2406.09756_MASt3R: Grounding Image Matching in 3D with MASt3R¶
GitHub: https://github.com/naver/mast3r
组织: NAVER LABS Europe
Google Scholar(93, 2025-04-16)
前言¶
SIFT (Scale-Invariant Feature Transform)¶
定义:
SIFT 是一种经典的计算机视觉算法,用于检测和描述图像中的局部特征。它由 David Lowe 在 1999 年提出,并在 2004 年进一步完善。主要功能:
关键点检测: SIFT 能够在图像中检测出具有尺度不变性和旋转不变性的关键点(即图像中的显著点)。这些关键点通常位于角点、边缘或其他纹理丰富的区域。
特征描述: 对于每个检测到的关键点,SIFT 生成一个描述符(descriptor),该描述符对光照变化、视角变化和尺度变化具有鲁棒性。
匹配: 通过比较两幅图像中关键点的描述符,可以找到它们之间的对应关系。
优点:
对光照、尺度和旋转变化具有很强的鲁棒性。
在相似条件下能够快速实现高精度匹配。
广泛应用于图像匹配、3D重建、物体识别等领域。
局限性:
计算复杂度较高,尤其是在处理高分辨率图像时。
对低纹理区域或重复模式的表现较差。
SIFT 是一种经典的关键点检测和描述算法,广泛应用于图像匹配任务中,尤其在早期的3D重建流水线中发挥了重要作用。
COLMAP¶
定义:
COLMAP 是一个开源的三维重建软件工具包,广泛用于计算机视觉和摄影测量领域。它由 Johannes Schönberger 等人开发并维护。主要功能:
稀疏重建: 通过多视图几何方法,从一组输入图像中生成稀疏的3D点云模型。
密集重建: 使用多视图立体视觉技术(Multi-View Stereo, MVS)生成密集的3D表面模型。
相机姿态估计: 通过图像匹配和束调整(Bundle Adjustment),计算每张图像的相机位置和姿态。
特征提取与匹配: 内置了 SIFT 等特征提取和匹配算法,用于处理图像间的对应关系。
优点:
高度灵活且易于使用,支持多种输入格式。
提供完整的3D重建流水线,从特征提取到最终的3D模型生成。
支持大规模场景的高效处理。
应用场景:
文化遗产保护(如古建筑的数字化重建)。
虚拟现实和增强现实中的环境建模。
自主导航和机器人技术中的地图构建。
COLMAP 是一个强大的3D重建工具包,集成了 SIFT 等算法,用于从图像生成稀疏和密集的3D模型,并在学术界和工业界得到了广泛应用。
ASMK (Aggregated Selective Match Kernels)¶
ASMK(Aggregated Selective Match Kernels)是一种用于图像检索(Image Retrieval)的经典方法,属于基于局部特征的图像表示技术。它由 Tolias et al. 在 2013 年提出,并在 2017 年的升级版中进一步改进,用于提升大型图像数据库中的检索性能。其核心思想是在传统 Bag-of-Words(BoW)框架的基础上,引入了选择性匹配和核函数聚合机制,使得图像特征表达更加精细和判别力更强。
🧠 核心思想 ASMK 是一种稀疏、可区分的图像特征编码方式,它主要包括以下几个关键组件:
局部特征提取
使用 SIFT、RootSIFT、DELF 或其他局部描述子提取图像的局部特征。
视觉词典(Visual Vocabulary)
通过 K-means 等聚类方法构建一个视觉词汇表,每个聚类中心代表一个视觉词。
Selective Matching(选择性匹配)
对于每个视觉词,只考虑与其相似度较高的局部特征对,以排除干扰信息,提升匹配的鲁棒性。
Match Kernels(匹配核函数)
对匹配局部特征对使用核函数(如内积或三角核)计算相似度,而不是简单计数,从而保留更多几何和语义信息。
Aggregation(聚合)
将每个视觉词下的局部特征描述子进行聚合(如使用 VLAD 或 Fisher Vector 风格的方式),最终得到整张图像的向量表示。
压缩与量化
通常采用二值哈希、PQ(Product Quantization)等方法压缩聚合向量,提高检索效率。
🧩 ASMK vs. 传统方法对比
特性 |
BoW |
VLAD |
Fisher Vector |
ASMK |
|---|---|---|---|---|
匹配方式 |
计数 |
残差聚合 |
概率建模 |
选择性匹配 + 核函数 |
匹配细粒度 |
低 |
中 |
高 |
高 |
特征区分性 |
一般 |
好 |
好 |
优秀 |
速度 |
快 |
中 |
慢 |
中 |
🧪 性能表现
ASMK 在多个图像检索基准(如 Oxford5k, Paris6k, Holidays, INSTRE)中取得领先性能。
尤其适用于细粒度检索任务,如地标识别、物体重识别等。
📌 变种与拓展
ASMK*:增加归一化和更复杂核函数的改进版。
DELF + ASMK:结合深度学习局部特征(如 DELF)和 ASMK 编码,成为近年来非常强大的组合。
GeM + ASMK:将全局描述与局部聚合互补,提高整体检索精度。
PnP(Perspective-n-Point)¶
from: 论文
🌼 定义
Fischler 和 Bolles 在 1981 年的经典论文《Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography》中首次提出了 Perspective-n-Point(PnP)问题的概念。
定义:给定一组已知的三维控制点及其在图像中的二维投影,估计相机的姿态(即位置和方向)。这项工作是计算机视觉中相机位姿估计的基础之一。
PnP(Perspective-n-Point)问题是计算机视觉中的一个基本问题,旨在通过已知的三维点与其在图像中的二维投影,估计相机的姿态(即位置和平移)。
📌 PnP 问题概述 PnP 问题的核心是给定一组已知的三维空间点及其在图像中的二维投影,求解相机的姿态(旋转矩阵 R 和平移向量 t)
🔍 常见的 PnP 求解方法
P3P(Perspective-3-Point):使用三个点对求解相机姿态,适用于最小解问
DLT(Direct Linear Transform):直接线性变换法,适用于点数较多的情
EPnP(Efficient PnP):高效的 PnP 解法,适用于大规模点集,计算效率
UPnP(Universal PnP):通用的 PnP 解法,适用于各种相机模
RPnP(Robust PnP):鲁棒的 PnP 解法,增强了对异常值的处理能
BA(Bundle Adjustment):束束调整,通过最小化重投影误差优化相机姿态和三维点位
🧭 应用领域
视觉 SLAM(Simultaneous Localization and Mapping):实现相机的实时定位与地图构建
增强现实(AR):实现虚拟对象与现实世界的准确对齐
三维重建:从二维图像中重建三维场景
机器人导航:帮助机器人在未知环境中定位和导航

Figure 1: Dense Correspondences. MASt3R extends DUSt3R as it predicts dense correspondences, even in regions where camera motion significantly degrades the visual similarity. Focal length can be derived from the predicted 3D geometry, making our approach a standalone method for camera calibration, camera pose estimation and 3D scene reconstruction, attaining and improving the performance of the state of the art on several extremely challenging benchmarks.
Abstract¶
🧠 背景:为什么要做这项研究?
