2505.02707_Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play¶
组织: Maitrix.org, UC San Diego, MBZUAI
Abstract¶
Voila 是一个先进的语音 AI 系统,目标是像人类一样自然、主动、富有情感地与人互动。
它采用端到端架构,能实现快速(195 毫秒)且连续的双向语音对话,保留语调、节奏和情感。
Voila 结合了大语言模型的推理能力和强大的语音建模,支持用户通过文本定义说话人的风格,还支持超百万种预设声音和从10秒音频快速定制新声音。
它不仅用于对话,还能应用于语音识别、语音合成和多语种翻译。
1. Introduction¶
核心问题:现有 AI 系统的交互方式太“被动”¶
当前的 AI(如 Siri、ChatGPT)都是“用户问、AI答”,属于被动、回合式交互。
真正自主的 AI应该能主动感知环境、预测用户需求,在合适的时机主动发起或回应交流,例如:
主动提醒用户前方有危险
感知情绪变化,及时安慰或建议
语音是实现自然交互的关键方式¶
相比文字,语音更自然、即时,能传递丰富情绪和意图(语调、节奏、情感等)。
人类对话中常有打断、同时说话、反馈声(如“嗯”、“哦”),这些在语音中才真实。
从传统语音助手到端到端语音大模型¶
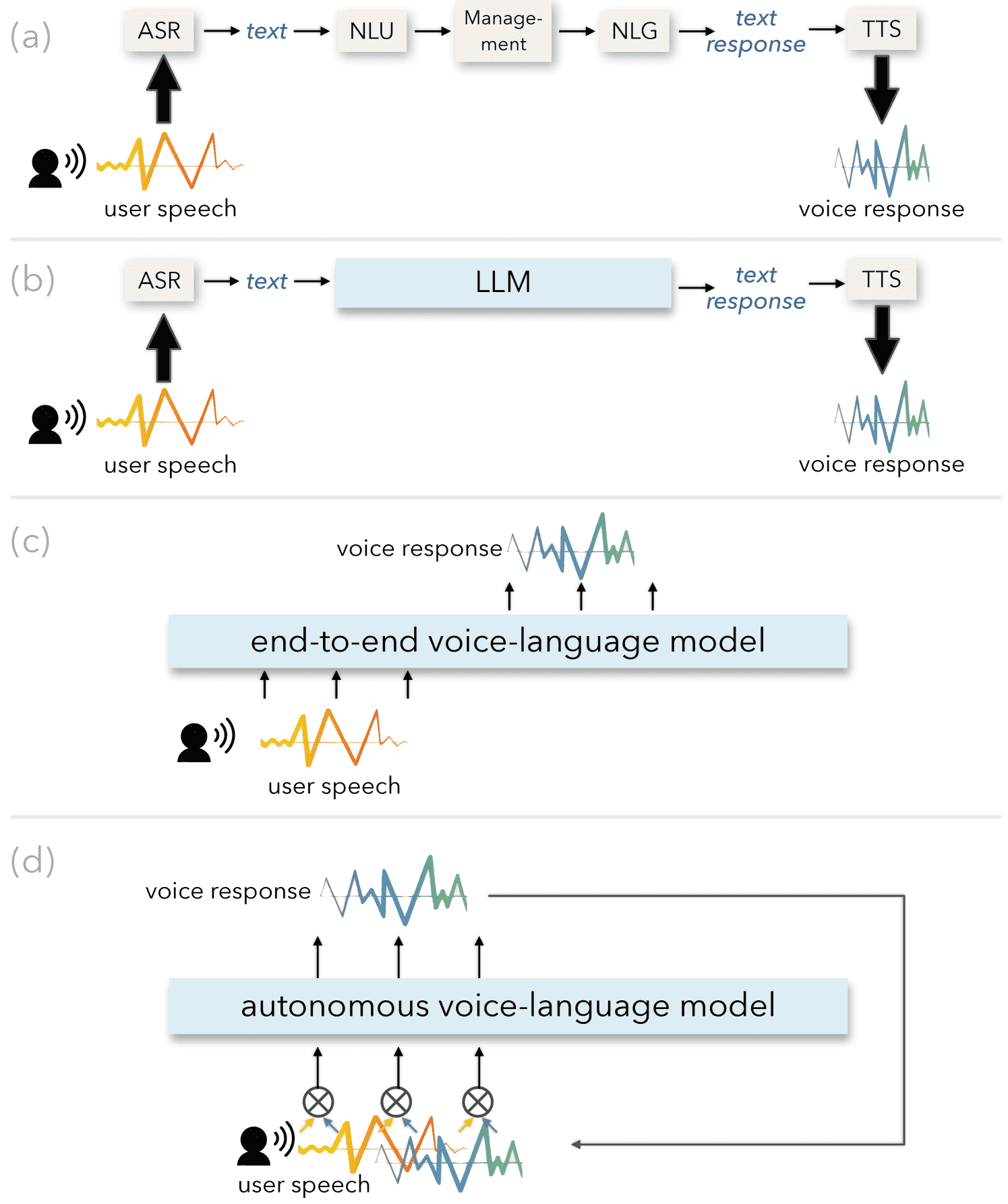
Figure 1:Different paradigms of voice conversation systems: (a) Traditional pipeline systems, such as Apple Siri, Amazon Alexa, and Google Assistant, launched in the 2010s; (b) Simplified pipeline systems using LLMs to handle text-based understanding and response generation; (c) End-to-end audio-in, audio-out systems that offer low latency and rich vocal nuances; (d) Autonomous systems that further enable dynamic, proactive interactions.
