2407.10671_Qwen2 Technical Report¶
组织: 阿里
GitHub: https://github.com/QwenLM/Qwen2
Abstract¶
Qwen2 是一系列新的大语言模型和多模态模型,参数量从 0.5B 到 72B,包括密集模型和专家混合模型。它在语言理解、生成、多语言、编程、数学和推理等任务上超过了大多数开源模型,包括前一代 Qwen1.5,并在多个评测中接近或超过闭源模型表现。
旗舰模型 Qwen2-72B 和其指令微调版本在多个评测中表现优异,并支持约 30 种语言,展现出强大的多语言能力。
1. Introduction¶
自从 ChatGPT 问世后,全球对大语言模型(LLM)兴趣高涨。Meta 发布的 Llama-3 开源模型性能接近 GPT-4,而 Claude-3 和 GPT-4o 也在 Chatbot 排行榜上表现优异。各类开源模型如 Qwen、Mistral、Gemma 等相继推出。
Qwen 团队此前已发布多个模型,包括语音模型 Qwen-Audio 和多模态模型 Qwen-VL。现在,他们发布了新一代模型 Qwen2,包括基础模型和指令微调版,适用于对话与智能体任务。
Qwen2 有多种规模,最小为 0.5B 参数(适合手机、耳机等设备),最大为 72B 以及一个 57B MoE 模型(每次激活 14B 参数)。所有模型使用超过 7 万亿 token 的高质量多语种数据训练,尤其在代码和数学上增强,以提升推理能力。
在后处理阶段,模型通过人类反馈进行微调(如 DPO 方法),以更好地理解和执行指令。
Qwen2 在多个基准测试中表现出色,部分指标甚至超过了同类开源或闭源模型。例如:
Qwen2-72B-Instruct 在 MT-Bench 上得分 9.1,Arena-Hard 为 48.1,LiveCodeBench 为 35.7。
Qwen2-72B 在 MMLU(通识测试)得分 84.2,HumanEval(编程能力)得分 64.6,GSM8K(数学)得分 89.5。
2. Tokenizer & Model¶
2.1 分词器¶
Qwen2 使用和 Qwen 相同的分词器,基于字节级BPE(Byte Pair Encoding)。
优点:
编码效率高(压缩率高)
适合多语言处理
所有模型都共享一个词表:包含 151,643 个常规token + 3个控制token
实际嵌入维度比词表大一些,以适应分布式训练的需求
2.2 模型结构¶
Qwen2 系列是基于 Transformer 的大语言模型,分为 4个密集模型(Dense) 和 1个专家模型(MoE)。
2.2.1 Qwen2 Dense 模型¶
特点如下:
基于 Transformer,使用因果掩码自注意力(Causal Mask Attention)
关键创新点:
Grouped Query Attention (GQA):优化 KV 缓存使用,推理更快
Dual Chunk Attention (DCA):支持长文本,通过分块增强长距离依赖捕捉能力
YARN机制:调整注意力权重以更好地泛化到更长文本
还使用:
SwiGLU激活函数
RoPE位置编码
QKV偏置、RMSNorm归一化、预归一化等技术以提升训练稳定性
2.2.2 Qwen2 MoE 模型(专家模型)¶
类似 Qwen1.5-MoE-A2.7B
用多个专家 FFN 替代原有 FFN,每个 token 被分配到一个或多个专家上执行计算
每个 token 只激活一部分专家,提高计算效率
关键设计:
精细专家划分:比传统 MoE 更小、更细的专家,允许组合更多不同专家
专家路由机制:结合共享专家与专用专家,让模型适应多任务场景
专家初始化方式:从已有密集模型迁移,并打乱参数,引入多样性与随机性,提升泛化能力
2.2.3 模型配置¶
Qwen2 系列包含五种规模:
0.5B、1.5B、7B(密集模型)
57B-A14B(MoE 模型,激活参数为14B)
72B(大规模密集模型)
Qwen2 相比 Qwen1.5,每个 token 的 KV 缓存占用更小,推理时更省显存,尤其适合长文本推理。
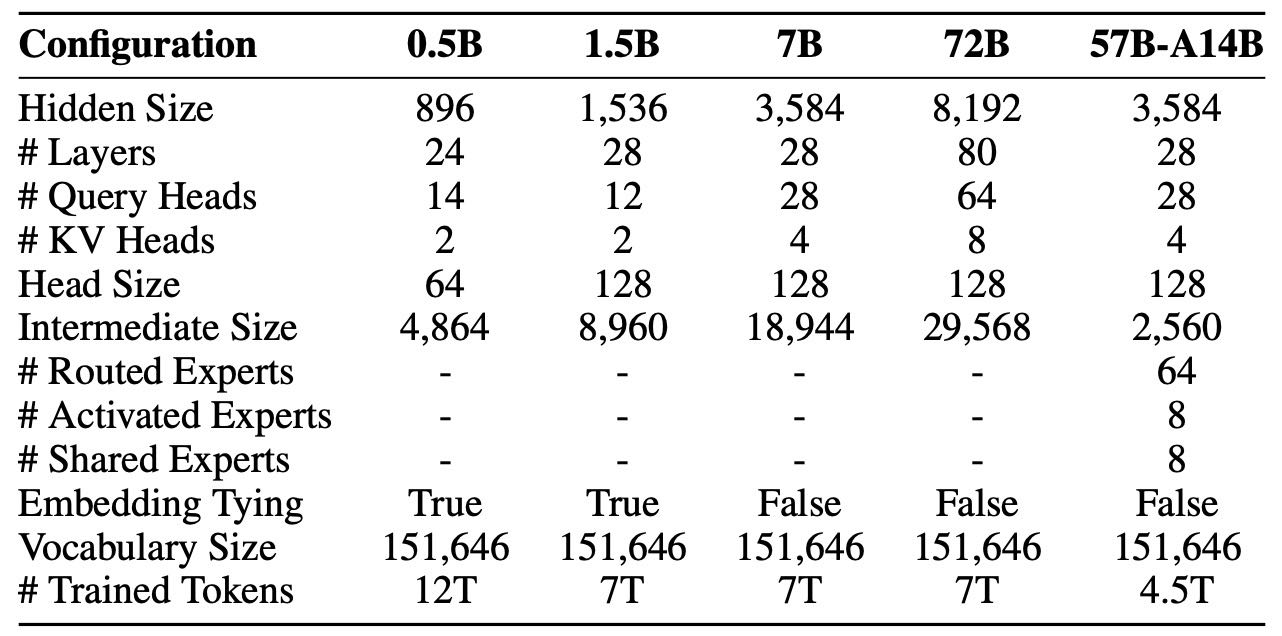
