计算机基础实战课¶
2022-07-20
彭东,网名 LMOS,Intel 傲腾项目关键开发者,《深度探索嵌入式操作系统:从零开始设计、架构和开发》作者。研究操作系统数十年,精通 Linux、BSD、SunOS 等开源操作系统内核,对 Windows 的 NT 内核也有一定研究。
曾独立开发过两套全新的操作系统内核:LMOS 和 LMOSEM。其中 LMOS 先后发布了 8 个测试版本,至今已是一个多进程、多 CPU、支持虚拟内存的全 64 位操作系统内核(x86_64 体系下),代码量达 10 万余行。LMOSEM(基于 ARM 体系)则是嵌入式操作系统的新尝试,实验了不同于 LMOS 的新架构、新代码。
课程设计¶
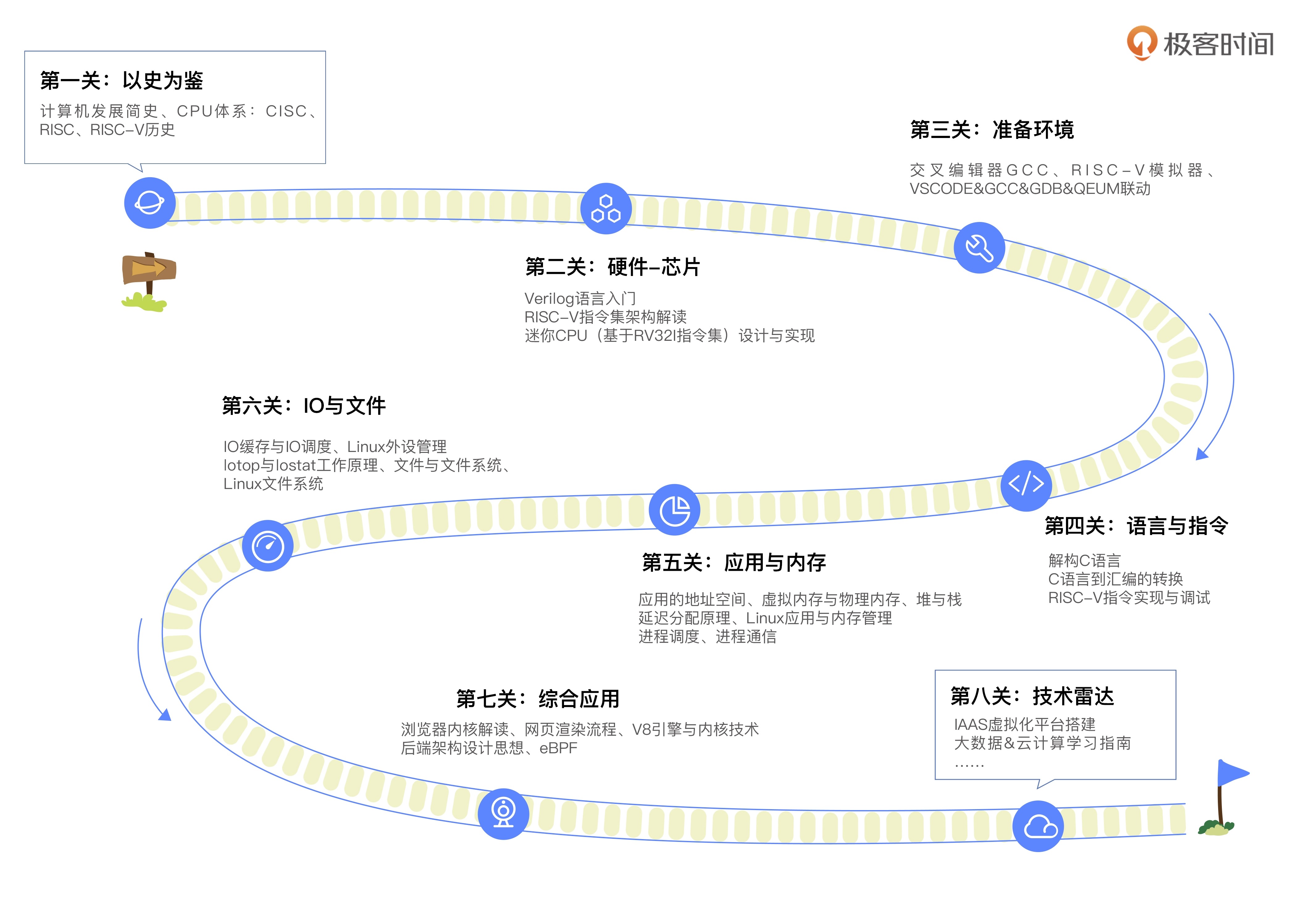
串联计算机从底层到应用的关键知识点,总计四个核心、八大关卡。
核心一:历史 学计算机基础,需要先学习它的历史,学习计算机是怎么一步步发展到今天这个样子的,以今天的状况推导未来的发展方向。我们会重点讨论编程架构是怎么创造出来的、CPU 从何而来、CISC 和 RISC 又各有什么优缺点。
核心二:硬件基础知识 了解硬件的工作机制对工程师实现优秀的应用软件非常重要。这里不但会详细讲解芯片的工作机制与原理,还会带你手把手实现一个五级流水线的迷你 RISCV 处理器(基于 Verilog,配套代码量 2882 行)。
核心三:软件基础知识 想要开发高性能的应用程序,语言与指令、应用与内存、IO 与文件方面的知识都是必修内容。这里我们会通过第三关到第六关四个章节带你掌握这些计算机软件基础中最核心、最重要的知识。
高级语言和低级语言之间如何互相转化?应用堆和栈内存有什么不同?多个进程之间如何通信?Linux 如何管理外设,又如何存放文件……这些重难点问题,一个都不会漏掉。
核心四:应用层基础知识 带你从底层角度审视前端技术跟后端架构,并探讨云计算、大数据与智能制造。这些热门领域都是对基础技术的综合应用,有助于你开阔视野,提升自己的知识迁移能力,让你真正学有所用。
01以史为鉴 (3讲)¶
01| CISC & RISC: 从何而来, 何至于此¶
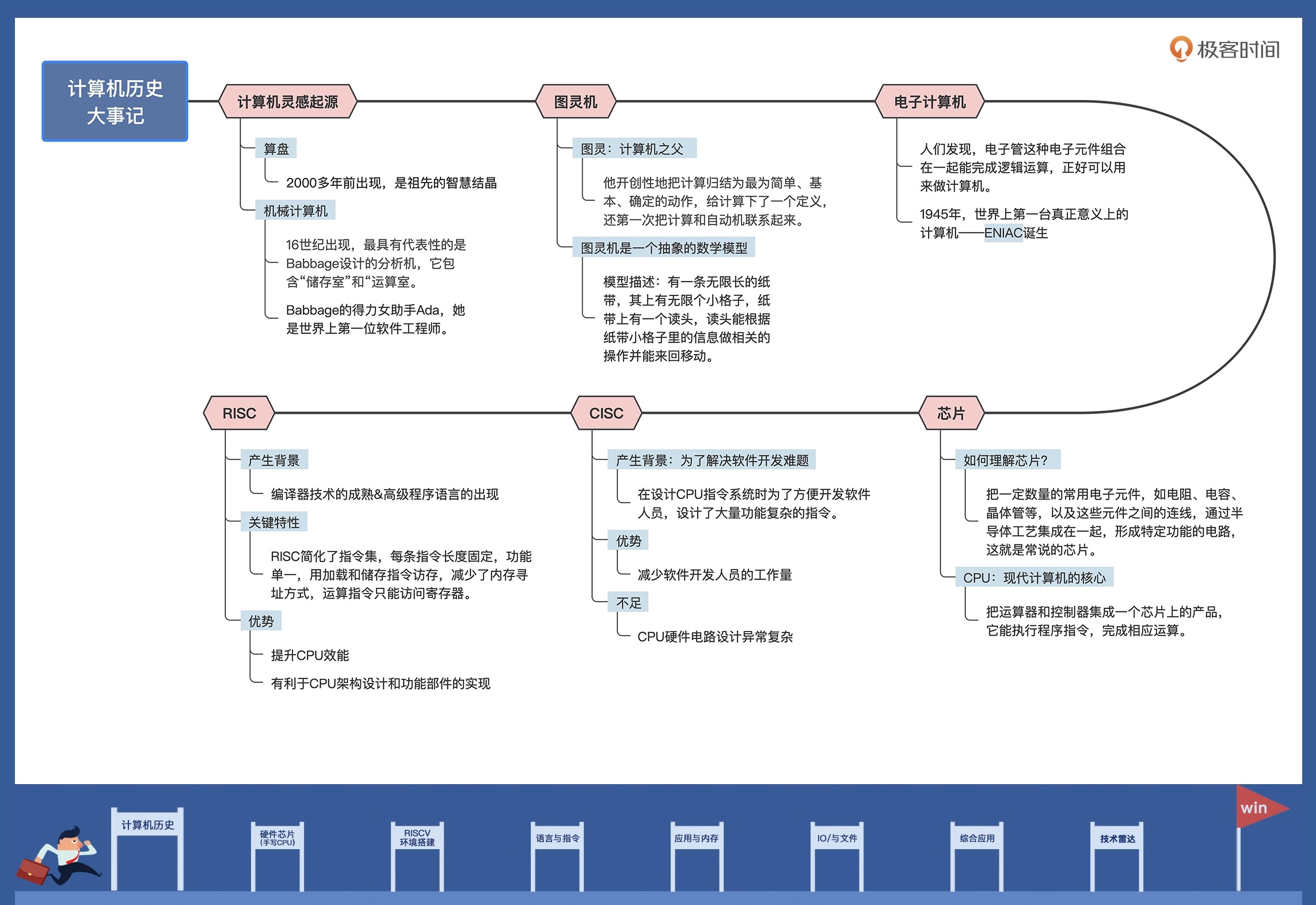
16 世纪,苏格兰人 John Napier 发表了论文,提到他发明了一种精巧设备,可以进行四则运算和解决方根运算。
18 世纪,英国人 Babbage 设计了一台通用分析机。设计理论非常超前,既有保存 1000 个 50 位数的“齿轮式储存室”,用于运算的“运算室”,还有发送和读取数据的部件以及负责在“存储室”、“运算室”运算运输数据的部件。Babbage 设计分析机的过程里,遇到了一位得力女助手——Ada,她是为分析机编写程序(计算三角函数的程序、伯努利函数程序等)的第一人,也是公认的世界上第一位软件工程师。
一个多世纪之后,现代电脑的结构几乎是 Babbage 分析机的翻版,无非是主要部件替换成了大规模集成电路。
1981 年,美国国防部花了十年光阴,才把开发军事产品所需的全部软件功能,都归纳整理到了一种计算机语言上,这种语言被正式命名为 ADA 语言。
电子计算机¶
1946 年,ENIAC 成功研制,它诞生于美国宾夕法尼亚大学,是世界上第一台真正意义上的电子计算机。ENIAC 占地面积约 170 平方米,它有多达 30 个操作台,重达 30 吨,耗电量 150 千瓦。这台机器包含了 17468 根电子管和 7200 根晶体二极管,1500 个继电器,6000 多个开关等许多其它电子元件,计算速度是每秒 5000 次加法或者 400 次乘法,大约是人工计算速度的 20 万倍。
