2409.17146_Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models¶
组织: Allen Institute for AI, University of Washington
Abstract¶
备注
亮点:不只开源模型权重,还开源了模型的训练数据。
目前最强的视觉语言模型(VLM)大多是闭源的。现有的开源模型通常依赖这些闭源模型生成的数据来训练,相当于“模仿”闭源模型,因此我们其实不知道如何从零开始构建高性能的开源VLM。
为了解决这个问题,作者推出了一个全新的开源模型系列 Molmo,并自建了高质量的数据集 PixMo,包括详细图像描述、图像问答和2D指点任务,这些数据完全不依赖其他闭源模型。
通过精心设计的模型结构、训练流程和优质数据,Molmo的72B版本在开源模型中性能领先,甚至超过了一些更大的闭源模型(如Claude 3.5 Sonnet 和 Gemini 1.5),仅次于GPT-4o。
1. Introduction¶
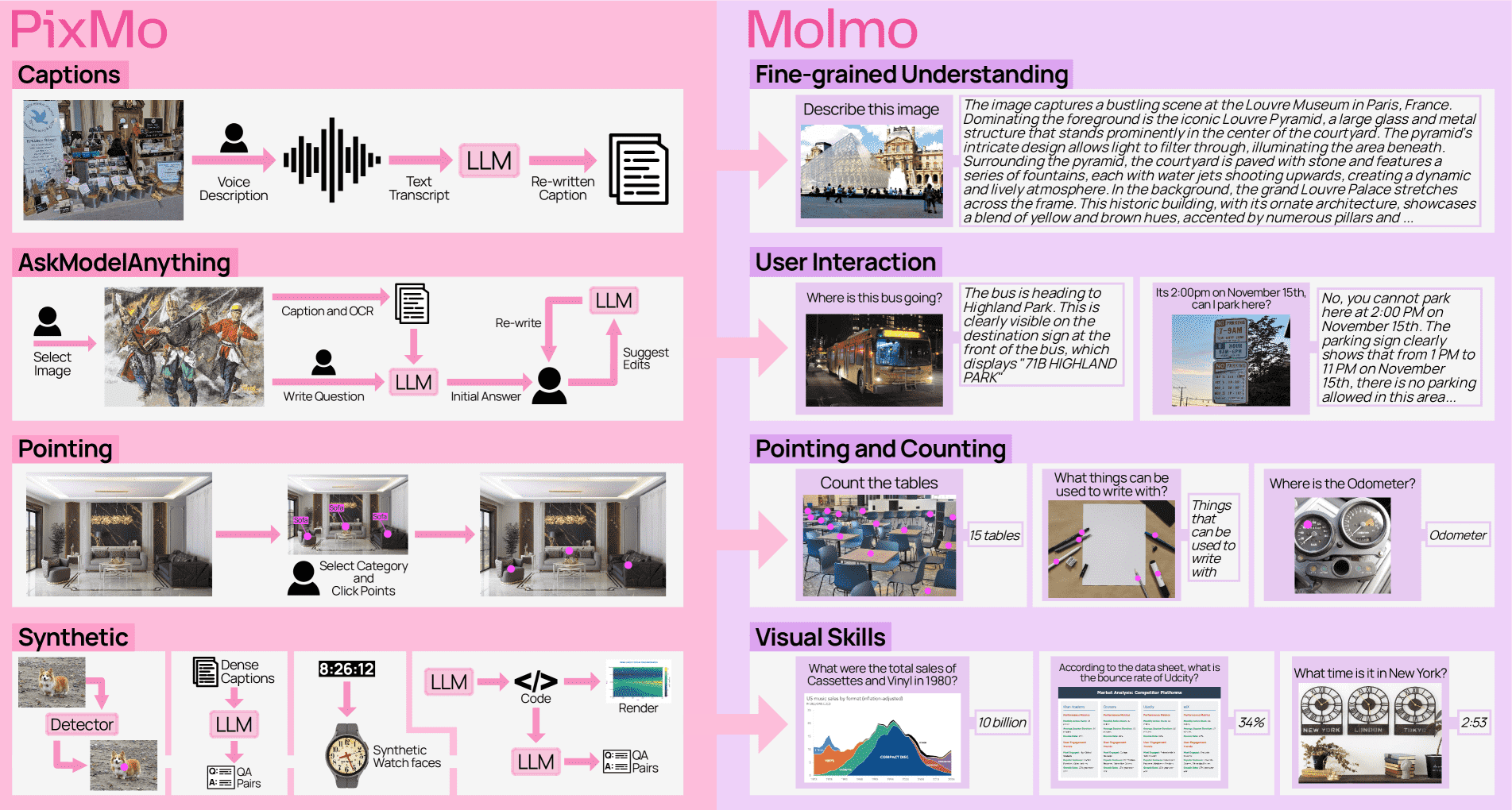
Figure 1: Datasets in PixMo (left) and the capabilities they enable in Molmo (right).
图片理解
PixMo consists of three annotated datasets and four synthetic datasets, all constructed without the use of VLMs.
The annotated datasets include:
dense captions (for pre-training),
instruction following (for fine-tuning), and
pointing (for fine-tuning, to support grounding and counting).
The four synthetic datasets augment these datasets by targeting additional skills (e.g., clock reading, document understanding).
