2210.XX_Ray v2 Architecture¶
https://docs.google.com/document/d/1tBw9A4j62ruI5omIJbMxly-la5w4q_TjyJgJL_jN2fI/preview
- 说明
本文档取代了之前描述 Ray 的论文;特别是,底层架构从 0.7 版到 0.8 版发生了很大变化。
自 v1.0 以来,核心架构基本保持不变,但对机器学习、在线服务和数据处理中的应用程序进行了重大扩展。
Overview¶
Ray 提供了一个简单但通用的 API(任务、Actor、对象),让开发者像写 Python 程序一样开发分布式应用,系统自动帮你处理并行、调度、内存、容错,既适合作为分布式程序的“胶水”,又能保证高性能和可靠性。
Ray 的 API 设计使得它很适合作为 “分布式胶水系统”,可以把多个不同的分布式库(比如 Torch Distributed、Serve、数据处理框架)灵活组合到一个应用里。
API philosophy¶
目标:提供一个 通用的分布式计算 API,适用于各种分布式应用。
- 核心思想:
开发者只需要写简单、通用的 Python 逻辑(比如用 Python 函数、类表达任务和服务)。
系统自动帮你处理复杂的执行细节,比如并行执行、分布式内存管理、调度、资源分配。
用户只关心“资源”(CPU/GPU 内存数量)而非具体机器,Ray 会帮你做调度、自动扩缩容。
总结: 开发者写的是单机 Python 代码风格的逻辑,但 Ray 把它自动变成可以跨多机并行执行的分布式程序。
System scope¶
- Ray 的核心编程抽象
Tasks:可以并行运行的函数。
Actors:带状态的服务实例,可以理解为轻量服务。
Objects:传递和共享数据的机制,背后有分布式对象存储。
- Ray 的应用范围
弹性批处理 / Serverless
机器学习训练(Ray AIR)
在线服务部署(Ray Serve)
数据处理(Ray Datasets、Modin、Dask-on-Ray)
Python 程序的并行计算,以及整合不同分布式框架。
System design goals¶
核心原则:
API 简单 用 Python 原生方式写分布式程序
API 通用 适用于各种类型应用
核心系统目标:
性能高 基于 gRPC,支持分布式共享内存、并行调度,性能比直接用 gRPC 更好
可靠性强 设计了分布式引用计数、容错机制,确保即使有节点失败也能恢复
有时,我们愿意牺牲其他理想目标(例如架构简单性)来换取这些核心目标。例如,Ray 包含分布式引用计数和分布式内存等组件,这些组件增加了架构复杂性,但对于性能和可靠性而言却是必需的。
Ray 2.0 的重大改进¶
首先,原本的 Global Control Store 组件已经全面升级为 Global Control Service(GCS)。新设计使系统协调更简洁,同时提高了整体可靠性,减少了中心节点的单点故障风险。
其次,分布式调度器功能变得更强大灵活。它引入了新的调度策略,并支持 Placement Groups,让用户可以更细致地控制任务如何分布在集群中的节点上。
在容错性方面,Ray 2.0 提供了多项改进。一个关键提升是引入对象重建功能,确保在节点失败时,丢失的数据对象可以被自动重建,提升系统恢复能力。同时,GCS 也增强了自身的容错能力,使得整个系统在面对节点失效、网络波动等情况时更加稳定。
最后,Ray 2.0 丰富了开发者用于管理和监控 Ray 集群的工具集。例如,它增加了原生的 Job Submission 支持,方便提交和跟踪分布式任务。同时推出了 KubeRay 组件,简化 Ray 在 Kubernetes 上的部署,并提供了更完善的应用观测能力,方便用户实时掌控集群运行状况。
Architecture Overview¶
Application concepts¶
- Task
是什么:一个远程调用的函数,也就是
@ray.remote标记的函数。特性:无状态(普通 remote function)或有状态(属于 Actor 的方法)。
怎么执行:异步调用,调用
.remote()后立刻返回一个ObjectRef(类似未来可获取结果的 Future 对象),可以之后ray.get()获取结果。
- Object
是什么:Task 执行完的返回值,或者你用
ray.put()显式放进 Ray 的值。特性:不可变,创建之后不能修改。
如何引用:用
ObjectRef来指向这个 Object。
- Actor
是什么:有状态的工作进程,是 @ray.remote class 的实例。
特性:可以保存内部状态,每个 Actor 有一个句柄,你可以通过这个句柄调用它的方法,这些方法可以改变 Actor 的内部状态。
- Driver
是什么:就是你启动 ray.init() 的主程序(比如 Python 的 __main__)。
它可以提交任务,但不会执行任务。
- Job
是什么:一个 Driver 启动后,它创建的所有 Tasks、Objects、Actors 的集合。
特性:一个 Driver 对应一个 Job。
Design¶
Ray 的设计哲学是:把分布式的复杂性隐藏起来,用熟悉的 Python(或 Java)接口,让你像本地编程一样调度跨节点的无状态函数和有状态服务,同时保证高吞吐、低延迟和容错性。
Components¶
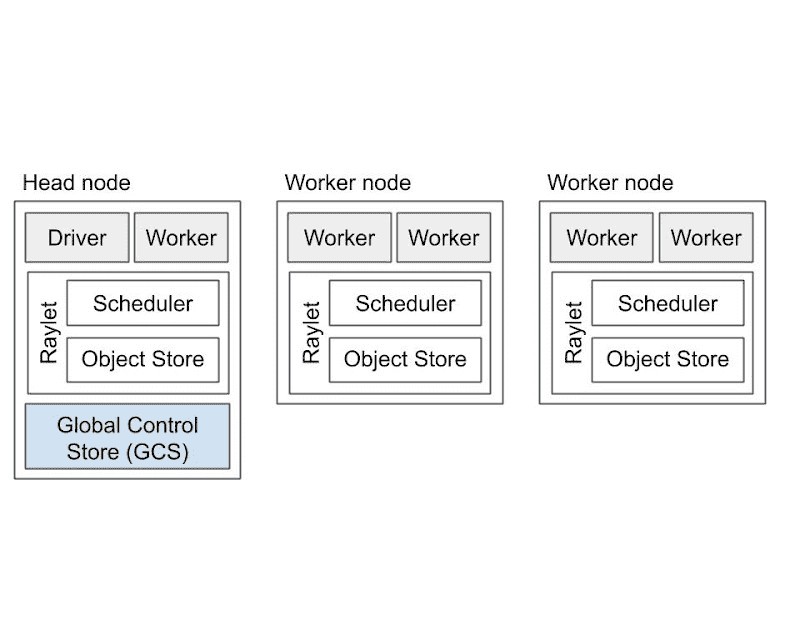
A Ray cluster.¶
worker Node¶
- Worker 进程(worker processes):
- 作用:具体执行 Tasks 或 Actor 方法。
无状态 Worker:可以重复执行任何 remote 函数。
Actor Worker:专门跑某个 Actor 的方法。
- 说明:
每个工作进程都与一个特定的作业相关联。
初始工作进程的默认数量等于机器上的 CPU 数量。
- 存储:
Ownership Table:记录这个 Worker 所引用对象(ObjectRefs)的元数据,如存储引用计数、对象位置。
In-Process Store:用于存储小对象,放在本地内存里。
- Raylet 进程:
- 作用:
管理每个节点上的共享资源。
与工作进程不同,raylet 在所有并发运行的作业之间共享。
- 两个主要组件
- 调度器(scheduler):
负责资源调度,决定任务在哪个节点跑。
负责资源管理、任务放置和执行存储在分布式对象存储中的任务参数。
集群中的各个调度器组成了 Ray分布式调度器。
- 共享内存对象存储 (Plasma Object Store):
用于存储大对象,可以跨节点传输。
集群中的各个对象存储组成了 Ray分布式对象存储。
每个 Worker 和 Raylet 都有唯一的 ID 和地址,进程死掉也不会复用 ID(ID “墓碑化”)。
Head Node¶
其中一个工作节点被指定为头节点。除了上述进程之外,头节点还承载其他能力:GCS, Driver processes
- GCS(Global Control Service):
一个管理集群级元数据(例如参与者的位置)的服务器,这些元数据以键值对的形式存储,可以由工作人员在本地缓存。
GCS 还管理一些集群级操作,包括安排放置组和参与者以及确定集群节点成员资格。
一般来说,GCS 管理的元数据访问频率较低,但可能被集群中的大多数或所有工作人员使用。