图像匹配(Image Matching)是3D视觉系统中的核心模块,它用于在不同视角下的图像中找到对应点。
尽管匹配本质上涉及相机姿态和场景几何,即3D信息,但过去的方法几乎都是从2D角度来处理问题。
❗问题:现有方法的局限
当前主流方法只在2D图像平面中寻找像素点的对应关系。
DUSt3R 作为一个基于 Transformer 的3D重建框架,显示出在视角变化大时匹配非常鲁棒,但其匹配的精度有限。
高精度的稠密匹配算法通常计算复杂度是二次方复杂度(quadratic complexity),在实际应用中会非常慢。
💡解决方案(这篇论文做了什么)
提出 MASt3R:增强版 DUSt3R,通过加入新的dense local feature head(输出稠密局部特征),使用额外的匹配损失函数进行训练,提升匹配能力。
引入 reciprocal matching(互惠匹配)机制:
显著加速匹配速度(数量级提升)。
附带理论保障。
还能进一步提升匹配性能。
🚀实验结果
MASt3R 在多个图像匹配任务上都超过现有 SOTA。
在最具挑战性的Map-free localization 数据集上,VCRE AUC 提升达 30% 的绝对值,说明匹配质量显著提升。
🧩关键词总结:
3D 图像匹配
DUSt3R 增强版(MASt3R)
Dense features(稠密局部特征)
Reciprocal matching(互惠匹配)
Transformer
极端视角鲁棒性
快速且精确的匹配
1. Introduction¶
① 研究动机与背景(Why)¶
图像匹配是所有 3D 视觉任务(如建图、定位、导航、测绘、机器人)中不可或缺的组成部分。
在 offline 阶段(建图)和 online 阶段(定位)都依赖匹配(如 COLMAP + PnP)。
目标:在两个图像中找到高精度、稠密且鲁棒的对应点,尤其是对视角和光照变化鲁棒。
② 传统方法回顾(What existed before)¶
经典三步匹配流程:
关键点提取(sparse, repeatable)
局部特征描述(如 SIFT)
基于特征距离进行匹配
优点:
快速(毫秒级)
小视角/光照变化下准确
缺点:
丢弃了全局几何上下文
容易受重复纹理、低纹理区域影响
匹配错误,尤其是在真实场景下表现不佳
③ 近年改进方向(What improved)¶
为了解决局部匹配不稳的问题,引入了全局上下文
SuperGlue:引入全局优化策略学习匹配先验
但如果关键点/特征不可靠,后处理也“补救”不了
Dense Matching(如 LoFTR):直接匹配整张图像
借助Transformer 的全局注意力机制
可鲁棒应对重复/低纹理区域
LoFTR 在 Map-free benchmark 上树立新 SOTA
⚠️ 但:LoFTR 的 VCRE 精度仅 34%,实际仍偏低。
④ 核心问题(Problem Statement)¶
大多数方法把匹配当作2D任务,而实际上它是一个3D任务。
匹配目标是找出观察同一 3D 点的像素
本质上由相机姿态和场景几何决定(epipolar 几何)
DUSt3R 虽然是 3D 重建方法,但其产出的“副产品”匹配结果已超过大多数 2D 方法
⑤ 本文提出的方法 MASt3R(Our Solution)¶
在 DUSt3R 上增强设计,专注提升匹配精度,同时保持鲁棒性。
增加 second head:回归稠密局部特征图(dense local feature maps)
使用 InfoNCE loss 进行匹配训练
提出 coarse-to-fine 匹配机制,多尺度处理匹配问题
关键技术突破:
reciprocal matching(互惠匹配)
快速算法(几乎快 100 倍)
精度和效率双提升
⑥ 三大贡献总结(Claimed Contributions)¶
提出 MASt3R 框架:基于 DUSt3R,具备高精度和鲁棒性,输出局部特征图用于匹配
提出 coarse-to-fine 多尺度匹配机制 + 高速 reciprocal matching 算法
在多个定位 benchmark 上超越 SOTA
🧠 思维导图式总结¶
核心问题:图像匹配 ≠ 纯2D问题 → 是3D问题
传统方法(SIFT/Keypoint):
✔ 快速
✘ 丢失全局几何,重复纹理/低纹理失败
密集方法(LoFTR):
✔ Transformer+全局匹配 → 更鲁棒
✘ 精度仍低(34% VCRE)
启发:DUSt3R 用于3D重建,其3D“副产品”匹配反而更好!
创新方法 MASt3R:
🔧 新增 dense feature head(InfoNCE loss)
🔁 Reciprocal Matching + Multi-scale Matching
🚀 快、准、鲁棒
贡献总结:
✅ MASt3R → 精度 + 鲁棒性兼备
✅ 快速 reciprocal matching,支持高分辨率
✅ SOTA 在多个 benchmark 上大幅领先
🧠 总结思维导图¶
图像匹配技术发展路线:
1️⃣ Keypoint-based Matching (经典)
- SIFT → SuperPoint
- 检测 + 描述 + 匹配
- ✔ 快速
- ✘ 本地信息,弱视角鲁棒
2️⃣ Dense/Semi-dense Matching (全局)
- LoFTR、DenseGAP
- ✔ 全局上下文,强鲁棒
- ✘ 计算量大,依然是2D方法
3️⃣ Pose Estimation → 提出更强 benchmark
- Aachen、Map-free 等
- 匹配能力成性能瓶颈
4️⃣ 3D-Aware Matching (趋势)
- Epipolar 约束、单目深度校正
- DUSt3R → 用 3D 重建做匹配,效果反超多数方法
- 本文工作:显式训练 dense features → 提升 DUSt3R 匹配精度
3. Method¶
🎯 任务目标
给定两张图像 \(I^{1}\) 和 \(I^{2}\),分别由两台相机 \(C^{1}\) 和 \(C^{2}\) 拍摄,其参数未知,我们希望恢复一组像素对应关系 \(\{(i,j)\}\),其中 \(i,j\) 是像素 \(i=(u_{i},\nu_{i}),j=(u_{j},\nu_{j})\in \{1,\ldots,W\}\times\{1,\ldots,H\}\),\(W, H\) 分别为图像的宽度和高度。为了简化起见,我们假设它们具有相同的分辨率,但不失一般性。最终网络可以处理不同宽高比的图像对。
🌐 整体架构(如图2所示)
输入:
两张图像 \( I^1 \), \( I^2 \)
使用 Vision Transformer (ViT) 编码每张图像特征:\( H^1, H^2 \)
解码:
使用两个交叉注意力解码器对图像特征进行联合解码,构建空间几何关系:\( H'^1, H'^2 \)
输出(每个像素):
一个 3D 点(PointMap):\( X^{1,1}, X^{2,1} \)
一个置信度值:\( C^1, C^2 \)
一个局部特征向量(在后续部分介绍)
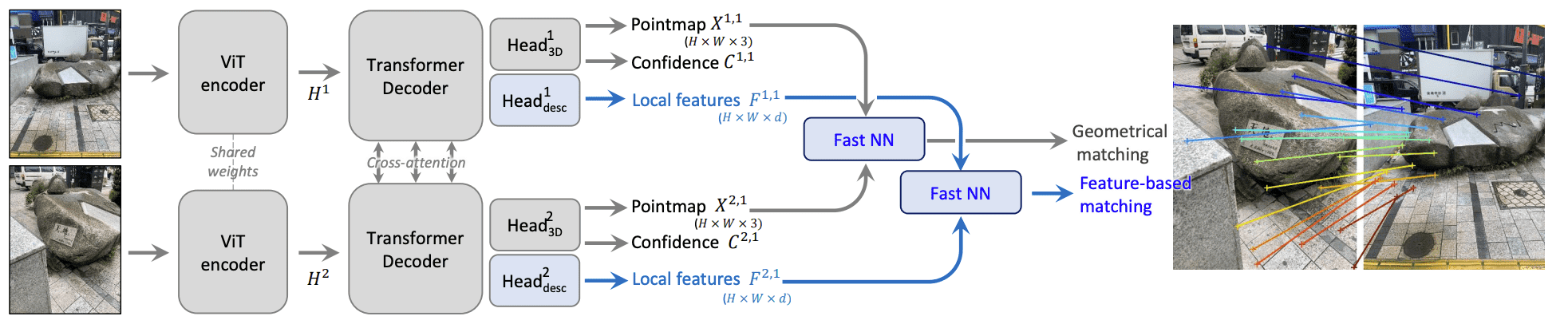
Figure 2: Overview of the proposed approach. Given two input images to match, our network regresses for each image and each input pixel a 3D point, a confidence value and a local feature. Plugging either 3D points or local features into our fast reciprocal NN matcher (3.3) yields robust correspondences. Compared to the DUSt3R framework which we build upon, our contributions are highlighted in blue.
3.1 The DUSt3R framework¶
DUSt3R 框架 的原理,它是一个可以从图像中联合完成相机标定(calibration)和三维重建(3D reconstruction) 的新方法。
🔧 DUSt3R 是什么?
