2301.02111_Vall-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers¶
组织: Microsoft
Abstract¶
我们提出了一种用于文本转语音(TTS)的语言建模方法,称为 VALL-E。
它不直接预测音频波形,而是将音频压缩成离散代码,再像语言模型那样生成这些代码。
传统的TTS系统通常是把文字转换成连续的音频信号(波形),这个过程需要精确生成每一帧的声音数据。
VALL-E 使用一个音频压缩器(叫做“神经音频编解码器”)先把音频转成一串“离散代码”,就像把音频变成一串符号或“词”。
VALL-E 像训练语言模型(比如GPT)那样,用这些离散代码作为“语言”,从文本预测出对应的代码序列。
原文
using discrete codes derived from an off-the-shelf neural audio codec model,
and regard TTS as a conditional language modeling task
rather than continuous signal regression as in previous work.
关键词解释
off-the-shelf:现成的,不需要自己重新开发。
neural audio codec:神经网络做的音频压缩工具,它把连续音频变成一组“代码”表示。
discrete codes:离散的符号(比如 token),而不是连续的波形。
VALL-E 在6万小时英语语音上进行训练,远超以往系统。
它只需一个3秒钟的说话人录音作为提示,就能合成出高质量、个性化的语音,而且保留了说话人的情感和声音环境。
实验表明,它在语音自然度和相似度上优于现有的零样本TTS系统。
1. Introduction¶
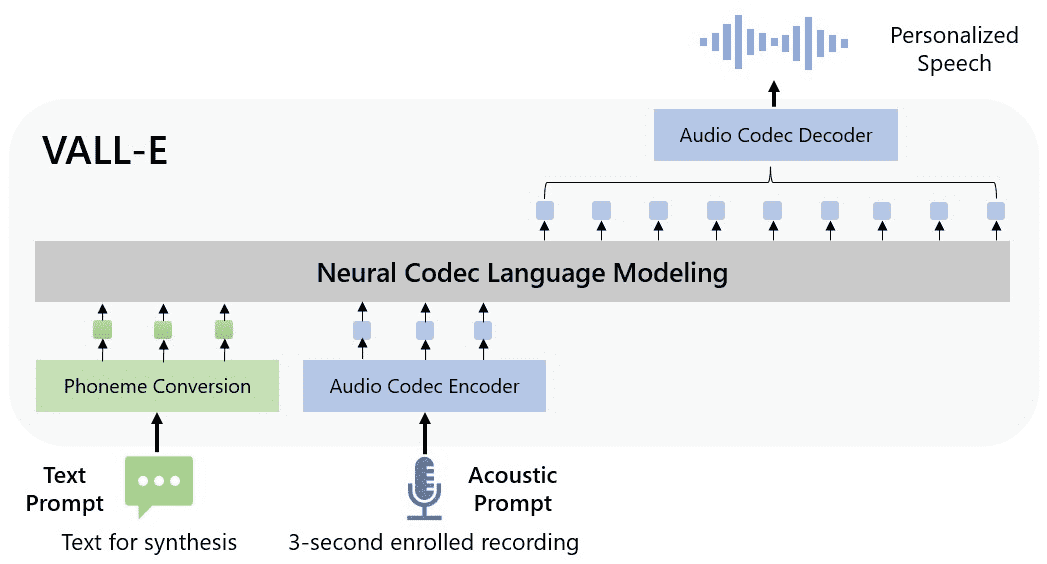
Figure 1: The overview of VALL-E. Unlike the previous pipeline (e.g., phoneme → mel-spectrogram → waveform), the pipeline of VALL-E is phoneme → discrete code → waveform. VALL-E generates the discrete audio codec codes based on phoneme and acoustic code prompts, corresponding to the target content and the speaker’s voice. VALL-E directly enables various speech synthesis applications, such as zero-shot TTS, speech editing, and content creation combined with other generative AI models like GPT-3 (Brown et al., 2020).
