2309.06180_Efficient Memory Management for Large Language Model Serving with PagedAttention¶
组织: 1.UC Berkeley 2.Stanford University 3.Independent Researcher 4.UC San Diego
大规模语言模型(LLM)的高吞吐量服务需要一次批处理足够多的请求。然而,现有的系统面临挑战,因为每个请求的键值缓存(KV缓存)内存非常庞大,并且会动态增长和缩小。当内存管理不当时,可能会因为内存碎片化和冗余复制而导致内存浪费,从而限制批处理大小。为了解决这个问题,我们提出了PagedAttention,这是一种受到操作系统中经典虚拟内存和分页技术启发的注意力算法。在此基础上,我们构建了vLLM,一个LLM服务系统,它实现了:(1)KV缓存内存的几乎零浪费;(2)请求内外KV缓存的灵活共享,进一步减少内存使用。
1. Introduction¶
讨论了大规模语言模型(LLM)在服务时的内存管理问题,并提出了一个新的算法和系统来提高服务效率。
- 贡献总结:
识别了在LLM服务中内存分配的挑战,并量化了这些挑战对服务性能的影响。
提出了PagedAttention,这是一种基于非连续分页内存存储KV缓存的注意力算法。
设计并实现了vLLM,一个基于PagedAttention的分布式LLM服务引擎。
对vLLM进行了评估,结果表明它显著优于现有的最先进解决方案。
2. Background¶
介绍了基于Transformer的大规模语言模型(LLM)的生成和服务过程,重点阐述了自回归生成、内存管理以及批处理技术。
2.1.Transformer-Based Large Language Models¶
- 语言建模和自回归分解:
语言建模的目标是预测一系列令牌(tokens)的概率。
由于语言有自然的顺序关系,通常将整个序列的联合概率分解为条件概率的乘积,也就是自回归分解(autoregressive decomposition)
- Transformer模型的自注意力机制:
核心组件是自注意力层(self-attention layers)。
自注意力层通过对输入的每个令牌进行线性变换,得到查询向量(query)、键向量(key)和值向量(value),然后计算注意力得分并生成输出
2.2.LLM Service & Autoregressive Generation¶
- 自回归生成过程:
- LLM服务通常用于条件生成任务,例如文本完成(completion API)或聊天机器人。
给定一个输入提示(prompt),LLM会根据输入生成一系列输出令牌。
由于自回归分解的特性,生成每个新令牌时,LLM会依赖于所有前面生成的令牌及其对应的键值向量(KV cache)。
这种生成是顺序的,且每个新令牌的生成依赖于前面的令牌,因此无法并行化。
- 在生成过程中,前面生成的令牌的KV缓存会被存储以供后续生成使用,这种缓存叫做KV缓存。
缓存的键和值向量对于同一个令牌在不同的位置会有所不同。
- 生成过程的两大阶段:
- 提示阶段(Prompt Phase):
在这个阶段,整个输入提示(𝑥1,…,𝑥𝑛)作为输入,通过并行化的矩阵乘法计算生成第一个新令牌的概率,计算过程中会生成键值向量。
这部分可以充分利用GPU的并行计算能力。
- 自回归生成阶段(Autoregressive Generation Phase):
在这个阶段,模型逐个生成剩余的令牌。
每生成一个新令牌,模型会计算新令牌的概率,并根据前面所有令牌的KV缓存来生成新的键值向量。
由于依赖关系,生成过程不能并行化,只能按顺序进行,这导致了计算效率低下,主要依赖内存,导致GPU计算资源未得到充分利用,进而增加了延迟。

Figure 3.KV cache memory management in existing systems.¶
- 图片说明:
- Three types of memory wastes:
– reserved, internal fragmentation, and external fragmentation
These three wastes exist that prevent other requests from fitting into the memory.
The token in each memory slot represents its KV cache.
Note the same tokens can have different KV cache when at different positions.
