2112.02418_YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone¶
组织: 巴西圣保罗大学, 法国Sopra Banking Software, 美国Defined.ai, 巴西联邦技术大学, 德国Coqui
关键词: cross-lingual zero-shot multi-speaker TTS, text-to-speech, cross-lingual zero-shot voice conversion, speaker adaptation.
关键概念¶
Phonemes(音素)¶
Phonemes(音素)是语言学中的一个基本概念,指的是在一种语言中能够区分词义的最小语音单位。
换句话说,音素是人们在说话时用来区别不同词汇的声音元素。
例如,在英语中,/p/和/b/就是两个不同的音素,因为它们能够区分出像“pat”(轻拍)和“bat”(蝙蝠)这样意义完全不同的词语。
音素通常通过国际音标(International Phonetic Alphabet, IPA)来表示,这是一套被设计用来精确表示全世界各种语言发音的符号系统。
Mel Spectrum(mel 频谱)¶
Mel 频谱(Mel Spectrum)是基于人类听觉感知特性对声音频谱的一种变换形式。
在语音处理和音频信号处理领域,Mel 频谱是一个重要的概念,因为它考虑到了人类听觉系统对于不同频率声音的感知并不是线性的这一事实。
具体来说,人类听觉系统更敏感于低频的声音而非高频的声音。
这意味着,同样幅度的变化,在低频区域会比在高频区域更容易被人耳察觉。
Mel 尺度正是为了模拟这种听觉感知特性而设计的,它通过一个非线性的转换将普通的频率尺度映射到Mel频率尺度上。
在这种尺度下,相邻的数值表示人耳感知上等距的声音频率。
Mel 频谱通常通过将信号的短时傅里叶变换(Short-time Fourier Transform, STFT)结果映射到Mel尺度上来获得。
首先,计算信号的STFT以得到线性频谱;
然后,应用一组三角形滤波器组(这些滤波器在Mel尺度上均匀分布),从而将线性频谱转换为Mel频谱。
这个过程有效地强调了那些对人类更为重要的低频部分,同时压缩了不太重要的高频部分。
Mel 频谱广泛应用于语音识别、音乐信息检索等领域中,作为特征提取的一部分,有助于提高各种音频处理任务的效果。
例如,在自动语音识别(ASR)系统中,Mel频谱系数(MFCCs)就是一种常见的基于Mel频谱的特征表示方法。
Fourier Transform(傅里叶变换)¶
傅里叶变换(Fourier Transform)是一种数学变换,它将时间域(或空间域)中的函数转换为频率域中的函数。
这种变换使得我们能够分析信号的频率成分,从而更好地理解和处理信号。
傅里叶变换在许多领域都有广泛的应用,包括工程学、物理学、信号处理和应用数学等。
基本思想是任何连续周期信号都可以表示为一组正弦和余弦波的无穷级数。
对于非周期信号,可以通过傅里叶变换将其表示为不同频率的正弦和余弦波的积分。
这意味着即使是非常复杂的信号,也可以通过了解其构成频率来理解其特性。