DUSt3R 是一个基于 Transformer 的网络,输入两张图像,就可以预测这两个视角下的三维点云(称为 pointmaps),这相当于对场景做了局部 3D 重建。
具体来说:
输出的是两个 dense 3D pointmaps:\(X^{1,1}\) 和 \(X^{2,1}\)。
每个 pointmap \(X^{a,b} \in \mathbb{R}^{H \times W \times 3}\) 表示 图像 \(I^a\) 中每个像素(总共 \(H \times W\) 个)在相机 \(C^b\) 坐标系下的三维位置。
比如:
\(X^{1,1}\) 是图像 \(I^1\) 的点在相机 \(C^1\) 坐标系下的 3D 点;
\(X^{2,1}\) 是图像 \(I^2\) 的点在相机 \(C^1\) 坐标系下的 3D 点。
通过把这两个视角下的点都映射到 同一个坐标系下(\(C^1\)),它就完成了:
相机之间的空间几何关系推断(= 标定)
每张图像的三维重建
🧠 网络结构:三步走
ViT 编码器(Siamese 架构):
两张图分别输入 Vision Transformer 编码器,得到特征表示 \(H^1\) 和 \(H^2\): $\( \boldsymbol{H}^{1}=\operatorname{Encoder}({\boldsymbol{I}}^{1}), \quad \boldsymbol{H}^{2}=\operatorname{Encoder}({\boldsymbol{I}}^{2}) \)$
双解码器(Intertwined Decoders):
两个 Decoder 对两个视角的特征进行交叉注意力处理,彼此通信,从而理解:
两个视角的相对位置关系
整个场景的 3D 几何
输出新的增强后的表示:\(H^{\prime 1}, H^{\prime 2}\)
预测头(Head):
把编码器和解码器的输出拼接后,输入到一个预测头,得到:
点云 \(X^{1,1}\) 和 \(X^{2,1}\)(3D 位置)
对应的置信图(Confidence Map)\(C^1\) 和 \(C^2\): $\( \boldsymbol{X}^{1,1},\boldsymbol{C}^{1}=\mathrm{Head}_{3\mathrm{D}}^{1}([\boldsymbol{H}^{1},\boldsymbol{H}^{\prime1}]) \)$
🧪 监督训练:回归损失(Regression Loss)
DUSt3R 用的是监督训练,即利用真实的 3D 点云作为 GT 来训练。
基本的回归损失形式: $\( \ell_{\mathrm{regr}}(\nu,i)=\left\|\frac{1}{z}X_{i}^{\nu,1}-\frac{1}{\hat{z}}\hat{X}_{i}^{\nu,1}\right\| \)$
\(\nu \in \{1, 2\}\):当前视角(图像)
\(i\) 是像素位置
\(X_{i}^{\nu,1}\) 是模型预测的 3D 点(在 \(C^1\) 下)
\(\hat{X}_{i}^{\nu,1}\) 是真实的 3D 点(ground truth)
这里的 \(\frac{1}{z}\) 和 \(\frac{1}{\hat{z}}\) 是归一化因子,目的是:
消除尺度(scale)的影响
更关注相对形状而不是绝对大小
这些因子定义为:所有有效点到原点的平均距离。
📏 改进:支持 metric-scale 重建
论文指出:
有些任务(比如 map-free visual localization)是需要绝对尺度的,也就是说不能用归一化。
因此,论文修改了损失:
如果 Ground Truth 是具有绝对尺度的(metric),那么就设 \(z = \hat{z}\),也就是不做归一化。
损失就变成了: $\( \ell_{\mathrm{regr}}(\nu,i)=\left\|X_{i}^{\nu,1}-\hat{X}_{i}^{\nu,1}\right\|/\hat{z} \)$
✅ 置信感知损失(Confidence-Aware Loss)
最终的损失函数考虑了置信度: $\( \mathcal{L}_{\mathrm{conf}}=\sum_{\nu\in\{1,2\}}\sum_{i\in\mathcal{V}^{\nu}}C_{i}^{\nu}\ell_{\mathrm{regr}}(\nu,i)-\alpha\log C_{i}^{\nu} \)$ 含义:
置信度 \(C_i^\nu\) 越高,损失的权重越大;
同时加入一个负的 \(\log C\) 项,鼓励模型在不确定的地方降低置信度,避免过度自信。
总结一句话:
DUSt3R 是一个用 Transformer 网络、从两张图像直接预测相机标定和 3D 重建的系统,它输出 dense pointmap,并通过有置信度的回归损失进行监督训练,同时支持对尺度敏感的任务。
3.2. Matching prediction head and loss¶
MASt3R 框架在 DUSt3R 基础上增加的“匹配预测头”(Matching prediction head)和它的匹配损失函数(Matching loss)。它的目的是解决 DUSt3R 在像素匹配精度上的不足。
💥 问题背景:DUSt3R 匹配不够准
虽然 DUSt3R 输出的点云(pointmap)可以用于像素级匹配(例如找图像1中像素和图像2中像素对应的点), 但:
点云是通过回归(regression)方式得到的,天然容易有 噪声;
DUSt3R 原始设计没有专门为像素级匹配训练;
所以,从 pointmap 里做“互相匹配”(reciprocal matching)虽然可行,但精度不够高。
✅ 解决方案:引入专门的匹配头(Matching Head)
为了解决这个问题,作者增加了一个新分支(head),专门用于学习像素匹配用的描述符(descriptor):
输出两个 dense 特征图:\(D^1\) 和 \(D^2\),每个像素都有一个 \(d\) 维的描述符。
形式上: $\( D^1 = \mathrm{Head}_{\mathrm{desc}}^1([H^1, H^{\prime1}]),\quad D^2 = \mathrm{Head}_{\mathrm{desc}}^2([H^2, H^{\prime2}]) \)$
输入是编码器输出 \(H\) 和解码器输出 \(H'\) 的拼接;
Head 是一个两层的 MLP,带 GELU 激活;
输出的每个描述符做单位范数归一化(unit-norm)。
🎯 匹配目标:用 infoNCE 训练高精度匹配
使用 InfoNCE 损失 来训练这个描述符:
Ground truth 匹配对记为:
\(\hat{\mathcal{M}} = \{(i, j) \mid \hat{X}_{i}^{1,1} = \hat{X}_{j}^{2,1} \}\)
表示图像1中像素 \(i\) 和图像2中像素 \(j\) 在 3D 上是同一个点。
损失函数形式如下(InfoNCE 对称版):
\( \mathcal{L}_{\mathrm{match}} = -\sum_{(i,j)\in\hat{\mathcal{M}}} \log\frac{s_{\tau}(i,j)}{\sum_{k\in\mathcal{P}^{1}}s_{\tau}(k,j)} + \log\frac{s_{\tau}(i,j)}{\sum_{k\in\mathcal{P}^{2}}s_{\tau}(i,k)} \)
其中:
相似度函数 \(s_\tau(i, j) = \exp(-\tau \cdot D_i^{1\top} D_j^2)\),是负的点积再取 softmax,\(\tau\) 是温度超参数;
第一项是图像2中像素 \(j\) 匹配图像1中所有候选像素 \(i\) 的 softmax;
第二项反过来,是图像1中像素 \(i\) 匹配图像2中所有 \(j\);
\(\mathcal{P}^{1}, \mathcal{P}^{2}\) 是参与计算损失的像素集合。
📌 损失的本质:交叉熵分类损失,目标是让某个像素只和唯一一个正确像素匹配成功,而不是周围的也算对。这和之前的回归损失不同,要求的是高精度匹配(sub-pixel precision)。
🧩 最终损失函数
最终,匹配损失和点云回归损失共同训练整个模型:
\(\mathcal{L}_{\mathrm{total}} = \mathcal{L}_{\mathrm{conf}} + \beta \mathcal{L}_{\mathrm{match}}\)
其中 \(\beta\) 是权重超参数,用于平衡回归损失和匹配损失。
✅ 总结一句话:
MASt3R 在 DUSt3R 基础上增加了一个专门用于像素精确匹配的“描述符预测头”和基于 InfoNCE 的匹配损失,从而实现高精度的稠密匹配,尤其适合 3D 重建、视觉定位等精度要求高的任务。
3.3. Fast reciprocal matching¶
MASt3R 中提出的一种高效的稠密像素匹配策略:Fast Reciprocal Matching(快速互相匹配)。它解决了像素级最近邻匹配在计算复杂度上的瓶颈问题,同时还能过滤离群点、提升匹配精度。
🌟 问题背景:互相匹配代价高
给定两个图像对应的特征图 \(D^1\) 和 \(D^2\),我们想找出可靠像素对应关系:
两个像素 \((i, j)\) 构成匹配对,当且仅当它们是彼此的最近邻(mutual nearest neighbors):
其中 \(\mathrm{NN}_A(D_j^B)\) 表示在特征空间中找到最近的点,基于 \(L_2\) 距离。
🔴 问题是:
每个图像有 \(H \times W\) 个像素;
所以直接暴力找全部互相最近邻,时间复杂度是 \(O(W^2 H^2)\),太慢了;
而且高维特征空间中(比如 \(d=128\)),使用 K-d tree 这类加速方法也变得低效。
🚀 解决方案:Fast Reciprocal Matching
核心思想:不从所有像素做最近邻搜索,而是从一个稀疏的初始像素集合开始,通过迭代扩展和验证来构建互相匹配对。
具体步骤如下:
1️⃣ 初始采样:从图像 \(I^1\) 中均匀采样一组稀疏像素点 \(k\) 个作为起始集:
\(\mathcal{U}^0 = \{\mathcal{U}_n^0\}_{n=1}^k\)
比如每隔 8 个像素采一个点。
2️⃣ 双向 NN 匹配 + 验证: 每轮迭代中,执行如下过程:
从 \(U^t\) 中的每个像素,在 \(D^2\) 中找最近邻,得 \(V^t\);
然后再从 \(V^t\) 中的每个像素,在 \(D^1\) 中找回最近邻,得 \(U^{t+1}\);
\(U^{t}\longmapsto[\mathrm{NN}_{2}(D_{u}^{1})]_{u\in U^{t}}\equiv V^{t}\longmapsto[\mathrm{NN}_{1}(D_{v}^{2})]_{v\in V^{t}}\equiv U^{t+1}\)
找出形成闭环的匹配对(即从 \(i\) 映射到 \(j\) 再映射回来仍然是 \(i\)):
\(\mathcal{M}_k^t = \{(U_n^t, V_n^t)\ |\ U_n^t = U_n^{t+1} \}\)
3️⃣ 收敛判定 + 过滤:
把已收敛的匹配对从下一轮的起始集中剔除,避免重复计算;
