2408.08435_ADAS: Automating Agentic Workflow Generation¶
组织: DeepWisdom, 香港科技大学, 中国人民大学 南京大学 复旦大学等
大型语言模型 (LLMs) 在解决跨不同领域的复杂任务方面表现出了巨大的潜力,通常通过采用遵循详细指令和操作序列的 agentic 工作流程。然而,构建这些工作流程需要大量的人力,限制了可扩展性和通用性。最近的研究试图自动生成和优化这些工作流程,但现有方法仍然依赖于初始手动设置,无法实现完全自动化和有效的工作流程生成。为了应对这一挑战,我们将工作流优化重新表述为 code-represented 的工作流上的搜索问题,其中 LLM-invoking 节点通过边连接。我们引入了 AF,这是一个自动化框架,它使用
蒙特卡罗树搜索有效地探索这个空间,通过代码修改、tree-structured experience 和执行反馈迭代地完善工作流程。对六个基准数据集的实证评估证明了 AF 的功效,与最先进的基线相比平均提高了 5.7%。此外,AF 使较小的模型在特定任务上的表现优于 GPT-4o,其推理成本(美元)仅为 4.55%。LLM have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using
Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow’s efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at this https URL.
Introduce¶
关键思想是将工作流建模为一系列互连的 LLM 调用节点,其中每个节点(Node)代表一个 LLM action,边(Edge)定义这些节点(LLM action)之间的逻辑(logic)、依赖(dependence)和流程(flow)。这种结构将工作流程转变为巨大的搜索空间,包含各种潜在的配置。我们的目标是有效地驾驭这个空间,自动生成优化的工作流程,最大限度地提高任务性能,同时最大限度地减少人为干预。
挑战:任务的多样性和复杂性带来了巨大的挑战,具体来说,每个任务可能有不同的需求、操作和依赖关系,这使得很难以统一而灵活的方式表示它们;此外,可能的工作流程的搜索空间(包括大量代码结构和节点配置)几乎是无限的,这为高效探索和优化带来了额外的挑战。
PRELIMINARY¶
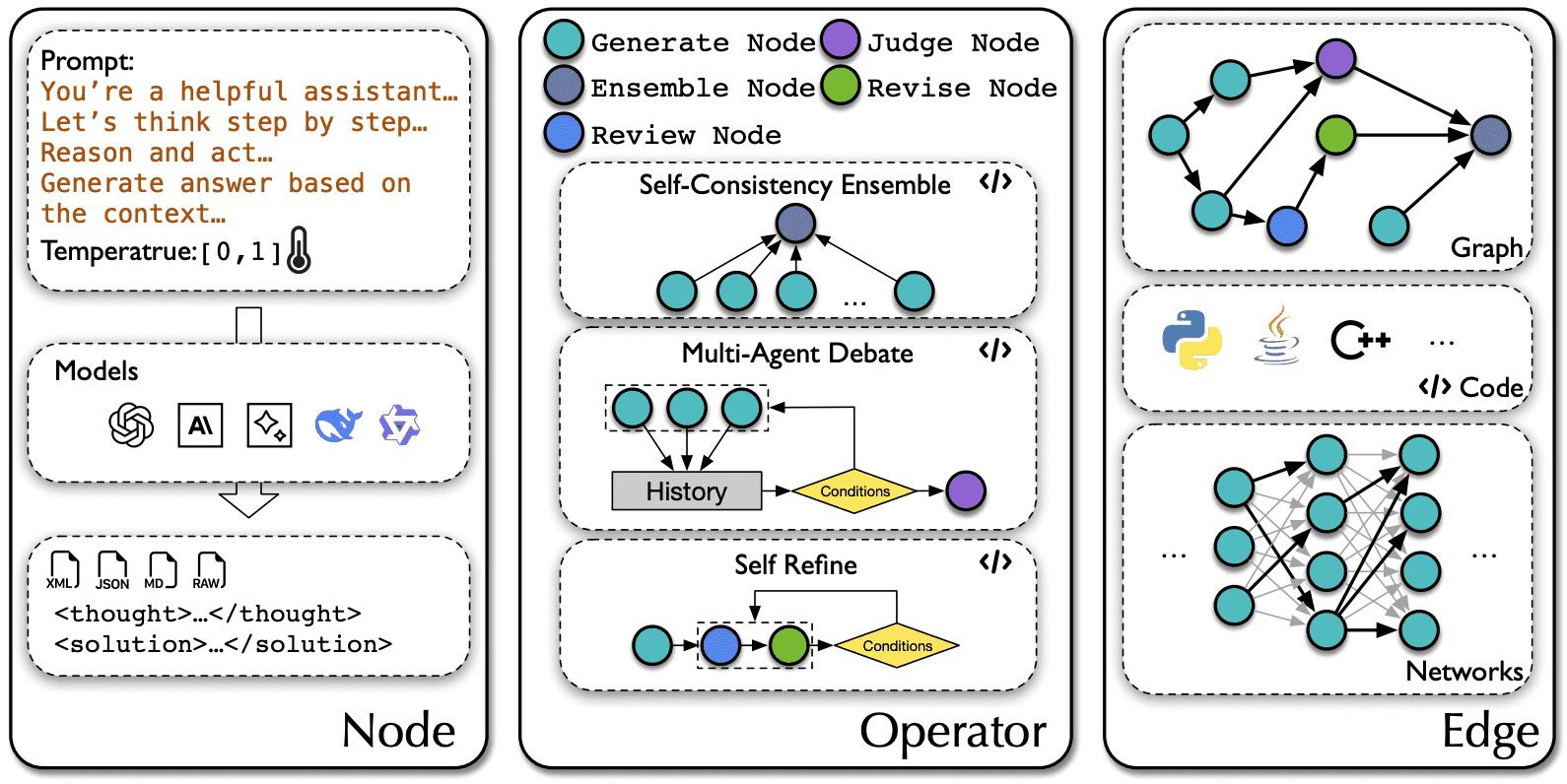
We demonstrate the optional parameters for Nodes, the structure of some Operators, and common representations of Edges.¶
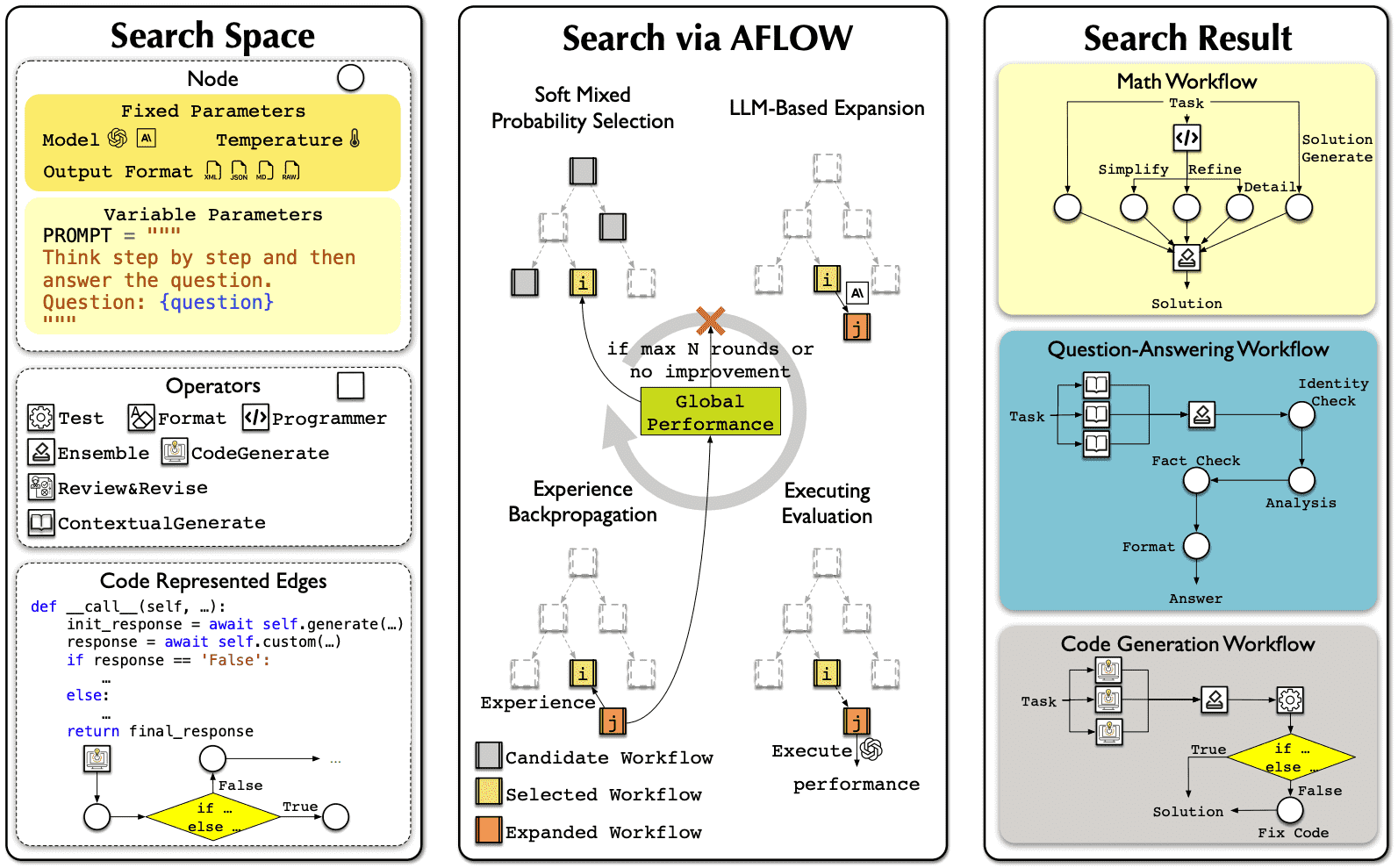
Overall AFLOW framework:通过设置一个搜索空间(搜索空间包括:仅有灵活prompt参数的节点、给定的算子集(operator set)和表示边缘的代码,AFLOW 在该空间内执行 MCTS-based 的搜索。通过专为工作流优化而设计的 MCTS 变体,AFLOW 迭代地循环执行下面操作直到达到最大迭代次数或满足收敛标准:Soft Mixed Probability Selection、LLM-Based Expansion, Execution Evaluation, and Experience Backpropagation。¶