1910.02054_DeepSpeed_ZeRO: Memory Optimizations Toward Training Trillion Parameter Models¶
微软
Blog: https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/
Abstract¶
背景与挑战:大型深度学习模型虽然能提供更高的准确性,但训练这些拥有数十亿到数万亿参数的模型面临巨大挑战。现有的解决方案如数据并行和模型并行在适应有限设备内存、同时保证计算、通信及开发效率方面存在根本性的局限。
ZeRO解决方案:ZeRO通过优化内存使用来大幅提升训练速度,并能够有效训练更大规模的模型。它通过消除数据并行和模型并行训练中的内存冗余,同时保持低通信量和高计算粒度,使得模型大小可以按照设备数量的比例扩展而维持高效。
性能展示:实验显示,ZeRO能够在400个GPU上实现超过100B参数的大模型训练,并且实现了超线性加速比,达到15 Petaflops的吞吐量。这代表了相比于最先进技术,模型大小增加了8倍,性能提升了10倍。
易用性:对于科学家来说,应用模型并行较难,而ZeRO无需依赖模型并行即可训练高达13B参数的大模型(例如,大于Megatron GPT 8.3B和T5 11B模型)。
实际影响:研究人员利用ZeRO的技术突破创造了世界上最大的语言模型(具有17B参数),并取得了破纪录的准确性。
1. Extended Introduction¶
1.背景与挑战: 随着深度学习模型,尤其是在自然语言处理(NLP)领域,变得越来越大(如BERT、GPT等),模型参数从数十亿增长到上百亿甚至千亿。大模型的训练面临着巨大的内存挑战,因为单一的设备(如GPU或TPU)无法容纳如此庞大的模型。而单纯增加更多设备并不能有效地扩展训练。
- 2.数据并行性(DP)和模型并行性(MP)的局限:
数据并行性(DP)在计算/通信效率上表现良好,但内存效率差。
模型并行性(MP)将模型按层划分至多个设备,从而提高内存效率,但会导致通信成本增加,且在多个节点上扩展时效率较差。
- 3.ZeRO的核心创新: ZeRO是针对大规模模型训练中内存使用问题的优化方案,分为两个主要部分:
ZeRO-DP:通过去除冗余内存,采用动态的通信调度,在数据并行训练时提高内存效率。它通过分割优化器状态、梯度和参数来减少内存消耗,最终可以实现大规模模型在多个GPU上的训练。
ZeRO-R:优化残余状态内存,包括激活值(在反向传播时使用)、临时缓冲区和碎片化内存。通过去除重复的激活值和合理分配缓冲区大小,ZeRO-R提高了内存的利用效率。
- 4.ZeRO的优势:
内存减少:通过ZeRO-DP,内存消耗可以大幅减少(比如64个GPU可以训练一个1万亿参数的模型)。
计算效率提升:ZeRO能够提高计算效率,使得训练速度比现有的最先进技术(SOTA)更快。
扩展性:ZeRO能够在更多的GPU上实现超线性加速,性能随着GPU数量的增加而显著提高。
不依赖复杂并行方式:ZeRO简化了大规模模型训练,数据科学家不需要担心模型的并行化,能够更自由地实验大规模模型。
5.与模型并行性的结合: 尽管ZeRO在内存优化上具有优势,但在一些情况下,结合模型并行性(MP)仍然是有意义的。比如在非常大的模型或特殊情况下,MP可以进一步优化激活内存消耗。
6.实现与评估: ZeRO已经被实现,并在100B参数级别的模型训练中展现了巨大的提升。相比于现有的技术(如Megatron),ZeRO能够处理更大的模型,训练速度提高了10倍以上,且在多个GPU上扩展性良好。