1947 年 12 月,美国贝尔实验室的肖克利、巴丁和布拉顿组成的研究小组,研制出了晶体管,才解决一个电子计算机用一万多根三极管,坏了其中一根,查找和维护都极为困难的问题。
芯片¶
1971 年,Intel 将运算器和控制器集成在一个芯片上,称为 4004 微处理器,这标志着 CPU 的诞生。
1978 年,开发的 8086 处理器奠定了 X86 指令集架构。此后,8086 系列处理器被广泛应用于个人计算机以及高性能服务器中。
CISC¶
复杂指令集计算机体系结构:CPU 的指令集越丰富、每个指令完成的功能越多,为该 CPU 编写程序就越容易,因为每一项简单或复杂的任务都有一条对应的指令,不需要软件开发人员写大量的指令。
CISC 的典型代表就是 x86 体系架构,x86 CPU 中包含大量复杂指令集,比如串操作指令、循环控制指令、进程任务切换指令等,还有一些数据传输指令和数据运算指令,它们包含了丰富的内存寻址操作。
RISC¶
精简指令集计算机体系结构:通常有 20 多条指令的简化指令集。每条指令长度固定,由专用的加载和储存指令用于访问内存,减少了内存寻址方式,大多数运算指令只能访问操作寄存器。而 CPU 中配有大量的寄存器,这些指令选取的都是工程中使用频率最高的指令。由于指令长度一致,功能单一,操作依赖于寄存器,这些特性使得 CPU 指令预取、分支预测、指令流水线等部件的效能大大发挥,几乎一个时钟周期能执行多条指令。
RISC 的代表产品是 ARM 和 RISC-V。其实到了现在,RISC 与 CISC 早已没有明显界限,开始互相融合了,比如 ARM 中加入越来越多的指令,x86 CPU 通过译码器把一条指令翻译成多条内部微码,相当于精简指令。x86 这种外 CISC 内 RISC 的选择,正好说明了这一点。
评论¶
延申阅读:
1、从MCU到SOC
2、从冯诺依曼结构到存算一体
3、Chiplet如何支撑后摩尔时代
4、碳基芯片
5、量子计算
拓展阅读-代码运行的原理,https://zhuanlan.zhihu.com/p/362950660
02| RISC特性与发展: RISC-V凭什么成为“半导体行业的Linux”¶
{kind=link}
RISC-V 从何而来¶
1981 年,伯克利分校已经设计出了第一代 RISC 指令集,之后又陆续设计了四代 RISC 指令集的架构。RISC-V 来命名该指令集架构,有两层意思:RISC-V 中的“V”,一方面代表第 5 代 RISC;另一方面,“V”取“ Variation”之意,代表变化。
2015 年,由最初的 25 个成员一起成立了非盈利性组织 RISC-V 基金会(RISC-V Foundation)。之后,有多达 300 个单位加入 RISC-V 基金会,其中包括阿里、谷歌、华为、英伟达、高通、麻省理工学院、普林斯顿大学、印度理工学院、中科院计算所、联发科等。这些学术机构、芯片开发公司、设计服务与系统厂商的加入,为 RISC-V 的发展建立了良好的生态环境。
RISC-V 是什么¶
RISC-V 是一套开放许可证书、免费的、由基金会维护的、一个整数运算指令集外加多个扩展指令集的 CPU 架构规范。
任何硬件开发商或者相关组织都可以免费使用这套规范,构建 CPU 芯片产品。
总结¶