🗣 背景¶
近年来语音合成(TTS)取得了巨大进步,但现有系统(主要使用梅尔谱图 + 声码器)仍依赖高质量干净录音数据,导致泛化能力差,特别是遇到没见过的说话人时表现不好。
🌟 创新点:VALL-E¶
VALL-E 是第一个基于语言模型的 TTS 框架,不再使用传统的梅尔谱图,而是使用音频编码器生成的离散语音 token(叫 acoustic tokens)作为中间表示。
它参考 GPT 的思路,把 TTS 看作一个“语言建模”任务,从而具备**“上下文学习”(in-context learning)能力**
🔧 做法¶
用 60,000 小时包含 7000+ 说话人的真实语音数据训练(大多来自 LibriLight)。
使用语音识别模型为这些语音生成对应的文本标签,虽然存在噪声,但数据量大、说话人多样。
合成流程:给 3 秒录音(确定说话人) + 文本音素(确定内容) → 生成语音 token → 用解码器还原出最终语音。
✅ 效果¶
在两个测试集(LibriSpeech 和 VCTK)中,VALL-E 在自然度和说话人相似度上都超过了当前最强的零样本 TTS 方法。
能保留原音的情绪(如愤怒)和环境(如回音),还能根据不同采样策略生成多个不同的版本。
📌 主要贡献总结¶
首次将 TTS 作为语言建模任务,实现了像 GPT-3 一样的上下文学习。
使用海量数据,表明“数据规模”在 TTS 中作用被低估了。
可以在同一个说话人下生成多个不同版本,保持情感和环境。
在“零样本”条件下仍生成自然且相似的语音,显著优于已有方法。

Table 1: A comparison between VALL-E and current cascaded TTS systems.
3. Background: Speech Quantization¶
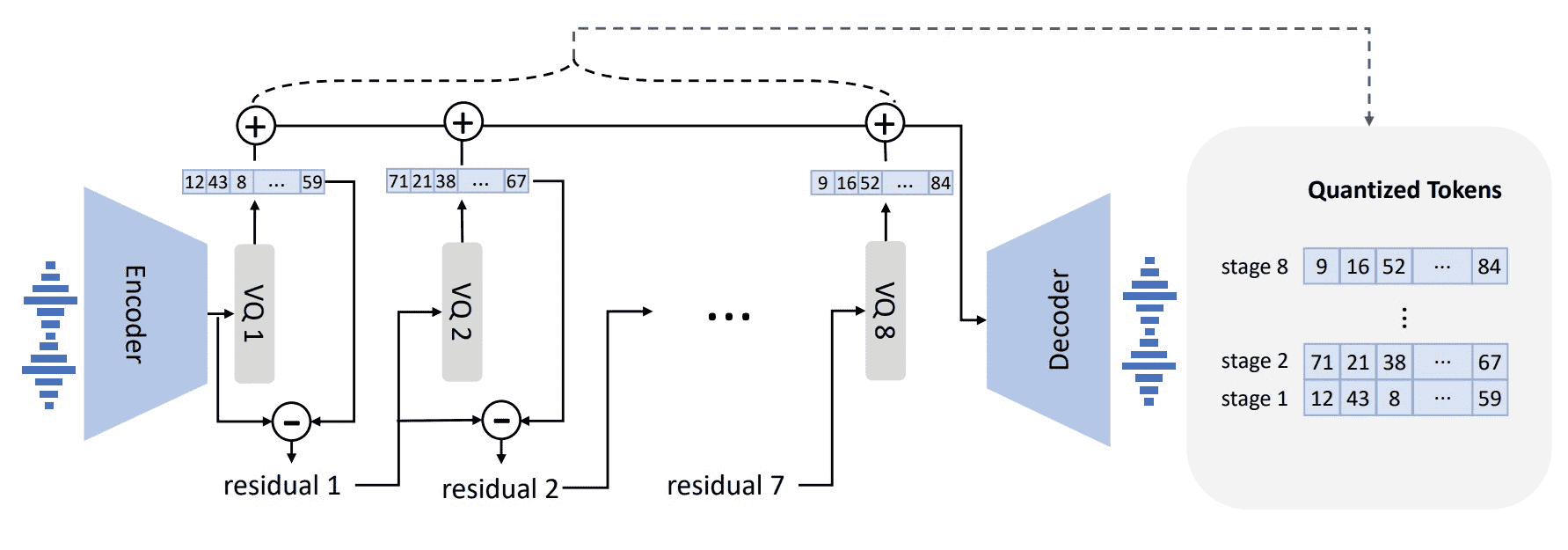
Figure 2: The neural audio codec model revisit. Because RVQ is employed, the first quantizer plays the most important role in reconstruction, and the impact from others gradually decreases.
