攻克视频技术¶
2013 年我还在浙大读硕士的时候,我就开始了视频编码与传输方向的研究。之后一步步转向视频编码的应用、传输策略的优化;再到高阶的视频网络传输、带宽预测、抗丢包等网络对抗技术;再后来就是人脸识别、表情识别和人流量检测等各种有意思的视频 AI 算法的落地。
目前是在声网 Agora 担任视频专家,主要从事视频编码和传输方面的工作。
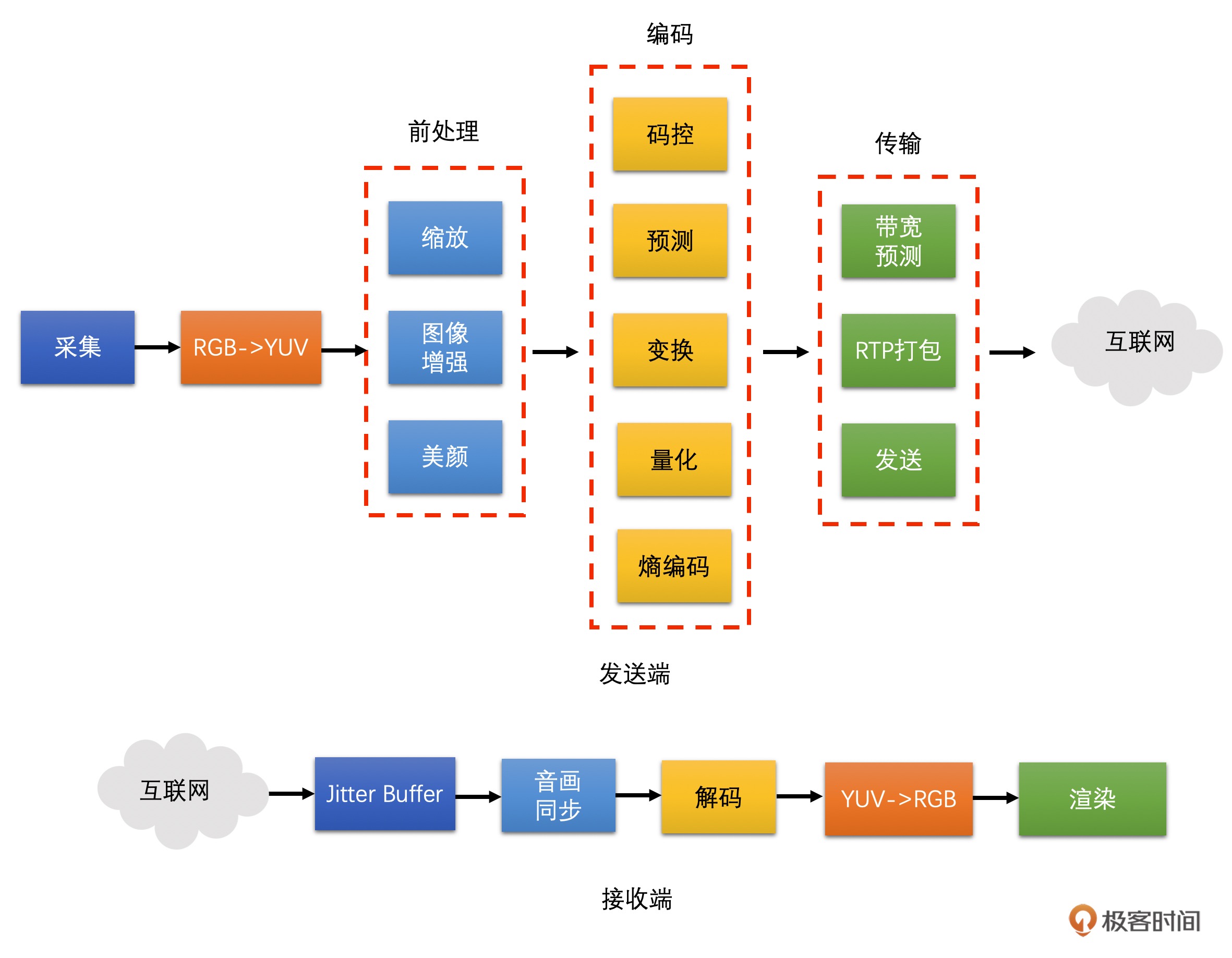
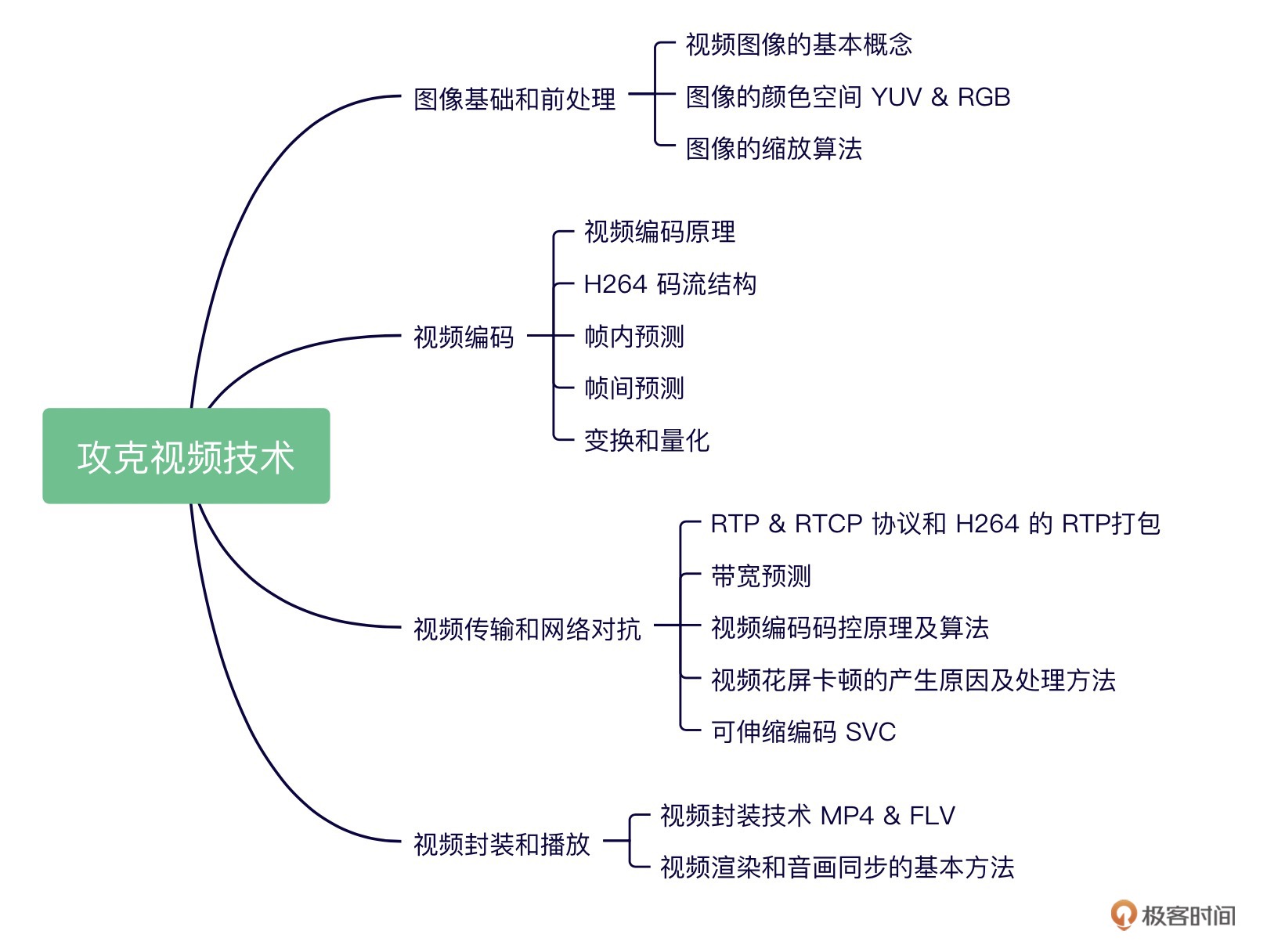
图像基础和前处理 (3 讲)¶
01| 基本概念: 从参数的角度看视频图像¶
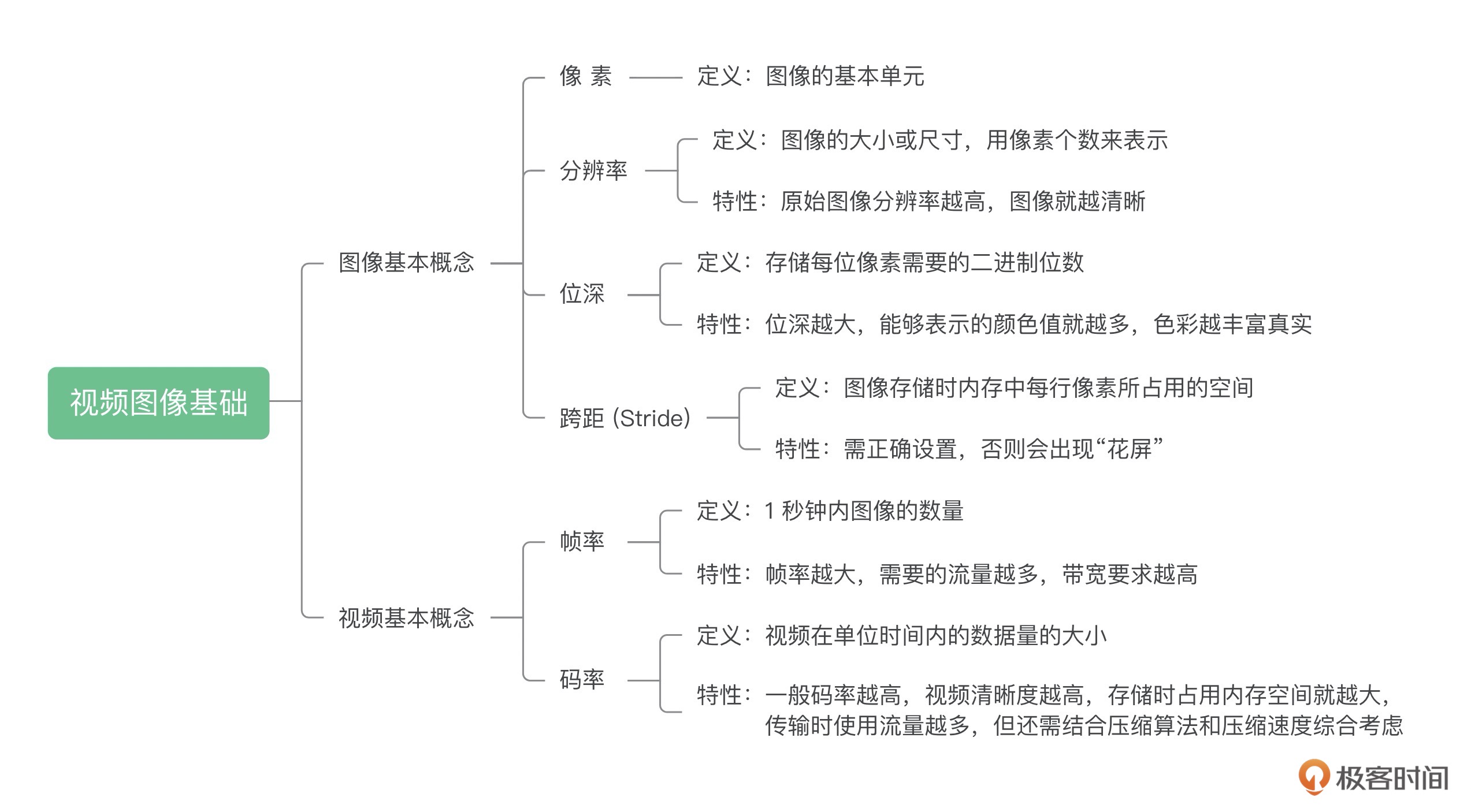
图像的基本概念:
像素
分辨率
位深
通常 R、G、B 各占 8 个位, 这个 8bit 就是位深
8 个位能表示 256 种颜色值,那 3 个通道的话就是 256 的 3 次方个颜色值
Stride
跨距,是图像存储的时候有的一个概念。它指的是图像存储时内存中每行像素所占用的空间。
视频行业常见的分辨率有:
QCIF(176x144)、CIF(352x288)、D1(704x576 或 720x576),
还有我们比较熟悉的 360P(640x360)、720P(1280x720)、1080P(1920x1080)、4K(3840x2160)、8K(7680x4320)
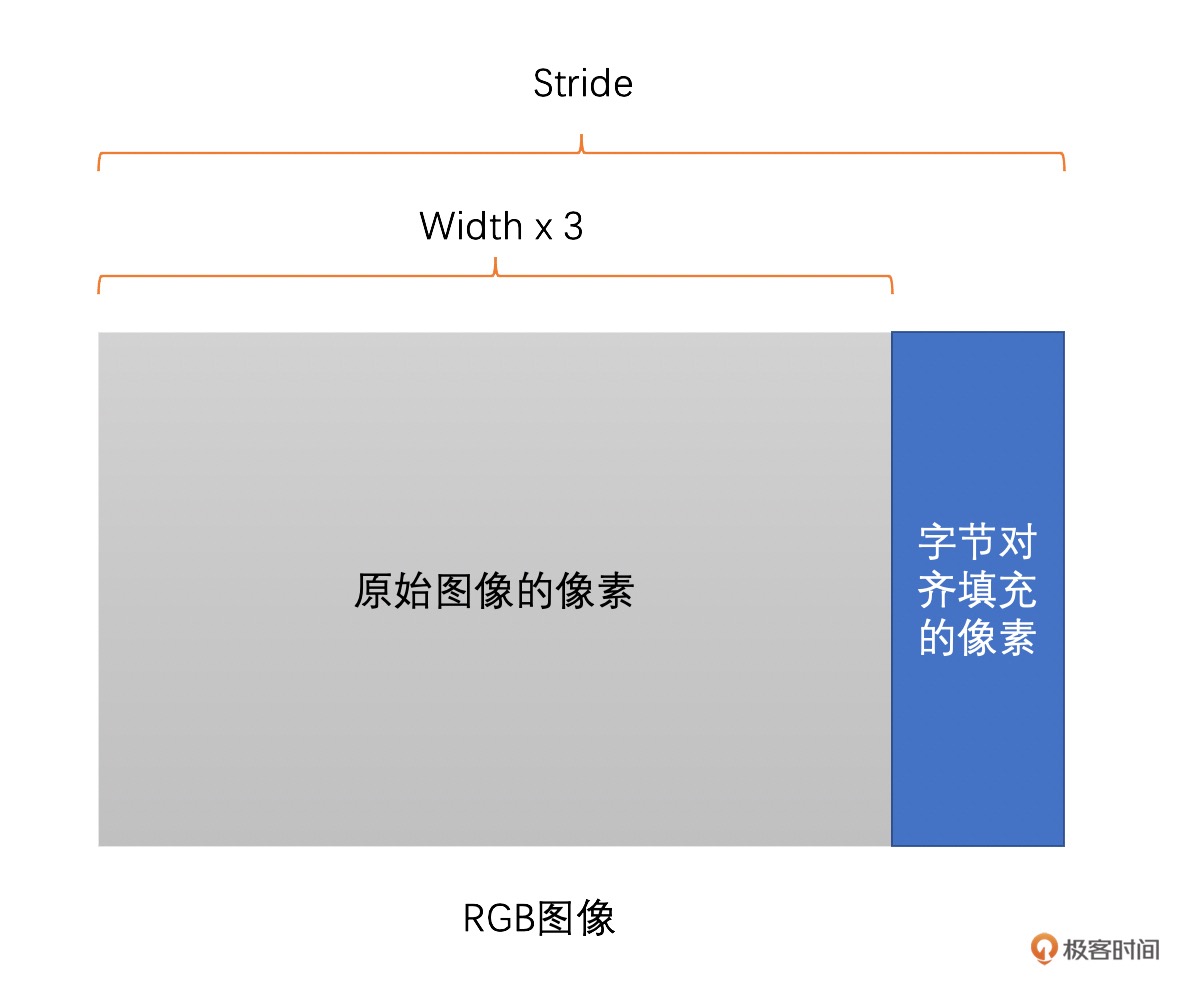