RISC-V 发源于加州伯克利分校,是该校第五代 RISC 指令集,即第五代精简指令集。起初是为了学生有一套用来学习研究的指令集。后来因为有技术泰斗 David Patterson 的加入,又成立 RISC-V 基金会,RISC-V 慢慢流行了起来。
02硬件-芯片(手写mini CPU) (9讲)¶
03| 硬件语言筑基.1: 从硬件语言开启手写CPU之旅¶
04| 硬件语言筑基.2: 我们的代码是怎么生成具体电路的¶
05| 指令架构: RISC-V到底在CPU设计上有哪些优势¶
06| 手写CPU.1: 迷你CPU架构设计与取指令实现¶
07| 手写CPU.2: 如何实现指令译码模块¶
08| 手写CPU.3: 如何实现指令执行模块¶
09| 手写CPU.4: 如何实现CPU流水线的访存阶段¶
10| 手写CPU.5: CPU流水线的写回模块如何实现¶
11| 手写CPU.6: 如何让我们的CPU跑起来¶
03环境准备 (2讲)¶
12| QEMU: 支持RISC-V的QEMU如何构建¶
13| 小试牛刀: 跑通RISC-V平台的Hello World程序¶
QEMU 就像计算机界的“孙悟空”,变化多端,能模拟出多种类型的 CPU,比如 IA32、AMD64、ARM、MIPS、PPC、SPARC、RISC-V 等。QUEM 通过动态二进制转换来模拟 CPU。除了 CPU,它还支持模拟各种 IO 设备,并提供一系列的硬件模型。这使得 QEMU 能模拟出完整的硬件平台,使得 QEMU 能运行各种操作系统,如 Windows 和 Linux。
上面运行的操作系统,认为自己在和硬件直接打交道,其实是同 QEMU 模拟出来的硬件打交道,QEMU 再将这些指令翻译给真正硬件进行操作。通过这种模式,QEMU 运行的操作系统就能和宿主机上的硬盘、网卡、CPU、CD-ROM、音频设备、USB 设备等进行交互了。
04语言与指令 (9讲)¶
14| 走进C语言: 高级语言怎样抽象执行逻辑¶
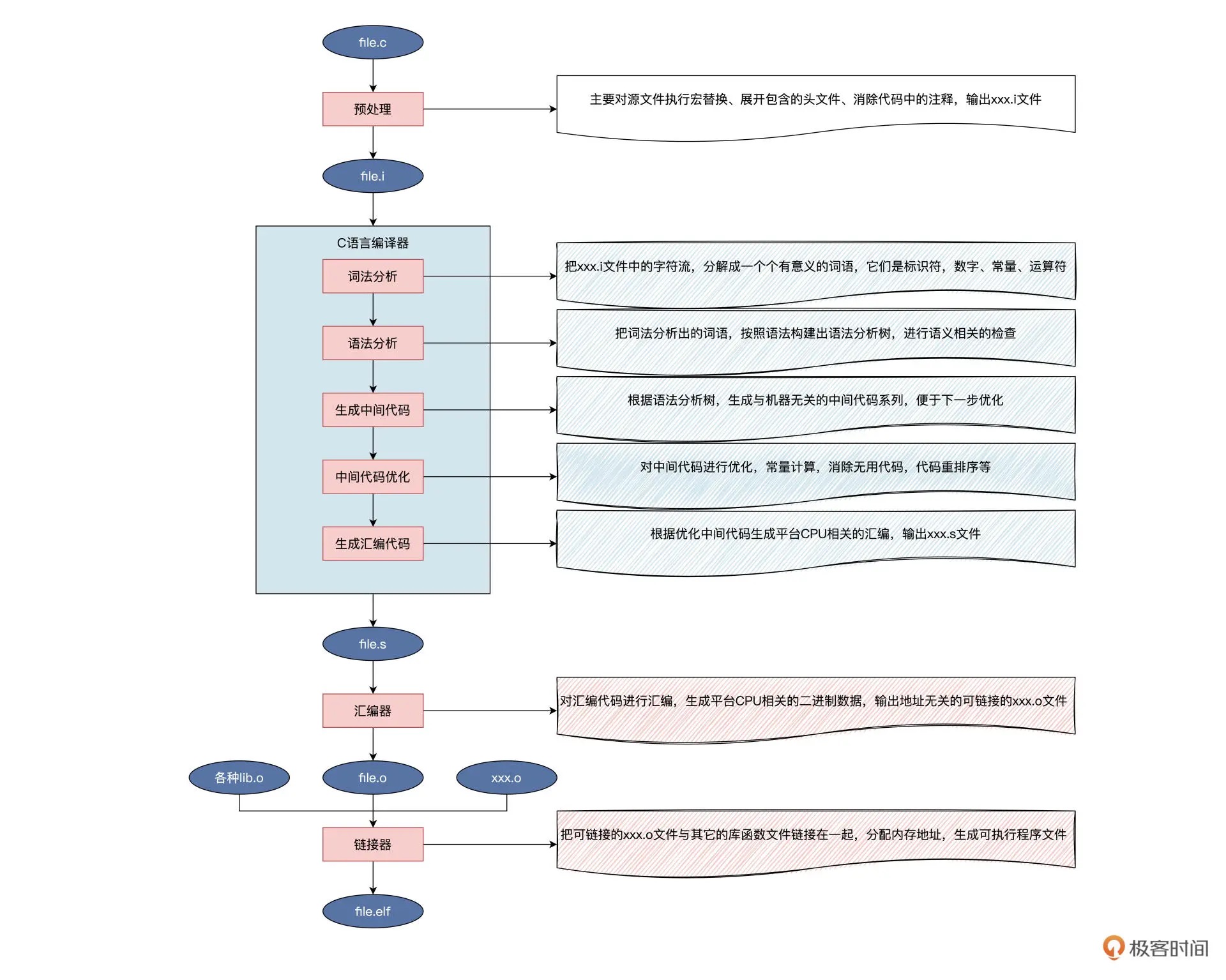
15| C与汇编: 揭秘C语言编译器的“搬砖”日常¶
16| RISC-V指令精讲.1: 算术指令实现与调试¶
17| RISC-V指令精讲.2: 算术指令实现与调试¶
18| RISC-V指令精讲.3: 跳转指令实现与调试¶
19| RISC-V指令精讲.4: 跳转指令实现与调试¶
20| RISC-V指令精讲.5: 原子指令实现与调试¶
21| RISC-V指令精讲.6: 加载指令实现与调试¶
22| RISC-V指令精讲.7: 访存指令实现与调试¶
05应用与内存 (8讲)¶
23|内存地址空间: 程序中地址的三种产生方式¶
24|虚实结合:虚拟内存和物理内存¶
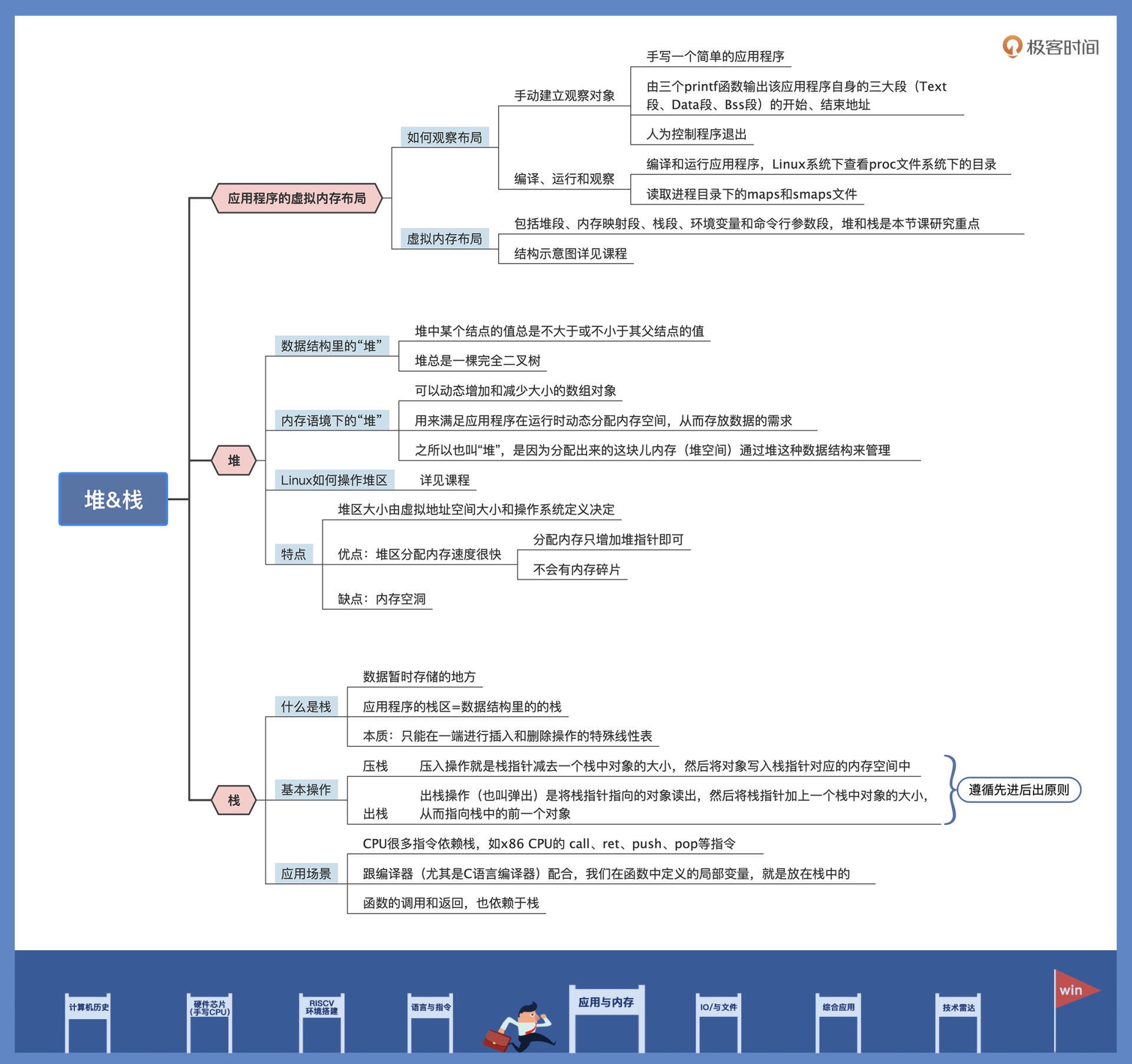
25|堆&栈:堆与栈的区别和应用¶
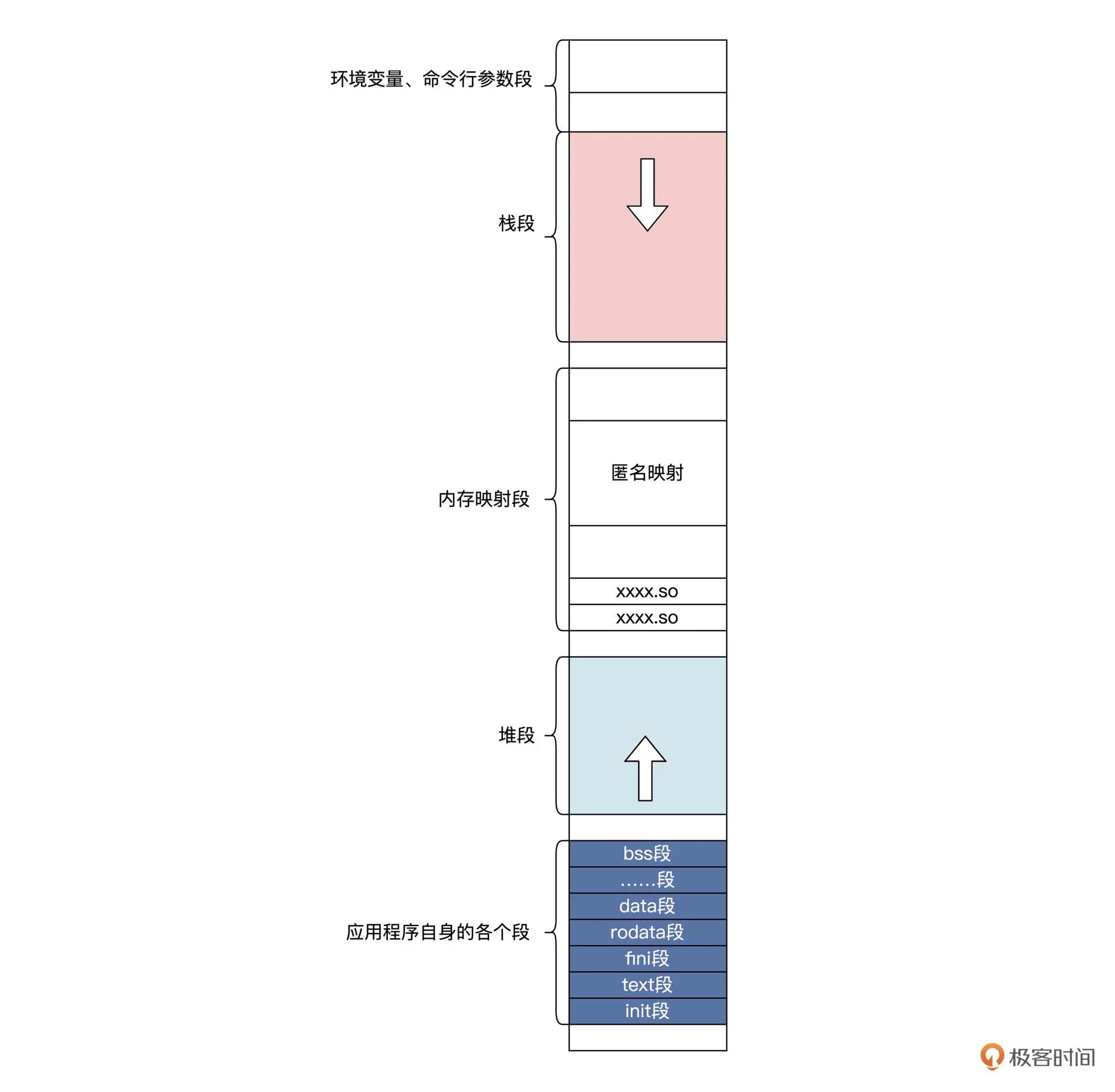
26|延迟分配:提高内存利用率的三种机制¶
无论是写时复制还是请求调页,都是一种内存优化技术,需要 MMU 等硬件的支持才能实施。正是因为物理内存的使用被推迟了,才导致多个应用可以看到的物理内存页面还有很多,因为总是在最后需要内存的时刻,才会分配物理内存。这种延迟分配的方式,可以更好地利用空闲内存,同时运行更多的应用,总体上让系统产生更大的吞吐量。
