2502.13923_Qwen2.5-VL¶
Abstract¶
Qwen2.5-VL 是 Qwen 系列中最新的多模态视觉语言大模型,在基础能力和创新功能上有显著提升。它可以更准确地识别图像、定位物体、解析文档、理解长时间视频(精确到秒级事件),支持从图表、表格、发票中提取结构化数据,还能处理不同分辨率的图像和小时级视频。
它采用从零训练的动态分辨率 Vision Transformer(ViT)架构,结合窗口注意力机制,在降低计算开销的同时保持高分辨率处理能力。
Qwen2.5-VL 不仅能理解静态图像和文档,还能作为交互式视觉智能体完成复杂任务,比如操作电脑和手机。它无需针对特定任务微调,就能在多个领域表现出色。
该模型有三个版本(72B、7B、3B),覆盖从边缘设备到高性能计算的不同需求,其中最大模型的性能可比肩 GPT-4o 和 Claude 3.5 Sonnet。小模型也在资源有限的环境中表现优异,并且保持了强大的语言理解能力。
1. Introduction¶
💡 背景介绍¶
大型视觉语言模型(LVLMs) 是人工智能的一项重大突破,将视觉感知与自然语言处理结合,推动多模态理解。
当前的LVLMs虽有进展,但在细粒度视觉感知和多模态推理上还不够强,相当于“夹心饼干的中间层”。
🎯 Qwen2.5-VL 的目标¶
加强模型对细节的感知能力(如更准确识别图像细节、理解视频等),构建坚实的基础层。
顶层是多模态推理,结合强大的语言模型和高质量问答数据来提升。
🧱 技术创新点¶
窗口注意力机制:提升视觉编码效率。
We implement window attention in the visual encoder to optimize inference efficiency
动态FPS采样:支持不同帧率的视频理解,适配长视频。
We introduce dynamic FPS sampling,
extending dynamic resolution to the temporal dimension and enabling comprehensive video understanding across varied sampling rates
改进时间建模(MRoPE):对齐到绝对时间,提升模型对时间顺序的理解。
We upgrade MRoPE in the temporal domain by aligning to absolute time, thereby facilitating more sophisticated temporal sequence learning
大规模高质量数据:预训练语料扩展到 4.1 万亿token,提高泛化能力。
We make significant efforts in curating high-quality data for both pre-training and supervised fine-tuning,
further scaling the pre-training corpus from 1.2 trillion tokens to 4.1 trillion tokens
🌟 Qwen2.5-VL 的关键能力¶