同时检查 \(V^{t+1}\) 和 \(V^t\) 的一致性,做双向验证;
重复该过程,直到大多数点都收敛,通常只需几轮。
4️⃣ 输出结果:
最终的匹配集合为:\(\mathcal{M}_k = \bigcup_t \mathcal{M}_k^t\)
即所有轮次中收敛的互相匹配对。
📊 理论优势和实际表现
计算复杂度:
\(O(k \cdot WH)\)
比全匹配的 \(O(W^2 H^2)\) 快了 \(WH/k\) 倍(比如 \(k=1\%\) 的像素,理论上快 \(100\times\));
结果更鲁棒:
虽然 \(\mathcal{M}_k\) 是完整匹配集 \(\mathcal{M}\) 的子集(最多 \(k\) 个匹配),
但由于迭代过程中只有稳定收敛的点才被保留,天然具有离群点过滤功能(outlier filtering);
实际上,这种方式反而能带来更高的匹配精度(参见 Fig. 3 (right));
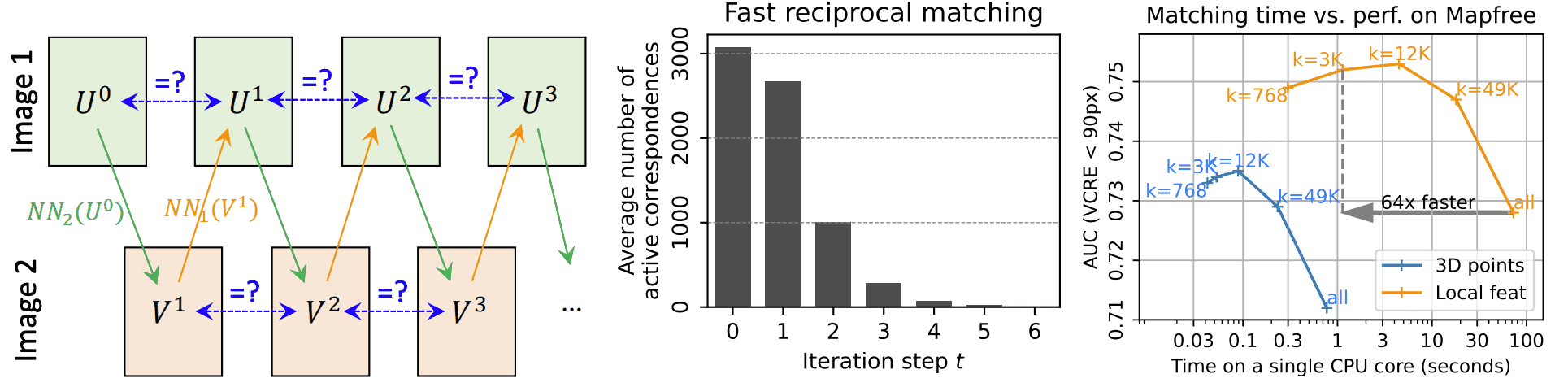
Figure 3: Fast reciprocal matching. Left: Illustration of the fast matching process, starting from an initial subset of pixels \(U^{0}\) and propagating it iteratively using 𝑁 𝑁 search. Searching for cycles (blue arrows) detect reciprocal correspondences and allows to accelerate the subsequent steps, by removing points that converged. Center: Average number of remaining points in \(U^{t}\) at iteration \(t=1\ldots6\) . After only 5 iterations, nearly all points have already converged to a reciprocal match. Right: Performance-versus-time trade-off on the Map-free dataset. Performance actually improves, along with matching speed, when performing moderate levels of subsampling.
✅ 总结一句话:
Fast Reciprocal Matching 是一种稀疏起始、迭代收敛、双向验证的快速像素匹配策略,不仅显著提升效率(\(O(kWH)\)),还能提升最终匹配的精度和鲁棒性。
3.4. Coarse-to-fine matching¶
MASt3R 为处理高分辨率图像匹配而提出的 Coarse-to-Fine Matching(粗到细匹配) 方法,用来克服 Transformer 在大图像上无法直接计算的问题。
⚠️ 问题背景
Transformer 的 attention 是 \(O((WH)^2)\) 的复杂度,所以:
MASt3R 默认只支持图像的最大边为 512 像素;
面对百万级像素图像(例如 1M 像素),需要先下采样才能输入;
但这种缩放操作会损失精度,导致:
匹配点位置不准确(定位误差);
甚至影响后续 3D 重建质量。
💡 解决方法:Coarse-to-Fine Matching
思路是:先低分辨率全局匹配,再局部高分辨率细化匹配。
详细流程如下:
1️⃣ Step 1:全局粗匹配(coarse match)
对下采样版本的两个图像进行匹配(如 512×512);
使用前面提到的 fast reciprocal matching 得到匹配集合:
\(\mathcal{M}_{k}^{0}\)
这是低分辨率下的粗匹配对。
2️⃣ Step 2:滑窗裁剪 + 匹配覆盖
对两个原始高分辨率图像生成滑动窗口:
每个窗口最大边为 512 像素,和 MASt3R 输入一致;
每个窗口重叠 50%,确保连续性;
枚举所有窗口对 \((w_1, w_2) \in W^1 \times W^2\);
然后采用贪心策略选出一组窗口对,尽可能覆盖 \(\mathcal{M}_k^0\) 中的粗匹配点(直到覆盖 90% 的粗匹配点为止)。
3️⃣ Step 3:局部细匹配(fine match)
对每对窗口 \((w_1, w_2)\):
使用 MASt3R 生成局部特征图:
\(D^{w_1}, D^{w_2} = \mathrm{MASt3R}(I^{1}_{w_1}, I^{2}_{w_2})\)
然后使用 Fast Reciprocal Matching 提取匹配点:
\(M^{w_1, w_2}_k = \mathrm{fast\_reciprocal\_NN}(D^{w_1}, D^{w_2})\)
4️⃣ Step 4:映射回原图并合并
将所有窗口对中提取到的匹配点 映射回原图坐标;
最后将它们拼接,得到全分辨率下的稠密匹配对。
✅ 总结一句话:
Coarse-to-Fine Matching 先在缩小图像上做全局粗匹配,再利用覆盖这些匹配的滑动窗口在原图上做局部细匹配,从而兼顾了效率与高分辨率精度。
🔍 优势亮点:
特性 |
描述 |
|---|---|
🎯 精度 |
保留高分辨率图像的细节,提高像素级定位精度 |
⚡ 效率 |
限定在小窗口区域做高分辨率计算,避免全图 ViT 推理开销 |
🔁 协同 |
和 fast reciprocal matching 机制天然兼容 |
🔍 控制 |
通过覆盖比例(如 90%)和平衡窗口数量进行速度-精度权衡 |
4. Experimental results¶
主要讲的是该方法的训练过程、所用数据集,以及在不同任务(特别是地图无关的定位 Map-Free Localization)上的表现。
4.1 描述训练方法;
4.2 评估在 Map-Free Relocalization Benchmark 上的定位精度;
4.3-4.5 则涉及其他数据集和任务(如Dense MVS等);
涉及的数据集种类非常广泛(共14个),涵盖室内/室外、真实/合成、物体/场景等;
最后在多个基准任务中,MASt3R的表现显著超过现有方法。
4.1. Training¶
✅ 模型架构与初始化
基于已有的 DUSt3R 模型架构;
编码器:ViT-Large,解码器:ViT-Base;
用DUSt3R的公开checkpoint初始化,继承其在3D匹配方面的能力。
✅ 数据与训练策略
使用 14个不同数据集(如CO3D, MegaDepth等),每个epoch随机采样 65 万对图像对;
训练总共 35 个 epoch,使用 余弦学习率衰减(cosine schedule);
图像最大边缩放为512像素(the largest image dimension is 512 pixels)
随机比例裁剪和变换保持主点不变,增强尺度不变性;
设置
initial learning rate set to 0.0001
local feature dimension to 𝑑 = 24
matching loss weight to 𝛽 = 1
✅ Correspondence sampling
从3D点图中找“互为最近邻”的对应点(reciprocal correspondences),每对图像随机抽取4096对;
若不够,则补充随机错配(保证真匹配比例稳定);
✅ 快速最近邻查找方法(Fast nearest neighbors)
对3D点匹配:用 K-d树;
对高维局部特征(d=24):改用 FAISS 库,因为K-d树在高维下效率很差(维度灾难);
4.2 Map-free localization¶
📚 Dataset description
使用 Map-Free Relocalization Benchmark:
没有地图,仅依赖一张参考图像进行定位;
It comprises a training, validation and test sets of 460, 65 and 130 scenes
评估指标:VCRE(Virtual Correspondence Reprojection Error) 和相机姿态精度。
🔎 Impact of subsampling
在这个任务上,不使用 coarse-to-fine matching,因为输入图像分辨率(720×540)已经接近 MASt3R 的工作分辨率(512×384)。
由于密集的 reciprocal matching 非常慢,即便使用了优化的最近邻查找,也很耗时。
所以他们采取了下采样的策略:只保留 \(k\) 个 reciprocal 对应点(来自公式 13)。
实验发现:适当下采样(如 \(k=3000\))反而提升了性能并加快速度(快了 64 倍)。
这种反直觉的现象(少点匹配更准)在补充材料中有进一步分析。
后续实验都使用 \(k=3000\) 作为默认配置。
✅ Ablations on losses and matching modes(损失函数和匹配模式的消融实验)
位姿估计方法统一使用:
通过预测匹配计算 Essential matrix,再算相对位姿;
或使用 PnP(效果类似);
场景尺度通过 DPT 估计深度(I-IV),或 MASt3R 直接预测深度(V)。
结论:
所有 MASt3R 方法都远优于 DUSt3R(训练更充分,数据更多)。
匹配 descriptors 明显优于匹配 3D 点(II vs. IV),印证了论文第 3.2 节中提到的:直接回归像素匹配不如通过特征匹配。
只用匹配损失(III)不如同时训练 3D + 匹配损失(IV),说明 3D 重建能辅助特征匹配。
比如旋转误差从 10.8° 降到 3.0°。
使用 MASt3R 直接输出的深度(V)进一步提升性能,说明深度预测和匹配是互补且高度相关的任务。
✅ Direct regression 的意外结果
作者还尝试了 MASt3R 的直接回归版本:不匹配,而是直接用 PointMap 回归相机位姿。
结果与使用匹配的方法差不多,这很意外。
不过作者指出:这只在这个特定数据集成立,其他定位任务中仍推荐使用匹配(+ 已知内参)来估计姿态。
✅ Qualitative results(定性分析)
图 4 展示了极端视角变化(甚至 180°)下的匹配效果。
MASt3R 能够成功匹配一些 2D 方法难以匹配的区域,即使外观变化很大。
这是因为 MASt3R 的匹配建立在 3D 场景理解基础上,而不是单纯基于图像局部外观。

Figure 4: Qualitative examples on the Map-free dataset. Top row: Pairs with strong viewpoint changes. Third one is a failure case. For clarity, we only draw a subset of all correspondences. Bottom row: We highlight interesting spots in close-up. These regions could hardly be matched by local keypoints. See text for details.