注意:GCS fault tolerance 是 Ray 2.0 中的新功能,允许 GCS在任意或多个节点上运行,而不是指定的头节点。
- Driver 进程:
驱动程序是一种特殊的工作进程,它执行顶层应用程序(例如 Python 中的 __main__)。
它可以提交任务,但不能自己执行任何任务。
请注意,驱动程序进程可以在任何节点上运行,但通常默认在头节点上运行。
- 集群级别服务:
处理其他集群级服务如:作业提交、自动扩缩容服务。
Ownership¶
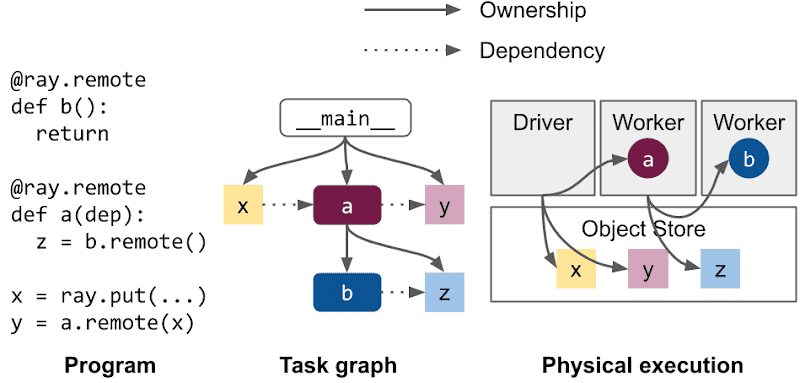
创建 ObjectRef 有两种方式:
x_ref = f.remote()
x_ref = ray.put()
- 概念:
每个
ObjectRef有一个 Owner Worker,负责跟踪它的生命周期、引用数等。 Owner 不一定是创建 Object 的那个 Worker,它是生成ObjectRef的 Worker。
- 好处:
低延迟,系统元数据分散在各 Worker,本地就能更新引用。
高吞吐,每秒 1 万个任务起步,集群扩展可达百万级任务。
简化架构,垃圾回收和元数据清理归 Owner 管理。
高可靠,一个 Worker 出错不会影响别的任务。
- 代价:
Object 的生命周期和 Owner 绑定,Owner 挂了对象也丢了。
Ownership 不能转移,一个 ObjectRef 的 Owner 一旦确定不会变。
Memory model¶
Ray 节点的内存大致分为 worker 执行时用的堆内存、共享内存对象存储、小对象直接存储在堆内存 以及 Ray 自己维护元数据的内存。开发者要特别关注自己 task 和 actor 占用的堆内存、对象的大小对存储位置的影响,以及引用计数等元数据开销。
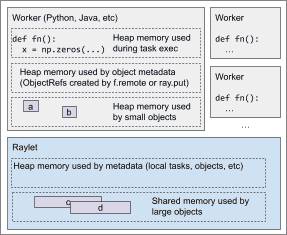
Types of memory used for a typical Ray node. The GCS (not shown) contains cluster-level metadata such as for nodes and actors.¶
- Ray may use memory in the following ways:
Heap memory used by Ray workers during task or actor execution
Shared memory used by large Ray objects
Heap memory used by small Ray objects
Heap memory used by Ray metadata
- Worker 堆内存: Heap memory used by Ray workers during task or actor execution
用途:被 Ray worker 在执行 task 或 actor 时使用。
原因:Ray 的任务和 actors 是并行运行的,通常并行数量 = CPU 核数。
- 开发者需要注意:
每个 task 的 单个堆内存使用量。
如果堆内存压力过高,Ray 会尝试 优先杀掉内存占用过高的 worker,以保证系统级的关键状态(如对象存储和系统进程)的正常运行。
- 共享内存(大对象):Shared memory used by large Ray objects
用途:存储较大的 Ray 对象(比如
ray.put()的值或任务返回的大对象)。- 工作机制:
Worker 调用
ray.put()或返回大对象时,Ray 会把这个值 复制到共享内存对象存储 中。这样可以在集群中其他 worker 也访问这个对象。
失败时可以尝试恢复对象;共享内存满了会 spill 到磁盘。
当所有 ObjectRef 都失效(超出作用域)后,对象会被垃圾回收。
零拷贝优化:如果对象支持 zero-copy 反序列化,
ray.get()或作为参数传递时,worker 直接拿到共享内存里的指针,不用复制。其他不支持 zero-copy 的对象会被反序列化,复制到接收方 worker 的堆内存。
- 小对象: Heap memory used by small Ray objects
用途:存储较小的 Ray 对象(默认 < 100KB)。
- 区别:
小对象不会放在共享内存对象存储,而是直接放在 owner 节点的内存对象存储里(In-Process Store)。
其他 worker 读取时(比如
ray.get())会把值 复制到自己的堆内存。同样有垃圾回收机制,和大对象一样。
- 元数据内存: Heap memory used by Ray metadata
- 用途:存储 Ray 运行时的元数据,主要包括:
任务的描述 (task specification)。
对象的元数据,比如 引用计数。
- 开销:
Ray v2.0 版本,一个在作用域内的 ObjectRef 的元数据开销预计是 几 KB。
- 核心进程及其元数据
- GCS:跟集群整体状态相关,比如:
总 actor 数。
总节点数。
总 placement groups。
- Raylet:本地调度器,跟本地的任务和对象相关:
本地排队的任务数。
这些任务的参数对象数。
本地共享内存或磁盘上存储的对象数。
- Worker:
提交的、还未完成或可能需要重试的任务数。
worker 拥有的对象数。
当前还在作用域内的对象数(尤其是语言层面的)。
Language Runtime¶
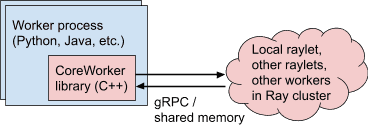
Ray workers interact with other Ray processes through the CoreWorker library.¶
- 核心实现是 C++,无论是 Python、Java,还是实验性的 C++ 前端,都通过嵌入的 Core Worker Library 来实现:
负责管理 Ownership Table、本地存储、gRPC 通信。
各语言共享同一个高性能实现。
Lifetime of a Task¶
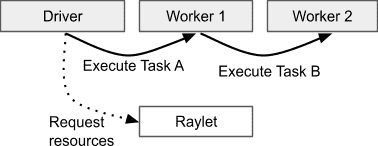
The process that submits a task is considered to be the owner of the result and is responsible for acquiring resources from a raylet to execute the task. Here, the driver owns the result of A, and Worker 1 owns the result of B.¶
- 核心概念
Task 的 Owner:提交任务的进程(通常是 driver 或 worker)是任务结果的 owner,负责:
1.确保任务被执行
2.负责追踪和解析任务返回的 ObjectRef (即任务的结果)
Task 的执行过程:
1. 提交 Task:Driver 或 Worker 提交任务,作为 owner
2. 传参处理:
• 小参数: it is copied directly from the owner’s in-process object store into the task specification, where it can be referenced by the executing worker.