2.3.Batching Techniques for LLMs¶
- 批处理提升计算效率:
通过将多个请求合并成一个批处理,可以提高GPU的计算利用率,因为多个请求可以共享同一模型的权重。批处理可以减少因单个请求的计算开销而浪费的资源,但批处理并非没有挑战。
问题一:请求到达时间不一致:请求可能在不同时间到达,简单的批处理策略会导致早到的请求必须等待其他请求,或者要延迟接收的新请求,这会引入队列延迟。
问题二:请求输入输出长度差异大:不同请求的输入和输出长度可能差异很大,简单的批处理方法可能会使用填充(padding)来使请求长度相同,从而浪费GPU计算和内存。
- 细粒度批处理(Fine-grained Batching):
- 为了解决这些问题,提出了细粒度批处理技术,如细胞批处理(cellular batching)和迭代级调度(iteration-level scheduling)。
这些方法不是在请求级别进行批处理,而是在迭代级别进行。
即每次迭代完成后,从批处理中移除已经完成的请求,并添加新的请求。
这样,新请求只需等待一轮迭代,而不是等待整个批处理完成。
- 优势:
这些方法避免了填充输入输出的需求,减少了内存浪费和计算浪费。
通过减少排队延迟和填充带来的低效,细粒度批处理技术显著提高了LLM服务的吞吐量。
总结¶
本文背景部分主要讲解了Transformer模型如何进行自回归生成、LLM服务的两大阶段(提示阶段和自回归生成阶段),以及目前在LLM服务中使用的批处理技术。
批处理提高了计算效率,但也面临着请求到达时间和输入输出长度不一致的问题。
为此,细粒度批处理机制被提出,以减少延迟和内存浪费,从而提高吞吐量。
3. Memory Challenges in LLM Serving¶
内存瓶颈:尽管细粒度批处理减少了计算浪费,并能更灵活地批处理请求,但由于GPU内存的限制,批处理的请求数量依然受限,尤其是在存储KV缓存的内存方面。因此,LLM服务的吞吐量很大程度上受限于内存容量(memory-bound)。
- 主要的内存管理挑战:
- 大型KV缓存:
- KV缓存的大小迅速增长:
例如,对于具有13B参数的OPT模型(Zhang et al., 2022),每个令牌的KV缓存需要800KB的空间。
假设模型最多生成2048个令牌,单个请求的KV缓存大小可达到1.6GB。
即使GPU的内存容量为数十GB,最多也只能处理几十个请求。
因此,内存分配对请求的并行处理造成了显著限制。
- GPU计算速度增长快,内存容量增长慢:
随着NVIDIA A100到H100的升级,计算能力(FLOPS)增长了超过2倍,但GPU的最大内存仍为80GB。
这表明,内存瓶颈会变得越来越严重。
- 复杂的解码算法:
