编译原理实战课¶
目录
语法分析¶
两个基本功:
1. 必须能够阅读和书写语法规则,也就是掌握「上下文无关文法」
Context-Free Grammar
2. 必须要掌握「递归下降算法」
两种算法思路:
1. 一种是自顶向下的语法分析
2. 一种是自底向上的语法分析
上下文无关文法¶
如何表达语法规则-示例:
int a = 2;
int b = a + 3;
return b;
扩展巴科斯范式(EBNF):
start:blockStmts ; // 起始 block : '{' blockStmts '}' ; // 语句块 blockStmts : stmt* ; // 语句块中的语句 stmt = varDecl | expStmt | returnStmt | block; // 语句 varDecl : type Id varInitializer? ';' ; // 变量声明 type : Int | Long ; // 类型 varInitializer : '=' exp ; // 变量初始化 expStmt : exp ';' ; // 表达式语句 returnStmt : Return exp ';' ; //return 语句 exp : add ; // 表达式 add : add '+' mul | mul; // 加法表达式 mul : mul '*' pri | pri; // 乘法表达式 pri : IntLiteral | Id | '(' exp ')' ; // 基础表达式 说明: 冒号左边的叫做非终结符(Non-terminal),又叫变元(Variable) 非终结符可以按照右边的正则表达式来逐步展开, 直到最后都变成标识符、字面量、运算符这些不可再展开的符号,也就是终结符(Terminal)。 终结符其实也是词法分析过程中形成的 Token。 约定: 非终结符以小写字母开头,终结符则以大写字母开头,或者是一个原始的字符串格式产生式(Production Rule),又叫做替换规则(Substitution Rule):
add -> add + mul add -> mul mul -> mul * pri mul -> pri 标准写法: 不用能竖线、*号 等 偷懒写法: 用竖线拼接一个变元的多个产生式 说明: 产生式的左边是非终结符(变元),它可以用右边的部分替代,中间通常会用箭头连接。 产生式不用 “*” 和 “+” 来表示重复,而是用迭代,并引入 “ε”(空字符串)。 所以 “blockStmts : stmt*” 可以写成下面这个样子: blockStmts -> stmt blockStmts | ε 例: a[a-zA-Z0-9]*bc 产生式: S0 -> aS1bc S1 -> [a-zA-Z0-9]S1 S1 -> ε
上下文无关文法四个特点:
1. 一个有穷的非终结符(或变元)的集合
2. 一个有穷的终结符的集合
3. 一个有穷的产生式集合
4. 一个起始非终结符(变元)
备注
学习编译原理,阅读和书写语法规则是一项基本功。针对高级语言中的各种语句,你要都能够手写出它们的语法规则来才可以。
递归下降算法¶
示例-变量声明语句的规则:
int a = 2;
int b = a + 3;
方式1-EBNF:
varDecl : types Id varInitializer? ';' ; // 变量声明
varInitializer : '=' exp ; // 变量初始化
exp : add ; // 表达式
add : add '+' mul | mul; // 加法表达式
mul : mul '*' pri | pri; // 乘法表达式
pri : IntLiteral | Id | '(' exp ')' ; // 基础表达式
方式2-产生式:
varDecl -> types Id varInitializer ';'
varInitializer -> '=' exp
varInitializer -> ε
exp -> add
add -> add + mul
add -> mul
mul -> mul * pri
mul -> pri
pri -> IntLiteral
pri -> Id
pri -> ( exp )
基于这个规则做解析的算法如下:
匹配一个数据类型(types)
匹配一个标识符(Id),作为变量名称
匹配初始化部分(varInitializer),而这会导致下降一层,使用一个新的语法规则:
匹配一个等号