写时复制是一种延迟分配内存的技术,可以优化内存的使用。Linux 在 fork 创建新应用时使用了 COW(Copy-on-write)技术。fork 通过对当前应用的关键数据结构复制,即可得到一个新应用,但当前应用和新应用会以只读方式共享物理内存,只有当其中一个应用试图修改数据时,就会为其分配一个物理内存页,将数据复制到新的物理内存页中。
请求调页的核心思路就是将内存推迟到使用时才分配。由于应用程序的局部性原理,使得应用总是会访问常用的页面,而不是在一定时间内顺序访问所有的页面。请求调页的思路就是等到应用产生了缺页异常,才为其分配一个物理内存页,这大大提高物理内存的整体利用率。
27|应用内存管理:Linux的应用与内存管理¶
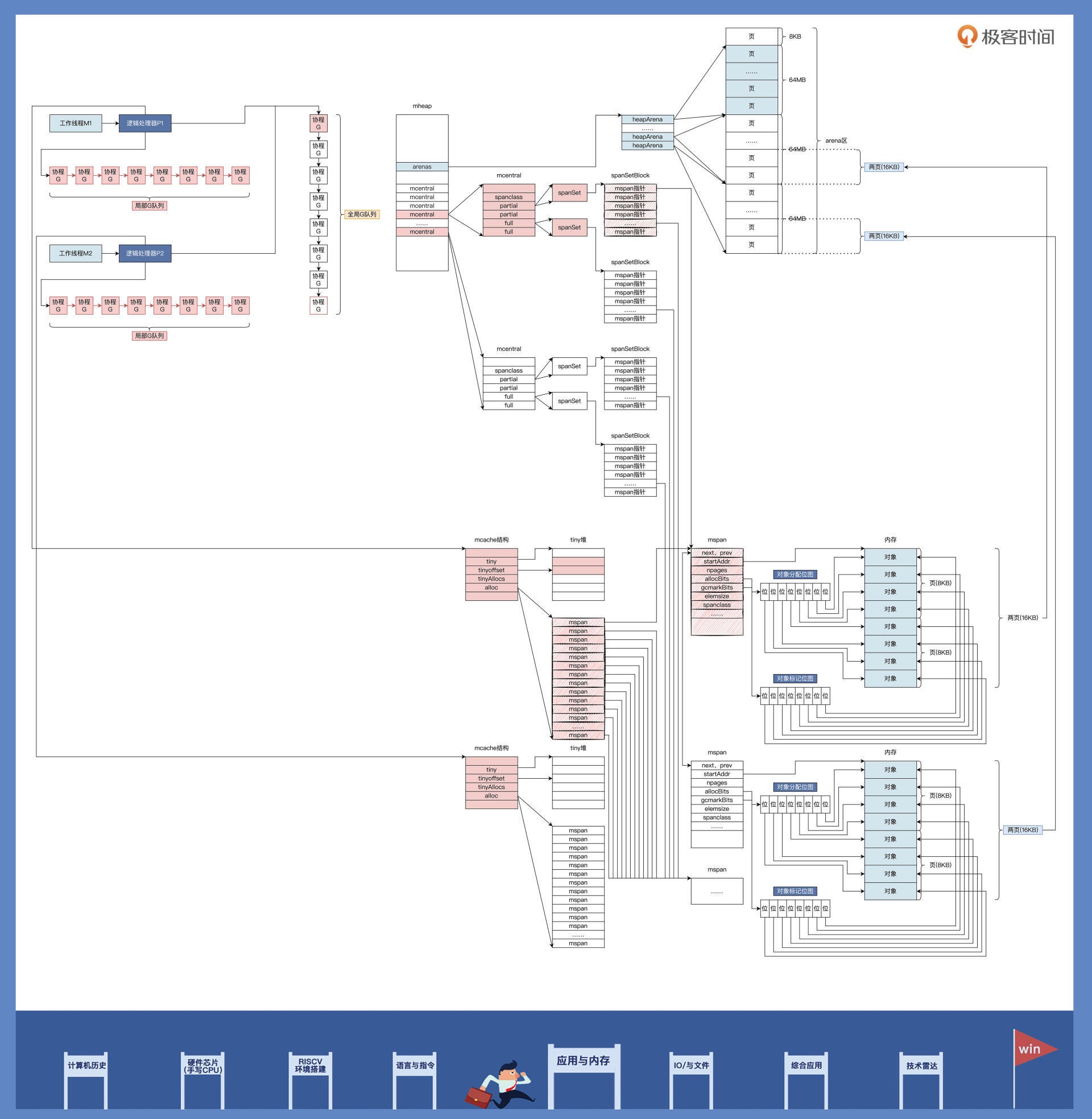
Golang 内存管理所用数据结构的关系:基本能图画出来的话,关系也就理清楚了。万一有些关联不确定,你可以做些猜想假设,并通过写点代码来验证。¶
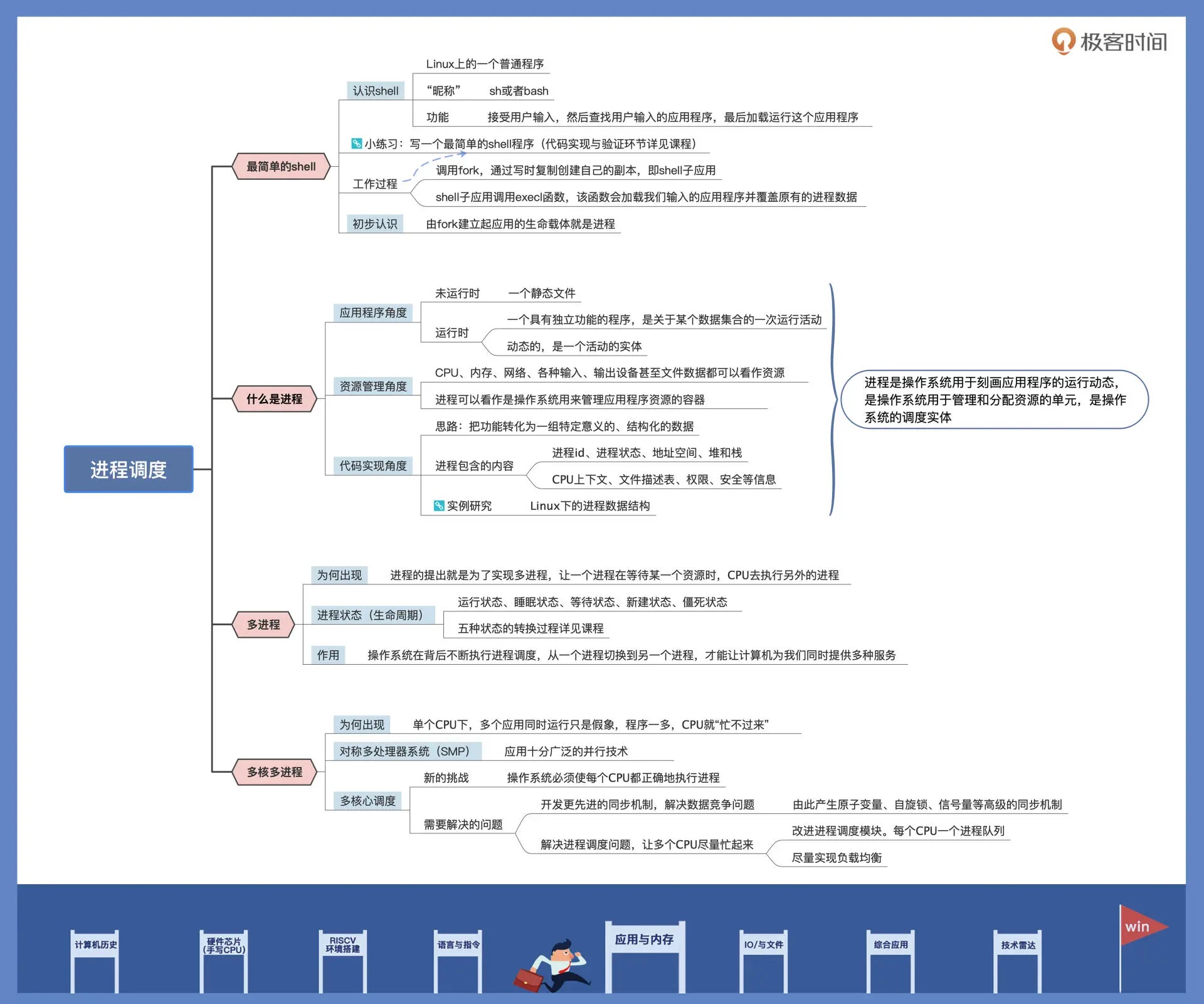
28| 进程调度:应用为什么能并行执行¶
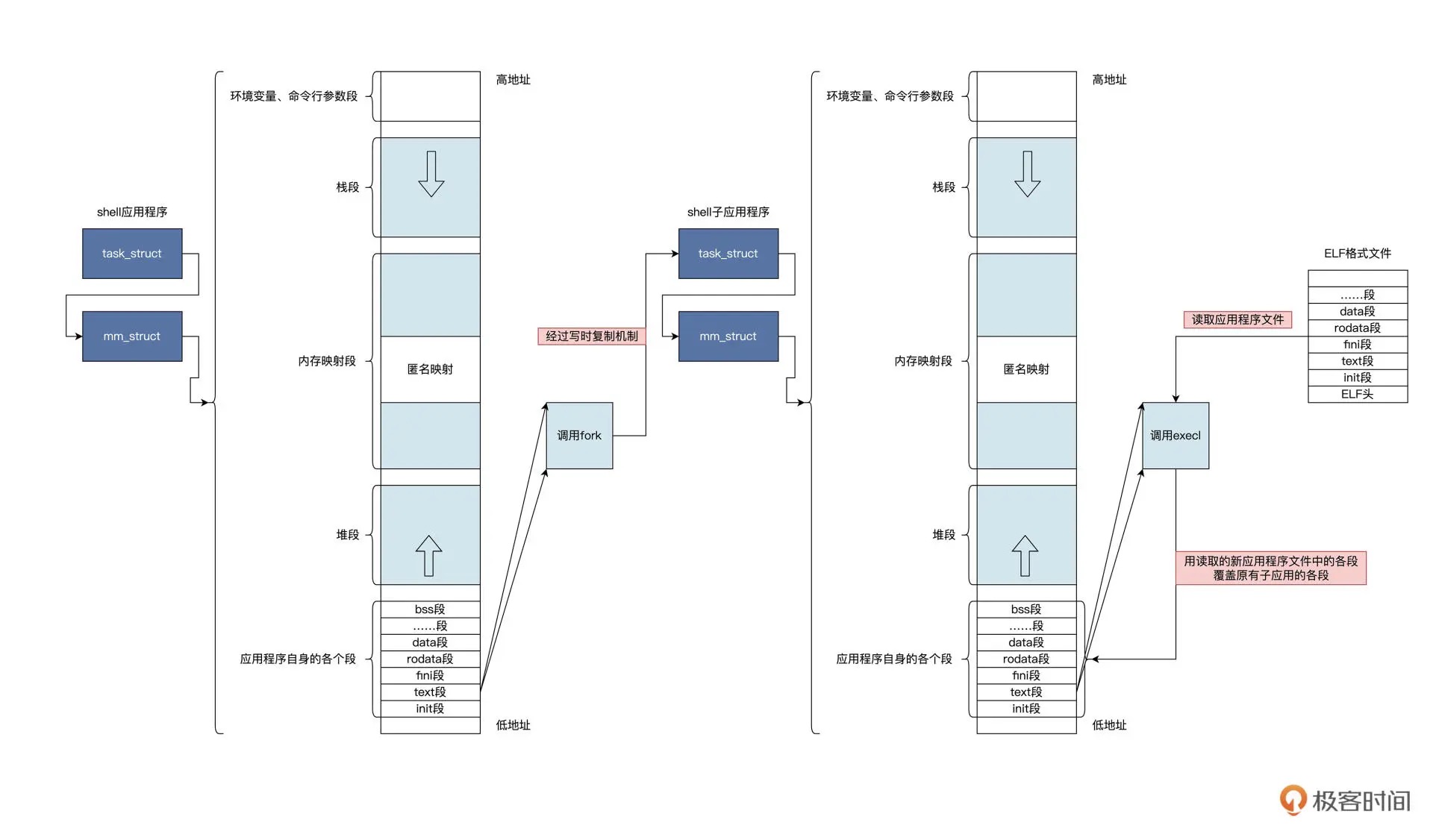
两个系统调用——fork 和 execl 示意图¶
什么是进程¶
应用程序角度¶
资源管理角度¶
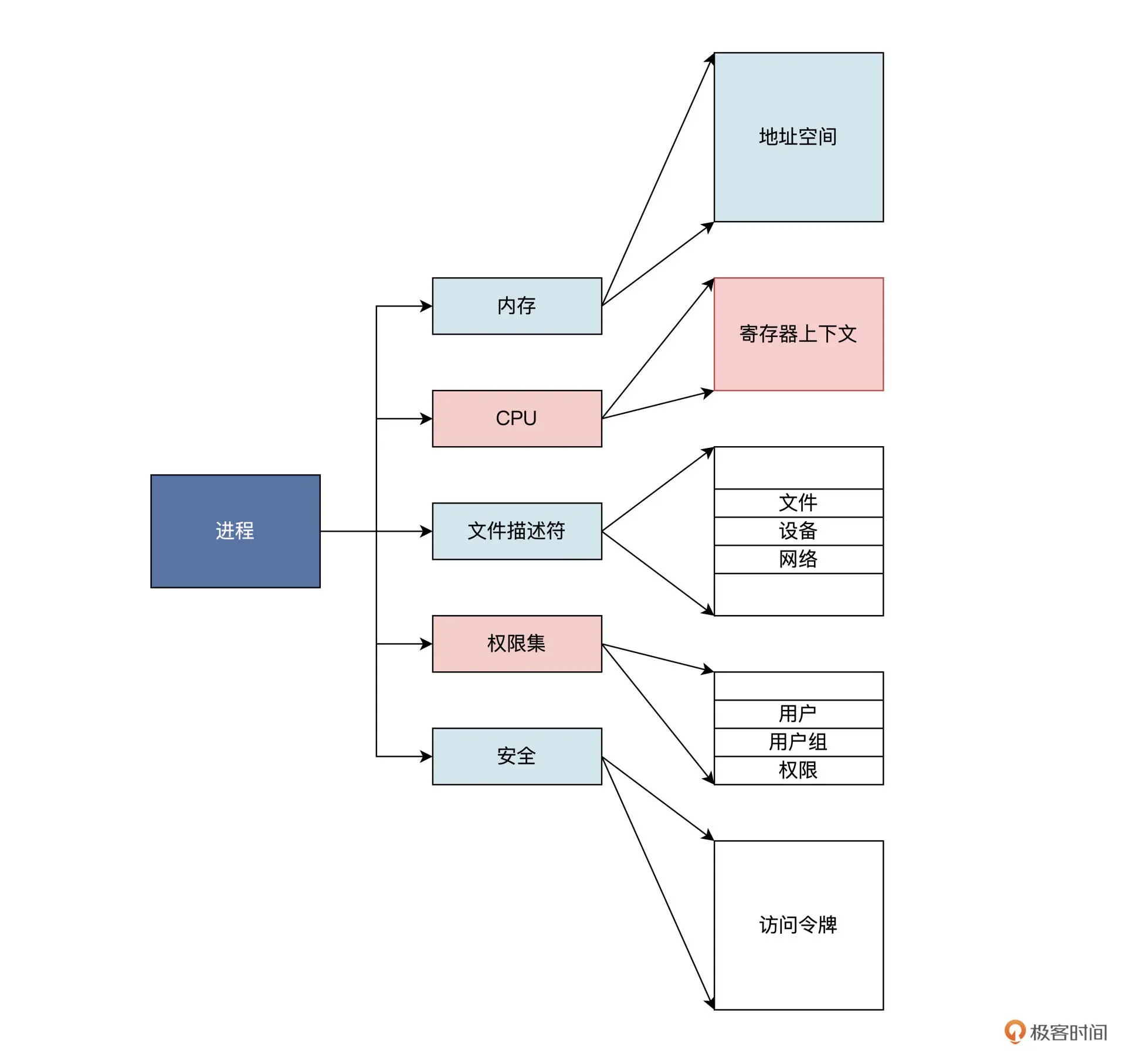
代码实现角度¶
…
多个进程¶
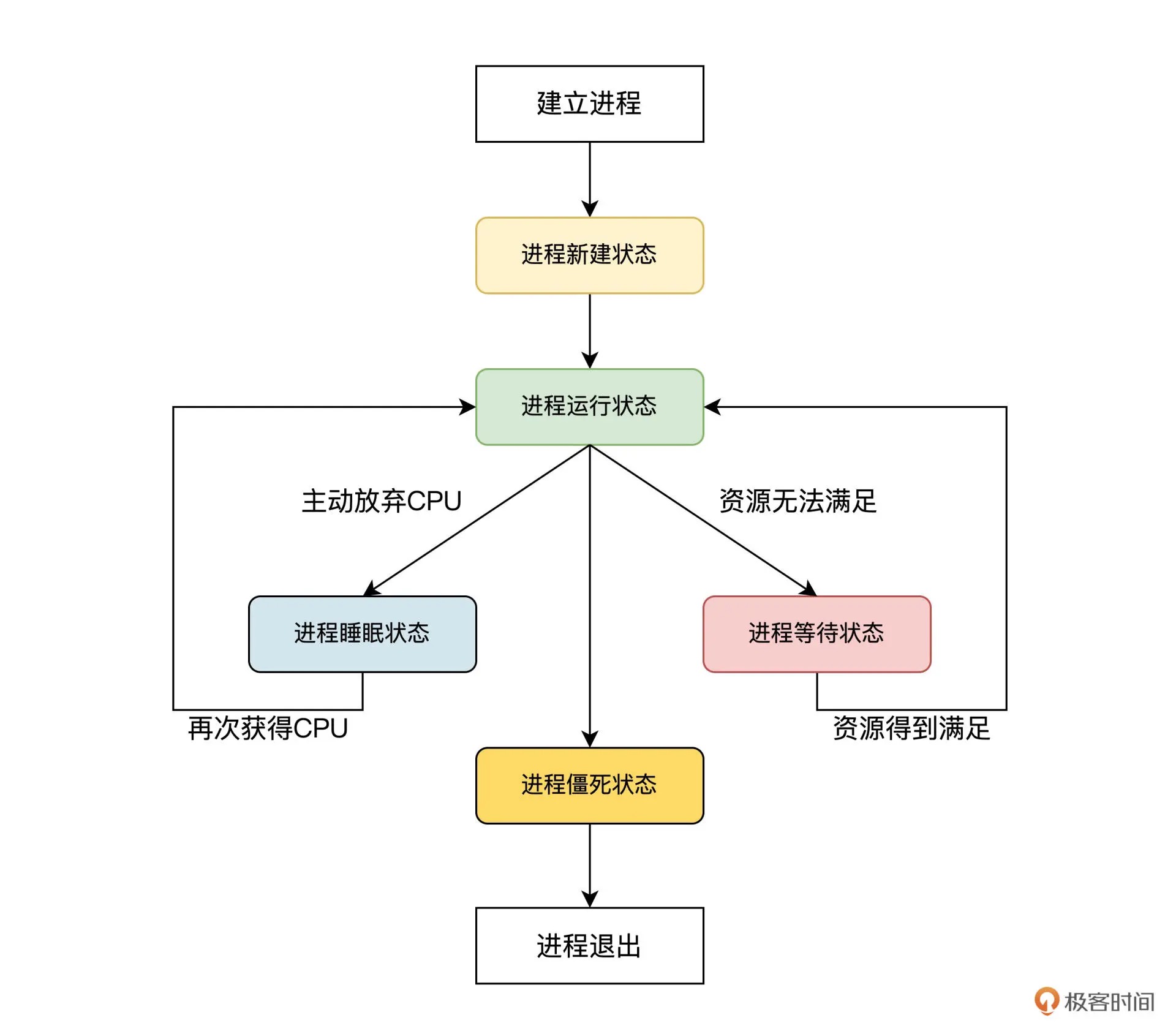
进程的各种状态之间如何转换¶
多核多进程¶
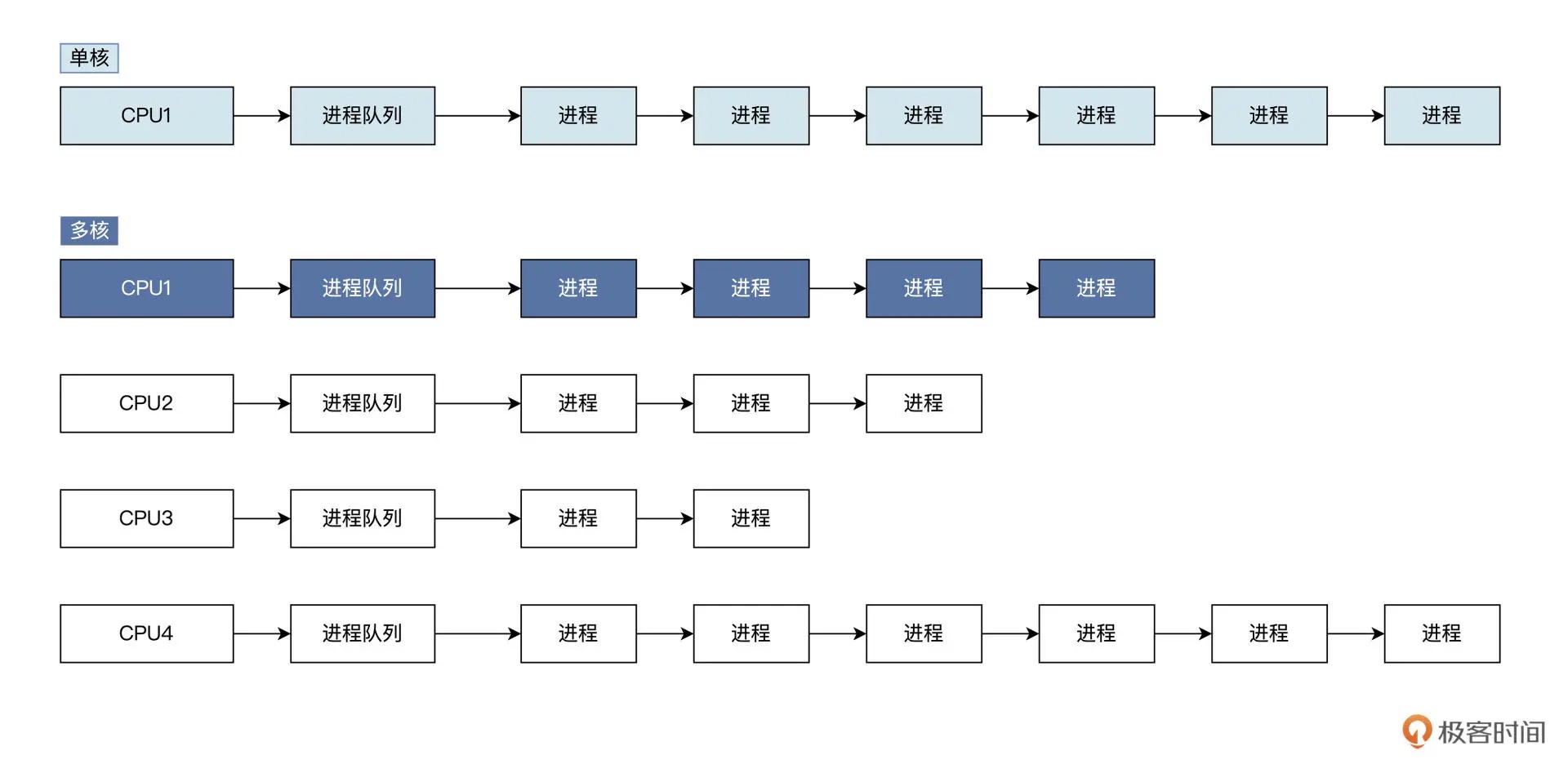
总结¶
备注
进程具备四大特性。首先是动态特性。进程的本质是程序在操作系统中的一次执行过程,进程是动态建立、动态消亡的,有自己的状态和生命周期;其次是并行特性。任何进程都可以同其他进程一起在操作系统中并行执行,尽管在单 CPU 上是伪并行;进程还具备独立特性。进程是操作系统分配和管理资源的独立单元,同时进程也是一个被操作系统独立调度和执行的基本实体;最后是异步特性。由于进程需要操作系统的资源而被制约,使进程具有执行的间断性,即进程之间按各自独立的、不可预知的速度向前推进执行。
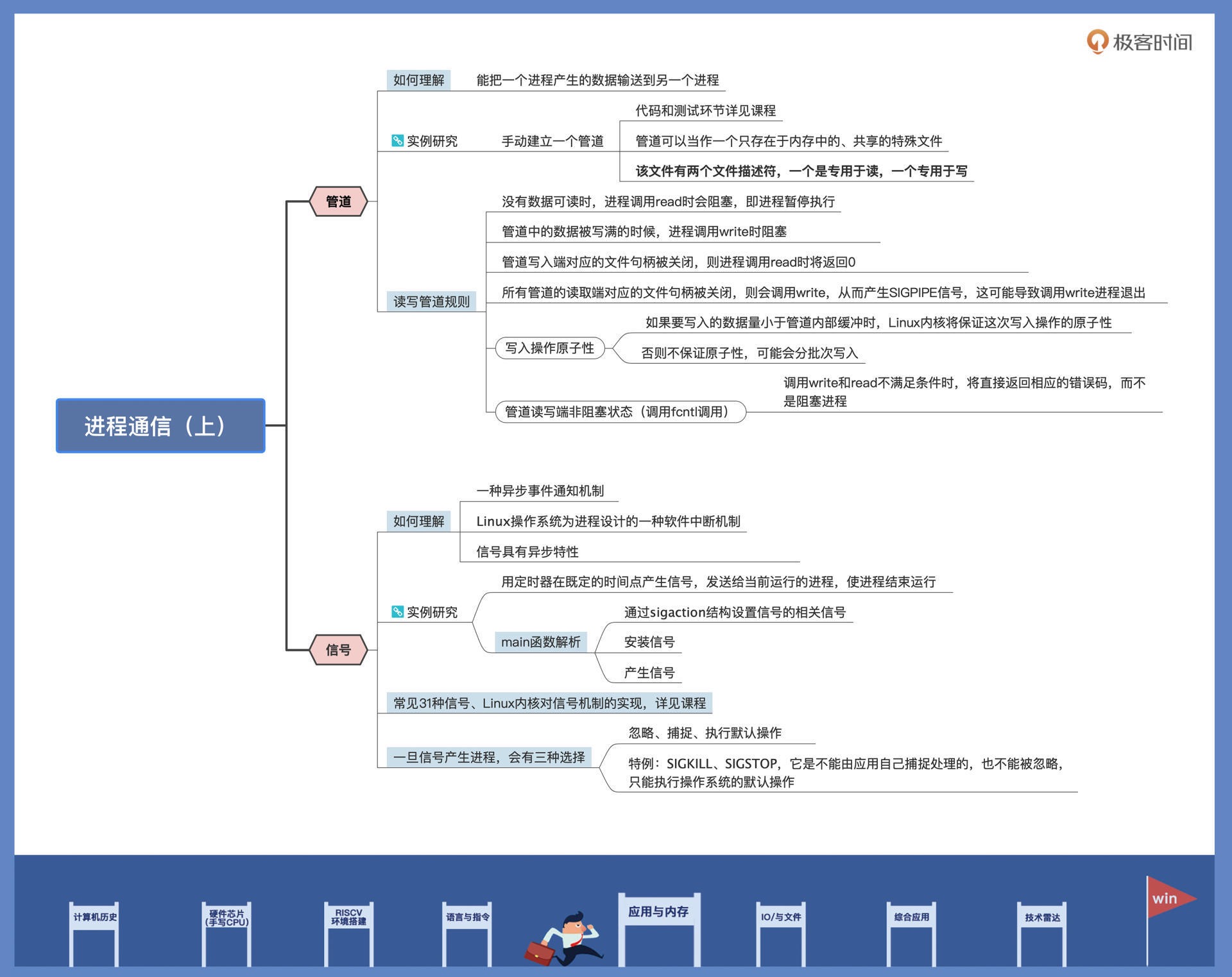
29|应用间通信.1: 详解Linux进程IPC¶
总结¶
进程之间要协作,就要有进程间通信机制,Linux 实现了多种通信机制,今天我们重点研究了管道和信号这两种机制。
管道能连接两个进程,一个进程的数据从管道的一端流向管道另一端的进程。如果管道空了则读进程休眠,管道满了则写进程休眠。这些同步手段由操作系统来完成,对用户是透明的。shell 中常使用“|”在两个进程之间建立管道,让一个进程的输出数据,成为另一个进程的输入数据。
信号也是 Linux 下经典的通信方式。信号比较特殊,它总是异步地打断进程,使得正在运行的进程转而去处理信号。信号来源硬件、系统,和其它进程。发送信号时,也能携带一些数据。
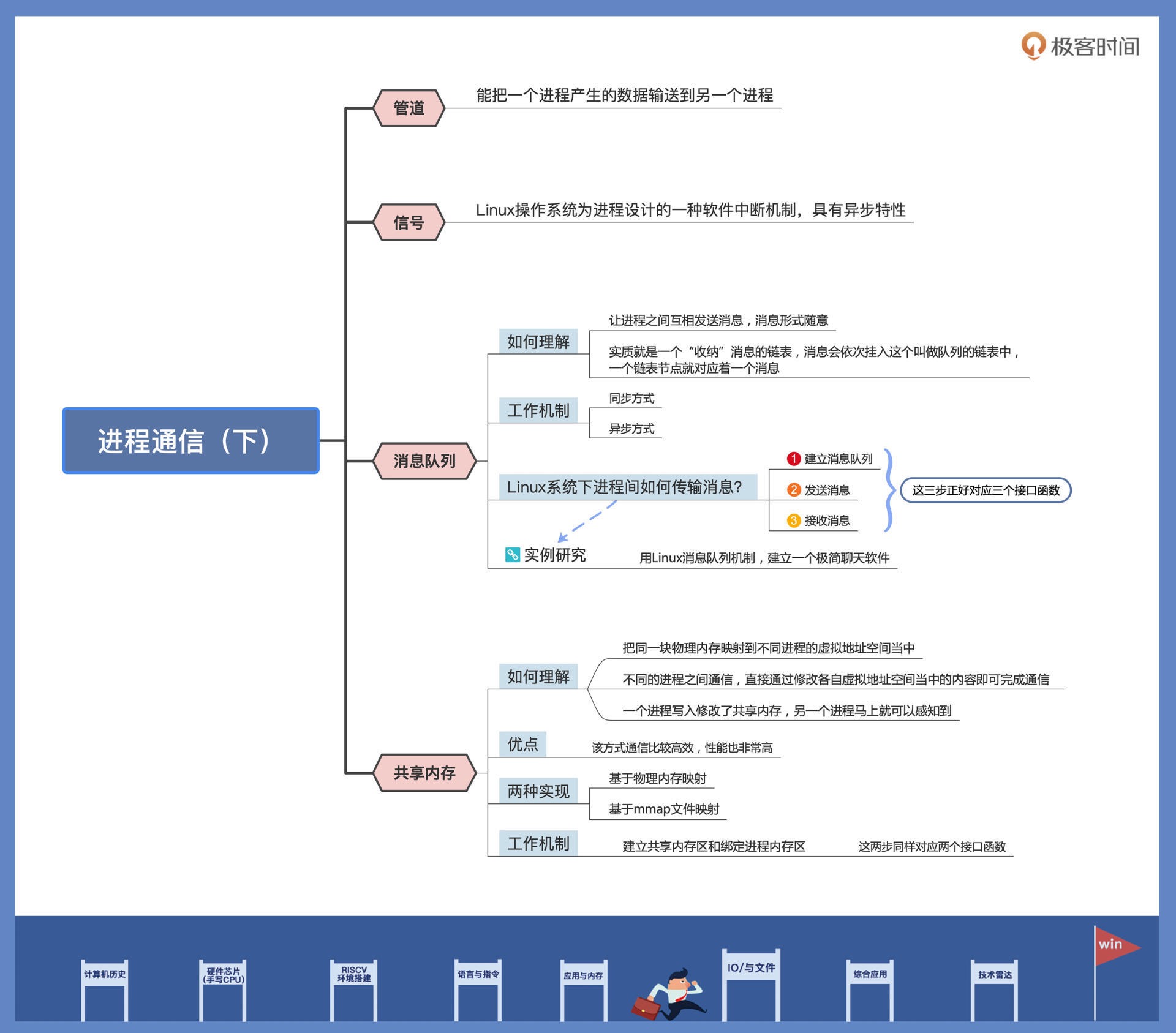
30|应用间通信.2: 详解Linux进程IPC¶
消息队列¶
Linux 系统下进程间传输消息要分三步走:
1. 建立消息队列
2. 发送消息
3. 接收消息
// 对应着下面这三个接口函数
int msgget (key_t __key, int __msgflg);
int msgsnd (int __msqid, const void *__msgp, size_t __msgsz, int __msgflg);