文档解析(Powerful document parsing capabilities):识别各种文档内容,包括手写、表格、化学公式等。
精确定位(Precise object grounding across formats):可输出坐标/JSON格式,准确找出并计数图中目标。
长视频理解(Ultra-long video understanding and fine-grained video grounding):能处理小时级视频,定位几秒内的事件。
强化Agent功能(Enhanced agent Functionality for computer and mobile devices):适配电脑和手机,能做出智能决策和操作。
🧠 架构亮点¶
使用 ViT(视觉Transformer)+ Qwen2.5 LLM 组合。
支持图像/视频输入,动态调整分辨率与帧率。
加入先进模块如 SwiGLU、RMSNorm、窗口注意力,提升效率与表现。
2. Approach¶
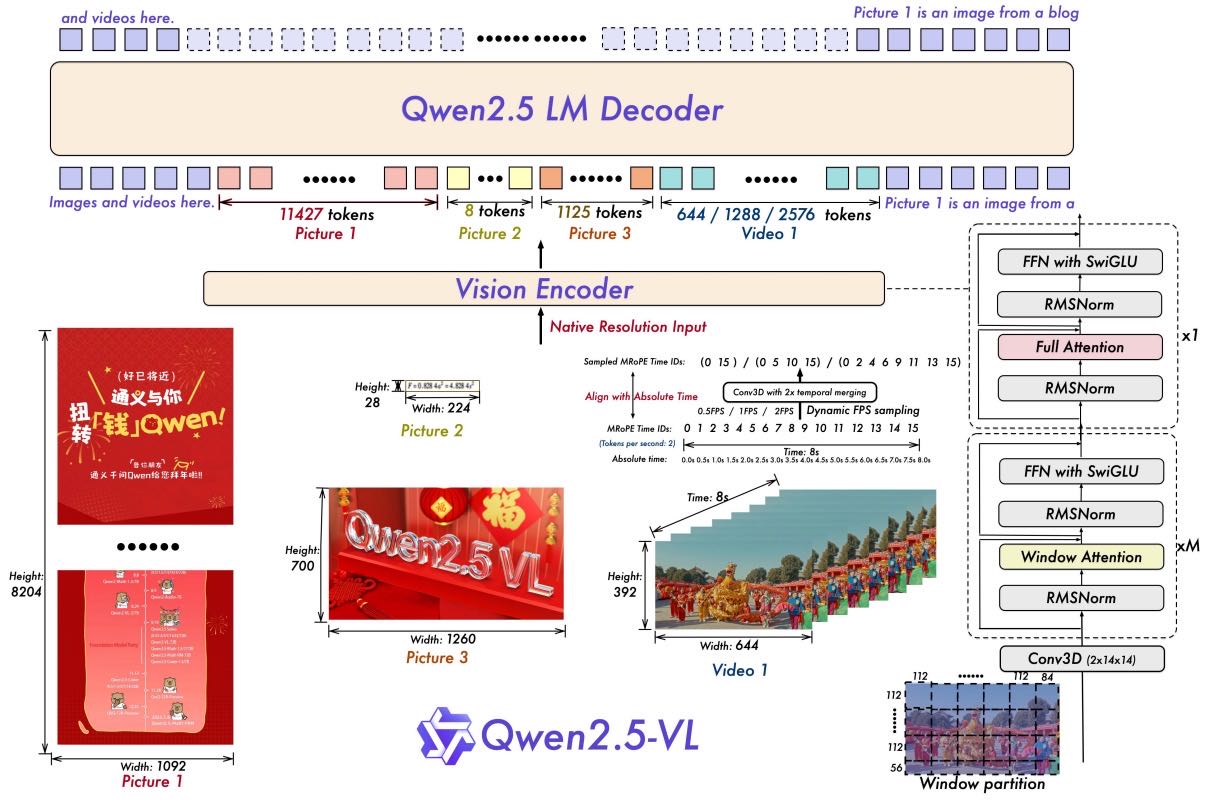
Figure 1: The Qwen2.5-VL framework demonstrates the integration of a vision encoder and a language model decoder to process multimodal inputs, including images and videos. The vision encoder is designed to handle inputs at their native resolution and supports dynamic FPS sampling. Images of varying sizes and video frames with different FPS rates are dynamically mapped to token sequences of varying lengths. Notably, MRoPE aligns time IDs with absolute time along the temporal dimension, enabling the model to better comprehend temporal dynamics, such as the pace of events and precise moment localization. The processed visual data is subsequently fed into the Qwen2.5 LM Decoder. We have re-engineered the vision transformer (ViT) architecture, incorporating advanced components such as FFN with SwiGLU activation, RMSNorm for normalization, and window-based attention mechanisms to enhance performance and efficiency.