傅里叶变换有几种形式:
连续傅里叶变换(Continuous Fourier Transform, CFT):适用于连续且无限长度的信号。
离散傅里叶变换(Discrete Fourier Transform, DFT):适用于离散采样点组成的有限长度序列,常用于数字信号处理。
快速傅里叶变换(Fast Fourier Transform, FFT):是一种高效的算法,用于计算离散傅里叶变换及其逆变换,大大减少了计算复杂度。
短时傅里叶变换(Short-time Fourier Transform, STFT)是傅里叶变换的一种扩展形式,
专门用于非平稳信号(即信号的频率内容随时间变化),通过在不同时刻对信号进行窗口化并应用傅里叶变换来获得信号的时频表示。
这种变换提供了信号在不同时间点上的频率成分信息,但它假设每个时间段内的频率成分是固定的。
在实际应用中,傅里叶变换可以帮助识别信号中的周期性成分、去除噪声、压缩数据等。例如,
在音频处理中,傅里叶变换可以用来分析声音的频谱成分;
在图像处理中,它可以用来进行图像压缩和特征提取。
此外,通过傅里叶变换,我们可以将时域中难以解决的问题转化为频域中较为简单的问题来解决。
与Mel Spectrum的区别
目的:傅里叶变换主要是为了分析信号的频率组成;而Mel频谱则旨在模仿人类听觉系统对声音的感知。
变换方式:傅里叶变换直接将时间域信号变换为频率域表示;Mel频谱在此基础上,进一步通过Mel滤波器组对频率轴进行非线性变换。
应用:傅里叶变换广泛应用于各种科学和工程领域;Mel频谱更常用于语音识别、音乐信息检索等需要考虑人类听觉特性的应用中。
尽管两者都是用于信号处理的重要工具,但它们的应用场景和实现方式有所不同。
傅里叶变换提供了一种通用的方法来分析信号的频率特征,而Mel频谱则特别适用于那些需要考虑人类听觉感知因素的任务。
Abstract¶
YourTTS 是一个支持多语言和多说话人零样本语音合成(TTS)的模型,基于 VITS 模型,并在此基础上做了改进。
它在多说话人零样本合成任务上达到了最先进水平,在语音转换任务上表现也很接近最优。
即使只有单说话人的数据,也能在低资源语言中取得不错效果。
此外,只需不到1分钟的语音就可以微调模型,实现高语音相似度和良好音质,适用于与训练数据差异很大的新说话人。
1. Introduction¶
这段内容主要介绍了语音合成(Text-to-Speech, TTS)中的“零样本多说话人语音合成(Zero-Shot Multi-Speaker TTS, ZS-TTS)”的研究进展和一个新方法 YourTTS。
一、背景和问题¶
传统 TTS 通常是基于一个固定说话人训练的。
新方向:零样本语音合成(ZS-TTS) —— 给模型听几秒钟陌生人的语音,就能模仿这个人的声音读出新句子。
这种方法可以帮助快速合成多个说话人的语音,甚至是从没见过的人。
二、已有方法发展¶
最早的方法基于 DeepVoice3 和 Tacotron 2,用了说话人嵌入(speaker embeddings)。
