WebAssembly 入门课¶
于航,2020-09-07
PayPal 高级软件工程师,WebAssembly 技术布道者,FCC (FreeCodeCamp China)上海技术社区负责人,QCon 和 GMTC 大会讲师、出品人。研究方向主要为 Web 前端基础技术架构、WebAssembly、LLVM 及虚拟机技术。曾出版国内第一本 WebAssembly 技术书籍《深入浅出 WebAssembly》。2017 年注册成为 W3C 官方 CG 成员,定期参与 CG 组织的在线视频研讨会议,为 Wasm 的标准化提出发展建议。2018 年,深度参与 Emscripten 编译器工具链项目的研发工作,并致力于推动国内 Wasm 技术的发展和落地实践。
课前必读¶
开篇词¶
重要的发展节点¶
2015 年 4 月,WebAssembly Community Group 成立;
2015 年 6 月,WebAssembly 第一次以 WCG 的官方名义向外界公布;
2016 年 8 月,WebAssembly 开始进入了漫长的 “Browser Preview” 阶段;
2017 年 2 月,WebAssembly 官方 LOGO 在 Github 上的众多讨论中被最终确定;
2017 年 2 月,一个历史性的阶段,四大浏览器(FireFox、Chrome、Edge、WebKit)在 WebAssembly 的 MVP(最小可用版本)标准实现上达成共识,这意味着 WebAssembly 在其 MVP 标准上的 “Brower Preview” 阶段已经结束;
2017 年 8 月,W3C WebAssembly Working Group 成立,意味着 WebAssembly 正式成为 W3C 众多技术标准中的一员。
2019 年 12 月,W3C 正式宣布,Wasm 将成为除现有的 HTML、CSS 以及 JavaScript 之外的第四种,W3C 官方推荐在 Web 平台上使用的 “语言”。
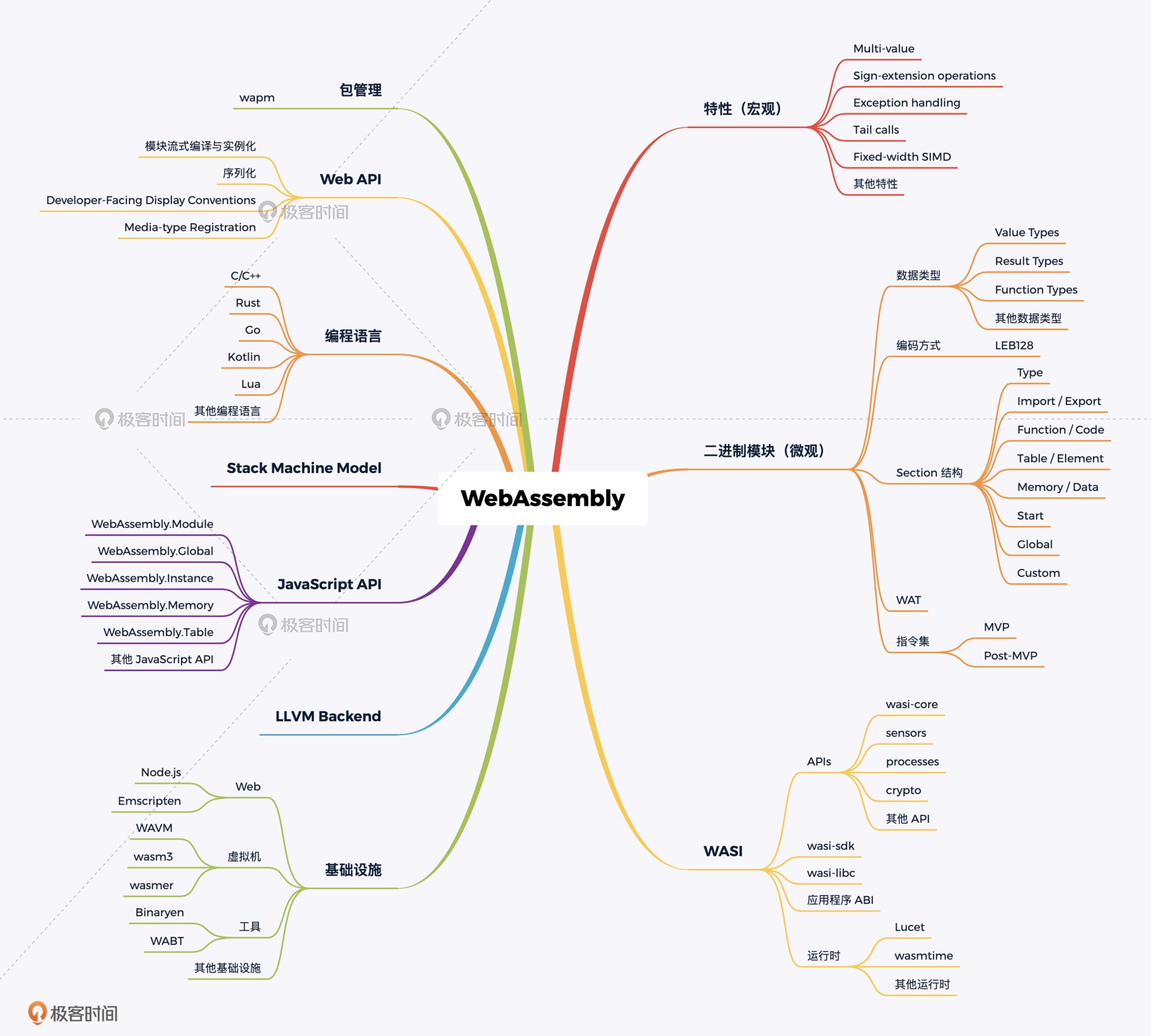
01 | 基础篇:学习此课程你需要了解哪些基础知识¶
JavaScript 语言和相关 API 的概念及用法、C/C++ 相关的一些语言及编译时特性,以及其他的一些计算机基础知识
02 | 历史篇:为什么会有 WebAssembly 这样一门技术¶
1995 年末,Brendan Eich 仅用了 10 天时间便发明出了 JavaScript 编程语言,而在随后的二十多年中,JavaScript 已经成为了不可动摇的,用于开发 Web 前端应用的必备编程语言之一。
2015 年,ECMAScript 2015 (ES6) 诞生,也标志着 JavaScript 开始进入了标准一年一更新的节奏中。