总之,ZeRO通过优化内存管理,解决了大规模模型训练中的内存瓶颈问题,并提供了一个高效、可扩展的解决方案,使得更大规模的模型能够在现有硬件上训练,同时提升训练速度和效率。
3 Where Did All the Memory Go?¶
这段内容深入探讨了在训练深度学习模型时,为什么模型训练所需的内存消耗远远超过存储模型参数所需的内存。
- 文中分为两大部分:
模型状态的内存消耗(包括优化器状态、梯度和模型参数)
残留内存消耗(包括激活值、临时缓冲区和内存碎片)。
3.1 Model States: Optimizer States, Gradients and Parameters¶
在模型训练中,模型状态(即优化器状态、梯度和参数)占据了大部分内存。
- 以Adam优化器为例,Adam需要存储两个关键的优化器状态:
动量(momentum):用于计算梯度的时间平均。
梯度方差(variance):用于计算每个参数的学习率。
因此,在使用Adam优化器训练模型时,必须为这两种状态、梯度和模型权重本身分别分配内存。
特别是在使用混合精度训练时,优化器状态通常会消耗更多内存。
混合精度训练使用16位浮点数(FP16)存储权重和激活值,但优化器仍然需要32位浮点数(FP32)存储权重和优化器的其他状态(如动量和方差),因此内存需求大幅增加。
- Mixed-precision Adam训练的内存需求:
假设一个模型有Ψ个参数,在混合精度训练下:
参数和梯度分别用FP16存储,内存需求为:2×Ψ bytes(参数) + 2×Ψ bytes(梯度)
优化器状态需要使用FP32存储,内存需求为:4×Ψ bytes(参数拷贝) + 4×Ψ bytes(动量) + 4×Ψ bytes(方差)
最终的总内存需求为:2×Ψ+2×Ψ+12×Ψ=16×Ψ bytes
对于一个有15亿参数的GPT-2模型,训练需求内存至少为24GB,而仅存储FP16参数本身只需要3GB。
可以看出,优化器状态所需的内存远超模型参数本身的内存需求。
3.2 Residual Memory Consumption¶
除了模型状态,残留内存(包括激活值、临时缓冲区和内存碎片)也占用了大量内存。
- 激活值
- 在训练过程中,激活值占据了很大一部分内存。
例如,一个1.5B参数的GPT-2模型在训练时,使用序列长度为1K、批量大小为32时,需要大约60GB的内存。
为了减少激活值的内存消耗,可以采用激活检查点技术,即在前向传播中计算某些激活值的中间结果,并在反向传播时重新计算这些激活值,这样可以节省内存。
- 激活检查点能将内存需求大约减少到原来的平方根,但会引入33%的额外计算开销。
例如,对于上述GPT-2模型,使用激活检查点后,内存需求可以降到8GB。
然而,即使采用激活检查点,更大的模型(如有1000亿参数的GPT类模型)activation memory仍然可能需要大约60GB的内存,这表明需要的激活内存随着模型规模的增加而急剧增长。
- 临时缓冲区
训练过程中会使用一些临时缓冲区来存储中间结果,例如在执行梯度归约(all-reduce)或梯度范数计算时,会将所有梯度合并成一个扁平化的缓冲区。
这些缓冲区在执行某些操作时,尤其是在跨设备的梯度传输中,需要使用较大的内存。
例如,对于一个有1.5B参数的模型,一个扁平化的FP32缓冲区可能需要6GB内存。
- 内存碎片
即使系统中有足够的总内存,也可能由于内存碎片导致内存分配失败。
内存碎片是指内存中有许多小的空闲区域,但它们无法满足大内存块的分配请求,导致内存不足。
这种情况在训练超大规模模型时尤为明显,可能会导致即使有30%以上的内存空闲,仍然会出现内存不足的问题。