传统语音助手(如 Siri):
模块化流水线,结构复杂,反应慢,理解能力弱。
使用 LLM 的语音助手:
使用 ASR + LLM + TTS,把语音转文字、处理再转语音。
好处:理解力更强。
问题:仍然有延迟大、丢失语音细节、只能被动回应等缺点。
端到端语音模型(audio-in, audio-out):
不经过文字中间步骤,直接处理音频,保留语音细节、延迟更低。
但仍然是回合式,不够“主动”。
解决方案:Voila 模型家族¶
Voila-e2e:端到端语音对话模型,支持低延迟、丰富语音表达、定制化人物设定。
Voila-autonomous:进一步支持同时收听和说话(全双工),实现实时自主交互。
Voila 的技术亮点¶
融合语音与文本:
使用多层 Transformer,将语义和声音特征分开处理。
构建 Voila-Tokenizer,把语音编码为 token,并与文字一起训练。
海量可定制声音:
只需上传几秒到几小时的音频,Voila 即可学会模仿说话人。
可搭配文本设定人物性格,创建拟人化 AI。
统一模型多任务处理:
一个模型可处理语音识别(ASR)、语音合成(TTS)、语音翻译等多种任务。
支持六种语言:英语、中文、法语、德语、日语、韩语。
3. Voila: Voice-Language Foundation Models¶
