1811.06965_GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism¶
组织: Google
扩大深度神经网络容量被认为是提高多种机器学习任务模型质量的有效方法。在许多情况下,将模型容量增加到超出单个加速器(accelerator)的内存限制,需要开发特殊的算法或基础设施。这些解决方案通常是特定于架构的,无法迁移到其他任务。为了应对高效且与任务无关的模型并行需求,我们提出了GPipe,一种管道并行库,能够将任何可以表示为一系列层的网络进行扩展。通过在不同的加速器上流水线处理不同的子序列层,GPipe提供了将各种不同网络高效扩展到巨大规模的灵活性。此外,GPipe采用了一种新颖的批次拆分流水线算法,使得当模型在多个加速器上进行分割时,几乎能够实现线性加速。我们通过在两种不同任务上训练大规模神经网络来展示GPipe的优势,这些任务具有不同的网络架构:(i) 图像分类:我们训练了一个包含5.57亿参数的AmoebaNet模型,并在ImageNet-2012上获得了84.4%的Top-1准确率,(ii) 多语种神经机器翻译:我们训练了一个单一的60亿参数、128层的Transformer模型,该模型在跨越100多种语言的语料库上表现出比所有双语模型更好的质量。
- Blog
Pipeline-Parallelism: Distributed Training via Model Partitioning: http://siboehm.com/articles/22/pipeline-parallel-training
收集¶
流水线并行的核心思想是:在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练。未划分前的数据,叫mini-batch。在mini-batch上再划分的数据,叫micro-batch。
Gpipe采用了一种非常简单粗暴但有效的办法:用时间换空间,在论文里,这种方法被命名为re-materalization,后人也称其为active checkpoint。具体来说,就是几乎不存中间结果,等到backward的时候,再重新算一遍forward
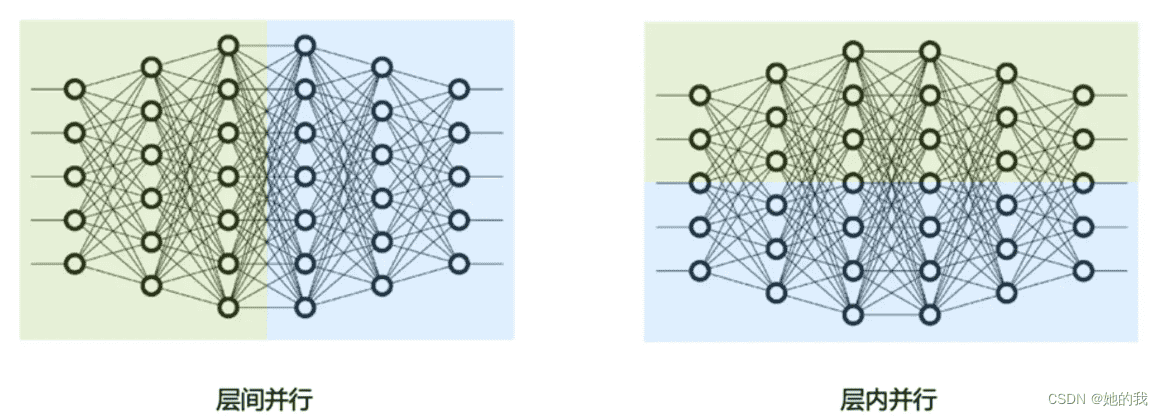
流水线并行和张量并行都可以看作是模型并行的一种,只是对模型切分的维度不同,流水线并行可以看作是层间并行,将模型不同的层放到不同的GPU上,张量并行看作是层内并行,是对层内具体的矩阵运算进行拆分。¶
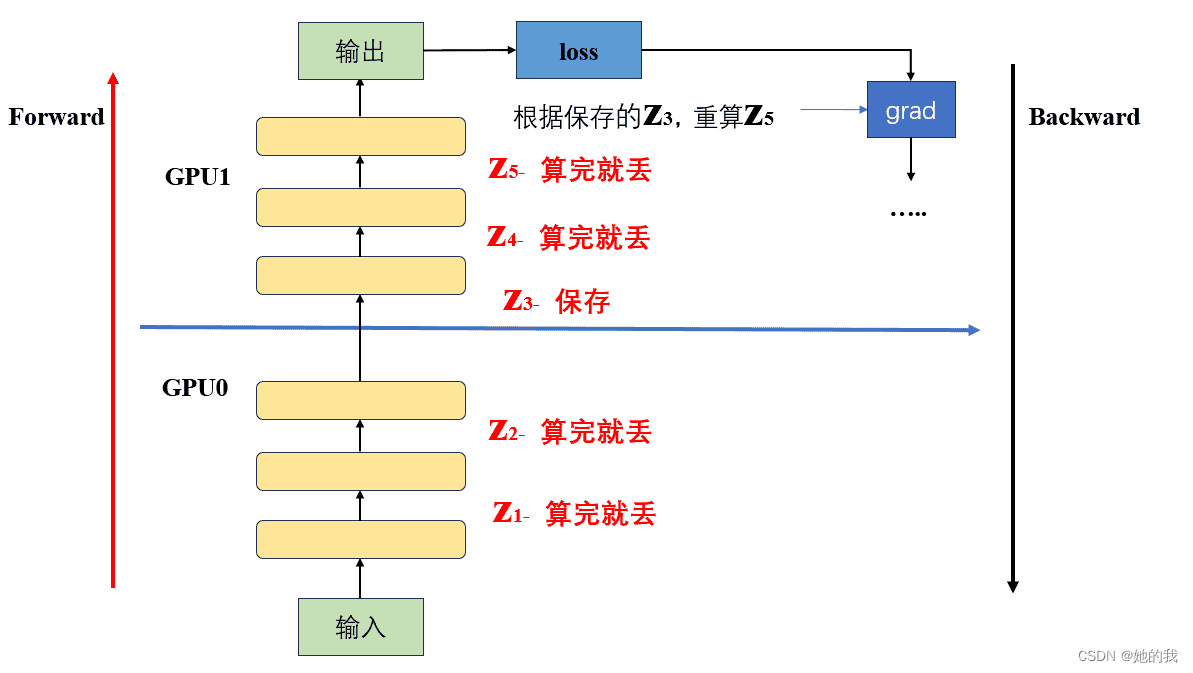
将模型放到两个GPU上,前向时,只将每个GPU最后一层输出的中间结果,传递给下一个GPU并保存,在反向传播需要用到丢弃的中间激活值时,在重新计算。从而减少了显存的占用。¶