一张 RGB 图像,分辨率是 1278x720。我们将它存储在内存当中,一行像素需要 1278x3=3834 个字节,3834 除以 16 无法整除。因此,没有 16 字节对齐。所以如果需要对齐的话,我们需要在 3834 个字节后面填充 6 个字节,也就是 3840 个字节做 16 字节对齐,这样这幅图像的 Stride 就是 3840 了。¶
视频的基本概念:
帧率
1 秒钟内图像的数量就是帧率
据研究表明,一般帧率达到 10~12 帧每秒,人眼就会认为是流畅的了。
在电影院看的电影帧率一般是 24fps(帧每秒),监控行业常用 25fps
常用的帧率有 15fps、24fps 和 30fps
码率
视频在单位时间内的数据量的大小,一般是 1 秒钟内的数据量
02| YUV & RGB¶
RGB¶
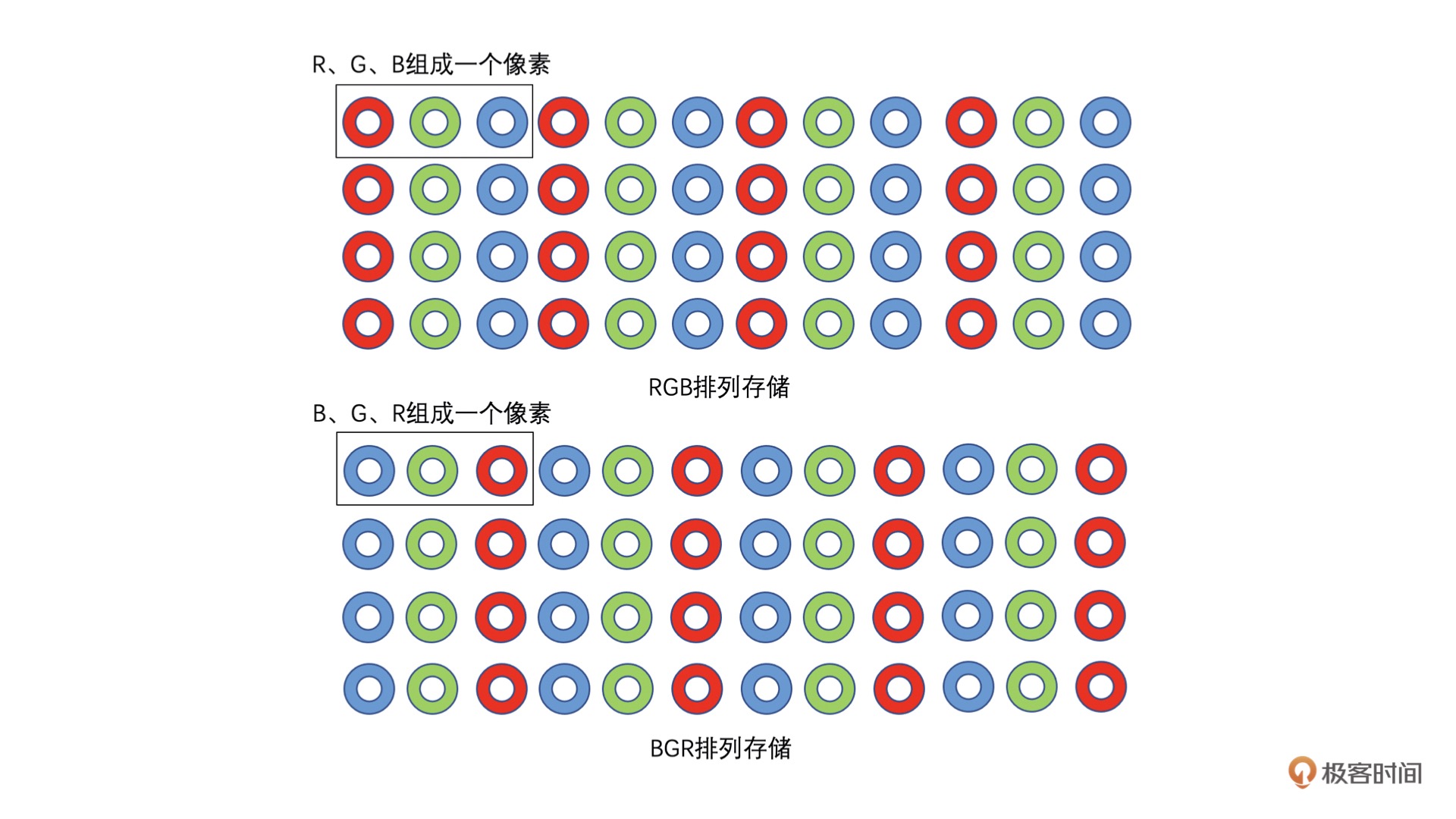
RGB 图像像素中 R、G、B 三个值并不一定是按 R、G、B 顺序排列的,也有可能是 B、G、R 顺序排列。¶
备注
因为 R、G、B 三个颜色是有相关性的,所以不太方便做图像压缩编码。所谓相关性是指一幅图像在 RGB 格式的时候,将 R、G、B 三个通道分离开来当作图像来看的话,R、G、B 三张图像内容几乎是一样的,只是颜色不同而已。具有相关性,如果拿来编码的话,三张图像同等重要,而且轮廓还差不多,但颜色又不同,因此不好编码。而 YUV 不同,YUV 中只有 Y 是图像的大体轮廓,没有颜色信息。U、V 是颜色信息。三张图像相互独立。并且人眼对于色彩信息相比图像的轮廓信息不敏感些。我们可以缩小 U、V 的大小,比如 YUV420 中 U、V 只有 Y 的 1/4 大小,本身就相比于 RGB 图像小了一半。然后我们编码的时候 Y、U、V 相关性很小,可以独立编码,也很方便。
YUV¶
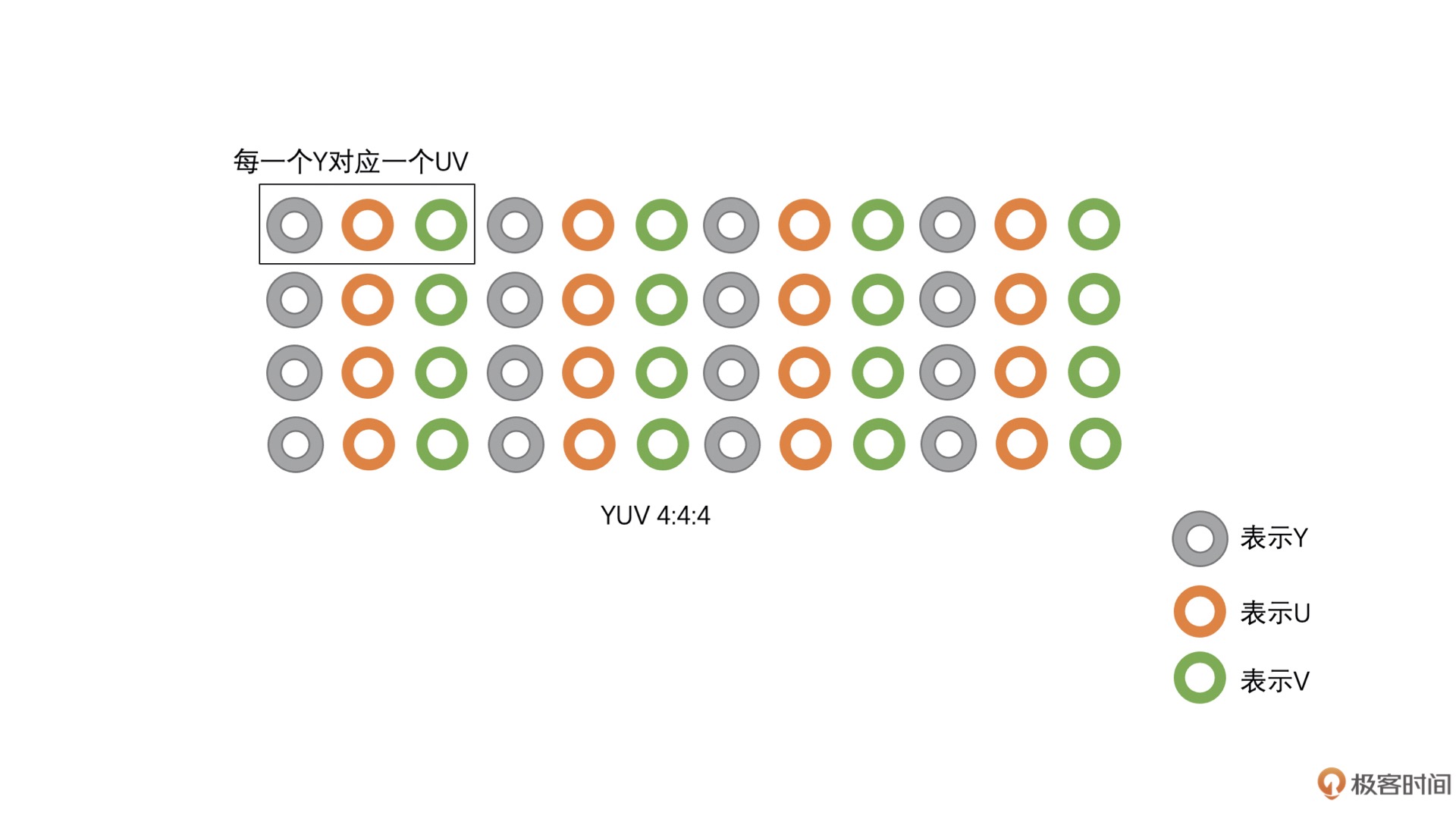