🧠 背景问题¶
原始音频是16位整数,每秒有几万帧,如果直接建模,需要输出 65536 个概率值/帧,非常复杂。
序列太长也导致生成速度慢,不适合直接用生成模型处理。
🔧 解决方案:语音量化¶
μ-law量化:将每帧压缩为256个值,质量不错,但序列长度没变,推理还是慢。
向量量化(VQ):比如 vq-wav2vec、HuBERT 用于提取特征,推理更快,但重建质量差,声音听起来不像原说话人。
AudioLM:结合了 自监督模型生成的token 和 神经codec生成的token,效果好。
🧰 本文做法¶
学习AudioLM,用 神经codec模型(比如EnCodec) 来把语音转成离散token,既压缩了数据又能保持说话人信息。
EnCodec模型特点:
保留说话人和声音细节,重建质量高。
有现成的decoder,不用自己训练vocoder。
序列变短,推理快。
📦 具体使用的模型:EnCodec¶
是一个卷积的编码-解码模型。
输入/输出是 24kHz 的音频。
把 24kHz 的音频编码为 75Hz 的嵌入,压缩比是 320倍。
使用 8个量化器(quantizer),每个有1024个代码。
一个10秒音频,会变成一个 750 × 8 的token矩阵(750个时间步,每步8个token)。
📈 总结¶
通过使用EnCodec等神经音频codec,音频数据可以被压缩成保留声音特征的离散token,既减小了模型负担,又提升了生成质量和速度。
4. VALL-E¶
4.1 Problem Formulation: Regarding TTS as Conditional Codec Language Modeling¶
我们把语音合成(TTS)看作一个有条件的“编解码语言建模”任务。具体来说:
每条语音(音频样本)都会先被转成一串音素(发音单位),然后再用一个预训练的神经编解码器把音频编码成一个由离散代码组成的矩阵(叫做声学码)。
每一行代表某一帧的8个离散代码,每一列来自不同的码本。
这个离散码矩阵可以用解码器重构出接近原始的语音。
在零样本TTS(给定从未见过的说话人,合成出该说话人风格的语音)中:
我们训练一个语言模型,输入是音素序列和一段3秒的录音(代表说话人风格),输出是声学码矩阵。
然后用神经解码器把这个矩阵变成最终语音。
目标是让模型学会从音素中获取“内容”,从录音中获取“说话人特征”,合成出内容一致、声音风格也匹配的语音。
4.2 Training: Conditional Codec Language Modeling¶
这段内容是讲 VALL-E 模型在训练中的两种语言建模方式:自回归(AR)和非自回归(NAR),它们如何配合使用来提升语音生成质量与速度。
🎯 总体目标
训练一个模型,可以将文字+声音提示(比如某人的一句话)转成目标语音(比如这人的另一句话),实现“零样本语音合成”。
🧱 编码结构:分层量化
音频会被编码成 多个层级的离散token(代码):
第一层:捕捉重要信息,比如说话人特征;
后续几层(2~8):逐步加入细节,提升音质。
4.2.1 Autoregressive(AR) Codec Language Modeling¶
输入:文字内容 + 声音提示的编码(第一层);
输出:目标语音的第一层token序列,一个个预测(自回归);
优点:可以灵活生成不同长度的音频,更适合控制说话节奏;
