2304.08485_LLaVA: Visual Instruction Tuning¶
组织: University of Wisconsin–Madison Microsoft Research, Redmond
Abstract¶
LLaVA: Large Language and Vision Assistant
研究人员用GPT-4生成图文指令数据,对多模态大模型进行训练,提出了LLaVA模型(图文助手)。
它把视觉编码器和语言模型连接起来,能理解图像和语言指令。
实验证明,LLaVA在看图聊天等任务上表现优秀,有时能像多模态GPT-4一样表现。
在一个图文任务数据集上,它的表现达到GPT-4的85.1%。在Science QA任务上,它与GPT-4联合使用,还刷新了准确率纪录(92.53%)。
1. Introduction¶
人类通过视觉、语言等多种方式理解世界。人工智能的目标之一是打造一个能听懂多模态(图像+语言)指令的通用助手。
目前,视觉大模型擅长图像分类、检测、分割、生成等任务,但任务处理通常是“固定的”,不能灵活理解语言指令。
另一方面,大语言模型(如 ChatGPT、GPT-4)展现出强大的指令理解能力,但它们是纯文本模型,不处理图像。
本论文提出:
视觉指令微调(Visual Instruction Tuning)的方法,让AI能同时理解图像和语言指令。
利用 ChatGPT/GPT-4 把图文数据转换为“图文指令数据”,用于训练。
构建一个新的多模态大模型(LMM),结合视觉编码器 CLIP 和语言解码器 Vicuna。
实验显示,这种训练方式效果很好,并且在多模态问答测试集 ScienceQA 上达到最先进水平(SoTA)。
发布了评测基准(LLaVA-Bench)和开源数据、代码、模型和可交互演示。
3. GPT-assisted Visual Instruction Data Generation¶
为了生成多模态指令跟随数据(即模型能根据图像理解并回答人类提出的问题),研究者提出利用 GPT-4 或 ChatGPT 来自动生成这类数据。
背景问题¶
现有的图文数据(如CC、LAION)很多,但指令跟随类型的数据很少,因为人工标注耗时又不清晰。
GPT模型在文本标注任务上表现很好,因此研究者想到用它来生成“图像理解+问答”的数据。
方法概述¶
输入信息:只使用图像的“文本描述”(如图像标题caption)和“目标框信息”(bounding boxes,表示物体类别及位置),不直接输入图像本身。
生成方式:
用GPT-4基于caption和box,设计出多个问题和对应的答案。
人工只制作少量示例作为种子(few-shot),GPT负责扩展生成。

Table 1: One example to illustrate the instruction-following data. The top block shows the contexts such as captions and boxes used to prompt GPT, and the bottom block shows the three types of responses. Note that the visual image is not used to prompt GPT, we only show it here as a reference.
三类生成数据¶
对话式问答(Conversation):GPT像助理一样回答关于图像的问题(如:图中是什么车?有几个人?物体位置?)。
详细描述(Detailed Description):GPT对图像进行全面丰富的自然语言描述。
复杂推理(Complex Reasoning):GPT回答需要逻辑推理的问题(如:图中人面临什么挑战?)。
成果¶
总共生成了 15.8万条高质量的指令数据:
5.8万条对话问答
2.3万条详细描述
7.7万条复杂推理
发现:GPT-4的效果比ChatGPT更好,特别是在空间推理方面。
4. Visual Instruction Tuning¶
4.1 Architecture¶
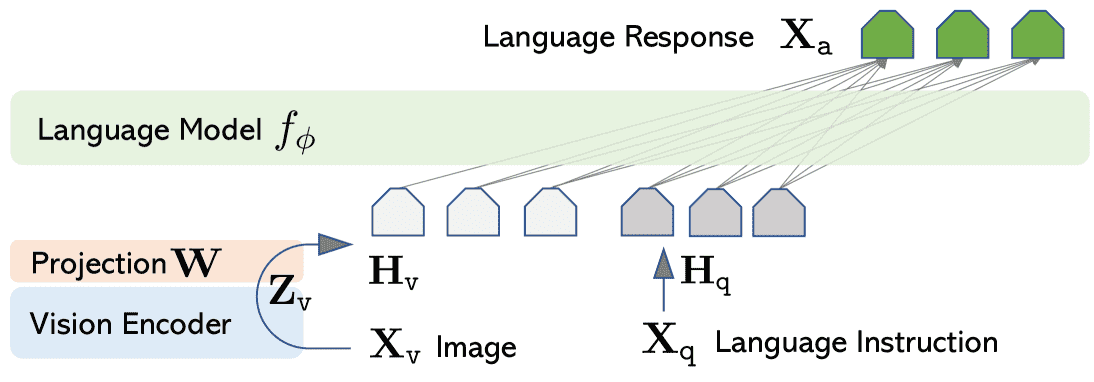
Figure 1:LLaVA network architecture.