2.1 Model Architecture¶
大型语言模型(Large Language Model):
使用 Qwen2.5 的预训练模型作为基础。
将原本的一维位置编码(1D RoPE)改成适用于多模态的“多模态旋转位置编码(MRoPE)”,支持图像和视频的时空位置对齐。
视觉编码器(Vision Encoder):
使用重新设计的 Vision Transformer(ViT):
输入图像尺寸会自动调整为28的倍数。
使用 2D RoPE + 窗口注意力(Window Attention)加速运算,仅有4层使用完整自注意力。
处理图像时将其划分为14x14的 patch;处理视频时将两个连续帧组合在一起,有效减少token数量。
使用更高效的归一化(RMSNorm)和激活函数(SwiGLU),提升兼容性和训练速度。
基于MLP的视觉-语言合并器(MLP-based Vision-Language Merger):
为了应对长序列图像特征带来的效率挑战,采用了一种简单有效的压缩方法,
在将特征序列送入大型语言模型之前对其进行压缩,从而减少计算成本并提供灵活的方式来动态压缩不同长度的图像特征序列。
用一个简单的 MLP 模块(2层全连接网络)将邻近的图像 patch 特征组合压缩,再输入 LLM。
减少序列长度,降低计算开销,并可适配不同图像分辨率。
模型特点:
原生支持不同图像分辨率,保持空间比例,避免图像拉伸。
原生支持不同视频帧率,可理解“绝对时间”,无需额外添加时间戳。
改进的 MRoPE:时间编码不再只和帧数相关,而是对齐真实时间,使模型能学习不同视频节奏。
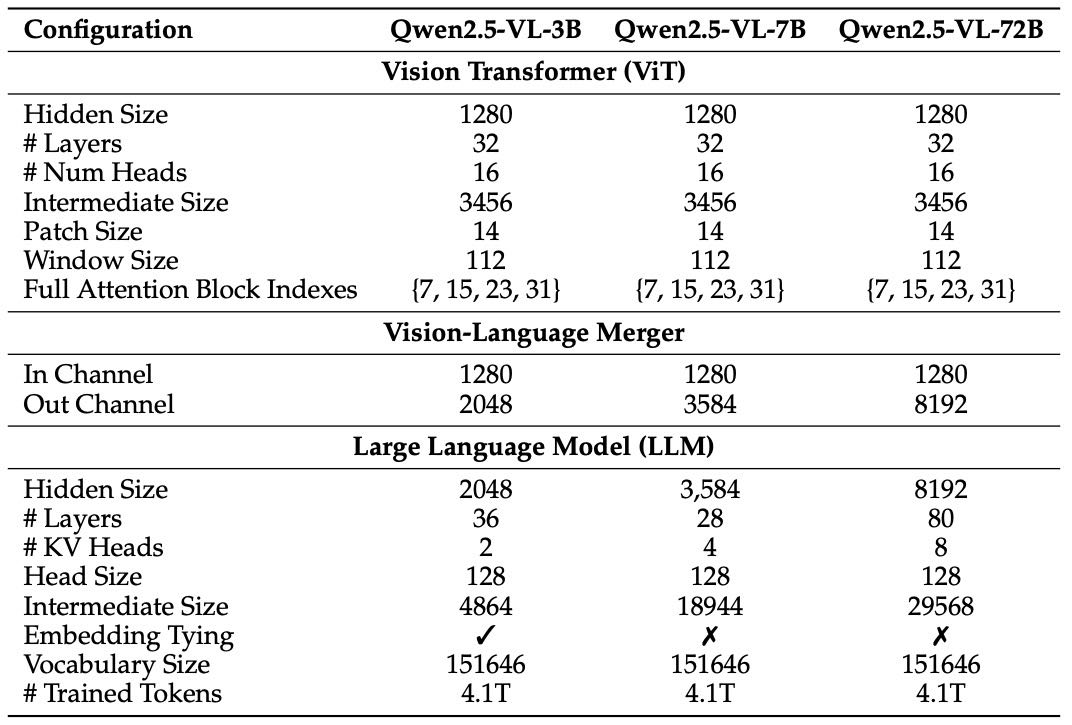
Table 1: Configuration of Qwen2.5-VL.