匹配一个表达式(在这个步骤会导致多层下降:exp->add->mul->pri->IntLiteral)
创建一个varInitializer对应的AST节点并返回
如果没有成功地匹配初始化部分,则回溯,匹配ε,也就是没有初始化部分。
匹配一个分号
创建一个varDecl对应的AST节点并返回
递归下降算法的特点是:
1. 对于一个非终结符,要从左到右依次匹配其产生式中的每个项,包括非终结符和终结符
2. 在匹配产生式右边的非终结符时,要下降一层,继续匹配该非终结符的产生式
3. 如果一个语法规则有多个可选的产生式,那么只要有一个产生式匹配成功就行
如果一个产生式匹配不成功,那就回退回来,尝试另一个产生式。
这种回退过程,叫做回溯(Backtracking)
递归下降算法两个缺点:
1. 第一个缺点,就是著名的左递归(Left Recursion)问题
解决1: 引入add',把左递归变成右递归:
add -> mul add'
add' -> + mul add' | ε
解决2: 把递归调用转化成循环
2. 第二个缺点,当产生式匹配失败的时候,必须要“回溯”,这就可能导致浪费
解决: 预读后续的一个 Token,判断该选择哪个产生式
对应算法: LL 算法家族
LL 算法¶
备注
计算 First 和 Follow 集合。
First 集合: 每个产生式开头可能会出现的 Token 的集合
Follow 集合: 对于某个非终结符后面可能跟着的 Token 的集合
LL(1) 中的:
第一个 L,是 Left-to-right
第二个 L,是 Leftmost 的缩写,意思是最左推导
LR 算法¶
其中的关键之处在于如何“拼凑”。
与 LL 算法对比:
优点: 不怕左递归
缺点: 缺少完整的上下文信息,编译错误信息不友好
语义分析¶
语义规则可以分为两大类:
1. 第一类规则与上下文有关。
2. 第二类规则与类型有关。
在语义分析过程中,会使用两个数据结构:
1. 一个是 AST,把语义分析时获得的一些信息标注在 AST 上,形成带有标注的 AST
2. 另一个是符号表,用来记录程序中声明的各种标识符,并用于后续各个编译阶段
上下文相关的分析¶
场景 1:控制流检查:
return、break 和 continue 等语句
场景 2:闭包分析:
要正确地使用闭包,就必须在编译期知道哪些变量是自由变量。
这里的自由变量是指在本函数外面定义的变量,但被这个函数中的代码所使用
在运行期,编译器就会用特殊的内存管理机制来管理这些变量。
所以,对闭包的分析,也是上下文敏感的。
场景 3:引用消解:
引用消解是一种非常重要的上下文相关的语义规则
作用域:
第一个使用场景,指的是变量、函数等标识符可以起作用的范围
第二个使用场景,是词法作用域(Lexical Scope)
符号表:
对于变量 a 来说,符号表中的基本信息可以包括:
1. 名称:a
2. 分类:变量
3. 类型:int
4. 作用域:foo 函数体
5. 其他必要的信息
类型分析和处理¶
备注
【定义】在计算机语言里,类型是数据的一个属性,它的作用是来告诉编译器或解释器,程序可以如何使用这些数据。
属性计算:
关于类型检查,编译器一般会采用属性计算的方法,
来计算出每个 AST 节点的类型属性,然后检查它们是否匹配。
1. 有些属性是通过子节点计算出来的,这叫做 S 属性
(Synthesized Attribute,综合出来的属性)
比如等号右边的类型。
2. 有些属性是根据父节点或者兄弟节点计算而来,这种属性叫做 I 属性
(Inherited Attribute,继承到的属性)
比如等号左边的 b 变量的类型。
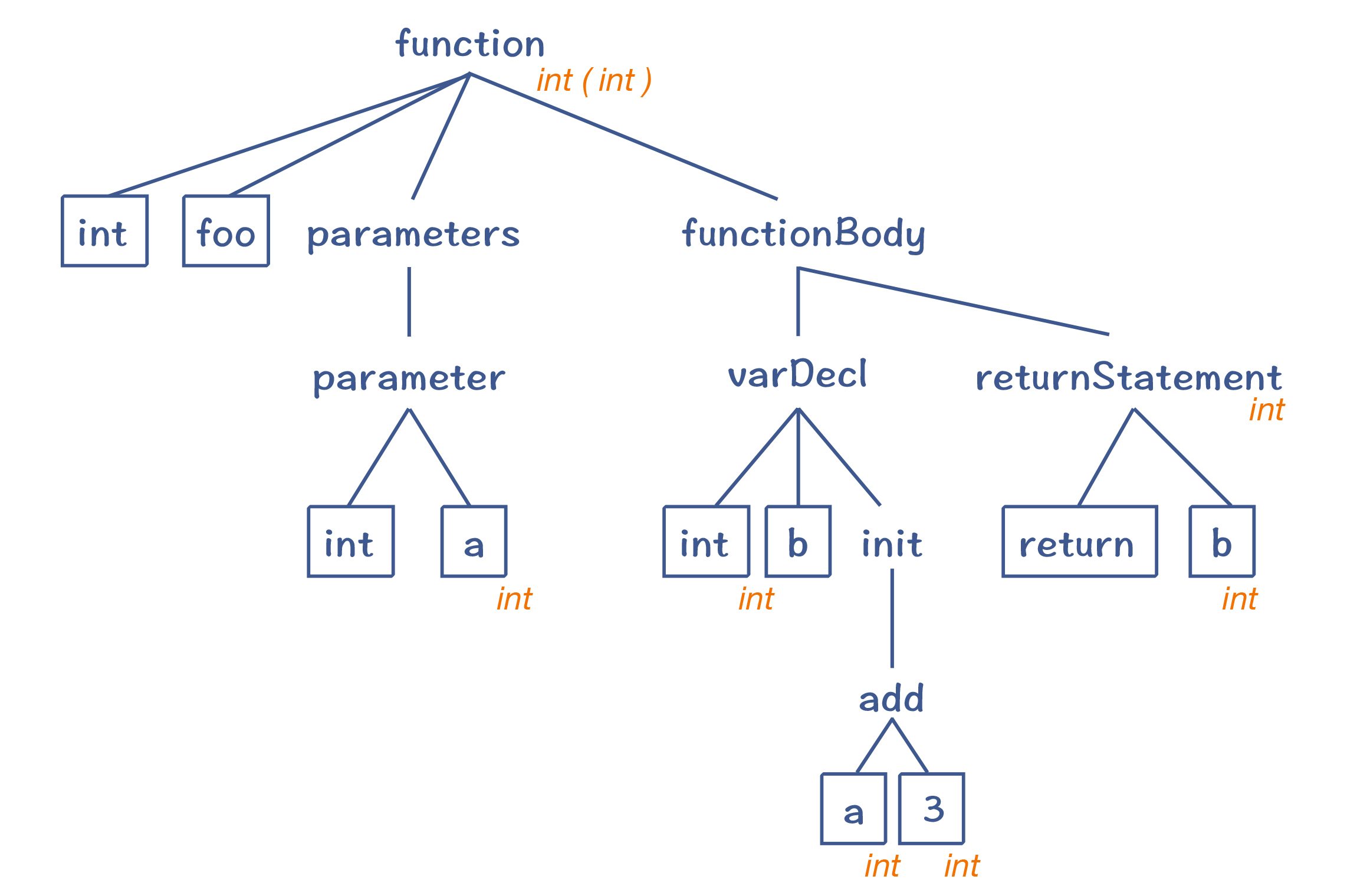
带有标注信息的 AST¶
运行时机制¶
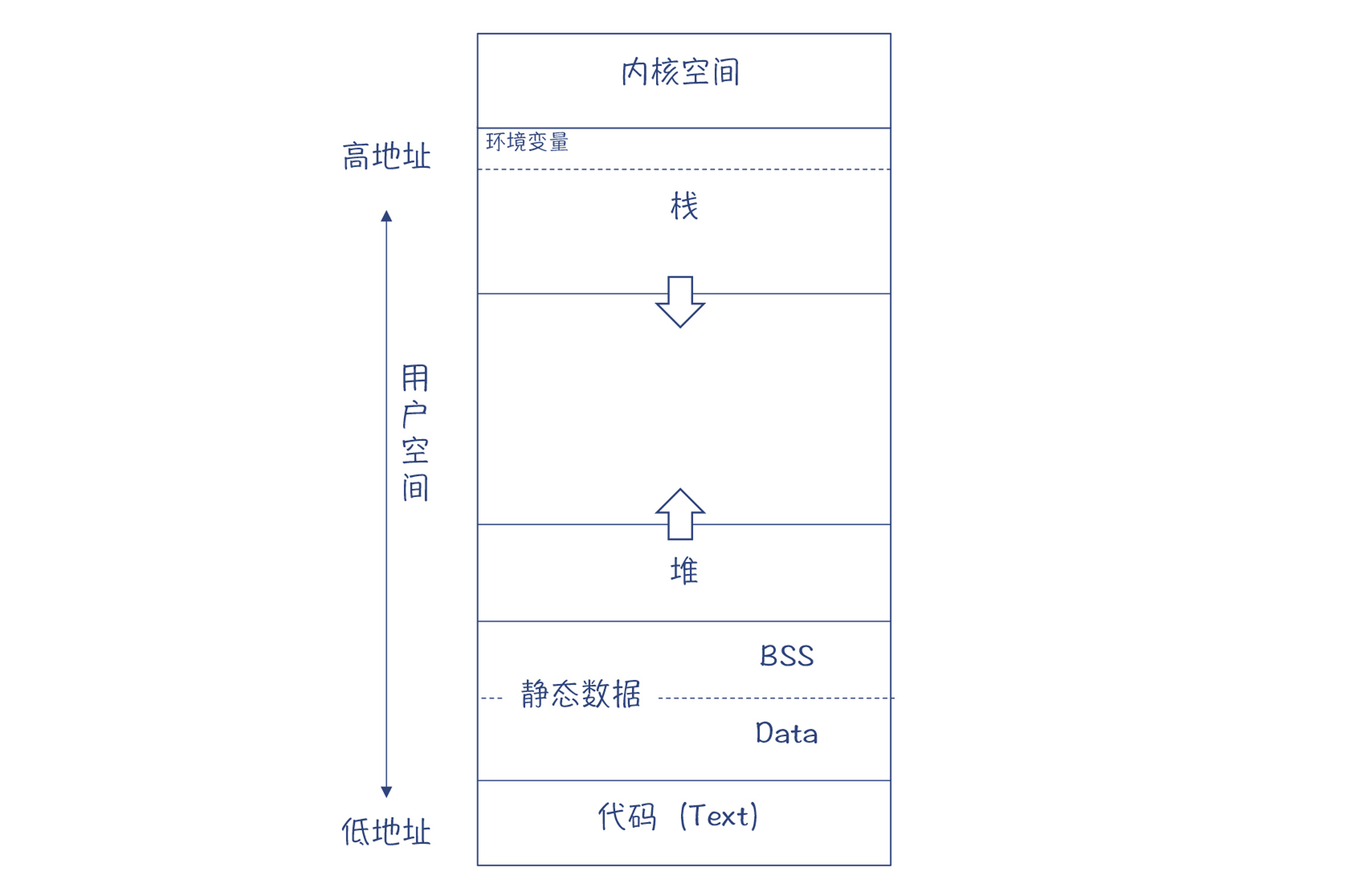
C 语言的内存布局方式¶
备注
[定义]除了硬件支撑,程序的运行还需要软件,这些软件叫做运行时系统(Runtime System),或者叫运行时(Runtime)。如:垃圾收集器,就是一个运行时的软件。进行并发调度的软件,也是运行时的组成部分。
虚拟机有两种模型:
1. 一种叫做栈机(Stack Machine)
2. 一种叫做寄存器机(Register Machine)
区别,主要在于如何获取指令的操作数
栈机是从栈里获取,而寄存器机是从寄存器里获取。这两种虚拟机各有优缺点。
中间代码 IR¶
基于抽象层次,IR 可以归结为:
1. HIR(基于源语言做一些分析和变换)