ssize_t msgrcv (int __msqid, void *__msgp, size_t __msgsz, long int __msgtyp, int __msgflg);
总结¶
这节课我们主要探讨了消息队列和共享内存
消息队列能使进程之间互相发送消息,这些消息的形式格式可以随意设定。从数据结构的角度看,消息队列其实是一个挂载消息的链表。发送消息的进程把消息插入链表,接收消息的进程则从链表上获取消息。同步手段由内核提供,即消息链表空了则接收进程休眠,消息链表满了发送进程就会休眠。
共享内存的实现是把同一块物理内存页面,映射到不同进程的虚拟地址空间当中,进程之间直接通过修改各自虚拟地址空间当中的内容,就能完成数据的瞬间传送。一个进程写入修改了共享内存,另一个进程马上就可以感知到。
06国庆策划 (3讲)¶
国庆策划01|知识挑战赛:检验一下学习成果吧¶
国庆策划02|来自课代表的学习锦囊¶
国庆策划03|揭秘代码优化操作和栈保护机制¶
07IO与文件 (6讲)¶
31|外设通信:IO Cache与IO调度¶
早期的 Cache 是位于 CPU 和内存之间的高速缓存,由于硬件实现的 Cache 芯片的速度仅次于 CPU,而内存速度远小于 CPU,Cache 只是为了缓存内存中的数据,加快 CPU 的性能,避免 CPU 等待内存。而 Buffer 是在内存中由软件实现的,用于缓存 IO 设备的数据,缓解由于 IO 设备过慢带来系统性能下降。
但是现在 Buffer 和 Cache 成了在计算机技术中被用滥的两个名词。在 Linux 的内存管理中,Buffer 指 Linux 内存的 Buffer Cache,而 Cache 是指 Linux 内存中的 Page Cache,翻译成中文分别叫做缓冲区缓存和页面缓存
对软件场景和硬盘结构进行了讨论,发现有了 IO Cache 以后,还需要对 IO 请求进行调度,才能使 IO 效率最大化,针对不同的场景有不同 IO 调度器,我们重点讨论了三种 IO 调度算法,分别是 Noop、CFQ、Deadline,其中综合性能最好的是 Deadline。然而硬件技术的升级又产生了固态硬盘,导致这些 IO 调度器没有了用武之地,不调度就是最好的调度。
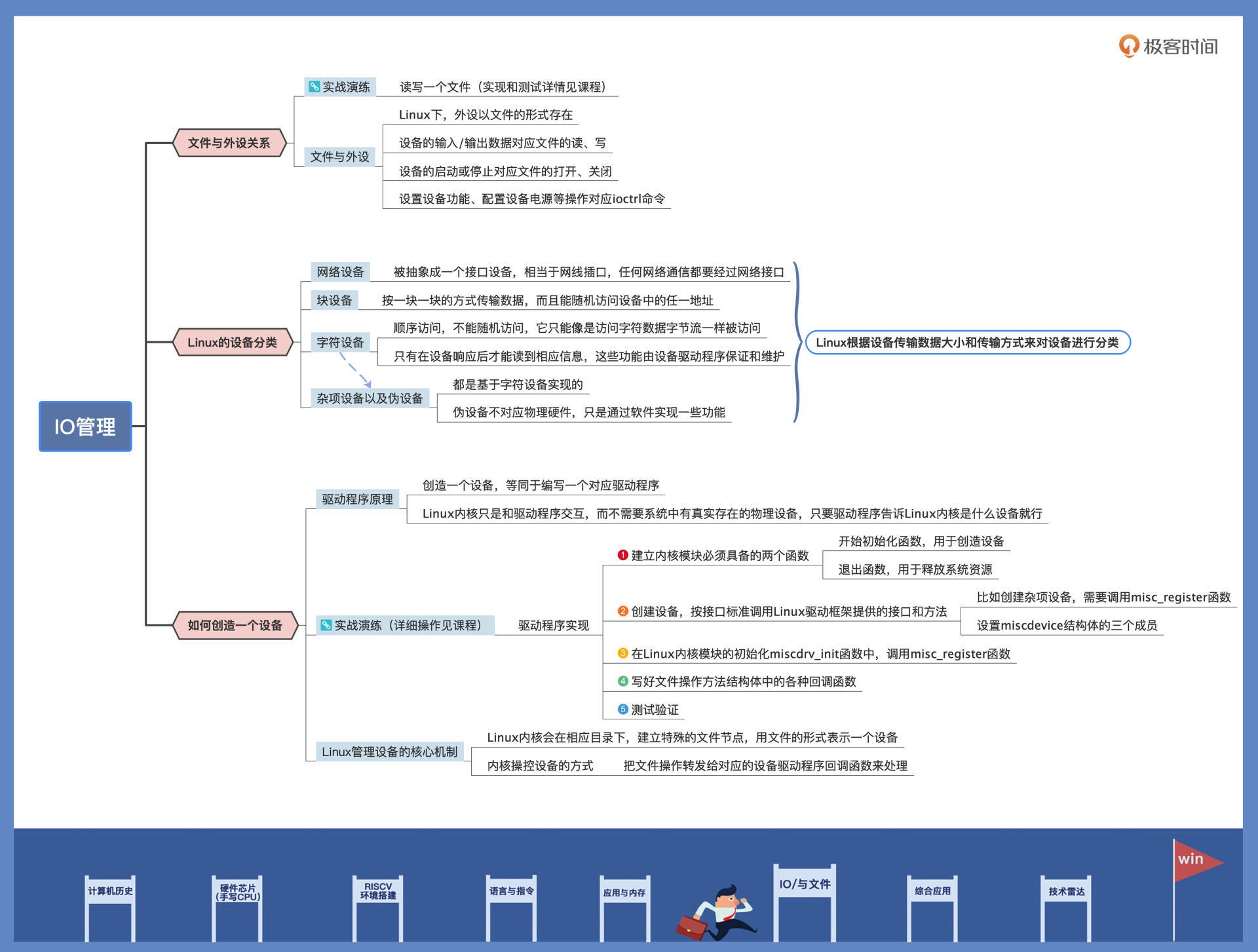
32|IO管理:Linux如何管理多个外设¶
33|iotop与iostat命令:聊聊命令背后的故事与工作原理¶
两大监控 IO 操作的神器,即 iostat 和 iotop。它们俩在以后的性能调优路上,将是我们最忠诚的伙伴,一个观察系统全局 IO 情况,另一个用来查看单个进程的 IO 情况。有了它们,我们就能精确定位 Linux 服务器上 IO 性能瓶颈所在。
34|文件仓库:初识文件与文件系统¶
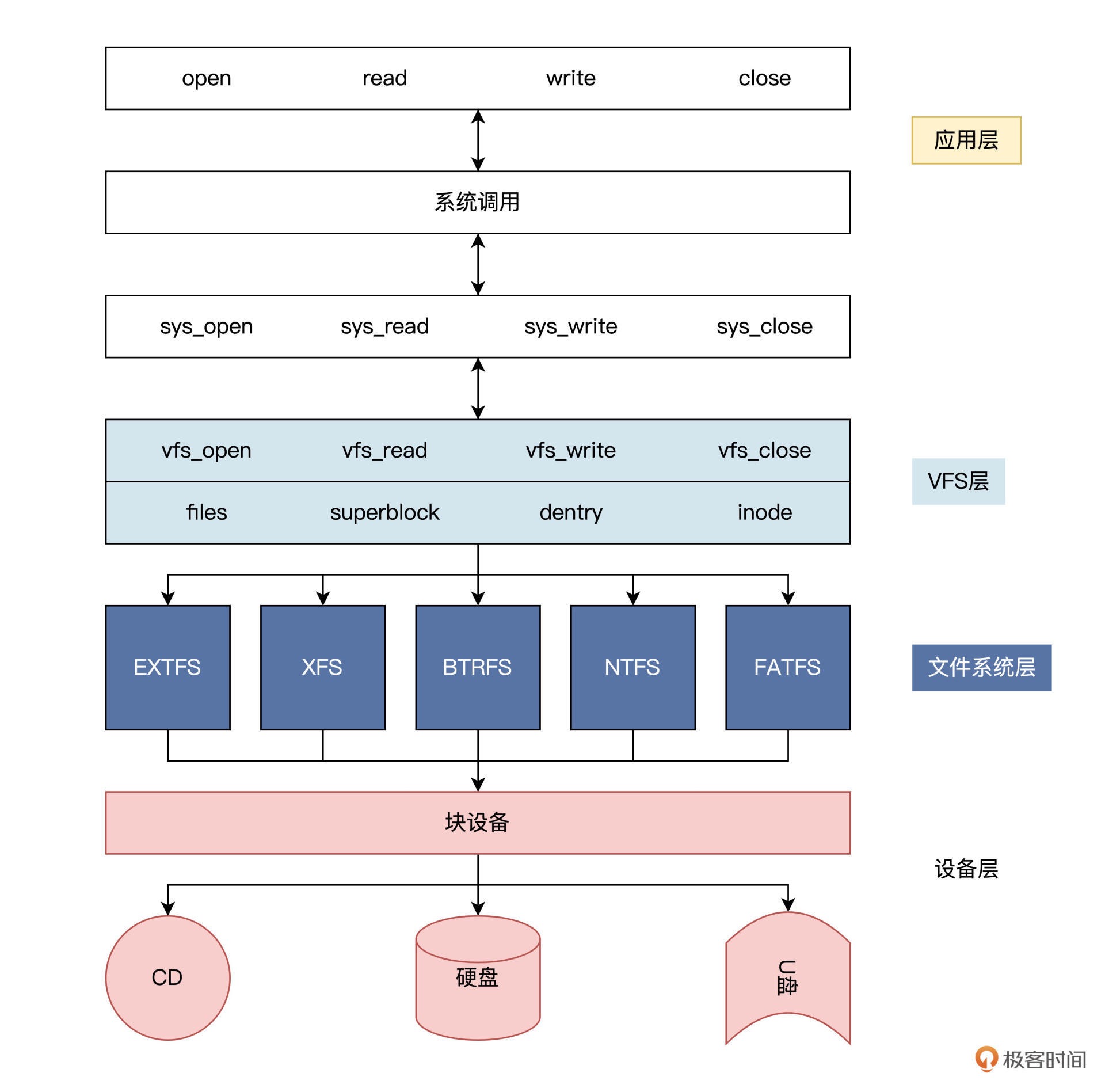
Linux 系统为了支持多种类型的文件系统,还进一步抽象出了 VFS。任何文件系统模块只要符合 VFS 对数据结构和操作函数集合的要求,都可以安装到 VFS 层中。VFS 的出现使得 Linux 支持多种文件系统成为可能。¶
35|Linux文件系统.1: Linux如何存放文件¶
建立虚拟硬盘¶
生成 100MB 的纯二进制的文件:
dd bs=512 if=/dev/zero of=hd.img count=204800
;bs:表示块大小,这里是512字节