2011 年Google于 Chrome 浏览器中发布的一项技术——NaCl,该技术旨在提供一个沙盒环境,可以让基于 C/C++ 语言编写的 Native 应用,安全地运行在浏览器中。NaCl 的全称 “Native Client”
2013 Mozilla 提出的 ASM.js,设计目标也是为了能够在 JavaScript 语言之外,为 “构建更高性能的 Web 应用” 这个目标,提供另外一种实现的可能。ASM.js 是 JavaScript 的一个严格子集。它是一种可用于编译器的目标语言,低层次且高效。该目标语言有效地为内存不安全语言(如 C/C++),描述了一个沙盒虚拟机运行环境。静态和动态验证相结合的方式,使得 JavaScript 引擎能够使用 AOT 等优化编译策略来验证 ASM.js 代码
2015 年 5 月。Chrome 团队的 Ben 正在为 V8 设计一种新的 Prototype(原型),而另一位团队成员 Rosbery ,正在为这种 Prototype 设计对应的字节码格式。在当时的谷歌内部,这两部分暂时被称为 ml-proto 与 v8-native-prototype。随着 V8 团队对 ml-proto 与 v8-native-prototype 的不断修改和优化,它们最终便成为了 Wasm 早期标准的一部分。
相关链接¶
EMCA:https://www.ecma-international.org/ecma-262/
NaCl/PNaCl:https://developer.chrome.com/native-client/nacl-and-pnacl
评论¶
TS 确实可以解决 “去优化” 的问题,但对于 JS 还是要通过:生成 AST、生成 IR、Lowering、优化编译器、Profiling、生成机器码这些步骤的。但对于 Wasm,仅需要 “生成机器码” 这一步基本就够了,大部分优化在静态编译时就已经完成了,引擎只需要对照 Wasm 的 ISA 翻译成目标机器的 ISA 就可以了,基本上只是一个汇编器的作用,而且目前也不需要静态链接。
由于 TS 的类型信息并没有给到 JavaScript 引擎来使用,所以即便整个程序是 well-organized 的,但是 JavaScript 引擎仍然还是需要通过运行时推导来推测出变量的具体类型。但也有的好处是,JIT 在假设某个变量的类型时,基本上都可以保证是正确的。这样引擎的去优化过程就会减少很多,性能会相对提高。
本质而言的话wasm 就是一套 vm 规范,实现 wasm 的是虚拟机。但1、Wasm 可以用于 Web(起源);2、WASI 提供了一套 out-of-web 的操作系统接口标准,并且基于 capability-based security 可以提供更加安全的上层应用实现(本身基于 Wasm)。无论是安全的代码复用,还是基于 VM 层的轻量级沙盒环境,都是很有价值和发挥空间的。