总结¶
模型状态(优化器状态、梯度、参数) 是训练过程中最消耗内存的部分,尤其是在使用混合精度训练时,优化器状态的内存消耗会非常高。
残留内存消耗(如激活值、临时缓冲区、内存碎片)也占据了大量内存,尤其是当模型规模增大时,这些内存消耗会变得更加显著。
内存碎片可能会导致无法有效利用可用内存,造成训练中的“内存溢出”问题。
4 ZeRO: Insights and Overview¶
这段内容介绍了ZeRO(Zero Redundancy Optimizer)以及它是如何通过两个优化策略来减少深度学习训练过程中的内存消耗,同时保持计算效率。
- ZeRO包括两部分优化:
ZeRO-DP(用于减少模型状态的内存占用)
ZeRO-R(用于减少残留内存消耗)
这段内容详细描述了这两部分优化的核心思想和方法。
4.1 Insights and Overview: ZeRO-DP¶
- ZeRO-DP的优化基于以下三个关键见解:
- 数据并行(DP)比模型并行(MP)具有更好的扩展效率:
数据并行(DP)与模型并行(MP)的一个关键区别是,DP在每个设备上处理更大颗粒度的计算,而MP将模型分成多个小块进行计算。
虽然MP能够在多个设备上分配计算负载,但它会引入更多的通信开销,尤其是在跨节点通信时。
DP的计算颗粒度较大,通信量较小,因此更能高效地扩展。
- 数据并行的内存效率差,模型状态在每个数据并行进程中都有冗余副本:
在数据并行中,所有进程都存储一份完整的模型状态(例如权重、梯度、优化器状态),这导致内存的冗余使用。
而模型并行则将模型分割成多个部分,避免了这种冗余。
- 并非所有模型状态在整个训练过程中都需要持续存在:
例如,一个模型的每一层的参数,只在该层的前向传播和反向传播时需要使用。
因此,不必在整个训练过程中一直保留所有模型状态。
备注
ZeRO-DP的核心思想是:通过将模型状态进行分割而非复制,避免数据并行中的内存冗余,同时保持数据并行的高效性。ZeRO-DP通过动态通信调度(即根据模型状态的时间性动态调节何时进行通信)来减少通信量,进而保持了数据并行的效率。
4.2 Insights and Overview: ZeRO-R¶
ZeRO-R侧重于减少模型训练中的残留内存消耗,特别是针对激活值、临时缓冲区和内存碎片的问题。
具体来说,ZeRO-R有以下优化:
4.2.1 减少激活内存消耗¶
- 两个关键见解:
- 模型并行需要复制激活内存:
当使用模型并行时,每个设备通常需要存储完整的激活值,这样就会造成冗余内存占用。
例如,如果我们将线性层的参数进行纵向分割并在两台GPU上并行计算,那么每台GPU都需要存储完整的激活值。
- 较大模型具有较高的算力密度:
像GPT-2这样的大型模型,计算密度非常高,意味着每次计算的激活值相对于所需的计算量较小,这使得即使带宽较低,也可以隐藏激活检查点的数据传输成本。
ZeRO的解决方案是通过分割激活检查点并跨多个GPU进行分配,减少冗余的激活内存。对于非常大的模型,ZeRO甚至可以将激活分割到CPU内存中,这样仍能保持较高的效率。
4.2.2 管理临时缓冲区¶
ZeRO-R通过使用固定大小的缓冲区来避免随着模型规模增大而导致临时缓冲区需求的膨胀,同时确保缓冲区足够大以保持效率。这样可以避免因缓冲区过大而导致内存占用不必要的增加。
4.2.3 管理内存碎片¶
内存碎片是由于短期和长期内存对象交替使用所导致的。具体来说,前向传播过程中的激活检查点是长期存在的,而重新计算的激活是短期存在的。同样,在反向传播中,激活梯度是短期存在的,而参数梯度是长期存在的。
