2412.12392_MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors¶
组织: Imperial College London
Project Page: https://edexheim.github.io/mast3r-slam
Video: https://youtu.be/wozt71NBFTQ
SLAM: Simultaneous Localization and Mapping(同步定位与地图构建)
IMU: Inertial Measurement Unit(惯性测量单元)
SfM: Structure from Motion(运动恢复结构)
DUSt3R
MASt3R
GPT¶
MASt3R-SLAM:是指一种实时单目稠密SLAM系统,基于两视图3D重建先验(如DUSt3R和MASt3R)构建。它利用高效的点图匹配、跟踪融合、图构建和回环检测技术,能够处理通用、时变的相机模型,并在已知校准下达到卓越的性能。具体来说,MASt3R-SLAM通过两视图的3D重建先验,从普通RGB视频中重建三维点云数据,为SpatialLM提供基础的空间理解信息。此外,它还能生成全局一致的位姿和密集几何结构,即使在未校准的情况下也优于部分基线方法,但存在未全局优化几何结构和对畸变图像适应性差的局限性。
点云重建是指将一系列在三维空间中分布的点(点云)通过特定算法转化为具有表面信息的三维模型的过程。点云重建涉及以下几个关键步骤:
数据获取:首先通过激光扫描、摄影测量等技术获取场景的点云数据。这些数据通常包含每个点的三维坐标,有时还包括颜色、强度等属性。
预处理:对点云进行去噪、去冗余等预处理操作,以提高重建质量。
算法选择:根据点云的特性选择合适的重建算法。常见的方法包括但不限于:
Marching Cubes算法:通过构建体素网格并根据阈值提取等值面来生成表面。
泊松表面重建:利用泊松方程生成光滑的表面。
基于深度学习的方法:如PointMVSNet、SSRNet等,通过神经网络学习点云的几何和纹理特征,生成高质量的表面。
Delaunay三角化:将点云转化为三角网格,确保表面的连贯性和细节。
表面生成:根据所选算法生成具有连续表面的三维模型。
后处理:对生成的模型进行优化,如去除孔洞、平滑表面等,以提高模型的质量和可用性。
先验知识¶
IMU¶
IMU是Inertial Measurement Unit的缩写,中文通常翻译为惯性测量单元。IMU是一种用于测量物体加速度、角速度以及有时还包括方向的传感器设备。
它通常由以下几种核心传感器组成:
加速度计(Accelerometer):用于测量物体的线性加速度。
陀螺仪(Gyroscope):用于测量物体的角速度(即旋转速度)。
磁力计(Magnetometer,可选):用于测量磁场强度和方向,类似于指南针的功能,帮助确定绝对方向。
在机器人、无人机、智能手机、自动驾驶汽车等领域,IMU是非常重要的传感器之一。它可以帮助设备感知自身的运动状态,即使在没有外部参考(如GPS信号)的情况下,也能提供短时间内的定位和姿态估计。
IMU在SLAM中的作用
在 Visual SLAM 中,IMU经常被用来与摄像头数据结合,形成所谓的视觉-惯性SLAM(Visual-Inertial SLAM, VI-SLAM)。这种组合可以弥补单一传感器的不足:
摄像头:虽然能提供丰富的环境信息,但在快速运动、低纹理场景或光线变化剧烈的情况下可能失效。
IMU:虽然能在短时间内提供精确的运动信息,但长时间使用会有漂移问题(误差累积)。
通过将两者结合起来,IMU可以在摄像头数据不可靠时提供补充信息,从而提高系统的鲁棒性和精度。
IMU是一种重要的传感器,在SLAM和其他定位导航任务中扮演着关键角色,尤其是在多传感器融合的系统中。
SfM¶
SfM是 Structure from Motion 的缩写,中文通常翻译为 运动恢复结构。
它是一种摄影测量技术,用于从一系列二维图像中重建出场景的三维结构。
SfM通过分析不同视角下拍摄的图像之间的共视关系(通常是特征点匹配),结合相机的位置和姿态信息,计算出被拍摄物体或场景的三维几何结构。
在SfM过程中,首先需要检测并匹配多幅图像中的特征点,然后利用这些匹配点来估计每张图像对应的相机位置和方向。
一旦相机参数被确定,就可以进一步计算出这些特征点在三维空间中的位置,从而构建出场景的三维模型。
这个过程可以解决多个子问题,包括相机定位、场景几何重建等,并且能够在没有事先知道场景深度信息的情况下,仅依靠输入的图像序列来重建场景的三维结构。
SLAM¶
SLAM(Simultaneous Localization and Mapping)中文叫:同步定位与建图。
一边移动,一边估计自己的位置(定位)
同时构建周围环境的地图(建图)
目标:自己不知道自己在哪,也没有地图,还能一边走一边画地图,同时知道自己走到了哪。
基本组成
传感器输入 | 获取环境信息。常见输入:摄像头(视觉SLAM)、激光雷达(LiDAR SLAM)、IMU(惯性测量单元)等
前端(Tracking) | 从连续的传感器数据中提取特征,进行帧与帧之间的运动估计(比如位姿变化)
地图构建(Mapping) | 利用观测到的环境信息,逐步构建出环境地图(点云、稠密模型、网格地图等)
后端优化(Backend) | 通过全局优化(比如图优化),对位姿和地图进行一致性调整,减少累计误差
回环检测(Loop Closure) | 当机器人回到之前去过的地方时,识别出来并进行地图和位姿的修正
重定位(Relocalization) | 万一丢失了位置,能够根据已有地图重新找回自己的位姿
SLAM的核心难点
漂移累积误差(越走越不准)
环境动态变化(有些东西会动)
计算量大(尤其是稠密建图)
感知的不确定性(光照变化、遮挡、传感器噪声)
常见SLAM分类
视觉SLAM(V-SLAM)
ORB-SLAM、DSO、LDSO
使用单目/双目/深度相机;成本低,信息丰富,但对光照敏感
激光SLAM
Cartographer、LOAM
使用激光雷达,测距精准,适合户外和大范围场景,但成本高
惯性SLAM
VINS-Mono、OKVIS
相机+IMU联合使用,抗快速运动和短期遮挡
多传感器融合SLAM
LVI-SAM、VINS-Fusion
视觉+激光+IMU融合,鲁棒性最强,但复杂度也高
central camera model¶
“Central camera model(中心相机模型)” 是计算机视觉和SLAM(Simultaneous Localization and Mapping)中一种非常常见和基础的假设。这个模型假设所有成像光线(即场景点到图像点之间的光线)都穿过一个公共点,这个点就是相机的光心(optical center)或主点(center of projection)。
✅ 通俗解释:
把中央相机模型想象成一个理想的针孔相机。所有来自三维世界的光线都会穿过这个针孔,并在图像平面上成像。
✅ 正式一点的定义:
成像过程可以被建模为一个投影变换,即场景点通过相机中心投影到图像平面;
所有成像光线在三维空间中汇聚于一个点(即相机中心);
这个模型包括了常见的相机模型,比如:
针孔相机模型(pinhole camera)
鱼眼相机(fisheye, 可近似)
广角相机(wide-angle)
等距投影相机(equiangular)
而非中心相机模型(non-central camera models),如某些类型的全景相机或多目系统中的镜头阵列,成像光线可能不会汇聚于一个点。
✅ 为什么强调使用 central camera model?