01核心原理篇 (6 讲)¶
03 | WebAssembly 是一门新的编程语言吗¶
定义:WebAssembly(缩写为 Wasm)是一种基于堆栈式虚拟机的二进制指令集。Wasm 被设计成为一种编程语言的可移植编译目标,并且可以通过将其部署在 Web 平台上,以便为客户端及服务端应用程序提供服务”。—— Wasm 官网
三种计算模型¶
堆栈机模型¶
堆栈机,全称为 “堆栈结构机器”,即英文的 “Stack Machine”。
堆栈机本身是一种常见的计算模型。
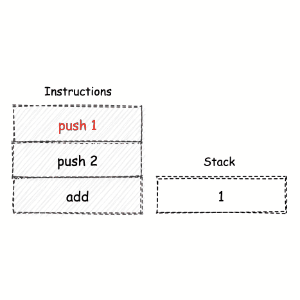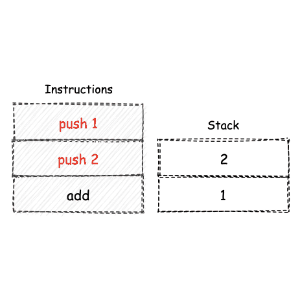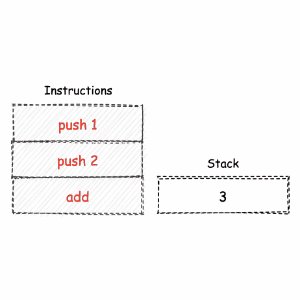
堆栈机使用栈结构作为数据的存储与交换容器,由于其 “后进先出” 的特性,使得我们无法直接对位于栈底的数据进行操作。因此在某些情况下,机器会使用额外的指令来进行栈数据的交换过程,从而损失了一定的执行效率。但另一方面,堆栈机模型最为简单且易于实现,对应生成的指令代码长短大小适中。¶
累加器机¶
累加器机是使用 “累加器”,来作为指令操作数的交换场所。累加器机实际上是一种较为古老的计算模型,它仅能够使用可存放单一值的累加器寄存器(后简称 “累加器”)单元,来作为指令操作数的暂存场所。因此,基于累加器机模型设计的指令一般都仅支持一个操作数。
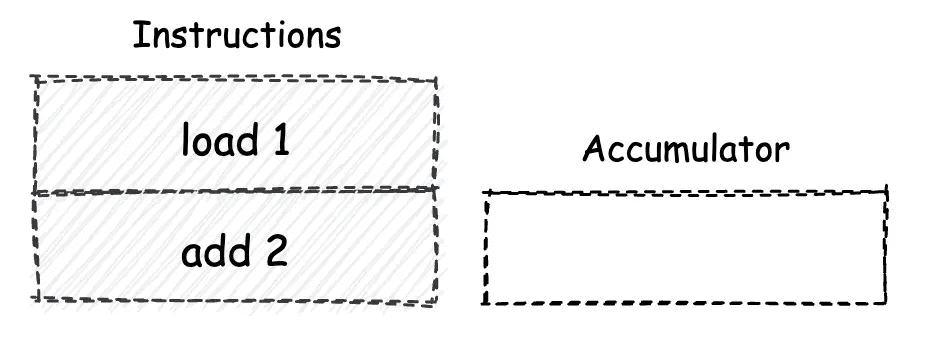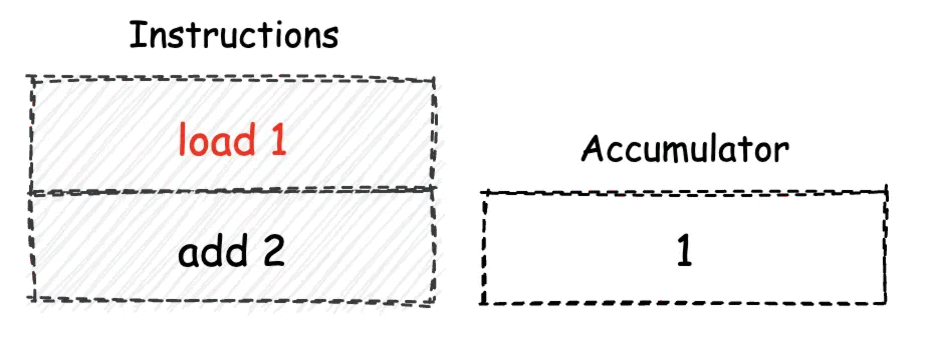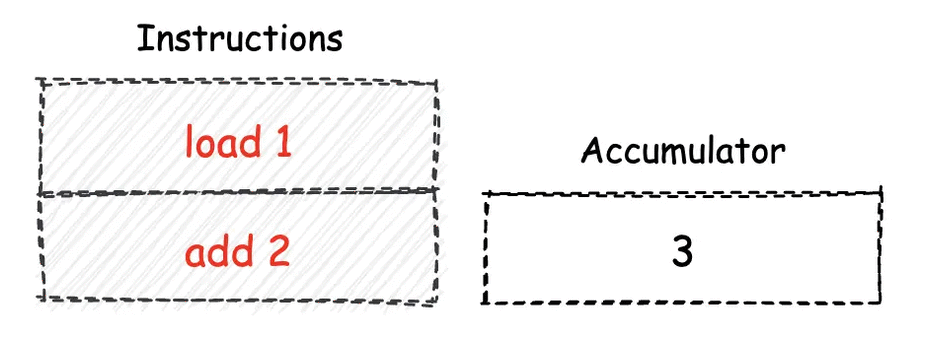
累加器机由于其内部只有一个累加器寄存器可用于暂存数据,因此在指令的执行过程中,可能会频繁请求机器的线性内存,从而导致一定的性能损耗。但另一方面,由于累加器模型下的指令最多只能有一个操作数,因此对应的指令较为精简。¶
寄存器机¶
另一种常用的计算模型被称为 “寄存器机”。顾名思义,基于这种计算模型的机器,将使用特定的 CPU 寄存器组,来作为指令执行过程中数据的存储和交换容器。
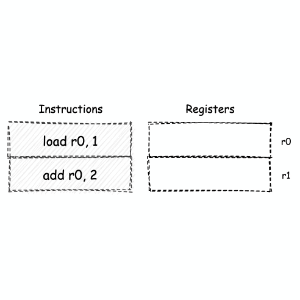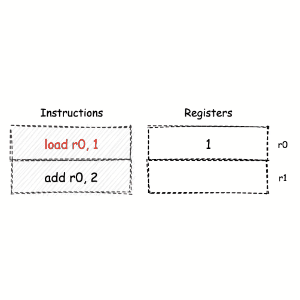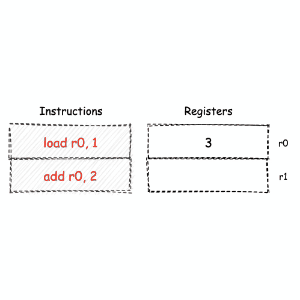
