PyTorch 深度学习实战¶
开篇词 | 如何高效入门 PyTorch¶
方远 2021-10-11
先后供职于百度和腾讯两家公司,任职高级算法研究员,目前在一家国际知名互联网公司 Line China 担任数据科学家,从事计算机视觉与自然语言处理相关的研发工作,每天为千万级别的流量提供深度学习服务。
01基础篇 (5 讲)¶
01 _ PyTorch: 网红中的顶流明星¶
使用 pip 安装 PyTorch¶
02 _ NumPy.1: 核心数据结构详解¶
Numpy 的很多知识点是与 PyTorch 融会贯通的,例如 PyTorch 中的 Tensor。
03 _ NumPy.2: 深度学习中的常用操作¶
一个图像分类的项目为例,看看 NumPy 的在实际项目中都有哪些重要功能
04| Tensor: PyTorch 中最基础的计算单元¶
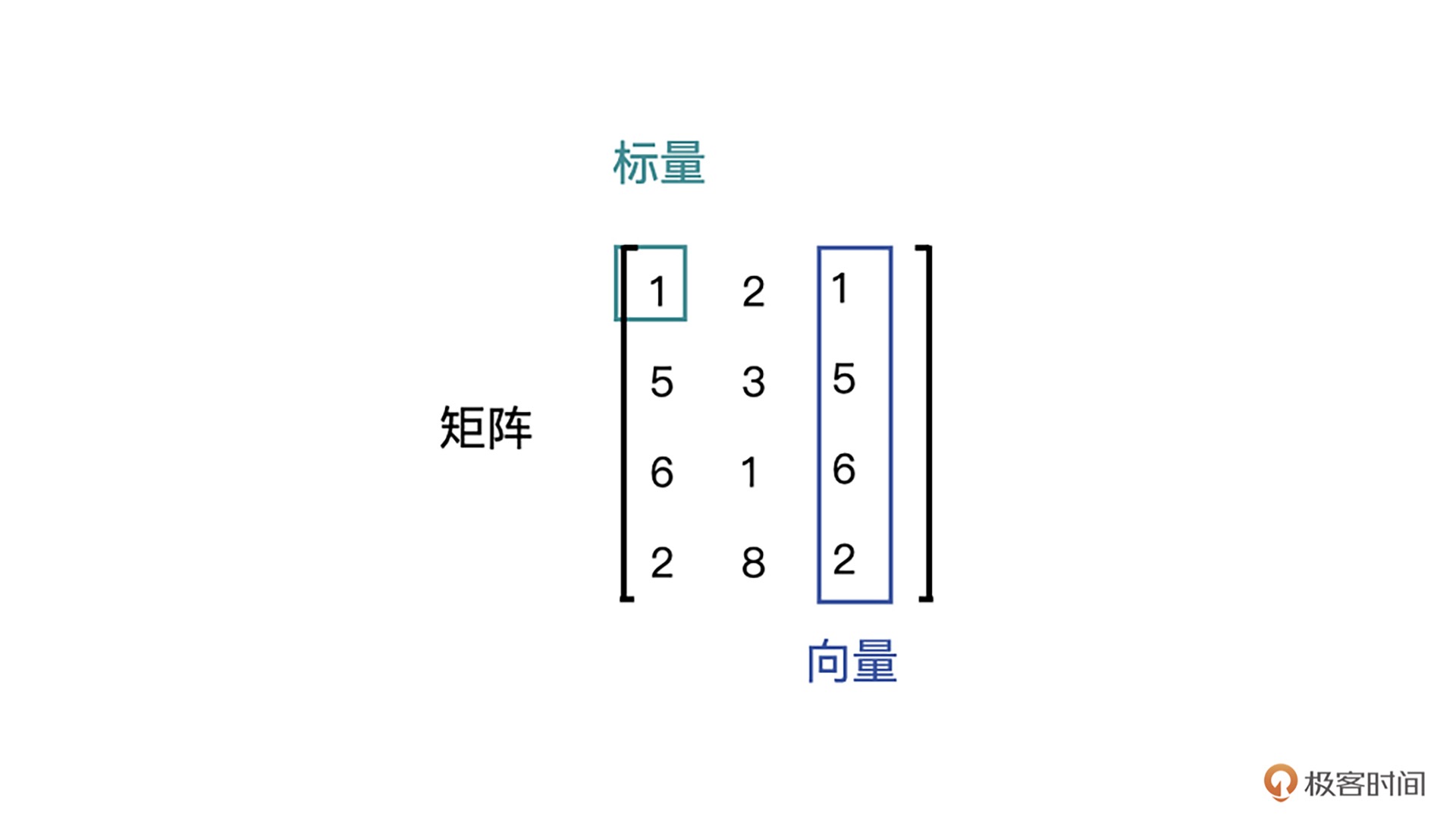
1.标量,也称 Scalar,是一个只有大小,没有方向的量,比如 1.8、e、10 等。2. 向量,也称 Vector,是一个有大小也有方向的量,比如 (1,2,3,4) 等。3. 矩阵,也称 Matrix,是多个向量合并在一起得到的量,比如 [(1,2,3),(4,5,6)] 等。¶
在 PyTorch 中我们称之为张量 (Tensor)。使用 Rank(秩)来表示这种 “维度”,比如标量,就是 Rank 为 0 阶的 Tensor;向量就是 Rank 为 1 阶的 Tensor;矩阵就是 Rank 为 2 阶的 Tensor。
05| Tensor 变形记: 快速掌握 Tensor 切分,变形等方法¶
Tensor 之间的连接操作,Tensor 内部的切分操作,以及基于索引或者筛选条件的数据选择操作。
02模型训练篇 (12 讲)¶
06| Torchvision.1: 数据读取-训练开始的第一步¶
Dataset 类¶
PyTorch 中的 Dataset 类是一个抽象类,它可以用来表示数据集。我们通过继承 Dataset 类来自定义数据集的格式、大小和其它属性,后面就可以供 DataLoader 类直接使用。
DataLoader 类¶
在实际项目中,如果数据量很大,考虑到内存有限、I/O 速度等问题,在训练过程中不可能一次性的将所有数据全部加载到内存中,也不能只用一个进程去加载,所以就需要多进程、迭代加载,而 DataLoader 就是基于这些需要被设计出来的。
DataLoader 是一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,它会根据参数 batch_size 的值生成一个 batch 的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。
什么是 Torchvision¶
PyTroch 官方为我们提供了一些常用的图片数据集,如果你需要读取这些数据集,那么无需自己实现,只需要利用 Torchvision 就可以搞定。
Torchvision 是一个和 PyTorch 配合使用的 Python 包。它不只提供了一些常用数据集,还提供了几个已经搭建好的经典网络模型,以及集成了一些图像数据处理方面的工具,主要供数据预处理阶段使用。简单地说,Torchvision 库就是常用数据集 + 常见网络模型 + 常用图像处理方法。
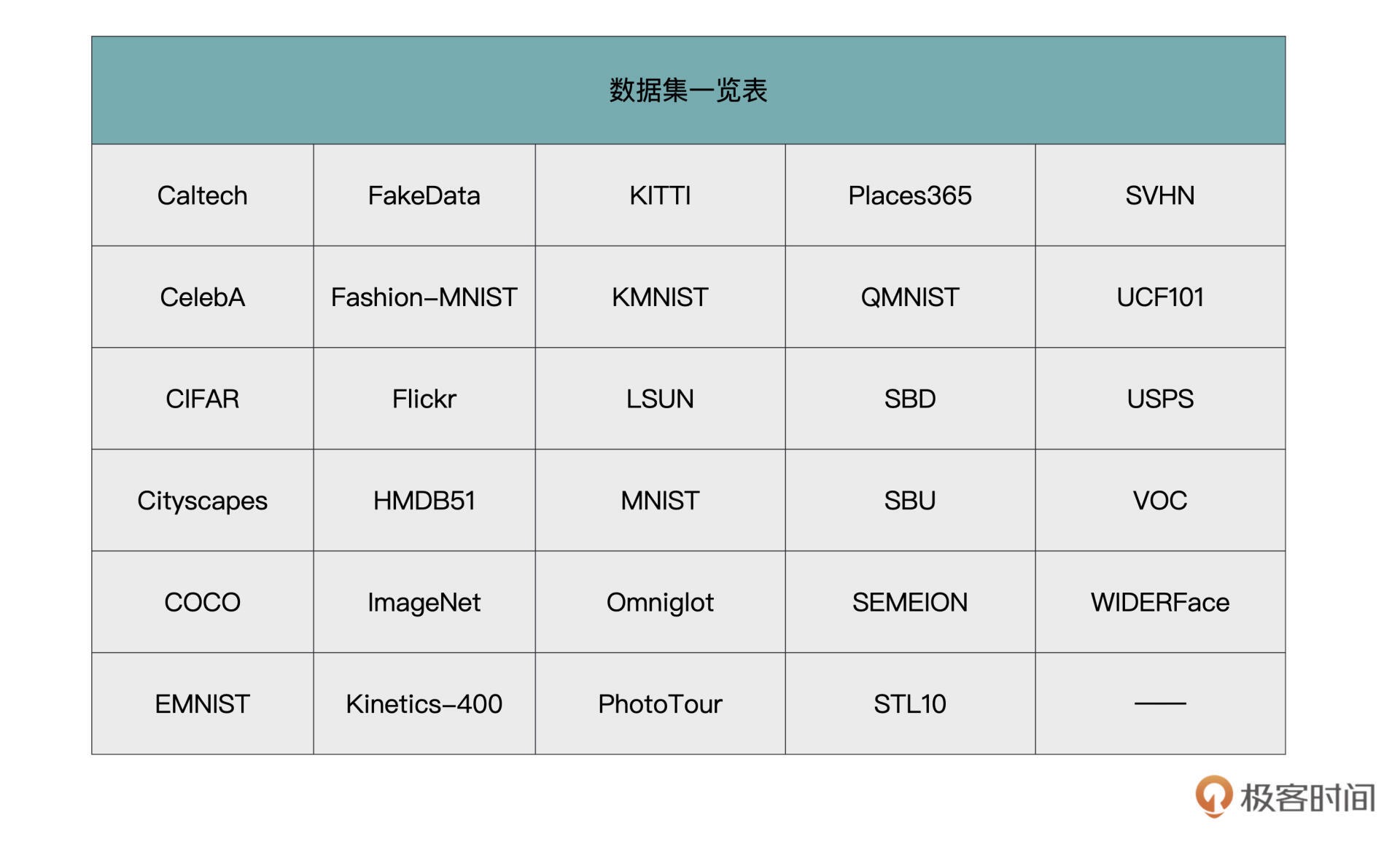
torchvision.datasets 包所有支持的数据集。各个数据集的说明与接口,详见链接 https://pytorch.org/vision/stable/datasets.html。¶
Torchvision包含了许多常用的视觉数据集,主要包括:
- MNIST - 手写数字识别数据集
- COCO - 物体检测和分割数据集
- LSUN - 场景识别数据集
- ImageNet - 图像分类数据集
- CIFAR - 小的图像分类数据集
- STL10 - 图像分类数据集
- SVHN - 街道视觉房屋数字数据集
- PhotoTour - 神经风格迁移数据集
- Flickr8k, Flickr30k and COCO Captions - 图像字幕数据集
- Cityscapes - 用于语义分割的urban street scenes数据集
- SBU Captioned Photo Dataset - 图像字幕数据集
- VOC - Pascal VOC object detection and segmentation dataset
通过torchvision.datasets轻松加载,例如:
python
from torchvision import datasets