总结一句话:
MASt3R 在 map-free camera localization 任务中表现非常出色,得益于其将特征匹配、3D 场景重建和深度估计融为一体的联合学习架构,大幅超过现有方法,且在效率和鲁棒性上都表现优异。
4.3. Relative pose estimation¶
✅ 一、Datasets and Protocol(数据集与实验设置) ◾ 数据集简介:
数据集 |
类型 |
关键特征 |
|---|---|---|
CO3Dv2 |
室内外混合,带类别 |
来自 37K 视频,600 万帧,51 个 COCO 类别;用 COLMAP 从每段视频的 200 帧重建相机姿态 |
RealEstate10k |
真实房产视频 |
80K 个 YouTube 视频片段(共 1000 万帧),相机姿态由 SLAM + BA 得到 |
作者使用 CO3Dv2 的 41 类和 RealEstate10k 的 1.8K 段测试视频。
每段视频中选 10 帧,在所有可能的图像对之间估计相对姿态(共 45 个组合)。
不使用真实的相机焦距(增加难度)!
✅ 二、Baselines and Metrics(对比方法和评估指标)
◾ MASt3R 怎么估姿态:
像之前一样,通过匹配点估计 Essential Matrix,再恢复相对姿态;
与其他方法不同:MASt3R 只使用图像对,不使用多视图信息;
所以与大多数 baseline 方法不完全公平(因为其他方法用更多信息);
只有 DUSt3R PnP 也是 pairwise。
◾ 对比方法(包括传统 SfM 和新型学习方法):
方法类型 |
方法名 |
|---|---|
学习方法 |
RelPose, RelPose++, PoseReg, PoseDiff, RayDiff, DUSt3R |
SfM 方法 |
PixSFM, COLMAP + SuperPoint + SuperGlue |
◾ 评估指标:
RRA@15:旋转角误差小于 15° 的匹配比例;
RTA@15:平移角误差小于 15° 的匹配比例;
mAA30:最小(RRA@30, RTA@30) 的准确率曲线下的面积(越高越好);类似 mAP,只不过评估姿态角度误差。
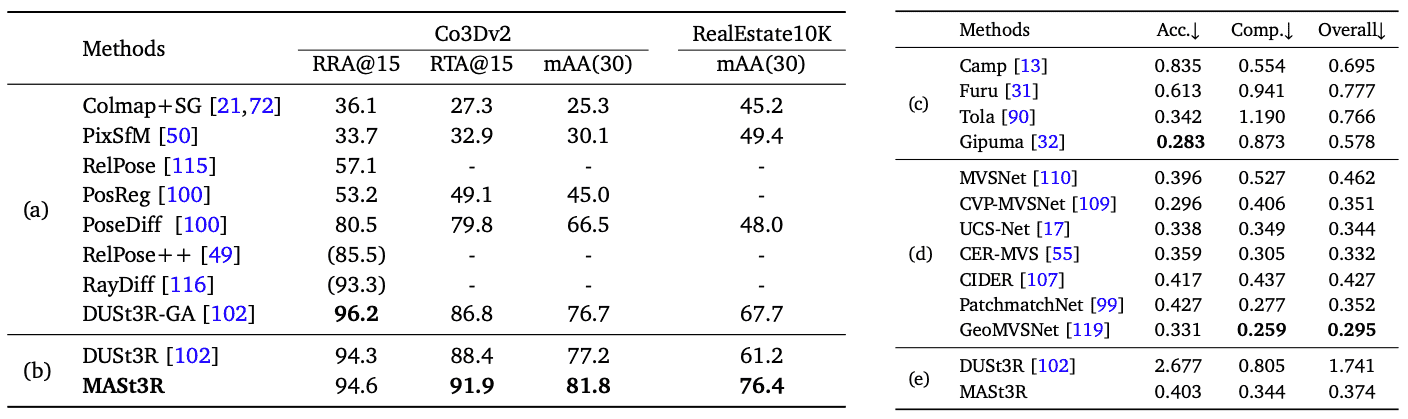
Table 3: Left(4.3节): Multi-view pose regression on the CO3Dv2 and RealEstate10K with 10 random frames. Parenthesis () denote methods that do not report results on the 10 views set, we report their best for comparison (8 views). We distinguish between (a) multi-view and (b) pairwise methods. Right(4.5节): Dense MVS results on the DTU dataset, in mm. Handcrafted methods (c) perform worse than learning-based approaches (d) that train on this specific domain. Among the methods that operate in a zero-shot setting (e), MASt3R is the only one attaining reasonable performance.
✅ 三、Results(实验结果)
传统 SfM 方法表现很差,原因:
很多图像对视角跨度大(有的达到 180°);
图像中物体小、背景少,难以三角测量;
3D-grounded 学习方法表现更好,如:
RayDiffusion、DUSt3R 和 MASt3R 是表现最强的;
MASt3R 在平移精度和整体准确率(mAA)上领先所有方法;
在 RealEstate10k 上,mAA 比最好的多视图方法高了 8.7 分;
比 DUSt3R(也只用图像对)高了 15.2 分!
✅ 总结一句话:
在非常困难的相对位姿估计任务中,即使只使用图像对(不像其他方法用多视图信息),MASt3R 依然在平移精度和总体准确率上大幅领先,展现了强大的鲁棒性和对小物体、大视角差场景的适应能力。
4.4. Visual localization(solute pose estimation)¶
◾ 数据集介绍:
数据集 |
场景类型 |
特点 |
|---|---|---|
Aachen Day-Night |
城市户外 |
4328 张参考图(相机已知),824 张白天 + 98 张夜晚查询图(手机拍摄) |
InLoc |
室内 |
9972 张 RGB-D 参考图 + 329 张查询图(iPhone7 拍摄),挑战在于光照变化大 |
◾ 评估指标:
Aachen:三个阈值:
0.25 米 & 2°
0.5 米 & 5°
5 米 & 10°
InLoc:三个阈值,角度固定(10°):
0.25 米、0.5 米、1 米
只有位移和旋转误差都小于阈值,图像才算成功定位。
◾ 实验结果亮点:
不同的检索图数量(Top-K retrieved images)对效果有影响:
使用 Top-40 检索图时,效果最佳;
在 InLoc 上表现 显著超越现有方法;
即便只用 Top-1 检索图(也就是只参考一张图),效果依然很强,体现出:
MASt3R 3D-grounded 匹配的鲁棒性;
作者也做了一个对比实验 —— 直接回归相机位姿(不做匹配):
效果很差,特别是数据集尺度大时(场景大时,误差更明显);
这说明:”匹配 + 估计” 的 pipeline 明显更稳,更可靠。
✅ 总结一句话:
MASt3R 在视觉定位中效果优异,尤其在仅使用一张参考图时依然表现稳定,远超回归方法,并且在室内 InLoc 数据集上首次大幅超越现有 SOTA 方法。
4.5 Multiview 3D Reconstruction(多视图三维重建)¶
这是指:在知道多张图像之间的匹配点后,通过三角测量恢复三维点云模型。
◾ 关键做法:
MASt3R 不依赖相机信息(内参/外参),先做匹配,再用 ground-truth 相机位姿做三角测量;
为了清除错误匹配点,作者还用了几何一致性后处理;
所有匹配都在全分辨率下进行(更精细);
◾ 数据集和评估指标:
数据集 |
说明 |
|---|---|
DTU |
多视图重建 benchmark,室内结构光获取的参考点云,广泛用于 3D 重建任务 |
指标:
Accuracy:重建点到真实点云最近距离的平均值;
Completeness:真实点云中每个点到重建点最近距离;
Chamfer Distance:以上两者的平均值(越低越好)
具体参见 Table 3
◾ 实验结果亮点:
手工方法(比如传统 SfM)远远不如学习方法;
数据驱动方法 Chamfer 距离减半;
MASt3R 是 zero-shot setting:
没有在 DTU 数据集训练、finetune;
直接使用模型就能达到高水平;
MASt3R 即使 不使用相机内参/姿态来做匹配,依然超越 DUSt3R baseline;
甚至与最好的训练方法竞争!
