2205.14135_FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness¶
组织:Stanford University,
- 关键缩写
HBM: high bandwidth memory
SRAM: Static Random-Access Memory
备注
【心得】硬件决定架构:SRAM与HBM在带宽和存储的实际情况决定了优化的方向。
Abstract¶
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic(平方) in sequence length.
Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup.
We argue that a missing principle is making attention algorithms IO-aware – accounting for reads and writes between levels of GPU memory.
We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM.
We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes.
We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method.
FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3× speedup on GPT-2 (seq. length 1K), and 2.4× speedup on long-range arena (seq. length 1K-4K).
FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
- Transformer 在长序列上的计算瓶颈
标准自注意力(self-attention)计算复杂度是 \(𝑂(𝑁^2)\) (时间和内存随序列长度 𝑁 的平方增长)
- 问题:
计算速度慢(slow)
占用大量显存(memory-hungry)
- 现有解决方案
已有的近似注意力方法(Approximate attention) 试图降低计算复杂度,但通常会影响模型质量,并且 在实际运行时间(wall-clock speed)上并未带来显著加速。
- FlashAttention:IO感知的精确注意力算法
核心思想:FlashAttention 优化 GPU 内存访问(IO-aware),利用 分块计算(tiling) 减少高带宽显存(HBM)和片上存储(SRAM)之间的数据传输。
- 关键优化点:
减少 HBM(high bandwidth memory) 访问次数:相比标准注意力,FlashAttention 通过更高效的计算方式减少数据在 GPU 内存中的读取/写入。
SRAM 优化:对于不同大小的片上存储(SRAM),FlashAttention 具有理论上的最优 IO 复杂度(optimal IO complexity)。
- 扩展到块稀疏注意力(Block-Sparse Attention)
块稀疏注意力(block-sparse attention) 是一种近似方法,通过仅计算部分注意力矩阵块来减少计算量。
- FlashAttention + Block-Sparse Attention 结合了两者的优点,使得:
计算速度更快(比所有现有的近似注意力方法都快)。
不会牺牲太多模型质量,同时仍能提升长序列 Transformer 的可扩展性。
- 总结
FlashAttention 是一个 IO-aware(内存感知) 的 Transformer 优化方法,通过减少 GPU 内存访问,提高了长序列 Transformer 的计算效率。
- 相比标准 Transformer 计算:
更快(higher speed),减少了显存访问带来的瓶颈。
更节省显存(lower memory footprint),支持更长的上下文序列。
不牺牲模型质量(maintains model quality),甚至在某些任务上取得更好效果。
1. Introduction¶
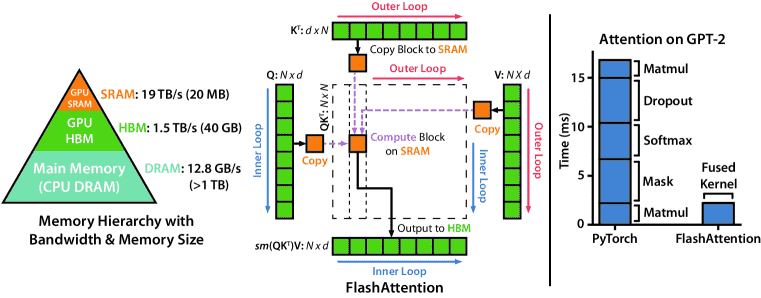