成像过程更容易建模,投影和反投影操作简单;
可以使用大量现有的三维重建、SLAM、SfM 等算法;
多数市售相机(包括RGB相机和深度相机)都能很好地拟合这个模型;
在稀疏和稠密匹配、点云合成、优化等方面效率高。
Abstract¶
We present a real-time monocular dense SLAM system designed bottom-up from MASt3R, a two-view 3D reconstruction and matching prior.
🔍 解释:
我们提出了一个实时、单目(monocular)、稠密(dense)的 SLAM 系统
这个系统是从 MASt3R 出发,自底向上设计的
MASt3R 是一个“基于两帧图像的三维重建与匹配的先验模型”
所谓“先验”是指它在实际 SLAM 系统之外就已经训练好,能提供几何结构、匹配信息等
小补充:
Monocular SLAM:只用一台普通摄像头做实时定位与建图
Dense:不只是稀疏点(如特征点),而是对整个场景的稠密深度估计
Equipped with this strong prior, our system is robust on in-the-wild video sequences despite making no assumption on a fixed or parametric camera model beyond a unique camera centre.
🔍 解释:
有了这个强大的 MASt3R 先验作为基础,我们的 SLAM 系统在各种“野外视频序列”(不受控拍摄)中也能表现得很稳健。
不需要假设摄像机有固定的参数模型(intrinsics),只假设有一个唯一的相机中心(即光心),可以泛化到多种相机设置。
📌 理解关键词:
“in-the-wild”: 指真实世界的视频,不是受控实验环境。
“no assumption on a parametric camera model”: 通常 SLAM 会依赖相机的焦距、主点等已知参数,这里他们不依赖这些。
We introduce efficient methods for pointmap matching, camera tracking and local fusion, graph construction and loop closure, and second-order global optimisation.
🔍 解释:我们提出了一整套高效的方法,包括:
点图匹配(pointmap matching):如何把新帧和已有点图对齐。
相机跟踪(camera tracking):估计当前相机的位置和姿态。
局部融合(local fusion):把新数据整合到已有地图中。
图构建和回环检测(graph construction & loop closure):构建关键帧图,并检测闭环(走回了原来来过的地方)。
二阶全局优化(second-order global optimization):在图的基础上,使用优化算法对所有位姿进行全局一致性调整。
With known calibration, a simple modification to the system achieves state-of-the-art performance across various benchmarks.
🔍 解释:
如果已知相机内参(即有 calibration),我们只需对系统稍作改动,就能在多个公开基准上达到最先进(SOTA)的性能。
Altogether, we propose a plug-and-play monocular SLAM system capable of producing globally consistent poses and dense geometry while operating at 15 FPS.
🔍 解释:
总之,我们提出了一个“即插即用(plug-and-play)”的单目 SLAM 系统。
它能在每秒15帧(15 FPS)的速度下,输出:
全局一致的相机位姿(不飘、不错位)
稠密的几何重建(不仅仅是关键点,而是连成面)
📌 总结
这段话介绍了一个新型的单目稠密 SLAM 系统,底层是基于 MASt3R 的双帧三维匹配先验。
该系统不依赖固定的相机模型,仅假设一个唯一光心,在各种自然视频中都表现稳定。
系统包括高效的点图匹配、相机跟踪、局部融合、图构建与闭环检测,以及二阶优化模块。
在已知相机参数时,只需小改动就能达到多个基准任务的 SOTA 性能。
最终,该系统实现了一个15 FPS的即插即用 SLAM,能输出全局一致的位姿和稠密场景几何。
1. Introduction¶
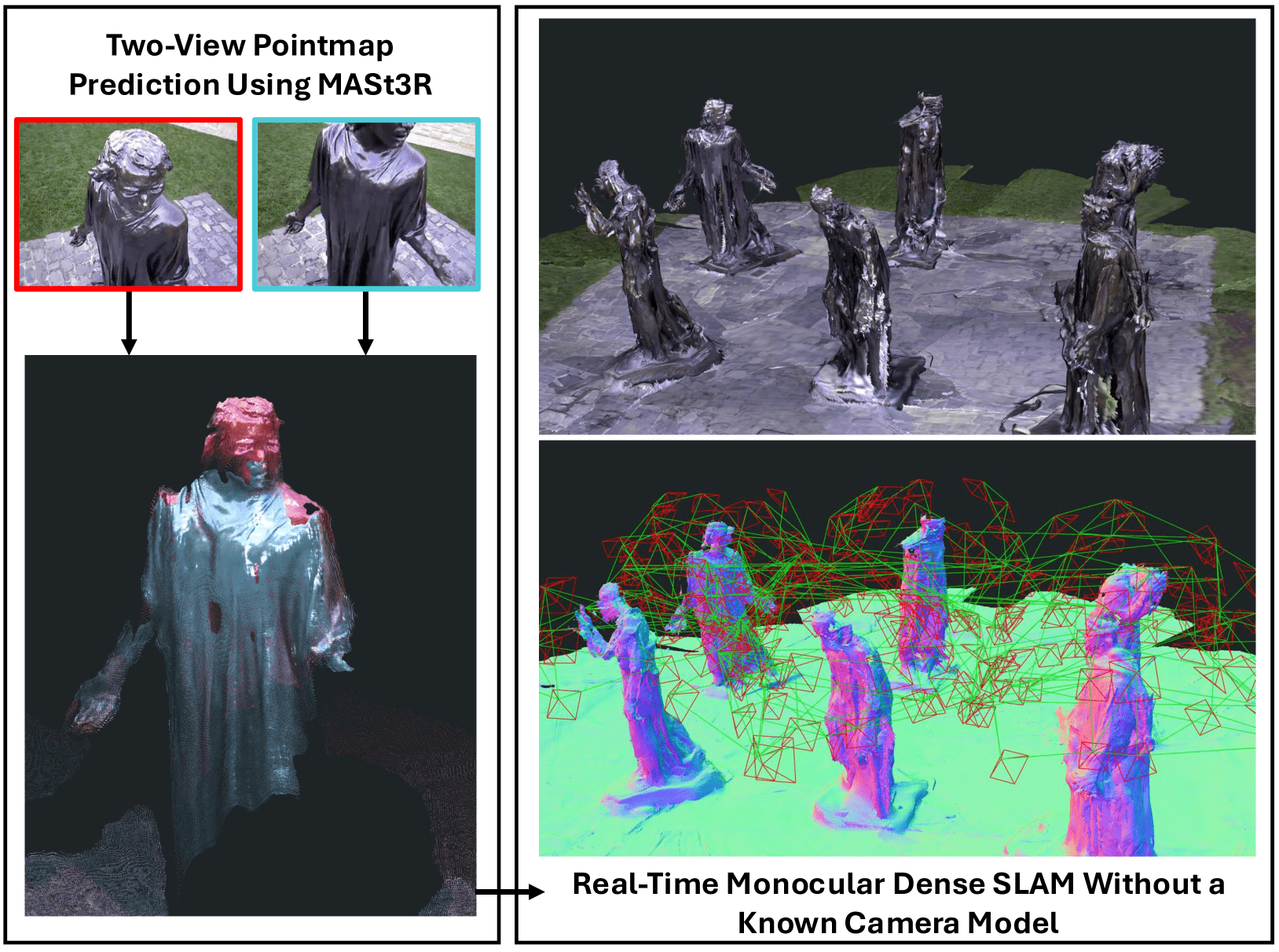
Figure 1:Reconstruction from our dense monocular SLAM system on the Burghers sequence. Using the two-view predictions from MASt3R shown on the left, our system achieves globally consistent poses and geometry in real-time even without a known camera model.