Table 1: Architecture of Qwen2 dense and MoE models. For MoE models, 57B-A14B denotes that the model has 57B parameters in total and for each token 14B parameters are active, the Intermediate size denotes that of each expert, and # Activated Experts excludes the shared experts.
3. Pre-training¶
备注
Qwen2 的预训练重点有两个方面:数据改进和长上下文处理。
预训练数据改进¶
数据质量更高:使用改进的过滤算法(包括启发式和模型辅助方法)清洗数据,还用已有模型合成高质量数据。
数据量更大:相比旧版本,收集了更多代码、数学和多语种数据(支持约30种语言,如中、英、西、法、德、阿、俄、韩、日、泰、越等)。
分布优化:用小模型做实验,优化不同来源数据的混合方式,使训练更接近人类学习方式。
最终选择了7万亿token的数据用于主力模型训练,虽然也尝试过12万亿token,但效果提升不明显。
小模型Qwen2-0.5B 用的是12万亿token数据。
MoE模型 额外用了4.5万亿token,遵循“循环利用”的思路。
加入多任务指令数据,增强模型理解上下文和执行指令的能力。
二、长上下文训练¶
把上下文长度从4096 token扩展到32768 token。
添加了大量高质量长文本。
修改RoPE参数(从10,000到1,000,000),以优化长文本处理。
使用了YARN机制和Dual Chunk Attention,让模型能处理最长131,072 token的输入,且性能保持良好。
4. Post-training¶
这段内容讲的是 Qwen2 模型在大规模预训练之后的“后训练”阶段,主要目的是提升模型的能力并使其更加符合人类价值观。
后训练的目标¶
提升模型在编程、数学、逻辑推理、指令跟随、多语言等领域的能力。
保证模型输出“有用、诚实、无害”,符合人类价值观。
尽量减少人工标注,采用可扩展的对齐策略。
📊 数据构建(4.1)¶
两类核心数据:
演示数据(Demonstration Data):指令和一个优质答案。
偏好数据(Preference Data):同一个指令对应两个答案,标记哪个更好。
数据来源:
人工协作标注(Collaborative Data Annotation):
Automatic Ontology Extraction: 用自动工具提取指令主题(ontology),人工优化。
Instruction Selection: 根据标签多样性、语义丰富性、复杂度和意图完整性等标准,挑选出具有代表性的指令。
Instruction Evolution: 利用 Qwen 模型自动给已有指令加条件,使其更复杂,提升难度多样性。
Human Annotation: 用不同的生成方法和模型生成多个回答,由人工进行偏好排序,得到最优答案及偏好数据。
自动数据合成(Automated Data Synthesis):
拒绝采样(Rejection Sampling):
针对数学题,生成多个解法,筛选正确且合理的路径。
对于数学等有标准答案的任务,LLM生成多个解题过程,保留答案正确且推理合理的部分作为示范数据,同时将正确与错误路径进行对比生成偏好数据。
执行反馈(Execution Feedback):
编程任务中运行代码和测试用例,自动评估效果。
用于编程任务。模型生成代码和测试用例,通过运行代码验证其正确性,从而生成示范和偏好数据。这种方法也可用于验证指令是否被遵守。
数据重用(Data Repurposing):
文学类任务用已有高质量文章+生成指令。
文学创作等任务对标注者要求高,研究者从公共领域收集高质量文本,用LLM生成相应指令,使这些文本与指令配对成为训练数据。角色扮演数据也是通过角色资料生成任务和回应的。
宪法反馈(Constitutional Feedback):
通过制定“价值准则”,指导模型生成符合/不符合标准的回答,用作训练数据。
制定一套原则(如安全性、价值观),指导LLM生成符合或违背这些原则的回答,用于构建训练和偏好数据集。
4.2 SUPERVISED FINE-TUNING¶
用 50 万条多领域指令数据进行两轮训练。
使用学习率衰减、梯度裁剪、权重衰减等技术防止过拟合。
4.3 人类反馈强化学习(RLHF)¶
我们用于RLHF(强化学习人类反馈)的训练分为两个阶段:离线训练和在线训练。