寄存器机内大多数与数据操作相关的指令,都需要在执行时指定目标寄存器,这无疑增加了指令的长度。过于灵活的数据操作,也意味着寄存器的分配和使用规则变得复杂。但相对的,众多的数据暂存容器,给予了寄存器机更大的优化空间。因此,通常对于同样的一段计算逻辑,基于寄存器机模型,可以生成更为高效的指令执行结构。¶
ISA 与 V-ISA¶
可以应用在诸如 i386、X86-64 等实际存在的物理系统架构上的指令集,我们一般称之为 ISA(Instruction Set Architecture,指令集架构)。
对另外一种使用在虚拟架构体系中的指令集,我们通常称之为 V-ISA,也就是 Virtual(虚拟)的 ISA。
对这些 V-ISA 的设计,大多都是基于堆栈机模型进行的。而 Wasm 就是这样的一种 V-ISA。
Wasm 虚拟指令集¶
标准的 Wasm 指令:
i32.const 1
i32.const 2
i32.add
如 “i32.const” 与 “i32.add” ,其实都是 Wasm 这个 V-ISA 指令集中,各个指令所对应的文本助记符(mnemonic)。实际当这些助记符被编译到 Wasm 二进制模块中时,会使用助记符所对应的二进制字节码(一般被称为 OpCode,你可以简单地将其理解为一些二进制数字),并配合一些编码算法来压缩整个二进制模块文件的体积。
Wasm 虽然有着类似汇编语言的这种 “助记符” 形式,但在大多数情况下,它仅被作为诸如 C/C++ 等高级编程语言的最终编译目标。编译器会自动处理从这些高级语言源代码到 Wasm 二进制指令的转换过程。而这也正如我们在开头所提到的那样,官方声称的 ”Wasm 被设计成为一种编程语言的可移植编译目标 “。
04 | WebAssembly 模块的基本组成结构到底有多简单¶
Section 概览¶
从整体上来看,同 ELF 二进制文件类似,Wasm 模块的二进制数据也是以 Section 的形式被安排和存放的。
对于 Section,你可以直接把它想象成,一个个具有特定功能的一簇二进制数据。通常,为了能够更好地组织模块内的二进制数据,我们需要把具有相同功能,或者相关联的那部分二进制数据摆放到一起。而这些被摆放在一起,具有一定相关性的数据,便组成了一个个 Section。
换句话说,每一个不同的 Section 都描述了关于这个 Wasm 模块的一部分信息。而模块内的所有 Section 放在一起,便描述了整个模块在二进制层面的组成结构。
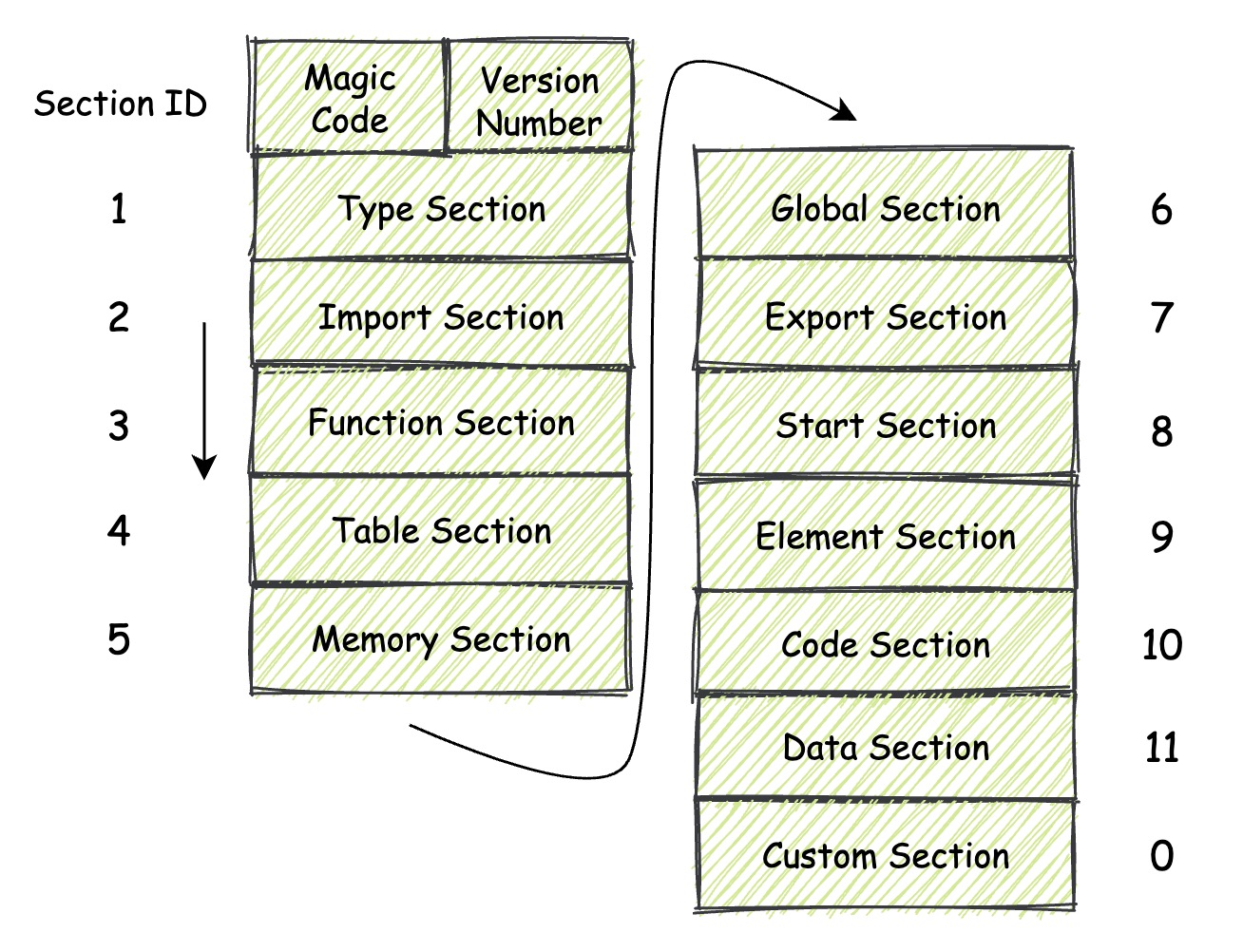
在一个标准的 Wasm 模块内,以现阶段的 MVP 标准为参考,可用的 Section 有如下几种。除了其中名为 “Custom Secton”外,其他的 Section 均需要按照每个 Section 所专有的 Section ID,按照这个 ID 从小到大的顺序,在模块的低地址位到高地址位方向依次进行 “摆放”。¶