Figure 1: Left: FlashAttention uses tiling to prevent materialization of the large N×N attention matrix (dotted box) on (relatively) slow GPU HBM. In the outer loop (red arrows), FlashAttention loops through blocks of the 𝐊 and 𝐕 matrices and loads them to fast on-chip SRAM. In each block, FlashAttention loops over blocks of 𝐐 matrix (blue arrows), loading them to SRAM, and writing the output of the attention computation back to HBM. Right: Speedup over the PyTorch implementation of attention on GPT-2.FlashAttention does not read and write the large N×N attention matrix to HBM, resulting in an 7.6× speedup on the attention computation.¶
- 挑战
- 自注意力(self-attention)计算复杂度是 \(𝑂(𝑁^2)\) (时间和内存随序列长度平方增长),导致:
计算 速度慢(runtime bottleneck)。
需要 大量显存(memory-hungry)。
- 现有方法的局限
- 近似注意力方法(Approximate Attention) 试图降低计算和显存需求,主要包括:
稀疏近似(sparse approximation)
低秩近似(low-rank approximation)
两者的组合
- 问题:
大多数方法未带来真正的加速(wall-clock speedup)。
- 原因:
主要关注 FLOP(浮点运算)减少,但这并不一定等同于实际计算加速。
忽略了 GPU 存储器访问(memory IO) 的开销,而 Transformer 计算往往受制于内存带宽,而非纯计算。
- FlashAttention:IO感知的优化
核心思想:优化 GPU 内存访问(IO-aware),减少 高带宽显存(HBM) 和 片上存储(SRAM) 之间的数据交换。
- a.FlashAttention 的工作方式
传统注意力 需要计算并存储整个 N×N 的注意力矩阵,导致 大量 HBM 访问(内存瓶颈)。
- FlashAttention 通过以下优化减少 HBM 访问:
- 使用分块(tiling)计算:
计算时 逐块(block-wise)加载 K 和 V 矩阵到 SRAM,避免存储整个注意力矩阵。
在每个块内部,逐块处理 Q 矩阵,计算结果后立即写回 HBM,减少数据传输。
- Softmax优化:
重新设计 Softmax 计算,使其可以 增量计算(incrementally computed),避免访问整个输入数据。
- 避免存储完整的中间注意力矩阵:
反向传播时,不存储完整注意力矩阵,而是 存储 Softmax 归一化因子,从而可以快速在 SRAM 内重计算,减少 HBM 访问。
- b.关键优化
避免 HBM 访问,降低 IO 开销,提高实际计算速度。
所有操作整合进一个 CUDA 核函数(kernel),减少 Python 代码带来的开销,实现更细粒度的 内存管理。
- 数学分析:IO 复杂度
- FlashAttention 需要的 HBM 访问次数:
公式: \(O(N^2 d^2 M^{-1})\)
d 是注意力头的维度
M 是 GPU 片上存储(SRAM)大小
- 标准注意力的 HBM 访问次数:
公式: Omega(N d + N^2)
- 结论:
FlashAttention 访问 HBM 的次数要少很多(最高可少 9 倍)。
在所有 SRAM 大小范围内,FlashAttention 达到了最优 IO 复杂度。
- FlashAttention 扩展到块稀疏注意力(Block-Sparse Attention)**
- Block-Sparse Attention 是一种近似注意力方法,按块进行稀疏计算,仅计算部分注意力矩阵:
计算复杂度降低到 线性级别(linear complexity)。
IO 复杂度也比 FlashAttention 进一步减少。
- 计算性能基准(Benchmarking Attention)
