Microsoft: Generative AI For Beginners¶
12 Lessons, Get Started Building with Generative AI 🔗 https://microsoft.github.io/generative-ai-for-beginners/
第一章: 简介¶
There are 5 key characteristics of Foundation Models:
- Pretrained
using large data and massive compute so that it is ready to be used without any additional training
- Generalized — one model for many tasks
unlike traditional AI which was specific for a task such as image recognition
- Adaptable
through prompting — the input to the model using say text
- Large
in terms of model size and data size e.g. GPT-3 has 175B parameters and was trained on about 500,000 million words, equivalent of over 10 lifetimes of humans reading nonstop!
- Self-supervised
- no specific labels are provided
and the model has to learn from the patterns in the data which is provided
第二章: 不同的 LLMs对比¶
提升 LLM 的输出结果准确度:
1. 根据上下文的提示工程。
这个想法是在提示时提供足够的背景信息,以确保获得所需的结果。
2. 检索增强生成,RAG。
例如,您的数据可能存在于向量数据库或 Web 端点中,为了确保在提示时包含此数据或其子集,您可以获取相关数据并对用户进行提示。
3. 微调模型。
根据自己的数据进一步训练模型,这使得模型更加准确并且能够响应您的需求,但可能成本高昂。
1. Prompt engineering with context.
The idea is to provide enough context when you prompt to ensure you get the responses you need.
2. Retrieval Augmented Generation, RAG.
Your data might exist in a database or web endpoint for example,
to ensure this data is included at the time of prompting,
you can fetch the relevant data and make that part of the user's prompt.
3. Fine-tuned model.
You trained the model further on your own data
which leads to the model being more exact and responsive to your needs but might be costly.
第三章: AI安全¶
使用微调模型的情形:
1. 使用微调模型
企业希望使用微调能力较差的模型(例如嵌入模型)而不是高性能模型,从而获得更具成本效益和快速的解决方案