• 大参数: 会隐式调用 ``ray.put()`` 存到 Object Store,并传 ``ObjectRef``
3. 等待依赖:如果参数里有 ``ObjectRef``,owner 等待它们 ready,无论在哪个节点
4. 请求资源:依赖 ready 后,owner 向分布式 scheduler 请求资源
5. 调度 Task:scheduler 分配 worker,并返回 worker 地址
6. 发送 Task:owner 通过 gRPC 发送 task spec 给 worker
7. 执行 & 存储返回值:
• 小结果 inline 直接返回到 owner in-process store
• 大结果放到本地 shared memory,通知 owner
失败处理:
Application-level:
Worker 活着,但任务出错(比如 Python 抛错)。
默认不会重试,异常会存储在返回值中。可配置允许部分异常自动重试
System-level:
Worker 崩溃或 raylet 挂掉,Ray 会自动重试任务到指定次数
- 重点 takeaway
任务依赖对象(ObjectRef):可以是本地或远程,Ray 会确保它 ready 后再执行
小 vs 大对象传输:小的直接传,大的用
ray.put(),避免重复传输建议手动ray.putowner 负责整个 task 生命周期
Lifetime of an Object¶
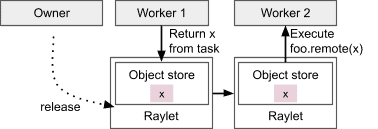
Distributed memory management in Ray. Workers can create and get objects. The owner is responsible for determining when the object is safe to release.¶
- 核心概念
Object = Ray 中的不可变值
Object 的 owner:创建
ObjectRef的 worker(通过提交任务或ray.put())owner 负责管理 Object 的生命周期
- Object 的存储方式
In-process store | 存储小对象,位于 worker 堆中,无容量限制,但容易内存爆
Distributed object store | 大对象存到 shared memory,超过容量会 spill 到磁盘,默认 30% RAM
- 对象引用计数
每个 worker 维护自己持有的
ObjectRef计数- 引用增加场景:
把
ObjectRef作为 task 参数传递Task 返回
ObjectRef或包含ObjectRef的对象
- 对象解析
两种方式获取 ObjectRef 的值:
1.`ray.get(ObjectRef)` 直接获取
2.作为 task 参数传递,worker 自动解析依赖
- 失败场景
owner 挂了,Object 无法获取,直接抛异常
分布式 object 丢失,Ray 会自动尝试重建
Lifetime of an Actor¶
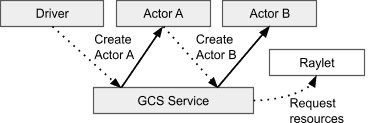
Unlike task submission, which is fully decentralized and managed by the owner of the task, actor lifetimes are managed centrally by the GCS service.¶
- 核心概念
Actor = 带状态的 task,生命周期由 GCS 统一管理
Actor Handle:创建 actor 后返回给用户,可以马上用
- Actor 生命周期直到:
创建者退出
所有 Handle 和 pending task 清零
Detached Actor 例外,需显式 ray.kill
- 创建 & 调用过程
创建 actor,提交 Actor Creation Task,等待依赖 ready
注册到 GCS,调度到特定资源,actor 启动
返回 Actor Handle,立刻可用,后续任务挂起直到 actor ready
调用 actor 方法时直接 gRPC 发送到 actor
Actor 任务默认串行,确保有状态执行顺序一致
- 并发 Actor
Ray 支持两类并发 Actor:
1.Async Actor:用 asyncio event loop 并发处理
2.Threaded Actor:后台线程并发
备注
注意:Ray API 线程安全,Actor 内部线程安全需用户自己保证
Owner |
提交 task 的 worker |
创建 ObjectRef 的 worker |
GCS 统一管理 |
|---|---|---|---|
存储 |
Task spec,参数小内嵌,大用 ray.put() |
小对象 in-process,大对象 shared memory |
Actor handle & metadata 存 GCS |
调度 |
分布式调度器 |
依赖就绪后 owner 触发 |
GCS 分配资源,创建后任务直接发给 Actor |
失败处理 |
应用级 vs 系统级 |
owner 挂掉或 object 丢失需重建 |
Actor 死亡可重建,detached 需显式 kill |
并发性 |
每次独立 task |
支持 async / threaded Actor 并发 |
Failure Model¶
核心思想是:Worker 及其任务、对象和资源,命运绑定;但通过一些机制(如 detached actor、自动重试等),你可以定制哪些部分可以活得更久、恢复更强。
System Model¶
- 节点同质性 & 容错
Ray 的 worker 节点都是同质化(homogeneous)设计:意思是,任何一个节点挂掉,都不会导致整个集群崩溃。
唯一的例外是 Head Node:因为它负责 GCS(Global Control Store)———— 也就是存储集群元数据的地方。
Ray 2.0 里增加了 GCS 容错机制,即 GCS 挂掉后,可以重启恢复,不会影响整个集群太多。
- 节点身份 & 心跳机制
每个节点有一个唯一 ID,节点间通过 心跳 互通有无。
- GCS 负责监控哪些节点是活着的。
如果某个节点 心跳超时,GCS 就认为它“死亡”, tombstone 掉它(等于是把它的 ID 作废)。
这个节点上的 Raylet(调度器)如果发现自己被标记死亡,也会主动退出。
要重启这个节点,得用一个新的 Node ID。
备注
注意:Ray 目前并不处理“网络分区”问题。如果某个 worker 节点跟 GCS 网络不通,会被误判成死亡。
- Worker 失败时的处理
- 每个 Raylet 监控本地的 worker 进程,如果发现某个 worker 死亡,会:
通知 GCS。
释放该 worker 占用的资源(比如 CPU),防止资源泄漏。
释放该 worker 创建的对象占用的内存(分布式对象存储里的)。
清理该 worker 的依赖、任务和内存记录,防止系统状态混乱。
Application Model¶
Ray 的任务和对象之间有一种叫 fate-sharing (命运共享) 的关系。
- 应用层的几条原则
子任务或子对象的生存期受制于父任务或父 worker,一旦父 worker 挂掉,它们就会被销毁。
想隔离失败影响,可以把关键任务拆到不同的子树里去运行(类似不同进程的思路)。
Driver 作为根节点,Driver 挂掉,整个应用的生命周期也结束。
例子¶
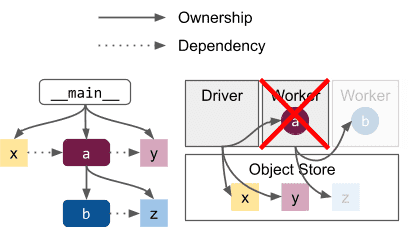
The system failure model implies that tasks and objects in a Ray graph will fate-share with their owner. For example, if the worker running a fails in this scenario, then any objects and tasks that were created in its subtree (the grayed out b and z) will be collected. The same applies if b were an actor created in a’s subtree (see Actor Death).¶
假设你有以下任务树:
Driver
└── Task A
└── Task B
└── Task Z (object)
- 如果 Task A 的 worker 崩溃:
那么 Task B 及其返回的对象 Task Z 全部都会被清理掉(即“命运共享”)。
如果 Driver 曾经拿到过
ObjectRef(z),在调用 ray.get(z) 时,会抛出异常,说找不到对象。
避免 Fate-sharing 的方法¶
- Detached Actor(脱离 Driver 生命周期的 Actor)
它是特殊的 actor,不受 Driver 的生命周期限制,不会随着 Driver 退出而销毁。
