2408.03314_Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters¶
UC Berkeley, Google DeepMind
这段内容探讨了大语言模型(LLM)在推理阶段(test-time)通过增加计算量来提升输出质量的研究,核心思想是如何让模型在面对复杂问题时,像人类一样花更多时间和精力去思考,从而得到更好的答案。
1. Introduction¶
1. 研究背景与核心问题¶
研究目的:探索大语言模型在推理阶段使用更多计算资源(即更多的推理步骤或计算时间)是否能显著提升其性能。
核心问题:在允许模型使用固定但不小的计算资源时,它在处理具有挑战性的任务(如数学推理)上能提升多少性能?
- 意义
性能优化:帮助确定在实际应用中,是增加模型参数规模更有效,还是增加推理时的计算量更划算。
部署灵活性:如果小模型在推理阶段增加计算就能媲美大模型,那么在设备端部署小模型+高效推理优化将成为可能,减少对大规模数据中心的依赖。
2. 主要研究方法¶
- 基于过程的验证(Process-Based Verification):
训练一个奖励模型(Reward Model),评估每一步推理的正确性
使用搜索算法(如树搜索)优化最终答案
- 自适应响应优化(Adaptive Response Refinement):
让模型 iteratively 修正自身的输出,而不是仅仅生成多个独立的答案
例如,模型可以在回答数学问题时进行多轮修改,提高正确率
这两种方法都旨在提高推理计算的利用效率,而不是简单增加计算资源。
3. 关键发现¶
- 难度自适应: 模型可以根据问题的难易程度自适应调整推理策略:
简单问题:逐步优化答案(Refinement)比并行生成多个答案(Best-of-N)更高效
复杂问题:搜索方法(如树搜索)更有效,因为它能探索不同的解题路径
- 模型规模 vs 推理计算量的权衡:
对于简单和中等难度问题,在小模型上增加推理计算,效果可以超过参数规模大 14 倍的模型。
对于非常复杂的问题,增加推理计算的收益有限,进一步的性能提升仍需依赖更大规模的模型预训练。
- 最优计算分配策略(Compute-Optimal Scaling)能大幅提升效率:
灵活分配推理阶段的计算资源(而不是一刀切地使用固定策略)能够显著提升模型性能
采用“compute-optimal”策略(即针对不同问题自适应分配计算资源),可以比Best-of-N方法减少4倍计算,但仍获得更优结果
4. 研究的意义¶
优化推理计算可以让LLMs在不增加预训练成本的情况下获得更好表现
这为小模型替代超大模型提供了新思路(如手机上的小模型可通过额外推理计算达到云端大模型的水平)
未来的AI可能更多地依赖推理时的动态优化,而不是仅靠预训练
5. 总结¶
这项研究证明了在推理阶段优化计算资源的巨大潜力,尤其在面对不同难度任务时,灵活调整计算策略可以有效提升模型性能,甚至在某些场景下超过大规模预训练模型。未来, “小模型+智能推理” 或将成为模型部署的新范式。
3. How to Scale Test-Time Computation Optimally¶
如何在推理阶段最优分配计算资源(即如何在给定的计算预算下选择最有效的策略),从而提高大语言模型(LLM)的性能。核心目的是通过一种称为 “推理计算优化策略(test-time compute-optimal scaling strategy)” 的框架来优化计算资源的使用。
- 问题设定
给定一个 提示(prompt) 和一个推理计算预算(test-time compute budget),如何选择最合适的策略来利用这个计算资源?