FlashAttention 比标准 PyTorch 自注意力快 3 倍(适用于 128-2K token),支持 最长 64K token 计算。
短序列(≤512 token):FlashAttention 比所有注意力方法都快。
长序列(>1K token):Linformer 等近似方法在某些情况比FlashAttention更快,但 Block-Sparse FlashAttention 比所有已知近似方法都快。
- 结论
FlashAttention 通过优化 GPU IO 访问 ,大幅减少 HBM 访问,从而:
提高 Transformer 训练速度(最多 7.6× 加速)
减少内存占用(从 \(O(N^2)\) 降为 \(O(N)\) )
支持更长序列(64K token)
在 NLP 和长文档任务上提升模型质量
最终,FlashAttention 不仅加速了 Transformer 训练,还开辟了更长上下文 Transformer 训练的新可能性! 🚀
2 Background¶
这段内容主要介绍了 GPU 硬件性能 和 标准自注意力(standard attention)实现 的计算特性,目的是解释为什么 自注意力计算在长序列上会成为瓶颈,以及 如何优化它(如 FlashAttention)。
2.1 Hardware Performance¶
GPU 内存层次结构(Memory Hierarchy)¶
- GPU 具有不同层级的存储器:
- 高带宽显存(HBM, High Bandwidth Memory):
容量大(40-80GB)
速度较快(1.5-2.0TB/s 带宽)
- On-Chip SRAM:
容量小(A100 GPU 每个计算单元仅 192KB)
速度极快(19TB/s 带宽,比 HBM 快 10 倍以上)
- 问题:
计算速度增长比内存访问速度更快 → HBM 访问成为计算瓶颈。
现代 Transformer 计算主要受 HBM 访问次数限制,因此 优化内存访问比减少计算量更重要。
GPU 执行模型(Execution Model)¶
- GPU 计算过程:
从 HBM 读取输入数据到 寄存器(registers) 和 SRAM。
在 SRAM 内进行计算。
计算完成后,将结果写回 HBM。
- 计算瓶颈 vs. 内存瓶颈(Compute-bound vs. Memory-bound)
- 计算受限(Compute-bound):
计算时间由 运算量 决定,内存访问时间较小。
例子:矩阵乘法(matrix multiplication)、卷积(convolution)。
- 内存受限(Memory-bound):
计算时间主要由 内存访问 决定,运算本身时间较短。
- 例子:
逐元素操作(elementwise operations)(如 ReLU、Dropout)
归约操作(reduction operations)(如 Softmax、BatchNorm)
内存优化方法: Kernel Fusion¶
目的:减少对 HBM 的访问,提高计算效率。
原理:多个操作共享相同的输入数据时,只从 HBM 加载一次,在 SRAM 内完成多个计算,然后再写回 HBM。
限制: - 反向传播(backward pass) 仍然需要存储中间结果到 HBM,影响 Kernel Fusion 的效率。
2.2 Standard Attention Implementation¶

自注意力计算流程¶
- 给定输入向量 (Q, K, V)(分别表示查询、键、值),标准自注意力计算:
计算注意力分数矩阵(Score Matrix): \(S = QK^T \in \mathbb{R}^{N \times N}\)
对 每一行 进行 Softmax 归一化,得到注意力权重: \(P = \text{softmax}(S) \in \mathbb{R}^{N \times N}\)
计算最终的注意力输出: \(O = PV \in \mathbb{R}^{N \times d}\)
- 其中:
N 是序列长度
d 是注意力头的维度(通常 ( \(d \ll N\) )
计算复杂度¶
- 时间复杂度:
矩阵乘法( \(QK^T\) ): \(O(N^2 d)\)
Softmax: \(O(N^2)\)
矩阵乘法 (PV): \(O(N^2 d)\)
总时间复杂度: \(O(N^2 d)\)
- 内存(HBM 访问)复杂度:
计算 S 和 P 需要存储 \(O(N^2)\) 级别的中间结果。
当 \(N \gg d\) (如 GPT-2:(N = 1024, d = 64) ),HBM 访问成为主要瓶颈。
