2308.04026_AgentSims: An Open-Source Sandbox for Large Language Model Evaluation¶
AgentSims: An Open-Source Sandbox for Large Language Model Evaluation
组织:宾夕法尼亚州立大学、北京航空航天大学、中山大学、浙江大学、华东师范大学
随着类似 ChatGPT 的LLM 在社区中盛行,如何评估其LLMs能力是一个悬而未决的问题。现有的评估方法存在以下缺点:(1) 评估能力受限,(2) 脆弱的基准,(3) 不客观的指标。我们建议基于任务的评估,即LLM代理在模拟环境中完成任务,是解决上述问题的一劳永逸的解决方案。我们推出了 AgentSims,这是一个易于使用的基础设施,供所有学科的研究人员测试他们感兴趣的特定能力。研究人员可以通过在交互式 GUI 上添加代理和建筑物来构建评估任务,或者通过几行代码部署和测试新的支持机制,即memory, planning and tool-use 系统。
With ChatGPT-like large language models (LLM) prevailing in the community, how to evaluate the ability of LLMs is an open question. Existing evaluation methods suffer from following shortcomings: (1) constrained evaluation abilities, (2) vulnerable benchmarks, (3) unobjective metrics. We suggest that task-based evaluation, where LLM agents complete tasks in a simulated environment, is a one-for-all solution to solve above problems. We present AgentSims, an easy-to-use infrastructure for researchers from all disciplines to test the specific capacities they are interested in. Researchers can build their evaluation tasks by adding agents and buildings on an interactive GUI or deploy and test new support mechanisms, i.e. memory, planning and tool-use systems, by a few lines of codes.
LLMs已经彻底改变了自然语言处理 (NLP) 及其他领域。它们在下面这些类型中表现出巨大的潜力:
小样本学习(Brown et al., 2020)、 代码生成(Nijkamp et al., 2023)、 推理(Yao et al., 2023) 其他任务
此外,LLM强大的自主代理 (Weng, 2023) 广泛用于解决复杂问题,如:
多模态生成 (Shen et al., 2023)、 软件开发 (Qian et al., 2023) 社会模拟 (Park et al., 2023)。
尽管已经改革(reformed)了 NLP 的范式(paradigm),但LLMs评估问题一直困扰着这个领域。
自从LLMs达到人类水平的自然语言理解 (NLU) 和自然语言生成 (NLG) 能力 (OpenAI, 2023),旧的基准测试就已经过时了。为了满足对新基准的迫切需求,NLP 社区引入了一系列新的评估任务和数据集,包括:
闭卷问答 (QA) 的知识测试(Hendrycks et al., 2020;Huang et al., 2023)、 以人为本的标准化考试(Zhong et al., 2023)、 多轮对话(Lin and Chen, 2023)、 推理(Liu et al., 2023a;基准作者,2023) 安全评估(Sun et al., 2023)
但是,这些新基准测试仍然存在许多问题:
1. 评估的能力受任务格式的限制 由于这些任务中的大多数都采用单轮次 QA 格式,因此它们不足以全面评估 LLMs 能力的各个方面。 如,他们不能评估模型在对话中遵守指令或模仿类似人类的社交互动的熟练程度。 2. 基准测试很容易被黑客入侵 在评估模型的能力时,避免测试集的泄漏至关重要。 尽管如此,考虑到LLM的预训练知识数据量,无意中将测试用例混合到训练集中变得越来越不可避免。(Gunasekar 等人,2023 年)。 3. 对于开放式QA,现有指标并不客观 前面开放式 QA 的指标都是自动指标,而人工打分是一个主观指标(周 et al., 2023)。 在这个LLM时代,基于文本段匹配的度量已经过时。为了缓解人工评分的高成本问题,今天的研究人员使用像 GPT4 这样对齐LLMs良好的 API 作为自动评分器。然而,这种方法最显着的问题是它无法评估超级 GPT4 级别的模型,并且LLMs偏向于特定特征(Wang et al., 2023b)。
基于这些观察结果,我们建议对LLM基准进行基于任务的评估。具体来说,在人为的社会经济环境中,LLM驱动的智能体应该完成预定的任务目标来证明他们的能力,就像人类在现实世界中完成目标或玩游戏来展示他们的能力一样。
基于任务的评估是当前问题的一劳永逸的解决方案:
1. 基于任务的评估可以测试一个LLM的整体能力。 社会模拟和适应的复杂性远远超出了简单的 QA,并且可以为 LLMs制定更具挑战性的任务。 LLM代理需要具备从 NLU 到心智理论 (ToM) 的能力(Premack 和 Woodruff,1978)。 2. 任务解决过程不太可能被黑客入侵。 与不更改的测试数据集不同,其格式可以轻松模仿并添加到训练数据中。 任务设置是多样化的,新兴的社会行为和群体不太可能被描述和包含在训练语料库中。 3. 任务通过率是一个客观指标。 与 ChatGPT 流行的评分方法相比,通过率不依赖于任何黑盒评分过程,即深度神经网络或人脑, 因此它在比较 LLMs能力时是相对客观和公平的.
