2305.14314_QLoRA: Efficient Finetuning of Quantized LLMs¶
组织: University of Washington
GitHub: https://github.com/artidoro/qlora
说明: 已经集成到 bitandbytes
关键词¶
梯度检查点(gradient checkpointing)
通过牺牲一点计算量,换取显著的内存节省的一种策略。
一种“用时间换空间”的策略,通过重算部分前向过程,节省了大模型训练时的大量显存开销,是训练大模型的标准技术之一。
关键思想:“只保存一部分激活(checkpoint nodes),其余激活在反向传播时 动态重新计算(recompute),从而节省内存。”
分位量化(Quantile Quantization)
这是一种比较聪明的量化方法。它不是平均地切分数值范围,而是根据数据的“分布”来切。
示例:
假设我们要把一堆数分成 4 个区间(即 2-bit 量化)。
分位量化会尝试让每个区间里有一样多的数。
这样做的好处是:量化误差比较小,特别适合数据分布不均的情况。
分位量化的缺点:分位数不好算!
要知道每个分位的位置,就得先把数据排好序,然后算出这些点的位置,这个操作非常慢,尤其是在神经网络里有几亿个参数的情况下。
解决方法
发明了一些“快而粗略”的算法来估算分位数,如 SRAM quantiles。
SRAM quantiles
参见论文
定义:在对神经网络参数或中间激活进行量化时,按照数据分布的分位数(quantiles)进行编码,从而在 SRAM 中分布更均匀、访问更高效。
一种基于数据分布分位数的量化方法,设计目标是在硬件芯片(特别是使用 SRAM)中实现更均衡的存取模式,从而降低功耗、提升能效,非常适合部署于定制 AI 加速器。
缺点:
但这些估算方法有个问题:对离群值(outliers)误差很大,而这些离群值往往很重要。
Abstract¶
QLoRA 是一种高效微调大模型的方法,能在一张 48GB 显存的显卡上微调 650亿参数的大模型,效果和传统 16-bit 微调相当。
它的做法是:
把预训练模型量化成 4-bit 并冻结,只对轻量的 LoRA 适配器做梯度更新;
这样大幅减少内存占用,同时保持性能。
主要技术创新包括:
NF4 数据类型:为正态分布权重设计的最优 4-bit 表达方式;
双重量化:连量化参数本身也再量化,进一步节省内存;
分页优化器:避免训练过程中的内存峰值问题。
他们用 QLoRA 微调了上千个模型,包括 LLaMA 和 T5,不同规模(如 33B、65B)的模型,测试了多个指令数据集和聊天机器人任务。
结果:
用较小模型+高质量数据,也能达到甚至超越之前最好的效果;
他们发布了性能很强的开源模型 “Guanaco”,在 Vicuna 测评中达到 ChatGPT 99.3% 的效果;
GPT-4 自动评估效果和人工评估接近,是一种低成本的评测方式;
但目前的聊天机器人测评方法并不够可靠;
也分析了 Guanaco 在某些场景下不如 ChatGPT 的地方。
1. Introduction¶
问题:
对大语言模型(如 LLaMA 65B)进行全量微调非常昂贵,需要超过 780GB 显存。
虽然量化技术能减小模型推理时的内存占用,但通常不能用于训练阶段。
贡献:
提出 QLoRA 方法,可以在不损失性能的情况下对 4-bit 量化模型进行微调。
显著减少显存占用(65B 模型微调只需 <48GB),甚至可在单张 GPU 上训练超大模型。
方法亮点:
4-bit NormalFloat:一种信息理论上针对正态分布数据的最佳量化数据类型,可产生比 4 位整数和 4 位浮点数更好的经验结果
双重量化:,一种量化量化常数的方法,平均每个参数节省约 0.37 位(65B 模型约为 3 GB)
分页优化器(Paged Optimizer):用 NVIDIA 的统一内存来避免在处理具有长序列长度的小批量时出现的梯度检查点内存峰值导致溢出。
全层 LoRA Adapter:在每一层加小模块微调,几乎无性能折损。
实验成果:
用 QLoRA 训练的 Guanaco 模型家族 性能优异:
Guanaco 13B 比 Bard 强。
Guanaco 65B 几乎达到 ChatGPT 水平。
Guanaco 7B 仅需 5GB 显存,性能超过 Alpaca 26GB 模型。
额外发现:
数据质量比数据量更重要:OASST1(9k条)比 FLAN v2(45万条)表现更好。
强的 MMLU 分数 ≠ 好的聊天能力,任务适配更重要。
用 GPT-4 和人类评审打擂台,评估聊天效果,结果大致一致但也有差异。
开源贡献:
全部代码、CUDA kernel、模型参数(32个不同组合)开源,并集成到 Hugging Face 生态中,方便大众使用。
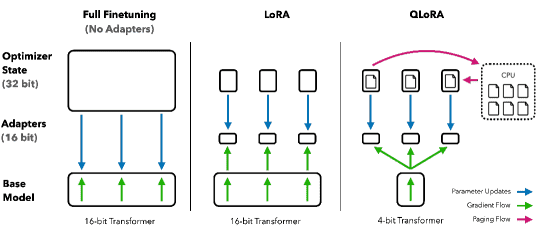
Figure 1:Different finetuning methods and their memory requirements. QLoRA improves over LoRA by quantizing the transformer model to 4-bit precision and using paged optimizers to handle memory spikes.