- LLM服务提供多种解码算法供用户选择,每种算法对内存管理的复杂性有不同的影响。例如,
当用户从单个输入提示请求多个随机样本时,提示部分的KV缓存(占总缓存的12%)可以共享,从而减少内存使用。
但在自回归生成阶段,由于样本的依赖关系和上下文,KV缓存不能共享。
- 对于更复杂的解码算法,如束搜索(beam search)
不同请求的“束”可以共享更多的KV缓存(在实验中最多节省55%的内存),并且共享的模式会随着解码过程的进行而变化。
- 调度不可预知的输入和输出长度:
- LLM服务的请求可能具有不同的输入和输出长度。
因此,内存管理系统需要处理各种长度的提示。
如果输出长度增加,生成的KV缓存也会占用更多内存,这可能会导致内存不足,无法为新请求或现有请求的生成过程提供足够的内存。
系统需要做出调度决策,例如删除或交换一些请求的KV缓存,以便腾出内存空间。
3.1.Memory Management in Existing Systems¶
- 现有系统的内存管理:
目前大多数深度学习框架(如PyTorch)要求将张量存储在连续的内存块中。因此,现有的LLM服务系统(如Yu et al., 2022; NVIDIA, 2023a)也将单个请求的KV缓存存储为一个跨不同位置的连续张量。
由于LLM输出长度不可预测,现有系统通常基于请求的最大序列长度静态分配内存块,而不考虑实际的输入或最终输出长度。这样就可能会导致内存浪费。
- 内存浪费的三个来源:
为未来令牌预留的内存(reserved slots):系统会预留内存空间以供未来的令牌使用,但在实际生成时,这部分空间可能并不会被使用。
内部碎片(internal fragmentation):由于为最大可能的序列长度过度分配内存,部分内存无法使用。
外部碎片(external fragmentation):由于内存分配器(如伙伴分配器)造成的碎片,某些空间可能永远不会被使用。
总结¶
- LLM服务中由于KV缓存管理引起的内存瓶颈问题,并强调了内存分配和管理中存在的挑战。主要问题包括:
KV缓存的快速增长,导致内存消耗巨大。
解码算法的复杂性,使得内存管理变得更加复杂。
请求的输入输出长度不可预测,导致内存分配的困难。
4. Method¶
本章详细描述了 vLLM(一个大规模语言模型(LLM)服务引擎)的设计和实现,重点是如何通过新的 PagedAttention 算法和 KV 缓存管理器 来优化内存管理,提高 GPU 使用效率,并解决传统模型在大规模并行处理中的内存瓶颈问题。
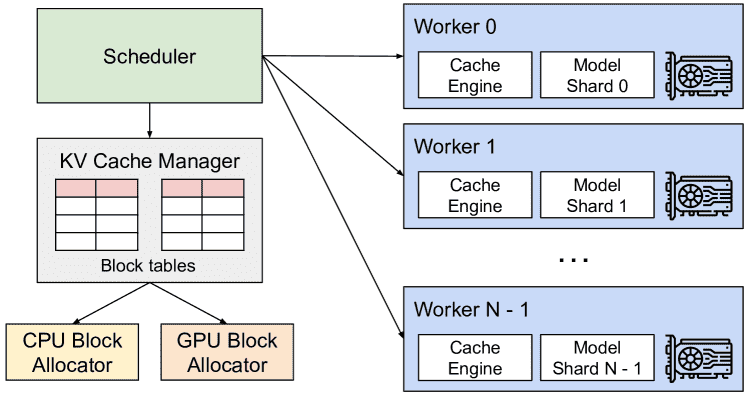
Figure 4.vLLM system overview.¶
4.1.PagedAttention¶
