趣谈 Linux 操作系统¶
第二部分 系统初始化 (4 讲)¶
06 x86架构¶
实模式(Real Pattern)
保护模式(Protected Pattern)
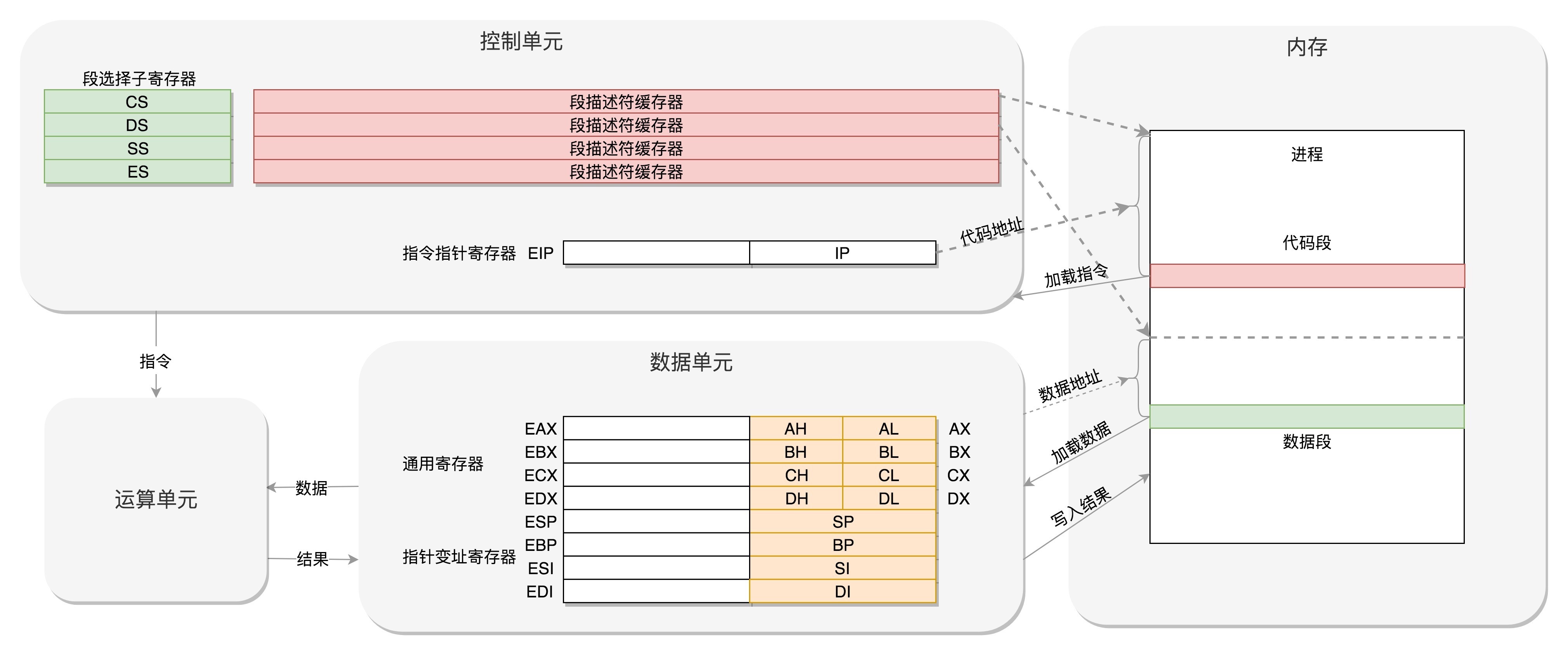
寄存器的作用¶
16 位寄存器¶
8086 处理器内部有 8 个 16 位的通用寄存器,分别是 AX、BX、CX、DX、SP、BP、SI、DI。其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
IP 寄存器就是指令指针寄存器(Instruction Pointer Register),指向代码段中下一条指令的位置。
切换进程时,每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16 位的段寄存器,分别是 CS、DS、SS、ES。 * CS 就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置; * DS 是数据段的寄存器。 * SS 是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则,push 就是入栈,pop 就是出栈。
IP 寄存器和通用寄存器都是 16 位的,偏移量也是 16 位的,但是 8086 的地址总线地址是 20 位。怎么凑够这 20 位呢?方法就是 “起始地址 *16+ 偏移量”,也就是把 CS 和 DS 中的值左移 4 位,变成 20 位的,加上 16 位的偏移量,这样就可以得到最终 20 位的数据地址。
无论真正的内存多么大,对于只有 20 位地址总线的 8086 来讲,能够区分出的地址也就 2^20=1M
32 位寄存器¶
通用寄存器有扩展,可以将 8 个 16 位的扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式,以兼容 16 位寄存器。
有点不兼容的就是段寄存器(Segment Register)因为当时总线是20位的,每次都要左移四位,也就意味着段的起始地址不能是任何一个地方,只是能整除 16 的地方。 * CS、SS、DS、ES 仍然是 16 位的,但是不再是段的起始地址。段的起始地址放在内存的某个地方。这个地方是一个表格,表格中的一项一项是段描述符(Segment Descriptor)。这里面才是真正的段的起始地址。而段寄存器里面保存的是在这个表格中的哪一项,称为选择子(Selector)。 * 这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。 * 如何兼容:在 32 位的系统架构下,将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern)。当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的。当需要更多内存的时候,你可以遵循一定的规则,进行一系列的操作,然后切换到保护模式,就能够用到 32 位 CPU 更强大的能力。 * 不能无缝兼容,但是通过切换模式兼容
汇编语言: http://www.cs.virginia.edu/~evans/cs216/guides/x86.html
Go Plan 9 汇编入门: https://www.bilibili.com/video/av46494102
《深入理解计算机系统》
07 | 从 BIOS 到 bootloader¶
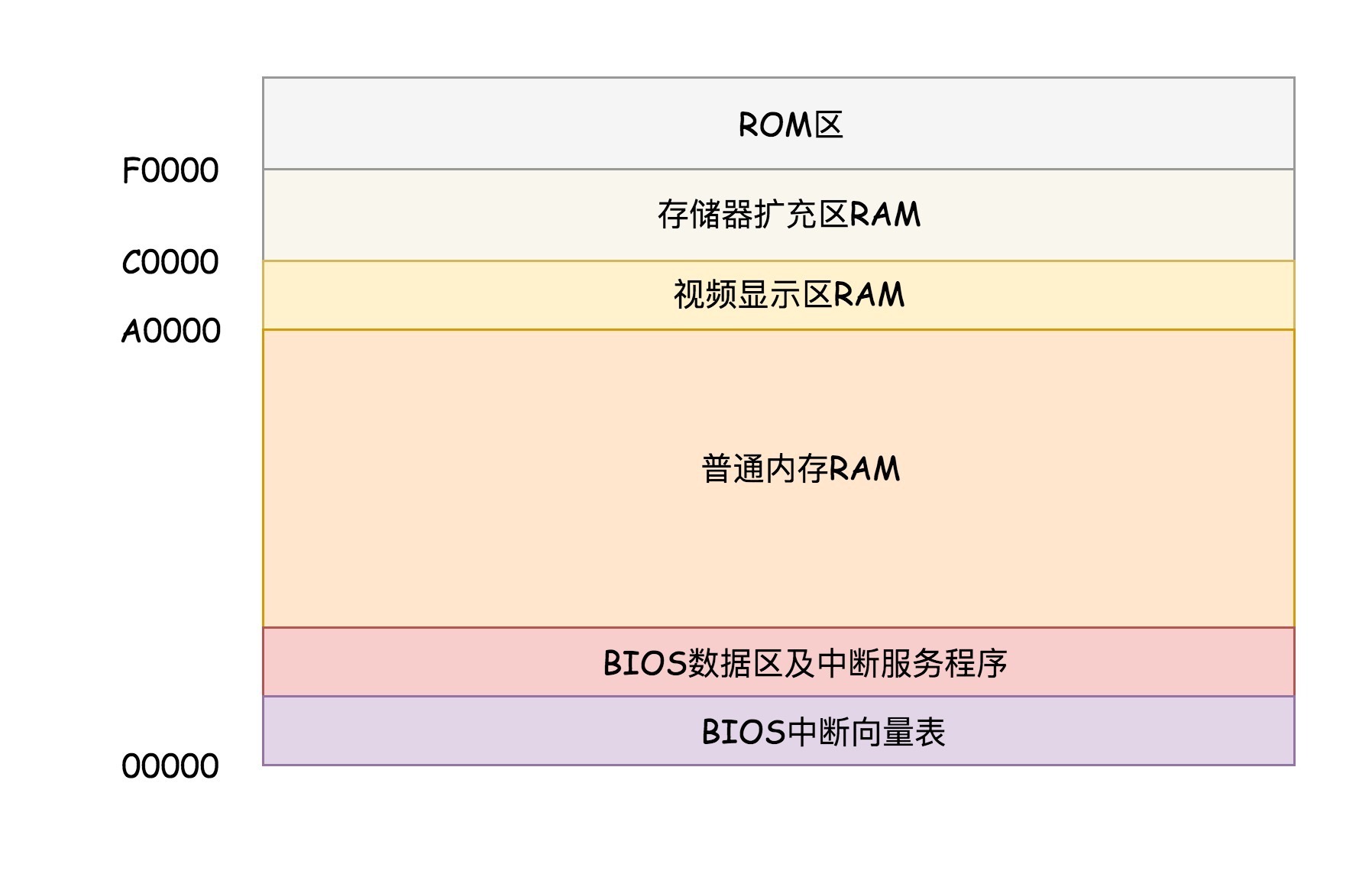
在 x86 系统中,将 1M 空间最上面的 0xF0000 到 0xFFFFF 这 64K 映射给 ROM,也就是说,到这部分地址访问的时候,会访问 ROM。当电脑刚加电的时候,会做一些重置的工作,将 CS 设置为 0xFFFF,将 IP 设置为 0x0000,所以第一条指令就会指向 0xFFFF0,正是在 ROM 的范围内。在这里,有一个 JMP 命令会跳到 ROM 中做初始化工作的代码,于是,BIOS 开始进行初始化的工作。¶
bootloader¶
操作系统一般都会在安装在硬盘上,在 BIOS 的界面上,你会看到一个启动盘的选项。启动盘有什么特点呢?它一般在第一个扇区,占 512 字节,而且以 0xAA55 结束。这是一个约定,当满足这个条件的时候,就说明这是一个启动盘,在 512 字节以内会启动相关的代码。
在 Linux 里面有一个工具,叫 Grub2,全称 Grand Unified Bootloader Version 2。顾名思义,就是搞系统启动的。可以通过 grub2-mkconfig -o /boot/grub2/grub.cfg 来配置系统启动的选项。
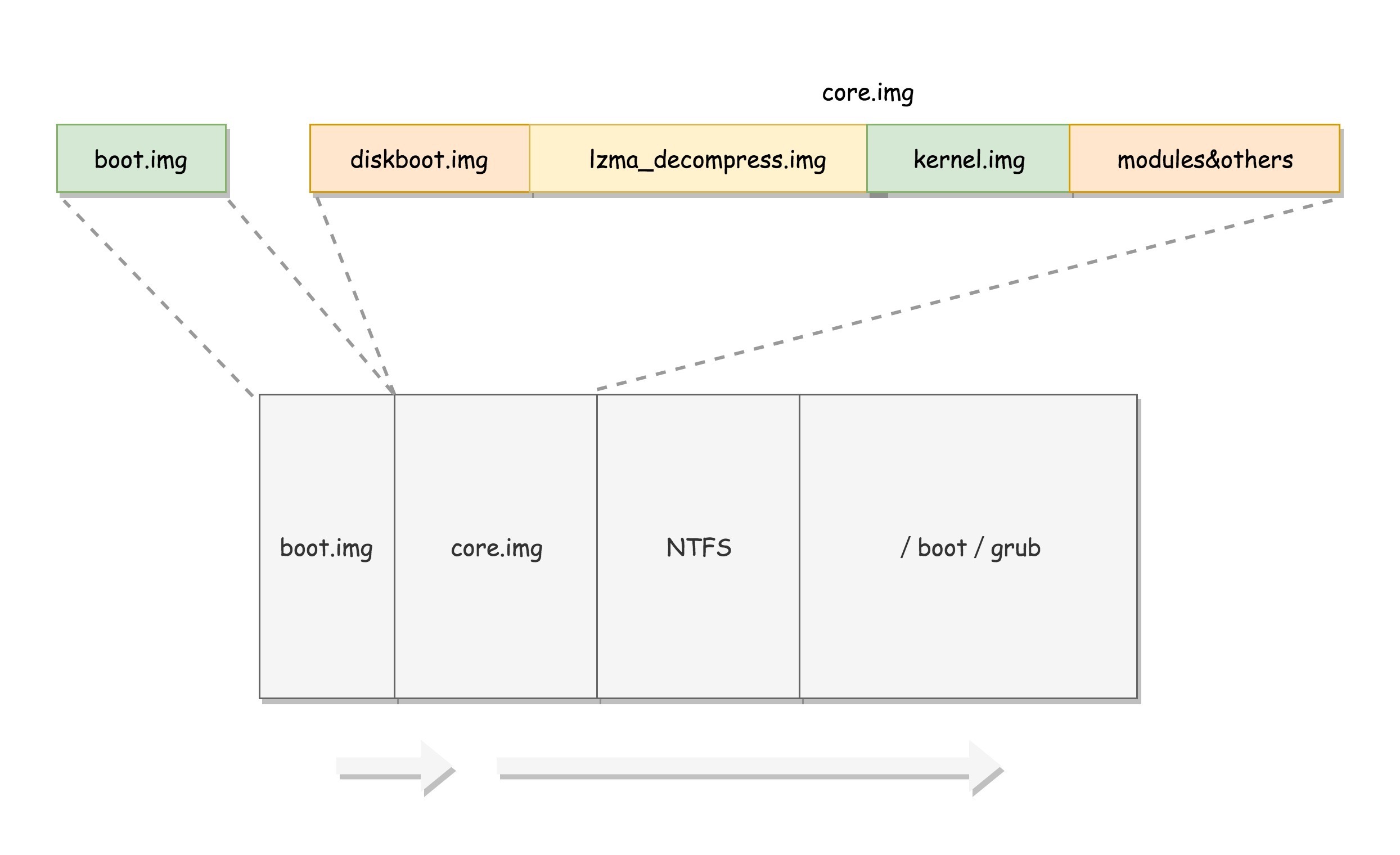
grub2 第一个要安装的就是 boot.img。它由 boot.S 编译而成,一共 512 字节,正式安装到启动盘的第一个扇区。这个扇区通常称为 MBR(Master Boot Record,主引导记录 / 扇区)。
BIOS 完成任务后,会将 boot.img 从硬盘加载到内存中的 0x7c00 来运行。由于 512 个字节实在有限,boot.img 做不了太多的事情。它能做的最重要的一个事情就是加载 grub2 的另一个镜像 core.img。
core.img 由 lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做很多事情。
boot.img 先加载的是 core.img 的第一个扇区。如果从硬盘启动的话,这个扇区里面是 diskboot.img,对应的代码是 diskboot.S。
boot.img 将控制权交给 diskboot.img 后,diskboot.img 的任务就是将 core.img 的其他部分加载进来,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块 module 对应的映像。这里需要注意,它不是 Linux 的内核,而是 grub 的内核。
lzma_decompress.img 对应的代码是 startup_raw.S,本来 kernel.img 是压缩过的,现在执行的时候,需要解压缩。在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行,但是随着我们加载的东西越来越大,实模式这 1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 调用 real_to_prot,切换到保护模式,这样就能在更大的寻址空间里面,加载更多的东西。
从实模式切换到保护模式¶
切换到保护模式要干很多工作,大部分工作都与内存的访问方式有关。第一项是启用分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。第二项是启动分页。能够管理的内存变大了,就需要将内存分成相等大小的块,这些我们放到内存那一节详细再讲。
切换保护模式的函数 DATA32 call real_to_prot 会打开 Gate A20,也就是第 21 根地址线的控制线。
对压缩过的 kernel.img 进行解压缩,然后跳转到 kernel.img 开始运行。
08 | 内核初始化¶
在操作系统里面,先要有个创始进程,有一行指令 set_task_stack_end_magic(&init_task)。这里面有一个参数 init_task,它的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为 0 号进程。这是唯一一个没有通过 fork 或者 kernel_thread 产生的进程,是进程列表的第一个。0号是启动过程,完成自己的使命就退了。主要作用是 链表头。
用 kernel_thread(kernel_init, NULL, CLONE_FS) 创建第二个进程,这个是 1 号进程(用户态祖先)。1 号进程对于操作系统来讲,有“划时代”的意义。因为它将运行第一个用户进程,形成一棵进程树。 一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES) 创建第三个进程,就是 2 号进程(内核态祖先)。
参考进程树:
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 2018 ? 00:00:29 /usr/lib/systemd/systemd --system --deserialize 21
root 2 0 0 2018 ? 00:00:00 [kthreadd]
root 3 2 0 2018 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 2018 ? 00:00:00 [kworker/0:0H]
root 9 2 0 2018 ? 00:00:40 [rcu_sched]
......
root 337 2 0 2018 ? 00:00:01 [kworker/3:1H]
root 380 1 0 2018 ? 00:00:00 /usr/lib/systemd/systemd-udevd
root 415 1 0 2018 ? 00:00:01 /sbin/auditd
root 498 1 0 2018 ? 00:00:03 /usr/lib/systemd/systemd-logind
......
root 32792 2580 0 Jan10 ? 00:00:00 sshd: root@pts/0
root 32794 32792 0 Jan10 pts/0 00:00:00 -bash
root 32901 32794 0 00:01 pts/0 00:00:00 ps -ef
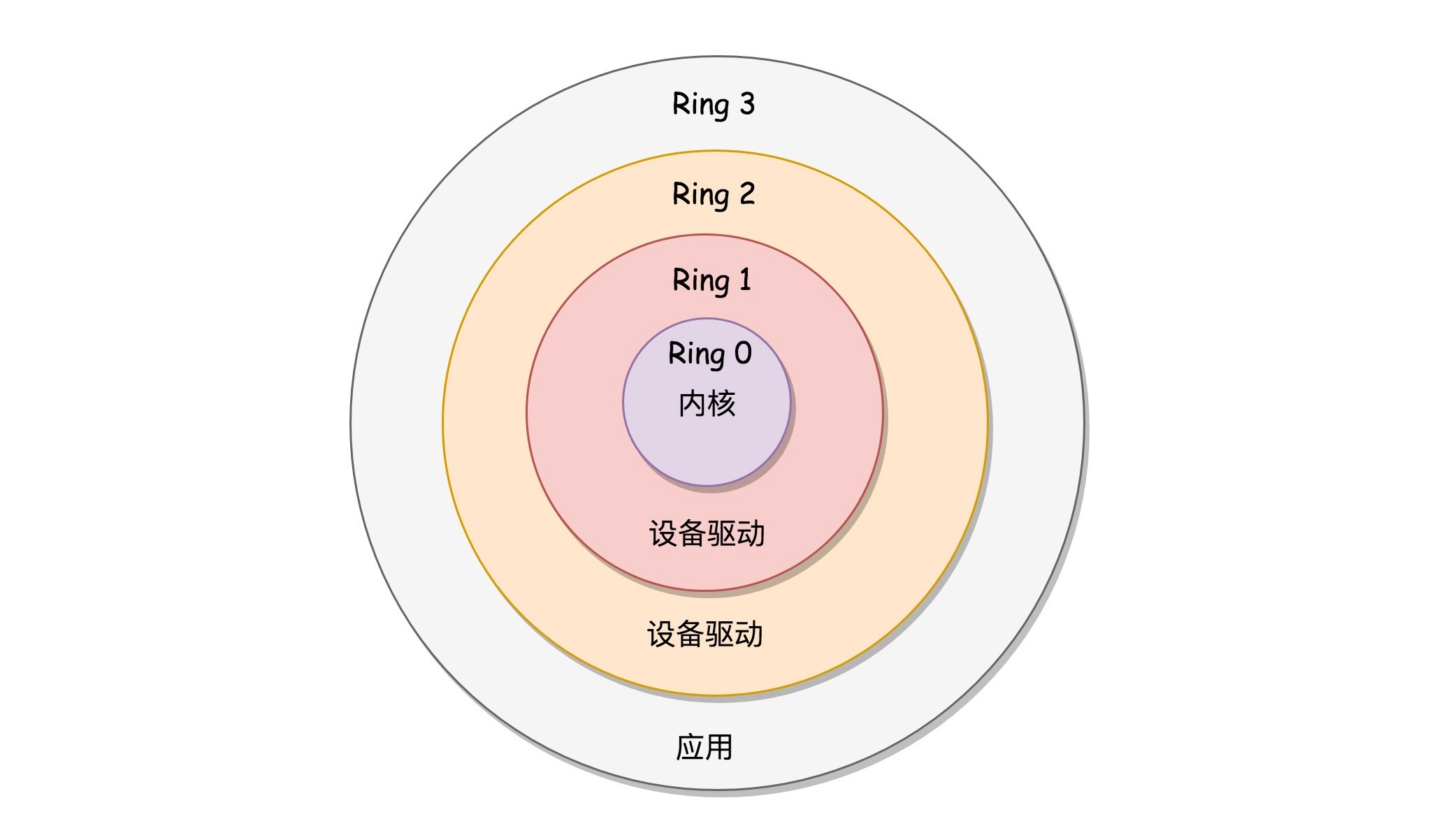
x86 提供了分层的权限机制,把区域分成了四个 Ring,越往里权限越高,越往外权限越低。操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。¶
保护模式除了可访问空间大一些,还有另一个重要功能,就是“保护”,也就是说,当处于用户态的代码想要执行更高权限的指令,这种行为是被禁止的,要防止他们为所欲为。
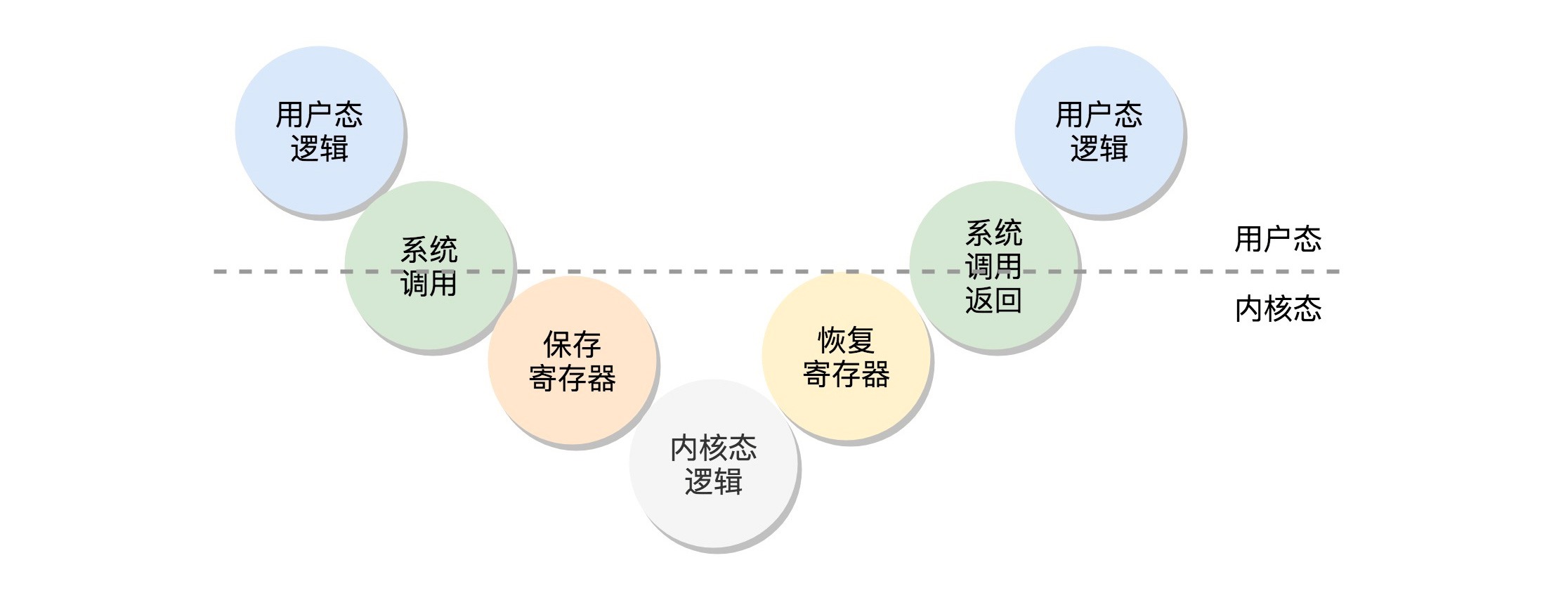
如果用户态的代码想要访问核心资源:这个过程就是这样的:用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态,然后接着运行。¶
参考¶
《庖丁解牛Linux内核分析》( https://j.youzan.com/BA2Fr9)
09 | 系统调用¶
系统调用是操作系统提供给程序设计人员使用系统服务的接口。Linux 提供了 glibc 库,它封装了系统调用接口,对上层更友好的提供服务
系统调用最终都会通过 DO_CALL 发起,这是一个宏定义:
- 32 位系统调用
- 用户态
- 将请求参数保存到寄存器
- 将系统调用名称转为系统调用号保存到寄存器 eax 中
- 通过软中断 ENTER_KERNEL 进入内核态
- 内核态
- 将用户态的寄存器保存到 pt_regs 中