单体 Section¶
这一类 Section 一般可以独自描述整个模块的一部分特征(或者说是功能),同时也可以与其他 Section 一起配合起来使用。
Type Section¶
Type Section 的 ID 为 1
首先,第一个出现在模块中的 Section 是 “Type Section”。顾名思义,这个 Section 用来存放与 “类型” 相关的东西。而这里的类型,主要是指 “函数类型”。
函数类型一般由函数的参数和返回值两部分组成。而只要知道了这两部分,我们就能够确定在函数调用前后,栈上数据的变化情况。
Start Section¶
Start Section 的 ID 为 8
为模块指定在其初始化过程完成后,需要首先被宿主环境执行的函数。
Global Section¶
Global Section 的 ID 为 6
主要存放了整个模块中使用到的全局数据(变量)信息。
Custom Section¶
Custom Section 的 ID 为 0
主要用来存放一些与模块本身主体结构无关的数据,比如调试信息、source-map 信息等等
VM(Virtual Machine,虚拟机)在实例化并执行一个 Wasm 二进制模块中的指令时,对于可以识别的 Custom Section,将会以特定的方式为其提供相应的功能。
VM 对于 Custom Section 的识别,主要是通过它 “头部” 信息中的 “name” 字段来进行。
互补 Section¶
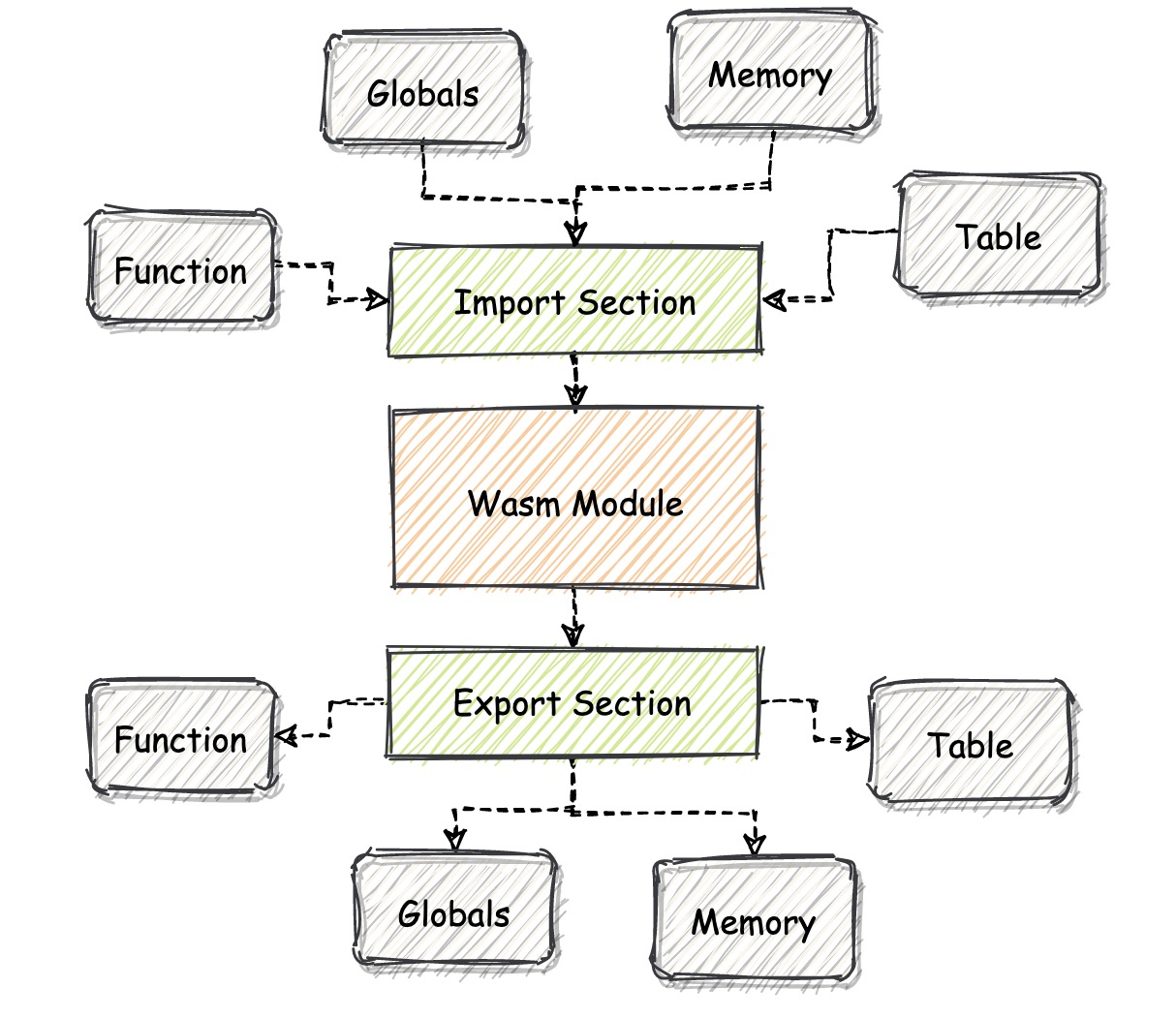
Import Section 和 Export Section¶
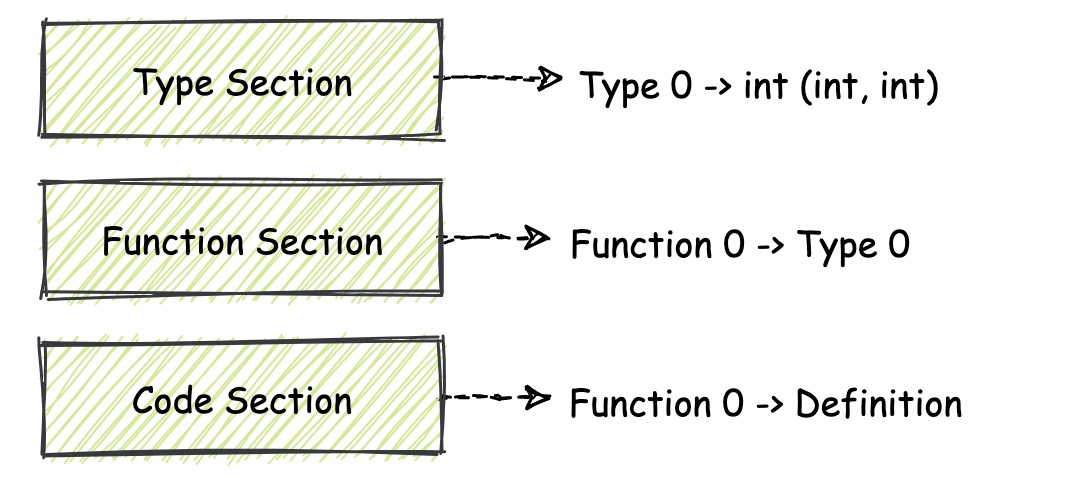
Function Section 和 Code Section:Function Section 中其实存放了这个模块中所有函数对应的函数类型信息,可以把它理解成一个通过整型的 indicies 来进行索引并调用的数组。Code Section 的组织结构从宏观上来看,你同样可以将它理解成一个数组结构,这个数组中的每个单元格都存放着某个函数的具体定义,也就是函数体对应的一簇 Wasm 指令集合。¶
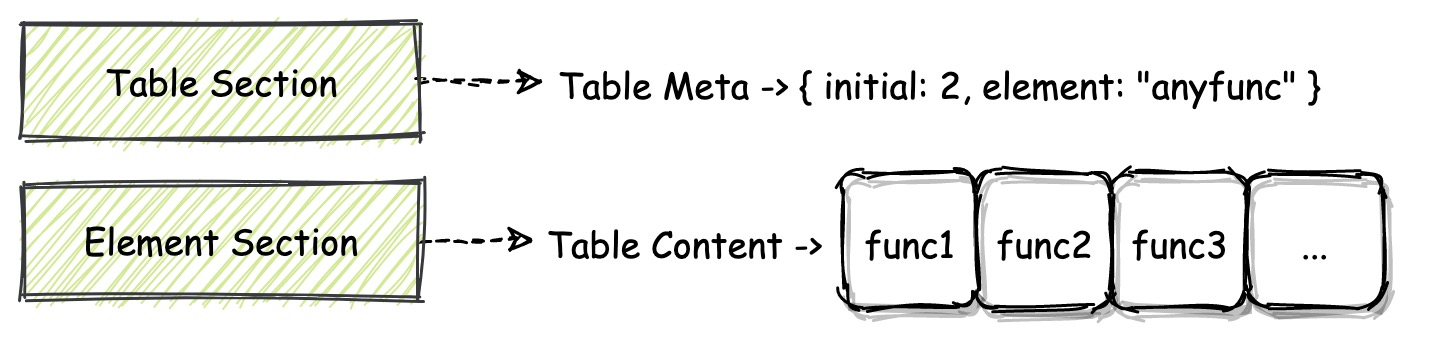