;if:表示输入文件,/dev/zero就是Linux下专门返回0数据的设备文件,读取它就返回0
;of:表示输出文件,即我们的硬盘文件
;count:表示输出多少块
把虚拟硬盘文件变成 Linux 下的回环设备:
sudo losetup /dev/loop0 hd.img
; 回环设备就是 Linux 下的块设备,用户可以将其看作是硬盘、光驱或软驱等设备
; 可以用 mount 命令把该回环设备挂载到特定目录下
回环块设备格式化,进而格式化 hd.img 文件:
sudo mkfs.ext3 -q /dev/loop0
将 hd.img 挂载到特定的目录下:
sudo mount -o loop ./hd.img ./hdisk/ ;挂载硬盘文件
36|Linux文件系统.2: Linux如何存放文件¶
通过写代码的方式,在文件系统中读取了文件数据。我们通过获取超级块、块组的描述符表,一步步完整地把文件内容读取出来,打印在屏幕上。
08综合应用 (6讲)¶
37|浏览器原理.1: 浏览器为什么要用多进程模型¶
览器内核的英文名为 Rendering Engine,你可以把它理解成一个渲染引擎,用途就是把文件资源转化成可视化的图像结果。
浏览器常见的浏览器内核有:
Blink、WebKit、Gecko、Trident
从 WebKit 看浏览器内核架构¶
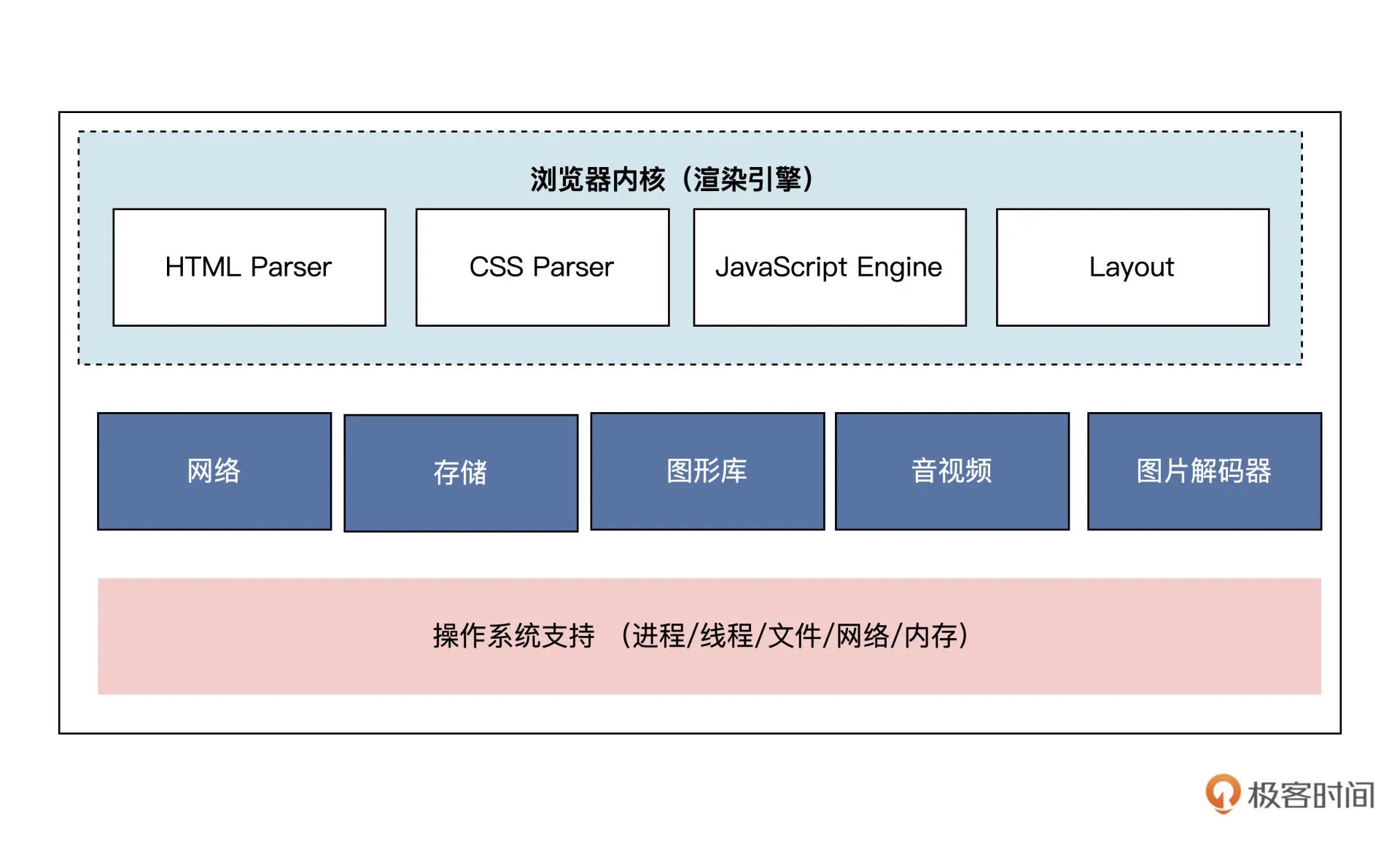
浏览器内核主要包含:HTML Parser,CSS Parser,Layout,JavaScript Engine 几部分¶
Chromium 浏览器架构解读¶
在 2013 年,Chromium 发布了 Blink 项目。这个项目是从 WebKit 项目独立出来的,它抽离出了一套新的编程接口和进程模型接口,同时浏览器内核屏蔽了 Chromium 底层的进程模型实现。
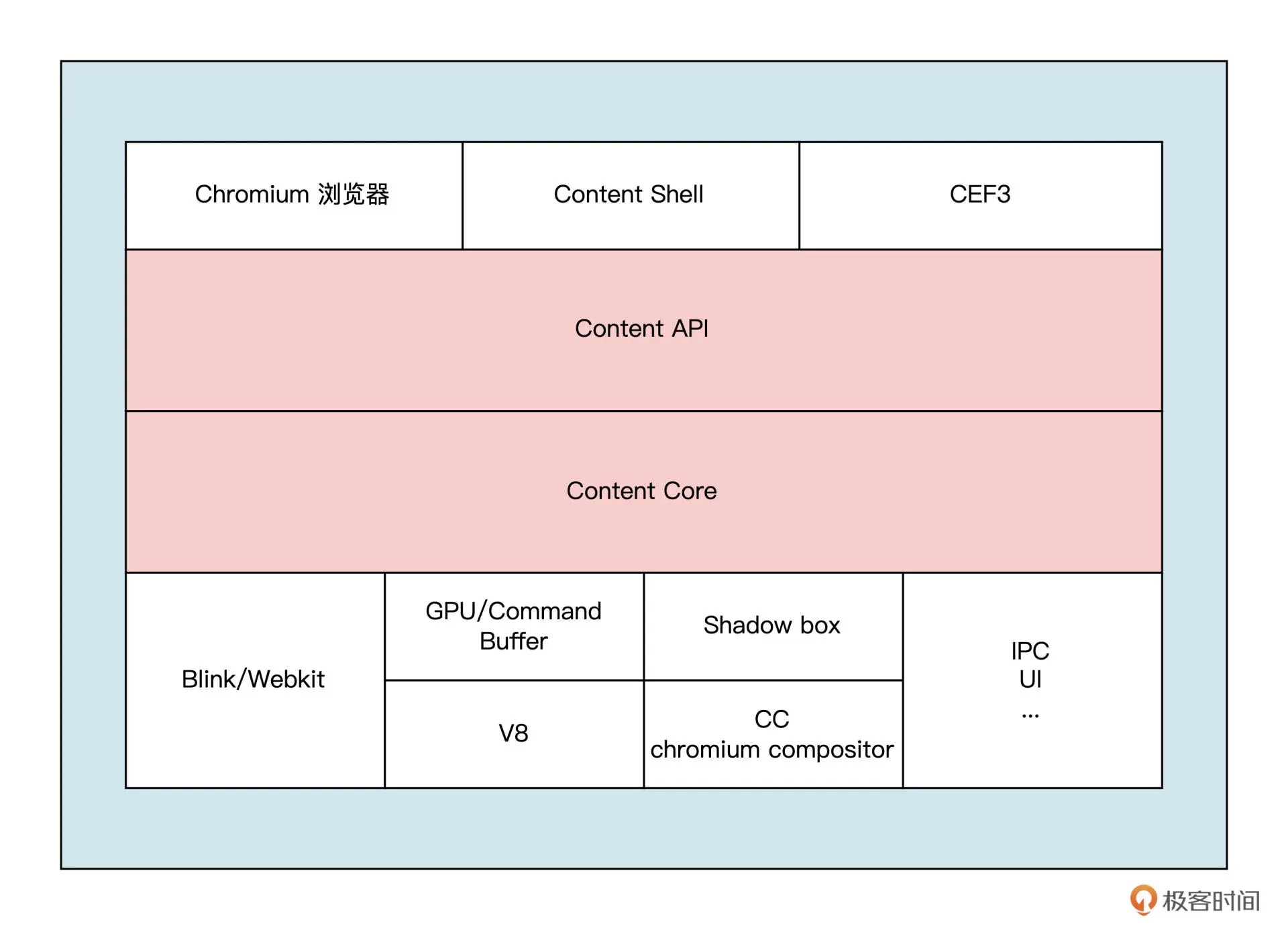
比较重要的是 Content 模块以及 Content 接口。Content 模块和接口是浏览器对渲染过程的抽象,它们将浏览器的渲染、插件、沙箱等功能,进行了包装和抽象,提供一个接口层,方便上层的应用调用。Chromium 中我们可以看到的浏览器可视化界面,它构建在 Content 接口之上,用于接收用户交互和展示界面,content shell 是一个简易版的浏览器,通常被第三方浏览器软件进行二次开发,它在 Andriod 系统上也应用广泛¶
浏览器下的多进程与多线程模型¶
Chromium 和 Blink 最大的一个特性就是采用了新的进程模型和线程模型。
Chrome 支持四种不同的进程模型模型:
1. Process-per-site-instance(默认)。这种进程模型会为每一个同一个域的实例都会创建一个 Renderer 进程。
2. Process-per-site。这种进程模型会为不同一个域创建独立的进程,同一域的不同实例共享同一个进程。
3. Process-per-tab。这种进程模型会为每个标签页创建一个 Renderer 进程。
4. Single process。这种进程模型不为页面创建任何独立的进程,所有渲染工作都在 browser 进程中(这种模式是实验性质的,不推荐使用)。
一共有以下几种进程:
1. 浏览器进程:主要负责用户交互、子进程管理和文件储存等功能;
2. 网络进程:浏览器主进程和渲染进程通过他来向操作系统申请端口以及与操作系统的协议栈进程通信;