目标:将图像信息与语言大模型(Vicuna)结合,使模型能理解并响应图文混合的指令。
组件:
图像通过 CLIP 的视觉编码器(ViT-L/14) 提取特征。
提取出的视觉特征经过一个线性变换(矩阵 W),转换成与语言模型的词向量维度相同的视觉 token(记作 Hᵥ)。
这个过程是轻量级的,可以快速试验,但也提到以后可以用更复杂的方法(比如 Flamingo 的交叉注意力或 BLIP-2 的 Q-former)提升效果。
4.2 Training¶

Table 2:The input sequence used to train the model. Only two conversation turns are illustrated here; in practice, the number of turns varies based on the instruction-following data. In our current implementation, we follow Vicuna-v0 to set the system message 𝐗 system-message and we set <STOP> = ###. The model is trained to predict the assistant answers and where to stop, and thus only green sequence/tokens are used to compute the loss in the auto-regressive model.
每张图片都配有一组多轮问答(例如:图+问题1,回答1,问题2,回答2……)。
对于每一轮:
第 1 轮的问题(instruction)是图片和文本问题的组合(顺序随机)。
后续轮次的问题直接是文本问题。
模型的输入包括:
系统提示(system message)
用户输入(Human)= instruction
助手输出(Assistant)= 回答
每段内容都以
<STOP>结束(标记为“###”)
训练目标:让语言模型在给定图像和问题的前提下,预测出正确的回答(自回归方式,只计算回答部分的 loss)。
5. Experiments¶
总体实验设计:¶
目标:评估 LLaVA 的图像理解与指令跟随能力。
方式:在两个任务上测试——多模态聊天机器人 和 ScienceQA 数据集。
训练配置:使用 8 张 A100 显卡,先在 CC-595K 图像数据上预训练,再在 LLaVA-Instruct-158K 上微调。
5.1 多模态聊天机器人(Multimodal Chatbot)¶
定性结果:
在 GPT-4 提出的图像理解例子上,LLaVA 的表现接近 GPT-4,明显优于 BLIP-2 和 OpenFlamingo。
BLIP-2 和 OpenFlamingo 更倾向于“描述图片”,而不是“根据问题做出回答”。
定量评估:
构造三元组(图片、文字描述、问题),由 GPT-4 评分评估模型回答的质量(包括有用性、准确性等)。