Table Section 和 Element Section:Table Section 可以简单理解成存放类型为 “anyfunc” 的函数指针,并且还可以通过指令 “call_indirect” 来调用这些函数指针所指向的函数。Table Section 的结构与 Function Section 类似,可以理解成数组的结构。在实际的 VM 实现中,虚拟机会将模块的 Table 结构,初始化在独立于模块线性内存的区域中,这个区域无法被模块本身直接访问。因此 Table 中这些 “小格子” 内具体存放的值,对于 Wasm 模块本身来说是不可见的。从二进制角度来看,在 Table Section 中,只存放了用于描述某个 Table 属性的一些元信息。比如:Table 中可以存放哪种类型的数据?Table 的大小信息?等等。Element Section 填充 Table Section 所描述的 Table 对象实际的数据。¶

Memory Section 和 Data Section:同 Table Section 的结构类似,借助 Memory Section,我们可以描述一个 Wasm 模块内所使用的线性内存段的基本情况,比如这段内存的初始大小、以及最大可用大小等等。¶
魔数和版本号¶
所谓魔数,你可以简单地将它理解为具有特定含义 / 功能的一串数字。如何识别一个二进制文件是不是一个合法有效的 Wasm 模块文件呢?其实同 ELF 二进制文件一样,Wasm 也同样使用 “魔数” 来标记其二进制文件类型。
一个标准 Wasm 二进制模块文件的头部数据是由具有特殊含义的字节组成的。其中开头的前四个字节分别为 “(高地址)0x6d 0x73 0x61 0x0(低地址)”,这四个字节对应的 ASCII 可见字符为 “asm”(第一个为空字符,不可见)。接下来的四个字节,用来表示当前 Wasm 二进制文件所使用的 Wasm 标准版本号。就目前来说,所有 Wasm 模块该四个字节的值均为 “(高地址)0x0 0x0 0x0 0x1(低地址)”,即表示版本 1。
示例:
int add (int a, int b) {
return a + b;
}
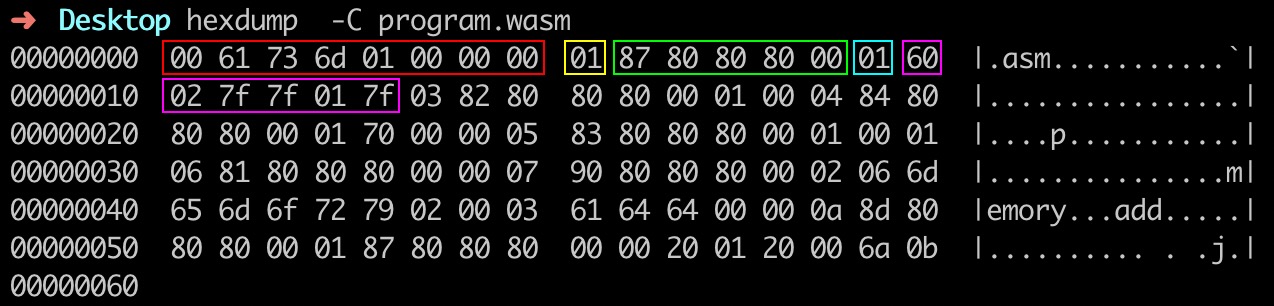
最开始红色方框内的前八个字节 “0x0 0x61 0x73 0x6d 0x1 0x0 0x0 0x0” 便是 Wasm 模块文件开头的 “魔数” 和版本号。¶
接下来的 “0x1” 是 Section 头部结构中的 “id” 字段,这里的值为 “0x1”,表明接下来的数据属于模块的 Type Section。
紧接着绿色方框内的五个十六进制数字 “0x87 0x80 0x80 0x80 0x0” 是由 varuint32 编码的 “payload_len” 字段信息,经过解码,它的值为 “0x7”,表明这个 Section 的有效载荷长度为 7 个字节(关于编解码的具体过程我们会在下一节课中进行讲解)。
Type Section 的有效载荷是由一个 “count” 字段和多个 “entries” 类型数据组成的。因此我们可以进一步推断出,接下来的字节 “0x1” 便代表着,当前 Section 中接下来存在的 “entries” 类型实体的个数为 1 个。