背景和挑战
Visual SLAM 是机器人和增强现实的基础技术,已经有了稳健准确的实现。但它还不能做到开箱即用,因为需要硬件知识和校准。
即便是最简单的单摄像头(无IMU)系统,也还没能在“野外环境”中稳定地实现既准确又一致的稠密地图构建。
如果能做到这点,将推动空间智能领域的研究。✅ 总结:
目前的视觉SLAM系统虽然发展不错,但离“即插即用”还有距离。
尤其是在没有额外传感器辅助(如IMU)的单目系统中,在真实世界中同时实现准确的定位和稠密建图仍然是一个未解决的难题。
技术难点和已有方法
单靠2D图像做稠密SLAM,需要解决时间变化的姿态、相机模型、3D场景几何这些复杂的问题。
人们提出了很多先验(有些是手工设计的,有些是数据驱动的),但这些方法都有问题:
单视图先验(如单目深度)存在模糊性、在不同视角之间不一致。
多视图先验(如光流)虽然减少了歧义,但姿态和几何是耦合的,难以分离。
但场景几何是跨视角不变的——这是解这些问题所需要的统一先验。
✅ 总结:
SLAM的难点是你要从视频中推断出相机的位置变化和3D场景结构,而这些任务本身是“耦合”的。
理想的做法是:找到一个统一的几何先验,能帮我们同时解决姿态估计、相机模型估计和3D建图。
关键突破:两视图重建先验
最近 DUSt3R 和 MASt3R 两个网络,用两张图像直接输出统一坐标系下的点云(pointmap),彻底改变了SfM的方式。
它们通过训练,可以隐式解决姿态、几何等子问题。未来还能适配不同畸变的相机。
两视图结构契合SfM的基础几何,也带来了模块化优势,便于后端决策和优化。
✅ 总结:
新一代方法(MASt3R)不再单独估计姿态或深度,而是直接预测点云,极大简化了SLAM流程。他们利用了这种方法的优势,把它用到了实时SLAM里。
本文工作简介
本文首次提出:将 MASt3R 这样的两视图先验引入实时SLAM框架,支持跟踪、建图和重定位。
与之前只在离线SfM中使用不同,我们的系统要增量处理图像,且保持实时性,所以要解决低延迟匹配、图优化等新挑战。
我们结合了滤波与优化思想,在前端局部过滤pointmap,为后端大规模优化打基础。
并且我们不依赖相机模型(只假设光线穿过一个相机中心),因此可以处理时间变化的任意相机模型。
若给出校准,还能达到最先进的轨迹精度和稠密几何效果。
✅ 总结:
他们提出的系统是第一个能在实时、无需相机模型的条件下完成稠密SLAM的系统,核心是使用MASt3R的两视图点云作为基础。它同时兼顾了精度、效率和通用性。
论文贡献总结
本文的贡献是:
第一个使用两视图3D先验(MASt3R)实现的实时稠密SLAM系统;
提出了高效的点云匹配、跟踪、局部融合、图优化等方法;
系统可支持任意、动态变化的相机模型,并达到SOTA效果。
✅ 总结:
本论文首次将“两视图点云预测”引入SLAM系统,设计了一套完整的解决方案,能做到高效、泛化强、重建效果好。
3. Method¶
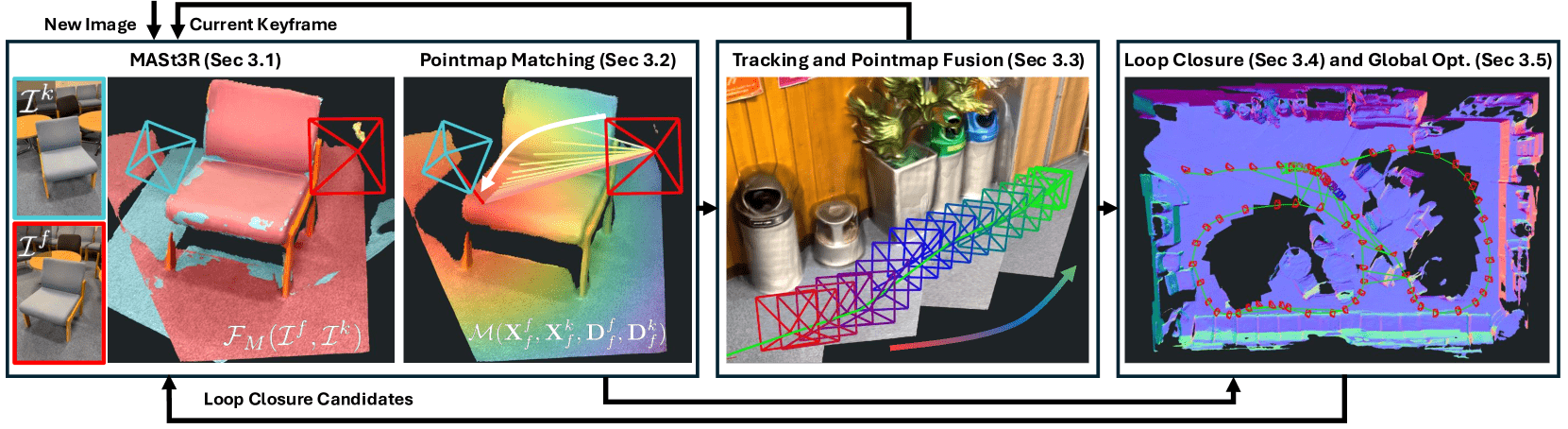
Figure 3:System diagram of MASt3R-SLAM.
New images are tracked against the current keyframe by predicting a pointmap from MASt3R and finding pixel matches using our efficient iterative projection pointmap matching.
流程如下:
当前帧输入(新图像)
用 MASt3R 预测该帧的 PointMap(即像素位置 → 三维坐标)
与当前 keyframe 的 pointmap 做像素级匹配(用了一种高效的 迭代投影点图匹配方法)
根据匹配点对,估计相机当前位姿(Tracking)
Tracking estimates the current pose and performs local pointmap fusion.