3. 渲染进程:主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面;
4. 插件进程:主要负责单个插件功能的运行;
5. GPU 进程:主要负责 3D 效果的实现以及 UI 的绘制。
渲染进程内部具体有以下线程:
GUI 线程:负责渲染浏览器中的页面,并解析 HTML,CSS;
JS 线程:负责处理 JavaScript 脚本程序;
事件触发线程:归属于浏览器而不是 JS 引擎,用来控制事件循环;
定时触发器线程:浏览器的定时任务,如 setInterval 与 setTimeout 事件,也包括浏览器内部的一些定时任务。
IO 线程:用来和其他进程进行 IPC 通信,接受发送消息;
异步 http 请求线程:处理所有的异步请求,如果有回调函数,就放入异步事件队列,由事件触发线程处理;
WebWorker 线程:每声明一个 WebWorker 就会新建一个 WebWorker 线程处理;
合成线程:在 GUI 渲染后执行,将 GUI 渲染线程生成的产物转换为位图。
38|浏览器原理.2: 浏览器进程通信与网络渲染详解¶
Chrome 已经不推荐使用 IPC::Channel 机制进行通信了,Chrome 实现了一种新的 IPC 机制—— Mojo。
Mojo 是一个跨平台 IPC 框架,它源于 Chromium 项目,主要用于进程间的通信,ChromeOS 用的也是 Mojo 框架。
39|源码解读: V8 执行 JS 代码的全过程¶
V8 不仅是 Chrome 的核心组件,还是 node.js 等众多软件的核心组件
V8 涉及到的技术十分广泛,包括操作系统、编译技术、计算机体系结构等多方面知识
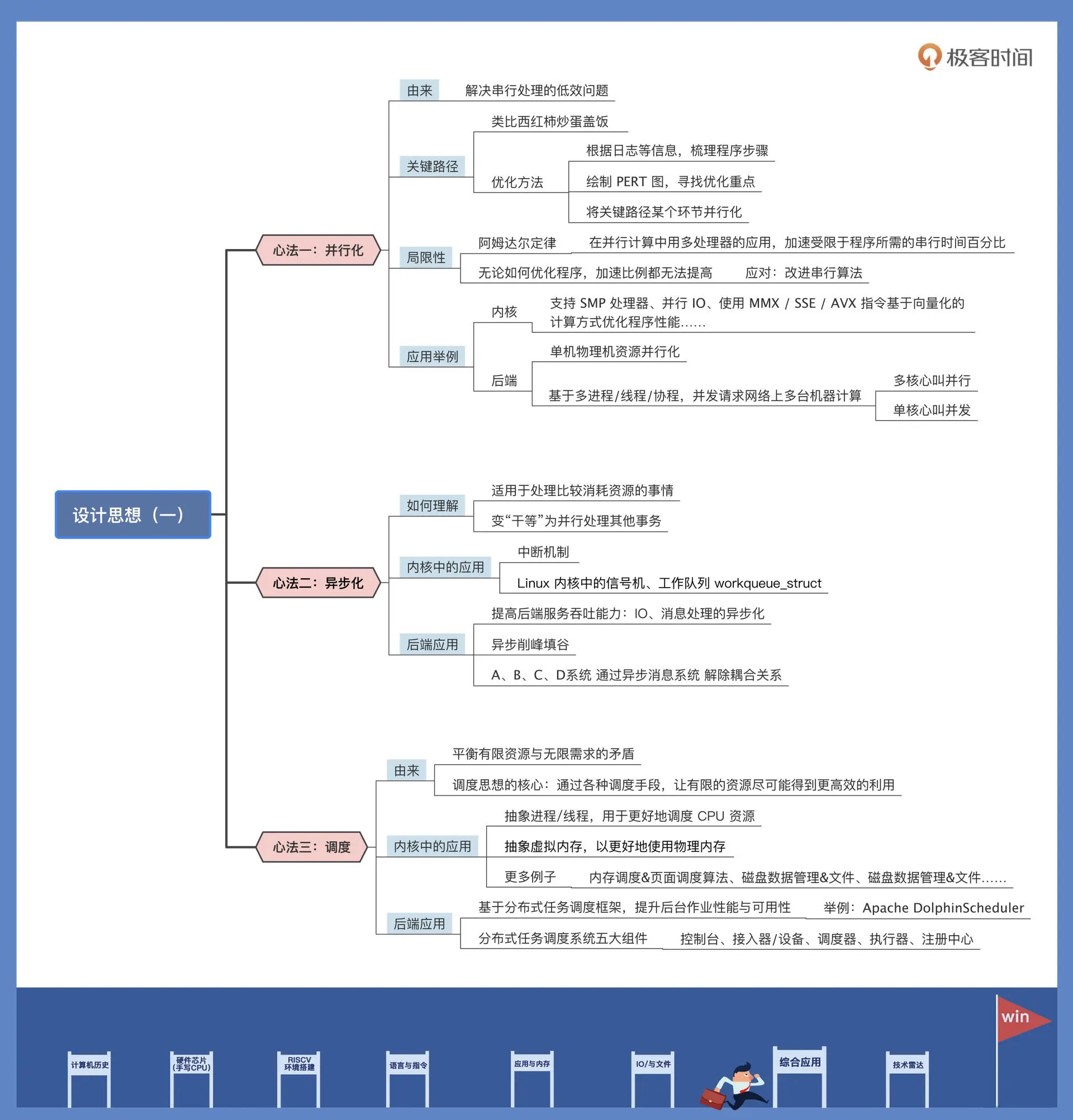
40|内功心法.1: 内核和后端通用的设计思想有哪些¶
关键路径和阿姆达尔定律¶
阿姆达尔定律是计算机工程中的一条经验法则,它的定义是:在并行计算中用多处理器的应用,加速受限于程序所需的串行时间百分比。
后端场景中的并行化思想¶
内核中,并行化思想有很多应用。比如说,支持 SMP 处理器、并行 IO、使用 MMX/SSE/AVX 指令基于向量化的计算方式优化程序性能之类的操作,本质上都是在用并行化的思路来提升性能。
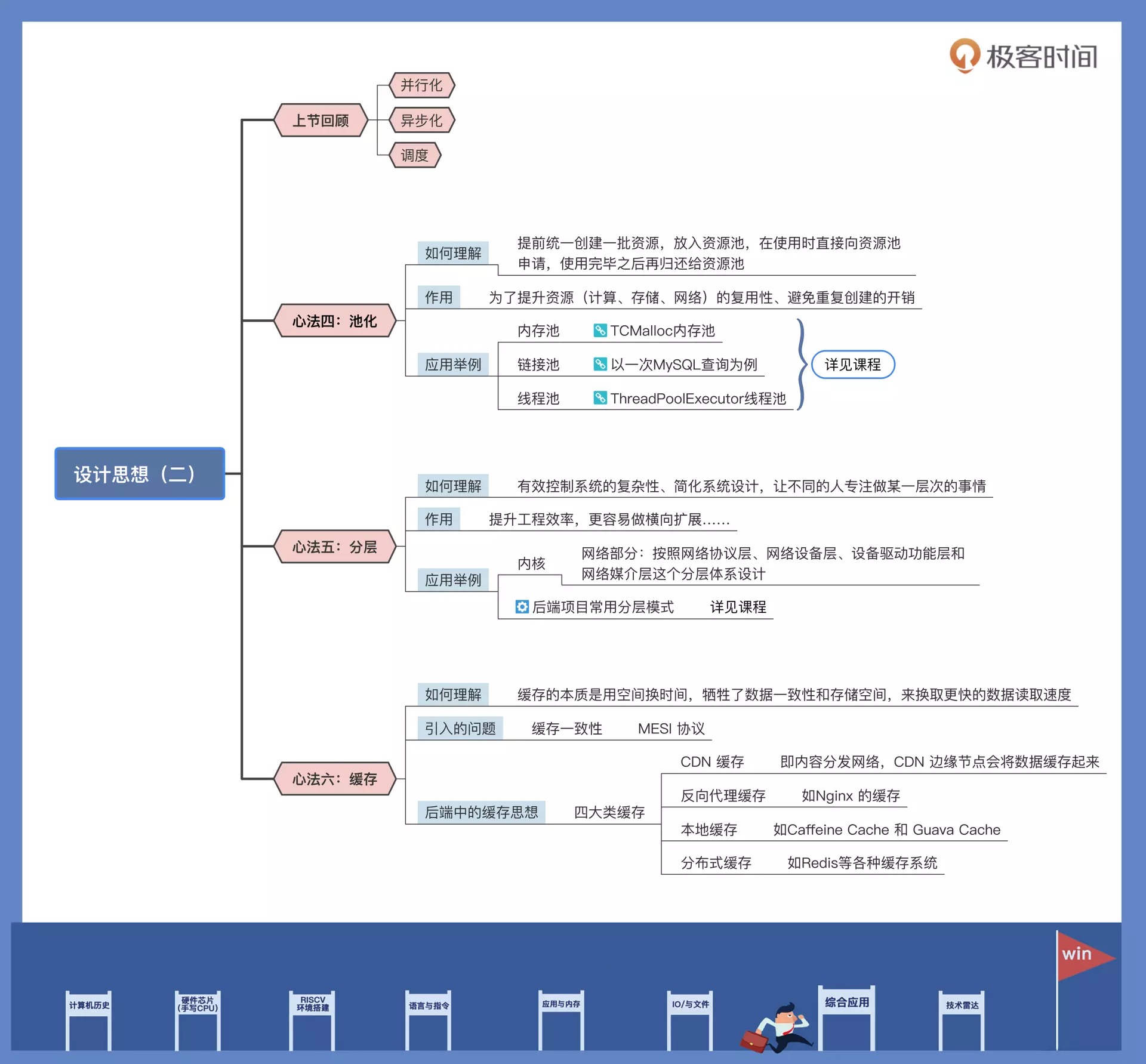
41|内功心法.2: 内核和后端通用的设计思想有哪些¶
42|性能调优: 性能调优工具eBPF和调优方法¶
1992 年伯克利实验室的 Steven McCanne 和 Van Jacobso 为了解决高性能的抓包、分析网络数据包的问题,在 BSD 操作系统上设计出了一种叫做伯克利数据包过滤器(BSD Packet Filter)的机制,并发表了《The BSD Packet Filter:A New Architecture for User-level Packet Capture》这篇论文。这套机制引入了一套只有 2 个 32 位寄存器、16 个内存位和 32 个指令集的轻量级虚拟机,包过滤技术的性能因此提升了 20 多倍。
1997 年的时候,Linux 操作系统从 Linux2.1.75 版本开始,就把 BPF 合并到了内核中了。
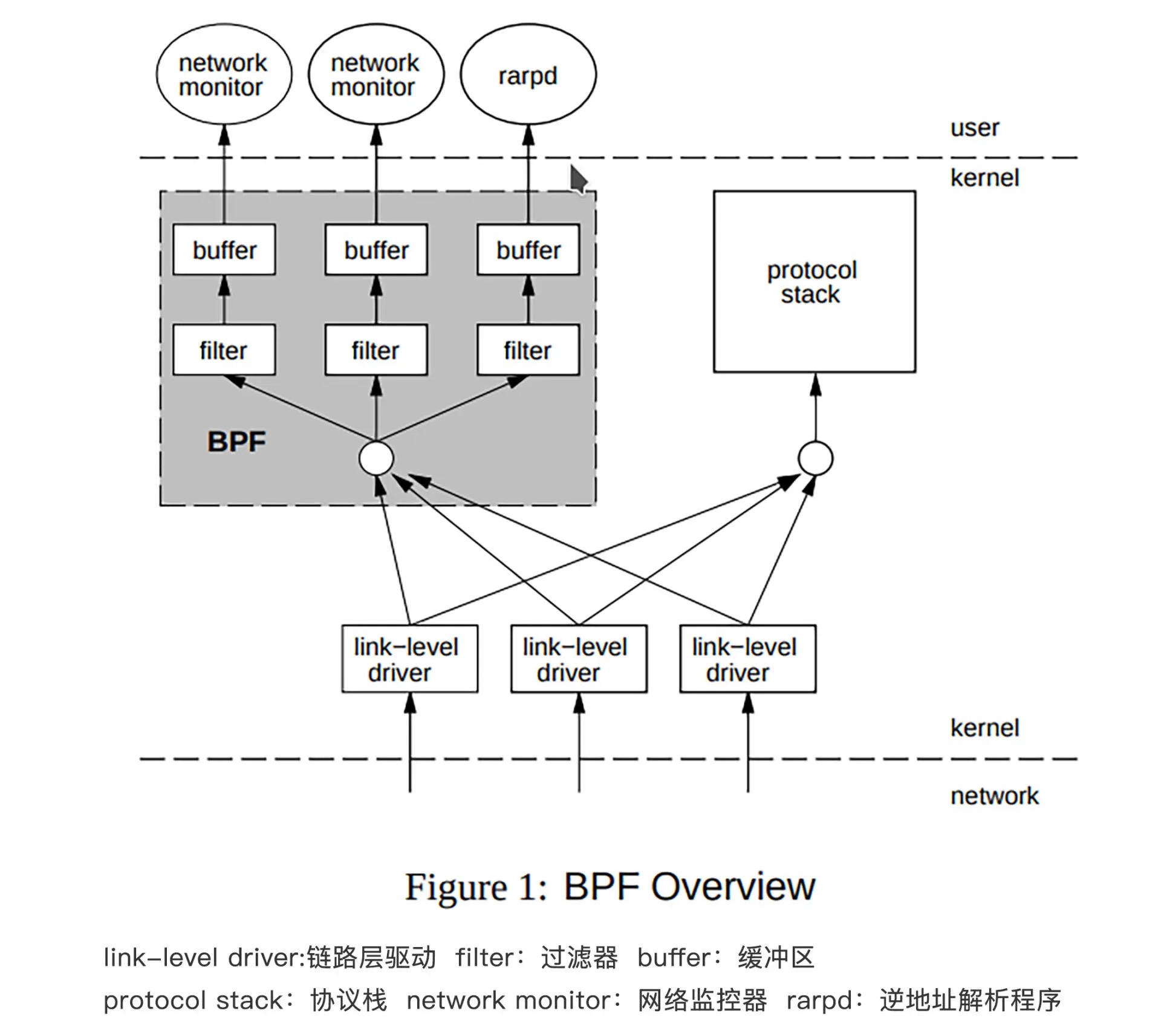
早期的 BPF 的架构¶