YUV 4:4:4¶
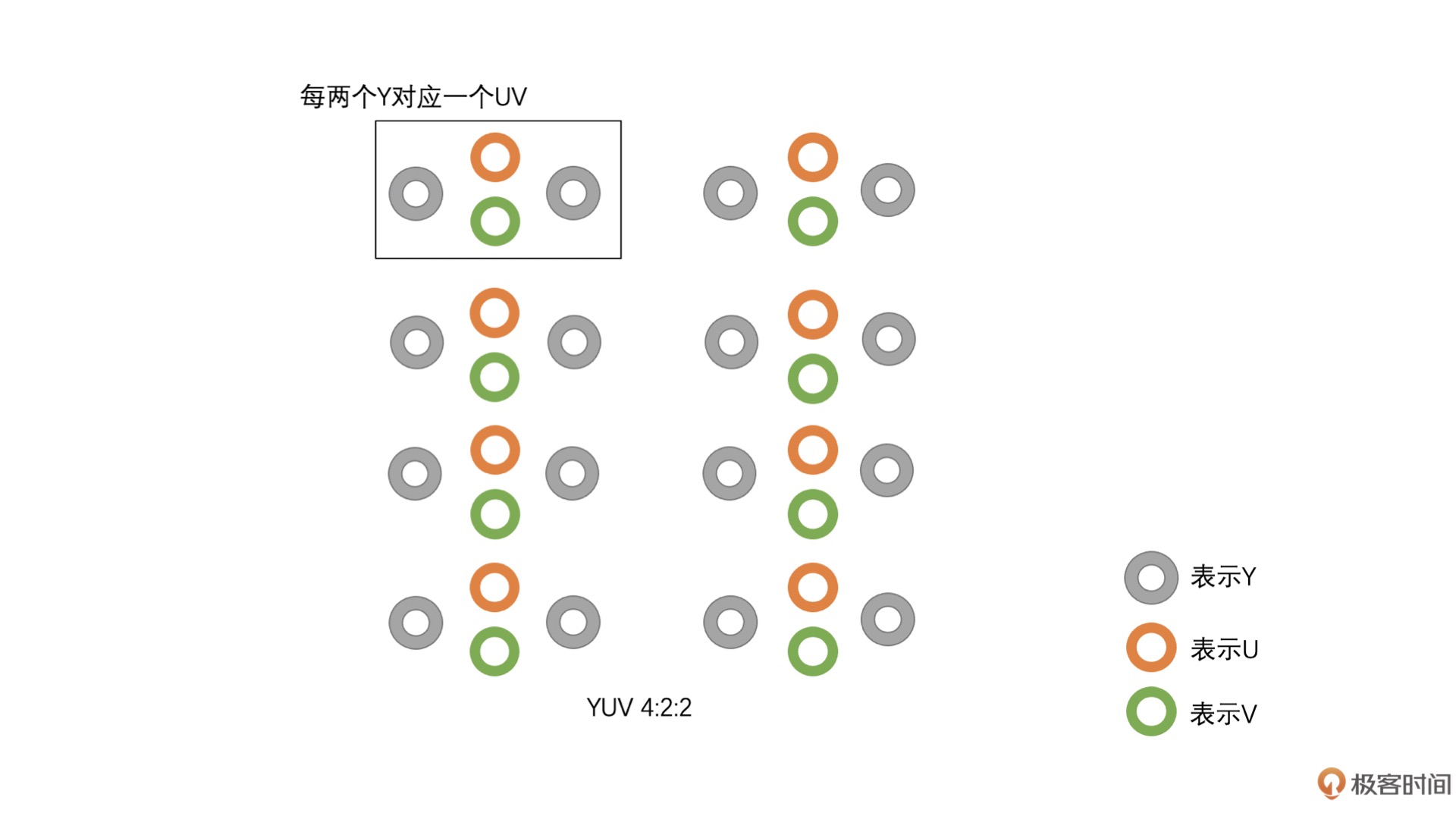
YUV 4:2:2¶
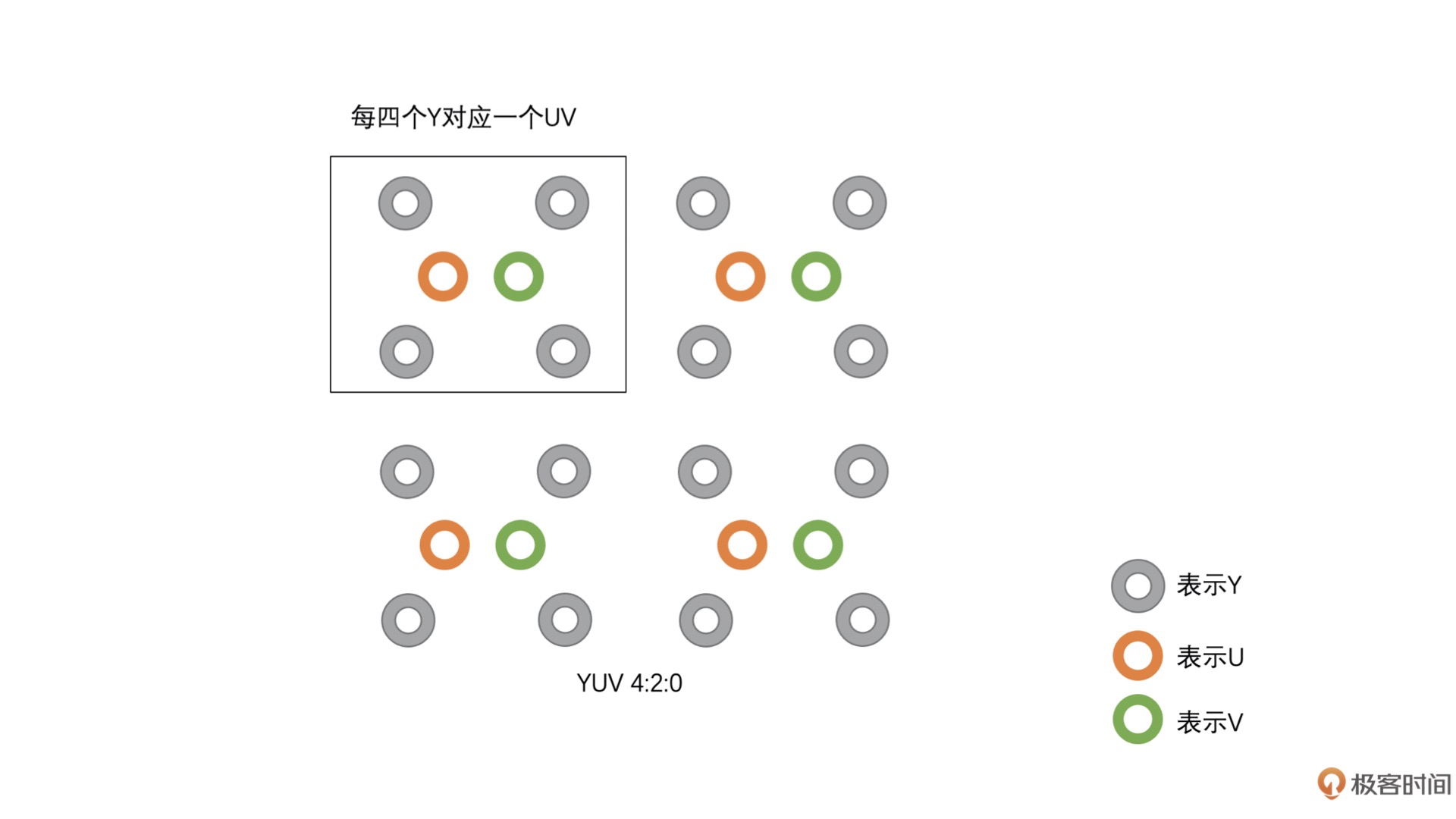
YUV 4:2:0¶
YUV 类型的存储方式¶
YUV 存储方式主要分为两大类:
Planar
Packed
Planar 格式的 YUV 是先连续存储所有像素点的 Y,然后接着存储所有像素点的 U,之后再存储所有像素点的 V,也可以是先连续存储所有像素点的 Y,然后接着存储所有像素点的 V,之后再存储所有像素点的 U。
Packed 格式的 YUV 是先存储完所有像素的 Y,然后 U、V 连续的交错存储。
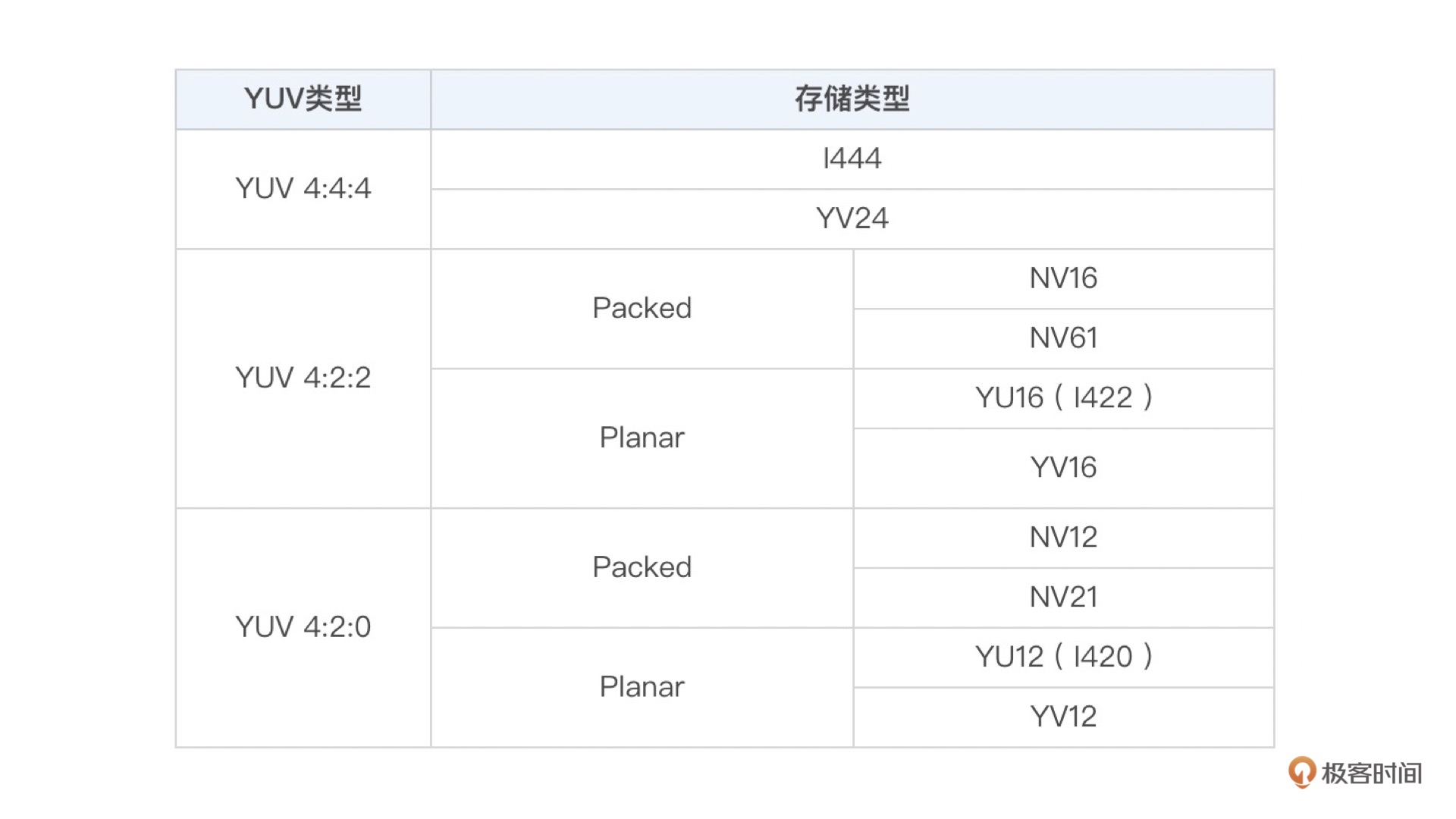
YUV 颜色空间的主要类型和存储方式¶
YUV 4:4:4¶
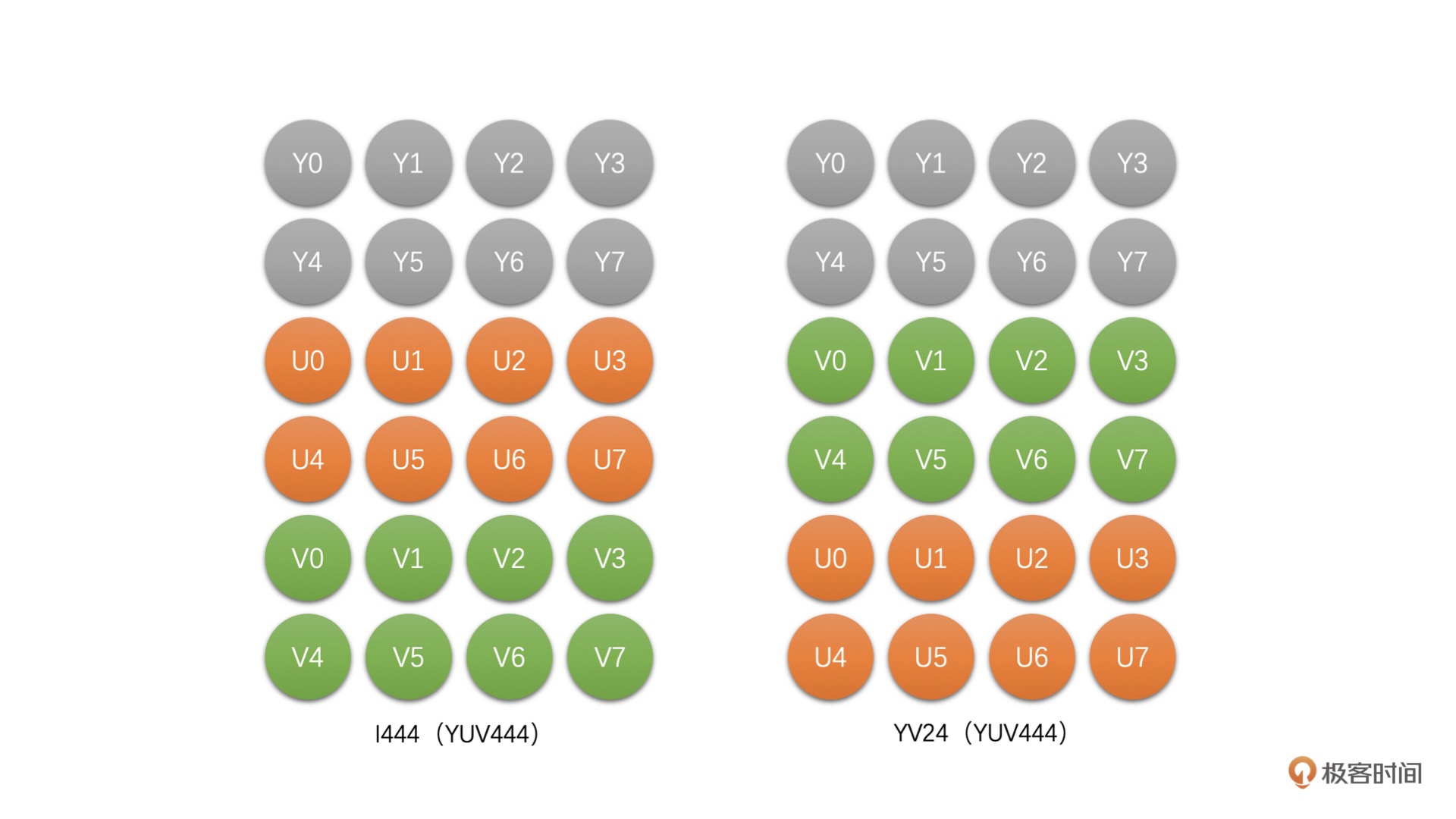
这种类型的 YUV 非常简单(I444, YV24)¶
YUV 4:2:2¶
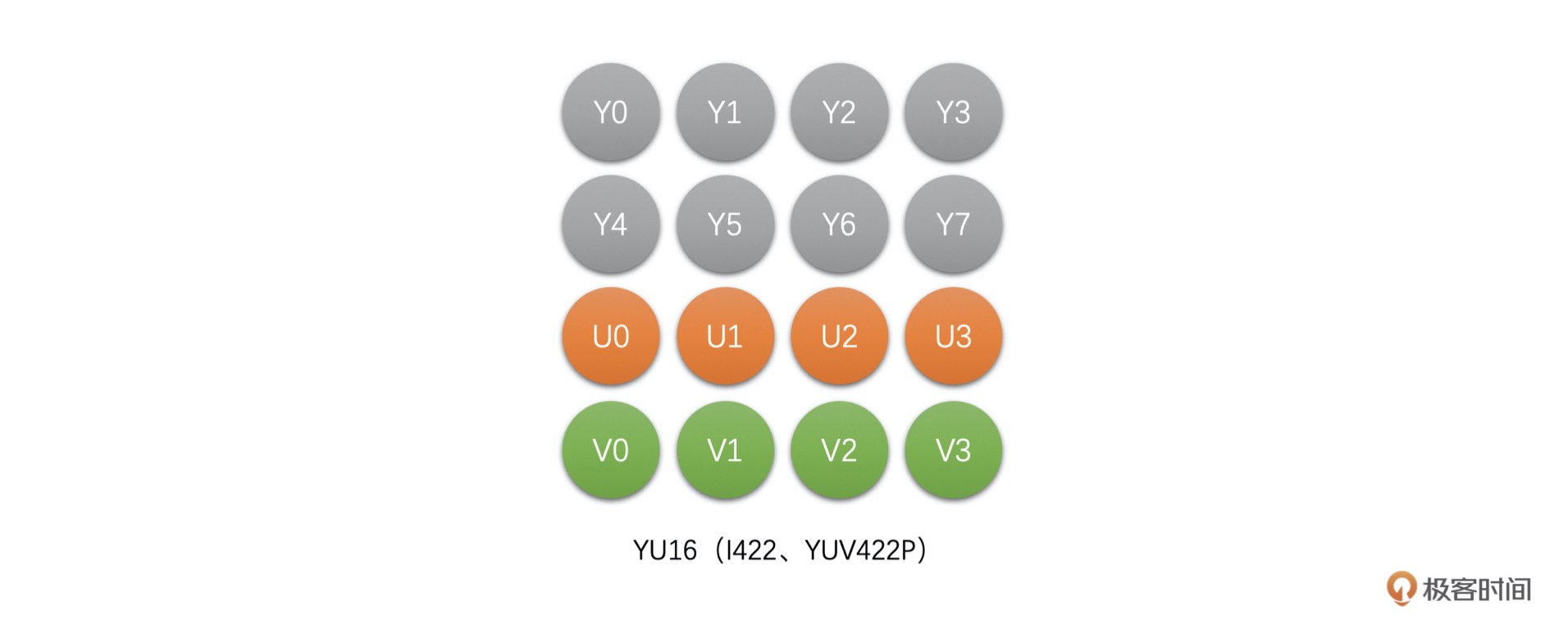
YU16(或者称为 I422、YUV422P):该类型是 Planar 格式,先存储完 Y,再存储 U,之后存储 V。¶
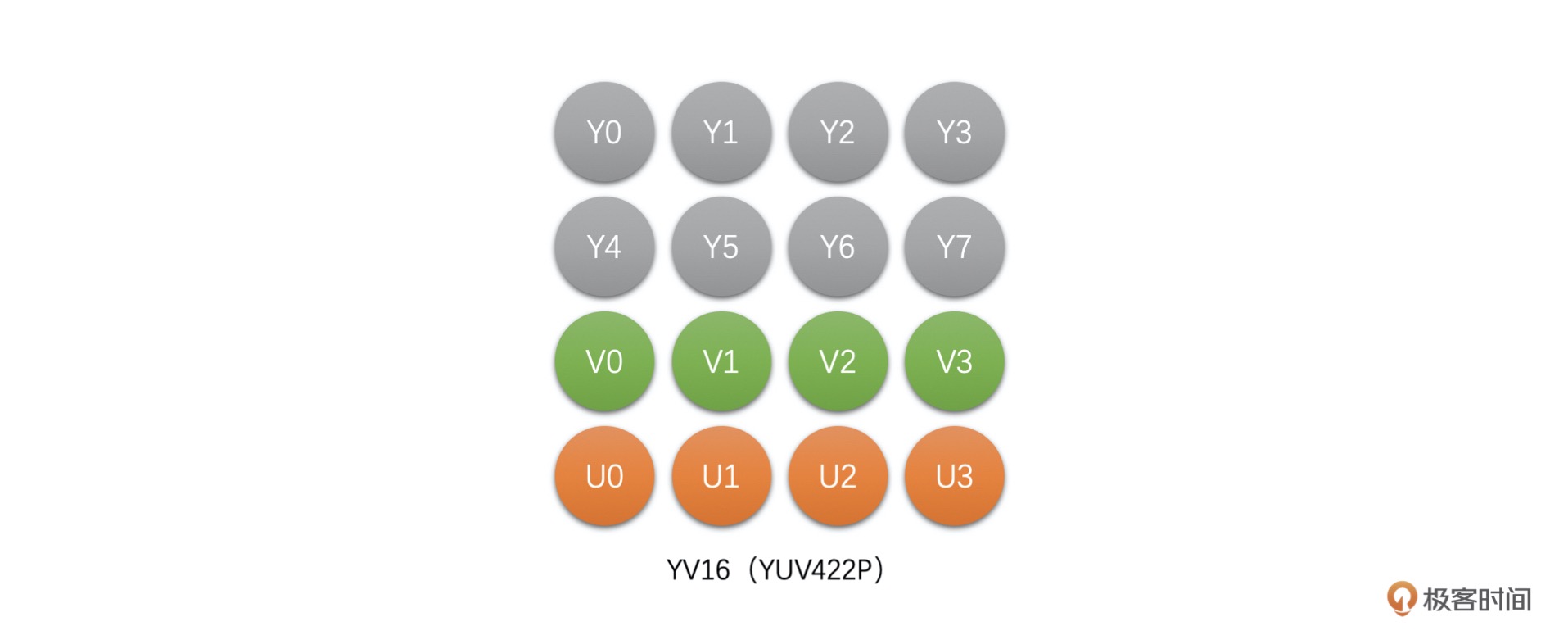
YV16(YUV422P):该类型也是 Planar 格式,先存储完 Y,再存储 V,之后存储 U。¶
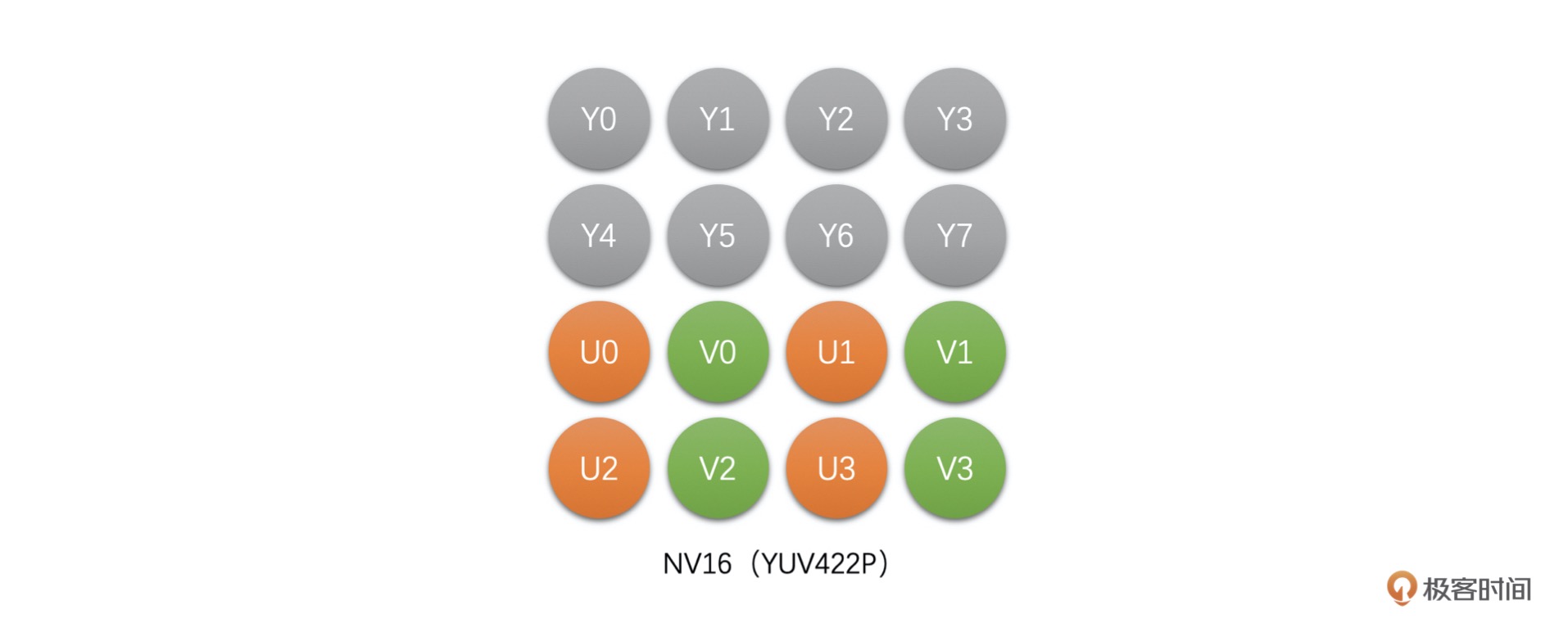
NV16(YUV422SP):这种类型是 Packed 格式,先存储完 Y,之后 U、V 连续交错存储。¶