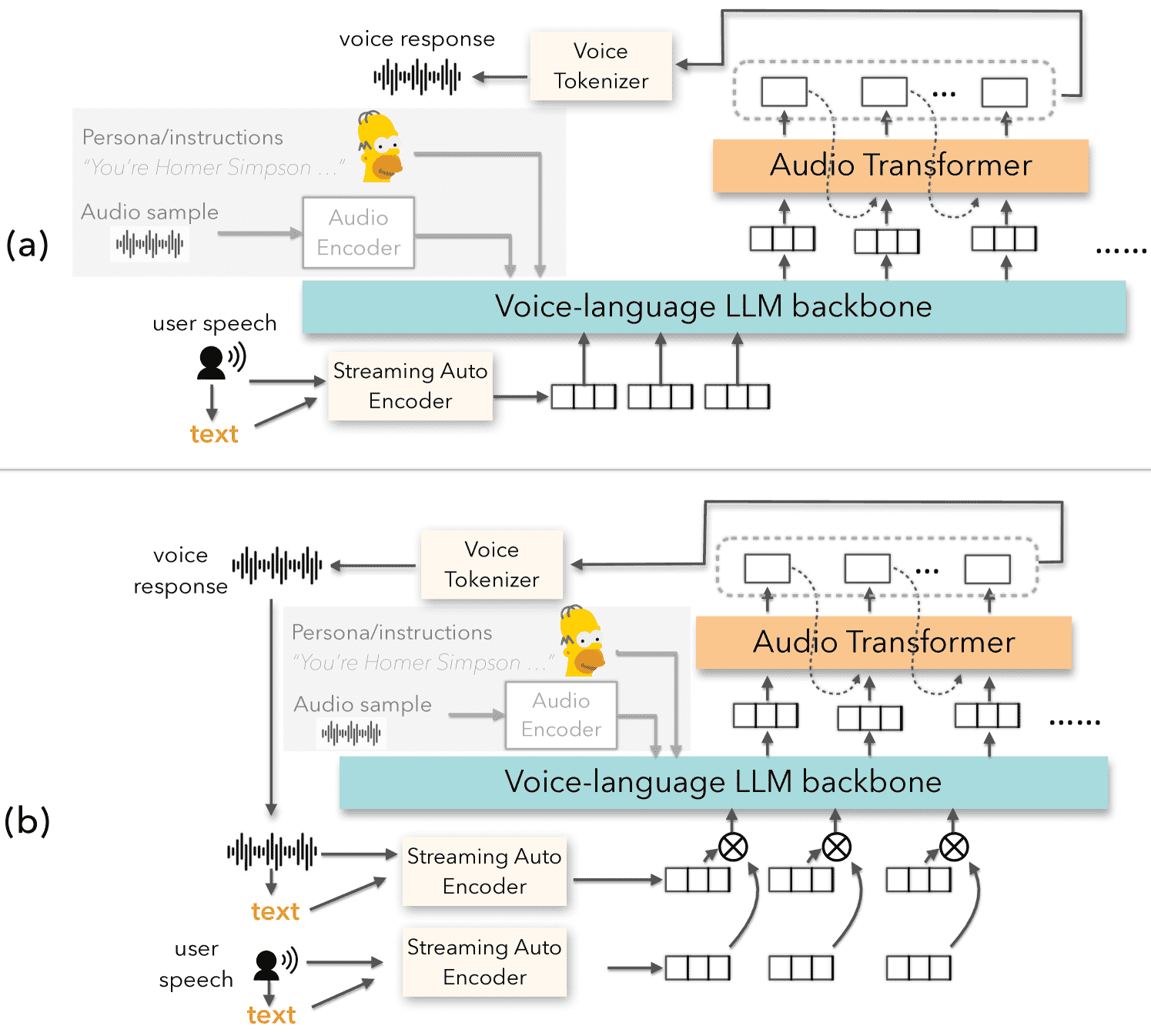
Figure 2:Voila models: (a) Voila-e2e for end-to-end voice conversation, (b) Voila-autonomous for autonomous interaction. Both models allow easy customization of speaker characteristics and voice via text instructions and audio samples.
Voila 是一个支持“听说同步、自然互动”的语音-语言大模型系统,可以实现真人般的语音对话,还支持个性化声音定制。
模型结构:
采用 分层多尺度 Transformer 架构。
包括两个主要部分:
语言模型主干(LLM):处理语义(理解你在说什么)。
音频 Transformer:根据语义生成音频 token。
最终通过 音频 tokenizer 把 token 解码为语音。
3.1 Voice Tokenizer¶
把连续语音转成离散 token 供 LLM 使用。
token 分两类:
语义 token:表达“说了什么”,但细节丢失(如情感、语气)。
声学 token:保留声音细节,但缺少语义。
Voila 结合二者优势,使用 4层 RVQ(残差向量量化):