✅ 总结一句话:
MASt3R 第一次在 zero-shot 情况下实现与有监督方法相当的重建精度,且完全不依赖相机标定,展示出超强的泛化能力。
✅ 总结总览
任务类型 |
MASt3R 优势 |
|---|---|
绝对定位 |
Top-1 表现依然优秀,超越多图方法,远超回归 |
3D 重建 |
无需训练、无相机信息也能达到领先精度 |
方法核心 |
3D-grounded feature matching + 可泛化到多任务 |
5. Conclusion¶
Grounding image matching in 3D with MASt3R significantly raised the bar on camera pose and localization tasks on many public benchmarks. We successfully improved DUSt3R with matching, getting the best of both worlds: enhanced robustness, while attaining and even surpassing what could be done with pixel matching alone. We introduced a fast reciprocal matcher and a coarse to fine approach for efficient processing, allowing users to balance between accuracy and speed. MASt3R is able to perform in few-view regimes (even in top1), that we believe will greatly increase versatility of localization.
通过将图像匹配“锚定”到 3D 上(即考虑三维几何约束),MASt3R 在多个公开数据集上显著提升了相机姿态估计和定位任务的性能。
我们在 DUSt3R 的基础上进一步引入了匹配机制,实现了双赢:
更强的鲁棒性(对不同视角、遮挡、模糊的适应力更好)
甚至超越了传统的像素级匹配方法的性能
我们设计了一个快速的互相匹配器(reciprocal matcher),以及**粗到细(coarse-to-fine)**的处理策略:
这使得在运行时可以灵活权衡精度和速度,适应不同的实际场景需求。
MASt3R 在少视图(few-view)场景下表现依然强大,甚至只用一张参考图(top1)就能进行高质量定位,
我们认为这将大大提升其在实际应用中的通用性和适应力。
✅ 总结一句话:
MASt3R 将图像匹配带入了 3D 维度,在姿态估计与定位任务中树立了新标杆。其高鲁棒性、运行效率与少图像适应性,使其在多种现实场景下具备强大实用价值。
Appendix¶
在附录 A 中展示了在不同任务上的额外定性示例
在附录 B 中提供了快速互惠匹配算法收敛性的证明及相关的性能增益深入研究
在附录 C 中展示了一个关于粗到精匹配影响的消融研究。
Appendix A Additional Qualitative Results¶
Appendix A 主要展示 MASt3R 在四个数据集上的实际视觉表现:
DTU(多视图3D重建)
InLoc(室内定位)
Aachen Day-Night(日夜城市定位)
Map-Free Benchmark(零地图定位)
🟧 1. MVS on DTU:三维重建质量
点云展示:Figure 5展示了 MASt3R 通过粗到细匹配获得的点云(三角化后);
没有用 GT 相机参数:全程没有使用相机内参或外参,而是one-versus-all 策略,即:每张图像都和所有其他图像匹配;
结果质量:
结构完整(即便是低对比区域如蔬菜表面、电源侧面);
纹理/材质/光照变化鲁棒(即使塑料反光、白色雕塑、高反射表面也能处理)。
📌 一句话总结:在不依赖相机参数的前提下,仍能实现高质量 3D 重建,是一项突破。

Figure 5: Qualitative MVS results on the DTU dataset simply obtained by triangulating the dense matches from MASt3R.
🟧 2. Qualitative Matching 结果(图6、7、8)
图6:Map-Free 数据集匹配结果
能处理视角极差变化(如两张图是互相对拍的),依然能匹配大致对应区域;
应对**尺度变化大、重复图案、环境变化(如光照不同)**等困难场景;
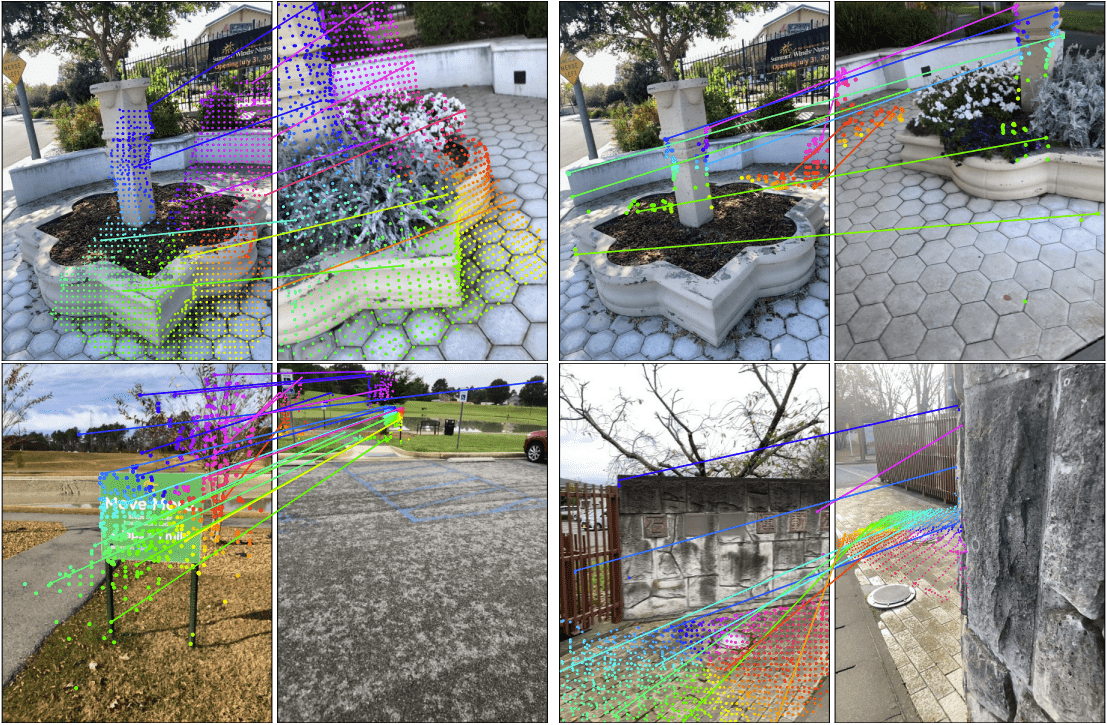
Figure 6: Qualitative examples of matching on Map-free localization benchmark.
图7:InLoc(室内)
即使面对面视角(如走廊)也能找到合理匹配;
显示其继承了 DUSt3R 在极端视角变化下的鲁棒性;

Figure 7: Qualitative examples of matching on the InLoc localization benchmark.
图8:Aachen Day-Night(城市日夜)
左列:白天图对白天图;
右列:夜晚图对夜晚图;
能有效处理日夜光照变化带来的匹配挑战。

Figure 8: Qualitative examples of matching on the Aachen Day-Night localization benchmark. Pairs from the day subset are on the left column, and pairs from the night subset are on the right column.