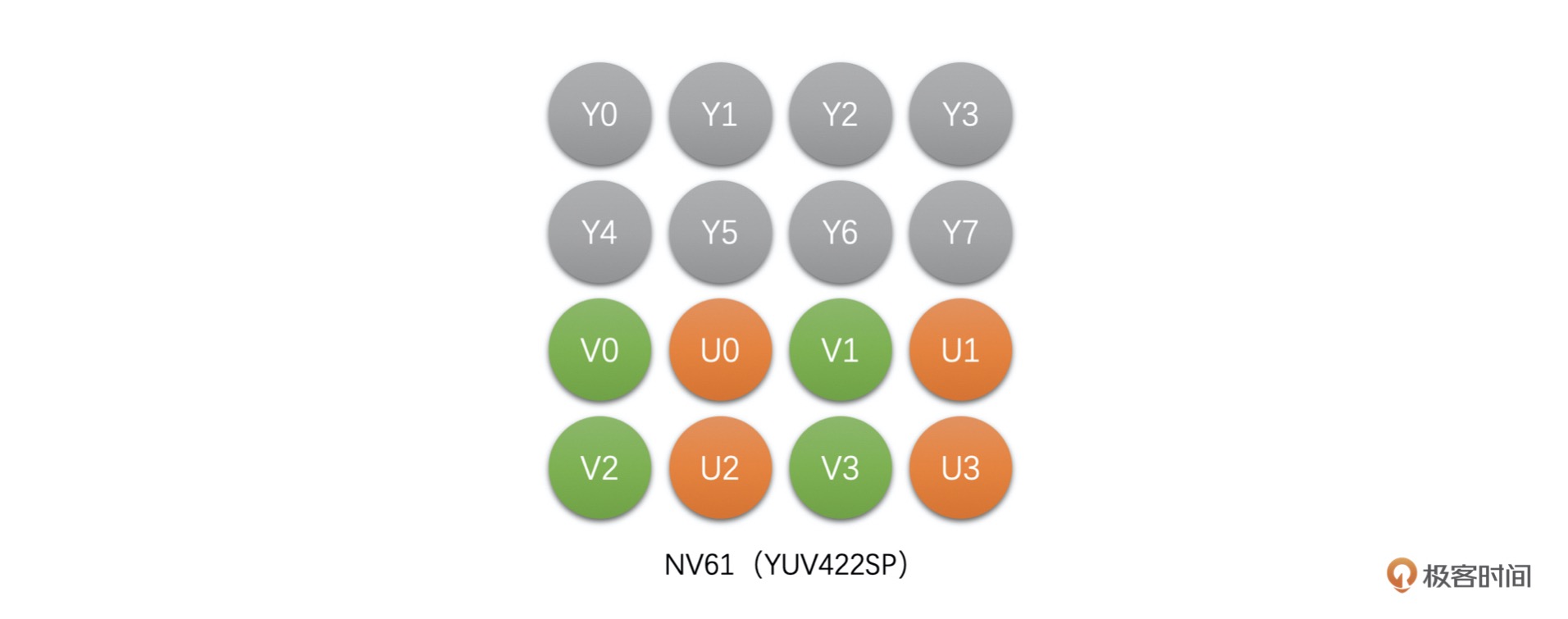
NV61(YUV422SP):这种也是 Packed 格式,与 NV16 不同,这种格式是先存储完 Y,之后 V、U 连续交错存储。¶
备注
4 x 2 像素的 YUV 4:2:2 只需要 16 个字节,而 RGB 图像则需要 24 个字节。也就是说,如果是 8bit 图像,那么 RGB 每一个像素需要 3 个字节,而 YUV 4:2:2 只需要 2 个字节。
YUV 4:2:0¶
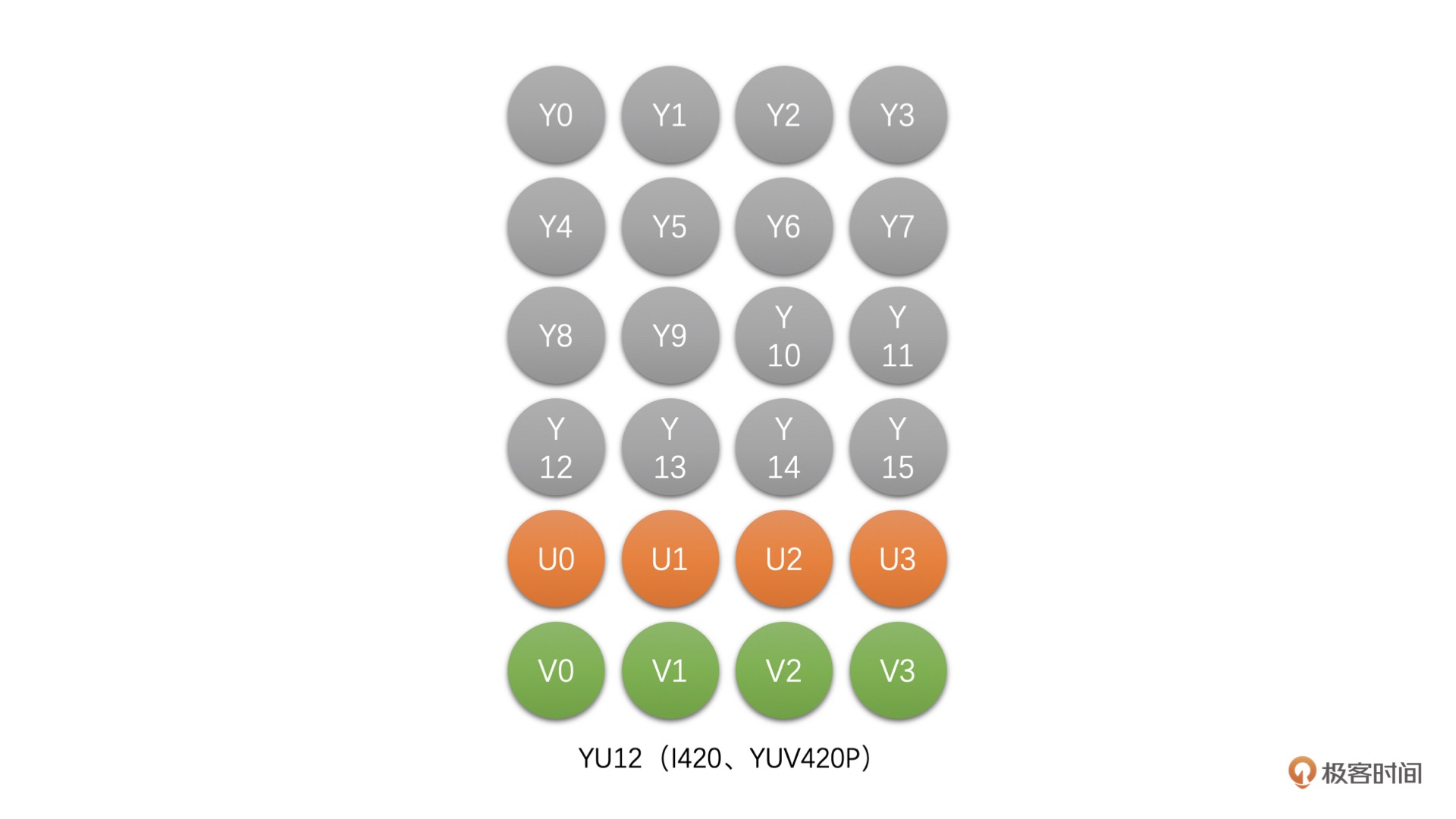
YU12(I420、YUV420P):这种类型是 Planar 格式,先存储完 Y,再存储 U,之后存储 V。例如,4 x 4 像素的 YU12 存储图如下图所示:¶
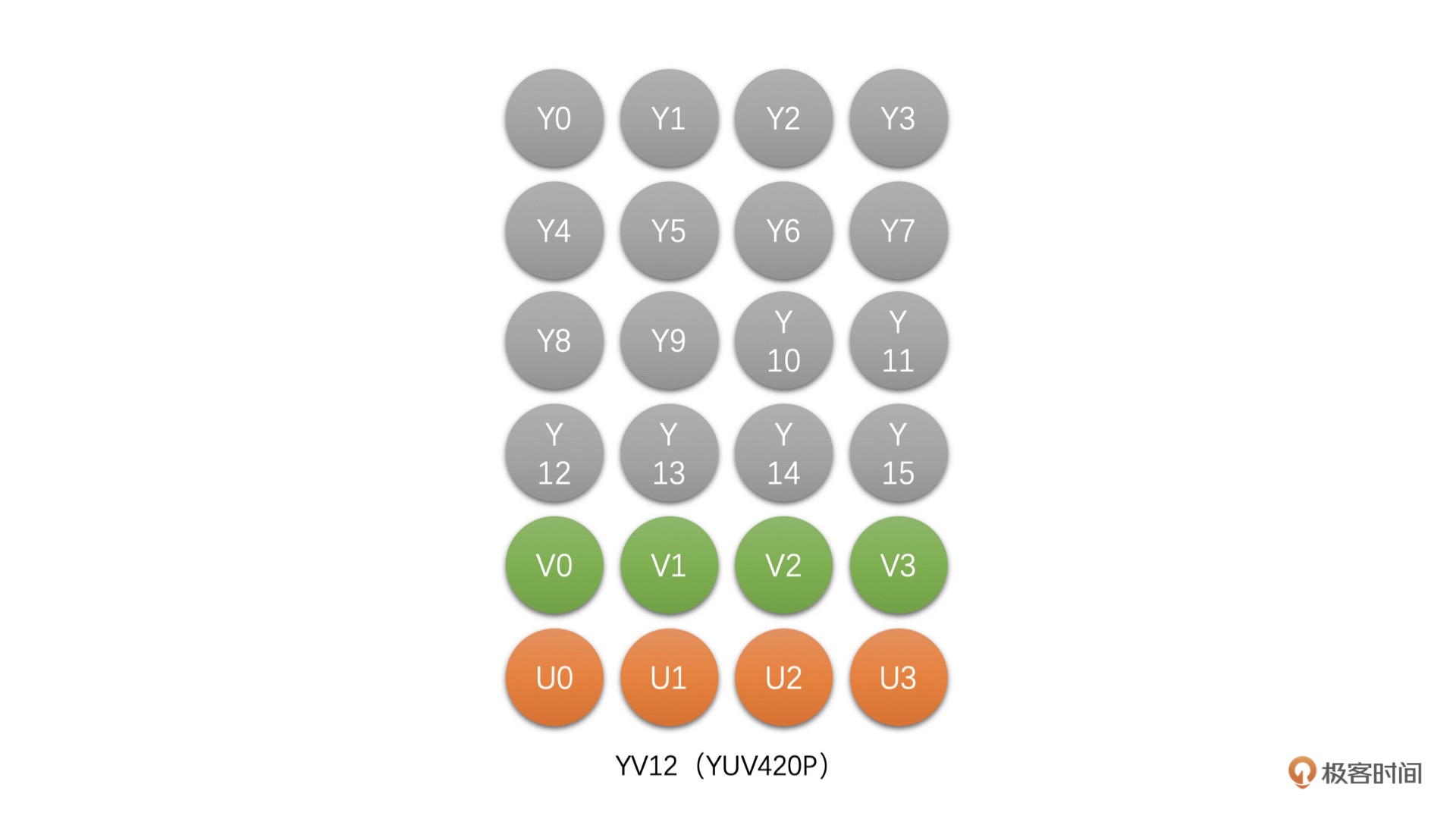
YV12(YUV420P):该类型也是 Planar 格式,先存储完 Y,再存储 V,之后存储 U。例如,4 x 4 像素的 YV12 存储图如下图所示:¶
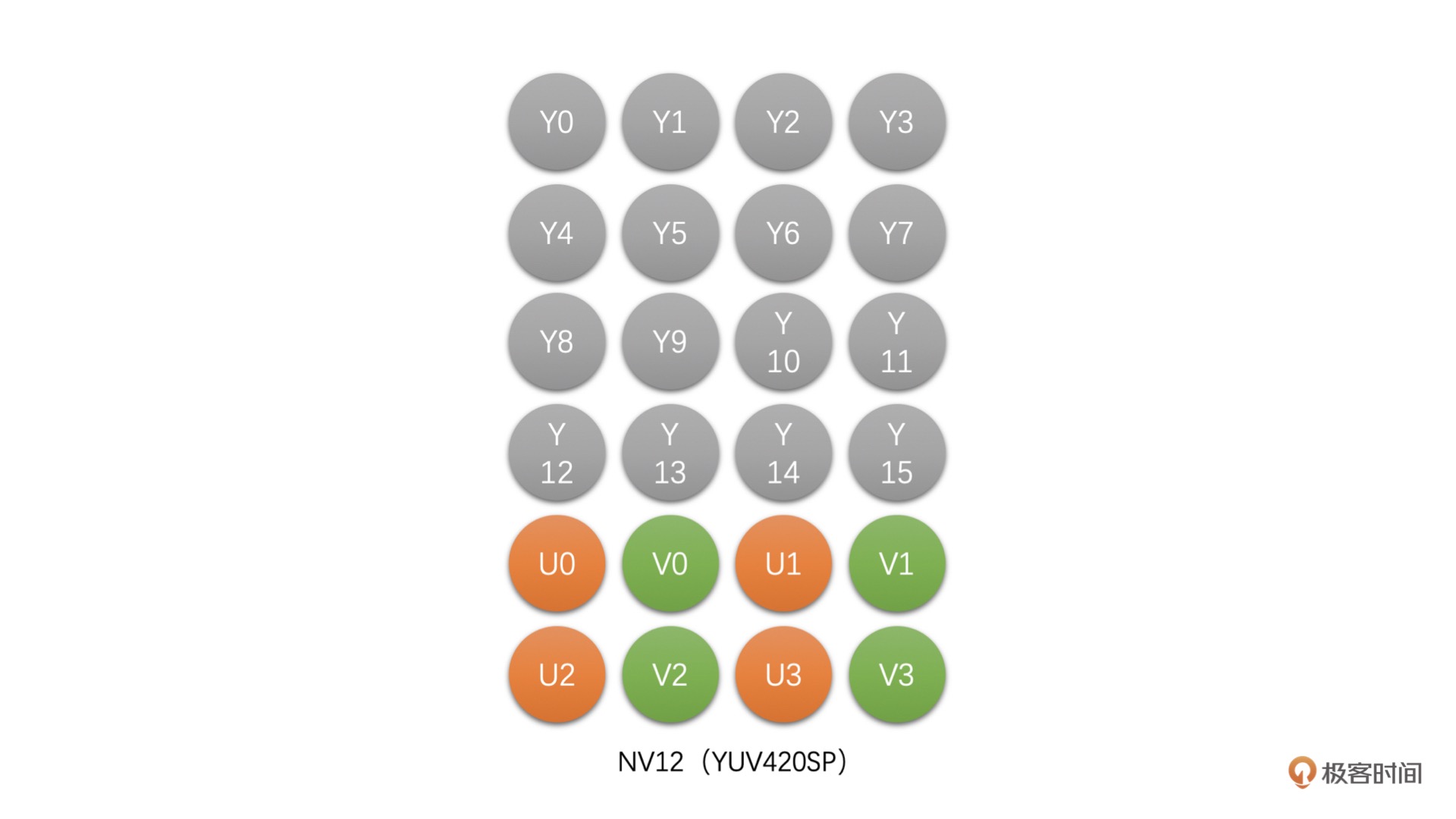
NV12(YUV420SP):这种类型是 Packed 格式,先存储完 Y,之后 U、V 连续交错存储。例如,4 x 4 像素的 NV12 存储图如下图所示:¶

NV21(YUV420SP):这种也是 Packed 格式,与 NV12 不同,这种格式是先存储完 Y,之后 V、U 连续交错存储。例如,4 x 4 像素的 NV21 存储图如下图所示:¶
备注