本质:跟 GPT 一样,是一个 decoder-only Transformer。
4.2.2 Non-Autoregressive Codec Language Modeling¶
说明:后续层(第2~8层):非自回归(NAR)语言模型
输入:文字 + 声音提示(8层全量) + 已预测的前几层token;
输出:当前层的token,并行生成;
优点:快,不再逐个预测;
训练方式:每次随机训练其中一层,输入为之前所有层的总和;
技巧:
使用 Adaptive Layer Norm 来告诉模型现在是第几层;
输出层和下一层的输入embedding层参数共享。
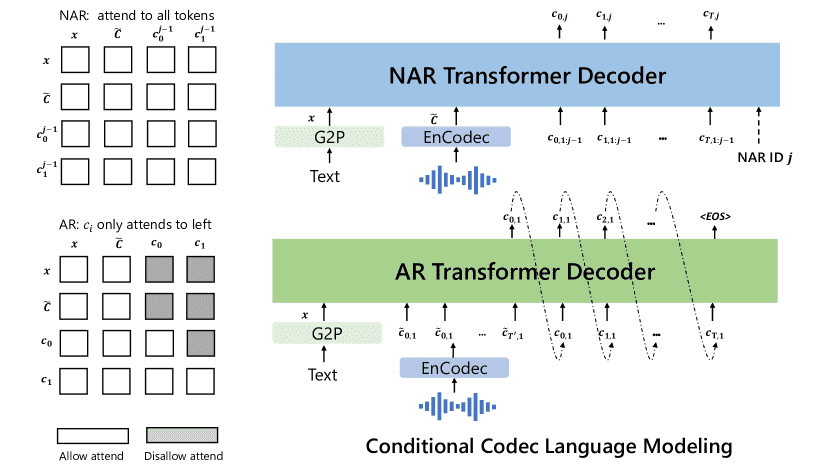
Figure 3:The structure of the conditional codec language modeling, which is built in a hierarchical manner. In practice, the NAR decoder will be called seven times to generate codes in seven quantizers.
总结¶
⚖️ 组合使用的好处
AR 负责第一层,保证语音长度和节奏合理;
NAR 负责细节,并行生成提升效率;
最终预测是:
p(C | x, C~) = AR 预测第1层 × NAR 预测第2~8层
4.3 Inference: In-Context Learning via Prompting¶
这段内容主要讲了 文本到语音(TTS)系统中的“提示式推理”(in-context learning via prompting)。
🌟核心概念简述:
In-Context Learning(上下文学习)
模型在没有再训练的情况下,仅通过输入“提示”(prompt)就能完成任务。
比如:直接根据一个新说话人的样本合成语音。
现有TTS的挑战
大多数TTS系统对新说话人效果差,或者需要额外微调,所以“in-context learning”能力不强。
怎么实现Prompting(提示)
把输入文本转成音素序列(phoneme prompt)
把目标说话人的录音转成音频特征(acoustic prompt)
然后喂给模型生成语音
🔹VALL-E 模式
输入:一句文本 + 一个目标说话人的录音(和转录)
方法:
把录音的转录音素加在输入文本前面(形成 phoneme prompt)
提取这段录音的音频特征作为 acoustic prefix
模型根据这些提示生成目标说话人风格的语音
🔹VALL-E-continual 模式
输入:某人说话的前3秒录音和文本
模型任务:继续生成后面的语音,让语音听起来是“连贯的”
方法和 VALL-E 类似,但语音是“上下文连续”的,不是换句话说
总结:
这段讲的是通过提示(Prompt)喂模型一些说话人的信息,就能让模型用这个说话人的风格合成语音,无需重新训练。
VALL-E 和 VALL-E-continual 是两种提示方式,分别用于语音克隆和语音续写。
5. Experiments¶
5.1 Experiment Setup¶
训练数据:用60,000小时的英文有声书音频(LibriLight),没有标注。大约7000个不同说话人。
标注模型:用Kaldi工具训练了一个传统的DNN-HMM模型对其中960小时进行了标注,得到语音与音素的对齐信息。
