2311.12022_GPQA: A Graduate-Level Google-Proof Q&A Benchmark¶
组织: 1New York University 2Cohere 3Anthropic, PBC
引用: 726(2025-06-26)
相关链接:
https://github.com/openai/simple-evals
数据集:
https://openaipublic.blob.core.windows.net/simple-evals/gpqa_diamond.csv
Abstract¶
研究者提出了一个很难的题库 GPQA,包含448道由生物、物理、化学领域专家设计的多项选择题。
即使是相关领域的博士或在读博士,正确率也只有65%;非专业但能力很强的人,在可上网搜索的情况下,平均花30多分钟也只能答对34%。
即使是最强的 GPT-4 模型,正确率也只有39%,说明这些题对人和 AI 都很难。
这个题库可以用来研究一个重要问题:
当 AI 比人更强时,人类怎样才能监督它的回答?
这个研究希望为“如何让专家从比自己强的 AI 那里获得可靠信息”提供方法。
1.Introduction¶
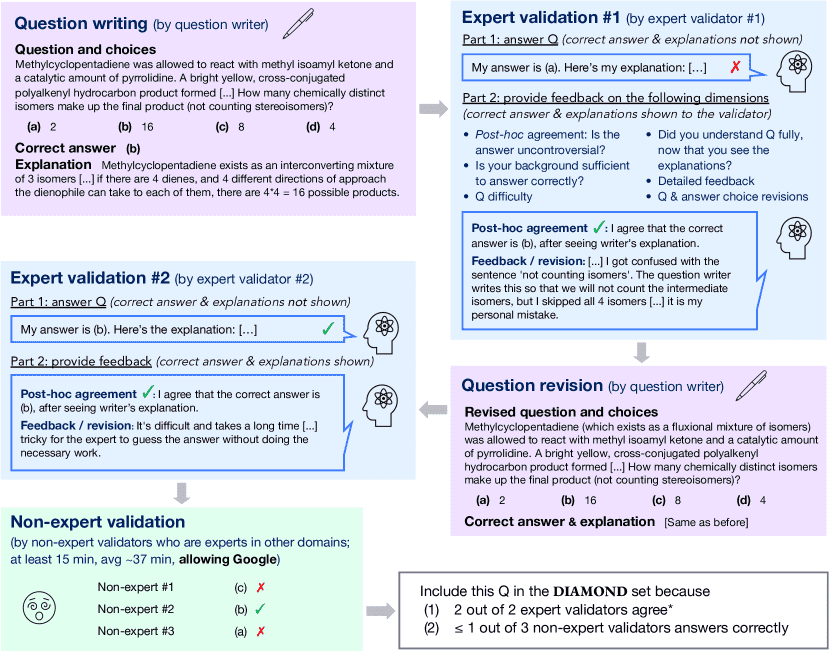
Figure 1:Our data creation pipeline. First, a question is written, and one expert in the same domain as the question gives their answer and feedback including suggested revisions to the question. Then, the question writer revises the question, and this revised question is sent to another expert in the same domain, as well as three non-expert validators who have expertise in other domains. We say that expert validators agree (*) if they either answer correctly initially, or if in the expert’s feedback after seeing the correct answer, they either clearly explain the mistake they made or explicitly demonstrate understanding of the question writer’s explanation; see Section 3.1 for more detail.