紧接着紫色方框内的六个十六进制数字序列 “0x60 0x2 0x7f 0x7f 0x1 0x7f” 便代表着 “一个接受两个 i32 类型参数,并返回一个 i32 类型值的函数类型”。
同样的分析过程,也适用于接下来的其他类型 Section,你可以试着结合官方文档给出的各 Section 的详细组成结构,来将剩下的字节分别对应到模块的不同 Section 结构中。
05 | 二进制编码:WebAssembly 微观世界的基本数据规则¶
LEB-128 整数编码¶
Unsigned LEB-128¶
使用 Unsigned LEB-128 来编码一个正整数 123456:
1. 首先将该十进制数转换为对应原码(与补码相同)的二进制表示方式
1 1110 0010 0100 0000
2. 将该二进制数用额外的 “0” 位进行填充,直至其总位数达到最近的一个 7 的倍数
0 0001 1110 0010 0100 0000
3. 将该二进制数以每 7 个二进制位为一组进行分组,每组之间以空格进行区分
0000111 1000100 1000000
4. 在最高有效位所在分组的左侧填充一个值为 “0” 的二进制位。而在其他分组的最高位左侧填充一个值为 “1” 的二进制位
00000111 11000100 11000000
5. 转换成对应的十六进制值,即为编码所得结果
0x7 0xc4 0xc0
Signed LEB-128¶
编码一个有符号的负整数 -123456:
1. 将该数字转换为对应的二进制表示形式
10 0001 1101 1100 0000
2. 对这个有符号数进行 “符号扩展” 操作
1 1110 0001 1101 1100 0000
3. 以每 7 个二进制位为一组进行分组
1111000 0111011 1000000
4. 在最高有效位所在分组的左侧填充一个值为 “0” 的二进制位。而在其他分组的最高位左侧填充一个值为 “1” 的二进制位
01111000 10111011 11000000
5. 转换成对应的十六进制值,即为编码所得结果
0x78 0xbb 0xc0
IEEE-754 浮点数编码¶
指数位采用了一种名为 “移码” 的值存储方法,以便能支持负数次幂。当我们计算该位的实际值时,会将从上一步中得到的幂次值与 127 相加,以得到该位的最终结果。
IEEE-754-1985(后面简称为 IEEE-754)标准编码32 位浮点数 “1234.567”:
1. 将浮点数按照整数位和小数位,分别转换成对应的二进制表示形式(“循环乘 2")
10011010010.10010001001001...