- 两种推理计算方法
修正建议分布(如:让模型在推理过程中自我修正,或多次修正其初始输出)。
使用验证器进行搜索(如:从多个候选答案中选出最好的,或使用更复杂的搜索策略,如束搜索(beam search)等)。
- 推理计算优化策略(基于问题难度估计的策略)
将问题划分为不同的难度等级。
对每个难度等级,选择最合适的计算策略。
通过交叉验证来选择最佳策略,确保模型能够在不同难度级别的问题上都表现良好。
交叉验证是为了避免在测试集中计算难度等级和选择计算策略时产生混淆,确保策略选择的有效性。
- 总结与启示
优化计算资源分配:根据问题的难度,灵活地选择计算策略,可以显著提高模型的推理性能。这种方法比起随机或均匀分配计算资源的传统方法,能带来显著的性能提升。
“探索-利用”问题:在实际应用中,如何平衡计算预算用于估计难度与实际执行计算策略是一个重要问题。未来的研究可能需要更多探索如何在实际部署中高效地进行这一权衡。
5. Scaling Test-Time Compute via Verifiers¶
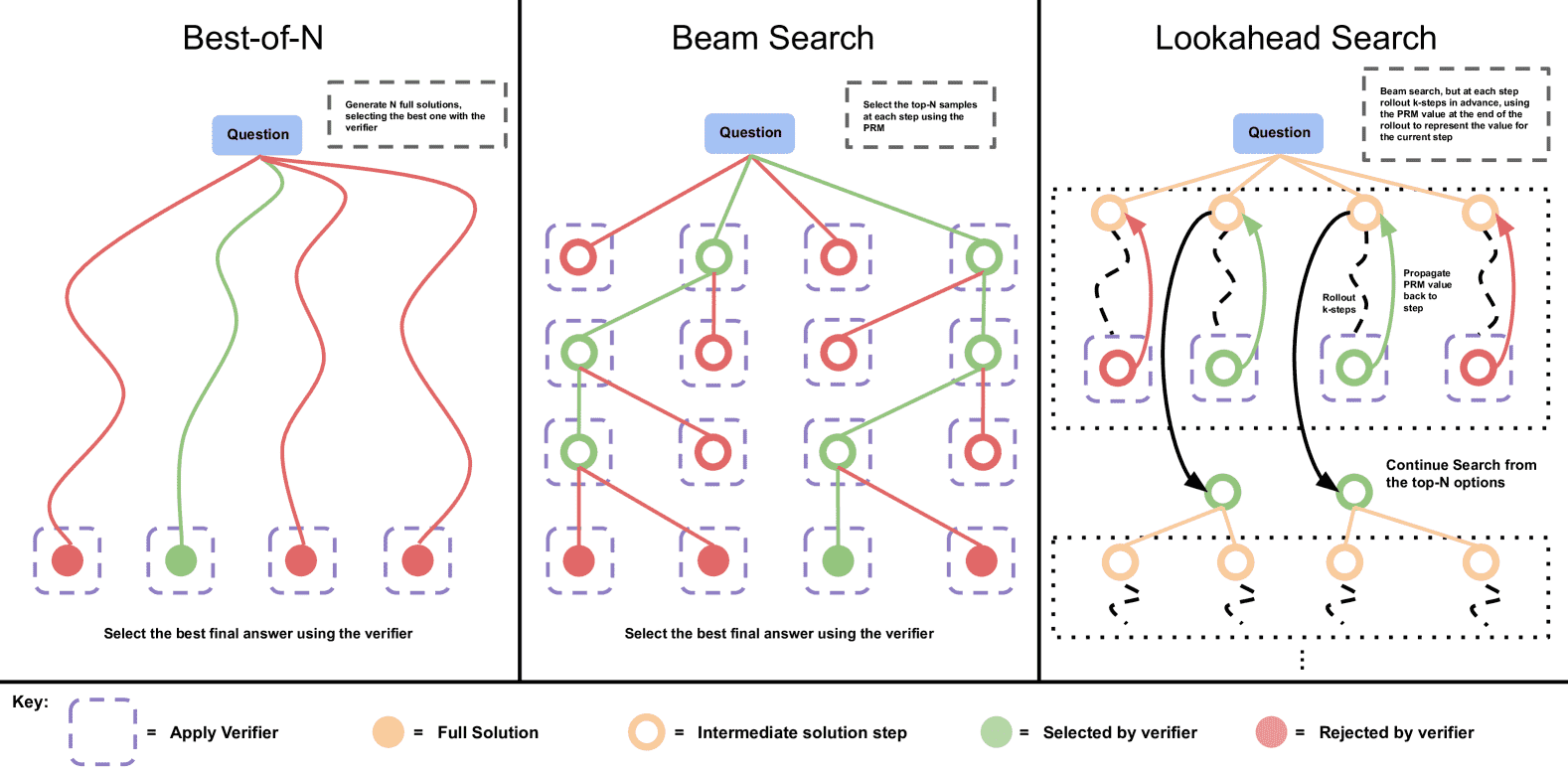
Figure 2:Comparing different PRM search methods.¶
Left: Best-of-N samples N full answers and then selects the best answer according to the PRM final score.