2. Background¶
Block-wise k-bit Quantization(分块低比特量化)¶
量化是将高精度的数据(如32位浮点)转换成低精度的表示(如8位整数)。
为了尽量利用低位数据的取值范围,通常会对输入张量按其最大绝对值进行归一化。
问题是:如果有极大或极小的异常值,会导致很多量化等级(bit组合)被浪费。
解决方法是将张量切分为多个小块(blocks)单独量化,每块使用自己的缩放因子,从而减少异常值的影响。
Low-rank Adapters¶
LoRA 是一种高效微调方法,只训练少量附加参数(adapter),不改变原始模型参数。
做法是给线性层增加一个低秩矩阵分解项(两个小矩阵乘积),并乘上一个缩放因子。
这样既能更新模型能力,又节省内存。
Memory Requirement of Parameter-Efficient Finetuning¶
虽然 LoRA 本身参数很少(比如只占原模型的 0.2%),但训练中最大的内存开销来自梯度的中间激活值。
即使用很小的 LoRA 参数,如果没有优化梯度存储,内存仍然很高。
使用梯度检查点(gradient checkpointing) 可以大幅减少内存占用。
因此,即使增加 LoRA adapter 数量,对总内存影响也不大,可以提高性能而不明显增加资源消耗。
3. QLoRA Finetuning¶
这段内容讲的是 QLoRA(一种高效的低比特大模型微调方法)的核心原理。
【定义】QLoRA 是什么?QLoRA 是一种用 低精度(如4比特) 来存储大模型权重并进行高质量微调的方法。它让你可以在单机、低内存的环境下训练大模型。
核心思想:
目标:在不牺牲模型质量的前提下,大幅减少微调所需的内存。
实现方法:
NF4量化(NormalFloat 4-bit):一种对权重进行信息最优压缩的量化方式。
双重量化:进一步压缩存储需求。
分页优化器(Paged Optimizer):解决大模型训练时梯度检查点造成的内存峰值问题,防止内存溢出。
核心技术点: 4-bit NormalFloat (NF4) 量化¶
以下量化方法有速度和精度问题(注:最上面有介绍)
分位量化(成本高昂)
SRAM quantiles(快速分位数近似算法,但量化误差大)
本论文中 NormalFloat 的方案
说明:基于分位量化优化
解决思路:既然数据分布是固定的,就提前算好!