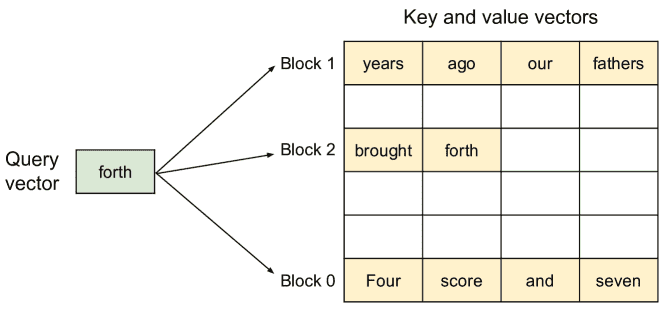
Figure 5.Illustration of the PagedAttention algorithm, where the attention key and values vectors are stored as non-contiguous blocks in the memory.¶
PagedAttention 是一个创新的注意力算法,灵感来源于操作系统中的分页技术。
传统的注意力机制将所有的键(key)和值(value)存储在连续的内存中,而 PagedAttention 允许这些键值对分散存储在非连续的内存块中。
具体来说,它将每个序列的 KV 缓存划分为固定大小的 KV 块,每个块包含一定数量的 token 的键和值向量。这样,在计算注意力时,算法通过读取这些非连续存储的块来执行计算。
分页存储(PagedStorage)使得内存管理更加灵活,因为可以动态分配和释放内存块,而不需要预先为每个 token 分配固定的内存位置。
4.2.KV Cache Manager¶
KV 缓存管理器 类似于操作系统的虚拟内存管理。
操作系统通过分页管理内存,允许程序认为它们在使用连续的内存,而实际内存可能是非连续的。
vLLM 采用了类似的思想,将每个请求的 KV 缓存分割成多个逻辑 KV 块,并动态地映射到 GPU 内存中。
通过这种方式,vLLM 不需要为每个可能的 token 都提前分配内存,而是根据需要逐步分配物理内存块,避免了内存浪费,并能有效支持大规模并行计算。
4.3.Decoding with PagedAttention and vLLM¶
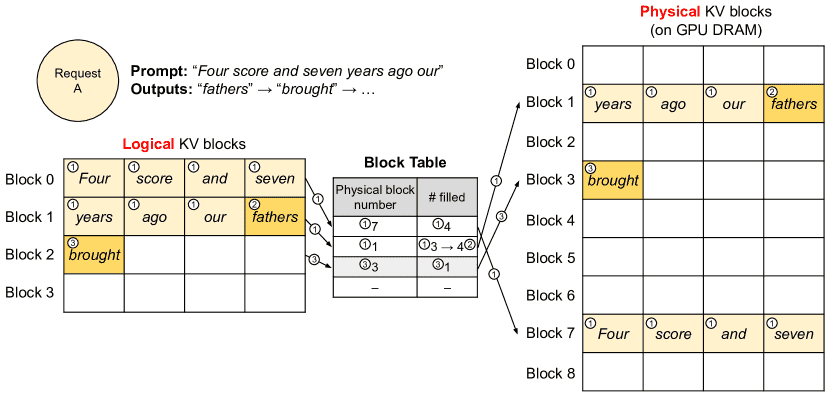
Figure 6.Block table translation in vLLM.¶
在解码过程中,vLLM 会根据需求动态分配和回收内存。
例如,在生成新的 token 时,vLLM 会使用 PagedAttention 算法读取之前生成的 KV 块,并将新的 KV 缓存存储到物理内存块中。这种方式减少了内存碎片化,并通过块共享提高了硬件利用率。
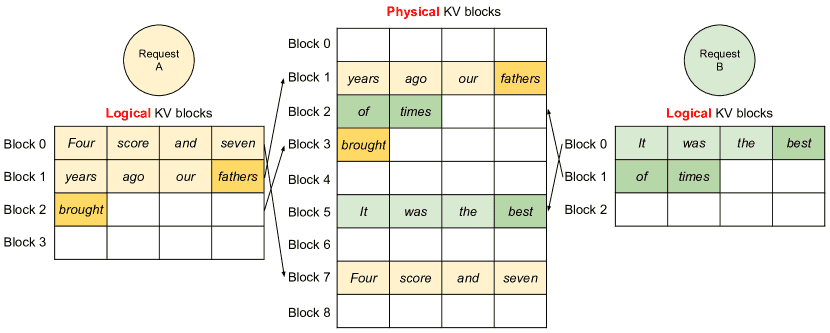
Figure 7.Storing the KV cache of two requests at the same time in vLLM.¶
4.4.Application to Other Decoding Scenarios¶
vLLM 还适应了其他解码策略,比如 并行采样(Parallel sampling) 和 束搜索(Beam search)。