📌 共同结论:
MASt3R 能在极端困难条件下保留匹配准确性;
即使匹配不精确,也能恢复出合理的相对位姿;
零样本情况下也能达到SOTA或接近SOTA水平。
✅ 最后一句点题:
“We hope this work will foster research in the direction of pointmap regression…”
我们希望这项工作能推动图像视觉任务中“点图回归”的研究发展 —— 特别是那些对鲁棒性与精度要求极高的任务。
B. Fast Reciprocal Matching¶
B.1. Theoretical study¶
Fast Reciprocal Matching(FRM)算法的理论收敛性证明,主要围绕它如何在图结构中高效地找到像素之间的互为最近邻(reciprocal nearest neighbor)对应关系。
🧠 背景与目标
传统的像素匹配方法(比如基于二分图匹配)通常计算的是全图的对应关系,这样计算量大。而FRM的目标是:
只匹配部分图,减少计算;
并且仍然保证匹配的正确性和理论上的收敛性。
📌 算法回顾
我们有两个图像的特征图 \(D^1, D^2 \in \mathbb{R}^{H \times W \times d}\)。
互为最近邻(mutual NN)的匹配点定义如下: $\( M = \{(i, j) \mid j = \mathrm{NN}_2(D_i^1) \text{ 且 } i = \mathrm{NN}_1(D_j^2)\} \)\( 也就是从图像1的像素\)i\(映射到图像2中最近的\)j\(,然后从\)j\(再映射回来,如果又回到\)i$,就认为这是一个合法的匹配对。
🔁 算法流程
起始: 从图像 \(I^1\) 中随机选择 \(k \ll HW\) 个起点 \(U^0\);
前向: 每个点找到在 \(I^2\) 中的最近邻,得 \(V^t\);
反向: \(V^t\) 中的点再找回在 \(I^1\) 中的最近邻,得 \(U^{t+1}\);
检查环: 如果 \(U^{t+1}\) 中某个点回到了初始位置,形成了闭环(互为最近邻),就记录下来;
迭代: 对未闭环的点继续进行上面的过程,直到收敛或达到最大轮数。
这个过程就像在图中来回“跳跃”,直到找到那些“闭环路径”。
🧩 图结构分析
FRM其实隐式地在一个有向二分图 \(\mathcal{G}\) 上操作,这个图的结构是这样的:
每个像素是一个节点;
每个节点有一条指向其最近邻的边;
所以每个节点出度为1;
这样的图由若干个子图 \(\mathcal{G}^i\) 组成,每个子图要么是一个简单的环,要么是一个有向树结构,最终指向某个环。
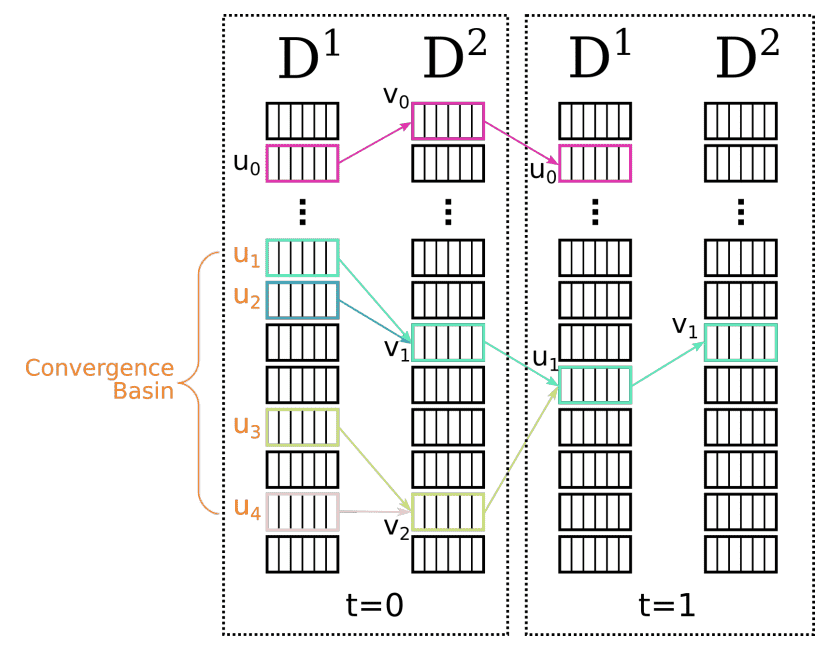
Figure 9: Illustration of the iterative FRM algorithm. Starting from 5 pixels in \(I^{1}\) at \(t=0\) , the FRM connects them to their Nearest Neighbors (NN) in \(I^{2}\) , and maps them back to their NN in \(I^{1}\) . If they go back to their starting point (top pink), a cycle (reciprocal match) is detected and returned. Otherwise (bottom) the algorithm continues iterating until a cycle is detected for all starting samples, or until the maximal number of iterations is reached. We show in orange the starting points of a convergence basin, i.e. nodes of a sub-graph for which the algorithm will converge towards the same cycle. For clarity, all edges of \(\mathcal{G}\) were not drawn.
图中橙色点表示属于同一个“收敛盆地(convergence basin)”的起始点。也就是说,这些点虽然初始位置不同,但迭代几轮之后,都会收敛到同一个 reciprocal match 上。
图中要点:
**粉色点(上方)**表示那些很快就构成 reciprocal match 的起始点。
**蓝色路径(下方)**展示那些需要多轮迭代才能收敛的点。
🧩 收敛性证明
🧠 “FRM在最近邻有向二分图\(\mathcal{G}\)上运行”
把两张图像 \(I^1\) 和 \(I^2\) 看作图的两个子集(两个节点集),构成一个二分图。
对于 \(I^1\) 中的每个像素 \(u\),我们会找到它在 \(I^2\) 中的最近邻(\(\mathrm{NN}_2(D_u^1)\)),连一条有向边过去。
反之亦然,\(I^2\) 中每个点也会连向 \(I^1\) 中它的最近邻。
所以这个图是一个有向二分图(Directed Bipartite Graph)。
🧩 “每个像素都在图中,都有指向自己的最近邻的边”
因为每个像素都至少会指向它的最近邻,所以没有“孤立点”,每个点都在图里参与构图。
❗“但不是所有像素之间都能相互到达(无完全连通)”
注意,虽然所有点都在图里,但这个图并不是一个强连通图。你从某些点出发,未必能到达图中的任意其他点。
例如,从点 \(u\) 出发只知道它最近邻是 \(v\),再从 \(v\) 找回最近邻是 \(u\),这个环就只有 \((u,v)\)。
其他点可能完全不能到达这对点,或者属于另一个完全不相连的“世界”。
🧍♀️↔️🧍♂️ “如果两个像素正好互为最近邻,它们就只互相连接,没有别的连边”
举个例子,假设图像 \(I^1\) 中的像素 \(u\) 的最近邻是图像 \(I^2\) 中的像素 \(v\),同时 \(v\) 的最近邻又是 \(u\)。
这两者就组成了一个 reciprocal match。
在图 \(\mathcal{G}\) 中,他们只互相有边,和其他任何像素没有连边。
🔗“因此,整个图\(\mathcal{G}\)是由多个互不连通的子图\(\mathcal{G}^i\)组成的”
由于像上面例子那样的点对只能彼此连接,整个图 \(\mathcal{G}\) 实际上被划分成了多个互不相通的子图。
每个子图 \(\mathcal{G}^i\) 就是某些点之间互相可达、互为最近邻关系形成的局部闭环或树形结构。
理论上最多可能有 \(HW\) 个子图(图像总像素数),但实际中会少于这个值。
📌 这也是为什么在图 9 里,会画出不同“收敛盆地”(convergence basins):每个盆地其实就是某个 \(\mathcal{G}^i\) 子图的内部路径。
📌 命题(Proposition) B.1:每个子图 \(\mathcal{G}^i\) 只可能有一个环
因为每个节点只指向一个目标,且图是有向的;所以一旦进入环中,无法逃出;自然无法有第二个环。
证明:如果你从某个子图 \(\mathcal{G}^i\) 中的任意节点开始,按照边(最近邻关系)走下去,一旦你走到了一个属于某个环(cycle)的节点,你将无法“跳出”这个环,因为每个点只有一条边指向它的最近邻,而这个最近邻关系已经构成了这个闭环,没有其他路径可以离开这个环。
🌳 引理(Lemma) B.2:每个子图是一个“以环为根”的有向树(arborescence)
要么它本身就是一个环;要么它像一棵倒置的树,所有路径最终都会进入那个唯一的环;在路径上,匹配的相似度是单调递增的,最终会达到最大值,从而进入环。
结构类比为:
u1 u2 u3
↘ ↓ ↘
v1 → v2 → v3 → v1 ← 一个根环(v1→v2→v3→v1)
u1, u2, u3是非环节点,它们指向某个环上的节点v1, v2, v3构成一个闭环这种结构就是所谓的 “special arborescence + root cycle”
小结:每个 FRM 子图 \(\mathcal{G}^i\) 最终都形成一个有向“树 + 根环”结构,也就是说:从任意点出发不断找最近邻,最终都能收敛到一个环(这个环即为 reciprocal match 结果)。这就是 FRM 算法能迭代收敛的理论保证。
