2206.09557_LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Generative Language Models¶
原标题: nuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
最新版本: 2024-06-01
组织: Pohang University of Science and Technology, NAVER Cloud
说明:关注人少,论文引用(154)
Abstract¶
最近,自监督学习和Transformer架构大幅提升了自然语言处理能力。但随着模型越来越大,在生成阶段出现了内存瓶颈问题。
为了缓解这个问题,研究者尝试将模型权重量化到4位以下,但保留激活值的高精度。
虽然推理速度提升了,但主要是因为减少了内存传输,而不是计算更快。
而减少内存传输需要用到资源消耗大的反量化过程。
本文提出了一个新的方法 LUT-GEMM,它可以:
跳过反量化过程,节省资源;
降低计算成本,比现有的权重量化方法更高效;
支持 分组量化,在压缩率和准确率之间灵活权衡。
实验显示,用 3-bit 量化和LUT-GEMM方法加速 OPT-175B 模型,在单个GPU上推理速度比OPTQ快了 2.1倍。
1. Instructions¶
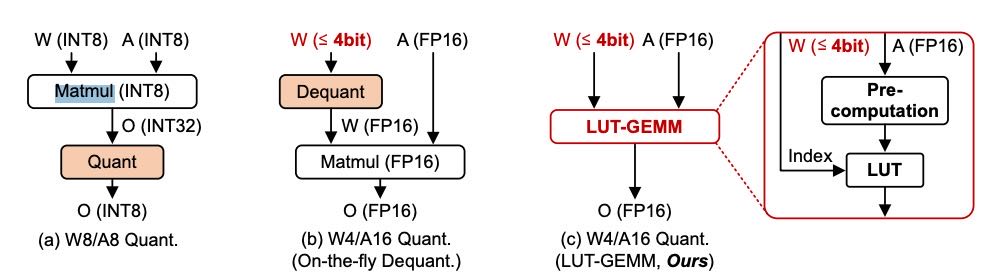
Figure 1: Three matrix multiplication schemes for W8/A8 or W4/A16 (i.e., weight-only) quantization format. Our proposed LUT-GEMM can adopt W4 and A16 without requiring an additional dequantization step.
近年来,大语言模型(LLM)在自然语言处理任务中表现出色,这得益于自监督学习和Transformer架构。但由于模型规模巨大(数十亿参数),无法在单个GPU上运行,只能用多GPU并行,带来通信开销,效率不高。
为此,研究者引入量化技术来压缩模型参数,减少对GPU资源的需求。传统做法是同时量化权重和激活值到8比特以内,但这会带来精度损失,特别是处理如softmax等非线性操作时效果不佳。
新趋势是只量化权重(如4比特),而激活保持高精度,这样可显著减小模型大小,同时维持更高准确率。
为了进一步提升效率,本文提出了一种新方法:LUT-GEMM。
LUT-GEMM 的核心优势:¶
利用一种叫 BCQ(二进制编码量化)的格式,既支持非均匀量化,也能表示均匀量化。
避免了传统量化方法中常见的反量化步骤(dequantization),运行更快。
针对大模型(如OPT-175B)测试表明,LUT-GEMM 比已有方法快 2.1倍,还能减少功耗和GPU使用量。
2. Background¶
2.1 GPU-Accelerated Generative LMs¶
在大语言模型(LLM)中,矩阵乘法占用了绝大部分推理时间(超 75%),远高于激活函数、归一化等操作。
因为显存有限,模型常需多张 GPU 协同运行,但这会增加通信开销。
GPU 非常适合加速矩阵运算,但要高效利用 GPU,需要足够大的 batch size来提高内存访问效率。
2.2 Quantization Methods and Limitations¶
为提升大模型的速度和吞吐量,研究者提出了多种方法,如
量化(Quantization):用更小的数据格式(如 INT8)来存储和计算,节省内存、提升速度。
剪枝(Pruning):删除不重要的神经元或连接。
知识蒸馏(Knowledge Distillation):用大模型训练小模型。
低秩分解(Low-rank Approximation):压缩权重矩阵。
INT8 的优势和挑战:
优势:更快、更省内存(比如比 FP16 少用一半内存),GPU(如 NVIDIA)也支持 INT8。
挑战:需要把激活值(activation) 也量化,而这很容易影响精度,尤其是有“异常值”(outlier)时。