在这些情景下,多个候选序列可以共享相同的 KV 缓存,从而节省内存。特别是在束搜索中,多个候选序列之间的 KV 缓存共享动态变化,vLLM 通过智能的内存管理避免了传统方法中频繁的内存复制开销。
Parallel sampling¶
在 并行解码 中,多个输出可以共享相同的输入 KV 缓存,从而大大节省内存。
复制时写入(copy-on-write) 技术允许多个请求共享相同的内存块,只有在需要修改时才进行复制,从而进一步减少内存使用。
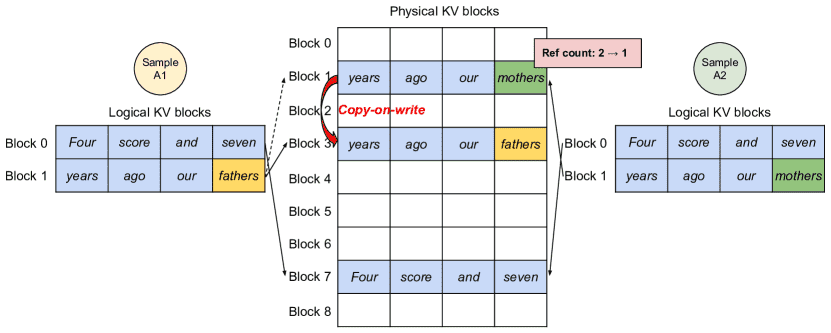
Figure 8.Parallel sampling example.¶
Beam search¶
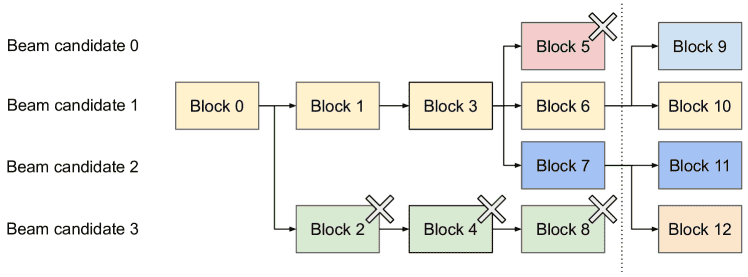
Figure 9.Beam search example.¶
Shared prefix¶
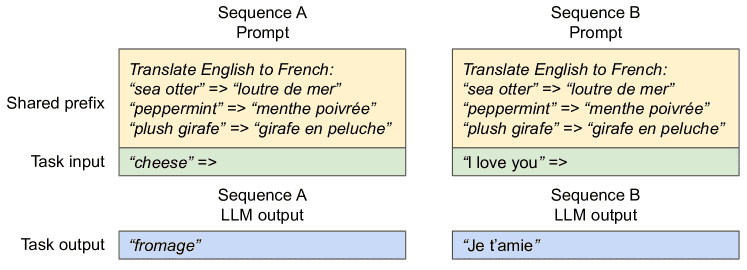
Figure 10.Shared prompt example for machine translation. The examples are adopted from (Brown et al., 2020).¶
4.5.Scheduling and Preemption¶
当请求数量超过系统的处理能力时,vLLM 会优先处理较早到达的请求。
针对内存紧张的情况,vLLM 采用了 页面交换(swapping) 和 重新计算(recomputation) 两种技术。
通过将被抢占的序列的 KV 缓存交换到 CPU 内存或重新计算缓存,vLLM 保证了高效的内存利用,并减少了内存瓶颈带来的影响。
4.6.Distributed Execution¶
vLLM 支持分布式执行,通过在多个 GPU 之间分配计算任务来处理大规模模型。
尽管每个 GPU 只处理部分注意力头,但所有 GPU 都共享相同的 KV 缓存管理器,并通过控制消息来同步内存映射和计算过程。
这种方式使得多个 GPU 可以协同工作,处理大规模语言模型,同时保证内存管理的一致性。
总结¶
总的来说,vLLM 通过创新的 PagedAttention 算法和基于虚拟内存思想的 KV 缓存管理器,成功解决了传统大规模语言模型在内存管理上的瓶颈问题。
它不仅优化了内存使用效率,还提高了硬件利用率,并且通过动态内存管理实现了高效的并行解码。这种内存管理方法的核心优势在于能够灵活处理不同的解码模式和请求负载,同时确保系统的吞吐量和响应时间。
5. Implementation¶
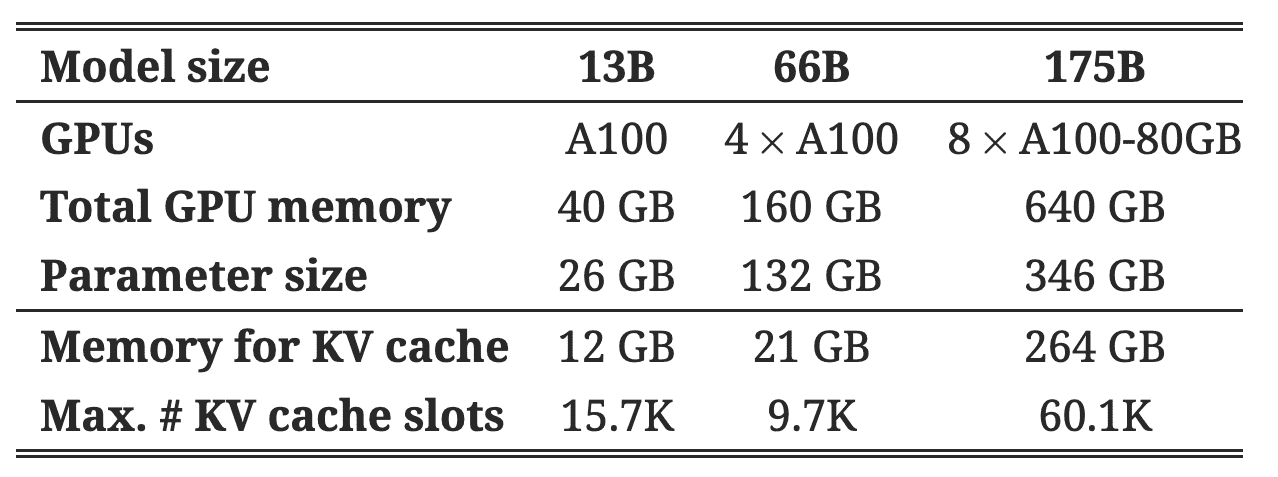
Table 1.Model sizes and server configurations.¶
- 计算公式