📌 背景现状¶
现在最强的多模态大模型(如 GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet)都属于闭源,模型权重、训练数据和代码都未公开。
一些开源尝试(如 LLaVA)虽然数据和模型是开放的,但性能远不如闭源模型。
最近一些性能更好的开源模型开始依赖闭源模型生成的合成数据,本质上是对闭源模型的“蒸馏”。
✅ Molmo 项目的突破¶
Molmo 系列模型发布了:完全开源的模型权重和训练数据。
不使用闭源模型生成的合成数据,是真正“从零开始”的开放式训练。
数据集叫 PixMo,质量高,是该项目成功的关键。
🗂️ PixMo 数据集亮点¶
712k 图像+超长描述(200+词):
用“语音描述”替代文字输入,提高细节丰富度和避免抄袭。
每条都有录音,确保不是从VLM生成的。
162k 指令跟随类标注(在73k图像上):
人类+语言模型交互编辑,得到准确答案。
230万“指点”标注(点击图像某点而非画框):
用于提升模型的定位、计数能力,也便于未来机器人/Agent执行动作。
新型“非VLM合成”数据集:
包括读钟表、读图表、理解表格等任务,用以增强特定能力。
🧠 模型训练方式¶
使用已有 LLM 和视觉编码器,结合:
两阶段训练流程
多视角图像裁剪策略
多注释处理方法
优化器与模态连接的新设计
📊 结果表现¶
Molmo 各版本在多个基准测试和用户喜好评估中表现接近或超过 GPT-4V。
MolmoE-1B 基于 OLMoE-1B-7B
Molmo-7B-O 和 Molmo-7B-D 分别基于 OLMo-7B 和 Qwen2 7B
最强的 Molmo-72B 模型几乎可媲美 GPT-4o,超过 Gemini 1.5 Pro 和 Claude 3.5。
基于 Qwen2 72B
还会发布一个完全开源(数据也100%开源)的版本供研究社区使用。
该模型基于 MetaCLIP 视觉编码器和 OLMo LLM
提供大量消融实验,帮助研究者理解模型和数据设计的影响。
2. Architecture¶
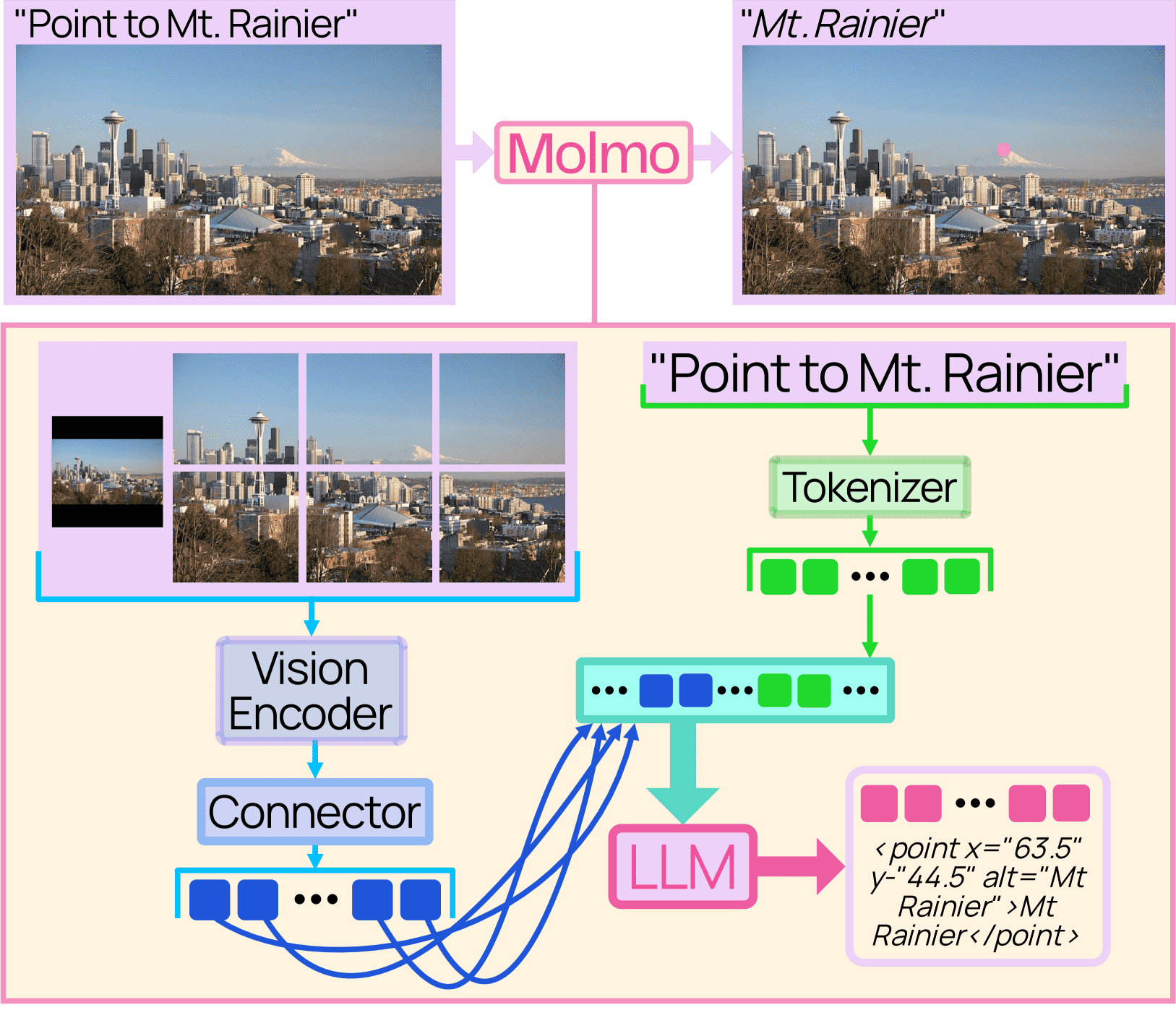
Figure 2:Molmo follows the simple and standard design of connecting a vision encoder and a language model.
