2312.07533_VILA: On Pre-training for Visual Language Models¶
GitHub: https://github.com/NVlabs/VILA
组织: NVIDIA MIT
Abstract¶
研究人员在构建视觉语言模型(VLM)时,探索了多种预训练策略,主要发现如下:
冻结LLM参数进行预训练,可以获得不错的零样本性能,但无法进行上下文学习,需要解冻LLM才行。
图文交错的数据用于预训练效果更好,单一图文对不够理想。
在指令微调时,重新加入纯文本数据,不仅可以避免文本任务性能下降,还能提升整体表现。
基于这些方法,他们提出了VILA模型系列,在多个基准测试中表现优于LLaVA-1.5,并具备以下能力:
多图推理
强上下文学习
更丰富的世界知识
此外,VILA还能部署在Jetson Orin等设备上进行边缘计算。
1. Introduction¶
背景
大语言模型(LLM)在语言任务上很强,加入图像输入后可以扩展到视觉语言任务(如图文问答、多模态推理等)。
当前很多研究关注指令微调(SFT、RLHF),而预训练阶段却缺少系统研究,但其实它对模型最终能力很关键。
本研究做了什么
探索视觉语言模型预训练的不同设计选项如何影响下游任务表现。
遵循“预训练 + 微调”的方法,对比不同的预训练设计(如是否冻结LLM、数据组织方式等)。
主要发现
冻结LLM在预训练时也能有不错的零样本表现,但缺乏上下文学习(ICL)能力;只有更新LLM参数才能让图文对齐更深入,提升ICL能力。
交错图文数据(图文混合)对预训练效果很重要,能提供准确的梯度更新,同时保持语言能力。
在微调阶段加入纯文本指令数据能缓解模型语言能力下降,还能提升图文任务表现。
成果与意义
提出了名为 VILA 的预训练方法,简单有效,优于当前最先进模型。
VILA 还展示出一些有趣能力,如:
多图推理(尽管训练时只用单图)
更强的上下文学习
更好的世界知识
2. Background¶
背景¶
他们发现:
更新LLM本身对实现“上下文学习”很关键;
使用图文交错的数据集(如MMC4)有助于预训练;
加入纯文本数据联合微调,有助于保留语言能力。
模型架构¶
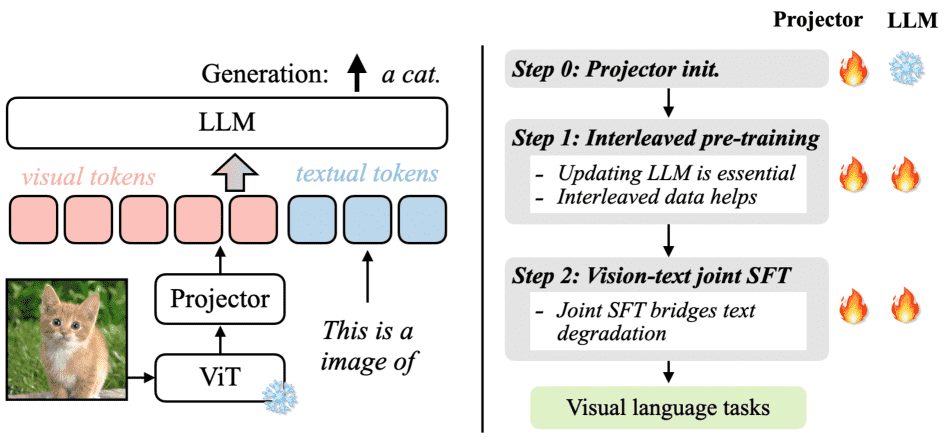
Figure 2:We study auto-regressive visual language model, where images are tokenized and fed to the input of LLMs. We find updating the LLM is essential for in-context learning capabilities, and interleaved corpus like [74] helps pre-training. Joint SFT with text-only data helps maintain the text-only capabilities.