为了解决这个问题:
LLM.int8() 方法只将一小部分离群值保持为 FP16,其余使用 INT8。
SmoothQuant 方法将激活值的波动“转移”到权重上,使得激活可以更容易地静态量化。
不过,INT8 的效果取决于使用场景:
**总结阶段(Summarization phase)**是计算密集型,INT8 提升显著;
这阶段会处理大量的输入(如一整段上下文),模型能重复使用权重。
数据主要在显存内部反复计算,几乎不怎么搬运数据。
计算占主导,GPU 的算力(比如 INT8 Tensor Core)能充分发挥,所以提速效果明显。
**生成阶段(Generation phase)**是内存受限型,INT8 提升有限。
每次只生成一个 token,前后步骤之间不能并行,需要按顺序来。
每一步都要从显存读取大量模型权重(比如注意力层),计算反而不是瓶颈。
内存带宽限制了速度,就算用了 INT8 也不能提升太多,提速有限。
备注
⁉️这段没太理解,为啥就算用了 INT8 也不能提升太多,提速有限
因此,研究者提出了 W4A16 格式:权重用 4-bit 表示,激活保留为 16-bit,从而在保证效果的同时减少内存访问。
如 AWQ、OPTQ 通过运行时动态反量化实现这一方式,尽管增加了反量化开销,但整体推理速度仍能提升。
2.3 二进制编码量化(BCQ)¶
BCQ 是一种不同于传统均匀量化的新方法,把权重向量表示为若干个 ±1 的二进制向量加权相加。
本文采用 BCQ 来量化权重,同时激活值仍保持高精度(未量化),以避免前面提到的准确率下降问题。
此外,作者扩展了 BCQ,使其能兼容其他量化策略(如均匀量化、分组量化),并支持后续提出的 LUT-GEMM 运算方法。
3. Design Methodology of LUT-GEMM¶
这段内容主要讲了LUT-GEMM方法的设计思路和实现原理
设计目标: LUT-GEMM旨在为大型语言模型(LLM)实现高性能且节能的推理,通过查找表(LUT)技术减少计算冗余,支持二值编码量化(BCQ)格式,避免复杂的解量化操作。
3.1 LUT based Quantized Matrix Multiplication¶
使用BCQ格式对权重做二值编码量化,激活保持全精度。
二值权重带来大量重复计算,LUT预先存储所有可能的激活和二值组合的乘积,避免重复计算和慢的逐位内存访问。
参数μ表示激活子向量长度,构建2^μ大小的LUT,从而用LUT检索替代部分计算,节省计算量。
3.2 LUT Based implementation on GPU¶
利用大量线程并行访问LUT,线程共享缩放因子避免性能下降。
线程配置需平衡资源,保证LUT利用率和减少同步开销。
多层二值矩阵(q层)依次计算累加。
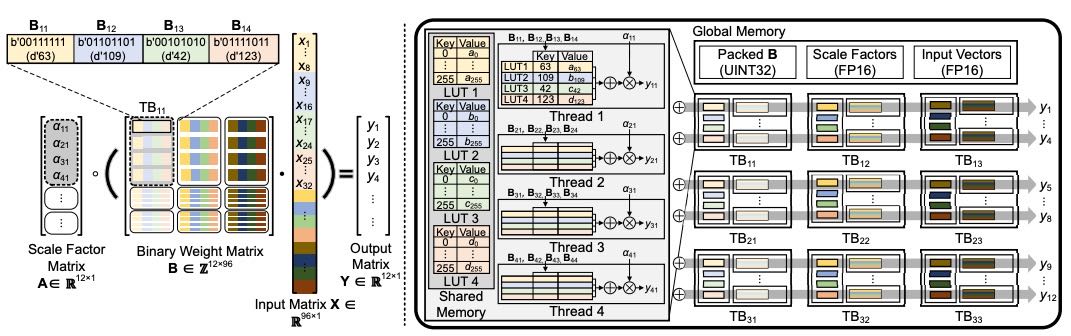
Figure 2: The overview of LUT-GEMM implementation on GPUs.
3.3 Representational Capability of LUT-GEMM¶
传统BCQ对称量化,不能表示零值,扩展后引入偏置项z,能表达非对称量化。
通过调整缩放因子和偏置,还能支持均匀量化,统一表示多种量化方案。
3.4 Latency-Accuracy Trade-Off for Improved Applicability¶
大模型权重多,单个缩放因子难以精确表达,采用分组量化(group-wise)用多个缩放因子减小误差。
分组大小g越大,内存占用越小,计算延迟越低。
LUT-GEMM延迟与内存占用成正比,可以通过调节q(量化位数)和g(分组大小)实现延迟-压缩率的权衡。
总结¶
LUT-GEMM通过查找表优化二值编码量化矩阵乘法,支持多种量化方式,在GPU上高效实现,且能根据需求调整精度与速度的平衡,显著减少LLM推理的计算量和资源消耗。
4. Experimental results¶
这段内容讲的是一种叫 LUT-GEMM 的新方法,在大语言模型推理中如何显著降低延迟和能耗。
🌟 核心观点总结¶
【定义】LUT-GEMM是什么?