后来加入了更多细化特征提取方法(如 Attentron 的注意力机制、ZSM-SS 的 Transformer 结构等)。
SC-GlowTTS 是第一个基于 flow 模型的 ZS-TTS 方法,提升了声音相似度。
这些方法虽然进步明显,但仍有问题:
模型对训练中没见过的说话人还不够准确;
对低资源语言(可用说话人少的语言)支持差;
不同声音特征的说话人效果仍然有限。
三、多语言 TTS 的趋势¶
现在还有一个趋势是 多语言 TTS,也就是一个模型能说多种语言。
有些还能进行 语码转换(code-switching) —— 一句话中切换语言,但保持相同声音。
这对 ZS-TTS 很有帮助:一个语言的说话人声音可以迁移到另一种语言中合成。
四、本文 YourTTS 的贡献¶
YourTTS 是一种新的 ZS-TTS 方法,创新点如下:
在英文语音合成上达到当前最好的效果(SOTA);
首次将多语言训练引入 ZS-TTS;
只用目标语言中一个人的声音,就能实现高质量跨语言语音转换;
即使目标说话人的声音差异很大,只需不到 1 分钟语音,也能微调出不错的效果。
五、实验资源¶
总结¶
YourTTS 是一种支持多语言、只需极少语音样本就能模仿新说话人声音的语音合成新方法,在准确性和灵活性上都领先现有方法。
2. YourTTS Model¶
YourTTS 是在 VITS 模型基础上改进的文本转语音(TTS)系统,具备 零样本多说话人、多语言合成 能力
✅ 主要创新点:¶
直接用原始文本而非音素(phonemes) 作为输入,方便支持缺乏音素工具的语言。
多语言支持:
给每个字符嵌入加入一个4维可训练的语言嵌入向量;
增加了 Transformer 编码器的层数和通道数。
端到端架构(E2E):
不使用 mel 频谱作为中间表示,而是用一个 潜变量 z 连接 TTS 模型与 HiFi-GAN 声码器;
使用 Posterior Encoder 从线性频谱图预测 z;
z 被同时用于解码器和声码器,提升了合成质量。
支持多说话人(Zero-Shot):
将外部说话人嵌入加入到各模块(解码器、声码器、Posterior Encoder 等)中;
使用全局条件(global conditioning)机制进行信息融合。
语音节奏建模:
使用随机时长预测器(Stochastic Duration Predictor)生成更自然的语音节奏;
训练时用 MAS(Monotonic Alignment Search)对齐,推理时则使用采样方式估计时长。
加入说话人一致性损失(SCL):
利用预训练的说话人编码器比较生成语音和真实语音的说话人一致性,提升说话人保真度。
🚀 推理过程概括:¶
文本输入 → 编码器生成 P(zₚ);
随机噪声 → 时长预测器 → 采样时长;
P(zₚ) → 反向 Flow 解码器 + 说话人嵌入 → 得到 z;
z → 声码器 → 合成语音。
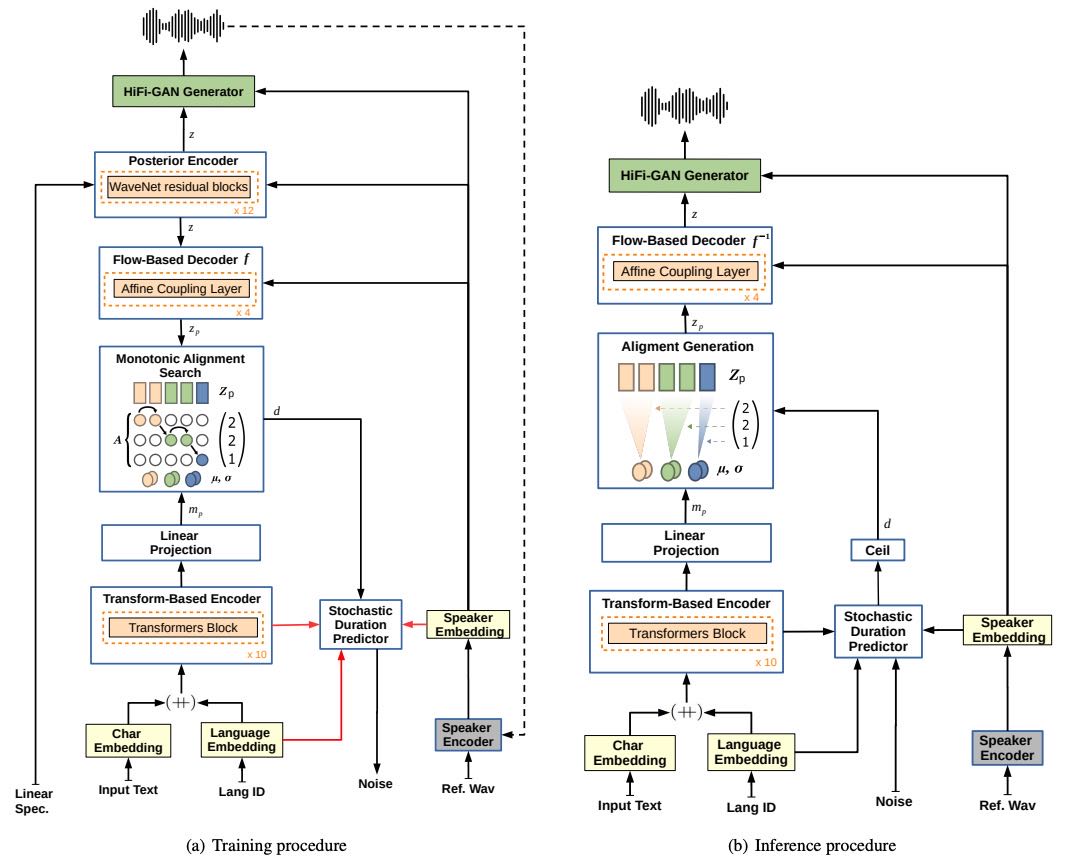
Figure 1: YourTTS diagram depicting (a) training procedure and (b) inference procedure.