模型架构简要说明¶
这个多模态模型由四个模块组成:
预处理器:把原图变成多个不同大小、不同裁剪的图像块。
图像编码器(ViT):对每个图像块独立提取 patch-level 特征。
连接器(vision-language connector):把 patch 特征池化后,通过 MLP 映射到 LLM 的输入空间。
解码式大语言模型(LLM):用于生成文本输出。
关键设计点¶
图像裁剪(Cropping):
由于 ViT 分辨率有限,整图处理难以获得细节(如 OCR)。
所以使用多块裁剪 + 一个低分辨率整图;裁剪块之间可以有重叠,这样每个 patch 可以保留邻域上下文。
重叠区域的特征不会送入 LLM,保证整体拼图一致。
连接器处理:
抽取 ViT 的第 -3 和 -10 层特征,再用注意力池化成一个 patch 向量。
比简单拼接特征效果好。
再用 MLP 映射到 LLM 的输入格式。
视觉 token 编排:
视觉 token 按从左到右、从上到下排序。
特别标记 token 用于分隔低/高分辨率块、标记每一行结束。
Dropout 策略:
LLM 用残差 dropout;图像编码器和连接器不用。
预训练时只对文字加 dropout,让模型更依赖图像而不是语言偏见。
微调时不使用这个策略。
多注释图像的训练(multi-annotation):
一张图的多个文字注释会合并成一个长序列,但通过注意力掩码,确保每个注释只能看自己和图像,而不是其他注释。
这样可以复用图像编码,节省训练时间和资源。
3. Data¶
PixMo 是一个多模态模型的数据集集合,共包含 7 个数据集,其中 3 个是人工标注的,4 个是合成数据:
PixMo-Cap:
收集了 71 万张图片,每张配有详细文字描述(平均196词)。
描述由人工语音录入后转写,再用语言模型优化生成。
PixMo-AskModelAnything:
包含 7.3 万张图片上的 16.2 万个图文问答对。
人工出题并审查由语言模型(结合OCR和图像描述)生成的答案。
PixMo-Points:
用于训练模型“指向”和“数数”的能力。
收集了 223k 图像上的 230 万个指向数据对,并包括“图中不存在”的情况。
还采集了 7.9 万个“指向解释”数据(用指向点辅助生成答案)。
PixMo-CapQA:
基于 PixMo-Cap 的图片和文字描述,让语言模型自动出题并回答,生成 21.4 万组问答对。
PixMo-Docs:
基于图文混合图像(如图表、表格、文件)生成代码,再生成 230 万组 QA(图像本身没用,仅用代码)。
PixMo-Clocks:
合成了 82.6 万张钟表图像,并生成对应的时间问答。
PixMo-Count:
使用检测器对网络图像中的目标计数,构建计数问答对数据集,训练集有 3.6 万张图,验证集/测试集各 540 张,难度高于现有的 CountBenchQA。
4. Training¶
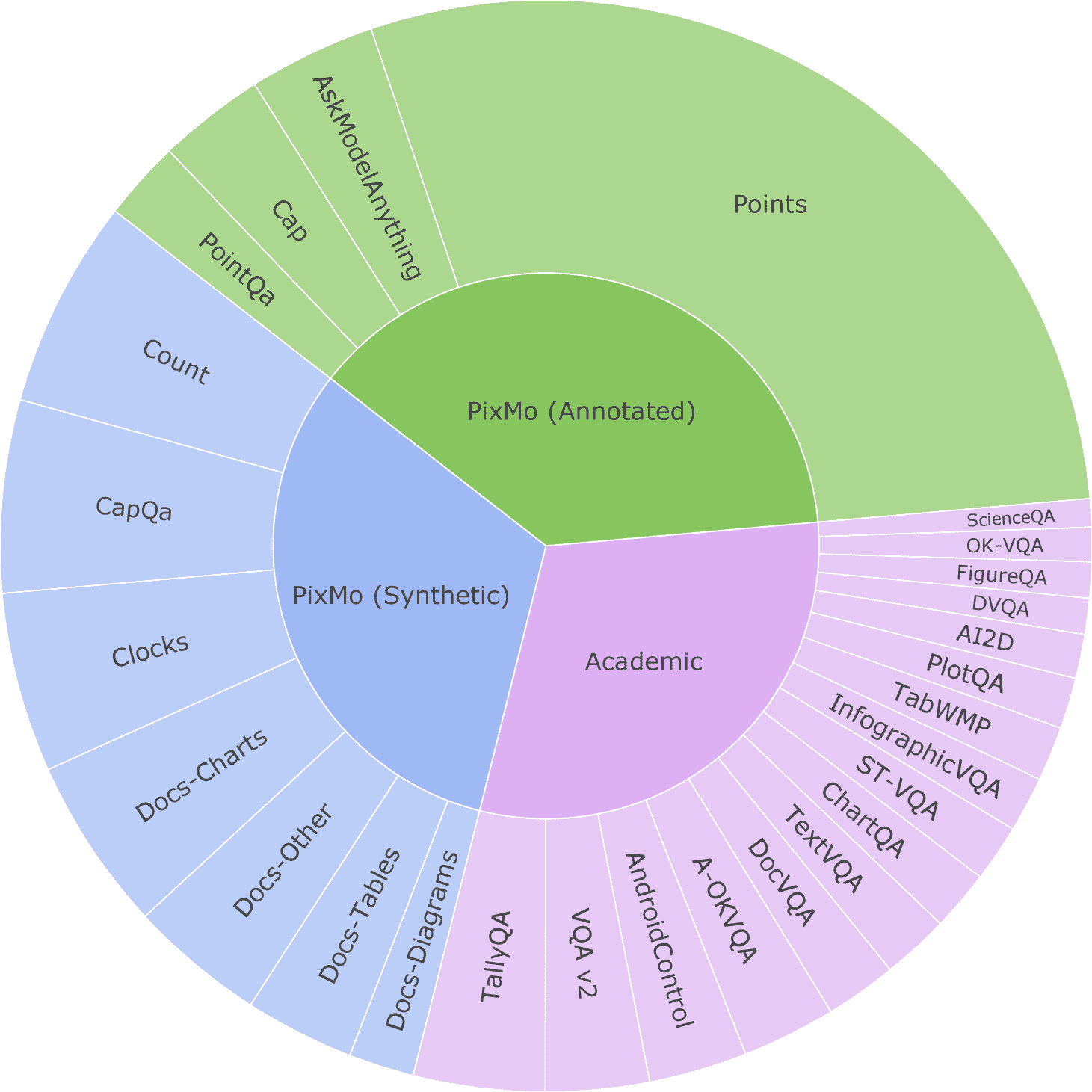