Center: Beam search samples N candidates at each step, and selects the top M according to the PRM to continue the search from.
Right: lookahead-search extends each step in beam-search to utilize a k-step lookahead while assessing which steps to retain and continue the search from. Thus lookahead-search needs more compute.
最佳N加权:我们从基LLM中独立采样N个答案,然后根据PRM的最终答案评分选择最佳答案。
束搜索:束搜索通过搜索PRM的逐步预测来优化PRM。我们的实现类似于BFS-V [48, 10]。具体来说,我们考虑固定数量的束N和束宽度M,步骤如下:
前瞻搜索:前瞻搜索通过模拟来改进PRM在每一步的价值估计。具体来说,在束搜索的每一步中,不是直接使用当前步骤的PRM评分来选择最佳候选,而是进行一次模拟,最多回滚k步,同时如果遇到解答结束则提前停止。为了减少模拟中的方差,我们使用温度0来执行回滚。回滚结束后,使用PRM在回滚结束时的预测来为当前步骤评分。换句话说,束搜索是前瞻搜索的特例,当k=0时。通过这种方法,我们可以提高每步价值估计的准确性,但这也增加了计算开销。
6. Refining the Proposal Distribution¶
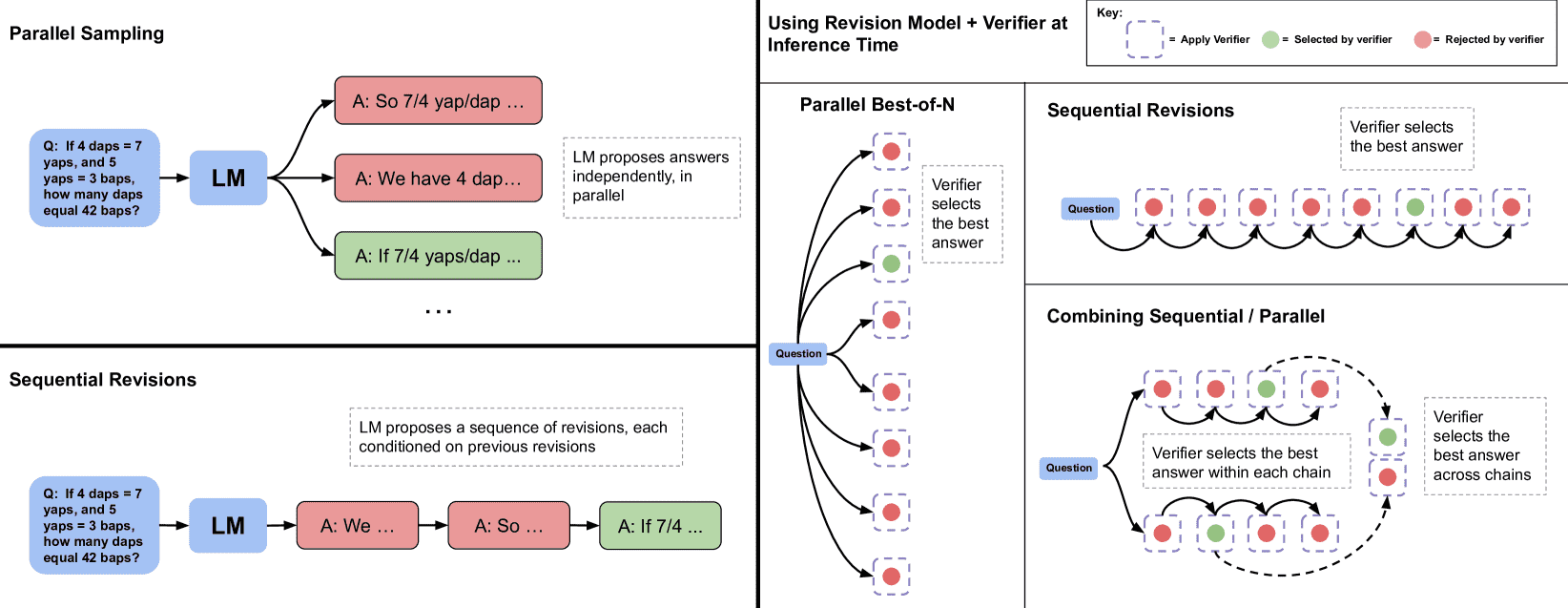
Figure 5:Parallel sampling (e.g., Best-of-N) verses sequential revisions. Left: Parallel sampling generates N answers independently in parallel, whereas sequential revisions generates each one in sequence conditioned