- 在系统调用函数表 sys_call_table 中根据调用号找到对应的函数
- 执行函数实现,将返回值写入 pt_regs 的 ax 位置
- 通过 INTERRUPT_RETURN 根据 pt_regs 恢复用户态进程
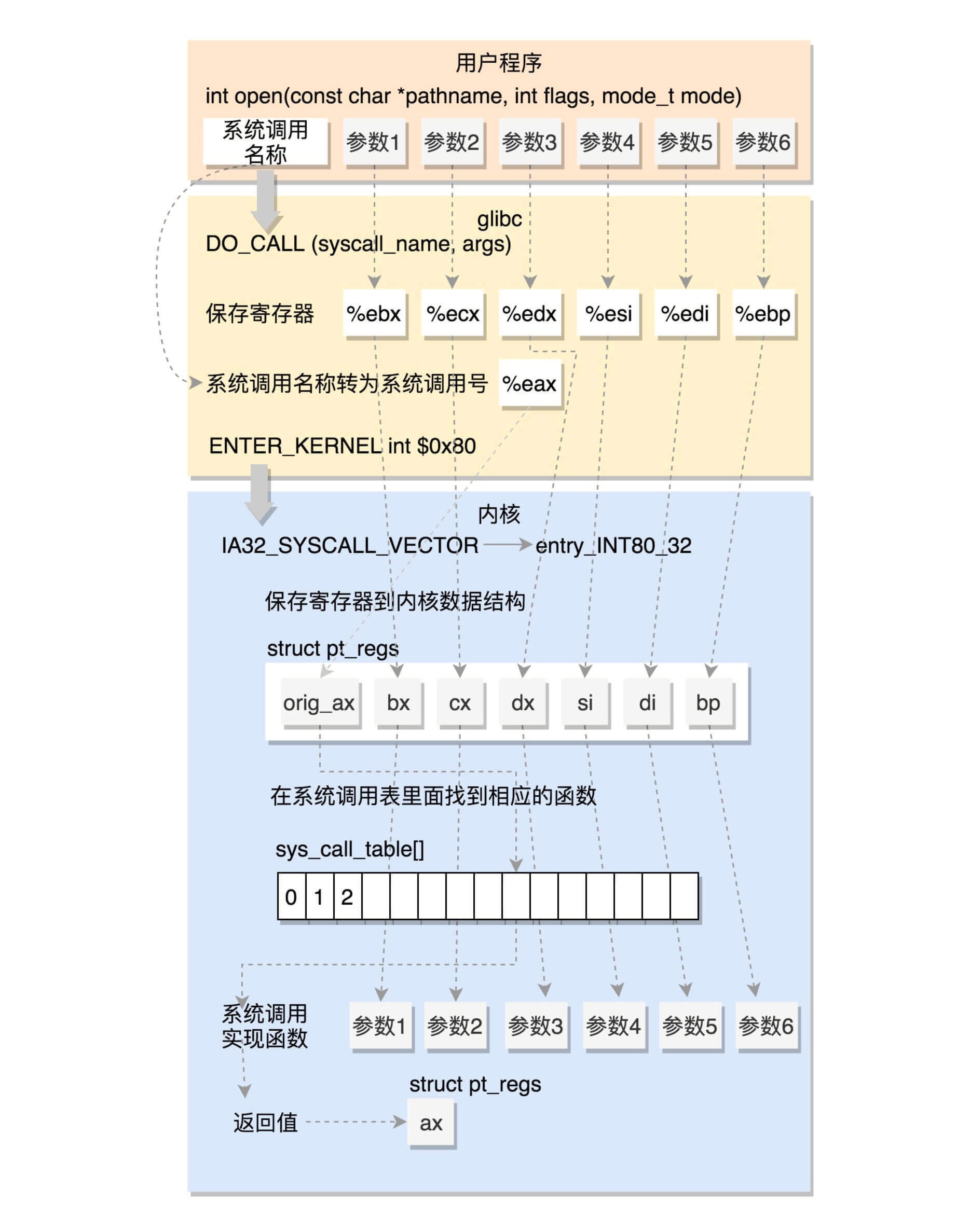
32位系统调用过程¶
参考¶
glibc 的源码理解(主要过程是 CPU 上下文切换的过程): https://www.gnu.org/software/libc/started.html
第三部分 进程管理 (10 讲)¶
10 | 进程¶
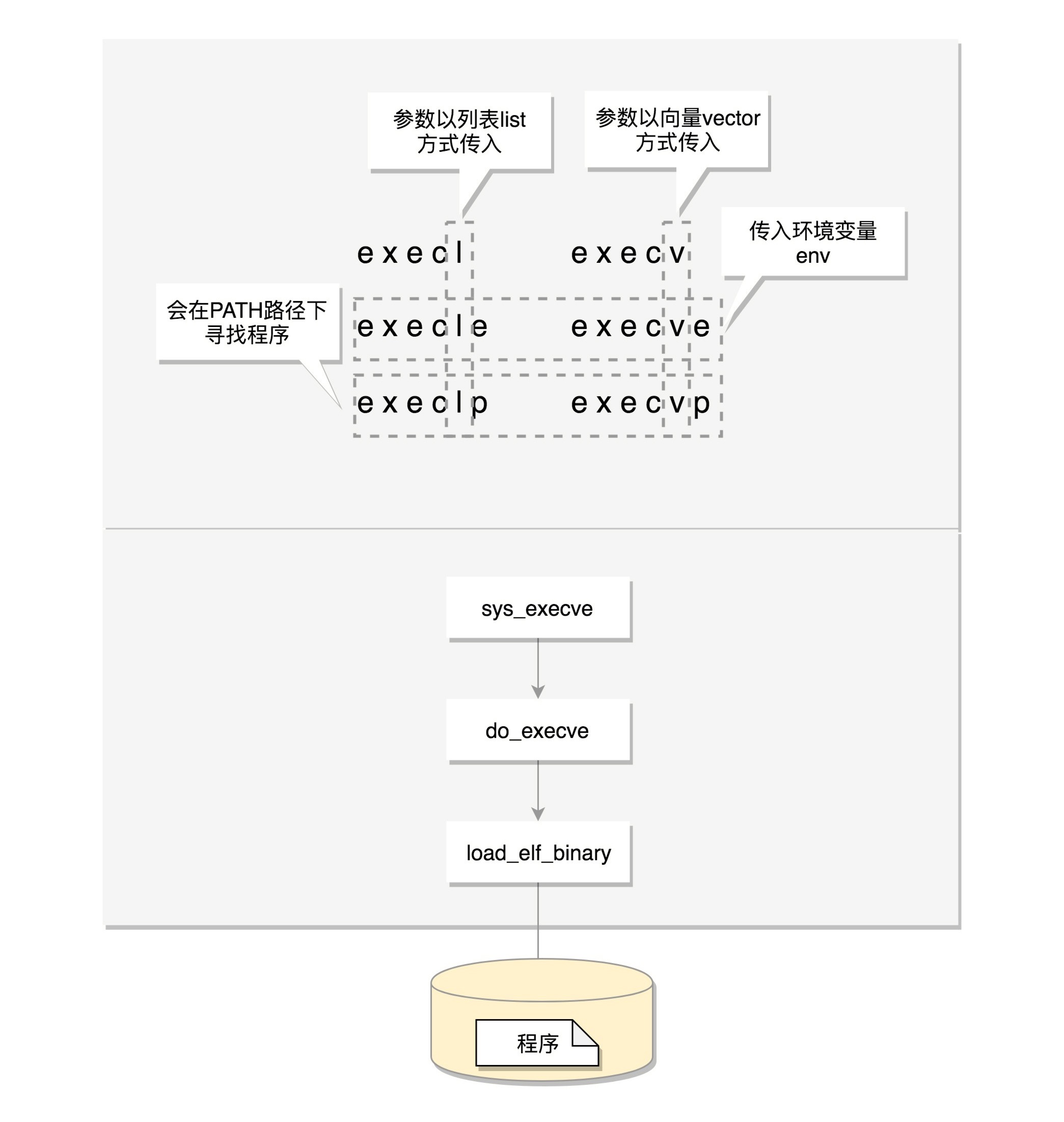
exec 是一组函数:
1. 包含 p 的函数(execvp, execlp)会在 PATH 路径下面寻找程序;
2. 不包含 p 的函数需要输入程序的全路径;
3. 包含 v 的函数(execv, execvp, execve)以数组的形式接收参数;
4. 包含 l 的函数(execl, execlp, execle)以列表的形式接收参数;
5. 包含 e 的函数(execve, execle)以数组的形式接收环境变量。
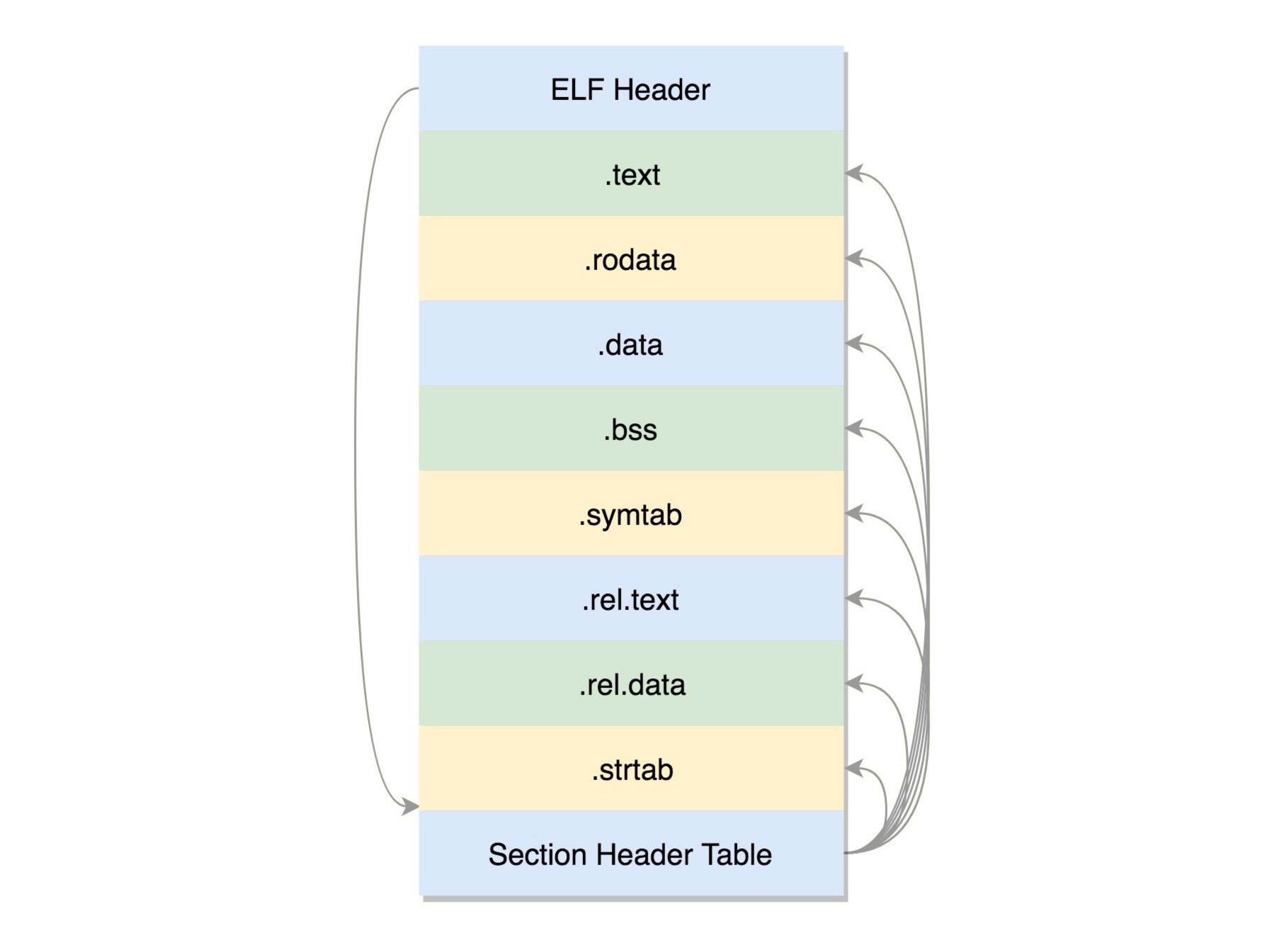
三种ELF格式文件:
1. .o 文件: 可重定位文件(Relocatable File)
2. 可执行文件
3. .so 文件: 动态链接库(Shared Libraries)
可重定位文件的 EFL 格式¶
ELF 文件的头是用于描述整个文件的。这个文件格式在内核中有定义,分别为 struct elf32_hdr 和 struct elf64_hdr。
section(也叫节)的作用:
1. .text:放编译好的二进制可执行代码 2. .data:已经初始化好的全局变量 3. .rodata:只读数据,例如字符串常量、const 的变量 4. .bss:未初始化全局变量,运行时会置 0 5. .symtab:符号表,记录的则是函数和变量 6. .strtab:字符串表、字符串常量和变量名
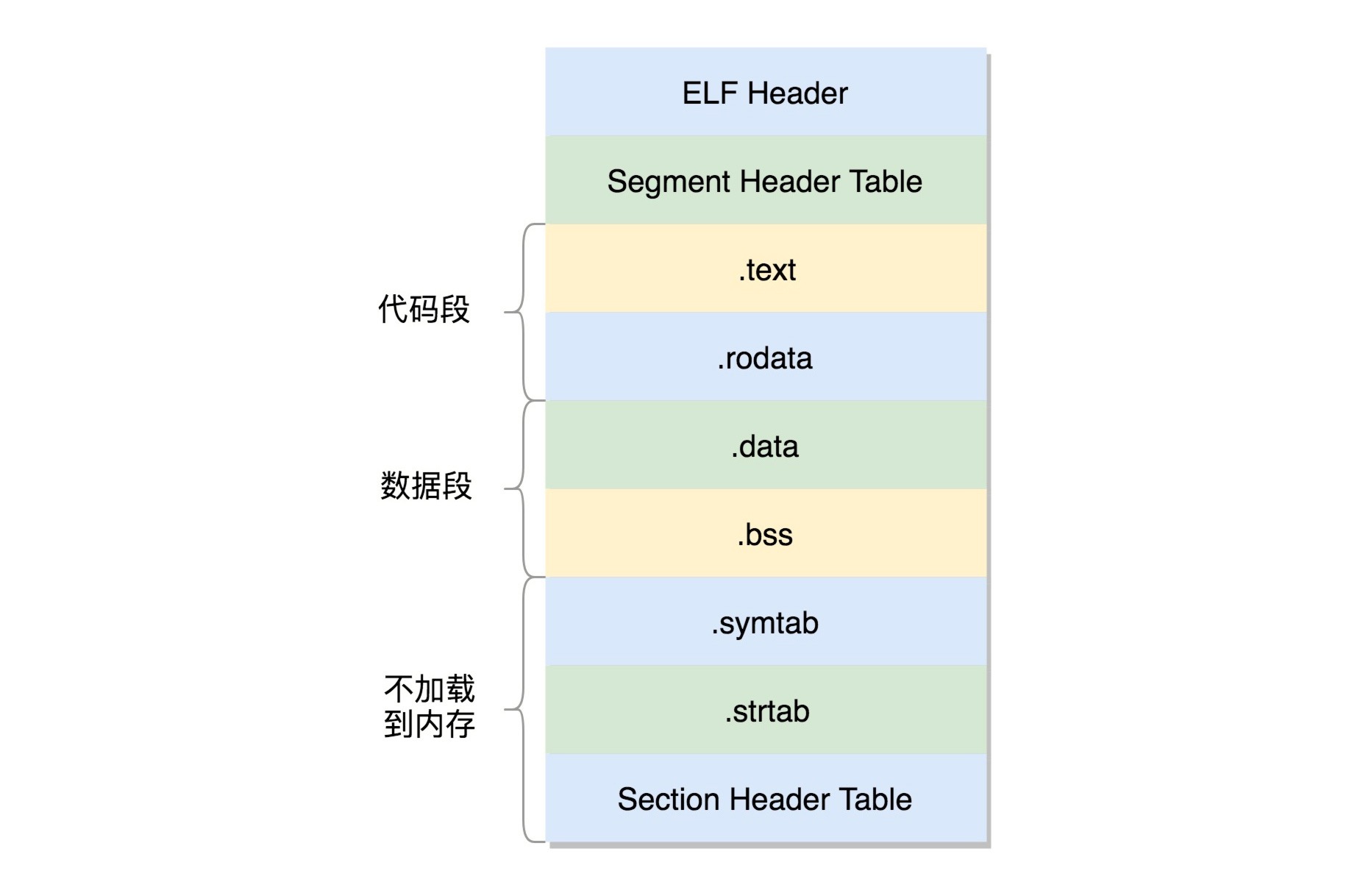
可执行文件的 ELF 格式¶
备注
动态链接库的 ELF 文件中还多了两个 section,一个是.plt,过程链接表(Procedure Linkage Table,PLT),一个是.got.plt,全局偏移量表(Global Offset Table,GOT)。
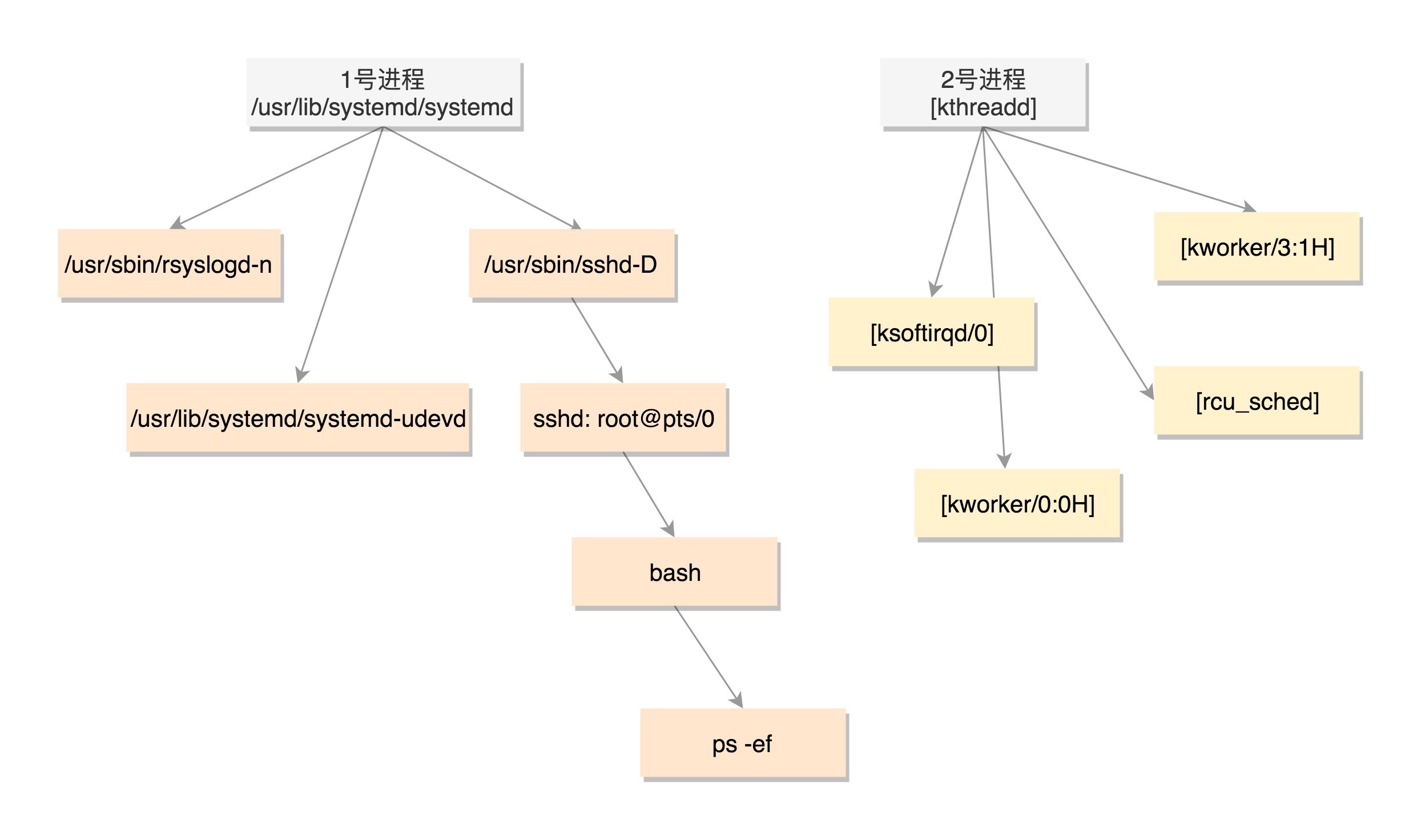
进程树¶
工具:
1. readelf 工具用于分析 ELF 的信息
2. objdump 工具用来显示二进制文件的信息
3. hexdump 工具用来查看文件的十六进制编码
4. nm 工具用来显示关于指定文件中符号的信息
参考¶
《程序员的自我修养-链接、装载和库》
11 | 线程¶
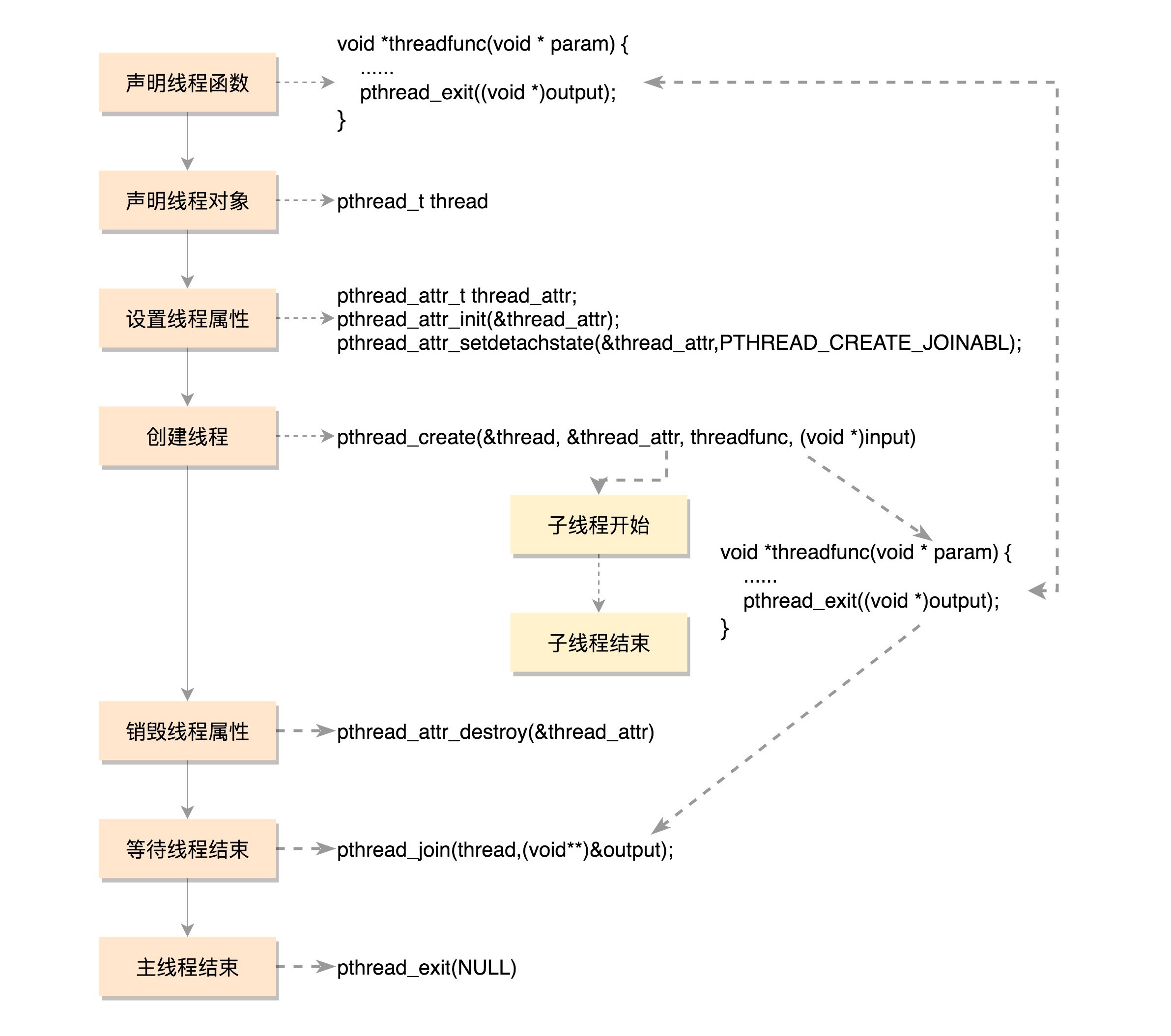
一个普通线程的创建和运行过程¶
线程的数据¶
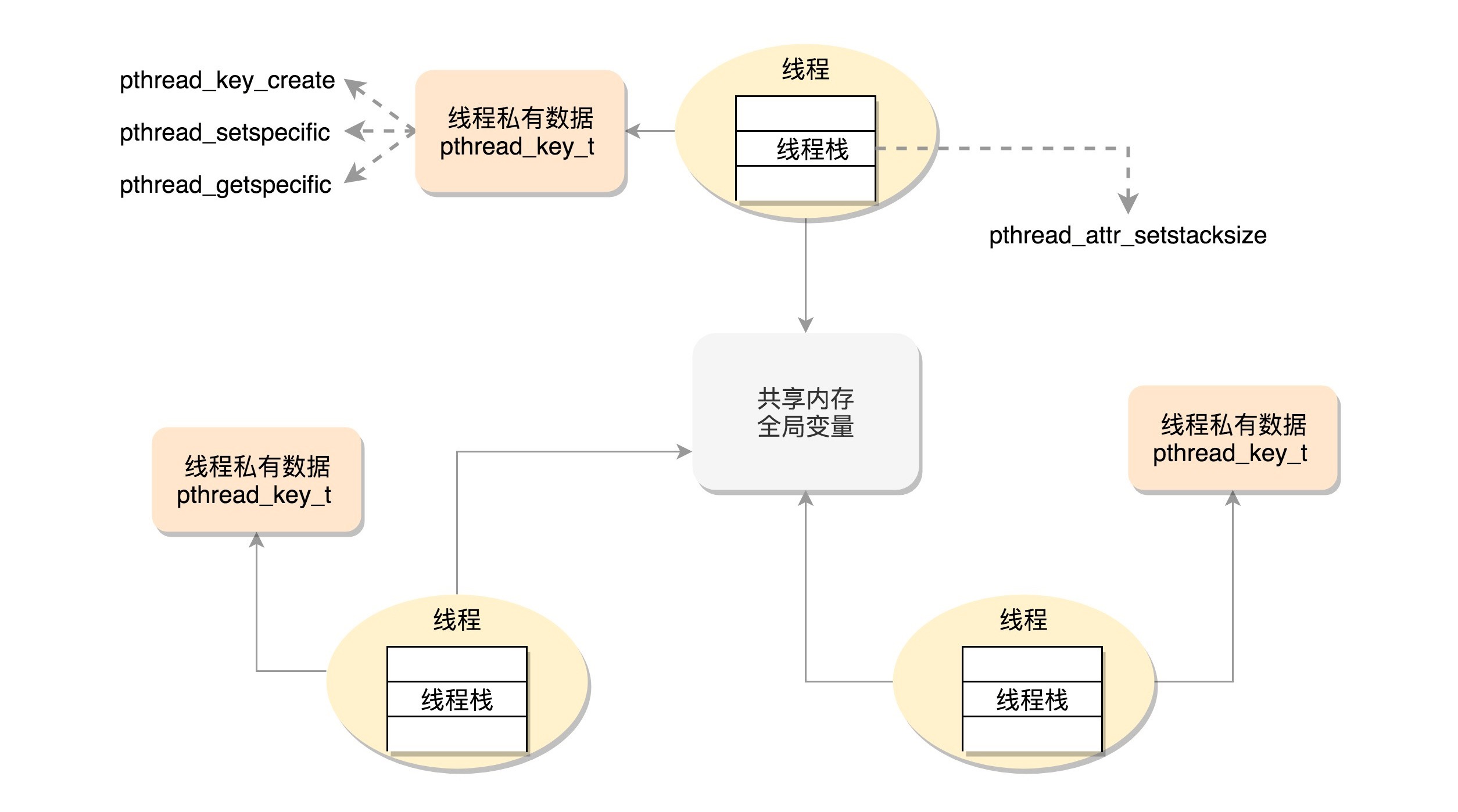
线程访问的数据细分成三类:1.线程栈上的本地数据2.在整个进程里共享的全局数据3.线程私有数据(Thread Specific Data)¶
线程栈上的本地数据:
如函数执行过程中的局部变量 通过命令 ulimit -a 查看,默认线程栈大小为 8192(8MB) 可通过下面函数修改指定栈的栈空间大小: int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize); 主线程在内存中有一个栈空间,其他线程栈也拥有独立的栈空间
在整个进程里共享的全局数据:
如全局变量 需要使用Mutex方式保守数据
线程私有数据(Thread Specific Data):
线程级别的全局变量(在本线程中,多函数可用) 创建 key: int pthread_key_create(pthread_key_t *key, void (*destructor)(void*)) 创建一个 key,伴随着一个析构函数 说明: key 一旦被创建,所有线程都可以访问它,但各线程的 key 值不同(同名而不同值的全局变量) 设置 key 对应的 value: int pthread_setspecific(pthread_key_t key, const void *value) 获取 key 对应的 value: void *pthread_getspecific(pthread_key_t key)
数据的保护¶
Mutex,全称 Mutual Exclusion,中文叫互斥
条件变量和互斥锁是配合使用的
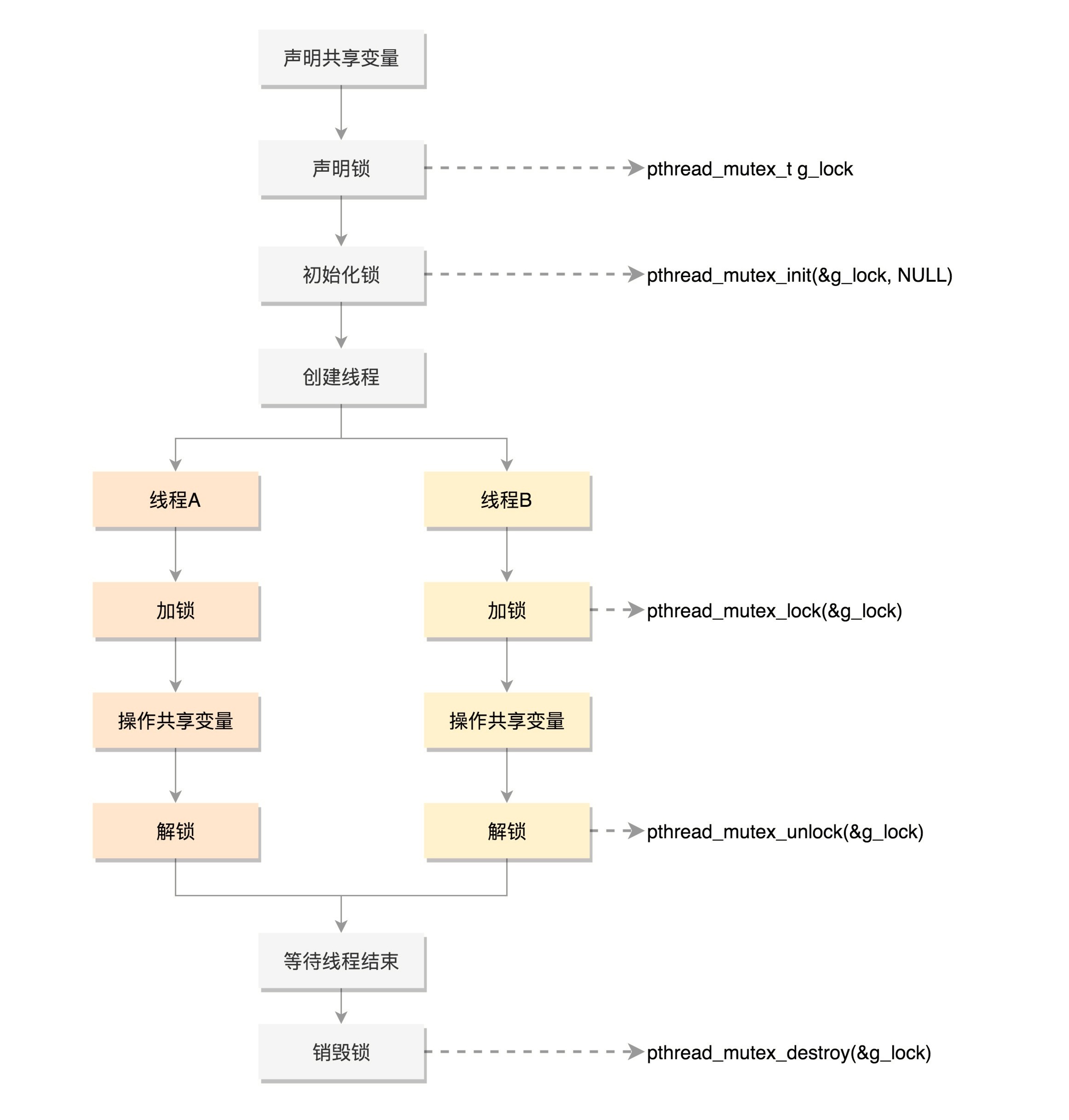
Mutex 的使用流程¶
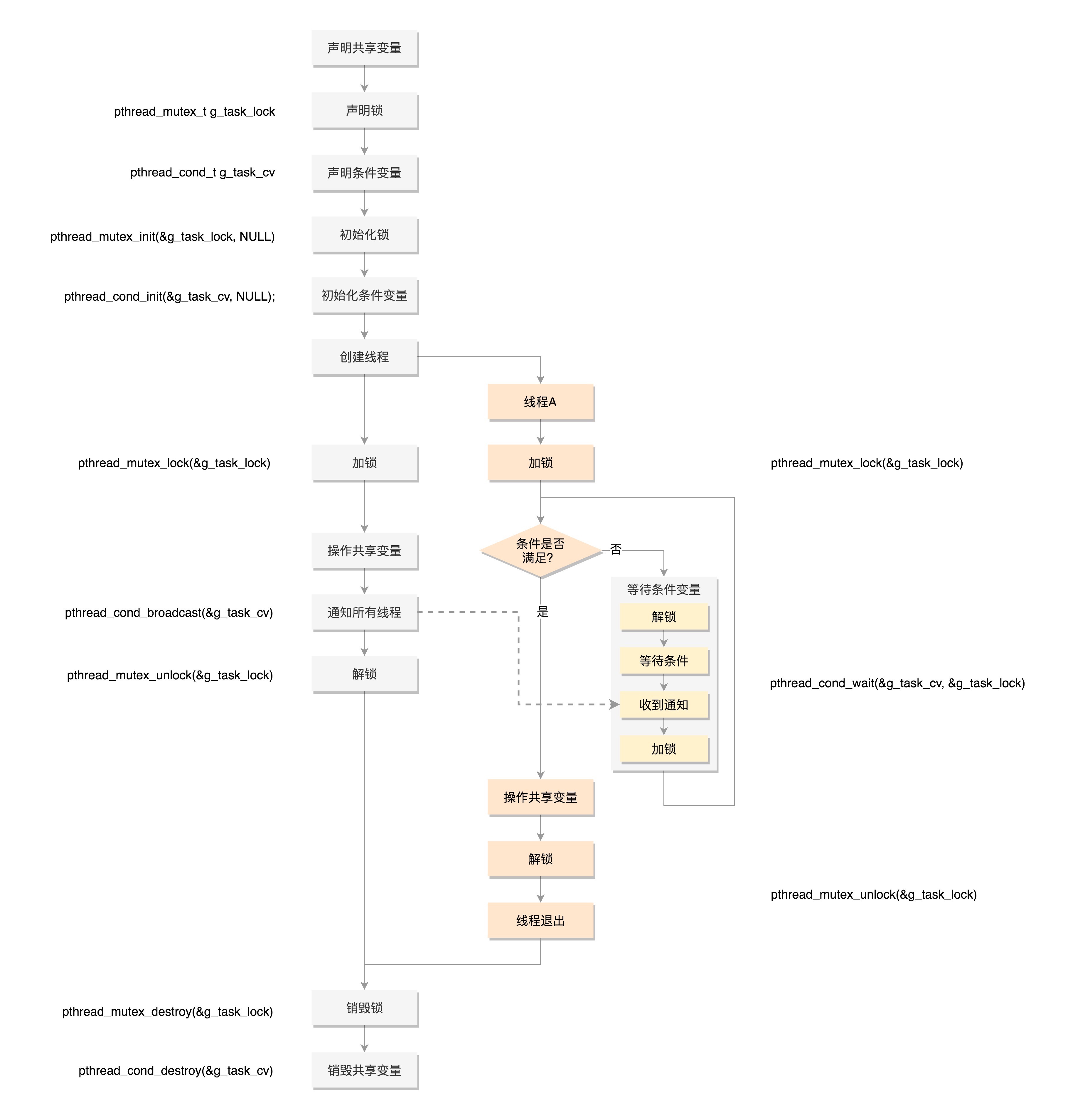
条件变量和互斥锁工作模式¶
参考¶
于渊写的《一个操作系统的实现》,《linux 内核设计与实现》《现代操作系统》《intel 汇编程序》《深入理解计算机系统》《unix 高级环境编程》
12 | 进程数据结构-上¶
在 Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构 task_struct 进行管理。
操作系统的理论是有多种模型的,用户进程和内核线程之间可能是多对一,一对一,多对多,Linux 是一对一。
每一个任务(task_struct)都应该包含哪些字段:
1. 任务 ID
2. 信号处理
3. 任务状态
4. 进程调度
5. 统计信息
6. 亲缘关系
7. 进程权限
8. 内存管理
9. 文件与文件系统
10. 内核栈
任务 ID:
// 进程id pid_t pid; // 线程组id pid_t tgid; // 主线程指针 struct task_struct *group_leader; 说明: 1. 只有主线程: pid 是自己,tgid 是自己,group_leader 指向的还是自己 2. 进程创建了线程: 线程有自己的 pid,tgid 就是进程的主线程的 pid,group_leader 指向主线程
信号处理:
/* Signal handlers: */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked; sigset_t real_blocked; sigset_t saved_sigmask; struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; unsigned int sas_ss_flags;
任务状态:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ int exit_state; unsigned int flags;
字段-state 可以取的值定义在 include/linux/sched.h 头文件中:
/* Used in tsk->state: */
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* Used in tsk->exit_state: */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* Used in tsk->state again: */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_NEW 2048
#define TASK_STATE_MAX 4096
字段-flags(标志)定义为宏,以 PF 开头:
// 表示正在退出
#define PF_EXITING 0x00000004
// 表示进程运行在虚拟 CPU 上
#define PF_VCPU 0x00000010
// 表示 fork 完了,还没有 exec
#define PF_FORKNOEXEC 0x00000040
进程调度:
// 是否在运行队列上 int on_rq; // 优先级 int prio; int static_prio; int normal_prio; unsigned int rt_priority; // 调度器类 const struct sched_class *sched_class; // 调度实体 struct sched_entity se; struct sched_rt_entity rt; struct sched_dl_entity dl; // 调度策略 unsigned int policy; // 可以使用哪些 CPU int nr_cpus_allowed; cpumask_t cpus_allowed; struct sched_info sched_info;
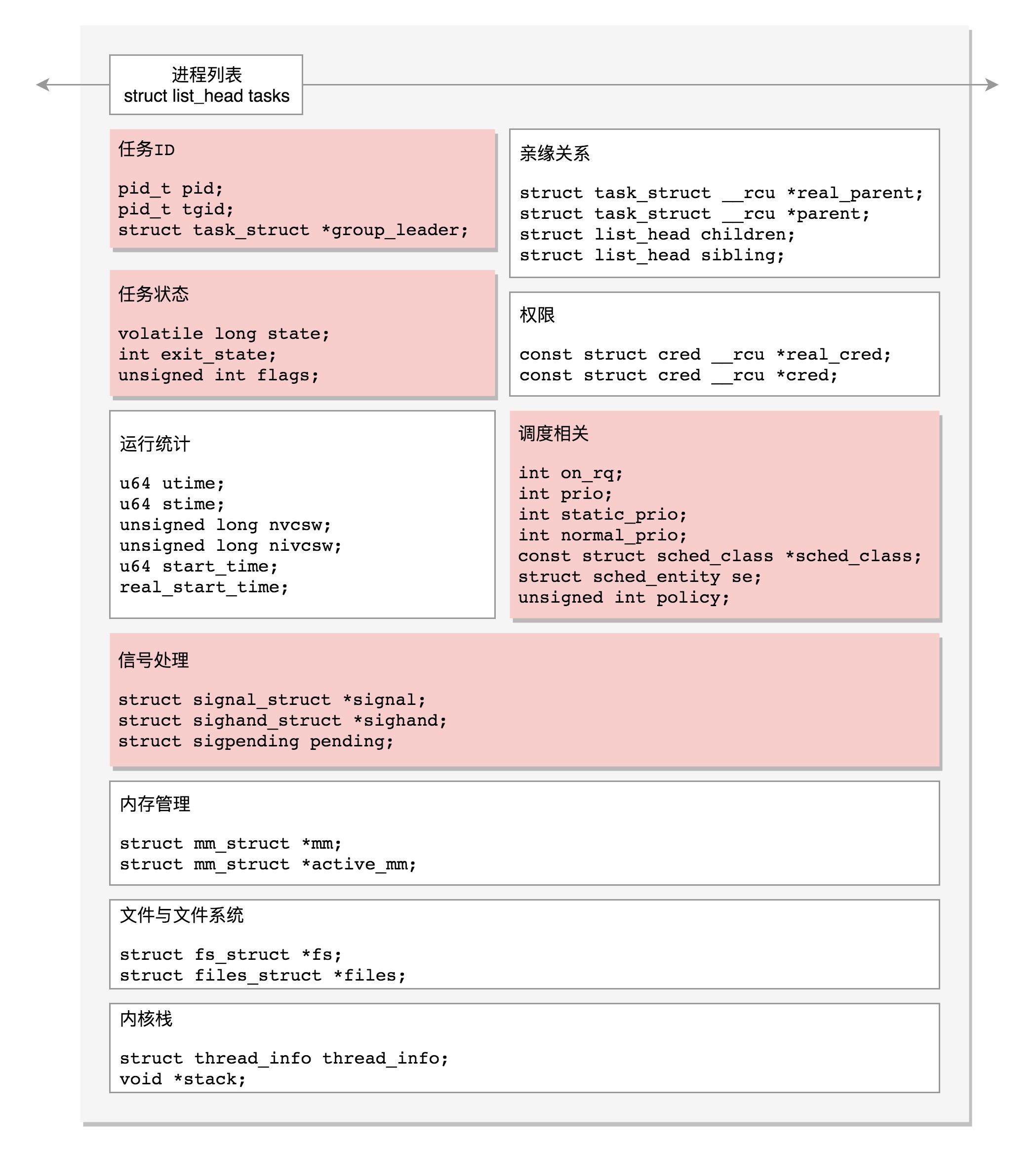
进程管理 task_struct 的结构图¶
参考¶
建议大家多看
/proc/<pid>下的相关信息
13 | 进程数据结构-中¶
统计信息:
u64 utime;// 用户态消耗的 CPU 时间 u64 stime;// 内核态消耗的 CPU 时间 unsigned long nvcsw;// 自愿 (voluntary) 上下文切换计数 unsigned long nivcsw;// 非自愿 (involuntary) 上下文切换计数 u64 start_time;// 进程启动时间,不包含睡眠时间 u64 real_start_time;// 进程启动时间,包含睡眠时间
亲缘关系:
struct task_struct __rcu *real_parent; /* real parent process */ struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ parent 指向其父进程。当它终止时,必须向它的父进程发送信号。 children 表示链表的头部。链表中的所有元素都是它的子进程。 sibling 用于把当前进程插入到兄弟链表中。
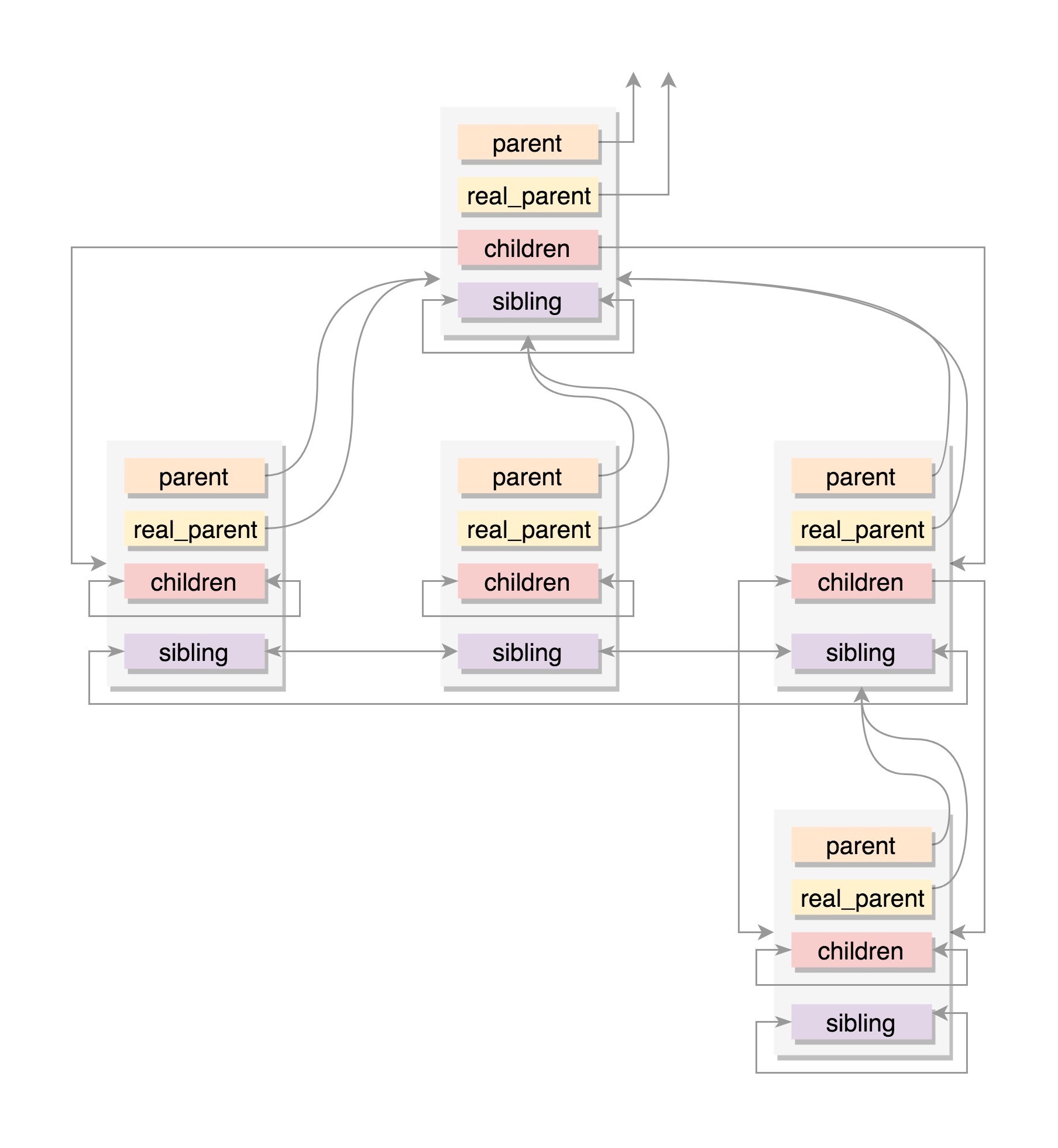
通常情况下,real_parent 和 parent 是一样的,但是也会有另外的情况存在。例如,bash 创建一个进程,那进程的 parent 和 real_parent 就都是 bash。如果在 bash 上使用 GDB 来 debug 一个进程,这个时候 GDB 是 parent,bash 是这个进程的 real_parent。¶
进程权限:
/* Objective and real subjective task credentials (COW): */ // Objective: 谁能操作我 const struct cred __rcu *real_cred; // 谁能操作我这个进程 /* Effective (overridable) subjective task credentials (COW): */ // Subjective: 我能操作谁 const struct cred __rcu *cred; // 我这个进程能够操作谁
cred 的定义:
struct cred {
......