离线训练阶段:使用事先准备好的偏好数据集,通过DPO方法让模型更倾向于人类更喜欢的回答。
在线训练阶段:模型边训练边调整,实时利用奖励模型的反馈。具体做法是:模型生成多个回答,由奖励模型选出最优和最差的,形成偏好对,再用DPO进行优化。
此外,我们使用一种叫Online Merging Optimizer的方法,来减少因对齐人类偏好而造成的性能下降(即“alignment tax”)。
5. Evaluation¶
🌟 总体评估方式:¶
对 基础模型 和 指令微调模型 都进行了评估。
评估维度包括:常识理解、语言理解与生成、编程、数学、推理等。
使用多种主流 基准数据集,大模型用 few-shot(少样本提示),小模型也参与 zero-shot。
指令微调模型还特别做了 人工偏好评估。
5.1 基础模型评估(Base Language Models)¶
使用标准基准测试(如 MMLU、GPQA、HumanEval 等),通过少样本(few-shot)或零样本(zero-shot)提示进行评估。
支持多种语言评估:包括中英等多语种。
各版本模型表现:
Qwen2-72B:
整体性能最强,胜过 Llama-3-70B 和 Qwen1.5 系列,
特别在通识知识、数学、代码生成和中文理解上表现突出
Qwen2-57B-A14B(MoE 稀疏模型):
仅激活 14B 参数就能达到 30B 密集模型的水平,效率与能力兼具。
Qwen2-7B:
在 16GB 显存下运行流畅,性能优于同级 Llama、Mistral 等模型,尤其擅长编码、数学和中文。
Qwen2-1.5B / 0.5B:
小模型也表现优异,尤其在中文和数学方面表现出色。
5.2 指令微调模型评估(Instruction-Tuned Models)¶
评估方法总览
使用公开评测集和内部测试集评估模型的基础能力和对人类偏好的适应情况。
重点评估长上下文能力和多语言能力。
执行安全性测试和数据污染分析确保模型可靠性。
公开评测结果(OPEN BENCHMARK EVALUATION)
通用能力评估:
使用 MMLU、HumanEval、GSM8K 等基准测试语言理解、编程、数学能力。
Qwen2-72B-Instruct 在语言、代码和数学上表现优秀,优于 Qwen1.5 和 Mixtral 等模型。
不同规模模型对比:
Qwen2-57B-A14B 和 Qwen2-7B 都在各自参数级别中表现出色。
小模型(1.5B、0.5B)也显著优于前代,主要得益于更大规模的预训练数据。
内部自动评测(IN-HOUSE AUTOMATIC EVALUATION)
中文和英文分别测试了模型在知识理解、生成、编程等方面的能力。
Qwen2 即使在小模型上也优于 Qwen1.5,同参数下更强,甚至72B超越了参数更多的Qwen1.5-110B。
长上下文能力(LONG CONTEXT CAPABILITIES)
使用 Needle in a Haystack、NeedleBench、LV-Eval 测试模型处理最长128K上下文的能力。
Qwen2-72B 和 Qwen2-7B 在长上下文提取信息方面表现非常出色,甚至超过声称支持1M上下文的模型。
多语言能力(MULTILINGUAL EVALUATION)
进行多语言人工评估,Qwen2-72B 在多语言任务中优于GPT-3.5,接近GPT-4-Turbo,略逊于Claude-3-Opus。
表明其多语言预训练和指令微调数据效果良好。
安全性与责任(SAFETY AND RESPONSIBILITY)
测试模型在违法、诈骗、色情、隐私等话题中的安全响应能力。
Qwen2-72B 表现优于 GPT-4 和 Mixtral,尤其在减少有害回答方面效果明显。
数据污染分析(CONTAMINATION ANALYSIS)
使用 n-gram 和最长公共子序列(LCS)双重方法去除训练集与测试集重合数据。
实验表明,即使在“严格去污染”条件下,模型性能变化不大,说明污染影响有限。
6. Conclusion¶
Qwen2 系列是新一代通用语言模型,参数规模从 0.5B 到 72B,包含密集架构和专家混合(MoE)架构版本。它比前代 Qwen1.5 和其他开源模型表现更好,在语言理解、生成、多语言、编程、数学和推理等多个方面都很强。这次更新特别增强了长文本、多语言、编程、数学、安全等能力。为了促进社区创新和普及,Qwen2 的模型权重是开源的,方便研究者和开发者应用在各种项目中,推动 AI 技术的发展和社会正向影响。