跟踪完以后,系统会把当前帧的 pointmap 融合进局部地图
相当于更新当前环境的 3D 点图表达(比稀疏点云更稠密)
When new keyframes are added to the backend, loop closure candidates are selected by querying the retrieval database using encoded MASt3R features.
新关键帧加入后,SLAM 会尝试找 闭环(判断自己是不是“又回到了以前的地方”)
用 MASt3R 编码后的全局图像特征 查询检索库,找闭环候选帧
Candidates are then decoded by MASt3R and if a sufficient number of matches is found, edges are added to the backend graph.
找到的候选帧,会用 MASt3R 重新解码生成 PointMap
然后再做一次匹配
匹配点数足够 → 添加一条图优化边(edge)到后端图里
Large-scale second-order optimisation achieves global consistency of poses and dense geometry.
所有关键帧和闭环边构成一个 图优化问题
通过 二阶优化方法(如 Gauss-Newton or Levenberg-Marquardt),
优化所有帧的位姿
优化所有点的稠密位置(地图)
✅ 最终保证系统全局一致(轨迹不漂,地图不扭)
总体流程(从左到右)
MASt3R模块(第3.1节)
输入:两张图像(新图像和当前关键帧)。
处理:
使用 MASt3R(Matching with 3D Scene Reconstruction)方法,从这两张图中推理出一个共享坐标系下的局部点云。
结果:
得到局部3D点云片段(PointMap)。
这里 MASt3R 的作用是用神经网络直接从两张图片里“推断出”它们共有的3D结构,而不是传统几何重建。
点云匹配(Pointmap Matching,第3.2节)
输入:新生成的局部点云片段。
处理:
将局部点云与之前已有的点云关键帧进行匹配,找出对应关系。
估计相对位姿变化。
结果:
通过匹配找到了新帧相对于已有地图的位置关系。
注意这里是点云和点云之间的匹配(不是图像特征匹配)。
跟踪与点云融合(Tracking and Pointmap Fusion,第3.3节)
输入:匹配后的点云及相机位姿。
处理:
进行连续帧跟踪(Tracking)。
把新观测到的点云融合到已有的地图中(Pointmap Fusion)。
结果:
累积出越来越完整、连续的三维点云地图。
闭环检测与全局优化(Loop Closure and Global Optimization,第3.4节 & 第3.5节)
输入:不断扩展的地图和轨迹。
处理:
检测闭环(Loop Closure)——判断当前的位置是否回到了之前经过的地方。
如果闭环成立,进行全局位姿优化,修正累积误差。
结果:
地图整体对齐、精度提升,减少漂移。
小结:MASt3R-SLAM是一个以学习到的局部3D重建为基础,配合点云匹配与闭环优化,实现单目相机稠密建图和精确定位的系统。
3.1 Preliminaries¶

Figure 2: Overview of iterative projective matching:
given the two pointmap predictions from MASt3R, the reference pointmap is normalised \(\psi\left(\mathbf{X}_{i}^{i}\right)\) to give a smooth pixel to ray mapping.
For an initial estimate of the projection \(\mathbf{p}_{0}\) of 3 D point \(\mathbf{x}\) from pointmap \(\mathbf{X}_{i}^{j}\) , the pixel is iteratively updated to minimise the angular difference \(\theta\) between the queried ray \(\psi\left(\left[\mathbf{X}_{i}^{i}\right]_{\mathbf{p}}\right)\) and the target ray \(\psi(\mathbf{x})\) .
After finding the pixel \(\mathbf{p}^{*}\) that achieves the minimum error, we have a pixel correspondence between \(\mathcal{I}^{i}\) and \(\mathcal{J}^{j}\) .
Figure 2: 分析
描述了 MASt3R 模型如何通过 pointmap(三维点图)进行 跨图像像素匹配(pixel correspondence) 的过程
给定 MASt3R 预测出的两个 pointmap(分别是来自图像 \(\mathcal{I}^i\) 和 \(\mathcal{J}^j\) 的三维点图)
我们将参考图像(即 \(\mathcal{I}^i\))的 pointmap \(\mathbf{X}_i^i\) 进行归一化,表示为 \(\psi\left(\mathbf{X}_{i}^{i}\right)\)。
这个归一化的目的是:👉 构造一个平滑的像素到视线(ray)之间的映射关系,
即:从图像中的一个像素位置,可以推导出它在三维空间中的射线方向。
从目标 pointmap(即图像 \(\mathcal{J}^j\) 对应的 \(\mathbf{X}_i^j\))中,取一个三维点 \(\mathbf{x}\)。
我们想知道它对应在参考图像 \(\mathcal{I}^i\) 中的像素位置 \(\mathbf{p}\)。
于是从一个初始的像素位置估计 \(\mathbf{p}_0\) 开始,通过迭代更新像素位置 \(\mathbf{p}\),使得两个射线之间的夹角 \(\theta\) 最小:
一个射线来自参考图像 pointmap 中某像素的 ray 映射:\(\psi\left(\left[\mathbf{X}_{i}^{i}\right]_{\mathbf{p}}\right)\)
一个射线是目标三维点 \(\mathbf{x}\) 的 ray 映射:\(\psi(\mathbf{x})\)
👉 也就是说,我们要在参考图像中找到这样一个像素 \(\mathbf{p}\),其对应的射线方向和目标三维点 \(\mathbf{x}\) 的方向尽可能接近。
📥 输入 & 输出:
他们使用一个叫 DUSt3R 的模块输入两张图像:
\(\mathcal{I}^i, \mathcal{I}^j \in \mathbb{R}^{H \times W \times 3}\)
即两张分辨率为 \(H \times W\) 的 RGB 彩图。
DUSt3R 会输出:
点图(Pointmaps):
\(\mathbf{X}^i_i, \mathbf{X}^j_i \in \mathbb{R}^{H \times W \times 3}\)
表示第 \(i\) 张图的每个像素在 3D 空间中的坐标。