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
......
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
......
} __randomize_layout;
说明:
1. uid 和 gid: 权限审核的时候,往往不比较这两个,也就是说不大起作用
2. euid 和 egid: 权限审核的时候,真正有作用的
3. fsuid 和 fsgid: 对文件操作会审核的权限
4. suid 和 sgid: 进程通过 setuid 设备时,原 uid,gid 保存位置
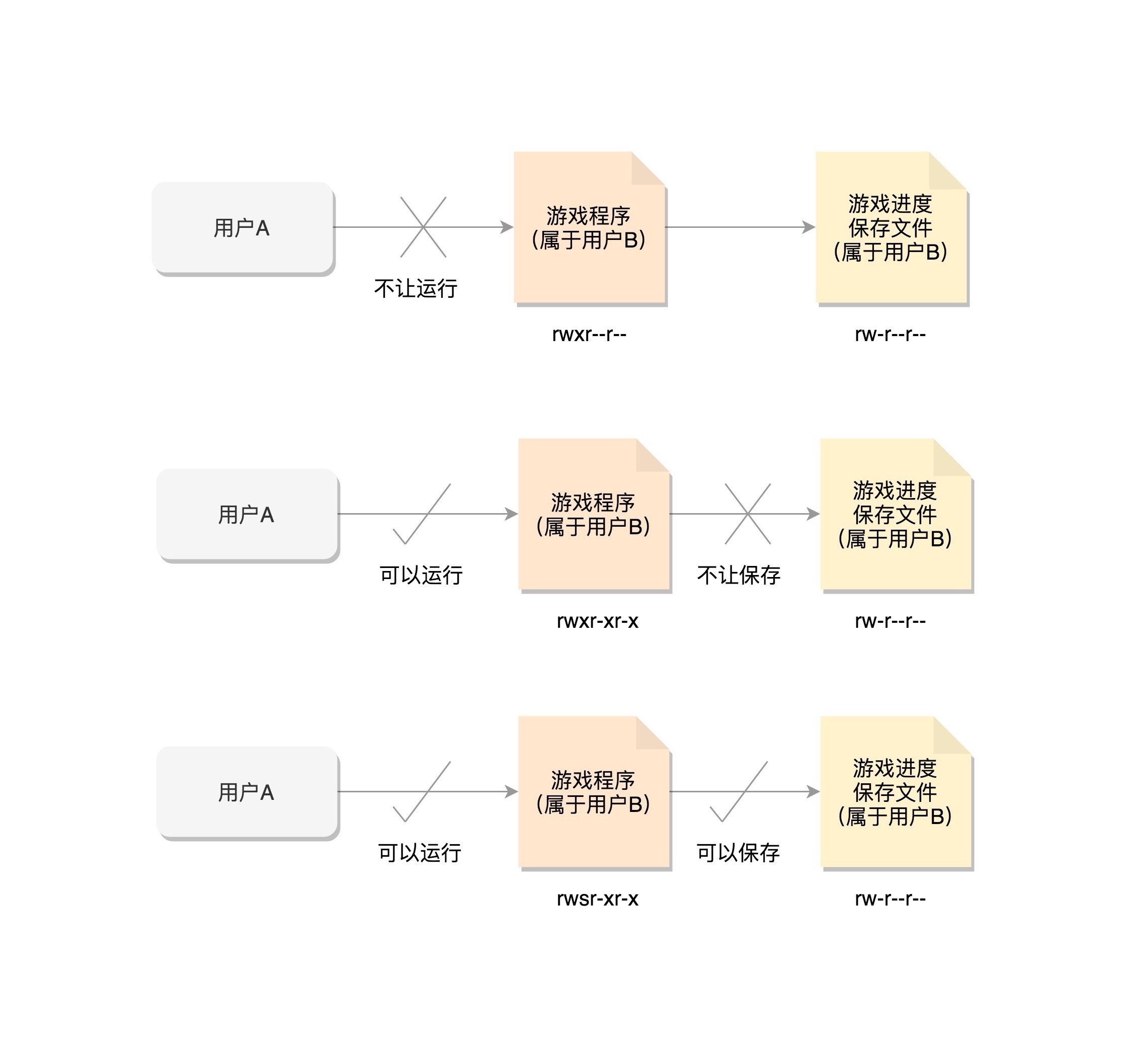
一般说来,fsuid、euid,和 uid 是一样的,fsgid、egid,和 gid 也是一样的。但是也有特殊的情况。通过 chmod u+s program 命令,给这个游戏程序设置 set-user-ID 的标识位,把游戏的权限变成 rwsr-xr-x 。这个时候,用户 A 再启动这个游戏的时候,创建的进程 uid 当然还是用户 A,但是 euid 和 fsuid 就不是用户 A 了,因为看到了 set-user-id 标识,就改为文件的所有者的 ID,也就是说,euid 和 fsuid 都改成用户 B 了,这样就能够将通关结果保存下来。¶
备注
在 Linux 里面,一个进程可以随时通过 setuid 设置用户 ID,所以,游戏程序的用户 B 的 ID 还会保存在一个地方,这就是 suid 和 sgid,也就是 saved uid 和 save gid。这样就可以很方便地使用 setuid,通过设置 uid 或者 suid 来改变权限。
内存管理:
struct mm_struct *mm; struct mm_struct *active_mm; 每个进程都有自己独立的虚拟内存空间
文件与文件系统:
/* Filesystem information: */ struct fs_struct *fs; /* Open file information: */ struct files_struct *files; 每个进程有一个文件系统的数据结构,还有一个打开文件的数据结构
14 | 进程数据结构-下¶
用户态函数栈¶
在用户态中,程序的执行往往是一个函数调用另一个函数。函数调用都是通过栈来进行的。
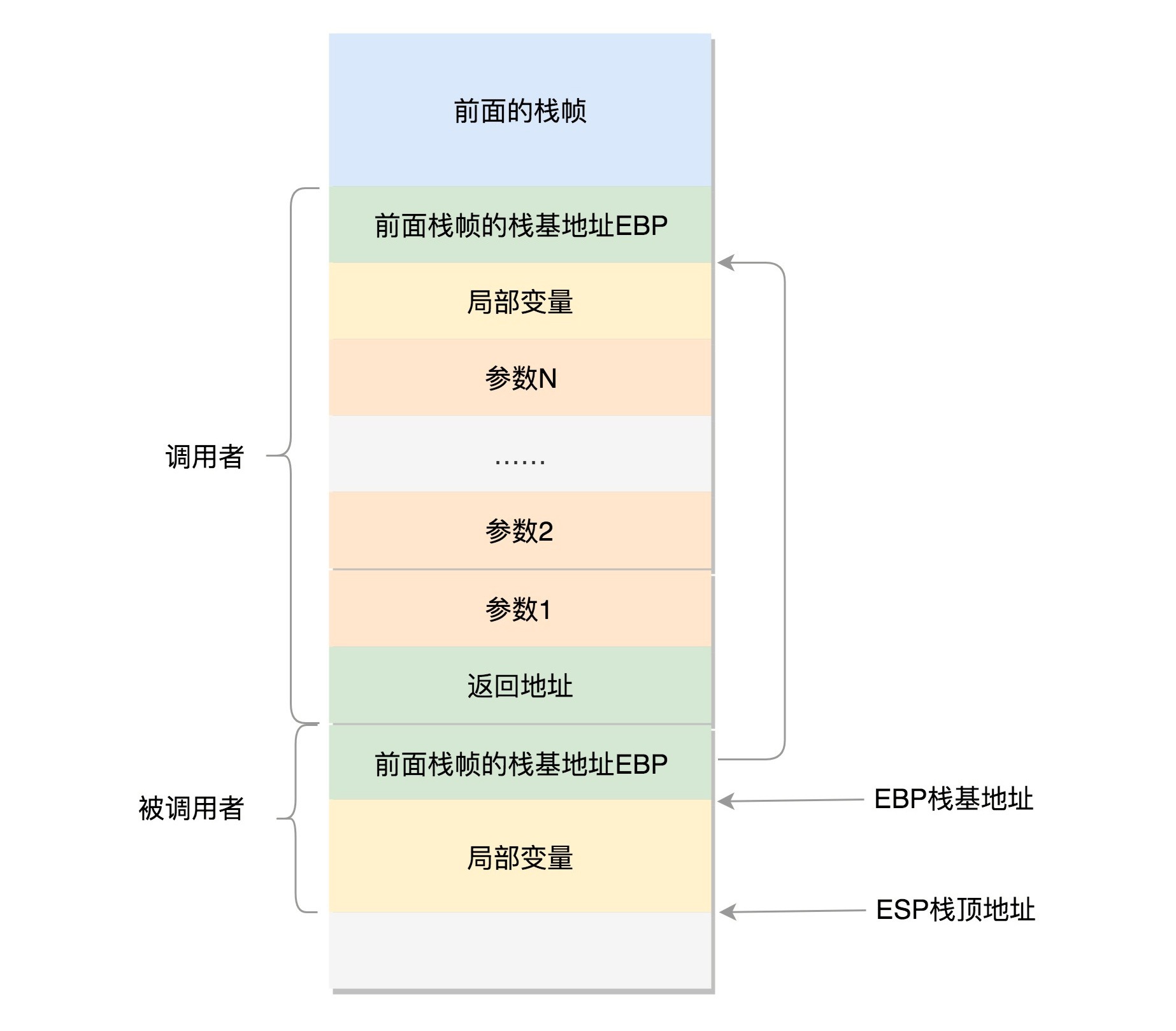
32 位操作系统,用户态函数调用过程¶
A 调用 B
A 的栈帧部分:包含 A 函数的局部变量,然后是调用 B 的时候要传给它的参数,然后返回 A 的地址,这个地址也应该入栈,这就形成了 A 的栈帧。
B 的栈帧部分:先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,接下来保存的是 B 的局部变量等等。
当 B 返回的时候,返回值会保存在 EAX 寄存器中,从栈中弹出返回地址,将指令跳转回去,参数也从栈中弹出,然后继续执行 A。
内核态函数栈¶
需要两个重要的成员变量:
struct thread_info thread_info;
void *stack;
Linux 给每个 task 都分配了内核栈(stack)。
内核栈在 32 位系统上 arch/x86/include/asm/page_32_types.h,是这样定义的:
一个 PAGE_SIZE 是 4K,左移一位就是乘以 2,也就是 8K
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
内核栈在 64 位系统上 arch/x86/include/asm/page_64_types.h,是这样定义的:
在 PAGE_SIZE 的基础上左移两位,也即 16K,并且要求起始地址必须是 8192 的整数倍
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
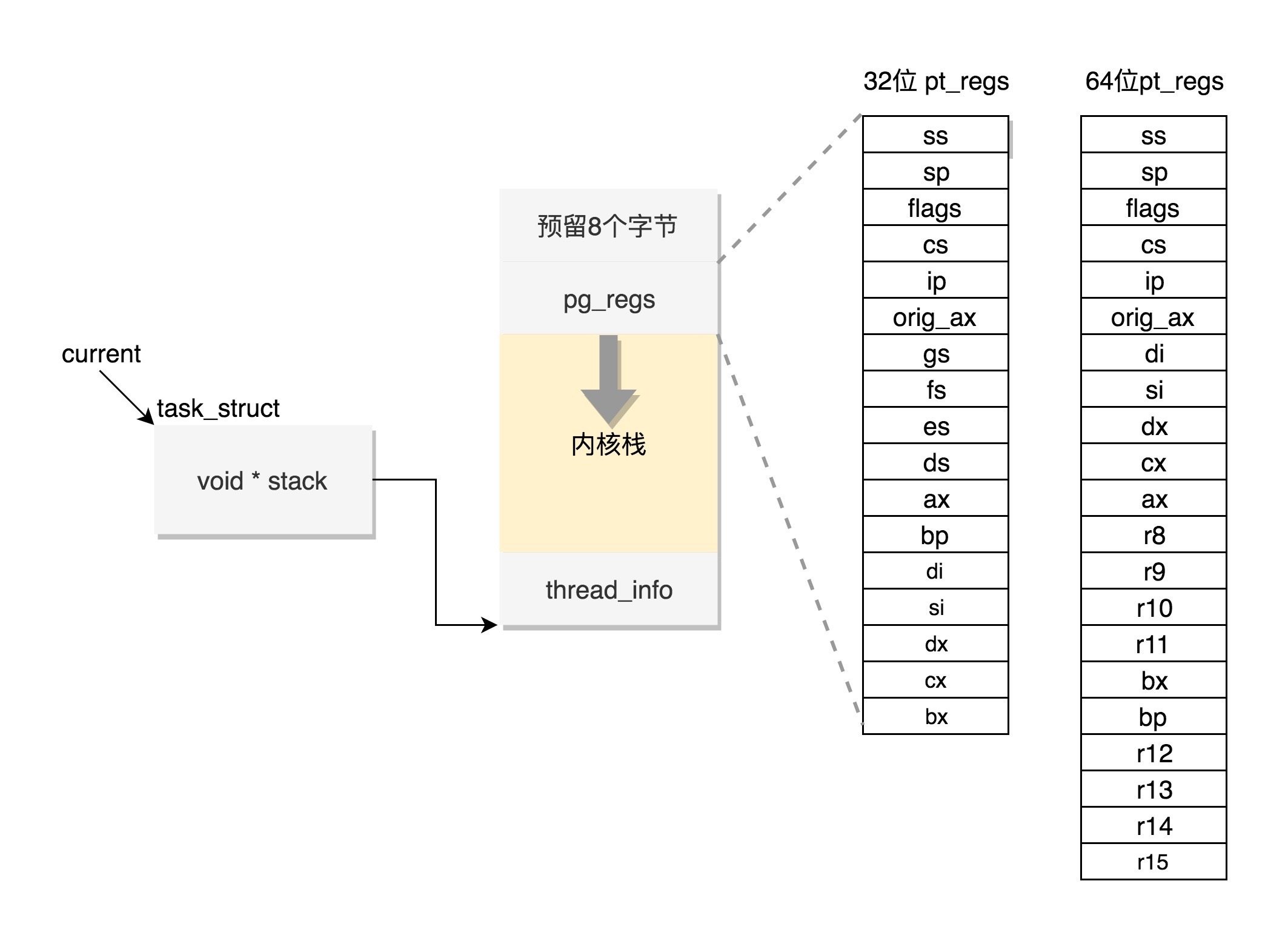
内核栈是一个非常特殊的结构¶
这段空间的最低位置,是一个 thread_info 结构。这个结构是对 task_struct 结构的补充。因为 task_struct 结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在 thread_info 里面。
15 | 调度-上¶
调度策略与调度类¶
在 Linux 里面,进程大概可以分成两种:
1. 实时进程
优先级的范围是 0~99
2. 普通进程
优先级的范围是 100~139
实时调度策略:
1. SCHED_FIFO
高优先级的进程可以抢占低优先级的进程
相同优先级的进程,遵循先来先得
2. SCHED_RR(轮流调度算法)
采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性
而高优先级的任务也是可以抢占低优先级的任务。
3. SCHED_DEADLINE
按照任务的 deadline 进行调度的
当产生一个调度点的时候,总选择 deadline 点最近的那个任务,并调度它执行
普通调度策略:
1. SCHED_NORMAL
普通的进程
2. SCHED_BATCH
后台进程,几乎不需要和前端进行交互
可以默默执行,不要影响需要交互的进程,可以降低它的优先级
3. SCHED_IDLE
特别空闲的时候才跑的进程
完全公平调度算法¶
CFS 全称 Completely Fair Scheduling,叫完全公平调度
需要记录下进程的运行时间。CPU 会提供一个时钟,过一段时间就触发一个时钟中断。就像咱们的表滴答一下,这个我们叫 Tick。
CFS 会为每一个进程安排一个虚拟运行时间 vruntime。
如果一个进程在运行,随着时间的增长,也就是一个个 tick 的到来,进程的 vruntime 将不断增大。
没有得到执行的进程 vruntime 不变。
显然,那些 vruntime 少的,原来受到了不公平的对待,需要给它补上,所以会优先运行这样的进程。
虚拟运行时间 vruntime += 实际运行时间 delta_exec * NICE_0_LOAD/ 权重
调度队列与调度实体¶
所有的调度策略都需要一个数据结构来对 vruntime 进行排序,找出最小的那个。这个能够排序的数据结构不但需要查询的时候,能够快速找到最小的,更新的时候也需要能够快速地调整排序,要知道 vruntime 可是经常在变的,变了再插入这个数据结构,就需要重新排序。能够平衡查询和更新速度的是树,在这里使用的是红黑树。
参考¶
http://www.wowotech.net/process_management/scheduler-history.html
https://www.ibm.com/developerworks/cn/linux/l-cn-scheduler/index.html
Posix Threads API: http://man7.org/linux/man-pages/man7/pthreads.7.html
16 | 调度-中¶
调度, 切换运行进程, 有两种方式:
- 进程调用 sleep 或等待 I/O, 主动让出 CPU
- 进程运行一段时间, 被动让出 CPU
进程上下文切换¶
上下文切换主要干两件事情:
1. 切换进程空间,也即虚拟内存
2. 切换寄存器和 CPU 上下文
17 | 调度-下¶
真正发生调度的种情况:
1. 主动调试
2. 抢占式调度
抢占式调度¶
可能抢占的场景:
1. 一个进程执行时间太长了,是时候切换到另一个进程了
2. 当一个进程被唤醒的时候
18 | 进程的创建¶
fork 系统调用的过程包含两个重要的事件:
1. 是将 task_struct 结构复制一份并且初始化
2. 试图唤醒新创建的子进程
19 | 线程的创建¶
线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的。
创建进程的话,调用的系统调用是 fork,在 copy_process 函数里面,会将五大结构 files_struct、fs_struct、sighand_struct、signal_struct、mm_struct 都复制一遍,从此父进程和子进程各用各的数据结构。
创建线程的话,调用的系统调用是 clone,在 copy_process 函数里面, 五大结构仅仅是引用计数加一,也即线程共享进程的数据结构。
其他:
$ pstree -apl pid看进程树
$ pstack pid 看栈
第四部分 内存管理 (7 讲)¶
20 | 内存管理-上¶
一个内存管理系统至少应该做三件事情:
1. 虚拟内存空间的管理,每个进程看到的是独立的、互不干扰的虚拟地址空间
2. 物理内存的管理,物理内存地址只有内存管理模块能够使用
3. 内存映射,需要将虚拟内存和物理内存映射、关联起来
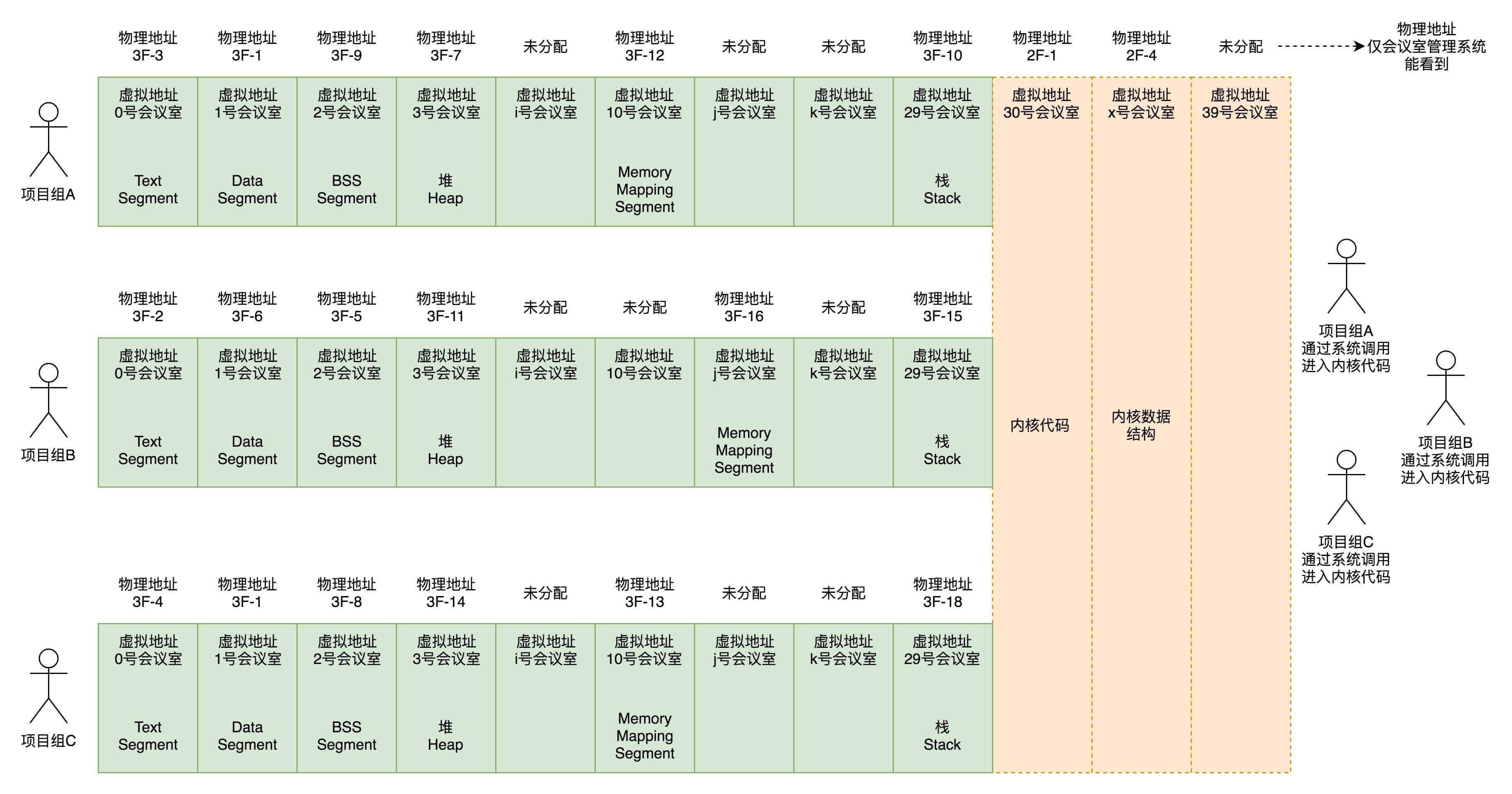
Text Segment 是存放二进制可执行代码的位置,Data Segment 存放静态常量,BSS Segment 存放未初始化的静态变量。内核的代码访问内核的数据结构,大部分的情况下都是使用虚拟地址的,虽然内核代码权限很大,但是能够使用的虚拟地址范围也只能在内核空间,也即内核代码访问内核数据结构。只能用 30 号到 39 号这些编号,不能用 0 到 29 号,因为这些是被进程空间占用的。内核代码也是 ELF 格式的,同样有 Text Segment、Data Segment 和 BSS Segment。¶