第一层用于语义,后三层用于声学特征。
训练用了 10 万小时的语音数据。
3.2 Text and Audio Alignment¶
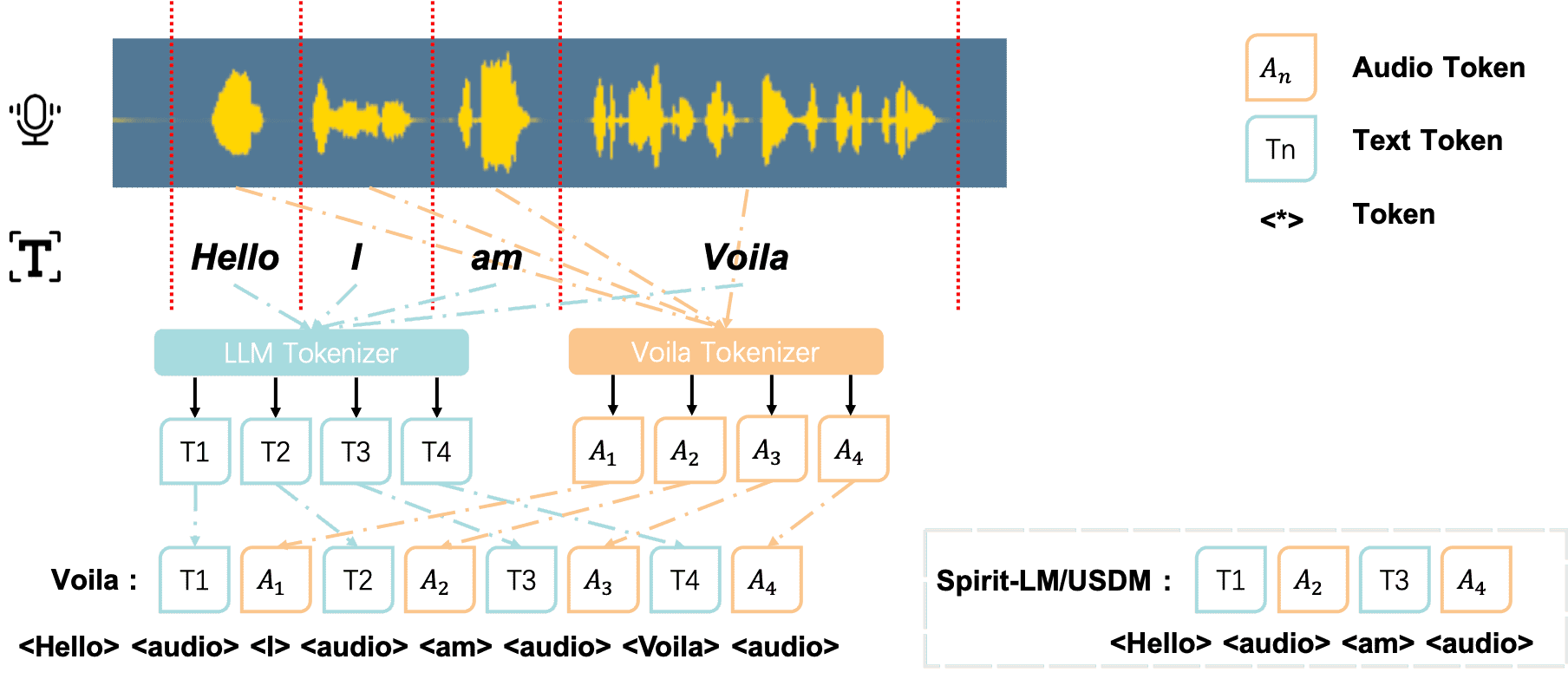
Figure 3:Text and audio interleaved alignment.
支持多任务训练(ASR, TTS, 指令跟随)。
输入输出都采用统一格式
<human> 输入 <voila> 输出 <eos>。提出了 文本-音频交错对齐策略:比如“Hello I am Voila”就按“
核心目标:
将文本和音频对齐,使模型能够在语音识别(ASR)、语音合成(TTS)和指令执行任务中统一处理两种模态。
Multi-task alignment¶
使用 Voila 的音频 tokenizer 将音频转成离散 token,并将这些 token 融入大模型的词表。
通过三类任务训练模型:
ASR:输入音频 token,输出文本。
格式:
<human> audio input <voila> text output <eos>audio input consists of discrete audio tokens and the model generates the corresponding transcript.
