推荐系统三十六式¶
目录
模型的角度,将推荐系统的模型分成:
1. 预测评分
2. 预测行为
看问题的角度,看推荐系统中一些永恒存在但是潜在的问题,包括:
1. 冷启动
2. EE 问题(探索与利用问题)
3. 安全问题
两方面的内容:
1. 一个是重新认识推荐系统关键元素的重要性
2. 一个是要建立起两个思维模式
开发一个推荐系统产品,有这么四个关键的元素需要注意:
1. UI 和 UE(权重4)
2. 数据(权重3)
3. 领域知识(权重2)
4. 算法(权重1)
两个思维模式:
1. 目标思维
2. 不确定性思维
为什么负责推荐系统产品的人一定要有不确定性思维:
1. 绝大多数推荐算法都是概率算法,因此本身就无法保证得到确切结果,只是概率上得到好的效果
2. 推荐系统追求的是目标的增长,而不是一城一池的得失
3. 如果去花时间为了一个 Case 而增加补丁,那么付出的成本和得到的收益将大打折扣
4. 本身出现意外的推荐也是有益的,可以探索用户的新兴趣,这属于推荐系统的一个经典问题:EE 问题
内容推荐¶
用户画像¶
1. Personas 属于交互设计领域的概念
2. User Profile 原本用于营销领域
营销人员需要对营销的客户有更精准的认识,从而能够更有针对性地对客户和市场制定营销方案
传统营销领域,是以市场销售人员为第一人称视角去看待客户的,也就是用户画像为营销人员服务
今天在媒体上看到的大多数 “用户画像” 案例分享,都停留在这个意思上
备注
越酷炫的用户画像越没什么用。用户画像应该给机器看,而不是给人看。用户画像是跟着使用效果走的,用户画像本身并不是目的。
推荐系统在对匹配评分前,则首先就要将用户和物品都向量化,这样才能进行计算。而根据推荐算法不同,向量化的方式也不同,最终对匹配评分的做法也不同。用户向量化后的结果,就是 User Profile,俗称 “用户画像”。所以,用户画像不是推荐系统的目的,而是在构建推荐系统的过程中产生的一个关键环节的副产品。
建立用户画像的关键因素:
1. 第一个是维度
2. 第二个是量化
用户画像构建方法分成三类:
1. 第一类就是查户口
直接使用原始数据作为用户画像的内容,如:
注册资料等人口统计学信息,或者购买历史,阅读历史等
除了数据清洗等工作,数据本身并没有做任何抽象和归纳。
这就跟查户口一样,没什么技术含量,但通常对于用户冷启动等场景非常有用。
2. 第二类就是堆数据
方法就是堆积历史数据,做统计工作,这是最常见的用户画像数据,常见的兴趣标签,就是这一类,
就是从历史行为数据中去挖掘出标签,然后在标签维度上做数据统计,用统计结果作为量化结果。
这一类数据贡献了常见的酷炫用户画像。
3. 第三类就是黑盒子
就是用机器学习方法,学习出人类无法直观理解的稠密向量,
也最不被非技术人员重视,但实际上在推荐系统中承担的作用非常大。
比如:
使用潜语义模型构建用户阅读兴趣,
或者使用矩阵分解得到的隐因子,
或者使用深度学习模型学习用户的 Embedding 向量。
这一类用户画像数据因为通常是不可解释,不能直接被人看懂。