21 | 内存管理-下¶
内存管理系统:
1. 虚拟内存空间的管理,将虚拟内存分成大小相等的页
2. 物理内存的管理,将物理内存分成大小相等的页
3. 内存映射,将虚拟内存页和物理内存页映射起来,并且在内存紧张的时候可以换出到硬盘中
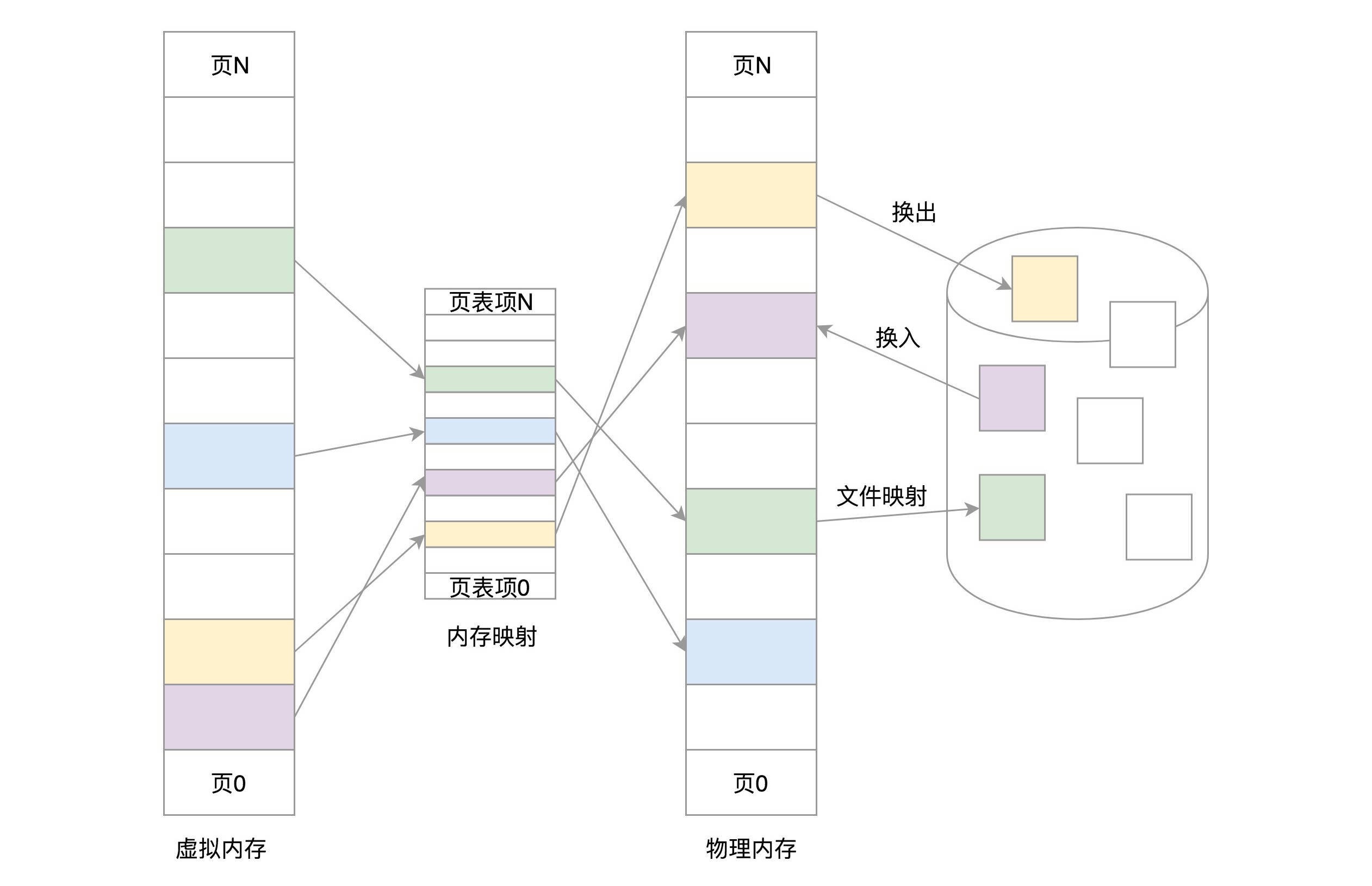
内存管理系统¶
分段机制¶
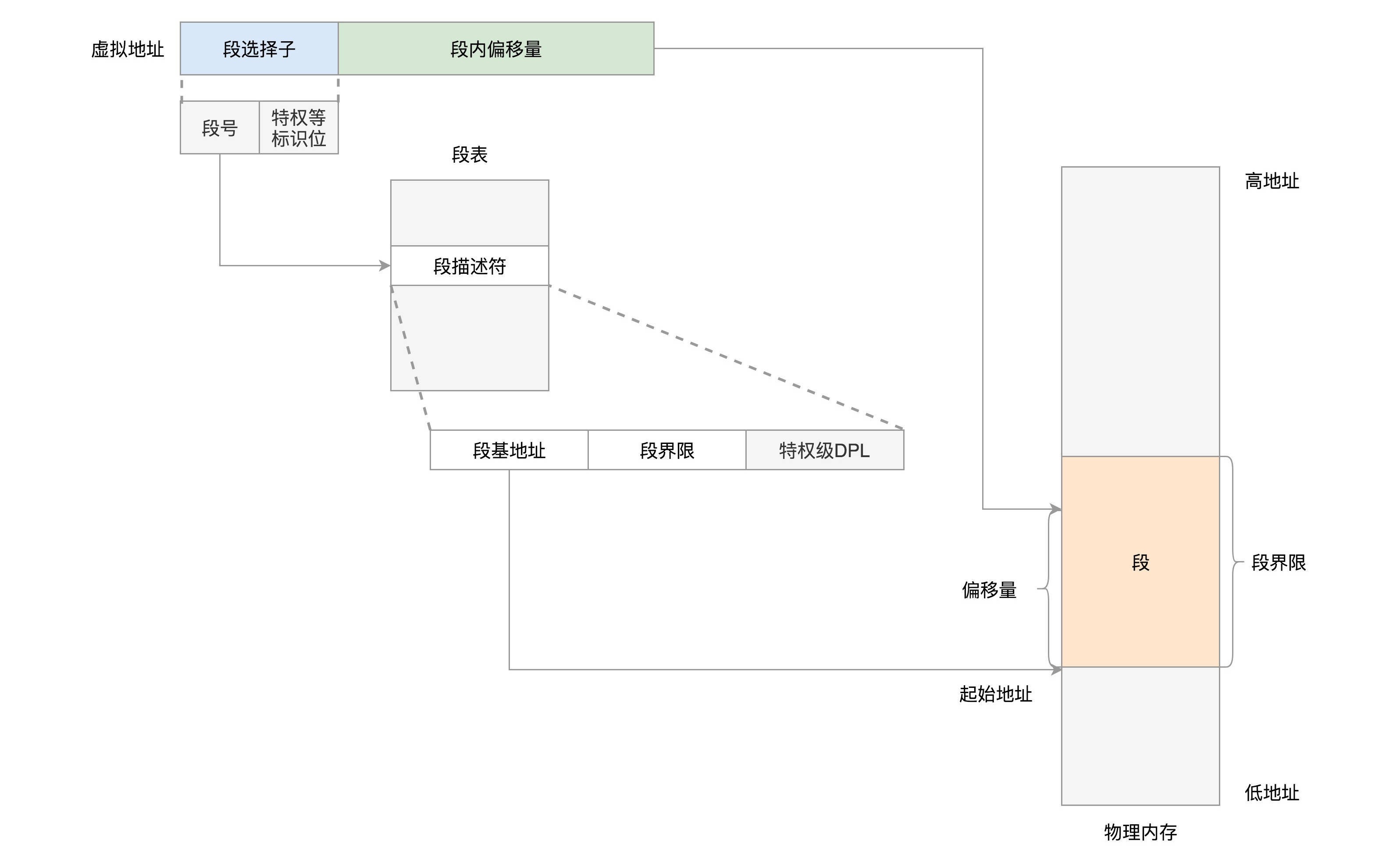
分段机制原理:分段机制下的虚拟地址由两部分组成,段选择子和段内偏移量。¶
段选择子里面最重要的是段号,用作段表的索引。
段表里面保存的是这个段的基地址、段的界限和特权等级等。
虚拟地址中的段内偏移量应该位于 0 和段界限之间。
如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
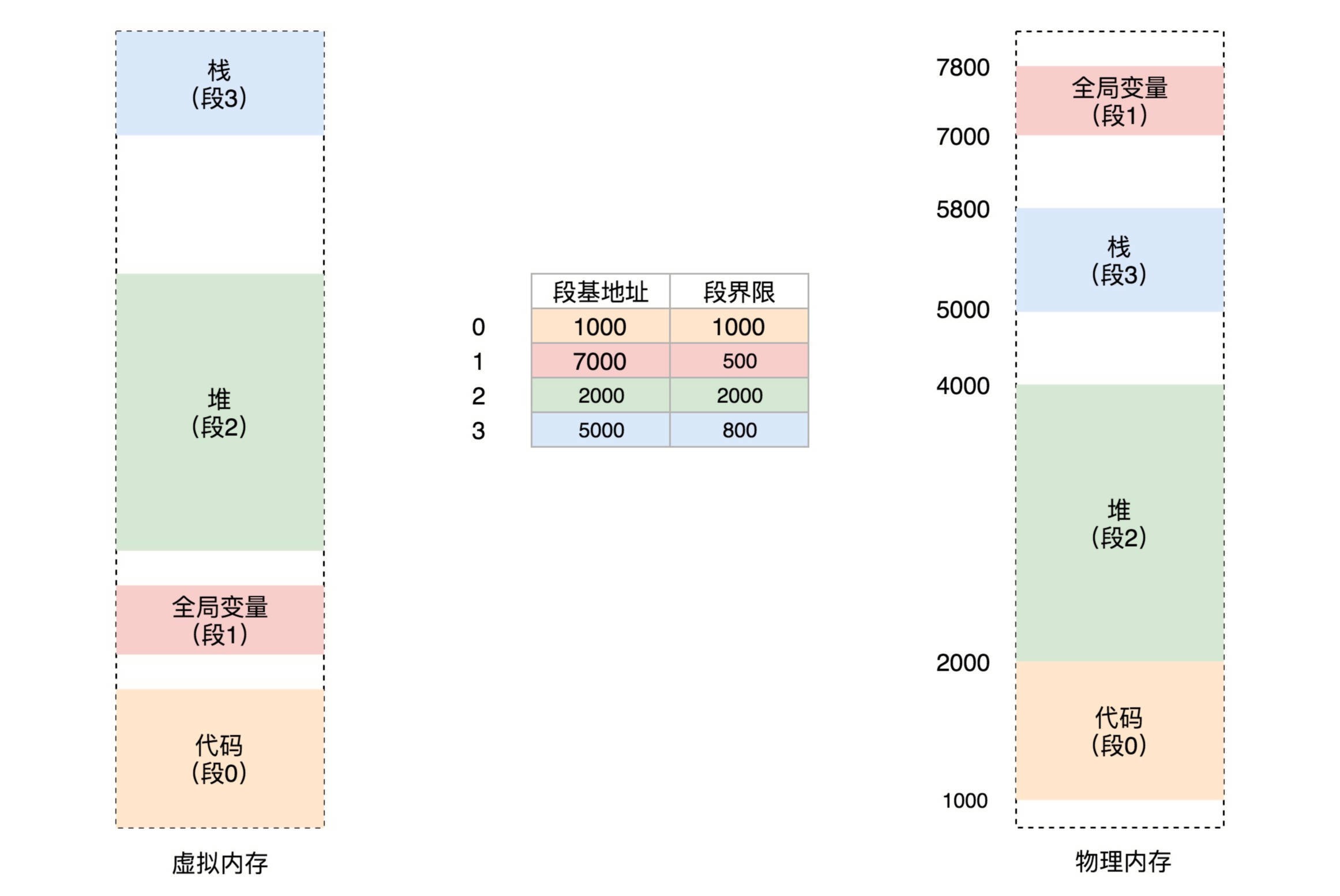
如果要访问段 2 中偏移量 600 的虚拟地址,我们可以计算出物理地址为,段 2 基地址 2000 + 偏移量 600 = 2600。¶
Linux 使用分段机制¶
在 Linux 里面,段表全称是段描述符表(segment descriptors),放在全局描述符表 GDT(Global Descriptor Table)里面。
备注
在 Linux 操作系统中,并没有使用到全部的分段功能。但分段可以做权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。
Linux 使用分页-Paging机制¶
备注
[优缺点]相比分布,分段容易碎片,不容易换出。
Linux 倾向于另外一种从虚拟地址到物理地址的转换方式,称为分页(Paging)
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫做换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。
页面的大小一般为 4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址
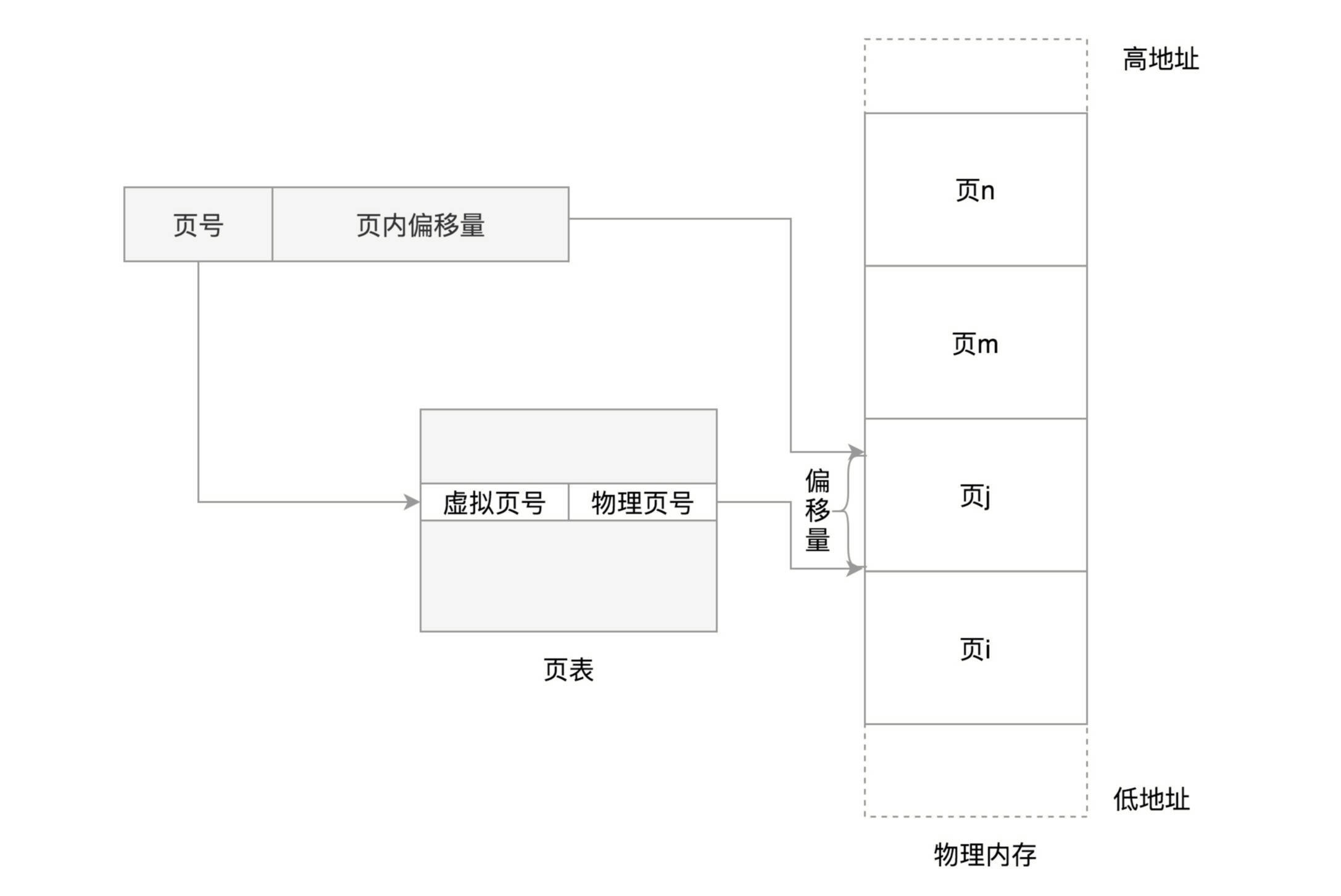
虚拟地址分为两部分,页号和页内偏移。¶
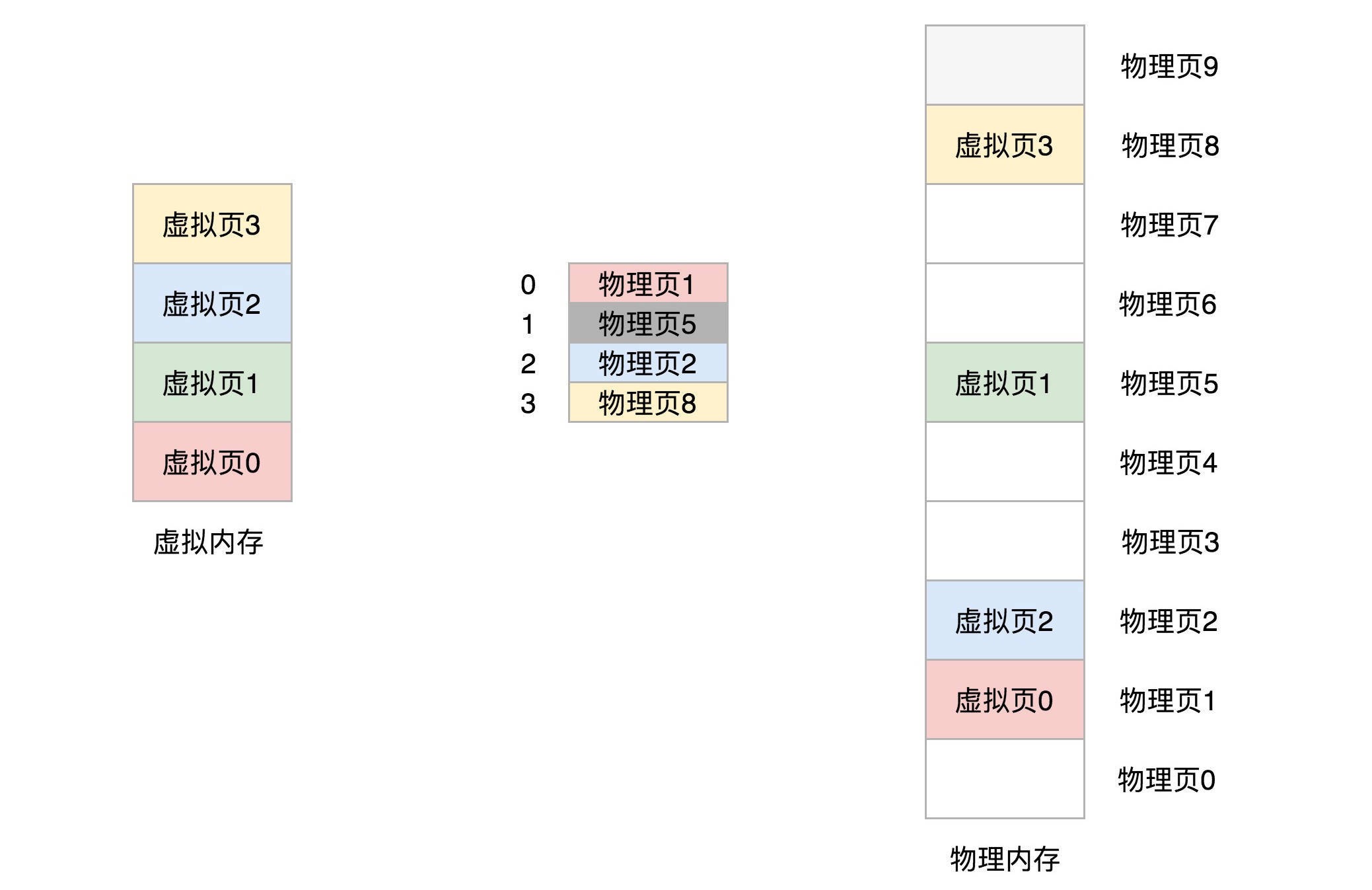
简单的页表的例子,虚拟内存中的页通过页表映射为了物理内存中的页。¶
备注
[缺点]32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了。
页表再分页¶
将页表再分页,4G 的空间需要 4M 的页表来存储映射。我们把这 4M 分成 1K(1024)个 4K,每个 4K 又能放在一页里面,这样 1K 个 4K 就是 1K 个页,这 1K 个页也需要一个表进行管理,我们称为``页目录表``,这个页目录表里面有 1K 项,每项 4 个字节,页目录表大小也是 4K。
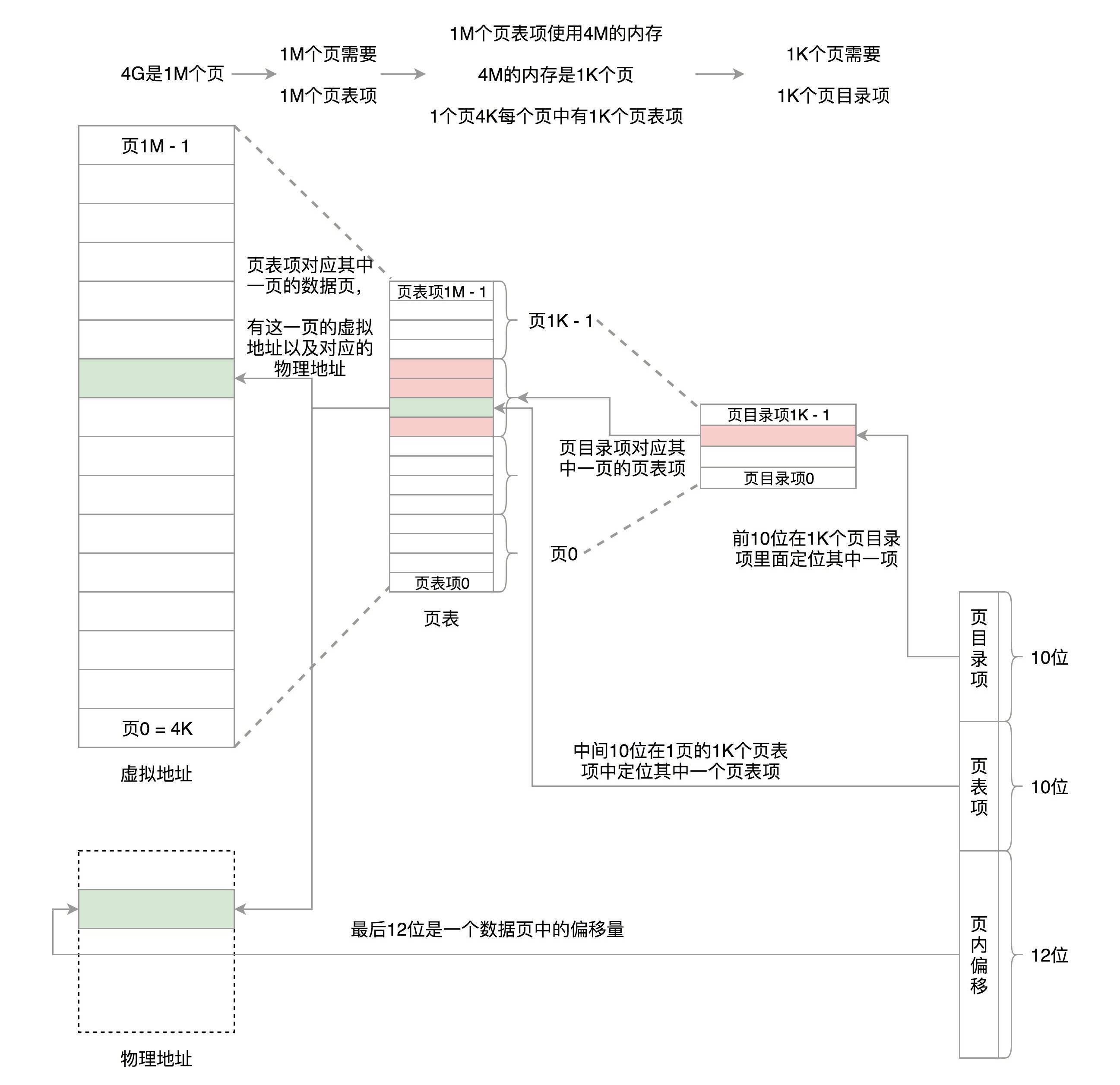
页目录有 1K 项,用 10 位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即 4K 的页表项。每个页表项也是 4 个字节,因而一整页的页表项是 1K 个。再用 10 位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是 4K,用 12 位可以定位这个页内的任何一个位置。这样加起来正好 32 位,也就是用前 10 位定位到页目录表中的一项。将这一项对应的页表取出来共 1k 项,再用中间 10 位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后 12 位定位到页中的具体位置访问数据。¶
备注
你可能会问,如果这样的话,映射 4GB 地址空间就需要 4MB+4KB 的内存,这样不是更大了吗?假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的 1M 个页表项共 4M 的内存,但是如果使用了页目录,页目录需要 1K 个全部分配,占用内存 4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多 4K,这样内存就节省多了。
64 位的系统¶
两级肯定不够了,就变成了四级目录,分别是全局页目录项 PGD(Page Global Directory)、上层页目录项 PUD(Page Upper Directory)、中间页目录项 PMD(Page Middle Directory)和页表项 PTE(Page Table Entry)。
参考¶
22 | 进程空间管理¶
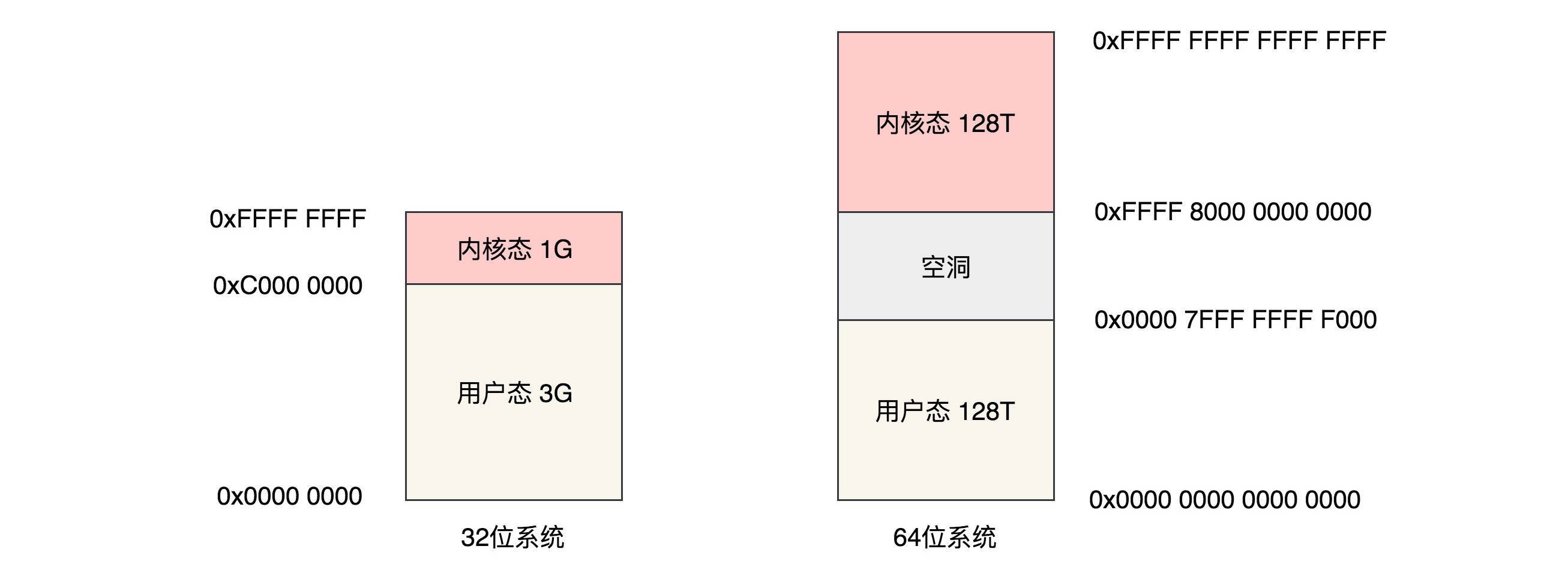
对于 32 位系统,最大能够寻址 2^32=4G,其中用户态虚拟地址空间是 3G,内核态是 1G。对于 64 位系统,虚拟地址用户态只使用了 48 位,同样,内核空间也是 128T,内核空间和用户空间之间隔着很大的空隙,以此来进行隔离。¶
23 | 物理内存管理-上¶
备注
物理页连续,page 放入一个数组中,称为平坦内存模型;2. NUMA(Non-uniform memory access) 采用非连续内存模型,页号不连续;3. 另外若内存支持热插拔,则采用稀疏内存模型
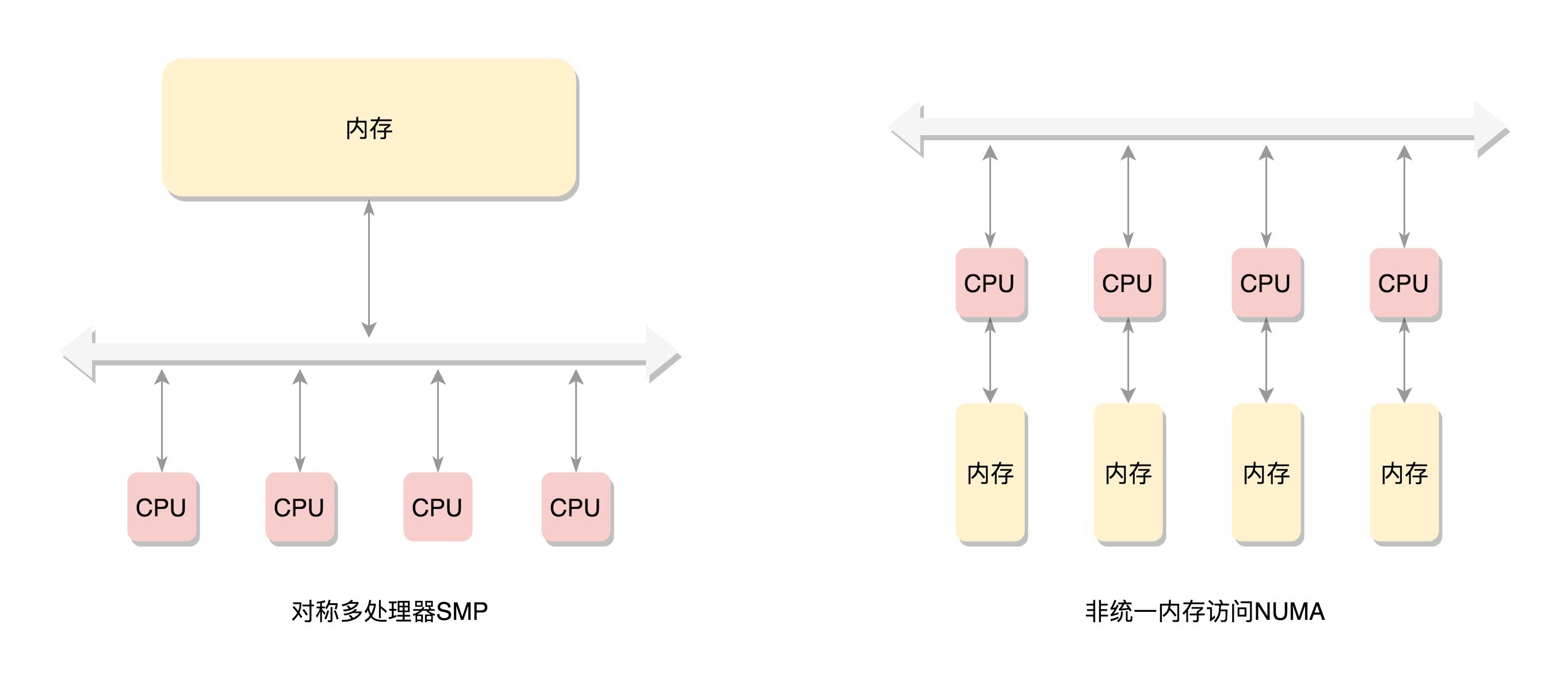
多个 CPU 通过总线访问内存,称为 SMP 对称多处理器 (采用平坦内存模型,总线成为瓶颈);每个 CPU 都有本地内存,访问内存不用总线,称为 NUMA 非一致内存访问¶
伙伴系统-Buddy System¶
备注
对于要分配比较大的内存,例如到分配页级别的,可以使用伙伴系统(Buddy System)。伙伴系统是一个能够 “尽可能减少内存外碎片” 的物理内存分配器。伙伴系统是一种非常精妙的实现方式,无论你使用什么语言,请自己实现一个这样的分配系统,说不定哪天你在做某个系统的时候,就用到了。
定义¶
备注
【定义】当两个小伙伴其中一个有任务时,两个小伙伴就会分开;而当任务完成后,比如报文已经被处理完毕,页面被释放,两个小伙伴又会重新团聚,手拉手合二为一。
伙伴系统支持连续物理页分配和释放,其主要思想是通过将物理内存划分成多个连续的块,然后以 “块” 作为基本单位进行分配。这些 “块” 的都是由一个或者多个连续的物理页组成,物理页的数量是 2 的 n 次幂(0 <= n <= MAX_ORDER)。
详解¶
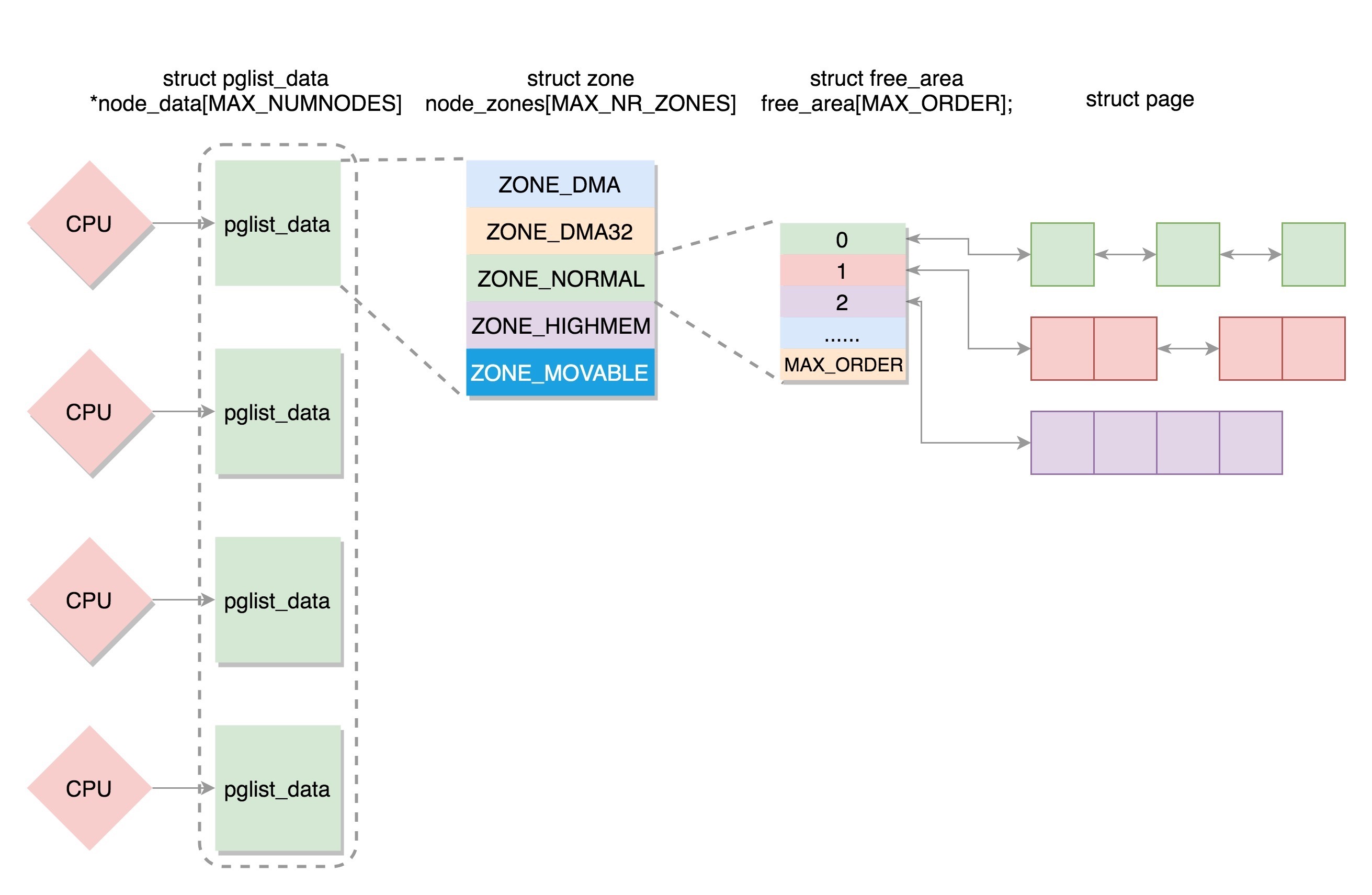
Linux 中的内存管理的 “页” 大小为 4KB。把所有的空闲页分组为 11 个页块链表,每个块链表分别包含很多个大小的页块,有 1(2^0)、2、4、8、16、32、64、128、256、512 和 1024(2^10) 个连续页的页块。最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。每个页块的第一个页的物理地址是该页块大小的整数倍。¶
备注
当向内核请求分配 (2^(i-1),2^i] 数目的页块时,按照 2^i 页块请求处理。如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中。
例如,要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
分裂合并的过程¶
当请求分配 N 个连续的物理页时,首先会去寻找一个合适大小的内存块,如果没有找到相匹配的空闲页,则将更为大的块分割成 2 个小块, 这两个小块就是 “伙伴” 关系。 分割得到的小块可以继续分裂,直到能够得到一个大小合适的块响应请求的分配。
同样,当一个块被释放后,分配器会找到其伙伴块,如果该伙伴块也处于空闲的状态,那么就将这两个伙伴块进行合并,形成一个大一号的空闲块, 大号的空闲块也可以继续向上合并。
24 | 物理内存管理-下¶
内存页总共分两类,一类是匿名页,和虚拟地址空间进行关联;一类是内存映射,不但和虚拟地址空间关联,还和文件管理关联。
对于物理内存来讲,从下层到上层的关系及分配模式如下:
1. 物理内存分 NUMA 节点,分别进行管理
2. 每个 NUMA 节点分成多个内存区域
3. 每个内存区域分成多个物理页面
4. 伙伴系统将多个连续的页面作为一个大的内存块分配给上层
5. kswapd 负责物理页面的换入换出
6. Slub Allocator 将从伙伴系统申请的大内存块切成小块,分配给其他系统
参考¶
Linux 交换分区 SWAP: https://mp.weixin.qq.com/s/6JVpke8bDKI9lvh_l6QF-w
25 | 用户态内存映射¶
用户态的内存映射机制包含以下几个部分:
1. 用户态内存映射函数 mmap,包括用它来做匿名映射和文件映射
2. 用户态的页表结构,存储位置在 mm_struct 中
3. 在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。
如果是匿名映射则分配物理内存;
如果是 swap,则将 swap 文件读入;
如果是文件映射,则将文件读入
26 | 内核态内存映射¶
内核态的内存映射机制,主要包含以下几个部分:
1. 内核态内存映射函数 vmalloc、kmap_atomic 是如何工作的;
2. 内核态页表是放在哪里的,如何工作的?swapper_pg_dir 是怎么回事;
3. 出现了内核态缺页异常应该怎么办?