视觉语言模型分两种:
基于交叉注意力;
基于自回归(本研究采用这个)。
该模型由三部分组成:
图像编码器(如ViT);
语言模型(LLM);
投影器(projector):连接视觉和语言的桥梁,可是线性层或小Transformer模块。
输入图文,输出文本。
训练流程分三阶段:¶
阶段0:初始化投影器
冻结图像编码器和LLM,仅训练投影器,使用图像-文字对。
阶段1:图文联合预训练
用图文交错数据或图文对进行预训练,让模型学会图文对齐。
阶段2:指令微调
在图文指令任务数据上微调模型,数据格式转为类似FLAN风格的提示形式。
评估方法¶
模型微调后在4个任务上评估:
OKVQA 和 TextVQA:用准确率;
COCO 和 Flickr:用CIDEr评分。
评估包括0-shot和4-shot,反映模型“上下文学习”能力。
3. On Pre-training for Visual Language Models¶
3.1 Updating LLM is Essential¶
两种训练方式比较:
**Prompt tuning(冻结LLM,只训练视觉投影器)**更简单,但性能差;
**Fine-tuning(微调LLM)**可显著提升模型的“in-context learning”能力(即给几个例子就能学会)。
结论:
只训练视觉投影器效果差;
预训练时冻结LLM不影响零样本表现,但会严重影响多样本学习能力;
简单的视觉投影器(比如线性层)反而更好,因为它迫使LLM自己学习处理视觉输入;
微调LLM能让视觉信息和文本信息在深层更好对齐,从而提升多模态理解能力。
3.2. Interleaved Visual Language Corpus Helps Pre-training¶

Table 2: Two image-text corpus considered for pre-training. The COYO captions are generally very short, which has a different distribution compared to the text-only corpus for LLM training. We sample each data source to contain 25M images by choosing samples with high CLIP similarities.
图文交错数据(如MMC4) vs. 图文配对数据(如COYO):
COYO文本短、信息少,训练后模型对纯文本能力下降严重(MMLU下降17%);
MMC4类似普通文本语料,能更好保留语言能力(MMLU只下降约5%);
MMC4能提升模型的视觉in-context学习能力;
把MMC4转成图文配对后,效果反而变差,说明“交错结构”本身很关键;
混合数据训练更好:
单独用COYO不好;
混合使用MMC4和COYO可以提升多样性,同时保留语言能力。
3.3. Recover LLM Degradation with Joint SFT¶
即便用了好的图文数据,语言能力仍会有轻微下降;
但这个下降只是“被掩盖”了,不是彻底丢失;
解决方法:在SFT阶段加入少量文本指令数据(如FLAN):
能恢复文本能力;
同时还能提升视觉语言表现;
说明文本指令数据有助于提升模型整体的“任务跟随能力”。
4. Experiments¶
4.1. Scaling up VLM pre-training¶
更高的图像分辨率:从 224×224 提高到 336×336,让模型捕捉更细节,有助于如 TextVQA 等任务。
更大的语言模型:除了用 LLaMA-2 7B,也尝试了 13B,性能更强。
更多样的数据:使用图文对和交错图文混合数据(约 5000 万张图),虽然规模不如亿级别,但提升明显。
更好的微调数据(SFT):借鉴了 LLaVA-1.5,更高质量多样化。
限制:计算资源限制,未能扩展到更大规模。
4.2. Quantitative Evaluation¶
视觉语言任务表现:在 12 个基准上优于 LLaVA-1.5(即使参数更小),包括中文任务(如 MMBench)。
纯文本任务表现:相比原始 LLaMA-2,7B 模型略有下降,13B 稍有提升,说明预训练对小模型影响较大。
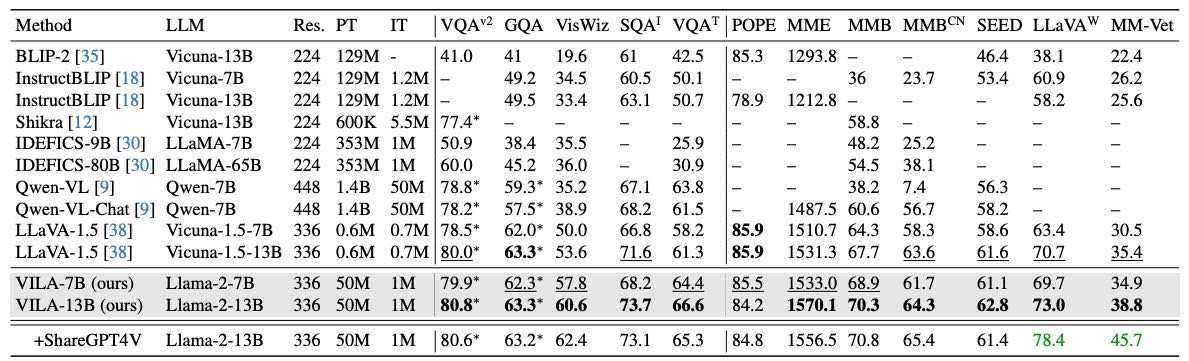
Table 5: Comparison with state-of-the-art methods on 12 visual-language benchmarks. Our models consistently outperform LLaVA-1.5 under a head-to-head comparison, using the same prompts and the same base LLM (Vicuna-1.5 is based on Llama-2), showing the effectiveness of visual-language pre-training. We mark the best performance bold and the second-best underlined.