重要
这个主要用于评估大模型的能力,比如评估openAI的gpt4与百度的文心的能力。分别用这两个大模型在一个模拟的环境中,生成多个Agent,让这些Agent之间进行对话,看哪个效果好。
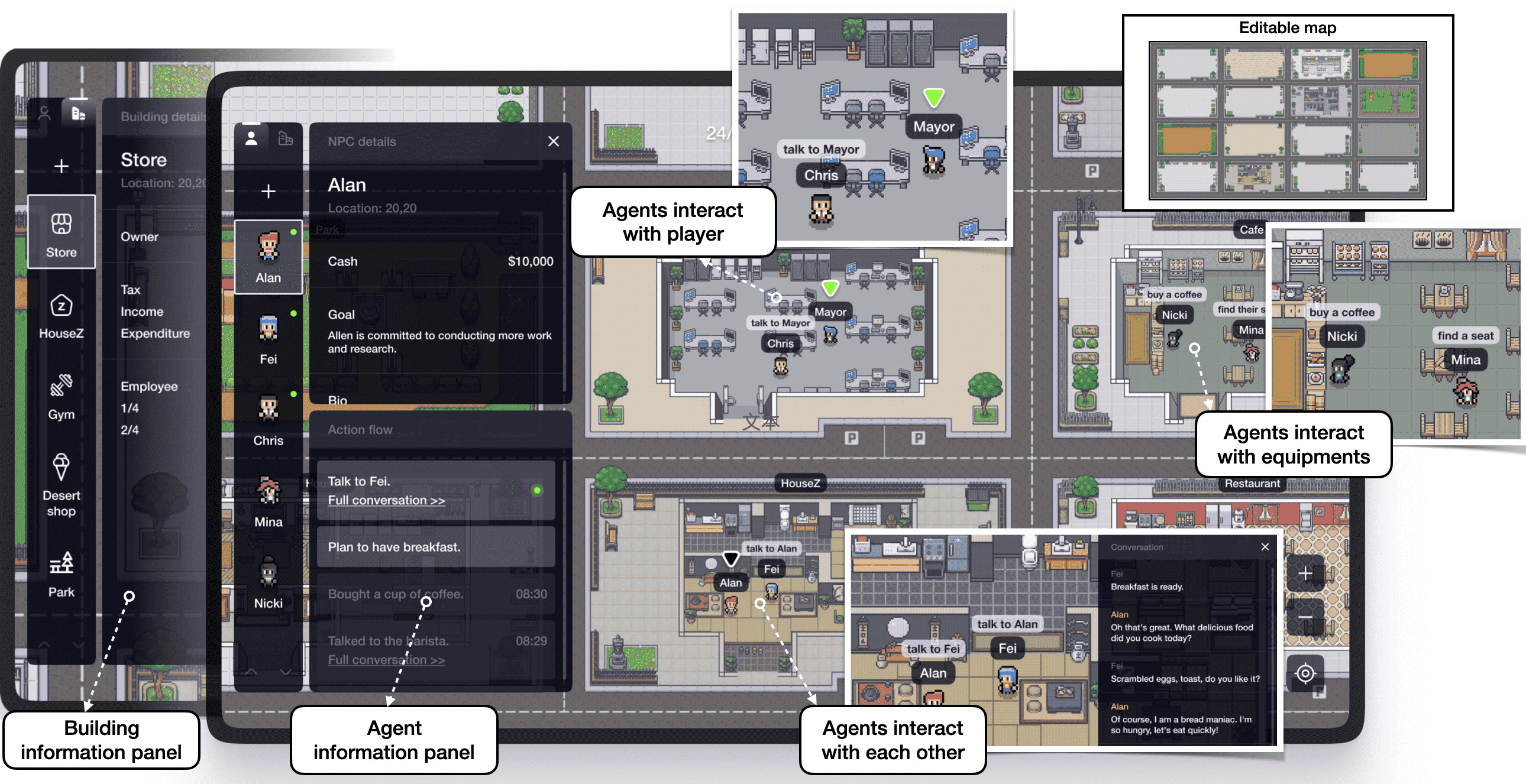