# 加载MNIST数据集
mnist = datasets.MNIST(root='data', train=True, download=True)
# 加载COCO Captions训练集
coco_captions = datasets.CocoCaptions(root='dir where images are',
annFile='train annotation json',
transform=transforms,
target_transform=None)
MNIST 数据集简介¶
为了让你进一步加深对知识的理解,我们以 MNIST 数据集为例,来说明一下这个模块具体的使用方法。
MNIST 数据集是一个著名的手写数字数据集,因为上手简单,在深度学习领域,手写数字识别是一个很经典的学习入门样例。
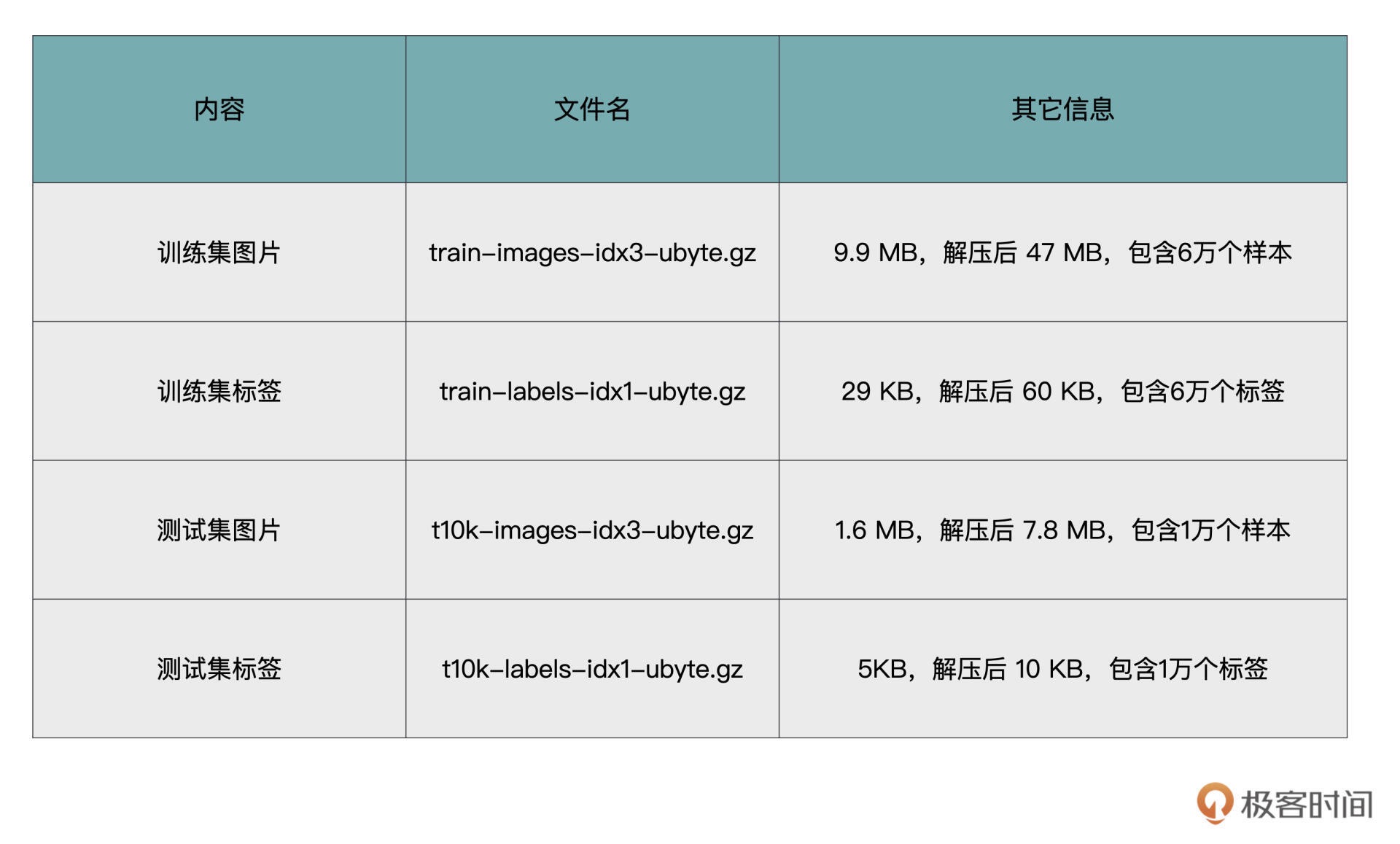
MNIST 数据集是 NIST 数据集的一个子集,包含了四个部分¶
07| Torchvision.2: 数据增强,让数据更加多样性¶
重点内容就是 torchvision.transforms 工具的使用。包括常用的图像处理操作,以及如何与 torchvision.datasets 结合使用。
常用的图像处理操作包括数据类型转换、图像尺寸变化、剪裁、翻转、标准化等等。Compose 类还可以将多个变换操作组合成一个 Transform 对象的列表。
08| Torchvision.3: 其他有趣的功能¶
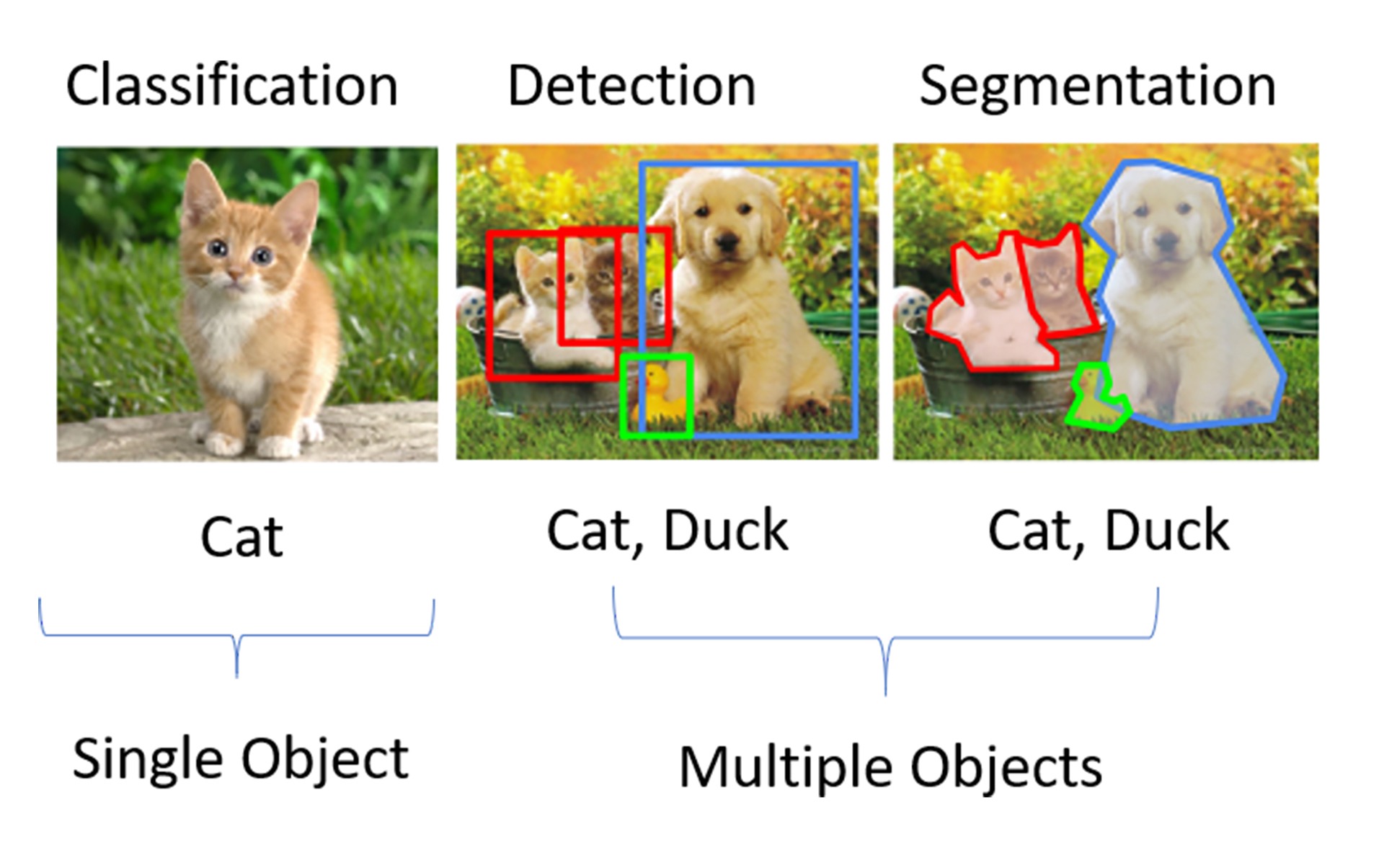
torchvision.models 模块中包含了常见网络模型结构的定义,这些网络模型可以解决以下四大类问题:图像分类、图像分割、物体检测和视频分类。图像分类、物体检测与图像分割的示意图如下图所示。¶
torchvision.models 模块为我们提供了深度学习中各种经典的网络结构以及训练好的模型
模型微调可以让我们在自己的小数据集上快速训练模型,并取得比较理想的效果。
9| 卷积.1: 如何用卷积为计算机 “开天眼”¶
稀疏连接与平移不变性是卷积的两个重要特点,但不是本专栏的重点
最简单的情况¶
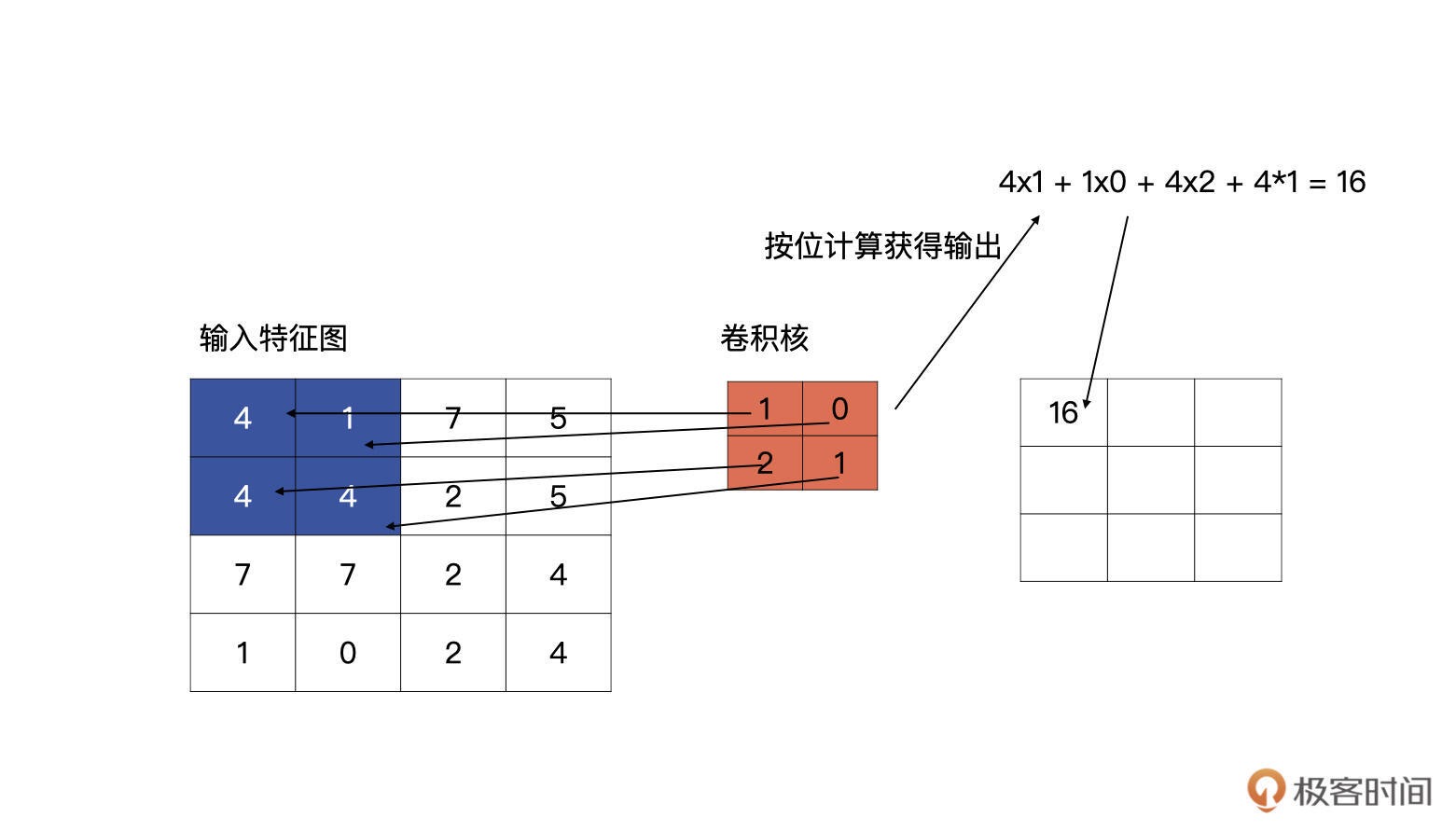
输入特征与卷积核计算时,计算方式是卷积核与输入特征按位做乘积运算然后再求和,其结果为输出特征图的一个元素¶
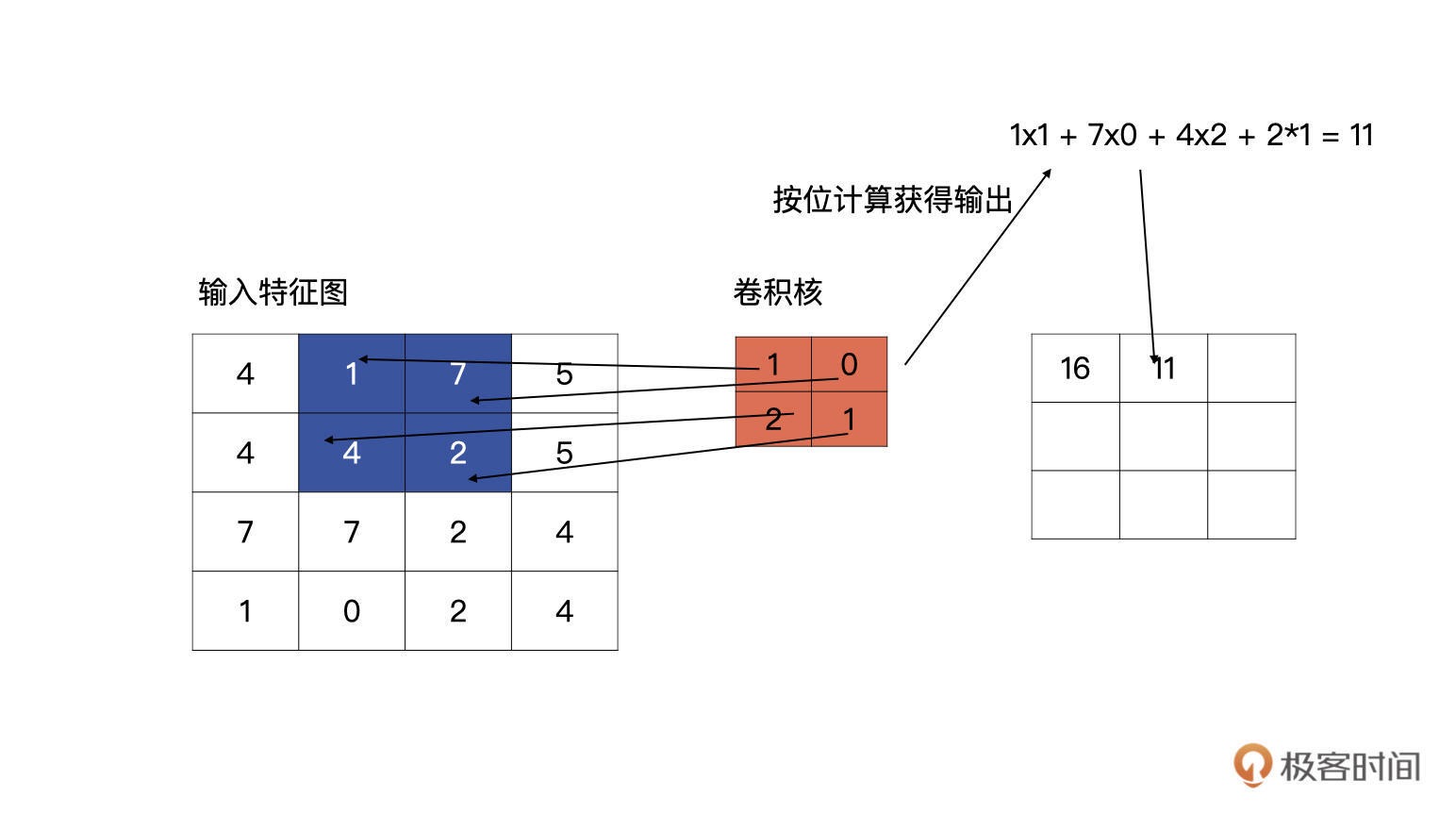
第一行第二个单元的计算……¶
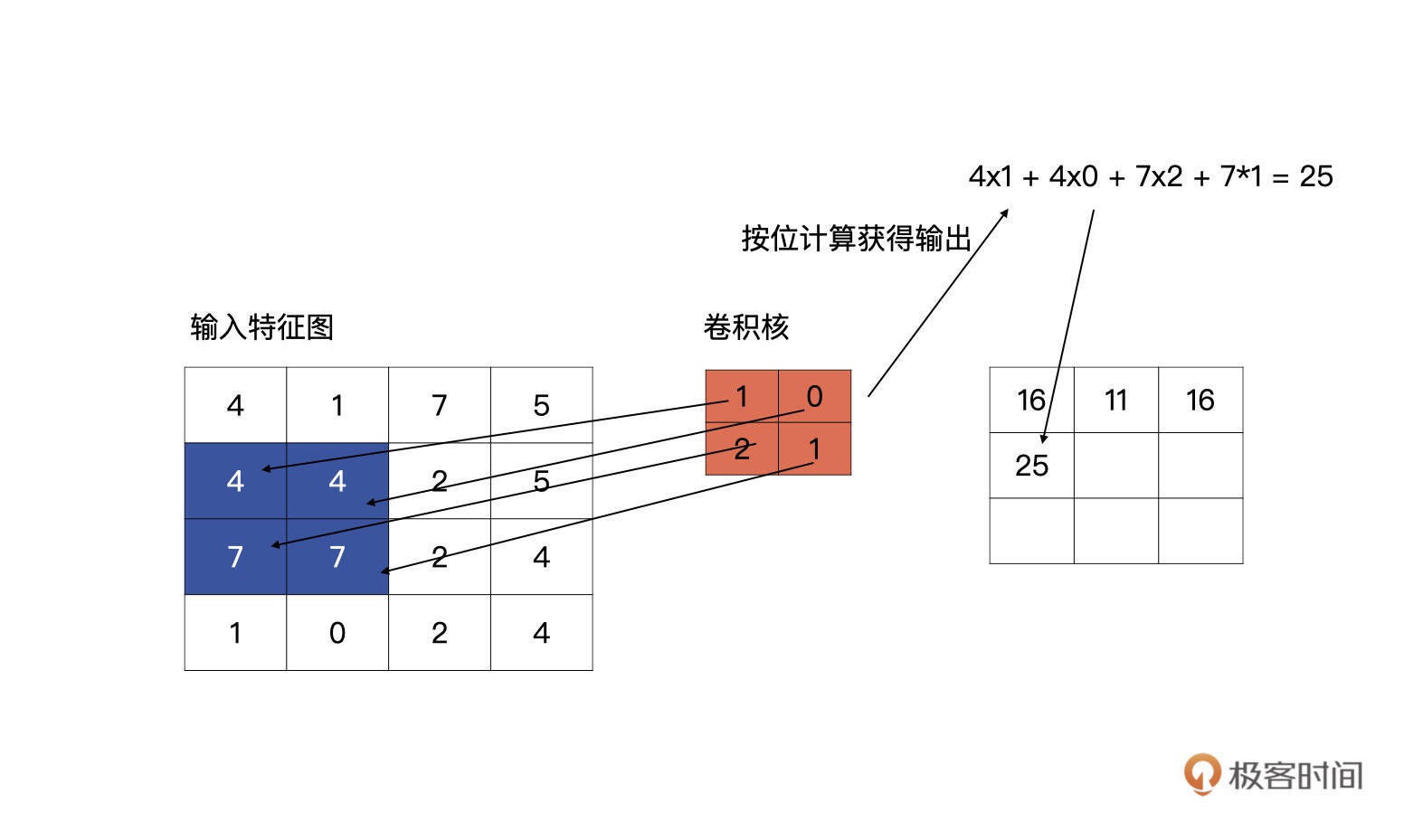
第二行第一个单元的计算……¶
标准的卷积¶
输入的特征有 m 个通道,宽为 w,高为 h;输出有 n 个特征图,宽为 w′ ,高为 h′;卷积核的大小为 kxk。
在刚才的例子中 m、n、k、w、h、w′ 、h′ 的值分别为 1、1、2、4、4、3、3。
而现在,我们需要把一个输入为 (m,h,w) 的输入特征图经过卷积计算,生成一个输出为 (n, h′, w′) 的特征图。
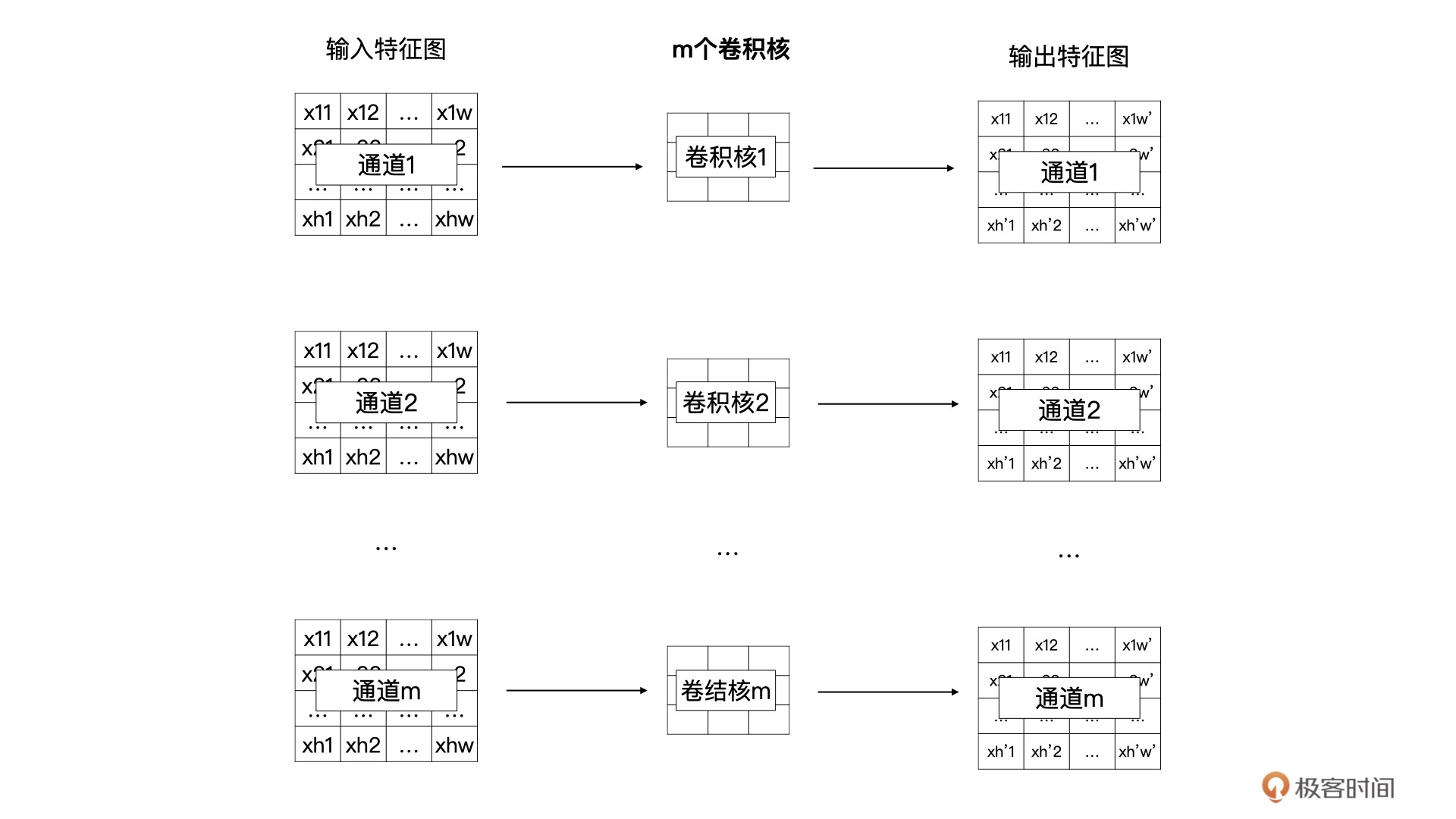
输出特征图的通道数由卷积核的个数决定的,所以说卷积核的个数为 n。根据卷积计算的定义,输入特征图有 m 个通道,所以每个卷积核里要也要有 m 个通道。所以,我们的需要 n 个卷积核,每个卷积核的大小为 (m, k, k)。
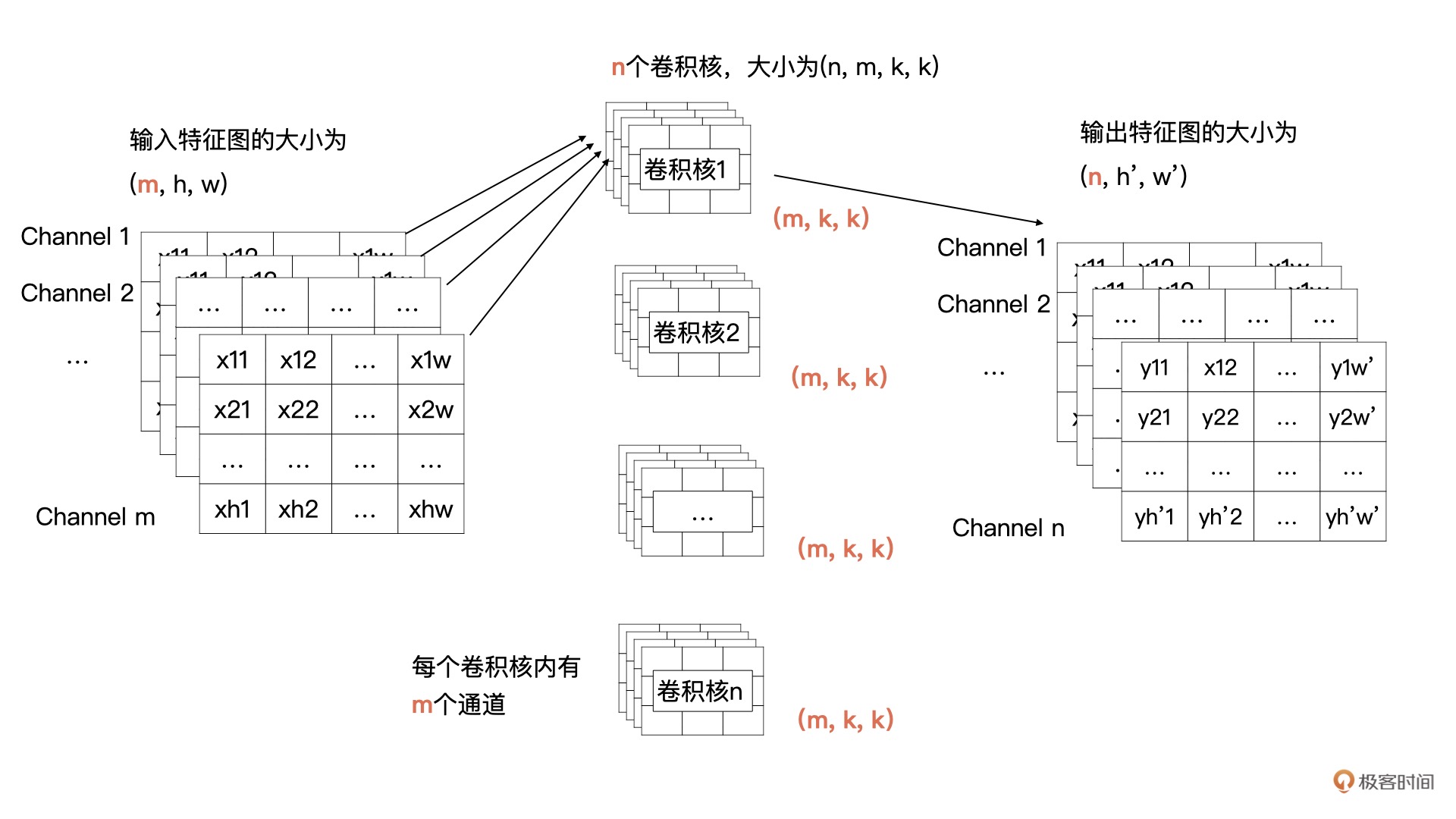
卷积核 1 与全部输入特征进行卷积计算,就获得了输出特征图中第 1 个通道的数据,卷积核 2 与全部输入特征图进行计算获得输出特征图中第 2 个通道的数据。以此类推,最终就能计算 n 个输出特征图。¶
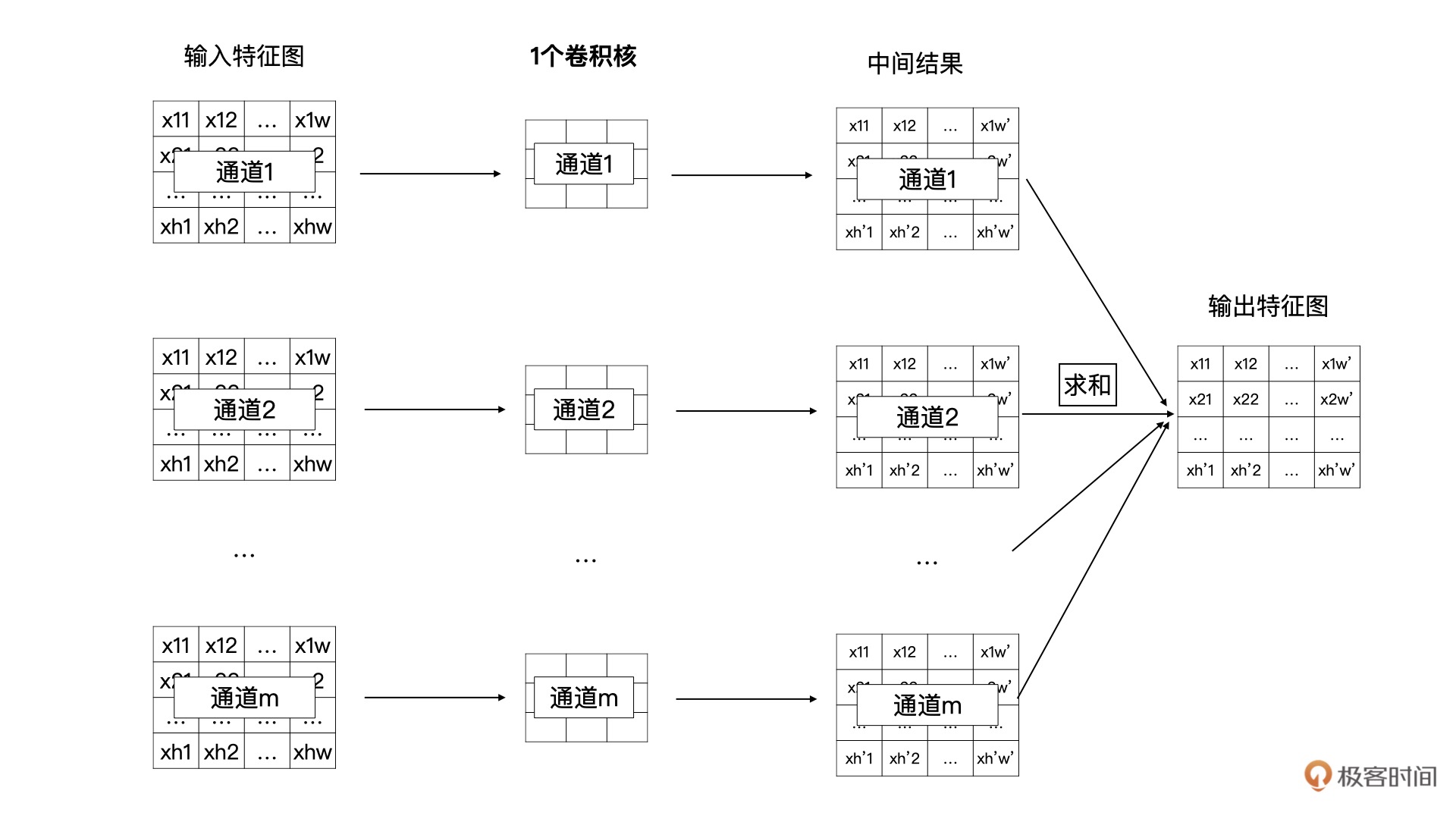
将特征图与一个卷积核计算的过程展开:一个卷积核中的 m 个卷积分别与输入特征图的 m 个通道数据进行卷积计算,生成一个中间结果,然后 m 个中间结果按位求和,最终就能获得 n 个输出特征图中的一个特征图¶
10| 卷积.2: 如何用卷积为计算机 “开天眼”¶
其它的卷积方式,这些卷积方式在应对不同问题时能够发挥不同的作用¶
深度可分离卷积(Depthwise Separable Convolution)¶
简单来说,深度可分离卷积就是我们刚才所说的在效果近似相同的情况下,需要的计算量更少。
深度可分离卷积(Depthwise Separable Convolution)由 Depthwise(DW)和 Pointwise(PW)这两部分卷积组合而成的。
Depthwise(DW)卷积过程¶
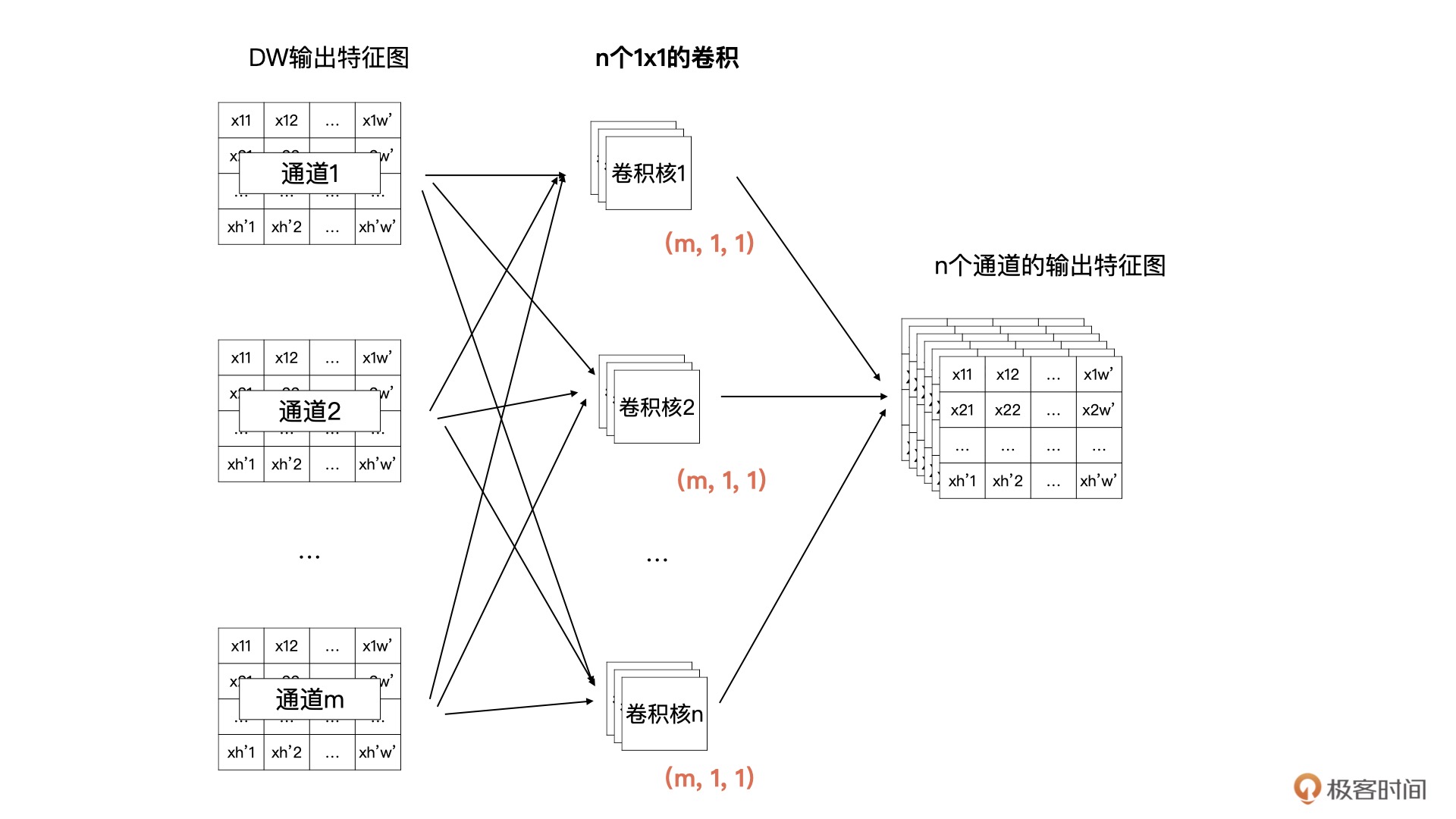
