数据分析实战 45 讲¶
2018-12-17
陈旸
清华大学计算机博士
备注
心得:快速看完
目录
思维导图¶
开篇词 | 你为什么需要数据分析能力¶
备注
学习数据分析的核心就是培养数据思维,掌握挖掘工具,熟练实践并积累经验。
推荐书¶
思维:
《思维简史:从丛林到宇宙》
数据处理:
《数据挖掘:概念与技术》
《Pentaho Kettle 解决方案》
《精益数据分析》
《Small Data》
《利用 Python 进行数据分析》
算法相关书籍¶
《Python数据挖掘与机器学习实战》里面有一些关于sklearn数据集的练习
《白话大数据与机器学习》这本书主要讲算法原理,没有太多实战。想要对原理更深入了解的话可以看看
《利用Python进行数据分析》 这本相对基础,没有太多算法部分,主要是关于Python的使用:数据结构,NumPy,Pandas,数据加载、存储、清洗、规整、可视化等。
《精益数据分析》 这本书是讲业务场景的,里面没有算法的部分,所以如果你想对业务场景有更深刻的理解,可以看下这本
统计学¶
《统计数据会说谎》
实战¶
01基础篇 (16 讲)¶
01 | 数据分析全景图及修炼指南¶
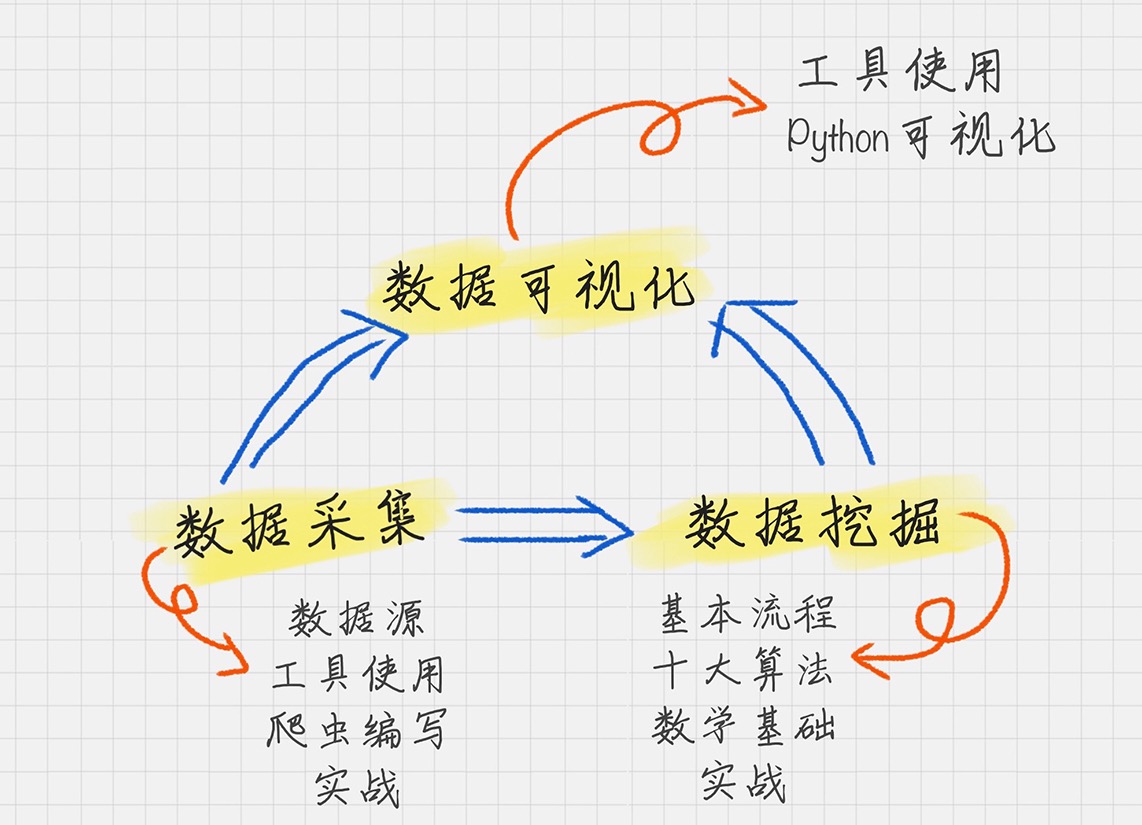
数据分析分成三个重要的组成部分:数据采集、数据挖掘、数据可视化¶
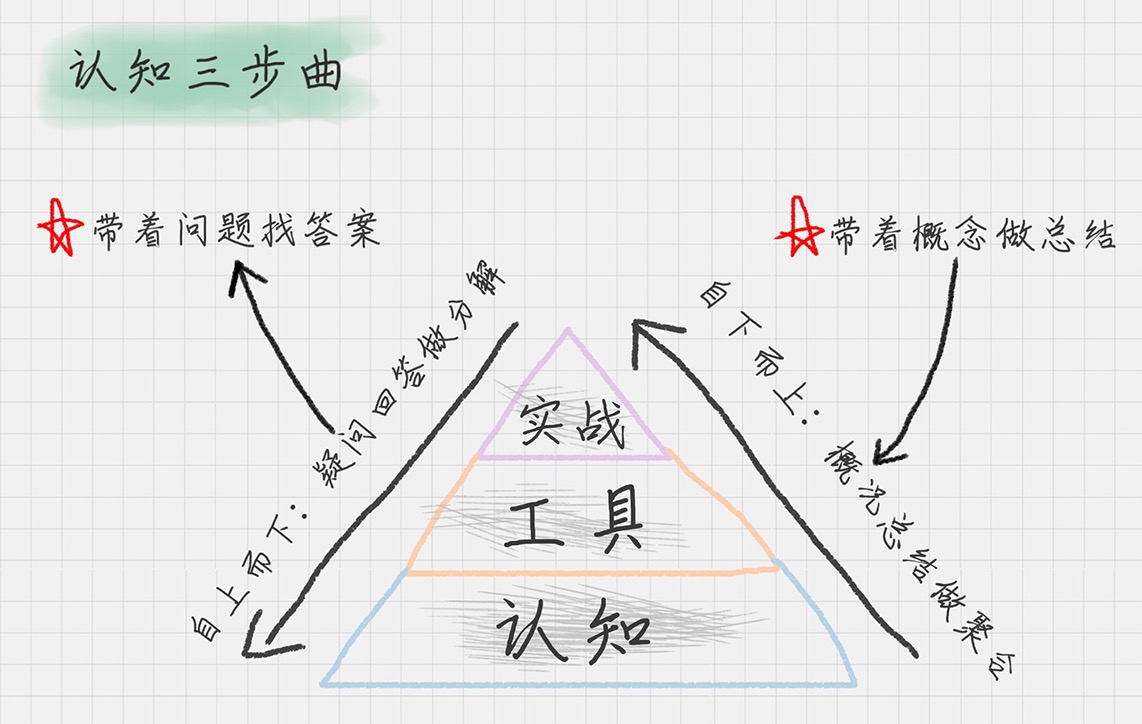
我们只有把知识转化为自己的语言,它才真正变成了我们自己的东西。这个转换的过程,就是认知的过程。¶
02 | 学习数据挖掘的最佳路径¶
数据挖掘的过程可以分成以下 6 个步骤:
1. 商业理解
数据挖掘不是我们的目的,我们的目的是更好地帮助业务
所以第一步我们要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义
2. 数据理解
尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等
这有助于你对收集的数据有个初步的认知
3. 数据准备
开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作
4. 模型建立
选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果
5. 模型评估
对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标
6. 上线发布
模型的作用是从数据中找到金矿,也就是我们所说的 “知识”
获得的知识需要转化成用户可以使用的方式,
呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。
数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要。
国际权威的学术组织 ICDM (the IEEE International Conference on Data Mining)评选出了十大经典的算法:
1. 分类算法
C4.5
朴素贝叶斯(Naive Bayes)
SVM: 支持向量机
KNN: K 最近邻算法
Adaboost
CART: 分类和回归树
2. 聚类算法
K-Means,EM
3. 关联分析
Apriori
4. 连接分析
PageRank
数据挖掘的数学原理:
1. 概率论与数理统计
2. 线性代数
3. 图论
4. 最优化方法
03 | Python 基础语法¶
刷题网站:
online judge
leetcode
pythontip
Kaggel
04 | Python 科学计算-NumPy¶
两个重要的对象:
1. ndarray(N-dimensional array object)解决了多维数组问题
2. ufunc(universal function object)则是解决对数组进行处理的函数
ufunc 函数:
1. 连续数组的创建
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
结果:
[1 3 5 7 9]
[1 3 5 7 9]
2. 算数运算
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
print np.add(x1, x2)
print np.subtract(x1, x2)
print np.multiply(x1, x2)
print np.divide(x1, x2)
print np.power(x1, x2)
print np.remainder(x1, x2)
结果:
[ 2. 6. 10. 14. 18.]