on previous attempts. Right: In both the sequential and parallel cases, we can use the verifier to determine the best-of-N answers (e.g. by applying best-of-N weighted). We can also allocate some of our budget to parallel and some to sequential, effectively enabling a combination of the two sampling strategies. In this case, we use the verifier to first select the best answer within each sequential chain and then select the best answer accross chains.¶
其他¶
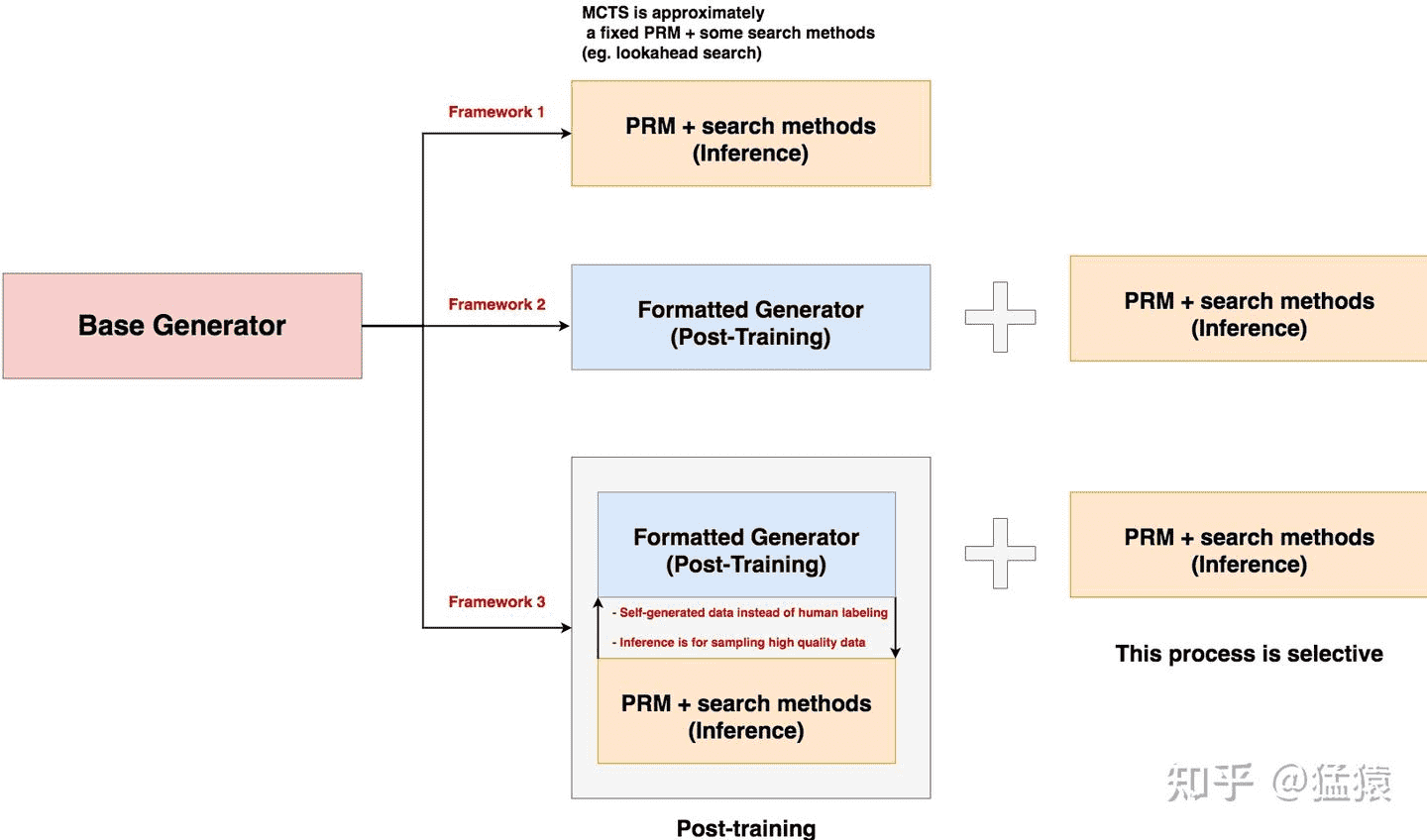
3种基于test-time scaling law的一般框架¶
- 框架1:base generator + Inference。
核心思想是,保持预训练好的generator不变,只通过优化inference来提升模型效果。
- inference阶段通常包括一个训练好的verifier + 某些搜索方法。
verifier的类型一般有PRM(Process-supervised Reward Model,用于评估中间步骤)和ORM(Outcome-supervised Reward Model,用于评估结果)两种。
图中我们用PRM来代表verifier。verifier是需要我们额外训练的,这里我们不把verifier的训练算在post-training中,而是直接算在inference里。
搜索方法指“使用verifier的评估结果来指引模型做生成”,常用的有best-of-N,beam search等等。