下标含义是“从图 \(i\)”得到的点图,在“相机 \(i\)”坐标系中表达。
置信度(Confidence):
\(\mathbf{C}^i_i, \mathbf{C}^j_i \in \mathbb{R}^{H \times W \times 1}\)
每个像素的深度/点图预测可信程度。
🧠 MASt3R 的额外输出:
相比 DUSt3R,MASt3R 在此基础上增加了“特征匹配头”,用于生成:
d 维匹配特征: $\( \mathbf{D}^i_i, \mathbf{D}^j_i \in \mathbb{R}^{H \times W \times d} \)$
每个像素位置的匹配描述子。
对应的置信度: $\( \mathbf{Q}^i_i, \mathbf{Q}^j_i \in \mathbb{R}^{H \times W \times 1} \)$
这些数据通过函数 \(\mathcal{F}_M(\mathcal{I}^i, \mathcal{I}^j)\) 得到,即 MASt3R 的前向推理输出。
📏 缩放一致性处理:
训练数据中,有些带有真实世界尺度(metric scale),但实际预测时,尺度很不一致。
为了解决这个问题,作者将所有相机位姿(pose)定义在: $\( \mathbf{T} \in \text{Sim}(3) \)$
即相似变换群 Sim(3):包括旋转、平移和尺度。
变换表达形式:
其中:
\( \mathbf{R} \in SO(3) \):旋转矩阵
\( \mathbf{t} \in \mathbb{R}^3 \):平移向量
\( s \in \mathbb{R} \):尺度因子
使用李代数 \(\boldsymbol{\tau} \in \mathfrak{sim}(3)\) 表示变换增量,更新操作为: $\( \mathbf{T} \leftarrow \boldsymbol{\tau} \oplus \mathbf{T} \triangleq \exp(\boldsymbol{\tau}) \circ \mathbf{T} \)$
即用指数映射将增量转换成变换矩阵并组合。
📸 相机模型假设与单位光线:
他们假设相机是中央投影模型(central camera),即所有光线穿过一个唯一中心。
为了处理镜头变焦或畸变,他们定义函数: $\( \psi(\mathbf{X}^i_i) \)$
该函数将点图中每个点归一化为单位方向光线,实现:
每帧自带自己的相机模型
可以统一处理时变相机参数或图像畸变
3.2 Pointmap Matching¶
描述了在 SLAM 系统中如何高效、准确地将两个图像之间的像素进行匹配,特别是如何利用 MASt3R 输出的 点图(pointmap)和特征(features) 进行高质量像素级配对。以下是逐段的中文解释和总结:
🔍 背景与问题¶
匹配(Correspondence) 是 SLAM 中最核心的部分之一,它对 跟踪(tracking) 和 建图(mapping) 都至关重要。本文的目标是在两张图像之间找到像素匹配对 \( \mathbf{m}_{i,j} \),其依赖于 MASt3R 网络输出的:
两张图的 点图:\(\mathbf{X}^i_i, \mathbf{X}^j_i\)
深度图或附加描述:\(\mathbf{D}^i_i, \mathbf{D}^j_i\)
传统的暴力匹配(brute-force)方式计算量是二次的,太慢;DUSt3R 用了 k-d tree 加速搜索,但会带来并行困难和匹配不准的问题。
🌐 MASt3R 的策略¶
MASt3R 网络会预测额外的高维特征,支持 宽基线匹配。
为了避免全局搜索的高计算成本,采用 粗到细(coarse-to-fine) 策略。
即便如此,稠密匹配仍需要几秒,稀疏匹配也慢于 k-d tree。
所以这篇论文不追求全局搜索效率,而是借鉴 优化(optimization)方法来进行局部搜索。
🌀 核心思想:迭代投影匹配(Iterative Projective Matching)¶
见图 2 的描述:
使用 MASt3R 输出的参考点图 \( \mathbf{X}^i_i \) 构建从 像素 → 射线(ray) 的映射 \( \psi(\cdot) \)。
给定一个在另一帧中的 3D 点 \( \mathbf{x} \in \mathbf{X}^j_i \),我们要找到它在参考帧(图像 i)中对应的像素位置 \( \mathbf{p} \)。
通过最小化两个射线方向之间的夹角 \( \theta \),来反复更新 \( \mathbf{p} \),直到找到最佳匹配像素 \( \mathbf{p}^* \): $\( \mathbf{p}^* = \arg \min_{\mathbf{p}} \|\psi([\mathbf{X}^i_i]_{\mathbf{p}}) - \psi(\mathbf{x})\|^2 \)$
欧氏距离可以转化为角度误差最小化: $\( \|\psi_1 - \psi_2\|^2 = 2(1 - \cos\theta) \)$
🔧 解法细节:优化求解¶
采用 Levenberg-Marquardt 非线性最小二乘法: $\( \delta \mathbf{p} = -(\mathbf{J}^T \mathbf{J} + \lambda \mathbf{I})^{-1} \mathbf{J}^T \mathbf{r} \quad \mathbf{p} \leftarrow \mathbf{p} + \delta \mathbf{p} \)$
由于点图光滑,大部分像素 在 10 次迭代内就能收敛。
支持大规模并行处理,每个点可独立处理。
初始投影估计 \( \mathbf{p}_0 \):
如果已有跟踪记录就用上次匹配;
否则默认使用单位映射(identity mapping)。
🔁 精细匹配:使用特征进一步优化¶
虽然几何初始匹配已经很准,为了进一步提高定位精度:
使用 MASt3R 输出的 像素级特征。
基于前面几何匹配提供的位置,在局部窗口中搜索最大特征相似度。
⚙️ 实现细节¶
所有几何匹配和特征搜索都用 自定义 CUDA kernel 实现,可并行运行:
跟踪:约 2ms;
后端匹配(建边):仅需几 ms;
与传统基于姿态估计的匹配不同,匹配过程不依赖位姿估计结果,更“纯净”。
🧠 总结一下核心贡献¶
项目 |
内容 |
|---|---|
问题 |
如何高效地在图像对之间建立像素级匹配 |
挑战 |
暴力搜索慢、kd-tree 不准,MASt3R 输出非标准相机模型 |
方法 |
用点图生成射线 → 在目标图像中找到最小射线角度误差的像素位置 |
优化策略 |
Levenberg-Marquardt + 自定义 CUDA 并行实现 |
特征增强 |
用粗匹配初始化后,局部窗口中搜索最大特征相似度 |
优点 |
匹配速度快、匹配质量高、泛用性强(不依赖传统相机模型) |
3.3 Tracking and Pointmap Fusion¶
主要讨论关于 Tracking 和 Pointmap 融合 的部分内容,核心目标是:如何高效且准确地估计当前帧相对于上一个关键帧的相对位姿,进而更新地图。下面我帮你逐段拆解:
📌 背景设定:Tracking 的目标¶
SLAM 的关键任务之一是 在已有地图的基础上估计当前帧的位置(pose),并更新地图。MASt3R-SLAM 是基于关键帧(keyframe-based)的系统:
当前帧记作:\(\mathcal{I}^f\)
上一关键帧记作:\(\mathcal{I}^k\)