[0. 0. 0. 0. 0.]
[ 1. 9. 25. 49. 81.]
[1. 1. 1. 1. 1.]
[1.00000000e+00 2.70000000e+01 3.12500000e+03 8.23543000e+05
3.87420489e+08]
[0. 0. 0. 0. 0.]
3. 统计函数
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.amin(a)
print np.amin(a,0)
print np.amin(a,1)
print np.amax(a)
print np.amax(a,0)
print np.amax(a,1)
结果:
1
[1 2 3]
[1 4 7]
9
[7 8 9]
[3 6 9]
4. 统计最大值与最小值之差 ptp ()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.ptp(a)
print np.ptp(a,0)
沿着 axis=0 轴的最大值与最小值之差
即 7-1=6(当然 8-2=6,9-3=6,第三行减去第一行的 ptp 差均为 6)
print np.ptp(a,1)
沿着 axis=1 轴的最大值与最小值之差
即 3-1=2(当然 6-4=2, 9-7=2,即第三列与第一列的 ptp 差均为 2)
结果:
8
[6 6 6]
[2 2 2]
5. 统计数组的百分位数 percentile ()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.percentile(a, 50)
print np.percentile(a, 50, axis=0)
print np.percentile(a, 50, axis=1)
结果:
5.0
[4. 5. 6.]
[2. 5. 8.]
6. 统计数组中的中位数 median ()、平均数 mean ()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
#求中位数
print np.median(a)
print np.median(a, axis=0)
print np.median(a, axis=1)
#求平均数
print np.mean(a)
print np.mean(a, axis=0)
print np.mean(a, axis=1)
5.0
[4. 5. 6.]
[2. 5. 8.]
5.0
[4. 5. 6.]
[2. 5. 8.]
7. 统计数组中的加权平均值 average ()
a = np.array([1,2,3,4])
wts = np.array([1,2,3,4])
print np.average(a) // 默认权重
(1+2+3+4)/4=2.5
print np.average(a,weights=wts) // 指定权重数组 wts
(1*1+2*2+3*3+4*4)/(1+2+3+4)=3.0
结果:
2.5
3.0
8. 统计数组中的标准差 std ()、方差 var ()
a = np.array([1,2,3,4])
print np.std(a)
print np.var(a)
结果:
1.118033988749895
1.25
9. NumPy 排序
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
print np.sort(a, axis=None)
print np.sort(a, axis=0)
print np.sort(a, axis=1)
结果:
[[2 3 4]
[1 2 4]]
[1 2 2 3 4 4]
[[2 3 1]
[4 4 2]]
[[2 3 4]
[1 2 4]]
05 | Python 科学计算-Pandas¶
两个核心数据结构:
Series
DataFrame
Series¶
Series 是个定长的字典序列:
两个基本属性:index 和 values
示例-Series:
import pandas as pd
from pandas import Series, DataFrame
x1 = Series([1,2,3,4])
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
d = {'a':1, 'b':2, 'c':3, 'd':4}
x3 = Series(d)
print x1
print x2
print x3
结果:
0 1
1 2
2 3
3 4
dtype: int64
a 1
b 2
c 3
d 4
dtype: int64
a 1
b 2
c 3
d 4
dtype: int64
DataFrame¶
可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
示例-DataFrame:
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
print df1
print df2
结果:
English Math Chinese
ZhangFei 65 30 66
GuanYu 85 98 95