1. Introduction¶
深度学习的进展与模型规模:过去十年,深度学习在多个领域取得了巨大的进步,尤其是在图像分类和自然语言处理(NLP)领域。图像分类中的表现提升(例如,ImageNet上的准确度提高)与模型规模的增加密切相关。类似的,NLP领域中,简单的浅层句子表示模型被更深更大的模型所超越。
更大模型的挑战:尽管更大的模型带来了显著的性能提升,但扩展神经网络时会面临许多实际挑战。硬件限制(如内存限制和GPU/TPU上的带宽限制)迫使用户将模型拆分成多个部分,并将这些部分分配到不同的加速器上。然而,设计高效的模型并行算法非常困难,通常需要在扩展能力、灵活性(或特定任务和架构的适配性)以及训练效率之间做出艰难选择。因此,大多数高效的模型并行算法往往是针对特定架构和任务的。
GPipe的引入:为了解决这些问题,文中介绍了GPipe,一个灵活的库,能够高效地训练大规模神经网络。GPipe通过将模型划分到不同的加速器上并支持重新计算(rematerialization),突破了单一加速器内存的限制。GPipe允许将每个模型定义为一系列层,并将连续的层分割成不同的”cells”(单元)。每个cell可以被放置到一个独立的加速器上,从而实现模型的分布式训练。
GPipe的流水线并行算法:在GPipe中,首先将一个mini-batch(小批量)的训练样本划分成更小的micro-batches(微批量),然后在不同的cells上对这些微批量进行流水线式执行。采用的是同步的mini-batch梯度下降法(SGD),即梯度会在整个mini-batch中的所有micro-batches上累积,并在mini-batch的结束时应用更新。因此,无论模型被划分为多少部分,GPipe都能保证梯度更新的一致性。
模型并行和数据并行结合:GPipe的这种分布式训练方式还可以与数据并行性结合,进一步提升训练的规模。
- GPipe在实际任务中的应用:
图像分类:在ImageNet 2012数据集上,使用GPipe训练了一个宽度为480×480的AmoebaNet模型。通过增加模型的宽度,参数量达到了5.57亿,最终在验证集上的top-1准确率为84.4%。
机器翻译:在机器翻译任务中,GPipe被用来训练一个128层、60亿参数的多语言Transformer模型,支持103种语言。与独立训练的350百万参数的双语Transformer模型相比,这个模型能够在100个语言对的翻译任务中表现更好。
总结来说,这段话讲述了GPipe如何通过分布式模型并行和流水线并行算法来高效训练大规模神经网络,克服了传统大模型训练中的内存和带宽限制问题,并展示了其在图像分类和机器翻译中的实际效果。
2. The GPipe Library¶
主要介绍了GPipe库的接口、算法和性能优化设计,重点说明了如何通过分布式计算来高效训练大规模神经网络。