HBM 访问的影响¶
Softmax 计算是 Memory-bound 操作,需要频繁访问 HBM。
注意力矩阵( \(N \times N\) )太大,必须存储在 HBM 中,导致大量数据传输,降低计算速度。
掩码(masking)和 Dropout 进一步增加了 逐元素计算,使得计算更受 HBM 访问限制。
标准注意力 vs. FlashAttention¶
标准注意力计算 HBM 访问复杂度: O(N^2)
- FlashAttention 通过减少 HBM 访问次数提高速度:
采用 分块计算(tiling),在 SRAM 内完成 Softmax 计算,避免存储完整的 ( N times N ) 矩阵。
- 优化点:
减少 HBM 访问次数(最多减少 9 倍)
计算更快(最大提升 7.6×)
支持更长的序列(如 64K token)
总结¶
标准注意力的主要问题¶
计算复杂度 O(N^2 d) ,使得 Transformer 难以扩展到长序列。
HBM 访问复杂度 O(N^2) ,使得计算 受内存带宽限制,导致训练速度慢。
逐元素操作(Softmax, Dropout, Masking) 增加了内存访问需求,进一步拖慢计算。
FlashAttention 如何优化¶
减少 HBM 访问,将计算尽量放在 高速 SRAM 内完成。
避免存储完整的 N times N 注意力矩阵,减少 O(N^2) 级别的显存占用。
提高计算吞吐量,加速 Transformer 训练 2-7.6×,并支持 更长的序列(64K token)。
最终,FlashAttention 通过优化 GPU 内存访问,使 Transformer 在长序列任务上更快、更高效、更节省内存! 🚀
3. FLASHATTENTION: Algorithm, Analysis, and Extensions¶
- FlashAttention 的核心目标
减少 HBM(高带宽显存)访问:避免存储和读取大规模的中间矩阵(如 S = QK^T 和 P = text{softmax}(S))。
提升计算效率:通过在片上 SRAM 进行计算,减少数据在 HBM ↔ SRAM 之间的交换,提高实际运行速度(wall-clock speedup)。
降低内存占用:避免 O(N^2) 级别的显存需求,使 Transformer 能够处理更长的序列(如 64K token)。
3.1 An Efficient Attention Algorithm With Tiling and Recomputation¶
目标是减少 HBM 访问次数,降低到 N 的次方(subquadratic, 增长速度小于二次函数,但大于线性函数)
Tiling(分块计算)¶
- 由于 Softmax 操作会涉及整行(即所有列的 K ),所以 FlashAttention 采用 块分解(block-wise decomposition) 计算:
将输入矩阵 Q, K, V 按 块(block) 分割。
每次只加载一个块到 SRAM 计算 Softmax,并存储部分统计量(如最大值和归一化因子),以便在不同块之间组合 Softmax 计算结果。
避免存储完整的 \(S = QK^T\) 和 \(P = \text{softmax}(S)\) 矩阵,而是 逐块计算并更新最终输出。
- 数学分解(Softmax 计算的优化)
- Softmax 计算需要:
计算每行的最大值 m(x) : \(m(x) := \max_i x_i\)
计算指数值 f(x) : \(f(x) := \begin{bmatrix} e^{x_1 - m(x)} & \ldots & e^{x_B - m(x)} \end{bmatrix}\)
计算 Softmax 归一化因子 ell(x) : \(\ell(x) := \sum_i f(x)_i\)
最终计算 Softmax: \(\text{softmax}(x) = \frac{f(x)}{\ell(x)}\)
- 当计算多个块 \(x=(x^{(1)}, x^{(2)})\) 时,可以递归计算:
\(m(x) = \max(m(x^{(1)}), m(x^{(2)}))\)
\(\ell(x) = e^{m(x^{(1)}) - m(x)} \ell(x^{(1)}) + e^{m(x^{(2)}) - m(x)} \ell(x^{(2)})\)
通过存储 m(x) 和 ell(x) 作为额外统计量,我们可以逐块计算 Softmax,而不需要存储完整的 \(N \times N\) 矩阵!