4.3. Qualitative Evaluation¶
多图推理:可从多张图中提取共同/差异信息,LLaVA 无法做到。
上下文学习:在视觉任务中具备 few-shot 学习能力,优于 LLaVA。
视觉链式推理(Visual CoT):加上“逐步思考”提示词可进行复杂视觉推理。
世界知识更好:能识别地标等常识性信息,准确率高于 LLaVA。

Figure 6: Our model VILA can reason over multiple images thanks to the pre-training process.
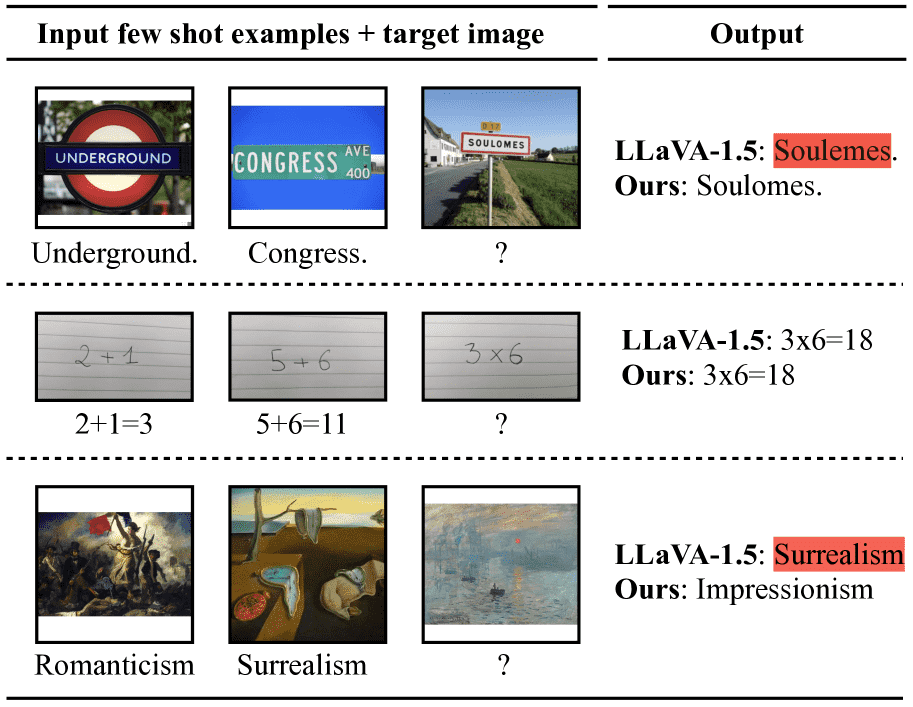
Figure 7: VILA has better in-context learning capability thanks to interleaved image text pretraining rather than single image-text pairs.We feed two image+text pairs and a third image as the context to prompt the VLM. LLaVA failed the first sample due to limited OCR capability, and failed the third examples by repeating the second sample semantic.

Figure 8: Our model is able to perform chain-of-thought reasoning given visual inputs. It is able to generate the correct answer when adding “Think step-by-step” to the prompt. Zoom in for a better view of the image details. Samples from [20, 65].
4.4 Other Learnings.¶
分辨率比 token 数量更重要:更高分辨率提升效果,即使最后使用的 token 更少,仍优于低分辨率。
压缩图像 token 可行:通过下采样 projector 降低 token 数量仍保持性能。
不冻结 LLM 效果更好:虽然冻结 LLM 加 visual expert 能保留文本能力,但整体表现不如直接微调。
LoRA 表现差于全量微调:低秩微调不如全参数微调。
数据顺序很关键:图文交错顺序影响上下文学习,错误排序会大幅降低准确率。
6. Conclusion¶
本文提出了一种改进大语言模型(LLM)用于视觉任务的预训练方法,叫做 VILA。
通过充分利用图文混合数据和优化文本处理方式,VILA 在多个视觉任务上超过了现有方法,同时保持了处理纯文本的能力。
它在多图推理、上下文学习、零样本/少样本任务中也表现出色。