2206.01861_ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers¶
组织: Microsoft
GitHub: https://github.com/microsoft/DeepSpeed 的一部分
引用(519, 2025-06-20)
Abstract¶
提出了一种叫ZeroQuant的后训练量化方法,用来高效压缩大型Transformer模型(比如BERT和GPT-3),让模型在推理时更快、更省内存,同时准确度几乎不受影响。
ZeroQuant有三大特点:
针对权重和激活值设计了细粒度、硬件友好的量化方案;
开发了一种不依赖原始训练数据的经济高效的逐层知识蒸馏算法(LKD);
优化了系统后端,减少量化带来的额外开销。
主要效果包括:
将权重和激活降到INT8,速度提升4-5倍左右;
结合LKD,将部分权重量化到INT4,内存占用减少3倍;
在大型开源模型(GPT-J 6B,GPT-NeoX 20B)上,INT8量化模型准确度和FP16相当,但效率提升超过5倍。
简而言之,就是用ZeroQuant能让大语言模型跑得更快、更省资源,还保持高精度。
1. Introduction¶
大规模自然语言模型(如BERT、GPT)性能强,但体积大,计算和内存成本高,部署难度大。
量化(将模型权重和激活用更低精度表示)是减少内存和加速推理的有效方法,但传统量化需要重新训练(QAT),耗时且需训练数据,现实中难以实现。
新兴的零样本量化和后训练量化(PTQ)能减少对训练数据和计算资源的依赖,但现有方法多针对计算机视觉且规模较小,且实际延迟提升不明显。
极端量化(如INT4)常用知识蒸馏提升精度,但对显存和计算资源需求大,因为要同时加载教师和学生模型。
本文提出ZeroQuant,一种端到端的后训练量化方案,支持INT8和混合INT4/INT8量化,特点包括:
细粒度硬件友好量化策略(权重按组,激活按token)减少误差并支持硬件加速;
创新分层知识蒸馏(LKD),分层逐步量化,迭代少,无需原始训练数据,显存占用低,适合大模型;
高度优化的推理后端,消除量化/反量化的高计算开销,显著提升推理速度。
实验结果:
ZeroQuant可无重新训练将BERT和GPT-3类模型量化为INT8,准确率保持,速度提升约4-5倍;
ZeroQuant+LKD支持混合INT4/INT8量化,内存减3倍,精度轻微下降,量化时间短,且可用其它数据集替代原训练集;
在大规模模型(GPT-J6B、GPT-NeoX20B)上,ZeroQuant带来显著速度提升和资源节省,推理延迟降低超过2倍,系统效率提升超5倍。
简单来说,ZeroQuant解决了大模型量化难、资源需求高的问题,实现了快速、低资源、高效的后训练量化和推理加速。
2. Relative Work¶
🌟 总体介绍:¶
模型压缩有很多方法,其中量化是最有前景的方向之一,因为它可以直接减小内存占用和计算量。
本文聚焦于NLP模型的量化研究。
🧠 主流方法 1:训练感知量化(QAT)¶
是最常见的做法:在训练阶段就考虑量化。
代表性工作用整数(如 INT2 / INT4)来量化 BERT 的权重和激活值。
有些方法引入Hessian矩阵信息,或采用分组量化来更精细控制。
有些使用知识蒸馏 + 数据增强将权重二值化或三值化。
这些方法大多需要完整重训练或微调整个模型,以恢复精度。
这种方式在处理像 GPT-3 这样的大模型时,成本极高,一般研究者难以承受。
🧠 主流方法 2:训练后量化(PTQ)¶
不需要重训,只在训练后进行量化,更省计算。
但通常会有明显的精度下降,尤其是在 Transformer 类模型中。
有些方法尝试非均匀量化或将异常值保留为高精度(如 FP32),但这种混合精度难以在 CPU/GPU 上高效运行。
也有人提出对某些激活用 FP16 保持高精度,但仍难以完全解决问题。
❗ 当前挑战:¶
GPT-3 类大模型的 PTQ 方案仍未解决;
对十亿级以上模型的 PTQ 研究很少;
缺乏支持精细量化的高效推理系统,难以实现在通用硬件上低延迟运行。
✅ ZeroQuant 的贡献:¶
它把系统后端(如硬件运行效率)也纳入算法设计中。
支持 BERT 和最大 200 亿参数的 GPT-3 类模型(如 GPT-NeoX)进行高效 PTQ。
能在多种任务上实现高精度和高效率。
3. Background and Challenges¶
这段内容主要介绍了在大模型(如 GPT-3 和 BERT)上使用 后训练量化(PTQ) 的挑战。
📌 背景知识¶
PTQ(后训练量化):不需要重新训练模型,只通过原模型加上标定数据即可完成量化,效率高于 QAT(训练中量化)。
一般做法是:用原始训练数据运行模型,然后根据平均值来调整量化的比例因子。
📌 存在的问题¶
1. GPT 和 BERT 上低比特量化难度大¶
目前研究主要集中在 BERT base 的 INT8 权重量化上,但对于:
更低精度(如 INT4)的探索很少;