只能通过显式调用 ray.kill(no_restart=True) 来手动销毁。
Detached actor 自己也可以创建对象或任务,这些会和它“命运共享”,只有它死掉,它们才会消失。
系统提供的恢复手段¶
Ray 提供了一些“自动容错”选项:
机制 作用
自动任务重试 某些失败的 task 可以自动重跑
Actor 重启 Actor 进程挂掉后自动恢复
对象 Spilling 对象写入磁盘,可跨 owner 生命周期
对象重建 (2.0 默认开启) 任务创建的对象如果丢了,Ray 会尝试重建
Object Management¶
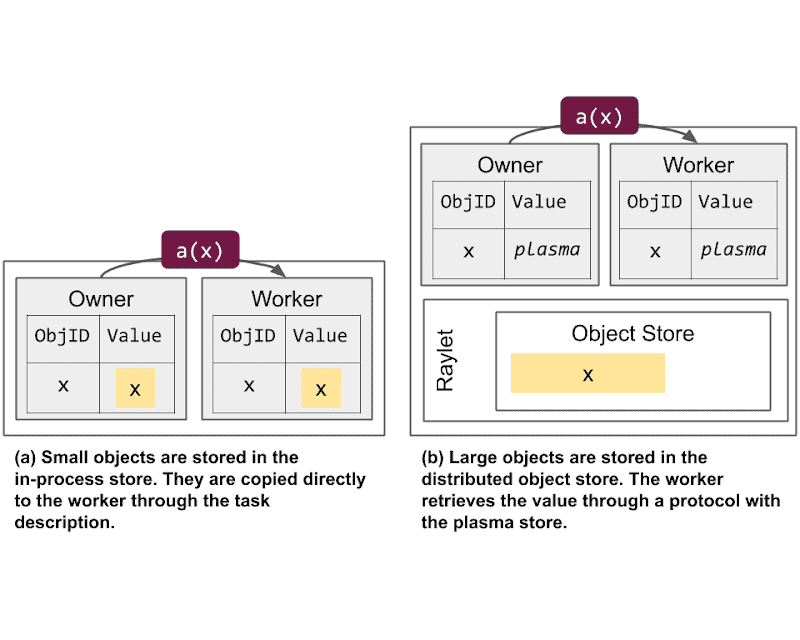
In-process store vs the distributed object store. This shows the differences in how memory is allocated when submitting a task (a) that depends on an object (x).¶
两种对象存储方式:
In-process store | 对象拥有者(worker)的进程内存中 | 小对象、小数据量
Distributed object store | 节点的 共享内存 (Plasma Store) | 大对象、大数据量,跨节点共享更高效
- 小对象
存在 In-process store(每个 worker 进程内自己的一块内存)。
- 好处:
快速直接内存拷贝 → 解析很快。
- 但有 两个限制:
多进程引用会导致额外内存拷贝,每个 borrower 会单独 copy 一份,浪费内存。
单机内存容量限制,一个 worker 机器内存不够放太多这种小对象。
- 大对象
存在 Distributed object store(即 Plasma,基于共享内存)。
- 特点:
同一节点上多个 worker 可以共享一个副本,节省内存。
通过 IPC (进程间通信) 直接取共享内存里的指针。
跨节点 可以拉取其他节点上的对象副本。
允许引用的对象总大小 超过单台机器内存上限,因为可以跨多节点分布。
整体吞吐可以随集群规模提升(多个节点上有多个副本)。
Object resolution¶
备注
Ray 根据对象大小自动决定存储位置:- 小对象 → 存 owner 自己进程里,速度快,适合轻量依赖。- 大对象 → 存在共享内存,跨进程/节点共享,内存更省,支持大规模数据。
备注
解析过程本质上是找对象在哪里,尽可能走本地(本地 in-process store 或 Plasma Store),不行再跨节点取副本。
解析指的是:拿到
ObjectRef,实际获取到对象内容(比如ray.get()或者作为 task 参数传入时)。- ObjectRef 由两部分组成:
- 唯一 28 字节 ID:
由生产这个对象的 task ID + 该 task 创建对象的序号拼接而成。
- 对象 owner 的地址:
Worker 唯一 ID
Worker 的 IP & 端口
本地 raylet 的唯一 ID
- 小对象的解析
直接从 owner 的 in-process store 复制。
- 举例:
Owner 调用 ray.get():直接本地找 in-process store 反序列化。
Owner 提交依赖任务:直接把对象值 inline 写进 task spec。
Borrower 解析时:直接拷贝 owner 的 in-process store 里的值。
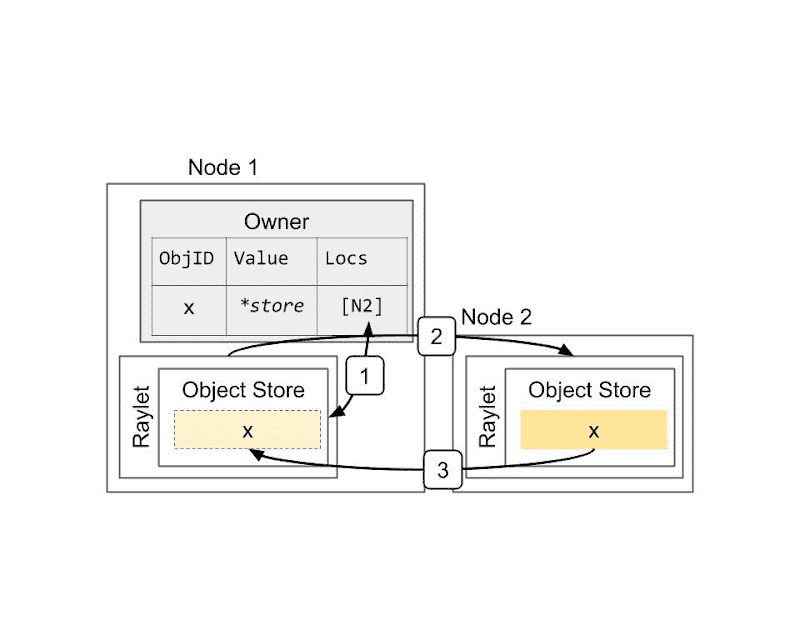
Resolving a large object. The object x is initially created on Node 2, e.g., because the task that returned the value ran on that node. This shows the steps when the owner (the caller of the task) calls ray.get: 1) Lookup object’s locations at the owner. 2) Select a location and send a request for a copy of the object. 3) Receive the object.¶
- 大对象的解析流程
假设对象 x 是在 Node 2 创建的(Task 在 Node 2 运行):
- 解析步骤:
Owner 查自己记录的对象位置(现在这些信息保存在 owner 进程,不在 GCS 了,从 v1.3+ 开始)。
选定一个存有对象的节点,发请求 拷贝对象。
收到对象副本。
- 本地有副本时
Borrower 的 worker 查本地共享内存(Plasma Store)。
找到 → 直接 IPC 读取共享内存指针,0 拷贝引用,多个 worker 可共享。
- 本地没副本时
Worker 通知本地 raylet。
- Raylet:
查 Object Directory(记录对象副本在哪些节点)。
从其他 raylet 请求拉取一份副本。
收到副本后,本地 Plasma Store 也存一份,方便下次直接用。
为什么要分小对象和大对象:
小对象 In-process store | 大对象 Distributed store
-------------------------------------|--------------------------------
解析速度快(本地直接内存拷贝) | 支持跨进程/跨节点共享,避免重复拷贝节省内存
多 borrower 会产生多份拷贝,占用更多内存 | 单节点共享,多个 worker 共享副本,节省内存
受限于机器内存容量 | 支持对象总量超出单机内存,因为对象分散在多个节点
如果引用频繁,owner 进程 CPU 会成为瓶颈 | 吞吐可以随着节点数增加,副本在多节点上存在
Memory management¶
备注
Ray 会尽可能把小对象留在本地内存、把大对象共享到分布式内存,但当内存吃紧时,它会通过清理副本、GC、spilling 乃至 fallback 到磁盘等手段,保证系统稳定运行。
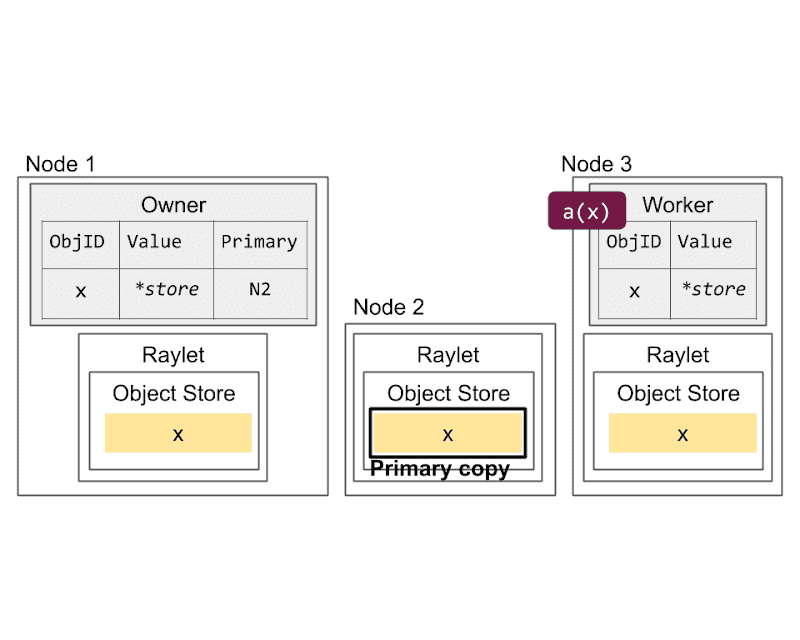
Primary copy versus evictable copies. The primary copy (Node 2) is ineligible for eviction. However, the copies on Nodes 1 (created through ray.get) and 3 (created through task submission) can be evicted under memory pressure.¶
Ray 的内存管理机制,尤其是它如何在内存压力大时管理对象的存储和清理,防止 Out-Of-Memory (OOM) 错误,同时又保证分布式计算的高效性和可用性。
- 小对象 vs 大对象 存储逻辑
- 小对象(体积小的数据):
执行任务的 worker 直接把它的值返回给对象 owner(创建它的 worker),存到 owner 的 in-process store(本地内存)。
生命周期:当所有引用不再存在时,直接删除。
- 大对象:
worker 把它存到 local shared memory store(共享内存,也叫 distributed object store)。
这个存储是节点级别的,所有同节点上的 worker 可以共享访问。
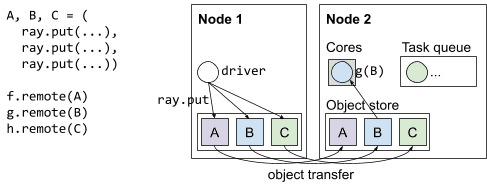
The types of objects that can be stored on a node. Objects are either created by a worker (such as A, B, and C on node 1), or a copy is transferred from a different node because it is needed by a local worker (such as A, B, and C on node 2).¶
- Primary Copy 和 Evictable Copies
- Primary Copy:
是大对象的第一份副本,由执行任务的 worker 存在本地 shared memory 中。
它 不能被清除(evict),只要还有引用在。
由 raylet “pin” 住————raylet 通过持有它在共享内存中的 buffer 引用,防止它被删除。
- Evictable Copies:
通过 ray.get 或者任务传参等创建的其他副本。
当本地内存紧张时,这些副本 可以被清除(LRU 策略)。
Handling out-of-memory cases¶
- 内存回收 & 清理机制
当一个对象的引用计数降为 0:
小对象:直接从 owner 的 in-process store 删除。
大对象:raylet 负责异步从 shared memory 中清除。

- 为什么可能 OOM?