Pointwise(PW)卷积过程¶
空洞卷积¶
感受野¶
感受野是计算机视觉领域中经常会看到的一个概念。
因为伴随着不断的 pooling(这是卷积神经网络中的一种操作,通常是在一定区域的特征图内取最大值或平均值,用最大值或平均值代替这个区域的所有数据,pooling 操作会使特征图变小)或者卷积操作,在卷积神经网络中不同层的特征图是越来越小的。
这就意味着在卷积神经网络中,相对于原图来说,不同层的特征图,其计算区域是不一样的,这个区域就是感受野。感受野越大,代表着包含的信息更加全面、语义信息更加抽象,而感受野越小,则代表着包含更加细节的语义信息。
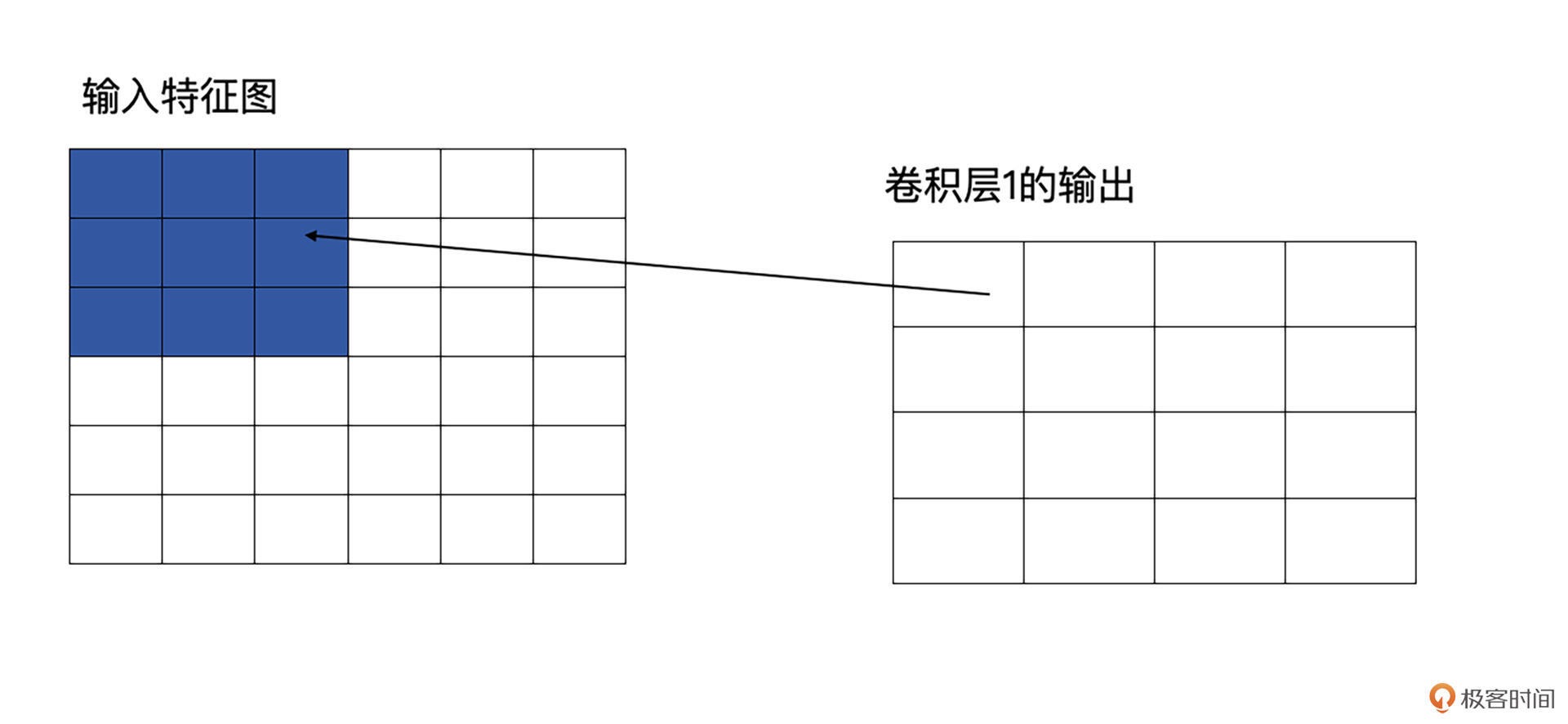
原图是 5x5 的图像,第一层卷积层为 3x3,这时它输出的感受野就是 3,因为输出的特征图中每个值都是由原图中 3x3 个区域计算而来的。¶
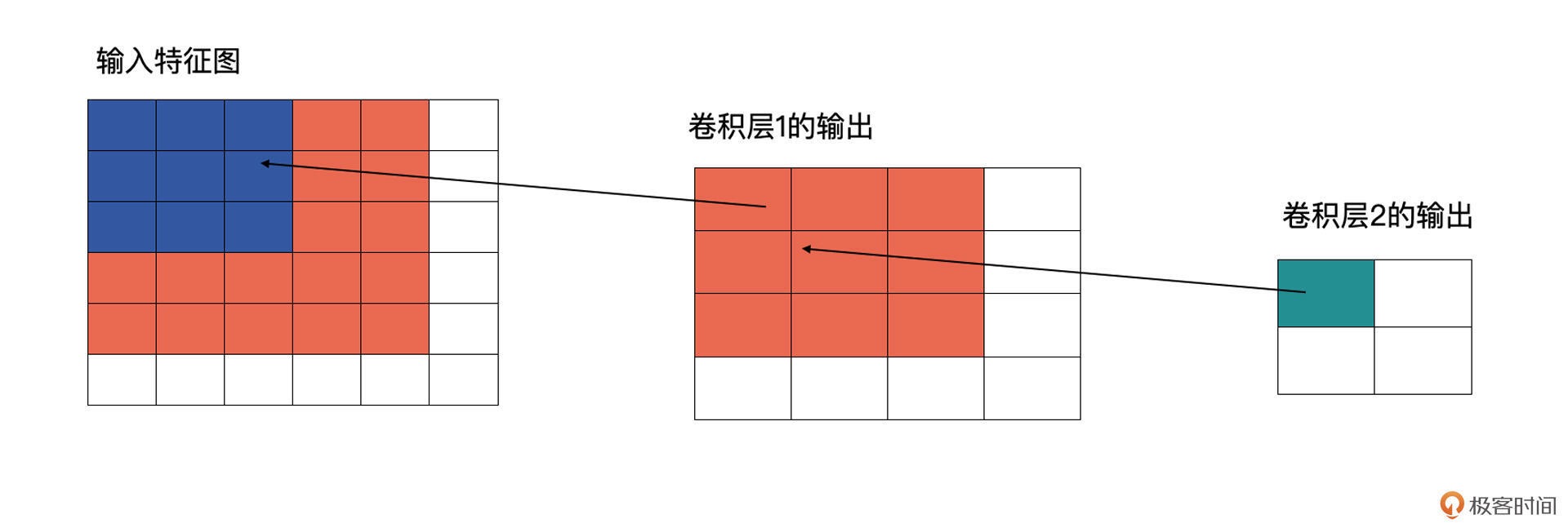
卷积层 2 也为 3x3 的卷积,输出为 2x2 的特征图。这时卷积层 2 的感受野就会变为 5(输入特征图中蓝色加橘黄色部分)¶
计算方式¶
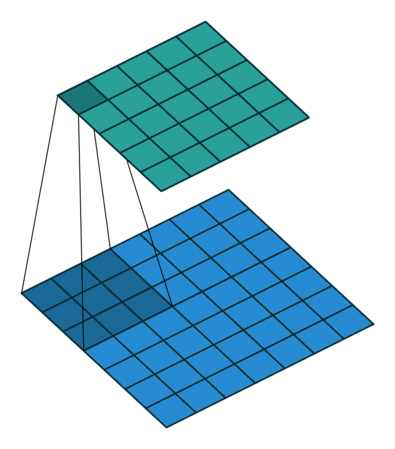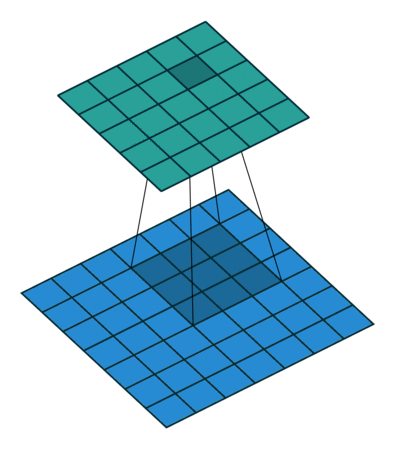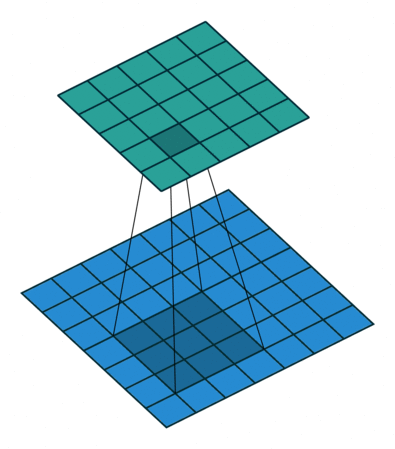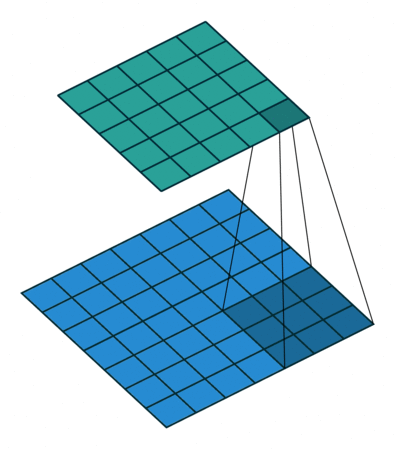
标准卷积是如何计算¶
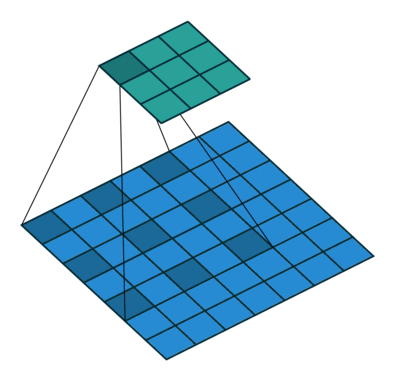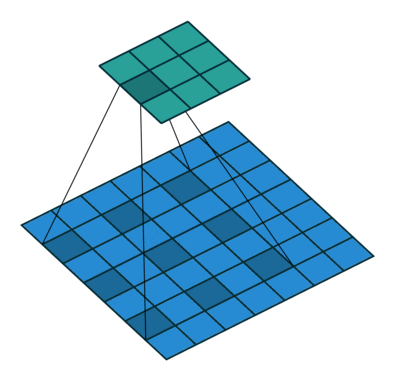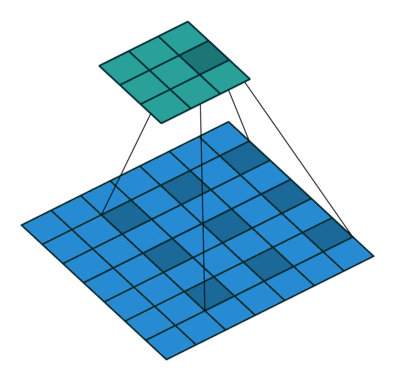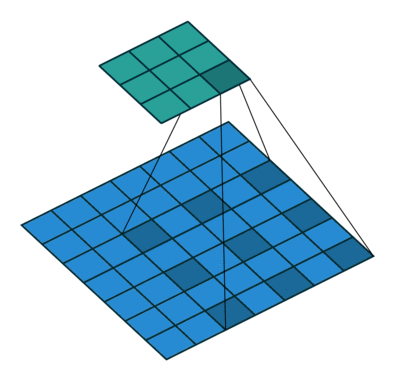
空洞卷积示意图¶
总结¶
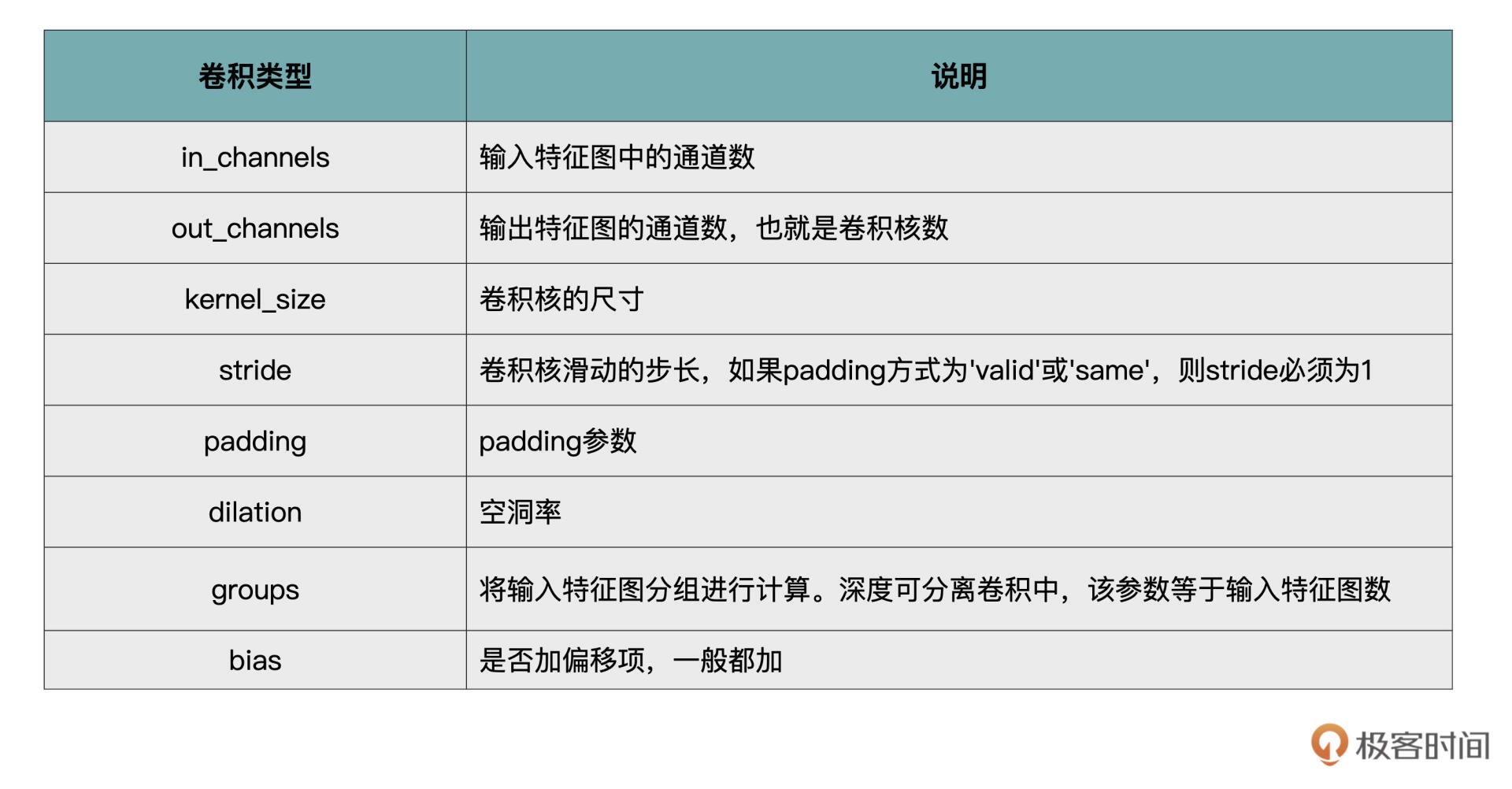
PyTorch 中卷积操作的各个重要参数¶
11| 损失函数: 如何帮助模型学会 “自省”¶
一个深度学习项目包括了模型的设计、损失函数的设计、梯度更新的方法、模型的保存与加载、模型的训练过程等几个主要模块。
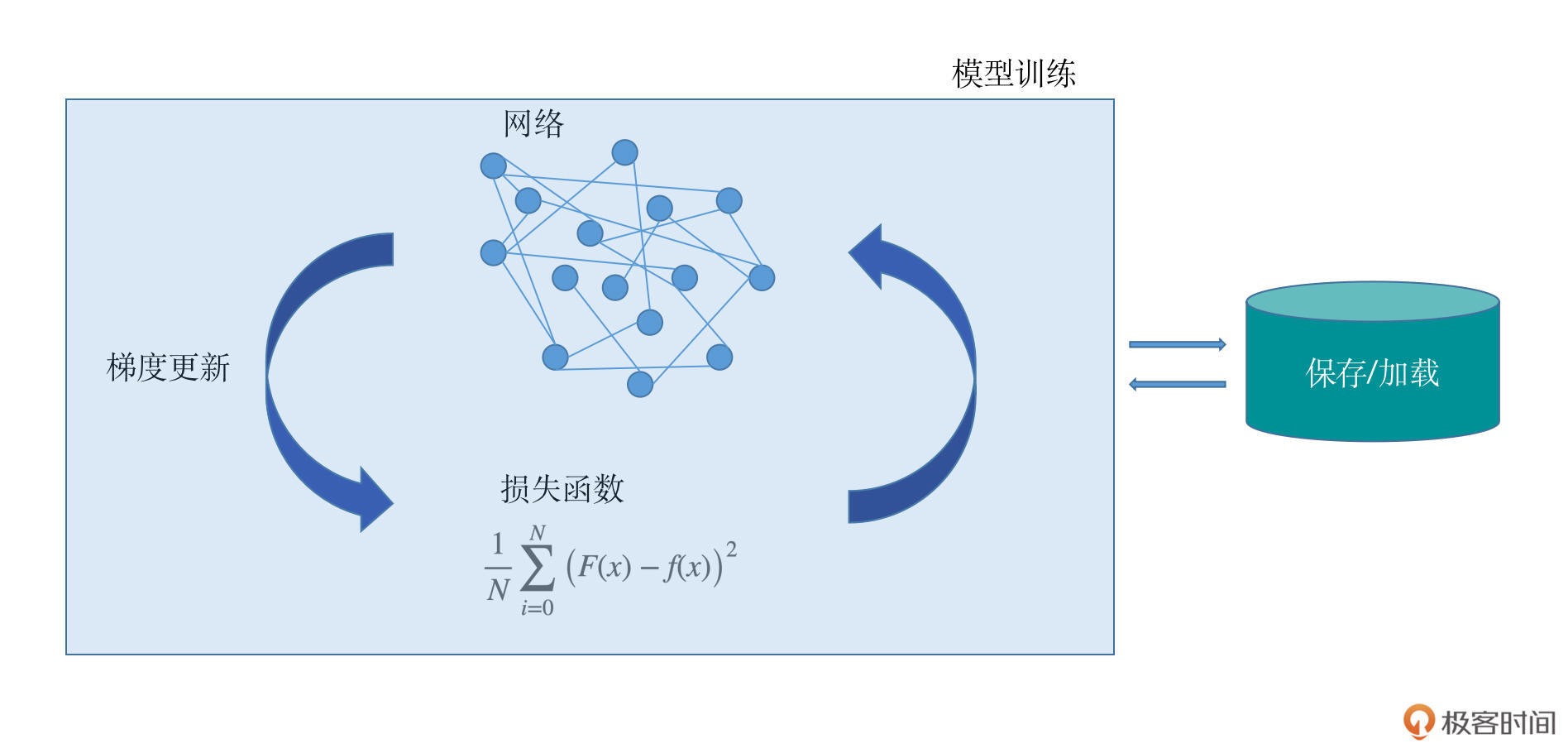
深度学习项目核心模块¶
损失函数是一把衡量模型学习效果的尺子,甚至可以说,训练模型的过程,实际就是优化损失函数的过程。
常见损失函数¶
5 种最基本的损失函数:
0-1 损失函数
平方损失函数
均方差损失函数和平均绝对误差损失函数
交叉熵损失函数
softmax 损失函数
12| 计算梯度: 网络的前向与反向传播¶
前馈网络¶
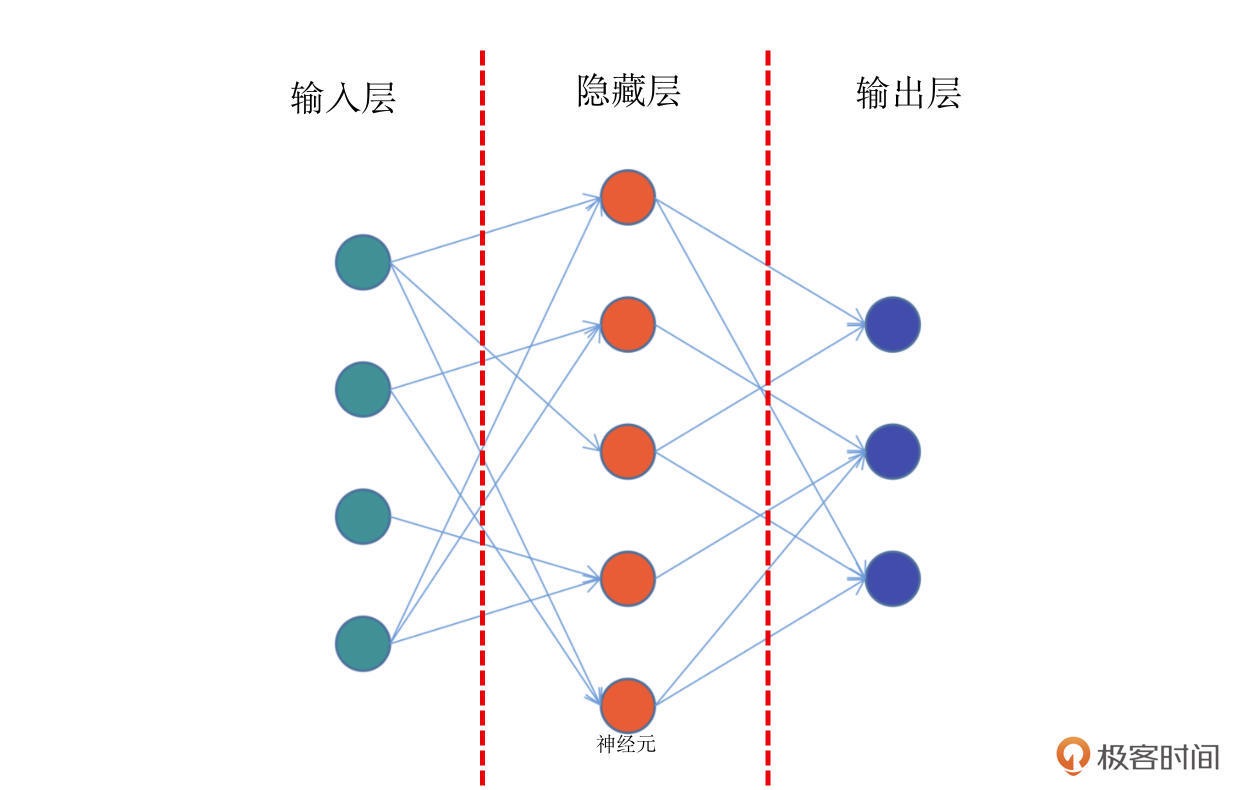
前馈网络,也称为前馈神经网络。顾名思义,是一种“往前走”的神经网络。它是最简单的神经网络,其典型特征是一个单向的多层结构。简化的结构如图¶
导数,梯度与链式法则¶
导数,也叫做导函数值。当函数值增量Δy 与变量 x 的增量Δx 的比值,在Δx 趋近于 0 时,如果极限 a 存在,我们就称 a 为函数 F(x) 在 x 处的导数。
偏导数,对于不止一个变量的函数,保持一个变量变化,而所有其他变量恒定不变的求导过程。
梯度,函数所有偏导数构成的向量就叫做梯度。梯度向量的方向即为函数值增长最快的方向。
链式法则,模型就是通过不断地减小损失函数值的方式来进行学习的。让损失函数最小化,通常就要采用梯度下降的方式,即:每一次给模型的权重进行更新的时候,都要按照梯度的反方向进行。换个方式再说一次:模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习。
反向传播¶
反向传播算法(Backpropagation)是目前训练神经网络最常用且最有效的算法。
模型就是通过反向传播的方式来不断更新自身的参数,从而实现了“学习”知识的过程。
反向传播的主要原理是:
1. 前向传播:数据从输入层经过隐藏层最后输出,其过程和之前讲过的前馈网络基本一致。
2. 计算误差并传播:计算模型输出结果和真实结果之间的误差,并将这种误差通过某种方式反向传播,即从输出层向隐藏层传递并最后到达输入层。
3. 迭代:在反向传播的过程中,根据误差不断地调整模型的参数值,并不断地迭代前面两个步骤,直到达到模型结束训练的条件。
13| 优化方法: 更新模型参数的方法¶
备注
为了得到最小的损失函数,我们要用梯度下降的方法使其达到最小值。
在一个多维空间中,对于任何一个曲面,我们都能够找到一个跟它相切的超平面。这个超平面上会有无数个方向,但是这所有的方向中,肯定有一个方向是能够使``损失函数``下降最快的方向,这个方向就是梯度的反方向。每次优化的目标就是沿着这个最快下降的方向进行,就叫做``梯度下降``。