大规模模型(如 GPT-3)的 PTQ 也很缺乏。
2. INT8 精度就已明显降低性能¶
用 INT8 激活(W16A8)量化,会明显损失准确率;
进一步将权重也量化到 INT8(W8A8),虽然对某些任务影响不大,但会显著降低语言生成任务(如 Wikitext-2)的表现;
用更低精度(如 W4/8A16)时,模型基本无法生成有意义的文本。
📌 原因分析¶
🔸 激活范围变化大¶
每个 token 的激活范围(数值大小)差异大,比如有的 token 激活范围是 35,有的是 8;
如果只用一个固定的量化范围,会使得小范围的 token 表达不清,精度下降。
🔸 注意力权重行之间差异大¶
GPT 的注意力输出矩阵中,不同行的数值大小差异可能高达 10 倍;
INT8 还勉强可以表示,但 INT4 只有 16 个数字,表示能力太弱,影响严重。
📌 小结¶
PTQ 虽然高效,但在大模型上易损失性能,特别是生成类任务;
主要挑战来自激活和权重范围波动大,尤其在低精度下更严重;
更复杂的技术(如知识蒸馏)虽然能改善精度,但代价太高,需要轻量替代方案。
4. Methodology¶
4.1 Fine-grained Hardware-friendly Quantization Scheme¶
背景问题:INT8量化虽然节省资源,但对BERT/GPT-3这类大模型会造成明显精度损失,原因是INT8无法很好表示每一行权重或每个token激活值的数值范围差异。
改进方案:
权重的分组量化:把权重矩阵分成小组,每组单独量化,比整体量化精度更高。
激活值的token级量化:为每个token单独计算量化范围(动态量化),避免激活值范围差异带来的误差。
硬件优化:针对NVIDIA A100等GPU架构设计,结合Warp Matrix Multiply (WMMA) 实现高效计算。
后端优化:通过融合量化操作(如和LayerNorm合并)减少内存访问开销,使token-wise量化既保留精度也提高运行速度。
4.2 Layer-by-layer Knowledge Distillation with Affordable Cost¶
传统蒸馏问题:需要完整教师模型、原始训练数据,并消耗大量内存/计算资源。
我们的方法(LKD):
一次只量化一个transformer层,用该层的未量化版本做“老师”。
只优化当前一层,降低内存消耗;
不依赖原始标签,只用输入X即可;
不需要完整训练,也不需要存教师模型。
4.3 Quantization-Optimized Transformer Kernels¶
问题:虽然量化降低了数据量,但频繁的量化/反量化操作会引入额外延迟,抵消性能收益。
优化方案:
使用CUTLASS库实现高效INT8矩阵乘法;
通过内核融合(kernel fusion)将激活量化、偏置加法、GeLU、LayerNorm等合并成一个操作,减少数据搬运;
将反量化也融合到GeMM中,进一步减少内存访问。
效果:最终显著提升BERT和GPT-3模型的推理速度。

Figure 2: The illustration of normal (left) and our fused (right) INT8 GeMM.
5. Results¶
背景与方法概述
ZeroQuant 是一种后训练量化(Post-Training Quantization, PTQ)方法,
目标是无需重新训练或只需极少计算,就能对大模型(如 BERT、GPT-3)进行高效的权重量化,保持高精度、降低成本。
实验设置
测试模型包括:BERT (base 和 large)、GPT-3 模型(350M、1.3B)、GPT-J 6B、GPT-NeoX 20B。
ZeroQuant-LKD 是在 ZeroQuant 基础上增加了轻量级蒸馏(Layer-wise Knowledge Distillation, LKD)。
量化表示说明
WxAy:表示权重使用 x 位量化,激活使用 y 位。例如
W4/8A16:MHSA 层权重为 INT8,FFC 层为 INT4;激活部分 Attention 计算使用 FP16,其余为 INT8。
🔍 BERT 实验主要结论¶
W8A8 下,普通 PTQ 精度下降 >10 点,但 ZeroQuant 仅下降 0.2,效果接近 QAT。
W4/8A16 极限量化下,PTQ 几乎完全失效,但 ZeroQuant 仍能达到 81.65,ZeroQuant-LKD 更可达 82.35。
相比 QAT,ZeroQuant-LKD 仅需几十秒/GPU 就能达到相似精度,训练开销减少 90 倍以上。
🔍 GPT-3 模型实验¶
W8A8 量化对准确率型任务影响小(仅下降 1.1%),对生成任务影响大(下降 4.7);ZeroQuant/LKD 可显著减小损失。
W4/8A16 极限量化下,ZeroQuant 仍有效,LKD 提升显著,例如 PPL 从 88.6 降到 30.6,仅花费 3.1 GPU 小时。
⚡ 推理速度提升¶