ZhaoYun 92 96 93
HuangZhong 88 77 90
DianWei 90 90 80
删除 DataFrame 中的不必要的列或行:
a. 删除列“语文” df2 = df2.drop(columns=['Chinese']) b. 删除行“张飞” df2 = df2.drop(index=['ZhangFei'])重命名列名 columns,让列表名更容易识别:
把列名 Chinese 改成 YuWen,English 改成 YingYu: df2.rename(columns={'Chinese': 'YuWen', 'English': 'Yingyu'}, inplace = True)去重复的值:
df = df.drop_duplicates() #去除重复行
格式问题:
a. 更改数据格式 df2['Chinese'].astype('str') df2['Chinese'].astype(np.int64) b. 数据间的空格 #删除左右两边空格 df2['Chinese']=df2['Chinese'].map(str.strip) #删除左边空格 df2['Chinese']=df2['Chinese'].map(str.lstrip) #删除右边空格 df2['Chinese']=df2['Chinese'].map(str.rstrip) #删除特殊的符号$ df2['Chinese']=df2['Chinese'].str.strip('$') c. 大小写转换 #全部大写 df2.columns = df2.columns.str.upper() #全部小写 df2.columns = df2.columns.str.lower() #首字母大写 df2.columns = df2.columns.str.title() d. 查找空值 # 哪个地方存在空值 NaN df.isnull () # 哪列存在空值: df.isnull ().any ()
apply 函数是 Pandas 中自由度非常高的函数:
# 对 name 列的数值都进行大写转化
df['name'] = df['name'].apply(str.upper)
# 定义个函数,在 apply 中进行使用
def double_df(x):
return 2*x
df1[u' 语文'] = df1[u' 语文'].apply(double_df)
# 定义更复杂的函数
def plus(df,n,m):
df['new1'] = (df[u' 语文']+df[u' 英语']) * m
df['new2'] = (df[u' 语文']+df[u' 英语']) * n
return df
df1 = df1.apply(plus,axis=1,args=(2,3,))
说明:
axis=1 代表按照列为轴进行操作
args 是传递的两个参数,即 n=2, m=3(在 plus 函数中使用到了 n 和 m,从而生成新的 df)
数据表合并¶
基本数据:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
基于指定列进行连接:
# 基于 name 这列进行连接 df3 = pd.merge(df1, df2, on='name')
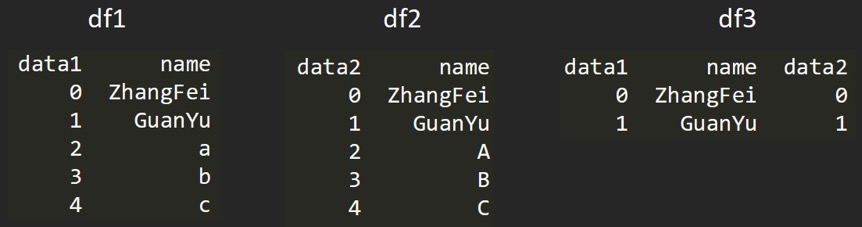
inner 内连接:
# 合并的默认情况 # df1, df2 相同的键是 name所以结果同上
left 左连接:
df3 = pd.merge(df1, df2, how='left')
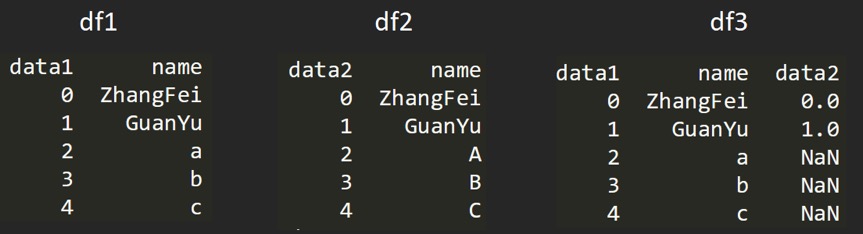
right 右连接:
df3 = pd.merge(df1, df2, how='right')
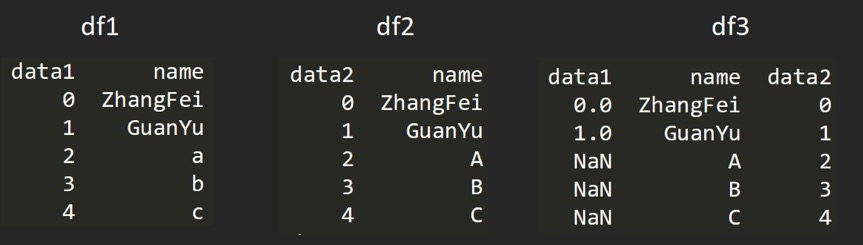
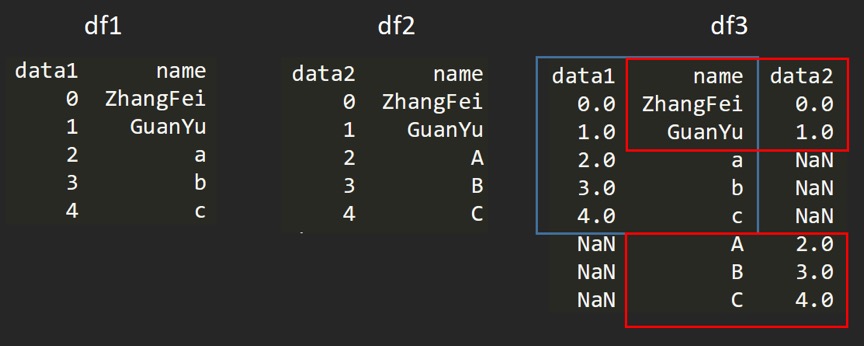
outer 外连接:
df3 = pd.merge(df1, df2, how='outer')
06 | 学数据分析要掌握哪些基本概念¶
三个重要的概念:
1. 商业智能
2. 数据仓库
3. 数据挖掘
07 | 用户画像: 标签化就是数据的抽象能力¶
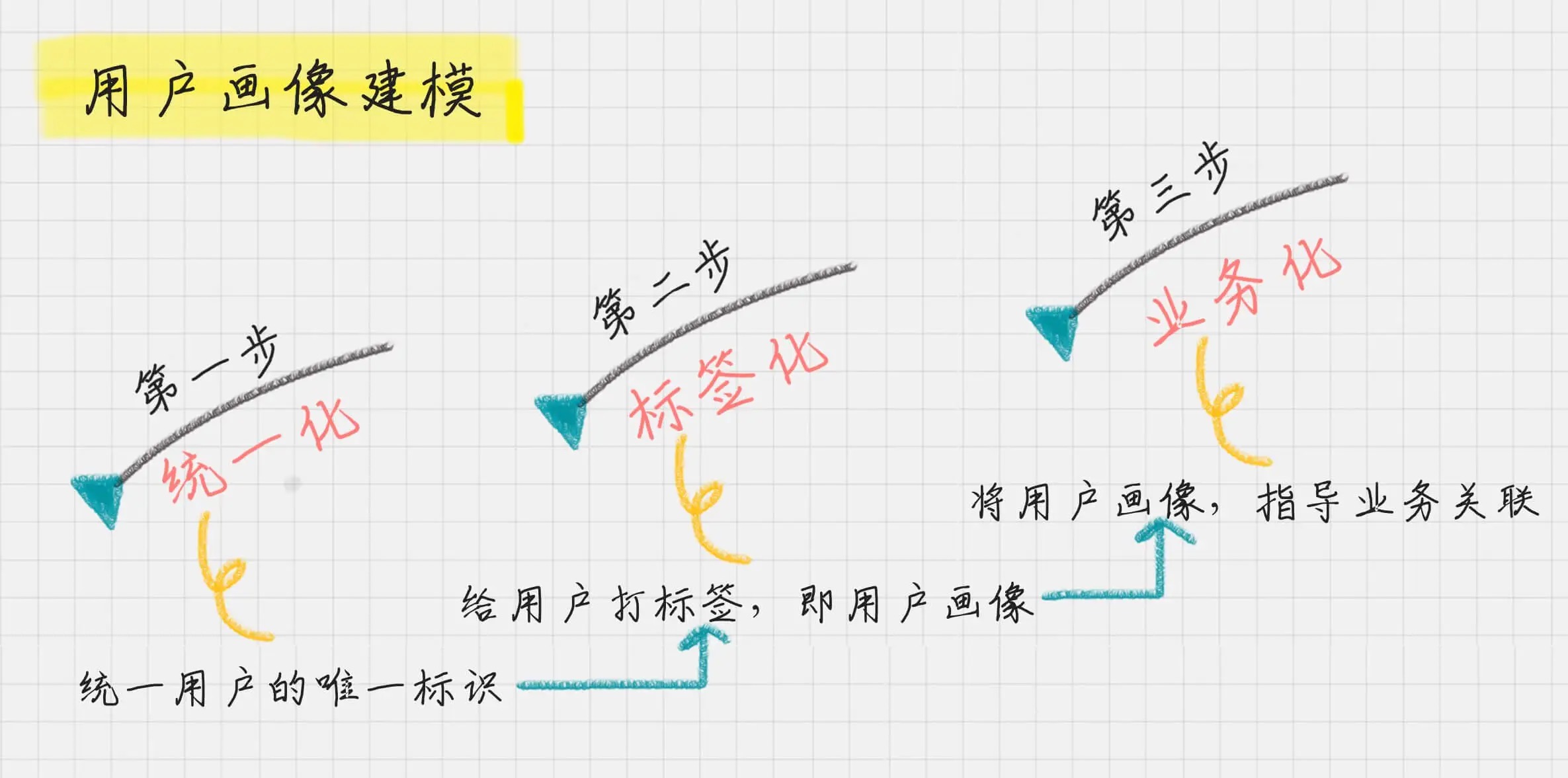
首先,确定唯一标识;其次,给用户打标签;分析业务价值¶
用户画像标签分类-“用户消费行为分析” 的准则:
1. 用户标签
包括了性别、年龄、地域、收入、学历、职业等
这些包括了用户的基础属性。
2. 消费标签
消费习惯、购买意向、是否对促销敏感
这些统计分析用户的消费习惯。
3. 行为标签
时间段、频次、时长、访问路径
这些是通过分析用户行为,来得到他们使用 App 的习惯。
4. 内容分析
对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,分析出用户对哪些内容感兴趣,
比如,金融、娱乐、教育、体育、时尚、科技等。
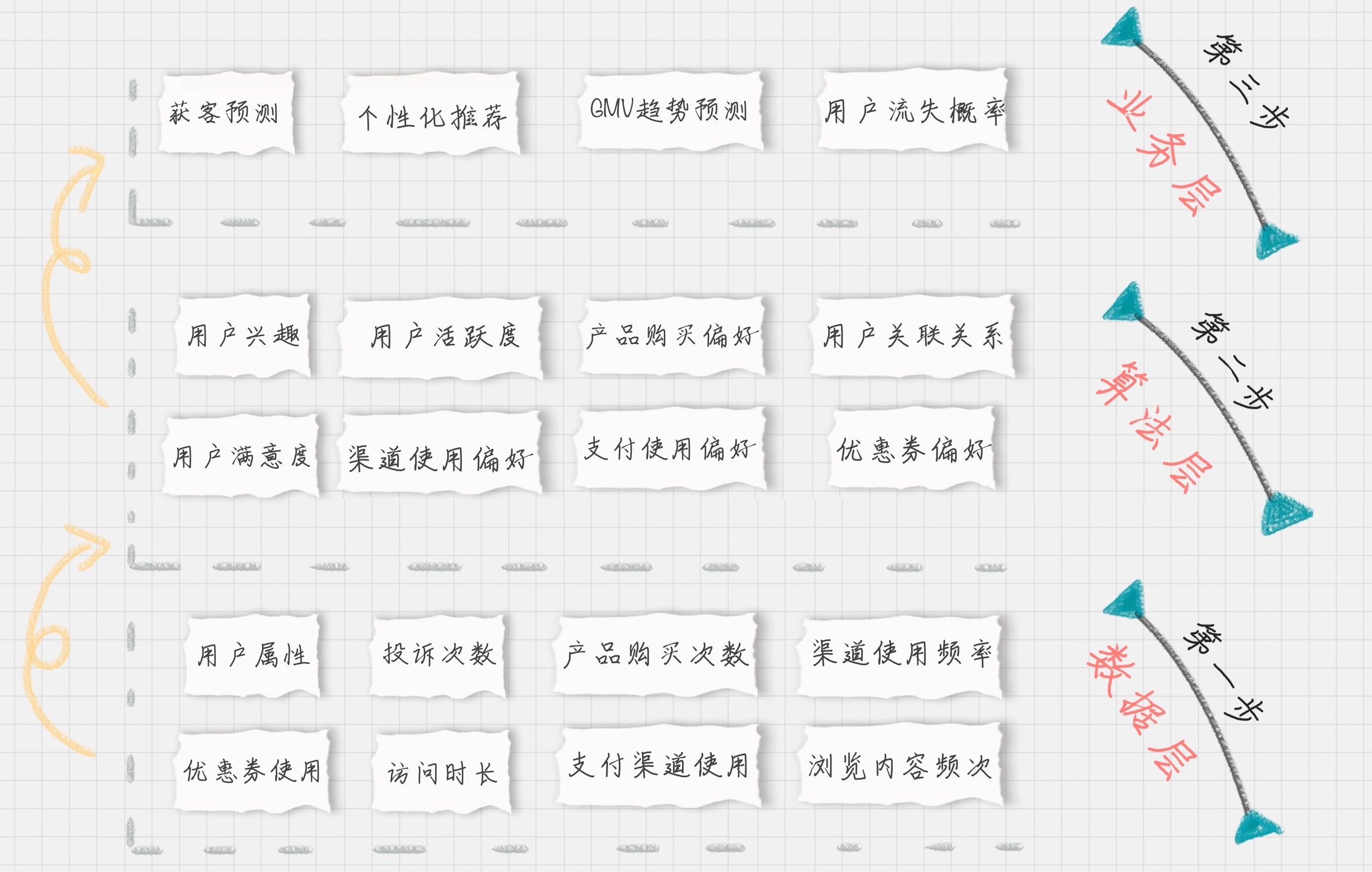
按照数据流处理的阶段来划分用户画像建模的过程,可以分为数据层、算法层和业务层。¶
08 | 数据采集: 如何自动化采集数据¶