第五部分 文件系统 (4 讲)¶
27 | 文件系统¶
文件系统的功能规划:
1. 文件系统要有严格的组织形式,使得文件能够以块为单位进行存储
2. 文件系统要有索引区,方便查找一个文件分成的多个块存放的位置
3. 文件系统要有缓存层,用于处理热点文件
4. 文件应该用文件夹的形式组织起来,方便管理和查询
5. Linux 内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用
6. 在用户态,每个打开的文件都有一个文件描述符,可通过各种文件相关的系统调用,操作这个文件描述符
文件系统相关系统调用:
- open 打开一个文件
- write 写数据
- lseek 重新定位读写位置
- read 读数据
- close 关闭文件
- stat/lstat 通过文件名获取文件信息;fstat 通过 fd 获取文件信息
- opendir 打开一个目录,生成一个目录流 DIR
- readdir 读取目录流的一个条目,自动指向下一个条目
- closedir 关闭目录流
28 | 硬盘文件系统¶
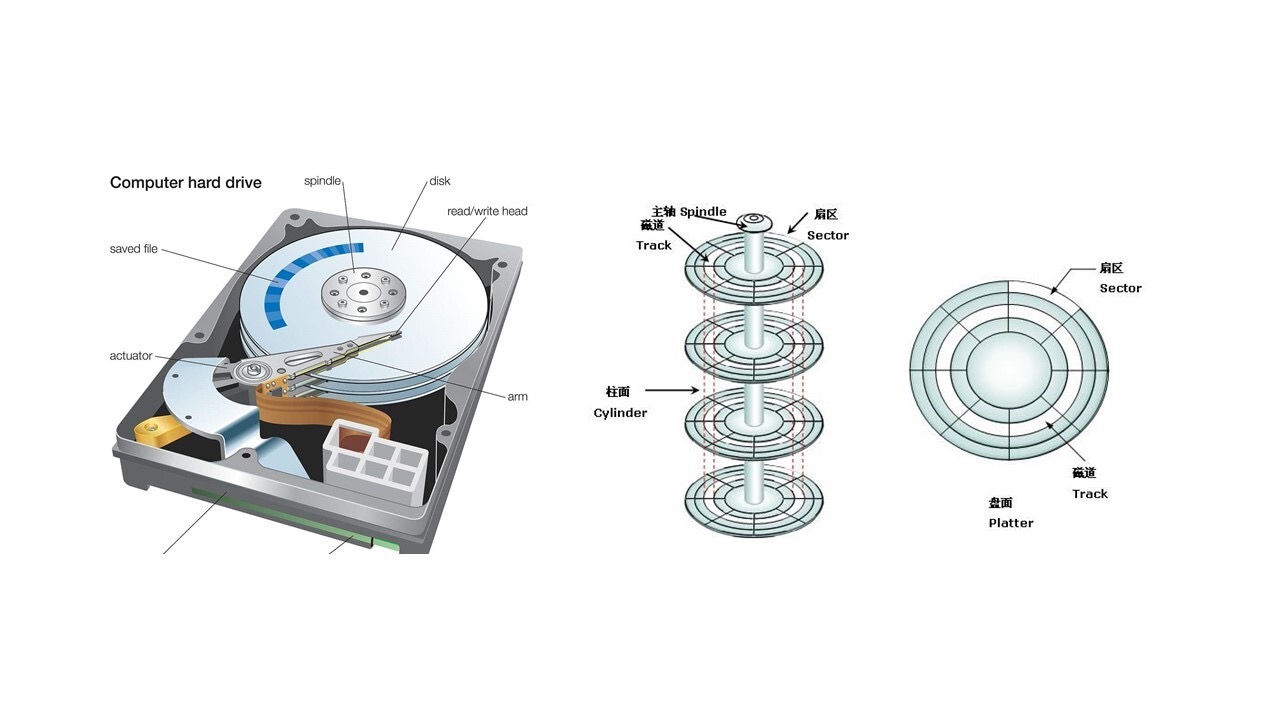
左边是实物图,中间圆的部分是磁盘的盘片,右边的图是抽象出来的图。每一层里分多个磁道,每个磁道分多个扇区,每个扇区是 512 个字节。¶
inode 与块的存储¶
备注
硬盘分成相同大小的单元,我们称为块(Block)。一块的大小是扇区大小的整数倍,默认是 4K。在格式化的时候,这个值是可以设定的。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。但这样也带来问题,找起来困难,需要设立一个索引区域,用来维护 “某个文件分成几块、每一块在哪里” 等等这些基本信息 ?另外,文件还有元数据部分,例如名字、权限等,这就需要一个结构 inode 来存放。
备注
什么是 inode 呢?inode 的 “i” 是 index 的意思,其实就是 “索引”。每个文件都会对应一个 inode;一个文件夹就是一个文件,也对应一个 inode。
inode 里面有文件的信息:
1. 读写权限 i_mode,
2. 属于哪个用户 i_uid,
3. 哪个组 i_gid,
4. 大小是多少 i_size_io,
5. 占用多少个块 i_blocks_io
inode 里面有文件相关的时间:
1. i_atime 是 access time,是最近一次访问文件的时间;
2. i_ctime 是 change time,是最近一次更改 inode 的时间;
3. i_mtime 是 modify time,是最近一次更改文件的时间
注意:
首先,访问可能只是打开看看,只会改变 access time。
其次,修改 inode,有可能修改的是用户和权限,没有修改数据部分,只会改变 change time。
最后,只有数据也修改了,才改变 modify time。
ext2 和 ext3¶
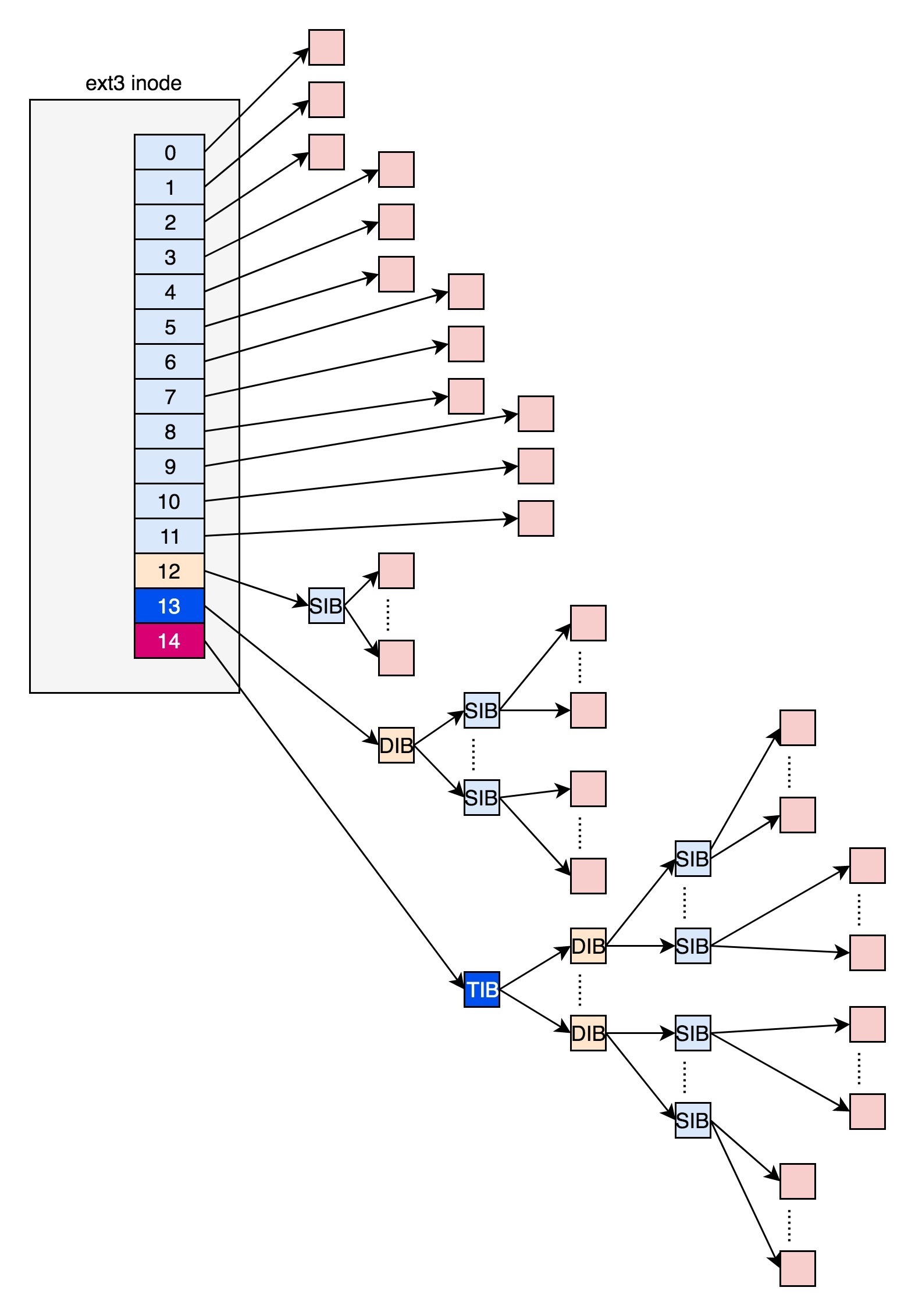
前 12 项直接保存了块的位置,也就是说,我们可以通过 i_block [0-11],直接得到保存文件内容的块。如果一个文件比较大,12 块放不下,可以让 i_block [12] 指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。之后还可以用用二次间接块(i_block [13])和三次间接块(i_block [14])¶
备注
这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
ext4¶
备注
引入了一个新的概念,叫做 Extents。【定义】一个文件大小为 128M,如果使用 4k 大小的块进行存储,需要 32k 个块。如果按照 ext2 或者 ext3 那样散着放,数量太大了。但是 Extents 可以用于存放连续的块,也就是说,我们可以把 128M 放在一个 Extents 里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
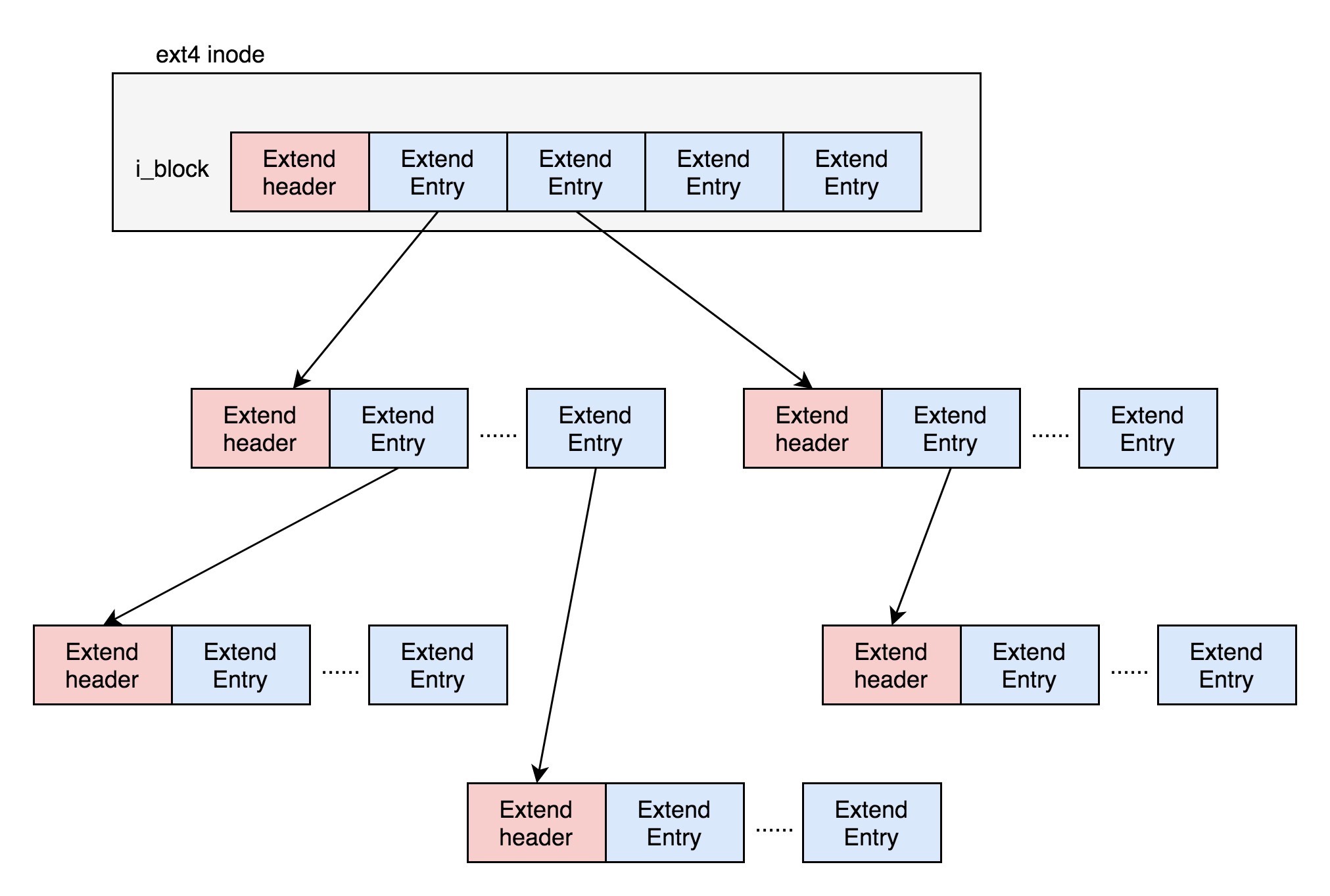
Exents 如何存储:保存成一棵树。树有一个个的节点,有叶子节点,也有分支节点。每个节点都有一个头,ext4_extent_header 可以用来描述某个节点。如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树。除了根节点(只有4项Entity),其他的节点都保存在一个块(4k)里面。¶
ext4_extent_header 结构:
struct ext4_extent_header {
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};
其中, eh_entries 表示这个节点里面有多少项。这里的项分两种:
1. 如果是叶子节点,直接指向硬盘上的连续块的地址,我们称为数据节点 ext4_extent
2. 如果是分支节点,指向下一层的分支节点或者叶子节点,我们称为索引节点 ext4_extent_idx
这两种类型的项的大小都是 12 个 byte:ext4_extent和ext4_extent_idx 结构:
// 数据节点
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
// 索引节点
struct ext4_extent_idx {
__le32 ei_block; /* index covers logical blocks from 'block' */
__le32 ei_leaf_lo; /* pointer to the physical block of the next level. leaf or next index could be there */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};
eh_depth 说明:
eh_depth>0 的节点就是索引节点,其中根节点深度最大
eh_depth=0 的是叶子节点。
除了根节点,其他的节点都保存在一个块(4k)里。4k 减去 ext4_extent_header 的 12 个 byte,剩下4096-12=4084。一个项(Entity)大小是12byte,剩下4084的能够放 340 项(4084/12=340.33),每个 extent 最大能表示 128MB 的数据,340 个 extent entity 会使你表示的文件达到 42.5GB。
inode 位图和块位图¶
专门弄了一个块来保存 inode 的位图。在这 4k 里面,每一位对应一个 inode,共可以表示 4∗1024∗8=2^15 个inode。如果是 1,表示这个 inode 已经被用了;如果是 0,则表示没被用。同样,我们也弄了一个块保存 block 的位图。
数据块的位图是放在一个块里面的,共 4k。每位表示一个数据块,共可以表示 4∗1024∗8=2^15 个数据块。如果每个数据块也是按默认的 4K,最大可以表示空间为 2^15∗4∗1024=2^27 个 byte,也就是 128M。也就是说按照上面的格式,如果采用 “一个块的位图 + 一系列的块”,外加 “一个块的 inode 的位图 + 一系列的 inode 的结构”,最多能够表示 128M。我们把这个结构称为一个块组。
块组描述符表
超级块
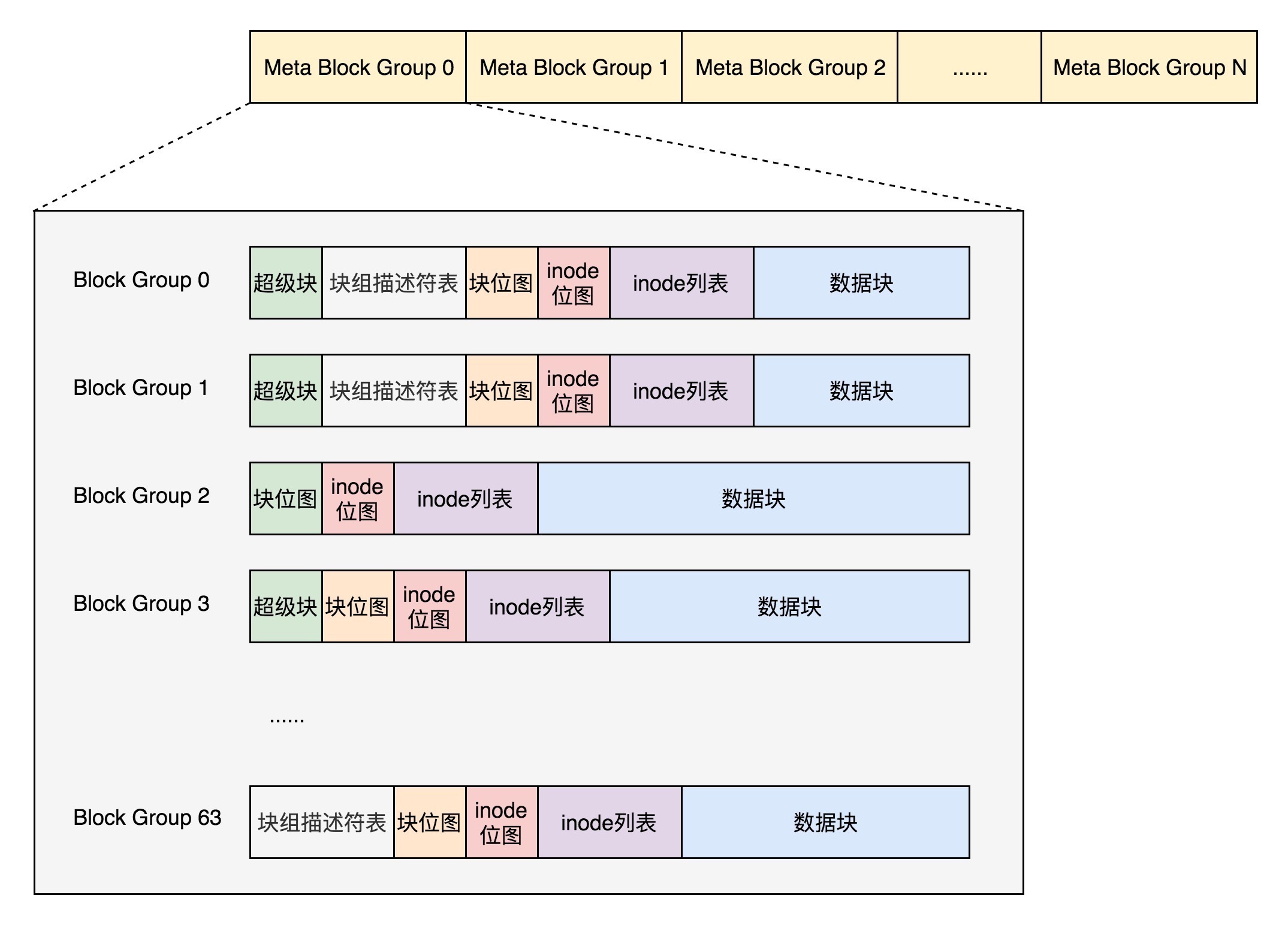
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含 64 个块组,这样一个元块组中的块组描述符表最多 64 项。我们假设一共有 256 个块组,原来是一个整的块组描述符表,里面有 256 项,要备份就全备份,现在分成 4 个元块组,每个元块组里面的块组描述符表就只有 64 项了,这就小多了,而且四个元块组自己备份自己的。¶
目录的存储格式¶
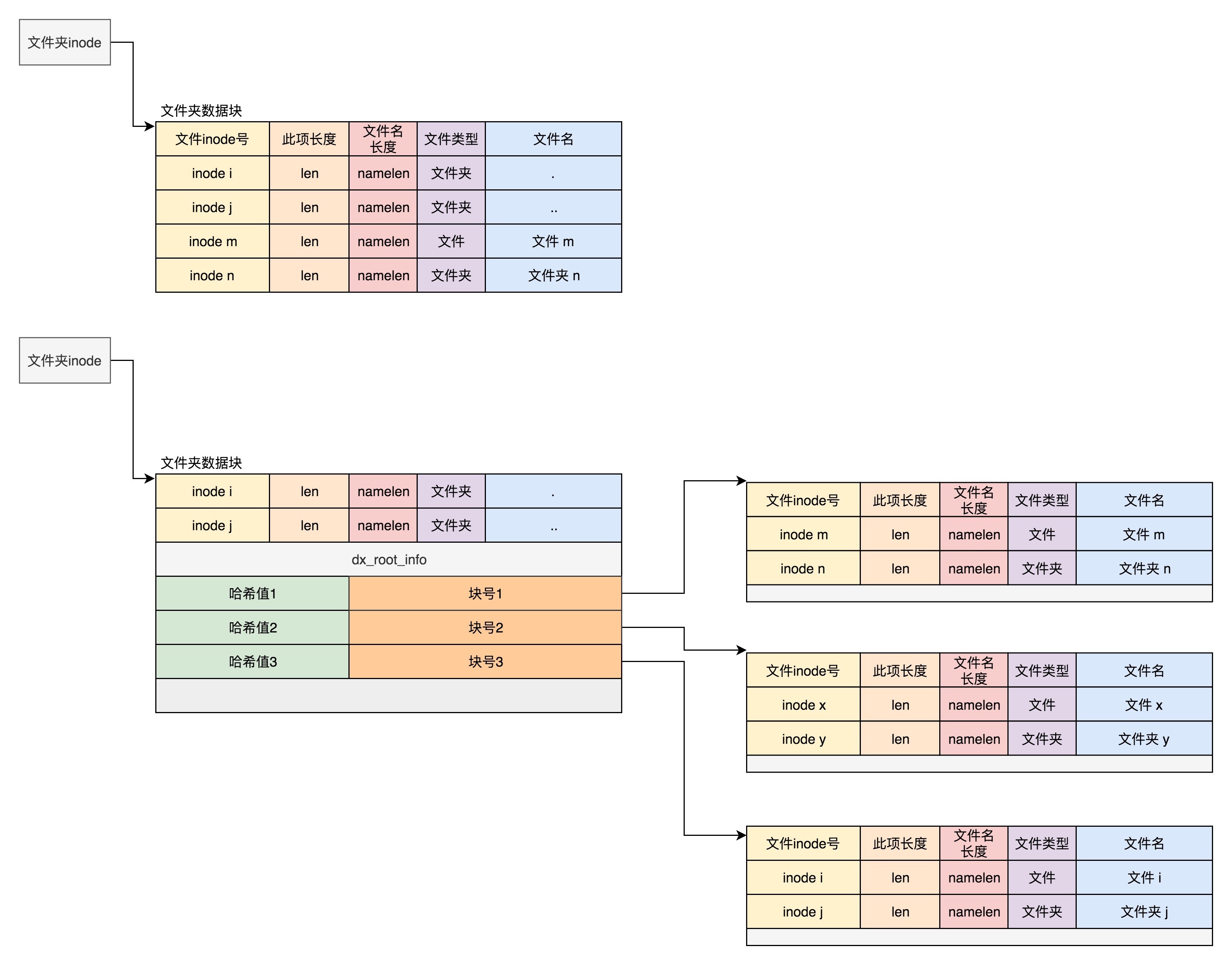
要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是 ext4_dir_entry_2 的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的 N 多的文件分散到很多的块里面,可以很快地进行查找。¶
软链接和硬链接的存储格式¶
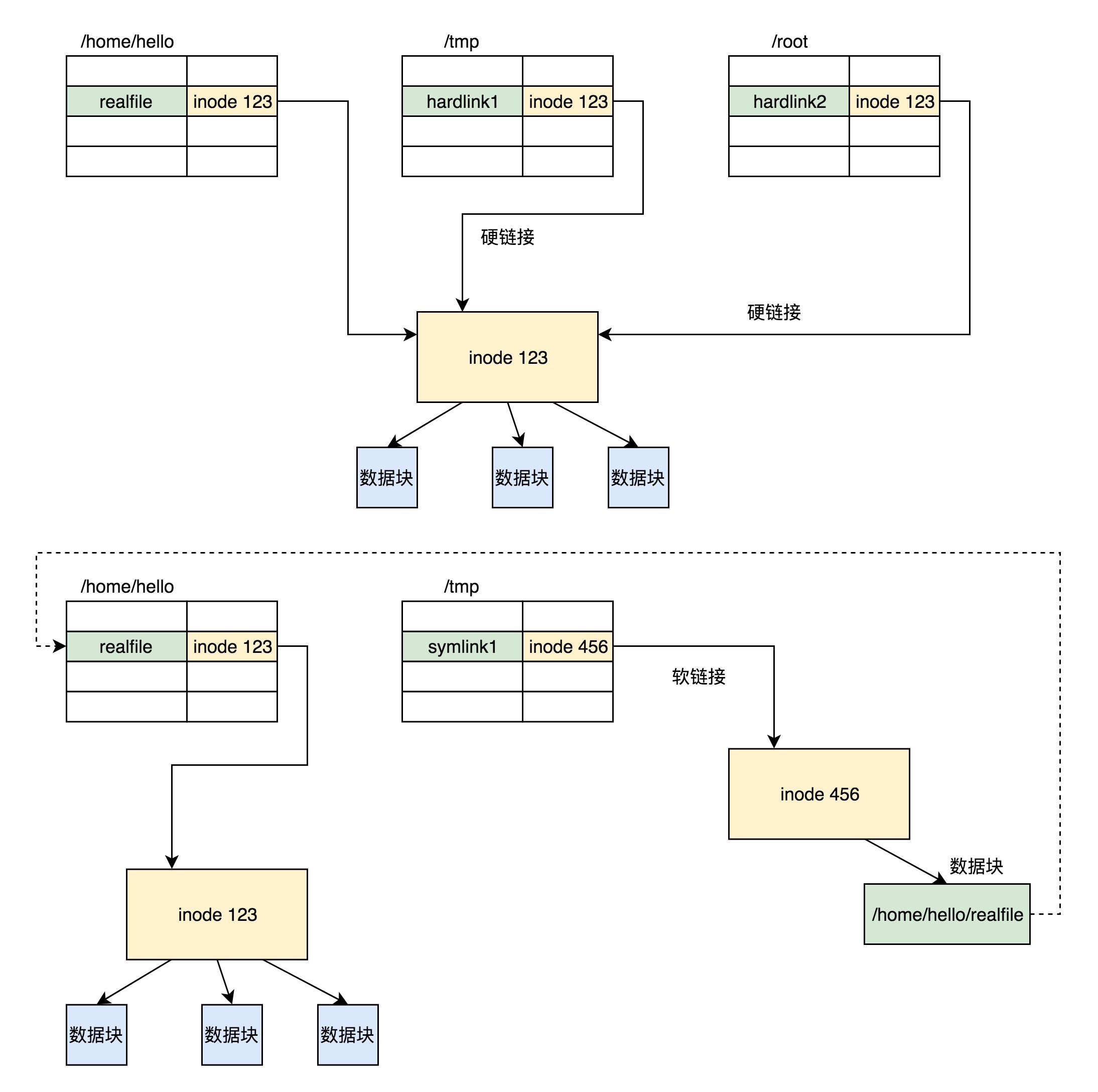
硬链接与原始文件共用一个 inode 的,但是 inode 是不跨文件系统的,每个文件系统都有自己的 inode 列表,因而硬链接是没有办法跨文件系统的。¶
总结¶
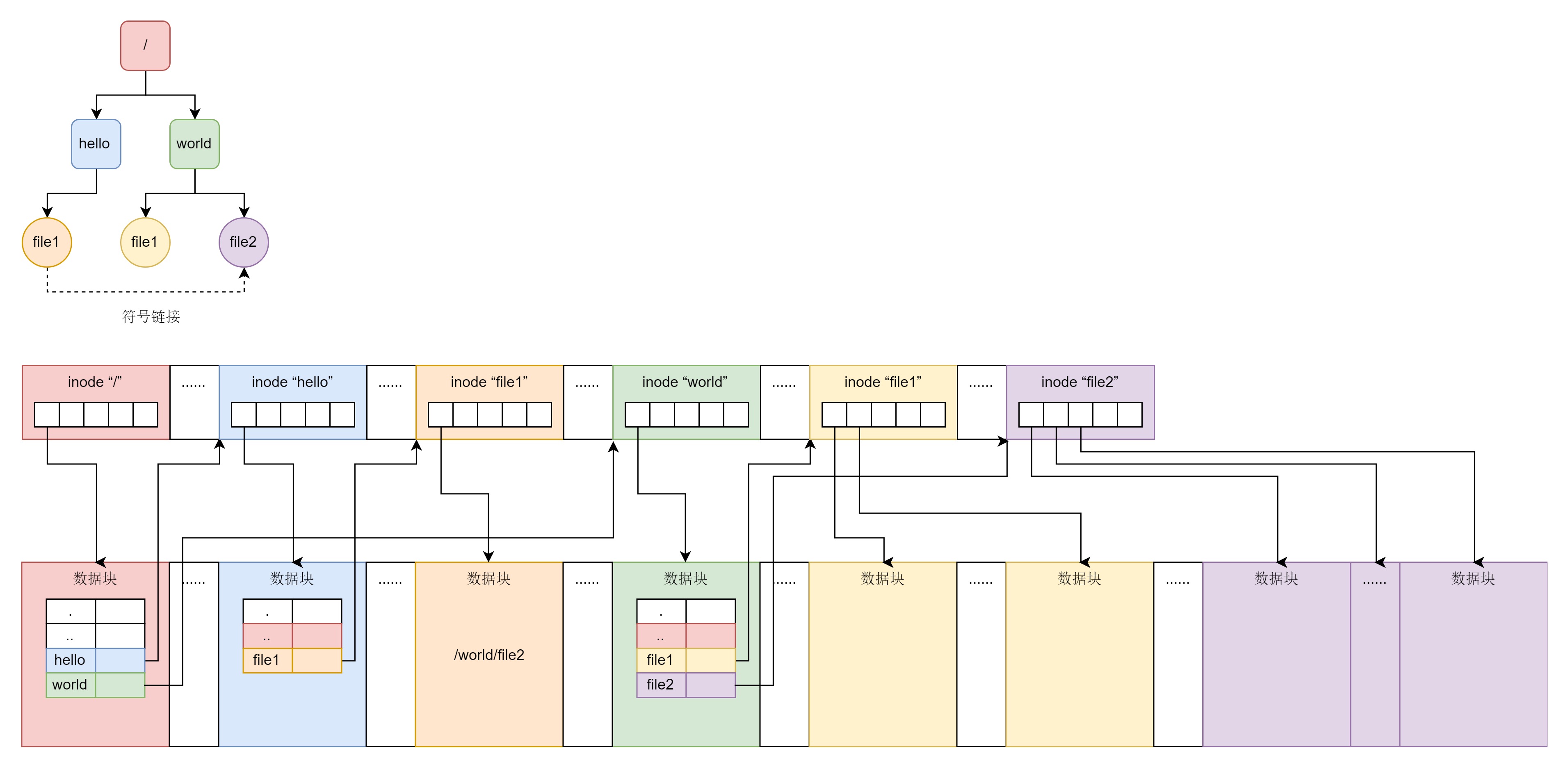
无论是文件夹还是文件,都有一个 inode。inode 里面会指向数据块,对于文件夹的数据块,里面是一个表,是下一层的文件名和 inode 的对应关系,文件的数据块里面存放的才是真正的数据。¶
29 | 虚拟文件系统¶
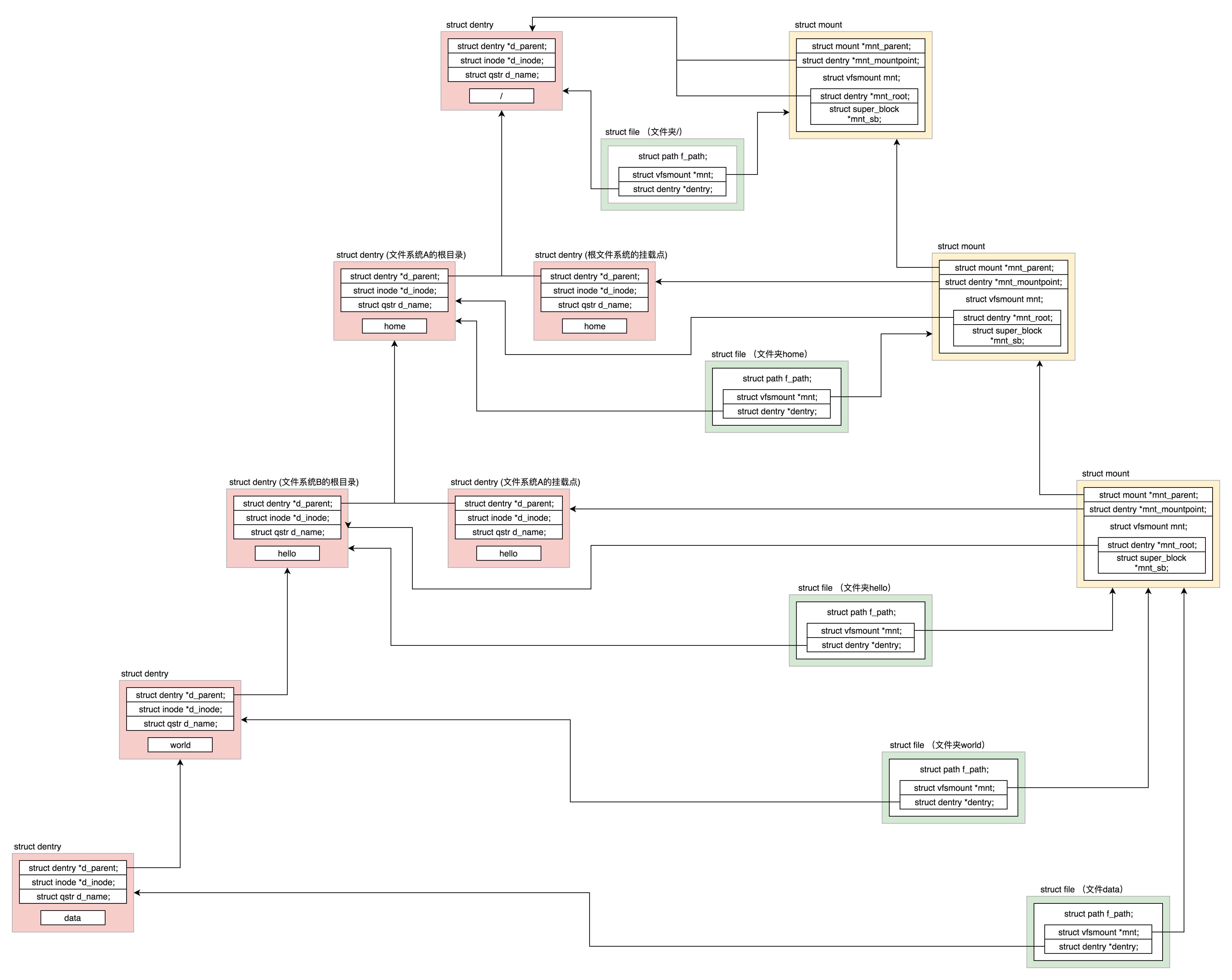
1.根文件系统是系统启动的时候挂载的,假设根文件系统下面有一个目录 home。2.另外有一个文件系统 A 挂载在这个目录 home 下面。在文件系统 A 的根目录下面有另外一个文件夹 hello。由于文件系统 A 已经挂载到了目录 home 下面,所以我们就有了目录 /home/hello,3.然后有另外一个文件系统 B 挂载在 /home/hello 下面。在文件系统 B 的根目录下面有另外一个文件夹 world,在 world 下面有个文件夹 data。由于文件系统 B 已经挂载到了 /home/hello 下面,所以我们就有了目录 /home/hello/world/data。¶
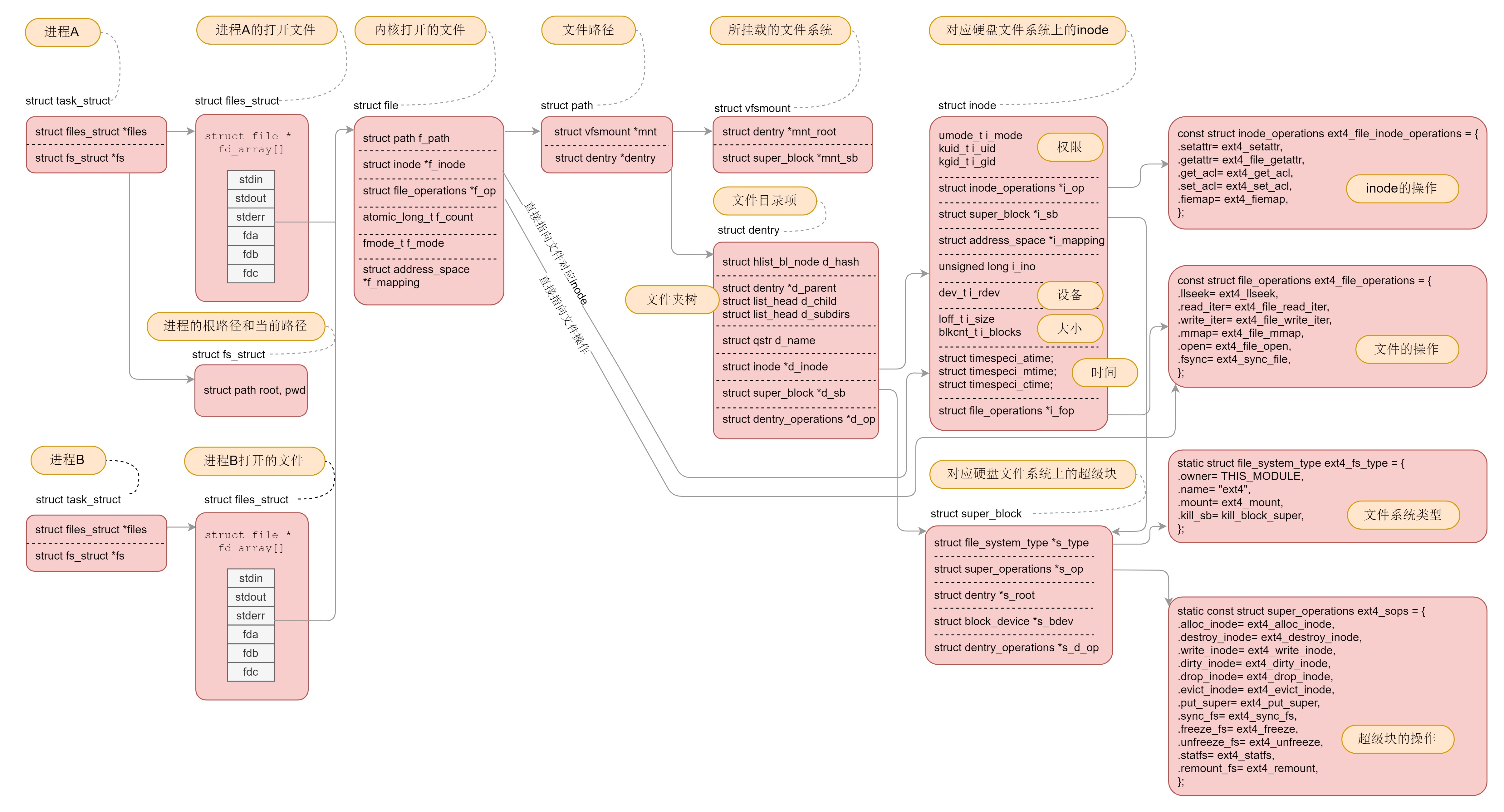
这张图十分重要,一定要掌握。字符设备、块设备、管道、进程间通信、网络等等,全部都要用到这里面的知识。¶
文章的核心就是把磁盘文件数据映射到进程中,可以把在磁盘的文件组织看成一种协议,内存中进程中的文件组织形式看成另外一种协议,内核就是这两个协议的中转 proxy, 带着这个主线看文章思路要明朗一些。inode 和 dentry 在一个文件系统挂载的时候怎么初始化和做好映射关系,这个是难点。
30 | 文件缓存¶
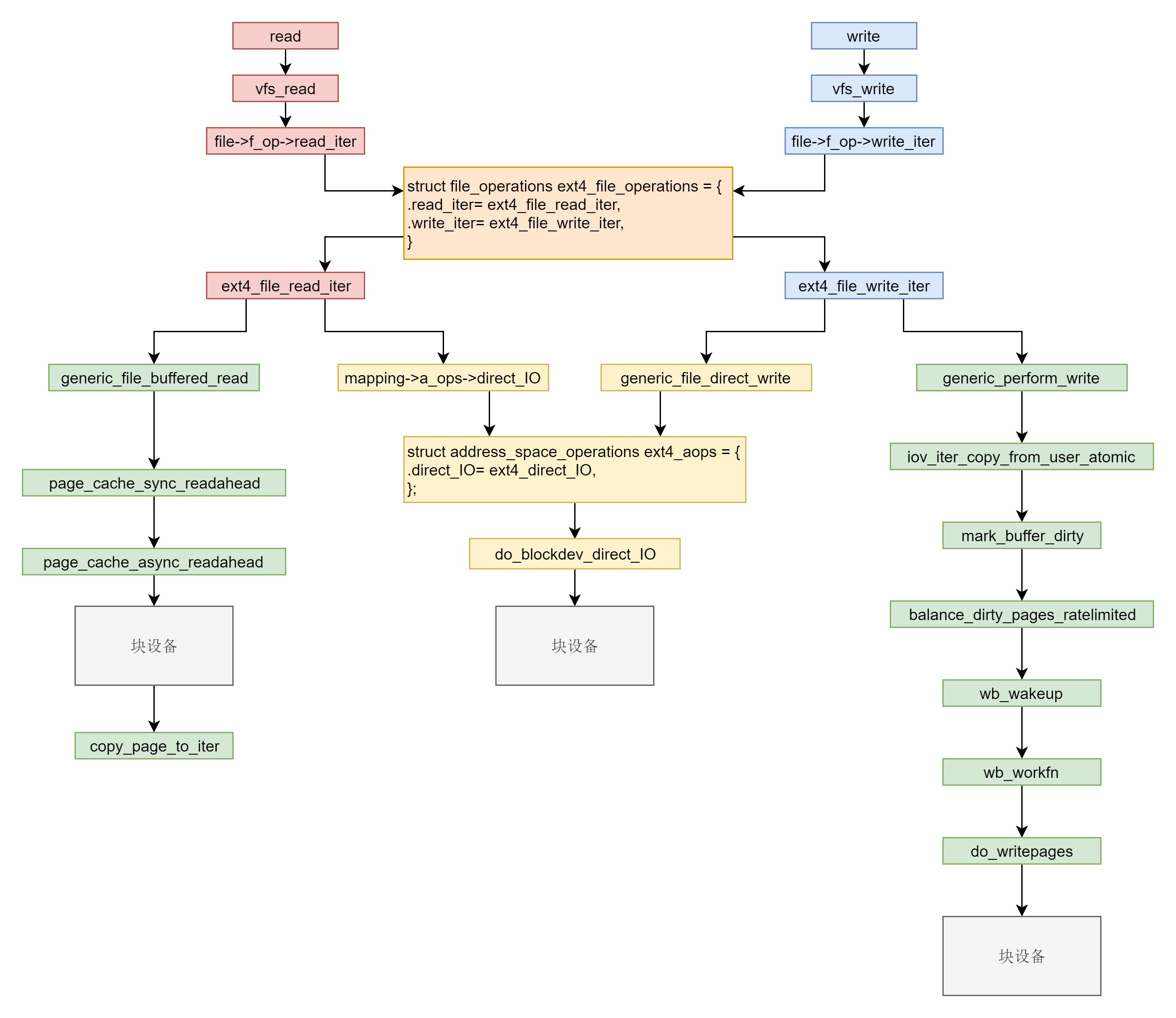
在系统调用层我们需要仔细学习 read 和 write。在 VFS 层调用的是 vfs_read 和 vfs_write 并且调用 file_operation。在 ext4 层调用的是 ext4_file_read_iter 和 ext4_file_write_iter。接下来就是分叉。你需要知道缓存 I/O 和直接 I/O。直接 I/O 读写的流程是一样的,调用 ext4_direct_IO,再往下就调用块设备层了。缓存 I/O 读写的流程不一样。对于读,从块设备读取到缓存中,然后从缓存中拷贝到用户态。对于写,从用户态拷贝到缓存,设置缓存页为脏,然后启动一个线程写入块设备。¶