小对象:Ray 没有限制 in-process store 的大小,如果一个 worker 持有大量小对象引用不释放,可能导致 本地 OOM。
- 大对象:共享内存是 有硬限制的,Raylet 负责控制。它会:
优先删除 evictable copies。
触发 Python GC,让 Python worker 试着清掉无用的 ObjectRef。
如果还不够,启动 Spilling(外部存储,通常是磁盘)。
如果 spilling 也无效,报错 ObjectStoreFullError 或 OutOfDiskError。
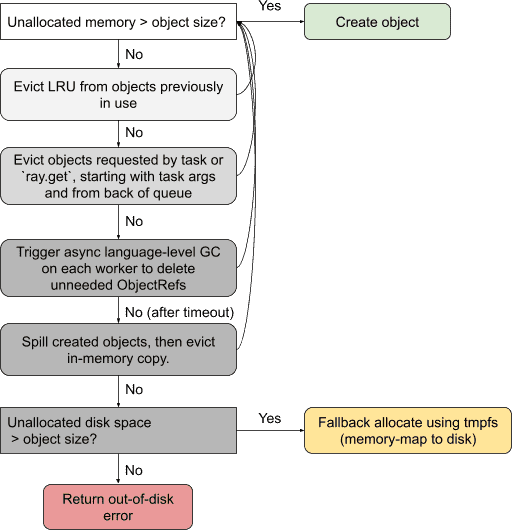
Raylet flowchart for handling an object creation request. If there is not enough available memory in the local object store to serve the request, the raylet attempts a series of steps to make memory available.¶
Object spilling¶
- Spilling 机制
- 为什么 Spilling?
对象多到内存放不下,spill 到外部(默认是本地磁盘,也支持 S3)。
- Spilling 流程:
Raylet 找到 primary copies。
发送 spill 请求给 IO worker。
IO worker 把对象写到外部存储。
Evict 掉内存里的 primary copy,释放空间。
如果引用计数变为 0,raylet 通知 IO worker 删除外部副本。
- 恢复 Spilled Object:
被其他任务需要时,raylet 可以从外部存储恢复。
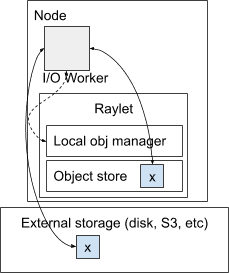
An overview of the design for spilling or restoring an object. The raylet manages a pool of I/O workers. I/O workers read/write from the local shared-memory object store and external storage.¶
- 内存调度策略细节
- 防止任务占用太多内存:
限制一个任务的 输入参数大小:默认 不超过 shared memory 70%,防止它阻塞对象创建。
- ray.get 的风险:
太多并发的 ray.get 大对象请求也可能造成 OOM,因为这些对象在任务执行完前不会释放。
- 解决方案:
OOM 时把新对象 fallback 到磁盘,代价是 I/O 性能变差,但能让应用继续运行。
Reference Counting¶
核心讲的是 Ray 如何追踪和管理 ObjectRef 的生命周期,防止内存泄漏,同时确保数据在系统崩溃或失效时可以恢复。
- Reference Counting 概念
每个 Ray worker 维护自己 “拥有” 的对象的 引用计数 (ref count)。
引用计数分两部分:
Python 本地引用计数:对象在 Python 代码中的 ObjectRef 被引用多少次,比如变量、数据结构内的引用。
Pending Task Count:本 worker 提交的、依赖这个对象的 未完成任务 的数量。
- 减计数时机:
Python ObjectRef 被垃圾回收(deallocated)
依赖该对象的 task 正常结束(哪怕抛出应用级异常)
- 核心思路:
Owner 节点 负责这个对象的引用计数。
任何其他节点(Borrower)拿到这个对象时,都要通知 owner,owner 记下它们还在用这个对象。
借用者(Borrower)释放对象时也会告诉 owner。
只有所有 borrower 都释放了,owner 才能真正回收对象。
【定义】borrower: The process that receives the copy of the
ObjectRefis known as a borrower.【定义】These references are tracked through a distributed reference counting protocol
示例:
# 说明
# 这是一个 Ray 远程函数
# 用 ray.get 把第一个对象拉取过来,即实际去用这个对象
# 重点:
# temp_borrow 任务开始时,会告诉 Owner 它借用了这个对象
# 任务结束后,会告诉 Owner 它不再借用,因为 x 变量只存在于这个函数内部,出了 scope 就没用了
@ray.remote
def temp_borrow(obj_refs):
# Can use obj_refs temporarily as if I am the owner.
x = ray.get(obj_refs[0])
# 说明
# 这是一个 Ray actor
# 重点
# 把对象引用保存成了 actor 的 成员变量,相当于 "长期借用"。
# 即使 borrow() 方法结束,actor 依然持有这个 x_ref,不会释放。
# 所以 Owner 会一直认为这个 Borrower actor 还在借用 x_ref,直到这个 actor 终止或调用代码显式释放。
@ray.remote
class Borrower:
def borrow(self, obj_refs):
# We save the ObjectRef in local state, so we are still borrowing the object once this task finishes.
self.x = obj_refs[0]
# Owner 是运行 foo.remote() 的节点,它会初始化 x_ref 的引用计数。
x_ref = foo.remote()
# 说明
# 告诉 Owner:“我正在借用 x_ref。”
# temp_borrow 执行完成后:告诉 Owner:“我已经不用 x_ref 了。”
temp_borrow.remote([x_ref]) # Passing x_ref in a list will allow `borrow` to run before the value is ready.
# 说明
# Borrower actor 把 x_ref 保存到自己的成员变量 self.x,这个变量在 actor 生命周期内都存在。
# 所以它是一个 长期借用者,会导致 Owner 一直保留这个对象,直到 actor 退出或释放 self.x
b = Borrower.remote()
b.borrow.remote([x_ref]) # x_ref can also be borrowed permanently by an actor.
临时 borrow:函数级别,只在函数执行时借用,结束就释放。
长期 borrow:actor 级别,持久保留 ObjectRef(比如存到成员变量里),Owner 会一直追踪它,直到 actor 消失。
下面这段讲的是 Ray 在传递 ObjectRef 的“套娃”场景下,引用计数协议是怎么跟踪的:
@ray.remote def parent(): y_ref = child.remote() x_ref = ray.get(y_ref) x = ray.get(x_ref) @ray.remote def child(): x_ref = foo.remote() return x_ref
图示理解:
x_ref (由 child worker 生成)
│
└── wrapped in → y_ref (child 返回)
│
└── parent worker 接收到 y_ref
│
└── parent worker 取出 x_ref
Object Failure¶
备注
Ray 中对象丢失时,能恢复就恢复,不能恢复主要看 owner 是否还活着和对象是否有 lineage 信息,尤其是大对象通过 lineage reconstruction 机制有机会被重新生成,但 ray.put、非幂等任务或 owner 挂了这些情况直接失败。
- 对象失败恢复的基本原则 - 核心机制:
如果 owner(拥有这个对象的 worker)还活着,Ray 会尽力尝试恢复丢失的对象。
如果恢复失败,Ray 会抛出一个 应用层级异常,并且异常里会说明失败的原因。
如果 owner 已经死掉,无论这个对象的副本是不是还在集群别的节点上,任何 worker 想 ray.get() 这个对象时都会收到一个 “owner 已死” 的错误。
- 小对象的处理
小对象 存储在 owner 自己进程内的 object store。
这意味着如果 owner 挂了,这些小对象就直接丢失。
- 其他 worker 想访问这个对象时:
Ray 会告诉它:owner 已经死了。
并且这个错误会被缓存到 worker 自己的本地 object store 中。
后续如果 ray.get() 这个对象,就会直接抛出错误。
- 大对象 & Lineage Reconstruction(血缘重建机制)
这些对象存储在 分布式内存(shared distributed memory) 中,副本可以存在多个地方。
如果 非主副本 (non-primary copies) 丢失 —— 没关系。
- 主副本丢失 时:
Owner 会试图找到其他剩余副本,选一个新的主副本。
如果所有副本都没了,Ray 会尝试 通过重新执行创建这个对象的任务,重新生成这个对象,这就是 Lineage Reconstruction。
- 什么是 Lineage Reconstruction
- Ray 会为每个对象维护一个 lineage ref count:
表示这个对象有多少个下游任务依赖它,这些任务在必要时也可以重新执行。
只要存在任务依赖这个对象,Ray 会保留这个对象的 血缘信息(task specification),以便之后可以重新跑。
- 一旦 lineage ref count = 0:
Ray 会清理掉这个对象对应的 task spec(血缘信息),释放内存。
⚠️ 注意:即使对象的值被 GC 了,血缘信息和对象值的 GC 是分开的!