四类数据源:
1. 开放数据源
一般是针对行业的数据库
如美国人口调查局开放了美国的人口信息、地区分布和教育情况数据。
除了政府外,企业和高校也会开放相应的大数据
2. 爬虫抓取
3. 传感器
图像、视频、或者某个物体的速度、热度、压强等
4. 日志采集
Python 爬虫利器:
Requests、XPath、Pandas
Selenium,PhantomJS
Puppeteer(可以控制 Headless Chrome)
与 Selenium 相比,Puppeteer 直接调用 Chrome 的 API 接口,不需要打开浏览器,直接在 V8 引擎中处理
同时这个组件是由 Google 的 Chrome 团队维护的,所以兼容性会很好
09|数据采集工具-八爪鱼¶
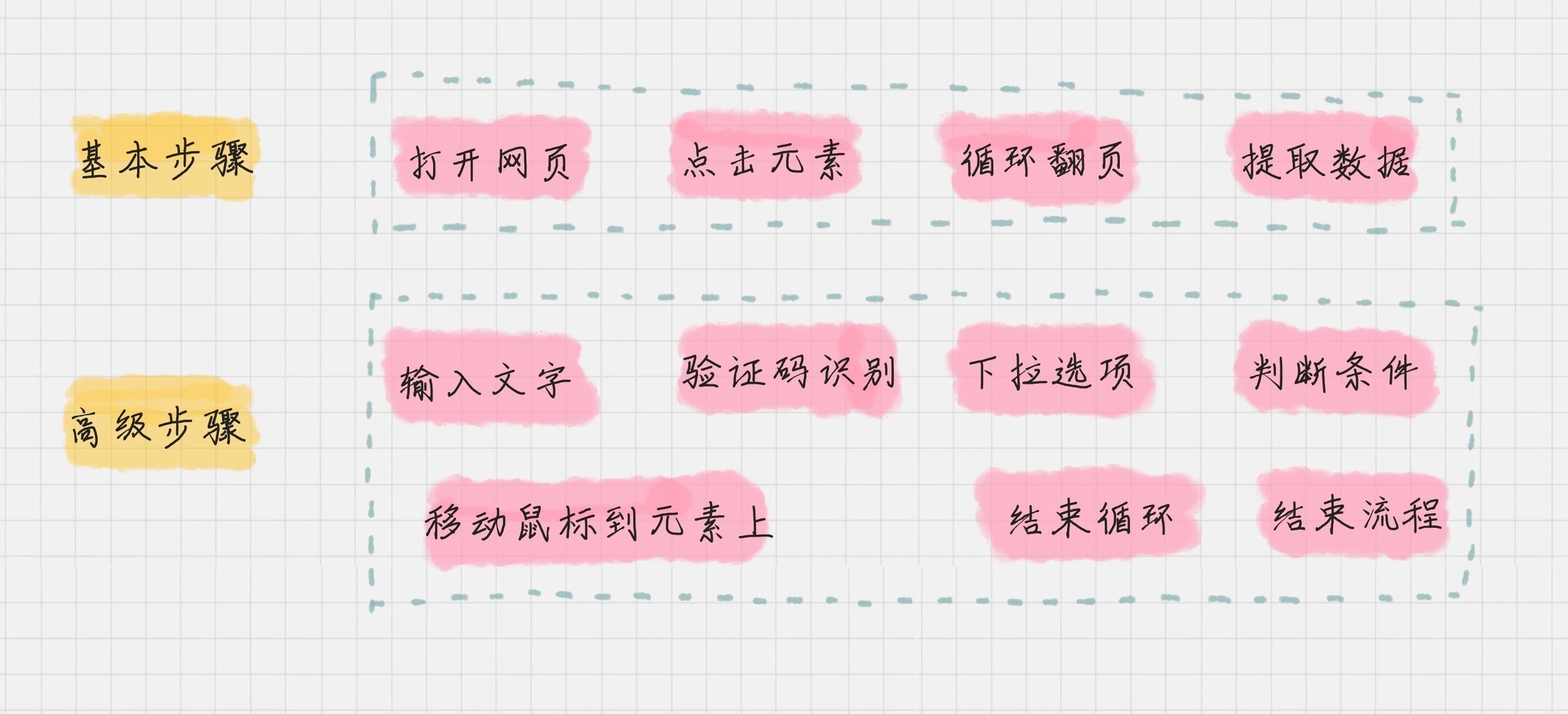
八爪鱼的流程步骤有两类,可以划分为基本步骤和高级步骤。¶
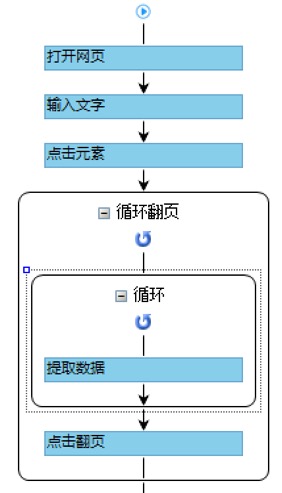
八爪鱼流程视图¶
10|Python爬虫¶
爬虫的流程:
1. 打开网页
2. 提取数据
3. 保存数据
11 | 数据清洗: 占据80%的处理时间¶
备注
数据科学家80%的时间都花在数据处理上
数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”:
1. 完整性
单条数据是否存在空值,统计的字段是否完善
2. 全面性
观察某一列的全部数值
比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。
可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身
3. 合法性
数据的类型、内容、大小的合法性
比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等
4. 唯一性
数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的
行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次
完整性:
问题 1:缺失值 常见的三种操作: 删除:删除数据缺失的记录 均值:使用当前列的均值 高频:使用当前列出现频率最高的数据 例: 用平均年龄进行填充 df['Age'].fillna(df['Age'].mean(), inplace=True) 例: 用高频年龄填充 age_maxf = train_features['Age'].value_counts().index[0] train_features['Age'].fillna(age_maxf, inplace=True) 问题 2:空行 # 删除全空的行 df.dropna(how='all',inplace=True)全面性:
问题:列数据的单位不统一 统一的度量单位,将磅(lbs)转化为千克(kgs) # 获取 weight 数据列中单位为 lbs 的数据 rows_with_lbs = df['weight'].str.contains('lbs').fillna(False) print df[rows_with_lbs] # 将 lbs转换为 kgs, 2.2lbs=1kgs for i,lbs_row in df[rows_with_lbs].iterrows(): # 截取从头开始到倒数第三个字符之前,即去掉lbs weight = int(float(lbs_row['weight'][:-3])/2.2) df.at[i,'weight'] = '{}kgs'.format(weight)合理性:
问题:非 ASCII 字符 # 删除非 ASCII 字符 df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True) df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)唯一性:
问题 1:一列有多个参数 # 切分名字,删除源数据列 df[['first_name','last_name']] = df['name'].str.split(expand=True) df.drop('name', axis=1, inplace=True) 问题 2:重复数据 # 删除重复数据行 df.drop_duplicates(['first_name','last_name'],inplace=True)
12 | 数据集成¶
数据集成就是将多个数据源合并存放在一个数据存储中(如数据仓库),从而方便后续的数据挖掘工作。
数据集成的两种架构:
ELT: 提取 (Extract)——加载 (Load)——变换 (Transform)
ETL: 提取 (Extract)——转换 (Transform)——加载 (Load)
13 | 数据变换¶
备注
数据变换是数据准备的重要环节,它通过数据平滑、数据聚集、数据概化和规范化等方式将数据转换成适用于数据挖掘的形式。
常见的变换方法:
1. 数据平滑
去除数据中的噪声,将连续数据离散化。
这里可以采用分箱、聚类和回归的方式进行数据平滑
2. 数据聚集