Recomputation(重计算)¶
目标:避免存储 O(N^2) 级别的中间矩阵(如 S 和 P),同时确保反向传播能够正确计算梯度。
- 问题:
传统 Transformer 训练时,反向传播需要存储注意力矩阵 S 和 P 来计算梯度,导致显存占用过高。
- FlashAttention 解决方案:
仅存储最终输出 O 和 Softmax 归一化因子 \(m, \ell\)
在反向传播时 重计算 S, P,而不是从 HBM 读取整个矩阵
通过 SRAM 内部计算 Softmax 和矩阵乘法,减少 HBM 访问
- 优点:
牺牲额外的 FLOPs(计算量)来减少 HBM 访问,提升整体训练速度。
反向传播仍然可以高效进行,无需额外存储大矩阵。
Implementation details: Kernel Fusion(内核融合)¶
- 目标:在单个 CUDA Kernel 内完成所有计算,减少 HBM 访问次数:
1.一次性加载数据:从 HBM 加载 Q, K, V 到 SRAM。
- 2.在 SRAM 内完成所有计算:
矩阵乘法 \(QK^T\)
Softmax 计算(带掩码和 Dropout)
矩阵乘法 PV
3.将最终结果写回 HBM,避免多次访问 HBM。
- 效果:
避免反复读取和写入大规模数据到 HBM。
显著提高 GPU 计算效率(最高加速 7.6×)。
伪代码解析¶

- 输入:
输入矩阵 Q, K, V (存储在 HBM)
片上存储(SRAM)大小 M
- 步骤:
- 设定分块大小:
\(B_c = \left\lceil \frac{M}{4d} \right\rceil\)
\(B_r = \min\left(\left\lceil \frac{M}{4d} \right\rceil, d\right)\)
B_c 和 B_r 决定了 块大小,用于 SRAM 计算。
- 初始化输出矩阵:
\(\mathbf{O}\) :存储最终结果(初始化为 0)。
\(\ell, m\) :存储 Softmax 统计量(初始化为 0 和 -∞)。
- 将输入矩阵划分为多个块:
Q 分为 T_r 个块,每个大小为 B_r times d 。
K, V 分为 T_c 个块,每个大小为 B_c times d 。
- 主循环(遍历所有块):
- 外循环(遍历 K, V 的块):
将当前块 K_j, V_j 从 HBM 加载到 SRAM。
- 内循环(遍历 Q 的块):
加载 Q_i 到 SRAM。
计算 S_{ij} = Q_i K_j^T 并执行 Softmax 计算(仅存储统计量)。
计算 O_i 并写回 HBM。
备注
Theorem 1. Algorithm 1 returns \(O = softmax(QK^T)V\) with \(𝑂(𝑁^2𝑑)\) FLOPs and requires 𝑂(𝑁) additionalmemory beyond inputs and output.
3.2 Analysis: IO Complexity of FlashAttention¶
本文主要讲了在处理注意力机制(Attention Mechanism)时,FLASHATTENTION算法与标准注意力算法在硬件内存访问次数上的对比。
备注
Theorem 2 Let 𝑁 be the sequence length, 𝑑 be the head dimension, and 𝑀 be size of SRAM with 𝑑 ≤ 𝑀 ≤ 𝑁𝑑 . Standard attention (Algorithm 0) requires \(Θ(𝑁𝑑 + 𝑁^2)\) HBM accesses, while FlashAttention (Algorithm 1) requires \(\Theta(𝑁^2𝑑^2𝑀^{−1})\) HBM accesses.