常见的梯度下降方法¶
批量梯度下降法(Batch Gradient Descent,BGD)
随机梯度下降(Stochastic Gradient Descent,SGD)
小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
备注
三节课(第 11 到 13 节课),分别学习了损失函数、反向传播和优化方法(梯度下降)的概念。这三个概念也是深度学习中最为重要的内容,其核心意义在于能够让模型真正做到不断学习和完善自己的表现。
14| 构建网络: 一站式实现模型搭建与训练¶
讲了一个例子
15| 可视化工具: 如何实现训练的可视化监控¶
TensorFlow 中,最常使用的可视化工具非
Tensorboard莫属PyTorch则使用
TensorboardX(PyTorch 1.8 之后的版本自带 TensorboardX)FaceBook 也为 PyTorch 开发了一款交互式可视化工具
Visdom
备注
可视化工具的主要目的,是为了帮助我们在深度学习模型的训练过程中,实时监控一些数据,例如损失值、评价指标等等
16| 分布式训练: 如何加速你的模型训练¶
分布式训练原理¶
DP: DataParallel
DDP: DistributedDataParallel
在分布式训练中,主要有 DP 与 DDP 两种模式。其中 DP 并不是完整的分布式计算,只是将一部分计算放到了多张 GPU 卡上,在计算梯度的时候,仍然是“一卡有难,八方围观”,因此 DP 会有负载不平衡、效率低等问题。而 DDP 刚好能够解决 DP 的上述问题,并且既可以用于单机多卡,也可以用于多机多卡,因此它是更好的分布式训练解决方案。
怎么分布:
单机多卡
多机多卡
常用命令:
torch.cuda.is_available() 函数来判断当前的机器是否有可用的 GPU
torch.cuda.device_count() 则可以得到目前可用的 GPU 的数量
获得 GPU 的一个实例
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
03实战篇 (9 讲)¶
17| 图像分类.1: 图像分类原理与图像分类模型¶
图像分类原理¶
以此需求为例: 建立一个图像分类模型,提供自动识别有极客时间 Logo 图片的功能。
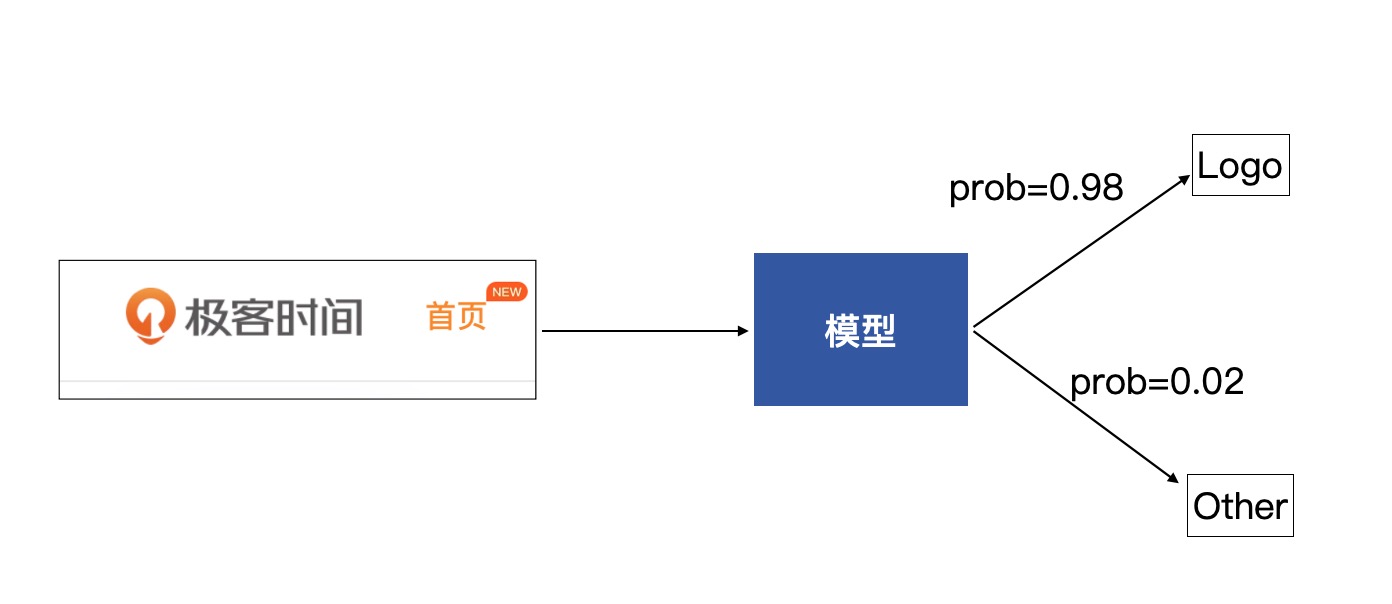
这个模型会接收一张图片,然后会输出一组概率,分别是该图片为 Logo 的概率与该图片为其他图片的概率,从而通过概率来判断这张图片是 Logo 类还是 Other 类¶
感知机¶
输入的图片,就是输入 X,将其展开后,可以获得输入 X 为
X=x1, x2, …, xn,而模型可以看做有两个节点,每个节点都会有一个输出,分别代表着对输入为 Logo 和 Other 的判断,但这里的输出暂时还不是概率,只是模型输出的一组数值。
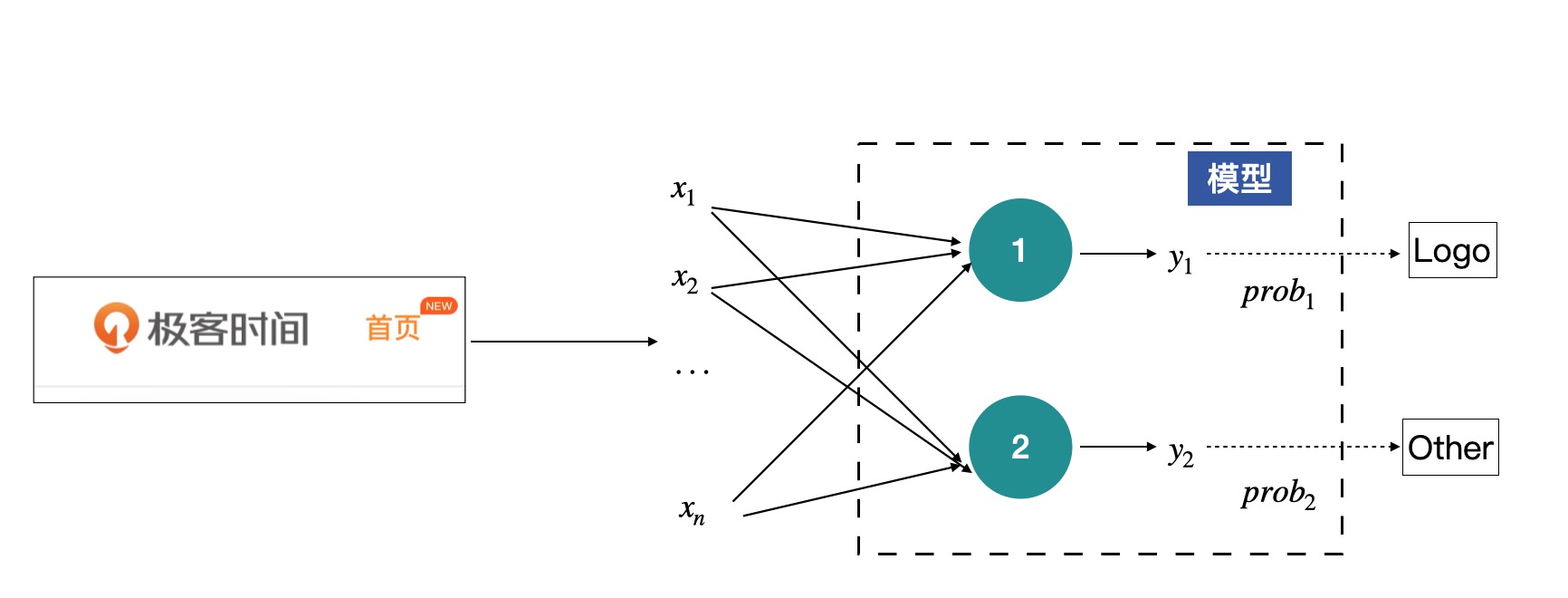
如图这个结构其实就是感知机了,中间绿色的节点叫做神经元,是感知机的最基本组成单元。上图中的感知机只有中间一层(绿色的神经元),如果有多层神经元的话,我们就称之为多层感知机。¶
神经元是关于输入的一个线性变换,每一个输入 x 都会有一个对应的权值,上图中的 y 的计算方式为:
Yi = δ(Wi1X1 + Wi2X2+ ... + WinXn + Bi), i=1,2
Wi1 Wi2... + Win: 神经元的权重
Bi: 神经元的偏移项
权重与偏移项都是通过模型学习到的参数
δ 为激活函数(可选, 常用的有Softmax, sigmod)
Softmax 函数: 将一组数值,也就是 y1, y2 转换为一组对应的概率,概率和为 1。
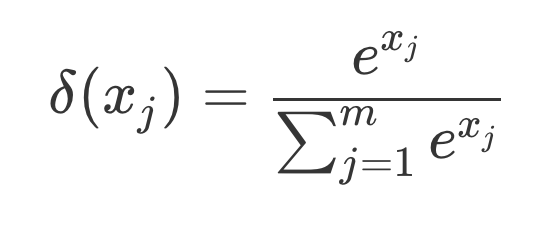
Softmax 的计算公式¶
用 Softmax 函数对原始的输入 y 做个转化,将 y 中的数值转化为一组对应的概率:
import torch
import torch.nn as nn
# 2 个神经元的输出 y 的数值为
y = torch.randn(2)
print(y)
输出:tensor ([0.2370, 1.7276])
m = nn.Softmax(dim=0)
out = m(y)
print(out)
输出:tensor ([0.1838, 0.8162])
Softmax 也不是每一个问题都会使用。我们根据问题的不同可以采用不同的函数,例如,有的时候也会使用 sigmoid 激活函数,sigmoid 激活函数是将 1 个数值转换为 0 到 1 之间的概率。