2. MIR(独立于源语言和 CPU 架构做分析和优化)
3. LIR(依赖于 CPU 架构做优化和代码生成)
HIR:
最主要的功能包括:
1. 发现语法错误
2. 分析符号之间的依赖关系(以便进行跳转、判断方法的重载等)
3. 根据需要自动生成或修改一些代码(提供重构能力)
AST 也可以算作一种 IR:
1. 开发 IDE
2. 代码翻译工具(从一门语言翻译到另一门语言)
3. 代码生成工具
4. 代码统计工具
HIR,还可以做一些高层次的代码优化,比如:
5. 常数折叠
6. 内联
有些 HIR 并不是树状结构(比如可以采用线性结构):
但一般会保留诸如条件判断、循环、数组等抽象层次比较高的语法结构
MIR:
大量的优化算法是可以通用的,没有必要依赖源语言的语法和语义,也没有必要依赖具体的 CPU 架构。
这些优化包括:
1. 部分算术优化
2. 常量和变量传播
3. 死代码删除等
示例:
int foo (int a){
int b = 0;
if (a > 10)
b = a;
else
b = 10;
return b;
}
对应的 TAC:
BB1:
b := 0
if a>10 goto BB3 //如果t是false(0),转到BB3
BB2:
b := 10
goto BB4
BB3:
b := a
BB4:
return b
说明:
TAC 用 goto 语句取代了 if 语句、循环语句这种比较高级的语句
当然也不会有类、继承这些高层的语言结构。
但是,它又没有涉及数据如何在内存读写等细节,书写格式也不像汇编代码,
与具体的目标代码也是独立的。
LIR:
Java 的 JIT 编译器输出的 LIR 信息,里面的指令名称已经跟汇编代码很像了,
并且会直接使用 AMD64 架构的寄存器名称
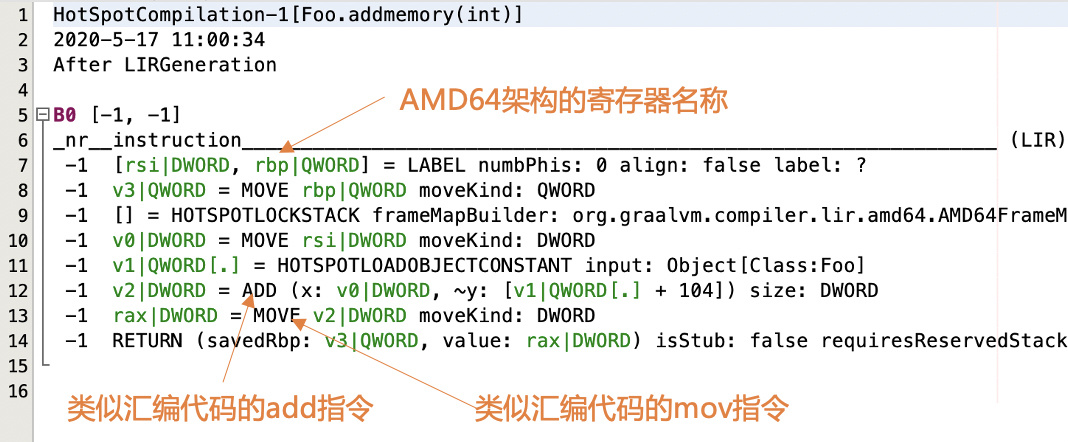
Java 的 JIT 编译器的 LIR¶
IR 的数据结构:
1. 线性结构
类似 TAC 的线性结构(Linear Form)
可以把代码表示成一行行的指令或语句,用数组或者列表保存就行了。
其中的符号,需要引用符号表,来提供类型等信息。
这种线性结构有时候也被称作 goto 格式
2. 树结构
AST 就是一种树结构
缺点: 可能有冗余的子树
3. 有向无环图(DAG)
在树结构的基础上,消除了冗余的子树
4. 程序依赖图(PDG)
显式地把程序中的数据依赖和控制依赖表示出来,形成一个图状的数据结构
基于这个数据结构,我们再做一些优化算法的时候,会更容易实现
说明: 编译器会根据需要,选择合适的数据结构
IR 设计范式-SSA 格式:
SSA: Static Single Assignment
使用SSA的原因: 使用 SSA 的形式,体现了精确的“使用 - 定义(use-def)”关系。
并且由于变量的值定义出来以后就不再变化,使得基于 SSA 更容易运行一些优化算法。
示例: y = x1 + x2 + x3 + x4
普通 TAC:
y := x1 + x2;
y := y + x3;
y := y + x4;
说明: y 被赋值了三次
SSA 的形式:
t1 := x1 + x2;
t2 := t1 + x3;
y := t2 + x4;
代码优化¶
常见的代码优化方法:
1. 机器无关的优化
如把常数值在编译期计算出来(常数折叠)
2. 机器相关的优化
利用某硬件特有的特征,比如 SIMD 指令可以在一条指令里完成多个数据的计算
3. 优化的范围
局部优化: 基本块内
全局优化: 针对整个函数(或过程)
过程间优化: 跨越多个函数(或过程)做优化
思路 1:把常量提前计算出来:
常数折叠(Constant Folding)
常数传播(Constant Propagation)
稀疏有条件的常数传播(Sparse Conditional Constant Propagation)
思路 2:用低代价的方法做计算:
代数简化(Algebra Simplification)
强度折减(Strength Reduction)
思路 3:消除重复的计算:
拷贝传播(Copy Propagation)
值编号(Value Numbering)
公共子表达式消除(Common Subexpression Elimination,CSE)
部分冗余消除(Partial Redundancy Elimination,PRE)
思路 4:化零为整,向量计算:
SIMD(Single Instruction Multiple Data)指令
超字级并行(Superword-Level Parallelism,SLP)