相比 FP16:
BERT 模型使用 INT8 速度提升约 2.3–5.2 倍
GPT-3 模型生成 50 个 token,速度提升约 4 倍
🚀 大模型扩展性验证¶
GPT-J 6B 在 3 个生成任务中,ZeroQuant 保持精度,速度提升 3.67 倍。
GPT-NeoX 20B 中发现 Attention 输入特别敏感,因此保留该部分为 FP16,其余使用 INT8,最终达到 5.2 倍吞吐提升,GPU 使用从 2 块降为 1 块。
🧪 消融实验结果¶
对 BERTlarge 进行分析:
Group-wise weight quantization 由随机预测提升至 66.52。
加上 token-wise activation quantization,再提升 14.54 点。
再加 LKD,提升 0.56 点。
🔐 无原始训练数据也能用 LKD¶
即使没有原始训练集(如 PILE),使用 Wikipedia 或随机数据也能训练 LKD 并显著提升性能。
用 Wikipedia 数据,效果几乎等同原始数据。
6. Conclusions¶
随着大模型越来越大,如何高效部署它们变得很重要。
虽然已有研究把量化方法用在BERT上,但目前还没人做过以下三点:
应用于GPT-3这类10亿参数以上的大模型;
使用超低精度(比如INT8)的量化;
提供完整的线上推理部署方案。
本文提出了一种精细的压缩方法,对权重和激活值都进行了INT8量化,适用于最多20B参数的模型(如GPT-NeoX-20B)。
同时,引入了一种便宜有效的逐层知识蒸馏技术,使模型在几乎不损失准确率的前提下,比FP16版本缩小了3倍。
最后,还搭建了系统后端,实测BERT提速可达5.19倍,GPT-NeoX提效达5.2倍。
Appendix A Background¶
一、Transformer结构(A.1)¶
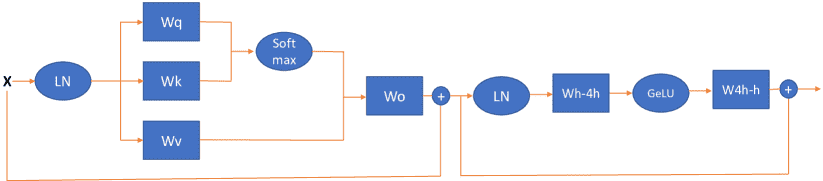
Figure A.1: The illustration of a Transformer-block.
Transformer通常由三部分组成:嵌入层(embedding)、多个编码器/解码器层(encoder/decoder layers)、最后的分类器(classifier)。
本文关注的是Transformer中最耗计算和内存的部分——encoder/decoder层(也叫Transformer Block)。
每个Transformer Block由两个子模块组成:
多头自注意力(MHSA)
前馈神经网络(FFC)
Transformer模型有三种类型:
仅编码器(如BERT)
仅解码器(如GPT)
编码器+解码器(如T5)
本文主要研究前两种,但方法也适用于第三种。
二、量化基础(A.2)¶
量化是把高精度数值(如FP16/FP32)转成低精度(如INT4/INT8),以减少模型大小和提高运行速度。
本文使用对称的均匀标量量化器,即: $\( x_{quantize} = round(clamp(x / S, -2^{(bit-1)}, 2^{(bit-1)} - 1)) \)$
bit是使用的位数(比如 8 表示 INT8)S是缩放因子clamp限制范围,round是四舍五入
对权重矩阵的量化,S 是固定的,一般取最大绝对值。
对激活值(activations)来说,由于它们在推理时变化,S 需要动态计算。但为了加速,实际中通常会用训练数据预先估计一个静态 S,这样能减少延迟,但也可能影响量化效果。
Appendix D Details about System Optimization¶
整体优化目标:¶
通过将模型权重和激活量化为 INT8 格式,使用专门的 Tensor Core(比 FP16/FP32 高效 2-4 倍)来加速矩阵乘法(GeMM),以提升推理效率。
主要优化方法:¶
定制高效计算计划(Schedule):
使用 CUTLASS 工具根据不同输入(如 batch size、序列长度等)生成多种执行计划。
在运行时选择填充最少、执行最快的计划。
高效的激活量化实现:
把激活量化操作与其他操作(如 Bias 加法、GELU、LayerNorm)融合在一起,减少内存访问,提升效率。
使用 FP16 转 INT8 提高内存带宽利用率。
高效的反量化(Dequantization):
INT8 GeMM 输出是 INT32,需要转回 FP16。
将反量化过程与 GeMM 结果一起处理,避免额外开销。
在计算 GeMM 时提前加载缩放因子,进一步减少延迟。
小模型优化 - CUDA Graph 加速:
对于 BERT 等小模型,INT8 推理速度快,但 CPU-GPU 通信开销变大。
用 CUDA Graph 记录推理过程后复用,减少每次推理的启动开销,特别适合小模型。
总结¶
核心是讲 通过量化、融合操作、并行优化和 CUDA Graph 重用技术,在 GPU 上高效地实现低精度推理,最大限度提升吞吐量并降低延迟。