ZeRO的优化方法是:通过动态内存碎片整理,将激活检查点和梯度数据移动到预分配的连续内存缓冲区,从而减少内存碎片带来的影响。这样不仅提高了内存的可用性,还减少了内存分配器寻找空闲内存的时间,提高了效率。
总结¶
- ZeRO通过两种优化方式有效减少了训练大规模模型时的内存消耗:
ZeRO-DP优化了数据并行中的内存效率,通过将模型状态进行分割而非复制,同时保留数据并行的计算效率。
ZeRO-R则通过减少激活内存消耗、合理管理临时缓冲区、以及处理内存碎片等方法,进一步优化了残留内存的使用,提升了大规模模型训练的效率。
这些优化方法不仅帮助降低了内存需求,同时也保持了训练过程中的高效性,使得大规模模型的训练更加可行。
5 Deep Dive into ZeRO-DP¶
这段内容深入探讨了ZeRO-DP(Zero Redundancy Optimizer for Data Parallelism)的工作原理,详细描述了它如何通过分割模型状态来减少内存占用,同时保持训练效率。
主要涉及了三个阶段的优化:Pₒₛ(优化器状态分割)、Pᵍ(梯度分割)、和Pₚ(参数分割)。
以下是各个部分的详细解释:
5.1 \(P_{os}\) : Optimizer State Partitioning¶
在传统的数据并行(DP)中,每个设备都复制模型的优化器状态(例如动量、学习率等),这会导致显著的内存开销。
ZeRO-DP通过将优化器状态分割成多个部分,避免了冗余存储。
例如,如果数据并行的度数是 Nᵈ,那么每个设备只更新和存储其中的 1/Nᵈ 个优化器状态。
- 内存节省:通过优化器状态分割,内存需求大幅减少。
例如,对于一个7.5B参数的模型,如果使用64个设备(Nᵈ = 64),则只需 31.4GB 内存,而传统DP方法需要 120GB。
随着 Nᵈ 的增大,内存需求大幅下降,甚至可以减少到原来的 1/4。
5.2 \(P_g\) : Gradient Partitioning¶
- 在ZeRO-DP中,每个数据并行进程仅需要计算并存储与其负责的参数对应的梯度。
这意味着在反向传播时,梯度的计算和存储只会针对当前设备的参数,避免了冗余存储。
梯度分割可以有效降低梯度的内存占用。
- 内存节省:通过梯度分割,内存需求进一步减少。
例如,在64个设备下,7.5B参数的模型只需要 16.6GB 内存,而标准DP方法需要 120GB。
随着 Nᵈ 的增大,内存需求下降的幅度更为显著,甚至可以减少到原来的 1/8。
- 附加优化:减少内存开销
为提高效率,ZeRO使用了bucketization策略,将梯度按照分区进行分组,然后一起进行梯度计算,减少了内存使用并同时优化了通信与计算的重叠。
相比传统的all-reduce操作,ZeRO使用reduce-scatter操作来减少内存占用。
5.3 \(P_p\) : Parameter Partitioning¶
- 与优化器状态和梯度一样,ZeRO还对模型参数进行分割。
每个数据并行进程只存储其负责的参数。
当进行前向传播和反向传播时,若需要其他进程负责的参数,会通过广播进行获取。
虽然这可能增加通信开销,但总体通信量的增加非常有限,约为标准DP的 1.5倍。
- 内存节省:通过参数分割,模型参数的内存需求也得到了显著降低。
例如,在64个设备下,7.5B参数的模型只需要 1.9GB 的模型状态内存,而传统DP方法需要 120GB。
这种分割方法使得ZeRO能够训练任意规模的模型,只要有足够的设备来共享模型状态。
5.4 Implication on Model Size¶
通过以上三个分割阶段(Pₒₛ, Pᵍ, Pₚ),ZeRO-DP在减少内存占用方面具有显著效果。