由各种各样的数据,经过清洗、统计、预处理、特征工程等方式,得到了用户的特征。在这个基础上,分出两条路,一条路是对特征的归纳和总结,得到用户画像,这个是给人看的,用于运营和产品了解用户和获取新客户;另一条路是通过建模的手段,得到用户对某类物品的偏好预测,这个是给机器看的,用于精细化地推荐。
用物品和用户的文本信息构建出一个基础版本的用户画像:
1. 把所有非结构化的文本结构化,去粗取精,保留关键信息
最关键也最基础,其准确性、粒度、覆盖面都决定了用户画像的质量
2. 根据用户行为数据把物品的结构化结果传递给用户,与用户自己的结构化信息合并
一. 结构化文本¶
从物品端的文本信息,利用成熟的 NLP 算法分析得到的信息有下面几种:
1. 关键词提取
最基础的标签来源,也为其他文本分析提供基础数据
常用 TF-IDF 和 TextRank。
2. 实体识别
人物、位置和地点、著作、影视剧、历史事件和热点事件等,
常用基于词典的方法结合 CRF 模型。
3. 内容分类
将文本按照分类体系分类,用分类来表达较粗粒度的结构化信息。
4. 文本
在无人制定分类体系的前提下,无监督地将文本划分成多个类簇也很常见,
别看不是标签,类簇编号也是用户画像的常见构成。
5. 主题模型
从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况,也很实用,
其实这也是一种聚类思想,主题向量也不是标签形式,也是用户画像的常用构成。
6. 嵌入
“嵌入”也叫作 Embedding,从词到篇章,无不可以学习这种嵌入表达。
嵌入表达是为了挖掘出字面意思之下的语义信息,并且用有限的维度表达出来。
TF-IDF:
TF 全称就是 Term Frequency,是词频的意思 在要提取关键词的文本中出现的次数 IDF 就是 Inverse Document Frequency 是逆文档频率的意思 提前统计好的,在已有的所有文本中, 统计每一个词出现在了多少文本中,记为 n,也就是文档频率 一共有多少文本,记为 N TF-IDF 提取关键词的思想来自信息检索领域,其实思想很朴素,包括了两点: a. 在一篇文字中反复出现的词会更重要 b. 在所有文本中都出现的词更不重要
TextRank:
a. 文本中,设定一个窗口宽度,比如 K 个词,统计窗口内的词和词的共现关系,将其看成无向图。 图就是网络,由存在连接关系的节点构成, 所谓无向图,就是节点之间的连接关系不考虑从谁出发,有关系就对了; b. 所有词初始化的重要性都是 1; c. 每个节点把自己的权重平均分配给“和自己有连接“的其他节点; d. 每个节点将所有其他节点分给自己的权重求和,作为自己的新权重; e. 如此反复迭代第 3、4 两步,直到所有的节点权重收敛为止。 通过 TextRank 计算后的词语权重,呈现出这样的特点:那些有共现关系的会互相支持对方成为关键词。内容分类:
短文本分类方面经典的算法是 SVM ,在工具上现在最常用的是 Facebook 开源的 FastText
实体识别:
对于序列标注问题,通常的算法就是隐马尔科夫模型(HMM)或者条件随机场(CRF) 实体识别还有比较实用化的非模型做法:词典法 工业级别的工具上 spaCy 比 NLTK 在效率上优秀一些。
聚类:
开源的 LDA 训练工具有 Gensim,PLDA 等可供选择
词嵌入:
Word Embedding Word2Vec 是用浅层神经网络学习得到每个词的向量表达, Word2Vec 最大的贡献在于一些工程技巧上的优化,使得百万词的规模在单机上可以几分钟轻松跑出来
二. 标签选择¶
最常用的是两个方法:卡方检验(CHI)和信息增益(IG)。基本思想是:
1. 把物品的结构化内容看成文档
2. 把用户对物品的行为看成是类别
3. 每个用户看见过的物品就是一个文本集合
4. 在这个文本集合上使用特征选择算法选出每个用户关心的东西
卡方检验:
CHI:
信息增益:
IG: Information Gain
用户画像的构建方法:
1. 查户口
2. 堆数据
3. 黑盒子
内容推荐¶
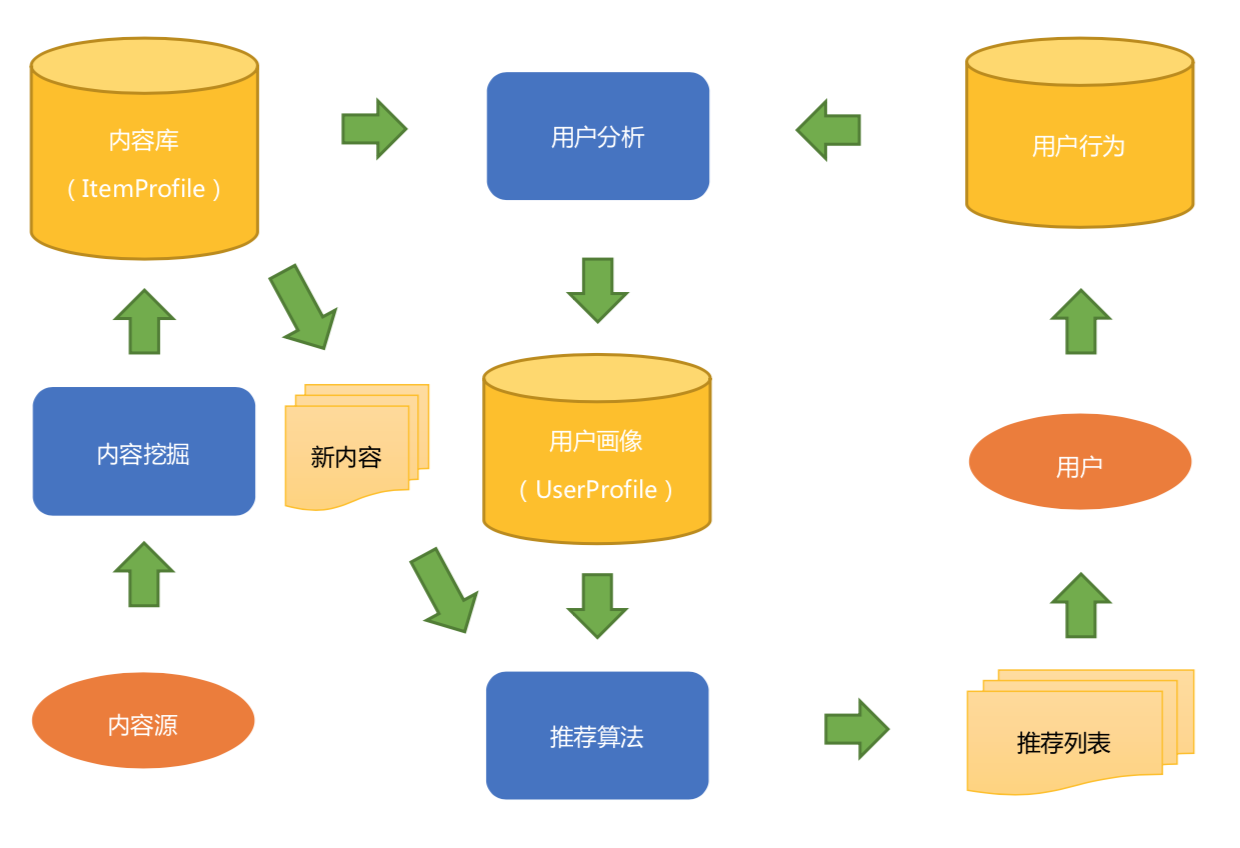
基于内容的推荐框架:
1. 内容源
2. 内容分析和用户分析
3. 内容推荐算法
近邻推荐¶
协同过滤是一个比较大的算法范畴。通常划分为两类:
1. 基于记忆的协同过滤(Memory-Based)
2. 基于模型的协同过滤(Model-Based)
基于用户的协同过滤¶
基于记忆的协同过滤的一种 —— 基于用户,或者叫做 User-Based, User to User。
先根据历史消费行为帮你找到一群和你口味很相似的用户;然后根据这些和你很相似的用户再消费了什么新的、你没有见过的物品,都可以推荐给你。这其实也是一个给用户聚类的过程,把用户按照兴趣口味聚类成不同的群体,给用户产生的推荐就来自这个群体的平均值;所以要做好这个推荐,关键是如何量化 “口味相似” 这个看起来很直接简单的事情。
原理:
1. 准备用户向量
这个向量有这么三个特点:
a) 向量的维度就是物品的个数;
b) 向量是稀疏的,也就是说并不是每个维度上都有数值
c) 向量维度上的取值可以是简单的 0 或者 1
1 表示喜欢过,0 表示没有
2. 用每一个用户的向量,两两计算用户之间的相似度
设定一个相似度阈值或者设定一个最大数量,为每个用户保留与其最相似的用户。
3. 为每一个用户产生推荐结果
实践¶
构造矩阵:
典型的稀疏矩阵存储格式: a. CSR:这个存储稍微复杂点,是一个整体编码方式。它有三个组成:数值、列号和行偏移共同编码。 b. COO:这个存储方式很简单,每个元素用一个三元组表示(行号,列号,数值),只存储有值的元素,缺失值不存储。
相似度计算:
相似度计算是个问题: a. 首先是单个相似度计算问题 降低相似度计算复杂度的办法有两种: 1) 对向量采样计算 这个算法由 Twitter 提出,叫做 DIMSUM 算法,已经在 Spark 中实现了 2) 向量化计算 想办法把循环转换成向量来直接计算 b. 如果用户量很大,两两之间计算代价就很大 有两个办法来缓解这个问题: 1) 将相似度计算拆成 Map Reduce 任务 2) 不用基于用户的协同过滤推荐计算:
节省计算的方法: a. 只有相似用户喜欢过的物品需要计算 b. 把计算过程拆成 Map Reduce 任务
一些改进:
a. 惩罚对热门物品的喜欢程度 热门的东西很难反应出用户的真实兴趣 b. 增加喜欢程度的时间衰减,一般使用一个指数函数