✅ 2.1.1 快速高效的视觉编码器(Vision Encoder)¶
🌟 设计目标:解决处理高分辨率图像时计算量大、效率低的问题。
🌟 技术细节:
窗口注意力机制(Window Attention):
大部分层只在局部窗口内做注意力计算,计算量随 patch 数量线性增长(而不是二次方关系)。
仅 4 层使用全局自注意力,确保全局信息捕捉能力。
位置编码
2D RoPE:增强对图像空间位置的理解。
3D Patch 划分(支持视频):
图像用 14×14 patch,视频中将相邻两帧合并处理,减少 token 数。
一致的模型设计风格:
使用 RMSNorm 和 SwiGLU,与语言模型保持一致,提高兼容性与训练效率。
从零训练(ViT),并经历多阶段训练:
包括 CLIP 预训练、图文对齐、端到端微调。
动态分辨率采样:
保留图像原始长宽比,训练时随机采样不同尺寸,提高泛化能力。
✅ 2.1.2 原生动态分辨率与帧率(Native Dynamic Resolution & Frame Rate)¶
🖼 空间处理:
不再统一缩放图像坐标,而是直接使用真实尺寸。
模型可以“自学”尺度信息,增强处理不同分辨率图像的能力。
🎞 时间处理(视频):
引入 动态帧率训练 + 绝对时间编码。
不靠手动加时间戳或额外的网络结构。
通过将时间编码与真实时间对齐,模型能自然地理解不同视频的“节奏”。
✅ 2.1.3 多模态旋转位置编码与绝对时间对齐(MRoPE with Absolute Time)¶
MRoPE: Multimodal Rotary Position Embedding
传统 MRoPE 的问题:
原本只根据“帧数”编码时间,不能反映事件发生的真实时间点。
Qwen2.5-VL 的改进:
将时间维度的编码 与实际时间对齐(absolute time)。
不同帧之间的时间间隔通过编码反映,使模型能理解“什么时候发生了什么”。
不增加计算成本,却提高了视频理解能力。
✅ 总结一句话:¶
Qwen2.5-VL 是一个优化了空间和时间理解能力的多模态大模型,具备高效图文视频融合能力,适配不同分辨率与帧率,能够在不增加计算成本的前提下更好理解视频节奏和图像结构。
2.2 Pre-Training¶
2.2.1 Pre-Training Data¶
数据构建
数据量升级:训练数据从 Qwen2-VL 的 1.2 万亿 token 提升到约 4 万亿 token。
多模态数据类型:包含图文对、OCR、视觉知识、多模态学术问答、定位、文档解析、视频描述、交互式 Agent 数据等。
数据质量控制:对图文数据进行清洗和打分,重点关注文本质量、图文相关性、互补性和信息密度平衡。
关键数据设计
Interleaved Image-Text Data:
确保图文搭配质量好,能增强推理与创作能力。
针对图文对应性弱、噪声多的问题,开发了 四阶段评分清洗系统,按以下标准评估图文质量:
文本质量
图文关联性
图文互补性
信息密度平衡
Grounding Data with Absolute Position Coordinates:
使用 图像的实际尺寸坐标(非相对坐标)表示物体位置,提高空间理解能力。
自建包含上万个类别、包括真实和合成的定位数据,支持边界框、点标注和自然语言描述。
Document Omni-Parsing Data:
将表格、图表、公式、音乐谱等文档元素统一转为结构化 HTML 格式,提高文档理解力。
OCR Data:
支持法语、德语、日语、阿拉伯语等多种语言,结合真实与合成图像训练。
Video Data:
涵盖不同帧率、长视频字幕、时间定位等,以增强视频理解能力。
训练时采用 动态帧率采样,涵盖不同 FPS。
为长视频生成多帧合成字幕,增强对长视频的理解。
支持多种时间格式的标注(如秒、时:分:秒:帧)。
Agent Data:
采集手机/网页/桌面截图,合成 UI 描述与操作流程,训练模型理解 UI 并具备决策能力。
用图形界面截图、UI 元素标注、操作轨迹等训练模型的感知与决策能力。
所有操作被统一为 函数调用格式,并通过人机协作生成推理解释,提升模型的真实环境表现力。
2.2.2 Training Recipe¶
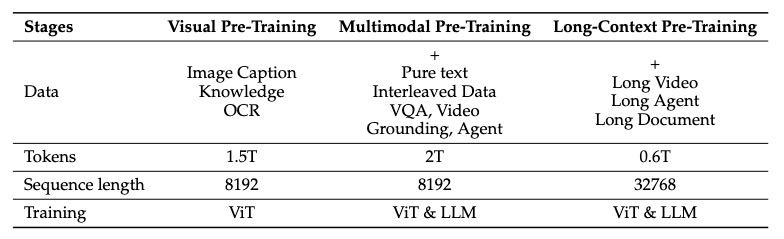 ]
]
Table 2: Training data volume and composition across different stages.