Figure 4:Datasets used for fine-tuning, shown in proportion to their sampling rates.
图片说明
Green denotes human-annotated data we collected,
blue denotes synthetic data we generated, and
purple represents pre-existing academic datasets.
PixMo-Docs has been subdivided into charts, tables, diagrams, and other.
✅ 预训练(Pre-training):¶
使用 PixMo-Cap 数据集,让模型根据图片生成文字描述或语音转录。
训练时使用提示词(prompt)控制生成风格和长度,90% 情况下会提示生成多长,这能提升效果。
无需单独训练视觉-语言连接器(以往做法),而是直接用更高的学习率+短 warmup 来快速调整连接器参数,简化流程。
训练 4 个 epoch,用 AdamW 优化器 + 余弦学习率衰减。不同部分用不同学习率(如 ViT、语言模型、连接器)。
所有超参数细节在附录中。
✅ 微调(Fine-tuning):¶
微调使用了 PixMo 系列数据 + 多个开源问答数据集(如 VQA、TextVQA、DocVQA、ChartQA 等)。
采用按数据集规模开方的采样率来抽样,太大的合成数据集会手动降低权重。
对于“指点”类任务(pointing),因为学习较慢,会特别加大权重。
为避免不同数据集中答案风格影响用户体验,使用 “风格标签”(如在问题前加
vqa2:)来引导模型使用特定格式。指点任务:模型返回标准化坐标(0~100),按从上到下、从左到右排序。也用于逐个“点数”提高计数表现。
某些 PixMo 自研数据集(如 Cap、Count)则不使用风格标签。
总结:¶
该方法简化了预训练流程,通过统一高效的训练机制训练视觉-语言模型;微调时,精心设计数据比例和风格控制,让模型既能应对评测集,也能提升用户交互质量。
5. Evaluation¶
✅ 整体介绍
研究对比了几十个视觉语言模型(VLMs)在11个评测数据集上的表现,数据集涵盖问答、图表、文档、计数、数学等不同任务。
最后按平均得分排序,并附有Elo评分和排名。
✅ 模型分类
API only(仅限调用):如 GPT-4V、GPT-4o,只能通过API使用,权重不开源。
开源权重(不开源数据):如 Qwen2-VL、InternVL2,公开模型权重但训练数据不公开。
开源权重 + 开源数据(部分使用蒸馏††):如 LLaVA 系列,训练数据可得,一些用蒸馏技术从闭源模型生成数据。
Molmo 系列(全开源):Molmo 系列完全开源,包括权重、数据、训练代码和评估流程。
✅ 评测数据集说明