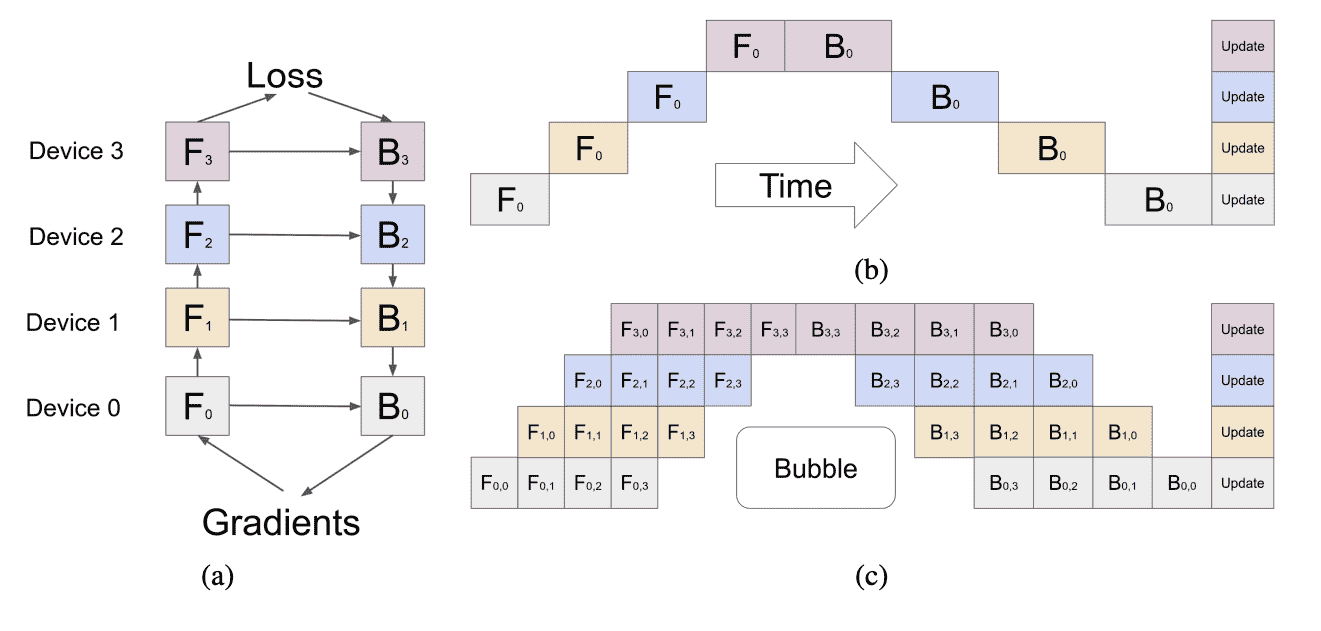
Figure 2: (a) An example neural network with sequential layers is partitioned across four accelerators. Fk is the composite forward computation function of the k-th cell. Bk is the back-propagation function, which depends on both Bk+1 from the upper layer and Fk. (b) The naive model parallelism strategy leads to severe under-utilization due to the sequential dependency of the network. (c) Pipeline parallelism divides the input mini-batch into smaller micro-batches, enabling different accelerators to work on different micro-batches simultaneously. Gradients are applied synchronously at the end.¶
2.1 接口设计(Interface)¶
模型定义:GPipe的核心是将深度神经网络定义为一个由L层(Layers)组成的序列。每一层 𝐿𝑖 包含一个前向计算函数 𝑓𝑖 和相应的参数 𝑤𝑖 。GPipe还允许用户定义一个计算成本估算函数 𝑐𝑖 ,来估算每层的计算成本。
模型分区:在GPipe中,用户可以指定将模型分为多少个分区(K cells)。然后将。每个cell包含连续的层。每个cell的参数集是这些层的参数集的并集,前向函数为这些层前向函数的复合。
自动反向传播:GPipe利用自动符号微分计算每个cell的反向传播函数(𝐵𝑘)。
- 简单接口:用户需要指定
分区数 𝐾
微批量数 𝑀
网络的层定义。
2.2 Algorithm¶
网络分区与计算:用户定义好网络的层、参数、前向函数和计算成本函数后,GPipe将网络分为K个cell,每个cell放置在一个加速器上。分区边界处会自动插入通信原语,以便在相邻分区之间传输数据。
计算效率优化:分区算法的目标是通过最小化各cell的成本方差,来平衡计算时间,从而提高流水线的效率。
- 前向传递与反向传递:
在前向传递时,GPipe将每个mini-batch划分为M个等分的微批量(micro-batches),然后在K个加速器上进行流水线操作。