循环向量化(Loop Vectorization)
思路 5:化整为零,各个优化:
聚合体的标量替换(Scalar Replacement of Aggregates,SROA)
思路 6:针对循环,重点优化:
在编译器中,对循环的优化从来都是重点,因为程序中最多的计算量都是被各种循环消耗掉的
方法:
1. 归纳变量优化(Induction Variable Optimization)
2. 边界检查消除(Unnecessary Bounds-checking Elimination)
3. 循环展开(Loop Unrolling)
4. 循环向量化(Loop Vectorization)
5. 重组(Reassociation)
6. 循环不变代码外提(Loop-Invariant Code Motion,LICM)
7. 代码提升(Code Hoisting,或 Expression Hoisting)
思路 7:减少过程调用的开销:
当程序调用一个函数的时候,开销是很大的,比如:
保存原来的栈指针、保存某些寄存器的值、保存返回地址、设置参数,等等
1. 尾调用优化(Tail-call Optimization)和尾递归优化(Tail-recursion Elimination)
2. 内联(inlining)
3. 内联扩展(In-Line Expansion)
4. 叶子程序优化(Leaf-Routine Optimization)
思路 8:对控制流做优化:
1. 不可达代码消除(Unreacheable-code Elimination)
2. 死代码删除(Dead-code Elimination)
3. If 简化(If Simplification)
4. 循环简化(Loop Simplification)
5. 循环反转(Loop Inversion)
6. 拉直(Straightening)
7. 反分支(Unswitching)
有些优化,就需要比较复杂的分析方法做支撑才能完成。这些分析方法包括:
1. 控制流分析
帮助我们建立对程序执行过程的理解,比如:
哪里是程序入口,哪里是出口,
哪些语句构成了一个基本块,基本块之间跳转关系,
哪个结构是一个循环结构(从而去做循环优化)
2. 数据流分析
帮助我们理解程序中的数据变化情况
3. 依赖分析
分析出程序代码的控制依赖(Control Dependency)和数据依赖(Data Dependency)关系。
这对指令排序和缓存优化很重要。
4. 别名分析
代码生成¶
寄存器分配的算法:
1. 寄存器染色算法
计算结果比较优化,但缺点是计算量比较大
2. 线性扫描算法
计算速度快,但缺点是有可能不够优化,适合需要编译速度比较快的场景,比如即时编译
public enum CompileState {
INIT(0), // 初始化
PARSE(1), // 词法和语法分析
ENTER(2), // 建立符号表
PROCESS(3), // 处理注解
ATTR(4), // 属性计算
FLOW(5), // 数据流分析
TRANSTYPES(6), // 去除语法糖:泛型处理
TRANSPATTERNS(7), // 去除语法糖:模式匹配处理
UNLAMBDA(8), // 去除语法糖:LAMBDA 处理 (转换成方法)
LOWER(9), // 去除语法糖:内部类、foreach 循环、断言等。
GENERATE(10); // 生成字节码
...
}
数据流分析框架的 5 个要素(以活跃性分析为例):
1. V: 代表被分析的值,这里是 alive,代表了控制流是否会到达这里。
2. I: 是 V 的初始值,这里的初始值是 LIVE;
3. D: 指分析方向。这个例子里,是从上到下扫描基本块中的代码;而有些分析是从下往上的。
4. F: 指转换函数,也就是遇到每个语句的时候,V 如何变化。
这里是在遇到 return 语句的时候,把 alive 变为 DEAD。
5. Λ: meet 运算,也就是当控制流相交的时候,从多个值中计算出一个值。
数据流分析包括:
1. 活跃性分析
2. 异常分析
3. 赋值分析
4. 本地变量捕获分析
解析树和 AST 的区别¶
备注
解析树又可以叫做 CST(Concrete Syntax Tree,具体语法树),与 AST(抽象语法树)是相对的:一个具体,一个抽象。它俩的区别在于:CST 精确地反映了语法规则的推导过程,而 AST 则更准确地表达了程序的结构。