TTS:输入文本,输出音频 token。
格式:
<human> text input <voila> audio output <eos>
指令执行:支持文本和音频任意组合输入输出,
如 Text→Text、Audio→Text 等共4种形式。
所有任务都采用对话格式训练,只在
<voila>到<eos>之间的响应部分计算损失。音频输出任务(如 TIAO、AIAO)会使用交错格式(text 和 audio token 交替)来增强模态对齐。
Text-audio interleaved alignment.¶
精细地将每个词与对应音频片段一一对应
如图 3 所示,给定语音输入 “Hello I am Voila”
输入序列被编码为 “
这种设计有助于实现细粒度对齐,并增强了模型生成富有表现力和同步性语音的能力
与之前方法(如 Spirit-LM、USDM)不同
它不只是交替,而是强制一对一绑定,从而提高表达能力和训练稳定性。
双向语音交互(图5):
Voila 同时处理用户的音频输入和自己的音频输出,两个流独立嵌入后融合(平均)输入到 LLM,再生成语音响应。
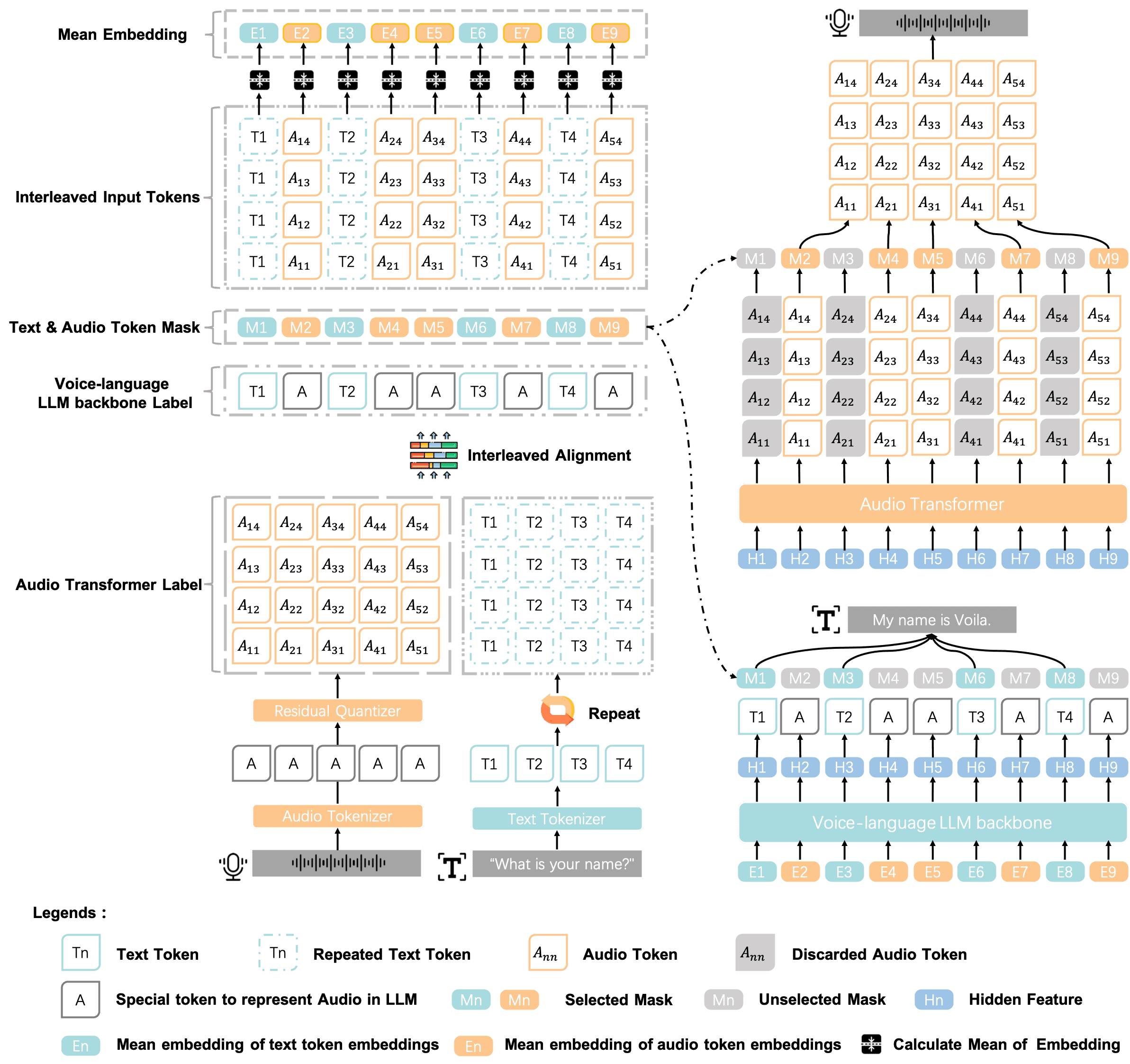
Figure 4:Input embedding and output decoding in Voila.