多模态大模型的训练流程,共分三阶段:
第一阶段:
只训练视觉编码器(ViT),用图像字幕、视觉知识和OCR数据,让它能更好地与语言模型配合。
第二阶段:
解冻全部参数,用更复杂的图文数据训练,包括多任务、VQA、数学题、视频理解等,让模型更好地理解图文关系。
第三阶段:
引入更长序列和视频、智能体任务的数据,提升模型处理长文本和复杂推理任务的能力。
为了解决图像大小和文本长度不一致带来的训练负载不均问题,他们通过动态数据打包和平衡GPU计算负载来提高效率。
前两阶段用8192长度,第三阶段扩展到32768长度。
2.3 Post-training¶
采用 两阶段优化:
监督微调(SFT)
直接偏好优化(DPO)
SFT:
目标是让模型学会如何更好地理解和执行用户指令,尤其是多模态任务(如图文问答)。
说明:
使用 ChatML 格式,明确对话角色、支持图文混合输入,并保持视觉和文字顺序关系。
微调用的数据约有 200万条,其中一半是纯文本,一半是图文/视频混合数据(主要为中英文)。
覆盖多种任务:问答、图像描述、数学题、编程、安全、文档识别、视频分析、智能体交互等。
2.3.1 Instruction Data¶
总计约 200 万条指令-响应对
分布:50% 文本任务 + 50% 多模态任务(图文/视频)
多语言:以中英文为主,适当加入多语种支持
多轮对话与单轮指令混合,情境包括:
单图输入、多图序列
多轮 QA,情感分析、对话规划等
2.3.2 Data Filtering Pipeline¶
由于开源和合成数据质量参差不齐,特别设计了两阶段数据过滤流程:
领域分类过滤
使用 Qwen2-VL-Instag 分类模型(由72B大模型派生)
分类方式:
8个主类别(如:代码、规划、文档等)
30个子类别(如代码生成、OCR提取等)
目的:
实现 按任务定制的数据处理规则
提高过滤精度与语义一致性
领域定制过滤
规则过滤(Rule-Based)
过滤内容:
重复样本、格式错误、非对齐图文
不完整或有害内容(如攻击性、敏感话题)
模型过滤(Model-Based)
使用 Qwen2.5-VL 系列的奖励模型进行评分:
评估维度:
Query:复杂性、上下文相关性
Answer:正确性、清晰度、完整性、有帮助性
视觉信息:是否被正确引用和解释
2.3.3 Rejection Sampling for Enhanced Reasoning¶
🧩 背景:
对于数学、编程、多模态推理类任务,仅靠指令学习不够,还需提升“推理质量”
🛠️ 方法:
用中间版本模型在带标准答案的数据集上生成结果
仅保留 答案完全正确的样本,剔除错误/不清晰/冗长样本
加强“思维链(Chain-of-Thought, CoT)推理”能力:
多步逻辑推理更容易学习
对视觉+语言任务特别关键,如:从图表中算面积等任务
🧪 附加过滤标准:
去除中英文混写(code-switching)
避免过长、重复、无效回答
使用规则与模型过滤“每一步中间推理”是否结合视觉信息准确
2.3.4 Training Recipe¶
阶段 |
内容 |
|---|---|
SFT |
冻结视觉Transformer(ViT),在多模态数据上微调语言模块,全面学习跨模态任务 |
DPO |
用“人类偏好数据”优化模型行为(每个样本只训练一次),增强对齐效果 |