4 x 4 像素的 YUV 4:2:0 只需要 24 个字节相比 RGB 图像需要 48 个字节,存储的大小少了一半。也就是说,如果是 8bit 图像,RGB 每一个像素需要 3 个字节。而 YUV 4:2:0 只需要 1.5 个字节。
RGB 和 YUV 之间的转换¶
Color Range 分为两种:
一种是 Full Range 一种是 Limited Range Full Range 的 R、G、B 取值范围都是 0~255 Limited Range 的 R、G、B 取值范围是 16~235
备注
BT709 和 BT601 定义了一个 RGB 和 YUV 互转的标准规范。BT601 是标清的标准,而 BT709 是高清的标准。

这两种标准分别在 Full Range 和 Limited Range 下的 RGB 和 YUV 之间的转换公式吧¶
03| 缩放算法¶
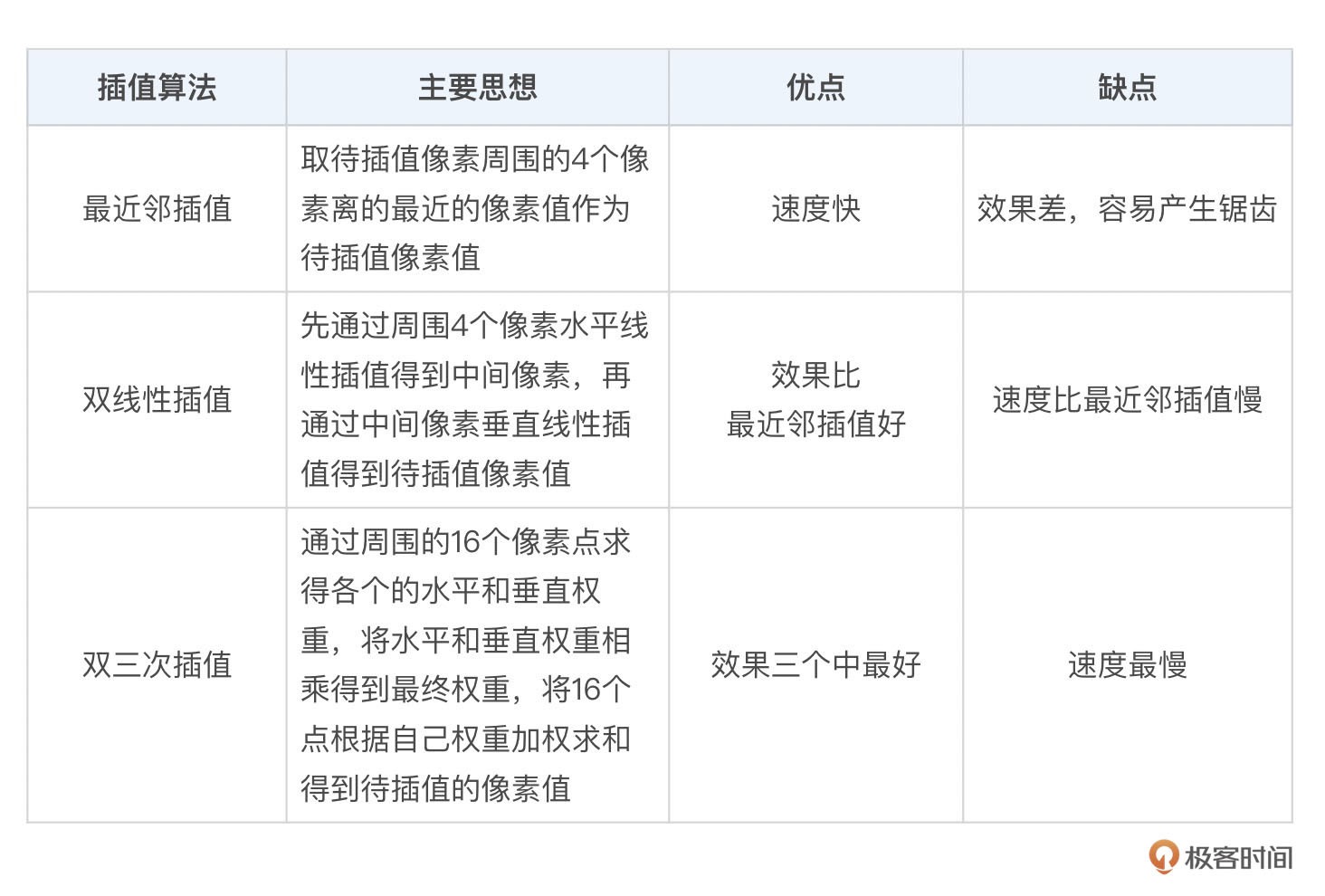
目前绝大多数图像的缩放还是通过插值算法来实现的,插值算法主要包括:
1. 最近邻插值算法(Nearest)
2. 双线性插值算法(Bilinear)
3. 双三次插值算法(BiCubic)
缩放的基本原理¶
图像的缩放就是将原图像的已有像素经过加权运算得到目标图像的目标像素。
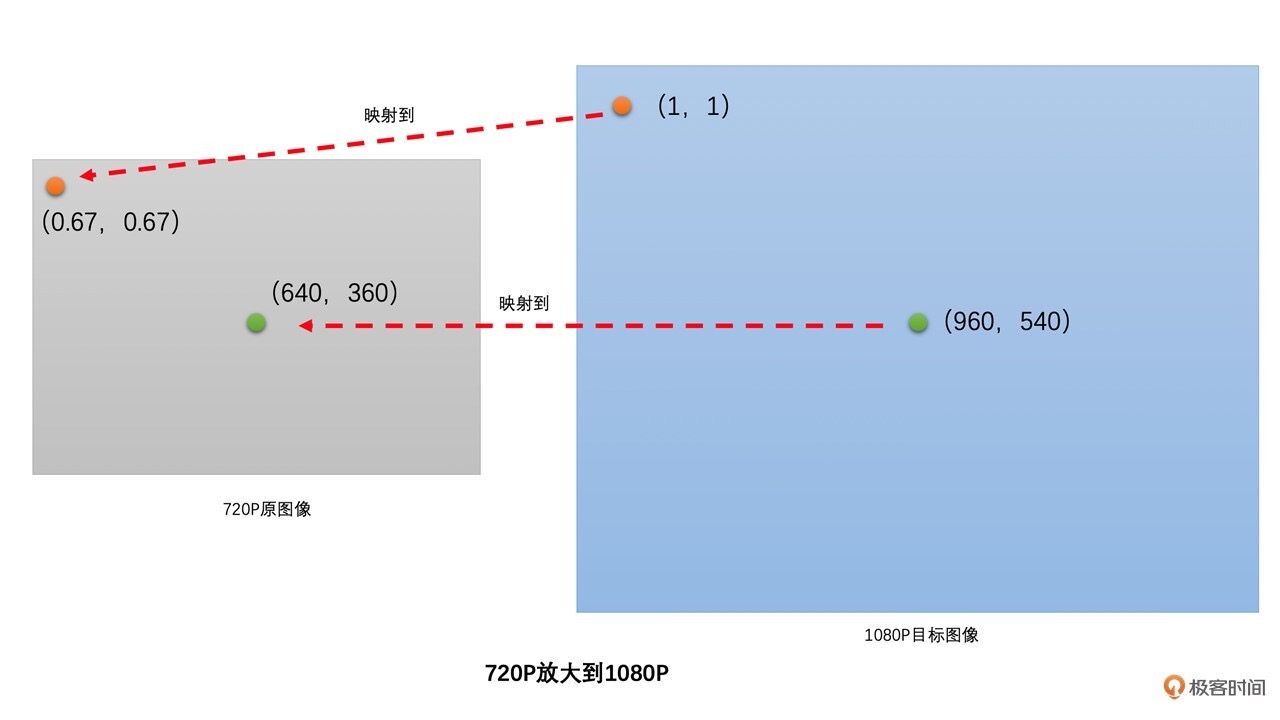
1080P 目标图像中的(0,0)位置就映射到 720P 原图像的(0,0)位置,取原图像(0,0)位置的像素值作为目标图像(0,0)位置的像素值。目标图像的(1,1)位置就映射到原图像中的(0.67, 0.67)位置。最后,通过原图像已有像素插值得到(0.67,0.67)位置的像素值,并将该像素值作为目标图像(1,1)位置的像素值。¶