随着大语言模型(LLM)能力迅速提升,未来它们可能能在某些方面超越人类,甚至推动科学知识前沿的发展。
但这也带来一个问题:我们如何确保模型的输出是“真实的”,特别是在人类也无法判断对错的问题上?这被称为“可扩展监督(scalable oversight)”问题。
为了研究这一问题,作者提出了一个评估数据集 GPQA,这是一个“研究生级别、谷歌也查不到答案”的多选题集,涵盖物理、化学、生物的子领域。
特点如下:
目的:用于测试未来比人类更强的模型是否仍能被有效监督。
设计标准:题目对领域专家是客观的,但对非该领域的博士级“非专家”来说非常难,即使他们能上网查资料(但不能用LLM)。
验证方法:每道题都由两个相关领域专家审阅和回答;非专家平均花37分钟答题,正确率仅34%;GPT-4 正确率39%,而随机猜测是25%;专家正确率是65%,但保守估算的一致性可达74%。
目的数据难度:要尽量接近“人类能力边界”,但仍有明确正确答案(由少数专家确认)。
附加措施:数据集加入了特殊字符串“canary string”,避免被无意中用于训练模型。
总结:GPQA 是一个高难度的科学问答集,用于评估未来超强 AI 是否还能被有效监督,尤其在人类都难判断的复杂问题上。
这段内容主要介绍了GPQA(Graduate-level Google-Proof Q&A)数据集的构建过程,目的是收集出即使有网络也难以查到答案的高质量学术难题
2.Data Collection¶
从生物、物理、化学三个领域的博士及在读博士中招募专家。
目标
设计专业难题,让专家能答对,非专家即使查资料也答不出。
数据构建流程(4 步)
专家出题:写下题目和选项,还需写解释说明正确答案。
第一位专家审题:验证是否准确、客观、具有挑战性。
修订题目:出题人根据反馈修改题目(可选)。
第二位专家验证:再次验证题目质量。
非专家挑战:3位非本领域的专家尝试回答,以确认题目的“难度”。
题目设计要求
不依赖选项也能答(适合自由回答场景)。
每题要标明子领域,便于分配审题者和答题者。
题目要有明确解释,指出为什么正确,其他选项为什么错。
非专家定义
非专家不是普通人,而是其他领域的专家。
禁止使用 AI 辅助工具(如语言模型)。
确保非专家花足够时间(平均每题 37 分钟)。
数据集统计与划分: 总共收集 546 题,划分为三个子集:
GPQA Extended:全题库。
GPQA(Main):去除专家不一致或非专家全答对的题,共 448 题。
GPQA Diamond:质量最优,专家全对且非专家多数错,共 198 题。
各领域表现
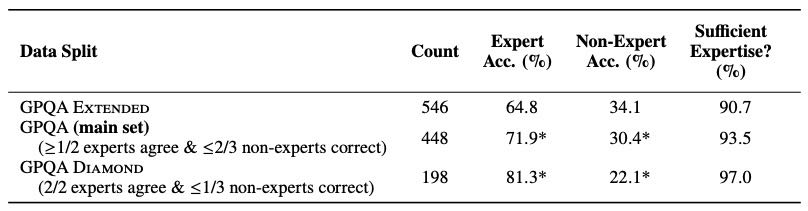
Table 2: Counts, expert accuracy, and non-expert accuracy for the extended set, the main set, and the diamond set.

Table 3: We break down the number of questions in each domain (in the extended set), as well as the expert and non-expert accuracies
为何只选这三类领域?