- 主要结论
标准注意力(Algorithm 0) 需要 \(\Theta(Nd + N^2)\) 次 HBM 访问。
FlashAttention(Algorithm 1) 只需要 \(\Theta(N^2d^2M^{-1})\) 次 HBM 访问。
由于 \(d^2 \ll M\) (在典型硬件条件下),FlashAttention HBM 访问次数远小于标准注意力,导致执行速度更快、内存占用更小。
证明思路(todo):需要时再细研究
备注
Proposition 3. Let N be the sequence length, d be the head dimension, and M be size of SRAM with 𝑑 ≤ 𝑀 ≤ 𝑁𝑑 . There does not exist an algorithm to compute exact attention with \(o(𝑁^2𝑑^2𝑀^{−1})\) HBM accesses for all M in the range [d, Nd]. 命题 3:不存在一种算法可以在所有 M 值(范围在 \([d, Nd]\) 内)上,以 低于 \(\Theta(N^2d^2M^{-1})\) 次 HBM 访问计算 精确注意力
3.3 Extension: Block-Sparse FlashAttention¶
主要介绍了Block-Sparse FLASHATTENTION算法,这是一种对FLASHATTENTION算法的扩展,旨在通过引入块稀疏性来降低计算复杂度。
- 核心思想:
块稀疏性(block sparsity)->跳过计算中不重要的部分,从而优化 Transformer 在长序列任务中的效率
- 算法背景:
标准 FlashAttention 已经通过 减少 HBM(高带宽显存)访问 来加速注意力计算,但仍然是 全连接(dense attention),计算复杂度仍然较高。
Block-Sparse FlashAttention 通过引入 块稀疏性(block sparsity),即只计算部分 重要的注意力块,减少计算负担,提高 Transformer 在长序列任务中的可扩展性。
- 算法原理:
给定输入矩阵Q、K和V,以及一个掩码矩阵M,目标是计算注意力矩阵S、概率矩阵P和输出矩阵O。
其中,\(S = QK^T,P = softmax(S ⊙ 𝟙_M),O = PV\)
掩码矩阵M具有块形式,即对于某些块大小B_r和B_c,所有k,l满足 \(M_{k,l} = M_{i,j},其中i = [k/B_r],j = [l/B_c]\)
4. Experiments¶
- Training Speed
- FlashAttention 显著加速 Transformer 模型训练:
BERT(序列长度 512):训练速度 比 MLPerf 1.1 记录快 15%。
GPT-2(序列长度 1K-4K):比 HuggingFace 的实现快 3 倍。比 Megatron-LM 快 1.8 倍。
Long-Range Arena (LRA) 基准测试:训练速度提升 2.4 倍。
- 为什么 FlashAttention 更快?
减少 HBM(高带宽存储)访问,降低内存传输开销。
优化计算流程,使用 SRAM(片上高速存储) 进行分块计算(tiling)。
整合 CUDA 内核(Kernel Fusion),避免重复数据加载,提高计算效率。
- Quality
- FlashAttention 使 Transformer 能够训练更长的序列,提高模型质量:
GPT-2(上下文长度 4K):训练速度比 Megatron GPT-2(上下文长度 1K)更快。困惑度(Perplexity)只有 0.7(困惑度越低,语言建模效果越好)。
长文档分类任务:训练更长序列后,分类性能提升 6.4 分。
- 突破性成果:
首次 Transformer 模型在 Path-X 任务(16K 序列长度)上取得优于随机的性能。
块稀疏 FlashAttention(Block-Sparse FlashAttention)是第一个能在 Path-256 任务(64K 序列长度)上取得优于随机表现的序列模型。
- 为什么 FlashAttention 提高了模型质量?
标准 Transformer 受限于 𝑂(𝑁^2)复杂度,难以扩展到长序列。
FlashAttention 计算复杂度近似线性 𝑂(𝑁),支持更长的上下文窗口,使模型能学习 更远距离的依赖关系。
更长的上下文窗口 → 更好的文本理解和生成能力。
- Benchmarking Attention.
- FlashAttention 和 Block-Sparse FlashAttention 的性能测量
- FlashAttention:
内存占用随序列长度线性增长(标准注意力是二次增长)。
最多比标准注意力快 3 倍(适用于 2K 以内的序列长度)。
- Block-Sparse FlashAttention:
运行时间随序列长度线性增长(比所有现有的近似注意力方法都快)。
适用于超长序列(64K 以上)。
- 为什么 FlashAttention 和 Block-Sparse FlashAttention 在长序列上更高效?