3. Experiments¶
介绍了一个多语言语音合成模型的实验流程,包括所用的编码器、数据集预处理方式、各类语言的来源和分布,以及逐步加入新语言的训练方式和优化方法。
整个研究的重点是实现“零样本多说话人语音合成”,即模型能模仿从未见过的说话人。
3.1 Speaker Encoder¶
使用了一个在 VoxCeleb2 数据集上训练的 H/ASP 模型,表现优于之前的模型(EER 仅 1.967,对比旧模型的 5.244)。
这个模型用于区分不同说话人,用在后续的语音合成任务中。
3.2 Audio datasets¶
语言: 英语、葡萄牙语、法语。
预处理: 所有音频降采样到 16kHz、去除静音、响度归一化。
各语言数据集:
英语: VCTK(109个说话人)+ LibriTTS 子集。
葡萄牙语: 10小时的单人语音数据,加了去噪处理。
法语: M-AILABS 数据集,2女3男,总175小时。
评估方式:
英语用 VCTK 测试集和 LibriTTS 的10个说话人。
葡语用 MLS 数据集的10个说话人。
法语由于原因未进行评估。
还用了 Common Voice 的4个说话人进行说话人适应实验。
3.3 Experimental setup¶
共进行 4 组训练实验:
只用英语数据(VCTK)
加入葡萄牙语数据(双语)
加入法语数据(三语)
在第3步基础上继续加入1151个英语说话人的数据(增强泛化)
训练策略:
使用迁移学习,从已在LJSpeech上训练100万步的模型开始。
每次添加新语言时继续训练,最后都进行了额外的微调(使用“说话人一致性损失”SCL,α=9)。
使用 HiFi-GAN 作语音合成器,优化器为 AdamW,使用语言平衡的采样方法。
4. Results and Discussion¶
评估方法:¶
MOS(平均意见得分):人工打分,评估合成语音的自然度。
SECS(说话人编码余弦相似度):衡量合成语音和原始说话人声音的相似性,越接近1越相似。
Sim-MOS(相似度MOS):人工主观评估合成语音与原始说话人是否相似。
实验设置:¶
使用英语(最多说话人)和葡萄牙语(最少说话人)做主观评估。
用VCTK、LibriTTS、MLS(葡萄牙语)等数据集。
实验涉及单语、多语模型,还引入了 SCL(说话人一致性损失) 来提高相似度。
主要发现:¶
1. VCTK 数据集:¶
实验1(单语)和实验2+SCL(双语)效果最好。
SECS显示SCL有提升,但Sim-MOS结论不明确。
所有实验的SECS竟然高于真实语音,可能是VCTK数据本身噪音较大。
综合质量(MOS)和相似度都接近甚至超过已有的最强方法(SOTA)。
2. LibriTTS 数据集:¶
实验4在相似度(SECS)上最好,可能因使用的说话人更多。
实验1(单语)在音质(MOS)上表现最好,因为训练数据更干净。
3. 葡萄牙语 MLS 数据集:¶
实验3+SCL 的音质最好。
相似度结果不一致:Sim-MOS 最好的是实验3,SECS 最好的是实验4+SCL。
男女表现有差距,因为模型只训练了男性葡语说话人,但仍能生成女性语音。
虽然只有一个葡语男性训练说话人,但效果和训练了100个英语说话人的Attentron模型相当,表明模型对低资源语言也有效。
加入法语(如实验3)提升了葡语的音质和相似度,原因是法语数据质量更高,减少了葡语噪声数据的影响。
4. SCL 的影响:¶
SECS 提升明显,说明 SCL 有助于学习说话人特征。
Sim-MOS 改善不明显,结果不确定。
可能会稍微降低语音质量,因为 SCL 可能引入了参考音频中的噪声或失真。
如果参考音频质量高,合成语音质量也会高。
总结¶