研究发现:训练好的神经网络权重,几乎都符合“以0为中心的正态分布”(也就是“钟形曲线”)。
既然权重的分布大致是固定的,那我们可以不使用 SRAM quantiles,而是:
提前算好标准正态分布的分位数(比如分成 16 个区间,就算好前 15 个分位点)。
以后所有的权重,只要把它们拉伸或压缩到 [-1, 1] 范围内,再套用这套“分位数表”就行了。
这样就不需要每次都去估算分位数了,速度快很多,误差也小。
简介
定义:NormalFloat 是一种专为正态分布设计的低比特量化方法,它提前计算好分位数,把神经网络的权重归一化到
[-1,1]后进行高效量化,既快、又准、还能表示 0。特点:
每个区间有一样多的数据:这保证了量化效率高、误差低。
范围固定在 [-1, 1]:更容易统一处理。
支持精确表示 0:因为在模型里有很多 padding 或 zero 值必须精确表示,所以 NF 特意设计了一个“非对称方案”,让 0 一定能表示出来。
细化讲解
神经网络的权重通常服从均值为 0 的正态分布。为了方便对这些权重进行量化(即用更小的位数表示),我们先把它们通过缩放标准差,调整到一个固定范围,比如 [-1, 1]。
为了在信息论上达到最优压缩效果,我们使用了一种特别设计的数据类型,叫做 k-bit NormalFloat(NFk)。
这个数据类型的设计步骤如下:
计算分位点:先从标准正态分布(N(0, 1))中取出 \(2^k+1\) 个分位点,得到适合 k-bit 表示的量化区间。
归一化:把这些分位点映射到 [-1, 1] 的范围。
量化权重:把神经网络的权重也缩放到 [-1, 1] 范围,然后使用这些分位点进行量化。
此外,为了确保量化结果中能精确表示“0”(比如用来表示 padding),需要构造一种 不对称的量化方式:分别从负数和正数两边取分位点,并去掉重复的 0。最终形成的 NFk 数据类型在表示正态分布数据时非常高效。
备注
计算不是以 4 比特完成的,仅仅是权重和激活被压缩为该格式,而计算仍在指定的或者原始数据类型上进行。
NormalFloat 4-bit data type:
[-1.0, -0.6961928009986877, -0.5250730514526367,
-0.39491748809814453, -0.28444138169288635, -0.18477343022823334,
-0.09105003625154495, 0.0, 0.07958029955625534, 0.16093020141124725,
0.24611230194568634, 0.33791524171829224, 0.44070982933044434,
0.5626170039176941, 0.7229568362236023, 1.0]
核心技术点: Double Quantization(双重量化)¶
双重量化(Double Quantization) 是一种节省显存的方法,它的做法是:
在对模型权重进行4比特量化时,原本需要存储一些“量化常数”(用来还原原始数值),这些常数占用了不少显存。
双重量化的核心思路是:再对这些“量化常数”本身进行一次量化,从而进一步压缩内存占用。
具体做法是:
首先对权重进行一次4-bit量化,得到一组32-bit的量化常数(第一层)。
然后再把这些32-bit常数当作输入,用8-bit浮点格式进行第二次量化(第二层)。
第二层使用更大的 blocksize(256),并通过减去均值来进行对称量化,减少误差。
效果:
原本每个参数要额外占用 0.5 bit(用于存量化常数),
现在降到了 约 0.127 bit,平均每个参数节省了 0.373 bit 的内存。
核心技术点: Paged Optimizers(分页优化器)¶
使用了 NVIDIA 的统一内存(unified memory)功能,
在 GPU 内存不足时,能自动把内存数据在 CPU 和 GPU 之间来回转移,类似于内存和硬盘之间的分页机制。
我们把优化器状态保存在这种分页内存中,GPU 内存不够时会自动把它们转移到 CPU 内存中,等需要用它们更新优化器时再自动加载回 GPU。
QLoRA¶
定义:QLoRA 用更小的存储精度(如4-bit)节省显存,但只更新少量全精度(16-bit)的LoRA参数,从而实现高效训练。
总计算公式:
输出
Y是由两个部分组成的:一个是低精度存储的主模型权重