标准注意力需要存储完整的 𝑁×𝑁 注意力矩阵,导致 显存占用爆炸。
FlashAttention 采用分块计算(tiling),避免存储完整矩阵,显存占用降低到 线性规模。
Block-Sparse FlashAttention 进一步跳过无用计算,只计算重要的注意力块,加速计算。
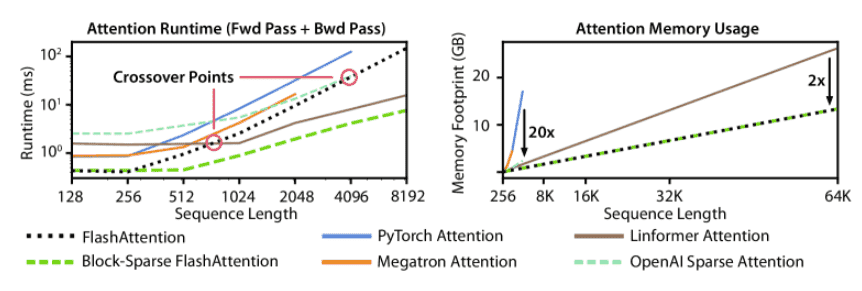
Figure 3:Left: runtime of forward pass + backward pass. Right: attention memory usage.¶
5. Limitations and Future Directions¶
本章节主要讨论了作者方法的局限性以及未来的改进方向,主要涉及三个方面:CUDA 编译、IO 感知深度学习、以及多 GPU IO 感知方法
- Compiling to CUDA
- 当前方法问题:目前的 IO 感知注意力(IO-aware attention)需要为每种新的注意力机制编写独立的 CUDA 内核。
CUDA 是较低级的编程语言,相比 PyTorch 这样的高级语言,开发难度大,需要更多的工程投入。
编写的 CUDA 实现可能无法直接迁移到不同的 GPU 架构,需要重新适配。
- 未来改进方向:
需要一种方法,在 PyTorch 这样的高级语言中编写注意力算法,然后自动编译为 IO 感知的 CUDA 代码。
这类似于 Halide 在图像处理中的做法(Halide 是一种专门用于优化图像处理计算的语言,能自动生成高效代码)。
- IO-Aware Deep Learning.
- 当前方法局限:
目前的方法主要优化 Transformer 中最占内存的计算——注意力机制(Attention)。
但 Transformer 中的每一层都会访问 GPU 的高带宽内存(HBM),不仅仅是注意力机制。
- 未来改进方向:
IO 感知的优化可以扩展到 Transformer 的其他模块,不仅仅是注意力。
例如,可能可以优化前馈网络(FFN)、归一化层(LayerNorm)等,进一步减少 GPU 内存瓶颈。
相关讨论在 附录 D(Appendix D) 中有详细介绍。
- Multi-GPU IO-Aware Methods
- 当前方法局限:
目前的方法是针对 单 GPU 上的注意力计算,并且已经是最优的(在一个常数因子范围内)。
但是,注意力计算可以并行化,如果可以跨多个 GPU 运行,可能会进一步提升效率。
- 未来改进方向:
未来可以研究如何在多个 GPU 之间并行执行注意力计算。
这涉及 GPU 之间的数据传输优化,需要新的 IO 分析方法。
Appendix B Algorithm Details¶
B.1 Memory-efficient forward pass¶
B.2 Memory-efficient backward pass¶
B.3 FlashAttention: Forward Pass¶

Algorithm 2 FlashAttention Forward Pass¶
B.4 FlashAttention: Backward Pass¶
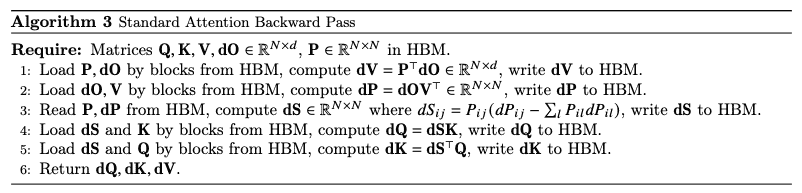
Algorithm 3 Standard Attention Backward Pass¶

Algorithm 4 FlashAttention Backward Pass¶
B.5 Comparison with Rabe and Staats¶
Appendix C Proofs¶
Proof of Theorem 1
Proof of Theorem 2
Proof of Proposition 3
Proof of Proposition 5