第六部分 输入输出系统 (5 讲)¶
31 | 输入与输出¶
输入输出设备分为两类:
1. 块设备(Block Device)
块设备将信息存储在固定大小的块中,每个块都有自己的地址。硬盘就是常见的块设备。
2. 字符设备(Character Device)
字符设备发送或接收的是字节流。而不用考虑任何块结构,没有办法寻址。鼠标就是常见的字符设备。
caption¶
/sys 路径下有下列的文件夹:
1. /sys/devices 是内核对系统中所有设备的分层次的表示
2. /sys/dev/char 维护一个按字符设备的主次号码 (major:minor) 链接到真实的设备 (/sys/devices 下) 的符号链接文件
3. /sys/dev/block 维护一个按块设备的主次号码 (major:minor) 链接到真实的设备 (/sys/devices 下) 的符号链接文件
4. /sys/block 是系统中当前所有的块设备
5. /sys/module 有系统中所有模块的信息
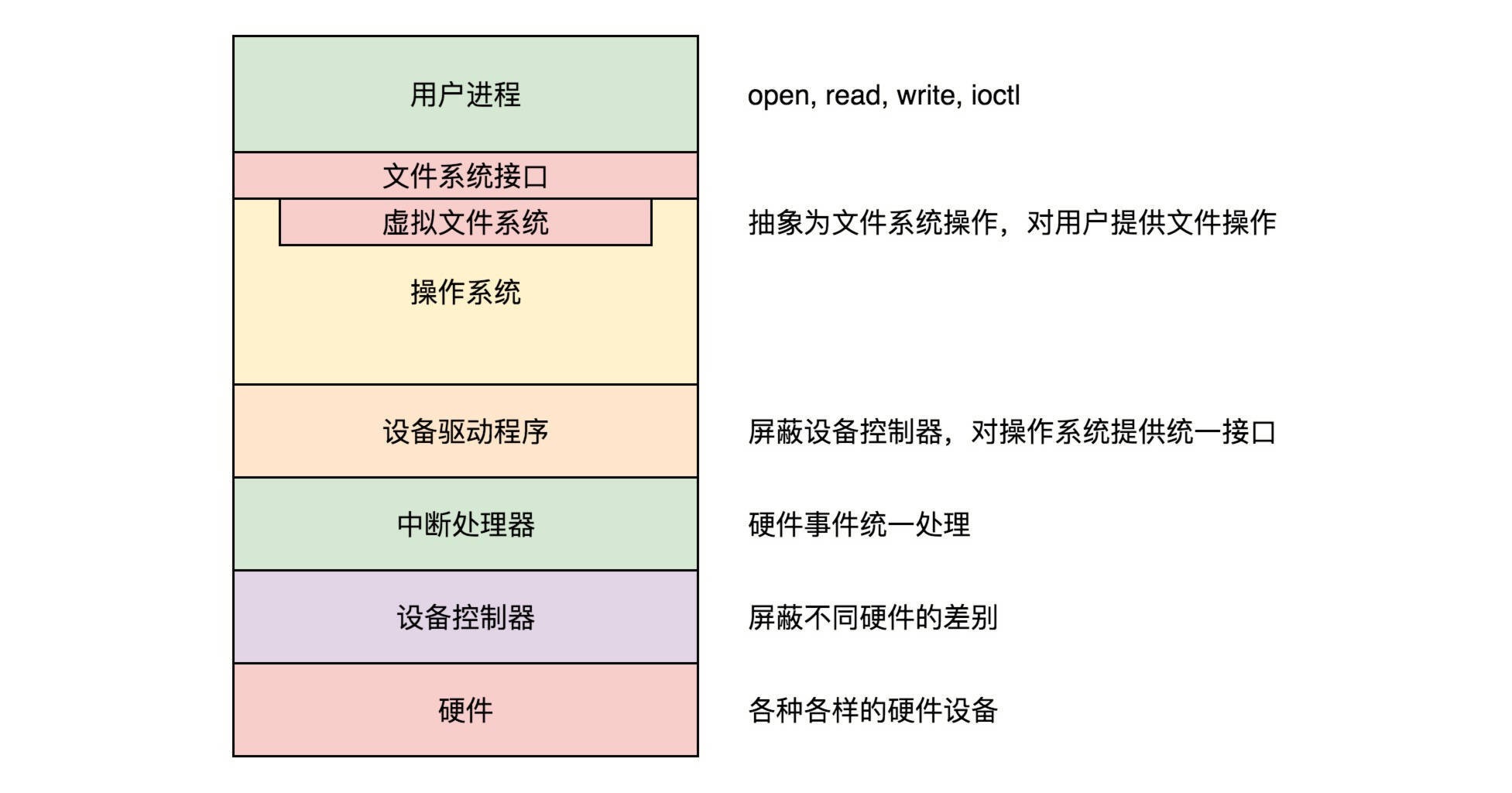
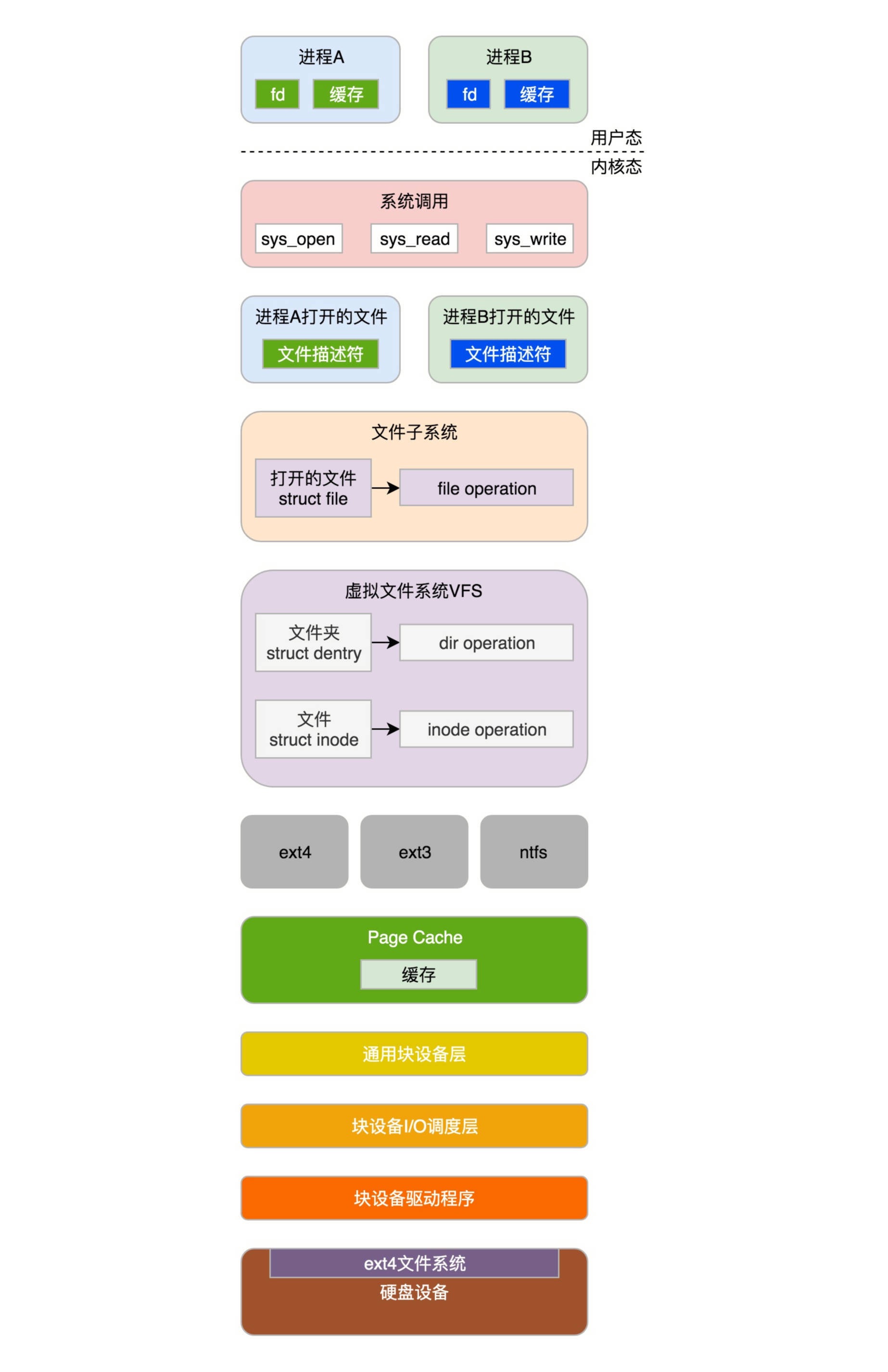
输入与输出设备的管理,内容比较多,需要层层屏蔽差异化的部分,给上层提供标准化的部分,最终到用户态,给用户提供了基于文件系统的统一的接口。¶
32 | 字符设备-上¶
内核模块¶
一个内核模块应该由以下几部分组成:
1. 头文件部分
2. 定义一些函数,用于处理内核模块的主要逻辑
3. 定义一个 file_operations 结构
4. 定义整个模块的初始化函数和退出函数
5. 调用 module_init 和 module_exit
6. 声明一下 lisense,调用 MODULE_LICENSE
字符设备¶
一个字符设备要能够工作,需要三部分配合:
1. 有一个设备驱动程序的 ko 模块,里面有模块初始化函数、中断处理函数、设备操作函数
2. 在 /dev 目录下有一个文件表示这个设备,这个文件在特殊的 devtmpfs 文件系统上,因而也有相应的 dentry 和 inode
3. 打开一个字符设备文件和打开一个普通的文件有类似的数据结构,有文件描述符、有 struct file、指向字符设备文件的 dentry 和 inode
33 | 字符设备-下¶
真正中断的发生还是要从硬件开始。这里面有四个层次:
1. 外部设备给中断控制器发送物理中断信号。
2. 中断控制器将物理中断信号转换成为中断向量 interrupt vector,发给各个 CPU。
3. 每个 CPU 都会有一个中断向量表,根据 interrupt vector 调用一个 IRQ 处理函数。
4. 在 IRQ 处理函数中,将 interrupt vector 转化为抽象中断层的中断信号 irq,调用中断信号 irq 对应的中断描述结构里面的 irq_handler_t。
参考¶
《Linux Device Drivers》
34 | 块设备-上¶
三种文件系统:
1. devtmpfs 文件系统
2. ext4 文件系统
3. bdev 伪文件系统
块设备比字符设备复杂多了,涉及三个文件系统,工作过程:
1. 所有的块设备被一个 map 结构管理从 dev_t 到 gendisk 的映射;
2. 所有的 block_device 表示的设备或者分区都在 bdev 文件系统的 inode 列表中;
3. mknod 创建出来的块设备文件在 devtemfs 文件系统里面,特殊 inode 里面有块设备号;
4. mount 一个块设备上的文件系统,调用这个文件系统的 mount 接口;
5. 通过按照 /dev/xxx 在文件系统 devtmpfs 文件系统上搜索到特殊 inode,得到块设备号;
6. 根据特殊 inode 里面的 dev_t 在 bdev 文件系统里面找到 inode;
7. 根据 bdev 文件系统上的 inode 找到对应的 block_device,根据 dev_t 在 map 中找到 gendisk,将两者关联起来;
8. 找到 block_device 后打开设备,调用和 block_device 关联的 gendisk 里面的 block_device_operations 打开设备;
9. 创建被 mount 的文件系统的 super_block。
35 | 块设备-下¶
对于 ext4 文件系统,它将 I/O 的调用分成两种情况::SSL
直接 I/O
缓存 I/O
第七部分 进程间通信 (7 讲)¶
36 | 进程间通信¶
管道模型¶
管道分为两种类型:
1. 匿名管道: “|” 表示的管道
2. 命名管道: 需要通过 mkfifo 命令显式地创建
命名管道的使用:
创建:
$ mkfifo hello
输入:
$ echo "hello world" > hello
输出:
$ cat < hello
hello world
消息队列模型¶
代码折叠
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
int main() {
int messagequeueid;
key_t key;
if((key = ftok("./messagequeuekey", 1024)) < 0)
{
perror("ftok error");
exit(1);
}
printf("Message Queue key: %d.\n", key);
if ((messagequeueid = msgget(key, IPC_CREAT|0777)) == -1)
{
perror("msgget error");
exit(1);
}
printf("Message queue id: %d.\n", messagequeueid);
}
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <getopt.h>
#include <string.h>
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:m:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ "message", 1, NULL, 'm'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
buffer.mtype = -1;
int len = -1;
char * message = NULL;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
buffer.mtype = atol(optarg);
break;
case 'm':
message = optarg;
len = strlen(message) + 1;
if (len > 1024) {
perror("message too long.");
exit(1);
}
memcpy(buffer.mtext, message, len);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && buffer.mtype != -1 && len != -1 && message != NULL){
if(msgsnd(messagequeueid, &buffer, len, IPC_NOWAIT) == -1){
perror("fail to send message.");
exit(1);
}
} else {
perror("arguments error");
}
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <getopt.h>
#include <string.h>
struct msg_buffer {
long mtype;
char mtext[1024];
};
int main(int argc, char *argv[]) {
int next_option;
const char* const short_options = "i:t:";
const struct option long_options[] = {
{ "id", 1, NULL, 'i'},
{ "type", 1, NULL, 't'},
{ NULL, 0, NULL, 0 }
};
int messagequeueid = -1;
struct msg_buffer buffer;
long type = -1;
do {
next_option = getopt_long (argc, argv, short_options, long_options, NULL);
switch (next_option)
{
case 'i':
messagequeueid = atoi(optarg);
break;
case 't':
type = atol(optarg);
break;
default:
break;
}
}while(next_option != -1);
if(messagequeueid != -1 && type != -1){
if(msgrcv(messagequeueid, &buffer, 1024, type, IPC_NOWAIT) == -1){
perror("fail to recv message.");
exit(1);
}
printf("received message type : %ld, text: %s.", buffer.mtype, buffer.mtext);
} else {
perror("arguments error");
}
return 0;
}
代码编译:
$ gcc -o init queue_create
$ gcc -o send queue_send
$ gcc -o recv queue_recv
创建:
$ touch messagequeuekey
$ ./queue_create
Message Queue key: 92536.
Message queue id: 32768.
备注
System V IPC 体系有一个统一的命令行工具: ipcmk,ipcs 和 ipcrm 用于创建、查看和删除 IPC 对象
ipcs -q 就能看到上面我们创建的消息队列对象:
# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x00016978 32768 root 777 0 0
发送:
$ ./send -i 32768 -t 123 -m "hello world"
接收:
$ ./recv -i 32768 -t 123
received message type : 123, text: hello world.