2. 考虑延迟
延迟对于特定用例很重要,因此不可能使用很长的提示,或者应该从模型中学习的示例数量不符合提示长度限制
3. 保持最新状态
企业拥有大量高质量的数据和真实标签,以及随着时间的推移保持这些数据最新所需的资源
潜在有害结果:
幻觉(Hallucinations)
有害内容(Harmful Content)
缺乏公平性(Lack of Fairness)
如何解决:
衡量潜在危害(Measure Potential Harms)
减轻潜在危害(Mitigate Potential Harms)
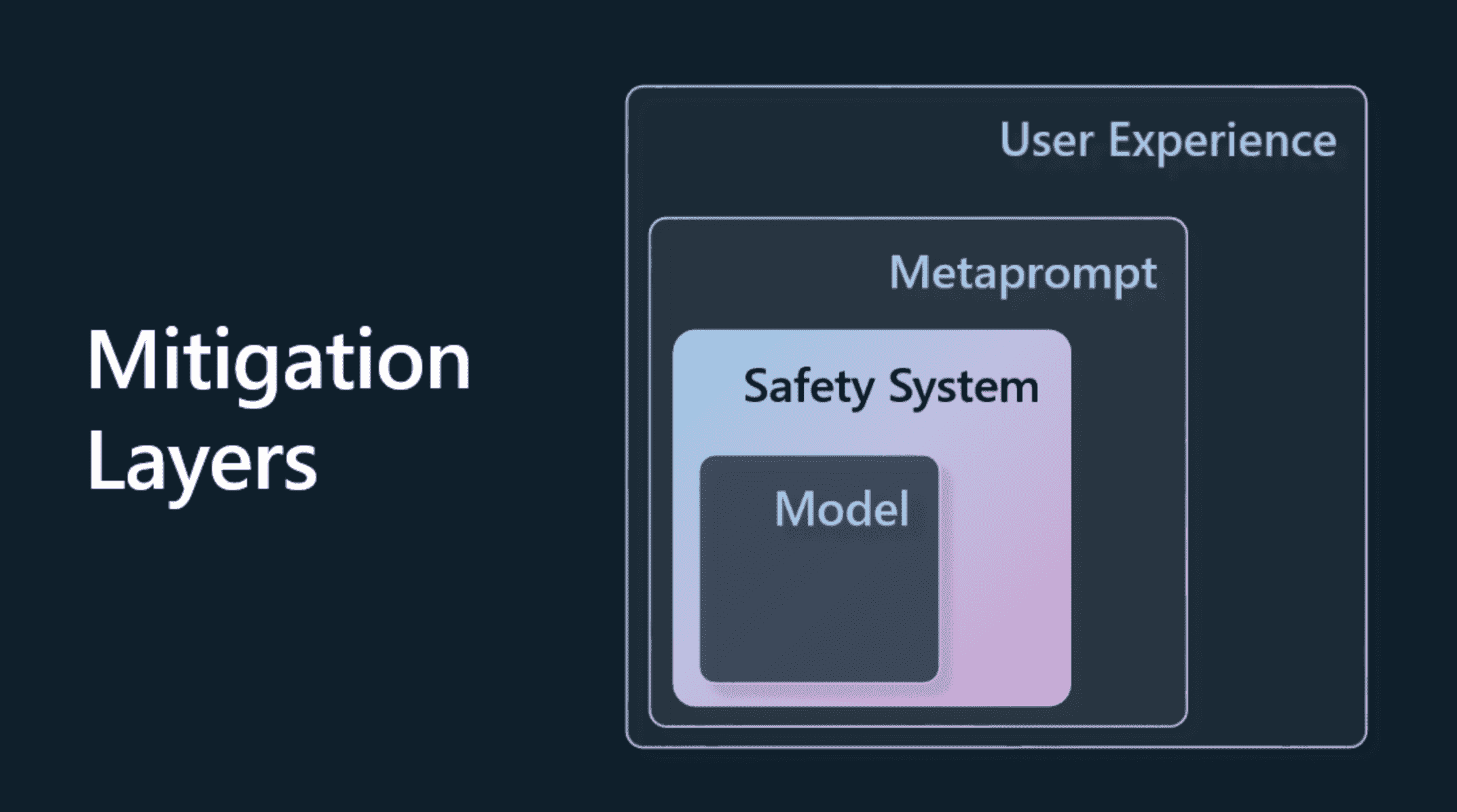
减轻潜在危害的方法:
1. 模型(Model)
为用例选择正确的模型, 使用自己的训练数据进行微调可以降低有害内容的风险。
2. 安全系统(Safety System)
安全系统是平台上为模型服务的一组工具和配置,有助于减轻伤害。
Azure OpenAI Service 上的内容过滤系统就是一个例子。
系统还应该检测越狱攻击和不需要的活动,例如来自网络机器人的请求。
3. 元提示(Metaprompt)
元提示和基础(grounding)是我们可以根据某些行为和信息指引或限制模型的方法。
这可以使用系统输入来定义模型的某些限制。 此外,提供与系统范围或领域更相关的输出。
它还可以使用检索增强生成 (RAG) 等技术,让模型仅从选定的可信来源中提取信息。
4. 用户体验(User Experience)
最后一层是用户通过应用程序界面以某种方式直接与模型交互的地方。
通过这种方式,我们可以设计 UI/UX 来限制用户可以发送到模型的输入类型以及向用户显示的文本或图像。
第四章: 提示工程基础¶
为什么我们需要提示工程:
1. 模型响应是随机的
2. 模型可以产生幻觉响应
3. 模型功能会有所不同
第五章: 提示工程进阶¶
提示技巧:
1. 少样本提示,这是最基本的提示形式。 这是一个带有几个示例的提示。
2. 思维链,这种类型的提示告诉 LLMs 如何将问题分解为步骤。
3. 生成的知识,为了提高提示的响应,您可以在提示中额外提供生成的事实或知识。
4. 从最少到最多,就像链式分析一样,这种技术是将问题分解为一系列步骤,然后要求按顺序执行这些步骤。
5. 自我完善,这种技术是修正 LLM 的输出,然后要求其改进。
6. 多维度提示。 这里想要的是确保 LLM 答案是正确的,并要求它解释答案的各个部分。 这是一种自我完善的形式。
1. Few shot prompting
2. Chain-of-thought
3. Generated knowledge
4. Least to most
5. Self-refine, critique the results
6. Maieutic prompting
第八章: 创建搜索应用¶
语义搜索是一种使用查询中单词的语义或含义来返回相关结果的搜索技术。(与关键字搜索对应)
示例: 假设您想买一辆汽车,您可能会搜索 “我的梦想汽车”,语义搜索会理解您并不是在 “梦想” 一辆车,而是想购买您的 “理想” 汽车。 语义搜索了解您的意图并返回相关结果。
文本嵌入是自然语言处理中使用的文本表示技术。 文本嵌入是文本的语义数字表示。 嵌入用于以机器易于理解的方式表示数据。
余弦相似度是两个向量之间相似度的度量,您还会听到这被称为 近邻搜索。从数学角度来看,余弦相似度测量投影在多维空间中的两个向量之间的角度的余弦。 这种测量是有益的,因为如果两个文档由于大小而相距欧几里得距离很远,它们之间的角度仍然较小,因此余弦相似度较高。
余弦相似度搜索,先对 查询 文本进行 _向量化_。 然后计算查询向量与嵌入索引中每个向量之间的余弦相似度。最后,按余弦相似度对结果进行排序,余弦相似度最高的文本片段与查询最相似。