2309.05516_AutoRound: Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs¶
组织: Intel
Abstract¶
大语言模型虽然能力强,但部署时对内存和存储要求很高。
SignRound 是一种新方法,用 SignSGD 优化量化过程,只需 200步 就能完成。
它结合了训练前量化(PTQ)和感知量化训练(QAT)的优点,支持 2~4位量化,效果好且成本低。
比如在2位时,平均准确率最多能提升 33.22%,在4位时几乎无损。
1. Introduction¶
为什么量化很重要?
大模型(LLMs)越来越常用,但它们太大了,运行在资源有限的设备(如手机)上有困难。
为了降低内存、存储和计算需求,人们研究量化(把模型用更低精度表示),特别是权重量化。
两种主要量化方式:
QAT(Quantization-Aware Training)
模型在训练时就考虑量化的影响,精度较高,但训练复杂、耗资源。
PTQ(Post-Training Quantization)
模型训练完再做量化,简单高效,但可能精度下降。
重点方向:权重量化
激活量化比较难,容易影响性能,所以本文只做权重量化。
权重量化的关键步骤是四舍五入(rounding)
常见的是RTN(round to nearest),但它忽略了权重之间的关系,效果不够好。
Adaptive Rounding尝试改进它,用更复杂的优化方法来决定怎么四舍五入。
本文提出的方法:SignRound
使用一种简单但有效的优化算法 SignSGD 来优化四舍五入过程,同时做权重截断(clipping)。
好处:
推理时不增加额外计算量。
在2到4比特量化下表现优异,甚至达到几乎无损。
在多个模型上泛化性好。
总结:
这篇文章提出了一种低成本、效果好、易用的权重量化优化方法(SignRound),
在不牺牲推理效率的前提下显著提升了模型量化后的性能。
2. Related Work¶
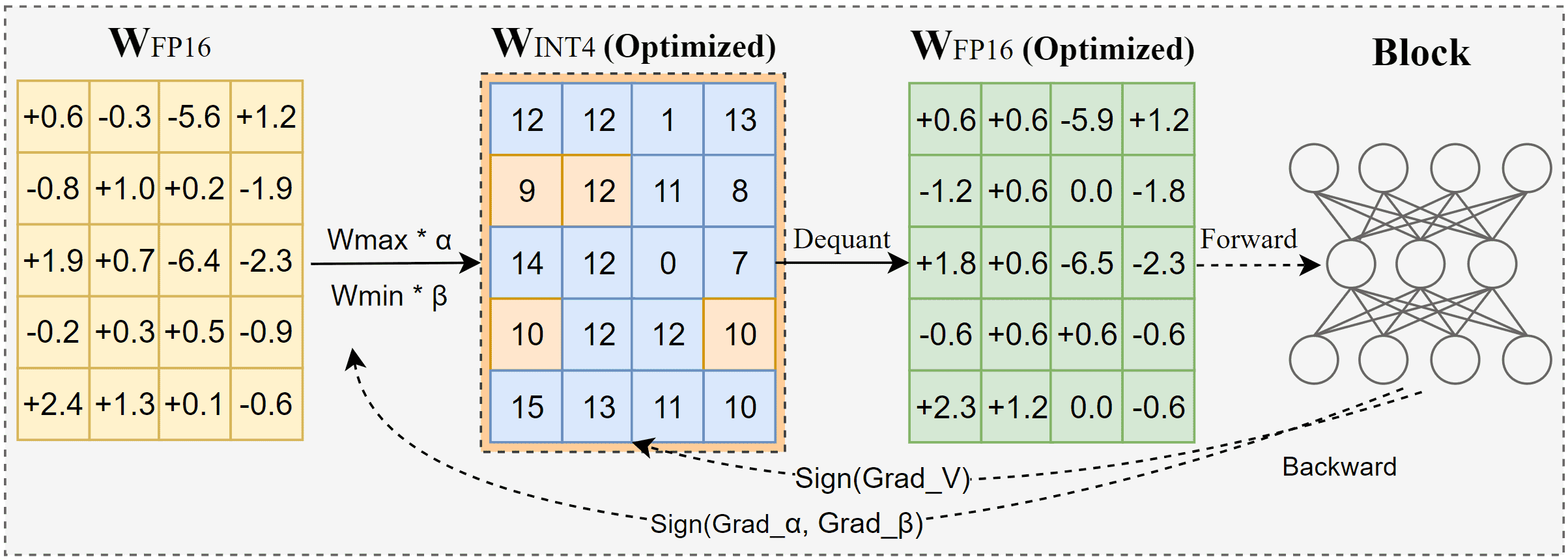
Figure 1:An illustration of SignRound. Unlike the direct rounding in RTN, SignRound performs signed gradient descent to fine-tune the rounding and weight clipping through block-wise output reconstruction. After lightweight forward and backward steps, \(W_{INT4}\) has been well optimized. Note that Quant and Dequant are two standard operations for quantization and dequantization respectively.