$ ./recv -i 32768 -t 123
fail to recv message.: No message of desired type
共享内存模型¶
创建一个共享内存,调用 shmget:
int shmget(key_t key, size_t size, int flag);
说明:
第一个参数是 key,是唯一定位一个共享内存对象,也可以通过关联文件的方式实现唯一性。
第二个参数是共享内存的大小。
第三个参数如果是 IPC_CREAT,表示创建一个新的。
通过 ipcs 命令查看这个共享内存:
$ ipcs --shmems
------ Shared Memory Segments ------
key shmid owner perms bytes nattch status
0x00000000 19398656 marc 600 1048576 2 dest
访问这一段共享内存,调用 shmat:
void *shmat(int shm_id, const void *addr, int flag);
说明:
at 代表 attach 的意思
参数 addr 通常的做法是将 addr 设为 NULL,让内核选一个合适的地址。
除非对于内存布局非常熟悉,否则可能会 attach 到一个非法地址。
返回值就是真正被 attach 的地方。
共享内存使用完毕:
1. 解除绑定
int shmdt(void *addr);
2. 删除这个共享内存对象
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
信号量¶
备注
信号量其实是一个计数器,主要用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
对于信号量来讲,会定义两种原子操作:
1. 一个是 P 操作,我们称为申请资源操作,这个操作会申请将信号量的数值减去 N
2. 另一个是 V 操作,我们称为归还资源操作,这个操作会申请将信号量加上 M
创建一个信号量:
int semget(key_t key, int num_sems, int sem_flags);
说明:
第一个参数 key
第二个参数 num_sems 不是指资源的数量,而是表示可以创建多少个信号量,形成一组信号量,
也就是说,如果你有多种资源需要管理,可以创建一个信号量组
初始化信号量的总的资源数量:
int semctl(int semid, int semnum, int cmd, union semun args);
union semun
{
int val;
struct semid_ds *buf;
unsigned short int *array;
struct seminfo *__buf;
}
说明:
第一个参数 semid 是这个信号量组的 id
第二个参数 semnum 才是在这个信号量组中某个信号量的 id
第三个参数是命令,如果是初始化,则用 SETVAL
第四个参数是一个 union。如果初始化,应该用里面的 val 设置资源总量。
无论是 P 操作还是 V 操作,我们统一用 semop 函数:
int semop(int semid, struct sembuf semoparray[], size_t numops);
struct sembuf
{
short sem_num; // 信号量组中对应的序号,0~sem_nums-1
short sem_op; // 信号量值在一次操作中的改变量
short sem_flg; // IPC_NOWAIT, SEM_UNDO
}
备注
信号量和共享内存都比较复杂,两者还要结合起来用,就更加复杂,它们内核的机制就更加复杂。
信号¶
信号没有特别复杂的数据结构,就是用一个代号一样的数字。Linux 提供了几十种信号,分别代表不同的意义。信号可以在任何时候发送给某一进程,进程需要为这个信号配置信号处理函数。当某个信号发生的时候,就默认执行这个函数就可以了。
socket 通信¶
进程间还可以利用 socket 通信
总结¶
管道,是命令行中常用的模式
消息队列其实很少使用,因为有太多的用户级别的消息队列,功能更强大。
共享内存加信号量是常用的模式。这个需要牢记,常见到一些知名的以 C 语言开发的开源软件都会用到它。
信号更加常用,机制也比较复杂。
37 | 信号-上¶
查看所有的信号:
# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
信号的作用:
$ man 7 signal
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
……
用户进程对信号的处理方式:
1. 执行默认操作
如上面的 Action:
Term,就是终止进程的意思。
Core 的意思是 Core Dump,也即终止进程后,通过 Core Dump 将当前进程的运行状态保存在文件里面
2. 捕捉信号
为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
3. 忽略信号
有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
备注
信号类似内核里面的中断,只不过是在用户态的
38 | 信号-下¶
信号处理最常见的流程主要是两步:
第一步是注册信号处理函数
第二步是发送信号和处理信号
信号的发送¶
在终端输入某些组合键的时候,会给进程发送信号,例如:
Ctrl+C 产生 SIGINT 信号
Ctrl+Z 产生 SIGTSTP 信号
硬件异常也会产生信号。比如:
1. 执行了除以 0 的指令,CPU 就会产生异常,然后把 SIGFPE 信号发送给进程
2. 进程访问了非法内存,内存管理模块就会产生异常,然后把信号 SIGSEGV 发送给进程
备注
同样是硬件产生的,对于中断和信号还是要加以区别。中断要注册中断处理函数,但是中断处理函数是在内核驱动里面的,信号也要注册信号处理函数,信号处理函数是在用户态进程里面的。
对于硬件触发的,无论是中断,还是信号,肯定是先到内核的,然后内核对于中断和信号处理方式不同。一个是完全在内核里面处理完毕,一个是将信号放在对应的进程 task_struct 里信号相关的数据结构里面,然后等待进程在用户态去处理。当然有些严重的信号,内核会把进程干掉。但是,这也能看出来,中断和信号的严重程度不一样,信号影响的往往是某一个进程,处理慢了,甚至错了,也不过这个进程被干掉,而中断影响的是整个系统。一旦中断处理中有了 bug,可能整个 Linux 都挂了。
内核在某些情况下,也会给进程发送信号。例如,向读端已关闭的管道写数据时产生 SIGPIPE 信号,当子进程退出时,我们要给父进程发送 SIG_CHLD 信号等。
39 | 管道¶
备注
所谓的匿名管道和命名管道,其实都是内核里面的一串缓存。
管道的创建,需要通过下面这个系统调用:
int pipe(int fd[2])
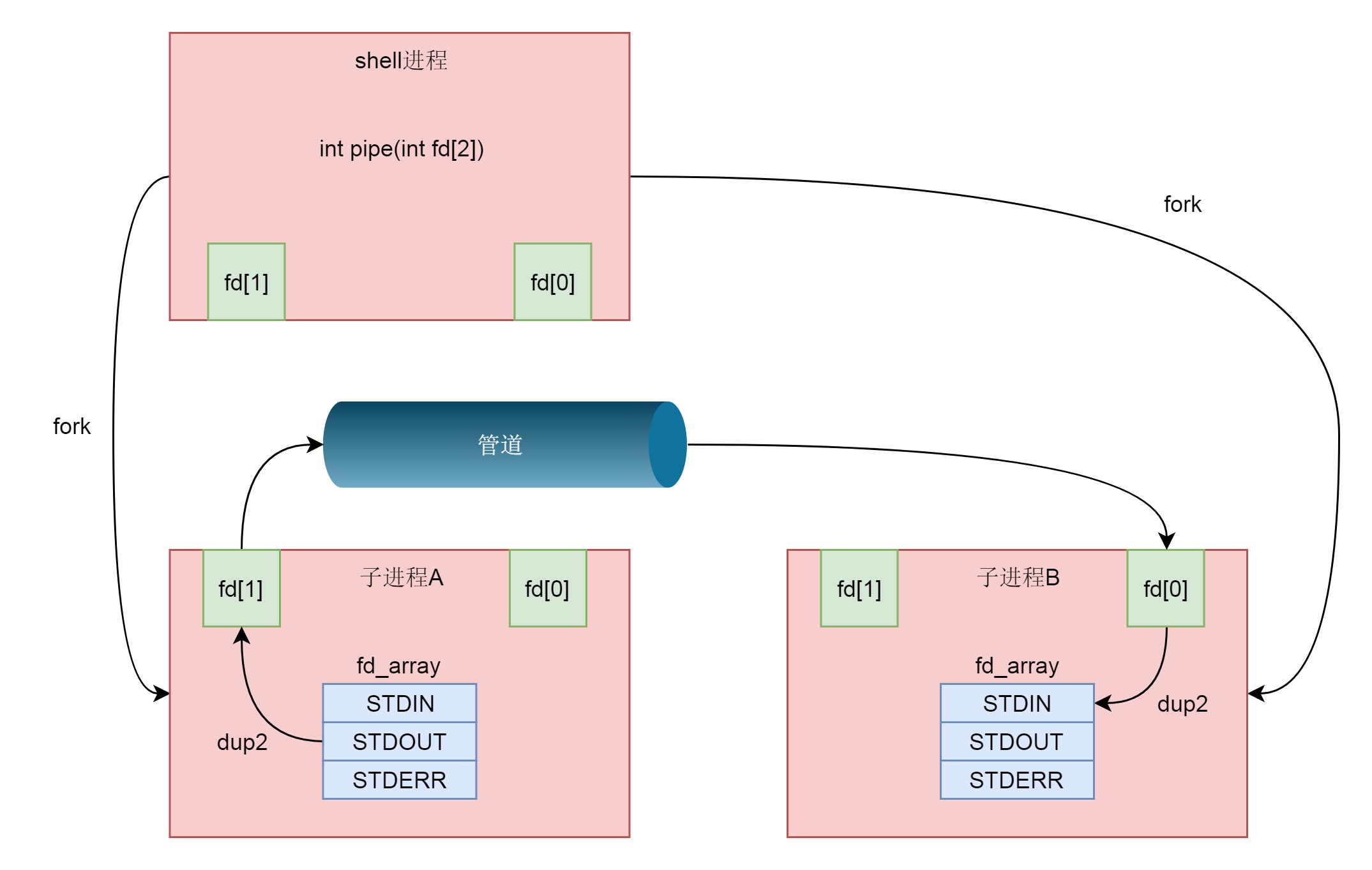
父进程通过 int pipe(int fd[2]) 创建管道,然后 fork 2个子进程,创建的子进程会复制父进程的 struct files_struct,在这里面 fd 的数组会复制一份,但是 fd 指向的 struct file 对于同一个文件还是只有一份,这样就做到了,两个进程各有两个 fd 指向同一个 struct file 的模式,两个进程就可以通过各自的 fd 写入和读取同一个管道文件实现跨进程通信了。然后父进程关闭读写fd,而子进程一个关闭写fd一个关闭读fd。¶
40 | IPC-上¶
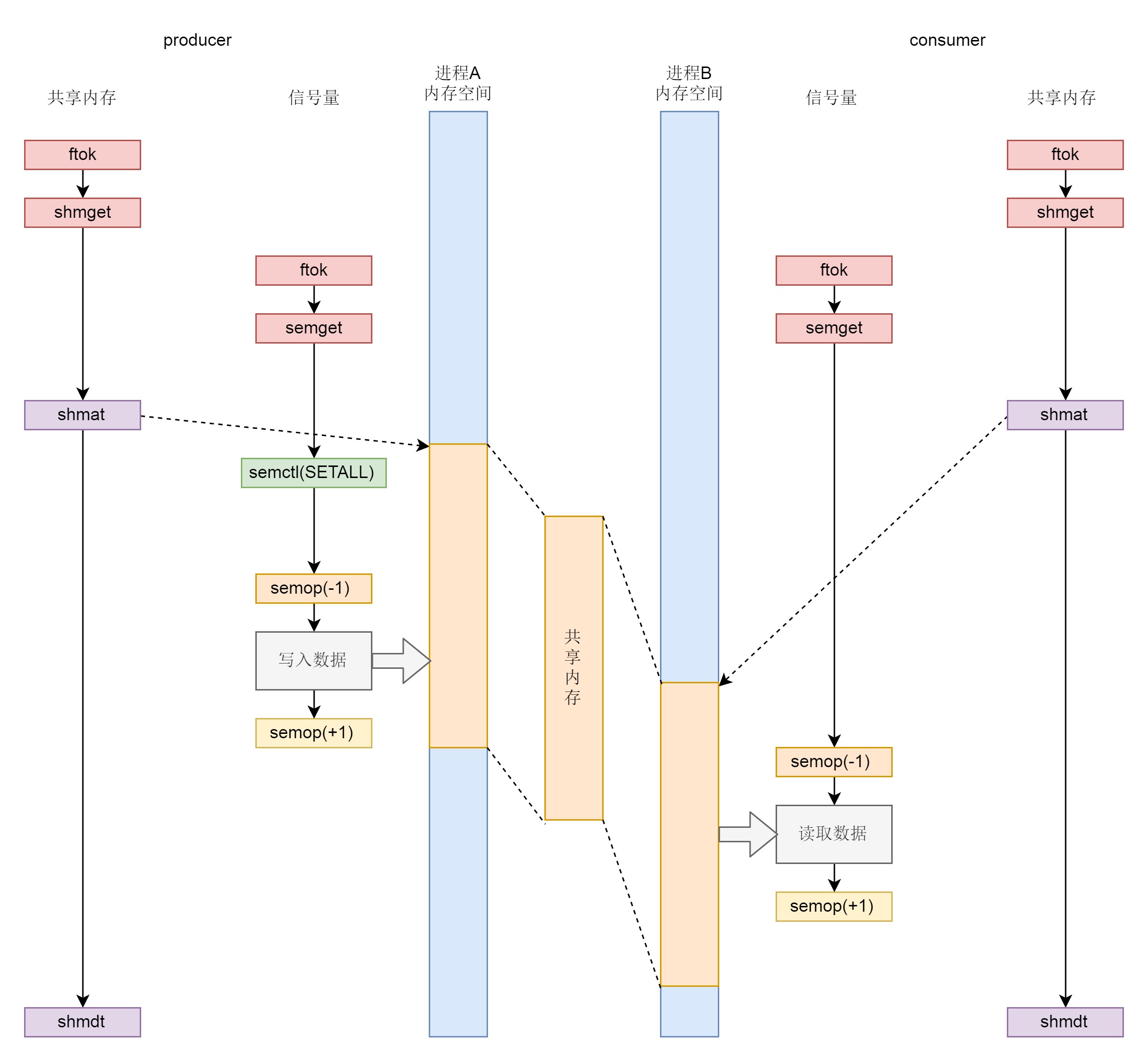
1.无论是共享内存还是信号量,创建与初始化都遵循同样流程,通过 ftok 得到 key,通过 xxxget 创建对象并生成 id;2.生产者和消费者都通过 shmat 将共享内存映射到各自的内存空间,在不同的进程里面映射的位置不同;3.为了访问共享内存,需要信号量进行保护,信号量需要通过 semctl 初始化为某个值;4.接下来生产者和消费者要通过 semop (-1) 来竞争信号量,如果生产者抢到信号量则写入,然后通过 semop (+1) 释放信号量,如果消费者抢到信号量则读出,然后通过 semop (+1) 释放信号量;5.共享内存使用完毕,可以通过 shmdt 来解除映射¶
41 | IPC-中¶
消息队列、共享内存、信号量: 这三种进程间通信机制是使用统一的机制管理起来的,都叫 ipcxxx:
$ ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00016988 32768 root 777 516 0
------ Semaphore Arrays --------
key semid owner perms nsems
0x00016989 32768 root 777 1
42 | IPC-下¶
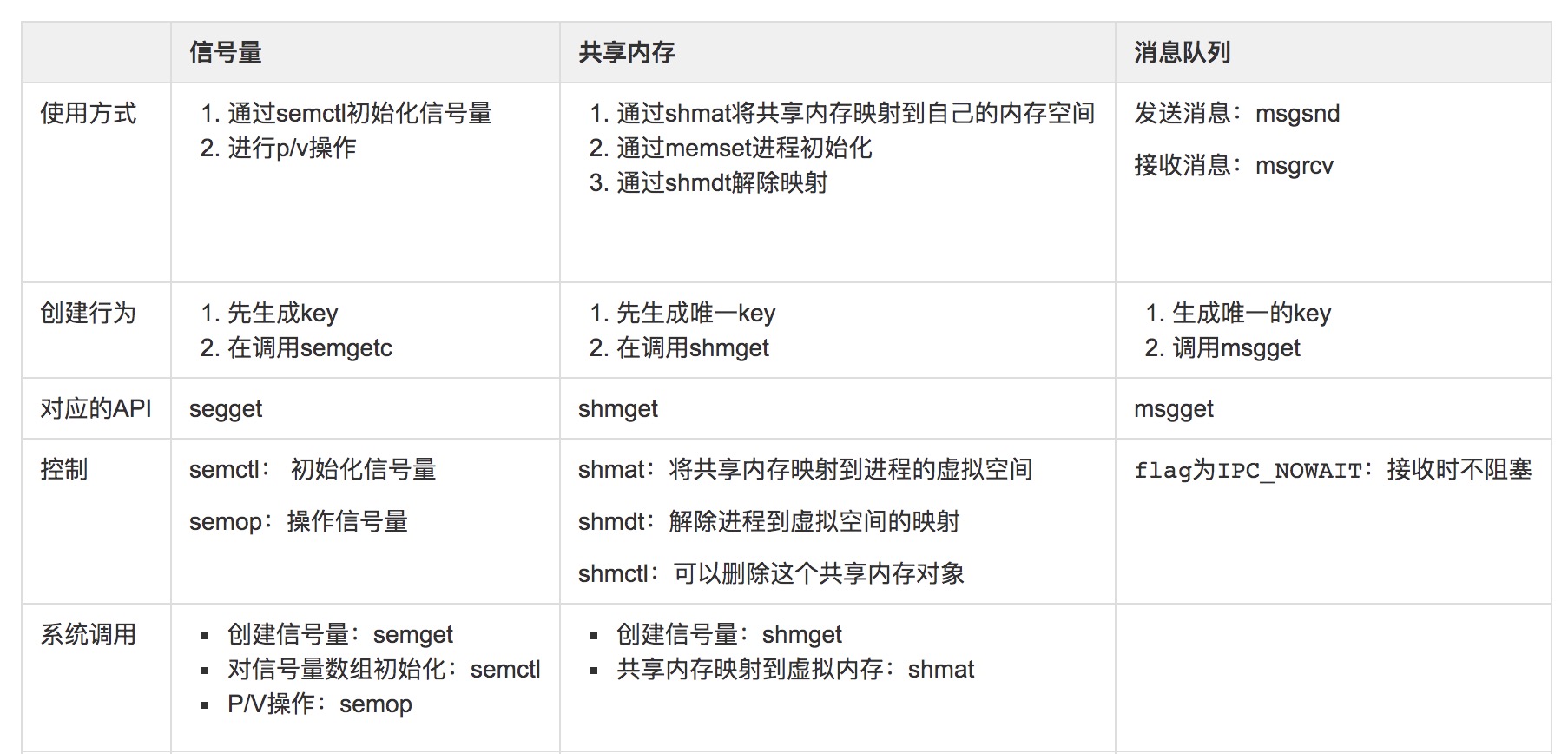
共享内存、信号量、消息队列,这三种进程间通信机制、行为创建 xxxget、使用、控制 xxxctl、对应的 API 和系统调用。¶
第八部分 网络系统 (7 讲)¶
43 Socket 通信之网络协议基本原理¶
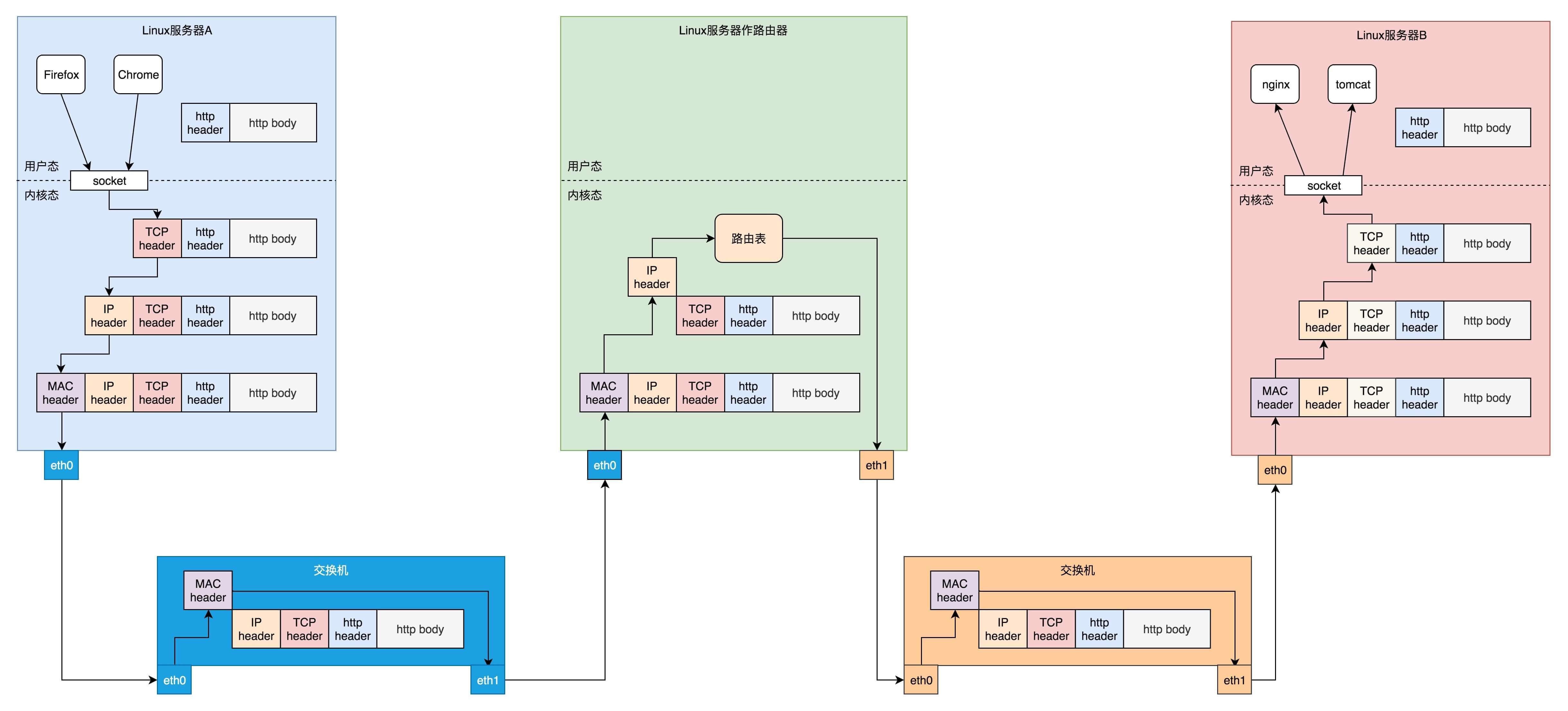
Socket 属于操作系统的概念,而非网络协议分层的概念。只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
44 | Socket 内核数据结构¶
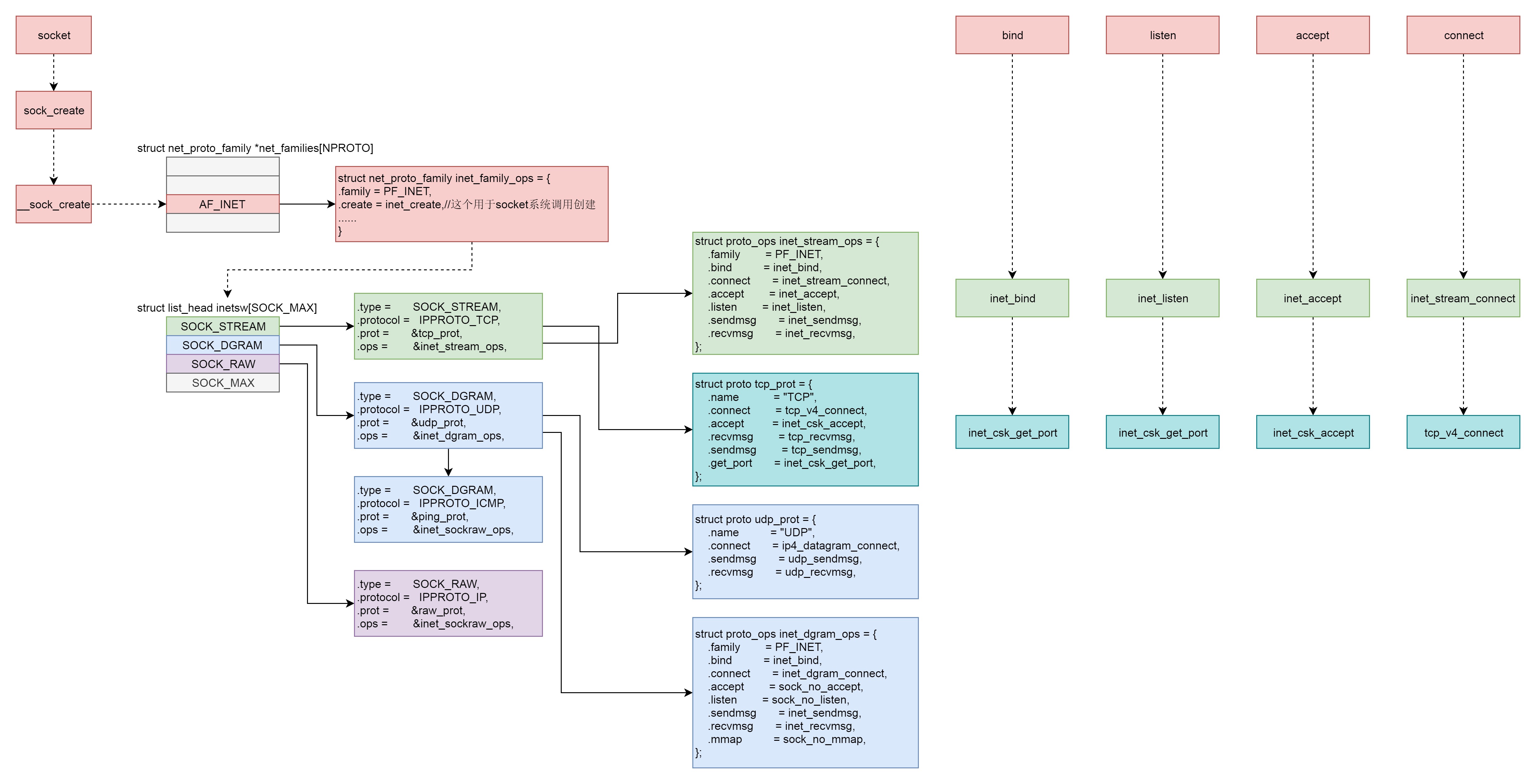
Socket 系统调用会有三级参数 family、type、protocal,通过这三级参数,分别在 net_proto_family 表中找到 type 链表,在 type 链表中找到 protocal 对应的操作。这个操作分为两层,对于 TCP 协议来讲,第一层是 inet_stream_ops 层,第二层是 tcp_prot 层。¶
系统调用规律:
1. bind
第一层调用 inet_stream_ops 的 inet_bind 函数,
第二层调用 tcp_prot 的 inet_csk_get_port 函数;
2. listen
第一层调用 inet_stream_ops 的 inet_listen 函数,
第二层调用 tcp_prot 的 inet_csk_get_port 函数;
3. accept
第一层调用 inet_stream_ops 的 inet_accept 函数,
第二层调用 tcp_prot 的 inet_csk_accept 函数;
4. connect
第一层调用 inet_stream_ops 的 inet_stream_connect 函数,
第二层调用 tcp_prot 的 tcp_v4_connect 函数。
45 | 发送网络包-上¶
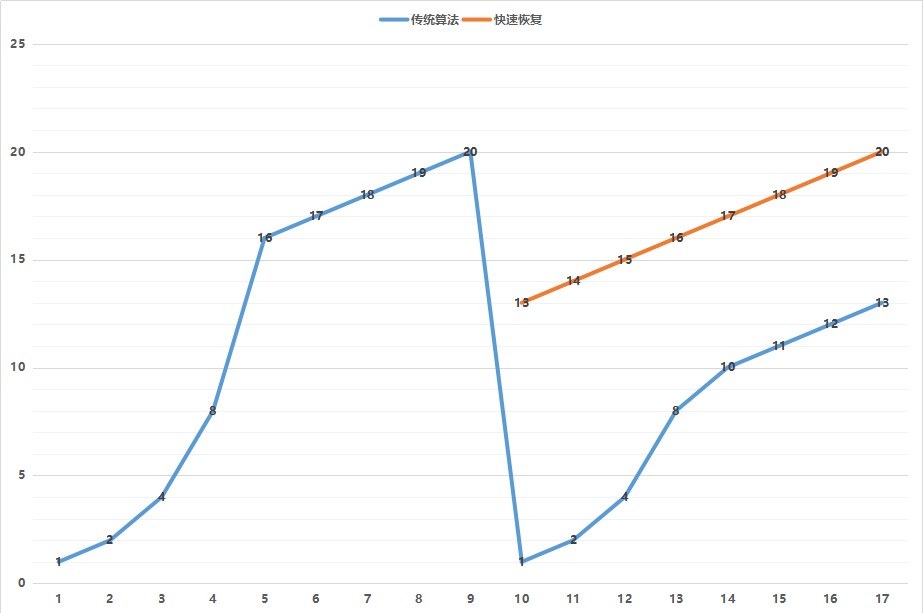
著名的拥塞窗口变化图。拥塞窗口的概念(cwnd,congestion window),就是说为了避免拼命发包,把网络塞满了,定义一个窗口的概念,在这个窗口之内的才能发送,超过这个窗口的就不能发送,来控制发送的频率。¶
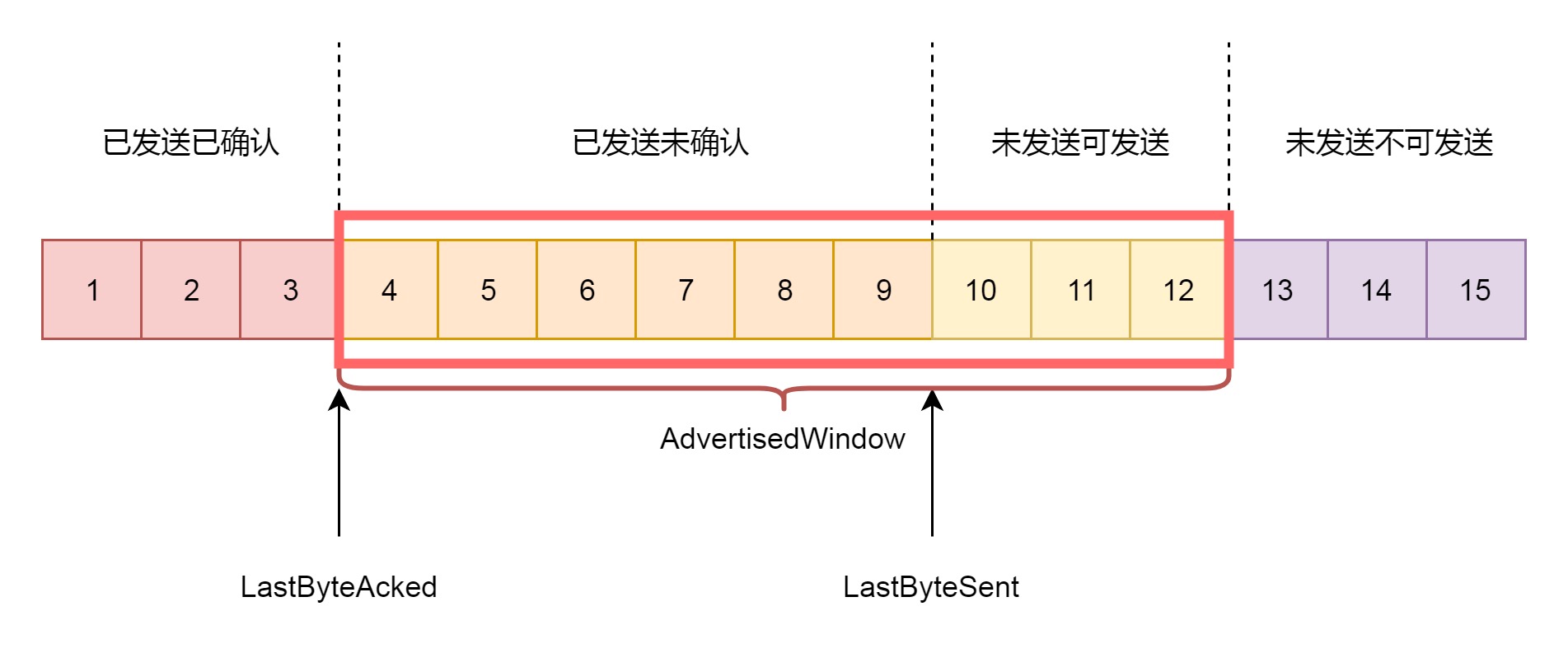
接收窗口rwnd 的概念(receive window),也叫滑动窗口。如果说拥塞窗口是为了怕把网络塞满,在出现丢包的时候减少发送速度,那么滑动窗口就是为了怕把接收方塞满,而控制发送速度。¶
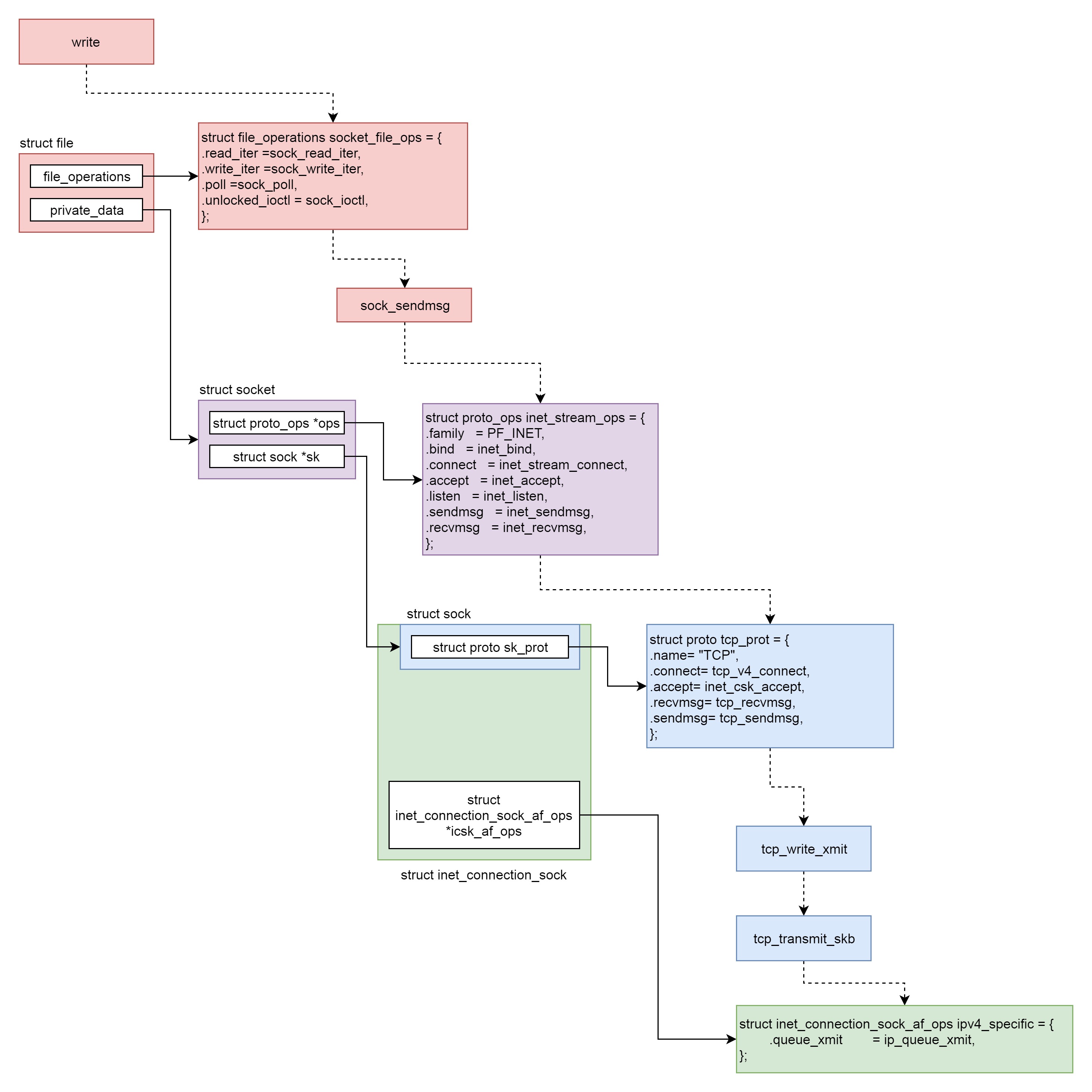
发送一个网络包的过程(从 VFS 层一直到 IP 层)分成几个层次:
VFS 层:write 系统调用找到 struct file,根据里面的 file_operations 的定义,调用 sock_write_iter 函数。sock_write_iter 函数调用 sock_sendmsg 函数。
Socket 层:从 struct file 里面的 private_data 得到 struct socket,根据里面 ops 的定义,调用 inet_sendmsg 函数。
Sock 层:从 struct socket 里面的 sk 得到 struct sock,根据里面 sk_prot 的定义,调用 tcp_sendmsg 函数。
TCP 层:tcp_sendmsg 函数会调用 tcp_write_xmit 函数,tcp_write_xmit 函数会调用 tcp_transmit_skb,在这里实现了 TCP 层面向连接的逻辑。
IP 层:扩展 struct sock,得到 struct inet_connection_sock,根据里面 icsk_af_ops 的定义,调用 ip_queue_xmit 函数。
46 | 发送网络包-下¶
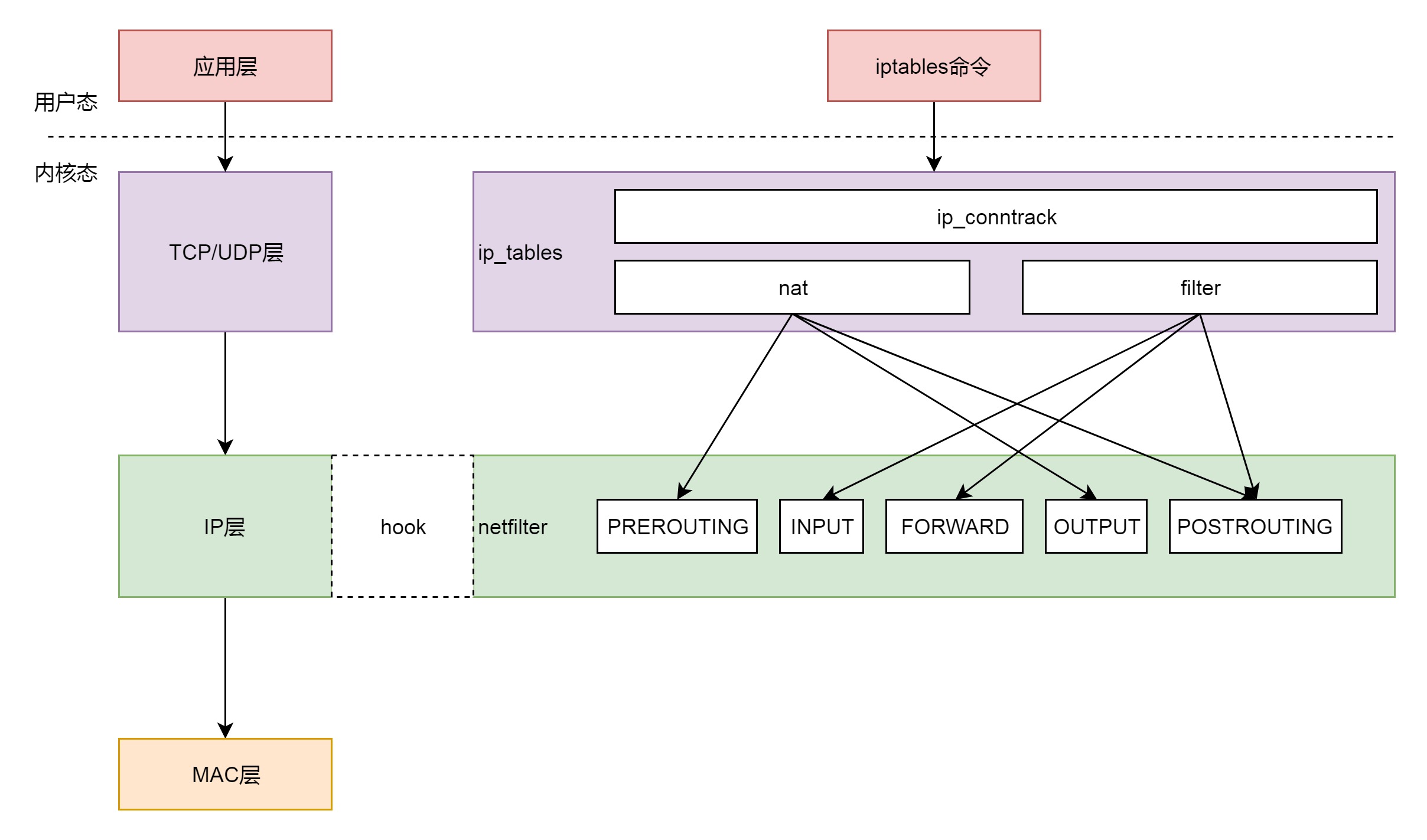
iptables 有表和链的概念,最终要的是两个表:filter 表和nat 表。¶
filter 表处理过滤功能,主要包含以下三个链:
1. INPUT 链:过滤所有目标地址是本机的数据包
2. FORWARD 链:过滤所有路过本机的数据包
3. OUTPUT 链:过滤所有由本机产生的数据包