- 代价
Lineage reconstruction 会导致 driver 端内存压力增大,因为血缘信息是要缓存的。
默认情况下,每个 worker 会试着在缓存超过 1GB 后去主动清理。
Task Management¶
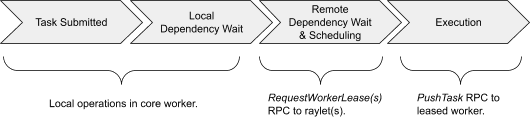
[Task execution]The scheduling workflow of a normal Ray task.¶
Dependency resolution¶
【定义】依赖解析:在 Ray 中,一个任务的参数(ObjectRef)必须先准备好,这个任务才会被调度。
简单例子¶
示例:
foo.remote(bar.remote())
理解:
1. caller 是调度 foo 的任务。
2. bar.remote() 先执行,生成 ObjectRef,并且 caller 本身拥有这个 ObjectRef。
3. caller 会 等待 bar 完成,然后把 bar 的结果放到本地 in-process object store 中。
4. 确保 foo 需要的参数已就绪,再去调度 foo。
为什么这么设计: 避免让 foo 在执行时还要等待参数传过来,确保 worker 资源不会浪费。
Borrowed Object¶
备注
【关键点】Caller 只有在参数 ready 后,才去调度任务,避免 worker 空等。对于 borrowed ObjectRef,caller 会联系 owner 确认参数是否创建好。
有时候:caller 并不是参数的 owner,只是 借用到别的 worker 拥有的 ObjectRef
示例:
@ray.remote
def caller(refs: List[ObjectRef]):
foo.remote(refs[0])
refs[0] 是别人传给 caller 的,caller 只是 借用了这个 ObjectRef
- 处理流程:
caller 反序列化 ObjectRef 时,会主动联系 owner。
owner 回复说 “我已经创建好这个对象” → caller 才认为依赖 ready。
如果 owner 死了,caller 会直接认为对象也丢了 → 不再等待(因为对象和 owner 命运共同体 fate-sharing)。
三种参数类型:
Plain value | `f.remote(2)` | 直接值,无需依赖处理 Inlined object | 小对象,如 `f.remote(small_obj_ref)` | 小于 100KB,直接内联存储在 caller 的任务规范里 Non-inlined object | `f.remote(large_or_pending_obj_ref)` | 大对象或等待中的对象,需要特别等待它到达本节点
Resource fulfillment¶
备注
【关键点】Caller 发请求给首选 raylet,依据数据本地性、节点亲和性或默认。raylet 会等待参数本地可用才分配 worker,防止资源浪费。Worker lease 可复用,提高效率。本地无资源时,spillback 到其他 raylet。
- 资源请求发送给首选 raylet
caller 决定把任务调度到哪个节点(raylet),依据几个策略:
策略 |
说明 |
|---|---|
— |
— |
数据本地性 Data locality |
选 已有最多 task 参数副本的节点 |
指定节点 Node affinity |
用户可以明确要求在哪个节点执行 |
默认 |
当前节点的 raylet |
- raylet 怎么分配 worker?
raylet 排队接收请求。
确定本地资源够用 → 分配一个 worker。
告诉 caller 哪个 worker 已经 leased 给它。
- Worker Lease 的作用
租约 lease 保证 worker 在 caller 生命周期内只归 caller 用,避免抢占。
- caller 可以在这个 worker 上 连续提交多个任务,条件是:
资源需求一样(比如 CPU 数)
共享内存参数一样
Runtime 环境一样
这样省去频繁找 scheduler 的开销。
- 多个 worker lease
Caller 可以持有多个 lease → 提高并发度。
Worker leases 缓存下来,减少调度系统负担。
- Spillback Scheduling(溢出调度)
如果当前 raylet 无法满足资源请求:
它会告诉 caller 去其他节点试试(remote raylet)。
remote raylet 可能接受或拒绝。
如果拒绝 → caller 再回到原 raylet 重新请求,循环直到有节点接受为止。
Resource Management and Scheduling¶
备注
Ray 把物理资源抽象成逻辑资源,提供灵活调度策略,通过 raylet + GCS + 多种策略实现高效的分布式任务资源管理和调度,同时为 gang scheduling 等高级场景提供原子性保障。
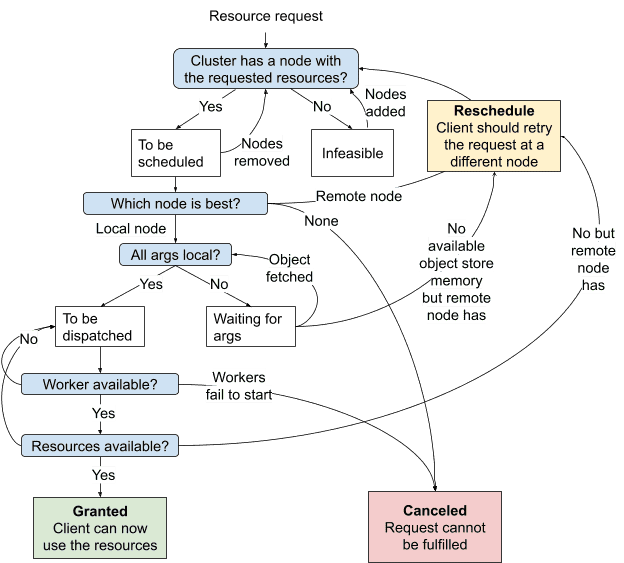
State machine of raylet distributed scheduling¶
- 资源的定义与用途
- 资源是 key-value 对:
key 是资源名,比如 “CPU”、”GPU”、”memory” 或自定义资源名。
value 是数量,是浮点数。
- 默认资源:
Ray 默认支持
CPU、GPU、memory,会在节点启动时 自动检测物理资源数量 并设置为逻辑资源。
- 自定义资源:
用户可以指定任何字符串作为资源名,譬如 {“special_gpu”: 1},可以用来标记某个节点具有特定硬件或软件功能。
这样,任务 /actor 只有在该节点才会被调度。
- 资源是逻辑的,不和物理绑定:
比如可以启动一个标记有 3 个 GPU 的 Ray 节点,即使该机器物理上没有 GPU。
物理资源不会被强制限制,Ray 只负责资源分配和调度,实际线程/内存控制由 OS 负责,用户要合理设置资源参数。
Ray 的调度机制¶
- 核心组件:Raylet(本地调度器)
- 每个 Raylet 负责跟踪本地节点的资源,有完整、实时一致的本地资源视图。
资源分配 -> Raylet 会减去本地资源数量。
资源释放/调用者死亡 -> Raylet 会归还资源。
- 集群级资源信息:
Raylet 也会通过 GCS(Global Control Store) 接收集群里其他节点的资源状态,但这个信息是最终一致性,存在延迟(默认每 100ms 同步一次)。
- 调度流程 (State Machine)
- 收到任务请求后,Raylet 的调度器会走以下几种状态:
Granted | 当前节点可以满足资源请求,直接分配 worker,执行任务
Reschedule | 当前节点发现别的节点更适合(根据当前看到的资源信息),拒绝请求,提示客户端去别的 raylet 试一下,称为 spillback scheduling
Canceled | 任务无法调度,比如请求的节点已死,或 runtime 环境无法创建,直接失败
- 调度策略 (Scheduling Policies)
- 默认 Hybrid 策略:
- 50% 临界阈值:
本地节点使用率低于 50%,优先本地调度(bin-packing)。
超过 50%,开始分发到其他节点(load balancing)。
先根据 Node ID 顺序分配,确保不同节点做决策时顺序一致。
利益:平衡本地利用率和全局负载。
- Spread 策略:
尽可能将任务均匀分散到不同节点(轮询)。
- Node Affinity 策略:
强制指定某个具体节点执行任务/actor。
节点死了可以选择软约束或硬约束,是放弃还是调度到其他节点。
- Data Locality 策略:
数据本地性由调用者决定,优先调度到 数据本地存储多的节点,调度器本身不主动感知数据位置(为减少 RPC 通信复杂度)。
- Placement Group 策略:
针对一组资源捆绑(bundle)调度,保证一组 task/actor 同时启动,资源分配原子性。
Placement Groups¶
- 作用:
用于 gang scheduling,即多 task/actor 需要同时获取资源才执行,避免部分节点资源空等。
- 一组资源可以选择:
PACK:尽量集中到一个节点。
SPREAD:尽量分散到不同节点。
- 实现机制:
使用 两阶段提交协议 由 GCS 协调,确保多个节点上的资源分配原子性。
- 中途某个节点或 GCS 崩溃:
节点崩溃 -> 回滚,重新申请。
