文的方法在多项任务上表现更好。同时,本文的方法也可以应用于其他领域,如计算机视觉等。
创新动机:本文的创新动机在于提高语言理解能力,以便更好地应用于自然语言处理任务。同时,本文的方法也可以为其他领域的预训练提供借鉴。
方法:
本文提出了一种通过生成式预训练来改善语言理解的方法。
该方法的前提是引入了一些概念和定义。具体方法如下:
1. 生成式预训练
通过在大规模文本数据上进行预训练,使用自回归模型来生成下一个词的概率分布。
这样可以使模型学习到语言的统计规律和语义信息。
2. 无监督预训练
在生成式预训练的基础上,使用无监督的方式进行预训练,即不需要标注的语料库。
这样可以更好地捕捉语言的结构和语义。
3. 微调
在预训练之后,使用有标注的数据集进行微调,以进一步提升模型的性能。
微调过程中,可以使用各种任务来训练模型,如文本分类、命名实体识别等。
概念和定义:
生成式预训练(Generative Pre-Training):一种通过在大规模未标记文本上进行预训练来提高自然语言处理任务性能的方法。
语言理解任务:包括问答任务、文本分类任务、命名实体识别任务等需要对自然语言进行理解和处理的任务。