对数据进行汇总
如 Max () 反馈某个字段的数值最大值,Sum () 返回某个字段的数值总和
3. 数据概化
将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。
比如说上海、杭州、深圳、北京可以概化为中国。
4. 数据规范化
使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中
常用的方法有:
最小 — 最大规范化
Z—score 规范化
按小数定标规范化
5. 属性构造
构造出新的属性并添加到属性集中
这里会用到特征工程的知识,因为通过属性与属性的连接构造新的属性,其实就是特征工程
比如说,数据表中统计每个人的英语、语文和数学成绩,你可以构造一个 “总和” 这个属性,来作为新属性
数据规范化的几种方法:
1. Min-max 规范化
Min-max 规范化方法是将原始数据变换到 [0,1] 的空间中
新数值 =(原数值 - 极小值)/(极大值 - 极小值)
2. Z-Score 规范化
新数值 =(原数值 - 均值)/ 标准差
优点:
算法简单,不受数据量级影响,结果易于比较
不足:
需要数据整体的平均值和方差,而且结果没有实际意义,只是用于比较
3. 小数定标规范化
通过移动小数点的位置来进行规范化
示例-SciKit-Learn 库:
1. Min-max 规范化
# 初始化数据,每一行表示一个样本,每一列表示一个特征
from sklearn import preprocessing
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行 [0,1] 规范化
# 新数值 =(原数值 - 极小值)/(极大值 - 极小值)
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print minmax_x
结果:
[[0. 0. 0.66666667]
[1. 1. 1. ]
[0. 1. 0. ]]
2. Z-Score 规范化
# 初始化数据
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行 Z-Score 规范化
# 每行每列的值减去了平均值,再除以方差
scaled_x = preprocessing.scale(x)
print scaled_x
结果:
[[-0.70710678 -1.41421356 0.26726124]
[ 1.41421356 0.70710678 1.06904497]
[-0.70710678 0.70710678 -1.33630621]]
3. 小数定标规范化
# 初始化数据
x = np.array([[ 0., -3., 1.],
[ 3., 1., 2.],
[ 0., 1., -1.]])
# 小数定标规范化
j = np.ceil(np.log10(np.max(abs(x))))
scaled_x = x/(10**j)
print scaled_x
结果:
[[ 0. -0.3 0.1]
[ 0.3 0.1 0.2]
[ 0. 0.1 -0.1]]
14 | 数据可视化¶
可视化视图超过 20 种:
文本表、热力图、地图、符号地图、饼图、
水平条、堆叠条、并排条、树状图、圆视图、并排圆、
线、双线、面积图、双组合、散点图、直方图、
盒须图、甘特图、靶心图、气泡图
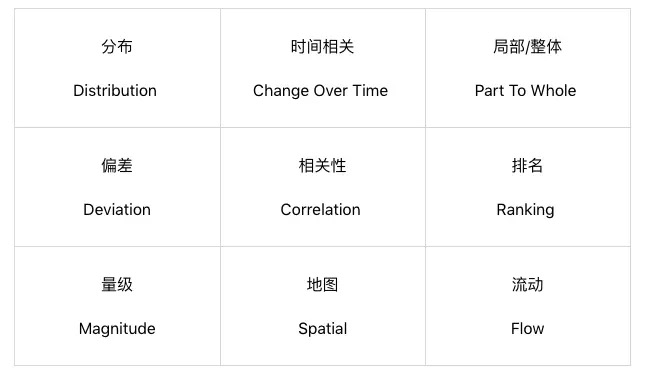
可视化视力的9种目的¶
15 | Python数据可视化的10种技能¶
可视化视图划分为 4 类:
1. 比较
比较数据间各类别的关系,或者是它们随着时间的变化趋势
比如折线图
2. 联系
查看两个或两个以上变量之间的关系
比如散点图
3. 构成
每个部分占整体的百分比,或者是随着时间的百分比变化
比如饼图
4. 分布
关注单个变量,或者多个变量的分布情况
比如直方图
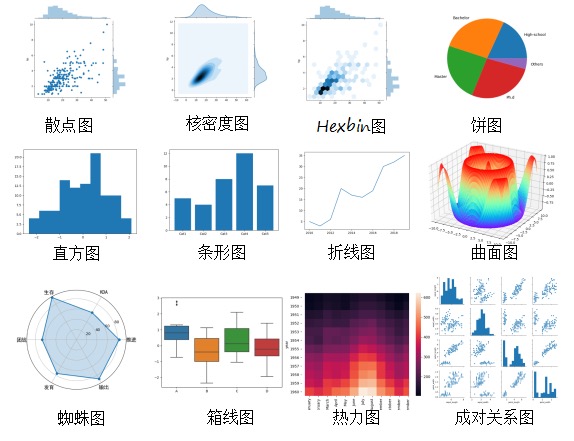
常用的10种视图,这些视图包括了散点图、折线图、直方图、条形图、箱线图、饼图、热力图、蜘蛛图、二元变量分布和成对关系。¶
备注
Matplotlib和Seaborn之间的关系就相当于 NumPy 和 Pandas 的关系。Seaborn 是基于 Matplotlib 更加高级的可视化库。
16 | 数据分析基础篇答疑¶
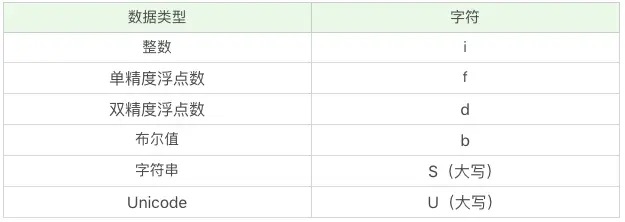
numpy 中的字符编码来表示数据类型的定义,比如 i 代表整数,f 代表单精度浮点数,S 代表字符串,S32 代表的是 32 个字符的字符串¶
02算法篇 (20 讲)¶
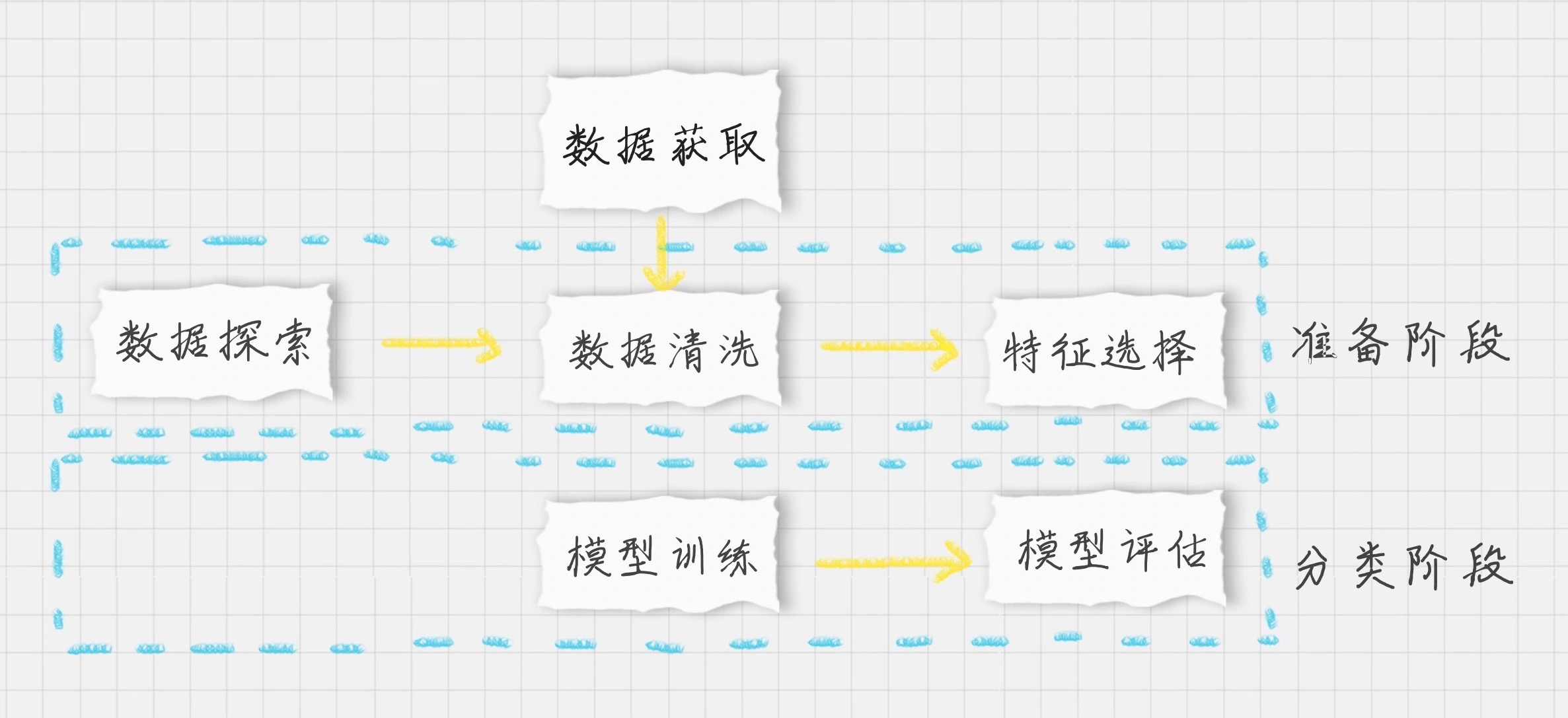
这个图很重要:所有的数据分析流程都可以参照这个图¶
17 | 决策树-ID3 和 C4.5¶
概念:
纯度、信息熵
信息增益、信息增益率
18 | 决策树-CART: 回归树/分类树¶
分类树是基于基尼系数做判断
回归树是基于偏差做判断
19 | 决策树-实战¶
基于决策树还诞生了很多数据挖掘算法,比如随机森林(Random forest)
模块 1:数据探索:
使用 info () 了解数据表的基本情况:行数、列数、每列的数据类型、数据完整度
使用 describe () 了解数据表的统计情况:总数、平均值、标准差、最小值、最大值等
使用 describe (include=[‘O’]) 查看字符串类型(非数字)的整体情况
使用 head 查看前几行数据(默认是前 5 行)
使用 tail 查看后几行数据(默认是最后 5 行)
模块 2:数据清洗:
补齐数据
模块 3:特征选择:
特征选择是分类器的关键
特征选择不同,得到的分类器也不同
模块 4:决策树模型:
a. 构造 ID3 决策树
b. 决策树训练
模块 5:模型预测 & 评估:
K 折交叉验证的原理是这样的:
a. 将数据集平均分割成 K 个等份
b. 使用 1 份数据作为测试数据,其余作为训练数据
c. 计算测试准确率
d. 使用不同的测试集,重复 2、3 步骤
模块 6:决策树可视化
20 | 朴素贝叶斯分类-原理¶
备注
朴素贝叶斯。它是一种简单但极为强大的预测建模算法。之所以称为朴素贝叶斯,是因为它假设每个输入变量是独立的。这是一个强硬的假设,实际情况并不一定,但是这项技术对于绝大部分的复杂问题仍然非常有效。
先验概率:通过经验来判断事情发生的概率,比如说“贝叶死”的发病率是万分之一,就是先验概率。再比如南方的梅雨季是 6-7 月,就是通过往年的气候总结出来的经验,这个时候下雨的概率就比其他时间高出很多。
后验概率:后验概率就是发生结果之后,推测原因的概率。比如说某人查出来了患有“贝叶死”,那么患病的原因可能是 A、B 或 C。患有“贝叶死”是因为原因 A 的概率就是后验概率。它是属于条件概率的一种。
条件概率:事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为 P(A|B),读作“在 B 发生的条件下 A 发生的概率”。比如原因 A 的条件下,患有“贝叶死”的概率,就是条件概率。
似然函数(likelihood function):把概率模型的训练过程理解为求参数估计的过程。
实际上贝叶斯原理就是求解后验概率
朴素贝叶斯模型由两种类型的概率组成:
1. 每个类别的概率P(Cj)
2. 每个属性的条件概率P(Ai|Cj)
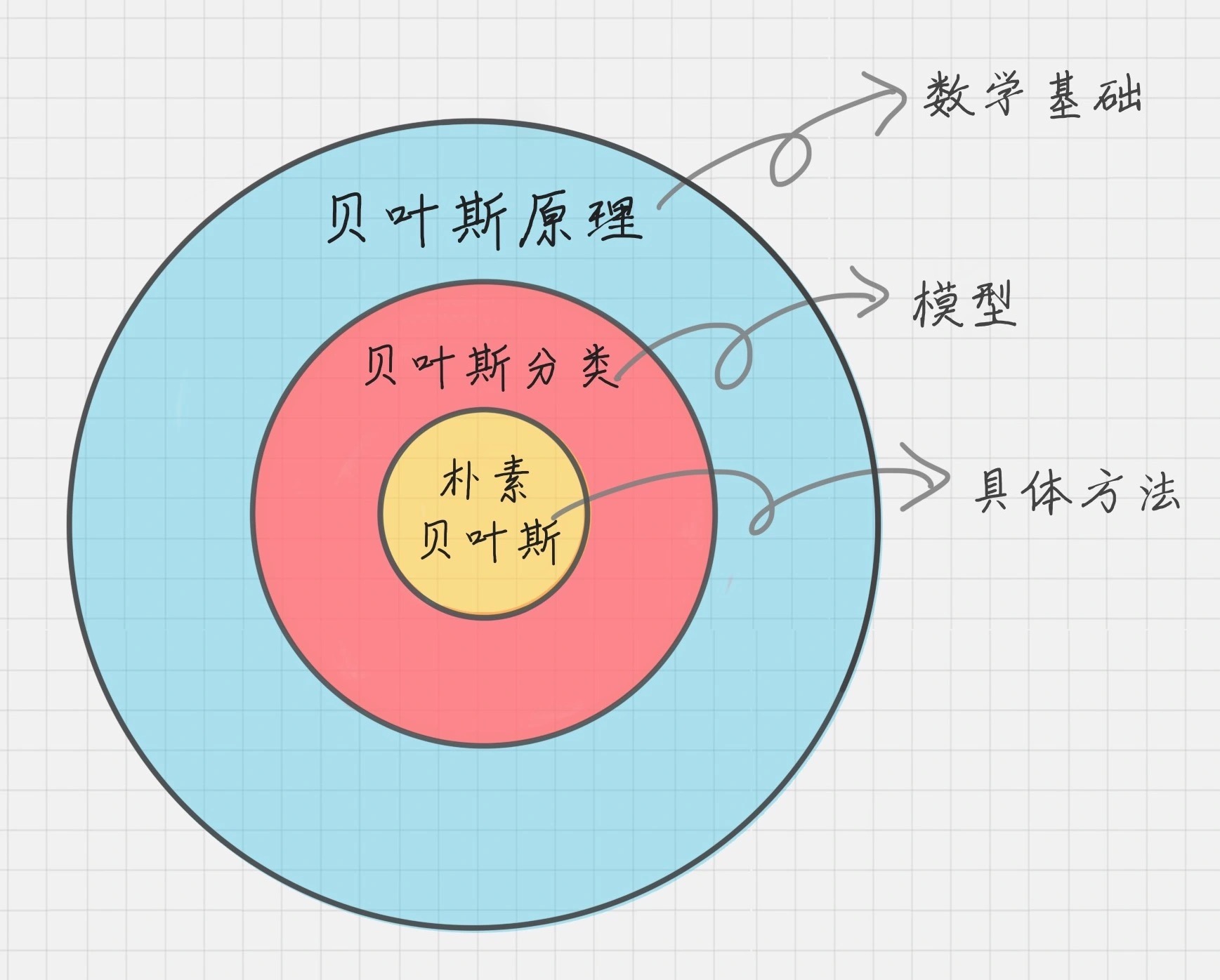
贝叶斯原理、贝叶斯分类和朴素贝叶斯:贝叶斯原理是最大的概念,它解决了概率论中“逆向概率”的问题,在这个理论基础上,人们设计出了贝叶斯分类器,朴素贝叶斯分类是贝叶斯分类器中的一种,也是最简单,最常用的分类器。朴素贝叶斯之所以朴素是因为它假设属性是相互独立的,因此对实际情况有所约束,如果属性之间存在关联,分类准确率会降低。不过好在对于大部分情况下,朴素贝叶斯的分类效果都不错。¶
21 | 朴素贝叶斯分类-实操¶
朴素贝叶斯分类最适合的场景就是文本分类、情感分析和垃圾邮件识别。
3 个朴素贝叶斯分类算法:
1. 高斯朴素贝叶斯(GaussianNB)
特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
2. 多项式朴素贝叶斯(MultinomialNB)
特征变量是离散变量,符合多项分布
在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
3. 伯努利朴素贝叶斯(BernoulliNB)
特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现
22|SVM-原理¶
SVM 最主要的思想就是硬间隔、软间隔和核函数
硬间接,就是完美数据下的完美情况,分出完美类
软间隔,就是中间总有杂质,情况总是复杂,分类总是有一点错误
核函数,高纬度打低纬度,核函数就是从低维到高维的映射关系。如果从高维到低维进行维度压缩的话,可能就会变得混沌不可分。但是从低维到高维,属性维度增加了,可以在另一个空间中变得线性可分。
22|SVM-实战¶
SVM 既可以做回归,也可以做分类器。
SVC 的构造函数:
model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’)
参数 kernel 代表核函数的选择,它有四种选择:
1. linear:线性核函数
2. poly:多项式核函数
3. rbf:高斯核函数(默认)
4. sigmoid:sigmoid 核函数
线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据。
多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大。
高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数。
sigmoid 经常用在神经网络的映射中。因此当选用 sigmoid 核函数时,SVM 实现的是多层神经网络。
参数 C 代表目标函数的惩罚系数:
惩罚系数指的是分错样本时的惩罚程度,默认情况下为 1.0。
当 C 越大时,分类器的准确性越高,但同样容错率会越低,泛化能力会变差
当 C 越小时,泛化能力越强,但是准确性会降低
参数 gamma 代表核函数的系数:
默认为样本特征数的倒数,即 gamma = 1 / n_features
24|KNN-原理¶