- 具体来说:
Pₒₛ(优化器状态分割)最大可以将内存需求减少 4倍。
Pᵍ(梯度分割)最大可以将内存需求减少 8倍。
Pₚ(参数分割)则使得内存需求与 Nᵈ(数据并行度)成反比,随着设备数量的增加,内存需求可以进一步减少。
- 影响:ZeRO使得原本只能训练小规模模型的DP方法,能够训练更大的模型。
比如在 Nᵈ = 64 时,ZeRO能够训练最大 7.5B、14B、128B 参数的模型。
若 Nᵈ = 1024,使用ZeRO的优化后,甚至能够训练 1万亿(Trillion)参数的模型。
总结¶
ZeRO-DP通过将模型的优化器状态、梯度和参数分割,显著减少了每个数据并行进程的内存需求。
这使得训练大规模模型成为可能,尤其是在有限的硬件资源下。
随着数据并行度(Nᵈ)的增加,内存消耗成比例地降低,能够支持更多设备共享模型状态,最终使得深度学习训练能够扩展到超大规模模型。
6 Deep Dive into ZeRO-R¶
这段内容详细介绍了 ZeRO-R(Zero Redundancy Optimizer for Memory Efficiency)的优化方法,旨在进一步减少内存消耗和提高训练效率。
主要介绍了三个优化技术:Pa(分割激活检查点)、CB(常数大小缓冲区)和 MD(内存碎片整理)。
以下是详细的解释:
6.1 \(P_a\) : Partitioned Activation Checkpointing¶
- 在模型并行(MP)训练中,传统方法需要复制激活值,这会导致内存冗余。
ZeRO-R通过将激活值分割并仅在需要时将其组合,从而避免了冗余存储。
具体来说,当模型的某一层计算完前向传播后,输入激活值会被分割并存储在不同的并行进程中,直到反向传播时需要这些激活值时,ZeRO-R会通过all-gather操作将激活值重新合并为一个副本。
这个过程称为 Pa(分割激活检查点)。
激活检查点:通过在训练过程中只存储分割的激活检查点,而不是完整的激活值副本,ZeRO-R显著减少了内存开销。
- 内存节省:例如,在训练一个100B参数的模型时,传统方法需要每个GPU大约33GB内存来存储激活检查点,而使用 Pa 后,只需要2GB内存。
此外,2GB的激活内存还可以被卸载到CPU,从而将激活内存占用降到几乎为零。
6.2 \(C_B\) : Constant Size Buffers¶
- 在训练过程中,一些操作的计算效率与输入数据的大小密切相关。
比如,在执行 all-reduce 等操作时,较大的输入数据可以更高效地使用带宽。
因此,高性能库如NVIDIA Apex或Megatron会将所有参数融合到一个大缓冲区中,以提高计算效率。
然而,这种融合缓冲区的内存开销与模型大小成正比,对于非常大的模型来说,可能会成为瓶颈。
为了解决这个问题,ZeRO使用了一个常数大小的融合缓冲区,无论模型多大,缓冲区的大小始终保持恒定。这样,尽管模型变大,内存开销不会成比例增加,同时也能保持较高的计算效率。
6.3 \(M_D\) : Memory Defragmentation¶
- 在训练过程中,尤其是使用激活检查点和梯度计算时,内存碎片问题常常出现。
具体来说,激活检查点和梯度的存储具有不同的生命周期,激活值和参数梯度是长期存在的,而其他一些计算所需的临时内存(如激活梯度)则是短期存在的。
短期内存和长期内存的交替使用会导致内存碎片化,进而影响内存分配效率。
- 内存碎片化问题:内存碎片化通常不会在内存充足时造成问题,但在内存有限的情况下,碎片化可能导致以下问题:
即使有足够的内存,内存分配器可能找不到一块连续的内存区域来满足分配请求,导致“内存不足(OOM)”错误。