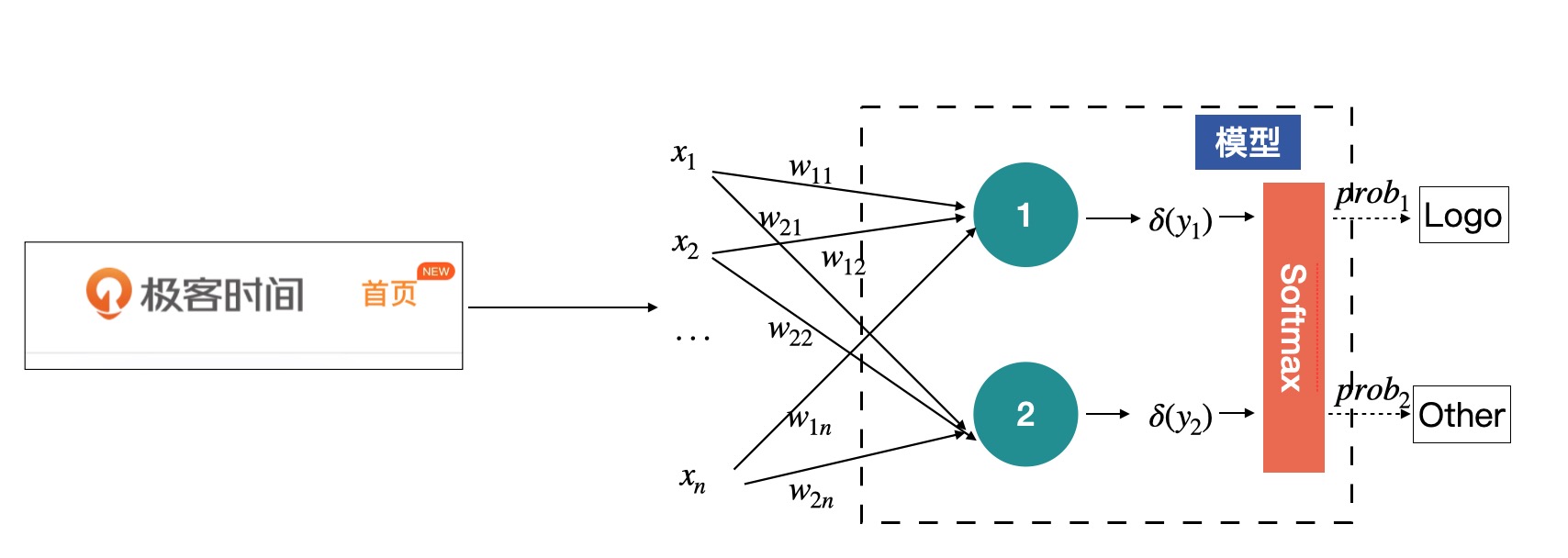
将 Softmax 补充到前面的模型里¶
全连接层¶
上图中绿色那一层。在卷积神经网络中称为全连接层,Full Connection Layer,简称 fc 层。一般都是放在网络的最后端,用来获得最终的输出,也就是各个类别的概率。
因为全连接层中的神经元的个数是固定的,所以说在有全连接层的网络中,输入图片是必须固定尺寸的。
全连接层推断的过程在 PyTorch 中是如何实现的:
x = torch.randint(0, 255, (1, 128*128), dtype=torch.float32)
fc = nn.Linear(128*128, 2)
y = fc(x)
print(y)
输出:tensor ([[ 72.1361, -120.3565]], grad_fn=<AddmmBackward>)
# 注意 y 的 shape 是 (1, 2)
output = nn.Softmax(dim=1)(y)
print(output)
输出:tensor ([[1., 0.]], grad_fn=<SoftmaxBackward>)
PyTorch 中全连接层用 nn.Linear 来实现:
in_features:输入特征的个数,在本例中为 128x128;
out_features:输出的特征数,在本例中为 2;
bias:是否需要偏移项,默认为 True。
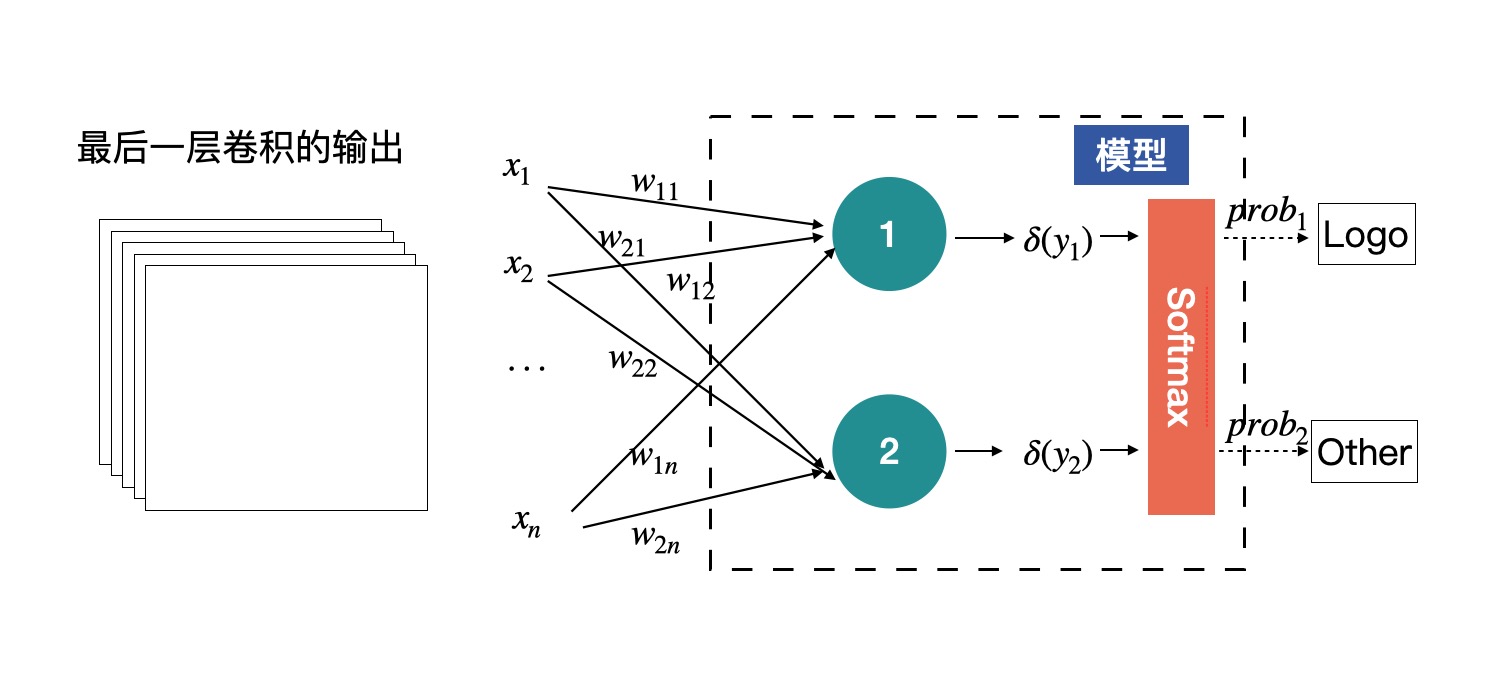
全连接层的输入,也不是原始图片数据,而是经过多层卷积提取的特征。¶
有的网络是可以接收任意尺度的输入的。只需要在最后的特征图后面加一个全局平均即可,也就是将每个特征图进行求平均,用平均值代替特征图,这样无论输入的尺度是多少,进入全连接层的数据量都是固定的。
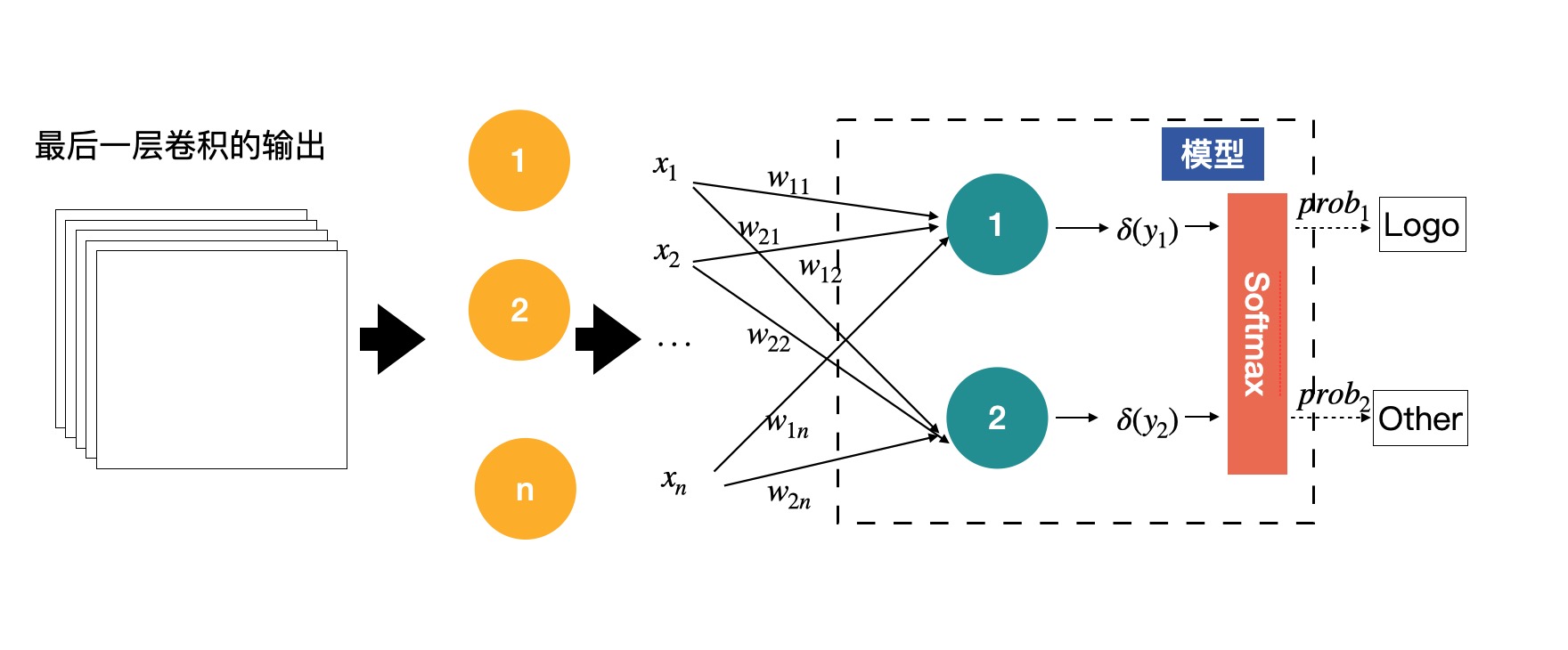
黄色的圈就是全局平均的结果,EfficientNet 就是采用这种方式,使得网络可以使用任意尺度的图片进行训练。¶
卷积神经网络¶
刚才说的多层感知机就是卷积神经网络的前身,由于自身的缺陷(参数量大、难以训练),使其在历史上有段时间一直是停滞不前,直到卷积神经网络的出现,打破了僵局。
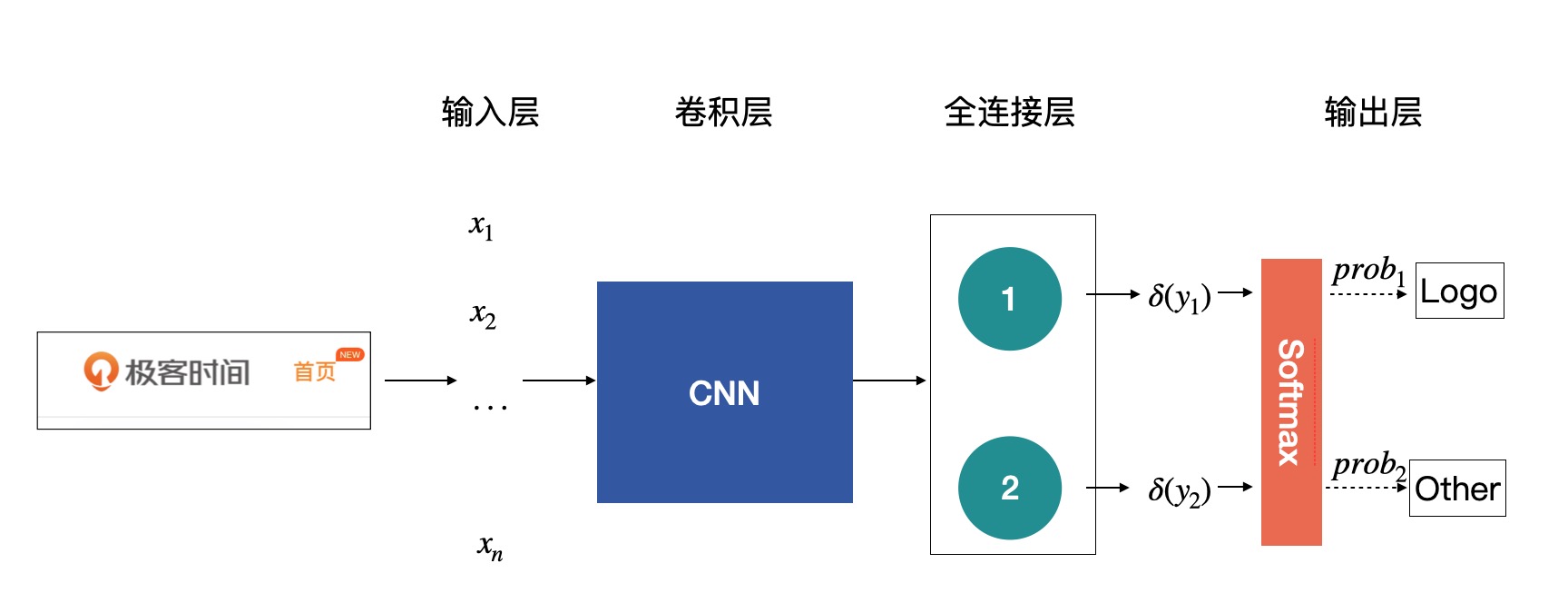
卷积神经网络的最大作用就是提取出输入图片的丰富信息,然后再对接上层的一些应用,比如前面提到的图片分类。把卷积神经网络应用到图像分类原理中,得到的此模型。在上图中,整个模型或者网络的重点全都在卷积神经网络那块,所以这也是我们的工作重点。¶
ImageNet¶
在业界中有个标杆 ——ImageNet,大家都用它来评价提出模型的好与坏。
ImageNet 本身包含了一个非常大的数据集,并且从 2010 年开始,每年都会举办一次著名的 ImageNet 大规模视觉识别挑战赛(The ImageNet Large Scale Visual Recognition Challenge ,ILSVRC),比赛包含了图像分类、目标检测与图像分割等任务。
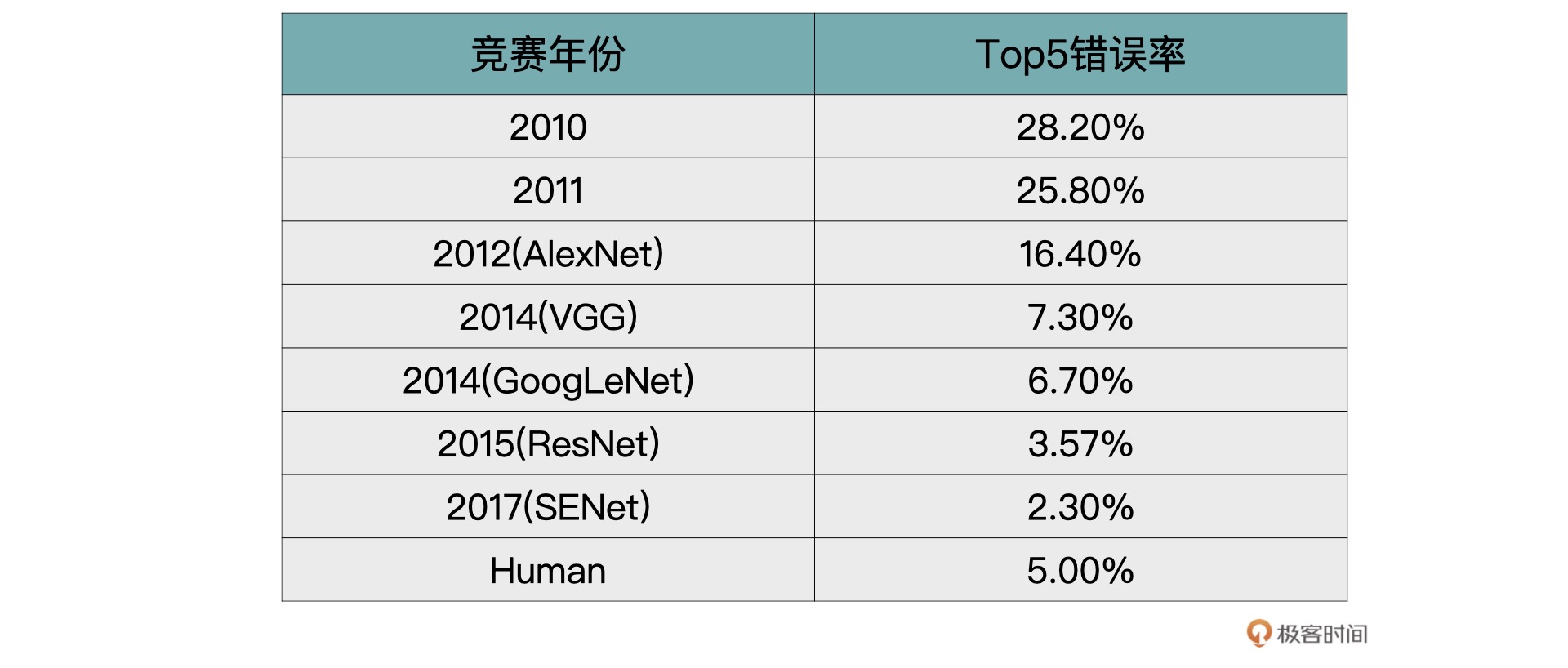
历年来 ImageNet 上 Top-5 的错误率¶
VGG¶
VGG 取得了 ILSVRC 2014 比赛分类项目的第 2 名和定位项目的第 1 名的优异成绩。
当年的 VGG 一共提供了 A 到 E6 种不同的 VGG 网络(字母不同,只是表示层数不一样)。VGG19 的效果虽说最好,但是综合模型大小等指标,在实际项目中 VGG16 用得更加多一点。
VGG 突破的一些重点:
证明了随着模型深度的增加,模型效果也会越来越好。
使用较小的 3x3 的卷积,代替了 AlexNet 中的 11x11、7x7 以及 5x5 的大卷积核。
GoogLeNet¶
2014 年分类比赛的冠军是 GoogLeNet(VGG 同年)。GoogLeNet 的核心是 Inception 模块。这个时期的 Inception 模块是 v1 版本,后续还有 v2、v3 以及 v4 版本。
如果使用 AlexNet 或者 VGG 中标准的卷积的话,每一层只能以相同的尺寸的卷积核来提取图片中的特征。
ResNet¶
残差神经网络。在 2015 年的 ImageNet 比赛中,模型的分类能力首次超越人眼,1000 类图片 top-5 的错误率降低到 3.57%。
在论文中作者给出了 18 层、34 层、50 层、101 层与 152 层的 ResNet。101 层的与 152 层的残差神经网络效果最好,但是受硬件设备以及推断时间的限制,50 层的残差神经网络在实际项目中更为常用。
总结¶
整个模型或者网络的重点全都在卷积神经网络那块¶
18| 图像分类.2: 如何构建一个图像分类模型¶
