2203.11147_GopherCite: Teaching language models to support answers with verified quotes¶
组织: Equal contributions,DeepMind,伦敦大学学院计算机科学系
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, …
Recent large language models often answer factual questions correctly. But users can’t trust any given claim a model makes without fact-checking, because language models can hallucinate convincing nonsense. In this work we use reinforcement learning from human preferences (RLHP) to train “open-book” QA models that generate answers whilst also citing specific evidence for their claims, which aids in the appraisal of correctness. Supporting evidence is drawn from multiple documents found via a search engine, or from a single user-provided document. Our 280 billion parameter model, GopherCite, is able to produce answers with high quality supporting evidence and abstain from answering when unsure. We measure the performance of GopherCite by conducting human evaluation of answers to questions in a subset of the NaturalQuestions and ELI5 datasets. The model’s response is found to be high-quality 80% of the time on this Natural Questions subset, and 67% of the time on the ELI5 subset. Abstaining from the third of questions for which it is most unsure improves performance to 90% and 80% respectively, approaching human baselines. However, analysis on the adversarial TruthfulQA dataset shows why citation is only one part of an overall strategy for safety and trustworthiness: not all claims supported by evidence are true.
最近的大型语言模型通常可以正确地回答事实问题。但是,如果没有事实核查,用户就无法相信模型所做的任何给定声明,因为语言模型可能会产生令人信服的胡说八道的幻觉。在这项工作中,我们使用来自人类偏好的强化学习(RLHP)来训练“开卷”QA模型,这些模型会生成答案,同时也为他们的主张引用具体的证据,这有助于评估正确性。支持证据来自通过搜索引擎找到的多个文档,或来自用户提供的单个文档。我们的 2800 亿参数模型 GopherCite 能够生成具有高质量支持证据的答案,并在不确定时放弃回答。我们通过对 NaturalQuestions 和 ELI5 数据集子集中的问题答案进行人工评估来衡量 GopherCite 的性能。发现该模型的响应在该自然问题子集上 80% 的时间是高质量的,在 ELI5 子集上为 67% 的时间。在最不确定的第三个问题中弃权,性能分别提高到 90% 和 80%,接近人类基线。然而,对对抗性 TruthfulQA 数据集的分析表明,为什么引用只是安全性和可信度整体策略的一部分:并非所有有证据支持的声明都是真实的。
备注
教语言模型用经过验证的引用来支持答案
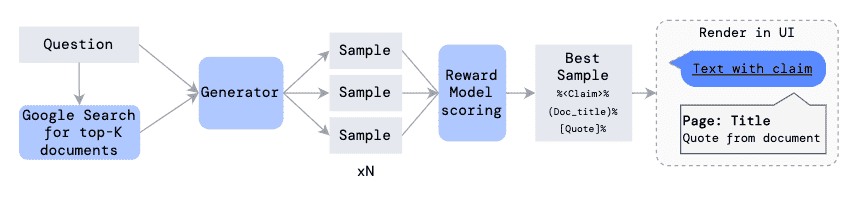
Figure 2: Diagram of the runtime answer generation procedure with reranking.¶
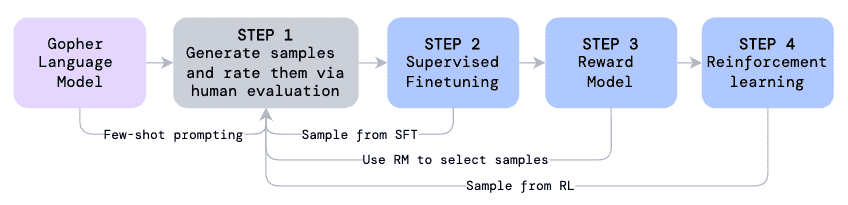
Figure 3: Diagram of the Self-Supported Question Answering training pipeline.¶