QAT(Quantization Aware Training)
量化感知训练方法在模型压缩中很常见,主要是通过微调来提升量化后的模型精度,通常效果比PTQ更好。
PTQ(Post-Training Quantization)
后训练量化不需要额外训练,计算资源消耗少,适合大语言模型(LLM)的量化。
大语言模型量化(LLM Quantization)
已有多种方法应对LLM量化的挑战,包括:
GPT3.int8():混合精度,保留重要通道。
AQLM:多码本量化的扩展。
ZeroQuantV2:用低秩矩阵恢复精度。
RPTQ:聚类通道再量化。
LLM-QAT:结合QAT优化。
SmoothQuant、SPIQ等:手动等效变换减少误差。
LRQ:少量可学习参数来提升泛化能力。
仅权重量化(Weight-Only Quantization)
只量化权重,激活仍用浮点数,适度压缩、保持精度:
GPTQ:用“最佳脑外科手术”法优化权重。
AWQ、TEQ、OmniQuant:使用等效变换,OmniQuant有权重剪裁。
HQQ:无需校准数据,速度快。
SqueezeLLM、EasyQuant、NUPES 等:用更复杂的优化策略提升精度。
本文聚焦于不增加推理负担的方法。
舍入方法(Rounding Methods)
Adaptive Rounding 把舍入当成优化问题,但只用二阶近似可能误差大。
FlexRound 更灵活,但需要模型专属超参数,不易扩展。
Oscillation-free 指出可学习参数可能引起不稳定。
AQuant 根据激活值动态调整边界以减少误差。
符号梯度下降(Signed Gradient Descent)
虽然不常用,但在某些场景下(如通信效率)有效:
比如当Hessian矩阵对角线占主导时,符号梯度优于普通梯度下降。
有些研究表明符号法在收敛速度上可能更快,甚至能在一定假设下达到最优。
3. Methodology¶
基本量化方法
想把模型的浮点权重 \(\mathbf{W}\) 转换成整数(量化),
然后还能近似还原(反量化)。
量化、反量化权重 的公式如下:
\(s\):缩放因子,用于将浮点变成整数
\(zp\):零点偏移
\(\left\lfloor \cdot \right\rceil\):四舍五入
\(\left\lfloor \cdot \right\rceil\)通常使用 RTN 方法执行
缺点:RTN 是一种逐元素四舍五入的方法,但它忽略了权重之间的相关性,效果有限。
改进点:引入可训练参数
为了更好地量化,我们引入三个可训练参数:
V(扰动项):在四舍五入前加入,用来微调每个权重的量化效果。
\[ \widetilde{\mathbf{W}} = s \cdot \text{clip}\left( \left\lfloor \frac{\mathbf{W}}{s} + zp + \mathbf{V} \right\rceil, n, m \right) \]α(alpha)和 β(beta):用来调整权重最大/最小值的裁剪范围,使得计算出来的缩放因子 \(s\) 更合理。
\[ s = \frac{\max(\mathbf{W}) \cdot \alpha - \min(\mathbf{W}) \cdot \beta}{2^{\text{bit}} - 1} \]
训练方法(SignRound 算法)
为了优化这三个参数,作者使用一个迭代训练算法(如下步骤):
用原始模型推理出输出
y_f。对当前权重进行量化,得出量化版本
w~。用量化模型输出
y_q。计算
y_q和y_f之间的均方误差(loss)。如果当前 loss 更小,则保存当前的 \(V, \alpha, \beta\)。
使用 SignSGD 优化器继续调整 \(V, \alpha, \beta\)。
最终优化的目标是:量化和反量化权重
备注
提出了一种引入可训练参数的智能量化方法,使大模型在压缩时尽可能保留原始性能。
4. Experiments¶
任务类型: 包括 11 个 zero-shot 语言任务(如 HellaSwag、PIQA、LAMBADA 等)和 3 个困惑度(PPL)数据集(如 WikiText2、PTB、C4)。
评估工具: 使用 lm-eval-harness 工具
量化方式: 仅对 Transformer 的线性层进行 weight-only 量化,不包括嵌入层或输出层
设置: 使用 W4G-1、W4G128、W3G128、W2G128 等配置(表示 4/3/2bit 精度 + 分组粒度)。
校准样本: 从 pile-10k 中随机选取 512 条样本,避免过拟合。
所测模型:使用主流开源模型如 LLaMA-V1/V2、Mistral-7B,模型参数覆盖从 7B 到 70B。
与主流方法对比(GPTQ, AWQ, HQQ, OmniQuant 等)效果都有提升
消融实验(Ablation Study):对比 SignSGD 和 Adam 优化器,发现 SignSGD 表现更稳、更优,尤其是在低比特量化任务中。
5. Conclusion¶
提出了一种高效简洁的量化方法 SignRound,用于优化大语言模型中的权重取整。它通过带符号的梯度下降和权重裁剪,在200步内完成优化,比如量化 LLAMA-V2-70B 只需约 2.5 小时。实验表明,SignRound 在大多数情况下优于其他方法,并且在新模型中生成效果也很好。通过为不同模型调整参数,性能还能进一步提升。