编码方式:用EnCodec模型把音频转换为声学编码。
模型架构:自回归(AR)和非自回归(NAR)模型都使用相同的Transformer结构,共12层,1024维嵌入。
训练方式:在16块V100显卡上训练,共训练80万步。
评估方式
自动评估:
语音识别准确率(WER):反映语音内容的准确性。
说话人相似度(SPK):使用WavLM-TDNN模型评估合成语音是否和原说话人声音相似。
人工评估:
CMOS:语音自然度,对比基线模型打分,范围 -3 到 +3。
SMOS:说话人相似度评分,1 到 5 分。
5.2 LibriSpeech Evaluation¶
LibriLight 训练数据和 LibriSpeech 测试清洁数据之间没有说话人重叠
VALL-E 比基线模型 YourTTS 在内容准确性(WER)和说话人相似度(SPK)上都更好。
引入“连续语音片段作为提示”后(VALL-E-continual),WER 进一步下降。
人类评估也显示 VALL-E 合成语音接近原声,超过 YourTTS。
消融实验
对 NAR 模型:
没有提示时,性能最差。
有音素提示后内容大幅提升(WER 下降)。
加入声学提示后,说话人相似度大幅提高。
对 AR 模型:
去掉声学提示,说话人相似度下降明显,说明提示信息非常重要。
5.3 VCTK Evaluation¶
VALL-E 即使从未见过这些说话人,也能生成非常相似的语音。
在看过和没看过的说话人两种情况下,VALL-E 表现都优于 YourTTS。
人类评估显示 VALL-E 的自然度甚至略高于原始音频(可能因 VCTK 数据本身含有噪音)。
5.4 Qualitative Analysis¶
多样性:
传统TTS(语音合成)系统对同一文本只能生成一种语音,
而VALL-E引入了采样机制,使得即使输入相同,也能生成不同的语音表现(如语速、重音、口音等),更具多样性。
这对需要多样语音数据的任务(比如语音识别)很有用。
保留声学环境:
VALL-E能保留提示音频中的环境特征,比如混响效果,而传统方法只会生成干净语音。
这是因为VALL-E训练数据更丰富,覆盖了更多声学条件。
保留情绪:
即使没有专门训练情绪数据,VALL-E也能在“零样本”的情况下保留提示语音中的情绪(如开心、生气等),
传统方法通常需要带有情绪标签的数据集来实现这一点。
6. Conclusion, Limitations, and Future Work¶
我们提出了 VALL-E,一种基于语言模型的语音合成方法,用音频编码码作为中间表示。
模型在6万小时语音数据上预训练,能实现零样本学习,在LibriSpeech和VCTK两个数据集上都达到了最好的效果。
它还能保留说话人的情感和环境信息,生成多样化语音。
但VALL-E仍有一些问题:
合成稳定性差:有时会漏读、重复或发音不清,这是因为模型是自回归的,注意力机制不稳定。未来可能用非自回归模型或改进注意力机制解决。
数据覆盖不全:虽然训练数据量很大,但对口音说话人和不同说话风格的覆盖仍不足,影响了某些数据集的表现。未来将扩大数据多样性,提升表现。
模型结构待优化:目前用两个模型预测不同编码,未来可以尝试用一个统一模型,或用全非自回归模型加快速度。
潜在风险:VALL-E能模拟说话人声音,可能被滥用于伪造身份。未来将开发检测机制,并遵守微软AI负责任使用原则。