要估计的是它们之间的位姿变换:\(\mathbf{T}_{kf}\)
系统已经有了上一关键帧的点图(pointmap):\(\tilde{\mathbf{X}}^k_k\),表示的是关键帧自身坐标系下的 3D 点。
🔧 如何估计 \(\mathbf{T}_{kf}\)(当前帧对关键帧的相对位姿)?¶
他们通过特征匹配得到 \(\mathcal{F}_M(\mathcal{I}^f, \mathcal{I}^k)\) 来计算对应点,然后通过最小化误差来估计 \(\mathbf{T}_{kf}\)。
🧮 方式一:最小化 3D 点误差¶
误差函数:
\(\tilde{\mathbf{X}}^k_{k,n}\):关键帧的 3D 点
\(\mathbf{X}^f_{f,m}\):当前帧的 3D 点,先通过 \(\mathbf{T}_{kf}\) 变换到关键帧坐标系
\(\mathbf{q}_{m,n}\):匹配置信度,由之前的特征匹配模块计算
\(w(\mathbf{q}, \sigma^2)\):是根据置信度 \(\mathbf{q}\) 调整误差权重的函数(如下)
\(\rho\) 表示使用 Huber loss,增加对异常值的鲁棒性。
❗️问题:3D 点误差容易受到深度误差影响¶
作者指出,因为深度预测存在误差,导致 3D 点误差的计算会被“拉偏”,尤其是在点图不一致或误差较大时。
✅ 改进:使用 Ray(射线)误差来代替¶
假设相机是中心投影模型(central camera assumption),我们可以将 3D 点归一化成单位向量,也就是从相机中心发射出去的一条方向射线。
新的误差函数如下:
\(\psi(\cdot)\) 是单位化操作(normalize 到方向向量)。
这样带来的好处是:只考虑方向差异,不受深度误差影响,尤其适合 baseline 大的情况。
相当于在多对匹配点之间,寻找能让所有射线对齐的 \(\mathbf{T}_{kf}\)。
⚖️ 处理纯旋转退化的问题¶
如果只有方向信息,可能会在纯旋转场景下发生退化(因为方向不变,位置可任意变)。为此,作者加了一个微小的距离误差项(depth consistency term),以防止退化,但加权很小,避免带来和之前 3D 点误差相同的问题。
🔄 如何优化?使用 Gauss-Newton + IRLS 迭代求解¶
最终优化是通过 IRLS(Iteratively Reweighted Least Squares)+ Gauss-Newton:
\(\boldsymbol{\tau}\):当前位姿更新量
\(\mathbf{r}\):残差向量
\(\mathbf{J}\):Jacobian(解析形式)
\(\mathbf{W}\):权重矩阵(含匹配置信度和鲁棒核)
📌 小结¶
模块 |
内容 |
意义 |
|---|---|---|
Tracking |
估计 \(\mathbf{T}_{kf}\),当前帧相对于上一个关键帧的位姿 |
保持实时跟踪 |
Ep (3D 点误差) |
用匹配点的 3D 坐标直接算残差 |
精度高但易受深度影响 |
Er (Ray 误差) |
只对比方向(单位化射线) |
更鲁棒,适合 baseline 大和深度不准场景 |
优化方法 |
IRLS + Gauss-Newton |
快速且鲁棒 |
匹配权重 |
由置信度 + Huber loss 控制 |
降低错误匹配的影响 |
📌 3.4 图构建与回环检测(Graph Construction and Loop Closure)¶
这一节讲的是如何构建关键帧之间的图结构,以及如何检测并修正轨迹漂移(loop closure)。
🔹何时添加关键帧:¶
每当当前帧与上一个关键帧的匹配点数 小于一个阈值 ωk,就会添加一个新的关键帧 𝒦i。
然后在 新关键帧𝒦i与前一个关键帧𝒦i−1之间添加一条双向边,加入图中边集 ℰ。
这样可以在时间序列上约束姿态估计,但会有累积漂移问题(drift)。
🔹回环检测机制:¶
为了解决大范围或小范围的回环(即回到之前去过的位置),使用了 ASMK(Aggregated Selective Match Kernel) 图像检索框架:
以前是用于离线处理,他们修改为可增量在线使用。
方法是:
把新关键帧的特征编码后拿去查找最相似的 K 张图。
如果匹配得分超过阈值 ωr,就送入 MASt3R 解码器(用于图像匹配)。
如果匹配点数超过阈值 ωl,就把这两个关键帧连接起来(添加双向边)。
然后将新关键帧的编码特征加进检索库。
📌 3.5 后端优化(Backend Optimisation)¶
这一节讲的是如何进行全局优化,让所有关键帧的位姿(姿态)和几何结构保持一致(不漂移、不冲突)。
🔹输入:¶
所有关键帧的当前位姿估计 𝐓WCi
每个关键帧对应的 canonical pointmap(标准化点云地图) 𝑿̃ii
🔹目标:¶
最小化所有关键帧之间的 “射线误差”(ray error)。
为了处理姿态自由度(7自由度,Sim(3):包含旋转、平移、尺度),固定第一个关键帧作为参考。
🔹公式解读(式10):¶
Eg 是全局优化目标函数。
每条边(i, j)表示两个关键帧之间的匹配。
𝑚, 𝑛 是两个关键帧之间匹配点的索引。
ψ() 是某种射线投影函数,把三维点投影为归一化向量。
Tij 是两个关键帧之间的相对位姿变换。
w(…) 是权重函数,根据匹配质量(或深度不确定性)调整误差影响。
ρ 是鲁棒损失函数(防止异常值影响过大)。
最终使用高效的二阶优化(Gauss-Newton),构建稀疏 Hessian 矩阵(规模为 7N x 7N),使用 CUDA 并行实现,优化速度非常快。
📌 3.6 重定位(Relocalisation)¶
如果系统跟踪失败(匹配点不够),就会进入重定位模式:
查询检索库,匹配得分需要满足更高要求。
如果成功匹配多个图像,就添加为新关键帧并恢复跟踪。
📌 3.7 相机标定(Known Calibration)¶
这个系统可以在不知道相机内参的情况下运行。但如果有相机标定信息,可以提高精度:
优化做法有两点:¶
在 tracking 和 mapping 中,使用已知相机模型约束 pointmap 投影方向(只优化深度维度)。
将误差从射线空间转换为像素空间。
公式(式11)解释:¶
EΠ 是在有相机标定情况下的优化目标。
pii,m 是像素点。
Π 是相机投影函数,把3D点投影到图像平面。
优化目标是:实际像素点和3D点投影的差距越小越好。
仍然使用鲁棒损失函数和匹配权重函数进行优化。
4. Results¶
4.1 Camera Pose Estimation¶
这段是论文 MASt3R-SLAM 中关于相机位姿估计(Camera Pose Estimation)实验的总结部分。
🧠 总体理解¶
该段主要说明他们提出的 SLAM 方法在多个公开数据集(TUM RGB-D、7-Scenes、ETH3D-SLAM 和 EuRoC)上的 相机轨迹精度(ATE)评估结果,并与现有的先进系统进行对比。
📍术语解释¶
ATE (Absolute Trajectory Error):表示重建相机轨迹和真实轨迹之间的差距(单位:米),数值越小越好。
Monocular system:只用一台普通RGB相机(没有深度传感器)来做SLAM。
Calibration:标定信息(相机内参,比如焦距、主点等),如果没有就叫 uncalibrated。
Ours*:他们的方法在不使用已知相机标定信息的情况下的表现。
Real-time:指的是系统可以实时运行。