GCS 崩溃 -> 恢复时重新 ping 所有参与节点,重试。
- 生命周期:
- Placement Group 属于创建它的 job 或 detached actor。
创建者结束时自动销毁。
也可以手动调用 remove_placement_group 销毁。
- 销毁时:
所有依赖这个 PG 的 actor 和任务会被杀死。
资源立即释放。
- 故障恢复:
如果某节点死亡:
Placement Group 保持部分分配状态,失去的 bundle 会优先调度恢复。
保证高优先级恢复调度,直到全组分配完成。
总结¶
本地 Raylet 管理资源一致性,全局视图依赖 GCS 最终一致广播。
调度策略灵活可配置,默认 Hybrid 策略兼顾利用率和负载均衡。
支持 Placement Group 提高大规模、需要同步启动场景的可靠性。
调度过程中的失败或延迟都有对应重试机制,比如 spillback 和两阶段提交。
Actor management¶
Actor creation¶
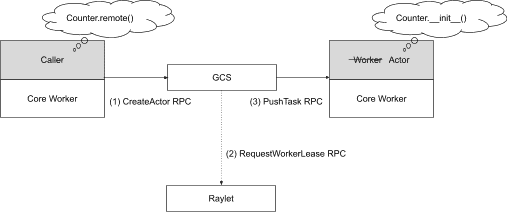
Actor creation tasks are scheduled through the centralized GCS service.¶
- Actor 的创建过程的基本流程:
- 注册 Actor
当你在 Python 代码里创建一个 @ray.remote 类实例(Actor)时,首先 创建者 worker 会将这个 Actor 注册到 GCS (Global Control Store)。
如果是 detached actor(生命周期脱离创建者,带名字的),注册是 同步 进行的,避免名字冲突。
如果是 非-detached actor(默认),注册是 异步 进行的,更高效。
- 调度 Actor 创建任务
Actor 注册完后,GCS 负责将 Actor 创建任务 调度到某个节点去执行,流程与普通 task 调度一样(走 Ray 的分布式调度协议)。
- Actor handle 的提前使用
在 Actor 真正被创建出来之前,创建者可以开始用 actor handle 提交任务或传递 handle 给别的 task/actor。
- 但为了防止创建者崩溃后,其他任务还持有未注册的 handle 出错,Ray 会:
等待注册完成后再允许任务提交;
提交依然是异步的,只是 Ray 会 缓冲住这些 task,等 actor 注册完成后才发出去。
- 通知其他持有 handle 的 worker
Actor 创建完成后,GCS 会通过 pub-sub 通知所有持有 actor handle 的 worker,并更新 Actor 的运行信息(比如 RPC 地址)。
等通知完成后,之前缓冲的任务才会真正发送到 Actor 上执行。
Actor task execution¶
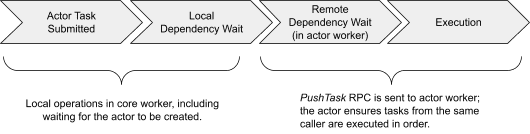
The scheduling workflow of a Ray actor task.¶
每个 actor handle 代表一个调用者,它记录了 actor 进程的 RPC 地址
一旦 actor 创建完成,所有 handle 直接通过 gRPC 向 actor 进程发起远程调用
Actor 可以 并发处理多个调用(虽然图示简化为一个)
任务的执行顺序 是有控制的,Ray 保证 actor 上任务的执行是有序的(FIFO)
Actor death¶
- 非-detached actor:
推荐默认使用。
生命周期和它的 handle 绑定。
- 所有 handle 都失效 / 任务执行完 / 创建者退出 时,Ray 会:
由创建者通知 GCS。
GCS 发 KillActor RPC 通知 actor 退出,释放资源。
如果创建者崩溃,GCS 通过心跳检测发现,也会主动杀死 actor。
Actor 死亡后,提交到它的所有 pending 任务会失败,抛 RayActorError。
- detached actor:
生命周期独立,必须手动销毁。
适合全局服务、长时间存在的 actor。
Actor 崩溃 & 容错¶
Actor 可能运行中意外崩溃(比如 sys.exit() 或异常)。
默认:崩溃时,提交到它的任务都会失败,RayActorError。
- Ray 提供两种容错机制:
max_restarts - 可以配置 actor 崩溃后 自动重启 N 次。 - 重启时,GCS 会重新提交 actor 创建任务。 - 所有持有 handle 的 client 会缓存任务,直到 actor 重启完成。 - 如果超过最大重启次数,所有挂起任务失败。
max_task_retries - 针对每个 actor 任务,允许 失败后自动重试 N 次。 - 适合幂等任务,用户不需要手动处理 RayActorError。
Global Control Service¶
备注
GCS 是 Ray 的大脑,负责集群管理、调度协调、元数据存储。虽然单点故障会影响核心功能,但可通过持久化 Redis 提升容错性,保障集群稳定运行。
Overview¶
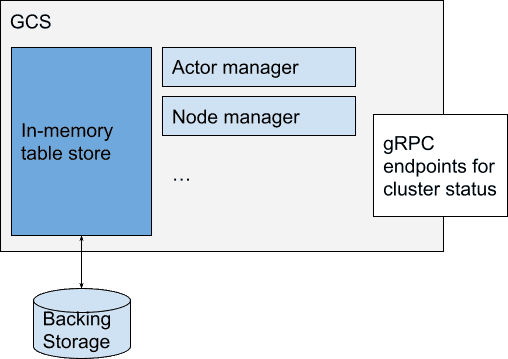
- 什么是 GCS
GCS = Global Control Service
它是 Ray 的控制中心,负责整个集群的管理和协调。
所有 raylet(Ray 的 worker 节点守护进程)和其他进程通过 GCS 发现彼此,协调工作。
外部服务,比如 自动扩缩容 (autoscaler) 和 dashboard,也通过 GCS 与 Ray 集群通信。
- 实现细节:
目前 GCS 是 单线程 处理,只有心跳检测 & 资源 polling 是多线程的(后续会往多线程优化)。
- 如果 GCS 挂掉了,会影响哪些功能
节点管理 (Node management) | 负责节点加入/删除通知,广播给所有 raylets
资源管理 (Resource management) | 负责同步全局资源状态,防止调度时信息不一致
Actor 管理 | 负责 Actor 的创建/删除/监控 & 自动重建
Placement Group 管理 | Placement Group 的生命周期和调度
元数据存储 (Metadata store) | 提供轻量级 KV 存储(适合小型数据)
Worker 管理 | 监控 raylet 上的 worker 崩溃,清理相关状态
Runtime Environment 管理 | 管理运行环境包,跟踪引用计数,执行垃圾回收
此外,GCS 也提供 gRPC 接口,外部服务可以查询集群状态(比如 actor、worker、节点信息)
- 存储机制
默认:GCS 使用 内存中的 HashMap,速度快,但 一旦崩溃,数据丢失。
可选:配置为 写入 Redis,实现持久化(特别推荐部署高可用 Redis)。
Node management¶
Raylet 启动时,会向 GCS 注册自己。
GCS 将节点信息存储,并广播给所有 raylets。
心跳检测:定期检测每个 raylet 是否存活。
如果某个 raylet 崩溃,GCS 广播死亡事件,其他 raylet 清理相关状态。
- Worker 死亡报告:
raylet 会上报它管理的 worker 死亡,GCS 同样广播,确保清理任务。
Resource management¶
GCS 每 100ms 拉取所有 raylet 的资源使用情况。
同时广播整个集群的资源视图,确保各 raylet 了解全局状态。
调度效率严重依赖资源信息的新鲜度,不新鲜可能错误调度。
Autoscaler 通过 GCS 获取集群负载,决定加/减节点。
Actor 管理¶
所有 Actor 必须先在 GCS 注册,才能被调度。
Detached Actor 的拥有者 是 GCS。
GCS 也负责监控 Actor 是否存活,并根据配置重启 Actor。
Placement Group 管理¶
GCS 负责 Placement Group 的创建、调度、删除。
使用 两阶段提交协议 保证 Placement Group 创建过程一致性。
Metadata store¶
- GCS 内部有一个 轻量级 Key-Value 存储,用来存储:
集群 dashboard 地址。
Remote function 定义。
Runtime 环境的工作目录 & 使用计数。
Ray Serve 等库的元数据。
⚠️ 注意:这个存储只适合小数据,不适合用作大规模存储(比如任务或对象元数据是放 worker 里的)。
Fault tolerance¶
默认 GCS 数据存储在内存,崩溃后全部丢失。
- 如何实现容错?