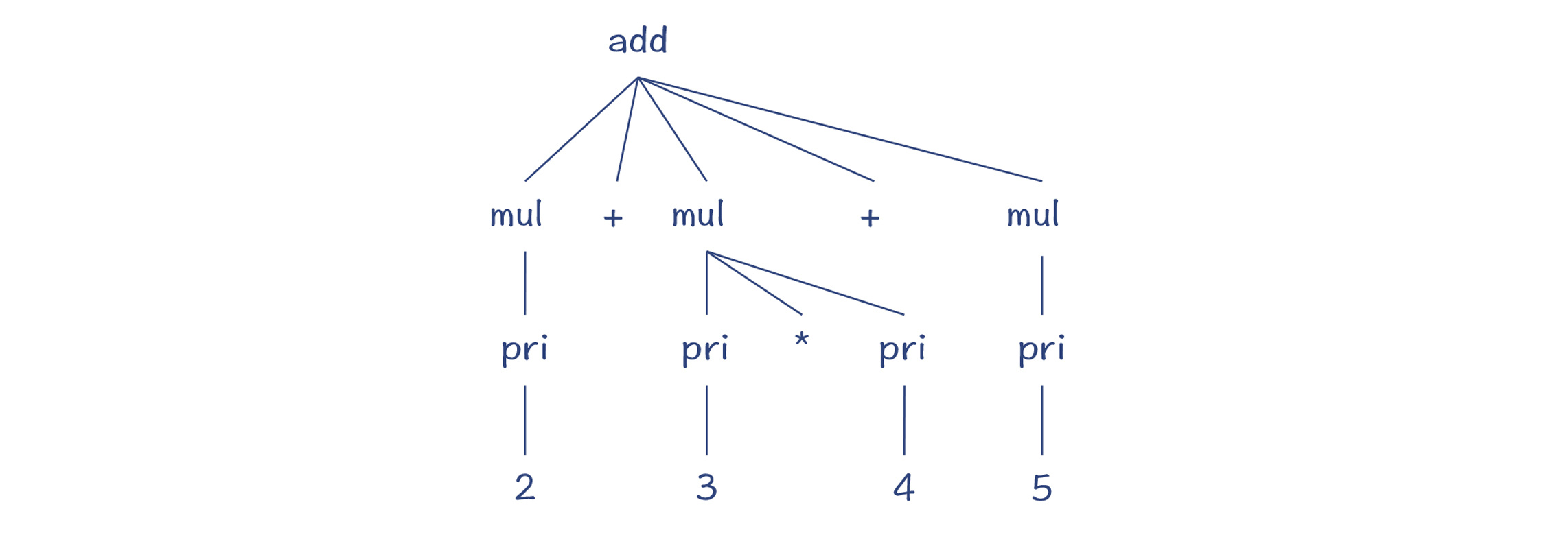
CST 的特点¶
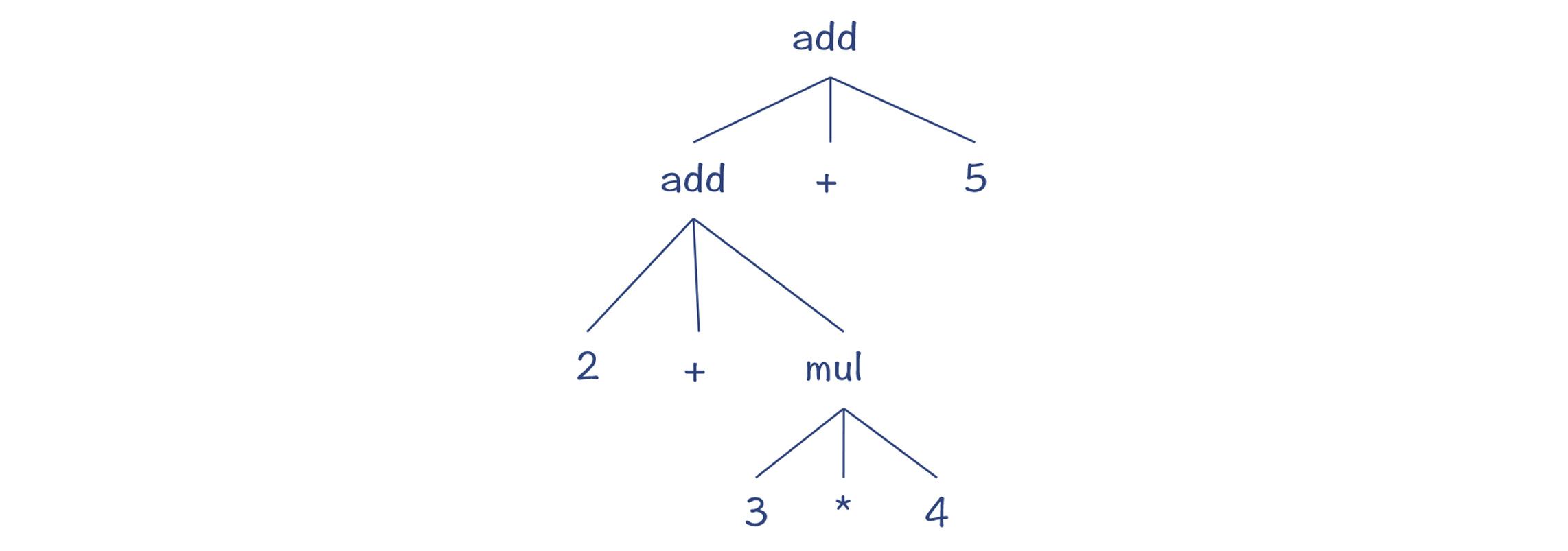
对应的 AST¶
Golang¶
词法分析&语法分析:
cmd/compile/internal/syntax:
词法分析器是 scanner.go
语法分析器是 parser.go
语义分析:
cmd/compile/internal/gc:
typecheck.go // 主要程序,处理: 类型检查,名称消解(Name Resolution)和类型推导
SSA:
cmd/compile/internal/ssa:
1. 值(Value):
Value 是 SSA 的最主要构造单元,它可以定义一次、使用多次
在定义一个 Value 的时候,需要:
一个标识符(ID)作为名称、
产生该 Value 的操作码(Op)、
一个类型(Type,就是代码中 <> 里面的值),
以及一些参数
a. 操作码有两类:
一类是机器无关的,其定义在 gen/genericOps.go
一类是机器相关的,它是面向特定的 CPU 架构的,其定义在 gen/XXXOps.go 中。
比如,AMD64Ops.go 中是针对 AMD64 架构 CPU 的操作码信息。
b. 类型信息
通常就是 Go 语言中的类型。
但有几个类型是只会在 SSA 中用到的特殊类型:
内存 (TypeMem) 类型: 代表的是全局的内存状态。
如果一个操作码带有一个内存类型的参数,那就意味着该操作码依赖该内存状态。
如果一个操作码的类型是内存类型,则意味着它会影响内存状态。
TypeFlags类型,也就是 CPU 的标志位类型。
2. 基本块(Block)
Go 编译器中的基本块有三种:
a. 简单(Plain)基本块,它只有一个后继基本块;
b. 退出(Exit)基本块,它的最后一个指令是一个返回指令;
c. 还有 if 基本块,它有一个控制值,并且它会根据该值是 true 还是 false,跳转到不同的基本块。
3. 函数(Func)
函数是由多个基本块构成的。
它必须有一个入口基本块(Entry Block),但可以有 0 到多个退出基本块,就像一个 Go 函数允许包含多个 Return 语句一样。
Go 的 IR 在运行时就是保存在 Value、Block、Func 等内存结构中,就像 AST 一样
优化:
Pass: cmd/compile/internal/ssa/compile.go
寄存器分配(regalloc.go)
cmd/compile/internal/ssa 目录:
1. cse.go 里面是消除公共子表达式的算法
2. nilcheck.go 是被用来消除冗余的 nil 检查代码
Go 语言的另外两个编译器,gccgo 和 GoLLVM
官方文档,介绍了 gc 的主要结构: https://github.com/golang/go/blob/release-branch.go1.14/src/cmd/compile/README.md
官方文档,介绍了 gc 的 SSA: https://github.com/golang/go/blob/release-branch.go1.14/src/cmd/compile/internal/ssa/README.md
- 在这两篇博客里,作者做了一个实验:如果往 Go 里面增加一条新的语法规则,需要做哪些事情。你能贯穿性地了解一个编译器的方法:
gc 编译器采用的汇编语言是它自己的一种格式,是 “伪汇编”。这两篇文章中有 Go 汇编的细节
Erlang¶
Actor 模式 VS OOP:
面向对象语言之父阿伦・凯伊(Alan Kay),Smalltalk 的发明人,在谈到面向对象时是这样说的:
对象应该像生物的细胞,或者是网络上的计算机,它们只能通过消息互相通讯。
对我来说 OOP 仅仅意味着消息传递、本地保留和保护以及隐藏状态过程,并且尽量推迟万物之间的绑定关系。
I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages (so messaging came at the very beginning – it took a while to see how to do messaging in a programming language efficiently enough to be useful)
…
OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things. It can be done in Smalltalk and in LISP.