最近邻插值¶
缺点,得到的放大图像大概率会出现块状效应,而缩小图像容易出现锯齿。
优点,就是不需要太多的计算,速度非常的快。
最近邻插值:
首先,将目标图像中的目标像素位置,映射到原图像的映射位置。
然后,找到原图像中映射位置周围的 4 个像素。
最后,取离映射位置最近的像素点的像素值作为目标像素。
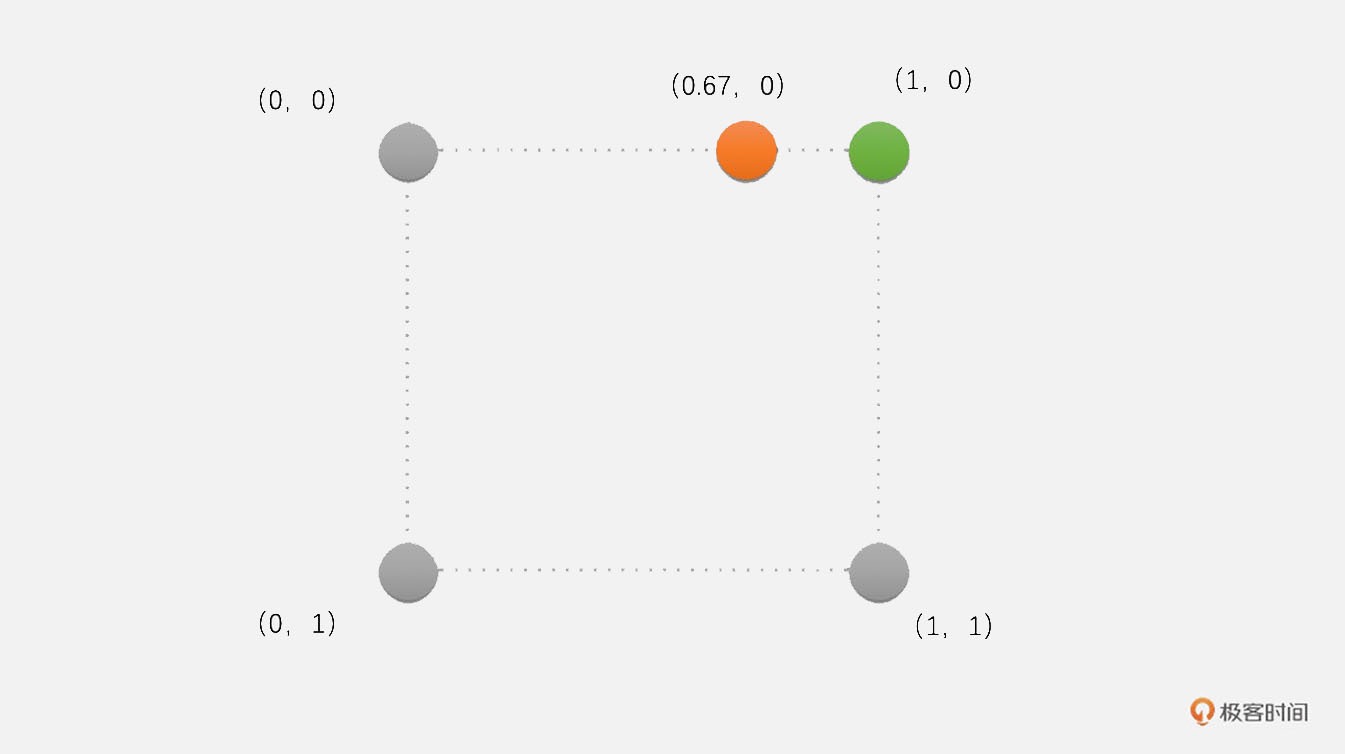
示例:将图像从 720P 放大到 1080P->目标图像中像素点(1,0)对应原像素点(0.67,0),其中距离(0.67,0)最近的位置很明显是(1,0)位置的像素。因此,我们将原图像中(1,0)位置的像素值赋值给目标图像(1,0)位置的像素点。¶
双线性插值¶
具体实现需要时看
双三次插值¶
具体实现需要时看
三种插值法对比¶

最近邻插值得到的图像有很多块效应,效果最差;双线性插值稍好于最近邻插值一些,但是比较模糊;双三次插值效果最好,对比度也明显好于双线性插值。¶
视频编码 (5讲)¶
04| 编码原理¶
假设有一个电影视频(YUV4:2:0),分辨率是 1080P,帧率是 25fps,并且时长是 2 小时,如果不做视频压缩的话,它的大小是 1920 x 1080 x 1.5 x 25 x 2 x 3600 = 521.4G。
视频编码的原理¶
人眼对于亮度信息更加敏感,而对于色度信息稍弱,所以视频编码是将 Y 分量和 UV 分量分开来编码的。
对于每一帧图像,又是划分成一个个块来进行编码的,这一个个块在 H264 中叫做宏块,而在 VP9、AV1 中称之为超级块,其实概念是一样的。宏块大小一般是 16x16(H264、VP8),32x32(H265、VP9),64x64(H265、VP9、AV1),128x128(AV1)这几种。