简而言之:这个研究表明,作者提出的方法在零样本多说话人语音合成中表现优异,特别适用于低资源语言,同时使用SCL在部分情况下能增强说话人相似度,但可能略影响音质。
5. Zero-Shot Voice Conversion¶
这段内容讲的是 YourTTS 模型在“零样本语音转换”(Zero-Shot Voice Conversion)任务上的表现。
【定义】零样本语音转换:不需要在训练时见过某个说话人,也能模仿这个人的声音进行语音转换。
🧠 模型设计亮点:¶
不向编码器提供说话人信息,让模型学到“与说话人无关”的语音表示。
使用外部的说话人嵌入(speaker embedding)来实现模仿新说话人声音。
只需一段参考语音,就能模仿这个新说话人说任意内容。
🧪 实验设置:¶
用的是 YourTTS 模型,并与 AutoVC、NoiseVC 等模型在 VCTK 数据集上做对比。
使用训练时没见过的说话人(共 8 个,男女各一半)。
同时测试 英语内部转换 和 葡萄牙语内部转换,还测试了 跨语言转换(英语 ↔ 葡语)。
📊 实验结果:¶
✅ 英语 → 英语:¶
YourTTS 得分:MOS 4.20,Sim-MOS 4.07(表示自然度和相似度都很高)
比 AutoVC 和 NoiseVC 明显更好。
✅ 葡语 → 葡语:¶
YourTTS 得分:MOS 3.64,Sim-MOS 3.43
男性转男性比女性转女性效果好(因为训练中缺少葡语女性语音)
🔄 英语 ↔ 葡语(跨语言):¶
效果接近于葡语内部转换
但当要将葡语男性转成英语女性时,效果明显下降(模型没学到葡语女性声音)
📌 结论:¶
YourTTS 模型即使没有见过说话人,也能实现高质量语音转换。
但在性别或语言数据不平衡时,会影响效果,特别是在女性声音转换上。
6. Speaker Adaptation¶
问题背景:
不同的录音条件和说话人会影响多说话人TTS模型的效果,尤其是那些声音与训练集中差别很大的说话人。
实验方法:
选了4位说话人(葡萄牙语和英语各2位,男女各一),每人20–61秒语音。
基于之前训练好的模型,用这少量语音对每个说话人单独微调。
训练时仍保留原多语言数据集,并通过加权采样保证每批数据有1/4来自目标说话人。
训练细节:
微调进行了1500步,用之前的评估方法来评估效果。
结果总结:
微调后,即便只用不到1分钟语音,模型在“相似度”(Sim-MOS)上有显著提升。
英语中,微调后男女说话人效果接近真实语音;SECS甚至比真实语音还高,可能因为模型学会了模仿录音中的失真特征。
葡萄牙语中,微调后“自然度”略下降但“相似度”大幅提高。例子:男声从3.35提升到4.19(只用31秒),女声从2.77提升到4.43(只用20秒)。
结论:
微调能显著提升相似度,用20秒语音就能模仿声音特征。
但要保证语音自然度,最好使用超过45秒语音。
微调后语音转换能力也明显增强,尤其是葡萄牙语和法语。
7. Conclusions, limitations and future work¶
我们提出了 YourTTS 模型,在 VCTK 数据集上实现了零样本多说话人语音合成和语音转换的最新效果(SOTA)。
它还能用单一说话人的数据在目标语言中生成不错的结果,
并且在说话人声音和录音条件差异很大的情况下,用不到1分钟的语音就能适应新说话人。
但也存在一些问题:
在多语言语音合成中,模型有时会生成不自然的语速;
有些单词会发音错误,尤其是葡萄牙语,因为我们没有使用音素转写;
葡语中,说话人性别会影响表现,因为训练中缺乏女性语音;
虽然20秒语音可用于说话人适配,但超过45秒效果更好。
未来计划:
改进语速预测器;
支持更多语言训练;
用于低资源语种的语音识别数据增强。