Alan 对面向对象的理解,强调消息传递、封装和动态绑定,没有谈多态、继承等。
对照这个理解,你会发现 Actor 模式比现有的流行的面向对象编程语言,更加接近面向对象的实现。
采用 Actor 模式,会有两方面的问题:
1. 由于 Actor 之间不共享任何数据,因此不仅增加了数据复制的时间,还增加了内存占用量
这也不完全是缺点:
a. 通过在编写程序时,尽量降低消息对象的大小,从而减少数据复制导致的开销
b. 另一方面,消息传递的方式对于本机的 Actor 和集群中的 Actor 是一样的
这就使得编写分布式的云端应用更简单,从而在云计算时代可以获得更好的应用
2. 基于消息的并发机制,基本上是采用异步的编程模式,这就和通常程序的编程风格有很大的不同
Actor 模式¶
Erlang有两个显著的优点:
1. 首先,对并发的支持非常好,所以它也被叫做面向并发的编程语言(COP)
2. 第二,用 Erlang 可以编写高可靠性的软件,可以达到 9 个 9
这两个优点都与 Actor 模式有关:
1. Erlang 的软件由很多 Actor 构成
2. 这些 Actor 可以分布在多台机器上,相互之间的通讯跟在同一台机器上没有区别
3. 某个 Actor 甚至机器出现故障,都不影响整体系统,可以在其他机器上重新启动该 Actor
4. Actor 的代码可以在运行时更新
并发调度机制¶
什么时候调度比较好:
一个可选的调度时机,就是让 Actor 每处理完一条消息,就暂停一下,让别的 Actor 有机会运行。 如果处理一条消息所花费的时间太短,比如有的消息是可以被忽略的, 那么处理多条消息,累积到一定时间再去调度也行。
能否实现抢占式的调度呢:
对 Reduction 做计数
I/O 与调度的关系:
在 Erlang 的最底层,所有的 I/O 都是用事件驱动的方式来实现的。 系统收到了一块数据,就调用应用来处理,整个过程都是非阻塞的
内存管理机制¶
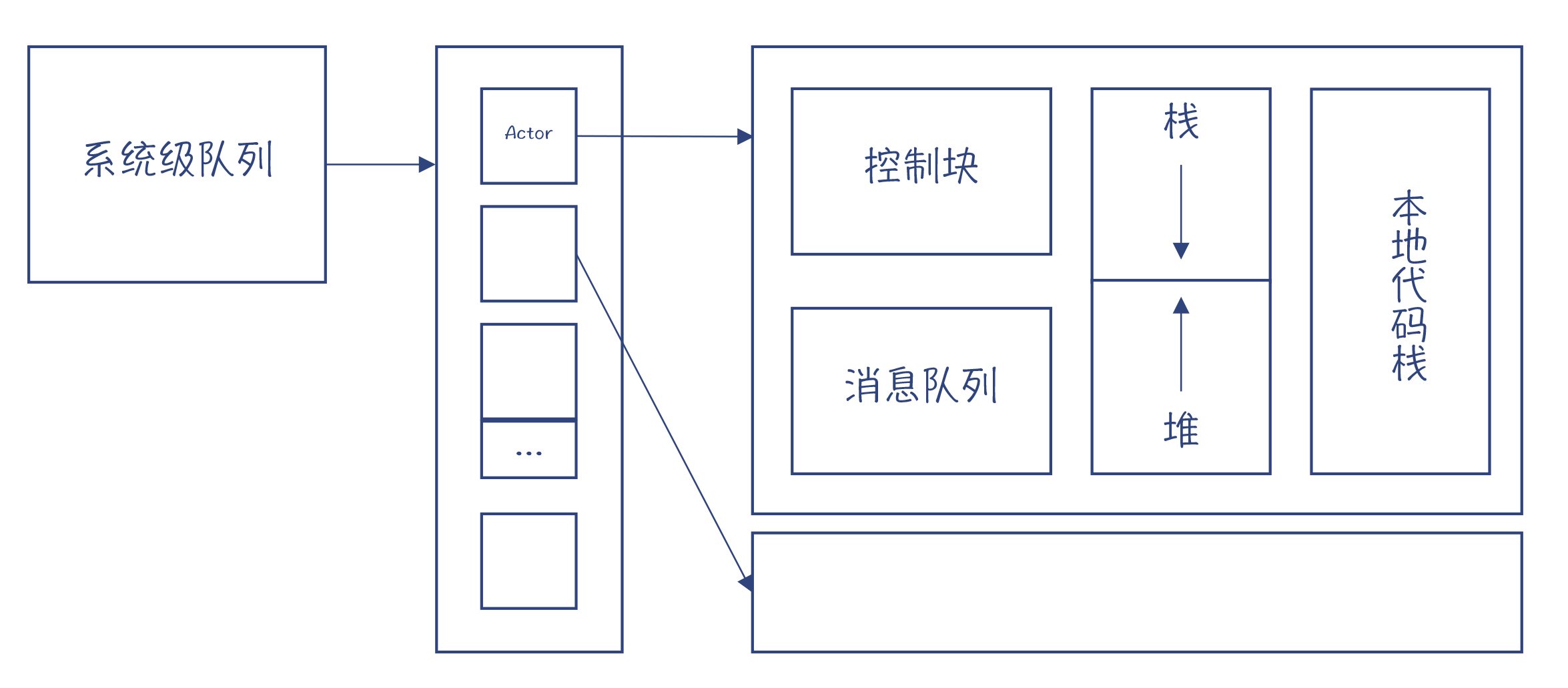
Erlang 的内存模型¶
备注
Erlang 的堆与其他语言有很大的区别,它的每个 Actor 都有自己的堆空间,而不是像其他编程模型那样,不同的线程共享堆空间。
由于每个 Actor 都有自己的堆,因此会给垃圾收集带来很大的便利:
1. 因为整个程序划分成了很多个 Actor,每个 Actor 都有自己的堆
所以每个 Actor 的垃圾都比较少,不用一次回收整个应用的垃圾,所以回收速度会很快。
2. 由于没有共享内存,所以垃圾收集器不需要停下整个应用,而只需要停下被收集的 Actor。
这就避免了 “停下整个世界(STW)” 问题,而这个问题是 Java、Go 等语言面临的重大技术挑战。
3. 如果一个 Actor 的生命周期结束,那么它占用的内存会被马上释放掉。
这意味着,对于有些生命周期比较短的 Actor 来说,可能压根儿都不需要做垃圾收集。
并发¶
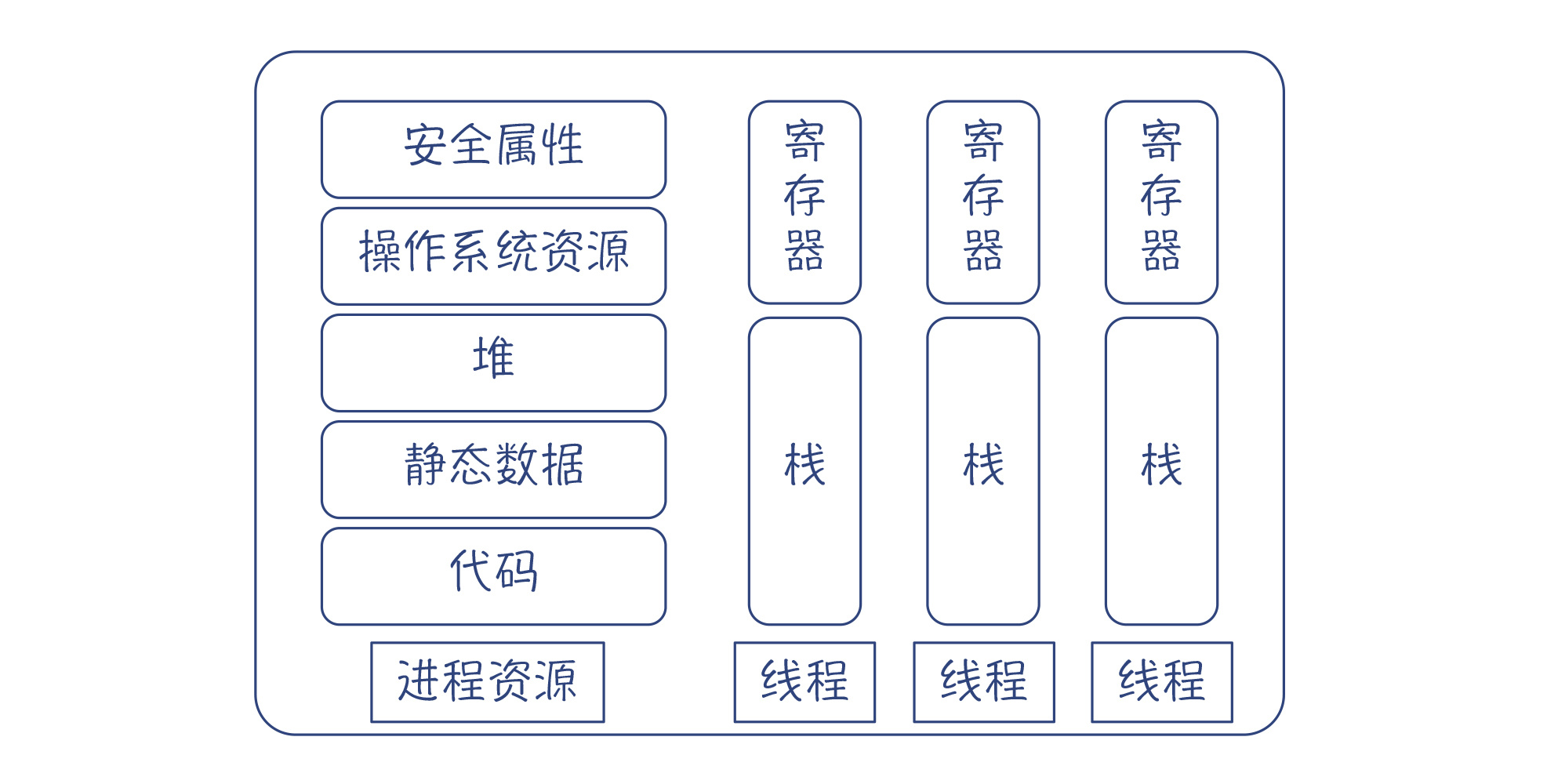
进程的共享资源和线程私有的资源¶
Python 的 Async io 和协程的关系: https://realpython.com/async-io-python/
元编程-Meta-Programming¶
备注
元编程是一种把程序当做数据来处理的技术。因此,采用元编程技术,你可以把一个程序变换成另一个程序。
备注
元编程的基本特征:把程序当做数据去处理。在计算机语言里说的元编程技术,通常是指用这门语言本身提供的功能,就能处理它自己的程序。

元编程处理的对象是程序¶
广义元编程:
1. 编译器
2. 静态分析工具
3. 动态分析工具
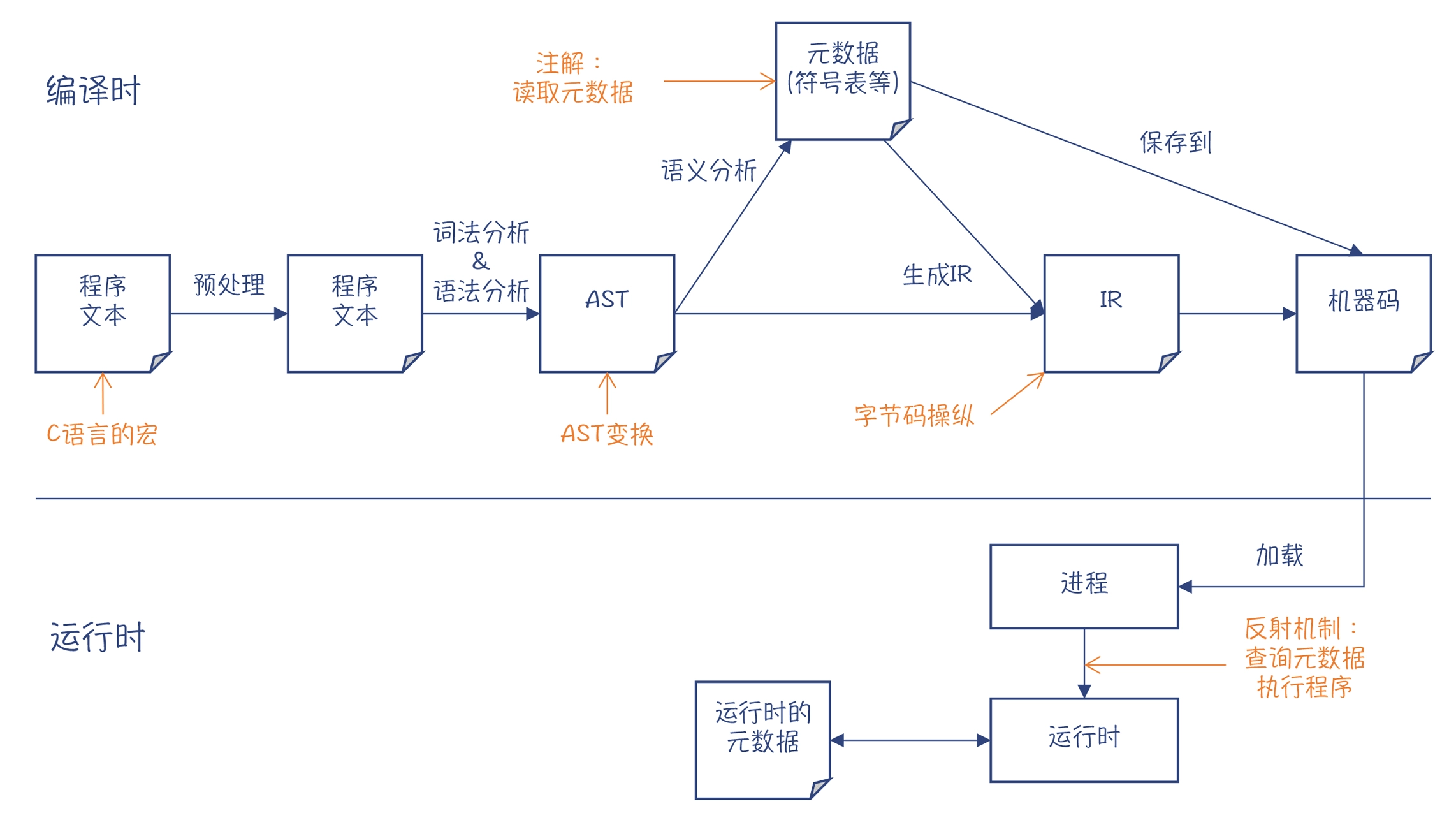
各种不同的元编程技术起作用的时机¶
Meta 的含义¶
Meta 来自希腊文,意思是 “在…… 之后(after)” 和 “超越……(beyond)”。加上这个词缀后,Meta-Somthing 所形成的新概念就会比原来的 Somthing 的概念的抽象度上升一层。
例:
Physics => Metaphysics
Data => Metadata
Language => Metalanguage
Meta 的层次¶
关系数据库:
M0: 数据
M1: 表结构
M2: 关系模型
M3: MOF
程序:
M0: 程序中的对象
M1: 程序中的类