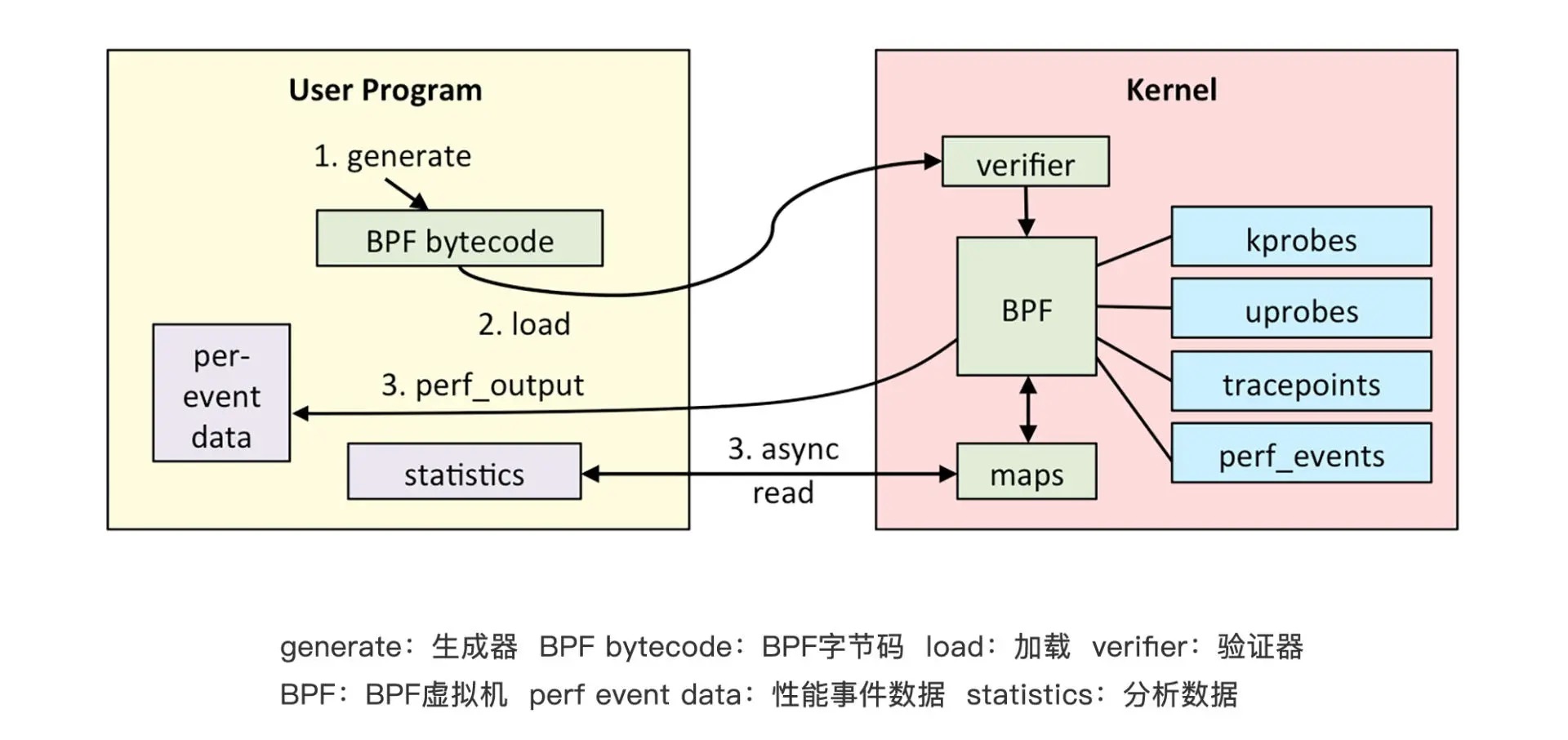
eBPF 的架构简图¶
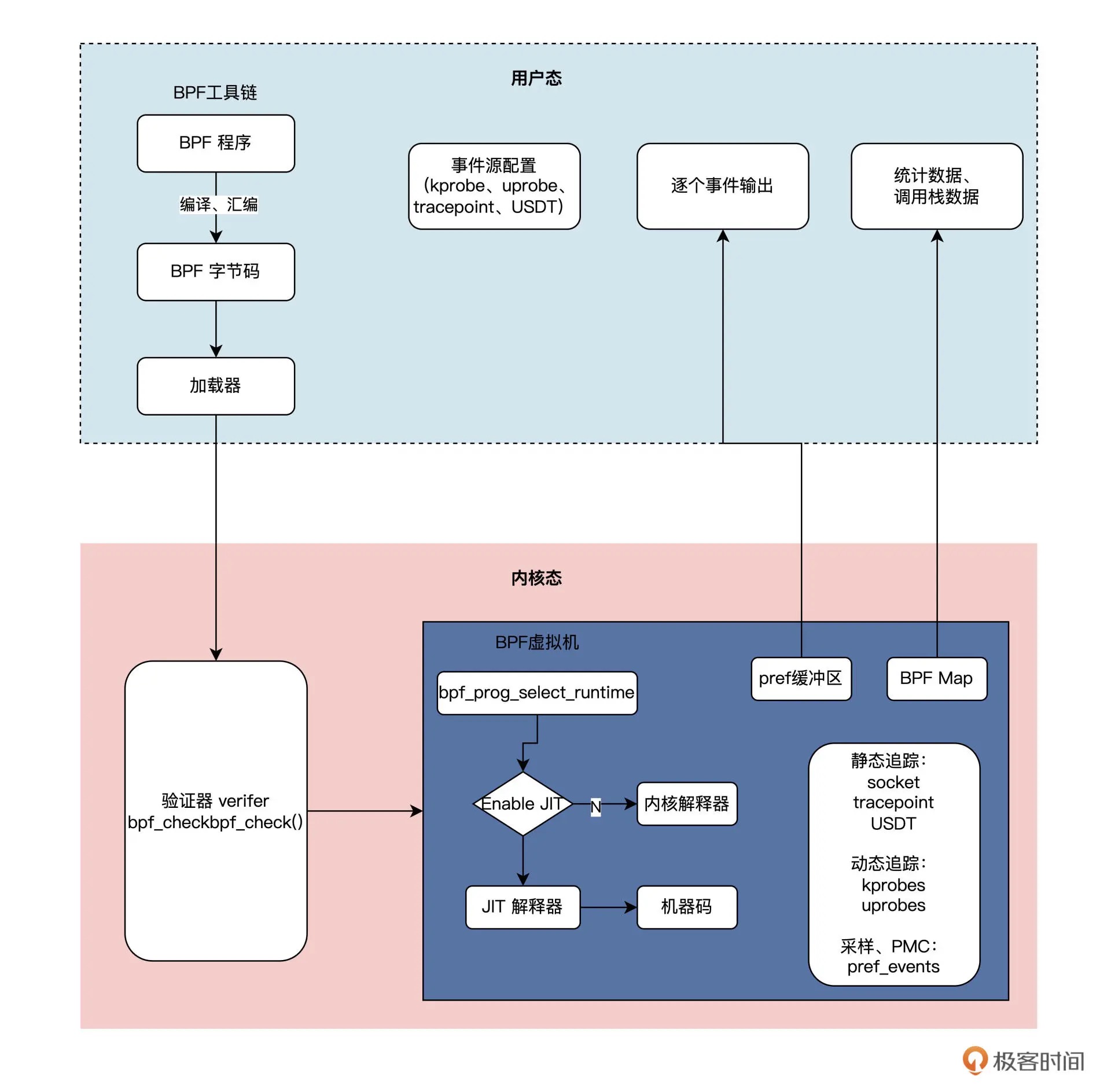
eBPF 整体结构图¶
BPF 程序的类型包括:
1. kprobes:是一种在内核中实现动态追踪的机制,可以跟踪 Linux 内核中的函数入口或返回点,但这套 ABI 接口并不稳定。不同的内核版本的变化带来的 ABI 差异,有可能会导致跟踪失败
2. uprobes:用来实现用户态程序动态追踪的机制。与 kprobes 类似,区别在于跟踪的函数是用户程序中的函数而已
3. tracepoints:内核中的静态跟踪。Tracepoints 是内核开发者维护的 tracepoint,可以提供稳定的 ABI 接口,但是由于开发者维护,数量和场景可能会受到限制
4. perf_events:定时采样处理器中的性能监控计数寄存器(Performance Monitor Counter)
09结束语 (4讲)¶
10技术雷达 (5讲)¶
加餐01|云计算基础:自己动手搭建一款IAAS虚拟化平台¶
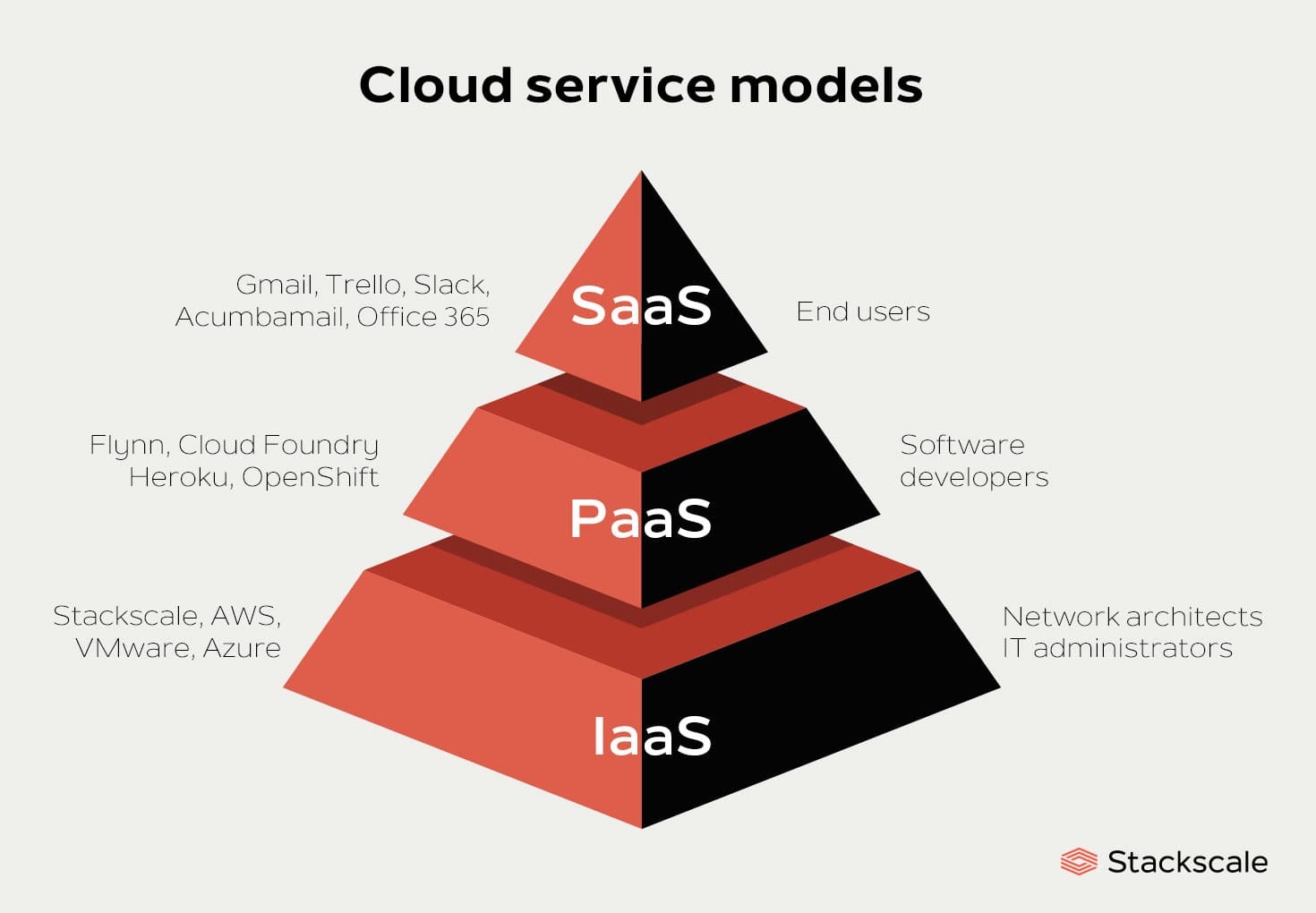
云计算分为三层,分层模型图¶
加餐02 学习攻略.1: 大数据&云计算究竟怎么学¶
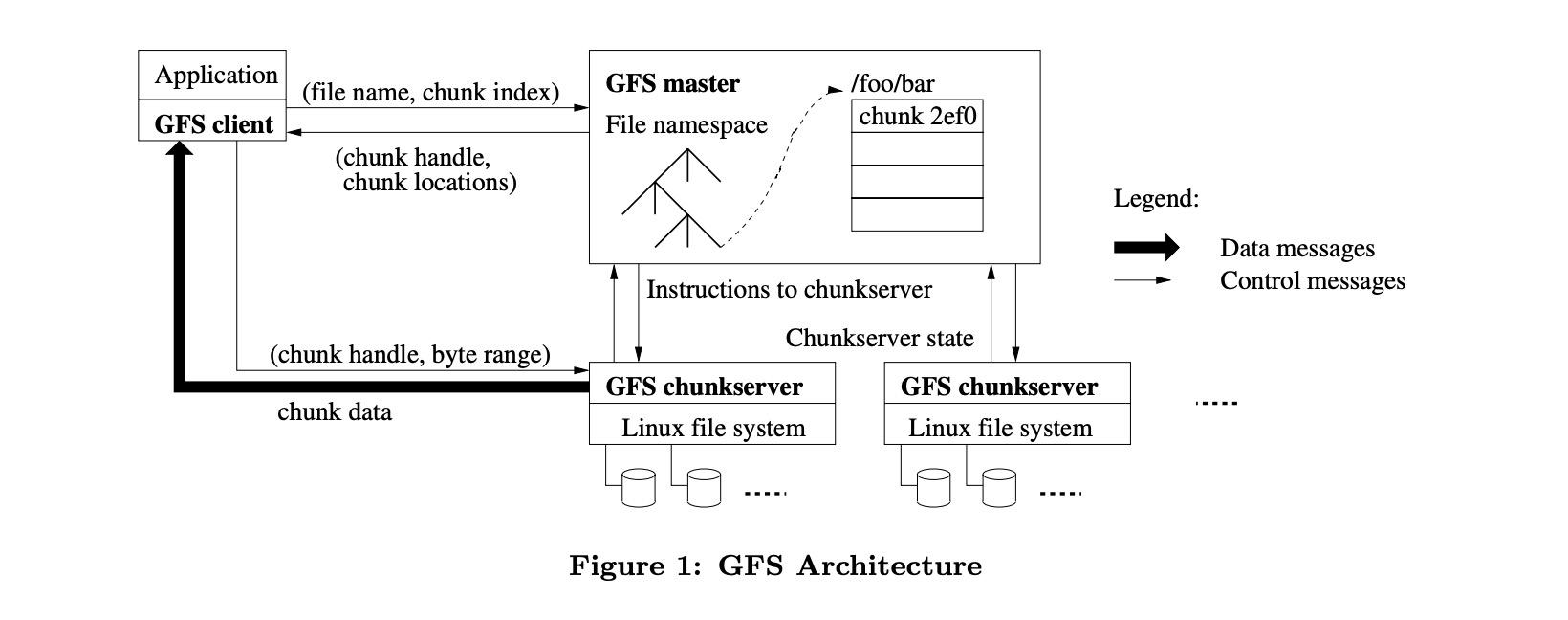
GFS 架构图:是一种分布式文件系统,它为 Google 的大型数据处理应用提供了数据存储和访问功能¶
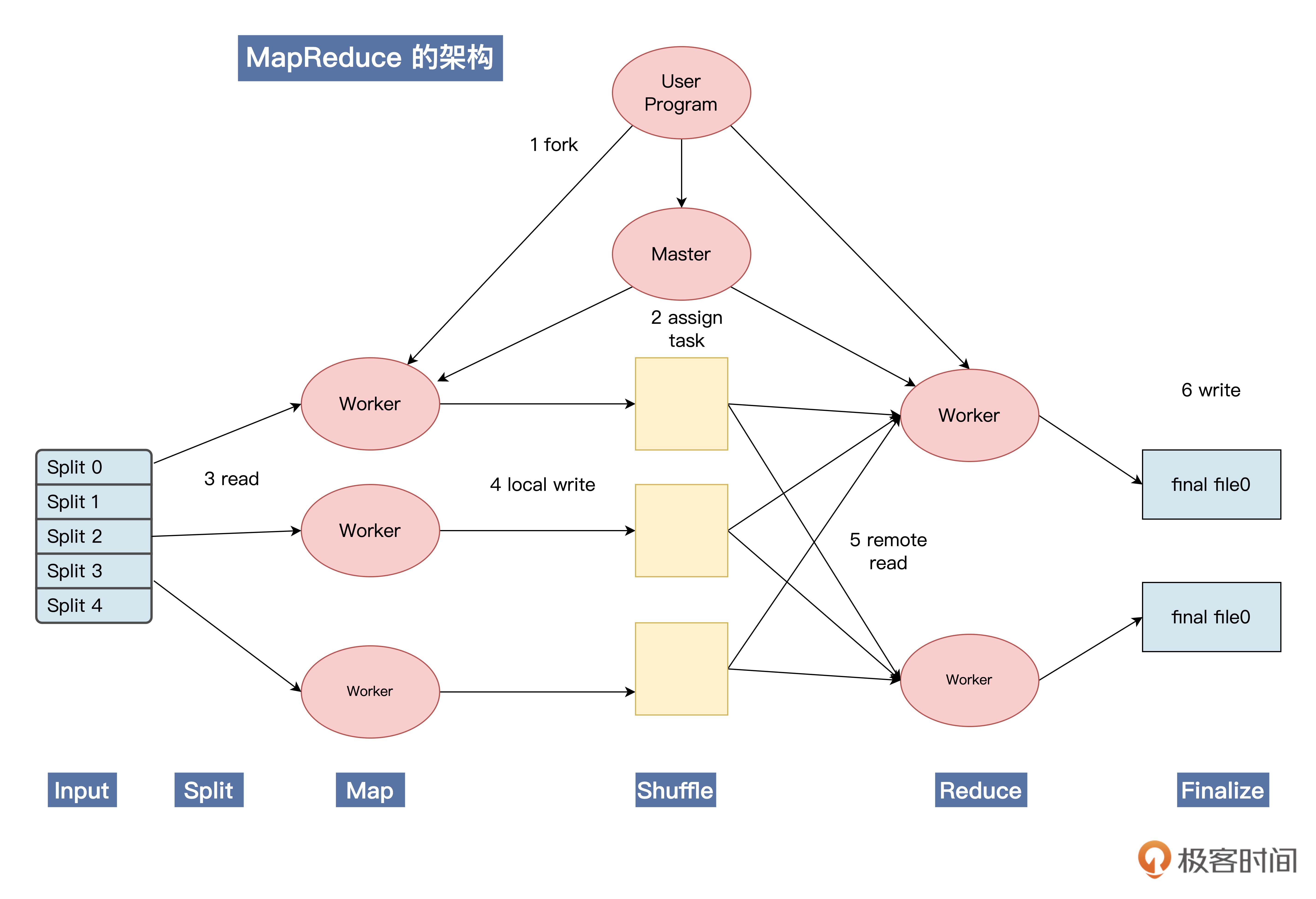
MapReduce 的架构图:一种编程模型,它允许开发人员更方便地处理大量数据¶
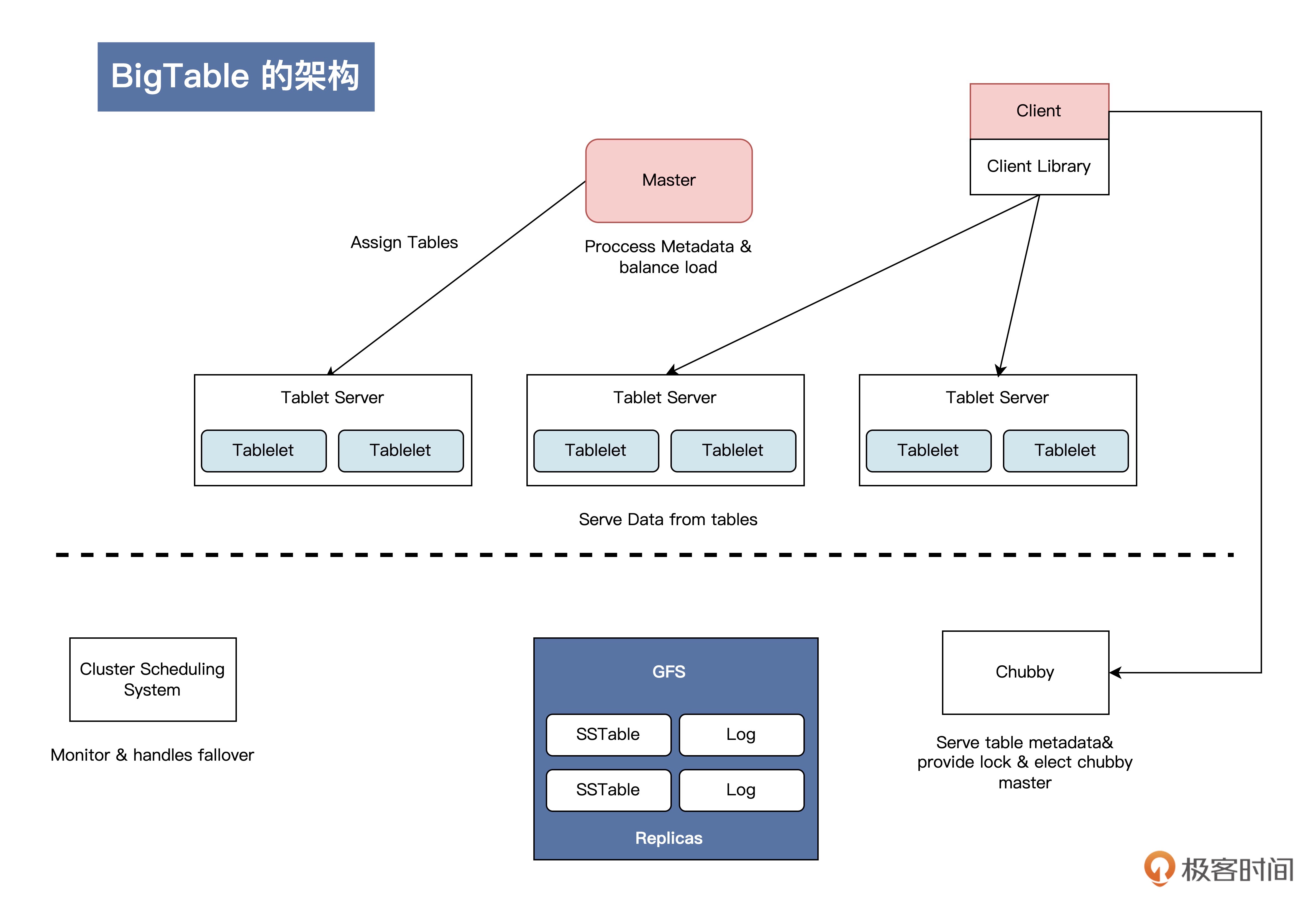
BigTable 架构图:是一种高性能的分布式存储系统,它可以处理海量的结构化数据¶
加餐03|学习攻略.2: 大数据&云计算究竟怎么学¶
HDFS 是 Hadoop 的分布式文件系统,它可以将海量数据分布在集群中的多个节点上进行存储,采用多副本机制保证数据安全。
YARN 是 Hadoop 的资源管理系统,负责调度任务并管理资源。
ZooKeeper 是分布式协调服务,提供分布式锁、队列、通知等功能,常用于分布式系统的配置管理、分布式协调和集群管理。
加餐04|谈谈容器云与和CaaS平台¶
CaaS 平台首先要满足 Kubernetes 集群的基本调度和生命周期管理,这是最基础的能力。CaaS 平台可以自动化完成 Kubernetes 集群的部署、扩容、升级,无需人工操作。通过不同的 IaaS provider 插件,可以将 Kubernetes 集群部署在 IaaS 服务或其他云服务上。
CaaS 平台还要具备 Kubernetes 集群高可用的调度能力,HA deploy 通过部署多 master/etcd 节点实现高可用,当 IaaS 支持高级放置策略时,也支持将 master/etcd 节点放置于不同的节点上,进一步提升可用性。
CaaS 还要提供监控、告警、日志管理、分析、可视化在内的一系列可观测性功能,展示所有 Kubernetes 集群资源消耗的统计数据。
加餐05|分布式微服务与智能SaaS¶
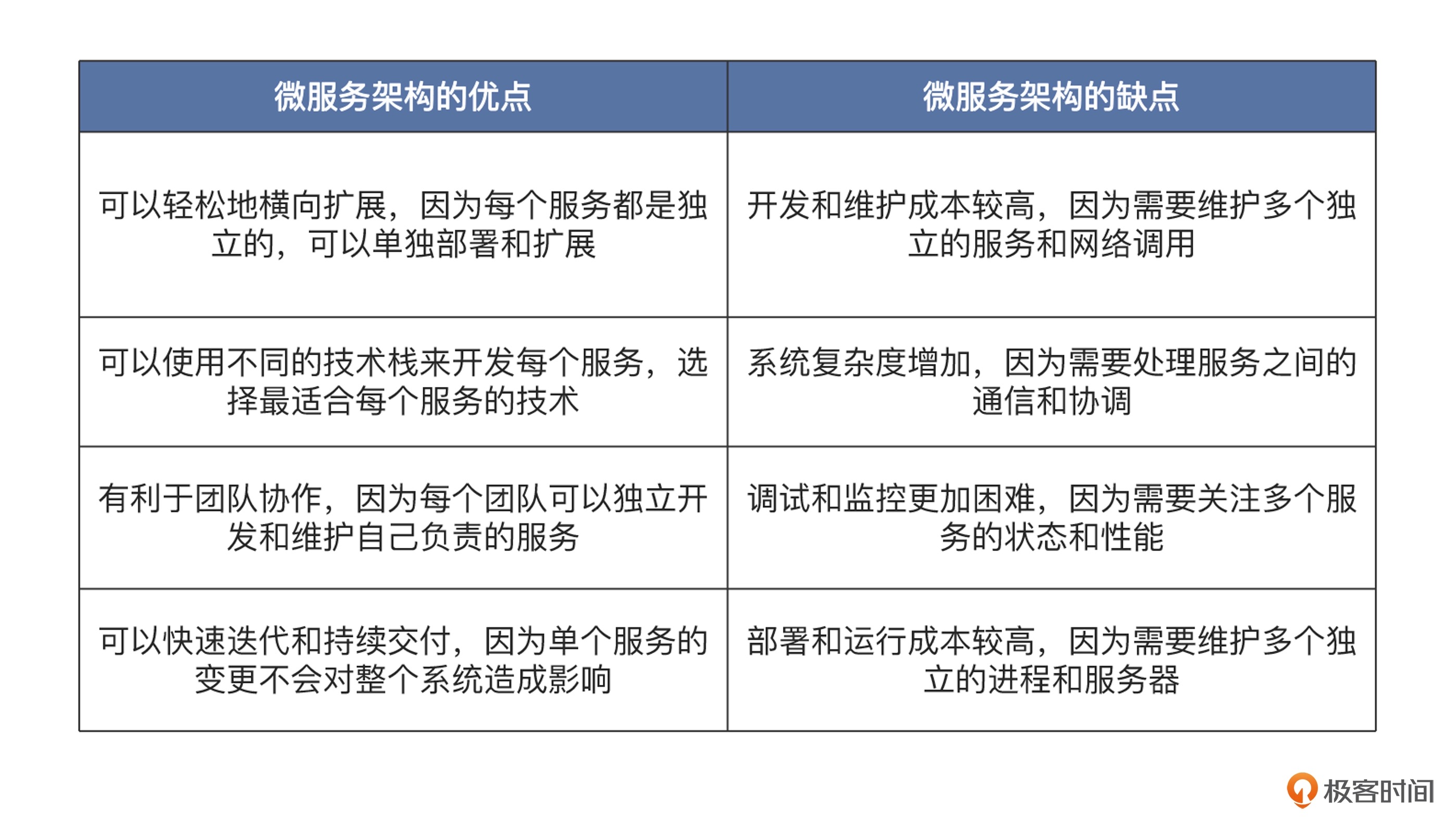
微服务架构优点和缺点¶
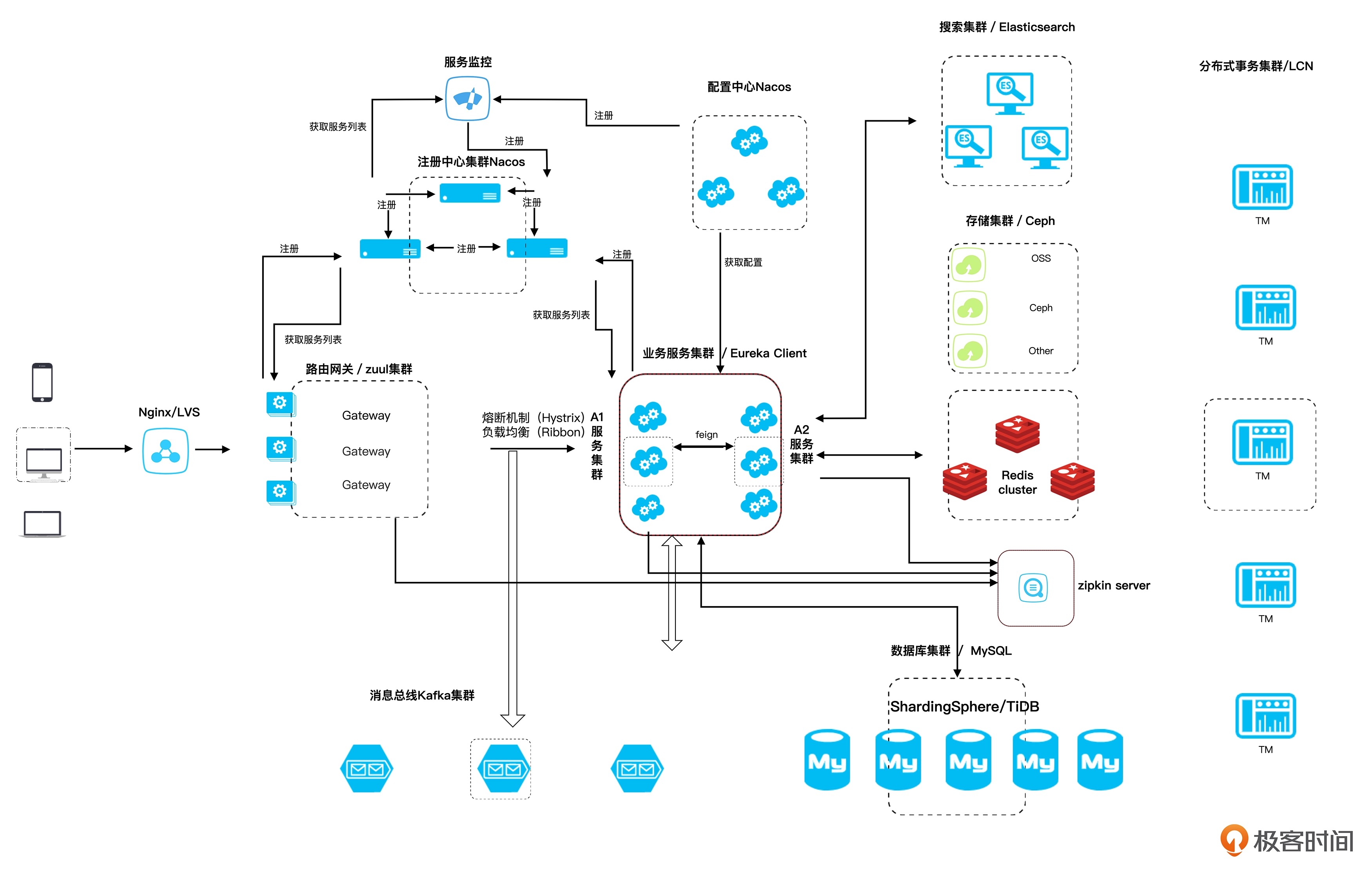
简化版的微服务架构图¶