图像一般都是有数据冗余的,主要包括以下 4 种:
1. 空间冗余
比如说将一帧图像划分成一个个 16x16 的块之后,相邻的块很多时候都有比较明显的相似性,这种就叫空间冗余。
2. 时间冗余
一个帧率为 25fps 的视频中前后两帧图像相差只有 40ms,两张图像的变化是比较小的,相似性很高,这种叫做时间冗余。
3. 视觉冗余
我们的眼睛是有视觉灵敏度。
人的眼睛对于图像中高频信息的敏感度是小于低频信息的。
有的时候去除图像中的一些高频信息,人眼看起来跟不去除高频信息差别不大,这种叫做视觉冗余。
4. 信息熵冗余
使用 Zip 等压缩工具去压缩文件,将文件大小减小,这个对于图像来说也是可以做的,这种冗余叫做信息熵冗余。
备注
视频编码就是通过减少上述 4 种冗余来达到压缩视频的目的。
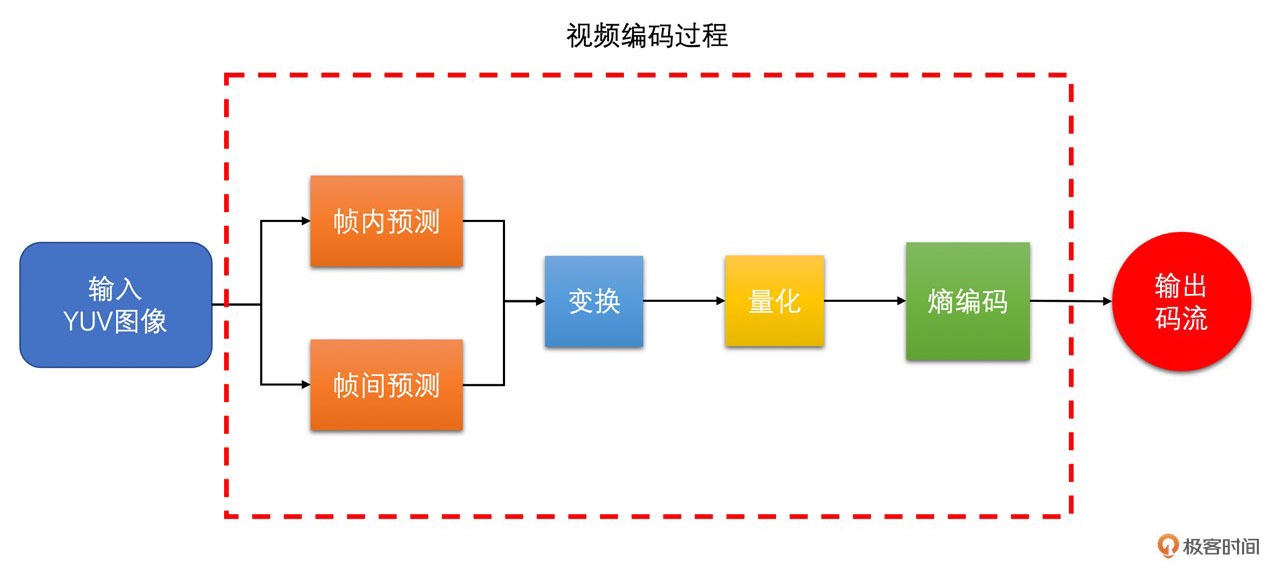
视频编码主要分为熵编码、预测、DCT 变换和量化这几个步骤:
1. 熵编码(以行程编码为例)
视频编码中真正实现 “压缩” 的步骤,主要去除信息熵冗余。在出现连续多个 0 像素的时候压缩率会更高。
2. 帧内预测
为了提高熵编码的压缩率,先将当前编码块的相邻块像素经过帧内预测算法得到帧内预测块,再用当前编码块减去帧内预测块得到残差块,从而去掉空间冗余。
3. 帧间预测
类似于帧内预测,在已经编码完成的帧中,先通过运动搜索得到帧间预测块,再与编码块相减得到残差块,从而去除时间冗余。
4. DCT 变换和量化
将残差块变换到频域,分离高频和低频信息。
由于高频信息数量多但大小相对较小,又人眼对高频信息相对不敏感,