LLaVA 表现接近 GPT-4 提供的上限答案。
两个基准测试:
LLaVA-Bench (COCO)
使用 COCO 数据集中 30 张图像,生成 90 个问题,涵盖对话、描述、推理等三种类型。
加入多样化指令数据后,模型表现提升显著,最终整体得分达到 85.1%。
LLaVA-Bench (In-the-Wild)
更具挑战性的真实世界图像(如饭店餐食和冰箱)。
对比中,LLaVA 优于 BLIP-2(+29%)和 OpenFlamingo(+48%)。
一些细节问题依然存在错误,表明模型在图像理解上仍有限。
5.2 ScienceQA 多模态问答¶
数据集:
ScienceQA 涵盖 2 万多个题目,包含图文、多选题,涉及多个学科。
方法:
LLaVA 首先预测推理过程再预测答案,训练 12 轮。
获得 90.92% 的准确率,接近当前最佳方法 MM-CoT(91.68%)。
模型融合探索:
用 GPT-4 弥补 LLaVA 的不足,形成两种融合策略:
GPT-4 补充:当 GPT-4 无法回答时用 LLaVA 的答案,准确率提升到 90.97%。
GPT-4 评审:当两个模型答案不同,让 GPT-4 再次判断哪个答案对,最终准确率达到 92.53%,创下新记录。
原因:GPT-4 能识别哪些题其实不需要图像,有助于纠正 LLaVA 的错误。
消融实验(Ablation):
视觉特征层次:使用倒数第二层效果更好。
推理顺序:先推理收敛更快,但最终效果差别不大。
跳过预训练:准确率下降 5%,预训练很重要。
模型规模:13B 模型比 7B 表现好 1%。
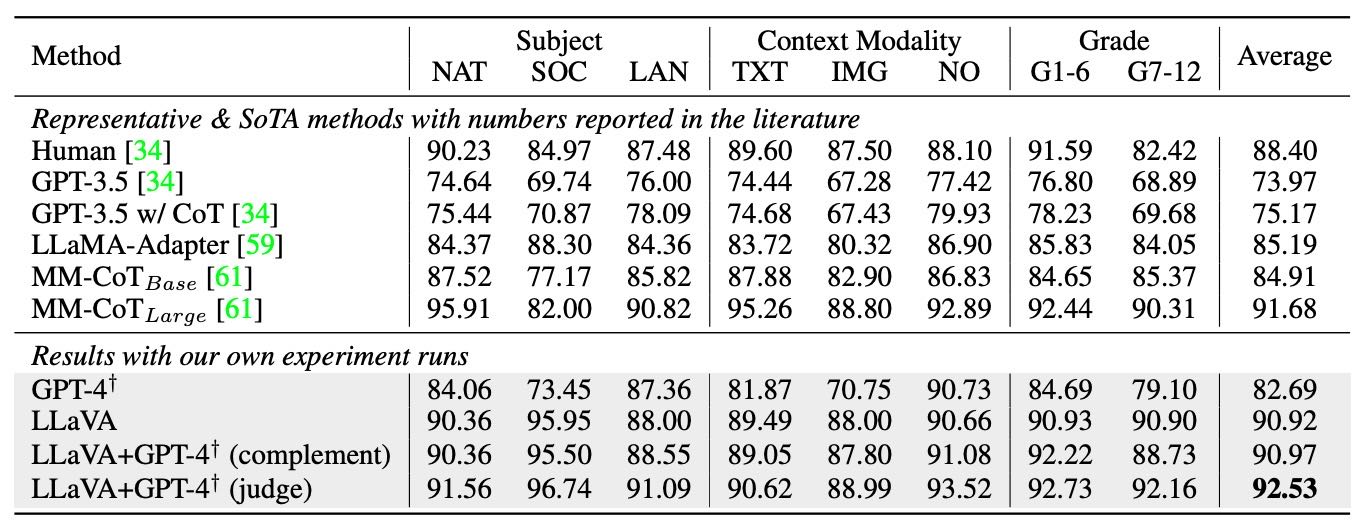
Table 7:Accuracy (%) on Science QA dataset. †Text-only GPT-4, our eval. Our novel model ensembling with the text-only GPT-4 consistently improves the model’s performance under all categories, setting the new SoTA performance.
Question categories:
NAT = natural science,
SOC = social science,
LAN = language science,
TXT = text context,
IMG = image context,
NO = no context,
G1-6 = grades 1-6,
G7-12 = grades 7-12.
6. Conclusion¶
本文提出了一种视觉指令微调的方法,并自动生成图文指令数据,用于训练名为 LLaVA 的多模态模型,使其能根据人类指令完成视觉任务。
LLaVA 在 ScienceQA 上达到了新的最优成绩,并在多模态对话中表现出色。
还首次提出了一个评估多模态指令能力的基准。这项工作是视觉指令微调的起点,主要聚焦于现实任务,并希望能推动后续研究。