2006.09503_PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training¶
组织: Microsoft Research, Carnegie Mellon University, Stanford University
标签: Pipeline_Parallelism
- 说明
1.在调度上,还是采用和PipeDream一样的1F1B
2.在权重更新的粒度上,采用类似Gpipe的方式,每输入m个microbatch,这m个microbatch使用相同的参数做向前和反向,累积梯度之后更新一次参数。和PipeDream的本质区别也就是梯度更新的频率,PipeDream-2BW每m个microbatch更新一次,而PipeDream每个microbatch都更新一次。PipeDream-2BW这样的好处是只需要保存两个版本的梯度,节省内存。
3.PipeDream-Flush中只维护单个权重版本并引入定期流水线刷新(pipeline flush),以确保权重更新期间的权重版本保持一致,通过这种方式以执行性能为代价降低了峰值内存。
Abstract¶
许多最先进的机器学习成果是通过增加现有模型中参数的数量来实现的。然而,像这些大规模模型的参数和激活值通常无法全部存放在单个加速器设备的内存中;这意味着必须将大模型的训练分布到多个加速器上。在这项工作中,我们提出了PipeDream-2BW,这是一个支持内存高效流水线并行的系统。PipeDream-2BW采用了一种新颖的流水线和权重梯度合并策略,并结合了权重的双重缓冲机制,以确保高吞吐量、低内存占用,并且具有类似于数据并行的权重更新语义。此外,PipeDream-2BW能够自动将模型分配到可用的硬件资源上,同时考虑到硬件约束条件,如加速器的内存容量和互连拓扑结构。PipeDream-2BW可以通过类似的最终模型精度,将大规模GPT和BERT语言模型的训练加速最多20倍。
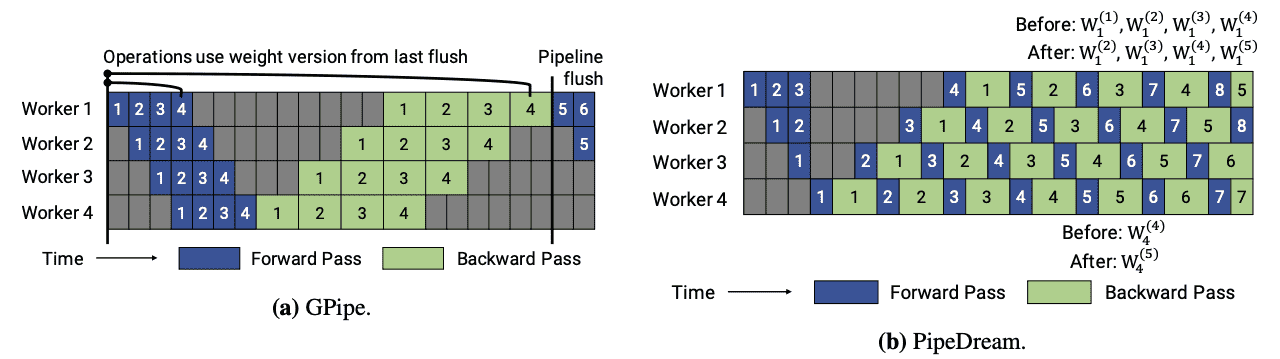
Figure 1. Timelines of different pipeline-parallel executions. Without loss of generality, forward and backward passes are assumed to take twice as long as forward passes; forward passes are shown in blue and backward passes are shown in green. Numbers indicate microbatch ID, time is shown along x-axis, per-worker utilization is shown along the y-axis. GPipe maintains a single weight version, but periodically flushes the pipeline. PipeDream does not introduce periodic pipeline flushes, but maintains multiple weight versions.¶