AI2D、ChartQA、DocVQA、TextVQA:主要测试图像+文本的理解与问答。
MathVista、CountBenchQA、PixMo-Count:数学题、自然图像中计数任务。
MMMU、RealWorldQA、InfoQA:综合或现实场景下的视觉问答。
✅ 重点观察
GPT-4o 表现最佳(平均分 78.5,Elo 排名第1)。
开源模型中的最强者是 Molmo-72B(平均分 81.2,Elo 排名第2),其在多个任务上表现接近或超过 GPT-4o。
Qwen2-VL-72B 在开源模型中也表现出色(平均 79.4,排名第12)。
LLaVA 系列得分较低,尤其是小模型(7B、13B)蒸馏自闭源模型但性能受限。
PixMo-Count 是新的、难度更高的“计数”测试集,用来评估模型对自然图像中对象数量的理解能力。
6. Ablations¶
实验指标¶
使用了两个核心指标:
F1分数(cap F1):衡量模型生成图像描述的准确性(预训练阶段评估)。
11-avg:11个任务的平均准确率。
模型结构的消融实验结论:¶
视觉编码器:用不同的编码器(CLIP、SigLIP、MetaCLIP)效果差不多,MetaCLIP 是完全开源的,也表现良好。
图像分辨率:提高图像分辨率和使用多图像裁剪(crop)通常能提升性能。
文本dropout策略:预训练时加入“只文本使用dropout策略”的新方法有助于生成更好的描述。
裁剪方式:多个、重叠的裁剪比单张低分辨率图像效果更好。
长度控制的描述任务:让模型学习根据指定长度生成描述,对下游任务有帮助。
注意力池化:比传统的特征堆叠方法更好。
数据的消融实验结论:¶
PixMo-Cap 数据集:从 0 增加到 712k 图像显著提升了性能。
数据来源:自己的 PixMo-Cap 比 ShareGPT4v/o 的网络数据更有效;人工标注和 GPT-4o 生成的描述效果接近。
PixMo 的微调数据集:对文档类和计数类任务帮助很大,比传统学术数据集效果更好。
关于“计数”能力的实验结论:¶
链式推理更优:先指出物体位置再计数比直接输出数量更准确。
位置顺序有影响:按规律(上到下、左到右)训练比随机顺序更好。
位置推理重要:准确的位置信息和点数显著提升效果,随机信息反而会伤害性能。
坐标表达形式:用普通文字表示坐标比用特别的“位置token”效果更好。
人类评估结论:¶
使用 PixMo 数据(特别是 PixMo-Cap 和 PixMo-AMA)生成的回答更受用户喜欢。
仅使用学术数据表现很差。
GPT-4o 生成的描述也不错,说明图像多样性和高质量模型很重要。
强调:无需依赖私有模型,也可以训练出有竞争力的视觉语言模型(VLM)。
Appendix A: Model Details¶
一、图像编码(Image Encoding)¶
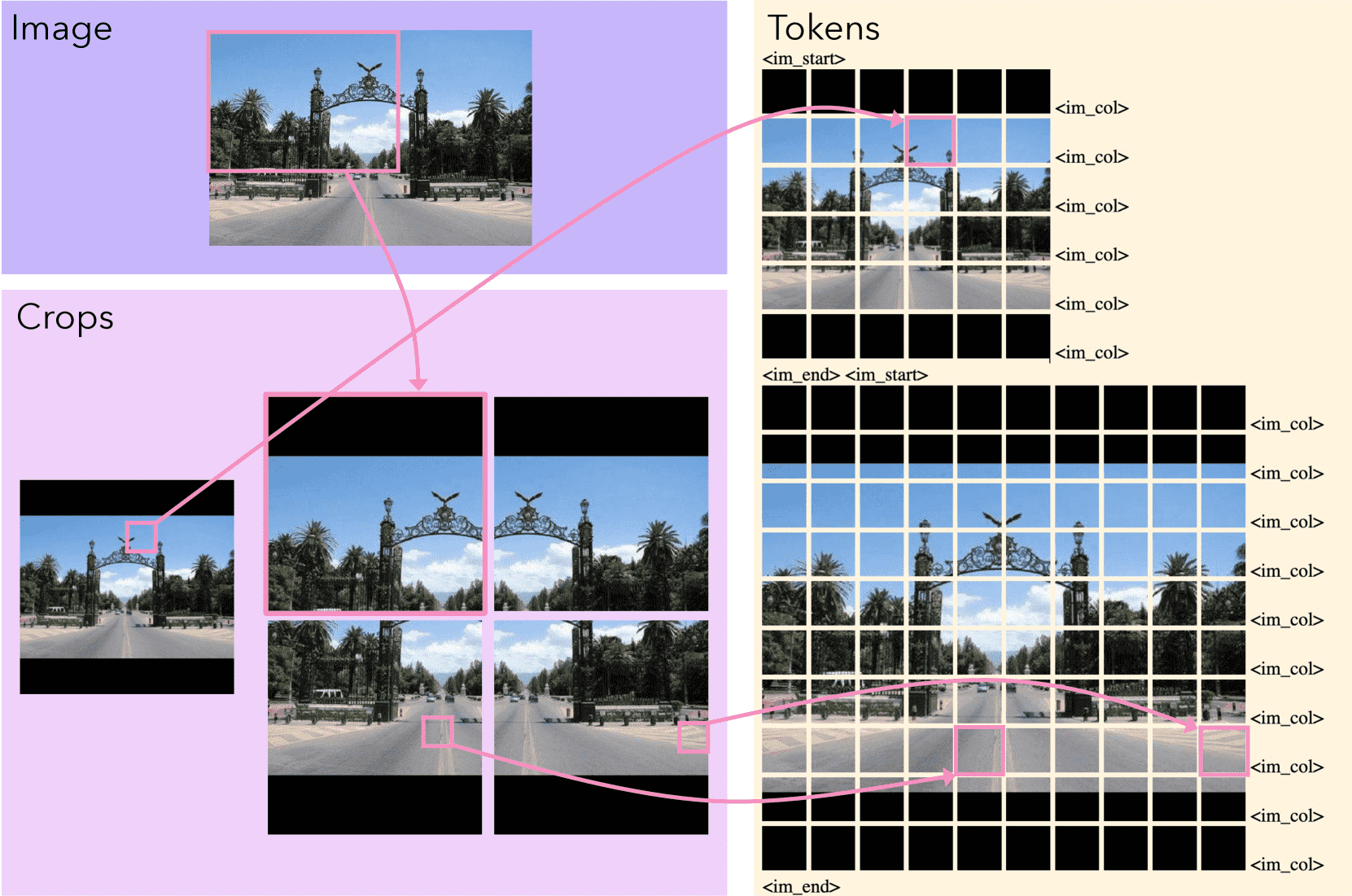
Figure 7:Converting an image into tokens.