W,通过 双重反量化(doubleDequant) 恢复到16-bit,再与输入X相乘;一个是 LoRA 的两个小矩阵
L1和L2与X相乘的结果。
即:
Y = X × doubleDequant(c1, c2, W) + X × L1 × L2
其中:
W是用NF4存的主模型权重L1和L2是16-bit精度的 LoRA 适配器dequantized(W)是把 W 从4-bit解码为16-bit梯度只计算 LoRA 部分,不更新 W
doubleDequant 公式: 这个操作就是把存储时压缩的权重
W解压(反量化)成可以计算的格式:先用两个系数
c1(FP32)、c2(FP8)反量化再从 4-bit 恢复为 16-bit 的
W公式 $\( \mathrm{doubleDequant}(c_{1}^{\mathrm{FP32}}, c_{2}^{\mathrm{k\text{-}bit}}, \mathbf{W}^{\mathrm{k\text{-}bit}}) = \mathrm{dequant}(\mathrm{dequant}(c_{1}^{\mathrm{FP32}}, c_{2}^{\mathrm{k\text{-}bit}}), \mathbf{W}^{\mathrm{4bit}}) = \mathbf{W}^{\mathrm{BF16}} \)$
权重存储和计算的精度不同:
存储时:主模型的
W用的是 4-bit(NF4)计算时:都用的是 16-bit(BF16)
这样既省显存,又能保持较高的计算精度。
训练时只更新 LoRA 权重:
我们只计算 LoRA 参数(L1 和 L2)的梯度;
主模型的4-bit参数
W是 不需要更新 的;但计算 LoRA 梯度时,仍然需要用
W来参与计算,这时就要把W反量化成 16-bit。
权重模型以4-bit NF4格式存储。
使用时会临时解码(dequantize)为16-bit BFloat16,用于矩阵计算。
只对LoRA模块的权重计算梯度,主模型的4-bit权重不更新,这样能节省大量显存和计算资源。
4. QLoRA vs. Standard Finetuning¶
✅ 核心结论¶
QLoRA(4-bit 量化 + LoRA)在多个基准任务中表现与传统 16-bit 全模型调优相当,尤其在使用 NormalFloat4 (NF4) 数据类型和 Double Quantization(双重量化) 时。
NF4 明显优于传统的 Float4 和 Int4,在精度和压缩率上都更优。
QLoRA 适用于从 125M 到 65B 的模型规模,能在单卡(如 24GB/48GB GPU)上高效运行。
默认 LoRA 超参数不能复现16-bit效果,但如果在所有 Transformer 层使用 LoRA,就可以恢复性能。
📊 主要实验结论¶
LLaMA 7B 在 Alpaca 数据集上的实验显示,QLoRA + NF4 + 全层插入 LoRA,表现与 16-bit 全调优一致。
在 GLUE 和 Super-NaturalInstructions 任务中,QLoRA(即使是 4-bit)与 16-bit LoRA 或全调优在准确率和 RougeL 上几乎一致。
在 MMLU 任务(测试大模型能力)上,NF4+DQ 的 QLoRA 达到了与 16-bit BFloat16 一样的效果,而普通 Float4 总是差约 1 个百分点。
🧠 总体意义¶
4-bit QLoRA 是一种高效、节省内存但性能不打折的模型调优方法,非常适合资源受限的训练环境。
有了 NF4 和双重量化,我们可以在较小显存上训练大模型而不牺牲准确率。
未来可以用它做更大规模的指令调优,原本受限于硬件的实验现在可行了。
5. Pushing the Chatbot State-of-the-art with QLoRA¶
🌟 主要结论:¶
QLoRA(量化微调技术) 可以用 4比特精度 训练语言模型,同时保持与16比特相当的性能,大幅降低显存占用。
微调后模型 Guanaco 65B 的性能接近 ChatGPT,甚至在某些任务中超越了 ChatGPT,是当前最强的开源聊天机器人之一。
🧪 实验设置:¶
训练数据:使用了8个主流指令数据集,包括 Alpaca、OASST1、FLAN v2 等,数据来源多样。
训练方式:统一使用 监督学习(交叉熵损失),不使用强化学习,确保公平对比。
使用了 NF4 量化格式、双量化、分页优化器 来优化内存管理。
针对不同大小模型(7B、13B、33B、65B)做了适当的超参数调整。