键值对大小会与模型的参数占用内存的比例相关
如:13B模型的kv对大小可能是 0.768MB
前面提到: 13B参数的OPT模型,每个令牌的KV缓存需要800KB的空间
前端:使用 FastAPI 提供用户接口
推理引擎:用 8,500 行 Python 和 2,000 行 C++/CUDA 代码实现。关键的控制组件(如调度器和块管理器)是用 Python 写的,关键操作(如 PagedAttention)则使用 CUDA 内核实现。
5.1.Kernel-level Optimization¶
主要讲解了如何为PagedAttention优化GPU内核,以解决现有系统在处理特定内存访问模式时的效率问题。
- 这里有三种主要的优化策略:
- 融合重塑和块写入(Fused reshape and block write):
在每个Transformer层中,新的键值对(KV缓存)被分割成多个块,并调整为适合块读取的内存布局,然后按照块表中指定的位置进行保存。
为了减少内核启动的开销,将这两个操作(重塑和写入)融合到一个单独的内核中,从而提升效率。
- 融合块读取和注意力计算(Fusing block read and attention):
对FasterTransformer中的注意力内核进行调整,使其能够根据块表读取KV缓存,并实时进行注意力计算。
为了确保内存访问的合并(coalesced),每个GPU warp(线程组)会被分配去读取一个块。
此外,还支持在一个请求批次中处理不同长度的序列。
- 融合块拷贝操作(Fused block copy):
拷贝操作通常由“写时复制”(copy-on-write)机制触发,可能涉及到不连续的内存块。
如果使用cudaMemcpyAsync进行数据传输,这会导致频繁的小数据拷贝,增加开销。
为了解决这个问题,实现了一个内核,将不同块的拷贝操作批量处理,减少内核调用次数,从而优化性能。
5.2.Supporting Various Decoding Algorithms¶
- vLLM 支持多种解码算法,使用三种主要的方法:
fork(分叉):从一个已有的序列创建一个新的序列。
append(追加):向已有序列追加新的 token(标记)。
free(释放):删除一个序列。
在并行采样中,vLLM 使用 fork 方法从一个输入序列生成多个输出序列,之后使用 append 方法逐步添加新 token,并使用 free 方法删除满足停止条件的序列。类似的策略也适用于 beam search 和前缀共享。
6. Evaluation¶
本章主要讲述了vLLM系统在不同工作负载下的性能评估,重点是对比其与现有推理引擎(如FasterTransformer和Orca)的表现。通过一系列实验,评估了vLLM在多个维度上的优势,尤其是在吞吐量、内存管理和推理效率方面。