在反向传递时,GPipe根据前向传递时使用的相同模型参数来计算每个微批量的梯度。在每个mini-batch结束时,所有微批量的梯度会累积,并在所有加速器上更新模型参数。
批归一化:如果网络中使用了批归一化(Batch Normalization),在训练过程中会计算每个微批量的输入统计量,并跟踪整个mini-batch的移动平均,以便在评估时使用。
2.3 Performance Optimization¶
减少激活内存需求:GPipe通过重新计算(re-materialization)来减少激活内存需求。在前向传递过程中,每个加速器仅存储分区边界处的输出激活值。反向传递时,k-th加速器重新计算每个cell的复合前向函数。
气泡开销(Bubble Overhead):由于分区可能导致每个加速器之间的空闲时间(即“气泡开销”),这个空闲时间与微批量数和分区数相关。=
低通信开销:GPipe的通信开销较低,因为只需要在加速器之间传递分区边界处的激活张量。因此,即使在没有高速互联的加速器上,也能实现高效的扩展性能。
不平衡负载:尽管GPipe的分区算法是针对均匀分配内存和计算的情况进行优化的,但由于不同层的内存需求和计算量可能不均衡,可能会导致负载不平衡。在这种情况下,改进的分区算法可能会进一步提高性能。
3. Performance Analyses¶
这段文字详细介绍了GPipe在不同模型架构(AmoebaNet卷积模型和Transformer序列到序列模型)上的性能分析,重点分析了可扩展性、效率和通信成本。
重计算(Re-materialization):GPipe通过重计算来减少中间激活的内存需求,从而使得训练更大模型变得可行。
流水线并行(Pipeline Parallelism):通过流水线并行,GPipe允许将模型分配到多个加速器,从而提高训练效率并克服单一加速器内存的限制。
【总结】GPipe的优点在于它能够通过重计算和流水线并行有效地扩展大规模模型,降低内存需求,尤其是在使用多个加速器时可以显著提升模型的规模。
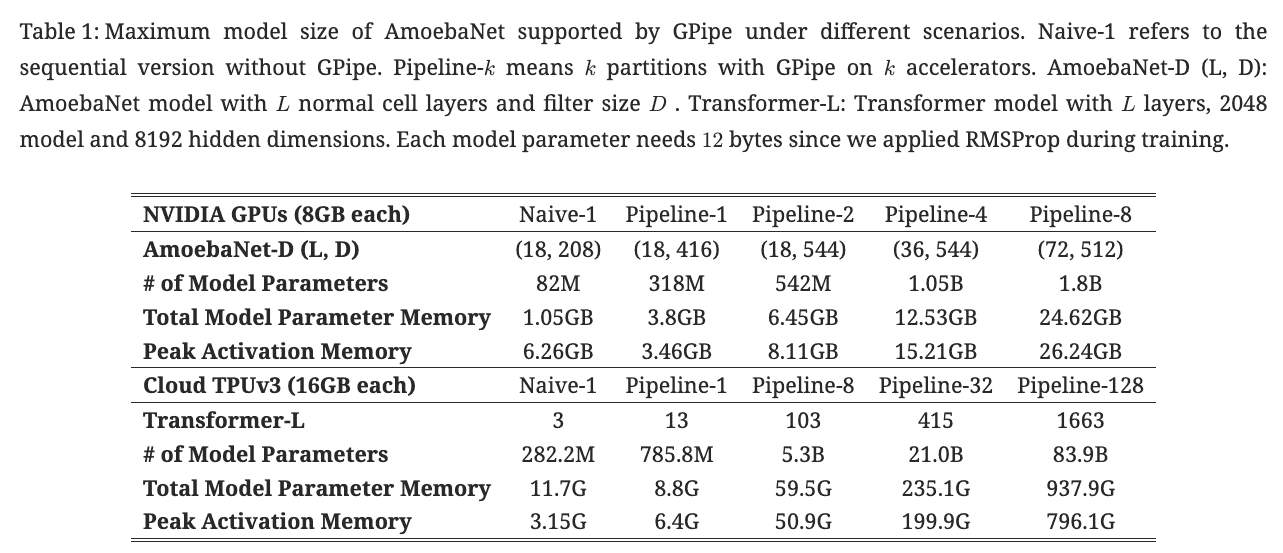
Table 1: Gpipe分别在AmoebaNet(图像)和Transformer(自然语言)两个大模型测试效果。¶
We evaluate GPipe performance with two very different types of model architectures: an AmoebaNet convolutional model and a Transformer sequence-to-sequence model.
- AmoebaNet convolutional model
input image size of 224×224 and mini-batch size of 128
Without GPipe, a single accelerator can train up to an 82M-parameter AmoebaNet, constrained by device memory limits.
Owing to re-materialization in back-propagation and batch splitting, GPipe reduces the intermediate activation memory requirements from 6.26GB to 3.46GB, enabling a 318M-parameter model on a single accelerator.
With model parallelism, we were able to scale AmoebaNet to 1.8 billion parameters on 8 accelerators, 25x more than what is possible without GPipe.
In this case, the maximum model size did not scale perfectly linearly due to the imbalanced distribution of model parameters over different layers in AmoebaNet.
- Transformer sequence-to-sequence model
fixed vocabulary size of 32k, sequence length 1024 and batch size 32.
Each Transformer layer has 2048 for model dimension, 8192 for feed-forward hidden dimension and 32 attention heads.
Re-materialization allows training a 2.7× larger model on a single accelerator.
With 128 partitions, GPipe allows scaling Transformer up to 83.9B parameters, a 298× increase than what is possible on a single accelerator.
Different from AmoebaNet, the maximum model size scales linearly with the number of accelerators for Transformer, since each layer has the same number of parameters and input sizes.