📊 数据集逐个解释¶
✅ TUM RGB-D 数据集:¶
对比的系统包括:DROID-SLAM、DPV-SLAM、GO-SLAM,这些都是当前比较强的 SLAM 方法。
他们的方法:
使用一个现成的“两视图几何先验”而不是端到端网络(如 DROID)。
即使在不使用相机标定信息的情况下(Ours*),表现也优于 DROID-SLAM*(只在首帧做标定)。
说明使用3D重建先验(3D priors)对于无标定的 dense SLAM 系统效果很好。
✅ 7-Scenes 数据集(表格分析):¶
表格中展示了各方法在 7 个子场景下的 ATE 值(越小越好),最右是平均值。
结果:
Ours(有标定)平均 ATE = 0.047(比 DROID-SLAM 更好)
Ours*(无标定)平均 ATE = 0.066,也优于 NICER-SLAM(0.086)
重点是:Ours* 是实时的,仅使用一个先验,而 NICER-SLAM 是离线的,使用多个先验(深度、法线、光流)
✅ ETH3D-SLAM 数据集:¶
是一个非常困难的数据集,之前只用于 RGB-D 方法评估。
因为是单目系统,原始官方评估门槛太高,所以他们用了训练集做评估。
他们的方法在这个数据集上表现突出:
虽然其他方法在准确率上可能略胜一筹,但他们的方法在“鲁棒性(robustness)”上更强(能跑完更多轨迹)
所以在 ATE 和 AUC(曲线下面积)指标上都最好。
✅ EuRoC 数据集:¶
是一个用于微型飞行器的标准视觉SLAM数据集,包含复杂的运动和失真。
无标定版本中,他们做了图像去畸变(undistortion),但不提供标定信息给 SLAM 系统。
尽管被 DROID-SLAM 超过(后者用了 10% 灰度图扩展训练),他们的结果仍然很优秀(ATE=0.041m)。
强调他们的系统并非基于 DROID-SLAM,而是使用新颖的 3D reconstruction prior 路线。
✅ 总结亮点¶
对比维度 |
他们的方法 |
|---|---|
是否实时 |
✅ 是(区别于一些离线方法) |
是否使用标定 |
✅ 和 ❌ 两种情况都有,且无标定表现也强 |
是否依赖 DROID-SLAM 架构 |
❌ 否,他们是另一种路线 |
创新点 |
使用“两视图几何+3D先验”替代端到端匹配系统 |
效果 |
在多个数据集上 ATE 优于或接近最强系统 |
如果你需要我把这些内容做成一个讲解 PPT 的结构或者用更通俗类比方式讲给非技术人员听,也可以说一声 😄
这段内容主要是对 MASt3R-SLAM 系统在密集几何重建(Dense Geometry)方面的性能评估,包括定量实验、可视化结果和消融实验。我们可以分段来理解:
🔍 4.2 Dense Geometry Evaluation:密集几何评估¶
🌍 评估设置:¶
对比对象:与 DROID-SLAM 和 Spann3R 进行对比。
数据集:
EuRoC(室内工业场景,带Vicon真值轨迹)
7-Scenes(日常室内物体场景,RGB-D)
对齐方式:
EuRoC:通过对齐相机轨迹(与Vicon)来对齐点云。
7-Scenes:利用数据集提供的位姿将深度图反投影生成参考点云,然后用 ICP 对齐预测点云(因为RGB和深度之间的标定未知)。
📏 评估指标:¶
Accuracy(准确性):预测点到最近参考点的距离。
Completion(完备性):参考点到最近预测点的距离。
Chamfer Distance:上述两个指标的平均值。
使用了最大阈值 0.5m 来限制误差范围。
✅ 7-Scenes 评估结果:¶
MASt3R(无论是否有标定)和 Spann3R 的重建精度都比 DROID-SLAM 更好,说明 3D重建先验带来了优势。
Spann3R 以两种设置运行(每20帧一个关键帧 vs 每2帧一个关键帧),表现有差异,说明不依赖测试时优化的方法难以泛化。
MASt3R 的无标定系统取得了 最佳 Accuracy 和 Chamfer Distance,原因是:7-Scenes 的标定数据只是出厂默认值,不是特别精确。
✅ EuRoC 评估结果:¶
Spann3R 被排除,因为 EuRoC 不是“以物体为中心”的数据集,Spann3R 不适用。
尽管 DROID-SLAM 在轨迹误差(ATE)更低,但 MASt3R 在几何上表现更好(点云质量)。
DROID-SLAM 的 Completion 更高,是因为它重建了大量噪声点,导致点云更“饱满”,但不够准确。
MASt3R 在 Accuracy 上显著优于 DROID-SLAM,且其无标定版本在 Chamfer Distance 上也超过 DROID-SLAM —— 说明即使轨迹误差大一点,但几何重建质量依然更好。
🖼️ 4.3 Qualitative Results:可视化结果¶
展示了多个挑战场景下的重建质量:
Burghers 场景:反光材质、难以匹配特征,MASt3R 依然能重建出结构。
TUM、EuRoC 场景:展示了不同环境下的位姿和密集重建质量。
极端变焦:如图7所示,即便两个关键帧之间有显著缩放差异,MASt3R 的无标定系统也能保持良好表现。
🧪 4.4 Ablation Studies:消融实验¶
📌 探索影响性能的关键设计选择:¶
🧮 光线误差 vs 点误差:¶
无标定情境下,采用光线误差(ray error)比使用3D点误差更鲁棒,有效缓解预测点图(pointmap)不准确的问题。
🔁 Canonical Pointmap 的更新策略:¶
在 TUM、7-Scenes 和 EuRoC 上测试了不同策略:
用最新的点或最后一个点更新 → 容易几何不完整或出现漂移。
Weighted fusion(加权融合):在无标定条件下取得最低 ATE,且在 EuRoC 上比其他方法好 1.3cm,说明在多相机模型上融合是有效的。
🧩 匹配策略:¶
对比不同特征匹配方法:
MASt3R 提出一种 并行投影匹配 + 特征细化(parallel projective matching with feature refinement) 方法:
精度高
运算速度快(2ms vs 原始方法 2s)
让整个系统加速了 40 倍!
🧠 总结:¶
MASt3R 即使在无标定条件下,也能在几何重建质量上超过当前最佳系统,特别是在 Accuracy 和 Chamfer Distance 上。
借助 3D 重建先验,能带来更稳定的几何重建效果,尤其在不完美标定或多模型场景下更鲁棒。
并行优化、融合策略、光线误差等设计让 MASt3R 具备了实时性 + 精度的双重优势。
如果你正在研究视觉 SLAM、密集重建、或者希望理解无标定系统如何做到鲁棒精确,这部分内容非常具有启发意义。需要我为这些内容做一页PPT大纲吗?
当然可以!这段内容分为两部分,第5节:Limitations and Future Work(局限与未来工作) 和 第6节:Conclusion(结论)。我们逐段来拆解:
5. Limitations and Future Work(局限与未来工作)¶
这一部分总结了 MASt3R-SLAM 当前存在的一些不足,并指出了未来可能的改进方向。
🧱 局限1:全局几何优化不完善¶
While we can estimate accurate geometry by filtering pointmaps in the frontend, we do not currently refine all geometry in the full global optimisation.