总结¶
总体来看,vLLM在吞吐量、内存管理和延迟方面相较于现有系统(如FasterTransformer和Orca)表现更为优秀。
特别是在内存共享、并行采样和束搜索等场景下,vLLM能够显著提高系统的效率,并减少内存使用。这使得vLLM在处理大规模LLM推理任务时,尤其是在高请求速率和复杂任务(如聊天机器人和翻译)的情况下,能够提供更高的性能和更低的延迟。
7. Ablation Studies¶
本章讨论了vLLM在多个设计选择上的消融实验(Ablation Studies),通过消融实验评估了不同设计决策的影响
7.1.Kernel Microbenchmark¶
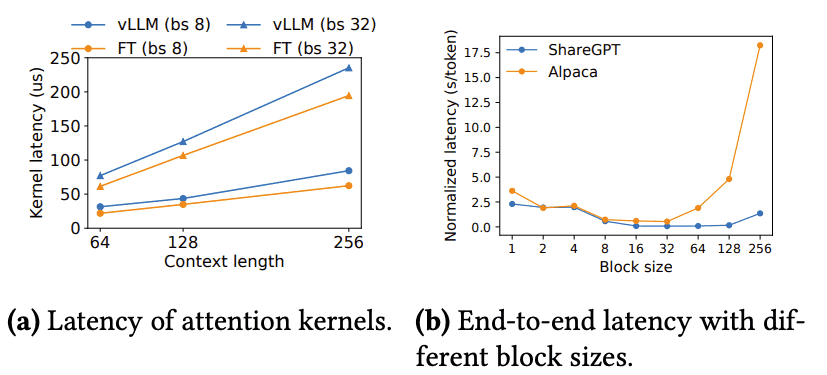
Figure 18.Ablation experiments.¶
背景:vLLM使用PagedAttention技术来优化内存访问模式,涉及对KV缓存的动态块映射,这对GPU操作的性能(特别是块读写和注意力操作)产生影响。相比现有的系统,vLLM的GPU内核(如在第5节讨论的)需要额外的开销来访问块表、执行额外的分支操作以及处理可变的序列长度。
实验结果:如图18(a)所示,与高度优化的FasterTransformer实现相比,vLLM的注意力内核延迟高出20%-26%。这个额外的开销仅影响注意力操作,并不会影响其他操作(如线性操作)。尽管存在开销,但vLLM在端到端性能上的表现显著优于FasterTransformer。
7.2.Impact of Block Size¶
背景:在vLLM中,块大小的选择对性能有很大影响。块太小会导致无法充分利用GPU的并行性来读取和处理KV缓存,而块太大则会增加内存碎片,并减少共享的可能性。
- 实验结果:图18(b)评估了不同块大小下vLLM的性能,使用了ShareGPT和Alpaca数据集的基础采样负载。实验结果显示:
在ShareGPT数据集上,块大小16到128之间表现最好。
在Alpaca数据集上,块大小16和32表现良好,但块大小过大(如64及以上)会显著降低性能,因为数据序列比块大小短,导致浪费内存。
结论:在实践中,vLLM发现块大小16足够大,能够有效利用GPU,并且足够小,以避免大部分工作负载中的内存碎片化。因此,vLLM将默认块大小设置为16。
7.3.Comparing Recomputation and Swapping¶
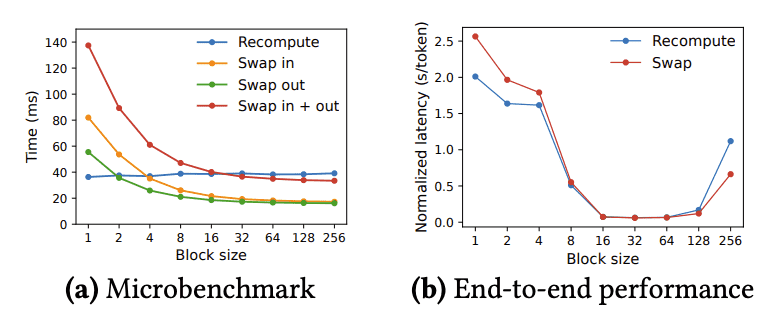