由于频繁的内存查找和分配,内存分配效率降低,导致整体训练效率下降。
- ZeRO通过 内存碎片整理(MD) 技术在运行时动态处理碎片问题。
具体做法是预先分配好连续的内存块用于存储激活检查点和梯度,并在这些数据产生时,将它们复制到预先分配的内存块中。
这样,MD不仅允许ZeRO在内存受限时训练更大的模型和使用更大的批次,还能提高内存使用的效率。
总结¶
- ZeRO-R通过以下三项优化大幅度提升了模型训练的内存效率:
Pa(分割激活检查点):通过分割和动态组合激活值,减少了内存冗余。
CB(常数大小缓冲区):避免了大模型训练中因缓冲区过大而导致的内存瓶颈。
MD(内存碎片整理):通过预分配连续内存并在训练过程中动态管理,减少了内存碎片化的影响。
这些优化使得ZeRO能够在有限的设备内存上训练更大的模型,同时提高了内存使用效率和计算性能。
7 Communication Analysis of ZeRO-DP¶
这段内容分析了ZeRO-DP(Zero Redundancy Optimizer-Data Parallel)在使用不同优化策略时的通信量。重点讨论了 ZeRO-DP 的内存效率与通信效率之间的权衡,具体解释了 ZeRO-DP 在不同配置下的通信开销。
- ZeRO-DP 通过移除内存冗余来提高大规模模型训练的内存效率,但这是否会导致通信开销的增加?这段内容提供了两个主要的答案:
ZeRO-DP 在使用 P_o 和 P_g 时不会增加额外的通信开销,同时可以减少最多 8倍 的内存占用。
当使用 P_p(参数分割)与 P_o 和 P_g 一起时,ZeRO-DP 的通信量最多增加 1.5倍,但内存占用可以进一步减少 N_d 倍。
7.1 Data Parallel Communication Volume¶
在数据并行训练中,每个数据并行进程需要对梯度进行平均(在反向传播结束时),然后更新模型参数。
- 这个过程通过 all-reduce 操作实现,all-reduce 是一种常见的通信操作,通常包含两个步骤:
reduce-scatter:将数据在不同进程中分散并做合并。
all-gather:所有进程汇总已经合并的数据。
- 对于大模型来说,all-reduce 通常受到通信带宽的限制,因此数据移动量(即通信量)是关键。
标准的 all-reduce 操作总共涉及 2Ψ 数据量的通信(这里 Ψ 表示每次训练步骤的数据量)。
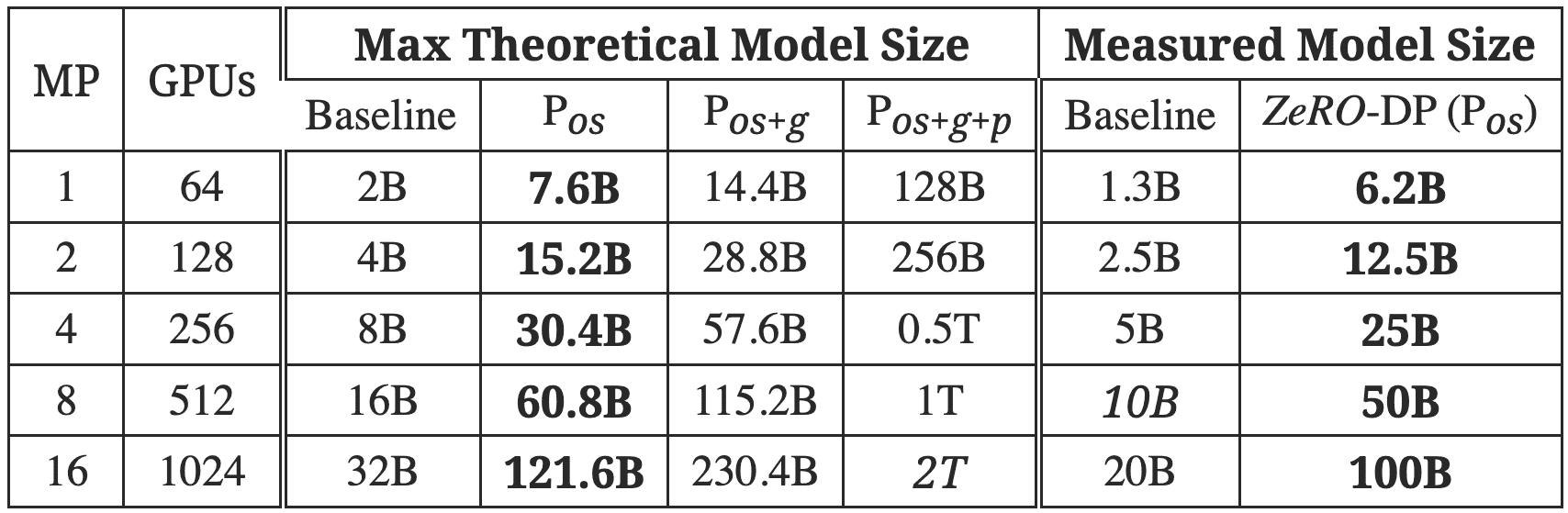
Table 2:Maximum model size through memory analysis (left) and the measured model size when running with ZeRO-OS (right). The measured model size with Pos matches the theoretical maximum, demonstrating that our memory analysis provides realistic upper bounds on model sizes.¶
7.2 ZeRO-DP Communication Volume¶
7.2.1 Communication Volume with \(P_{os+g}\)¶
在 ZeRO-DP 中,梯度分割(gradient partitioning)使得每个进程只存储自己需要更新的梯度部分。因此,传统的 all-reduce 被替换为 scatter-reduce 操作,通信量仅为 Ψ。之后,每个进程更新它所负责的参数,并通过 all-gather 操作收集所有更新后的参数,这也需要 Ψ 的通信量。因此,ZeRO-DP 在这种配置下的总通信量是 Ψ + Ψ = 2Ψ,与标准的 数据并行(DP) 没有区别。