MCTS(Monte-Carlo Tree Search,蒙特卡洛搜索树)算法也可以表示成PRM + 搜索方法的形式。在MCTS中,会通过一些探索(explore)步骤来学习价值函数,而我们训练好的PRM则替代了这个探索过程。
- 框架2:base generator + formatted post training + Inference
先在基础模型上做一些格式化的post-training,然后采用优化inference的方式提升模型效果
所谓格式化的post-training,是指你通过sft,或者强化学习等方式,使得模型从“只产生结果”变成“同时产生中间步骤和结果”。在这个过程中,你既可以只关注模型是否遵循了格式,也可以同时关注格式 + 中间结果质量。
框架2和1的差别在于,框架1是个纯inference优化,它没有做过formatted,所以需要我们在搜索前通过prompt诱导模型按格式产出内容后再搜索。框架2除了formatted外,也可以还同时初步关注了中间结果的质量。
- 框架3: base generator + formatted post training(with inference filtering method) + Inference (selective)
这种办法会在基础模型上通过自生产训练数据的方式做post-training(避开人工标注),同时借助inference的方法,从自产数据中筛选高质量的数据,用这些数据做对齐。
由于这种方法天然考虑了思考步骤的格式和质量,所以后续的inference方法可以视需要决定要不要添加。
- deepmind基于这个框架做的两种方案:
- 方法一:利用PRM(Process-supervised Reward Model)指引搜索
post-training:只引导模型对齐格式 + 训练基于过程的verifier(PRM)
inference:使用PRM指引搜索
- 方法二:通过sft直接改变模型的输出分布(Revise proposal distribution)
post-training:通过sft方式引导对齐格式 + 保障中间结果基本质量 + 训练基于过程的verifier(PRM),这里直接用了的方案一中的PRM。
inferece:使用PRM指引搜索