图片理解
输入编码:
We use audio tokens produced by the four-layer RVQ tokenizer
文本 token 每个重复4次以匹配音频 token 的维度。
然后组成交错序列并转为 embedding。
模型处理:
用 backbone LLM 处理这些 embedding。
输出结果再输入 audio transformer 生成音频 token。
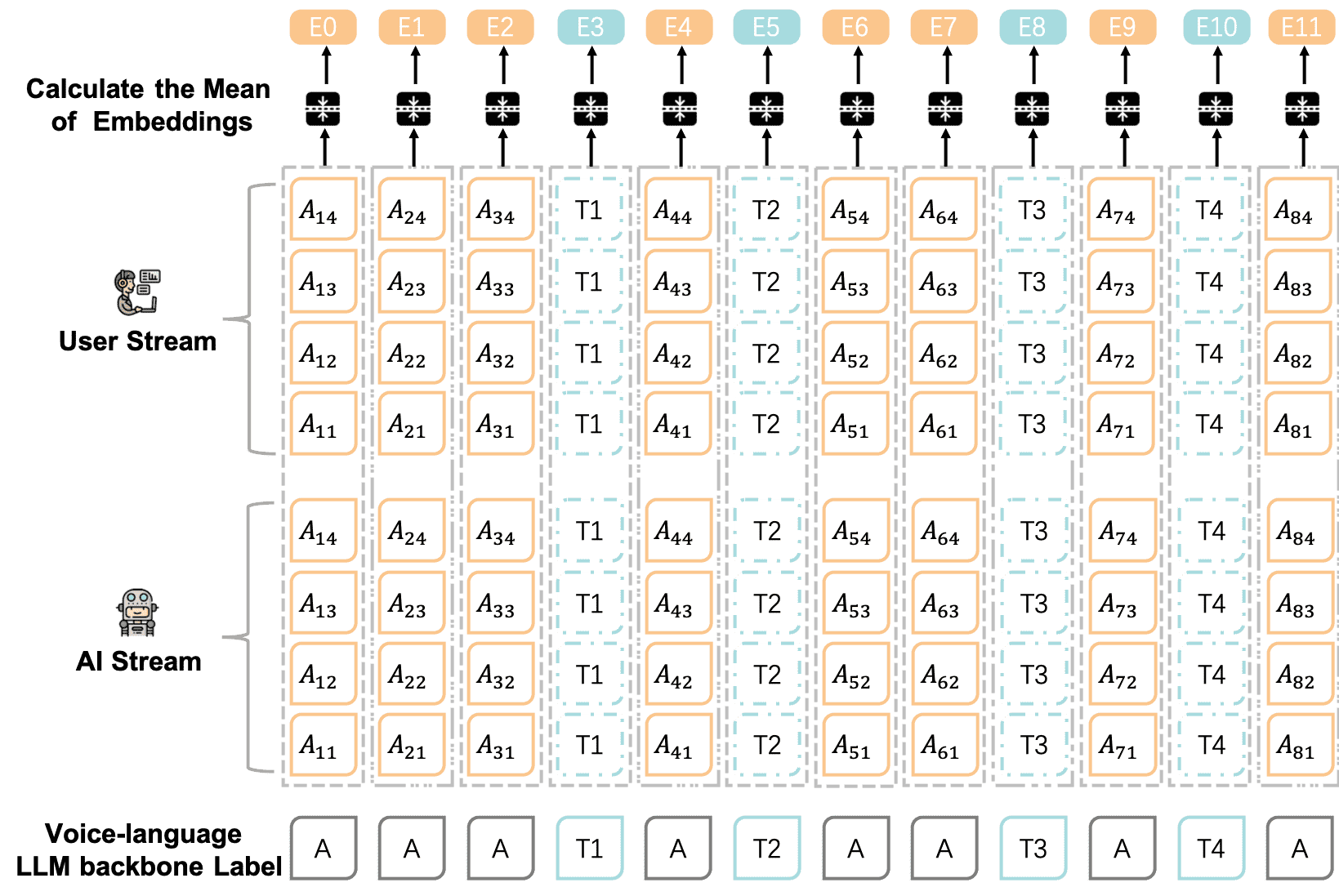
Figure 5:Voila-autonomous two-stream inputs, including user’s audio stream and Voila ’s own audio stream.