意思是:
虽然前端能通过点图(pointmap)滤波获得较准确的几何信息,
但在整个系统的 全局优化(global optimisation) 中,目前还没有统一优化所有点云几何。
也就是说,点图之间可能存在局部正确但全局不一致的问题。
While DROID-SLAM optimises per-pixel depth via bundle adjustment, this framework permits incoherent geometry.
DROID-SLAM 做得更进一步:它通过 BA(Bundle Adjustment)对每个像素的深度做优化,虽然这样可以收敛,但可能会导致几何不连贯(incoherent geometry)。
MASt3R 没有走这条路。
✅ 未来方向:如果能有一个方法:
在实时条件下,
同时保持 MASt3R 本身预测结果的局部一致性,
又能让点图在三维空间中全局一致(globally consistent), 👉 那会是非常有价值的研究方向!
📷 局限2:仅在针孔模型(pinhole camera)图像上训练¶
Since MASt3R is only trained on images with pinhole images, its geometry predictions degrade with increasing distortion.
MASt3R 当前只在针孔相机图像上训练(最常见的相机模型),
所以当输入图像存在畸变(比如鱼眼、广角)时,预测效果会明显下降。
✅ 未来方向:
训练支持多种相机模型(camera models)的数据(包括广角、鱼眼等),
MASt3R 的架构本身是无参数化相机模型假设的(non-parametric camera model),所以在框架上是兼容的,只需训练即可支持。
🖥️ 局限3:解码器效率低、成为系统瓶颈¶
Using the decoder at full resolution is currently a bottleneck, especially for low-latency tracking and checking loop closure candidates.
解码器运行在全分辨率图像上,虽然提高了输出质量,但也带来了计算瓶颈,
特别是影响:
低延迟跟踪(tracking)
回环检测(loop closure)等关键实时模块。
✅ 未来方向:
提高网络吞吐率(network throughput),
减轻解码器负担,可以显著提升系统整体效率。
🧾 6. Conclusion(总结)¶
We present a real-time dense SLAM system based on MASt3R…
这部分总结了 MASt3R-SLAM 的主要贡献:
🎯 系统亮点¶
是一个基于 MASt3R 的 实时、密集 SLAM 系统;
可以处理现实世界(in-the-wild)的视频数据;
在多个标准数据集上取得了 state-of-the-art(SOTA) 级别的表现。
⚙️ 方法差异¶
Much of the recent progress… followed DROID-SLAM… We take a different approach…
近期 SLAM 研究(如 DROID-SLAM)通常采用端到端框架:输入图像 → 光流更新 → 优化位姿和几何。
MASt3R-SLAM 走了一条不同的路:
利用一个预训练的几何先验(off-the-shelf geometric prior),
非端到端,但构建了一个系统,可以在保持高精度位姿估计的同时,输出一致的密集几何重建。
🧠 总结一句话版:¶
MASt3R-SLAM 是一个可实时运行的密集 SLAM 系统,采用预训练几何先验而非端到端训练,首次实现了兼具高精度位姿估计与一致密集重建的系统表现。未来的改进方向包括全局几何一致性优化、多相机模型支持以及解码器效率优化。
8. Initialisation(初始化)¶
这节讲的是:系统刚开始运行的时候,怎么获得第一张关键帧的点云图(pointmap)?
平时跟踪时(见第3.3节),为了减少网络计算量,系统会复用上一帧的点云图。但在刚启动时是没有上一帧的。
所以:初始化方法很简单——直接把第一帧图像输入 MASt3R 网络,做一次单目深度预测,生成点云图。
虽然单目预测本身不精确,但后续系统会通过多帧信息融合和加权滤波器来逐渐优化这个初始点图。
✅ 简化理解:第一次起步时先粗略估计个地图,跑起来后再逐步精修。
9. Runtime Breakdown(运行时分析)¶
讲的是:MASt3R-SLAM 各部分运行时间的占比分析。
Tracking(跟踪):每一帧都执行,>20 FPS,速度非常快;
Keyframing(关键帧提取):频率较低,只在运动变化大时发生;
系统中最耗时的是 encoder 和 decoder(占总时间约 64%),因为每次都要用 MASt3R 网络解码图像。
有回环检测(如 TUM fr1/room 和 EuRoC MH01)时,后端优化的时间占比会上升;
整体仍然可以实时运行,网络部分是瓶颈;
得益于模块化设计与高效优化器,能实现实时 + 全局一致的 dense SLAM。
✅ 简化理解:核心瓶颈是神经网络解码部分,其它跟踪、优化都够快。
10. Evaluation Setup(评估设置)¶
主要描述系统在多个数据集上的评估方式和对比实验细节:
10.1 轨迹评估¶
使用固定参数对所有数据集进行一致性评估(比如关键帧阈值 ωₖ = 0.333)。
回环检测要求匹配质量较高(匹配比例 > 0.3 或 0.5)才能重新连接轨迹;
实验中和多个主流方法对比:如 DROID-SLAM、NICER-SLAM 等;
在 ETH3D 数据集上是首次做单目 SLAM,对所有方法都本地重新运行以确保公平。
✅ 重点:设置了统一参数、严格回环检测标准,确保评估公平。
10.2 几何精度评估¶
对于 Ground Truth 点云,会剔除不可见或无效点。
对于预测点云,一律不进行后处理(体现真实预测效果);
指标方面:
使用 Chamfer Distance 平均值 和 RMSE Chamfer(更关注偏差大的点);
图9展示了 MASt3R-SLAM 在 7-Scenes 上比 DROID-SLAM 有更一致的几何重建;
图10展示了 EuRoC 的三维重建效果:MASt3R-SLAM 产生 outlier 更少、场景一致性更高。
✅ 结论:MASt3R-SLAM 的密集几何预测比 DROID 更“整洁”,尤其在 RMSE 上更具优势。
ATE 轨迹误差表(Tab. 8)¶
这是 EuRoC 各个子序列上的轨迹误差对比表(单位为米):
DROID-SLAM 平均误差最低(0.022m);
MASt3R-SLAM 略高(0.041m),但大幅优于 DeepFactors、DeepV2D 等旧方法;
尽管 DROID 在轨迹表现上略好,但 MASt3R-SLAM 胜在几何一致性与运行稳定性;
最后一行是未做相机标定(Uncalibrated)的结果,误差会略大(0.164m),但仍然具有实用价值。
✅ 结论:MASt3R-SLAM 的轨迹误差略逊 DROID,但远超旧架构,且几何质量优异。
11. EuRoC 结果总结¶
EuRoC 是对单目系统挑战最大的场景(大范围、快运动、曝光变化大);
DROID 有专门为灰度图做增强训练,所以在这种场景下表现更强;
但相比其他几何先验方法(如 DeepV2D),MASt3R-SLAM 的轨迹表现提升明显;
并且在未标定设置下仍然有效,说明方法具有较强的通用性和鲁棒性。
✅ 总结:虽然 DROID 更强,但 MASt3R-SLAM 在复杂条件下表现稳定,是一个“更一致、更干净”的选择。