备注
在Transformer上,Gpipe基本实现了模型大小(参数量)和GPU个数之间的线性关系。例如从32卡增到128卡时,模型的大小也从21.08B增加到82.9B,约扩4倍。但对AmoebaNet而言,却没有完全实现线性增长。例如从4卡到8卡,模型大小从1.05B到1.8B,不满足2倍的关系。本质原因是AmoebaNet模型在切割时,没有办法像Transformer一样切得匀称,保证每一块GPU上的内存使用率是差不多的。因此对于AmoebaNet,当GPU个数上升时,某一块GPU可能成为木桶的短板。
4. Image Classification¶
使用GPipe进行图像分类任务的实验,特别是在AmoebaNet模型上的应用,以及模型如何在转移学习任务中表现良好。
实验展示了GPipe如何有效地扩展AmoebaNet,并且在ImageNet数据集上取得了很好的性能。
转移学习的结果表明,通过在大规模数据集上预训练,模型能够迁移到其他图像分类任务,并在这些任务上表现出竞争力的结果。这些实验进一步验证了更强大的预训练模型(如AmoebaNet)在转移学习中的优势。
总的来说,这段文字强调了使用GPipe进行大规模图像分类训练的成功,以及在多个目标数据集上通过转移学习达到的优秀效果。
5. Massive Massively Multilingual Machine Translation¶
描述了如何使用GPipe扩展自然语言处理(NLP)中的神经机器翻译(NMT)模型,尤其是多语言机器翻译任务。重点分析了大规模多语言任务中的模型扩展性、深度与宽度的平衡、深度模型的训练挑战以及大批量训练等方面的实验结果。
- 总结
多语言翻译任务证明了GPipe在大规模NMT任务中的灵活性和可扩展性,使得训练更大规模的模型成为可能。
深度与宽度的权衡:增加深度对低资源语言有显著的性能提升,而增加宽度则有助于高资源语言的提升。
深度模型的训练挑战:虽然深度模型有更强的表示能力,但也带来了训练不稳定的问题。通过调整初始化和截断logit值等方法,可以缓解这些问题。
大批量训练:通过显著增加批量大小,训练效果得到了提升,尤其是在高资源语言对的翻译任务中。
6. Design Features and Trade-Offs¶
- 模型并行的核心思想和挑战
模型并行的核心思想是将神经网络分割成多个计算单元(如层),然后将这些单元分配到不同的设备上。这允许扩展网络的规模,尤其是在处理超大模型时。
- 然而,这也带来了两个主要问题:
硬件利用率低:设备间的负载不均,可能导致某些设备空闲。
设备间通信瓶颈:当模型被分割到多个设备时,设备间需要频繁交换数据,导致高通信开销。
- 不同并行方法的比较
- SPMD(Single Program Multiple Data)
一种将数据并行的单指令多数据(SIMD)扩展到张量维度的方式。
SPMD允许将每个计算分割到多个设备上,从而使单个矩阵乘法(或单层的模型参数)在多个加速器上线性扩展。
- 优点:
可以通过扩展加速器数量来线性扩展矩阵乘法和模型参数。
- 缺点:
高通信开销:为了合并每个矩阵乘法的输出,SPMD使用大量的类似AllReduce的操作,这导致了大量通信开销。特别是在没有高速互连的设备上,这会成为瓶颈。
受限于网络架构:SPMD对需要并行化的操作类型有限制。例如,在卷积层的通道维度上进行分割效率低,因为这些通道是全连接的,而在空间维度上分割则需要复杂的“halo区域”技术。
扩展深度困难:为了扩展模型的深度,SPMD要求将每一层分割到更多的加速器上,进而增加了设备间的通信负担。
- Pipeline Parallelism
PipeDream是一个基于pipeline parallelism(流水线并行)的最新方法,旨在减少用于参数服务器的通信开销。它通过将前向传播和反向传播交替进行,来最大化硬件利用率。
- 问题:
权重过时:由于异步更新反向传播,导致模型权重过时,这可能影响优化过程。
多个版本副本:为了避免过时问题,PipeDream需要在每个加速器上维护多个版本的模型副本,这限制了它能够扩展的模型大小。
- GPipe的创新
- GPipe提出了一种新的流水线并行方法
它在执行微批次时,先进行流水线操作,最后对整个小批量进行同步的梯度更新。
这种新的批分割流水线并行算法结合重计算(re-materialization),能够大规模扩展微批次,同时避免了异步梯度更新的问题。
- 优点:
高效的通信:与SPMD相比,GPipe在扩展时引入的通信开销非常小,因为通信仅发生在微批次的分区边界,而且每个微批次的通信开销是微不足道的。这使得GPipe能够在没有高速设备互连的情况下有效运行。
线性扩展:模型的大小可以随着加速器数量的增加而线性扩展,不会像SPMD那样受到通信瓶颈的制约。
简单的通信模式:设备间仅需在分区边界交换激活张量,避免了大量冗余的通信。
- 缺点:
单层内存限制:目前,GPipe假设单个加速器的内存足以容纳单个层的计算。如果某层的内存需求超过单个加速器的内存容量,GPipe的应用就会受到限制。
复杂的微批次分割:某些层(如BatchNorm)需要跨微批次进行计算,这使得微批次分割变得复杂。BatchNorm在训练中需要使用微批次的统计量,但在评估时却需要全小批量的统计量。