一个图像分类项目的实践。虽然项目规模较小,但是在真实项目中的每一个环节都包含在内了,可以说是麻雀虽小,五脏俱全。
数据准备其实是最关键的一步,数据的质量直接决定了模型好坏。所以,在开始训练之前你应该对你的数据集有十足的了解才可以。例如,验证集还是否可以反映出训练集、数据中有没有脏数据、数据分布有没有偏等等。
19| 图像分割.1: 详解图像分割原理与图像分割模型¶
图像分割¶
图像分类是将一张图片自动分成某一类别,而图像分割是需要将图片中的每一个像素进行分类。
图像分割可以分为语义分割与实例分割,两者的区别是语义分割中只需要把每个像素点进行分类就可以了,不需要区分是否来自同一个实例,而实例分割不仅仅需要对像素点进行分类,还需要判断来自哪个实例。
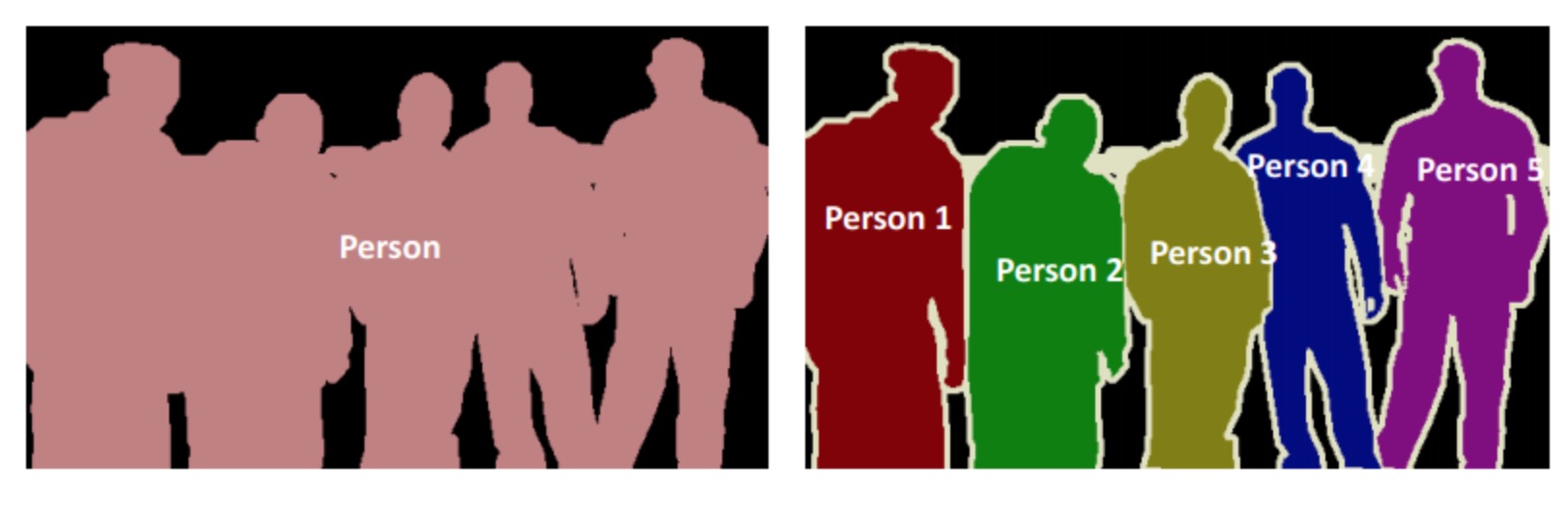
左侧为语义分割,右侧为实例分割¶
语义分割原理¶
语义分割原理其实与图像分类大致类似,主要有两点区别。首先是分类端不同,其次是网络结构有所不同。
分类端¶
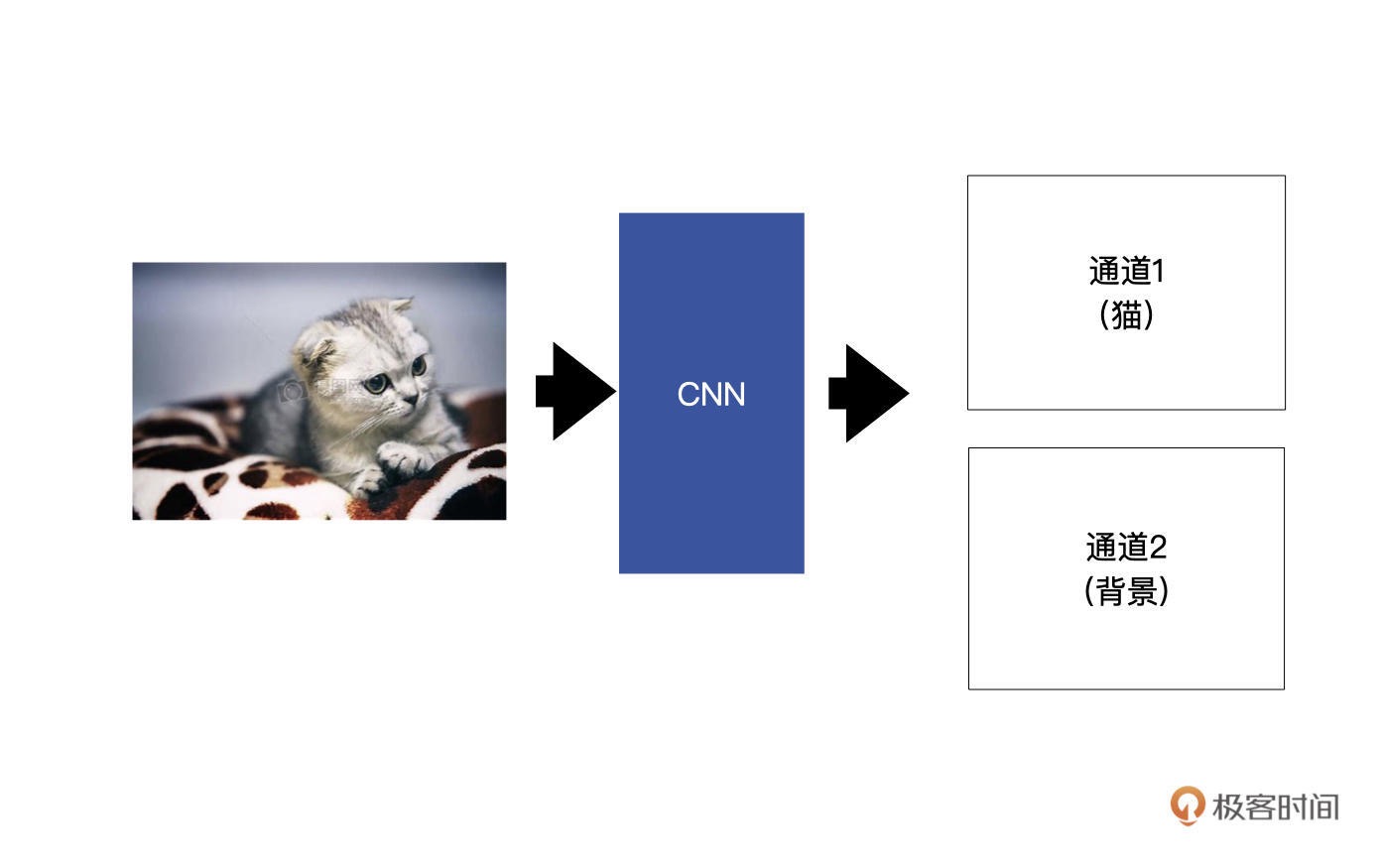
在图像分割中,同样是利用卷积层来提取特征,最终生成若干特征图。只不过最后生成的特征图的数目对应着要分割成的类别数。举一个例子,假设我们想要将输入的小猫分割出来,也就是说,这个图像分割模型有两个类别,分别是小猫与背景。¶
这里我给你再举一个例子,来说明一下如何判断每个像素的类别。假设,通道 1 中(0,0)这个位置的输出是 2,通道 2 中(0,0)这个位置的输出是 30。经过 softmax 转为概率后,通道 1(0, 0)这个位置的概率为 0,而对应通道 2 中 (0,0) 这个位置的概率为 1,我们通过概率可以判断出,在(0,0)这个位置是背景,而不是小猫。
网络结构¶
在分割网络中最终输出的特征图的大小要么是与输入的原图相同,要么就是接近输入。这么做的原因是,我们要对原图中的每个像素进行判断。当输出特征图与原图尺寸相同时,可以直接进行分割判断。当输出特征图与原图尺寸不相同时,需要将输出的特征图 resize 到原图大小。
在图像分类中,经过多层的特征提取,最后生成的特征图都是很小的。而在图像分割中,最后生成的特征图通常来说是接近原图的。
备注
说把特征提取看做 Encoder 的话,那在图像分割中还有一步是 Decoder。Decoder 的作用就是对特征图尺寸进行还原的过程,将尺寸还原到一个比较大的尺寸。这个还原的操作对应的就是上采样。而在上采样中我们通常使用的是转置卷积。
转置卷积¶
转置卷积的计算原理,这也是这节课的重点内容。
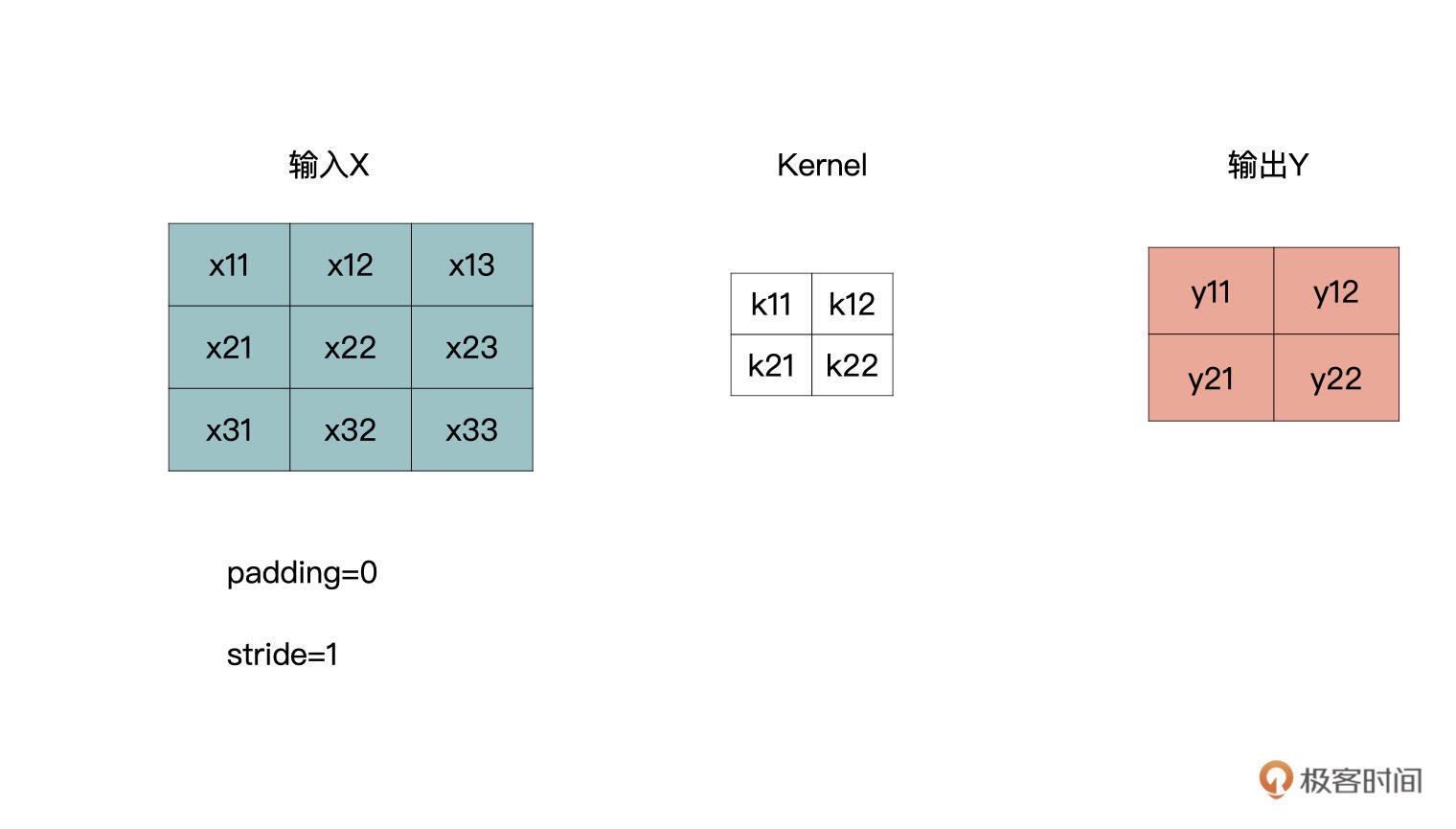
从之前的学习我们可以知道,卷积操作是一个多对一的运算,输出中的每一个 y 都与输入中的 4 个 x 有关。其实,转置卷积从逻辑上是卷积的一个逆过程,而不是卷积的逆运算。也就是说,转置卷积并不是使用上图中的输出 Y 与卷积核 Kernel 来获得上图中的输入 X,转置卷积只能还原出一个与输入特征图尺寸相同的特征图。¶
我们将转置卷积中的卷积核用 k’表示,那么一个 y 会与四个 k’进行还原,如下所示:
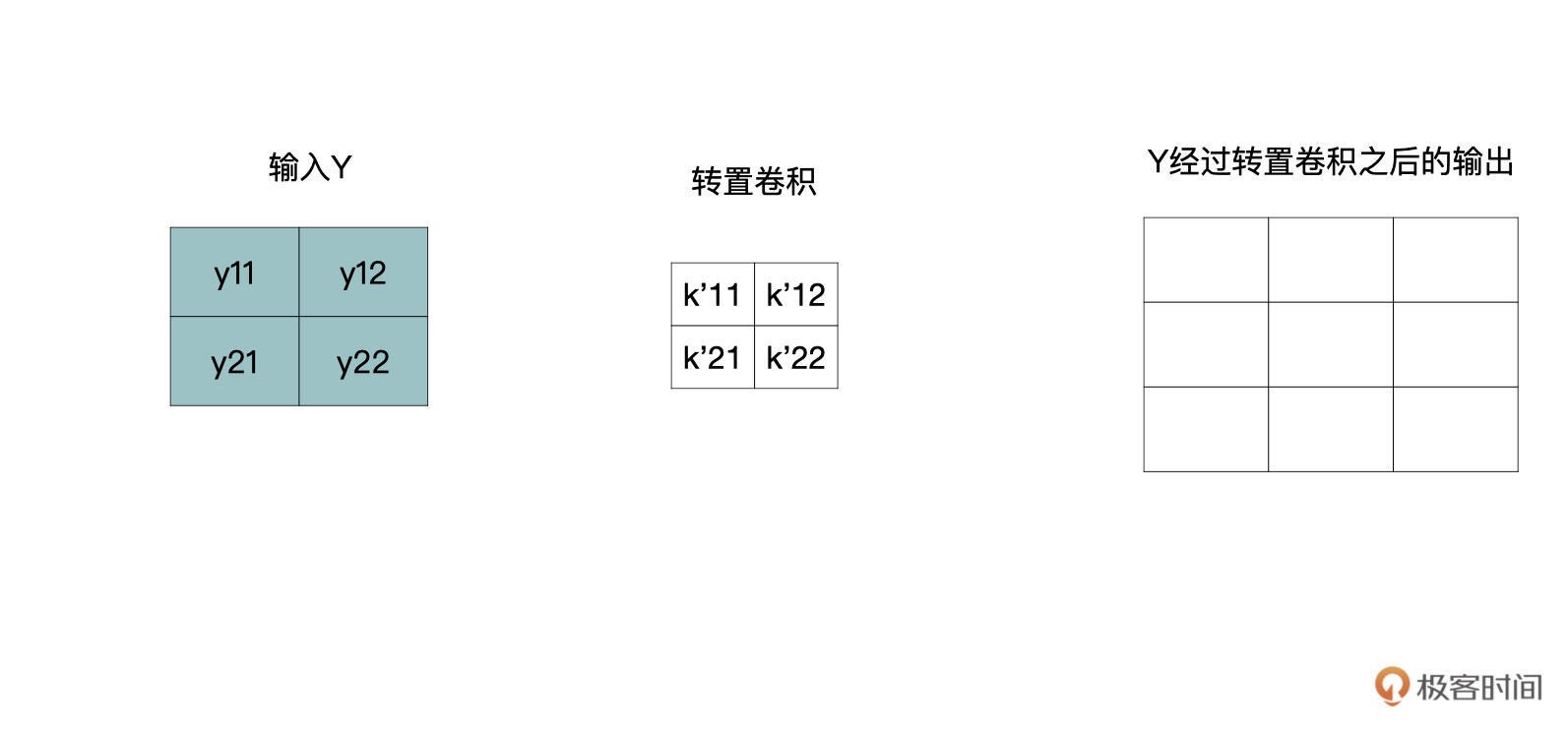
还原尺寸的过程如下所示,下图中每个还原后的结果都对应着原始 3x3 的输入。

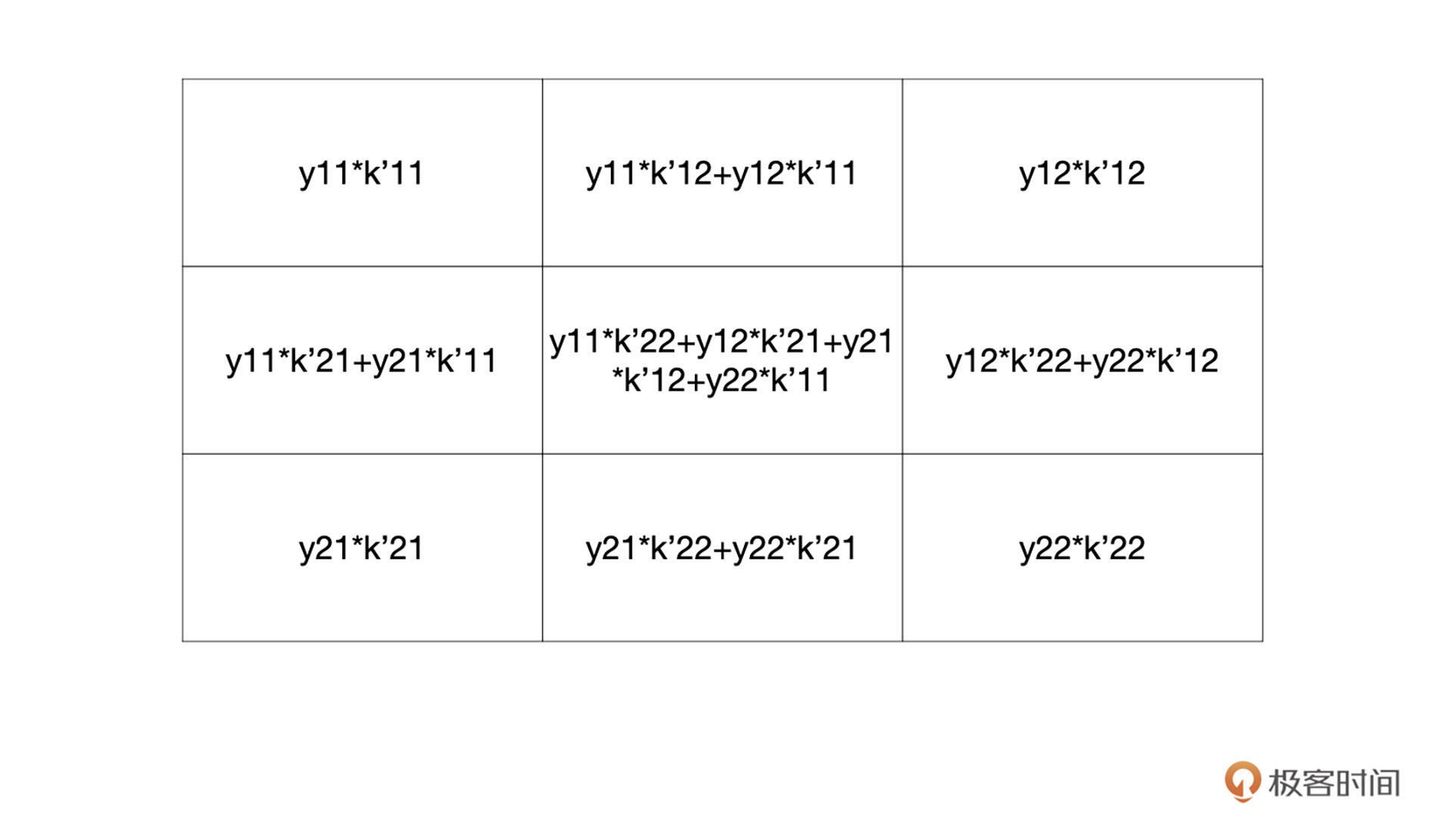
通过观察你可以发现,有些部分是重合的,对于重合部分把它们加起来就可以了,最终还原后的特征图如下:
上面的结果,我们又可以通过下面的卷积获得:
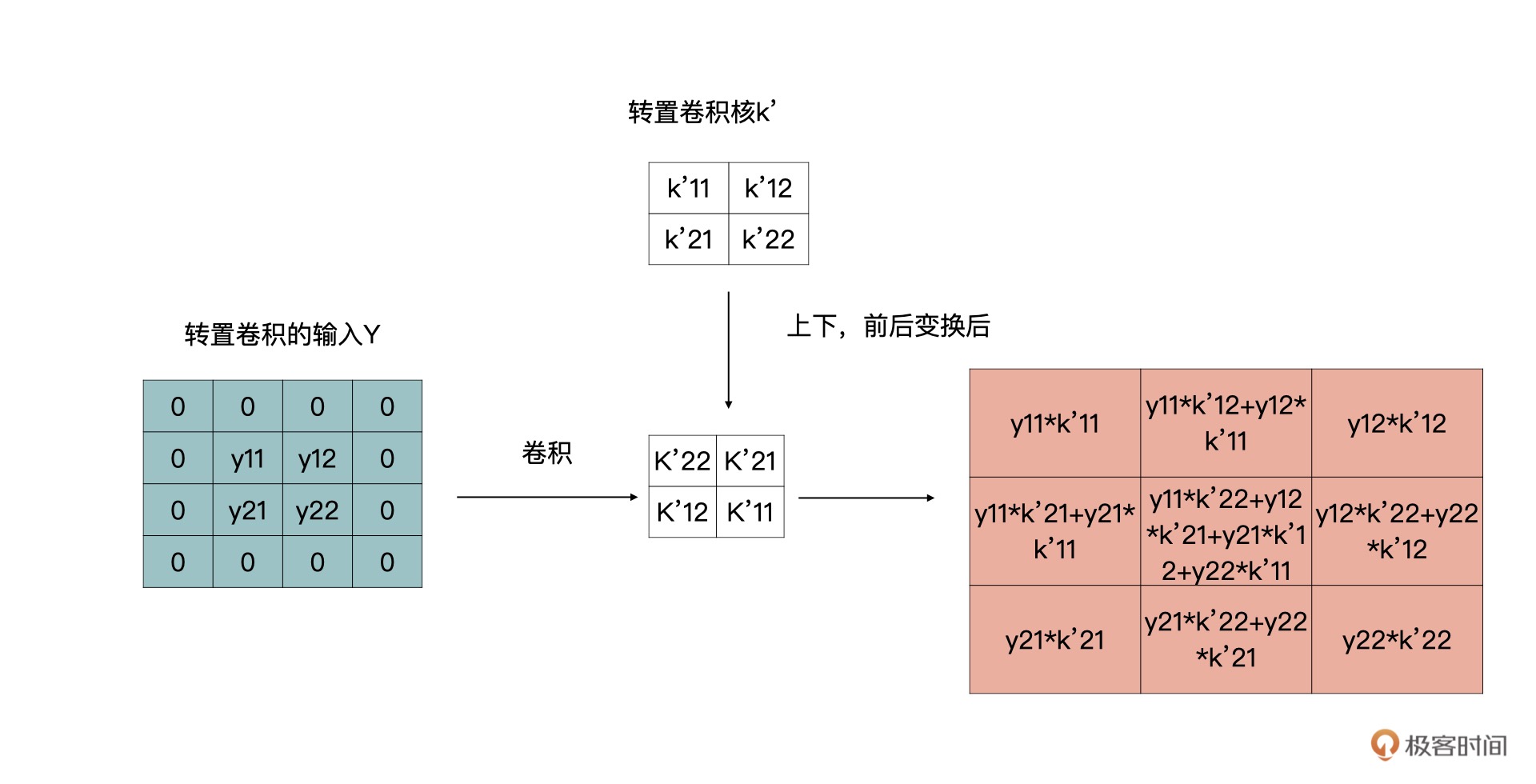
转置卷积计算又变回了卷积计算。¶
转置卷积的计算过程如下:
1. 对输入特征图进行补零操作。
2. 将转置卷积的卷积核上下、左右变换作为新的卷积核。
3. 利用新的卷积核在 1 的基础上进行步长为 1,padding 为 0 的卷积操作。
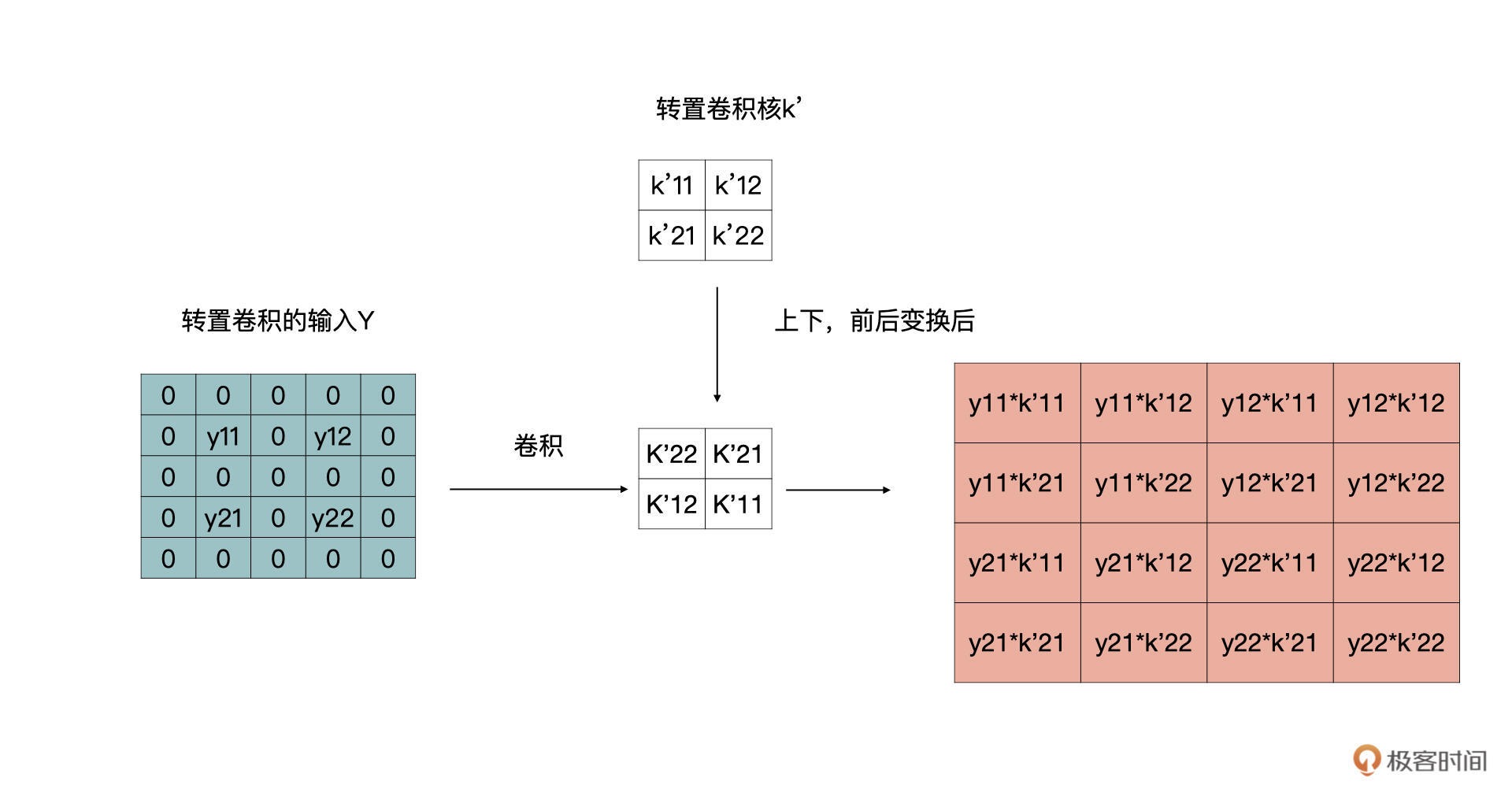
刚才的例子里,stride 是等于 1 的,如果等于 2 时,按照同样的套路,可以转换为如下的卷积变换。 同时,我们也可以得到结论,上文中第一步,补零的操作是,在输入的特征图的行与列之间补 stride-1 个行与列的零
公开数据集¶
最著名的就是 COCO 了,链接如下:https://cocodataset.org/#detection-2016。一共有 80 个类别,超过 2 万张图片。
20| 图像分割.2: 如何构建一个图像分割模型¶
了解了图像分割的数据准备,需要使用 Labelme 工具为图像做标记。数据质量的好坏决定了最终模型的质量,所以你要对数据的标注好好把握。在使用 Labelme 标记完成之后,我们可以使用 label2voc.py 将 json 转换为 Mask。