工程、会计、法律等尝试过,但题目质量达不到要求。
选这三类是因为内容复杂、专家多、适合制造“高质量、谷歌难查”的问题。
3.Dataset Analysis¶
一、问题客观性(Question Objectivity)¶
目标:评估问题是否有明确、无争议的正确答案。
方法:
专家答题准确率是一个衡量标准(但不能完全依赖,因为专家也会出错)。
答后反思:让专家看题目作者的答案和解释,再确认题目是否客观。
结果:
大约 74% 的题目被认为是客观的。
第一位专家正确率是 66.5%,第二位是 64.8%。
即使出错,80%+ 的专家在看到解释后认可题目是对的,说明很多错误是因为粗心或领域太专。
90%+ 专家认为自己对题目领域有足够的专业知识。
专家错误分析:
在 191 个错误中,约 46% 专家后来明确表示自己错了,题目是好的。
这些错误被进一步分类,用来判断是否将题目纳入更高质量的数据集。
最终估计:
排除明显的专家失误后,客观题比例为 73.6% - 76.4%。
二、问题难度(Question Difficulty)¶
目标:验证题目是否对非该领域专家足够困难。
方法:
每题让 3 个非本领域的专家作答。
非本领域专家答题平均正确率仅 34.1%,说明题目确实很难。
非本领域专家通常花很多时间(中位数 30 分钟):
有人用编程模拟解物理题。
有人阅读多篇学术论文寻找答案。
总结一句话:¶
这个数据集的问题大多数是客观的(约 74%),但很难,即使是其他领域的专家也很难答对。
4.Baseline¶
🌟背景¶
为了研究“非专家+AI”组合是否能在监督任务中达到专家水平,研究者设计了一个叫 GPQA 的难题集。
它分为三个子集:扩展集(Extended)、主集(Main) 和 钻石集(Diamond),难度逐级增加。
🧪实验设置¶
Closed-book(闭卷):模型只能用自己训练时学到的知识,不允许联网。
Open-book(开卷):模型可以联网搜索信息。
📊结果总结¶
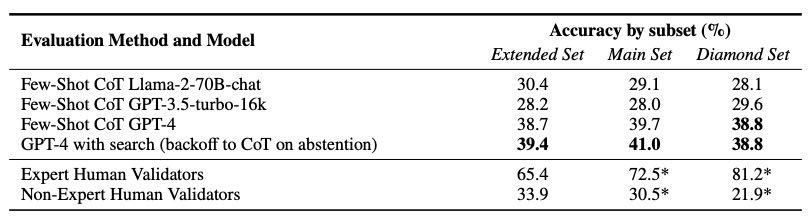
Table 5: Baseline model accuracies on the full, main, and diamond sets, containing 546, 448, and 198 q
GPT-4 表现比非专家好,但远不如专家。
GPT-4 加了搜索后,效果只略好一点,原因可能是它不会很好地用搜索引擎,或提示词没调好。
非专家准确率低,但如果能用 GPT-4 辅助,有可能提升到接近专家的水平。
这为“AI辅助监督系统”提供了实验基础。
🔁额外说明¶
数据子集之间模型表现差别不大。
非专家的准确率在难度更高的题目集中被低估了,因为这些题目是特意挑选出他们答得不好的题目。
6.Limitations¶
规模太小:只有 448 个样本,因成本高、筛选严格。数据太少,不适合训练模型,做准确率比较时统计能力也不足,只有差距很大(比如从 50% 到 60%)才看得出明显效果。
“非专家”也很专业:他们使用的是非常熟练的“非专家”来评估非专家的能力上限。这对实验有帮助,但不代表一般现实中的“非专家”,所以其他实验需要自己重新评估。
可能存在偏见:数据来自 Upwork 上的专家,没有控制地域或人口背景,因此可能导致数据在内容、话题或语言上存在偏差。例如,有些问题默认用“他”来指代科学家,而不是性别中立的词。
不能完全适用于超越人类的系统:虽然这个数据集是为了帮助研究如何监督比人更强的 AI,但它仍然不能完全模拟这个场景。一个可能的改进方法是:用那些现在没人能答但未来可能有答案的问题来测试 AI,等将来能验证时再评估 AI 的表现。
GPQA 是一个精挑细选的小数据集,用于测试 AI 的科学问答能力,但它太小、偏向强“非专家”、可能有偏见,也不完全适用于未来超强 AI 的评估。
7.Conclusion¶
他们发布了一个叫 GPQA 的多选题数据集,内容涵盖生物、物理、化学,由专业人士编写,非常有挑战性。
专家认为这些题有 74% 的客观性(不是主观猜测),
即使是非常努力、动用了资源、每题花30分钟的非专家,也只有 34% 的答对率,
最强的 GPT-4 模型也只答对了 39%。
这个数据集非常接近人类专业知识的边界,希望能用它来做“可扩展监督实验”,帮助我们建立监督超级 AI 的方法。