利用这个特点,使用 QStep 对 DCT 系数进行量化,将大部分高频信息量化为 0,达到去除视觉冗余的目的。
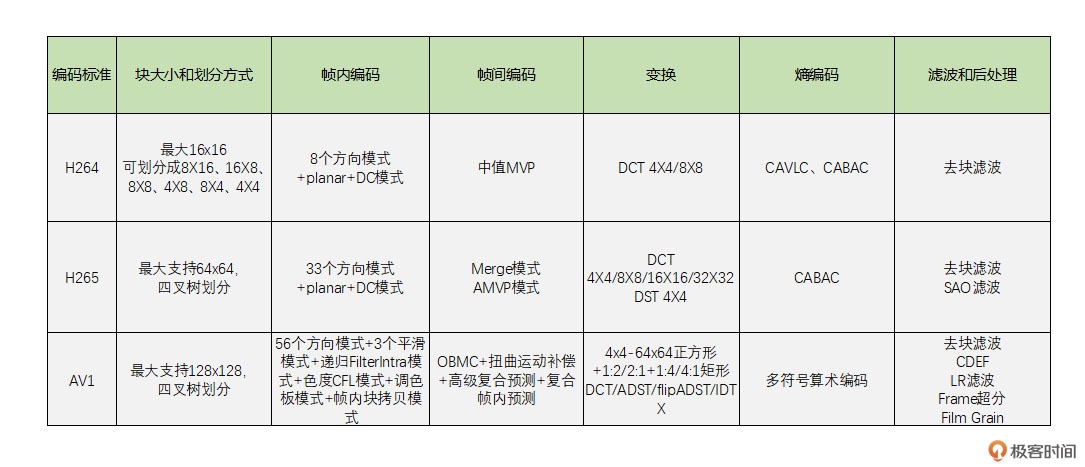
H264、H265、AV1 这三代编码算法的区别。¶
目前普通产品还是使用 H264 最多,而 H265 因为专利费使用得比较少。
VP8 和 VP9 是完全免费的
由于 H265 需要付高额的版权费,以谷歌为首的互联网和芯片巨头公司组织了 AOM 联盟,开发了新一代压缩编码算法 AV1,并宣布完全免费,以此来对抗高额专利费的 H265。
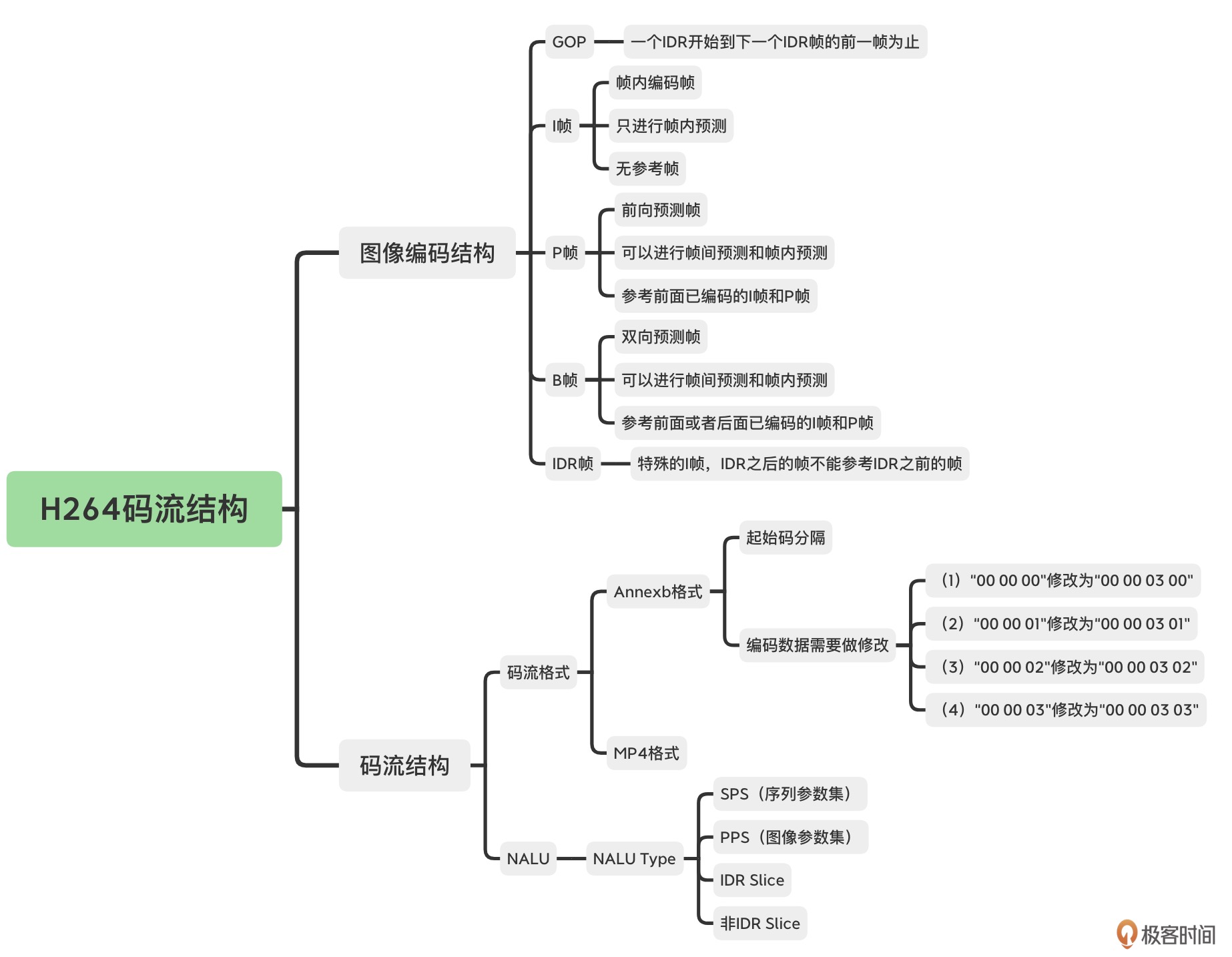
05| 码流结构¶
待处理
需要时再细看
06| 帧内预测¶
待处理
需要时再细看
07| 帧间预测¶
待处理
需要时再细看
08| 变换量化¶
参考¶
编解码相对来说是比较难的。再一次推荐 leixiaohua 大佬的 CSDN 博客,可以去看一看。
毕厚节老师的 H264 标准的书
评论¶
音视频同步是很难的、还有带宽预测、视频编码。其实 RTC 是几乎是音视频最难的使用场景
一般来说我们还是会使用提高 QP 和降低 QP 的方式来实现码率基本恒定。提高 QP 画面会变模糊一些,会有可能出现马赛克,但是码率会降低。降低 QP 画面会变清晰。码率也会提高。QP 是视频编码中的量化参数(Quantization Parameter)的缩写。它决定视频编码的压缩率和视频质量。
一般来说:1、对清晰度要求高,可以选择变化的码率。2、RTC 场景,一般使用固定码率。
同一个原始视频,在同一个压缩算法和压缩速度前提下,码率越大,清晰度就越大,失真越小。