🔁 推论(Corollary) B.3:无论从图 \(\mathcal{G}^i\) 中哪个像素出发,FRM 算法总会收敛到 reciprocal match(互为最近邻的匹配对)。
这意味着FRM是收敛的,且一定会找到对应的点对。
✅ 总结一句话
Corollary B.3 保证了 FRM 算法从任意初始点出发都能在有限步内收敛,并最终找到 reciprocal match,对整个算法的稳定性和高效性提供了理论支撑。
✅ 命题(Proposition) B.4:FRM从 \(k\) 个起点出发,最多能找到 \(k\) 个匹配(实际可能更少)
这是由于不同起点可能落入同一个子图并共享同一个匹配路径。
B.2. Performance improves with fast matching¶
主要解释了 Fast Reciprocal Matching (FRM) 相对于传统全图匹配方法的优势,不只是计算速度快,而且还能在性能(比如姿态估计、投影误差)上表现得更好。
🔹1. FRM 使性能显著提升(来自图2和图9)
FRM 倾向于优先采到那些 有大“汇聚盆地”(basin) 的 reciprocal match
举个类比:你从地图上随机撒点,点越多越可能落在“大的水池”里,FRM 就会更快找到这些“池子里的好匹配”
图9:下图是“大 basin”,多个起点最后走向同一个 reciprocal match;上图是“小 basin”,只有少数起点才可能找到那个 match
🔹2. Basin 越大,越容易命中;但匹配密度却越低
“大 basin”意味着从更多的像素出发都能走向那个 match → 稳定可靠
但这些 basin 内部的 reciprocal match 数量密度较低(因为点太分散)
所以:
全图暴力匹配:虽然覆盖所有 match,但可能很多都集中在局部(密集但不稳定)
FRM:偏向大 basin,结果空间分布更均匀、结构更稳定(即便少了一些 match)
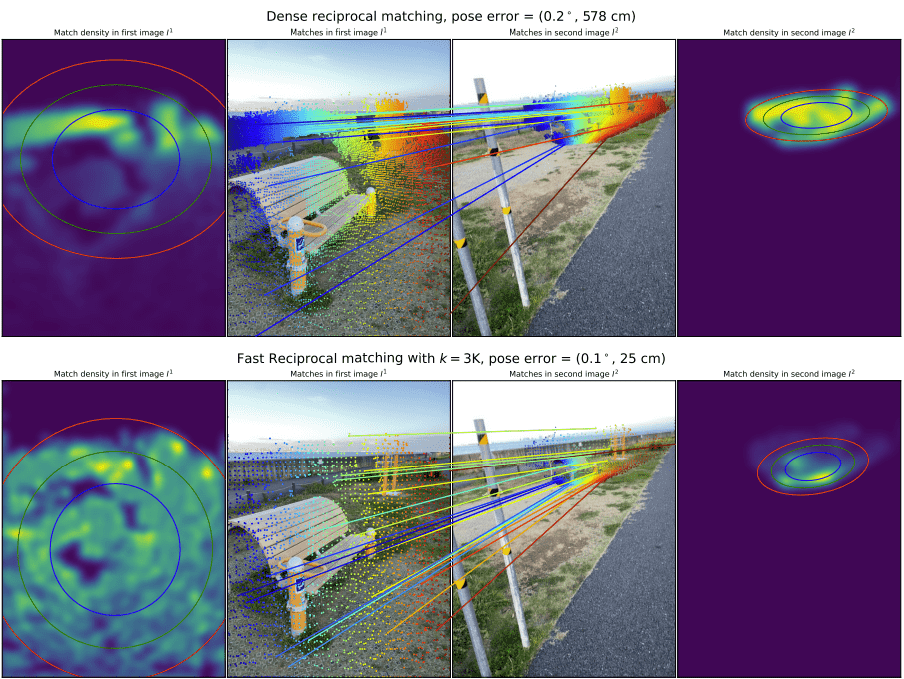
Figure 10: Illustration of the difference in matching density when using dense reciprocal matching (baseline) and fast reciprocal matching with \(k=3000\) . Fast reciprocal matching samples correspondences with a bias for large convergence basins, resulting in a more uniform coverage of the images. Coverage can be measured in terms of the mean and standard deviation \(\sigma\) of the point matches in each density map, plotted as colored ellipses (red, green and blue correspond respectively to \(1\sigma,1.5\sigma\) and \(2\sigma\mathrm{\dot{\Omega}}\) ).
🔹3. 更均匀的空间分布 → 更好的几何估计
这句非常关键:
如果匹配点都集中在某一小块区域(如角落),RANSAC 估算相机姿态就容易不准确甚至失败;
而 FRM 的 basin-biased 效果,会让匹配点在整张图上分布得更均匀;
→ 更好的本质矩阵估计 / 位姿估计
如图10所示。由于空间覆盖更均匀,RANSAC 能够比在小图像区域内密集堆积点的情况下更好地估计极线,从而提供更好且更稳定的姿态估计。

Figure 11: Illustration of convergence basins for one of the image in fig. 10. Each basin is filled with the same (random) color. A convergence basin is an area for which any of its point will converge to the same correspondence when applying the fast reciprocal matching algorithm.
🔹4. 对比实验:三种 subsampling 策略
实验方式: 从完整的 reciprocal match 集合 \(\mathcal{M}\) 中取样
方式有三种:
随机 subsample,取出和 FRM 一样多的匹配点
❌ 结果非常差,因为有可能全都集中在某小区域
basin-biased subsample
利用每个 reciprocal match 的 basin 大小作概率分布,优先采大 basin
✅ 结果反而比用全部匹配点还好(因为密度均衡 + 去噪)
FRM 本身
实际结果几乎与 basin-biased 相同,但计算量远远更低(因为不用预先知道 basin 大小)
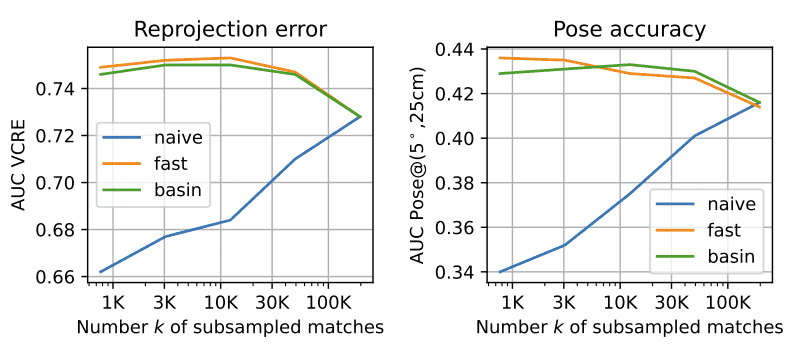
Figure 12: Comparison of the performance on the Map-free benchmark (validation set) for different subsampling approaches: ‘naive’ denotes the random uniform subsampling of the original full set of reciprocal matches; ‘fast’ denotes the proposed fast reciprocal matching; and ‘basin’ denotes random subsampling weighted by the size of the convergence basin. The ‘fast’ and ‘basin’ strategies perform similarly whereas naive subsampling leads to catastrophic results.
🔹5. 结论
无论你用哪种 RANSAC(普通/鲁棒/最小化重投影误差),只要你的匹配点来自 FRM,都会带来更好的几何估计结果。
✅ 总结一句话:
FRM 不是简单地加速匹配,而是借助 basin 结构在“高效+均衡分布”的同时,带来了更稳定、精度更高的几何估计效果 —— 甚至优于暴力全图匹配。
C. Coarse-to-Fine¶
主要讲的是 MASt3R 中 “Coarse-to-Fine” 匹配策略的重要性,尤其是相对于只使用 Coarse 匹配(coarse-only)的方法,它在视觉定位和**多视角重建(MVS)**任务上性能提升非常明显。
🧭 一、Coarse vs. Coarse-to-Fine 区别
Coarse-only:直接在低分辨率下做匹配(图像下采样后就直接做对应关系)
Coarse-to-Fine:
先在低分辨率下找粗匹配;
然后在高分辨率原图上做精细对齐(通常是局部 refinement)
🔑 优点:
效率高(coarse阶段快速全局对齐)+ 精度高(fine阶段提升局部几何细节)
🌇 二、视觉定位任务:Aachen Day-Night
图像原始分辨率:1600×1200 和 1024×768,分别缩小为 512×384 或 384×512
测试了三个阈值下的定位成功率:
(0.25m, 2°):高精度
(0.5m, 5°):中精度
(5m, 10°):低精度容忍度
✅ 总结一句话:
Coarse-to-Fine 不只是性能微调,而是决定性地提升匹配的几何精度、视觉定位成功率和 MVS 重建质量。 尤其是在夜间、遮挡、低纹理等困难条件下,这种策略能显著提升结果。
D. Detailed experimental settings¶
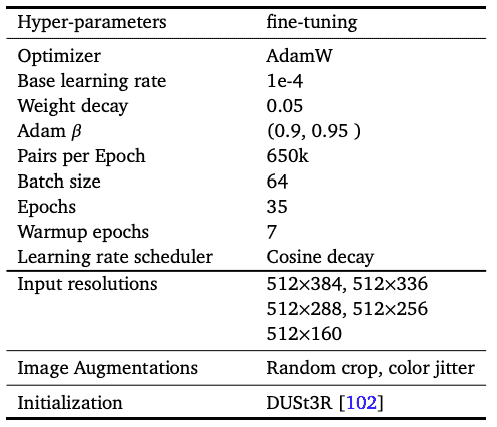
Table 6: Detailed hyper-parameters for the training