KNN 的英文叫 K-Nearest Neighbor,应该算是数据挖掘算法中最简单的一种。
KNN 的工作原理:
1. 计算待分类物体与其他物体之间的距离
2. 统计距离最近的 K 个邻居
3. 对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类
距离的计算方式有下面五种方式:
1. 欧氏距离
2. 曼哈顿距离
3. 闵可夫斯基距离
4. 切比雪夫距离
5. 余弦距离

绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。¶
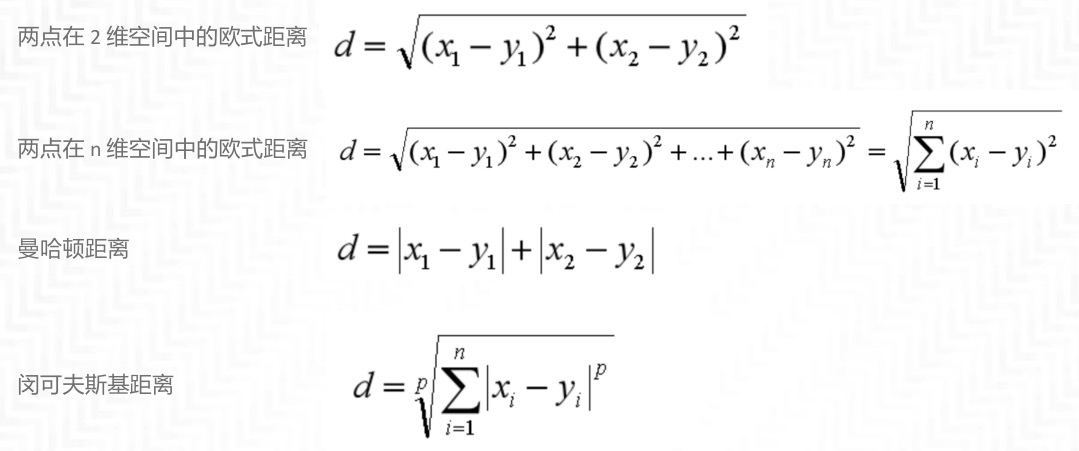
闵可夫斯基距离不是一个距离,而是一组距离的定义。其中 p 代表空间的维数,当 p=1 时,就是曼哈顿距离;当 p=2 时,就是欧氏距离;当 p→∞时,就是切比雪夫距离。二个点之间的切比雪夫距离就是这两个点坐标数值差的绝对值的最大值,用数学表示就是:max(|x1-y1|,|x2-y2|)。余弦距离实际上计算的是两个向量的夹角,是在方向上计算两者之间的差异,对绝对数值不敏感。¶
备注
【回归 VS 分类】如果想要对未知电影进行类型划分,这是一个分类问题。如果是一部新电影,已知它是爱情片,想要知道它的打斗次数、接吻次数可能是多少,这就是一个回归问题。
25|KNN-实战¶
KNN 构造函数:
KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’, leaf_size=30)
参数-n_neighbors:
即 KNN 中的 K 值,代表的是邻居的数量。
K 值如果比较小,会造成过拟合。
如果 K 值比较大,无法将未知物体分类出来。
一般我们使用默认值 5。
参数-weights:是用来确定邻居的权重,有三种方式:
1. weights=uniform,代表所有邻居的权重相同
2. weights=distance,代表权重是距离的倒数,即与距离成反比
3. 自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数
参数-algorithm:用来规定计算邻居的方法,它有四种方式:
1. auto
根据数据的情况自动选择适合的算法,默认情况选择 auto
2. kd_tree
也叫作 KD 树,是多维空间的数据结构,方便对关键数据进行检索,
不过 KD 树适用于维度少的情况,一般维数不超过 20,如果维数大于 20 之后,效率反而会下降
3. ball_tree
也叫作球树,它和 KD 树一样都是多维空间的数据结果,
不同于 KD 树,球树更适用于维度大的情况
4. brute
也叫作暴力搜索
和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索
当训练集大的时候,效率很低
参数-leaf_size:
代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度
26 | K-Means-原理¶
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,你可以理解这个算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。
27 | K-Means-实战¶
K-Means 聚类工具
数据规范化工具
图像处理工具
28 | EM 聚类-原理¶
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法。
K-Means 是通过距离来区分样本之间的差别的,且每个样本在计算的时候只能属于一个分类,称之为是硬聚类算法。而 EM 聚类在求解的过程中,实际上每个样本都有一定的概率和每个聚类相关,叫做软聚类算法。
EM 算法相当于一个框架,常用的 EM 聚类有 GMM 高斯混合模型和 HMM 隐马尔科夫模型。
29 | EM 聚类-实战¶
EM 的两个步骤,E 步和 M 步:
E 步相当于通过初始化的参数来估计隐含变量
M 步是通过隐含变量来反推优化参数
最后通过 EM 步骤的迭代得到最终的模型参数
30|关联规则挖掘-原理¶
关联规则:
最早是由 Agrawal 等人在 1993 年提出的
1994 年 Agrawal 等人又提出了基于关联规则的 Apriori 算法
至今 Apriori 仍是关联规则挖掘的重要算法。
提升度有三种可能:
公式:提升度 (A→B)= 置信度 (A→B)/ 支持度 (B)
1. 提升度 (A→B)>1:代表有提升
2. 提升度 (A→B)=1:代表有没有提升,也没有下降
3. 提升度 (A→B)<1:代表有下降
FP-Growth 算法¶
备注
Apriori 的改进算法
Apriori 在计算的过程中有以下几个缺点:
1. 可能产生大量的候选集
因为采用排列组合的方式,把可能的项集都组合出来了
2. 每次计算都需要重新扫描数据集,来计算每个项集的支持度
FP-Growth 算法,它的特点是:
1. 创建了一棵 FP 树来存储频繁项集
在创建前对不满足最小支持度的项进行删除,减少了存储空间
2. 整个生成过程只遍历数据集 2 次,大大减少了计算量
31|关联规则挖掘-实战¶