2. 将从上一步得到的二进制小数,以 “科学计数法” 的形式进行表示
1.001101001010010001001001... * 2^10
3. 计算指数位对应的十进制数值。
即将上述 2 的幂次值 10,再加上 127,得到 137,换算成二进制序列即:
10001001
4. 剩下 23 位的 “小数位”
00110100101001000100100
=>
0 10001001 00110100101001000100100
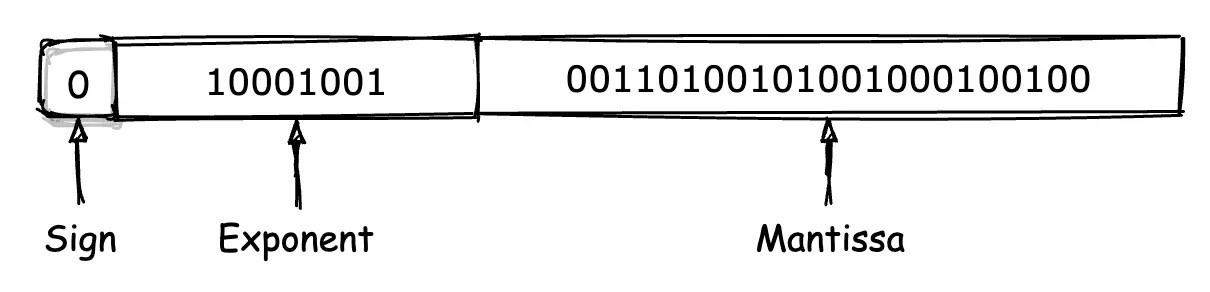
浮点数 1234.567 在 IEEE-754 编码下的完整组成形式¶
UTF-8 字符串编码¶
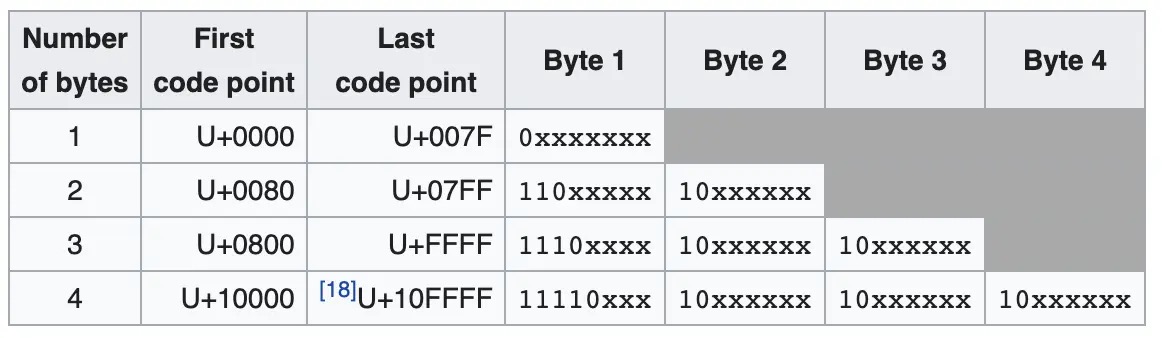
UTF-8 的编码结果值可能会有着从最少 1 个字节到最多 4 个字节不等的长度¶
以汉字 “极(U+6781)” 为例,来介绍 UTF-8 编码的具体过程:
1. 将该汉字对应的码位值展开成二进制序列的形式
01100111 10000001
2. 根据上图中第三行对应的规则(码位值位于 [U+0800, U+FFFF] 之间),替换出 UTF-8 编码对应的三个字节
11100110 10011110 10000001
Wasm 数字类型¶
对于整数的编码,Wasm 并没有 “直接使用” LEB-128,而是在其基础之上又做了进一步的约束
Wasm 将其模块内部所使用到的数字值分为以下三种类型:
1. uintN(N = 8 / 16 / 32)
占用 N 个 bit 的无符号整数,并以小端模式进行存储
2. varuintN(N = 1 / 7 / 32)
使用 Unsigned LEB-128 编码,具有 N 个 bit 长度的可变长无符号整数
3. varintN(N = 7 / 32 / 64)
使用 Signed LEB-128 编码,具有 N 个 bit 长度的可变长无符号整数