图片说明
The image (top left) is turned into a single low-res and several overlapping high-res crops (bottom left).
Padding (the black borders) is used so each crop is square and the aspect ratio of the image is preserved.
The final token sequence for the image (right, arranged top-down left-to-right with line breaks for clarity)
is built by extracting patch-level features from the crops,
shown here using images of the patches, and special tokens.
An image start and image end token are placed before/after the high-res and low-res patches, and column tokens are inserted after each row of patches.
This example uses 4 high-res crops and extracts features from 36 (6×6) patches per crop,
in practice Molmo typically uses 12 high-res crops and extracts features from 144 (12×12) patches per crop.
把图像分成一个低分辨率图和多个重叠的高分辨率小块(crop)。
每个小块都是正方形,并通过黑边(padding)保持原图宽高比。
使用 ViT(视觉Transformer)对每个小块提取patch特征,再加上特殊token(如图像开始、结束、列标记)。
每个patch根据是否包含padding加上不同的embedding,帮助模型区分黑边和真实内容。
最终图像被编码为一个token序列,可与文本序列拼接输入给模型。
二、超参数(Hyperparameters)¶
提供了不同规模模型(1B, 7B, 72B)在预训练与微调阶段的详细参数。
包括:图像编码器、连接器(图像到语言的桥接模块)、语言模型(LLM)的参数设置,如层数、维度、激活函数、学习率等。
所有训练采用 AdamW 优化器与 cosine 衰减学习率。
Molmo-72B 模型训练速度更快,因此训练步数较少。
三、实现细节(Implementation)¶
使用 PyTorch + FSDP 实现多卡训练,不使用 FlashAttention,但用 PyTorch 自带的 SDPA 来加速。
启用了混合精度(AMP),但权重和梯度保留为 float32 精度以保证训练稳定。
梯度归一化使用“全设备平均的 loss token 数”,避免短句样本被误判为更重要。
最大输入长度为 2304 tokens,太长的输入会被截断。
每个训练 batch 内混合不同任务的样本,训练过程稳定无异常。
Appendix B: Training Details¶
一、预训练(Pre-Training)¶
训练数据:每张图像配对一个图文(caption)和一个音频转写(transcript),每个 epoch 随机选一个 transcript。
训练方式:图文和音频一起训练(multi-annotation)。
输入格式:使用自然语言提示词,如
long_caption:或transcript:。90% 的情况加上“长度提示”(例如long_caption_83:),提供输出长度的大致建议;10% 的情况不加提示以保持灵活性。长度提示生成方式:字符数/15 加上随机噪声,目的是让模型控制输出长度但保留自由度。
长度控制效果:长度提示能在精度(准确性)和召回率(覆盖性)之间做权衡,模型能很好地遵守提示。
二、微调(Fine-Tuning)¶
任务多样:涵盖了问答、图表理解、指点(pointing)、计数、表格分析、文档理解、控制模拟器操作等任务。
输入输出格式:
多选题:用 “Choices:” 加换行列出选项,模型输出选项字母。
多答案题:只用最常见的答案。
指点任务:用 HTML-like 格式标出图中坐标,如
<point x="10.0" y="10.0" alt="cat">cat</point>。特殊处理:比如如果问“有多少个xxx”但没有指点信息,就提示“不要指点”。
部分任务优化:
AI2D:图中标出区域的字母标签,支持透明和不透明两种框,训练时两种都用。
ChartQA:因合成数据质量差,训练时降低其权重。
AndroidControl:只输入屏幕截图和指令,输出动作位置(x,y)和描述。
三、训练资源消耗(Training Time)¶
模型 |
预训练 |
GPU数 |
GPU小时数 |
微调 |
GPU数 |
GPU小时数 |
|---|---|---|---|---|---|---|
1B-E |
33.3h |
8 |
264 |
13.3h |
64 |
850 |
7B-D |
8.6h |
64 |
550 |
11.2h |
128 |
1.4k |
7B-O |
8.9h |
64 |
570 |
13.5h |
128 |
1.7k |
72B |
33.3h |
128 |
4.2k |
32.4h |
256 |
8.3k |
所有训练使用了 H100 GPU 和高速网络连接。
Appendix C: Evaluation Results¶