之后我们学习了一种非常高效且实用的模型–UNet,并使用 PyTorch 实现了其网络结构。
目标检测数据标注工具: https://github.com/tzutalin/labelImg
21 _ NLP基础.1: 详解自然语言处理原理与常用算法¶
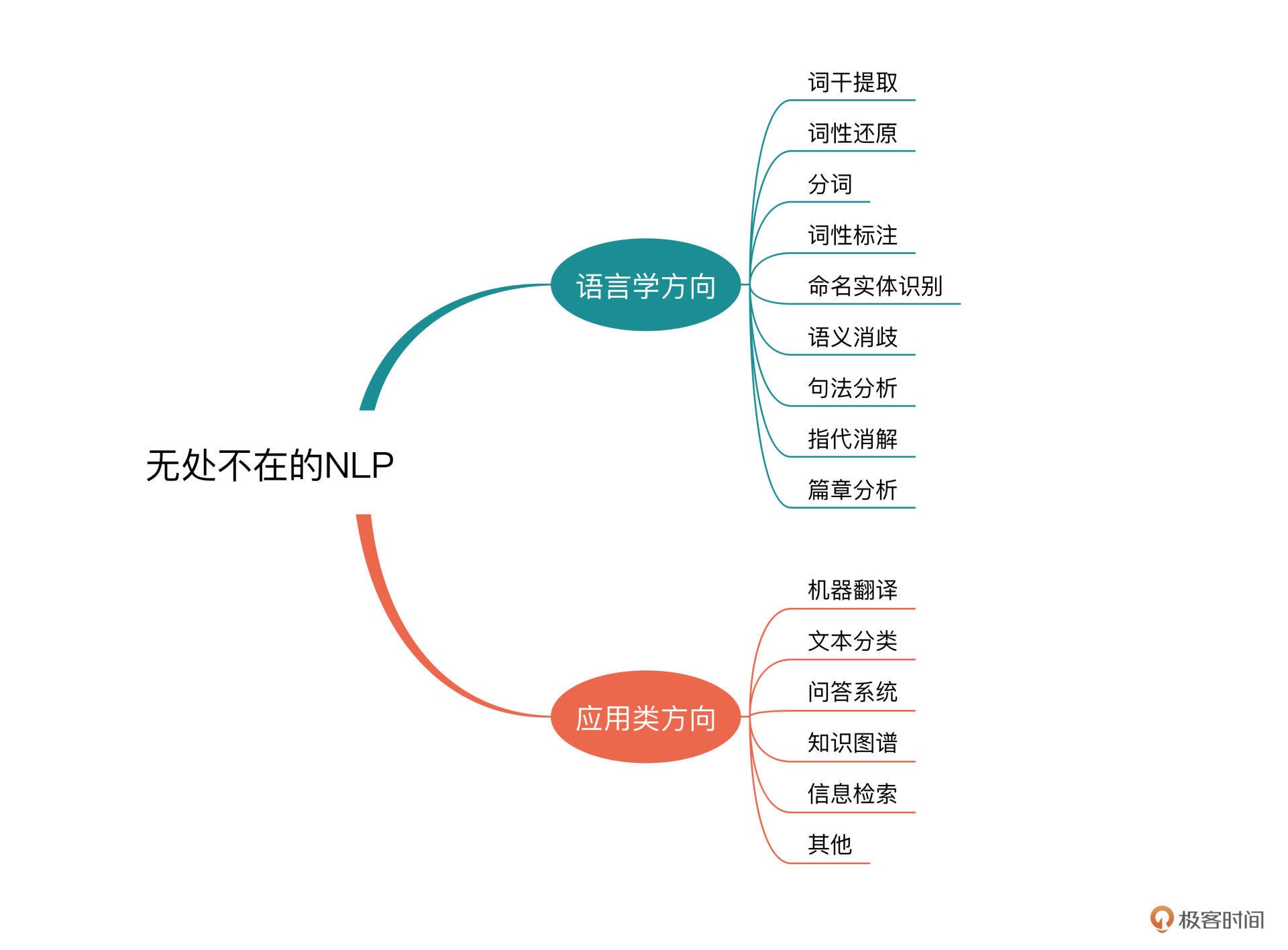
常见的语言学的方向包括:
词干提取、词形还原、分词、词性标注、
命名实体识别、语义消歧、句法分析、指代消解、篇章分析
侧重 “处理” 和 “应用” 方面的方向有:
机器翻译、文本分类、问答系统、知识图谱、信息检索
分词¶
备注
参见【分词】章节
关键词的提取¶
备注
参见【关键词提取】章节
22 _ NLP基础.2: 详解语言模型与注意力机制¶
语言模型¶
备注
参见【语言模型】章节
注意力机制¶
备注
参见【注意力机制】章节
小结¶
通过语言模型,我们可以将语言文字变成可以计算的形式,让文字之间有了更为直接的关联。有了注意力机制,我们可以让模型了解到哪些是应该被更加关注的内容,从而提高语言模型的效果。
23 _ 情感分析: 如何使用LSTM进行情感分析¶
一个情感分析项目,一起来对影评文本做分析。
24 _ 文本分类: 如何使用BERT构建文本分类模型¶
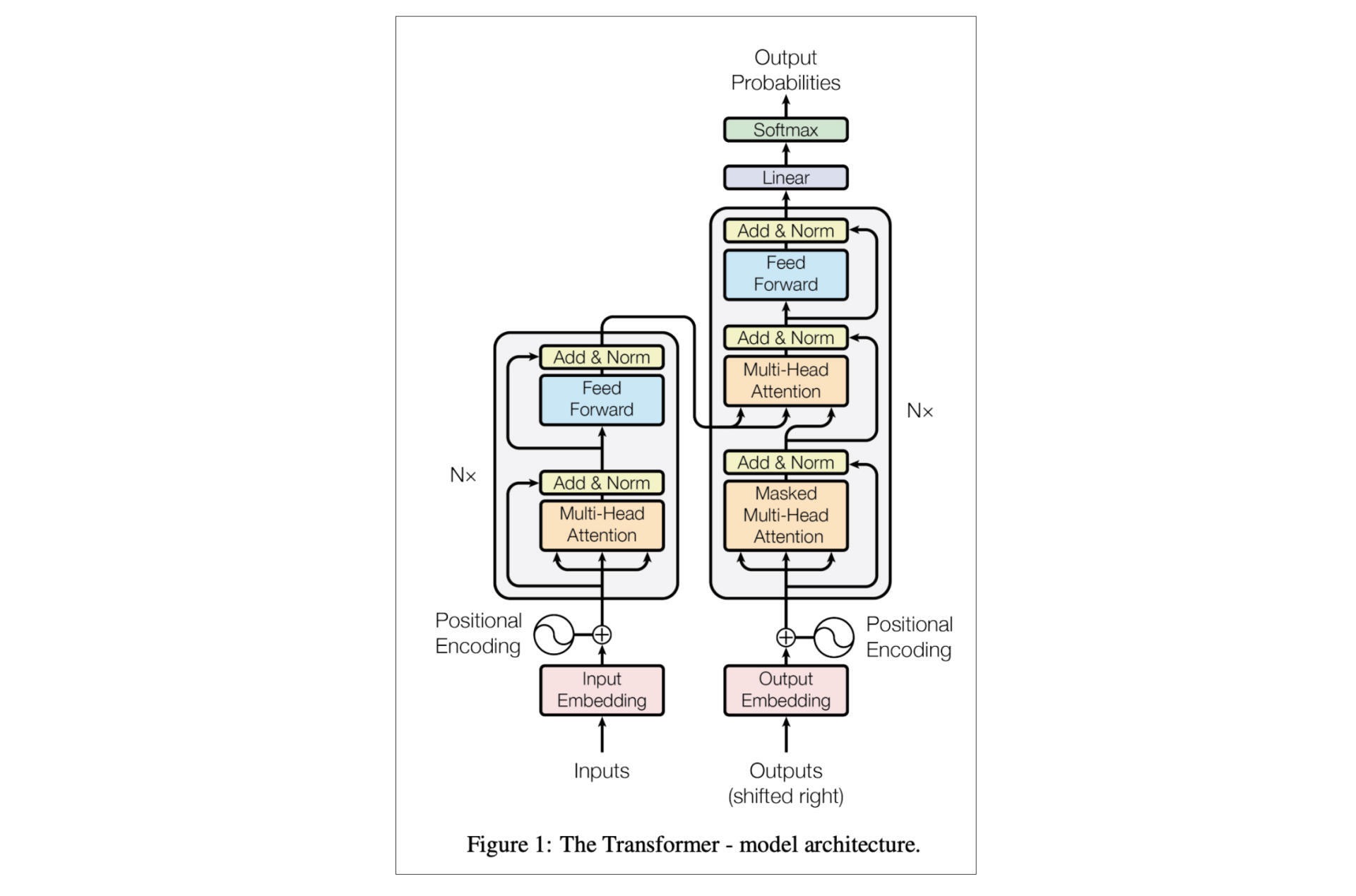
BERT 的理论框架主要是基于论文《Attention is all you need》中提出的 Transformer,而后者的原理则是刚才提到的 Attention。其最为明显的特点,就是摒弃了传统的 RNN 和 CNN 逻辑,有效解决了 NLP 中的长期依赖问题。¶
BERT 采用了基于 MLM 的模型训练方式,即 Mask Language Model。因为 BERT 是 Transformer 的一部分,即 encoder 环节,所以没有 decoder 的部分(其实就是 GPT)
MLM 的思想也非常简单,就是在训练之前,随机将文本中一部分的词语(token)进行屏蔽(mask),然后在训练的过程中,使用其他没有被屏蔽的 token 对被屏蔽的 token 进行预测。
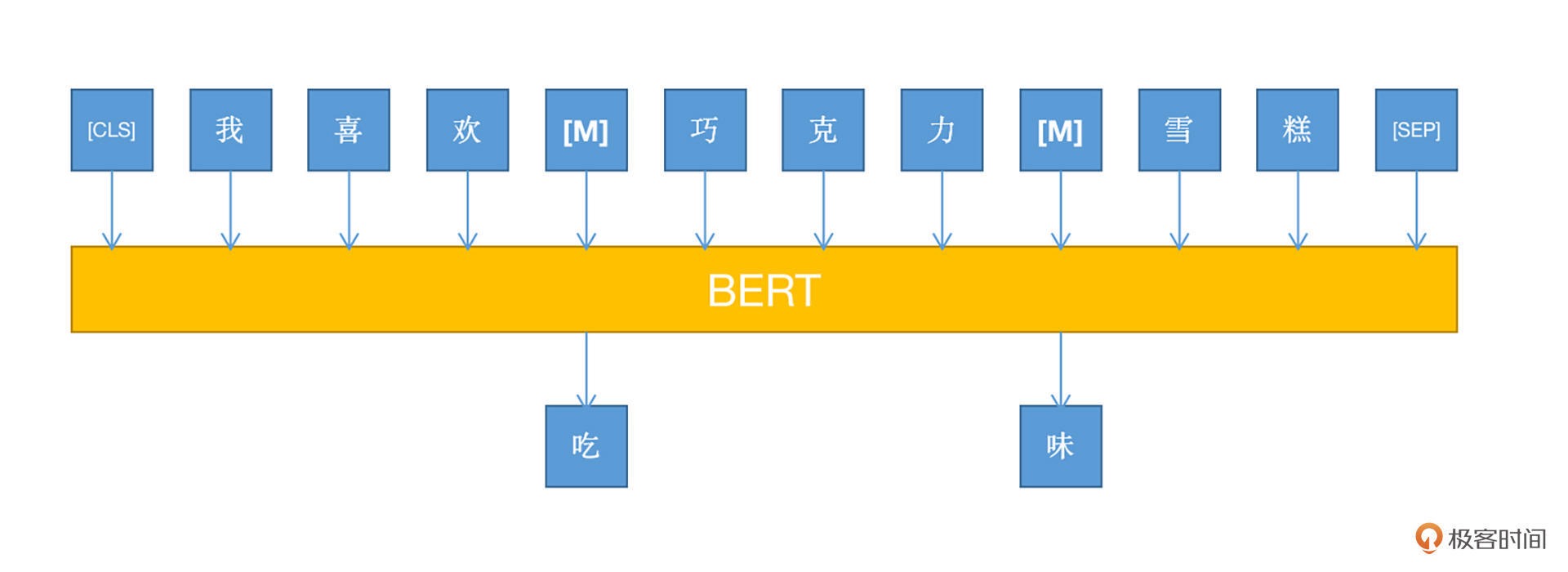
BERT 还有多语言的优势,通过基于字符、字符片段、单词等不同粒度的 token 覆盖并作
WordPiece,能够覆盖上百种语言,甚至可以说,只要你能够发明出一种逻辑上自洽的语言,BERT 就能够处理。
思考题¶
BERT 处理文本是有最大长度要求的(512),那么遇到长文本,该怎么办呢?
截断法:
截断法是非常常用办法,大致分为三种,head 截断,tail 截断,head+tail 截断。 head 截断即从文本开头直到限制的字数。 tail 截断是从结尾开始往前截断。 head+tail 截断,开头和结尾各保留一部分,比例参数是一个可以调节超参数。 缺点:处理方法较为暴力,不是太长的文本
2.Pooling 法,缺点性能较差
压缩法,提取文本中有限 segment,但压缩效果可能会很有限。
25 _ 摘要: 如何快速实现自动文摘生成¶
问题背景¶
自动文摘技术,就是自动提炼出一些句子来概括整篇文章的大意,用户通过读摘要就可以了解到原文要表达的意思。
抽取与生成¶
自动文摘有两种解决方案:
一种是抽取式(Extractive)的,就是从原文中提取一些关键的句子,组合成一篇摘要
一种是生成式(Abstractive)
评价指标¶
评价自动摘要的效果通常使用 ROUGE(Recall Oriented Understudy for Gisting Evaluation)评价。
ROUGE 评价法参考了机器翻译自动评价方法,并且考虑了 N-gram 共同出现的程度。这个方法具体是这样设计的:首先由多个专家分别生成人工摘要,构成标准摘要集;然后对比系统生成的自动摘要与人工生成的标准摘要,通过统计二者之间重叠的基本单元(n 元语法、词序或词对)的数目,来评价摘要的质量。通过与多专家人工摘要的对比,提高评价系统的稳定性和健壮性。
ROUGE 主要包括以下 4 种评价指标:
1.ROUGE-N,基于 n-gram 的共现统计
2.ROUGE-L,基于最长公共子串
3.ROUGE-S,基于顺序词对统计
4.ROUGE-W,在 ROUGE-L 的基础上,考虑串的连续匹配。
BART¶
备注
参见【BART】章节
快速文摘生成¶
使用 pipeline 生成文摘的例子:
from transformers import pipeline
summarizer = pipeline("summarization")
ARTICLE = """ <content>.