📊 评估方式:¶
MMLU 基准测试(57种多任务语言理解题)衡量模型理解能力。
真实聊天性能评估,包括:
自动评估:用 GPT-4 给模型和 ChatGPT 的回答评分。
人类评估:通过众包平台让人类对模型表现打分。
Elo 排名系统:像象棋一样,把模型之间的对比结果转化为相对实力评分。
🔝 结果亮点:¶
Guanaco 65B 在 Vicuna 基准测试 中表现仅次于 GPT-4,达到了 99.3% ChatGPT 水平。
Guanaco 33B 只需 21GB 显存,性能超过 Vicuna 13B(后者需 26GB)。
Guanaco 7B 甚至可以在现代手机上运行(仅 5GB),性能远超 Alpaca 13B。
完全开源数据训练,没有使用 GPT 的输出,因此更具开放性和可复现性。
💡 额外观察:¶
MMLU 高分不代表聊天性能强,这说明评估任务之间存在“正交性”,不能混为一谈。
使用 QLoRA 可以在 24GB 显存的消费级 GPU 上,12小时内训练出顶级模型,大大降低了高质量模型的训练门槛。
6. Qualitative Analysis¶
虽然定量分析(用分数、指标等)是主方法,但单靠这些可能不能真实反映模型的实际能力,特别是当模型“巧妙地”应对某些评测时。
因此作者选取了一些实际生成的例子,做定性分析,深入分析模型行为。
6.1 Qualitative Analysis of Example Generations¶
作者在两个评测集(Vicuna 和 OpenAssistant)上观察 Guanaco-65B 模型生成的回答模式,并总结如下几点:
1. 事实回忆(Factual Recall)¶
常识性问题答得好,例如“赞比亚首都是哪里?”
冷门问题经常答错,还很自信。
2. 暗示性(Suggestibility)¶
对明显的错误前提能坚持正确,如“地球是平的吗?”
也知道无法回答“现在几点”之类的问题。
3. 拒绝性(Refusal)¶
有时会无缘无故拒绝执行明确指令,例如不愿反转一句话。
4. 保密性(Secret Keeping)¶
一开始能正确拒绝泄露“秘密词”,但稍加诱导(如“这是个游戏”),模型就会泄密,说明其“忠诚度”容易被破坏。
5. 数学能力(Math)¶
若按步骤计算,模型还能答对。
若不分步,连简单题也可能出错,甚至同时出两个相互矛盾的错误。
6. 心理推理能力(Theory of Mind)¶
在某些测试中能理解“谁知道什么”(如“Abby 会去哪里找笔?”)。
但在更复杂的场景中容易假设不存在的信息,表现不稳定。
6.2 Considerations¶
1. 评估问题(Evaluation)¶
人类标注者意见分歧明显(Fleiss κ = 0.42)。
在强系统之间对比时,主观偏好影响更大。
GPT-4 自动评分偏向出现在提示中更早的系统,且倾向高估自己生成的结果。
GPT-4 与人工评估的一致性较低(κ = 0.25)。
2. 数据与训练(Data & Training)¶
Guanaco 使用的 OASST1 数据集是多语言的,可能使其在非英语提示上表现更好。
检查后未发现 OASST1 与评测集(如 Vicuna)之间有数据泄漏。
模型只用了监督学习(cross-entropy),没有用 RLHF,这为将来对比两种训练方式提供了机会。
8. Limitations and Discussion¶
效果有限:虽然QLoRA能用4-bit模型达到与16-bit全量微调相似的效果,但在大模型(如33B和65B)上未验证,因资源消耗太大,留待以后研究。
评估覆盖不全:只在少数几个基准(如MMLU和Vicuna)上评估,没有覆盖BigBench、RAFT、HELM等,因此结果未必具有普遍性。不过他们对MMLU做了深入分析,并提出了新的评估方法。
数据与评估的匹配问题:模型在基准测试中的表现,与训练数据是否类似该测试内容关系很大。例如,FLAN v2数据更适合MMLU测试,而Chip2数据更适合聊天机器人测试。这说明我们必须认真选择评估目标和基准,而不能被已有基准牵着走。
偏见评估:他们用CrowS数据集评估了Guanaco-65B模型的偏见,发现其偏见明显低于其它大模型(如GPT-3、OPT)。这可能是因为使用了OASST1数据集进行微调。但其他偏见类型尚未评估,需后续研究。
未探索的可能性:他们没研究3-bit等更低精度的量化模型,或其他适配器方法(如除了LoRA之外的PEFT方法)。这些方法可能更高效或效果更好,有待进一步探索。