配置 GCS 将数据持久化到 高可用 Redis。
- GCS 重启时,会从 Redis 恢复所有数据,包括:
Raylet 注册信息
Actor 状态
Placement Groups
- 恢复期间,以下功能暂停:
Actor 创建/删除/重建
Placement Group 管理
资源管理
新节点注册
新 worker 启动
但已有的 task 和 actor 仍然活着,因为它们不直接依赖 GCS 操作。
Cluster Management¶
- Ray 的集群管理架构 非常模块化,核心包括:
资源调度+动态扩缩容 (Autoscaler)
多租户环境隔离 (RuntimeEnv + Ray agent)
多种作业提交和监控 API
灵活接入 Kubernetes (KubeRay)
完善的日志、指标和状态可观测性
整体来说,这段内容主要围绕 Ray 的集群管理,分为几个模块讲解:集群中涉及的辅助进程、Autoscaler(自动扩缩容)、作业提交、运行时环境、多租户、KubeRay、Ray 可观测性等。
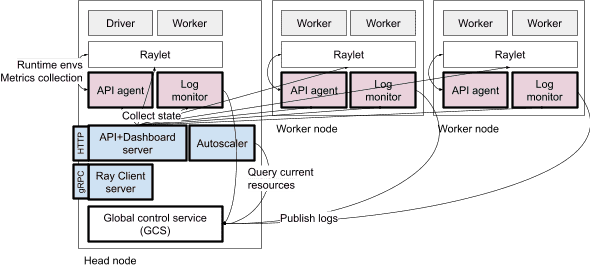
Auxiliary processes involved in cluster management. Blue processes are singletons that live on the head node. Pink processes are launched per-node and manage auxiliary operations for their local node.¶
- 辅助进程负责
集群节点增删
监控节点状态
提交作业
集群运行时环境管理
日志收集
具体辅助进程:
Autoscaler | 自动增减节点 | 定期根据资源需求和当前节点,动态增删节点
Ray Client server | 提供客户端交互接口(远程开发时用) | 类似于一个 proxy 服务器
API server (Dashboard server) | 提供集群 API 接口和 Dashboard | 集群状态查询、作业提交、API 入口
API agent (Ray agent) | 收集节点 metrics,管理本节点运行时环境 | 每个节点一个
Log monitor | 监控本节点日志、错误推送到 driver | 每个节点一个
Autoscaler¶
- 主要功能:
动态增减节点,使得集群能满足当前任务/actor 需求,但不会冗余。
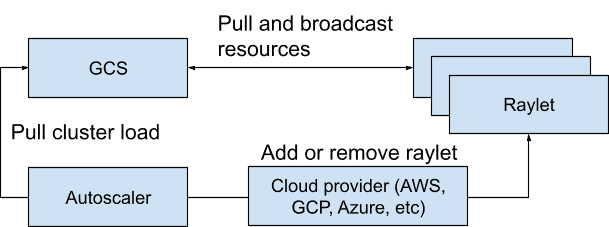
Autoscaler pulls current cluster load from the GCS and invokes cloud providers to add or remove machines¶
- 工作流程:
应用提交任务、actor、placement groups,声明需要的资源(CPU/GPU/内存)
调度器评估当前资源能否满足,不能满足的任务进入 pending 队列
Autoscaler 周期性读取 GCS 中的资源快照,包含当前节点、资源需求、pending 任务
Bin-packing 算法 计算需要新增多少节点才能满足所有运行中和 pending 任务
调用 Node Provider 接口(支持 AWS、GCP、K8s、本地等)增删节点
新节点启动后,注册到集群,接受任务
- 扩缩容细节:
Downscaling:节点空闲超过 5 分钟(无任务/actor/对象),会被移除。
Upscaling speed:限制 pending 节点数,避免过快扩容。默认设置是当前节点数的 100%。
Heterogeneous Node Types:支持多种节点类型(不同实例规格、角色、镜像),可以针对性分配特定任务。
Job Submission¶
Ray 提供 CLI、Python SDK、REST API 提交作业。
- 核心流程:
CLI → Python SDK → HTTP 请求 → 集群 API Server
- 每个作业会有一个 Job Supervisor Actor 在 Head Node 上运行
负责启动子进程执行用户指定的作业命令
管理作业状态(PENDING, RUNNING, SUCCEEDED, FAILED),状态保存在 GCS
作业日志直接写在 Head Node 文件中,API 可读取或流式获取
停止作业通过设置一个 stop 事件,由 supervisor actor 终止子进程
未来计划:将 Job Supervisor actor 也支持调度到非 Head Node 上,减轻 Head Node 压力
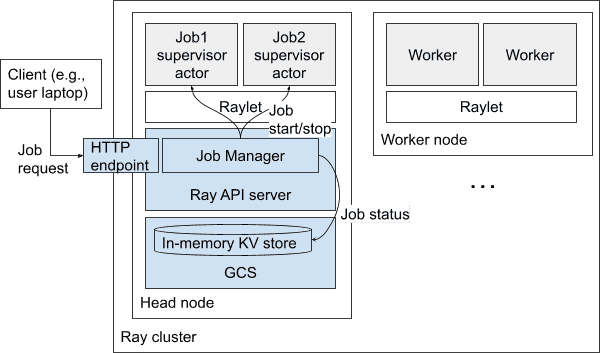
A diagram of the architecture of Ray Job Submission. Blue boxes indicate singleton services that manage job submission, among other cluster-level operations.¶
Runtime Environments and Multitenancy¶
- 运行时环境 指定每个作业/actor/task 所需的依赖,比如:
Python 包 (
pip install)环境变量
Conda 环境
远程文件
- 核心机制:
RuntimeEnvAgent:每个节点都有,负责安装环境,gRPC 服务
当任务/actor 需要特定环境时,Raylet 请求本节点的 RuntimeEnvAgent 创建环境
环境资源有缓存,多个任务可以复用,超过缓存限制时会清理不使用的
扩展性:未来支持用户自定义插件来安装特殊资源(例如 PEX 文件)
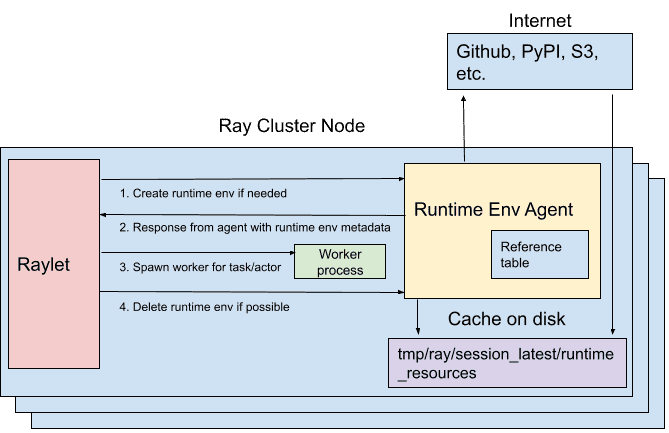
KubeRay¶
- KubeRay 适用于 Kubernetes 环境:
每个 Ray 节点运行在一个 Kubernetes Pod。
采用 Operator 模式:
定义 RayCluster CRD 表示集群期望状态。
KubeRay Operator 负责创建/管理 Pod 以满足定义。
Ray Observability¶
- 提供多种监控、日志、指标功能
- ✨ Ray Dashboard
HTTP 服务器,运行在 Head Node。
聚合全局系统状态,提供 Web UI 展示。
- ✨ Log Aggregation
所有 actor、task 的 stdout/stderr 被重定向到日志文件。
Log monitor 进程 每个节点都有,周期性读取日志文件,通过 GCS 发布给 Driver。
- ✨ Metrics
各组件 (GCS, Raylet, Worker) 发 metrics 给本地 Ray agent。
默认支持 Prometheus,集成 OpenCensus。
- ✨ Ray State API
2.0 引入,通过 CLI/Python SDK 查询当前集群状态(任务、actor、节点等)。
特点:Ray 不将运行元数据持久化到数据库,而是 分布式保存在 worker 上,和 worker 生命周期绑定,查询时实时拉取。
Appendix¶
Architecture diagram¶
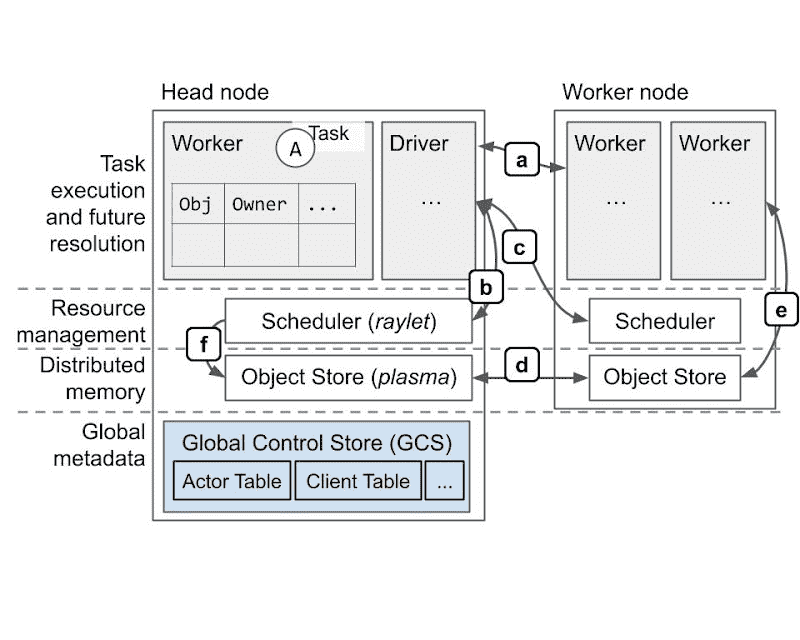
Architecture and protocols¶
Ray 分布式系统的核心架构和执行过程,尤其是 任务调度、对象存储、跨节点资源管理 以及 垃圾回收 的细节。
- 核心概念梳理
Ray 是一个分布式计算框架,任务(Task)和对象(Object)可以跨多个节点(Node)分布执行和存储。
gRPC 协议 用于节点间通信。
- 对象存储分为两种:
In-process memory store(进程内存,适合小对象,效率高)
Shared memory object store(跨节点共享,适合大对象)
todo