一种新的矩阵乘法实现方式,直接用量化后的权重进行计算,无需反量化(dequantization)。
可以极大地减少计算量和延迟。
4.1 Kernel(内核)对比结果¶
Latency Comparisons with Various Kernels
传统cuBLAS(用FP32/FP16)速度慢;
OPTQ / AWQ有提升,但仍需反量化,有额外开销;
LUT-GEMM完全跳过反量化,速度更快。
Comparison with FP16 Tensor Parallelism
多GPU的cuBLAS并不会线性加速,原因:
GPU之间通信开销大;
一些GPU空等,利用率低;
能耗也反而上升。
LUT-GEMM 单GPU 下反而更高效,用得少,跑得快,耗能低。
4.2 端到端推理延迟¶
LUT-GEMM在LLaMA模型中的表现
即便是大模型如 LLaMA-65B,如果使用 3/4bit量化 + LUT-GEMM,也能在1~2个GPU上完成推理;
举例:
LLaMA-30B 用LUT-GEMM(3bit)比cuBLAS快2.41倍;
LLaMA-65B 用LUT-GEMM(3bit)比cuBLAS快2.04倍;
结合更先进的量化(如2bit + 微调),效果还可以更好。
并行越多不一定越快
增加GPU并不一定能有效降低延迟,主要是 通信成了瓶颈;
LUT-GEMM 的加速效果反而更突出,因为它本身计算更快,通信相对拖后腿。
📌 总结一句话¶
LUT-GEMM 是一种能在不牺牲太多精度的前提下,显著降低延迟、能耗和硬件需求的矩阵乘法方案,非常适合大语言模型的高效部署。
5. Accelerating Quantized OPT-175B¶
这段内容的核心意思是:LUT-GEMM 是一种高效的量化推理方法,可以显著降低 OPT-175B 等大模型的推理延迟,并且极大减少所需的 GPU 数量(从 8 块降到 1 块)
主要结论:
LUT-GEMM 能加速推理:
它直接使用量化后的权重(不需要反量化),所以生成每个 token 的延迟更低。
显著降低 GPU 使用量:
原来用 FP16 推理 OPT-175B 需要 8 块 A100 GPU,使用 LUT-GEMM 和 3-bit 权重量化后,只需要 1 块 GPU,延迟仍然相当(比如:约 51.6ms/token)。
比 OPTQ 更快:
在相同 3-bit 设置下,LUT-GEMM 推理速度是 OPTQ 的 2.1 倍,因为省去了反量化步骤。
可接受的精度损失:
虽然更激进的量化(例如 2-bit 或更小的 group size)会稍微降低精度(表现为 perplexity 略上升),但整体影响不大(例如从 8.34 增加到 9.58)。
6. Conclusion¶
本文提出了一个叫 LUT-GEMM 的高效矩阵乘法方法
它可以直接处理量化后的权重,不需要反量化,速度比 GPTQ 快 2.1 倍。
它支持均匀和非均匀量化的模型。
限制:
主要适用于单个 batch 推理,batch 越大,性能提升越小,这是因为核心和查找表之间的内存带宽有限。
不过,随着硬件的发展,这个问题可能会慢慢变得不重要。
Appendix A LLM Inference Latency Breakdown¶
在A100显卡上用NVIDIA的FasterTransformer工具,对不同规模的OPT大语言模型(从6.7B到175B参数)进行了推理延迟分析。
主要发现如下:
推理延迟主要由矩阵乘法决定,占总时间的75%以上;
这是因为Transformer中每层都包含多头注意力和前馈网络,这些都需要大量的线性计算;
模型越大,显卡之间的通信开销越明显,这是由于单个GPU内存不够,需要多个GPU协同完成。
Appendix B Detailed Implementation¶
每个线程块(TB)先用一部分输入值
x进行预计算,填充l个查找表(LUTs)。这些 LUTs 存在 GPU 的共享内存中,供块内所有线程共享,用来减少昂贵的全局内存访问。
多个线程同时处理
B矩阵的一些行,提升吞吐量。线程从 LUT 中取出并加总值后,会获取一次缩放因子,乘出部分结果。
这些部分结果最终会通过
atomicAdd跨线程块累加,得到最终输出。因为 LUT 存在共享内存中,带宽很高(例如 A100 是 19TB/s),访问 LUT 比执行多个浮点运算更快。
而且每 8 个隐藏维度只需 1KB 的 LUT,大部分 GPU 的共享内存都足够装下所有 LUT(如 A100 可支持高达 32 万的隐藏维度,而 GPT-3 是 12,288)。