1. 图像字幕评估指标(cap F1)¶
选取了 1500 张图像(从 2730 张中随机抽样)作为评估集,每张图像有最多 6 个语音转录文本(作为参考答案)。
使用 GPT-4o 来分析和比对模型生成的字幕(g)与真实文本(T)中的“原子句子”(最基本的信息单位)。
召回率(Recall):看模型生成的句子中有多少能在真实文本中找到匹配。
准确率(Precision):看模型生成的句子中有多少是和真实文本一致的。
最终指标 cap F1 是准确率和召回率的调和平均数。
虽然这个指标不是完美的,但它和人类主观评价一致,因此在模型开发中很有用。
2. 人类评估¶
定义了 10 类问题(如输出格式、细节问答、文档理解等),每类约 1500 张图像搭配问题。
两轮评估:一轮是对主要模型进行,另一轮是对一些改动版本(消融实验)进行。
评估方式:给标注员展示图像、问题和两个模型的回答,匿名判断哪个更好,或是否打平。
使用 Bradley-Terry 模型计算 Elo 排名,参考了 Chatbot Arena 的方法。
3. AndroidControl 任务¶
只给模型一个任务指令和当前安卓界面截图,让其控制安卓系统完成任务。
在特定测试集上评估,用每一步的准确率(step-wise accuracy)作为指标。
Appendix D: Result Details¶
1. Chatbot Arena 排名¶
这是一个第三方评测视觉语言模型(VLM)表现的排行榜。
Molmo-72B 是一个开源模型,在开源或开放权重模型中表现最好,但仍落后于一些闭源API模型如 Gemini 和 GPT-4o。
Molmo 团队自己也做了 Elo 评分,在自评中 Molmo-72B 排名更高(第2名),可能因为评测题型不同。
Molmo 擅长“计数”和“图像描述”类题目。
2. 读钟表任务(Clock Reading)¶
他们创造了一个新的合成数据集 PixMo-Clocks,用来训练模型识别钟表时间。
用这些数据训练的 Molmo 系列模型,在真实世界的钟表图片测试中表现远超其他大模型,甚至接近专门为读表设计的模型。
MolmoE-1B、Molmo-7B-D 表现最好,准确率超过 65%,而 GPT-4o 等主流API模型仅有个位数准确率。
3. 指点任务(Pointing Task)¶
评估模型是否能根据问题准确地指出图片中的物体。
使用人工验证的数据集和精确的分割掩码来计算精度、召回率和 F1 分数。
Molmo 系列模型在这项任务上表现也很好(F1 约在 72-75%)。
若训练和测试时图片裁剪数目不一致,表现会下降。
Appendix E Ablations Details¶
1. Vision encoder(视觉编码器)¶
默认使用的是 OpenAI 的 CLIP。
实验中也测试了 MetaCLIP、SigLIP 等开源模型,表现相近。
MetaCLIP 是完全开源的,包括模型和训练数据;如果早点测试,原本应作为默认模型。
用 DINOv2(只用图像训练,无文本)表现也接近,用户评分略低(45% vs 55%)。
2. Image resolution(图像分辨率)¶
更多图像裁剪(crop)= 更高分辨率,通常带来更好效果。
某些任务(如文档类)推理时使用更多 crop 比训练时更多反而更好。
但描述和计数任务,训练/推理 crop 数需一致,否则效果下降。
3. Dropout(丢弃策略)¶
在 LLM 中使用 dropout 有利于训练。
一种新策略:仅对文本 token 应用 dropout,有助模型更依赖视觉信息,减少幻觉(hallucination)。
4. Length conditioning(长度提示)¶
在训练 caption 时加入长度提示显著提高效果。
虽然长度提示只用于预训练,但也能改善下游任务效果。
5. PixMo-Cap 数据规模¶
使用的描述数据越多(最多 712k 图),性能越好。
不使用 PixMo-Cap 数据时,用户偏好明显下降(胜率仅 35%)。
6. Pre-training data(预训练数据)¶
尝试使用 LAION 作为第一阶段预训练数据,发现无明显好处。
使用 GPT-4 生成的描述代替 PixMo-Cap,效果不如原数据。
将 PixMo-Cap 图片用 GPT-4o 生成描述再训练,效果很好。
使用原始或清洗过的语音转录文本,效果都略差于默认混合策略。
7. Supervised fine-tuning data(有监督微调数据)¶
仅用学术数据效果较差(72.2% vs 76.8%)。
PixMo-Docs、PixMo-Points 和 PixMo-Count 对提升文档/计数类任务效果最关键。
其他 PixMo 数据对指标影响小,但可增强模型功能,提升用户体验。
8. Counting(计数任务)¶
用纯文本(如 0.0~100.0)表示点位比引入 1000 个特殊 token 效果更好。
9. 其他消融实验¶
测试了不同的编码层选择、学习率预热步数和梯度归一化方式,整体变化不大。
默认设置(灰色行)通常是效果最优的。
Appendix F Data Details¶
这段内容介绍了PixMo数据集的三个子集和它们的特点。
PixMo-Points¶
包含:22.9万张图片,198万个指向性表达(例如“这个地方”、“那个东西”)。
每张图片平均有8.7条表达,每条表达平均5.5个点。
每张图平均47.7个点;其中35.9万条表达没有目标(即无指向点)。
相比之前的数据集(如gRefCOCO和RefCOCO系列),PixMo-Points规模更大、多目标更多,也更高效(用点而非分割区域)。
PixMo-Cap¶
让标注者根据图像口述回答7个问题,如:
一眼看图像是什么?
有哪些物体及数量?
图片中文字内容?
物体在哪儿?
有哪些细节?
背景是什么?
风格和颜色?