图片理解:Voila 同时处理用户的音频输入和自己的音频输出,两个流独立嵌入后融合(平均)输入到 LLM,再生成语音响应。
3.3 One Million Pre-built Voices and Customizing New Voices¶
Voila 是一个端到端的语音生成系统,支持用户自定义语音角色。它不同于传统需要额外 TTS 模块的做法,而是直接在模型中集成了语音定制功能。
主要做法是使用一个“可学习的特殊 token”来表示说话人的声音特征(如音色、语调、口音),这个特征由 Wespeaker 工具从音频中提取出来,并在生成语音时引导模型模仿目标声音。
在训练中,模型通过三个特殊 token 表示语音特征的起始、参考和结束段,分别用于 TTS 和聊天任务,避免混淆。
推理时,只需一段音频(几秒到几小时都行),系统就能生成匹配声音的语音响应。加上文字描述角色个性,还能创建高度拟人的语音角色。
Voila 已预构建了超过一百万种语音,用户也可以在使用时灵活定制新声音。
4. Experiments¶
4.1 Voila Benchmark¶
Voila Benchmark 是一个用来评估语音-语言模型(Voice-Language Models, VLMs)的测试集。
它从 5 个常用的文本评测数据集中抽样(包括 MMLU、MATH、HumanEval、NQ-Open 和 GSM8K),并用 TTS(文本转语音)技术转换为语音,从而覆盖多个领域。
总共包含 1580 个样本,涵盖 66 个主题。
因为原始文本中有些内容(如公式、代码)不适合直接转语音,研究者用 GPT-4o 先把这些文本改写成适合朗读的版本,再用 Google TTS 生成音频。
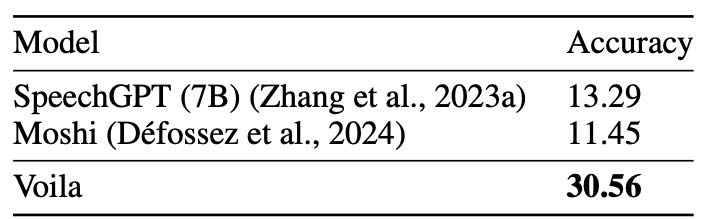
Table 1: Overall performance on Voila Benchmark
4.2 Evaluation on Voila Benchmark¶
语音理解(语音转文字)评估:
用 Whisper 把模型输出的语音转成文字,然后用 GPT-4o 比较转录结果和标准答案的相似度,评分范围 0-100。
对比模型:
与两个开源语音-语言模型 SpeechGPT 和 Moshi 进行了对比。Voila 在整体表现上更好,特别是在数学和代码领域表现明显更强,说明它的语音-文本对齐和推理能力更强。
4.3 Evaluation on ASR and TTS¶

Table 3: Results of ASR.
ASR(语音转文字):
用 LibriSpeech 数据集评估,指标是词错误率(WER)。
Voila 在不使用训练数据的情况下 WER 为 4.8%,使用训练数据后可降到 2.7%,达到当前最佳水平。
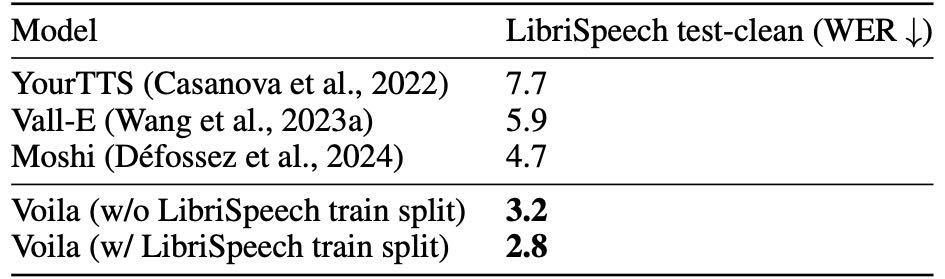
Table 4: Results of TTS.
TTS(文字转语音):
用 HuBERT 转录 Voila 生成的语音并计算 WER。
Voila 的 WER 为 3.2%(使用训练数据时是 2.8%),优于对比模型。
5. Conclusion¶
我们推出了 Voila,一种 voice-language 基础模型家族,能自主完成语音对话、语音识别(ASR)、语音合成(TTS)等任务。
通过创新的语音编码、层次化建模和音频-文本对齐技术,Voila 在性能上达到或超过当前最先进水平。
它采用多尺度 Transformer 架构,深度融合语音与语言,能细致处理语义和声音信息。
Voila 还支持高度定制,让用户打造多样化、有表现力的语音角色,提升交互体验。
整体上,Voila 向自主、具同理心的语音 AI 迈出了重要一步,并已开放模型和代码,推动进一步研究。