Figure 19.(a) Overhead of recomputation and swapping for different block sizes. (b) Performance when serving OPT-13B with the ShareGPT traces at the same request rate.¶
背景:vLLM支持两种恢复机制:重新计算和交换(swapping)。为了了解这两种方法的权衡,实验评估了它们在不同块大小下的端到端性能和微基准开销。
- 实验结果:图19展示了重新计算和交换的开销对比:
交换(Swapping):当块大小较小时,交换会导致较大的开销,因为小块大小会导致大量小数据的CPU与GPU之间传输,限制了有效的PCIe带宽。
重新计算(Recomputation):重新计算的开销在不同块大小下保持恒定,因为它不依赖KV块。因此,当块大小较小的时候,重新计算比交换更高效。
两者的比较:当块大小较大时,交换效率较高;但重新计算的开销从未超过交换延迟的20%。在16到64的中等块大小范围内,两者的端到端性能相当。
- 定义
重计算是一种内存节省技术,通常用于深度学习模型训练过程中。当模型太大以至于无法将所有激活值(activations)都保存在显存中时,可以使用重计算策略。这种方法的基本思想是在反向传播期间重新计算前向传播的结果,而不是保存它们。因此,重计算的开销主要来自于额外的前向计算步骤,而这些步骤的时间消耗是相对固定的,不依赖于块大小。
交换则是另一种内存管理策略,它涉及将数据从GPU显存移动到CPU内存或反之。这种操作涉及到PCIe带宽的使用,其性能受制于数据传输的速度。对于小块大小,由于需要频繁地进行数据交换,这会导致大量的小型数据传输,进而限制了有效的PCIe带宽利用率,并增加了总的延迟。而对于大块大小,虽然每次交换的数据量增加,但由于减少了交换次数,整体的延迟反而会降低。
总结¶
内核微基准:虽然PagedAttention带来了额外的注意力操作开销,但它没有影响模型的整体性能,反而提升了端到端性能。
块大小的选择:块大小对性能有显著影响,适当的块大小(如16)能够有效利用GPU的并行处理能力,并减少内存碎片,从而优化性能。
恢复机制的选择:重新计算在小块大小下更高效,交换在大块大小下表现更好,但两者在中等块大小下的性能相近。根据不同的工作负载和块大小,可以选择更合适的恢复策略。
10. Conclusion¶
本文提出了PagedAttention,一种新的注意力算法,允许将注意力的键和值存储在非连续的分页内存中,并展示了vLLM,一个通过PagedAttention实现高吞吐量的LLM服务系统,具有高效的内存管理。
受到操作系统启发,我们展示了如何将虚拟内存和写时复制等成熟技术适应于高效管理KV缓存,并处理LLM服务中的各种解码算法。
我们的实验表明,vLLM在吞吐量上比现有的最先进系统提高了2到4倍。