应用场景¶
基于用户的协同过滤有两个产出:
1. 相似用户列表
2. 基于用户的推荐结果
基于物品的协同过滤¶
通常也被叫作 Item-Based
基于物品的协同过滤算法诞生于 1998 年,是由亚马逊首先提出的,并在 2001 年由其发明者发表了相应的论文( Item-Based Collaborative Filtering Recommendation Algorithms )
原理¶
基于用户的协同过滤有这么几个问题:
1. 用户数量往往比较大,计算起来非常吃力,成为瓶颈
2. 用户的口味其实变化还是很快的,不是静态的,所以兴趣迁移问题很难反应出来
3. 数据稀疏,用户和用户之间有共同的消费行为实际上是比较少的
而且一般都是一些热门物品,对发现用户兴趣帮助也不大
基于物品的算法怎么就解决了上面这些问题:
1. 物品的数量,或者严格的说,可以推荐的物品数量往往少于用户数量;
所以一般计算物品之间的相似度就不会成为瓶颈。
2. 物品之间的相似度比较静态,它们变化的速度没有用户的口味变化快;
所以完全解耦了用户兴趣迁移这个问题。
3. 物品对应的消费者数量较大,对于计算物品之间的相似度稀疏度是好过计算用户之间相似度的
计算物品相似度¶
物品之间的相似度计算是这个算法最可以改进的地方。通常的改进方向有下面两种:
1. 物品中心化
2. 用户中心化
计算推荐结果¶
有两种应用场景:
1. 第一种属于 TopK 推荐,形式上也常常属于类似 “猜你喜欢” 这样的
2. 第二种属于相关推荐
相似度¶
推荐算法分为两个门派:
一个是机器学习派
另一个就是相似度门派
相似度的计算方法:
1. 欧氏距离
2. 余弦相似度
3. 皮尔逊相关度
4. 杰卡德(Jaccard)相似度
矩阵分解¶
近邻模型的问题:
1. 物品之间存在相关性,信息量并不随着向量维度增加而线性增加;
2. 矩阵元素稀疏,计算结果不稳定,增减一个向量维度,导致近邻结果差异很大的情况存在。
备注
【定义】就是把原来的大矩阵,近似分解成两个小矩阵的乘积,在实际推荐计算时不再使用大矩阵,而是使用分解得到的两个小矩阵。
个人成长¶
你得具备三个核心素质:
1. 有较强的工程能力,能快速交付高效率少 Bug 的算法实现,虽然项目中不一定要写非常大量的代码
虽然世人目光都聚焦在高大上的推荐算法上,
然而算法模块确实是容易标准化的,开源算法实现一般也能满足中小厂的第一版所需,
而实现整个推荐系统的路径却不可复制,这个实现路径就是工程。
2. 有较强的理论基础,能看懂最新的论文,虽然不一定要原创出漂亮的数学模型
对于一个从事推荐系统的工程师来说,一定需要有数理基础。
高等数学、概率统计、线性代数
3. 有很好的可视化思维,将不直观的数据规律直观地呈现出来,向非工程师解释清楚问题所在,原理所在
在做数据分析和清洗工作时,需要想办法直观地呈现出来,
在工具层面,掌握一些常用的绘图工具就很有必要了:
Python 中的 Matplotlib
R 语言中的 ggplot2
Linux 命令里面的 Gnuplot
Windows 里的 Excel
加分项:
1. 学习能力
2. 沟通能力
3. 表达能力