DPO 样本来源:
图文问答 + 纯文本任务
用于让模型“更像人类回答方式”,如更简洁、礼貌、有逻辑
3. Experiments¶
总体情况
Qwen2.5-VL 是一个多模态模型,支持图文、视频、文档等多种输入,性能在多个任务上达到了或超过了业界最强模型(如 GPT-4o、Claude 3.5、InternVL2.5)。
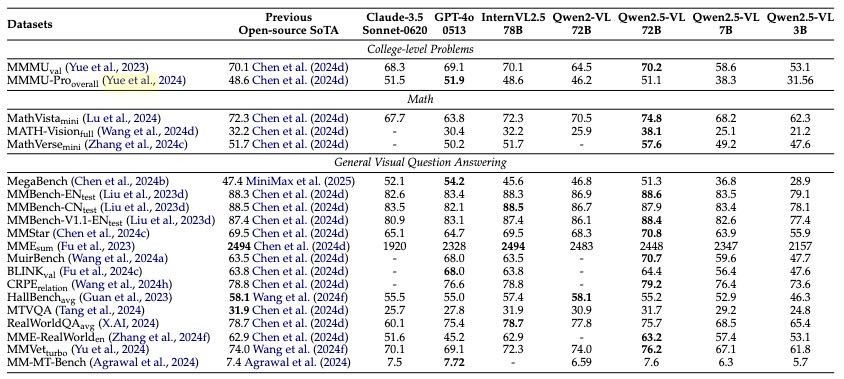
Table 3: Performance of Qwen2.5-VL and State-of-the-art.
Comparison with the SOTA Models
如Table 3所示,Qwen2.5-VL 在多个任务上超过了 SOTA 模型
Performance on Pure Text Tasks
Qwen2.5-VL 在多个文本任务(如数学、编程、对齐任务)上也表现出领先的能力,不输同规模的纯文本大模型。
Quantitative Results
General Visual Question Answering
在多种视觉问答数据集上(如 MMBench、MMStar、MMVet 等)都取得了领先成绩。
多图、多语言、主观问答表现也很强。
Document Understanding and OCR
在文本识别和文档理解任务(如 OCRBench、InfoVQA、CC-OCR)中表现优异,超过了 Google Gemini 1.5-Pro。
Spatial Understanding
在物体定位任务中(比如 ODinW、CountBench)取得领先,特别是点定位和计数能力大幅提升。
结合“检测后计数”提示方式,在 CountBench 上达到了 93.6 的准确率。
Video Understanding and Grounding
在多个视频问答与时间定位任务中(如 Charades-STA、LVBench)超过 GPT-4o。
能处理最长 768 帧,视频 Token 不超过 24,576。
Agent 能力(屏幕交互与控制)
在 UI 元素定位任务(如 ScreenSpot)上表现领先,ScreenSpot Pro 得分达 43.6%,远超同类模型。
在 Android 设备控制与交互中表现优异,可在真实设备环境下作为智能体完成任务。
总结:Qwen2.5-VL-72B 是一个全能型多模态大模型,在视觉、文本、视频、交互等多种任务中都展现出强大能力,并具备良好的可扩展性(3B/7B版本也有不错表现)。
4. Conclusion¶
Qwen2.5-VL 是一款先进的视觉-语言多模态模型系列,擅长图像识别、目标定位、文档解析和长视频理解,适用于静态和动态任务。它支持动态分辨率处理和绝对时间编码,能高效处理各种输入,同时通过窗口注意力机制降低计算成本。该系列适用于从边缘设备到高性能计算的多种场景。
其中,旗舰版 Qwen2.5-VL-72B 在文档和图示理解上可媲美或超过 GPT-4o 和 Claude 3.5 Sonnet,并在纯文本任务上也有强劲表现;轻量级的 7B 和 3B 模型在同尺寸模型中表现更优,兼具效率和通用性。整体上,Qwen2.5-VL 在多模态模型领域树立了新标杆,有助于构建更智能、更互动的系统,实现感知与实际应用的桥接。