Apriori 算法的核心就是理解频繁项集和关联规则。在算法运算的过程中,还要重点掌握对支持度、置信度和提升度的理解。在工具使用上,你可以使用 efficient-apriori 这个工具包,它会把每一条数据中的项(item)放到一个集合(篮子)里来处理,不考虑项(item)之间的先后顺序。
32 | PageRank-原理¶
PageRank 有很广的应用领域,在许多网络结构中都有应用,比如计算一个人的微博影响力等。
33 | PageRank-实战¶
将一个复杂的网络图,通过 PR 值的计算、筛选,最终得到了一张精简的网络图。在这个过程中我们学习了 NetworkX 工具的使用,包括创建图、节点、边及 PR 值的计算。
34|AdaBoost-原理¶
AdaBoost 算法与随机森林算法一样都属于分类算法中的集成算法
集成的含义就是集思广益,博取众长,当我们做决定的时候,我们先听取多个专家的意见,再做决定。
集成算法通常有两种方式,分别是投票选举(bagging)和再学习(boosting)。
投票选举的场景类似把专家召集到一个会议桌前,当做一个决定的时候,让 K 个专家(K 个模型)分别进行分类,然后选择出现次数最多的那个类作为最终的分类结果。
再学习相当于把 K 个专家(K 个分类器)进行加权融合,形成一个新的超级专家(强分类器),让这个超级专家做判断。
Boosting 的含义是提升,它的作用是每一次训练的时候都对上一次的训练进行改进提升,在训练的过程中这 K 个“专家”之间是有依赖性的,当引入第 K 个“专家”(第 K 个分类器)的时候,实际上是对前 K-1 个专家的优化。而 bagging 在做投票选举的时候可以并行计算,也就是 K 个“专家”在做判断的时候是相互独立的,不存在依赖性。
35|AdaBoost-实战¶
回归:AdaBoostRegressor
分类:AdaBoostClassifier
36 | 数据分析算法篇答疑¶
数据集列表:
Titanic: Machine Learning from Disaster
Titanic 乘客生存预测
https://www.kaggle.com/c/titanic
House Prices-Advanced Regression Techniques
预测房价
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
MNIST 手写数字识别
https://www.kaggle.com/scolianni/mnistasjpg
Passenger Satisfaction
乘客满意度,提供了美国航空公司 US Airline 乘客满意度数据
https://www.kaggle.com/johndddddd/customer-satisfaction
Bike Sharing Demand
自行车共享数据库,用于预测自行车的共享需求
https://www.kaggle.com/lakshmi25npathi/bike-sharing-dataset
San Francisco Building Permits
5 年时间,三藩市 20 万的建筑许可
https://www.kaggle.com/aparnashastry/building-permit-applications-data
San Francisco Crime Classification
12 年时间的三藩市的犯罪记录
https://www.kaggle.com/kaggle/san-francisco-crime-classification
03实战篇 (7 讲)¶
37|数据采集实战-自动化运营微博¶
微博自动化运营的实战
Selenium WebDriver
38 | 数据可视化实战-毛不易歌曲词云展示¶
词云工具 WordCloud
39|数据挖掘实战1-信用卡违约率分析¶
随机森林
GridSearchCV
40|数据挖掘实战2-信用卡诈骗分析¶
精确率、召回率和 F1 值
41|数据挖掘实战3-比特币走势预测¶
常用的模型算法,包括 AR、MA、ARMA、ARIMA 模型等
AR 的英文全称叫做 Auto Regressive,中文叫自回归模型
MA 的英文全称叫做 Moving Average,中文叫做滑动平均模型
ARMA 的英文全称是 Auto Regressive Moving Average,中文叫做自回归滑动平均模型
ARIMA 的英文全称是 Auto Regressive Integrated Moving Average 模型,中文叫差分自回归滑动平均模型,也叫求合自回归滑动平均模型
42 | 深度学习1¶
常用的神经网络:
FNN(Fully-connected Neural Network)指的是全连接神经网络
CNN 叫作卷积神经网络(卷积层、池化层和全连接层)
RNN 称为循环神经网络
43 | 深度学习2-Keras搭建深度学习网络做手写数字识别¶
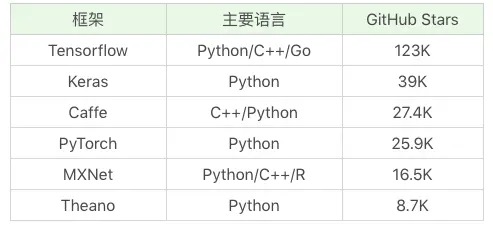
常用的深度学习框架对比¶
04工作篇 (2 讲)¶
44|如何培养你的数据分析思维¶
培养数据分析思维是重要不紧急的事
45 | 求职简历中没有相关项目经验¶
简历是最好的工作梳理
结束语¶
理论到处有,实战最重要
方法比努力更重要