用户可以在左侧面板中创建代理和建筑物,并在主屏幕中观察代理的行为。除了先设置后观察外,用户还可以扮演市长并与代理交谈以干预实验。¶
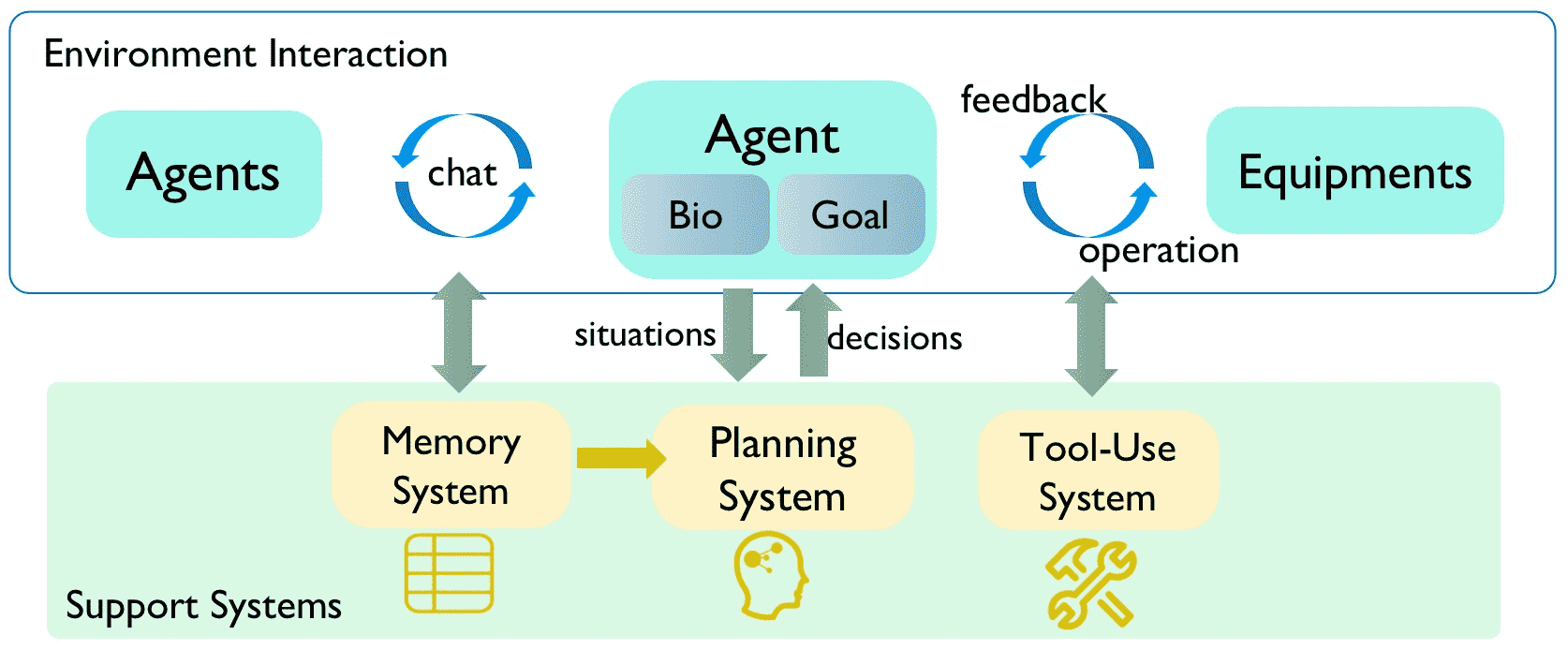
Figure 2:Overview of AgentSims architecture¶