nat 表主要处理网络地址转换,可以进行 SNAT(改变源地址)、DNAT(改变目标地址),包含以下三个链:
1. PREROUTING 链:可以在数据包到达时改变目标地址
2. OUTPUT 链:可以改变本地产生的数据包的目标地址
3. POSTROUTING 链:在数据包离开时改变数据包的源地址
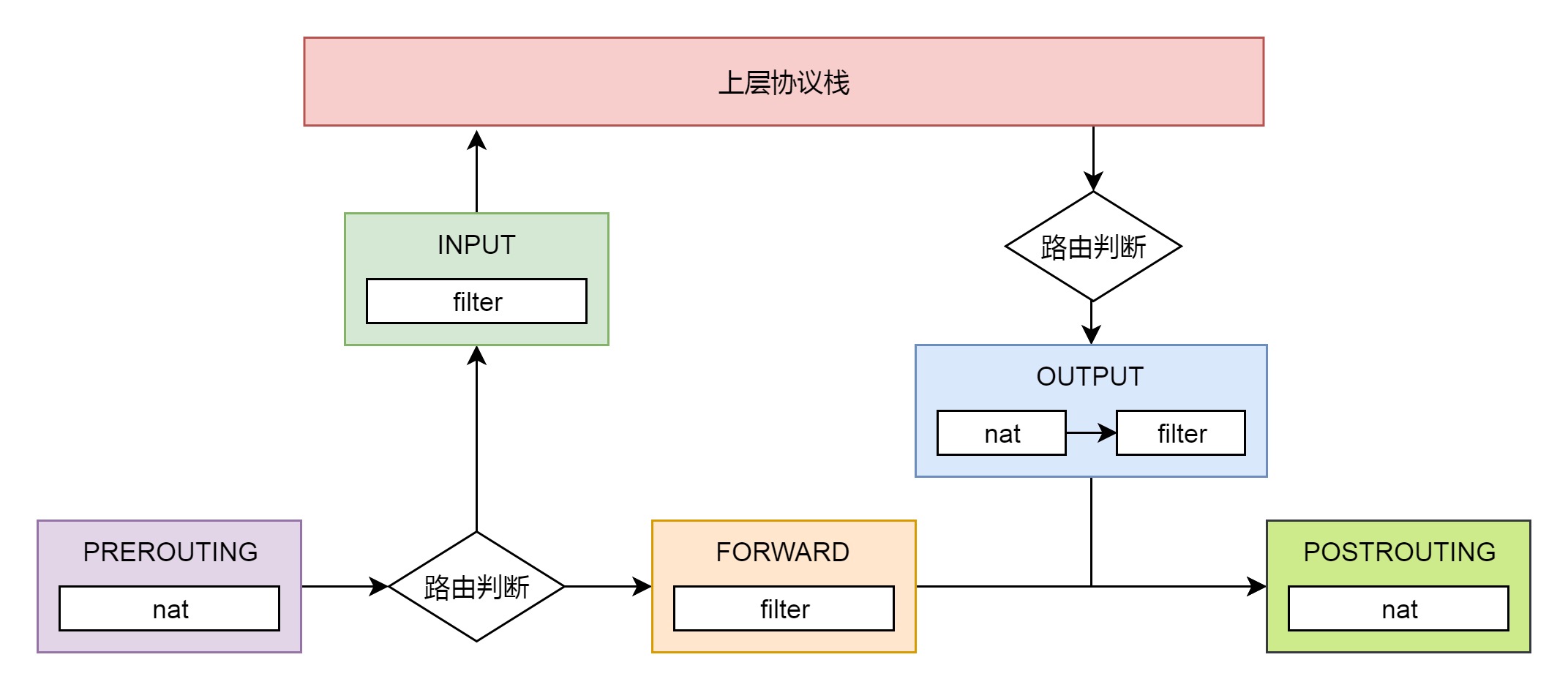
发送一个网络包的过程(从 IP 层到MAC 层)分成几个层次:
IP 层:ip_route_output_ports 函数里面会调用 fib_lookup 查找路由表。FIB 全称是 Forwarding Information Base,转发信息表,也就是路由表。
在 IP 层里面要做的另一个事情是填写 IP 层的头。
在 IP 层还要做的一件事情就是通过 iptables 规则。
MAC 层:IP 层调用 ip_finish_output 进行 MAC 层。
MAC 层需要 ARP 获得 MAC 地址,因而要调用 ___neigh_lookup_noref 查找属于同一个网段的邻居,他会调用 neigh_probe 发送 ARP。
有了 MAC 地址,就可以调用 dev_queue_xmit 发送二层网络包了,它会调用 __dev_xmit_skb 会将请求放入队列。
设备层:网络包的发送会触发一个软中断 NET_TX_SOFTIRQ 来处理队列中的数据。这个软中断的处理函数是 net_tx_action。
在软中断处理函数中,会将网络包从队列上拿下来,调用网络设备的传输函数 ixgb_xmit_frame,将网络包发到设备的队列上去。
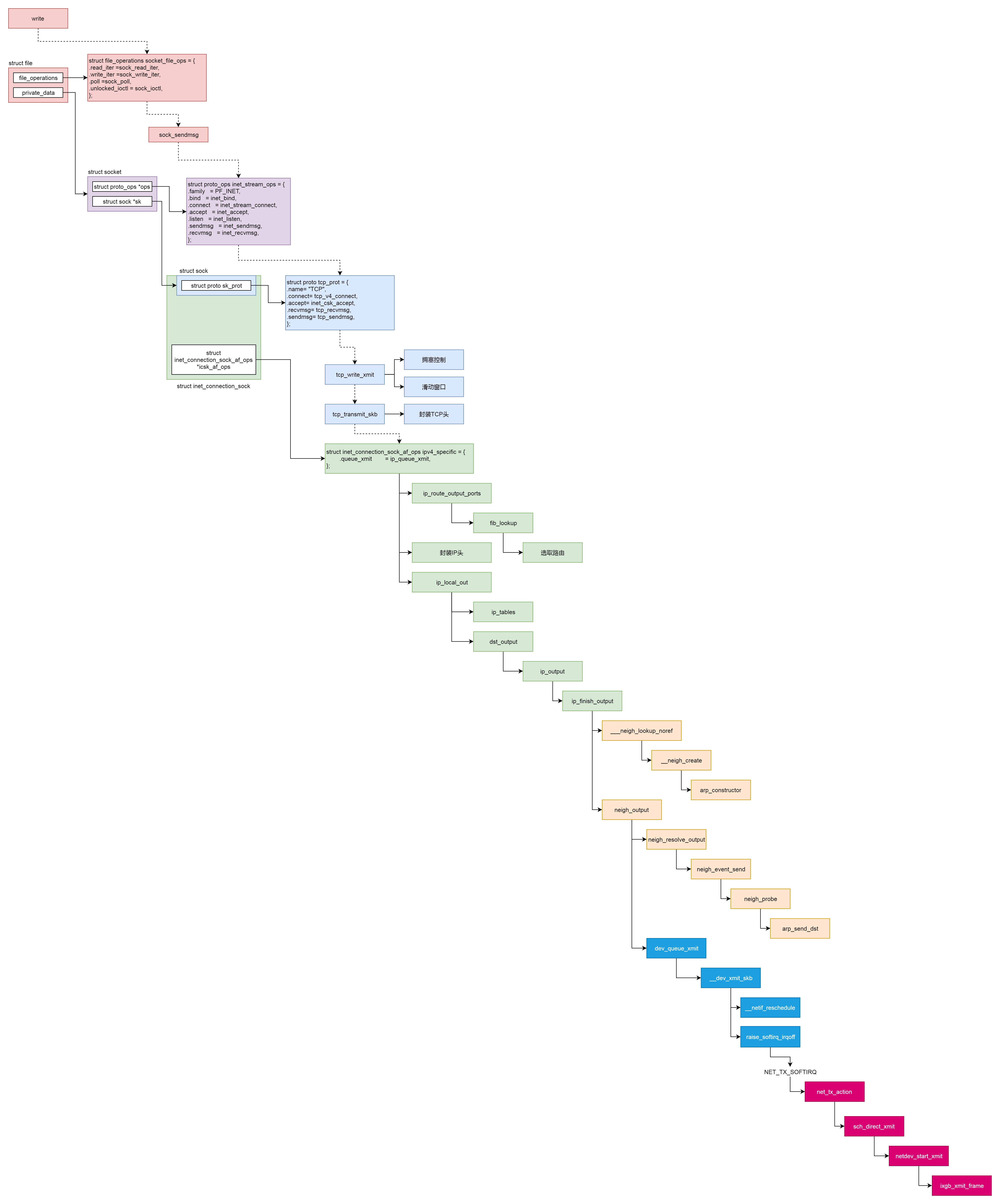
发送一个网络包的整个过程¶
47 | 接收网络包-上¶
接收网络包(从硬件网卡解析到 IP 层),分以下几个层次:
硬件网卡接收到网络包之后,通过 DMA 技术,将网络包放入 Ring Buffer。
硬件网卡通过中断通知 CPU 新的网络包的到来。
网卡驱动程序会注册中断处理函数 ixgb_intr。
中断处理函数处理完需要暂时屏蔽中断的核心流程之后,通过软中断 NET_RX_SOFTIRQ 触发接下来的处理过程。
NET_RX_SOFTIRQ 软中断处理函数 net_rx_action,net_rx_action 会调用 napi_poll,进而调用 ixgb_clean_rx_irq,从 Ring Buffer 中读取数据到内核 struct sk_buff。
调用 netif_receive_skb 进入内核网络协议栈,进行一些关于 VLAN 的二层逻辑处理后,调用 ip_rcv 进入三层 IP 层。
在 IP 层,会处理 iptables 规则,然后调用 ip_local_deliver,交给更上层 TCP 层。
在 TCP 层调用 tcp_v4_rcv。
48 | 接收网络包-下¶
接收网络包(IP 层解析到 Socket 层),分以下几个层次:
在 TCP 层调用 tcp_v4_rcv,这里面有三个队列需要处理,如果当前的 Socket 不是正在被读;取,则放入 backlog 队列,如果正在被读取,不需要很实时的话,则放入 prequeue 队列,其他情况调用 tcp_v4_do_rcv;
在 tcp_v4_do_rcv 中,如果是处于 TCP_ESTABLISHED 状态,调用 tcp_rcv_established,其他的状态,调用 tcp_rcv_state_process;
在 tcp_rcv_established 中,调用 tcp_data_queue,如果序列号能够接的上,则放入 sk_receive_queue 队列;如果序列号接不上,则暂时放入 out_of_order_queue 队列,等序列号能够接上的时候,再放入 sk_receive_queue 队列。
第九部分 虚拟化 (7 讲)¶
49 | 虚拟机¶
三种虚拟化方式¶
完全虚拟化(Full virtualization):
虚拟化软件会模拟假的 CPU、内存、网络、硬盘,让虚拟机内核以为可以操作硬件 缺点是:慢,而且往往慢到不能忍受
硬件辅助虚拟化(Hardware-Assisted Virtualization):
将标志位设为虚拟机状态,直接在 CPU 上执行大部分的指令,不需要虚拟化软件在中间转述 除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行 Intel 的 VT-x: grep “vmx” /proc/cpuinfo AMD 的 AMD-V: grep “svm” /proc/cpuinfo
半虚拟化(Paravirtualization):
访问网络或者硬盘的时候,为了取得更高的性能,也需要让虚拟机内核加载特殊的驱动, 也是让虚拟机内核从代码层面就重新定位自己的身份,不能像访问物理机一样访问网络或者硬盘,而是用一种特殊的方式
Linux 相关软件:
1. 完全虚拟化: 单纯使用 qemu
2. 硬件辅助虚拟化: qemu + kvm
查看内核模块中是否含有 kvm: lsmod | grep kvm
3. 半虚拟化:
网络需要加载 virtio_net
存储需要加载 virtio_blk
总结¶
虚拟化的本质是用 qemu 的软件模拟硬件,但是模拟方式比较慢,需要加速;
虚拟化主要模拟 CPU、内存、网络、存储,分别有不同的加速办法;
CPU 和内存主要使用硬件辅助虚拟化进行加速,需要配备特殊的硬件才能工作;
网络和存储主要使用特殊的半虚拟化驱动加速,需要加载特殊的驱动程序。
其他¶
虚拟化有 2 种类型:
1. bare-metal hypervisor,直接在硬件层之上模拟,效率高。比如 xen/Citrix xen server,vmware vSphere,Microsoft hyper-v,KVM
2. os hypervisor,通过主机 OS 模拟,效率低。比如我们常用的 virtualbox,vmware workstation
50 | 计算虚拟化之 CPU-上¶
略
51 | 计算虚拟化之 CPU-下¶
略
52 | 计算虚拟化之内存¶
内存变成了四类:
1. 虚拟机里面的虚拟内存(Guest OS Virtual Memory,GVA)
这是虚拟机里面的进程看到的内存空间;
2. 虚拟机里面的物理内存(Guest OS Physical Memory,GPA)
这是虚拟机里面的操作系统看到的内存,它认为这是物理内存;
3. 物理机的虚拟内存(Host Virtual Memory,HVA)
这是物理机上的 qemu 进程看到的内存空间;
4. 物理机的物理内存(Host Physical Memory,HPA)
这是物理机上的操作系统看到的内存。
53 | 存储虚拟化-上¶
略
54 | 存储虚拟化-下¶
略
55 | 网络虚拟化¶
略
第十部分 容器化 (4 讲)¶
56 | 容器¶
容器实现封闭的环境主要要靠两种技术:
1. 一种是看起来是隔离的技术,称为 namespace(命名空间)。
在每个 namespace 中的应用看到的,都是不同的 IP 地址、用户空间、进程 ID 等。
2. 另一种是用起来是隔离的技术,称为 cgroup(网络资源限制)
57 | Namespace 技术¶
namespace 相关的技术,有六种类型:
1. UTS
2. User
3. Mount
4. Pid
5. Network
6. IPC
常用指令¶
运行 /bin/bash,并且进入 nginx 所在容器的 namespace:
$ nsenter --target 58212 --mount --uts --ipc --net --pid -- env --ignore-environment -- /bin/bash
离开当前的 namespace,创建且加入新的 namespace,然后执行参数中指定的命令:
$ unshare --mount --ipc --pid --net --mount-proc=/proc --fork /bin/bash
常用的函数¶
创建一个新的进程,并把它放到新的 namespace 中:
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
将当前进程加入到已有的 namespace 中:
int setns(int fd, int nstype);
当前进程退出当前的 namespace,并加入到新创建的 namespace:
int unshare(int flags);
备注
clone 和 unshare 的区别是,unshare 是使当前进程加入新的 namespace;clone 是创建一个新的子进程,然后让子进程加入新的 namespace,而当前进程保持不变。
代码折叠
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
int main() {
int messagequeueid;
key_t key;
if((key = ftok("./messagequeuekey", 1024)) < 0)
{
perror("ftok error");
exit(1);
}
printf("Message Queue key: %d.\n", key);
if ((messagequeueid = msgget(key, IPC_CREAT|0777)) == -1)
{
perror("msgget error");
exit(1);
}
printf("Message queue id: %d.\n", messagequeueid);
}
运行过程:
$ echo $$
64267
$ ps aux | grep bash | grep -v grep
root 64267 0.0 0.0 115572 2176 pts/0 Ss 16:53 0:00 -bash
$ ./a.out
clone() returned 64360
In child process.
$ echo $$
1
$ ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ exit
exit
child has terminated
$ echo $$
64267
58 | cgroup 技术¶
cgroup 定义了下面的一系列子系统,每个子系统用于控制某一类资源:
1. CPU 子系统,主要限制进程的 CPU 使用率
2. cpuacct 子系统,可以统计 cgroup 中的进程的 CPU 使用报告
3. cpuset 子系统,可以为 cgroup 中的进程分配单独的 CPU 节点或者内存节点
4. memory 子系统,可以限制进程的 Memory 使用量
5. blkio 子系统,可以限制进程的块设备 IO
6. devices 子系统,可以控制进程能够访问某些设备
7. net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制
8. freezer 子系统,可以挂起或者恢复 cgroup 中的进程
验证 Docker 的参数与 cgroup 的映射关系:
$ docker run -d
--cpu-shares 513 --cpus 2 --cpuset-cpus 1,3
--memory 1024M --memory-swap 1234M --memory-swappiness 7
-p 8081:80 testnginx:1
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3dc0601189dd testnginx:1 "/bin/sh -c 'nginx -…" About a minute ago Up About a minute 0.0.0.0:8081->80/tcp ng_con
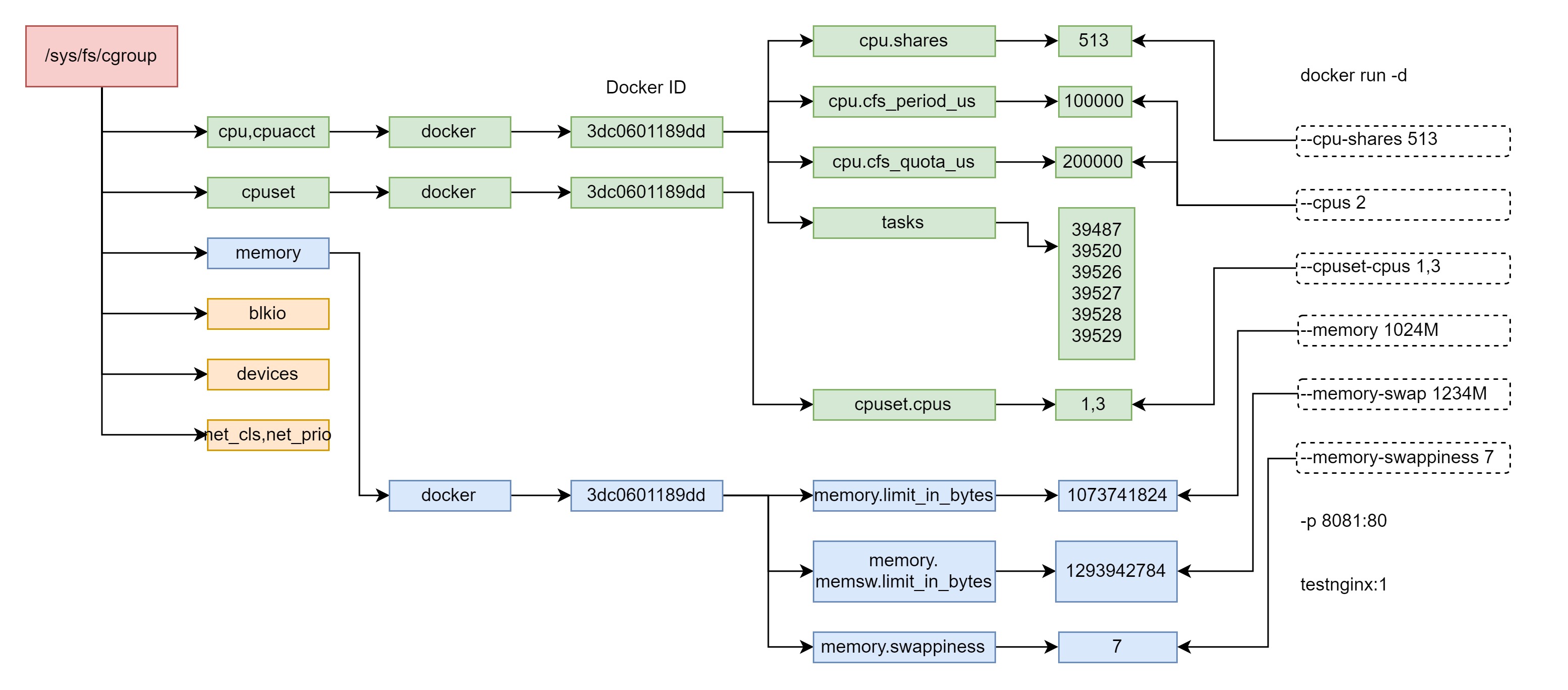
cgroup 对于 Docker 资源的控制,在用户态的表现¶
查看 cgroup:
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
59 | 数据中心操作系统¶
统一的存储常常有三种形式:
1. 对象存储
将文件作为一个完整对象的方式来保存
每一个文件都应该有一个唯一标识这个对象的 key,而文件的内容就是 value。
对象可以分门别类地保存在一个叫作存储空间(Bucket)的地方,像文件夹。
2. 分布式文件系统
缺点是分布式文件系统的性能和规模是个矛盾,
规模一大性能就难以保证,性能好则规模不会很大,
所以不像对象存储一样能够保持海量的数据。
3. 分布式块存储
相当于云硬盘,也即存储虚拟化的方式
只不过将盘挂载给容器而不是虚拟机
三种进程:
1. 交互式命令行
K8S Job 负责批量处理短暂的一次性任务 (Short Lived One-off Tasks)
2. nohup(长期运行)的进程
K8S Deployment
3. 系统服务
K8S DaemonSet
4. 周期性进程
K8S Crontab
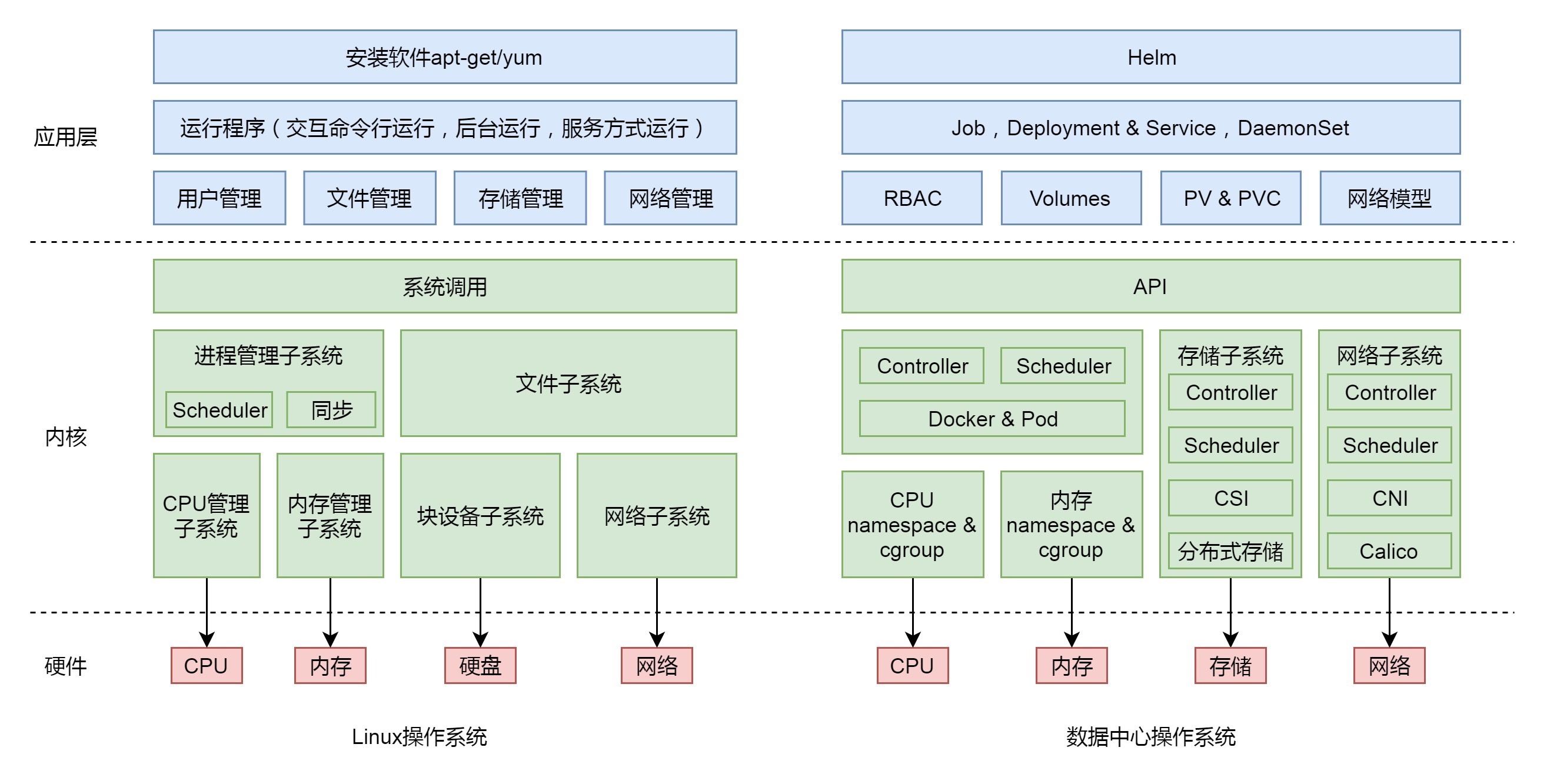
数据中心操作系统的功能¶
实战串讲篇 (9 讲)¶
略
学习攻略¶
学习攻略-1¶
《数据结构与算法分析:C 语言描述》
《汇编语言:基于 x86 处理器》
《别以为真懂 Openstack:虚拟机创建的 50 个步骤和 100 个知识点》