"""
print(summarizer(ARTICLE, max_length=130, min_length=30))
'''
输出:
[{'summary_text': ' <summary> '}]
'''
不想使用 Transformers 提供的预训练模型,而是想使用自己的模型或其它任意模型:
from transformers import BartTokenizer, BartForConditionalGeneration
# 1. 第一步: 实例化一个 BART 的模型和分词器对象
# BartForConditionalGeneration 类是 BART 模型用于摘要生成的类
# BartTokenizer 是 BART 的分词器
# from_pretrained () 方法,加载预训练模型
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
# 2. 第二步: 对原始文本进行分词
inputs = tokenizer([ARTICLE], max_length=1024, return_tensors='pt')
# 3. 第三步: 生成文摘
summary_ids = model.generate(inputs['input_ids'], max_length=130, early_stopping=True)
# 4. 第四步: 利用分词器解码得到最终的摘要文本
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(summary)
Fine-tuning BART¶
模型加载¶
模型加载部分和前面一样:
from transformers import BartTokenizer, BartForConditionalGeneration
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model = BartForConditionalGeneration.from_pretrained('facebook/facebook/bart-large-cnn')
数据准备¶
读取 IMDB 数据集的训练数据的示例:
import datasets
train_dataset = datasets.load_dataset("imdb", split="train")
print(train_dataset.column_names)
'''
输出:
['label', 'text']
'''
从多个 csv 文件中加载数据:
data_files = {"train": "train.csv", "test": "test.csv"}
dataset = load_dataset("namespace/your_dataset_name", data_files=data_files)
print(datasets)
示例输出:
{train: Dataset({
features: ['idx', 'text', 'summary'],
num_rows: 3668
})
test: Dataset({
features: ['idx', 'text', 'summary'],
num_rows: 1725
})
}
预处理操作:
def add_prefix(example):
example['text'] = 'My sentence: ' + example['text']
return example
updated_dataset = dataset.map(add_prefix)
updated_dataset['train']['text'][:5]
示例输出:
['My sentence: Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"My sentence: Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'My sentence: They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .',
'My sentence: Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
]
使用自定义的数据集 fine-tuning BART 模型:
from transformers.modeling_bart import shift_tokens_right
dataset = ... # Datasets 的对象,数据集需有 'text' 和'summary' 字段,并包含训练集和验证集
# 此函数中的主要操作就是调用 tokenizer 来将文本转化为词语 id
def convert_to_features(example_batch):
input_encodings = tokenizer.batch_encode_plus(example_batch['text'], pad_to_max_length=True, max_length=1024, truncation=True))
target_encodings = tokenizer.batch_encode_plus(example_batch['summary'], pad_to_max_length=True, max_length=1024, truncation=True))
labels = target_encodings['input_ids']
decoder_input_ids = shift_tokens_right(labels, model.config.pad_token_id) # Auto-Regressive,目的是将 Decoder 的输入向后移一个位置
labels[labels[:, :] == model.config.pad_token_id] = -100
encodings = {
'input_ids': input_encodings['input_ids'],
'attention_mask': input_encodings['attention_mask'],
'decoder_input_ids': decoder_input_ids,
'labels': labels,
}
return encodings
dataset = dataset.map(convert_to_features, batched=True)
columns = ['input_ids', 'labels', 'decoder_input_ids','attention_mask',]
# 生成选择训练所需的数据字段,并生成 PyTroch 的 Tensor
dataset.set_format(type='torch', columns=columns)
模型训练¶
使用用于训练文本生成模型的 Seq2SeqTrainer 类进行训练:
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
training_args = Seq2SeqTrainingArguments(
output_dir='./models/bart-summarizer',# 模型输出目录
num_train_epochs=1, # 训练轮数
per_device_train_batch_size=1, # 训练过程 bach_size
per_device_eval_batch_size=1, # 评估过程 bach_size
warmup_steps=500, # 学习率相关参数
weight_decay=0.01, # 学习率相关参数
logging_dir='./logs', # 日志目录
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=dataset['train'],
eval_dataset=dataset['validation']
)
trainer.train()
加餐| 基础模型¶
基础模型 Foundation model¶
在 2021 年,斯坦福大学的学者在论文 On the Opportunities and Risks of Foundation Models 中,以基础模型(Foundation Model)来命名这样的模型。
定义: A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks. 意思就是说,基础模型是利用大量数据进行训练,可以在广泛的下游任务中通过微调等手段进行应用的模型。
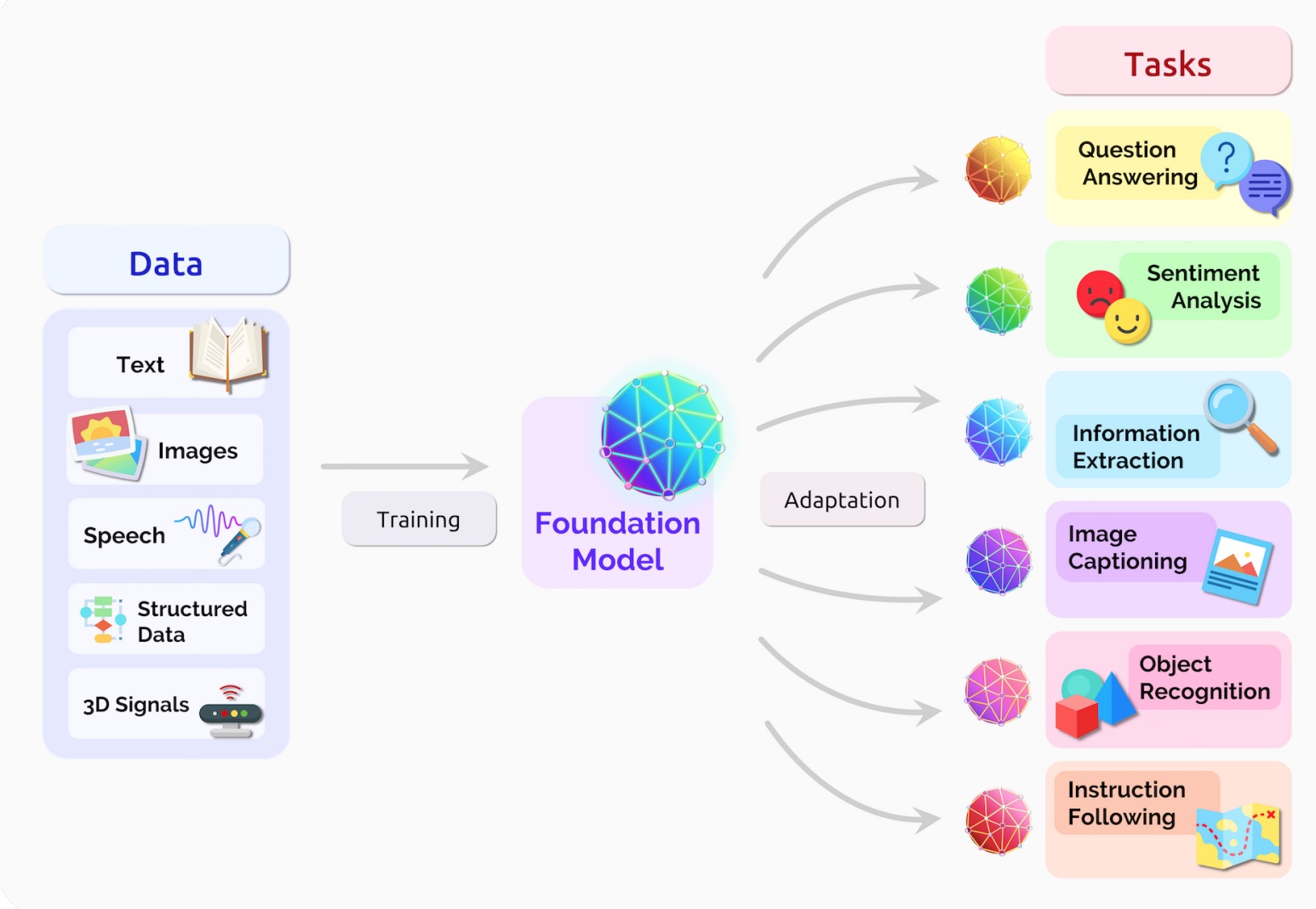
简单来说,有了基础模型,就可以把原先 “单一任务,单一模型” 转变为 “多样任务,通用模型”,无需再为每个任务单独设计模型。图片来源:https://arxiv.org/pdf/2108.07258.pdf¶
为什么基础模型可以做到这些呢?同样,论文中给出了这样的回答。
Transfer learning is what makes foundation models possible, but scale is what makes them powerful. Scale required three ingredients: (i) improvements in computer hardware — e.g., GPU throughput and memory have increased 10× over the last four years (§4.5: systems); (ii) the development of the Transformer model architecture [Vaswani et al. 2017] that leverages the parallelism of the hardware to train much more expressive models than before (§4.1: modeling); and (iii) the availability of much more training data
归纳一下,就是说基础模型成为可能,主要有三个原因。1. 算力的提升2.Transformer 技术的提升3. 大规模数据的活用。此外,对于基础模型的性能,scaling 这个概念也是至关重要的。对于 scaling 来说,迭代次数、数据规模和参数量这三个变量是非常重要的。
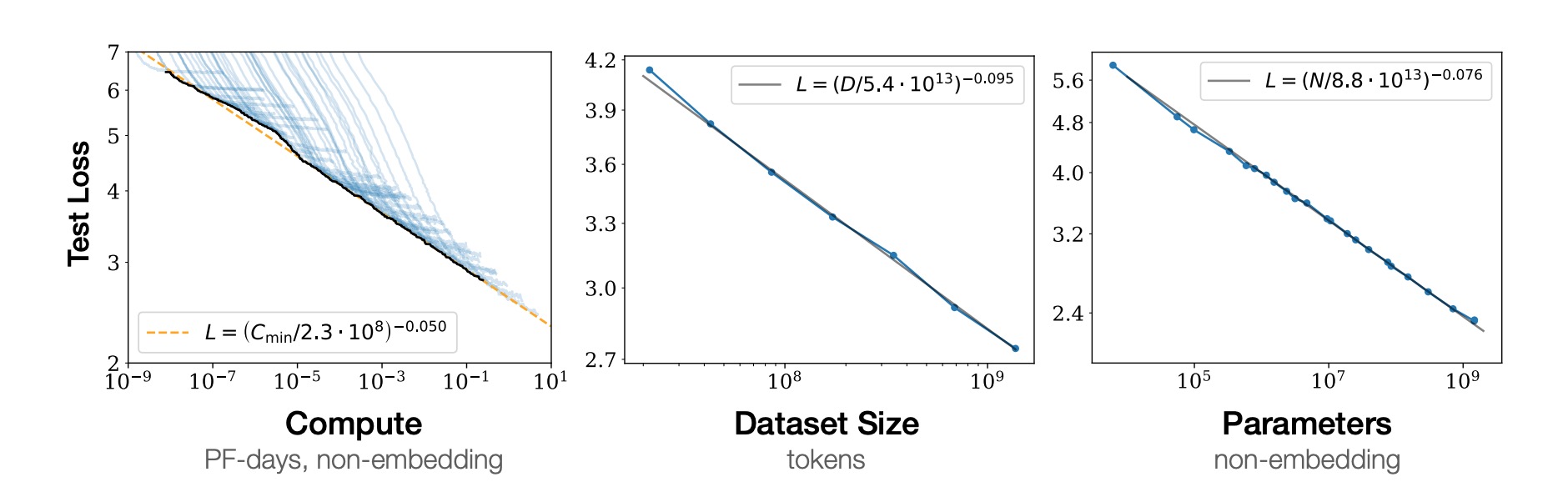
通过此实验截图也可以看到,随着这三个变量的增大,基础模型的性能会提高。这三个变量也是如今高性能 AI 模型的的重要指导方针了,各大研究机构与企业正在竞相将深度模型扩大规模。图片来源:https://arxiv.org/pdf/2001.08361.pdf¶
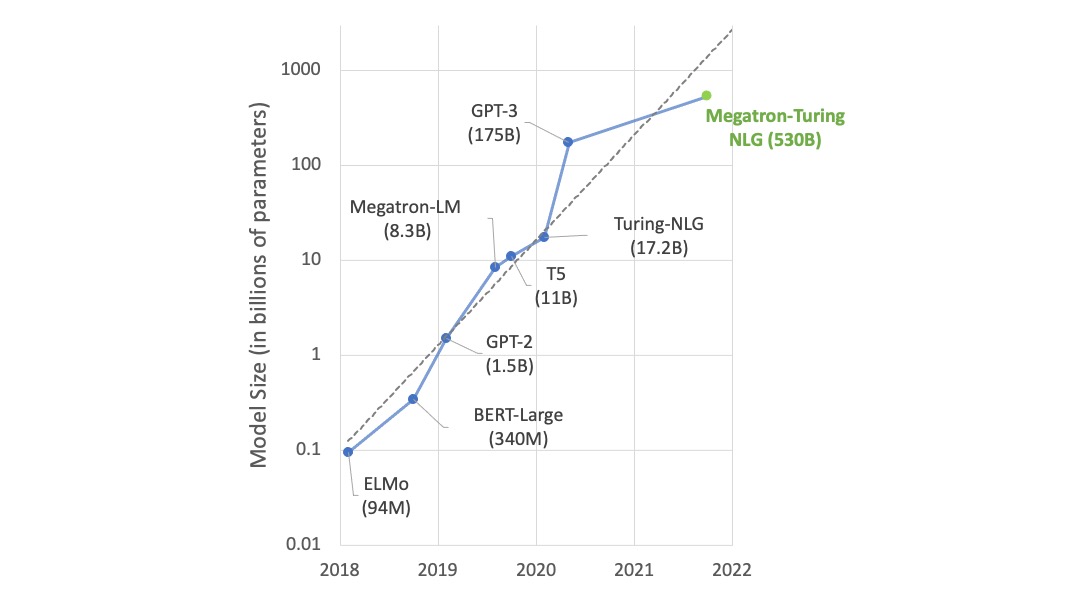
语言模型的参数数量以每年 10 倍的速度增长。¶
基础模型的代表¶
从应用的角度看,基础模型可以分为语言模型与多模态模型。
语言模型¶
Large Language Model(LLM)是使用大量文本数据进行训练、可以处理自然语言任务的模型。
通常来说对大语言模型进行微调,就可以生成针对不同任务的自然语言模型,比方说文本分类、情感分析、摘要生成、文本生成与智能问答等等细分模型。
2018 年 Google 推出的 BERT,还有 2020 年 OpenAI 的 GPT-3 就是两个很好的代表。
在大语言模型中比较有代表性的模型有:
GPT-3、 MT-NLG、 PaLM
多模态模型¶
模态其实是数据来源的一种形式。对我们人类来说,有视觉、触觉、嗅觉等 “数据来源”。延伸到计算机中就是图像、文本以及音频等数据形式了,这些形式就是计算机的多模态了。
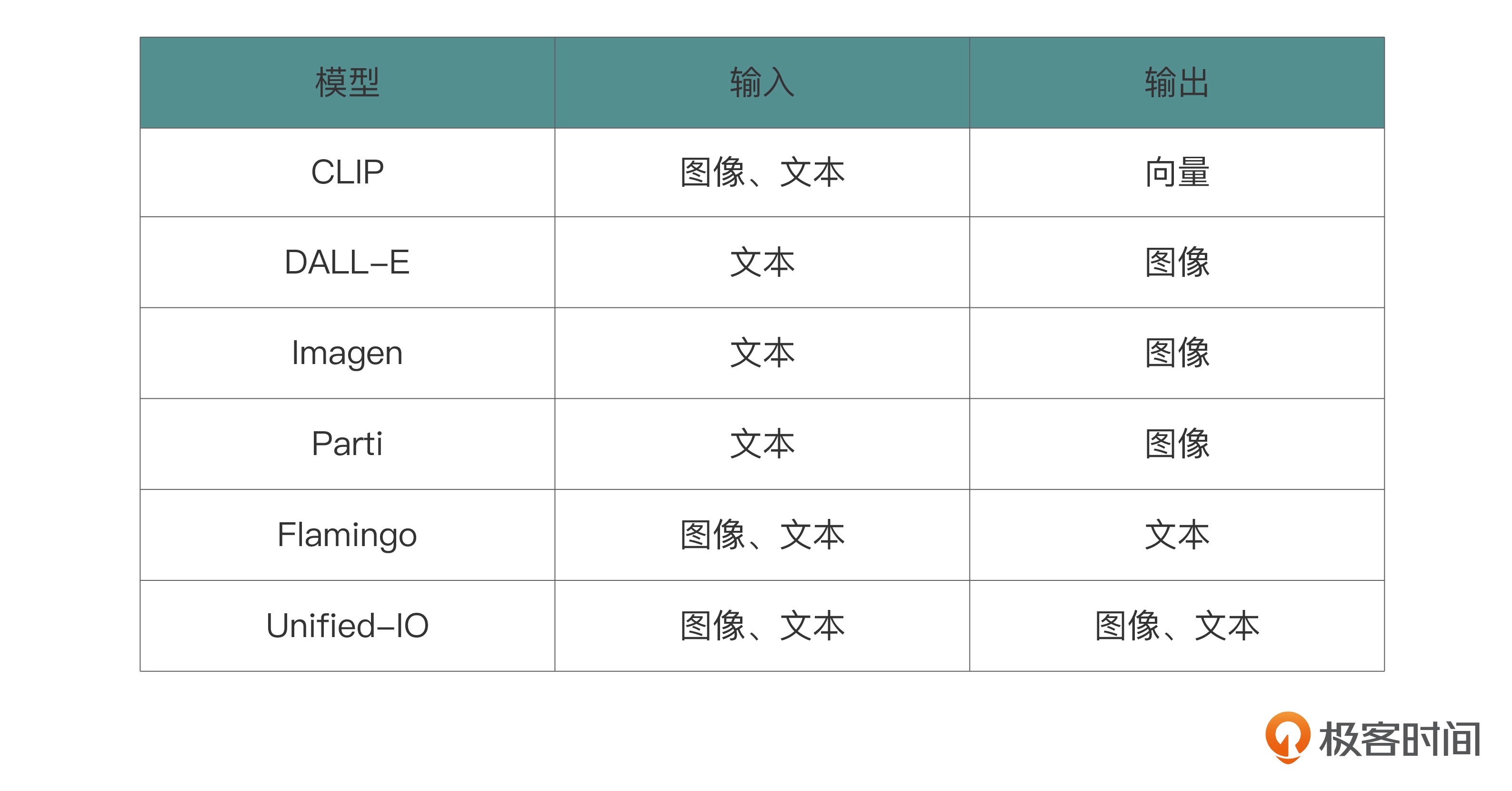
具有代表性的多模态模型¶
2021 年的 CLIP 被认为是视觉和语言处理的基础模型的重大突破。CLIP 包括两个编码器,它们将文本和图像映射到相同的特征空间。使用 CLIP,可以在不进行任何额外训练的情况下解决图像分类问题。
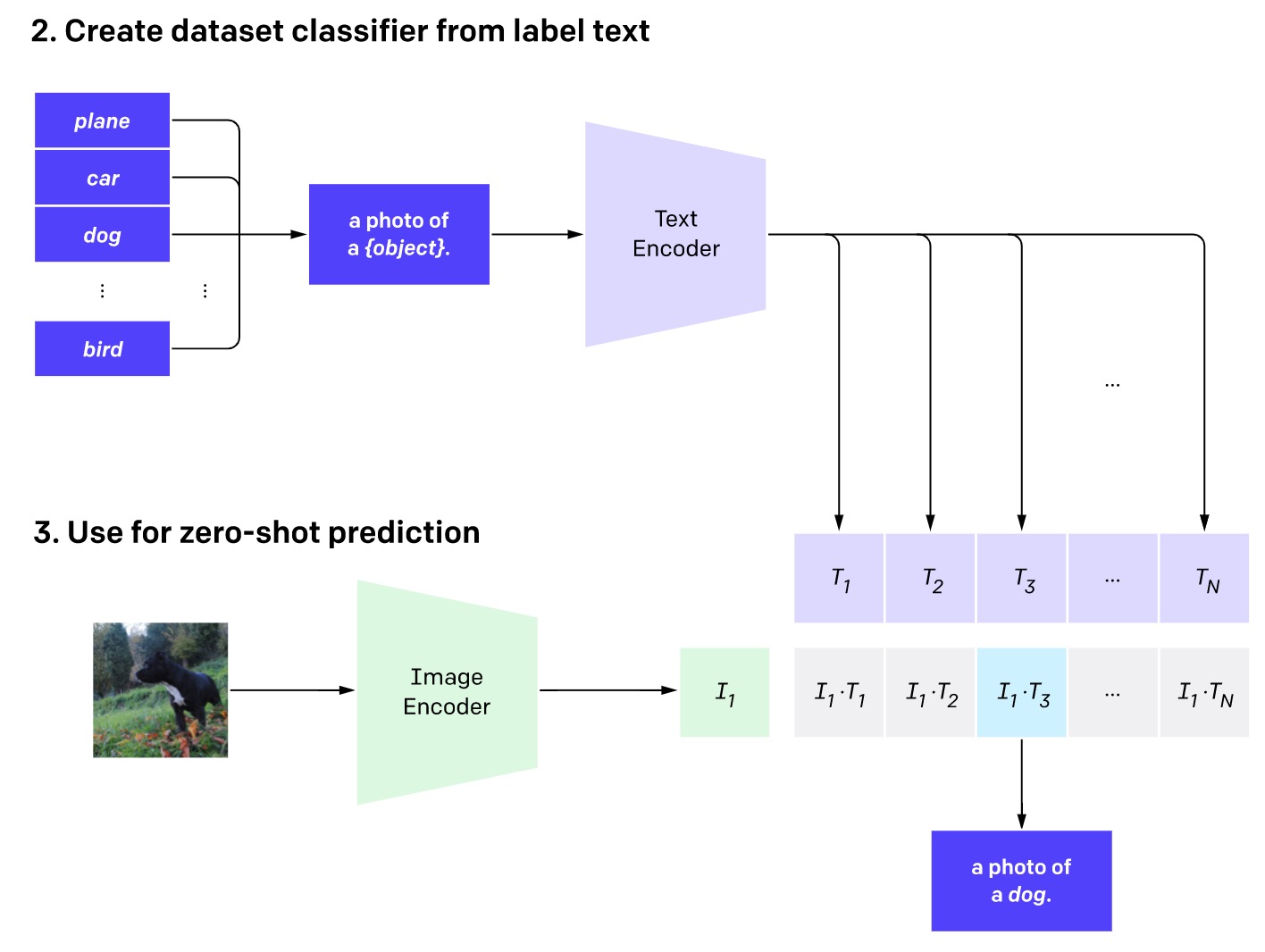
CLIP 用于图像分类具体的机制:首先要将每个候选类别用文本形式表示(例如,“狗的照片”),再输入到文本编码器中。接下来,将要分类的图像输入到图像编码器中。然后计算从图像获取的向量与候选类别得到的多个向量之间的余弦相似度。最后,将具有最高相似度的类别作为输出结果。¶
OpenAI 在 2023 年 3 月 14 日最新发布的 GPT-4 就是一个多模态模型,这也是它与 GPT-3 最大的区别了。它不仅可以接受文本数据作为输入,同样可以接受图像数据作为输入,然后以文本的形式进行输出。
结束语| 人生充满选择, 选择与努力同样重要¶
保持好奇¶
人工智能是一个更新迭代非常快的领域,以前很火的内容,可能没过多久就过时或者很少使用了,比如之前的 RNN 之于现在的 Attention。所以你一定要多看论文,每年的顶会论文都是最好的学习资料。
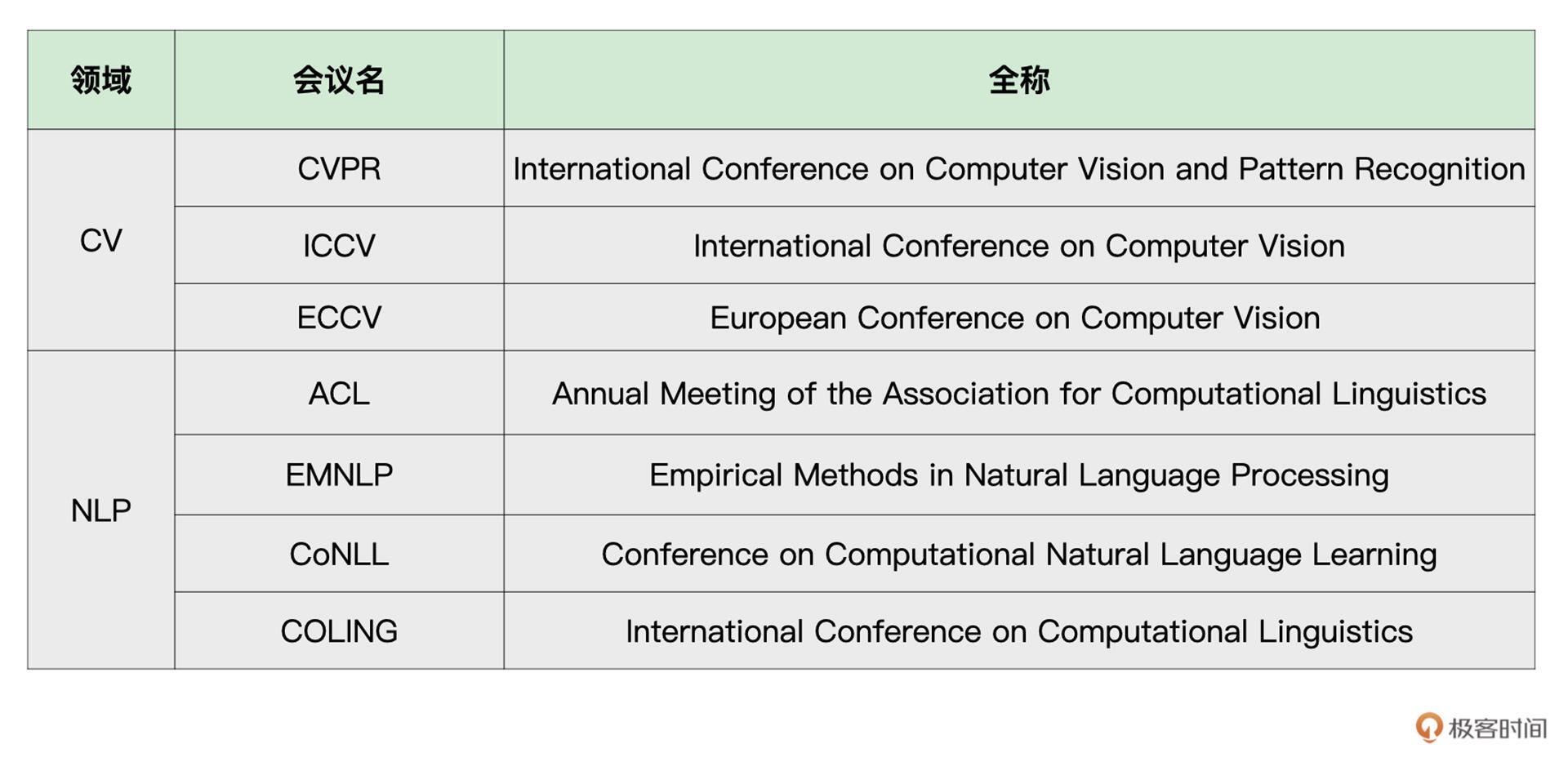
CV 和 NLP 领域的顶会,除此外,还有不少是比较综合性的人工智能会议,比如 IEEE、ICLR 等等¶