7.2.2 Communication Volume with \(P_{os+g+p}\)¶
- 在使用 参数分割(P_p) 时,每个数据并行进程只存储它需要更新的参数。因此,在前向传播过程中,进程需要接收所有其他分区的参数,但这种操作可以通过流水线技术来避免额外的内存开销。具体来说,每个数据并行进程在计算对应模型部分的前向传播之前,会广播它负责的分区权重给其他所有进程。一旦前向传播完成,这些参数可以被丢弃。
这种优化方式使得通信量为 Ψ × N_d,其中 N_d 是数据并行进程的数量。因此,通信量会按照模型分割进行多次合并和分发,最终的通信量为 3Ψ。
与标准的 DP 相比,这种方式的通信量增加了 1.5倍(即 3Ψ),但能够减少内存开销。
备注
这块总结的不好,需要时需要直接看原Paper
8. Communication Analysis of ZeRO-R¶
本节重点讨论了 ZeRO-R 中 P_a(激活检查点分割) 的通信开销与基础的 模型并行(MP) 比较,以及其如何影响训练效率。
9. Step Towards 1 Trillion Parameters¶
本节讨论了 ZeRO 如何帮助训练超过 1 万亿参数的大型模型,以及其在现有硬件上能够达到的训练效率。
10. Implementation and Evaluation¶
概述了ZeRO-100B系统的实现、评估和性能指标,ZeRO-100B能够高效地训练最大可达170B参数的大型语言模型。
10.1 Implementation and Methodology¶
实现:ZeRO-100B是在PyTorch中实现的,并且与任何模型(作为torch.nn.Module)兼容。它集成了完整的优化方案(Pos+g 和 ZeRO-R),可以像标准的数据并行(DP)一样使用,无需修改模型本身。
硬件:实验是在由400个V100 GPU(25个DGX-2节点)组成的集群上进行的,节点间通信带宽为800 Gbps。
10.2 Speed and Model Size¶
ZeRO-100B使得最多可训练170B参数的模型,比之前最大的Megatron-LM模型大了8倍,并且性能提高了多达10倍。
ZeRO-100B在GPU上的吞吐量可达15 PetaFlops,相比传统的模型并行(MP),表现出了显著的性能提升。
结论¶
ZeRO-100B在大规模模型训练方面实现了显著的突破,能够在当前硬件上高效训练最大可达170B参数的模型。它减少了内存消耗、提升了性能,并且简化了传统的模型并行(MP)和流水线并行(PP),使得更多的数据科学家能够训练最先进的模型。
11. Concluding Remarks¶
从高性能计算(HPC)和系统的角度来看,我们认为ZeRO代表了大规模模型训练领域的革命性转变。虽然我们的实现——ZeRO-100B使得模型大小增加了8倍,吞吐量提升超过10倍,并且在现代GPU集群上实现了超线性加速,训练了世界上最大的模型,但这仅仅是冰山一角。ZeRO整体具有进一步提升模型规模的潜力,能够使未来的万亿参数模型训练成为可能。
或许,我们对ZeRO最为乐观的地方在于它不对数据科学家提出任何障碍。与现有的模型并行(MP)和流水线并行(PP)方法不同,ZeRO不需要对模型进行重构,使用起来与标准数据并行(DP)一样简单,这使得ZeRO成为未来大规模模型训练研究的理想候选方案。