M2: 计算机语言,包括: 词法规则、语法规则、语义规则
M3: 产生式、EBNF
元编程技术的分类¶
根据处理对象的不同:
1. 语义层对象,如: 类
2. AST
3. 程序的文本
4. 字节码
元编程技术起作用的时机:
1. 静态元编程技术只在编译期起作用
C++ 的模板技术
Java 注解技术
一旦编译完毕以后,元程序跟普通程序一样,都会变成机器码
2. 动态元编程技术会在运行期起作用
Java 的反射机制
Java 程序能在运行期进行类型判断,也是基于同样的原理
不同语言的元编程技术¶
Java 的元编程技术:
注解: 注解处理过程自始至终都借助了编译器提供的能力: 先是通过编译器查询被注解的程序的元数据, 然后生成的新程序也会被编译器编译掉。 所以你能得出一个结论:所谓元编程,某种意义上就是由程序来调用编译器提供的能力。 反射机制: 短板: 性能比较低。 基于反射机制编写的程序的效率,比同样功能的静态编译的程序要低好几倍。 所以,如何提升运行期元编程功能的性能,是编译技术研究的一个重点。Python、JavaScript 等脚本语言的元编程技术:
a. 程序文本生成和 eval 就是动态生成程序的文本字符串,然后动态编译并执行。 这种方式虽然简单粗暴,容易出错,有安全隐患,但在某些特殊场景下还确实很有用。 b. 动态获取程序信息、动态修改程序 特点: 1. 就是用程序可以很方便地获取对象的元数据,比如某个对象有什么属性、什么方法 2. 就是可以很容易地为对象添加属性和方法,从而修改对象类 Lisp 语言的元编程技术:
本来就是一个嵌套的树状结构,其实跟 AST 没啥区别 这种能够直接操纵 AST 的能力让 Lisp 特别灵活
C++ 的元编程技术:
C++ 的模板元编程(Template Metaprogramming)技术
泛型¶
具体实现机制上,有:
1. 类型擦除
2. 具体化
3. 模板元编程
函数式编程¶
计算模型其实不仅仅可以用图灵机来表达。早在图灵机出现之前,阿隆佐・邱奇(Alonzo Church)就提出了一套 Lambda 演算的模型。并且,计算机科学领域中的很多人,其实都认为用 Lambda 演算来分析可计算性、计算复杂性,以及用来编程,会比采用图灵机模型更加简洁。而 Lambda 演算,就是函数式编程的数学基础。
备注
实际上,邱奇是图灵的导师。当年图灵发表他的论文的时候,编辑看不懂,所以找邱奇帮忙,并推荐图灵成为他的学生,图灵机这个词也是邱奇起的。所以师生二人,对计算机科学的发展都做出了很大的贡献。
函数式编程的几个特点:
1. 函数作为一等公民
函数可以像一个数值一样,被赋给变量,也可以作为函数参数。
如果一个函数能够接受其他函数作为参数,或者能够把一个函数作为返回值,那么它就是高阶函数。
2. 纯函数(Pure Function)
在函数式编程里面,有一个概念叫做纯函数。
纯函数是这样一种函数,即相同的输入,永远会得到相同的输出。
对于纯函数来说,它不依赖外部的变量,这个叫做引用透明(Reference Transparency)。
纯函数的这种 “靠谱”、可预测的特征,就给我们的编程工作带来了很多的好处。
可以延迟求值(Lazy Evaluation)。
纯函数没有副作用(Side Effect)。
3. 不变性(Immutability)
程序会根据需要来创建对象并使用它们,但不会去修改对象的状态。
如果有需要修改对象状态的情况,那么去创建一个新对象就好了。
好处:
由于函数不会修改对象的状态,所以就不存在并发程序中的竞争情况,进而也就不需要采用锁的机制。
所以说,函数式编程更适合编写并发程序。
这个优势,也是导致这几年函数式编程复兴的重要原因。
4. 声明式(Declarative)的编程风格
体现: 递归函数的大量使用
总体思想:
像数学那样去使用函数和值,使可变动部分最小化,让软件的结构变得简单、可预测,
从而获得支持并发、更简洁的表达等优势
备注
在函数式编程中,会希望函数像数学中的函数那样纯粹,即不依赖外部(引用透明),也不改变外部(无副作用),从而带来计算时间、运行时替换等灵活性的优势。
编程风格:
1. 命令式(Imperative)编程
2. 声明式(Declarative)编程
远程办公¶
我曾经接触过一个芬兰公司的 CEO,他们主要做嵌入式 Linux 的技术服务。一百多人的公司,平常办公室是没什么人的。据说他们公司有的员工,可以一边上班,一边去全世界旅游。
WordPress 的母公司 Automattic 有上千名员工,分布在全球 75 个国家,全部都是远程办公。
好处:
1. 员工可能会在工作上做更多的投入
2. 没有了地域限制,公司也就可以充分任用全球各地的人才
3. 没有了地域的限制,公司也可能更容易拓展自己的市场
挑战:
公司的角度:
1. 对于管理体系,有着更高的要求
很多工作是难以直接度量绩效的,比如说研发工作就比销售工作更难衡量绩效。
2. 如何能保证采用远程办公模式,不会让企业变成一团散沙,纪律涣散、效率低下
员工的角度:
1. 自我管理能力
管理自己这件事情,也是消耗注意力的
例: 直播编码。为了帮助管理自己的行为,因为这时候你必须更加集中注意力在自己的工作上
2. 办公环境的因素
3. 心理上的挑战
白天晚上都在家里,会容易心理疲劳
4. 降低沟通的效率
准备:
从公司的角度出发:
1. 企业管理者要建立一个意识:远程办公是企业必须要面对的管理考验
2. 从看住人,转换到管绩效
3. 建立拥抱远程办公的文化,给员工授权和赋能
知识密集型的,对员工的绩效评估比较难,人员更换的成本也相对较高。
对于这类工作,可以多向那些开源软件公司学习:
建立一个拥抱远程办公的公司文化,去吸引那些对工作充满兴趣和热爱的人
4. 充分利用 IT 技术
从员工的角度出发:
1. 员工也要建立一个意识:无论是否远程办公,都要向绩效负责,管理好自己的工作
2. 正视远程办公对自我管理的高要求,养成良好的工作习惯
3. 建立激进的协作习惯
4. 最重要的:为兴趣而工作,为自己而工作
如何学习¶
从心理的角度看待学习技术的过程:
1. 学习的目的和动力问题:
我为什么要学习这么难的技术?学一些比较容易的、应用层面的技术不就行了吗?
2. 自信心和勇气的问题:
以我的能力,能学会这么难的技术吗?
3. 学习过程中的心态调节和习惯养成问题
如何看待学习中经常遇到的挫折?总是找不到时间怎么办?等等。
用出世的态度,做入世的事情
一个缺乏美学素养、哲学素养和沟通能力等素质的软件工程师,潜力可能是有限的。
一个人的基础素质,决定了他的思维方式、思维质量和眼光,那些看上去没用的基础知识、基础原理,其实是真正做大事、承担重任所需要的素质
如果你的目标是持续进步,那要培养自己另一种习惯,就是习惯于获得那些艰难的乐趣,这种乐趣是真正的充实的乐趣
写技术博客: 因为你要写出东西来,所以会逼迫自己把思路理清楚
涌现(Emergence):把很多个体连接起来,构成一个更高级的存在的现象(蜂群, 人类的大脑)
复杂系统破除了对还原论的迷信。也就是,即使你把一个系统分割成一个个的 “零件”,并且完全理解了每个 “零件”,你也可能无法理解整体系统。因为整体不等于部分的简单相加,比如说,就算你理解了一个社会的经济体中的每个企业和消费者的行为,你也无法准确掌控宏观经济。
思想或理论:
系统论、控制论和信息论三大论
协同学、博弈论、突变论、混沌理论、分型理论、耗散结构和复杂性理论
复杂系统: 三体现象、蝴蝶效应、混沌系统
复杂系统: 软件领域、天气系统、生态系统、经济系统、社会系统,甚至包括人体本身
采用复杂系统的思维做研究。比如:
采用演化的思维做心理学的研究,就形成了进化心理学的分支
(其实更恰当的翻译方法是演化心理学,因为演化是没有方向性的)。
这个学科的基本逻辑,就是:
现在人类具有的某种心理特质(比如为什么恋爱中男人更主动,女人更矜持),都是在进化中形成的。
因为凡是没有这种心理特质的人类,都已经在进化过程中被淘汰了
收集¶
SQL 解析:
MySQL 是用 Bison 生成 Parser 的
MySQL Workbench 使用 Antlr 生成 Parser
阿里的一个开源中间件 OpenCat 则使用了完全手写的 Parser,叫 Druid
Flink 的 SQL 解析似乎是基于 Apache 的另一个项目 calsite
Schema:
XML
JSON
DTD
EBNF
ASDL
参考¶
编辑器的 incremental parsing¶
Incremental Parsing: https://dl.acm.org/doi/abs/10.1145/357062.357066
A simple and efficient incremental LL(1) parsing https://link.springer.com/chapter/10.1007%2F3-540-60609-2_24
Efficient and Flexible Incremental Parsing https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.83.7015&rep=rep1&type=pdf