PixMo-Docs¶
用大模型生成带图表/文字的图片数据。
核心方法:用文本大模型写程序生成图像(如图表、表格、流程图等),再由另一个大模型生成训练用的描述数据。
支持的工具包括:Matplotlib、Plotly、LaTeX、HTML、Vega-Lite、Mermaid、Graphviz。
可以通过“人物设定”来丰富数据风格(如 BBQ 爱好者的菜单设计)。
用Claude 3.5生成代码,用GPT-4o-mini生成指令调优数据,成本更低。
开放性比较(图13)¶
图13展示了不同视觉语言模型(VLM)的开放性,按以下维度分类:
是否开放权重、数据和代码。
是否包含“蒸馏数据”(即训练用的数据来自其他闭源模型生成的图文)。
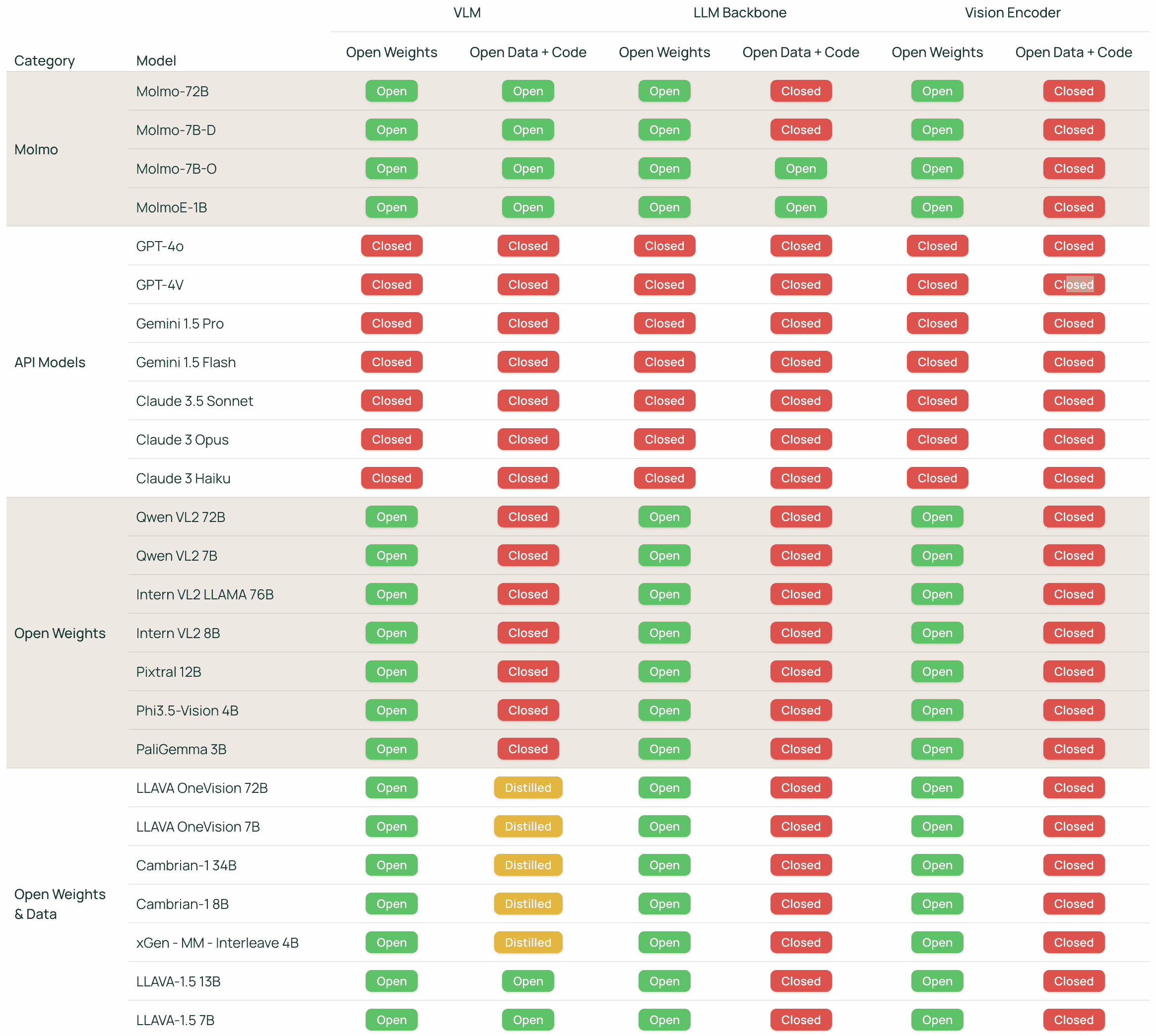
Figure 13:VLM Openness Comparison.
图片说明
We characterize the openness of VLMs based on two attributes (open weights, open data and code) across three model components (the VLM and its two pre-trained components, the LLM backbone and the vision encoder).
In addition to open vs. closed, we use the ”distilled” label to indicate that the data used to train the VLM includes images and text generated by a different, proprietary VLM, meaning that the model cannot be reproduced without a dependency on the proprietary VLM.
Appendix G Dataset Examples¶
作者展示了 PixMo 系列数据集中随机选取的一些样本,包含不同子任务的数据类型。每个子任务都有对应的图示(Figure 14~24),图中粗体文字是模型的输入提示,粉色点表示关键点信息。
这些子任务包括:
PixMo-Cap:图像描述
PixMo-AskModelAnything:问答任务
PixMo-Points:关键点标注
PixMo-Points with explanations:关键点+解释
PixMo-CapQA:图像描述相关问答
PixMo-Clocks:时间/钟表识别
PixMo-Count:计数任务
PixMo-Docs:文档类图像理解,包括图表、表格、流程图等